
Unmanned Aerial Vehicle–Light Detection and Ranging-Based Individual Tree Segmentation in Eucalyptus spp. Forests: Performance and Sensitivity



Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area and Field Data
2.2. LiDAR Data Collection and Pre-Processing
2.3. Individual Tree Segmentation Algorithms
2.3.1. Watershed Algorithm
2.3.2. Local Maximum Algorithm
2.3.3. Euclidean Distance Clustering Algorithm
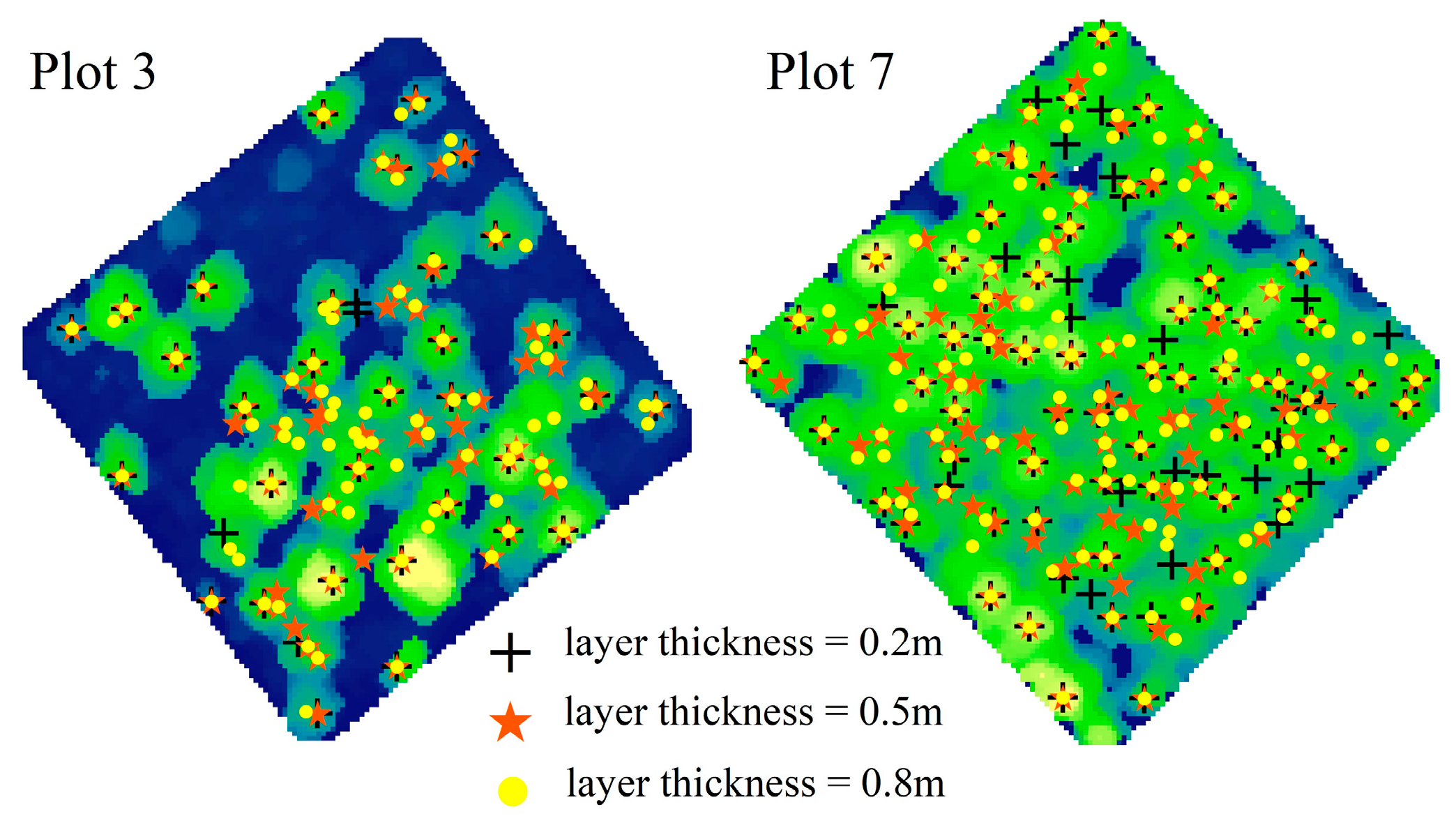
2.3.4. Layer Stacking Algorithm
2.4. Accuracy Assessment
3. Results
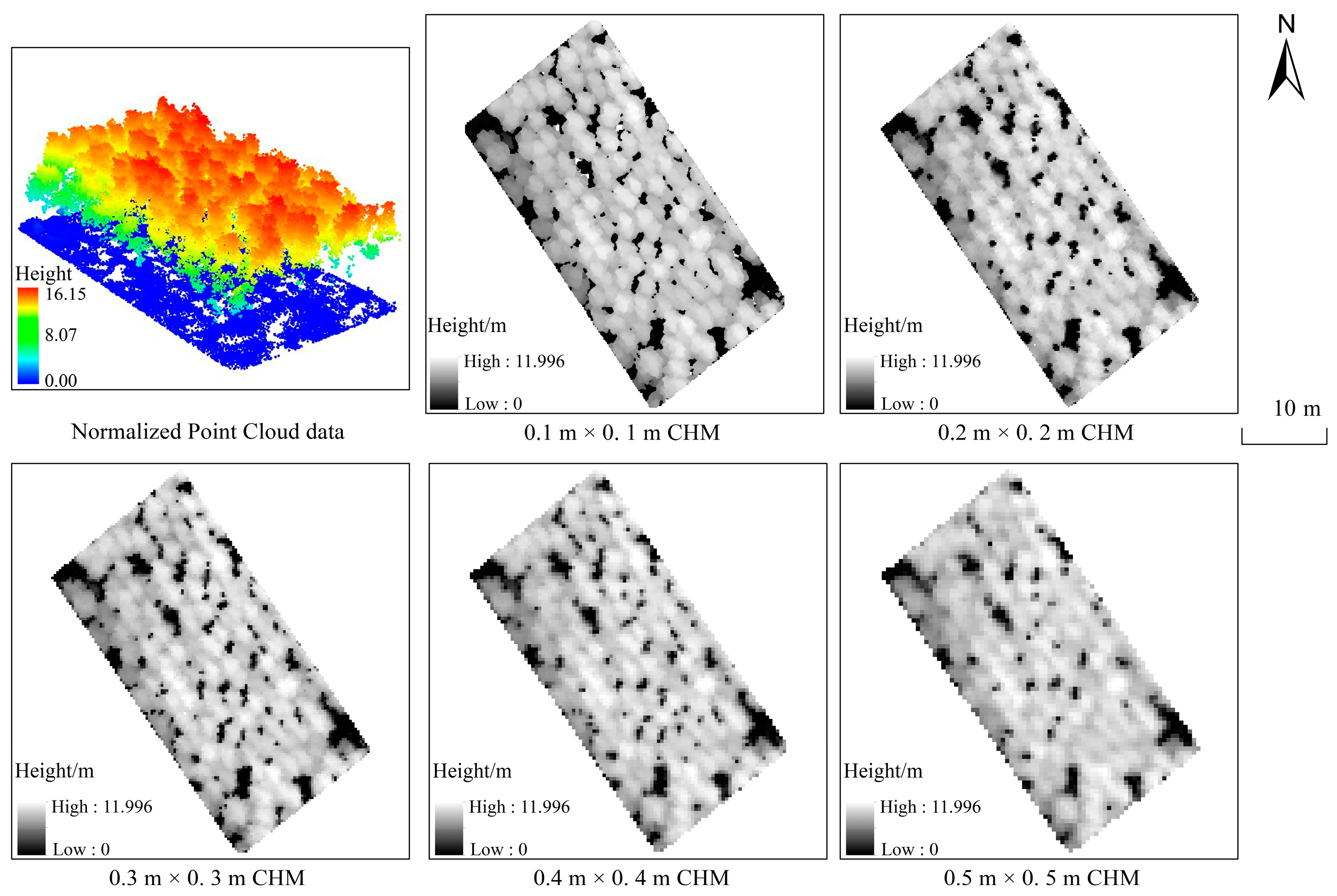
3.1. The Generation of Two Data Models
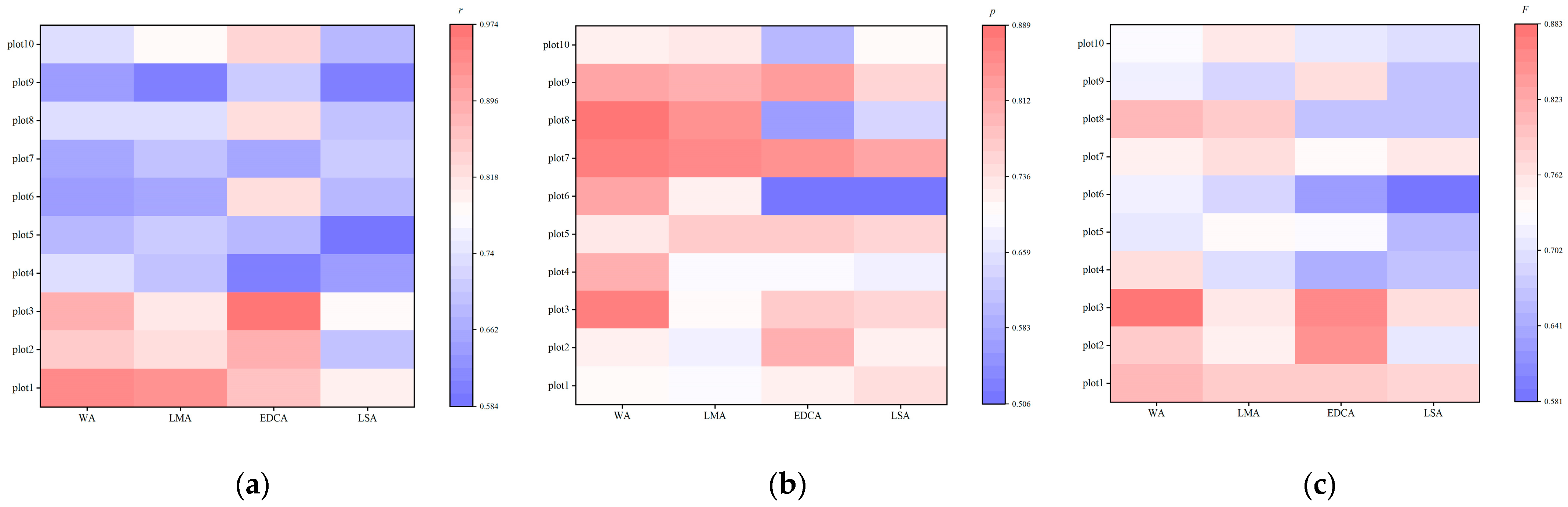
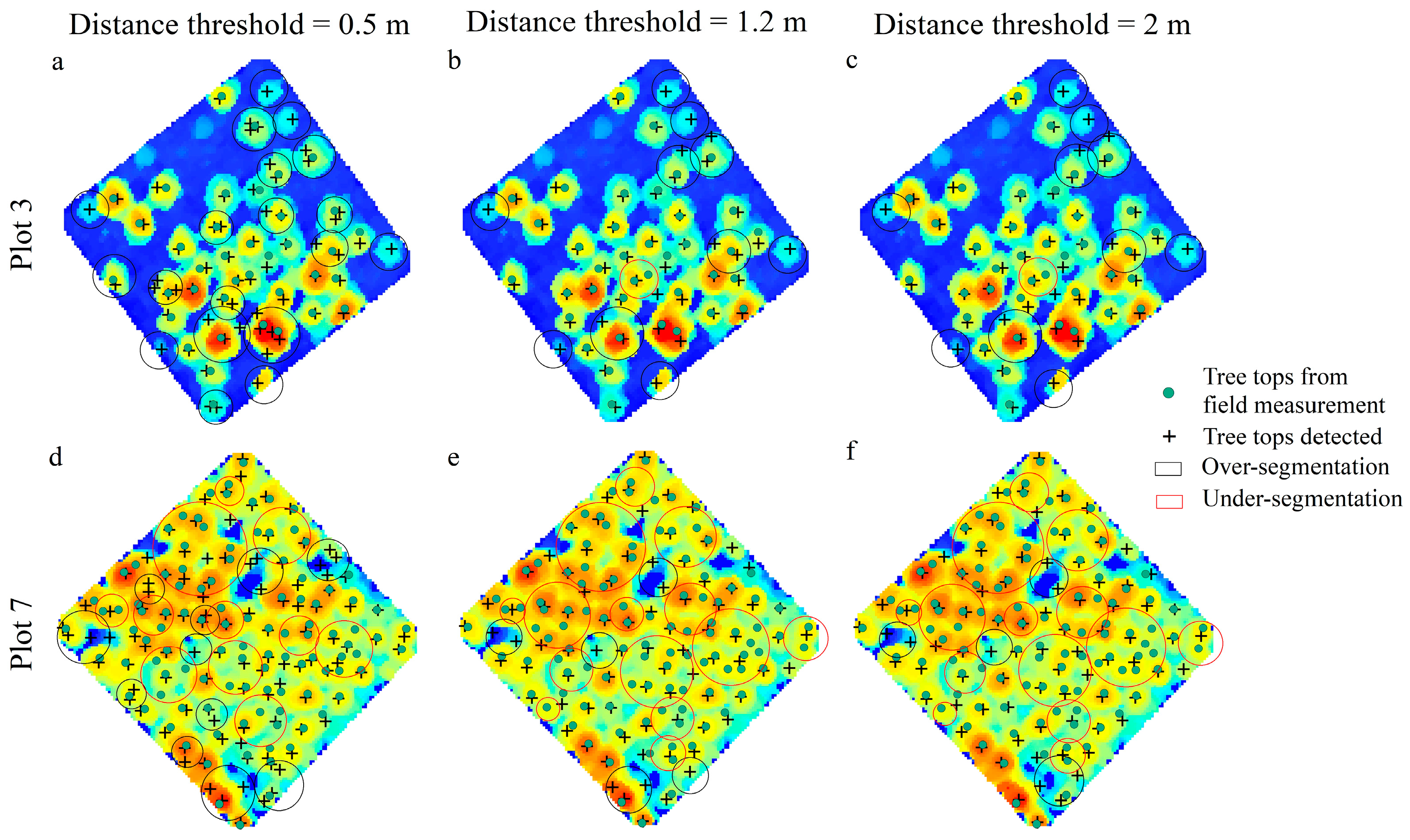
3.2. Individual Tree Segmentation
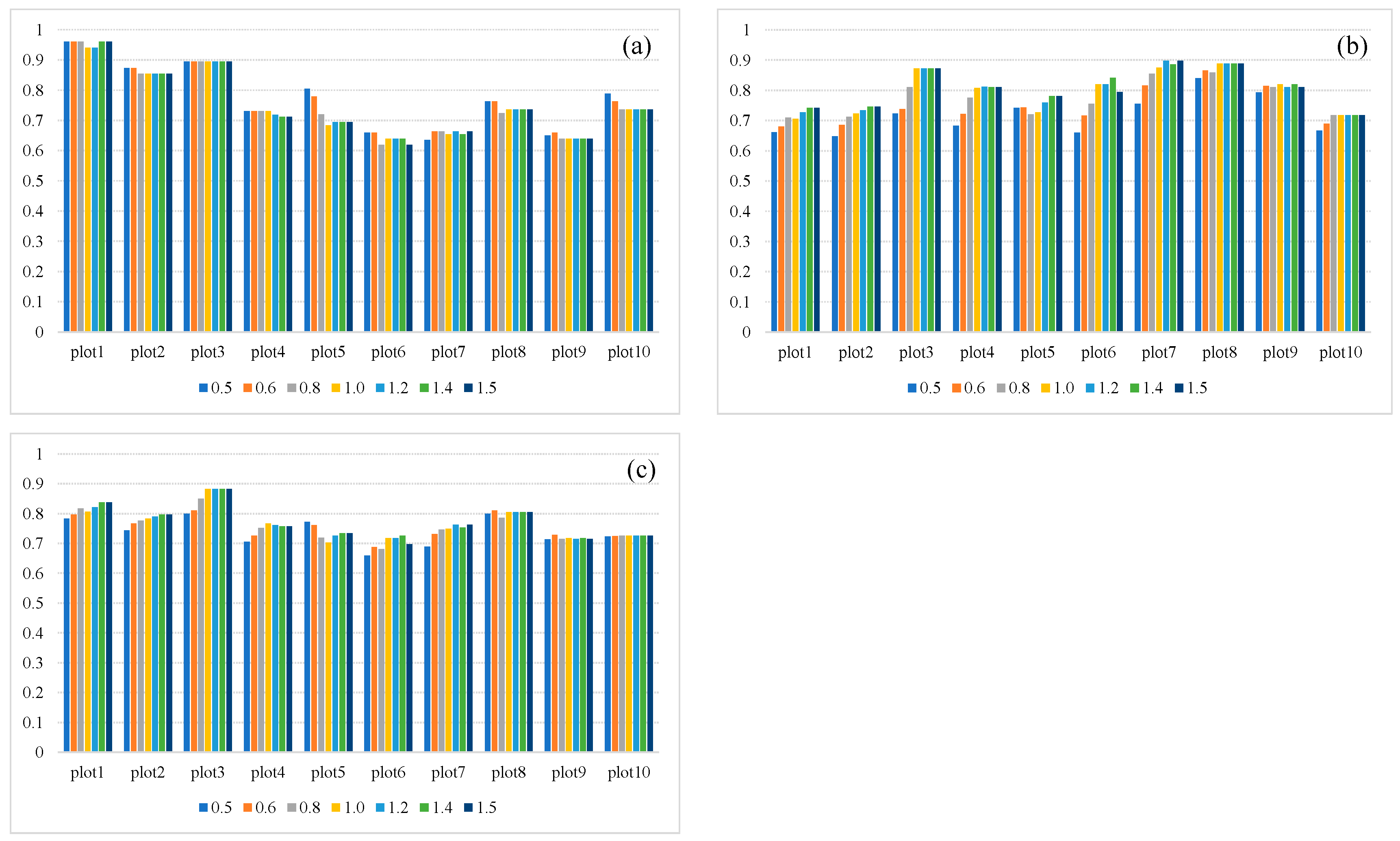
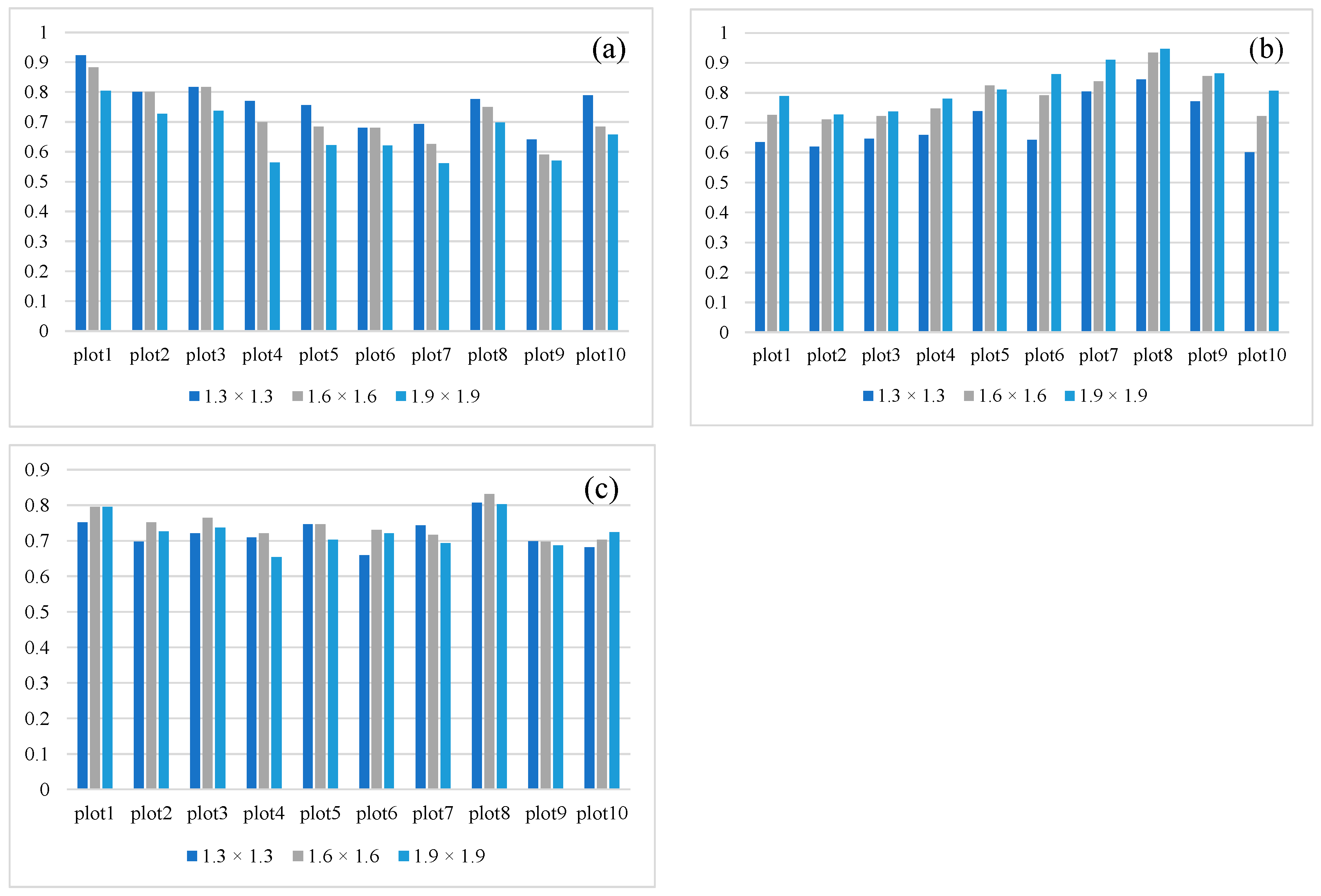
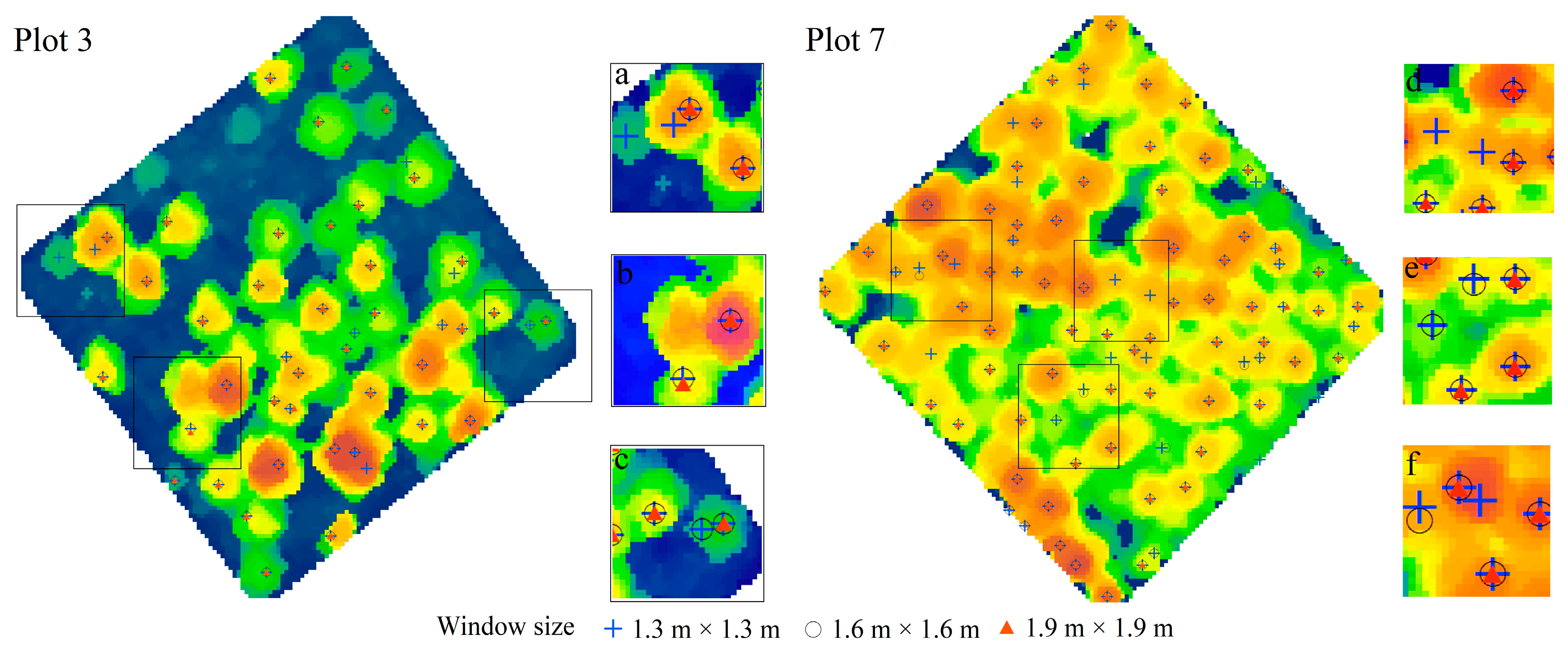
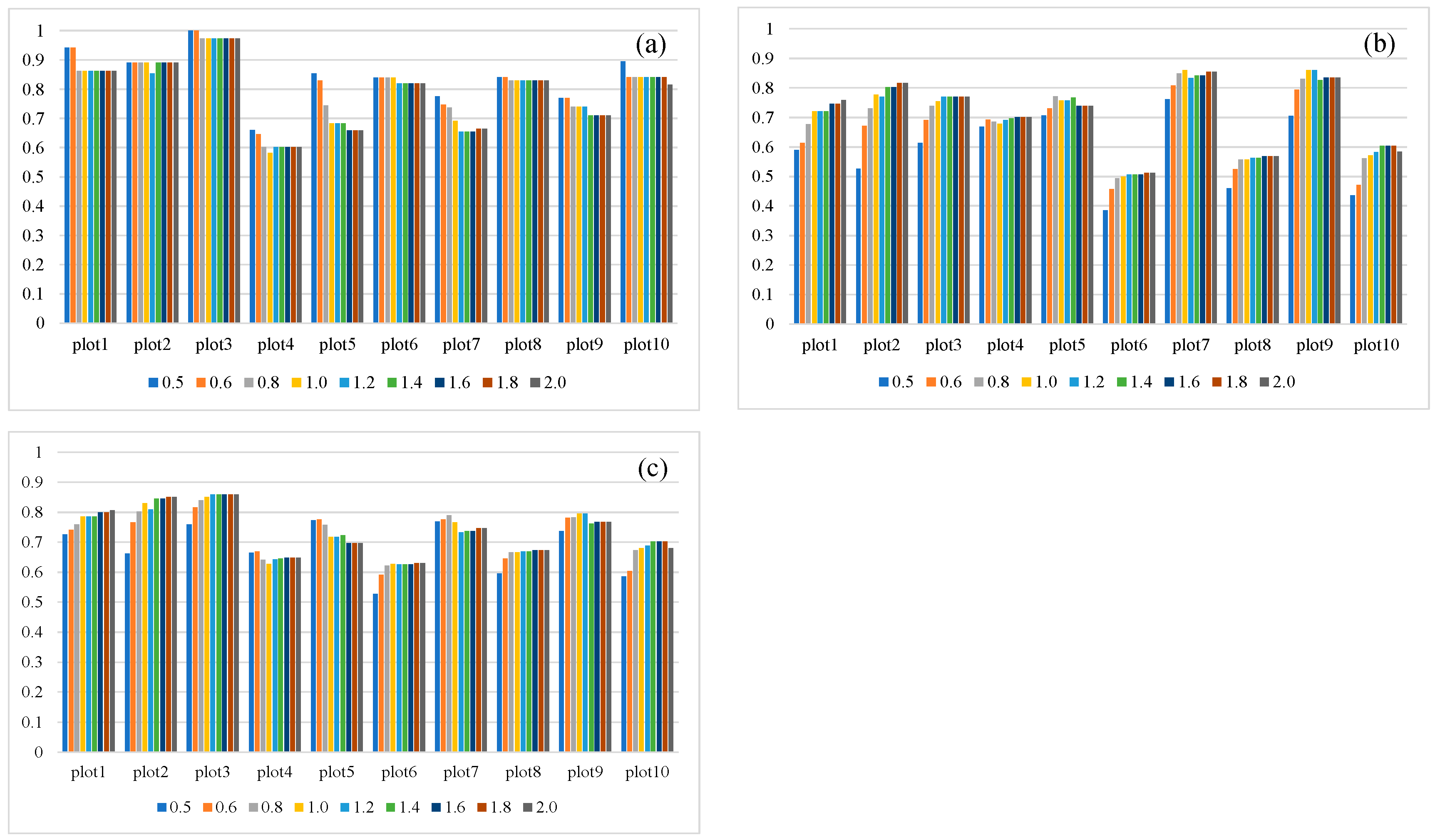
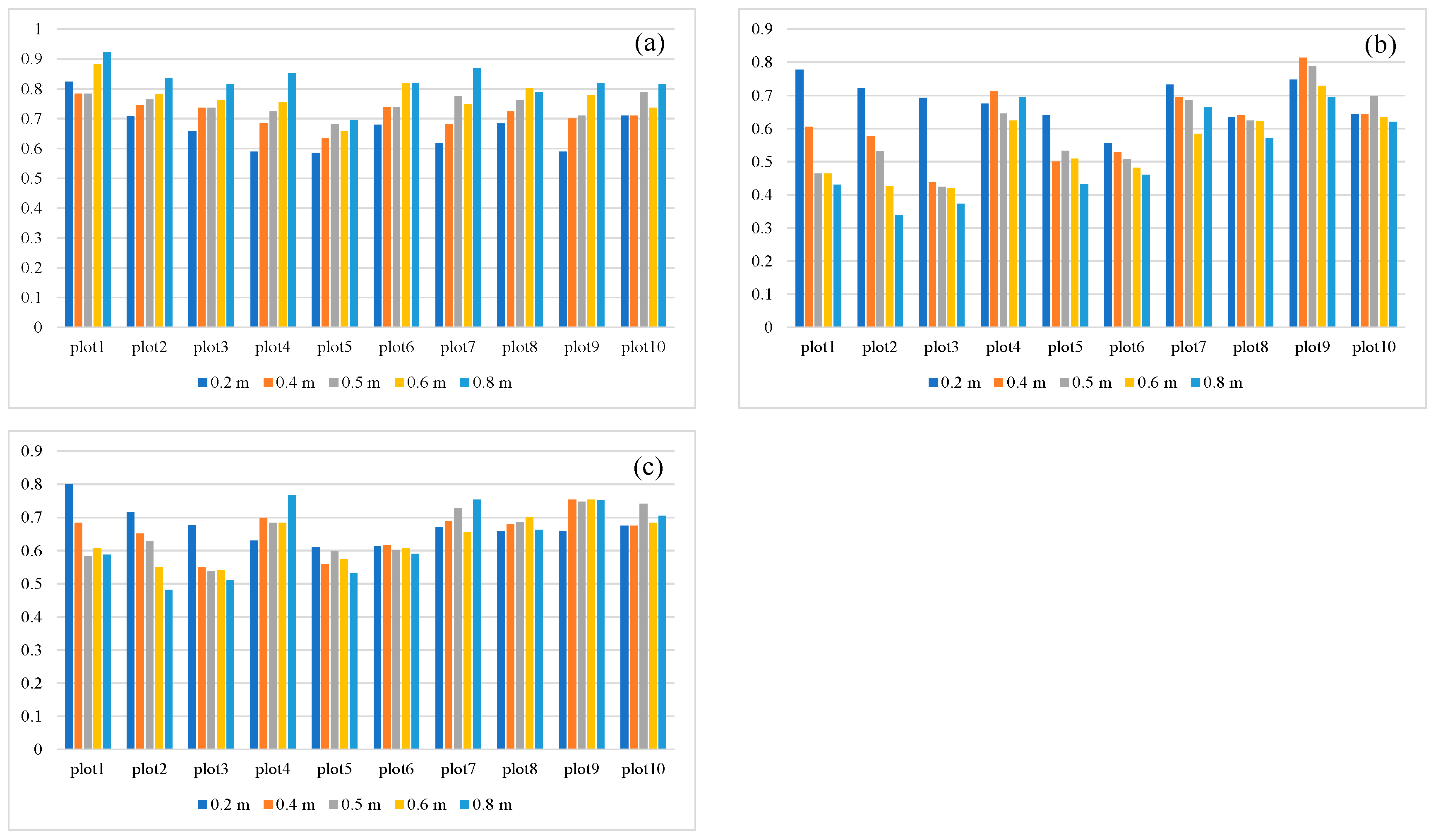
3.3. Sensitivity Analysis
3.3.1. Watershed Algorithm
3.3.2. Local Maximum Algorithm
3.3.3. Euclidean Distance Clustering Algorithm
3.3.4. Layer Stacking Algorithm
4. Discussion
4.1. Performance of the Methods
4.2. Sensitivity of the Parameters
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hutapea, F.J.; Weston, C.J.; Mendham, D.; Volkova, L. Sustainable management of Eucalyptus pellita plantations: A review. For. Ecol. Manag. 2023, 537, 120941. [Google Scholar] [CrossRef]
- Turnbull, J.W. Eucalypt plantations. New For. 1999, 17, 37–52. [Google Scholar] [CrossRef]
- Rockwood, D.L.; Rudie, A.W.; Ralph, S.A.; Zhu, J.Y.; Winandy, J.E. Energy product options for eucalyptus species grown as short rotation woody crops. Int. J. Mol. Sci. 2008, 9, 1361–1378. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Xiao, X.; Zhao, L.; Qin, Y.; Doughty, R.; Wang, X.; Dong, J.; Yang, X. Mapping Eucalyptus plantation in Guangxi, China by using knowledge-based algorithms and PALSAR-2, Sentinel-2, and Landsat images in 2020. Int. J. Appl. Earth Obs. Geoinf. 2023, 120, 103348. [Google Scholar] [CrossRef]
