
An Adaptive Spectral Clustering Algorithm Based on the Importance of Shared Nearest Neighbors



Abstract
:1. Introduction
2. Similarity Graphs
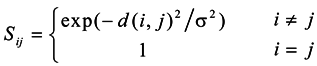
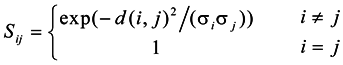
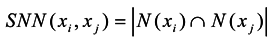
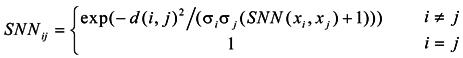
3. Similarity Matrix Based on the Importance of Shared Nearest Neighbors
3.1. The Importance of Node
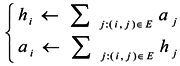
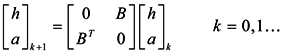
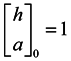 ; Equation (4) will converge when the number of iterations is odd or even times, respectively [16]. When getting the “authority score” and a “hub score” for every vertex, the score of vertex importance can be calculated as Im = (h+a). Obviously, the importance of one vertex is related to the vertex’s out-degree, in-degree and neighboring vertexes’ importance, to represent the structure and properties characteristics of the network. Similarly, we can utilize the score of vertex importance to construct a similarity matrix in graph G.
; Equation (4) will converge when the number of iterations is odd or even times, respectively [16]. When getting the “authority score” and a “hub score” for every vertex, the score of vertex importance can be calculated as Im = (h+a). Obviously, the importance of one vertex is related to the vertex’s out-degree, in-degree and neighboring vertexes’ importance, to represent the structure and properties characteristics of the network. Similarly, we can utilize the score of vertex importance to construct a similarity matrix in graph G.3.2. Similarity Matrix Based on the Importance of Shared Nearest Neighbors

{kind=link}
{kind=link}
{kind=link}
| Similarity matrix based on the importance of shared nearest neighbors: |
|---|
Input: n data vertexes, 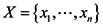 ; ;Output: similarity matrix SNEW. |
Step1. Construct an adjacency matrix B of graph G according to Equation (7). The construction of adjacency matrix B can be similar to the ɛ-neighborhood technique.
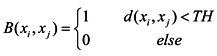
|
Step2. Set 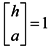 , and iterate an even number of times with Equation (4). Stop upon convergence and get the importance score of every vertex , and iterate an even number of times with Equation (4). Stop upon convergence and get the importance score of every vertex 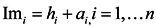 . . |
