
Estimation of Forest Stock Volume Combining Airborne LiDAR Sampling Approaches with Multi-Sensor Imagery

Abstract
:1. Introduction
2. Materials and Methods
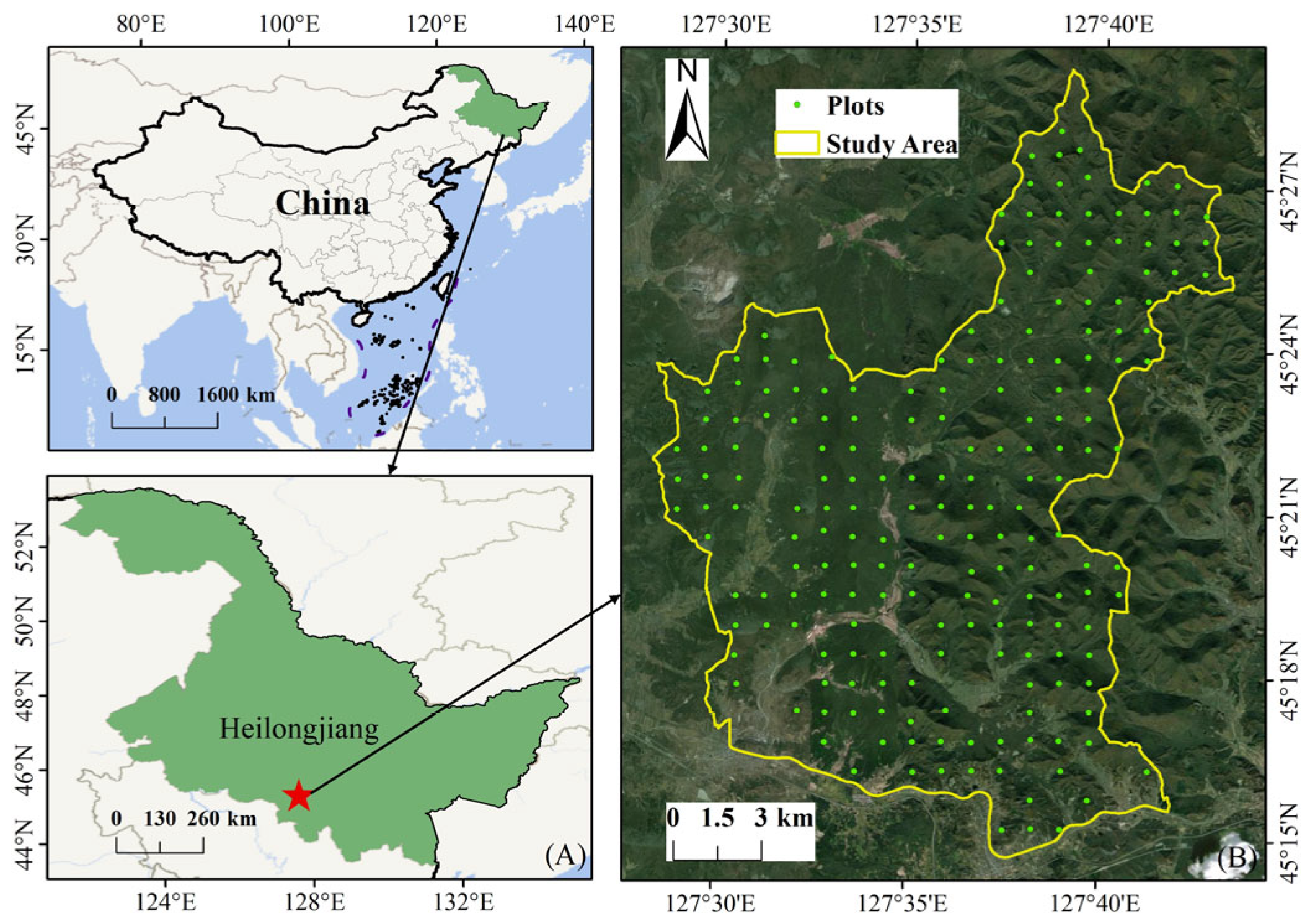
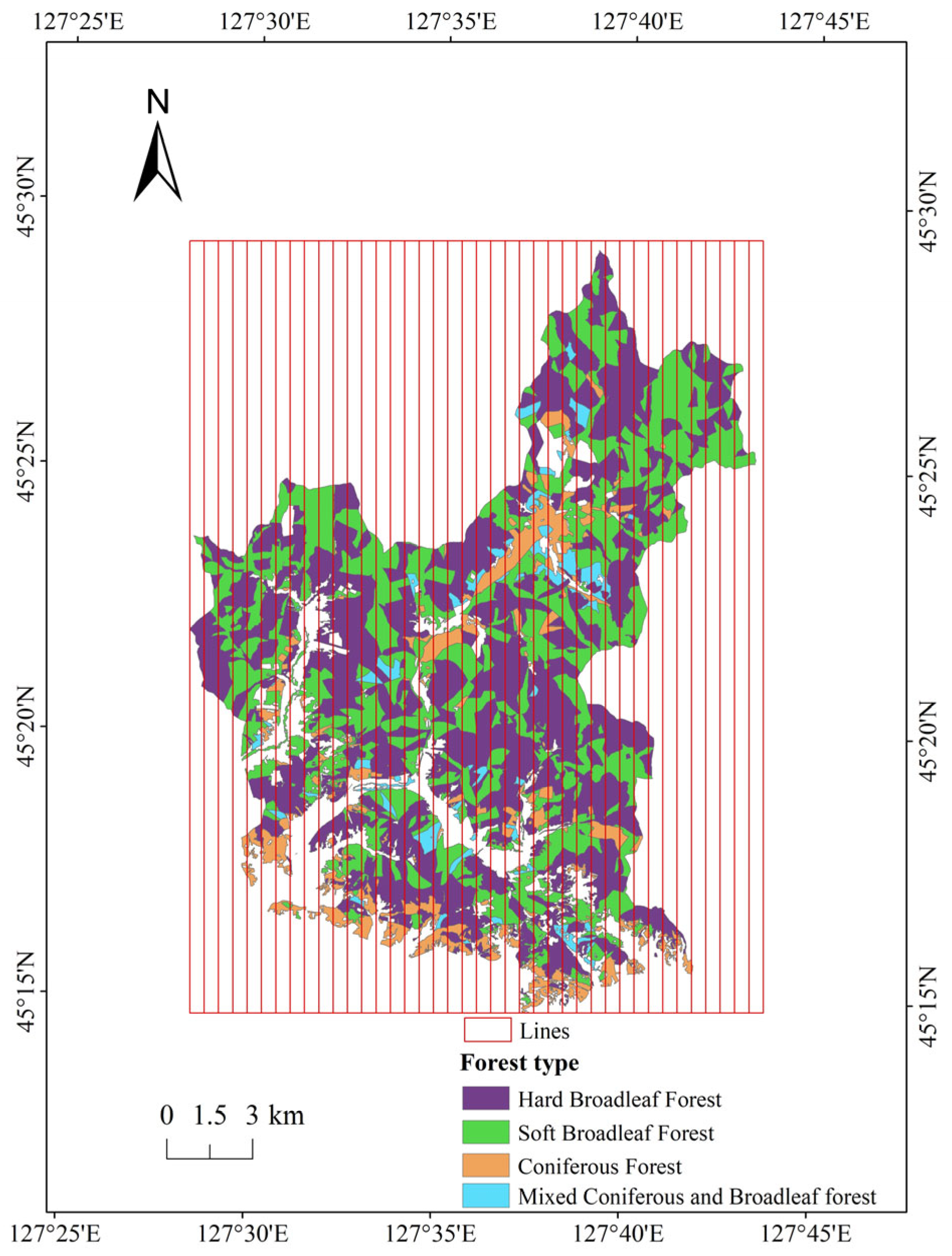
2.1. Study Area
2.2. Field and Multi-Sensor Data Acquisition
2.3. Methods
2.3.1. Remote Sensing Data Processing
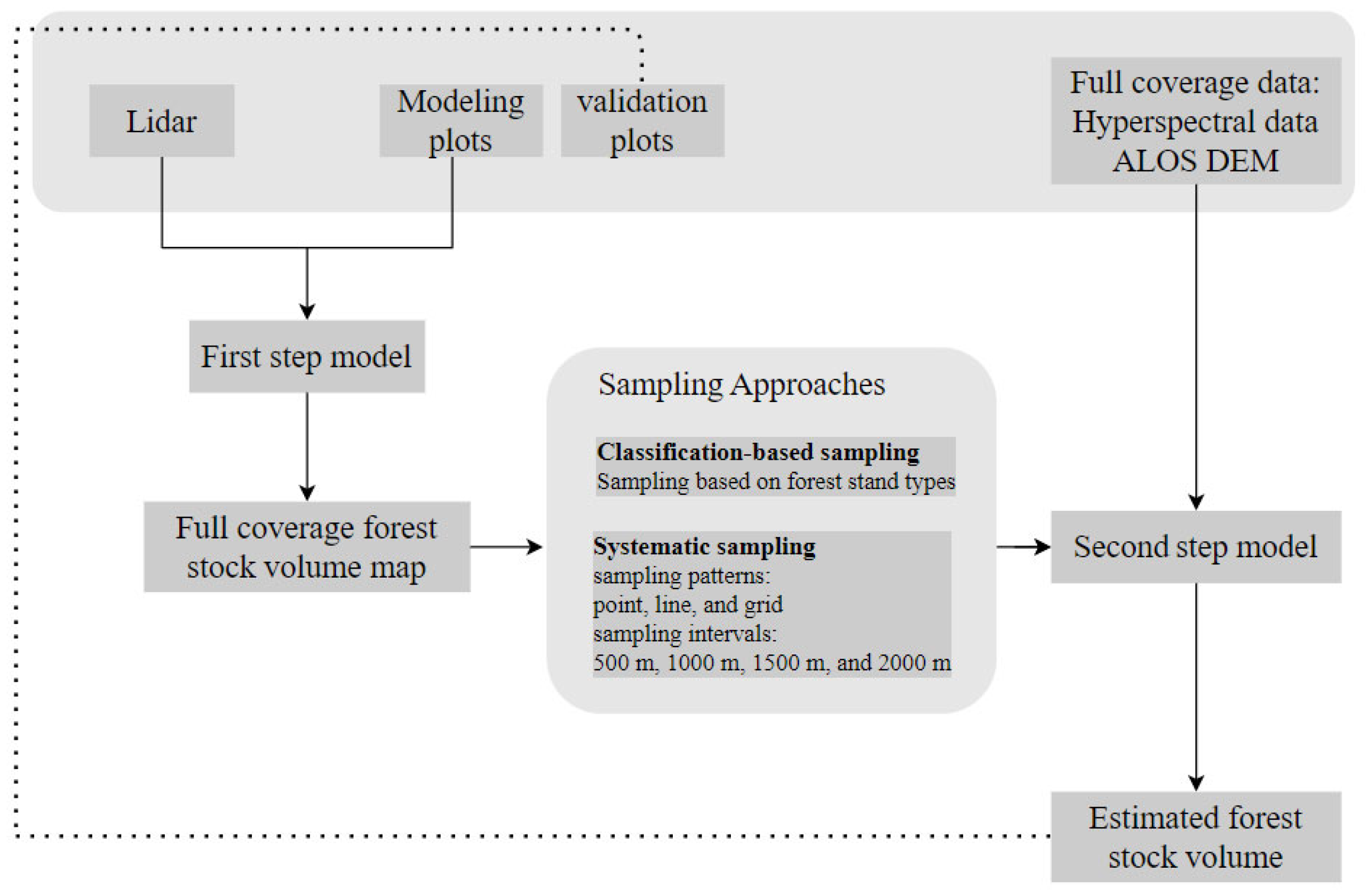
2.3.2. Overview
2.3.3. Modeling and Feature Selection
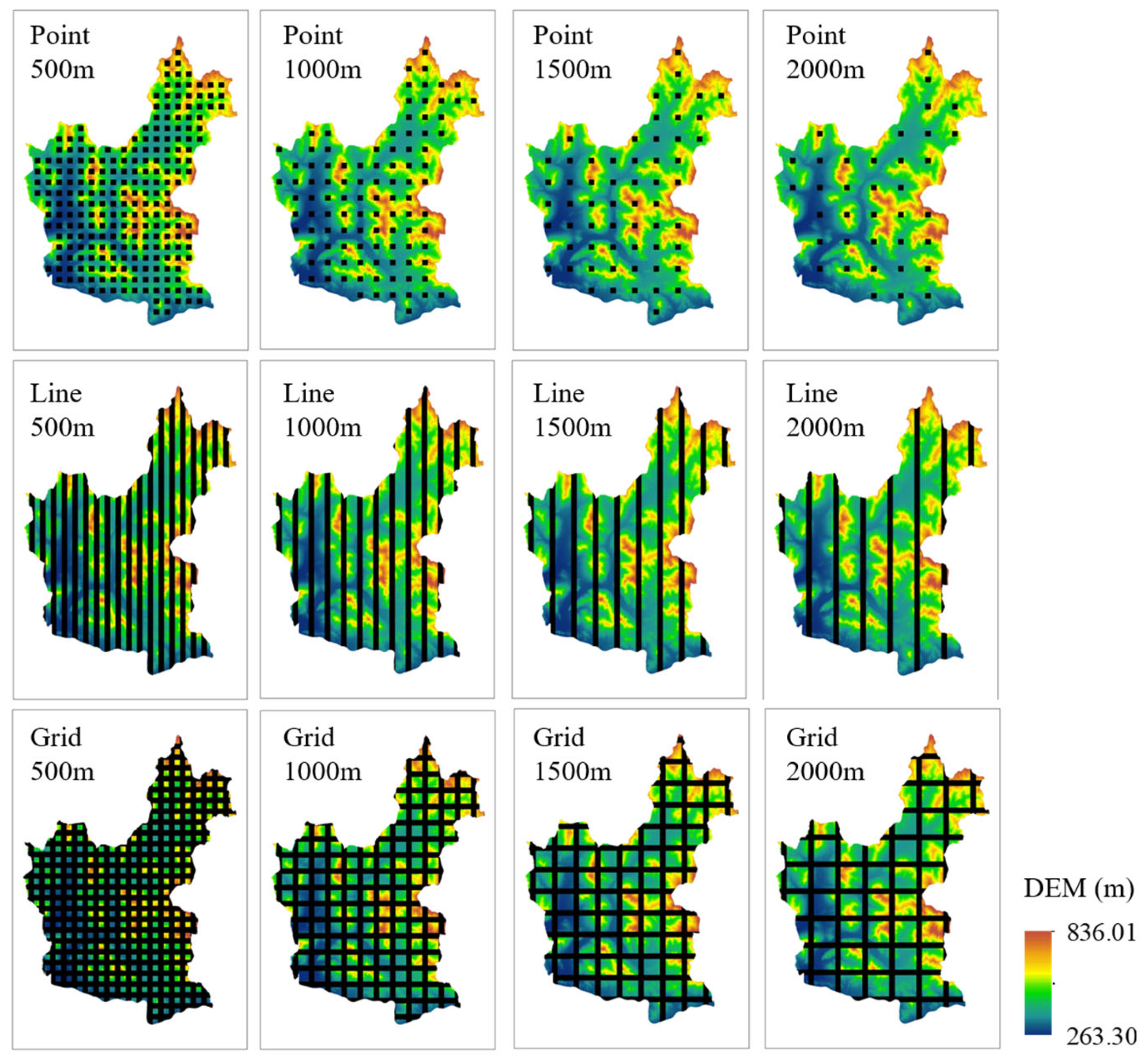
2.3.4. Systematic Sampling
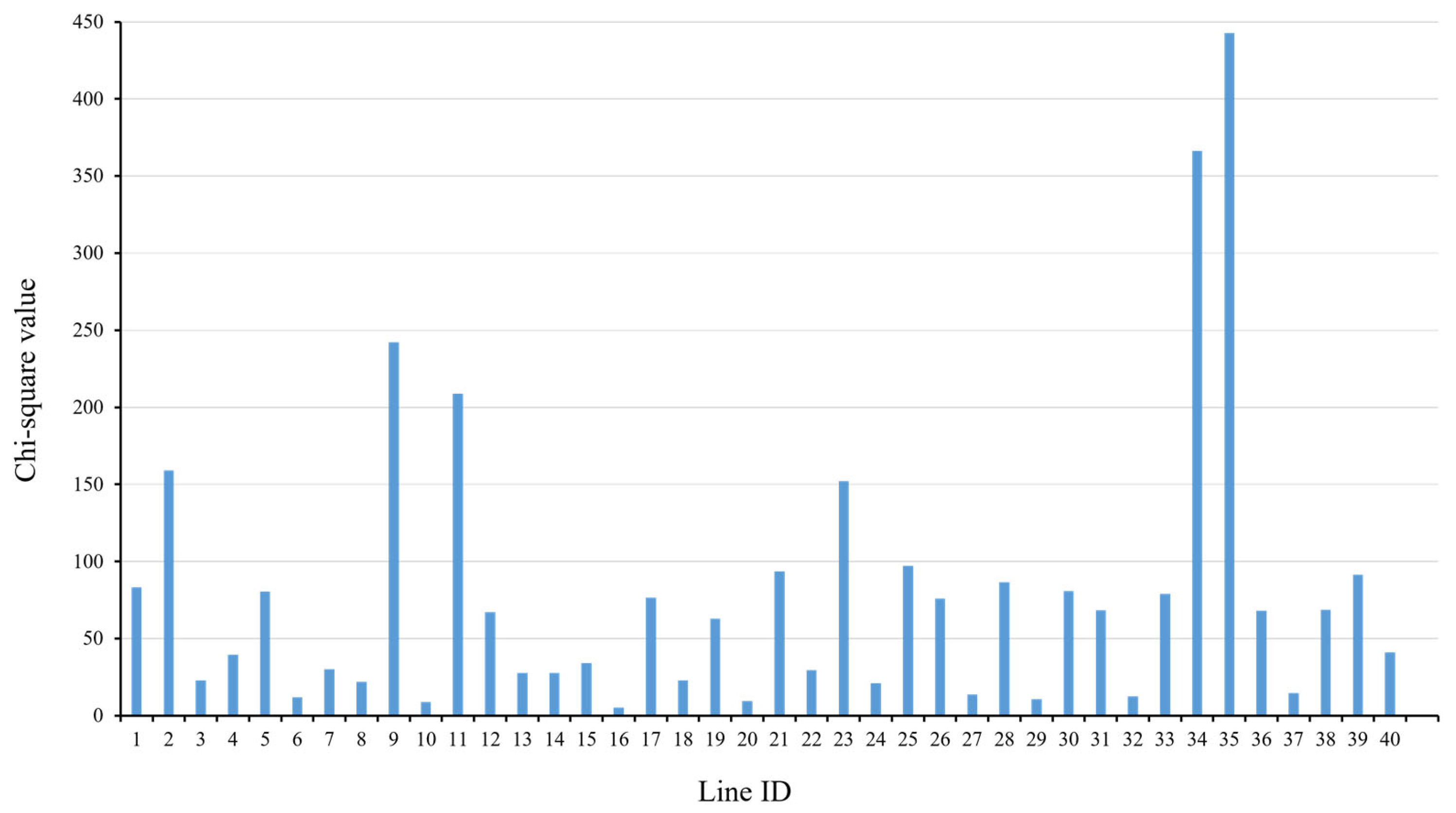
2.3.5. Sampling Based on Forest Stand Types
2.3.6. Accuracy Evaluation
3. Results
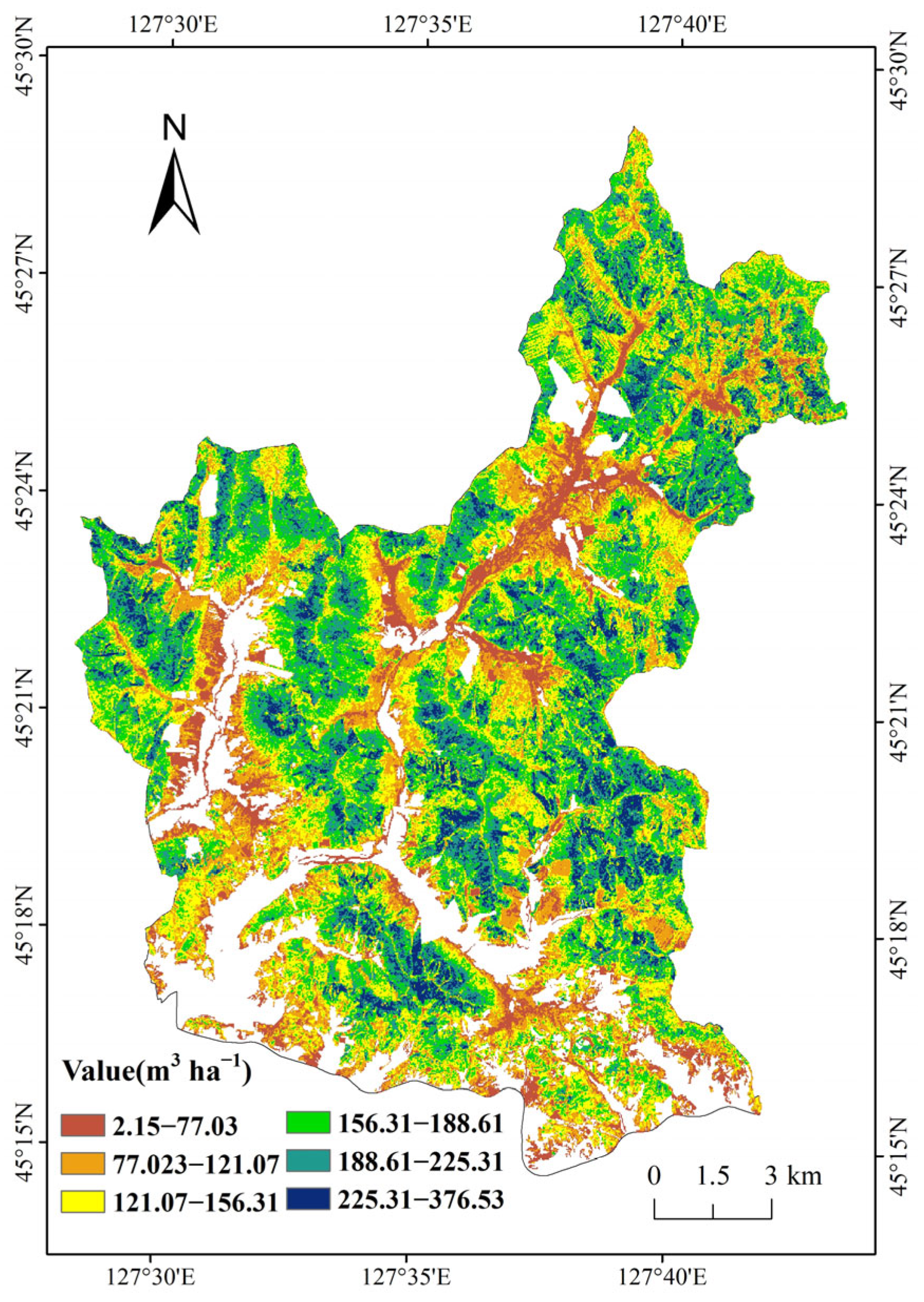
3.1. Full-Coverage LiDAR Forest Stock Volume Estimation
3.2. Systematic Sampling for Forest Stock Volume Estimation
3.3. Classification-Based Sampling for Forest Stock Volume Estimation
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pan, Y.D.; Birdsey, R.A.; Fang, J.Y.; Houghton, R.; Kauppi, P.E.; Kurz, W.A.; Phillips, O.L.; Shvidenko, A.; Lewis, S.L.; Canadell, J.G.; et al. A Large and Persistent Carbon Sink in the World’s Forests. Science 2011, 333, 988–993. [Google Scholar] [CrossRef]
- Condés, S.; McRoberts, R.E. Updating national forest inventory estimates of growing stock volume using hybrid inference. For. Ecol. Manag. 2017, 400, 48–57. [Google Scholar] [CrossRef]
- Liang, X.L.; Hyyppä, J.; Kaartinen, H.; Lehtomäki, M.; Pyörälä, J.; Pfeifer, N.; Holopainen, M.; Brolly, G.; Pirotti, F.; Hackenberg, J.; et al. International benchmarking of terrestrial laser scanning approaches for forest inventories. ISPRS J. Photogramm. 2018, 144, 137–179. [Google Scholar] [CrossRef]
- Boisvenue, C.; Smiley, B.P.; White, J.C.; Kurz, W.A.; Wulder, M.A. Integration of Landsat time series and field plots for forest productivity estimates in decision support models. For. Ecol. Manag. 2016, 376, 284–297. [Google Scholar] [CrossRef]
- Hao, Y.S.; Widagdo, F.R.A.; Liu, X.; Quan, Y.; Dong, L.H.; Li, F.R. Individual Tree Diameter Estimation in Small-Scale Forest Inventory Using UAV Laser Scanning. Remote Sens. 2021, 13, 24. [Google Scholar] [CrossRef]
- Tomppo, E.; Olsson, H.; Ståhl, G.; Nilsson, M.; Hagner, O.; Katila, M. Combining national forest inventory field plots and remote sensing data for forest databases. Remote Sens. Environ. 2008, 112, 1982–1999. [Google Scholar] [CrossRef]