- Zhang, H.; Guan, D.; Song, M. Biomass and carbon storage of eucalyptus and Acacia plantations in the Pearl River Delta, South China. For. Ecol. Manag. 2012, 277, 90–97. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Tomppo, E.O.; Næsset, E. Advances and emerging issues in national forest. Scand. J. For. Res. 2010, 25, 368–381. [Google Scholar] [CrossRef]
- Hamraz, H.; Contreras, M.A.; Zhang, J. A robust approach for tree segmentation in deciduous forests using small-footprint airborne LiDAR data. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 532–541. [Google Scholar] [CrossRef]
- Corona, P.; Chirici, G.; McRoberts, R.E.; Winter, S.; Barbati, A. Contribution of large-scale forest inventories to biodiversity assessment and monitoring. For. Ecol. Manag. 2011, 262, 2061–2069. [Google Scholar] [CrossRef]
- Qin, H.; Zhou, W.; Yao, Y.; Wang, W. Individual tree segmentation and tree species classification in subtropical broadleaf forests using UAV-based LiDAR, hyperspectral, and ultrahigh-resolution RGB data. Remote Sens. Environ. 2022, 280, 113143. [Google Scholar] [CrossRef]
- Kellner, J.R.; Armston, J.; Birrer, M.; Cushman, K.C.; Duncanson, L.; Eck, C.; Falleger, C.; Imbach, B.; Kral, K.; Krucek, M.; et al. New opportunities for forest remote sensing through ultra-high-density drone lidar. Surv. Geophys. 2019, 40, 959–977. [Google Scholar] [CrossRef]
- Magnussen, S.; Nord-Larsen, T.; Riis-Nielsen, T. Lidar supported estimators of wood volume and aboveground biomass from the Danish national forest inventory (2012–2016). Remote Sens. Environ. 2018, 211, 146–153. [Google Scholar] [CrossRef]
- Wang, Y.; Hyyppä, J.; Liang, X.; Kaartinen, H.; Yu, X.; Lindberg, E.; Holmgren, J.; Qin, Y.; Mallet, C.; Ferraz, A.; et al. International Benchmarking of the Individual tree detection methods for modeling 3-D canopy structure for silviculture and forest ecology using airborne laser scanning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5011–5027. [Google Scholar] [CrossRef]
