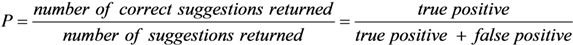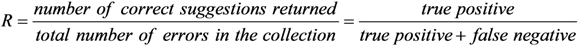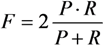1. Introduction and Motivations
Human communication processes are nowadays increasingly integrated with the Web. As a result, a huge quantity of natural language text can be instantly accessed through search engines, as a live linguistic corpus [
1]. This consists of a variety of text types and styles, such as colloquial, formal, technical, scientific, medical, legal, journalistic, and so on. With respect to edited texts, web-based texts are produced in a wider variety of contexts, with different writing styles. The problem of text checking in different contexts remains to a large extent still unsolved [
2]. Human language is also influenced by evolutionary processes characterized by emergence, self-organization, collective behavior, clustering, diversification, hierarchy formation, and so on [
3,
4,
5,
6]. For this reason, new research methodologies and trends based on direct observable data have gained an increasing interest in natural language processing (NLP) [
7,
8]. In this paper, we present a text analysis approach that is intrinsically embodied in the Web and is based on the paradigm of
emergence, in contrast with the classical and common paradigm of
cognitivism [
9]. In the following, we first classify NLP methods according to such paradigms, and then we provide a better characterization of our approach.
Generally speaking, in the literature there are three basic approaches to NLP,
i.e., symbolic, statistical and connectionist [
10].
Symbolic approaches are based on representation of knowledge about language, derived from human introspective data. Two examples of this category are the following: (i) Rule-Based Systems, which rely on morphological/syntactic generators [
11]; (ii) Semantic Networks, which are based on a structure of labeled relations and concepts [
12]. Quite different are
statistical approaches, which employ directly observable data to develop a mathematical model of linguistic phenomena [
13,
14]. Two examples of this category are the following: (i) Markov Models, which can predict the next symbol or word in a sequence [
15,
16]; (ii) Language Usage Patterns, in which NLP expressions are analyzed by means of surveys for performing statistical inference [
2]. By contrast, in
connectionist approaches a model is a network of interconnected simple processing units with knowledge embodied in the weights of the connections. Connections reflect local structural relationships that can result in dynamic global behavior. Similarly to statistical approaches, connectionist approaches develop models from observable data. However, with connectionist systems linguistic models are harder to observe, because the architectures are less constrained than statistical ones, so as to allow
emergent phenomena [
9].
Both symbolic and statistical approaches belong to the cognitivist paradigm [
9]. In this paradigm, the system is a descriptive product of a human designer, whose knowledge has to be explicitly formulated for a representational system of symbolic information processing. This designer-dependent representation biases the system, and constrains it to a consequence of the cognitive analysis of human activity. Indeed, it is well known that symbolic systems are highly context-dependent, neither scalable nor manageable [
17], ineffectual in optimizing both grammar coverage and resultant ambiguity [
17]. With respect to symbolic systems, statistical systems are more robust in the face of noisy and unexpected inputs, allowing broader coverage and being more adaptive [
10]. Actually, every use of statistics is based upon a symbolic model, and statistics alone is not adequate for NLP [
2,
10]. In contrast, connectionist systems can exhibit higher flexibility, by dynamically acquiring appropriate behavior on the given input, so as to be more robust and fault tolerant [
10].
The connectionist approach discussed in this paper takes inspiration from the
emergent paradigm [
9], which reflects the dynamic sociological characteristics of natural languages. The underlying idea is that simple mechanisms, inspired by basic human linguistic capabilities [
16], can lead to an emergent collective behavior, representing an implicit structure of the sentence in terms of relationships between words. With this approach, the most important consideration in the modeling is that global (
i.e., language) -level relationships between words must not be explicitly modeled, neither in logical nor mathematical terms. Such relationships must be kept
embodied in the corpus [
9]. Indeed, in contrast with a cognitivist system, which does not need to be embodied, an emergent system is dependent on the physical platform in which it is implemented,
i.e., the platform in which the corpus itself resides [
9].
When using the Web as a corpus, representativeness and correctness are two important topics of debate [
1,
18,
19]. With regard to representativeness, let us consider some typical events of human conversation and their availability in both web-based and conventional text.
Production and reception: many conversations have one speaker and one hearer; this one-to-one conversation is largely available on the Web; in contrast, many conventional text have one writer and many readers, e.g., a Times newspaper article.
Speech and text: there are orders of magnitude more speech events than writing events; web-based messaging is very close to speech events; in contrast, most conventional corpus research has tended to focus on text production rather than on speech production.
Background language: rumors and murmurs are conversational events greatly available on social networks; in contrast, these kinds of events are poorly covered by conventional text.
Copying: in the text domain, copyright, ownership and plagiarism restrict cut-and-paste authorship, whereas in the Web domain the open access paradigm enables new language production events.
With regard to correctness, a fundamental paradigm shift has been occurring since the introduction of the Web as a corpus. In contrast to paper-based, copy-edited published texts, web-based texts are produced by a large variety of authors, cheaply and rapidly with little concerns for formal correctness [
1]. For instance, a Google search for “I beleave”, “I beleive”, and “I believe” gives 257,000, 3,440,000, and 278,000,000 hits, respectively. Hence, all the “erroneous” forms appear, but much less often than the “correct” forms. From the formal standpoint, the Web is a dirty corpus, but expected usage is much more frequent than what might be considered noise. Actually, a language is made of a core of lexis, grammar, constructions, plus a wide array of sublanguages, used in each of a myriad of human activities. In the last decade, an extensive literature on sophisticated mathematical model for word frequency distributions has been produced with the aim of modeling sublanguage mixtures [
1,
20].
Let us consider a simple positive feedback: for a given sentence, the more occurrences of the sentence in a corpus, the more correctness of the sentence [
21]. Here, the
open-world assumption is considered: any phraseology that is used in some sublanguage events of human conversation can be positively assessed [
20]. However, it is unlikely that many occurrences of the same sentence are found in a corpus [
1]. Moreover, for an incorrect sentence it should be important to show which part of the sentence is actually incorrect. Hence, a structural analysis of the sentence able to allow emerging relationships between words should be considered. Here, we emphasize that this analysis should be performed at the syntagmatic level, by identifying and rating elementary segments within the text (syntagms) [
22]. Nevertheless, the number of occurrences of a text segment is strongly affected by the usage of its terms. For instance, unfamiliar proper nouns and unusual numbers may drastically limit the number of occurrences of a segment. Hence, some transformations of segments should be taken into account, to allow substitution of terms within the same category that does not affect the structural relationships.
