Object-Based Tree Species Classification Using Airborne Hyperspectral Images and LiDAR Data


Abstract
:1. Introduction
2. Materials and Methods
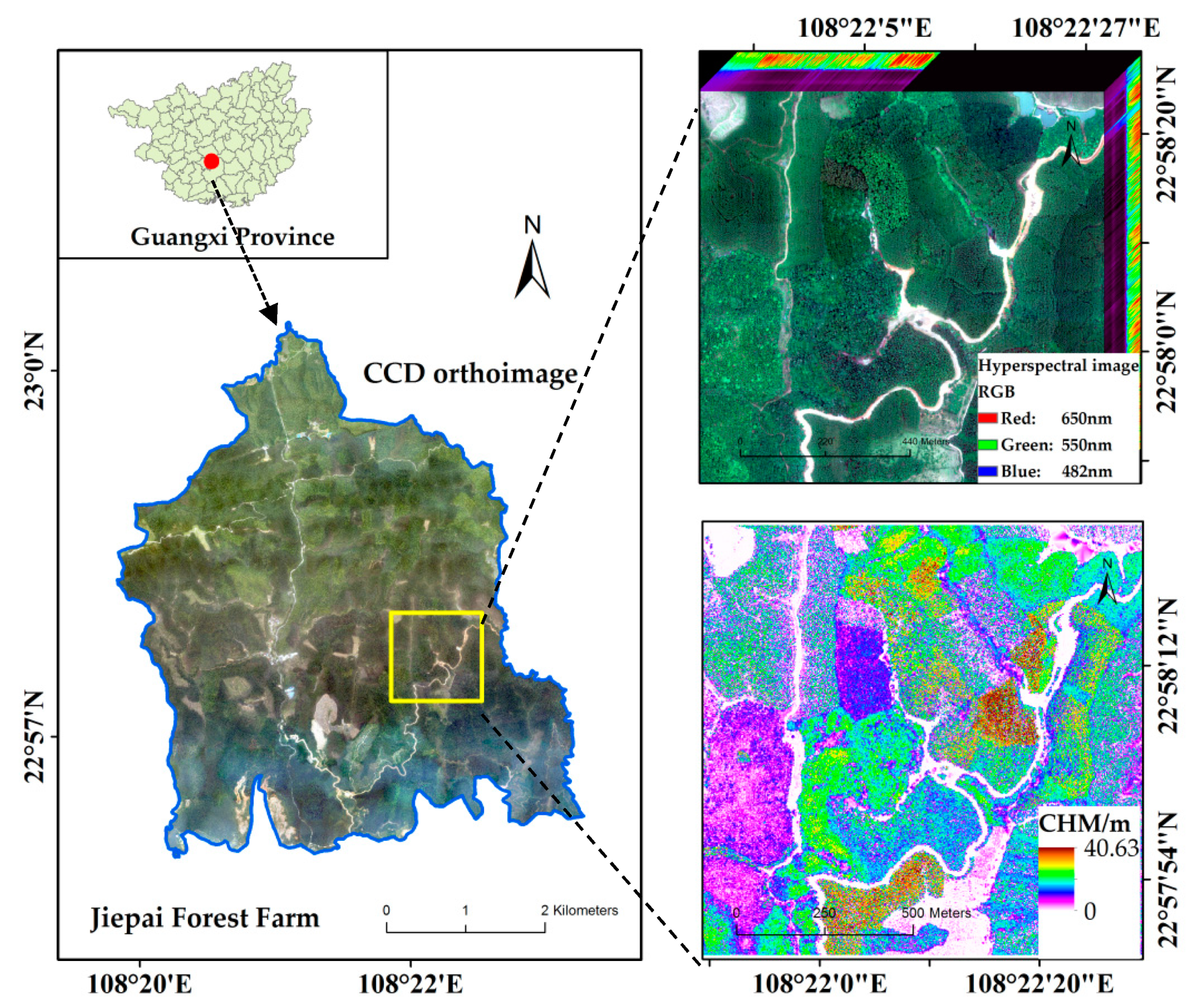
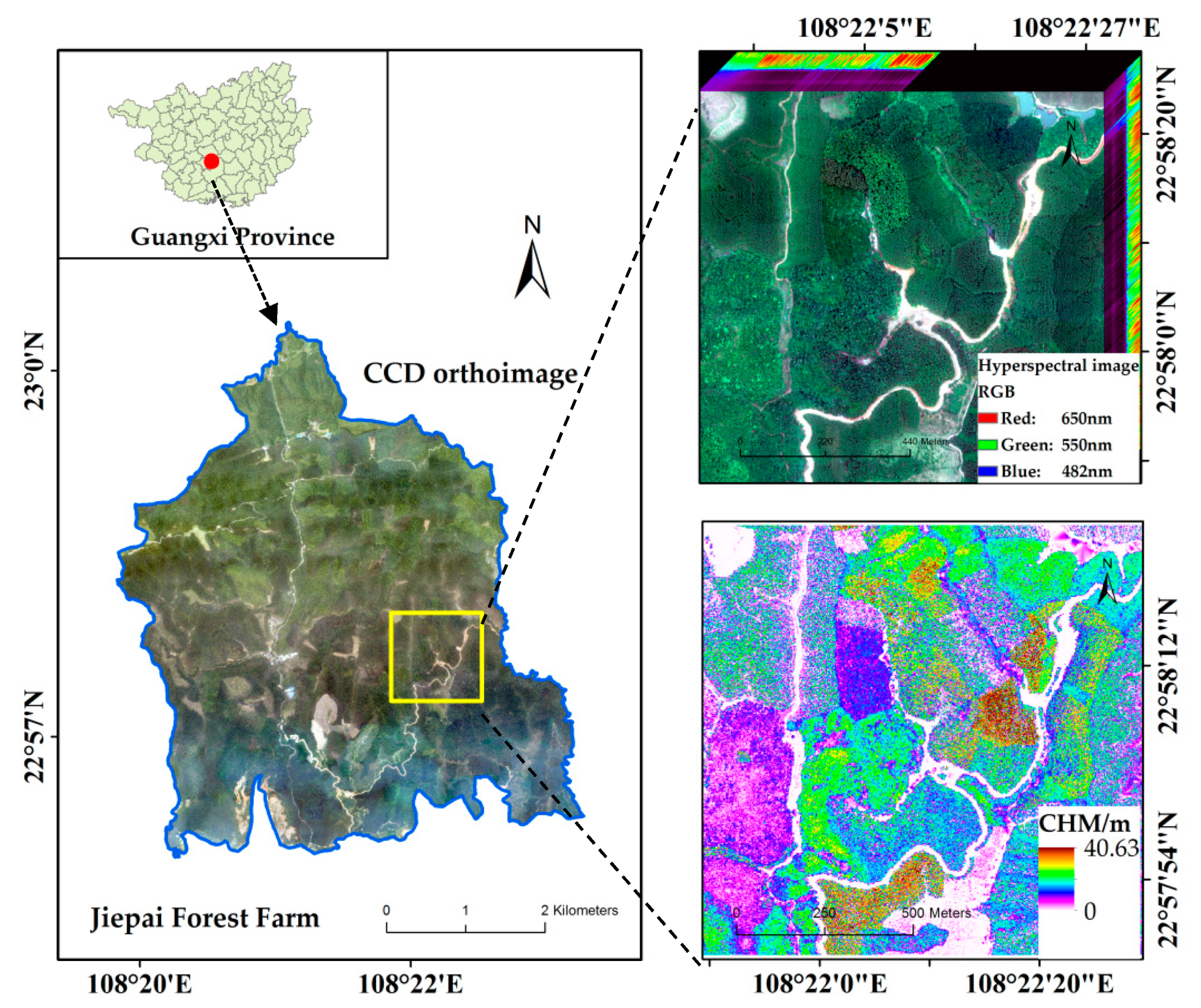
2.1. Study Area
2.2. Data Collection and Preprocessing
2.2.1. Data Collection
2.2.2. Data Preprocessing
2.3. Sample Collection
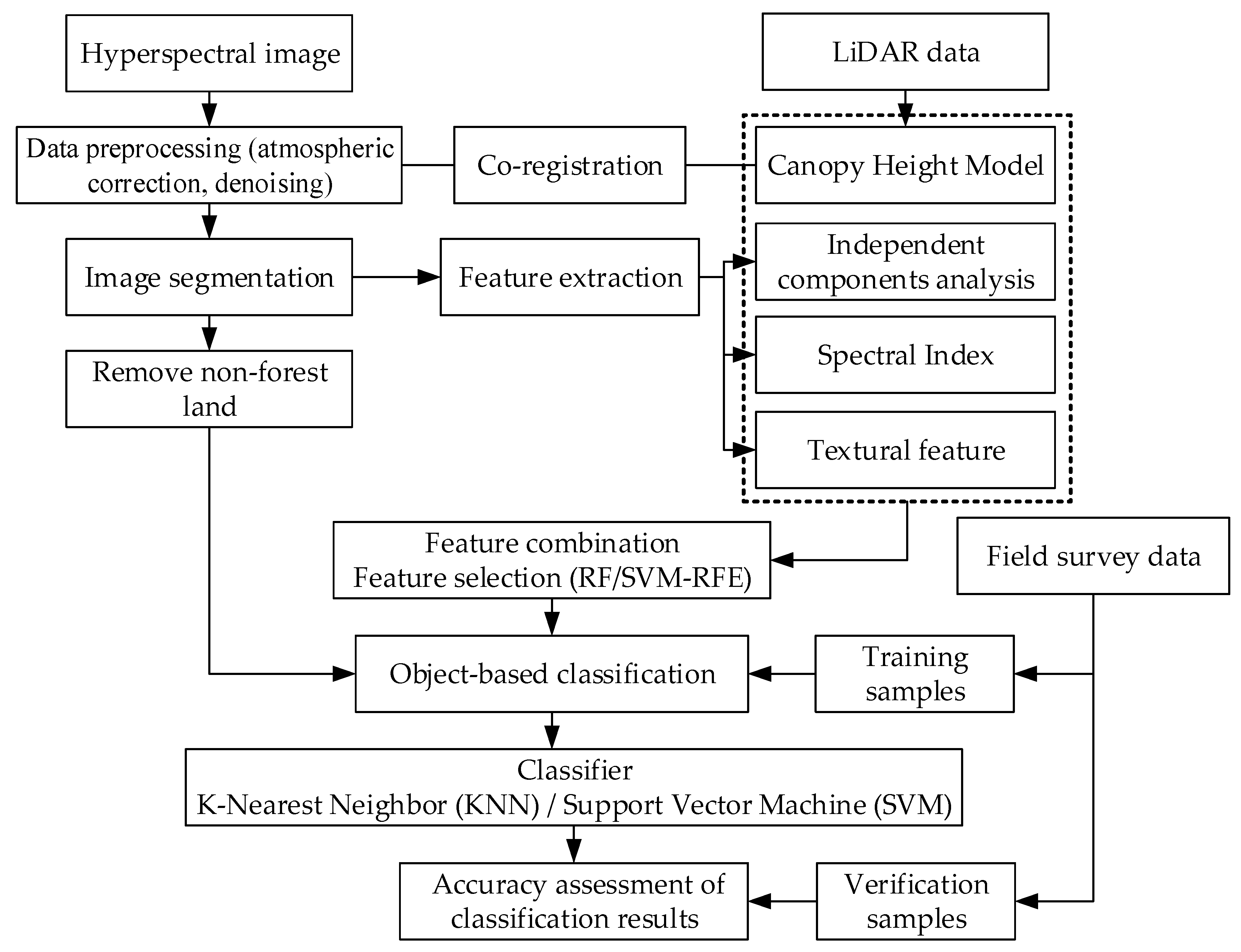
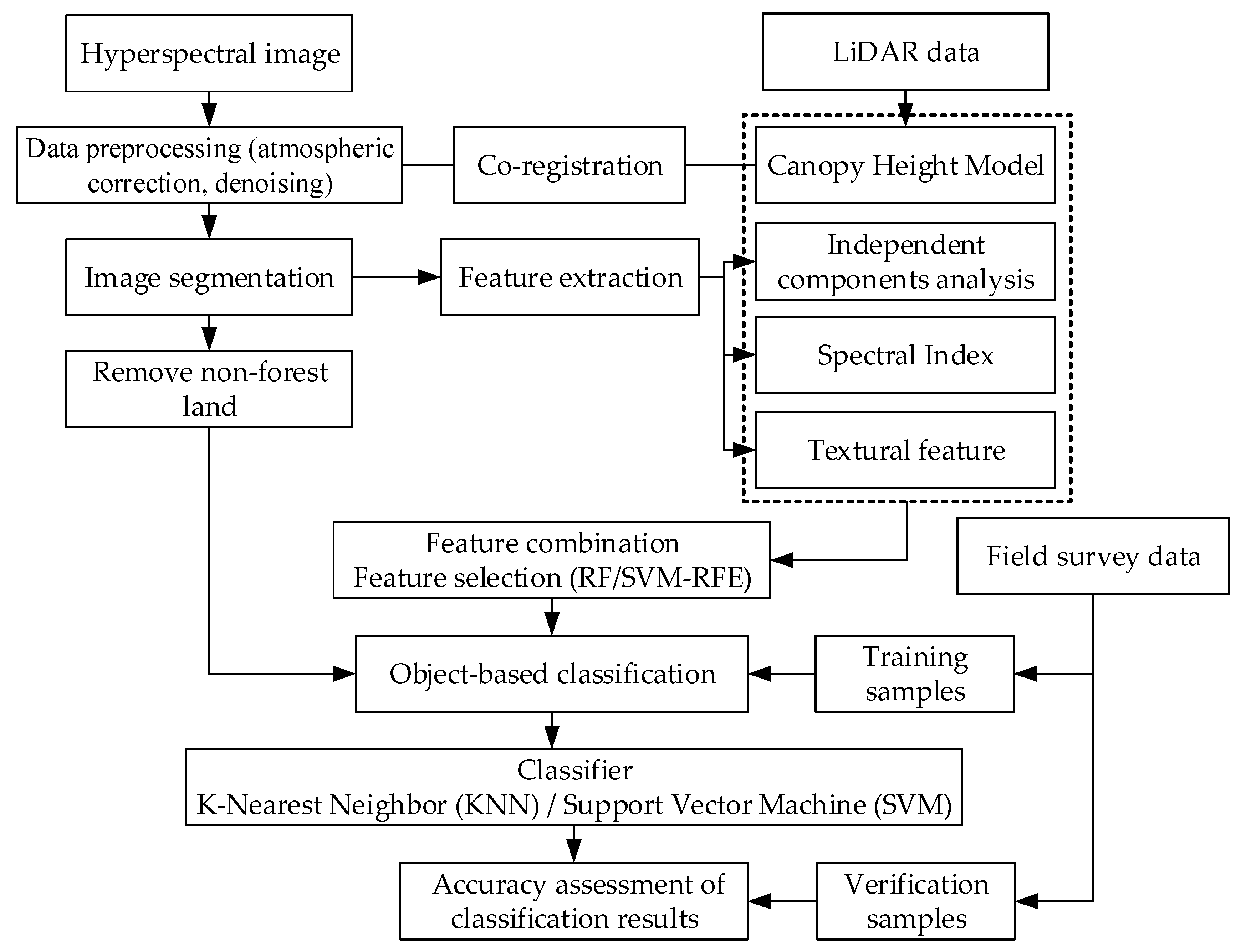
2.4. Workflow Description
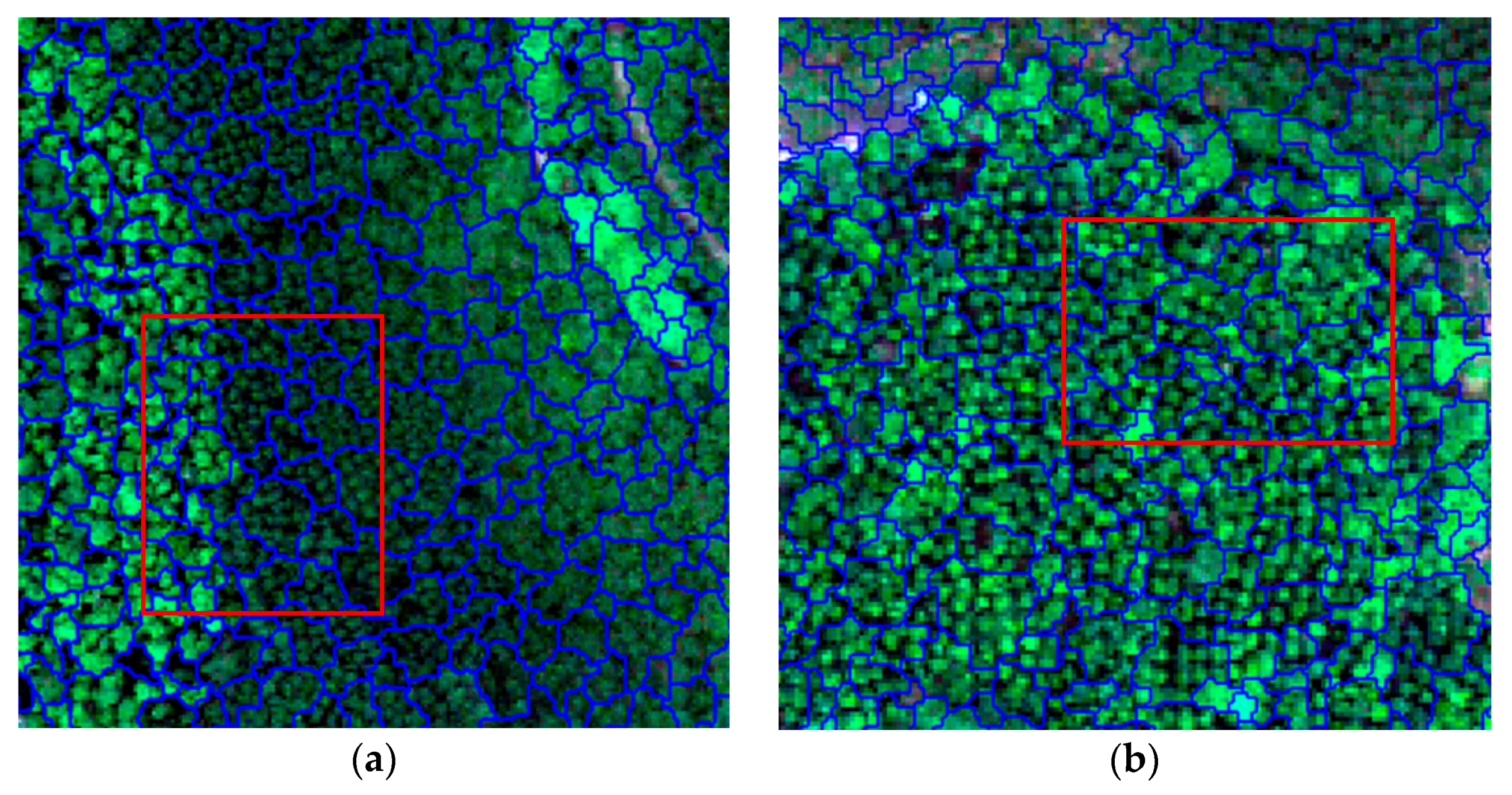
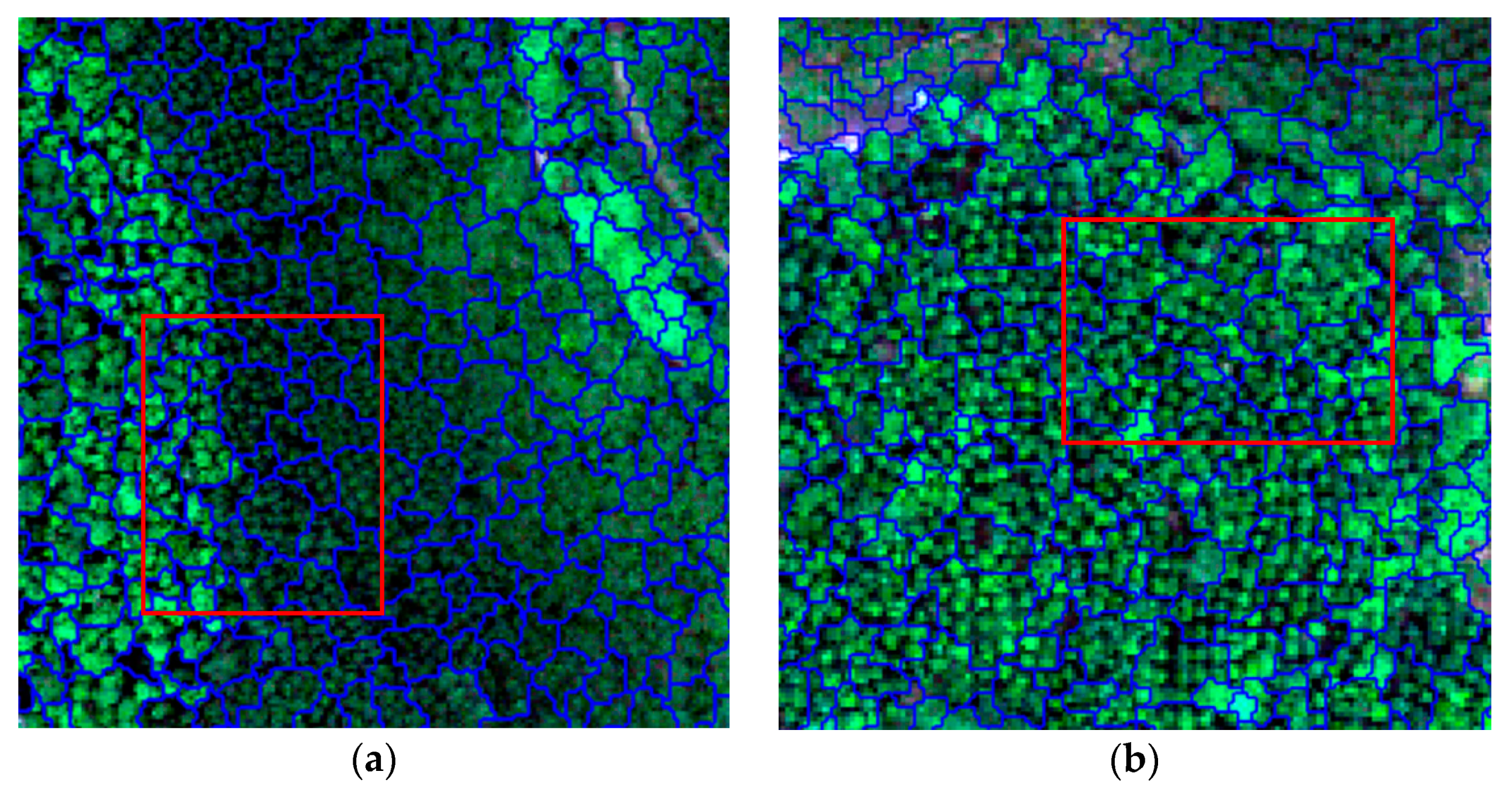
2.5. Image Segmentation
2.6. Stratified Classification
2.7. Feature Variables Extraction and Selection
2.7.1. Independent Components Analysis
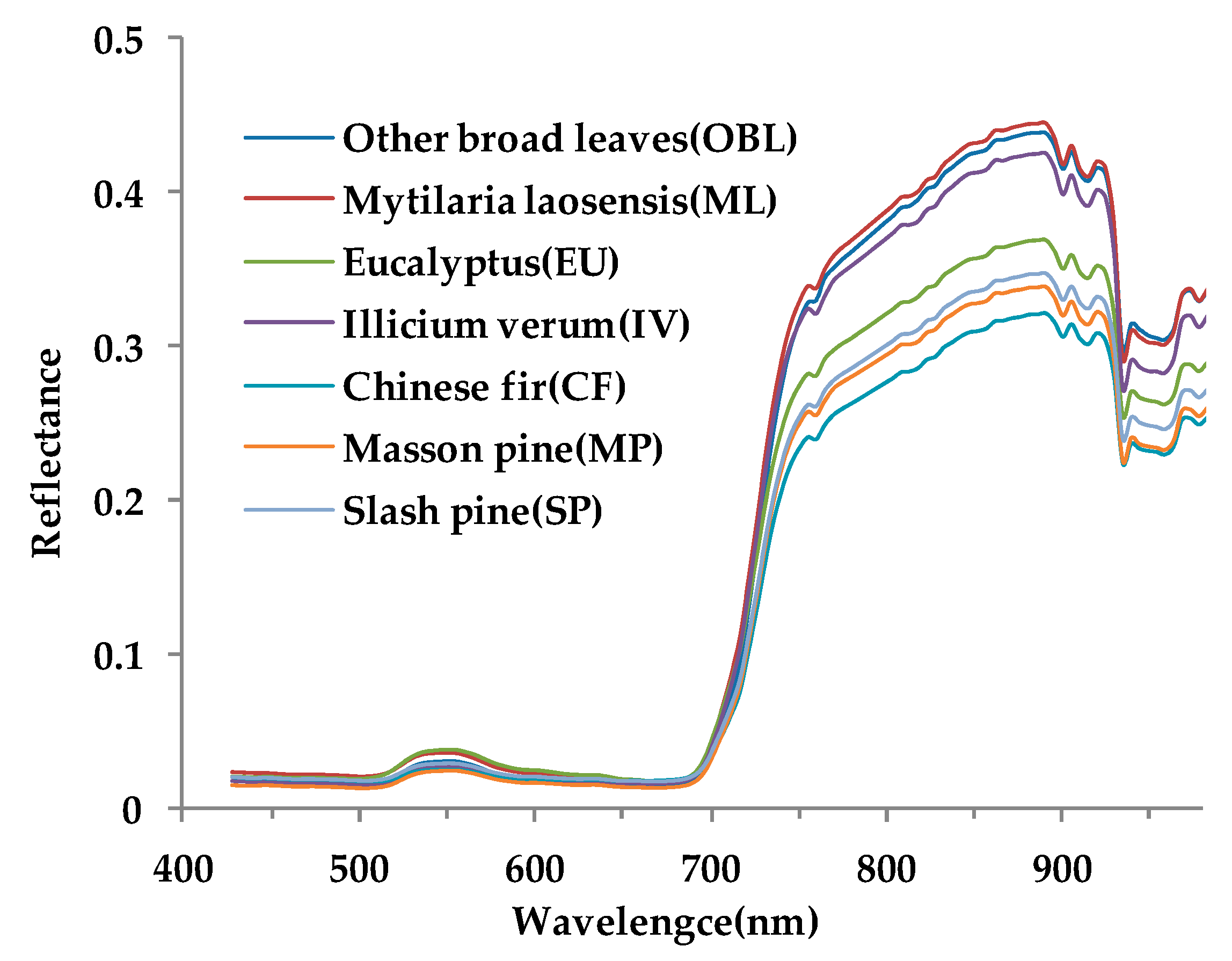
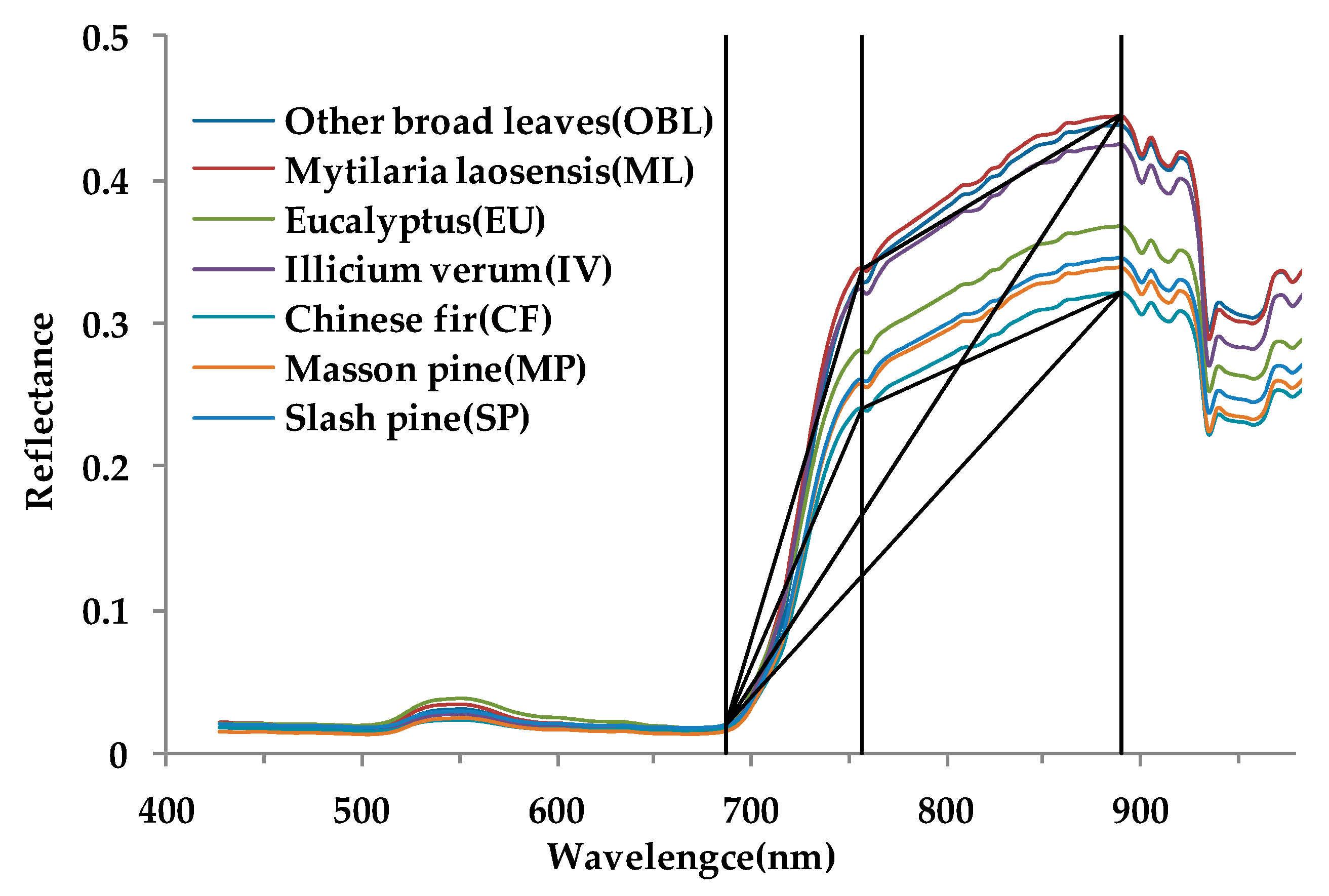
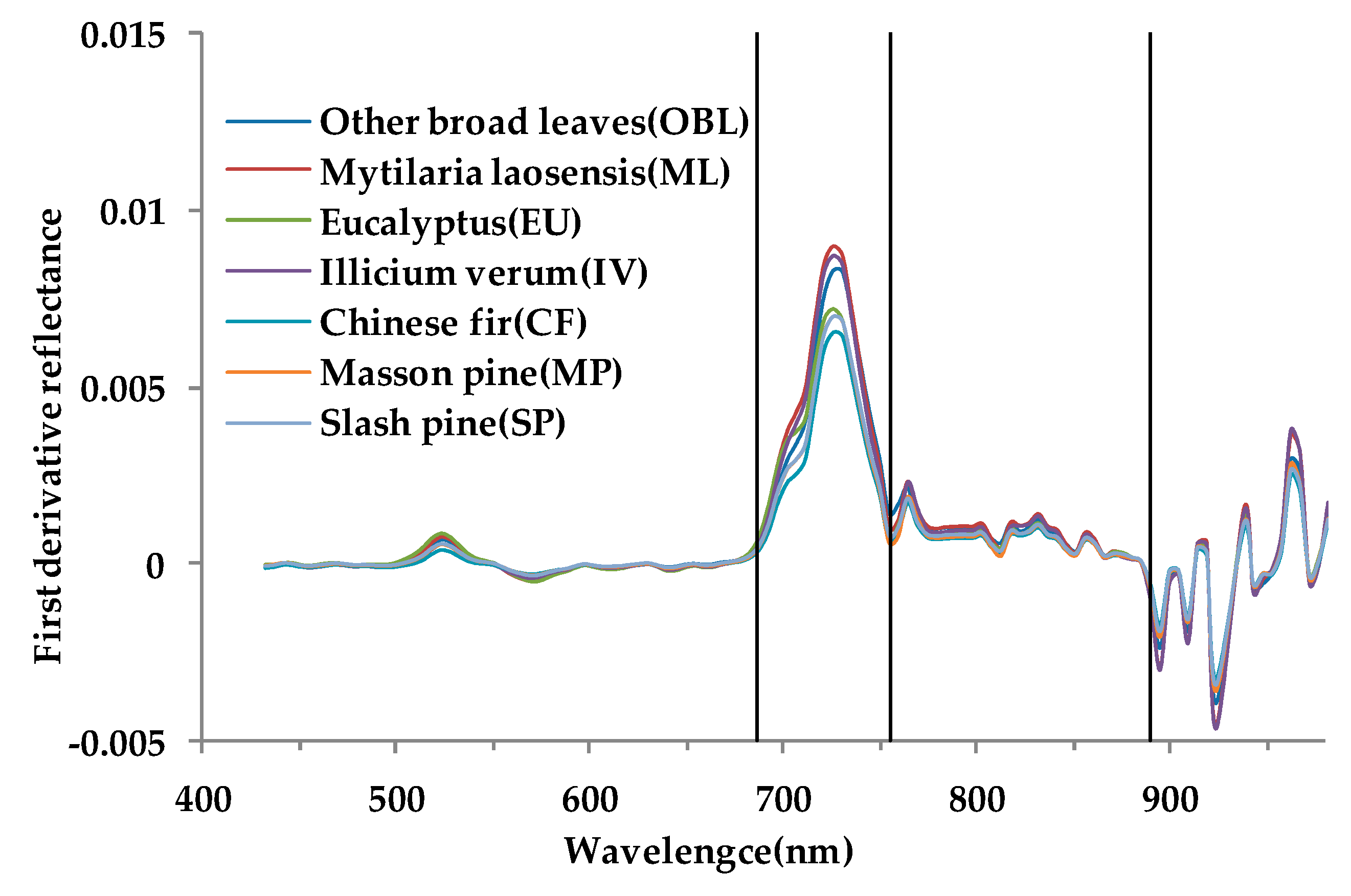
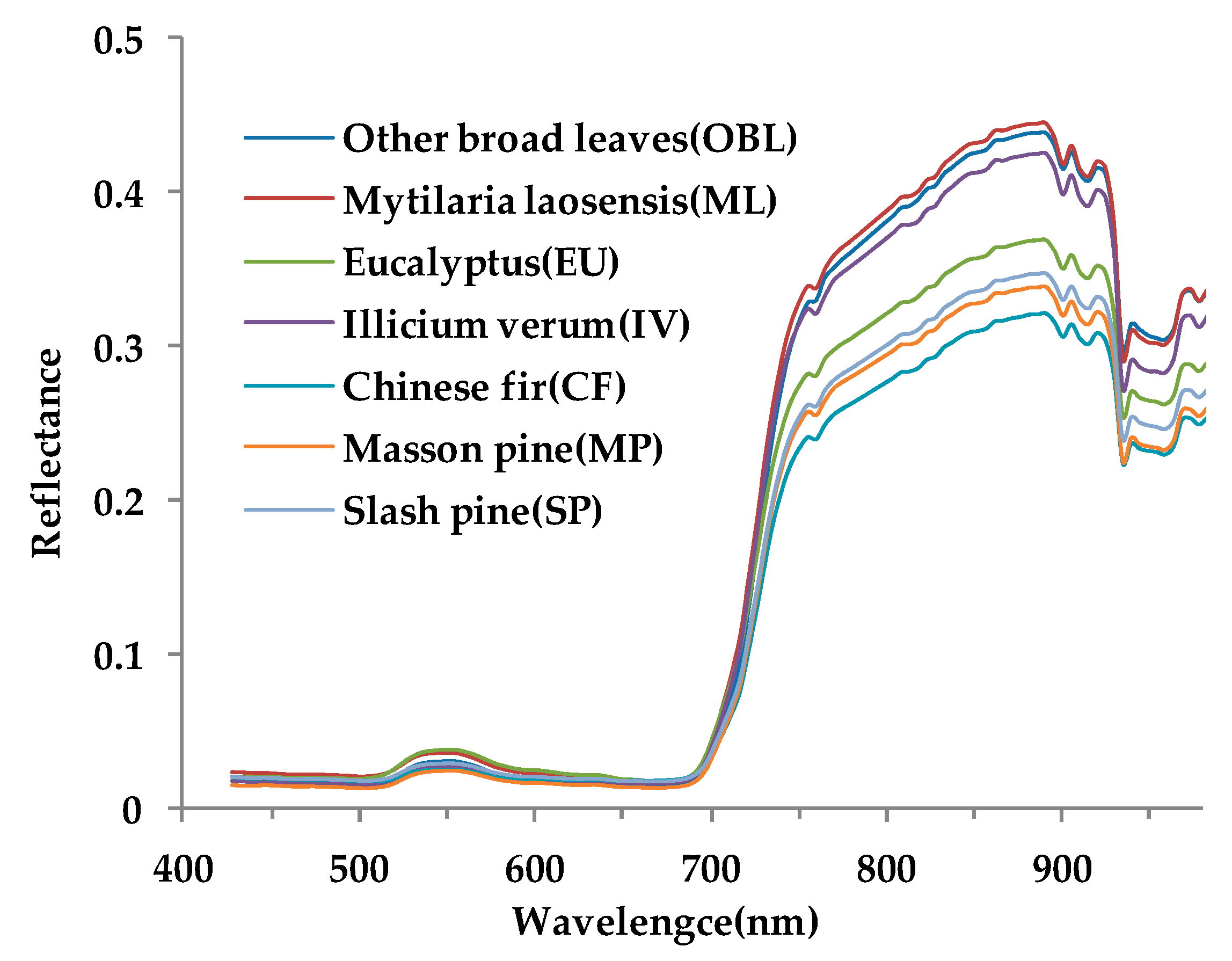
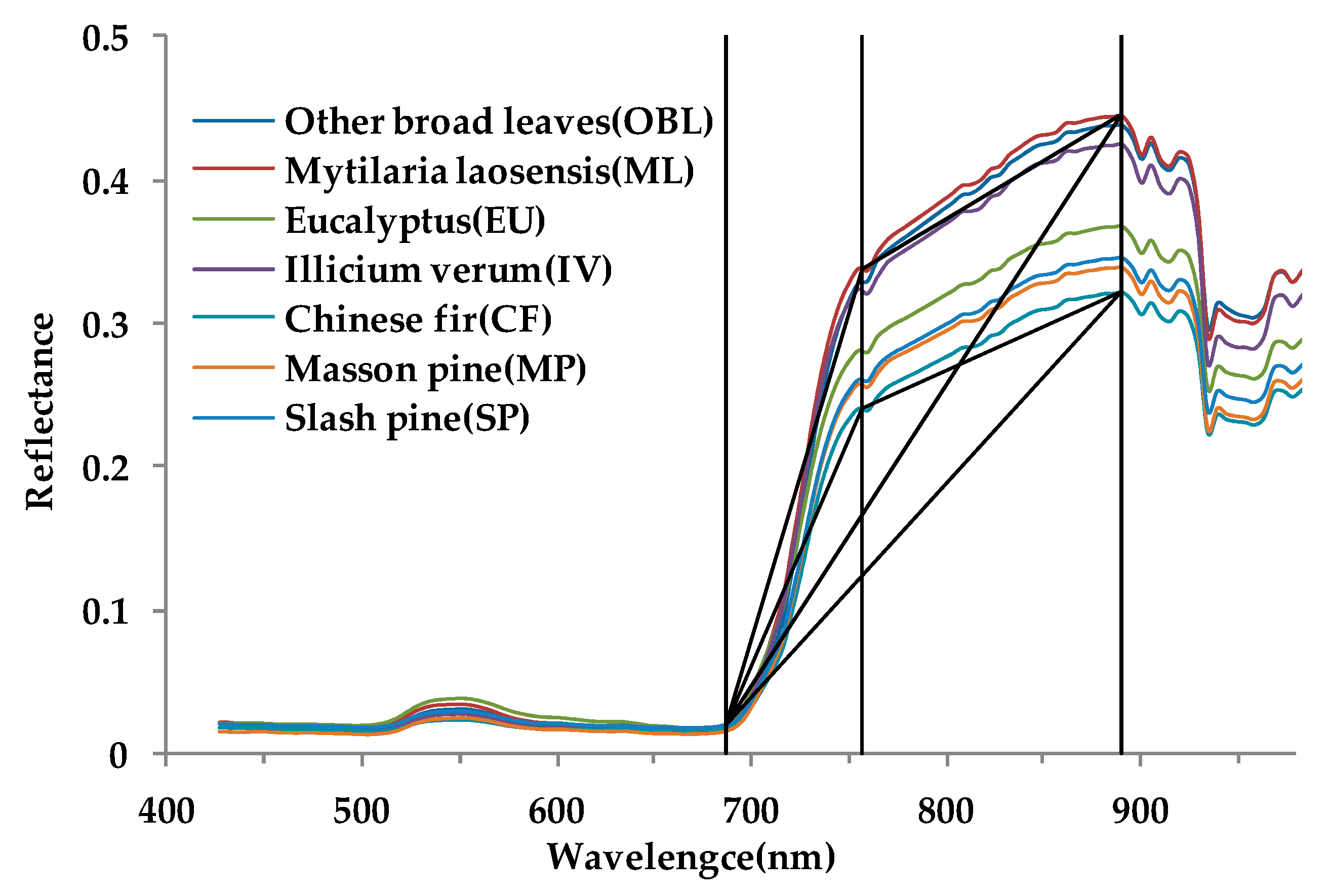
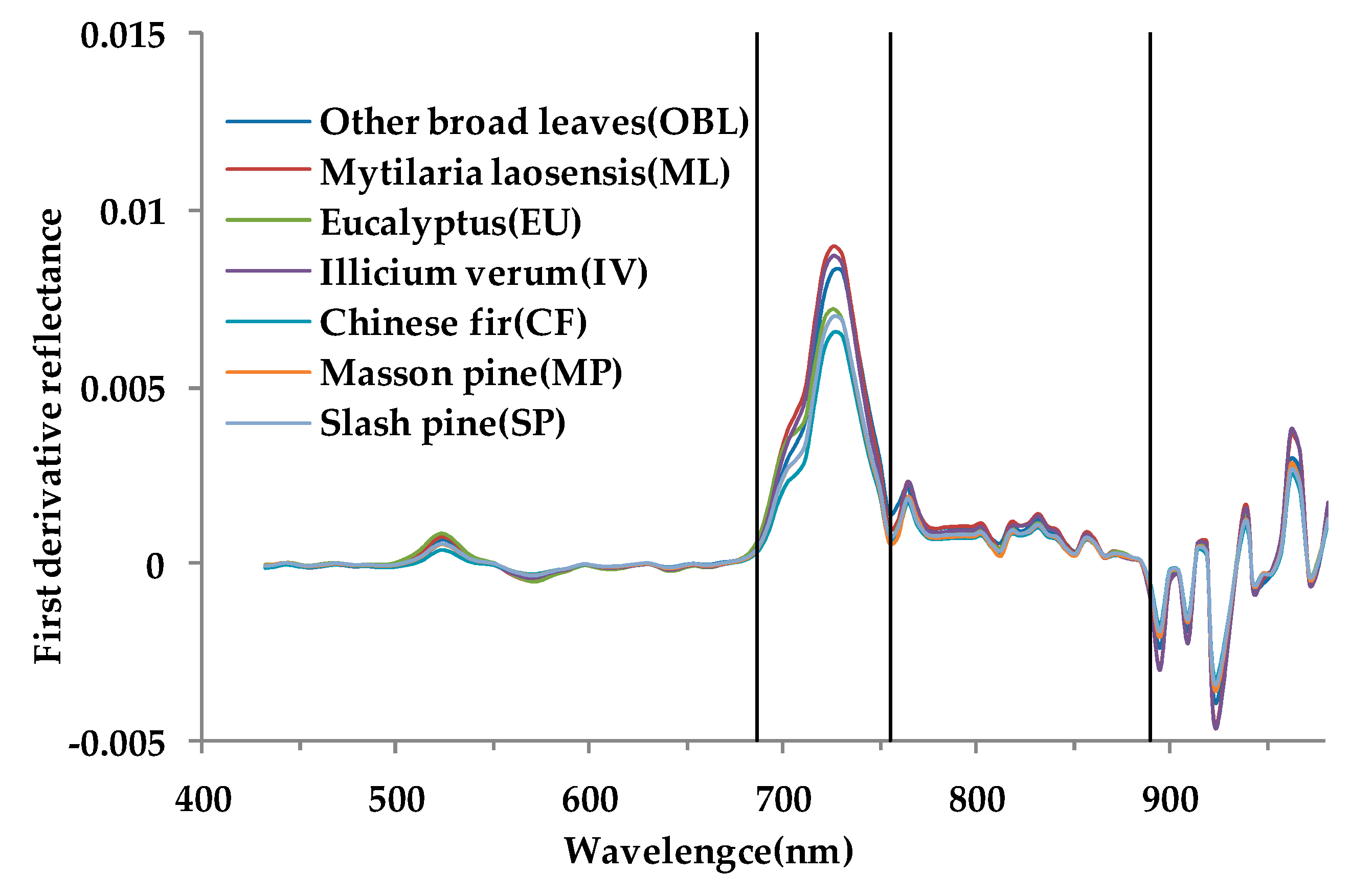
2.7.2. Spectral Index
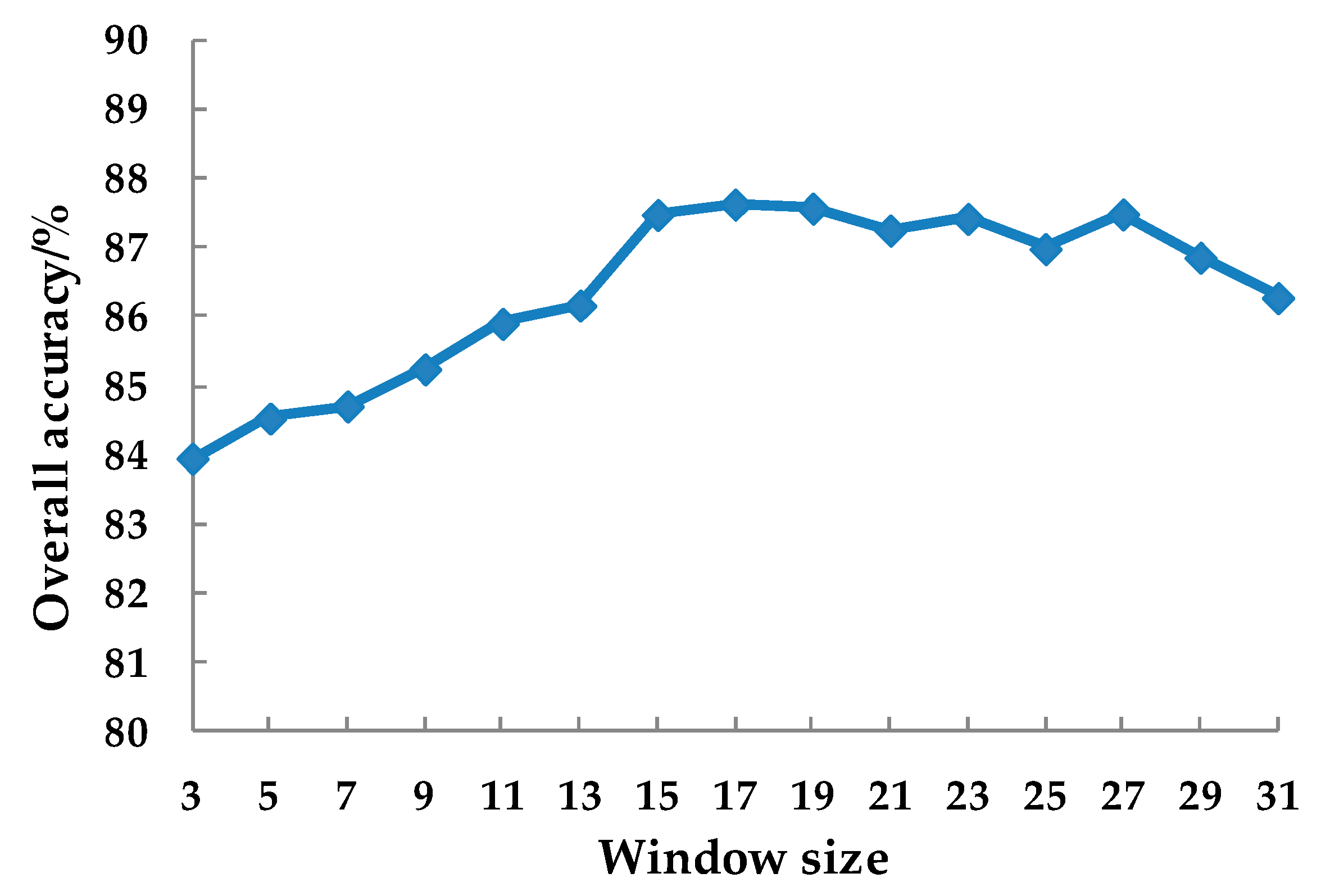
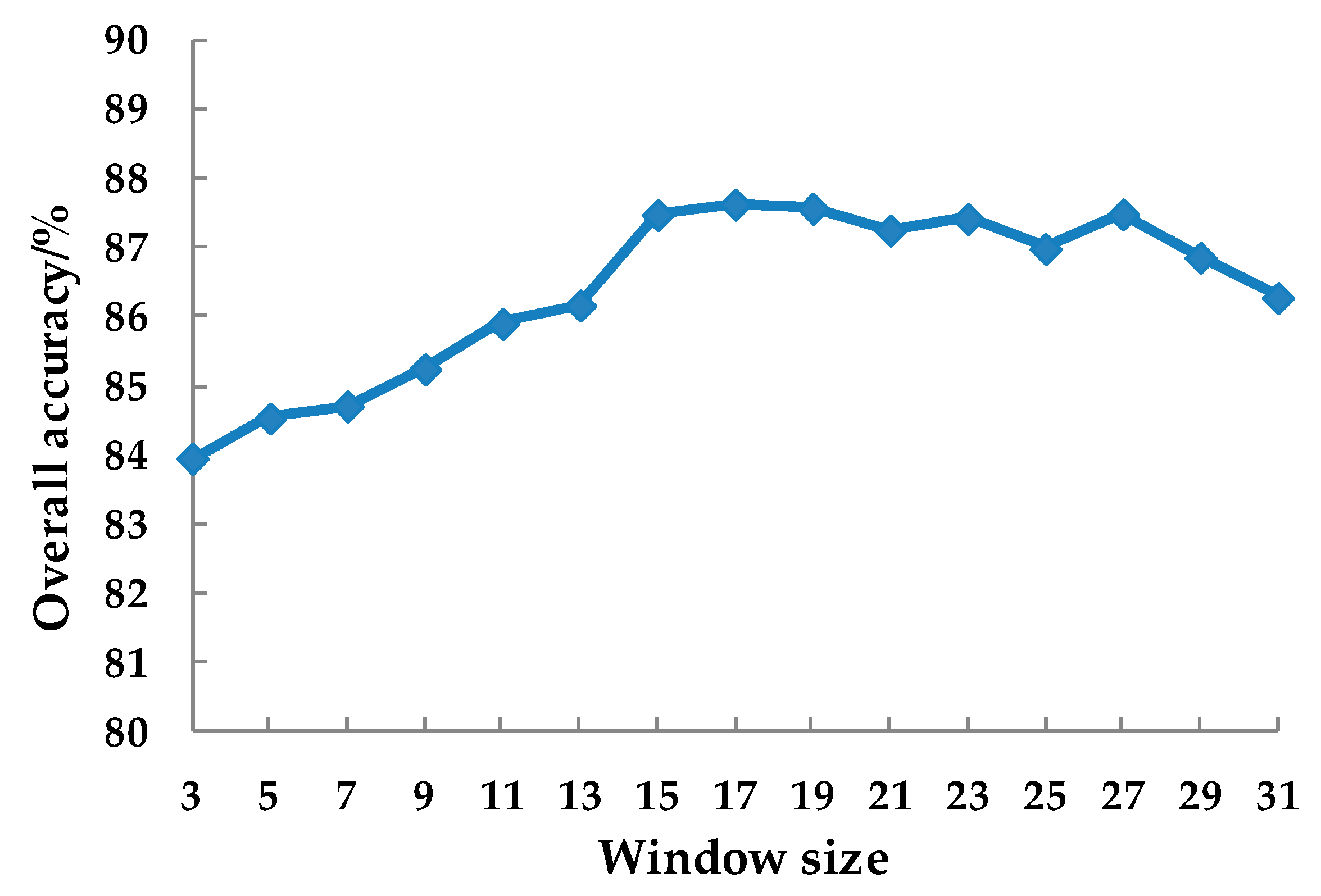
2.7.3. Textural Feature
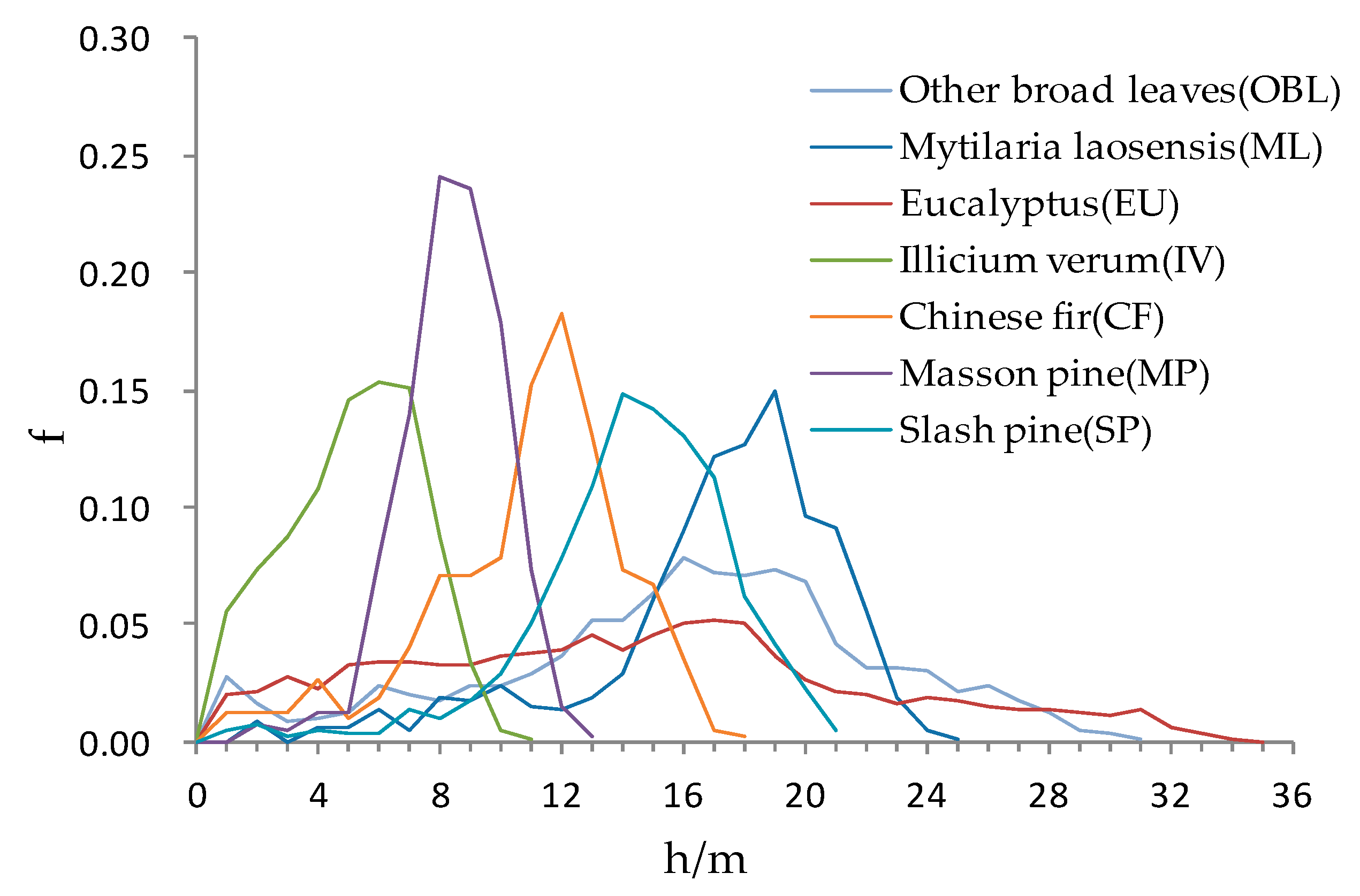
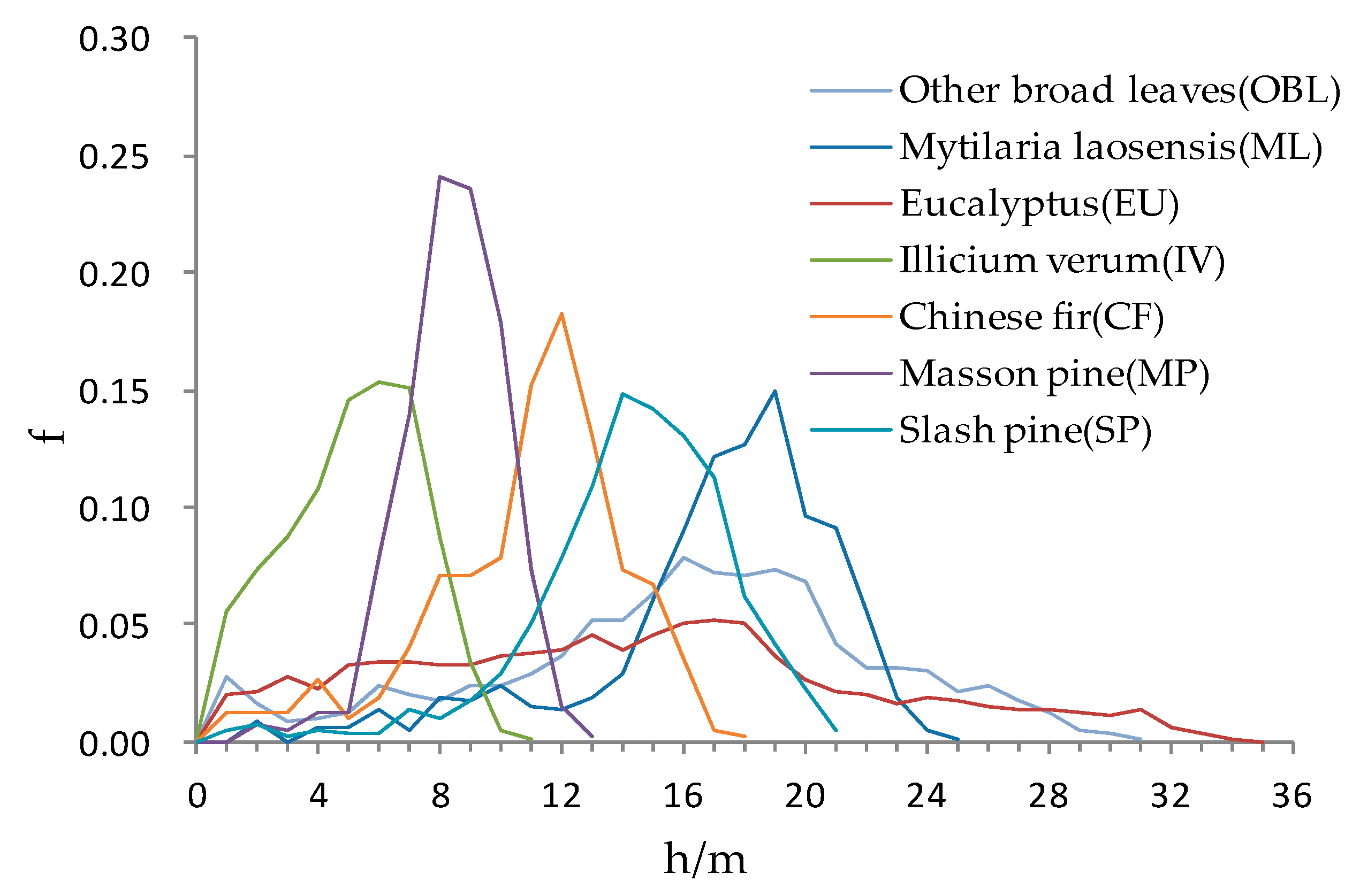
2.7.4. Canopy Height Model from LiDAR Data
2.7.5. Selection of Optimal Variable Combination
2.8. Object-Based Classification
2.8.1. Classification Method
2.8.2. Determination of Classification Scheme
2.8.3. Accuracy Assessment of Classification Results
3. Results
3.1. Image Segmentation Results
3.2. Extraction of Forest Land
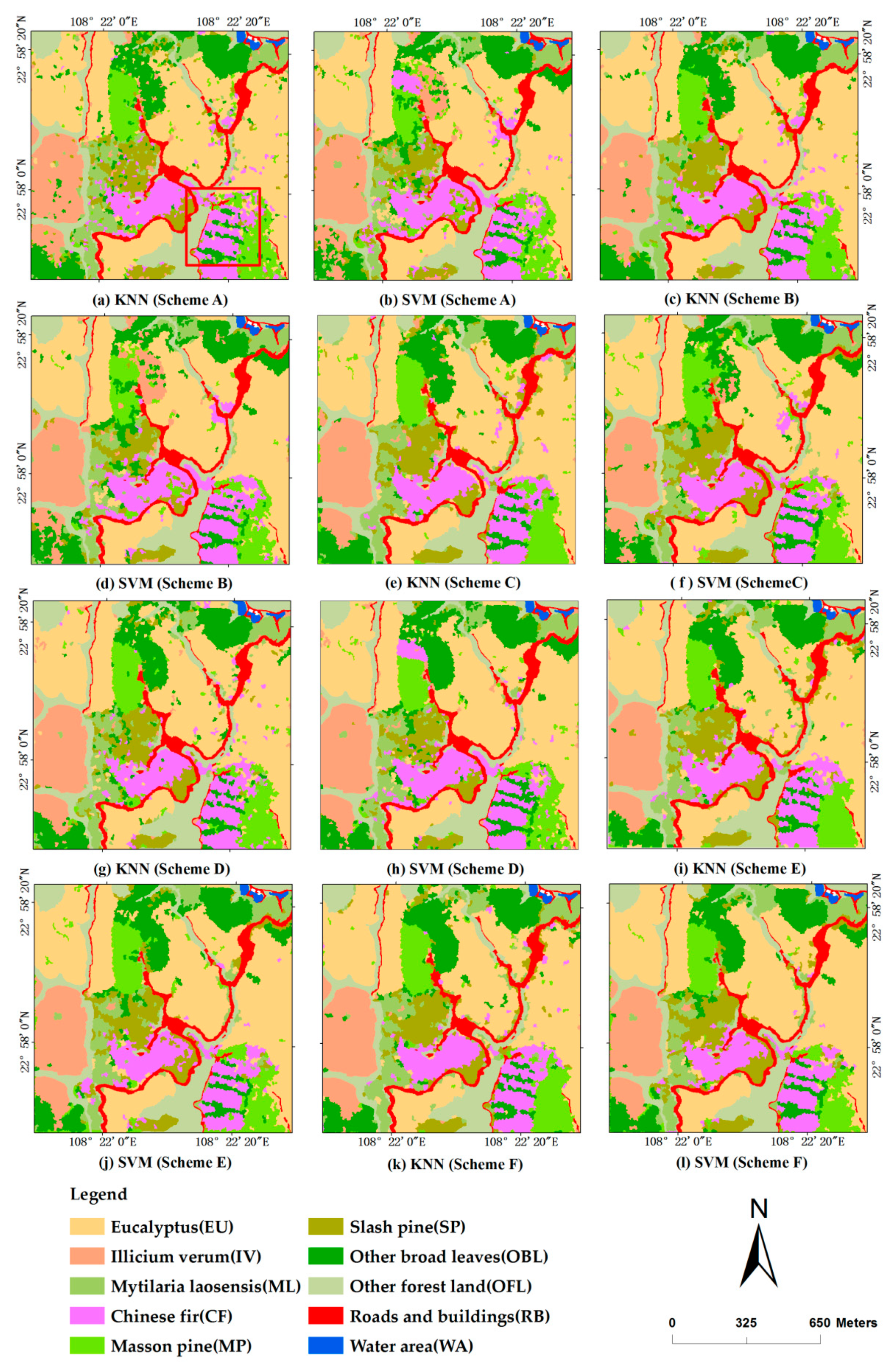
3.3. Comparison of Tree Species Classification Results
4. Discussion
4.1. Comparison of Classification Results Based on Two Classifiers
4.2. The Role of Spectral Index Features
4.3. The Role of Texture Features
4.4. The Role of Canopy Height Model
5. Conclusions
- (1)
- Compared with the KNN classifier, the SVM classifier has higher classification accuracy, with the highest classification accuracy of 94.68% and a Kappa coefficient of 0.937. It shows that the SVM classifier has better performance when the number of training samples is limited. By eliminating redundant features, the classification accuracy and performance of the SVM classifier can be further improved, and the recursive feature elimination based on the SVM feature selection method is better than random forest.
- (2)
- In the spectral indices, NDVI, PRI, GNDVI, SL2, and PSRI are in the selected feature subsets, indicating that the newly constructed SL2 spectral index plays a role in improving classification accuracy. At the same time, the preferred spectral indices are closely related to vegetation chlorophyll and carotenoids, and four indices are related to near-infrared band. These factors can effectively distinguish different tree species.
- (3)
- With the addition of texture features, the classification accuracy of both classifiers is significantly improved. The overall classification accuracy of slash pine, masson pine, and Illicium verum was higher than other species of broad leaves. Therefore, the selected texture window size is more suitable for small crown tree species, which implies that using a single texture window size has certain limitations. Considering the type of forest, using multiscale texture window size should be a new research topic in improving tree species classification.
- (4)
- CHM height information has a significant effect on improving the classification accuracy of tree species especially other broad-leaved species. It can effectively distinguish tree species with similar spectral features, but different tree heights. The accuracy of the CHM is affected by the terrain. In hilly areas, the CHM may reflect incorrect tree heights. In addition, the CHM has a certain relationship with the LiDAR point cloud density, and therefore the influence of point cloud density and terrain factors on CHM and tree species classification need further analysis.