- Hu, T.; Sun, X.; Su, Y.; Guan, H.; Sun, Q.; Kelly, M.; Guo, Q. Development and performance evaluation of a very low-cost UAV-Lidar system for forestry applications. Remote Sens. 2020, 13, 77. [Google Scholar] [CrossRef]
- Zheng, G.; Moskal, L.M. Retrieving leaf area index (LAI) using remote sensing: Theories, methods and sensors. Sensors 2009, 9, 2719–2745. [Google Scholar] [CrossRef] [PubMed]
- Wagner, F.H.; Ferreira, M.P.; Sanchez, A.; Hirye, M.C.; Zortea, M.; Gloor, E.; Phillips, O.L.; Filho, C.R.S.; Shimabukuro, Y.E.; Aragão, L.E. Individual tree crown delineation in a highly diverse tropical forest using very high resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 362–377. [Google Scholar] [CrossRef]
- You, H.; Liu, Y.; Lei, P.; Qin, Z.; You, Q. Segmentation of individual mangrove trees using UAV-based LiDAR data. Ecol. Inform. 2023, 77, 102200. [Google Scholar] [CrossRef]
- Hamraz, H.; Contreras, M.A.; Zhang, J. Vertical stratification of forest canopy for segmentation of understory trees within small-footprint airborne LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 130, 385–392. [Google Scholar] [CrossRef]
- Cao, L.; Coops, N.C.; Sun, Y.; Ruan, H.; Wang, G.; Dai, J.; She, G. Estimating canopy structure and biomass in bamboo forests using airborne LiDAR data. ISPRS J. Photogramm. Remote Sens. 2019, 148, 114–129. [Google Scholar] [CrossRef]
- Chen, Q.; Gao, T.; Zhu, J.; Wu, F.; Li, X.; Lu, D.; Yu, F. Individual tree segmentation and tree height estimation using leaf-off and leaf-on UAV-LiDAR data in dense deciduous forests. Remote Sens. 2022, 14, 2787. [Google Scholar] [CrossRef]