- Saarela, S.; Grafström, A.; Ståhl, G.; Kangas, A.; Holopainen, M.; Tuominen, S.; Nordkvist, K.; Hyyppä, J. Model-assisted estimation of growing stock volume using different combinations of LiDAR and Landsat data as auxiliary information. Remote Sens. Environ. 2015, 158, 431–440. [Google Scholar] [CrossRef]
- Kilpeläinen, P.; Tokola, T. Gain to be achieved from stand delineation in LANDSAT TM image-based estimates of stand volume. For. Ecol. Manag. 1999, 124, 105–111. [Google Scholar] [CrossRef]
- Chrysafis, I.; Mallinis, G.; Tsakiri, M.; Patias, P. Evaluation of single-date and multi-seasonal spatial and spectral information of Sentinel-2 imagery to assess growing stock volume of a Mediterranean forest. Int. J. Appl. Earth Obs. 2019, 77, 1–14. [Google Scholar] [CrossRef]
- Long, J.P.; Lin, H.; Wang, G.X.; Sun, H.; Yan, E.P. Mapping Growing Stem Volume of Chinese Fir Plantation Using a Saturation-based Multivariate Method and Quad-polarimetric SAR Images. Remote Sens. 2019, 11, 1872. [Google Scholar] [CrossRef]
- Chen, L.; Ren, C.Y.; Zhang, B.; Wang, Z.M. Multi-Sensor Prediction of Stand Volume by a Hybrid Model of Support Vector Machine for Regression Kriging. Forests 2020, 11, 296. [Google Scholar] [CrossRef]
- Santi, E.; Paloscia, S.; Pettinato, S.; Chirici, G.; Mura, M.; Maselli, F. Application of Neural Networks for the retrieval of forest woody volume from SAR multifrequency data at L and C bands. Eur. J. Remote Sens. 2015, 48, 673–687. [Google Scholar] [CrossRef]
- Cartus, O.; Kellndorfer, J.; Rombach, M.; Walker, W. Mapping Canopy Height and Growing Stock Volume Using Airborne Lidar, ALOS PALSAR and Landsat ETM. Remote Sens. 2012, 4, 3320–3345. [Google Scholar] [CrossRef]
- Puliti, S.; Saarela, S.; Gobakken, T.; Ståhl, G.; Næsset, E. Combining UAV and Sentinel-2 auxiliary data for forest growing stock volume estimation through hierarchical model-based inference. Remote Sens. Environ. 2018, 204, 485–497. [Google Scholar] [CrossRef]
- Chen, L.; Ren, C.Y.; Zhang, B.; Wang, Z.M.; Liu, M.Y.; Man, W.D.; Liu, J.F. Improved estimation of forest stand volume by the integration of GEDI LiDAR data and multi-sensor imagery in the Changbai Mountains Mixed forests Ecoregion (CMMFE), northeast China. Int. J. Appl. Earth Obs. 2021, 100, 102326. [Google Scholar] [CrossRef]
- Gong, P.; Pu, R.L.; Biging, G.S.; Larrieu, M.R. Estimation of forest leaf area index using vegetation indices derived from Hyperion hyperspectral data. IEEE T Geosci. Remote 2003, 41, 1355–1362. [Google Scholar] [CrossRef]
