Abstract
Hyperspectral images are widely used in several real-life applications. In this paper, we investigate on the compression of hyperspectral images by considering different aspects, including the optimization of the computational complexity in order to allow implementations on limited hardware (i.e., hyperspectral sensors, etc.). We present an approach that relies on a three-dimensional predictive structure. Our predictive structure, 3D-MBLP, uses one or more previous bands as references to exploit the redundancies among the third dimension. The achieved results are comparable, and often better, with respect to the other state-of-art lossless compression techniques for hyperspectral images.
1. Introduction
Hyperspectral imaging instruments collect information by exploring the electromagnetic spectrum of a specific geographical area. In contrast to the human eye and traditional camera sensors, which can only perceive visible light (i.e., the wavelengths between 360 to 760 nanometers (nm)), spectral imaging techniques allow to cover a significant portion of wavelengths (i.e., the frequencies of ultraviolet and infrared rays). It is important to note that the spectrum is subdivided into different spectral bands. Therefore, hyperspectral images can be viewed as three-dimensional data (often referred as datacubes).
For instance, the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) [1] hyperspectral sensor (NASA Jet Propulsion Laboratory (JPL) [2]) measures from 380 to 2500 nm of the electromagnetic spectrum. In particular, the spectrum is subdivided into 224 spectral bands.
From the analysis of hyperspectral data, it is possible to identify and/or classify materials, objects, etc. Such capabilities are related to the fact that some objects and materials have a unique signature (a sort of fingerprint) in the electromagnetic spectrum, therefore this fingerprint can be used for identification purposes.
Hyperspectral data are widely used in real-life applications including agriculture, mineralogy, physics, surveillance, etc. For instance, in geological applications the capabilities of hyperspectral remote sensing are exploited to identify various types of minerals or to search for minerals and oil.
One of the most important parameters to evaluate the precision of a sensor is the spectral resolution, which is the width between two adjacent bands. For instance, by considering the AVIRIS hyperspectral images, the spectral resolution is 10 nm. The spatial resolution is a relevant aspect too. Informally, the spatial resolution denotes how extensive is the geographical area mapped by the sensor into a pixel. It could be difficult to recognize materials and/or objects from a pixel, if a too wide area is mapped into it.
Many hundreds of gigabytes can be produced every day by a single hyperspectral sensor. Therefore, it is necessary to compress these data, in order to transmit and to store them efficiently. Since such data are often used in delicate tasks and there are high costs involved in the acquisitions, lossless compression is generally required.
This paper focuses on a novel technique for the lossless compression of hyperspectral images. The proposed algorithm is based on the predictive coding model and the proposed predictive structure uses a configurable multiband three-dimensional structure. It is possible to customize our predictor by individuating the number of the previous bands which will be used as references and the wideness of the prediction context. Through appropriate configurations of such parameters, the computational complexity and the memory usage can be optimized depending on the hardware available.
Because of its high configurability, our algorithm is suitable for “on board” implementations on hardware with limited capabilities, as for example on an airplane or on a satellite.
The experimental results we have achieved are comparable and often better, with respect to other state of the art approaches. Our scheme provides a good trade-off between computational complexity/memory usage and compression performances.
The rest of the paper is organized as follows: Section 2 briefly reviews previous work on lossless and lossy compression of hyperspectral images, Section 3 outlines the proposed lossless compression approach and Section 4 focuses on the description of experimental results. Finally, Section 5 highlights our conclusion and future work directions.
2. Related Works
Lossless compression of hyperspectral images is generally based on the predictive coding model. The predictive-based approaches have different advantages: they use limited resources in terms of computational power and memory usage and achieve good compression performances. Often, these models are suitable for on board implementations.
Spectral-oriented Least SQuares (SLSQ) [3], Linear Predictor (LP) [3], Fast Lossless (FL) [4], CALIC-3D [5], M-CALIC [5], and RLS [6] are among the state-of-art predictive-based techniques.