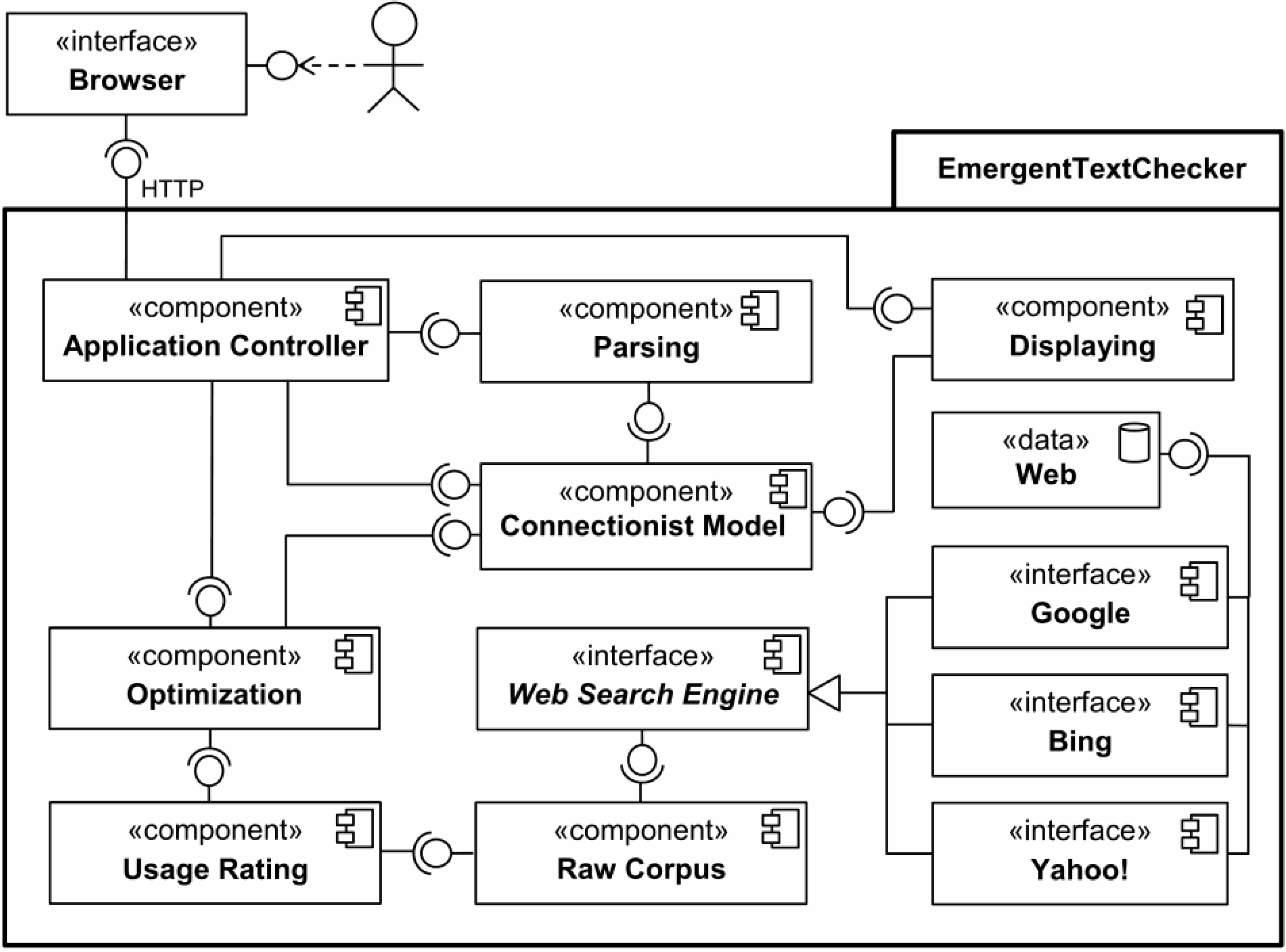
In our approach, we avoid identifying codes, rules or constraints that underlie the production and interpretation of text. For this reason, our method could be applied, with no changes, to many other languages that have enough available n-grams on the Web. The fundamental assumption of our grammarless approach is that the strength of word relationships can arise via a structural disassembly process of the sentence, upon language agnostic operators such as segmentation and substitution. This process is fundamental so as to allow the sublanguages knowledge to be kept embodied in the corpus.
To avoid an explicit representation, words relationships are represented in a connectionist model [
17,
23,
24], whose weights are trained via an unsupervised optimization process. Here, clustering is essential to identify atypical and misused parts, structurally opposed to commonly used parts. Finally, from the connectionist model, an output is derived so as to provide a visual representation [
25] of the sentence able to give the writer an informative insight of the text usage.
The paper is organized as follows.
Section 2 covers the related work on open-world approaches to textual analysis. In
Section 3, we introduce the problem formulation.
Section 4 is devoted to the connectionist model and its components.
Section 5 describes the determination of weights of the connections.
Section 6 is focused on experimental results.
Section 7 draws some conclusions and future works.
2. Open-World Approaches to Textual Analysis: Related Work
To the best of our knowledge, no work has been done in the field of text analysis using a connectionist model and the Web. However, there are a number of research projects that pursue textual analysis tasks using the Web as a corpus. In this section, we intend to characterize and present such open-world approaches with the aim of providing a landscape of the current methodologies.
In the
closed-world assumption, any linguistic analysis that cannot be generated by the grammar is assumed to be ungrammatical. In contrast, statistical parsers are considerably more open-world. For example, unknown words do not present a problem for statistical parsers. A possible approach to produce more open grammar-based approach is to relax the interpretation of constraints in the grammar. For instance, rules can be interpreted as soft constraints that penalize analyses in which they fail. However, any option that makes the grammar-based approach open-world requires a very higher computational effort, and needs parsing algorithms capable of handling massive ambiguity [
20].
Grammar-based approaches model explicit linguistic knowledge that is closer to meaning. Indeed, grammar-based analyses explicitly represent predicate-argument structure. However, predicate-argument structure can be also recovered using statistical methods [
26]. Grammar-based approaches are also often described as more linguistically based, while statistical approaches are viewed as less linguistically informed. However, this difference between the two approaches is misleading [
20], because there are only different ways of modeling linguistic knowledge in the two approaches. Indeed, in the grammar-based approach linguists explicitly write the grammars, while in statistical approaches linguists annotate the corpora with syntactic parses. Hence, linguistic knowledge plays a central role in both approaches. While many features used in statistical parsers do not correspond to explicit linguistic constraints, such features encode psycolinguistic preferences and aspects of world knowledge. Hence, from a high-level perspective, the grammar-based and the statistical approaches view parsing fundamentally in the same way, namely as a specialized kind of inference problem [
20].
A direct comparison with our system in terms of result is not currently feasible, due to functional, architectural and structural differences with the open-world approaches to textual analysis available in the literature.
From a
functional standpoint, the research field of open-world approaches to text correction is characterized by a variety of specialized NLP sub-tasks. Examples of NLP tasks are: real-world error correction; near-synonym choice; preposition choice; adjective correction; adjective ordering; context-sensitive spelling correction; part-of-speech tagging; word sense disambiguation; noun countability detection; language-specific grammatical error correction made by native-language-specific people, and so on [
27]. Common examples of application of statistical NLP are: the classification of a period as end-of-sentence; the classification of a word into its part-of-speech class; the classification of a link between words as a true dependency. In contrast, our system does not model linguistic sub-tasks.
From an architectural standpoint, for each aforementioned NLP sub-task linguistic knowledge is injected in the system through specific algorithms, parameters, and training data. Most tasks of statistical NLP methods to text correction are classification problems tackled via machine learning methods. Classifiers can logically be trained only on specific linguistic problems and on a selected data set. Training process leads to scalability issues when applied to complex problems or to large training sets without guidance. For this reason, web-based NLP models are typically supervised models using annotated training data, or unsupervised models which rely on external resources such as taxonomies to strengthen results. In contrast, our system does not adopt some form of linguistic training or some form of linguistic supervision.