- Psomas, A.; Kneubühler, M.; Huber, S.; Itten, K.; Zimmermann, N.E. Hyperspectral remote sensing for estimating aboveground biomass and for exploring species richness patterns of grassland habitats. Int. J. Remote Sens. 2011, 32, 9007–9031. [Google Scholar] [CrossRef]
- Roth, K.L.; Roberts, D.A.; Dennison, P.E.; Peterson, S.H.; Alonzo, M. The impact of spatial resolution on the classification of plant species and functional types within imaging spectrometer data. Remote Sens. Environ. 2015, 171, 45–57. [Google Scholar] [CrossRef]
- Quan, Y.; Li, M.Z.; Hao, Y.S.; Liu, J.Y.; Wang, B. Tree species classification in a typical natural secondary forest using UAV-borne LiDAR and hyperspectral data. Gisci Remote Sens. 2023, 60, 2171706. [Google Scholar] [CrossRef]
- Wan, L.M.; Lin, Y.Y.; Zhang, H.S.; Wang, F.; Liu, M.F.; Lin, H. GF-5 Hyperspectral Data for Species Mapping of Mangrove in Mai Po, Hong Kong. Remote Sens. 2020, 12, 656. [Google Scholar] [CrossRef]
- Kandare, K.; Dalponte, M.; Orka, H.O.; Frizzera, L.; Naesset, E. Prediction of Species-Specific Volume Using Different Inventory Approaches by Fusing Airborne Laser Scanning and Hyperspectral Data. Remote Sens. 2017, 9, 400. [Google Scholar] [CrossRef]
- De Almeida, C.T.; Galvao, L.S.; Aragao, L.E.D.E.; Ometto, J.P.H.B.; Jacon, A.D.; Pereira, F.R.D.; Sato, L.Y.; Lopes, A.P.; Graça, P.M.L.D.; Silva, C.V.D.; et al. Combining LiDAR and hyperspectral data for aboveground biomass modeling in the Brazilian Amazon using different regression algorithms. Remote Sens. Environ. 2019, 232, 111323. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Hartig, F.; Latifi, H.; Berger, C.; Hernández, J.; Corvalán, P.; Koch, B. Importance of sample size, data type and prediction method for remote sensing-based estimations of aboveground forest biomass. Remote Sens. Environ. 2014, 154, 102–114. [Google Scholar] [CrossRef]
- Koch, B. Status and future of laser scanning, synthetic aperture radar and hyperspectral remote sensing data for forest biomass assessment. ISPRS J. Photogramm. 2010, 65, 581–590. [Google Scholar] [CrossRef]
- Chirici, G.; Giannetti, F.; McRoberts, R.E.; Travaglini, D.; Pecchi, M.; Maselli, F.; Chiesi, M.; Corona, P. Wall-to-wall spatial prediction of growing stock volume based on Italian National Forest Inventory plots and remotely sensed data. Int. J. Appl. Earth Obs. 2020, 84, 101959. [Google Scholar] [CrossRef]