- Popescu, S.C. Estimating biomass of individual pine trees using airborne lidar. Biomass Bioenergy 2007, 31, 646–655. [Google Scholar] [CrossRef]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Bouvier, M.; Durrieu, S.; Fournier, R.A.; Renaud, J.P. Generalizing predictive models of forest inventory attributes using an area-based approach with airborne LiDAR data. Remote Sens. Environ. 2015, 156, 322–334. [Google Scholar] [CrossRef]
- Vastaranta, M.; Kankare, V.; Holopainen, M.; Yu, X.; Hyyppä, J.; Hyyppä, H. Combination of individual tree detection and area-based approach in imputation of forest variables using airborne laser data. ISPRS J. Photogramm. Remote Sens. 2012, 67, 73–79. [Google Scholar] [CrossRef]
- Næsset, E. Practical large-scale forest stand inventory using a small-footprint airborne scanning laser. Scand. J. For. Res. 2004, 19, 164–179. [Google Scholar] [CrossRef]
- Means, J.E.; Acker, S.A.; Fitt, B.J.; Renslow, M.; Emerson, L.; Hendrix, C.J. Predicting Forest Stand Characteristics with Airborne Scanning Lidar. Photogramm. Eng. Remote Sens. 2000, 66, 1367–1371. [Google Scholar]
- Yu, X.; Hyyppä, J.; Holopainen, M.; Vastaranta, M. Comparison of Area-Based and Individual Tree-Based Methods for Predicting Plot-Level Forest Attributes. Remote Sens. 2010, 2, 1481–1495. [Google Scholar] [CrossRef]
- Ma, K.; Chen, Z.; Fu, L.; Tian, W.; Jiang, F.; Yi, J.; Du, Z.; Sun, H. Performance and sensitivity of individual tree segmentation methods for UAV-LiDAR in multiple forest types. Remote Sens. 2022, 14, 298. [Google Scholar] [CrossRef]
- Wu, X.; Shen, X.; Cao, L.; Wang, G.; Cao, F. Assessment of individual tree detection and canopy cover estimation using unmanned aerial vehicle based light detection and ranging (UAV-LiDAR) data in planted forests. Remote Sens. 2019, 11, 908. [Google Scholar] [CrossRef]
- Yao, W.; Krzystek, P.; Heurich, M. Tree species classification and estimation of stem volume and DBH based on single tree extraction by exploiting airborne full-waveform LiDAR data. Remote Sens. Environ. 2012, 123, 368–380. [Google Scholar] [CrossRef]