The Consultative Committee for Space Data Systems (CCSDS) has specified the CCSDS 123 standard, which outlines a method for lossless compression of multispectral and hyperspectral image data and a format for storing the compressed data [7,8]. The main objective is to establish a Recommended Standard for a multispectral and hyperspectral images, and to specify the compressed data format. In literature, many proposed approaches implement the recommendations of the CCSDS 123 standard for the lossless compression of hyperspectral images, as for instance, the ones described in [9,10,11].
Other approaches are designed for offline compression, since they use more sophisticated techniques and/or they require the complete availability of the hyperspectral image. These approaches are not suitable for an on board implementation but can achieve better compression performances. Mielikainen, in [12], proposed an approach for the compression of hyperspectral image through Look-Up Table (LUT). LUT predicts each pixel by using all the pixels in the current and in the previous band, by searching the nearest neighbor, in the previous band, which has the same pixel value as the pixel located in the same spatial coordinates as the current pixel. LUT has high compression performances, but it uses more resources in terms of memory and CPU usage.
Other lossless techniques are based on dimensionality reduction through principal component transform [13] or they are based on the clustered differential pulse code modulation [14]. An error-resilient lossless compression technique is proposed in [15].
For the lossy compression of hyperspectral images, the compression algorithms are generally based on 3D frequency transforms: as for examples 3-D Discrete Wavelet Transform (3D-DWT) [16], 3-D Discrete Cosine Transform (3D-DCT) [17], Karhunen–Loève transform (KLT) [18], etc. These approaches are easily scalable. On the other hand, they must maintain the entire hyperspectral image at the same time in memory. Locally optimal Partitioned Vector Quantization (LPVQ) [19,20] applies a Partitioned Vector Quantization (PVQ) scheme independently to each pixel of the hyperspectral image.
The variable sizes of the partitions are chosen adaptively and the indices are entropy coded. The codebook is included as part of the coded output. This technique can be used also in lossless mode, but the high costs required in terms of CPU and memory do not allow an on board implementation.
3. Lossless Multiband Compression for Hyperspectral Images (LMBHI)
Hyperspectral images present two typologies of correlations:
- inter-band correlation;
- intra-band correlation.
In particular, contiguous bands are strongly correlated (inter-band correlation) and the pixels are generally correlated, since, for instance, two adjacent pixels map adjacent areas, possibly composed of the same material, etc. (intra-band correlation). Such characterizations are exploited by the compression strategies, in order to optimize the redundancy among the third dimension. The main aim of our approach, which we denoted as Lossless MultiBand compression for Hyperspectral Images (LMBHI), is to exploit the correlation with a predictive coding model.
In detail, for each pixel, , of the input hyperspectral image, LMBHI performs the prediction of the current pixel, , by selecting the appropriate prediction context of X (three-dimensional or a bi-dimensional contexts).
All the pixels that belong to the first band are predicted by using a bi-dimensional predictive structure: the 2-D Linearized Median Predictor (2-D LMP) [21], which exploits only the intra-band correlation, since the first band has no reference bands. The other pixels are predicted by using a new three-dimensional predictive approach, which uses a prediction context composed of the neighboring pixels of and its reference pixels in the previous bands.
Once the prediction step is computed, the prediction error (defined in Equation (1)) is modeled and coded.
3.1. Review of the 2-D Linearized Median Predictor (2D-LMP)
The 2-D Linearized Median Predictor (2D-LMP) [21] uses a prediction context that is composed by three neighboring pixels of , namely, , , and , as shown in Figure 1. In particular, the predictive structure is derived from the well-established 2-D Median Predictor, which is used in JPEG-LS [22]. The 2-D Median Predictor has the following predictive structure outlined in the Equation (2).
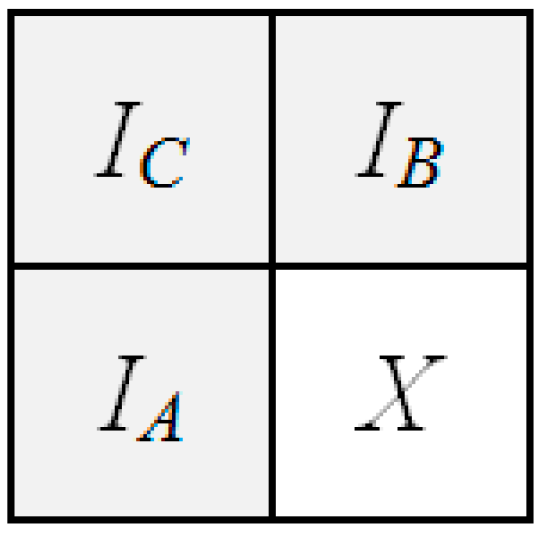
Figure 1.