| Step3. Look for shared nearest neighbor vertexes between xi and xj, and find the maximal importance in shared nearest neighbors; set it as: ; |
| Step4. Get a new kind of similarity matrix by Equation (8):
|
3.3. An Improved Adaptive Spectral Clustering Algorithm
| Adaptive spectral clustering algorithm based on the importance of shared nearest neighbors: |
|---|
| Input: n data vertexes: , clustering number: K: Output: K clusters, |
| Step1. Get the similarity matrix SNEW according to the calculation steps of the Table1; |
| Step2. Define D to be the diagonal matrix, where , and compute the Laplacian matrix ; |
| Step3.Compute the first K largest eigenvalues of the Laplacian matrix and their corresponding eigenvectors ; construct a matrix ; |
| Step4. Construct the matrix Y by normalizing each row in U, where ; |
| Step5. Treat each row of Y as a vertex in space Rk and cluster them into K clusters via k-means or other clustering algorithms for the ultimate clustering results, . |
4. Experiments
4.1. Evaluation Metric
4.2. Parameter Settings
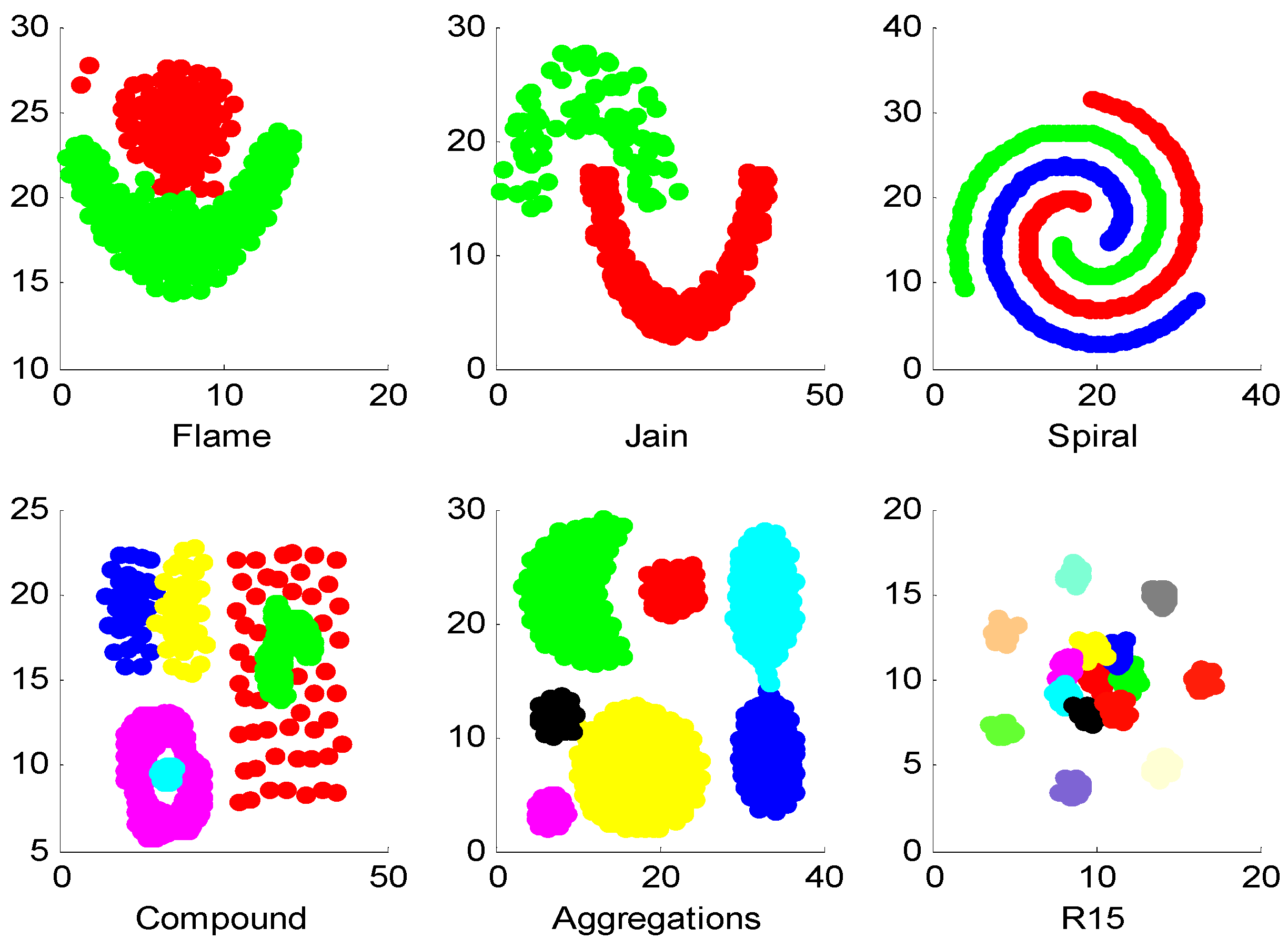
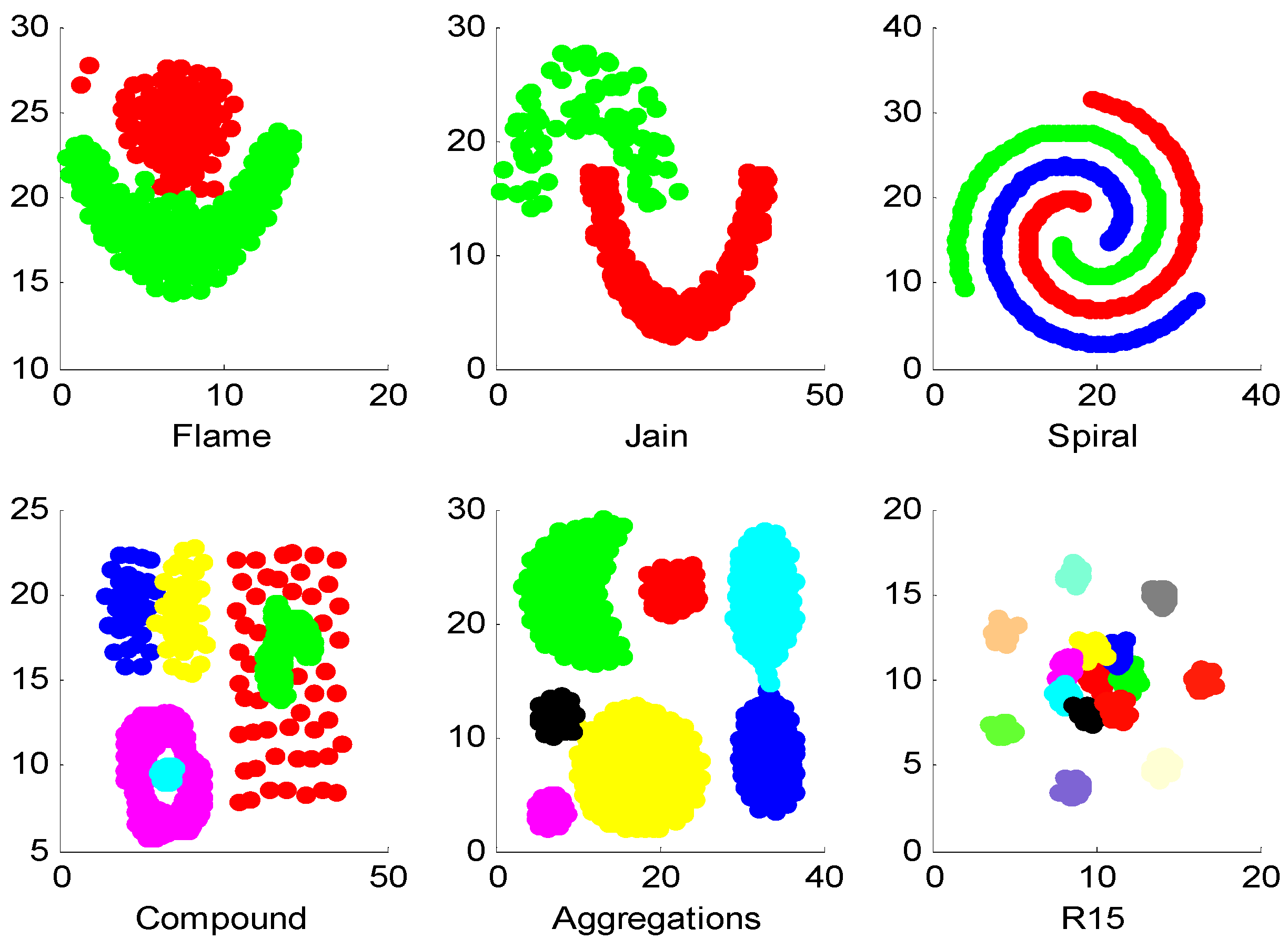