From a structural standpoint, with a linguistically informed approach there is a dualist distinction between computational processes and data structures. In contrast, our emergent system is characterized by fine-grained coupling between behavioral model and environment. Indeed, web data organization is a structural part of the algorithm, and data output is comprehensive and visually well integrated with the human perception (embodiment).
More specifically, in the remainder of the section we summarize the open-world approaches to text detection and correction relevant with respect to our work.
In [
14], the authors present a method for correcting real-world spelling errors,
i.e., words that occur when a user mistakenly types a correctly spelled word when another was intended. The method first determines some probable candidates and then finds the best one among them, by considering a string similarity function and a frequency value function. The string similarity function is based on a modified version of the Longest Common Subsequence (LCS) measure. To find candidate words of the word having spelling error, the Google Web 1T
n-gram data set is used.
An unsupervised statistical method for correcting preposition errors is proposed in [
19]. More specifically, the task is to find the best preposition from a set of candidates that could fill in the gap in an input text. The first step is to categorize an
n-gram type based on the position of the gap in the Google
n-gram data set,
n ranging from 5 to 2. In the second step, the frequency of the
n-gram is determined, and then the best choice preposition is established.
In [
28] the authors propose a way of using web counts for some tasks of lexical disambiguation, such as part-of-speech tagging, spelling correction, and word sense disambiguation. The method extracts the context surrounding a pronoun (called
context patterns) and determines which other words (called
pattern fillers) can take the place of the pronoun in the context. Pattern fillers are gathered from a large collection of
n-gram frequencies. Given the
n-gram counts of pattern fillers, in the supervised version of the method, a labeled set of training examples is used to train a classifier that optimally weights the counts according to different criteria. In the unsupervised version, a score is produced for each candidate by summing the (un-weighted) counts of all context patterns.
A method for detecting grammatical and lexical English errors made by Japanese is proposed in [
29]. The method is based on a corpus data, which includes error tags that are labeled with the learners’ errors. Error tags contain different types of information,
i.e., the part of speech, the grammatical/lexical system, and the corrected form. By referring to information on the corrected form, the system is able to convert erroneous parts into corrected equivalents. More specifically, errors are first divided into two groups,
i.e., the omission-type error and the replacement-type error. The former is detected by estimating whether or not a necessary word is missing in front of each word, whereas the latter is detected by estimating whether or not each word should be deleted or replaced with another word. To estimate the probability distributions of data the Maximum Entropy (ME) model is used. Finally, the category with maximum probability is selected as the correct category.
In [
30] a method for detecting and correcting spelling errors is proposed, by identifying tokens that are semantically unrelated to their context and are spelling variations of words that would be related to the context. Relatedness to the context is determined by a measure of semantic distance. The authors experimented different measures of semantic relatedness, all of which rely on a WordNet-like hierarchical thesaurus as their lexical resource.
A multi-level feature based framework for spelling correction is proposed in [
31]. The system employs machine learning techniques and a number of features from the character level, phonetic level, word level, syntax level, and semantic level. These levels are evaluated by a Support Vector Machine (SVM) to predict the correct candidate. The method allows correcting both non-word errors and real-world errors simultaneously using the same feature extraction techniques. The method is not confined to correct only words from precompiled lists of confused words.
In [
32], the authors analyze the advantages and limitations of the trigrams method, a statistical approach that uses word-trigram probabilities. Conceptually, the basic method follows the rule: if the trigram-derived probability of an observed sentence is lower than that of any sentence obtained by replacing one of the words with a spelling variation, then the original is supposed to be an error and the variation corresponds to what the user intended. The authors present new versions of this algorithm that use fixed-length windows, designed so that the results can be compared with those of other methods.
An efficient hybrid spell checking methodology is proposed in [
33]. The methodology is based upon phonetic matching, supervised learning, and associative matching in a neural system. The approach is aimed at isolated word error correction. It maps character onto binary vectors and two storage-efficient binary matrices that represent the lexicon. The system is not language-specific and then it can be used with other languages, by adapting the phonetic codes and transformation rules.
3. Problem Formulation
Our system aims at providing a continuous-valued representation of word relationships in a given sentence.
Figure 1 shows a sample sentence with some relationships (connections) between words. Here, subsequences of words,
i.e., word
n-grams, involved in each connection are represented in boldface.
Some general properties of subsequences are the following: (i) subsequences can be made of non-contiguous words, as represented in the first n-gram; (ii) subsequences can be overlapped; (iii) a suitable number of subsequences can be generated so as to cover all the words in the sentence; (iv) a subsequence does not usually correspond to a clause, since a grammarless approach is used.
Figure 1.
Example sentence with some arcs showing dependencies between words.
Figure 1.
Example sentence with some arcs showing dependencies between words.
A sentence with the corresponding subsequences can be represented as a connectionist model. Each word is represented by a node of the network, and the connections between nodes represent word relationships. Weak (or strong) connections model weak (or strong) relationships between its words. Connections strength can be based on the usage of their subsequences on the Web.
In general, different segmentations of a sentence in subsequences are possible. Hence, a suitable optimization method should be able to identify the better segmentation so as to emphasize subsequences with very low usage.
Finally, a suitable displaying method should provide an intuitive manner of expressing the relevant information owned by the connectionist model.
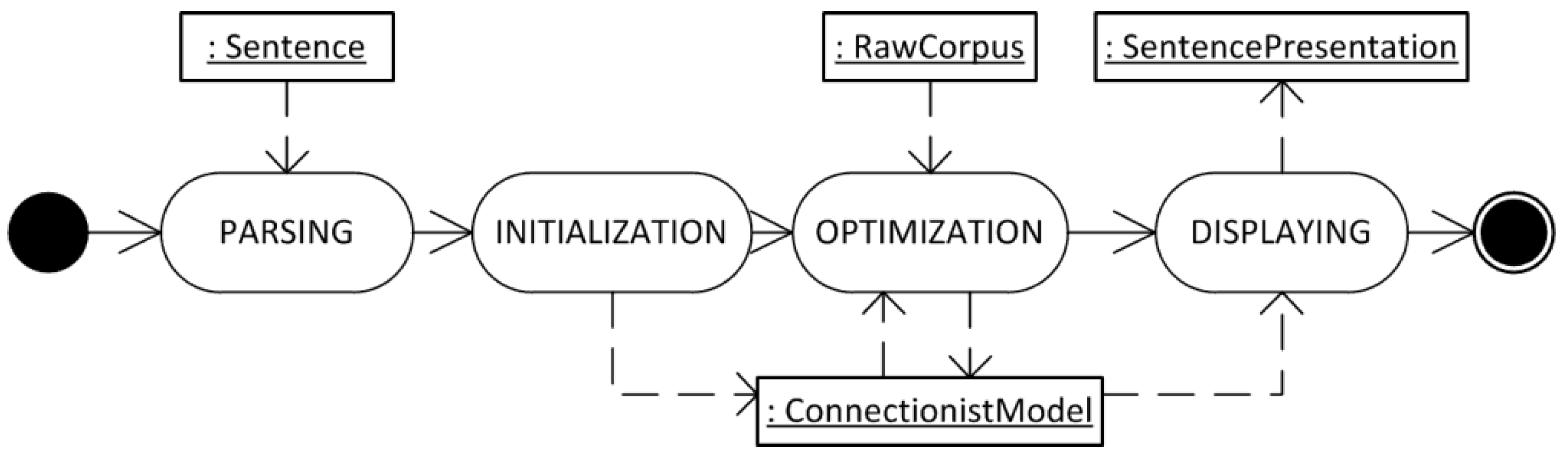
Figure 2 shows an UML activity diagram of the macro activities of our approach to text analysis. Here, activities (represented by oval shapes) are connected via control flow (solid arrow), whereas input/output data object (rectangles) are connected via data flow (dashed arrow).
