4.1. Reduction to CNF-SAT Solving
In this section, we describe two approaches to solve Co-Clustering∞ via CNF-SAT. The first approach is based on a straightforward reduction of a Co-Clustering∞ instance to one CNF-SAT instance with clauses of size at least four. Note that this does not yield any theoretical improvements in general. Hence, we develop a second approach, which requires solving many CNF-SAT instances with clauses of size at most . The theoretical advantage of this approach is that if k and ℓ are constants, then there are only polynomially many CNF-SAT instances to solve. Moreover, the formulas contain smaller clauses (for , we even obtain polynomial-time solvable 2-SAT instances). While the second approach leads to (theoretically) tractable special cases, it is not clear that it also performs better in practice. This is why we conducted some experiments for empirical comparison of the two approaches (in fact, it turns out that the straightforward approach allows one to solve larger instances). In the following, we describe the reductions in detail and briefly discuss the experimental results.
We start with the straightforward polynomial-time reduction from Co-Clustering∞ to CNF-SAT. We simply introduce a variable () for each pair of row index and row block index (respectively, column index and column block index ) denoting whether the respective row (column) may be put into the respective row (column) block. For each row i, we enforce that it is put into at least one row block with the clause (analogously for the columns). We encode the cost constraints by introducing clauses , for each pair of entries with . These clauses simply ensure that and are not put into the same cluster. Note that this reduction yields a CNF-SAT instance with variables and clauses of size up to .
Based on experiments (using the PicoSAT Solver of Biere [
17]), which we conducted on randomly generated synthetic data (of size up to
), as well as on a real-world dataset (
animals with attributes dataset [
18] with
and
), we found that we can solve instances up to
using the above CNF-SAT approach. In our experiments, we first computed an upper and a lower bound on the optimal cost value
c and then created the CNF-SAT instances for decreasing values for
c, starting from the upper bound. The upper and the lower bound have been obtained as follows: Given a
-C
o-C
lustering∞ instance on
, solve
-C
o-C
lustering∞ and
-C
o-C
lustering∞ separately for input matrix
. Let
and
denote the
- and
-co-clustering, respectively, and let their costs be
and
. We take
as a lower bound and
as an upper bound on the optimal cost value for an optimal (
)-co-clustering of
. It is straightforward to argue the correctness of the lower bound, and we next show that
is an upper bound. Consider any pair
, such that
i and
are in the same row block of
, and
j and
are in the same column block of
(that is,
and
are in the same cluster). Then, it holds
. Hence, just taking the row partitions from
and the column partitions from
gives a combined (
)-co-clustering of cost at most
.
From a theoretical perspective, the above naive approach of solving Co-Clustering∞ via CNF-SAT does not yield any improvement in terms of polynomial-time solvability. Therefore, we now describe a different approach, which leads to some polynomial-time solvable special cases. To this end, we introduce the concept of cluster boundaries, which are basically lower and upper bounds for the values in a cluster of a co-clustering. Formally, given two integers , an alphabet Σ and a cost c, we define a cluster boundary to be a matrix . We say that a -co-clustering of satisfies a cluster boundary if for all . It can easily be seen that a given -co-clustering has cost at most c if and only if it satisfies at least one cluster boundary , namely the one with .
The following “subtask” of C
o-C
lustering∞ can be reduced to a certain CNF-SAT instance: Given a cluster boundary
and a C
o-C
lustering∞ instance
I, find a co-clustering for
I that satisfies
. The polynomial-time reduction provided by the following lemma can be used to obtain exact C
o-C
lustering∞ solutions with the help of SAT solvers, and we use it in our subsequent algorithms.
Lemma 1. Given a Co-Clustering∞-instance and a cluster boundary , one can construct in polynomial time a CNF-SAT instance φ with at most variables per clause, such that φ is satisfiable if and only if there is a ()-co-clustering of , which satisfies .
Proof. Given an instance of Co-Clustering∞ and a cluster boundary , we define the following Boolean variables: For each , the variable represents the expression “row i could be put into row block ”. Similarly, for each , the variable represents that “column j could be put into column block ”.