- (5)
- Object-based classification can avoid the phenomenon of “salt and pepper” and classification accuracy is affected by the segmentation accuracy. However, segmentation scale parameters are difficult to determine adaptively, so rapid optimization and improvement of segmentation parameters are quite important to improve classification accuracy.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, D.; Fan, S.; He, A.; Yin, F. Forest resources and environment in China. J. For. Res. 2004, 9, 307–312. [Google Scholar] [CrossRef]
- Cheng, S.; Xu, Z.; Su, Y.; Zhen, L. Spatial and temporal flows of China’s forest resources: Development of a framework for evaluating resource efficiency. Ecol. Econ. 2010, 69, 1405–1415. [Google Scholar] [CrossRef]
- Brockerhoff, E.G.; Jactel, H.; Parrotta, J.A.; Quine, C.P.; Sayer, J. Plantation forests and biodiversity: Oxymoron or opportunity? Biodivers. Conserv. 2008, 17, 925–951. [Google Scholar] [CrossRef]
- Yang, J.; Wang, F. Developing a quantitative index system for assessing sustainable forestry management in Heilongjiang Province, China: A case study. J. For. Res. 2016, 27, 611–619. [Google Scholar] [CrossRef]
- Liu, S.; Xia, C.; Feng, W.; Zhang, K.; Ma, L.; Liu, J. Estimation of vegetation carbon storage and density of forests at tree layer in Tibet, China. Chin. J. Appl. Ecol. 2017, 28, 3127–3134. [Google Scholar] [CrossRef]
- Adams, A.B.; Pontius, J.; Galford, G.L.; Merrill, S.C.; Gudex-Cross, D. Modeling carbon storage across a heterogeneous mixed temperate forest: The influence of forest type specificity on regional-scale carbon storage estimates. Landsc. Ecol. 2018, 33, 641–658. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Sterenczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Ni, X.; Zhou, Y.; Cao, C.; Wang, X.; Shi, Y.; Park, T.; Choi, S.; Myneni, R.B. Mapping Forest Canopy Height over Continental China Using Multi-Source Remote Sensing Data. Remote Sens. 2015, 7, 8436–8452. [Google Scholar] [CrossRef] [Green Version]
- Kempeneers, P.; Sedano, F.; Seebach, L.; Strobl, P.; San-Miguel-Ayanz, J. Data Fusion of Different Spatial Resolution Remote Sensing Images Applied to Forest-Type Mapping. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4977–4986. [Google Scholar] [CrossRef]
- Zhu, X.; Liu, D. Accurate mapping of forest types using dense seasonal Landsat time-series. ISPRS J. Photogramm. Remote Sens. 2014, 96, 1–11. [Google Scholar] [CrossRef]
- Gong, P.; Pu, R.; Yu, B. Conifer species recognition with seasonal hyperspectral data. J. Remote Sens. 1998, 2, 211–217. [Google Scholar] [CrossRef]
- Shen, X.; Cao, L. Tree-Species Classification in Subtropical Forests Using Airborne Hyperspectral and LiDAR Data. Remote Sens. 2017, 9, 1180. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Kazakova, A.; Moskal, L.M.; Styers, D.M. Object-Based Tree Species Classification in Urban Ecosystems Using LiDAR and Hyperspectral Data. Forests 2016, 7, 122. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Rivard, B.; Sanchez-Azofeifa, A.; Castro-Esau, K. Intra and inter-class spectral variability of tropical tree species at La Selva, Costa Rica: Implications for species identification using HYDICE imagery. Remote Sens. Environ. 2006, 105, 129–141. [Google Scholar] [CrossRef]
- Dian, Y.; Li, Z.; Pang, Y. Spectral and Texture Features Combined for Forest Tree species Classification with Airborne Hyperspectral Imagery. J. Indian Soc. Remote Sens. 2015, 43, 101–107. [Google Scholar] [CrossRef]