Figure 2.
Overall activities involved in our emergent approach to text analysis.
Figure 2.
Overall activities involved in our emergent approach to text analysis.
At the beginning, the sentence is
parsed and then converted into an initial
connectionist model instance. The sentence is completely broken up into (overlapped) segments by a
segmentation operator. Afterwards, the
connectionist model instance goes through an
optimization process, which optimizes the connections by using the usage information available in the
raw corpus instance,
i.e. the Web. Finally,
connectionist model information is
displayed,
i.e., transferred to a visual representation of the sentence, namely a
sentence presentation instance [
25,
34].
More specifically,
Figure 3 shows the macro activities of the optimization process. First, a
segmentation of the sentence is performed, producing a series of
n-grams of the sentence itself. Then, one of two possible operators is applied, namely
generalization or
commutation. The former is an operator that employs the class of a specific word in place of the world itself, whereas the latter is an operator which substitutes a word with another more popular word which is structurally similar. Afterwards, the
usage of each
n-gram in the corpus is rated. Finally, the
n-grams with the lowest usage are determined. In order to find the best setting, all these activities may be carried out a number of times, as represented by the loop in the Figure.
Figure 3.
Macro activities of the optimization process.
Figure 3.
Macro activities of the optimization process.
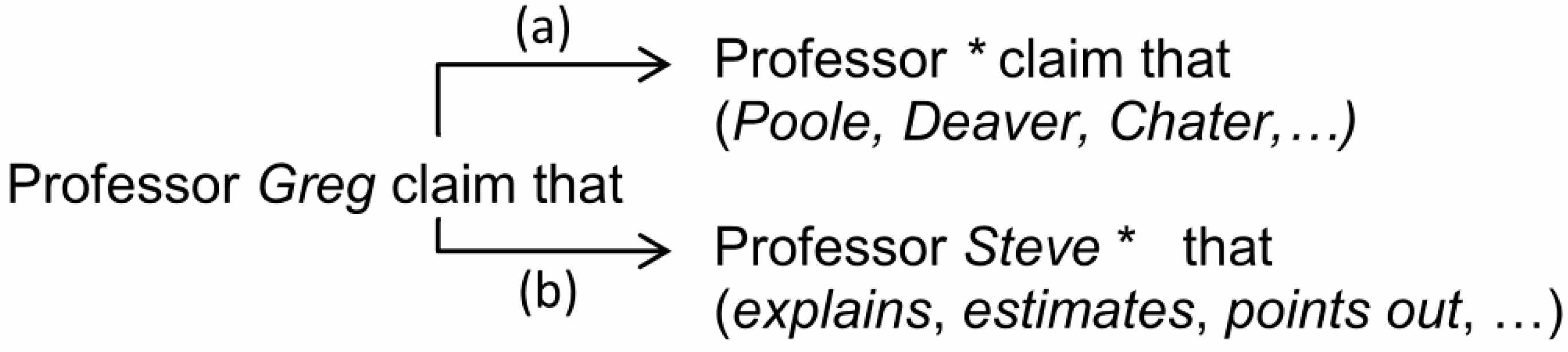
Figure 4a shows an example of generalization, in which the individual name “Greg” is replaced with any other individual name that can be found in the Corpus by using the wildcard.
Figure 4b shows an example of commutation, in which the individual name “Greg” is replaced with the more popular name “Steve” and the word “claim” is generalized. Each of these alternatives affects the
usage rating of the phrase, and allows a better robustness of the
optimization process. For example, without the generalization operator, usage rating may be strained by an unpopular word.
Figure 4.
An example of generalization (a) and commutation (b) operators.
Figure 4.
An example of generalization (a) and commutation (b) operators.
In the next section, we introduce some definitions to formalize our method.
5. The Determination of the Weights
In this section, we elaborate on the determination of the weights of the connectionist model. Weights are mainly established via an optimization procedure, which aims at separating low usage from normal/ high usage. For a single optimization process, different segmentations of the sentence are possible. For each segmentation process, the precise usage of each n-gram is calculated.
Usage values of the connections are divided into categories so that usage values in the same category are as similar as possible, and usage values in different categories are as dissimilar as possible. Further, each usage value can belong to more than one category. This soft clustering process is used to optimize the weights of the connections in the network.
The optimization process aims at discovering low usage segments in the sentence. For this reason we adopt the following proximity function, which tends to zero as
x1 and
x2 tend to infinity:
where
f is a scaling factor which is automatically adapted. More specifically,
Figure 9 shows two simple scenarios of proximity space
y = arctan(
x/f), corresponding to two different curves with different values of the scaling factor
f. On both curves, the same precise usage values are considered,
i.e.,
x1, …,
x4. With the lower scaling factor (
f' = 500), high usage values are considered very similar in the proximity space, whereas low usage values are considered very dissimilar. However, a very low scaling factor would consider all usage values almost identical and equal to 1 in the proximity space. With the higher scaling factor (
f = 9000), usage values in the proximity space
y are almost linearly connected with the source space.
Figure 9.
Two simple scenarios with the adopted proximity space.
Figure 9.
Two simple scenarios with the adopted proximity space.
In our approach, the scaling factor is automatically adapted by maximizing the proximity between the minimum and the maximum usages in the sentence, e.g.,
y1 and
y4 in
Figure 9.