We now define a Boolean CNF formula containing the following clauses: a clause for each row and a clause for each column . Additionally, for each and each , such that element does not fit into the cluster boundary at coordinate , that is , there is a clause ). Note that the clauses and ensure that row i and column j are put into some row and some column block, respectively. The clause expresses that it is impossible to have both row i in block and column j in block if does not satisfy . Clearly, is satisfiable if and only if there exists a ()-co-clustering of satisfying the cluster boundary . Note that consists of variables and clauses. ☐
Using Lemma 1, we can solve Co-Clustering∞ by solving many CNF-SAT instances (one for each possible cluster boundary) with variables and clauses of size at most . We also implemented this approach for comparison with the straightforward reduction to CNF-SAT above. The bottleneck of this approach, however, is the number of possible cluster boundaries, which grows extremely quickly. While a single CNF-SAT instance can be solved quickly, generating all possible cluster boundaries together with the corresponding CNF formulas becomes quite expensive, such that we could only solve instances with very small values of and .
4.2. Polynomial-Time Solvability
We first present a simple and efficient algorithm for
-C
o-C
lustering∞, that is the variant where all rows belong to one row block.
Theorem 4. -Co-Clustering∞ is solvable in time.
Proof. We show that Algorithm 1 solves -Co-Clustering∞. In fact, it even computes the minimum , such that has a -co-clustering of cost c. The overall idea is that with only one row block all entries of a column j are contained in a cluster in any solution, and thus, it suffices to consider only the minimum and the maximum value in column j. More precisely, for a column block of a solution, it follows that . The algorithm starts with the column that contains the overall minimum value of the input matrix, that is . Clearly, has to be contained in some column block, say . The algorithm then adds all other columns j to where , removes the columns from the matrix and recursively proceeds with the column containing the minimum value of the remaining matrix. We continue with the correctness of the described procedure.
| Algorithm 1: Algorithm for (1, ∗)-Co-Clustering∞. |
| Input: , , . |
| Output: A partition of [n] into at most ℓ blocks yielding a cost of at most c, or no if no such partition exists. |
![Algorithms 09 00017 i001]() |
If Algorithm 1 returns at Line 12, then this is a column partition into blocks satisfying the cost constraint. First, it is a partition by construction: the sets are successively removed from until it is empty. Now, let . Then, for all , it holds (by definition of ) and (by definition of ). Thus, holds for all , which yields cost∞.
Otherwise, if Algorithm 1 returns no in Line 5, then it is clearly a no-instance, since the difference between the maximum and the minimum value in a column is larger than c. If no is returned in Line 13, then the algorithm has computed column indices and column blocks for each , and there still exists at least one index in when the algorithm terminates. We claim that the columns all have to be in different blocks in any solution. To see this, consider any with . By construction, . Therefore, holds, and columns and contain elements with distance more than c. Thus, in any co-clustering with cost at most c, columns must be in different blocks, which is impossible with only ℓ blocks. Hence, we indeed have a no-instance.
The time complexity is seen as follows. The first loop examines in time all elements of the matrix. The second loop can be performed in time if the and the are sorted beforehand, requiring time. Overall, the running time is in . ☐
From now on, we focus on the
case, that is we need to partition the rows into two blocks. We first consider the simplest case, where also
.
Theorem 5. (2, 2)-Co-Clustering∞ is solvable in time.
Proof. We use the reduction to CNF-SAT provided by Lemma 1. First, note that a cluster boundary
can only be satisfied if it contains the elements
and
. The algorithm enumerates all
of these cluster boundaries. For a fixed
, we construct the Boolean formula
. Observe that this formula is in two-CNF form: The formula consists of
k-clauses,
ℓ-clauses and 2-clauses, and we have
. Hence, we can determine whether it is satisfiable in linear time [
19] (note that the size of the formula is in
). Overall, the input is a yes-instance if and only if
is satisfiable for some cluster boundary
. ☐
Finally, we show that it is possible to extend the above result to any number of column blocks for size-three alphabets.
Theorem 6. (2, ∗)-Co-Clustering∞ is -time solvable for .
Proof. Let be a (2, ∗)-Co-Clustering∞ instance. We assume without loss of generality that . The case is solvable in time by Theorem 5. Hence, it remains to consider the case . As , there are four potential values for a minimum-cost ()-co-clustering. Namely, cost zero (all cluster entries are equal), cost , cost and cost . Since any ()-co-clustering is of cost at most and because it can be checked in time whether there is a ()-co-clustering of cost zero (Observation 1), it remains to check whether there is a ()-co-clustering between these two extreme cases, that is for .