The prediction context of the 2D-LMP predictive structure. The gray part is already coded and the white part is not coded yet.
Basically, Median Predictor is in charge of selecting one of the above three options, depending on the context. By combining all the three options, it is possible to obtain the predictive structure of 2D-LMP, defined as in the Equation (3).
3.2. 3-D MultiBand Linear Predictor (3D-MBLP)
The Multiband Linear Predictor (3D-MBLP) uses a prediction context by considering two parameters:
- : number of the previous bands, that are considered for the prediction;
- : number of the samples for the current and each previous band, which will be used for the creation of the prediction context.
First of all, we define a bi-dimensional enumeration , graphically represented in Figure 2. The main aim of such an enumeration, is to permit the relative indexing of the pixels with respect to the pixel which is currently under analysis (which has as index in Figure 2).
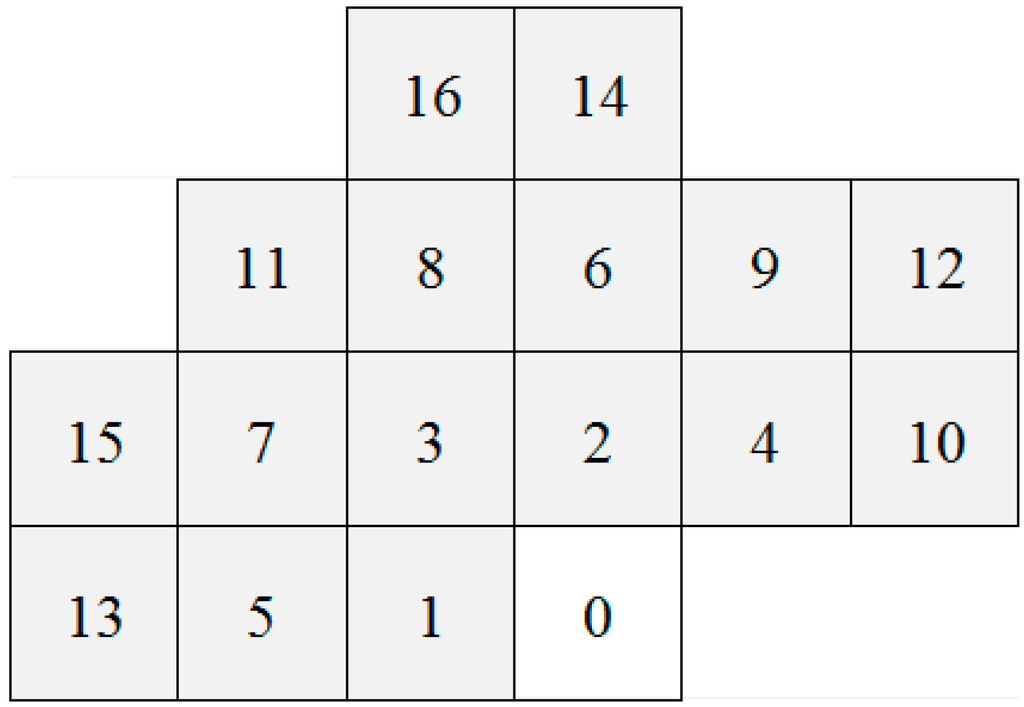
Figure 2.
The enumeration we used for the relative indexing with respect to the current pixel, identified with 0 as index.
In order to define the prediction context of 3D-MBLP, we use the following notations:
- : indicates the -th pixel of the -th band, according to the enumeration ;
- : denotes the pixel that has the same spatial coordinates of , of the j-th band, according to the enumeration .