- De Souza, G.S.A.; Soares, V.P.; Leite, H.G.; Gleriani, J.M.; do Amaral, C.H.; Ferraz, A.S.; Silveira, M.V.D.; dos Santos, J.F.C.; Velloso, S.G.S.; Domingues, G.F.; et al. Multi-sensor prediction of stand volume: A support vector approach. ISPRS J. Photogramm. 2019, 156, 135–146. [Google Scholar] [CrossRef]
- Li, S.Q.; Quackenbush, L.J.; Im, J. Airborne Lidar Sampling Strategies to Enhance Forest Aboveground Biomass Estimation from Landsat Imagery. Remote Sens. 2019, 11, 1906. [Google Scholar] [CrossRef]
- Matasci, G.; Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W.; Zald, H.S.J. Large-area mapping of Canadian boreal forest cover, height, biomass and other structural attributes using Landsat composites and lidar plots. Remote Sens. Environ. 2018, 209, 90–106. [Google Scholar] [CrossRef]
- Li, W.; Niu, Z.; Shang, R.; Qin, Y.C.; Wang, L.; Chen, H.Y. High-resolution mapping of forest canopy height using machine learning by coupling ICESat-2 LiDAR with Sentinel-1, Sentinel-2 and Landsat-8 data. Int. J. Appl. Earth Obs. 2020, 92, 102163. [Google Scholar] [CrossRef]
- Rahlf, J.; Breidenbach, J.; Solberg, S.; Næsset, E.; Astrup, R. Comparison of four types of 3D data for timber volume estimation. Remote Sens. Environ. 2014, 155, 325–333. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Nelson, R.F.; Næsset, E.; Orka, H.O.; Coops, N.C.; Hilker, T.; Bater, C.W.; Gobakken, T. Lidar sampling for large-area forest characterization: A review. Remote Sens. Environ. 2012, 121, 196–209. [Google Scholar] [CrossRef]
- Tsui, O.W.; Coops, N.C.; Wulder, M.A.; Marshall, P.L. Integrating airborne LiDAR and space-borne radar via multivariate kriging to estimate above-ground biomass. Remote Sens. Environ. 2013, 139, 340–352. [Google Scholar] [CrossRef]
- Hudak, A.T.; Lefsky, M.A.; Cohen, W.B.; Berterretche, M. Integration of lidar and Landsat ETM+ data for estimating and mapping forest canopy height. Remote Sens. Environ. 2002, 82, 397–416. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J. An airborne lidar sampling strategy to model forest canopy height from Quickbird imagery and GEOBIA. Remote Sens. Environ. 2011, 115, 1532–1542. [Google Scholar] [CrossRef]
- Quan, Y.; Li, M.Z.; Hao, Y.S.; Wang, B. Comparison and Evaluation of Different Pit-Filling Methods for Generating High Resolution Canopy Height Model Using UAV Laser Scanning Data. Remote Sens. 2021, 13, 2239. [Google Scholar] [CrossRef]
