Standard and Specific Compression Techniques for DNA Microarray Images


Abstract
:
1. Introduction
2. State of the Art of DNA Microarray Image Compression
2.1.Preprocessing
2.1.1. Denoising
2.1.2. Segmentation
2.2. Transform
2.3. Quantization
2.4. Entropy Coding
2.4.1. Segmentation Based Coding
2.4.2. Context-Based Coding
2.5. General Techniques Adapted to Microarray Images
2.6. Postprocessing
2.6.1. Spot Detection
2.6.2. Spot Identification
2.6.3. Spot Classification
2.6.4. Distortion Results
2.7. Technique Summary
2.8. Lossless Compression Results Comparison
2.8.1. Image Sets Used in the Literature
2.8.2. Comparison of Results
3. Compression Standards
3.1. Tested Image Sets
3.2. General Compression Schemes
3.3. Image Compression Standards
3.4. Image Properties Affecting Compression Performance
4. Conclusions and Future Work
Acknowledgments
References
- Moore, S. Making chips to probe genes. IEEE Spectr. 2001, 38, 54–60. [Google Scholar] [CrossRef]
- Satih, S.; Chalabi, N.; Rabiau, N.; Bosviel, R.; Fontana, L.; Bignon, Y.J.; Bernard-Gallon, D.J. Gene expression profiling of breast cancer cell lines in response to soy isoflavones using a pangenomic microarray approach. Omics J. Integr. Biol. 2010, 14, 231–238. [Google Scholar] [CrossRef]
- Giri, M.S.; Nebozhyn, M.; Showe, L.; Montaner, L.J. Microarray data on gene modulation by HIV-1 in immune cells: 2000–2006. J. Leukoc. Biol. 2006, 80, 1031–1043. [Google Scholar] [CrossRef]
- Nalbantoglu, O.U.; Russell, D.J.; Sayood, K. Data compression concepts and algorithms and their applications to Bioinformatics. Entropy 2010, 12, 34–52. [Google Scholar] [CrossRef] [PubMed]
- Giancarlo, R.; Scaturro, D.; Utro, F. Textual data compression in computational biology: A synopsis. Bioinformatics 2009, 25, 1575–1586. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Lonardi, S. Storage and transmission of microarray images. Drug Discov. Today 2005, 10, 1689–1695. [Google Scholar] [CrossRef]
- Adjeroh, D.A.; Zhang, Y.; Parthe, R. On denoising and compression of DNA microarray images. Pattern Recogn. 2006, 39, 2478–2493. [Google Scholar] [CrossRef]
- Lukac, R.; Plataniotis, K.; Smolka, B.; Venetsanopoulos, A. A Data-Adaptive Approach to cDNA Microarray Image Enhancement. In Proceedings of the International Conference on Computational Science (ICCS ’05), Atlanta, GA, USA, 22–25 May 2005; pp. 886–893. [Google Scholar]
- Smolka, B.; Plataniotis, K. Ultrafast Technique of Impulsive Noise Removal With Application To Microarray Image Denoising. In Proceedings of the Image Analysis and Recognition, Toronto, ON, Canada, September 2005; Kamel, M., Campilho, A., Eds.; Springer-Verlag: Berlin, Germany, 2005; Volume 3656, pp. 990–997. [Google Scholar]
- Chen, X.; Duan, H. A Vector-Based Filtering Algorithm for Microarray Image. In Proceedings of the IEEE/ICME International Conference on Complex Medical Engineering, Beijing, China, 23–27 May 2007; Volume 1–4, pp. 794–797. [Google Scholar]
- Zifan, A.; Moradi, M.H.; Gharibzadeh, S. Microarray image enhancement by denoising using decimated and undecimated multiwavelet transforms. Signal Image Video Process. 2010, 4, 177–185. [Google Scholar] [CrossRef]
- Faramarzpour, N.; Shirani, S.; Bondy, J. Lossless DNA microarray image compression. In Proceedings of the 37th Asilomar Conference on Signals, Systems and Computers; 2003; Volume 2, pp. 1501–1504. [Google Scholar]
- Jornsten, R.; Vardi, Y.; Zhang, C. On the Bitplane Compression of Microarray Images. In Proceedings of the 4th International Conference on Statistical Data Analysis Based on the L1-Norm and Related Methods, Neuch’tel, Switzerland, 4–9 August 2002. [Google Scholar]