In the following, we suppose that the current band is the -th band. In particular, by using our notations, it is possible to observe that can be also addressed as In detail, the 3D-MBLP predictor is based on the least squares optimization technique and the prediction is computed by means of the Equation (4).
The coefficients: are chosen to minimize the energy of the prediction error described by the Equation (5).
can be rewritten in matrix notation by means of the following equation:
where
and .
Subsequently, by taking the derivate of and by setting it to zero, we obtain the optimal coefficients by means of the Equation (6).
Once the coefficients , which solve the linear system Equation (6), are computed, the prediction, , of the current pixel , can be calculated.
3.3. Modeling and Coding of Prediction Errors
Starting from the consideration that a prediction error can assume positive or negative values. Similarly to [23], we use an invertible mapping function (highlighted in the Equation (7)), in order to have only non-negative values. It is important to note that the mapping function does not alter the redundancy among the errors. For the coding of the mapped prediction errors we use the Arithmetic Coder (AC) scheme.
3.4. Computational Complexity
The main computational costs of our approach are due to the resolution of the linear system Equation (6), used to generate the optimal coefficients, which need the computation of the predicted pixel. By using the normal equation method, the linear system can be solved with floating-point operations [24]. Figure 3 shows the trend of the computational complexity of our predictive model, in terms of number of operations (-axis) that are required for the solving of the linear system, by using configurations with different parameters (-axis).
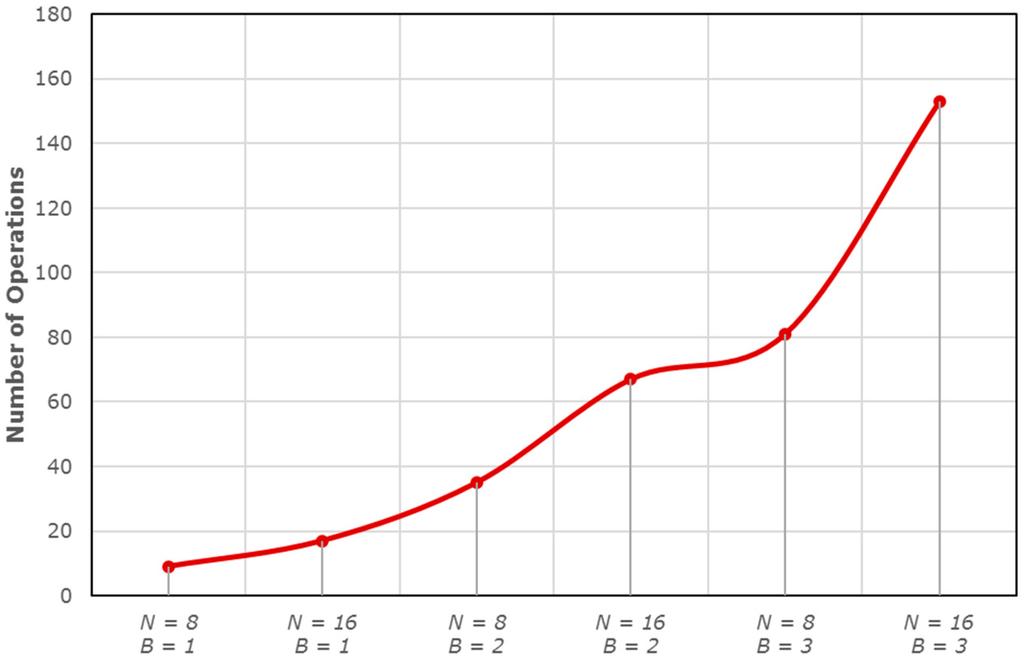
Figure 3.
The number of operations (-axis) required to solve the linear system Equation (6), by using different parameters (-axis).
If we use only the previous band as a reference (), only about 20 operations are needed to solve the system. Instead, four or nine times more operations are required if we use two previous bands () or three previous bands (). A linear system can have three kinds of solutions: no solutions, one solution, and infinity solutions. In the first and the third scenarios, the proposed predictive structure cannot perform the prediction. In these scenarios, it is desirable to use another low-complexity predictive structure and we have used the 3-D Distances-based Linearized Median Predictor (3D-DLMP) [21].