Avoiding a pair
means to find a co-clustering without a cluster containing
x and
y. If
(Case 1), then the problem comes down to finding a (
)-co-clustering avoiding the pair
. Otherwise (Case 2), the problem is to find a (
)-co-clustering avoiding the pair
and, additionally, either
or
.
Case 1. Finding a ()-co-clustering avoiding :
In this case, we substitute , and . We describe an algorithm for finding a ()-co-clustering of cost one (avoiding ). We assume that there is no ()-co-clustering of cost one (iterating over all values from two to ℓ). Consider a ()-co-clustering of cost one, that is for all , it holds or . For , let denote the ()-co-clustering where the column blocks and are merged. By assumption, for all , it holds that , since otherwise, we have found a ()-co-clustering of cost one. It follows that or holds for all . This can only be true for .
This proves that there is a (
)-co-clustering of cost one if and only if there is a (
)-co-clustering of cost one. Hence, Theorem 5 shows that this case is
-time solvable.
Case 2. Finding a ()-co-clustering avoiding and (or ):
In this case, we substitute , and if has to be avoided, or if has to be avoided. It remains to determine whether there is a ()-co-clustering with cost zero, which can be done in time due to Observation 1. ☐
4.3. Fixed-Parameter Tractability
We develop an algorithm solving
-C
o-C
lustering∞ for
based on our reduction to CNF-SAT (see Lemma 1). The main idea is, given matrix
and cluster boundary
, to simplify the Boolean formula
into a 2-S
at formula, which can be solved efficiently. This is made possible by the constraint on the cost, which imposes a very specific structure on the cluster boundary. This approach requires to enumerate all (exponentially many) possible cluster boundaries, but yields fixed-parameter tractability for the combined parameter
.
Theorem 7. -Co-Clustering∞ is -time solvable for .
In the following, we prove Theorem 7 in several steps.
A first sub-result for the proof of Theorem 7 is the following lemma, which we use to solve the case where the number
of possible row partitions is less than
.
Lemma 2. For a fixed row partition I, one can solve Co-Clustering∞ in time. Moreover, Co-Clustering∞ is fixed-parameter tractable with respect to the combined parameter ().
Proof. Given a fixed row partition , the algorithm enumerates all different cluster boundaries . We say that a given column j fits in column block if, for each and , we have (this can be decided in time for any pair ). The input is a yes-instance if and only if for some cluster boundary , every column fits in at least one column block.
Fixed-parameter tractability with respect to is obtained from two simple further observations. First, all possible row partitions can be enumerated in time. Second, since each of the clusters contains at most different values, the alphabet size for yes-instances is upper-bounded by . ☐
The following lemma, also used for the proof of Theorem 7, yields that even for the most difficult instances, there is no need to consider more than two column clusters to which any column can be assigned.
Lemma 3. Let be an instance of -Co-Clustering∞, be an integer, , and be a cluster boundary with pairwise different columns, such that for all .
Then, for any column , two indices and can be computed in time , such that if I has a solution satisfying with , then it has one where each column j is assigned to either or .
Proof. We write ( for any solution with ). Given a column and any element , we write for the number of entries with value a in column j.
Consider a column block
,
. Write
for the three values, such that
,
and
. Note that
. We say that column
j fits into column block
if the following three conditions hold:
Note that if Condition (1) is violated, then the column contains an element that is neither in nor in . If Condition (2) (respectively Condition (3)) is violated, then there are more than (respectively ) rows that have to be in row block (respectively ). Thus, if j does not fit into a column block , then there is no solution where . We now need to find out, for each column, to which fitting column blocks it should be assigned.
Intuitively, we now prove that in most cases, a column has at most two fitting column blocks and, in the remaining cases, at most two pairs of “equivalent” column blocks.
Consider a given column . Write and . If , then Condition (1) is always violated: j does not fit into any column block, and the instance is a no-instance. If , then, again, by Condition (1), j can only fit into a column block where . There are at most two such column blocks: we write and for their indices ( if a single column block fits). The other easy case is when , i.e., all values in column j are equal to a. If j fits into column block , then, with Conditions (2) and (3), , and is one of the at most two column blocks having : again, we write and for their indices.
