A Survey on Star Identification Algorithms



Abstract
:1. Introduction
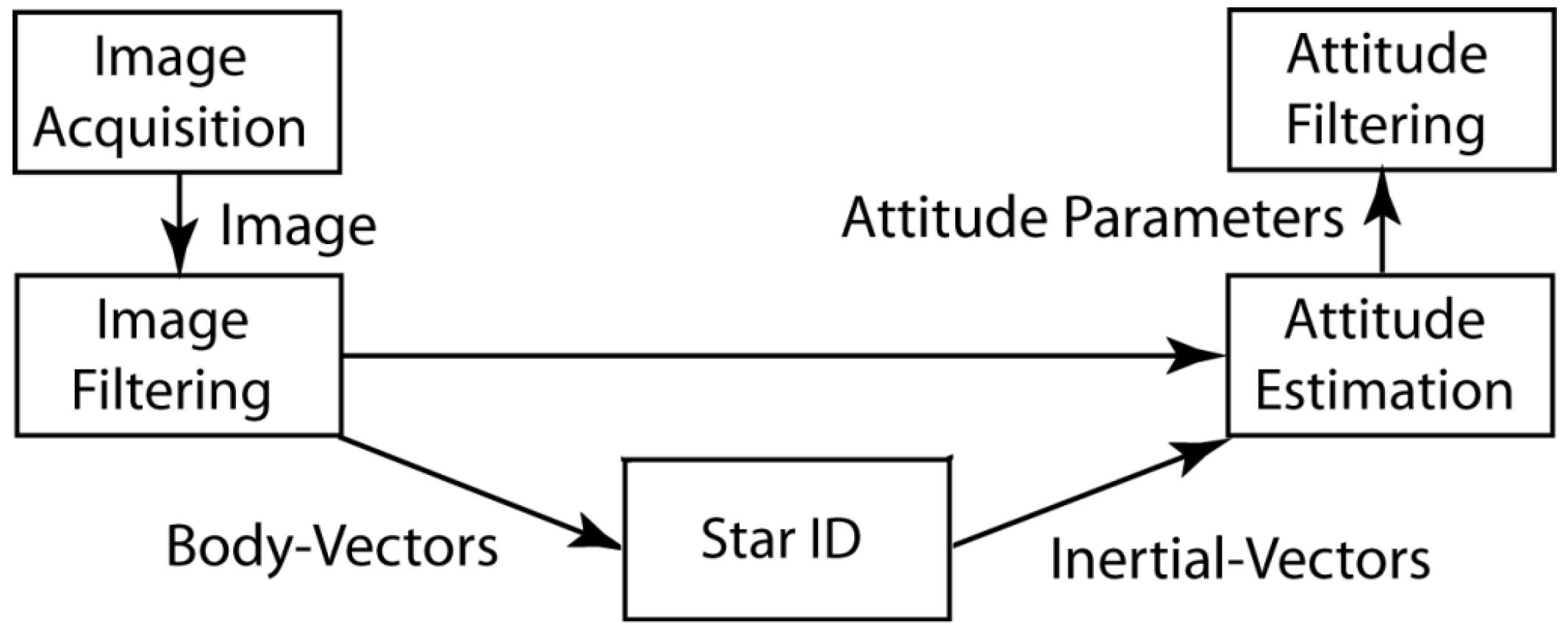
