
A Direct Search Algorithm for Global Optimization

Abstract
:1. Introduction
2. Direct Search Methods and Global Optimization
2.1. Local Optimization Approaches
2.2. Global Optimization Approaches
3. A Direct Search Algorithm for Global Optimization
3.1. Notation
Set of integer numbers in interval : .Closed convex hull of a set : .Difference set .Larger integer less than or equal to x: .Inner product of Euclidean space: .p-norm of Euclidean space: , .∞-norm of Euclidean space: .
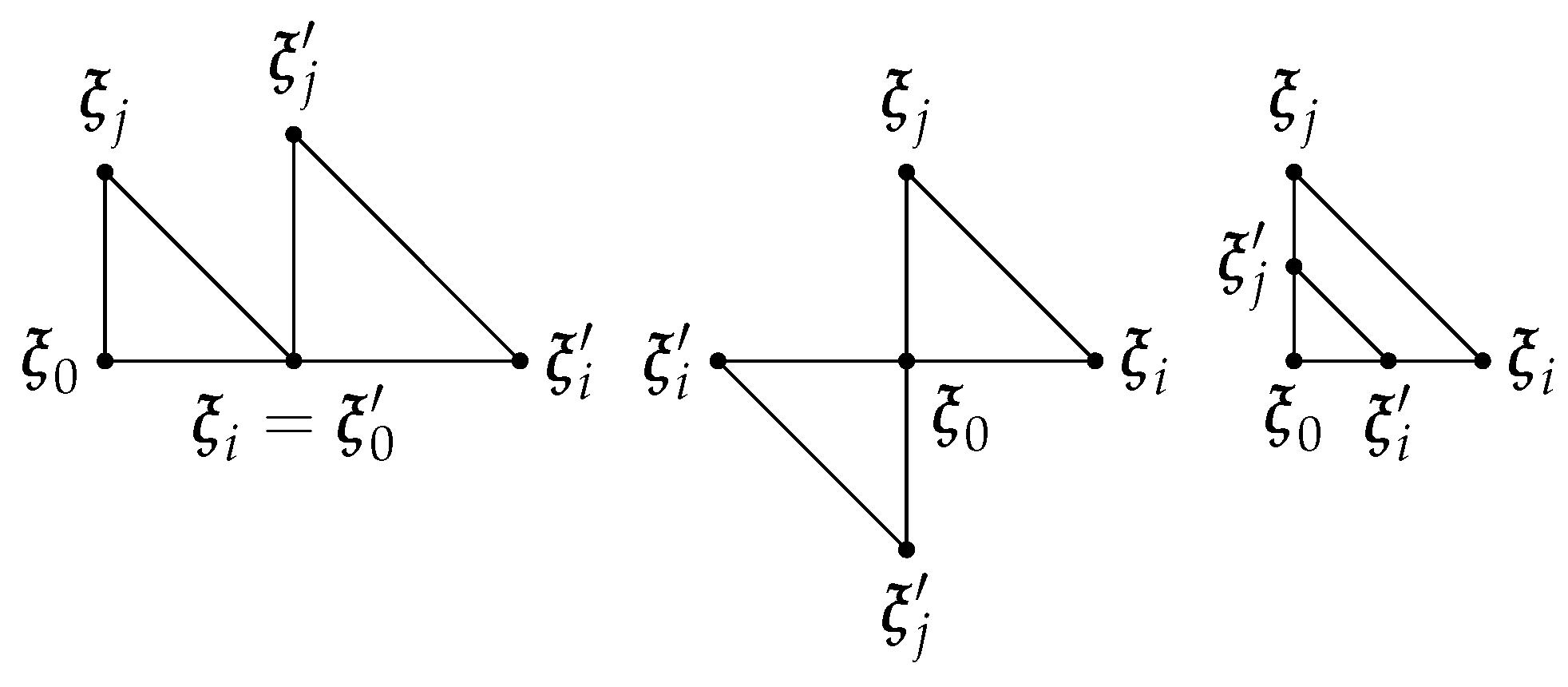
3.2. Review of the Basic Geometric Results about n-Simplices
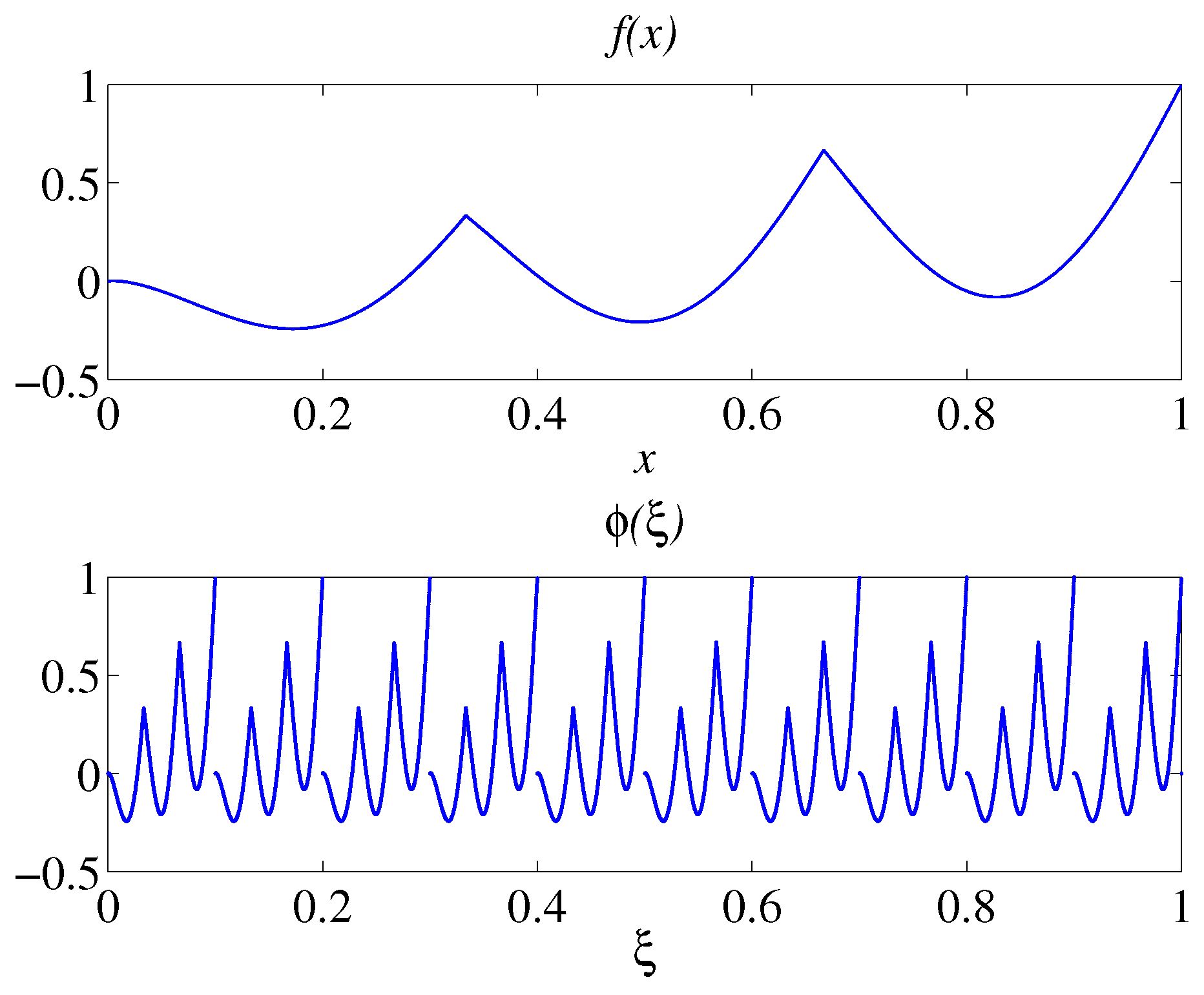
3.3. Function Transformation
- (i)
- The function φ is continuous for any , such that .
- (ii)
- Let be such that and , then .
3.4. The Basic Algorithm
3.4.1. Function Transformation
3.4.2. Initial Simplex
3.4.3. Expansive Translation
3.4.4. Rotation
3.4.5. Shrinkage
3.4.6. Sufficient Decrease Condition
3.4.7. Stopping Criterion
3.4.8. Space Transformation
3.4.9. Implementation
| Algorithm 1 Basic algorithm. | |
| |
| |
| |
| |
| |
| |
| ▹ Local direct search |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| ▹ Expansive translation |
| |
| |
| |
| |
| |
| ▹ Rotation |
| |
| |
| |
| |
| ▹ Shrinkage |
| |
| |
| |
| |
| |
| |
| |
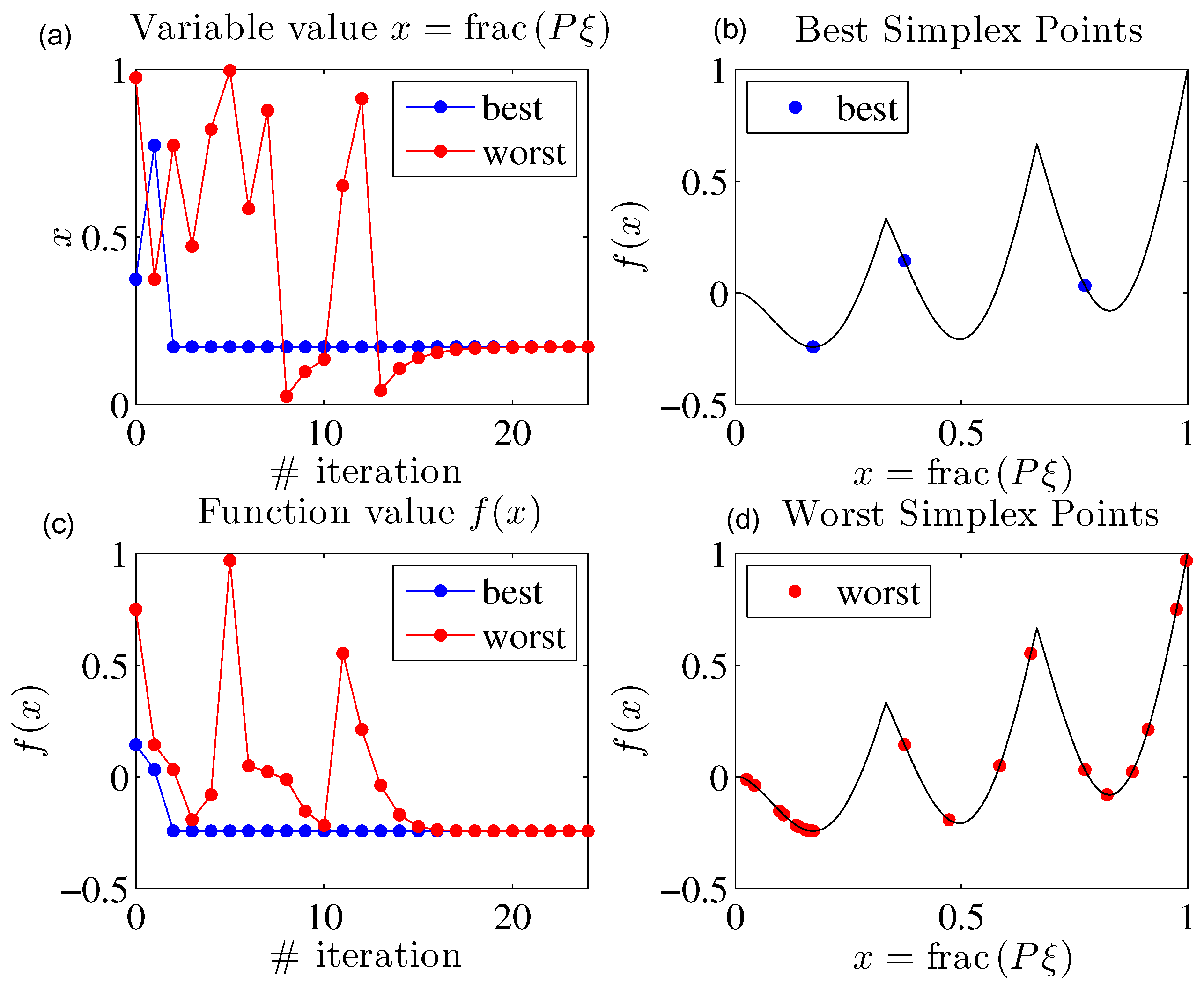
3.5. Convergence of the Basic Algorithm
3.6. The Complete Algorithm
3.6.1. Initial Point
3.6.2. Best Point Storage
3.6.3. Implementation of the Complete Algorithm