4. Experimental Results
We performed experiments on two datasets of AVIRIS hyperspectral images: the 1997 AVIRIS Dataset (Section 4.1) and the CCSDS Dataset (Section 4.2).
In our experiments we considered also the PAQ8 algorithm (described in [25]) for the coding of the prediction error. PAQ8 is a state-of-the-art lossless compression algorithm that belongs to the PAQ family of compression algorithm. It is important to note that the PAQ8 family is strictly related to the well-established Prediction by Partial Matching scheme (PPM) [26]. In general, the PAQ8 algorithm achieve a high degree of compression performances, but the PAQ8 scheme has significant computational complexity. Therefore, such scheme is not fully adequate to be used for on board applications.
The experiments are performed by using a non-optimized Java-based proof-of-concept of our approach, which employs few minutes on a medium-end laptop (equipped with an Intel Core i5 4200 M processor and 8 GB of RAM).
4.1. 1997 AVIRIS Dataset
Each one of AVIRIS hyperspectral image of the AVIRIS ’97 dataset is subdivided into scenes (the number of scenes is highlighted in Table 1). It is important to note that each scene has 614 columns, 512 lines, and 224 spectral bands. In addition, each pixel is stored by using 16 bits.

Table 1.
Description of the dataset used.
In Table 2 and Table 3, we report the results achieved by using with and , respectively. Subsequently, in Table 4 and Table 5, we report the results achieved, by using B = 2. Finally, Table 6 and Table 7 report the results achieved by using and the parameter equal to 8 and equal to 16, respectively. All the results are reported in terms of Bits Per Sample (BPS). In each table we report the results achieved by using both the AC and the PAQ8 schemes for the coding of the prediction errors.
Table 2.
Achieved results by using the following parameters: , . (N.P. indicates that the scene is not present).
Table 3.
Achieved results by using the following parameters: , .
Table 4.
Achieved results by using the following parameters: , .
Table 5.
Achieved results by using the following parameters: , .
Table 6.
Achieved results by using the following parameters: , .
Table 7.
Achieved results by using the following parameters: , .
In Table 8 and Table 9, the average results on all the tested hyperspectral images are reported. In detail, the first column indicates the parameter and from the second to the fourth columns the average results for , , and, respectively.
Table 8.
Average Results on the 1997 AVIRIS Images (AC).
Table 9.
Average Results on the 1997 AVIRIS Images (PAQ8).
As it is possible to observe from Figure 4 and Figure 5, which graphically represent the average results, the best results are achieved when the following parameters are used: and (Figure 4b and Figure 5b). The worst results are obtained by using the following parameters: and .
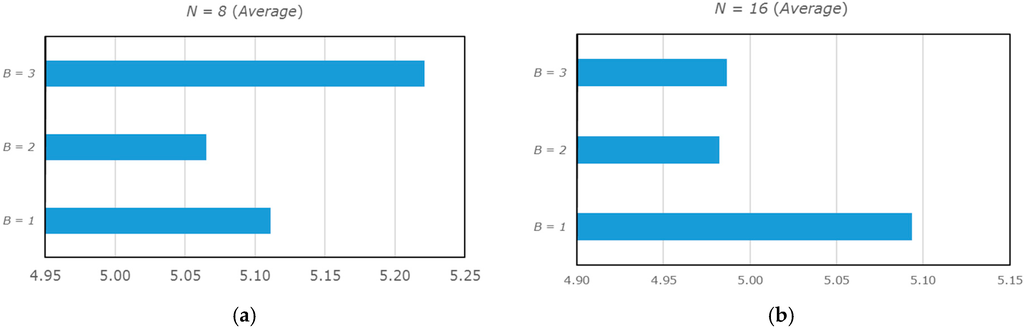
Figure 4.
Graphical representation of the average results by using the AC scheme for the coding of the prediction errors. (a) and (b).