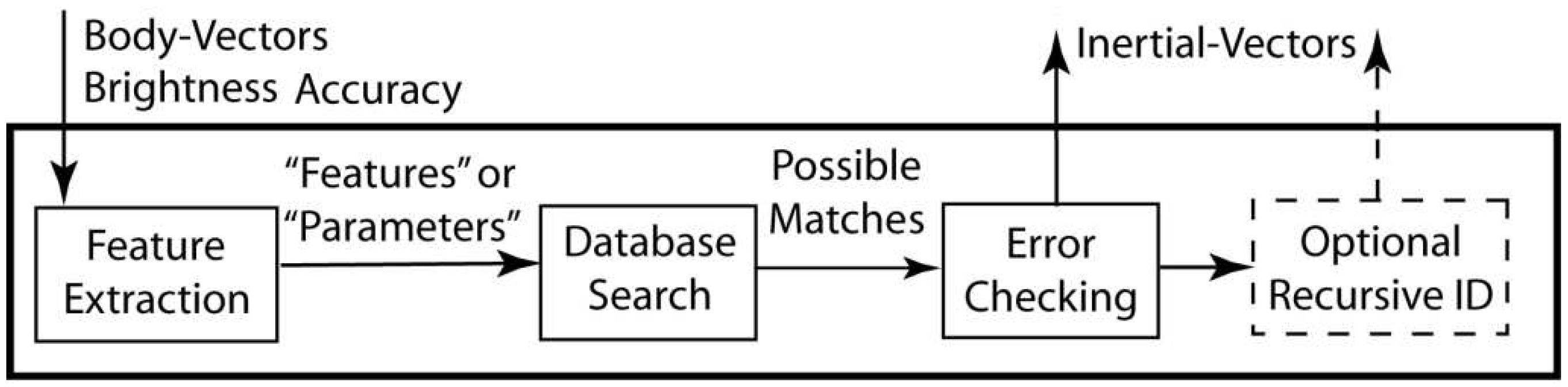
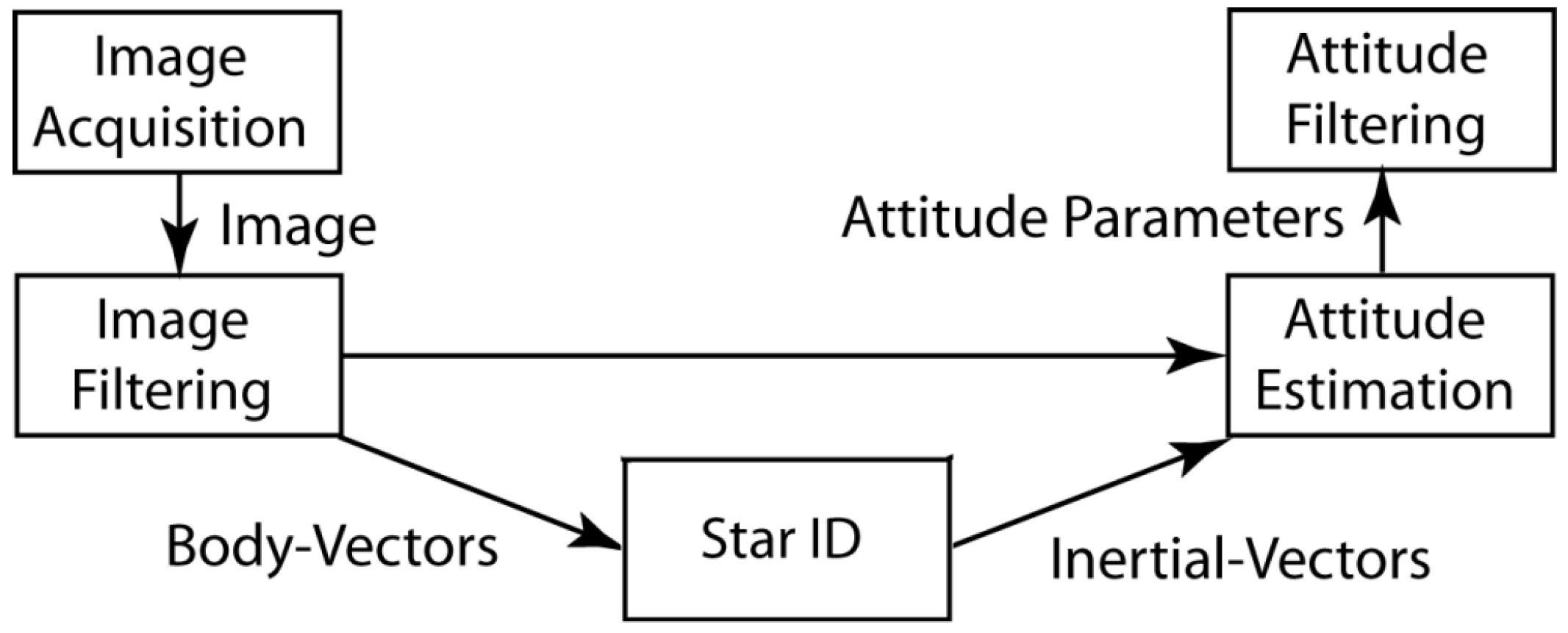
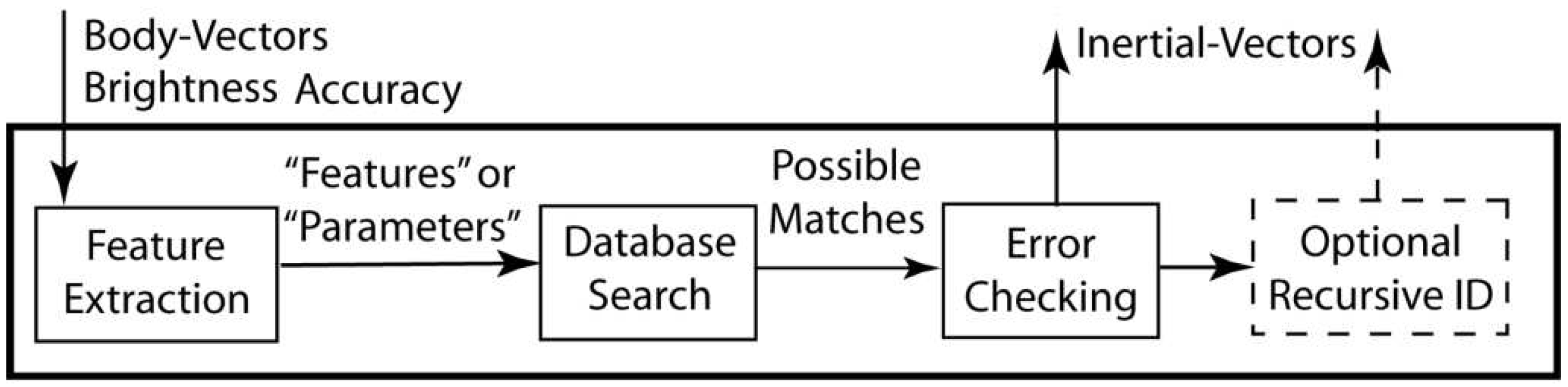