| Algorithm 2 Complete algorithm GDS. |
|
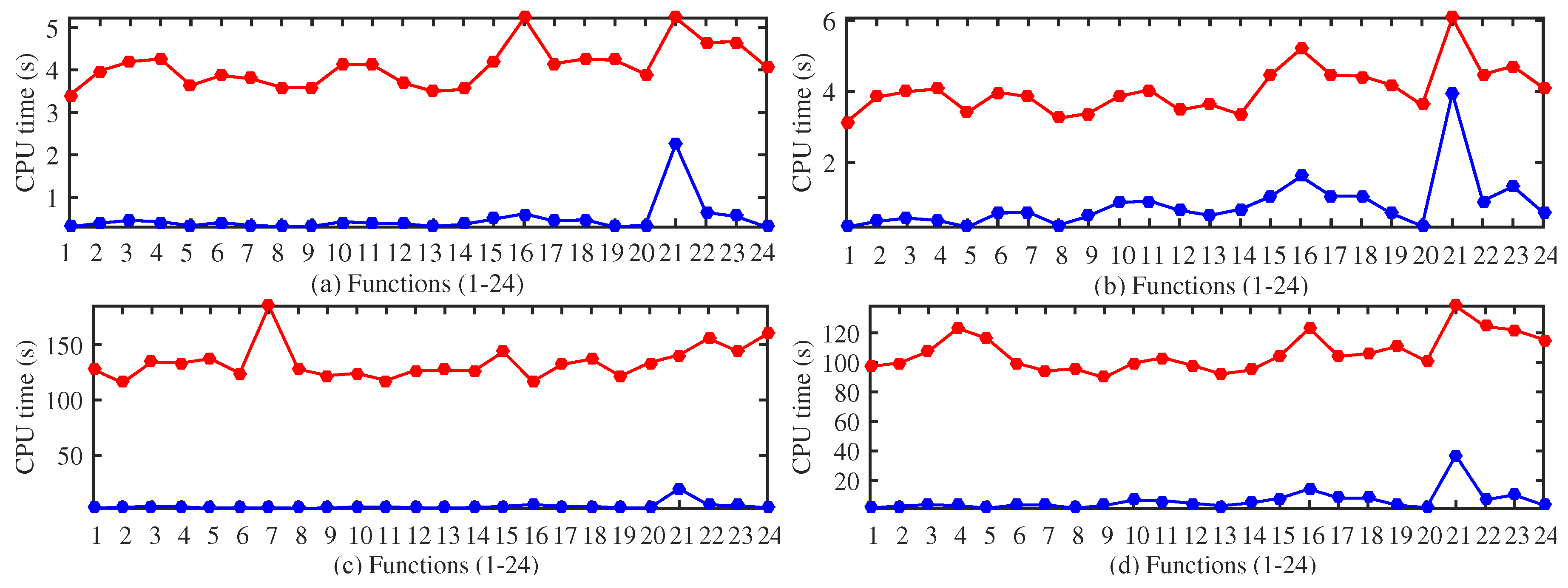
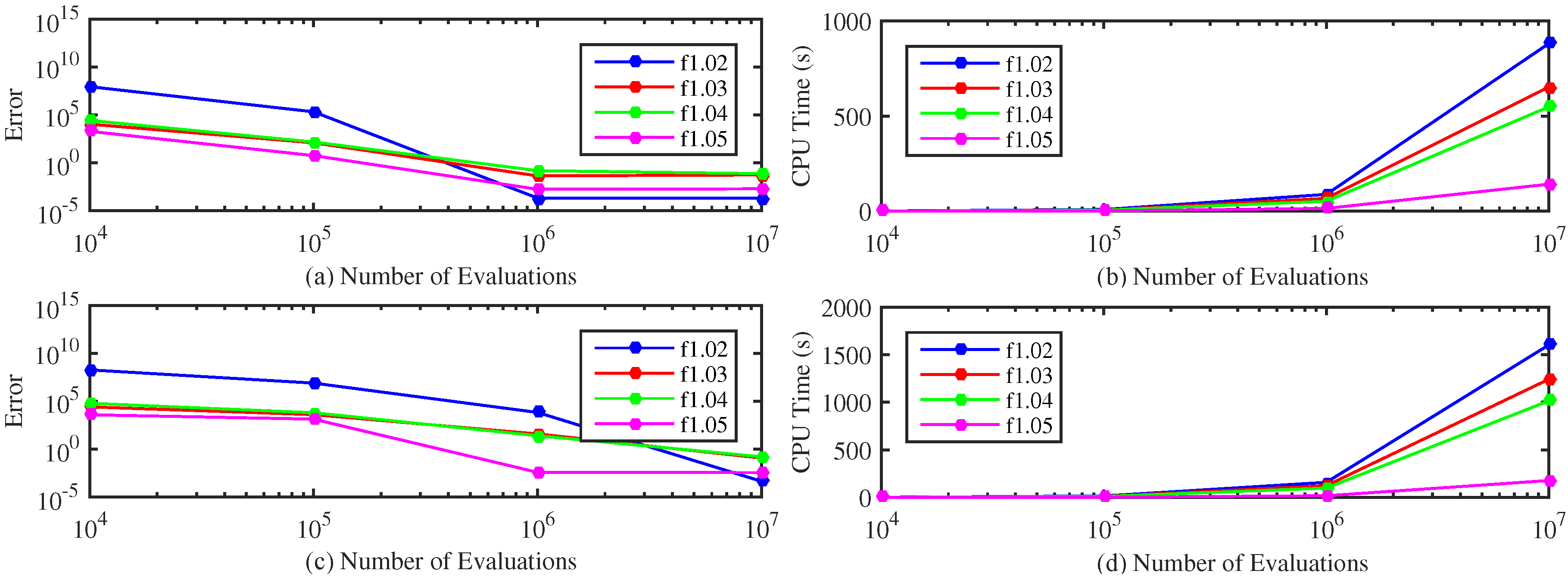
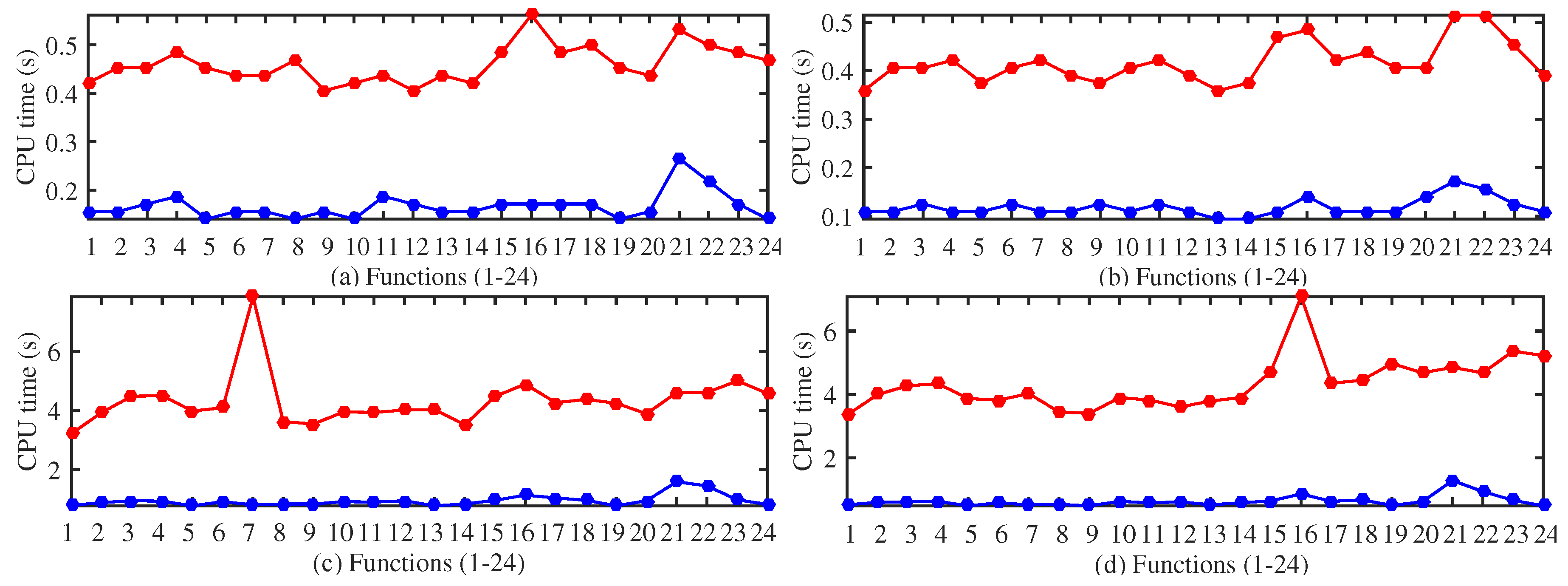
4. Experimental Study
4.1. Test Functions
4.2. Selection of the GDS Parameters
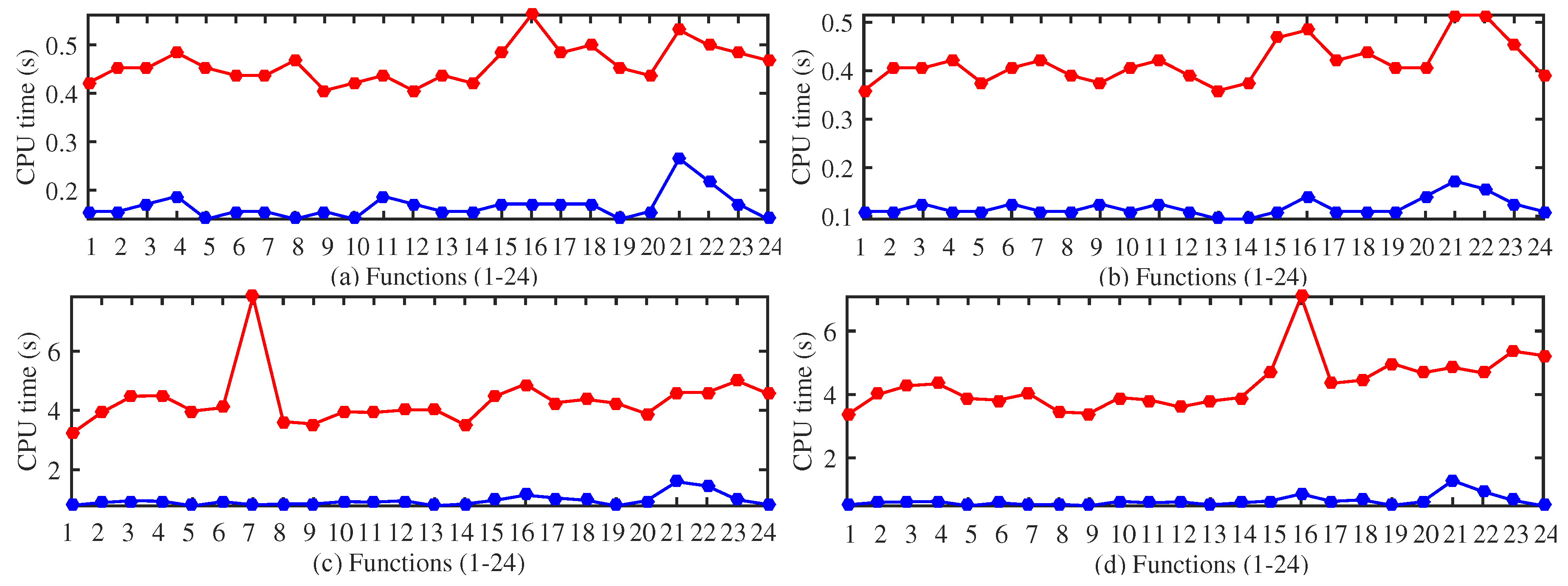
4.3. Performance Evaluation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lewis, R.M.; Torczon, V.; Trosset, M.W. Direct Search Methods: Then and Now. J. Comput. Appl. Math. 2000, 124, 191–207. [Google Scholar] [CrossRef]
- Cohn, A.; Scheinberg, K.; Vicente, L. Introduction to Derivative-Free Optimization; MOS/SIAM Series on Optimization; SIAM: Philadelphia, PA, USA, 2009. [Google Scholar]
- Pinter, J.D. Global Optimization: Software, Test Problems, and Applications. In Handbook of Global Optimization; Pardalos, P.M., Romeijn, H.E., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2002; Volume 2. [Google Scholar]
- Kolda, T.G.; Lewis, R.M.; Torczon, V. Optimization by Direct Search: New Perspectives on Some Classical and Modern Methods. SIAM Rev. 2003, 45, 385–482. [Google Scholar] [CrossRef]
- Neumaier, A. Complete Search in Continuous Global Optimization and Constraint Satisfaction. Acta Numer. 2004, 13, 271–369. [Google Scholar] [CrossRef]
- Conn, A.R.; Scheinberg, K.; Vicente, L.N. Introduction to Derivative-Free Optimization; SIAM: Philadelphia, PA, USA, 2009; Volume 8. [Google Scholar]