4.3. Experiments on Synthetic Datasets
| Datasets | Spectral Clustering Algorithm | ||
|---|---|---|---|
| SSC | SNNSC | SNNISC | |
| Flame | 0.95 | 0.97 | 0.97 |
| Jain | 1 | 1 | 1 |
| Spiral | 1 | 1 | 1 |
| Compound | 0.54 | 0.54 | 0.54 |
| Aggregations | 0.97 | 0.98 | 0.97 |
| R15 | 0.99 | 0.99 | 0.99 |
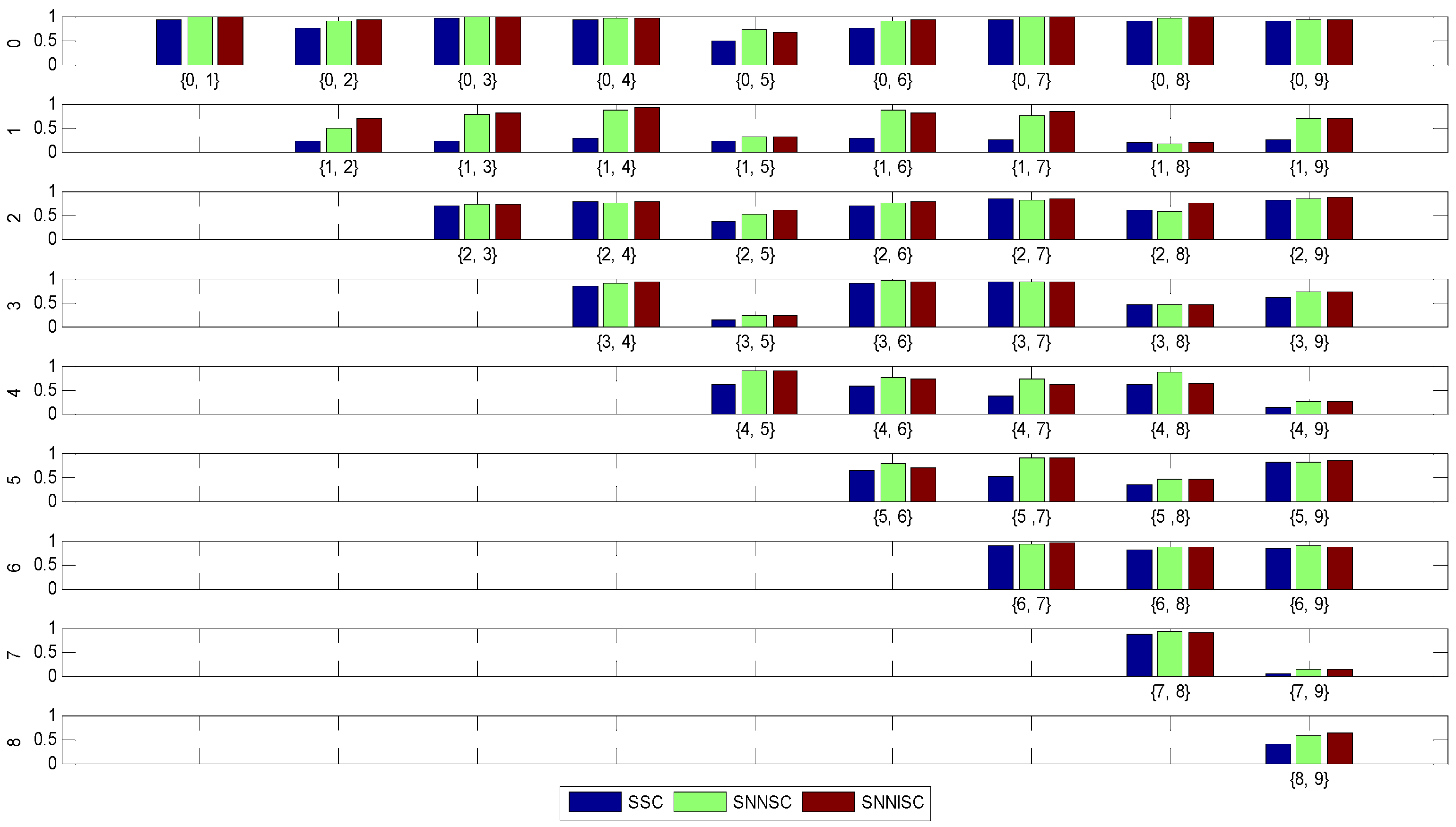
4.4. Experiments on UCI Datasets
| Datasets | Spectral Clustering Algorithm | ||
|---|---|---|---|
| SSC | SNNSC | SNNISC | |
| Iris | 0.82 | 0.83 | 0.92 |
| Ionosphere | 0.22 | 0.22 | 0.23 |
| Breast Tissue | 0.20 | 0.22 | 0.18 |
| Banknote | 0.29 | 0.58 | 0.56 |
| Seeds | 0.71 | 0.71 | 0.71 |
| Fertility | 0.11 | 0.11 | 0.12 |
| Libras | 0.37 | 0.37 | 0.38 |
| Glass | 0.27 | 0.23 | 0.24 |
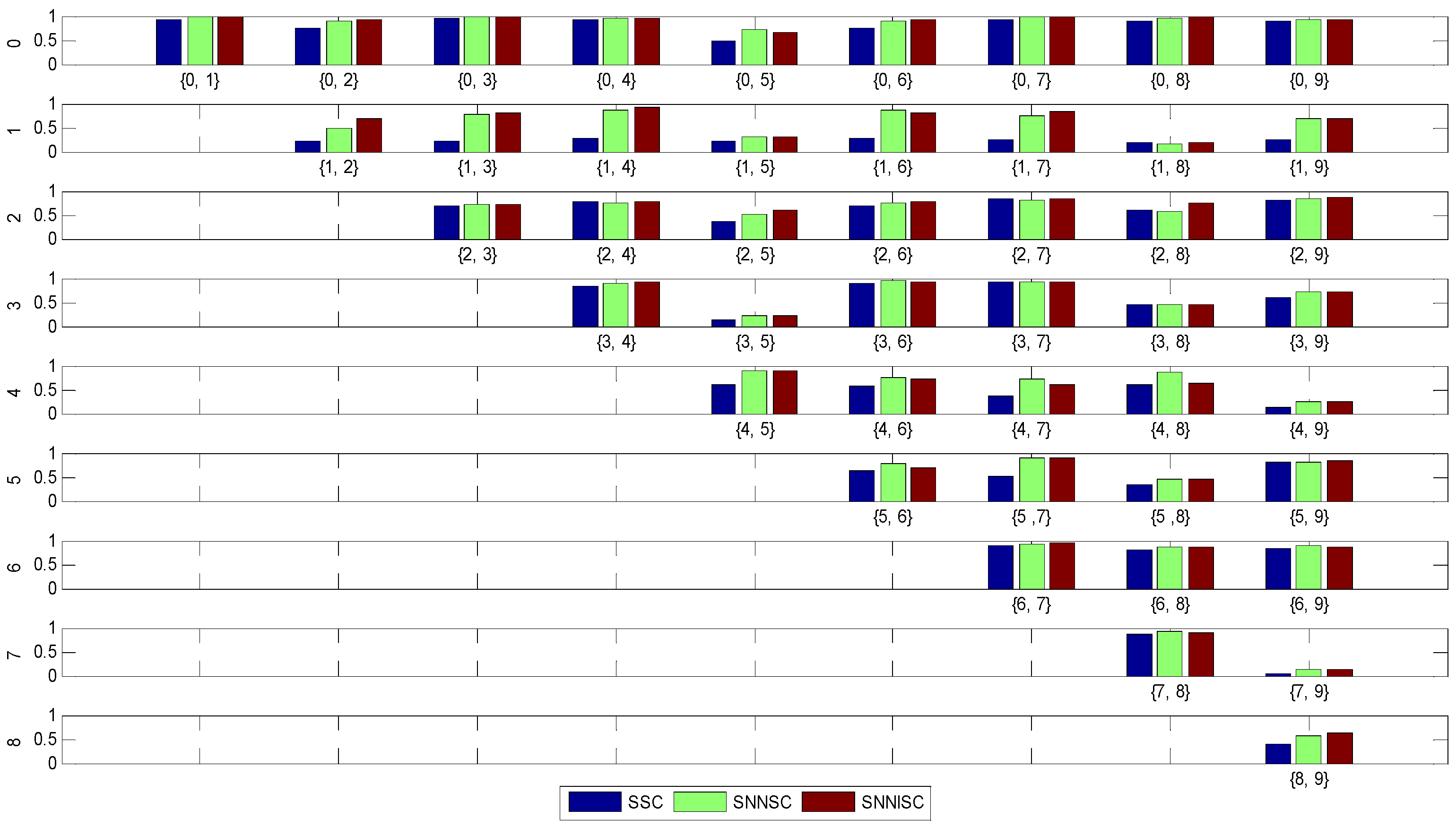
4.5. Experiments on MNIST Datasets

| Clustering Results | Spectral Clustering Algorithm | ||
|---|---|---|---|
| SSC | SNNSC | SNNISC | |
| Mean | 0.59 | 0.73 | 0.74 |
| Standard deviation | 0.28 | 0.24 | 0.23 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Xiaoyan, C.; Guanzhong, D.; Libing, Y. Survey on Spectral Clustering Algorithm. Comput. Sci. 2008, 35, 14–18. [Google Scholar]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Jordan, F.; Bach, F. Learning