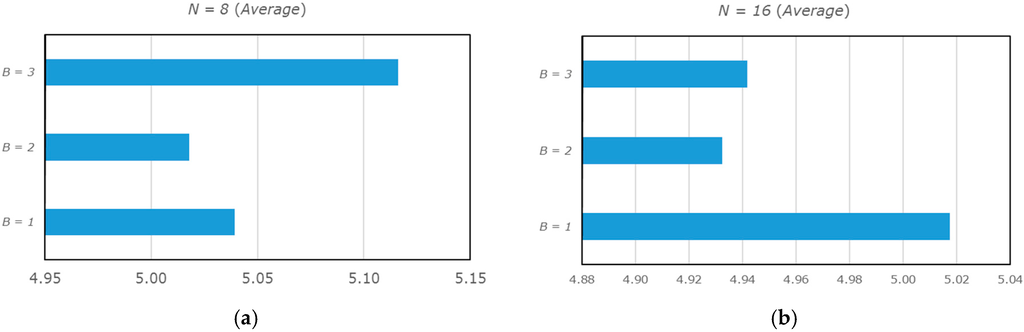
Figure 5.
Graphical representation of the average results by using the PAQ8 scheme for the coding of the prediction errors. (a) and (b).
Comparison with other Approaches
In order to compare the experimental results achieved by our approach, we consider the Compression Ratio (C.R.) as a measure for the compression performances. In detail, Table 10 reports the results achieved by considering several parameters on all the hyperspectral images of the used dataset. More precisely, the results are reported in terms of C.R. and they are compared with other state of the art lossless compression schemes.
Table 10.
Compression results, in terms of compression ratio (C.R.) achieved by LMBHI (by using various parameter configurations), compared to other lossless compression methods.
From the experimental results, it should be observed that LMBHI gets its best results by using two previous bands as references (i.e. when the following parameter is used: ), LMBHI outperforms, in average, all the other state of the art approaches.
On the other hand, when only the previous band is used (i.e., when ), LMBHI outperforms all the compared state of the art techniques, with the exception of LPVQ. But, LPVQ is not suited for on board implementation.
In this latter case, our approach achieves better results with respect to LPVQ on three of the five hyperspectral images: Moffett Field, Jasper Ridge, and Low Altitude, but LPVQ gains on Cuprite and especially on Lunar Lake. In addition, LUT obtains better results of our approach on two of four compared hyperspectral images: Lunar Lake and Jasper Ridge.
The high flexibility and adaptability of our approach makes it considerable for on board implementations. In fact, the coding parameters can be customized depending on the hardware available.
4.2. CCSDS Dataset
In this section we focus on the experimental results we have achieved by considering the CCSDS Dataset, which is composed by five calibrated and seven uncalibrated hyperspectral images. This dataset is provided by Consultative Committee for Space Data Systems (CCSDS) Multispectral and Hyperspectral Data Compression [27].
In Table 11, we shortly describe the dataset by reporting the number of scenes (second column) and the number of samples per line (third column) for the calibrated and the uncalibrated images (first column). The samples of the calibrated and the uncalibrated images are stored by using 16 bits (16-bit signed integer for the calibrated and 16-bit unsigned for the uncalibrated), except for the Hawaii and Maine images in which the samples are stored by using 12 bits (unsigned) [27]. Each image is composed by 512 lines.
Table 11.
Description of the CCSDS dataset.
In Table 12, we report our results in terms of bits-per sample (BPS). The results refer to the calibrated hyperspectral images (first column), by using several configurations for our approach (columns from the second to the fourth). Analogously to Table 12, in Table 13 we report our experimental results for the uncalibrated images. In each table, we report the results by using the AC and the PAQ8 schemes.
Table 12.
Achieved results for the calibrated images of the CCSDS dataset.
Table 13.
Achieved results for the uncalibrated images of the CCSDS dataset.
The best results are achieved when the following configuration is used: and .
Comparison with Other Approaches
We have compared our results on the CCSDS dataset with other state-of-art approaches. Table 14 reports the results achieved by considering several values for the and parameters on the calibrated hyperspectral images of the CCSDS dataset, by using the AC scheme as well as the PAQ8 scheme for the coding of the prediction errors.
Table 14.