- Shinzato, E.T.; Shimabukuro, Y.E.; Coops, N.C.; Tompalski, P.; Gasparoto, E.A. Integrating area-based and individual tree detection approaches for estimating tree volume in plantation inventory using aerial image and airborne laser scanning data. iForest 2016, 10, 296. [Google Scholar] [CrossRef]
- Hyyppä, J.; Hyyppä, H.; Leckie, D.; Gougeon, F.; Yu, X.; Maltamo, M. Review of methods of small-footprint airborne laser scanning for extracting forest inventory data in boreal forests. Int. J. Remote Sens. 2008, 29, 1339–1366. [Google Scholar] [CrossRef]
- Hall, S.A.; Burke, I.C.; Box, D.O.; Kaufmann, M.R.; Stoker, J.M. Estimating stand structure using discrete-return lidar: An example from low density, fire prone ponderosa pine forests. For. Ecol. Manag. 2005, 208, 189–209. [Google Scholar] [CrossRef]
- Qin, Y.; Ferraz, A.; Mallet, C.; Iovan, C. Individual tree segmentation over large areas using airborne LiDAR point cloud and very high resolution optical imagery. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 800–803. [Google Scholar]
- Popescu, S.C.; Wynne, R.H. Seeing the trees in the forest. Photogramm. Eng. Remote Sens. 2004, 70, 589–604. [Google Scholar] [CrossRef]
- Chen, Q.; Baldocchi, D.; Gong, P.; Kelly, M. Isolating individual trees in a savanna woodland using small footprint lidar data. Photogramm. Eng. Remote Sens. 2006, 72, 923–932. [Google Scholar] [CrossRef]
- Wang, L.; Gong, P.; Biging, G.S. Individual tree-crown delineation and treetop detection in high-spatial-resolution aerial imagery. Photogramm. Eng. Remote Sens. 2004, 70, 351–357. [Google Scholar] [CrossRef]
- Heurich, M. Automatic recognition and measurement of single trees based on data from airborne laser scanning over the richly structured natural forests of the Bavarian Forest National Park. For. Ecol. Manag. 2008, 255, 2416–2433. [Google Scholar] [CrossRef]
- Ma, K.; Xiong, Y.; Jiang, F.; Chen, S.; Sun, H. A novel vegetation point cloud density tree-segmentation model for overlapping crowns using UAV LiDAR. Remote Sens. 2021, 13, 1422. [Google Scholar] [CrossRef]