spectral clustering. Adv. Neural Inf. Process. Syst. 2004, 16, 305–312. [Google Scholar]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On Spectral Clustering: Analysis and an algorithm. Proc. Adv. Neural Inf. Process. Syst. 2001, 14, 849–856. [Google Scholar]
- Fischer, B.; Buhmann, J.M. Path-based clustering for grouping of smooth curves and texture segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 513–518. [Google Scholar] [CrossRef]
- Chang, H.; Yeung, D.Y. Robust path-based spectral clustering. Pattern Recognit. 2008, 41, 191–203. [Google Scholar] [CrossRef]
- Yang, P.; Zhu, Q.; Huang, B. Spectral clustering with density sensitive similarity function. Knowl.-Based Syst. 2011, 24, 621–628. [Google Scholar] [CrossRef]
- Gong, Y.C.; Chen, C. Locality spectral clustering. In AI 2008: Advances in Artificial Intelligence; Springer: Berlin; Heidelberg, Germany, 2008; pp. 348–354. [Google Scholar]
- Zhang, T.; Liu, B. Spectral Clustering Ensemble Based on Synthetic Similarity. In Proceedings of the 2011 Fourth International Symposium on ComputationalIntelligence and Design (ISCID), Hangzhou, China, 28–30 October 2011; Volume 2, pp. 252–255.