- Fagan, M.E.; DeFries, R.S.; Sesnie, S.E.; Arroyo-Mora, J.P.; Soto, C.; Singh, A.; Townsend, P.A.; Chazdon, R.L. Mapping Species Composition of Forests and Tree Plantations in Northeastern Costa Rica with an Integration of Hyperspectral and Multitemporal Landsat Imagery. Remote Sens. 2015, 7, 5660–5696. [Google Scholar] [CrossRef] [Green Version]
- Johansen, K.; Phinn, S. Mapping structural parameters and species composition of riparian vegetation using IKONOS and landsat ETM plus data in Australian tropical savannahs. Photogramm. Eng. Remote Sens. 2006, 72, 71–80. [Google Scholar] [CrossRef]
- Du, P.; Xia, J.; Zhang, W.; Tan, K.; Liu, Y.; Liu, S. Multiple Classifier System for Remote Sensing Image Classification: A Review. Sensors 2012, 12, 4764–4792. [Google Scholar] [CrossRef]
- Wu, Q.; Zhong, R.; Zhao, W.; Fu, H.; Song, K. A comparison of pixel-based decision tree and object-based Support Vector Machine methods for land-cover classification based on aerial images and airborne lidar data. Int. J. Remote Sens. 2017, 38, 7176–7195. [Google Scholar] [CrossRef]
- Kaszta, Z.; Van de Kerchove, R.; Ramoelo, A.; Cho, M.A.; Madonsela, S.; Mathieu, R.; Wolff, E. Seasonal Separation of African Savanna Components Using Worldview-2 Imagery: A Comparison of Pixel- and Object-Based Approaches and Selected Classification Algorithms. Remote Sens. 2016, 8, 763. [Google Scholar] [CrossRef] [Green Version]
- Pu, R.; Landry, S. A comparative analysis of high spatial resolution IKONOS and WorldView-2 imagery for mapping urban tree species. Remote Sens. Environ. 2012, 124, 516–533. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Erdemir, M.Y.; Tonbul, H. Classification of semiurban landscapes from very high-resolution satellite images using a regionalized multiscale segmentation approach. J. Appl. Remote Sens. 2017, 11. [Google Scholar] [CrossRef]
- Byun, Y.G.; Han, Y.K.; Chae, T.B. A multispectral image segmentation approach for object-based image classification of high resolution satellite imagery. Ksce. J. Civ. Eng. 2013, 17, 486–497. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree Species Classification with Random Forest Using Very High Spatial Resolution 8-Band WorldView-2 Satellite Data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Shi, J.; Yue, G.; Zhao, L.; Nan, Z.; Wu, X.; Qiao, Y.; Wu, T.; Zou, D. Object-Oriented Vegetation Classification Based on Fusion Decision Tree Method in Yushu Area. Acta Prataculturae Sin. 2013, 22, 62–71. [Google Scholar]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in Spectral-Spatial Classification of Hyperspectral Images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, A.; Fassnacht, F.E.; Joshi, P.K.; Koch, B. A framework for mapping tree species combining hyperspectral and LiDAR data: Role of selected classifiers and sensor across three spatial scales. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 49–63. [Google Scholar] [CrossRef]
- Liu, L.; Coops, N.C.; Aven, N.W.; Pang, Y. Mapping urban tree species using integrated airborne hyperspectral and LiDAR remote sensing data. Remote Sens. Environ. 2017, 200, 170–182. [Google Scholar] [CrossRef]
- Hollaus, M.; Wagner, W.; Eberhoefer, C.; Karel, W. Accuracy of large-scale canopy heights derived from LiDAR data under operational constraints in a complex alpine environment. ISPRS J. Photogramm. Remote Sens. 2006, 60, 323–338. [Google Scholar] [CrossRef]
- Heinzel, J.; Koch, B. Exploring full-waveform LiDAR parameters for tree species classification. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 152–160. [Google Scholar] [CrossRef]