- Pang, Y.; Li, Z.; Ju, H.; Lu, H.; Jia, W.; Si, L.; Guo, Y.; Liu, Q.; Li, S.; Liu, L.; et al. LiCHy: The CAF’s LiDAR, CCD and Hyperspectral Integrated Airborne Observation System. Remote Sens. 2016, 8, 398. [Google Scholar] [CrossRef]
- Guo, Q.; Li, W.; Yu, H.; Alvarez, O. Effects of Topographic Variability and Lidar Sampling Density on Several DEM Interpolation Methods. Photogramm. Eng. Remote Sens. 2010, 76, 701–712. [Google Scholar] [CrossRef]
- Zhen, Z.; Yang, L.; Ma, Y.; Wei, Q.B.; Il Jin, H.; Zhao, Y.H. Upscaling aboveground biomass of larch (Henry) plantations from field to satellite measurements: A comparison of individual tree-based and area-based approaches. Gisci Remote Sens. 2022, 59, 722–743. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Keydan, G.P.; Merzlyak, M.N. Three-band model for noninvasive estimation of chlorophyll, carotenoids, and anthocyanin contents in higher plant leaves. Geophys. Res. Lett. 2006, 33, L11402. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Sims, D.A.; Gamon, J.A. Relationships between leaf pigment content and spectral reflectance across a wide range of species, leaf structures and developmental stages. Remote Sens. Environ. 2002, 81, 337–354. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Evangelides, C.; Nobajas, A. Red-Edge Normalised Difference Vegetation Index (NDVI705) from Sentinel-2 imagery to assess post-fire regeneration. Remote Sens. Appl. Soc. Environ. 2020, 17, 100283. [Google Scholar] [CrossRef]
- Gamon, J.A.; Peñuelas, J.; Field, C.B. A narrow-waveband spectral index that tracks diurnal changes in photosynthetic efficiency. Remote Sens. Environ. 1992, 41, 35–44. [Google Scholar] [CrossRef]
- Merzlyak, M.N.; Gitelson, A.A.; Chivkunova, O.B.; Rakitin, V.Y.U. Non-destructive optical detection of pigment changes during leaf senescence and fruit ripening. Physiol. Plant. 2002, 106, 135–141. [Google Scholar] [CrossRef]
- Jordan, C.F. Derivation of Leaf-Area Index from Quality of Light on the Forest Floor. Ecology 1969, 50, 663–666. [Google Scholar] [CrossRef]
- You, W.Q.; Wang, Z.Y.; Lu, F.; Zhao, Y.S.; Lu, S. Spectral indices to assess the carotenoid/chlorophyll ratio from adaxial and abaxial leaf reflectance. Spectrosc. Lett. 2017, 50, 387–393. [Google Scholar] [CrossRef]
- Vogelmann, J.E.; Rock, B.N.; Moss, D.M. Red edge spectral measurements from sugar maple leaves. Int. J. Remote Sens. 2007, 14, 1563–1575. [Google Scholar] [CrossRef]