- Rios, L.M.; Sahinidis, N.V. Derivative-free optimization: A review of algorithms and comparison of software implementations. J. Glob. Optim. 2013, 56, 1247–1293. [Google Scholar] [CrossRef]
- Swann, W.H. Direct Search Methods. In Numerical Methods for Unconstrained Optimization; Murray, W., Ed.; Academic Press: Salt Lake City, UT, USA, 1972; pp. 13–28. [Google Scholar]
- Evtushenko, Y.G. Numerical methods for finding global extrema (case of a non-uniform mesh). USSR Comput. Math. Math. Phys. 1971, 11, 38–54. [Google Scholar] [CrossRef]
- Strongin, R. A simple algorithm for searching for the global extremum of a function of several variables and its utilization in the problem of approximating functions. Radiophys. Quantum Electron. 1972, 15, 823–829. [Google Scholar] [CrossRef]
- Sergeyev, Y.D.; Strongin, R. A global minimization algorithm with parallel iterations. USSR Comput. Math. Math. Phys. 1989, 29, 7–15. [Google Scholar] [CrossRef]
- Dennis, J.E.J.; Torczon, V. Direct Search Methods On Parallel Machines. SIAM J. Optim. 1991, 1, 448–474. [Google Scholar] [CrossRef]
- Hooke, R.; Jeeves, T. Direct search solution of numerical and statistical problems. J. ACM 1961, 8, 12–229. [Google Scholar] [CrossRef]
- Nelder, J.A.; Mead, R. A Simplex Method for Function Minimization. Comput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Spendley, W.; Hext, G.R.; Himsworth, F.R. Sequential Application of Simplex Designs in Optimisation and Evolutionary Operation. Technometrics 1962, 4, 441–461. [Google Scholar] [CrossRef]