- Lonardi, S.; Luo, Y. Gridding and Compression of Microarray Images. In Proceedings of the IEEE Computational Systems Bioinformatics Conference, Stanford, CA, USA, 16–19 August 2004; pp. 122–130. [Google Scholar]
- Hua, J.; Liu, Z.; Xiong, Z.; Wu, Q.; Castleman, K. Microarray BASICA: Background adjustment, segmentation, image compression and analysis of microarray images. EURASIP J. Appl. Signal Process. 2004, 2004, 92–107. [Google Scholar] [CrossRef]
- Chen, Y.; Dougherty, E.R.; Bittner, M.L. Ratio-based decisions and the quantitative analysis of cDNA microarray images. J. Biomed. Opt. 1997, 2, 364–374. [Google Scholar] [CrossRef]
- Bierman, R.; Maniyar, N.; Parsons, C.; Singh, R. MACE: Lossless Compression and Analysis of Microarray Images. In Proceedings of the ACM Symposium on Applied Computing (SAC ’06), Dijon, France, 23–27 April 2006; pp. 167–172. [Google Scholar]
- Neekabadi, A.; Samavi, S.; Razavi, S.A.; Karimi, N.; Shirani, S. Lossless Microarray Image Compression Using Region Based Predictors. In Proceedings of the International Conference on Image Processing, San Antonio, TX, USA, 16 September–19 October 2007; Volume 1–7, pp. 913–916. [Google Scholar]
- Battiato, S.; Rundo, F. A Bio-Inspired CNN With Re-Indexing Engine for Lossless DNA Microarray Compression and Segmentation. In Proceedings of the 16th International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; Volume 1–6, pp. 1717–1720. [Google Scholar]
- Battiato, S.; Blasi, G.D.; Farinella, G.M.; Gallo, G.; Guarnera, G.C. Ad-hoc segmentation pipeline for microarray image analysis. Proc. SPIE 2006, 6064, 300–311. [Google Scholar]
- Battiato, S.; Rundo, F.; Stanco, F. Self organizing motor maps for color-mapped image re-indexing. IEEE Trans. Image Process. 2007, 16, 2905–2915. [Google Scholar] [CrossRef] [PubMed]
- Battiato, S.; Farinella, G.; Gallo, G.; Guarnera, G. Neurofuzzy Segmentation of Microarray Images. In Proceedings of the 19th International Conference on Pattern Recognition (ICPR ’08), Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Karimi, N.; Samavi, S.; Shirani, S.; Behnamfar, P. Segmentation of DNA microarray images using an adaptive graph-based method. IET Image Process. 2010, 4, 19–27. [Google Scholar] [CrossRef]
- Uslan, V.; Bucak, I.O. Clustering-Based Spot Segmentation of cDNA Microarray Images. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Buenos Aires, Argentina, 31 August–4 September 2010; pp. 1828–1831. [Google Scholar]
- Li, Z.; Weng, G. Segmentation of cDNA Microarray Image using Fuzzy c-mean Algorithm and Mathematical Morphology. Key Engineering Materials 2011, 464, 159–162. [Google Scholar] [CrossRef]
- Burrows, M.; Wheeler, D.J. A Block-Sorting Lossless Data Compression Algorithm. Technical Report 124; HP: Palo Alto, CA, USA, 1994. [Google Scholar]
- Peters, T.J.; Smolikova-Wachowiak, R.; Wachowiak, M.P. Microarray Image Compression Using a Variation of Singular Value Decomposition. In Proceedings of the Annual International Conference of the IEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007; Volume 1–16, pp. 1176–1179. [Google Scholar]
- Avanaki, M.R.N.; Aber, A.; Ebrahimpour, R. Compression of cDNA microarray images based on pure-fractal and wavelet-fractal techniques. ICGST Int. J. Graph. Vis. Image Process. GVIP 2011, 11, 43–52. [Google Scholar]
- Jornsten, R.; Wang, W.; Yu, B.; Ramchandran, K. Microarray image compression: SLOCO and the effect of information loss. Signal Process. 2003, 83, 859–869. [Google Scholar] [CrossRef]