- Jing, L.; Hu, B.; Noland, T.; Li, J. An individual tree crown delineation method based on multi-scale segmentation of imagery. ISPRS J. Photogramm. Remote Sens. 2012, 70, 88–98. [Google Scholar] [CrossRef]
- Balsi, M.; Esposito, S.; Fallavollita, P.; Nardinocchi, C. Single-tree detection in high-density LiDAR data from UAV-based survey. Eur. J. Remote Sens. 2018, 51, 679–692. [Google Scholar] [CrossRef]
- Zaforemska, A.; Xiao, W.; Gaulton, R. Individual tree detection from UAV LiDAR data in a mixed species woodland. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W13, 657–663. [Google Scholar] [CrossRef]
- Koch, B.; Heyder, U.; Weinacker, H. Detection of individual tree crowns in airborne lidar data. Photogramm. Eng. Remote Sens. 2006, 72, 357–363. [Google Scholar] [CrossRef]
- Hu, X.; Chen, W.; Xu, W. Adaptive Mean Shift-Based Identification of Individual Trees Using Airborne LiDAR Data. Remote Sens. 2017, 9, 148. [Google Scholar] [CrossRef]
- Ayrey, E.; Fraver, S.; Kershaw, J.A.; Kenefic, L.S.; Hayes, D.; Weiskittel, A.R.; Roth, B.E. Layer Stacking: A novel algorithm for individual forest tree segmentation from LiDAR point clouds. Can. J. Remote Sens. 2016, 43, 16–27. [Google Scholar] [CrossRef]
- Morsdorf, F.; Meier, E.; Kötz, B.; Itten, K.I.; Dobbertin, M.; Allgöwer, B. LiDAR-based geometric reconstruction of boreal type forest stands at single tree level for forest and wildland fire management. Remote Sens. Environ. 2004, 92, 353–362. [Google Scholar] [CrossRef]
- Lu, X.; Guo, Q.; Li, W.; Flanagan, J. A bottom-up approach to segment individual deciduous trees using leaf-off lidar point cloud data. ISPRS J. Photogramm. Remote Sens. 2014, 94, 1–12. [Google Scholar] [CrossRef]
- Shendryk, I.; Broich, M.; Tulbure, M.G.; Alexandrov, S.V. Bottom-up delineation of individual trees from full-waveform airborne laser scans in a structurally complex eucalypt forest. Remote Sens. Environ. 2016, 173, 69–83. [Google Scholar] [CrossRef]