- Lagarias, J.; Reeds, J.; Wright, M.; Wright, P. Convergence Properties of the Nelder-Mead Simplex Method in Low Dimensions. SIAM J. Optim. 1998, 9, 112–147. [Google Scholar] [CrossRef]
- Conn, A.; Gould, N.; Toint, P. Trust-Region Methods; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2000. [Google Scholar]
- Regis, R.; Shoemaker, C. Constrained global optimization of expensive black box functions using radial basis functions. J. Glob. Optim. 2005, 31, 153–171. [Google Scholar] [CrossRef]
- Custodio, A.; Rocha, H.; Vicente, L. Incorporating minimum Frobenius norm models in direct search. Comput. Optim. Appl. 2010, 46, 265–278. [Google Scholar] [CrossRef]
- Conn, A.; Le Digabel, S. Use of quadratic models with mesh-adaptive direct search for constrained black box optimization. Optim. Methods Softw. 2013, 28, 139–158. [Google Scholar] [CrossRef]
- Lewis, R.; Torczon, V. Pattern search algorithms for bound constrained minimization. SIAM J. Optim. 1999, 9, 1082–1099. [Google Scholar] [CrossRef]
- Lewis, R.; Torczon, V. Pattern search algorithms for linearly constrained minimization. SIAM J. Optim. 2000, 10, 917–941. [Google Scholar] [CrossRef]
- Lewis, R.; Torczon, V. A globally convergent augmented Lagrangian pattern search algorithm for optimization with general constraints and simple bounds. SIAM J. Optim. 2002, 12, 1071–1089. [Google Scholar] [CrossRef]