- Jornsten, R.; Yu, B. “Comprestimation”: Microarray Images in Abundance. In Proceedings of the Conference on Information Sciences and Systems, Princeton, NJ, USA, 15–17 March 2000. [Google Scholar]
- Weinberger, M.J.; Seroussi, G.; Sapiro, G. The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG-LS. IEEE Trans. Image Process. 2000, 9, 1309–1324. [Google Scholar] [CrossRef]
- Taubman, D.S.; Marcellin, M.W. JPEG2000: Image Compression Fundamentals, Standards and Practice; Kluwer Academic Publishers: Boston, MA, USA, 2002. [Google Scholar]
- Said, A.; Pearlman, W.A. A new fast and efficient image codec based on set partitioning in hierarchical trees. IEEE Trans. Circuits Syst. Video Technol. 1996, 6, 243–250. [Google Scholar] [CrossRef]
- Bierman, R.; Singh, R. Influence of Dictionary Size on the Lossless Compression of Microarray Images. In Proceedings of the 20th International Symposium on Computer-Based Medical Systems, Maribor, Yugoslavia, 20–22 June 2007; Kokol, P., Podgorelec, V., MiceticTurk, D., Zorman, M., Verlic, M., Eds.; pp. 237–242. [Google Scholar]
- Zhang, Y.; Parthe, R.; Adjeroh, D. Lossless Compression of DNA Microarray Images. In Proceedings of the IEEE Computational Systems Bioinformatics Conference, Stanford, CA, USA, 8–11 August 2005; pp. 128–132. [Google Scholar]
- Zhang, Y.; Adjeroh, D. Prediction by partial approximate matching for lossless image compression. IEEE Trans. Image Process. 2008, 17, 924–935. [Google Scholar] [CrossRef]
- Neves, A.J.R.; Pinho, A.J. Lossless Compression of Microarray Images. In Proceedings of the International Conference on Image Processing, ICIP, Atlanta, CA, USA, 8–11 August 2006; pp. 2505–2508. [Google Scholar]
- Neves, A.J.R.; Pinho, A.J. Lossless compression of microarray images using image-dependent finite-context models. IEEE Trans. Med. Imaging 2009, 28, 194–201. [Google Scholar] [CrossRef]
- Wang, X.; Ghosh, S.; Guo, S.W. Quantitative quality control in microarray image processing and data acquisition. Nucleic Acids Res. 2001, 29, e75. [Google Scholar] [CrossRef] [PubMed]
- Sauer, U.; Preininger, C.; Hany-Schmatzberger, R. Quick and simple: Quality control of microarray data. Bioinformatics 2004, 21, 1572–1578. [Google Scholar] [CrossRef] [PubMed]
- Kim, P.G.; Park, K.; Cho, H.G. A quality measure model for microarray images. Int. J. Inf. Technol. 2005, 11, 117–124. [Google Scholar]
- Xu, Q.; Hua, J.; Xiong, Z.; Bittner, M.L.; Dougherty, E.R. The effect of microarray image compression on expression-based classification. Signal Image Video Process. 2009, 3, 53–61. [Google Scholar] [CrossRef]
- Xu, Q.; Hua, J.; Xiong, Z.; Bittner, M.; Dougherty, E. Accuracy of Differential Expression Detection With Compressed Microarray Images. In Proceedings of the International Workshop on Genomic Signal Processing and Statistics (GENSIPS ’06), College Station, TX, USA, 28–30 May 2006; pp. 43–44. [Google Scholar]
- Lonardi, S.; Luo, Y. MicroZip microarray image set. Available online: http://www.cs.ucr.edu/yuluo/MicroZip/ (accessed November 2011).
- Stanford Yeast Cell-Cycle Regulation Project. Yeast microarray image set. Available online: http://genome-www.stanford.edu/cellcycle/data/rawdata/individual.html (accessed on November 2011).
- Terry Speed Microarray data analysis group. ApoA1 microarray image set. Available online: http://www.stat.berkeley.edu/users/terry/zarray/Html/apodata.html (accessed on November 2011).
- Swiss Institute for Bioinformatics (SIB). ISREC microarray image set. Available online: http://www.isrec.isb-sib.ch/DEA/module8/P5 chip image/images/ (accessed on November 2011).