Finally, consider a column j with , and let be such that j fits into . Then, by Condition (1), the “middle-value” for column block is . The pair must be from . We write for the four column blocks (if they exist) corresponding to these four cases. We define if j fits into , and otherwise. Similarly, we define if j fits into , and otherwise.
Consider a solution assigning j to , with . Since j must fit into , the only possibility is that and . Thus, j fits into both and , so Conditions (2) and (3) imply and . Since , we have and . Thus, placing j in either column block yields the same row partition, namely and . Hence, the solution assigning j to , can assign it to , instead, without any further need for modification.
Similarly, with and , any solution assigning j to or can assign it to without any other modification. Thus, since any solution must assign j to one of , it can assign it to one of instead. ☐
We now give the proof of Theorem 7.
Proof. Let be a -Co-Clustering∞ instance. The proof is by induction on ℓ. For , the problem is solvable in time (Theorem 4). We now consider general values of ℓ. Note that if ℓ is large compared to m (that is, ), then one can directly guess the row partition and run the algorithm of Lemma 2. Thus, for the running time bound, we now assume that . By Observation 2, we can assume that .
Given a (
)-co-clustering
, a cluster boundary
satisfied by
, and
, each column block
is said to be:
with equal bounds if ,
with non-overlapping bounds if ,
with properly overlapping bounds otherwise.
We first show that instances implying a solution containing at least one column block with equal or non-overlapping bounds can easily be dealt with.
Claim 1. If the solution contains a column-block with equal bounds, then it can be computed in time.
Proof. Assume, without loss of generality, that the last column block, , has equal bounds. We try all possible values of . Note that column block imposes no restrictions on the row partition. Hence, it can be determined independently of the rest of the co-clustering. More precisely, any column with all values in can be put into this block, and all other columns have to end up in the other blocks, thus forming an instance of -Co-Clustering∞. By induction, each of these cases can be tested in time. Since we test all values of u, this procedure finds a solution with a column block having equal bounds in time. ☐
Claim 2. If the solution contains a (non-empty) column-block with non-overlapping bounds, then it can be computed in time.
Proof. Write s for the index of the column block with non-overlapping bounds, and assume that, without loss of generality, . We try all possible values of , and we examine each column . We remark that the row partition is entirely determined by column j if it belongs to column block . That is, if , then and . Using the algorithm described in Lemma 2, we deduce the column partition in time, which is bounded by . ☐
We can now safely assume that the solution contains only column blocks with properly overlapping bounds. In a first step, we guess the values of the cluster boundary . Note that, for each , we only need to consider the cases where , that is, for , we have . Note also that, for any two distinct column blocks and , we have or . We then enumerate all possible values of (the height of the first row block), and we write . Overall, there are at most cases to consider.
Using Lemma 3, we compute integers for each column j, such that any solution satisfying the above conditions (cluster boundary and ) can be assumed to assign each column j to one of or .
We now introduce a 2-Sat formula allowing us to simultaneously assign the rows and columns to the possible blocks. Let be the formula as provided by Lemma 1. Create a formula from where, for each column , the column clause is replaced by the smaller clause . Note that is a 2-Sat formula, since all other clauses or already contain at most two literals.
If is satisfiable, then is satisfiable, and admits a ()-co-clustering satisfying . Conversely, if admits a ()-co-clustering satisfying with , then, by the discussion above, there exists a co-clustering where each column j is in one of the column blocks or . In the corresponding Boolean assignment, each clause of is satisfied and each new column clause of is also satisfied. Hence, is satisfiable. Overall, for each cluster boundary and each , we construct and solve the formula defined above. The matrix admits a ()-co-clustering of cost one if and only if is satisfiable for some and .
The running time for constructing and solving the formula , for any fixed cluster boundary and any height , is in , which gives a running time of for this last part. Overall, the running time is thus . ☐
Finally, we obtain the following simple corollary.
Corollary 2. (2, ∗)-Co-Clustering∞ with is fixed-parameter tractable with respect to parameter and with respect to parameter ℓ.