- Kolda, T.; Lewis, R.; Torczon, V. A Generating Set Direct Search Augmented Lagrangian Algorithm for Optimization with a Combination of General and Linear Constraints; Sandia National Laboratories: Livermore, CA, USA, 2006.
- Audet, C.; Dennis, J.E. A pattern search filter method for nonlinear programming without derivatives. SIAM J. Optim. 2004, 14, 980–1010. [Google Scholar] [CrossRef]
- Abramson, M.; Audet, C.; Dennis, J. Filter pattern search algorithms for mixed variable constrained optimization problems. Pac. J. Optim. 2007, 3, 477–500. [Google Scholar]
- Dennis, J.; Price, C.; Coope, I. Direct search methods for nonlinearly constrained optimization using filters and frames. Optim. Eng. 2004, 5, 123–144. [Google Scholar] [CrossRef]
- Solis, F.J.; Wets, R.J.B. Minimization by Random Search Techniques. Math. Oper. Res. 1981, 6, 19–30. [Google Scholar] [CrossRef]
- Pearl, J. Heuristics: Intelligent Search Strategies for Computer Problem Solving; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1984. [Google Scholar]
- Michalewicz, Z.; Fogel, D.B. How to Solve It: Modern Heuristics, 2nd ed.; Springer: Berlin, Germany, 2004. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Bäck, T. Evolutionary Algorithms in Theory and Pratice; Oxford University Press: New York, NY, USA, 1996. [Google Scholar]
- Larrañaga, P.; Lozano, J.A. Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation; Kluwer: Boston, MA, USA, 2002. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the 1995 IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948.