- Alonzo, M.; Bookhagen, B.; Roberts, D.A. Urban tree species mapping using hyperspectral and lidar data fusion. Remote Sens. Environ. 2014, 148, 70–83. [Google Scholar] [CrossRef]
- Colgan, M.S.; Baldeck, C.A.; Feret, J.B.; Asner, G.P. Mapping Savanna Tree Species at Ecosystem Scales Using Support Vector Machine Classification and BRDF Correction on Airborne Hyperspectral and LiDAR Data. Remote Sens. 2012, 4, 3462–3480. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Skidmore, A.K.; Wang, T.; Holzwarth, S.; Heiden, U.; Pinnel, N.; Zhu, X.; Heurich, M. Tree species classification using plant functional traits from LiDAR and hyperspectral data. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 207–219. [Google Scholar] [CrossRef]
- Voss, M.; Sugumaran, R. Seasonal effect on tree species classification in an urban environment using hyperspectral data, LiDAR, and an object-oriented approach. Sensors 2008, 8, 3020–3036. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, L.; Pang, Y.; Fan, W.; Li, Z.; Zhang, D.; Li, M. Fused airborne LiDAR and hyperspectral data for tree species identification in a natural temperate forest. J. Remote Sens. 2013, 17, 679–695. [Google Scholar]
- Cao, J.; Leng, W.; Liu, K.; Liu, L.; He, Z.; Zhu, Y. Object-Based Mangrove Species Classification Using Unmanned Aerial Vehicle Hyperspectral Images and Digital Surface Models. Remote Sens. 2018, 10, 89. [Google Scholar] [CrossRef] [Green Version]
- Pan, Z.; Luo, L. Peak of State-owned Forest Farms in Guangxi the Characteristics of Different Tree Species Forests Soil Research. J. Green Sci. Technol. 2017, 3, 116–118. [Google Scholar] [CrossRef]
- Mo, W.; Chen, J.; Tang, X. Thoughts and Suggestions on the Development of Under-forest Economy in Gaofeng Forest Farm. For. Econ. 2018, 40, 106–110. [Google Scholar] [CrossRef]
- Introduction of Gaofeng Forest Farm. Available online: http://www.gaofenglinye.com.cn/lcjj/index_13.aspx (accessed on 30 January 2019).
- Pang, Y.; Li, Z.; Ju, H.; Lu, H.; Jia, W.; Si, L.; Guo, Y.; Liu, Q.; Li, S.; Liu, L.; et al. LiCHy: The CAF’s LiDAR, CCD and Hyperspectral Integrated Airborne Observation System. Remote Sens. 2016, 8, 398. [Google Scholar] [CrossRef] [Green Version]
- AISA Eagle II. Available online: http://www.specim.fi/hyperspectral-remote-sensing/ (accessed on 30 January 2019).
- RIEGL LMS-Q680i. Available online: http://www.riegl.com/nc/products/airborne-scanning/ (accessed on 30 January 2019).
- DigiCAM-Digital Aerial Camera. Available online: https://www.igi-systems.com/digicam.html (accessed on 30 January 2019).
- Hao, J.; Yang, W.; Li, Y.; Hao, J. Atmospheric Correction of Multi-spectral Imagery ASTER. Remote Sens. Inf. 2008, 1, 78–81. [Google Scholar] [CrossRef]
- Axelsson, P. Processing of laser scanner data—Algorithms and applications. ISPRS J. Photogramm. Remote Sens. 1999, 54, 138–147. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, Y.; Liao, S.; Jia, W.; Chen, B.; Liu, L. Merged Airborne LiDAR and Hyperspectral Data for Tree Species Classification in Puer’s Mountainous Area. For. Res. 2016, 29, 407–412. [Google Scholar] [CrossRef]
- Li, N.; Lu, D.; Wu, M.; Zhang, Y.; Lu, L. Coastal wetland classification with multiseasonal high-spatial resolution satellite imagery. Int. J. Remote Sens. 2018, 39, 8963–8983. [Google Scholar] [CrossRef]
- Labib, S.M.; Harris, A. The potentials of Sentinel-2 and LandSat-8 data in green infrastructure extraction, using object based image analysis (OBIA) method. Eur. J. Remote Sens. 2018, 51, 231–240. [Google Scholar] [CrossRef]