Proof. Theorem 7 presents an FPT-algorithm with respect to the combined parameter . For -Co-Clustering∞ with , both parameters can be polynomially upper-bounded within each other. Indeed, (otherwise, there are two column blocks with identical cluster boundaries, which could be merged) and (each column block may contain two intervals, each covering at most elements). ☐



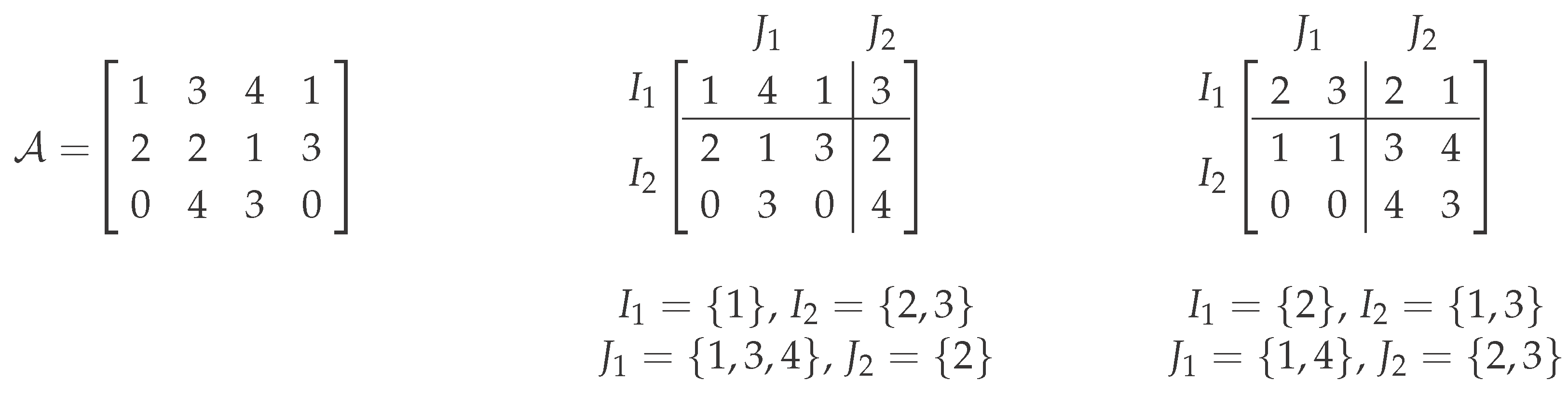

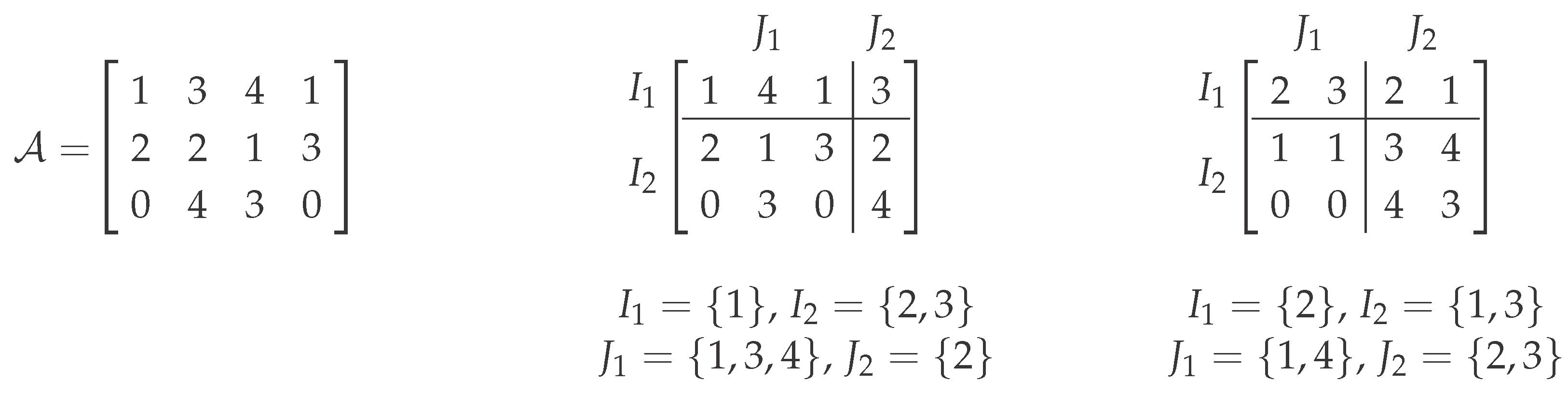{kind=link}
{kind=link}
{kind=link}
{kind=link}