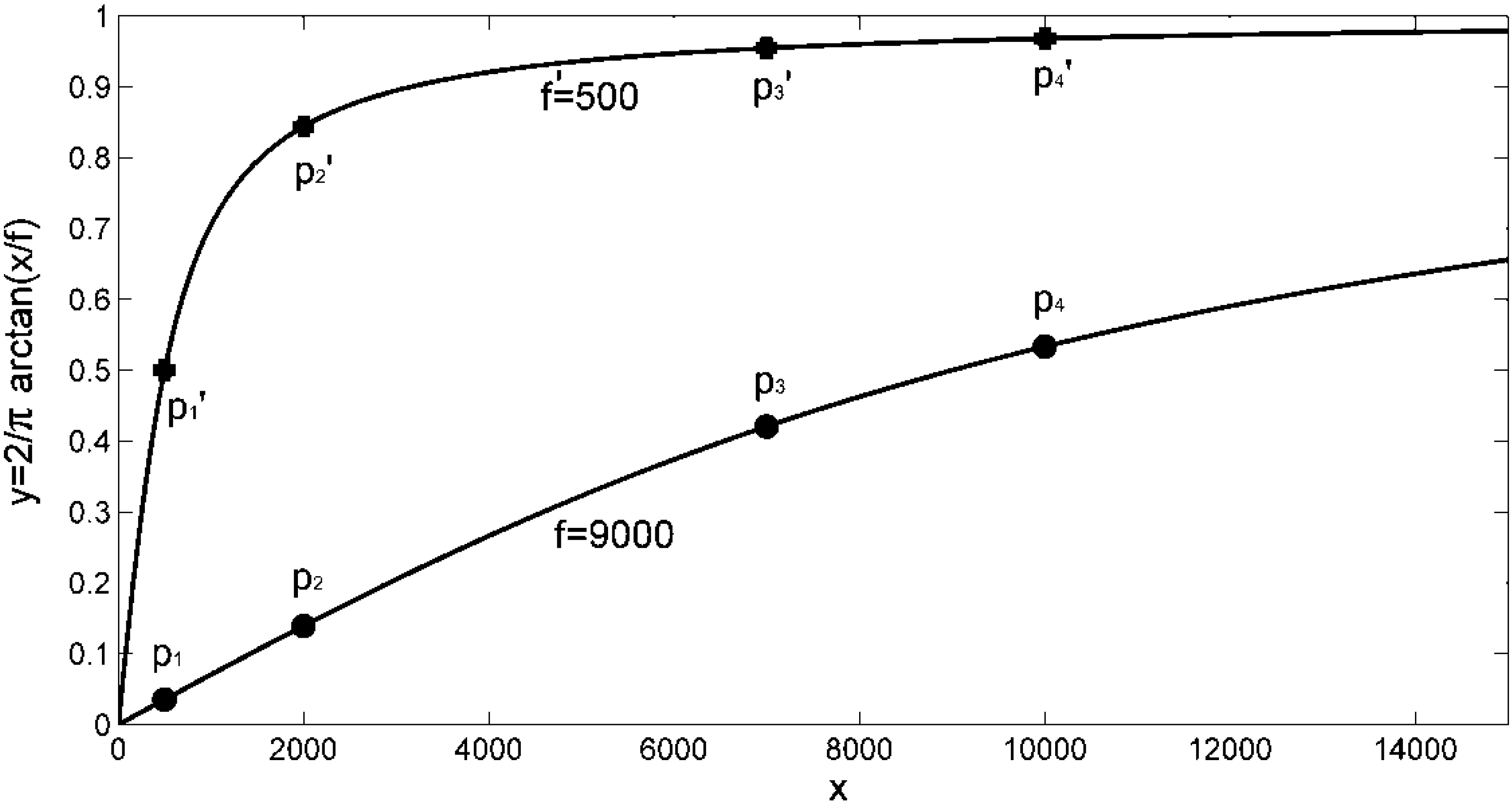
Figure 10 shows an example of differential proximity space
w = arctan(
a/z)
− arctan(
b/z), with
a > b. The example clearly shows that there is a unique global maximum of the proximity between
a and
b, that can be easily found by means of fundamentals of mathematical analysis. In conclusion, by using (9) with the adaptation of the scaling factor, high usage values are all considered similar, whereas differences between low usage values are sensed.
Figure 10.
A scenario of differential proximity space.
Figure 10.
A scenario of differential proximity space.
We adopted an implementation of a soft clustering process known as Fuzzy C-Means (FCM), with a simple iterative scheme and good convergence properties [
35]. The algorithm categorizes a set of data points
U = (
u1, …,
un) finding D cluster centers
C = (
c1, …,
cD) as prototypes and the fuzzy membership degrees
Ni = (
μi1, …,
μiD) of each data point
ui to the cluster centers, under the constraint
![]()
. The FCM algorithm introduces fuzzy logic with respect to the well-known K-Means (or Hard C-Means, HCM) clustering algorithm. The two algorithms are basically similar in design. The latter forces data points to belong exclusively to one category, whereas the former allows them to belong to multiple clusters with varying degrees of membership. Such degrees are crucial for measuring the quality of the process as well as for the determination of the connection weights, and then the fuzzy character of the clustering can be considered a requirement of our approach.
There is a plethora of fuzzy clustering methods available in the literature [
36]. For instance, the Fuzzy Self-Organizing Map (Fuzzy SOM) can be taken into consideration, as well as many other FCM derivatives. The most of them are iterative methods. Moreover, some of them are more robust to outliers, and less sensitive to the initial conditions. However, in our study most performance-related problems on the clustering are mitigated, because the clustering is made on a mono-dimensional space, with a proximity function that facilitates the granulation process, with a limited number of points and of clusters. Thus, the clustering process converges very quickly, in a very few iterations. We adopted the basic FCM version as it has been used very successfully in many applications, having a simple iterative scheme and good convergence properties.
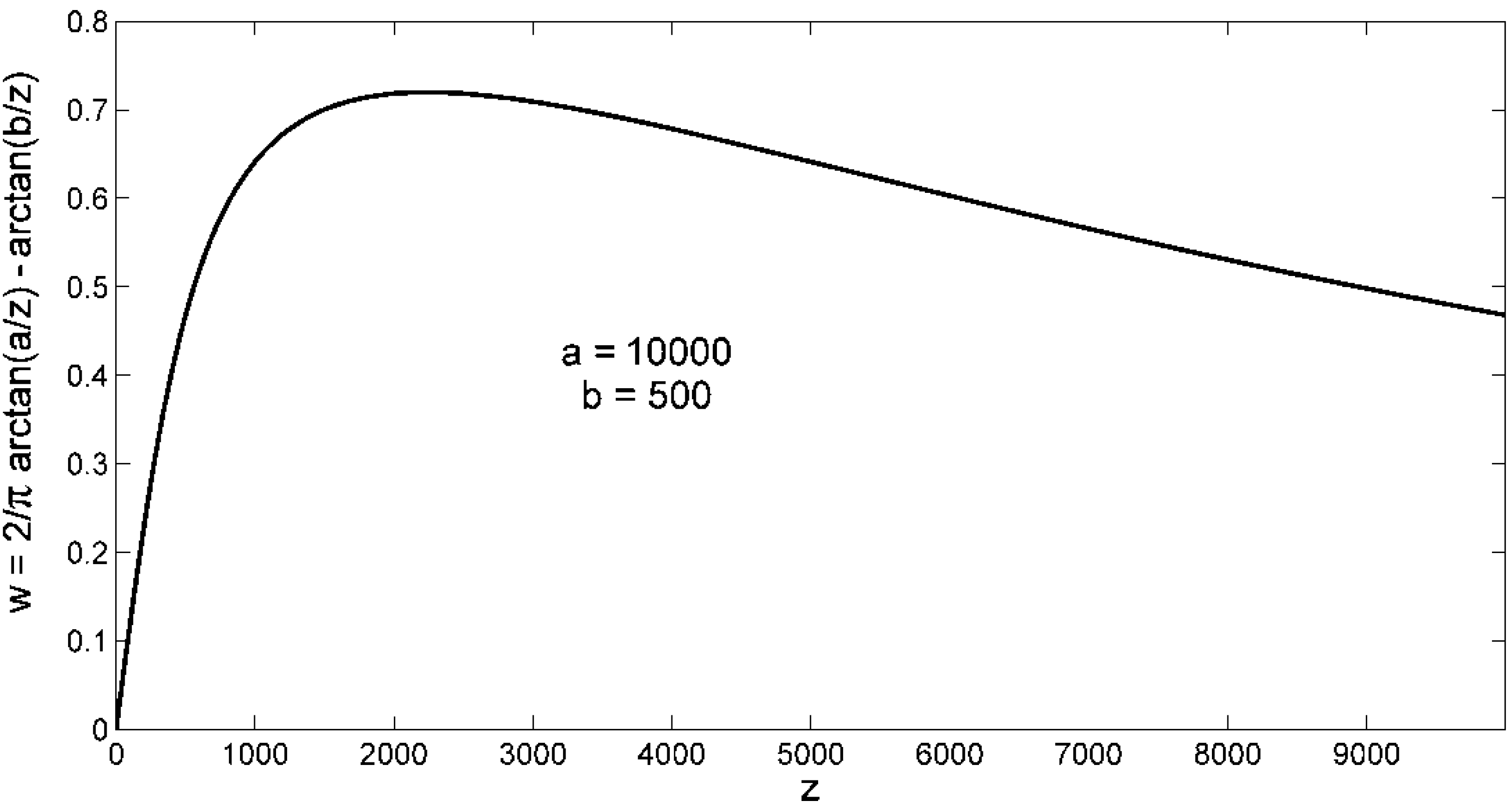
The FCM algorithm minimizes an objective function representing a clusters compactness measure, by iteratively improving fuzzy membership degrees until no further improvement is possible. More specifically, the cluster centers are computed as the weighted average of all data points,
i.e.,
![]()
, whereas the fuzzy membership degrees are computed as follows:
where
d is a proximity function and
m > 1 is a parameter called
fuzziness. The choice of the proximity function determines the success of a clustering algorithm on the specific application domain [
37]. As a proximity function, we adopted formula (9), which facilitates the granulation process. FCM approaches HCM when
m is approaching 1. The larger the value of
m (up to infinity), the larger the similarity of the clusters. The parameter is usually set to 2. We adopted this value since its effect is marginal in our system.