- Jiang, Z.; Huete, A.R.; Li, J.; Chen, Y. An analysis of angle-based with ratio-based vegetation indices. IEEE. Trans. Geosci. Remote Sens. 2006, 44, 2506–2513. [Google Scholar] [CrossRef]
- Koller, M.; Upadhyaya, S.K. Relationship between modified normalized difference vegetation index and leaf area index for processing tomatoes. Appl. Eng. Agric. 2005, 21, 927–933. [Google Scholar] [CrossRef]
- Omam, M.A.; Torkamani-Azar, F. Band selection of hyperspectral-image based weighted indipendent component analysis. Opt. Rev. 2010, 17, 367–370. [Google Scholar] [CrossRef]
- Lichtenthaler, H.; Lang, M.; Sowinska, M.; Heisel, F.; Miehe, J. Detection of vegetation stress via a new high resolution fluorescence imaging system. J. Plant. Physiol. 1996, 148, 599–612. [Google Scholar] [CrossRef]
- Bannari, A.; Morin, D.; Bonn, F.; Huete, A.R. A review of vegetation indices. Remote Sens. Rev. 1995, 13, 95–120. [Google Scholar] [CrossRef]
- Merzlyak, M.N.; Gitelson, A.A.; Chivkunova, O.B.; Rakitin, V.Y. Non-destructive optical detection of pigment changes during leaf senescence and fruit ripening. Physiol. Plant. 1999, 106, 135–141. [Google Scholar] [CrossRef] [Green Version]
- Sims, D.A.; Gamon, J.A. Relationships between leaf pigment content and spectral reflectance across a wide range of species, leaf structures and developmental stages. Remote Sens. Environ. 2002, 81, 337–354. [Google Scholar] [CrossRef]
- Hernandez-Clemente, R.; Navarro-Cerrillo, R.M.; Suarez, L.; Morales, F.; Zarco-Tejada, P.J. Assessing structural effects on PRI for stress detection in conifer forests. Remote Sens. Environ. 2011, 115, 2360–2375. [Google Scholar] [CrossRef]
- Haboudane, D.; Miller, J.R.; Tremblay, N.; Zarco-Tejada, P.J.; Dextraze, L. Integrated narrow-band vegetation indices for prediction of crop chlorophyll content for application to precision agriculture. Remote Sens. Environ. 2002, 81, 416–426. [Google Scholar] [CrossRef]
- Xue, J.; Su, B. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 2017. [Google Scholar] [CrossRef] [Green Version]
- Gitelson, A.A.; Merzlyak, M.N.; Chivkunova, O.B. Optical properties and nondestructive estimation of anthocyanin content in plant leaves. Photochem. Photobiol. 2001, 74, 38–45. [Google Scholar] [CrossRef]
- Huang, X.; Lu, Q.; Zhang, L. A multi-index learning approach for classification of high-resolution remotely sensed images over urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 90, 36–48. [Google Scholar] [CrossRef]
- Lu, D.; Li, G.; Moran, E.; Dutra, L.; Batistella, M. The roles of textural images in improving land-cover classification in the Brazilian Amazon. Int. J. Remote Sens. 2014, 35, 8188–8207. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhao, Y.; Pu, R.; Zhang, Z. Mapping Robinia Pseudoacacia Forest Health Conditions by Using Combined Spectral, Spatial, and Textural Information Extracted from IKONOS Imagery and Random Forest Classifier. Remote Sens. 2015, 7, 9020–9044. [Google Scholar] [CrossRef] [Green Version]
- Pu, R.; Gong, P. Hyperspectral remote sensing of vegetation bioparameters. Adv. Environ. Remote Sens. 2011, 7, 101–142. [Google Scholar]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Fusion of hyperspectral and LIDAR remote sensing data for classification of complex forest areas. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1416–1427. [Google Scholar] [CrossRef] [Green Version]
- Goetze, C.; Gerstmann, H.; Glaesser, C.; Jung, A. An approach for the classification of pioneer vegetation based on species-specific phenological patterns using laboratory spectrometric measurements. Phys. Geogr. 2017, 38, 524–540. [Google Scholar] [CrossRef]