- Penuelas, J.; Pinol, J.; Ogaya, R.; Filella, I. Estimation of plant water concentration by the reflectance Water Index WI (R900/R970). Int. J. Remote Sens. 2010, 18, 2869–2875. [Google Scholar] [CrossRef]
- Dong, L.H.; Zhang, Y.; Zhang, Z.; Xie, L.F.; Li, F.R. Comparison of Tree Biomass Modeling Approaches for Larch (Henry) Trees in Northeast China. Forests 2020, 11, 202. [Google Scholar] [CrossRef]
- Yu, X.H.; Ge, H.L.; Lu, D.S.; Zhang, M.Z.; Lai, Z.X.; Yao, R.T. Comparative Study on Variable Selection Approaches in Establishment of Remote Sensing Model for Forest Biomass Estimation. Remote Sens. 2019, 11, 1437. [Google Scholar] [CrossRef]
- Skowronski, N.S.; Clark, K.L.; Gallagher, M.; Birdsey, R.A.; Hom, J.L. Airborne laser scanner-assisted estimation of aboveground biomass change in a temperate oak-pine forest. Remote Sens. Environ. 2014, 151, 166–174. [Google Scholar] [CrossRef]
- Zhao, P.P.; Lu, D.S.; Wang, G.X.; Wu, C.P.; Huang, Y.J.; Yu, S.Q. Examining Spectral Reflectance Saturation in Landsat Imagery and Corresponding Solutions to Improve Forest Aboveground Biomass Estimation. Remote Sens. 2016, 8, 469. [Google Scholar] [CrossRef]
- Hao, Y.S.; Widagdo, F.R.A.; Liu, X.; Quan, Y.; Liu, Z.G.; Dong, L.H.; Li, F.R. Estimation and calibration of stem diameter distribution using UAV laser scanning data: A case study for larch forests in Northeast China. Remote Sens. Environ. 2022, 268, 112769. [Google Scholar] [CrossRef]
- Zhou, K.; Cao, L.; Liu, H.; Zhang, Z.N.; Wang, G.B.; Cao, F.L. Estimation of volume resources for planted forests using an advanced LiDAR and hyperspectral remote sensing. Resour. Conserv. Recy 2022, 185, 106485. [Google Scholar] [CrossRef]
- Wang, D.Z.; Qiu, P.H.; Wan, B.; Cao, Z.X.; Zhang, Q.F. Mapping α- and β-diversity of mangrove forests with multispectral and hyperspectral images. Remote Sens. Environ. 2022, 275, 113021. [Google Scholar] [CrossRef]
- Chen, Q.; Laurin, G.V.; Battles, J.J.; Saah, D. Integration of airborne lidar and vegetation types derived from aerial photography for mapping aboveground live biomass. Remote Sens. Environ. 2012, 121, 108–117. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plot Group | Plot Number | Volume (m3/ha) | |||
|---|---|---|---|---|---|
| Mean | Max | Min | SD | ||
| Modeling | 137 | 172.62 | 468.99 | 34.01 | 66.91 |
| Validation | 60 | 181.49 | 347.11 | 54.34 | 59.64 |
| Total | 197 | 175.32 | 468.99 | 34.01 | 64.76 |
| Metric Type | Metrics | Description |
|---|---|---|
| Height (38) | Hmax, Hmean | Maximum height, mean height |