The FCM method requires also the number of categories D as input. Different fuzzy partitions are obtained with different number of categories. Thus, a cluster validity index is required to validate each of the fuzzy partitions and to establish the optimal partition [
38],
i.e., the optimal number of categories. The FCM validation procedure used to determine the optimal number of clusters is made of the following steps:
- (i)
initialize the parameters of the FCM except for the number of clusters, D;
- (ii)
execute the FCM algorithm for different values of D, ranging from 2 to a maximum, established in the design stage or at runtime;
- (iii)
compute the validity index for each partition provided by step (ii);
- (iv)
choose the optimal partition and the optimal number of categories according to the validity index.
To find the optimal number of categories, we adopted the Xie-Beni validity index, which optimizes compactness and separation of categories [
39]:
where the numerator and the denominator indicate compactness and separation, respectively. Thus, the best partition corresponds to the minimum value of P.
In conclusion, the overall optimization process can be summarized as follows. First, a segmentation of the sentence into subsequences is performed. Second, the usage values (points) of each subsequence in the Web are computed. Third, a number of clusters is chosen. Fourth, point coefficients are assigned randomly for each cluster. Fifth, the centroid of each cluster is computed. Sixth, point coefficients are computed for each cluster. Seventh, go to the fifth step, if there is no convergence in coefficients. Eighth, the Xie-Beni index of clusters is computed. Ninth, go to the third step if a new number of clusters should be assessed. Tenth, provide the coefficients of the clustering process related to the best Xie-Beni index. Eleventh, coefficients are employed to assign the weights of the network.
More formally, the optimization algorithm can be defined as follows.
| Algorithm: optimization of the weights in the connectionist model |
| 1:00 | G ← Tokenize(input sentence); |
| 2:00 | G' ≡ (G(1), G(2),…, G(n)) ← Segment(G,s,o); |
| 3:00 | U ≡ (u1,…, un) ← ( ![]() , , ![]() ,…, ,…, ![]() ); ); |
| 4:00 | ![]() |
| 5:00 | for D = 2 to 5 do |
| 6:00 | t ← 0; |
| 7:00 | Initialize μih ϵ [0,1], 1 ≤ i ≤ n, 1 ≤ h ≤ D (categories); |
| 8:00 | do |
| 9:00 | ![]() , 1 ≤ h ≤ D; , 1 ≤ h ≤ D; |
| 10:00 | ![]() , 1 ≤ h ≤ D, 1 ≤ i ≤ n; , 1 ≤ h ≤ D, 1 ≤ i ≤ n; |
| 11:00 | t ← t+1; |
| 12:00 | while ![]() |
| 13:00 | ![]() |
| 14:00 | If P ≤ Popt |
| 15:00 | Popt ← P; Copt ← {ch}; Mopt ← {μih}; |
| 16:00 | end if |
| 17:00 | end for |
The result of this optimization process is made of: (i) the usage categories Copt; (ii) the membership degrees of each segment usage to all categories, Mopt. Let us assume that the lowest category is identified by h = 1. Hence, we take wk,h ≡ 1 − μ1,j in order to discover atypical, misused and outdated segments in the sentence.
Table 2 summarizes the parameters of the system, together with their typical values. Such values have been derived by maximizing the performance of the system over a subset of the sample sentences used in the experimental results (
Section 6).
Table 2.
Parameters of the algorithm and their typical values.
Table 2.
Parameters of the algorithm and their typical values.
| Parameter | Description | Value | Reference |
|---|
![]() | Search engine | google, bing, yahoo, all, random | Section 4.2 |
| π | Number of snippet pages to parse | from 2 to 5, to improve precision | Section 4.2 |
| o | Allowed overlapping n-grams | 1, 2 | Section 4.1 |
| lMIN, lMAX | Minimum and maximum allowed length of n-grams. | 3, 4 | Section 4.1 |
| f | Initial threshold of low usage | 3,000,00 | Section 5 |
| tMIN, tMAX | Minimum and maximum font size | 1,030 | Section 5 |
6. Experimental Results
In order to test the effectiveness of the system, a collection of 80 sentences have been derived from the British National Corpus (BNC) [
40]. More specifically, the extraction criterion was the following. First, the following list of the most frequent English word has been derived:
time,
year,
people,
way,
man,
day,
thing, child [
41]. Second, word pairs in the list have been used as a search criterion to find a collection of 30 sentences. Third, a new collection of 50 sentences has been produced by introducing mistakes in the first collection of sentences, and thus having 80 total sentences.
In order to measure the system performance, let us consider the system as a classifier whose results (expectation) are compared under test with trusted external judgments (observation). A correct result (true positive) is then an atypical subsequence discovered in the sentence, whereas a correct absence of result (true negative) is a good sentence where no atypical subsequence has been discovered, i.e., the lowest usage category is empty.(Actually, the lowest usage category contains the zero usage value by default, and then this condition from a technical standpoint means that the category contains the zero usage value only) Hence, the terms positive (the sentence is somewhere atypical) and negative (the sentence is good) refer to the expectation, whereas the terms true and false refer to whether that expectation corresponds to the observation.