- Pinho, A.; Paiva, A.; Neves, A. On the use of standards for microarray lossless image compression. IEEE Trans. Biomed. Eng. 2006, 53, 563–566. [Google Scholar] [CrossRef]
- Herna´ndez-Cabronero, M.; Blanes, I.; Serra-Sagristaá, J.; Marcellin, M.W. A Review of DNA Microarray Image Compression. In Proceedings of the IEEE International Conference on Data Compression, Communication and Processing, CCP, Palinuro, Italy, 21–24 June 2011; pp. 139–147. [Google Scholar]


{kind=link}
{kind=link}
| Preprocessin | Transform Quantization | Entropy coding | Generic | Postprocessing | |||
|---|---|---|---|---|---|---|---|
| Denoising | Segmentation | Segmentation | Context | ||||
| × [8], 2005 | ⊠ [13], 2002 | ⊠ [15], 2004 | × [30], 2000 | ⊠ [13], 2002 | ☐ [35], 2005 | × [27], 2007 | ⊠ [29], 2003 |
| × [9], 2005 | ☐ [12], 2003 | ⊠ [14], 2004 | ⊠ [29], 2003 | ⊠ [29], 2003 | ☐ [7], 2006 | × [28], 2011 | ⊠ [15], 2004 |
| × [7], 2006 | ⊠ [15], 2004 | ☐ [7], 2006 | × [27], 2007 | ☐ [12], 2003 | ☐ [37], 2006 | × [7], 2006 | |
| × [10], 2007 | ⊠ [14], 2004 | × [27], 2007 | ⊠ [15], 2004 | ☐ [38], 2009 | ⊠ [42], 2009 | ||
| × [11], 2010 | ☐ [17], 2006 | × [11], 2010 | ⊠ [14], 2004 | ||||
| ☐ [18], 2007 | × [28], 2011 | ☐ [17], 2006 | |||||
| ☐ [19], 2009 | ☐ [34], 2007 | ||||||
| ☐ [21], 2007 | |||||||
| ⊠ [19], 2009 | |||||||
| Dataset | Images | Size (px) |
|---|---|---|
| MicroZip [44] | 3 | > 1800 × 1900 |
| Yeast [45] | 109 | 1024 × 1024 |
| ApoA1 [46] | 32 | 1044 × 1041 |
| ISREC [47] | 14 | 1000 × 1000 |
| Algorithm | Year | MicroZip | Yeast | ApoA1 | ISREC | Unspecified |
|---|---|---|---|---|---|---|
| SLOCO [13] | 2002 | — | — | 8.556 | — | — |
| Faramarzpour [12] | 2003 | — | — | — | — | 9.091 |
| Hua [15] | 2004 | — | — | — | — | 6.985 |
| MicroZip [14] | 2004 | 9.843 | — | — | — | — |
| PPAM [35] | 2005 | 9.587 | 6.601 | — | — | — |
| MACE [17] | 2006 | — | — | — | — | 7.070 |
| Neves [37] | 2006 | 8.840 | — | 10.280 | 10.199 | — |
| Neekabadi [18] | 2007 | 8.856 | — | 10.250 | 10.202 | — |
| Battiato [19] | 2009 | 8.369 | — | 9.52 | 9.49 | — |
| Neves [38] | 2009 | 8.619 | — | 10.194 | 10.158 | — |
| Image set | Images | Size (px) | Average entropy (bpp) |
|---|---|---|---|
| MicroZip | 3 | > 1,800 × 1,900 | 9.831 |
| Yeast | 109 | 1, 024 × 1, 024 | 6.628 |
| ApoA1 | 32 | 1, 044 × 1, 041 | 11.033 |
| ISREC | 14 | 1, 000 × 1, 000 | 10.435 |
| Stanford | 20 | > 2, 000 × 2, 000 | 8.293 |
| Arizona | 6 | 4, 400 × 13, 800 | 9.306 |
| Algorithm | MicroZip | Yeast | ApoA1 | ISREC | Stanford | Arizona |
|---|---|---|---|---|---|---|