Comparison with other lossless compression methods (calibrated images). The results are reported in bits-per-sample (BPS).
Table 15 and Table 16 report the comparison between the proposed approach and other approaches for the 16-bit uncalibrated and 12-bit uncalibrated hyperspectral images of the CCSDS dataset.
Table 15.
Comparison with other lossless compression methods (16-bit uncalibrated images). The results are reported in bits-per-sample (BPS).
Table 16.
Comparison with other lossless compression methods (12-bit uncalibrated images). The results are reported in bits-per-sample (BPS).
From Table 12 and Table 13, it comes clear that the best results are achieved when the value of is equal to and is equal to .
By looking at Table 14, it should be observed that our approach, when the following configuration is used: and , achieves results that are comparable but slightly worse with respect to FL and FL# [27]. Our approach outperforms all the other techniques when the PAQ8 scheme is used for the coding of prediction errors with and . However, in such configuration the computational complexity of our approach is not suitable for on board implementations.
5. Conclusions and Future Works
In this paper, we have investigated on the lossless compression of hyperspectral images by introducing a multiband three-dimensional predictive structure, we named as 3D-MBLP.
Because of its configurability, it is possible to implement the algorithm on different typologies of sensors, by using appropriate configuration for each type of sensors. Moreover, the proposed approach can be also easily scaled for future generation sensors which will have better hardware capabilities. The experimental results we achieved are comparable and often outperform the other state of the art lossless compression techniques.
In future works, we will include a pre-processing stage before the compression of the hyperspectral image, which substantially reorders the bands by considering their correlation. This will possibly improve the compression performance as in [28,29].
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions to improve the quality of the paper.
Author Contributions
All the authors worked together and contributed equally.
Conflicts of Interest
The authors declare no conflict of interest.
References
- AVIRIS NASA Page. Available online: http://aviris.jpl.nasa.gov/ (accessed on 1 December 2015).
- Jet Propulsion Laboratory (JPL) Page. Available online: http://www.jpl.nasa.gov/ (accessed on 1 December 2015).
- Rizzo, F.; Carpentieri, B.; Motta, G.; Storer, J.A. Low-complexity lossless compression of hyperspectral imagery via linear prediction. IEEE Signal Process. Lett. 2005, 12, 138–141. [Google Scholar] [CrossRef]
- Klimesh, M. Low-complexity lossless compression of hyperspectral imagery via adaptive filtering. IPN Prog. Report 2005, 42, 1–10. [Google Scholar]
- Magli, E.; Olmo, G.; Quacchio, E. Optimized onboard lossless and near-lossless compression of hyperspectral data using CALIC. Geosci. Remote Sens. Lett. 2004, 1, 21–25. [Google Scholar] [CrossRef]
- Song, J.; Zhang, Z.; Chen, X. Lossless compression of hyperspectral imagery via RLS filter. Electron. Lett. 2013, 49, 992–994. [Google Scholar] [CrossRef]
- Shah, D.; Bera, K.; Sanjay, J. Software Implementation of CCSDS Recommended Hyperspectral Lossless Image Compression. Int. J. Image Gr. Signal Process. 2015, 4, 35–41. [Google Scholar] [CrossRef]
- Consultative Committee for Space Data Systems (CCSDS), Lossless Multispectral & Hyperspectral Image, Lossless Multispectral & Hyperspectral Image Compression. Available online: http://public.ccsds.org/publications/archive/123x0b1ec1.pdf (accessed on 5 February 2016).
- Snchez, J.E.; Auge, E.; Santal, J.; Blanes, I.; Serra-Sagrist, J.; Kiely, A.B. Review and implementation of the emerging CCSDS recommended standard for multispectral and hyperspectral lossless image coding. In Proceedings of the 2011 First International Conference on Data Compression, Communications and Processing (CCP), Palinuro, Italy, 21–24 June 2011; pp. 222–228.
- Keymeulen, D.; Aranki, N.; Hopson, B.; Kiely, A.; Klimesh, M.; Benkrid, K. GPU lossless hyperspectral data compression system for space applications. In Proceedings of the Aerospace Conference, Big Sky, MT, USA, 3–10 March 2012; pp. 1–9.