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Chakraborty, U.K. Advances in Differential Evolution; Springer Publishing Company: Berlin, Germany, 2008. [Google Scholar]
- Glover, F. Tabu Search—Part I. ORSA J. Comput. 1989, 2, 190–206. [Google Scholar] [CrossRef]
- Glover, F.; Laguna, M. Tabu Search; Kluwer Academic Publishers: New York, NY, USA, 1997. [Google Scholar]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B Cybern. 1996, 26, 29–41. [Google Scholar] [CrossRef] [PubMed]
- Dorigo, M.; Stützle, T. Ant Colony Optimization; Bradford Company: Scituate, MA, USA, 2004. [Google Scholar]
- Paulavičius, R.; Žilinskas, J. Simplicial Global Optimization; Springer: Berlin, Germany, 2014. [Google Scholar]
- Sergeyev, Y.D.; Strongin, R.G.; Lera, D. Introduction to Global Optimization Exploiting Space-Filling Curves; Springer: Berlin, Germany, 2013. [Google Scholar]
- Strongin, R.G.; Sergeyev, Y.D. Global Optimization with Non-Convex Constraints: Sequential and Parallel Algorithms; Springer: Berlin, Germany, 2013. [Google Scholar]
- Zhigljavsky, A.; Žilinskas, A. Stochastic Global Optimization; Springer: Berlin, Germany, 2008. [Google Scholar]
- Zhigljavsky, A.A. Theory of Global Random Search; Springer: Berlin, Germany, 2012. [Google Scholar]
- Shubert, B.O. A sequential method seeking the global maximum of a function. SIAM J. Numer. Anal. 1972, 9, 379–388. [Google Scholar] [CrossRef]
- Sergeyev, Y.D.; Kvasov, D.E. Global search based on efficient diagonal partitions and a set of Lipschitz constants. SIAM J. Optim. 2006, 16, 910–937. [Google Scholar] [CrossRef]
- Lera, D.; Sergeyev, Y.D. Lipschitz and Hölder global optimization using space-filling curves. Appl. Numer. Math. 2010, 60, 115–129. [Google Scholar] [CrossRef]
- Kvasov, D.E.; Sergeyev, Y.D. Lipschitz global optimization methods in control problems. Autom. Remote Control 2013, 74, 1435–1448. [Google Scholar] [CrossRef]
- Jones, D.R.; Perttunen, C.D.; Stuckman, B.E. Lipschitzian optimization without the Lipschitz constant. J. Optim. Theory Appl. 1993, 79, 157–181. [Google Scholar] [CrossRef]
- Gablonsky, J.M.; Kelley, C.T. A locally-biased form of the DIRECT algorithm. J. Glob. Optim. 2001, 21, 27–37. [Google Scholar] [CrossRef]
- Finkel, D.E.; Kelley, C. Additive scaling and the DIRECT algorithm. J. Glob. Optim. 2006, 36, 597–608. [Google Scholar] [CrossRef]
- Paulavičius, R.; Sergeyev, Y.D.; Kvasov, D.E.; Žilinskas, J. Globally-biased Disimpl algorithm for expensive global optimization. J. Glob. Optim. 2014, 59, 545–567. [Google Scholar] [CrossRef]
- Liu, Q.; Cheng, W. A modified DIRECT algorithm with bilevel partition. J. Glob. Optim. 2014, 60, 483–499. [Google Scholar] [CrossRef]
- Ge, R.P. The theory of filled function-method for finding global minimizers of nonlinearly constrained minimization problems. J. Comput. Math. 1987, 5, 1–9. [Google Scholar]
- Ge, R.; Qin, Y. The globally convexized filled functions for global optimization. Appl. Math. Comput. 1990, 35, 131–158. [Google Scholar] [CrossRef]
- Han, Q.; Han, J. Revised filled function methods for global optimization. Appl. Math. Comput. 2001, 119, 217–228. [Google Scholar] [CrossRef]
- Liu, X.; Xu, W. A new filled function applied to global optimization. Comput. Oper. Res. 2004, 31, 61–80. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L.; Xu, Y. New filled functions for nonsmooth global optimization. Appl. Math. Model. 2009, 33, 3114–3129. [Google Scholar] [CrossRef]
- Wolpert, D.; Macready, W. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Hansen, N.; Finck, S.; Ros, R.; Auger, A. Real-Parameter Black-Box Optimization Benchmarking 2009: Noiseless Functions Definitions; Research Report RR-6829; INRIA: Rocquencourt, France, 2009. [Google Scholar]
- Mathworks. MATLAB User’s Guide (R2010a); The MathWorks, Inc.: Natick, MA, USA, 2010. [Google Scholar]