| Gzip (LZ77) | 11.426 | 7.548 | 12.711 | 12.462 | 9.813 | 11.032 |
| AC (16-bit symbols) | 11.011 | 7.688 | 12.531 | 12.011 | 9.564 | 10.398 |
| XZ (LZMA2) | 9.696 | 6.385 | 11.321 | 11.015 | 8.163 | 9.284 |
| Bzip2 | 9.394 | 6.075 | 11.067 | 10.921 | 7.867 | 8.944 |
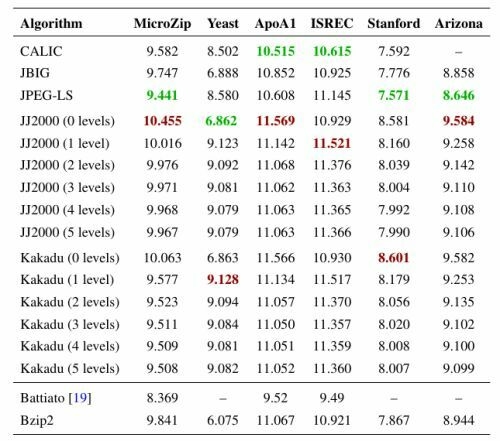
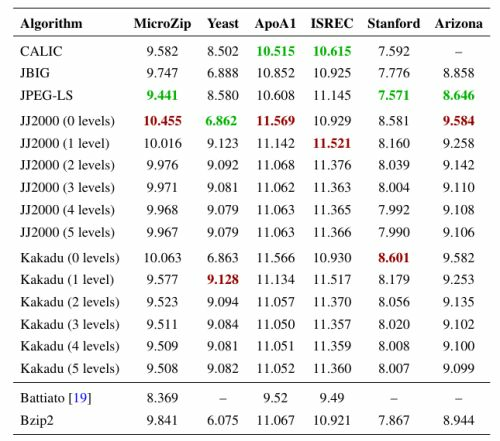
| Algorithm | MicroZip | Yeast | ApoA1 | ISREC | Stanford | Arizona |
|---|---|---|---|---|---|---|
| CALIC | 9.582 | 8.502 | 10.515 | 10.615 | 7.592 | – |
| JBIG | 9.747 | 6.888 | 10.852 | 10.925 | 7.776 | 8.858 |
| JPEG-LS | 9.441 | 8.580 | 10.608 | 11.145 | 7.571 | 8.646 |
| JJ2000 (0 levels) | 10.064 | 6.862 | 11.569 | 10.929 | 8.581 | 9.584 |
| JJ2000 (1 level) | 9.583 | 9.123 | 11.142 | 11.521 | 8.160 | 9.258 |
| JJ2000 (2 levels) | 9.530 | 9.092 | 11.068 | 11.376 | 8.039 | 9.142 |
| JJ2000 (3 levels) | 9.519 | 9.081 | 11.062 | 11.363 | 8.004 | 9.110 |
| JJ2000 (4 levels) | 9.517 | 9.079 | 11.063 | 11.365 | 7.992 | 9.108 |
| JJ2000 (5 levels) | 9.515 | 9.079 | 11.063 | 11.366 | 7.990 | 9.106 |
| Kakadu (0 levels) | 10.063 | 6.863 | 11.566 | 10.930 | 8.601 | 9.582 |
| Kakadu (1 level) | 9.577 | 9.128 | 11.134 | 11.517 | 8.179 | 9.253 |
| Kakadu (2 levels) | 9.523 | 9.094 | 11.057 | 11.370 | 8.056 | 9.135 |
| Kakadu (3 levels) | 9.511 | 9.084 | 11.050 | 11.357 | 8.020 | 9.102 |
| Kakadu (4 levels) | 9.509 | 9.081 | 11.051 | 11.359 | 8.008 | 9.100 |
| Kakadu (5 levels) | 9.508 | 9.082 | 11.052 | 11.360 | 8.007 | 9.099 |
| Battiato [19] | 8.369 | – | 9.52 | 9.49 | – | – |
| Bzip2 | 9.394 | 6.075 | 11.067 | 10.921 | 7.867 | 8.944 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2012 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernández-Cabronero, M.; Blanes, I.; Marcellin, M.W.; Serra-Sagristà, J. Standard and Specific Compression Techniques for DNA Microarray Images. Algorithms 2012, 5, 30-49. https://doi.org/10.3390/a5010030
Hernández-Cabronero M, Blanes I, Marcellin MW, Serra-Sagristà J. Standard and Specific Compression Techniques for DNA Microarray Images. Algorithms. 2012; 5(1):30-49. https://doi.org/10.3390/a5010030
Chicago/Turabian StyleHernández-Cabronero, Miguel, Ian Blanes, Michael W. Marcellin, and Joan Serra-Sagristà. 2012. "Standard and Specific Compression Techniques for DNA Microarray Images" Algorithms 5, no. 1: 30-49. https://doi.org/10.3390/a5010030
APA StyleHernández-Cabronero, M., Blanes, I., Marcellin, M. W., & Serra-Sagristà, J. (2012). Standard and Specific Compression Techniques for DNA Microarray Images. Algorithms, 5(1), 30-49. https://doi.org/10.3390/a5010030