- Alexander, C. Delineating tree crowns from airborne laser scanning point cloud data using Delaunay triangulation. Int. J. Remote Sens. 2009, 30, 3843–3848. [Google Scholar] [CrossRef]
- Duan, Z.; Zhao, D.; Zeng, Y.; Zhao, Y.; Wu, B.; Zhu, J. Assessing and Correcting Topographic Effects on Forest Canopy Height Retrieval Using Airborne LiDAR Data. Sensors 2015, 15, 12133–12155. [Google Scholar] [CrossRef]
- Yin, D.; Wang, L. Individual mangrove tree measurement using UAV-based LiDAR data Possibilities and challenges. Remote Sens. Environ. 2019, 223, 34–49. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, Y.; Zhang, Y.; Li, M.; Xie, M.; Mo, W. Response of vegetation normalized different vegetation index to different meteorological disaster indexes in karst region of Guangxi, China. Heliyon 2023, 9, e20518. [Google Scholar] [CrossRef]
- Vincent, L.; Soille, P. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef]
- Li, W.; Guo, Q.; Jakubowski, M.K.; Kelly, M. A new method for segmenting individual trees from the lidar point cloud. Photogramm. Eng. Remote Sens. 2012, 78, 75–84. [Google Scholar] [CrossRef]
- Yang, Q.; Su, Y.; Jin, S.; Kelly, M.; Hu, T.; Ma, Q.; Li, Y.; Song, S.; Zhang, J.; Xu, G.; et al. The influence of vegetation characteristics on individual tree segmentation methods with airborne LiDAR data. Remote Sens. 2019, 11, 2880. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Ene, L.; Gupta, S.; Heinzel, J.; Holmgren, J.; Pitkänen, J.; Solberg, S.; Wang, Y.; Weinacker, H.; Hauglin, K.M.; et al. Comparative testing of single-tree detection algorithms under different types of forest. Forestry 2012, 85, 27–40. [Google Scholar] [CrossRef]
- Zawawi, A.A.; Shiba, M.; Jemali, N.J.N. Accuracy of LiDAR-based tree height estimation and crown recognition in a subtropical evergreen broad-leaved forest in Okinawa, Japan. For. Syst. 2015, 24, e002. [Google Scholar]