- Keymeulen, D.; Aranki, N.; Bakhshi, A.; Luong, H.; Sarture, C.; Dolman, D. Airborne demonstration of FPGA implementation of Fast Lossless hyperspectral data compression system. In Proceedings of the NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Leicester, UK, 14–17 July 2014; pp. 278–284.
- Mielikainen, J. Lossless compression of hyperspectral images using lookup tables. IEEE Signal Process. Lett. 2006, 13, 157–160. [Google Scholar] [CrossRef]
- Pickering, M.; Ryan, M. Efficient spatial-spectral compression of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1536–1539. [Google Scholar] [CrossRef]
- Wu, J.; Kong, W.; Mielikainen, J.; Huang, B. Lossless Compression of Hyperspectral Imagery via Clustered Differential Pulse Code Modulation with Removal of Local Spectral Outliers. IEEE Signal Process. Lett. 2015, 22, 2194–2198. [Google Scholar] [CrossRef]
- Abrando, A.; Barni, M.; Magli, E.; Nencini, F. Error-Resilient and low-complexity on-board lossless compression of hyperspectral images by means of distributed source coding. IEEE Trans. Geosci. 2010, 48, 1892–1904. [Google Scholar] [CrossRef]
- Lim, S.; Sohn, K.; Lee, C. Compression for hyperspectral images using three dimensional wavelet transform. In Proceedings of the IGARSS, Sydney, Australia, 9–13 July 2001; pp. 109–111.
- Markman, D.; Malah, D. Hyperspectral image coding using 3D transforms. In Proceedings of the IEEE ICIP, Thessaloniki, Greece, 7–10 October 2001; pp. 114–117.
- Penna, B.; Tillo, T.; Magli, E.; Olmo, G. Transform coding techniques for lossy hyperspectral data compression. IEEE Trans. Geosci. 2007, 45, 1408–1421. [Google Scholar] [CrossRef]
- Carpentieri, B.; Storer, J.A.; Motta, G.; Rizzo, F. Compression of hyperspectral imagery. In Proceedings of the IEEE Data Compression Conference (DCC 03), Snowbird, UT, USA, 25–27 March 2003; pp. 317–324.
- Motta, G.; Rizzo, F.; Storer, J.A. Hyperspectral Data Compression; Springer Science: Berlin, Germany, 2006. [Google Scholar]
- Pizzolante, R.; Carpentieri, B. Lossless, low-complexity, compression of three-dimensional volumetric medical images via linear prediction. In Proceedings of the 18th International Conference on Digital Signal. Processing (DSP), Fira, Greece, 1–3 July 2013; pp. 1–6.
- Carpentieri, B.; Weinberger, M.; Seroussi, G. Lossless compression of continuous tone images. Proc. IEEE 2000, 88, 1797–1809. [Google Scholar] [CrossRef]
- Motta, G.; Storer, J.A.; Carpentieri, B. Lossless image coding via adaptive linear prediction and classifications. Proc. IEEE 2000, 88, 1790–1796. [Google Scholar] [CrossRef]
- Golub, G.H.; van Loan, C.F. Matrix Computations; The Johns Hopkins University Press: Baltimore, MD, USA, 1996. [Google Scholar]
- Knoll, B.; de Freitas, N. A Machine Learning Perspective on Predictive Coding with PAQ8. In Proceedings of the Data Compression Conference (DCC), Snowbird, UT, USA, 10–12 April 2012; pp. 377–386.
- Salomon, D.; Motta, G. Handbook of Data Compression; Springer: Berlin, Germany, 2010. [Google Scholar]
- Kiely, A.B.; Klimesh, M. Exploiting calibration-induced artifacts in lossless compression of hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2672–2678. [Google Scholar] [CrossRef]
- Carpentieri, B. Hyperpectral images: Compression, visualization and band ordering. Proc. IPCV 2011, 2, 1023–1029. [Google Scholar]
- Pizzolante, R.; Carpentieri, B. Visualization, band ordering and compression of hyperspectral images. Algorithms 2012, 5, 76–97. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).