1.1. Topics Covered, Notation, and Figures
- the feature extraction step,
- database search, and
- their utilization of independent pattern features in the star features based on how many stars are used in a pattern.
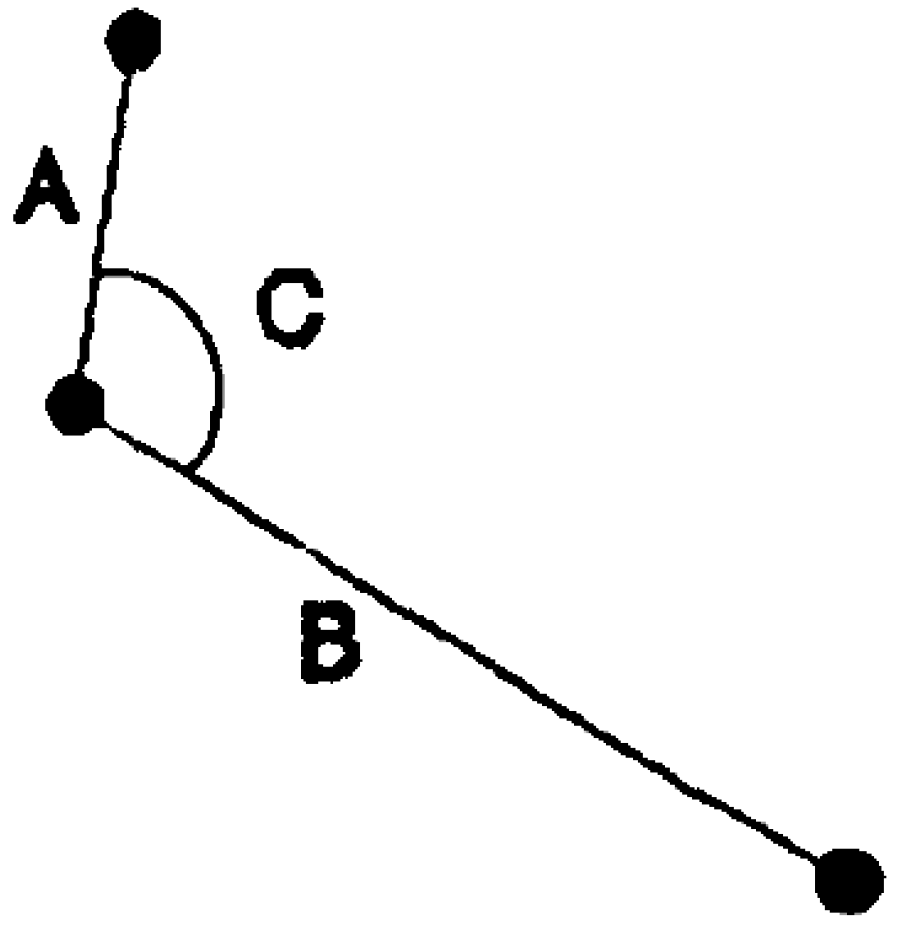