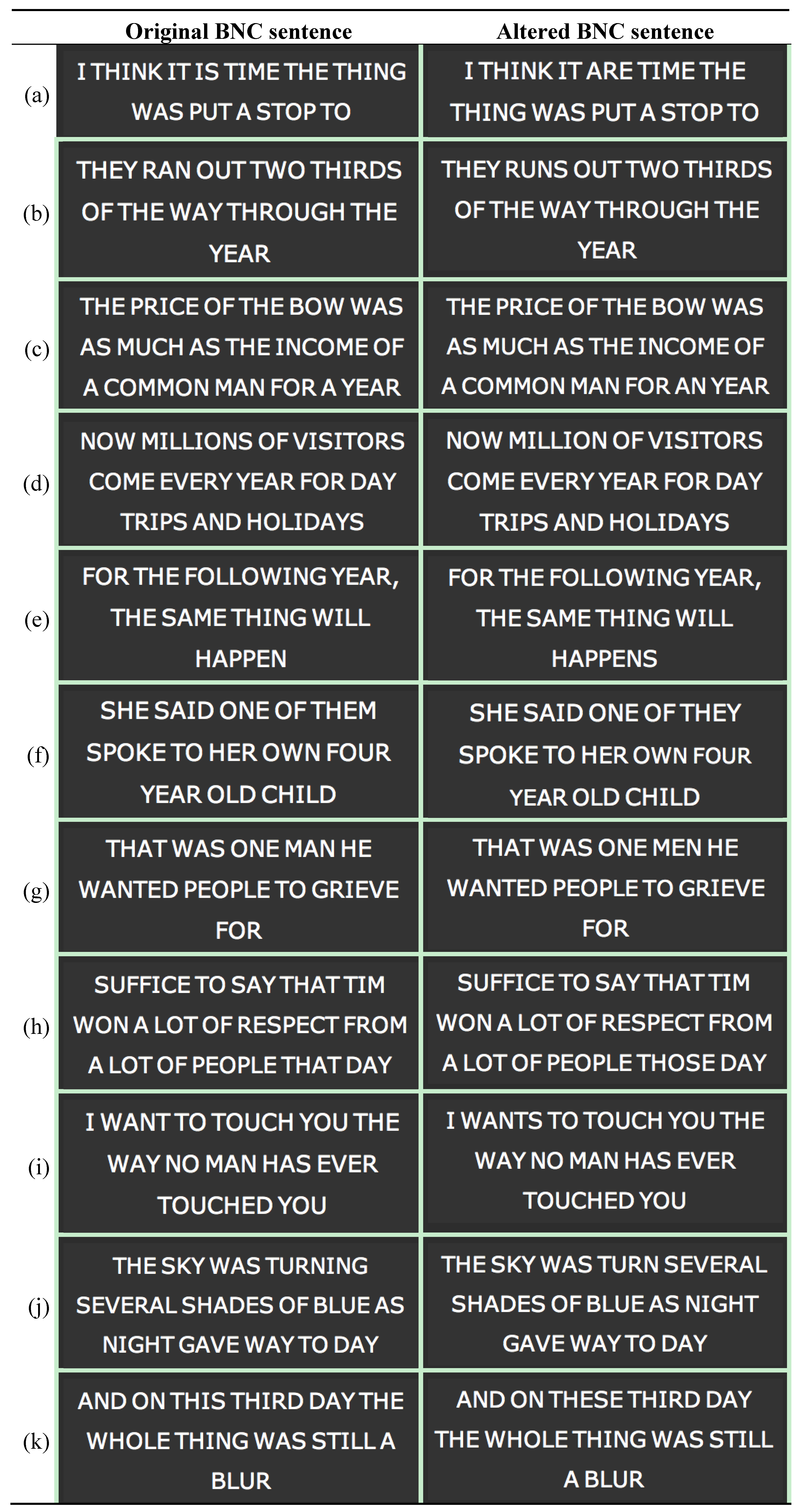
Figure 11 shows some examples of successful application of our system. Here, each black rectangle is a visual output of an input sentence. On the left side of the Figure, original BNC sentences are presented. All these sentences are correct from a grammatical standpoint, and then no atypical subsequences are available in the sentences. Hence, all cases on the left are true negatives. On the right side of the Figure, the same sentence of the left side is presented with some grammatical mistake, so as to have some atypical subsequence. In all cases, the system correctly identified the atypical segment. Hence, all cases on the right are true positive. It is worth noting, on the right of
Figure 11k and
Figure 11 (l), two examples of colored non-contiguous subsequences.
Table 3 shows some values related to the sentences of
Figure 11c. Here, it can be easily noticed that the atypical subsequence (represented in boldface) is characterized by a weight value
wk,h lower than the corresponding scaling factor
f.
Table 3.
Values related to the sentences of
Figure 11c.
Table 3.
Values related to the sentences of Figure 11c.
| That was one man he wanted people to grieve for. | | That was one man he wanted people to grieving for. |
| n. of subsequences: 4 | | n. of subsequences: 5 |
| n. of clusters: 2 | | n. of clusters: 2 |
| Xie-Beni index: 0.0000070033 | | Xie-Beni index: 0.000032159 |
| f = 29,851 | | f = 30,249 |
| n-grams | ![]() | wk,h | | n-grams | ![]() | wk,h |
| that was one | 888,034,526 | 0.9999888 | | that was one | 909,886,666 | 0.9999704 |
| one man he | 22,619,593 | 0.9999936 | | one man he | 25,481,131 | 0.9999779 |
| he wanted people to | 3,159,405 | 0.9999929 | | he wanted people | 3,272,179 | 0.9999997 |
| to grieve for | 2,896,900 | 0.9999896 | | people to grieving | 452 | 0.0000233 |
| | | | grieving for | 1,279,430 | 0.9999036 |
Figure 12 shows some peculiar examples of successful application of our system. Again, on the left side of the figure, original BNC sentences are presented. All these sentences are correct from a grammatical standpoint, and then no atypical subsequences have been detected. Hence, all cases on the left are true negatives. On the right side of the figure, the same sentence of the left side is presented with some grammatical mistake. However, such grammatical mistakes are not considered atypical by the system, in terms of usage. Moreover, it has been verified that, for a given mistake, in all cases found by the system the subsequences with the grammatical mistake have been employed with the same meaning as in the original sentence. Hence, all cases on the right are true negatives.
Table 4 shows some values related to the sentences of
Figure 12c. Here, it can be easily noticed that the subsequence “for an year” (represented in boldface) is characterized by a weight value
wk,h higher than the corresponding scaling factor
f, and then it is considered as a typical subsequence.
Table 4.
Values related to the sentences of
Figure 12c.
Table 4.
Values related to the sentences of Figure 12c.
| The price of the bow was as much as the income of a common man for a year. | | The price of the bow was as much as the income of a common man for an year. |
| n. of subsequences: 7 | | n. of subsequences: 7 |
| n. of clusters: 2 | | n. of clusters: 2 |
| Xie-Beni index: 0.00015013 | | Xie-Beni index: 0.00047737 |
| f = 47,763 | | f = 46,648 |
| n-grams | ![]() | wk,h | | n-grams | ![]() | wk,h |
| the price of | 2,175,898,647 | 0.9999531 | | the price of | 2,175,799,647 | 0.9996993 |
| of the bow was | 3,178,377 | 0.9999937 | | of the bow was | 643,519 | 0.9990948 |
| was as much | 235,902,800 | 0.9999546 | | was as much | 85,217,200 | 0.9997106 |
| much as the income | 223,002,490 | 0.9999547 | | much as the income | 65,702,378 | 0.9997141 |
| income of a | 46,863,789 | 0.9999612 | | income of a | 5,725,105 | 0.9998504 |
| a common man for | 784,401 | 0.9989659 | | a common man for | 495,611 | 0.9979714 |
| for a year | 1,944,067,782 | 0.9999531 | | for an year | 3,010,079 | 0.9999428 |
Thus far, we have shown true positive and true negative cases.