- Batista, M.H.; Haertel, V. On the classification of remote sensing high spatial resolution image data. Int. J. Remote Sens. 2010, 31, 5533–5548. [Google Scholar] [CrossRef]
- Liu, H.; An, H.; Wang, B.; Zhang, Q. WorldView-2 Tree Classification Based on Recursive Texture Feature Elimination. J. Beijing For. Univ. 2015, 37, 53–59. [Google Scholar]
- Liao, W.; Pizurica, A.; Scheunders, P.; Philips, W.; Pi, Y. Semisupervised local discriminant analysis for feature extraction in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 184–198. [Google Scholar] [CrossRef]
- Hu, S.; Liu, H.; Zhao, W.; Shi, T.; Hu, Z.; Li, Q.; Wu, G. Comparison of Machine Learning Techniques in Inferring Phytoplankton Size Classes. Remote Sens. 2018, 10, 191. [Google Scholar] [CrossRef] [Green Version]
- Dye, M.; Mutanga, O.; Ismail, R. Examining the utility of random forest and AISA Eagle hyperspectral image data to predict Pinus patula age in KwaZulu-Natal, South Africa. Geocarto Int. 2011, 26, 275–289. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Wang, B.; Li, F.; Zhang, Z. Feature clustering based support vector machine recursive feature elimination for gene selection. Appl. Intell. 2018, 48, 594–607. [Google Scholar] [CrossRef]
- Schultz, B.; Immitzer, M.; Formaggio, A.R.; Sanches, I.D.A.; Barreto Luiz, A.J.; Atzberger, C. Self-Guided Segmentation and Classification of Multi-Temporal Landsat 8 Images for Crop Type Mapping in Southeastern Brazil. Remote Sens. 2015, 7, 14482–14508. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Immitzer, M.; Böck, S.; Einzmann, K.; Vuolo, F.; Pinnel, N.; Wallner, A.; Atzberger, C. Fractional cover mapping of spruce and pine at 1 ha resolution combining very high and medium spatial resolution satellite imagery. Remote Sens. Environ. 2018, 204, 690–703. [Google Scholar] [CrossRef] [Green Version]
- Cai, S.; Liu, D. A comparison of object-based and contextual pixel-based classifications using high and medium spatial resolution images. Remote Sens. Lett. 2013, 4, 998–1007. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Yang, J.M.; Yu, P.T.; Kuo, B.C. A Nonparametric Feature Extraction and Its Application to Nearest Neighbor Classification for Hyperspectral Image Data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1279–1293. [Google Scholar] [CrossRef]
- Xun, L.; Wang, L. An object-based SVM method incorporating optimal segmentation scale estimation using Bhattacharyya Distance for mapping salt cedar (Tamarisk spp.) with QuickBird imagery. GIsci. Remote Sens. 2015, 52, 257–273. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Ma, L.; Cheng, L.; Li, M.; Liu, Y.; Ma, X. Training set size, scale, and features in Geographic Object-Based Image Analysis of very high resolution unmanned aerial vehicle imagery. ISPRS J. Photogramm. Remote Sens. 2015, 102, 14–27. [Google Scholar] [CrossRef]
- Maschler, J.; Atzberger, C.; Immitzer, M. Individual Tree Crown Segmentation and Classification of 13 Tree Species Using Airborne Hyperspectral Data. Remote Sens. 2018, 10, 1218. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; Liu, J.; Gong, J. UAV Remote Sensing for Urban Vegetation Mapping Using Random Forest and Texture Analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef] [Green Version]
- Su, W.; Zhang, C.; Yang, J.; Wu, H.; Deng, L.; Ou, W.; Yue, A.; Chen, M. Analysis of wavelet packet and statistical textures for object-oriented classification of forest-agriculture ecotones using SPOT 5 imagery. Int. J. Remote Sens. 2012, 33, 3557–3579. [Google Scholar] [CrossRef]
- Dian, Y.; Pang, Y.; Dong, Y.; Li, Z. Urban Tree Species Mapping Using Airborne LiDAR and Hyperspectral Data. J. Indian Soc. Remote Sens. 2016, 44, 595–603. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Common Name | Acronym | Scientific Name |