- Finkel, D.E. DIRECT Optimization Algorithm User Guide; Center for Research in Scientific Computation, North Carolina State University: Raleigh, NC, USA, 2003. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Func # | Description |
|---|---|
| 1.01 | Sphere |
| 1.02 | Ellipsoid separable with monotone x-transformation, condition 1e + 06 |
| 1.03 | Rastrigin separable with both x-transformations condition 10 |
| 1.04 | Skew Rastrigin–Bueche separable, condition 10, skew-condition 100 |
| 1.05 | Linear slope, neutral extension outside the domain (not flat) |
| 2.06 | Attractive sector function |
| 2.07 | Step-ellipsoid, condition 100 |
| 2.08 | Rosenbrock, original |
| 2.09 | Rosenbrock, rotated |
| 3.10 | Ellipsoid with monotone x-transformation, condition 1e6 |
| 3.11 | Discus with monotone x-transformation, condition 1e6 |
| 3.12 | Bent cigar with asymmetric x-transformation, condition 1e6 |
| 3.13 | Sharp ridge, slope 1:100, condition 10 |
| 3.14 | Sum of different powers |
| 4.15 | Rastrigin with both x-transformations, condition 10 |
| 4.16 | Weierstrass with monotone x-transformation, condition 100 |
| 4.17 | Schaffer F7 with asymmetric x-transformation, condition 10 |
| 4.18 | Schaffer F7 with asymmetric x-transformation, condition 1000 |
| 4.19 | F8F2 composition of 2D Griewank–Rosenbrock |
| 5.20 | Schwefel x sin(x) with tridiagonal transformation, condition 10 |
| 5.21 | Gallagher 101 Gaussian peaks, condition up to 1000 |
| 5.22 | Gallagher 21 Gaussian peaks, condition up to 1000, 1000 for global opt |
| 5.23 | Katsuuras repetitive rugged function |
| 5.24 | Lunacek bi-Rastrigin, condition 100 |
| Func | GDS | DIRECT | GDS | DIRECT | GDS | DIRECT | GDS | DIRECT |
|---|---|---|---|---|---|---|---|---|
| # | dim = 5 | nev = 1e+03 | dim = 5 | nev = 1e+04 | dim = 10 | nev = 1e+03 | dim = 10 | nev = 1e+04 |
| 1.01 | 3.647e+01 | 5.094e−04 | 9.920e−09 | 1.347e−04 | 1.422e+02 | 1.862e−01 | 9.826e−09 | 1.076e−03 |
| 1.02 | 2.400e+06 | 2.044e+00 | 8.064e−06 | 3.053e−01 | 1.072e+07 | 1.475e+05 | 2.020e−05 | 2.129e+00 |
| 1.03 | 3.649e+02 | 7.015e+00 | 2.002e-02 | 5.970e+00 | 6.338e+02 | 4.234e+01 | 7.859e−02 | 1.692e+01 |
| 1.04 | 2.507e+02 | 1.249e+01 | 1.696e−02 | 6.967e+00 | 9.518e+02 | 5.252e+01 | 1.058e+00 | 2.274e+01 |
| 1.05 | 6.767e+01 | 1.643e−02 | 7.809e−05 | 1.643e-02 | 1.788e+02 | 2.271e+01 | 1.986e−04 | 1.909e−02 |
| 2.06 | 6.348e+04 | 2.306e+00 | 3.497e−07 | 7.272e−01 | 5.778e+05 | 2.520e+01 | 1.435e−01 | 1.185e+01 |
| 2.07 | 4.044e+00 | 6.738e−01 | 5.543e−01 | 5.216e−03 | 2.796e+01 | 6.227e+00 | 5.254e+00 | 1.815e+00 |
| 2.08 | 3.644e+04 | 2.107e+00 | 1.647e+00 | 1.794e−02 | 2.066e+05 | 9.353e+01 | 3.141e+00 | 8.302e+00 |
| 2.09 | 7.835e+03 | 5.858e-01 | 2.433e−01 | 2.747e−02 | 8.654e+04 | 1.551e+01 | 5.383e+00 | 6.010e+00 |
| 3.10 | 1.426e+05 | 8.102e+02 | 9.892e+02 | 3.345e+01 | 7.788e+06 | 1.312e+04 | 3.999e+03 | 1.640e+03 |
| 3.11 | 1.003e+02 | 1.997e+01 | 5.722e+01 | 4.615e+00 | 1.647e+06 | 5.343e+01 | 1.023e+02 | 3.198e+01 |
| 3.12 | 4.213e+07 | 6.904e+00 | 4.372e+00 | 2.012e−02 | 2.597e+08 | 1.284e+05 | 5.751e+00 | 7.904e−01 |
| 3.13 | 8.841e+02 | 2.545e+00 | 1.067e+00 | 5.285e−02 | 2.388e+03 | 9.999e+01 | 2.036e+00 | 6.097e+00 |
| 3.14 | 2.356e+01 | 8.957e−03 | 8.020e−04 | 7.238e−04 | 5.779e+01 | 2.685e−01 | 2.232e−03 | 1.452e−02 |
| 4.15 | 1.920e+02 | 7.971e+00 | 5.014e+00 | 2.988e+00 | 7.494e+02 | 5.364e+01 | 6.365e+01 | 1.991e+01 |
| 4.16 | 3.869e+00 | 6.053e−01 | 6.144e−01 | 4.247e−03 | 3.089e+01 | 5.140e+00 | 2.428e+00 | 5.762e−01 |
| 4.17 | 1.069e+01 | 1.104e−01 | 9.849e−01 | 6.272e−03 | 2.350e+01 | 1.457e+00 | 1.265e+01 | 9.732e−02 |
| 4.18 | 4.694e+01 | 2.134e−01 | 2.395e+00 | 2.908e−02 | 5.608e+01 | 6.410e+00 | 5.172e+01 | 4.363e−01 |
| 4.19 | 2.775e+00 | 8.478e-02 | 5.901e−01 | 4.858e-02 | 2.127e+01 | 1.990e-01 | 2.630e+00 | 1.620e−01 |
| 5.20 | 1.983e+04 | 1.265e+00 | 2.392e−01 | 8.295e−01 | 7.714e+04 | 2.707e+00 | 9.283e-01 | 1.829e+00 |