Figure 13 shows some examples of unsuccessful application of our system. Again, on the left side of the Figure, original BNC sentences are presented. All these sentences are correct from a grammatical standpoint, and then no atypical subsequences have been detected. Hence, all cases on the left are true negatives. On the right side of the figure, the same sentence of the left side is presented with some grammatical mistake. However, such grammatical mistakes are not considered atypical by the system, in terms of usages. Moreover, it has been discovered that in the most cases found by the system, the subsequences with the grammatical mistakes were employed with a different meaning with respect to the original sentence. Hence, all cases on the right are false positives.
For example, some sentences with a different meaning with respect to the sentences of
Figure 13a-d are: (a) “
one of those was one”; (b) “
the opinions expressed in it do not reflect”; (c) “
the opinion of you does not reflect”; (d) “
if the whole thing were”. To solve this kind of problems, other constraints can be included in the search. For instance, when rating an initial/final subsequence of a sentence, only initial/final subsequences in the precise usage should be considered valid. For this reason, as a future works we will improve the precise usage calculation with additive features, so as to allow a more exact matching of the meaning.
From the above examples, it becomes then obvious that the test of the performance of our emergent system for text analysis cannot be carried out by means of automatic tools. Indeed, there are no cognitivist models of the observations available, and then the effectiveness of the system must be currently based on human observers.
We have measured the system performance by considering 80 sentences derived from the BNC as described at the beginning of this Section. As metrics, we adopted
Precision (
P),
Recall (
R), and
F-measure (
F) [
4], defined as follows:
Precision is a measure of exactness or quality, whereas recall is a measure of completeness or quantity. The F-measure combines precision and recall via the harmonic mean of them.
Table 5 and
Table 6 show the confusion matrix and the system performance, respectively. Both recall and precision are very high, thus confirming the effectiveness of our method.
Table 5.
Confusion matrix.
Table 5.
Confusion matrix.
| Actual class (observation) |
|---|
| Expected class (expectation) | 44 | 3 |
| True positive | False positive |
| (wrong sentence, atypical subsequence discovered) | (good sentence, atypical subsequence discovered) |
| 6 | 27 |
| False negative | True negative |
| (wrong sentence, | (good sentence, |
| nothing discovered | nothing discovered) |
Table 6.
Performance of the system.
Table 6.
Performance of the system.
| P | R | F |
| 0.94 | 0.88 | 0.91 |
7. Conclusions and Future Works
In this paper we presented a novel approach to text analysis able to overcome the designer-dependent representations of the available analyzers, which are more efficient but work as long as the system does not have to stray too far from the conditions under which these explicit representations were formulated. By using an emergent paradigm, in our approach interactions between words in the Web can be represented in terms of visual properties of the input text. In contrast, both symbolic and statistical approaches are cognitivist, involving a representation of a given pre-determined linguistic objective, established based on domain knowledge acquisition in the design process. Hence, cognitivist approaches are characterized by efficiency in solving specific application problems with more or less adaptability, in contradistinction with the emergent approach, which is characterized by embodiment, adaptation, autonomy, and self-organization.
Our approach to text analysis is based on the principles of connectionism and embodiment with the environment. The system employs hit counts and snippets provided by web search engines, in order to rate the subsequences of the input sentence, thus producing usage relationships between words of the sentence. A connectionist structure is then built to represent and optimize such relationships, via an unsupervised fuzzy clustering process. Finally, a visual output of the sentence is provided, with usage information. The system has been discussed and tested on a collection of sentences of the British National Corpus, showing its effectiveness in highlighting real-world spelling errors. Work is underway to improve the match between word segments and snippets, and to test the system with other languages. Indeed, the approach is completely grammarless and open-world, thus providing an efficient means of analysis of sublanguages in the Web. Moreover, a more usable and manageable version of the system is under development, to allow performing beta tests and collecting assessments of linguistics experts. Finally, a challenge for the future lies in studying the possibility of integration of our method with other web-based models.
Figure 11.
Some examples of successful application of our text analysis to the British National Corpus (BNC) data.
Figure 11.
Some examples of successful application of our text analysis to the British National Corpus (BNC) data.
Figure 12.
Some peculiar examples of successful application of our text analysis to the BNC data.
Figure 12.
Some peculiar examples of successful application of our text analysis to the BNC data.
Figure 13.
Some examples of unsuccessful application of our text analysis to the BNC data.
Figure 13.
Some examples of unsuccessful application of our text analysis to the BNC data.




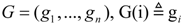
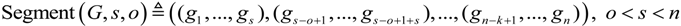
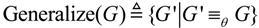

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 to denote the raw usage as the number of Web pages (hit counts) containing G found by the search engine
to denote the raw usage as the number of Web pages (hit counts) containing G found by the search engine  . The precise usage
. The precise usage  represents the raw usage excluding a proportion due to inaccurate results found in the hit counts according to a precision parameter π. More specifically:
represents the raw usage excluding a proportion due to inaccurate results found in the hit counts according to a precision parameter π. More specifically:
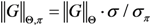
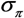 is the number of snippets found by parsing a number of pages equal to π, and
is the number of snippets found by parsing a number of pages equal to π, and 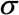 is the number of snippet with an exact match by considering also punctuation marks, case-sensitivity, adjacency, generalization (4).
is the number of snippet with an exact match by considering also punctuation marks, case-sensitivity, adjacency, generalization (4).
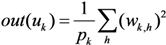
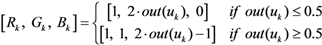


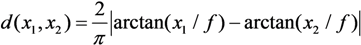
 . The FCM algorithm introduces fuzzy logic with respect to the well-known K-Means (or Hard C-Means, HCM) clustering algorithm. The two algorithms are basically similar in design. The latter forces data points to belong exclusively to one category, whereas the former allows them to belong to multiple clusters with varying degrees of membership. Such degrees are crucial for measuring the quality of the process as well as for the determination of the connection weights, and then the fuzzy character of the clustering can be considered a requirement of our approach.
. The FCM algorithm introduces fuzzy logic with respect to the well-known K-Means (or Hard C-Means, HCM) clustering algorithm. The two algorithms are basically similar in design. The latter forces data points to belong exclusively to one category, whereas the former allows them to belong to multiple clusters with varying degrees of membership. Such degrees are crucial for measuring the quality of the process as well as for the determination of the connection weights, and then the fuzzy character of the clustering can be considered a requirement of our approach. , whereas the fuzzy membership degrees are computed as follows:
, whereas the fuzzy membership degrees are computed as follows:
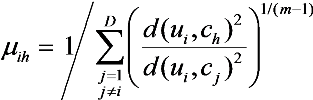
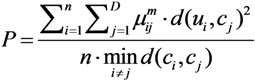
 ,
, 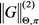 ,…,
,…,  );
);
 , 1 ≤ h ≤ D;
, 1 ≤ h ≤ D; , 1 ≤ h ≤ D, 1 ≤ i ≤ n;
, 1 ≤ h ≤ D, 1 ≤ i ≤ n;