|---|---|---|---|
| Non-forest land | Water area | WA | - |
| Roads and buildings | RB | - | |
| Forest land | Other forest land | OFL | - |
| Chinese fir | CF | Cunninghamia lanceolata (Lamb.) Hook. | |
| Eucalyptus | EU | Eucalyptus robusta Smith | |
| Illicium verum | IV | Illicium verum Hook.f. | |
| Mytilaria laosensis | ML | Mytilaria laosensis Lec. | |
| Slash pine | PE | Pinus elliottii Engelm. | |
| Masson pine | MP | Pinus massoniana Lamb. | |
| Other broad leaves | OBL | - |
| Hyperspectral: AISA Eagle II | |||
| Spectral range | 400~1000 nm | Spatial resolution | 1 m |
| Spectral resolution | 3.3 nm | Spectral bands | 125 |
| FOV | 37.7° | Spatial pixels | 1024 |
| IFOV | 0.646 mrad | Spectral sampling interval | 4.6 nm |
| Focal length | 18.5 mm | Bit depth | 12 bits |
| LiDAR: Riegl LMS-Q680i | |||
| Wavelength | 1550 nm | Laser beam divergence | 0.5 mrad |
| Laser pulse length | 3 ns | Cross-track FOV | ±30° |
| Maximum laser pulse repetition rate | 400 KHz | Vertical resolution | 0.15 m |
| Waveform sampling interval | 1 ns | Point density | 3.6 pts/m2 |
| CCD: DigiCAM-60 | |||
| Frame size | 8956 × 6708 | Pixel size | 6 µm |
| Imaging sensor size | 40.30 mm × 53.78 mm | Bit depth | 16 bits |
| FOV | 56.2° | Focal length | 50 mm |
| Spatial resolution | 0.2 m | ||
| Tree Species | Training Samples | Verification Samples | ||
|---|---|---|---|---|
| Image Objects | Number of Pixels | Image Objects | Number of Pixels | |
| Illicium verum (IV) | 65 | 3267 | 49 | 646 |
| Masson pine (MP) | 62 | 3116 | 43 | 555 |
| Slash pine (SP) | 45 | 2262 | 31 | 393 |
| Chinese fir (CF) | 64 | 3217 | 45 | 580 |
| Mytilaria laosensis (ML) | 58 | 2915 | 49 | 624 |
| Eucalyptus (EU) | 153 | 7691 | 97 | 1247 |
| Other broad leaves (OBL) | 75 | 3770 | 58 | 748 |
| Total | 522 | 26,238 | 372 | 4793 |
| Spectral Indices | Equation |
|---|---|
| Normalized difference vegetation index | |
| Plant senescence reflectance index | |
| Modified red edge simple ratio index | |
| Modified red edge normalized difference vegetation index | |
| Normalized green difference vegetation index | |
| Photochemical reflectance index | |
| Structure insensitive pigment index | |
| Anthocyanin reflectance index | |
| Vogelmann red edge index | |
| Slope between wavelengths 687 nm and 760 nm | Calculated as Equation (1) |
| Slope between wavelengths 687 nm and 890 nm | Calculated as Equation (2) |
| Triangle area enclosed by wavelengths 687 nm, 760 nm and 890 nm | Calculated as Equation (3) |
| Features | Description |
|---|---|
| Independent components analysis | The first five ICA transformation images. |
| Spectral index | Nine vegetation indices, including NDVI, PSRI, MRESRI, MRENDVI, GNDVI, PRI, SIPI, ARI1, VOG1, and three new constructed spectral indices, including SL1, SL2 and TA. |
| Textural features | Selected 17 × 17 texture window size extracted 24 textural features, including MEAN, VAR, HOM, CON, DIS, ENT, SM, COR calculated using GLCM with three bands (band 482 nm, band 550 nm and band 650 nm). |
| Canopy height model | Canopy height model obtained by LiDAR data, reflected the height information of each tree species. |
| Schemes | Feature Variables |
|---|---|
| Scheme A | The first five ICA transformation images, ICA1-ICA5. |
| Scheme B | The first five ICA transformation images stacking 13 spectral indices. |
| Scheme C | The feature variables in Scheme B stacking 24 textural features. |
| Scheme D | All feature variables stacking together, including the first five ICA transformation images, spectral indices, textural features, and CHM. |