| 5.21 | 1.751e+01 | 2.052e−04 | 9.300e−01 | 6.972e−06 | 7.886e+01 | 2.338e+00 | 6.676e+00 | 2.239e−03 |
| 5.22 | 4.032e+01 | 6.928e−01 | 6.024e−02 | 2.746e−04 | 8.485e+01 | 1.651e+00 | 7.272e+00 | 6.928e−01 |
| 5.23 | 1.395e+00 | 9.682e−01 | 6.205e−01 | 8.782e−01 | 2.247e+00 | 1.438e+00 | 7.203e−01 | 9.066e−01 |
| 5.24 | 9.572e+01 | 2.122e+01 | 1.108e+01 | 1.071e+01 | 2.673e+02 | 7.556e+01 | 9.847e+01 | 6.139e+01 |
| Func | GDS | DIRECT | GDS | DIRECT | GDS | DIRECT | GDS | DIRECT |
|---|---|---|---|---|---|---|---|---|
| # | dim = 20 | nev = 1e+04 | dim = 20 | nev = 1e+05 | dim = 40 | nev = 1e+04 | dim = 40 | nev = 1e+05 |
| 1.01 | 6.690e−2 | 1.456e−01 | 9.434e-09 | 2.626e−03 | 3.187e+02 | 2.533e+01 | 8.897e−09 | 5.976e−02 |
| 1.02 | 3.171e+03 | 1.570e+06 | 3.806e−05 | 3.471e+01 | 1.195e+07 | 2.904e+06 | 4.865e−02 | 2.904e+06 |
| 1.03 | 9.586e+00 | 5.187e+01 | 3.545e−02 | 3.620e+01 | 1.719e+03 | 5.029e+02 | 2.008e+00 | 9.027e+01 |
| 1.04 | 9.342e+00 | 6.536e+01 | 7.299e−02 | 6.174e+01 | 4.448e+03 | 5.542e+02 | 1.487e+00 | 1.165e+02 |
| 1.05 | 5.537e−01 | 3.190e+01 | 4.178e−04 | 2.201e−02 | 5.900e+02 | 3.495e+02 | 8.092e−04 | 4.421e+01 |
| 2.06 | 3.202e+01 | 6.464e+01 | 1.873e+00 | 3.152e+01 | 9.308e+05 | 1.415e+03 | 2.211e+00 | 1.177e+02 |
| 2.07 | 3.453e+01 | 1.654e+01 | 1.371e+01 | 6.260e+00 | 1.376e+02 | 1.234e+02 | 6.765e+01 | 4.261e+01 |
| 2.08 | 7.405e+01 | 6.866e+01 | 4.320e+00 | 3.332e+01 | 6.045e+05 | 7.049e+03 | 8.010e+01 | 1.602e+02 |
| 2.09 | 2.030e+01 | 5.129e+01 | 8.313e+00 | 3.241e+01 | 3.287e+05 | 2.260e+02 | 3.715e+01 | 1.424e+02 |
| 3.10 | 4.927e+04 | 1.210e+04 | 2.472e+03 | 4.680e+03 | 1.048e+07 | 2.325e+05 | 2.234e+04 | 6.582e+04 |
| 3.11 | 2.337e+02 | 8.049e+01 | 2.610e+02 | 6.898e+01 | 5.563e+02 | 1.885e+02 | 4.841e+02 | 1.792e+02 |
| 3.12 | 1.716e+04 | 1.010e+05 | 6.880e+00 | 1.499e+03 | 6.739e+08 | 2.964e+07 | 7.067e+00 | 1.240e+05 |
| 3.13 | 3.187e+01 | 1.404e+02 | 1.805e+00 | 1.050e+02 | 3.588e+03 | 9.766e+02 | 2.019e+00 | 1.607e+02 |
| 3.14 | 2.114e−02 | 2.780e−01 | 6.335e−04 | 8.335e−02 | 1.016e+02 | 6.893e+00 | 2.241e−03 | 3.609e−01 |
| 4.15 | 1.349e+03 | 1.125e+02 | 9.561e+01 | 6.304e+01 | 3.134e+03 | 4.190e+02 | 7.482e+02 | 2.579e+02 |
| 4.16 | 6.812e+00 | 5.866e+00 | 3.164e+00 | 3.113e+00 | 2.283e+01 | 1.475e+01 | 9.467e+00 | 8.788e+00 |
| 4.17 | 1.885e+01 | 1.854e+00 | 2.314e+01 | 4.799e−1 | 2.714e+01 | 5.368e+00 | 2.041e+01 | 1.716e+00 |
| 4.18 | 7.823e+01 | 5.327e+00 | 8.362e+01 | 1.387e+00 | 1.084e+02 | 2.034e+01 | 1.062e+02 | 8.653e+00 |
| 4.19 | 6.546e+00 | 2.504e−01 | 4.953e+00 | 2.307e−01 | 2.069e+01 | 2.504e−01 | 8.861e+00 | 2.504e−01 |
| 5.20 | 1.108e+00 | 1.973e+00 | 6.419e−01 | 1.837e+00 | 1.273e+05 | 2.104e+02 | 9.083e−01 | 2.075e+00 |
| 5.21 | 7.598e+00 | 5.096e−01 | 1.803e+00 | 1.227e−01 | 8.327e+01 | 7.596e+00 | 4.714e+00 | 1.086e+00 |
| 5.22 | 1.114e+01 | 2.024e+00 | 6.919e−01 | 7.305e−1 | 8.487e+01 | 1.260e+01 | 8.905e+00 | 6.475e+00 |
| 5.23 | 1.038e+00 | 1.229e+00 | 6.147e−01 | 1.175e+00 | 2.385e+00 | 2.263e+00 | 1.078e+00 | 1.798e+00 |
| 5.24 | 5.915e+02 | 1.532e+02 | 9.995e+01 | 1.532e+02 | 1.333e+03 | 3.299e+02 | 8.494e+02 | 3.055e+02 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baeyens, E.; Herreros, A.; Perán, J.R. A Direct Search Algorithm for Global Optimization. Algorithms 2016, 9, 40. https://doi.org/10.3390/a9020040
Baeyens E, Herreros A, Perán JR. A Direct Search Algorithm for Global Optimization. Algorithms. 2016; 9(2):40. https://doi.org/10.3390/a9020040
Chicago/Turabian StyleBaeyens, Enrique, Alberto Herreros, and José R. Perán. 2016. "A Direct Search Algorithm for Global Optimization" Algorithms 9, no. 2: 40. https://doi.org/10.3390/a9020040
APA StyleBaeyens, E., Herreros, A., & Perán, J. R. (2016). A Direct Search Algorithm for Global Optimization. Algorithms, 9(2), 40. https://doi.org/10.3390/a9020040