| HVAR, HSD, HCV | Variance of heights, standard deviation of heights, coefficient of variation of heights | |
| HSK, HK | Skewness of heights, kurtosis of heights | |
| HIQ | Interquartile distance of percentile heights | |
| H01, H05, H10, H20, H25, H30, H40, H50, H60, H70, H75, H80, H90, H95, H99 | Height percentiles. Point clouds are sorted by elevation. HX is the height of X% of the point clouds. | |
| AIH01, AIH05, AIH10, AIH20, AIH25, AIH30, AIH40, AIH50, AIH60, AIH70, AIH75, AIH80, AIH90, AIH95, AIH99 | Cumulative height percentiles. Point clouds are sorted by elevation and the cumulative height of all points is calculated. AIHX is the cumulative height of X% of the point clouds. | |
| Density (10) | D01, D02, D03, D04, D05, D06, D07, D08, D09 | Canopy return density. Point clouds are divided into ten slices of the same interval from low to high elevation. DX is the ratio of the number of echoes per layer. |
| Intensity (38) | Imax, Imean | Maximum intensity, mean intensity |
| IVAR, ISD, ICV | Variance of intensities, standard deviation of intensities, Coefficient of variation of intensities | |
| ISK, IK | Skewness of intensities, kurtosis of intensities | |
| HIQ | Interquartile distance of percentile intensities | |
| I01, I05, I10, I20, I25, I30, I40, I50, I60, I70, I75, I80, I90, I95, I99 | Intensity percentiles. Point clouds are sorted by intensity. IX is the intensity of X% of the point clouds. | |
| AII01, AII05, AII10, AII20, AII25, AII30, AII40, AII50, AII60, AII70, AII75, AII80, AII90, AII95, AII99 | Cumulative intensity percentiles. Point clouds are sorted by intensity and the cumulative intensity of all points is calculated. AIIX is the cumulative intensity of X% of the point clouds. | |
| Canopy (2) | CC | Canopy cover |
| CRR | Canopy relief ratio | |
| Topography (3) | DEM, Slope, Aspect | Elevation, slope, aspect |
| Abbr. | Vegetation Index | Equation | Reference |
|---|---|---|---|
| ARI1 | Anthocyanin Reflectance Index 1 | 1/B550 − 1/B700 | [39] |
| ARI2 | Anthocyanin Reflectance Index 2 | B800 (1/B550 − 1/B700) | [39] |
| CRI1 | Carotenoid Reflectance Index 1 | 1/B510 − 1/B550 | [39] |
| CRI2 | Carotenoid Reflectance Index 2 | 1/B510 − 1/B700 | [39] |
| EVI | Enhanced Vegetation Index | 2.5 (B797 − B673)/(B797 + 6 B673 − 7.5 B474 + 1) | [40] |
| mSR705 | Modified Red-Edge Simple Ratio Index | (B750 − B445)/(B750 + B445) | [41] |
| NDVI | Normalized Difference Vegetation Index | (B797 − B680)/(B797 + B680) | [42] |