| Scheme E | Features selected by RF, including four independent components, i.e., ICA2, ICA3, ICA4, ICA5, seven spectral index features, i.e., NDVI, PRI, GNDVI, PSRI, SL2, SIPI and ARI1, six texture features, i.e., HOM_G550, ENT_G550, CON_G550, COR_G550, DIS_R650, SM_R650, and CHM. |
| Scheme F | Features selected by SVM-RFE, including four independent components, i.e., ICA2, ICA3, ICA4, ICA5, five spectral index features, i.e., NDVI, PRI, GNDVI, SL2, and PSRI, eight texture features, i.e., HOM_G550, Mean_G550, DIS_G550, VAR_G550, CON_G550, ENT_G550, ENT_R650, VAR_R650, and CHM. |
| Schemes | KNN | SVM | ||
|---|---|---|---|---|
| Overall Accuracy (OA) | Kappa Coefficient | Overall Accuracy (OA) | Kappa Coefficient | |
| Scheme A | 80.51% | 0.767 | 83.08% | 0.798 |
| Scheme B | 84.25% | 0.812 | 86.25% | 0.836 |
| Scheme C | 87.11% | 0.846 | 90.86% | 0.891 |
| Scheme D | 90.28% | 0.884 | 93.26% | 0.920 |
| Scheme E | 89.42% | 0.874 | 94.14% | 0.930 |
| Scheme F | 89.86% | 0.879 | 94.68% | 0.937 |
| Tree Species | Scheme A | Scheme B | Scheme C | Scheme D | Scheme E | Scheme F | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PA | UA | PA | UA | PA | UA | PA | UA | PA | UA | PA | UA | |
| IV | 80.50 | 74.50 | 85.91 | 79.51 | 87.31 | 83.93 | 85.45 | 89.18 | 84.83 | 88.39 | 84.37 | 87.62 |
| EU | 93.91 | 89.80 | 96.23 | 91.39 | 93.91 | 93.98 | 96.23 | 95.09 | 95.75 | 95.90 | 97.27 | 95.74 |
| ML | 81.25 | 86.22 | 83.33 | 81.12 | 90.54 | 86.13 | 92.79 | 92.34 | 91.35 | 92.53 | 94.87 | 92.21 |
| CF | 83.62 | 79.25 | 87.41 | 85.93 | 90.17 | 90.33 | 88.28 | 96.06 | 92.24 | 92.56 | 88.10 | 96.05 |
| MP | 81.26 | 77.09 | 86.13 | 82.27 | 87.21 | 84.47 | 93.33 | 85.48 | 93.33 | 83.68 | 94.41 | 83.31 |
| SP | 62.09 | 72.62 | 81.17 | 80.56 | 90.08 | 81.01 | 90.33 | 84.52 | 84.99 | 85.20 | 85.24 | 87.24 |
| OBL | 64.30 | 71.79 | 61.36 | 79.97 | 68.72 | 81.59 | 81.68 | 84.16 | 78.48 | 81.19 | 78.48 | 81.87 |
| Tree Species | Scheme A | Scheme B | Scheme C | Scheme D | Scheme E | Scheme F | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PA | UA | PA | UA | PA | UA | PA | UA | PA | UA | PA | UA | |
| IV | 86.38 | 74.80 | 86.84 | 82.62 | 91.02 | 87.24 | 97.03 | 95.80 | 97.43 | 96.05 | 96.07 | 97.88 |
| EU | 95.27 | 91.95 | 93.50 | 93.06 | 96.23 | 95.77 | 94.39 | 92.03 | 90.71 | 89.84 | 89.17 | 92.64 |
| ML | 82.37 | 90.65 | 88.46 | 82.27 | 90.54 | 92.17 | 86.69 | 99.47 | 90.69 | 91.96 | 96.95 | 87.79 |
| CF | 88.62 | 82.37 | 87.24 | 91.01 | 90.52 | 92.43 | 100 | 83.80 | 97.37 | 99.37 | 91.19 | 90.89 |
| MP | 83.06 | 75.70 | 87.21 | 83.59 | 100 | 87.82 | 90.86 | 91.65 | 96.44 | 92.89 | 95.67 | 100 |
| SP | 71.25 | 83.58 | 90.08 | 80.82 | 93.13 | 82.62 | 93.87 | 91.89 | 92.79 | 90.19 | 100 | 95.20 |
| OBL | 62.43 | 75.32 | 68.32 | 82.82 | 74.33 | 91.15 | 89.57 | 93.58 | 91.18 | 95.52 | 94.83 | 93.54 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Zhang, X. Object-Based Tree Species Classification Using Airborne Hyperspectral Images and LiDAR Data. Forests 2020, 11, 32. https://doi.org/10.3390/f11010032
Wu Y, Zhang X. Object-Based Tree Species Classification Using Airborne Hyperspectral Images and LiDAR Data. Forests. 2020; 11(1):32. https://doi.org/10.3390/f11010032
Chicago/Turabian StyleWu, Yanshuang, and Xiaoli Zhang. 2020. "Object-Based Tree Species Classification Using Airborne Hyperspectral Images and LiDAR Data" Forests 11, no. 1: 32. https://doi.org/10.3390/f11010032
APA StyleWu, Y., & Zhang, X. (2020). Object-Based Tree Species Classification Using Airborne Hyperspectral Images and LiDAR Data. Forests, 11(1), 32. https://doi.org/10.3390/f11010032