- Guerra-Hernández, J.; Cosenza, D.N.; Rodriguez, L.C.E.; Silva, M.; Tomé, M.; Díaz-Varela, R.A.; González-Ferreiro, E. Comparison of ALS-and UAV (SfM)-derived high-density point clouds for individual tree detection in Eucalyptus plantations. Int. J. Remote Sens. 2018, 39, 5211–5235. [Google Scholar] [CrossRef]
- Peuhkurinen, J.; Mehtätalo, L.; Maltamo, M. Comparing individual tree detection and the area-based statistical approach for the retrieval of forest stand characteristics using airborne laser scanning in Scots pine stands. Can. J. For. Res. 2011, 41, 583–598. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Minimum | Maximum | Mean Value | Standard Deviation |
|---|---|---|---|---|
| Number of trees | n = 753 | |||
| DBH/cm | 2.50 | 15.80 | 7.76 | 2.81 |
| Tree Height/m | 3.57 | 18.00 | 10.17 | 3.01 |
| Crown/m | 1.20 | 3.80 | 2.10 | 0.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Y.; Lei, J.; Jin, J.; Shi, S.; Huang, Y. Unmanned Aerial Vehicle–Light Detection and Ranging-Based Individual Tree Segmentation in Eucalyptus spp. Forests: Performance and Sensitivity. Forests 2024, 15, 209. https://doi.org/10.3390/f15010209
Yan Y, Lei J, Jin J, Shi S, Huang Y. Unmanned Aerial Vehicle–Light Detection and Ranging-Based Individual Tree Segmentation in Eucalyptus spp. Forests: Performance and Sensitivity. Forests. 2024; 15(1):209. https://doi.org/10.3390/f15010209
Chicago/Turabian StyleYan, Yan, Jingjing Lei, Jia Jin, Shana Shi, and Yuqing Huang. 2024. "Unmanned Aerial Vehicle–Light Detection and Ranging-Based Individual Tree Segmentation in Eucalyptus spp. Forests: Performance and Sensitivity" Forests 15, no. 1: 209. https://doi.org/10.3390/f15010209
APA StyleYan, Y., Lei, J., Jin, J., Shi, S., & Huang, Y. (2024). Unmanned Aerial Vehicle–Light Detection and Ranging-Based Individual Tree Segmentation in Eucalyptus spp. Forests: Performance and Sensitivity. Forests, 15(1), 209. https://doi.org/10.3390/f15010209