- Cao, J.; Chen, P.; Zheng, Y.; Dao, Q. A Max-Flow-Based Similarity Measure for Spectral Clustering. ETRI J. 2013, 35, 311–320. [Google Scholar] [CrossRef]
- Yenialp, E.; Kalkan, H.; Mete, M. Improving Density Based Clustering with Multi-scale Analysis. Comput. Vis. Graph. 2012, 7594, 694–701. [Google Scholar]
- Fushing, H.; Wang, H.; Vanderwaal, K.; McCowan, B.; Koehl, P. Multi-scale clustering by building a robust and self correcting ultrametric topology on data points. PLoS ONE. 2013, 8, e56259. [Google Scholar] [CrossRef] [PubMed]
- Mall, R.; Langone, R.; Suykens, J.A.K. Self-tuned kernel spectral clustering for large scale networks. In Proceedings of the 2013 IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 385–393.
- Zelnik-Manor, L.; Perona, P. Self-tuning spectral clustering. NIPS 2004, 17, 1601–1608. [Google Scholar]
- Xinyue, L.; Jingwei, L.; Hong, Y.; Quanzeng, Y.; Hongfei, L. Adaptive Spectral Clustering Based on Shared Nearest Neighbors. J. Chin. Comput. Syst. 2001, 32, 1876–1880. [Google Scholar]
- Blondel, V.D.; Gajardo, A.; Heymans, M.; Senellart, P.; Dooren, P.V. A measure of similarity between graph vertices: Applications to synonym extraction and web searching. SIAM Rev. 2004, 46, 647–666. [Google Scholar] [CrossRef]
- Kleinberg, J.M. Authoritative sources in a hyperlinked environment. ACM 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Jarvis, R.A.; Patrick, E.A. Clustering using a similarity measure based on shared nearest neighbors. IEEE Trans. Comput. 1973, 22, 1025–1034. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. 2000, 22, 888–905. [Google Scholar]
- Synthetic data sets. Available online: http://cs.joensuu.fi/sipu/datasets/ (accessed on 15 November 2014).
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/datasets.html (accessed on 20 November 2014).
- Iris Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/Iris (accessed on 20 November 2014).
- Ionosphere Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/Ionosphere (accessed on 20 November 2014).
- Breast Tissue Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/Breast+Tissue (accessed on 20 November 2014).
- Banknote Authentication Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/banknote+authentication (accessed on 20 November 2014).
- Seeds Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/seeds (accessed on 20 November 2014).
- Fertility Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/Fertility (accessed on 20 November 2014).
- Libras Movement Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/Libras+Movement (accessed on 20 November 2014).
- Glass Identification Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/Glass+Identification (accessed on 20 November 2014).
- The MNIST dataset. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 20 November 2014).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, X.; Zhang, S.; Liu, Y. An Adaptive Spectral Clustering Algorithm Based on the Importance of Shared Nearest Neighbors. Algorithms 2015, 8, 177-189. https://doi.org/10.3390/a8020177
He X, Zhang S, Liu Y. An Adaptive Spectral Clustering Algorithm Based on the Importance of Shared Nearest Neighbors. Algorithms. 2015; 8(2):177-189. https://doi.org/10.3390/a8020177
Chicago/Turabian StyleHe, Xiaoqi, Sheng Zhang, and Yangguang Liu. 2015. "An Adaptive Spectral Clustering Algorithm Based on the Importance of Shared Nearest Neighbors" Algorithms 8, no. 2: 177-189. https://doi.org/10.3390/a8020177
APA StyleHe, X., Zhang, S., & Liu, Y. (2015). An Adaptive Spectral Clustering Algorithm Based on the Importance of Shared Nearest Neighbors. Algorithms, 8(2), 177-189. https://doi.org/10.3390/a8020177