| NDVI705 | Red-Edge Normalized Difference Vegetation Index | (B750 − B705)/(B750 + B705) | [43] |
| PRI | Photochemical Reflectance Index | (B531 − B570)/(B531 + B570) | [44] |
| PSRI | Plant Senescence Reflectance Index | (B680 − B500)/B750 | [45] |
| SR | Simple Ratio Index | B797/B680 | [46] |
| SIPI | Structure-Insensitive Pigment Index | (B800 − B445)/(B800 + B680) | [47] |
| VOG1 | Vogelmann Red-Edge Index 1 | B740/B720 | [48] |
| WBI | Water Band Index | B900/B970 | [49] |
| Sampling Pattern | Sampling Interval (m) | Pixel Count | RMSE (m3/ha) | RMSE% (%) | BIAS (m3/ha) | BIAS% (%) |
|---|---|---|---|---|---|---|
| Point | 500 | 85,006 | 56.46 | 31.11 | 22.37 | 12.32 |
| 1000 | 36,785 | 56.26 | 31.00 | 22.10 | 12.18 | |
| 1500 | 20,860 | 56.41 | 31.08 | 23.16 | 12.76 | |
| 2000 | 14,496 | 56.51 | 31.13 | 22.98 | 12.66 | |
| Line | 500 | 187,234 | 56.09 | 30.90 | 22.20 | 12.23 |
| 1000 | 124,691 | 55.81 | 30.75 | 21.55 | 11.87 | |
| 1500 | 97,024 | 56.21 | 30.97 | 22.00 | 12.12 | |
| 2000 | 75,242 | 57.42 | 31.64 | 24.89 | 13.71 | |
| Grid | 500 | 280,348 | 56.56 | 31.16 | 22.64 | 12.48 |
| 1000 | 207,548 | 56.37 | 31.06 | 22.07 | 12.16 | |
| 1500 | 165,927 | 56.28 | 31.01 | 22.07 | 12.16 | |
| 2000 | 132,812 | 56.99 | 31.40 | 23.97 | 13.21 |
| Sampling Lines | Pixel Count | RMSE (m3/ha) | RMSE% (%) | BIAS (m3/ha) | BIAS% (%) |
|---|---|---|---|---|---|
| Line 6, 10, 16, 20, 27, 29, 32, 37 | 82,291 | 55.56 | 30.61 | 20.68 | 11.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Quan, Y.; Wang, B.; Shi, J.; Ming, L.; Li, M. Estimation of Forest Stock Volume Combining Airborne LiDAR Sampling Approaches with Multi-Sensor Imagery. Forests 2023, 14, 2453. https://doi.org/10.3390/f14122453
Liu J, Quan Y, Wang B, Shi J, Ming L, Li M. Estimation of Forest Stock Volume Combining Airborne LiDAR Sampling Approaches with Multi-Sensor Imagery. Forests. 2023; 14(12):2453. https://doi.org/10.3390/f14122453
Chicago/Turabian StyleLiu, Jianyang, Ying Quan, Bin Wang, Jinan Shi, Lang Ming, and Mingze Li. 2023. "Estimation of Forest Stock Volume Combining Airborne LiDAR Sampling Approaches with Multi-Sensor Imagery" Forests 14, no. 12: 2453. https://doi.org/10.3390/f14122453
APA StyleLiu, J., Quan, Y., Wang, B., Shi, J., Ming, L., & Li, M. (2023). Estimation of Forest Stock Volume Combining Airborne LiDAR Sampling Approaches with Multi-Sensor Imagery. Forests, 14(12), 2453. https://doi.org/10.3390/f14122453