2. The Beginning
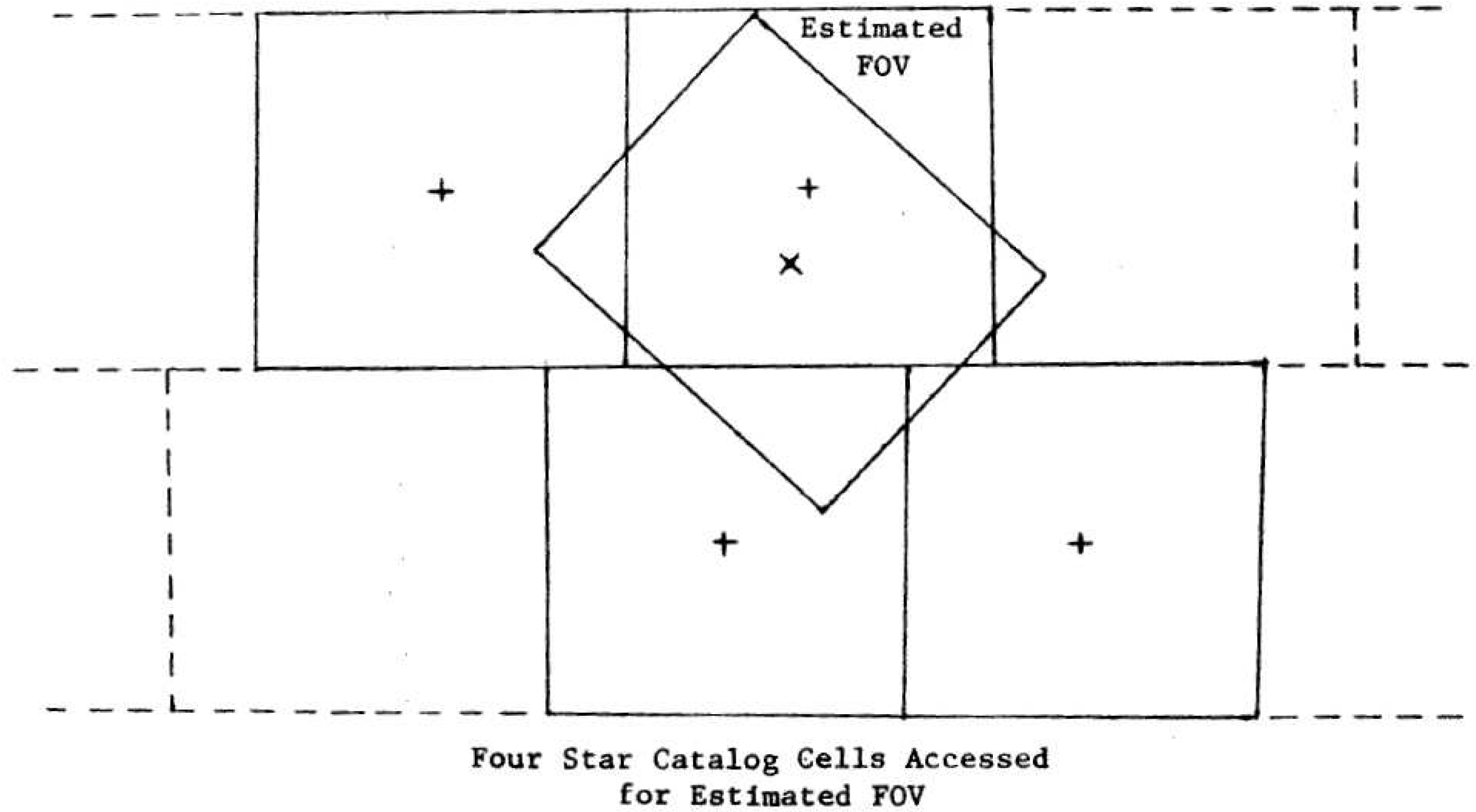
3. Search Process Acceleration
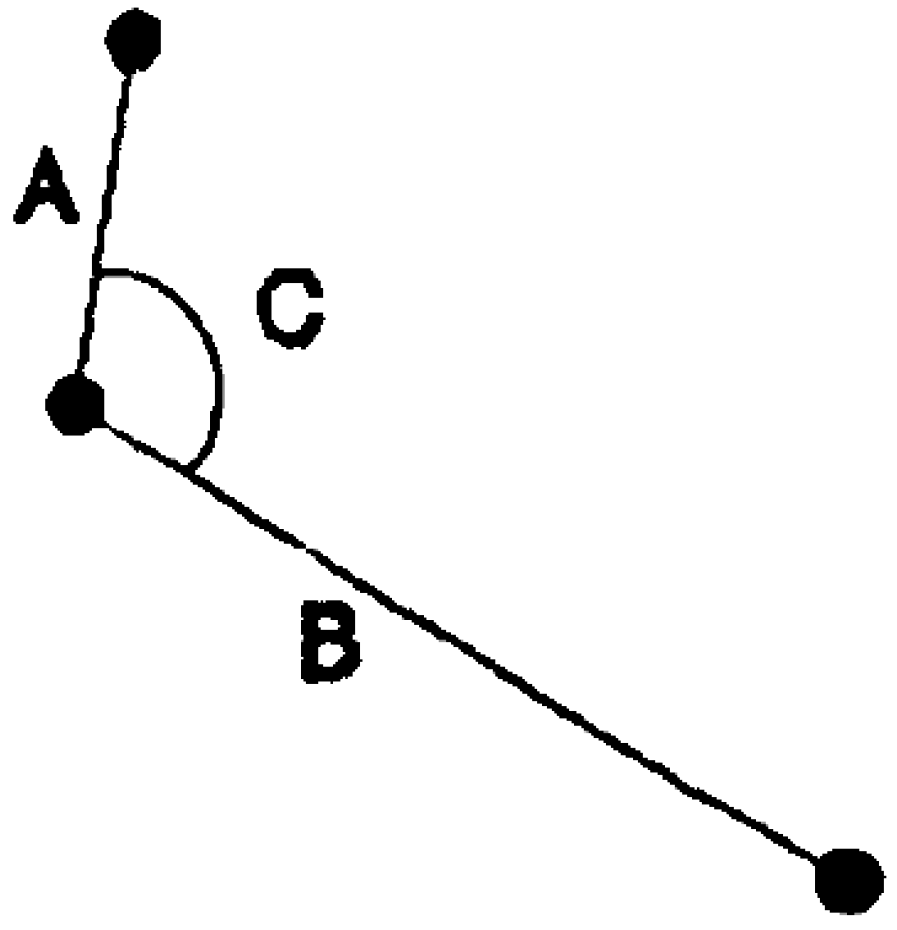
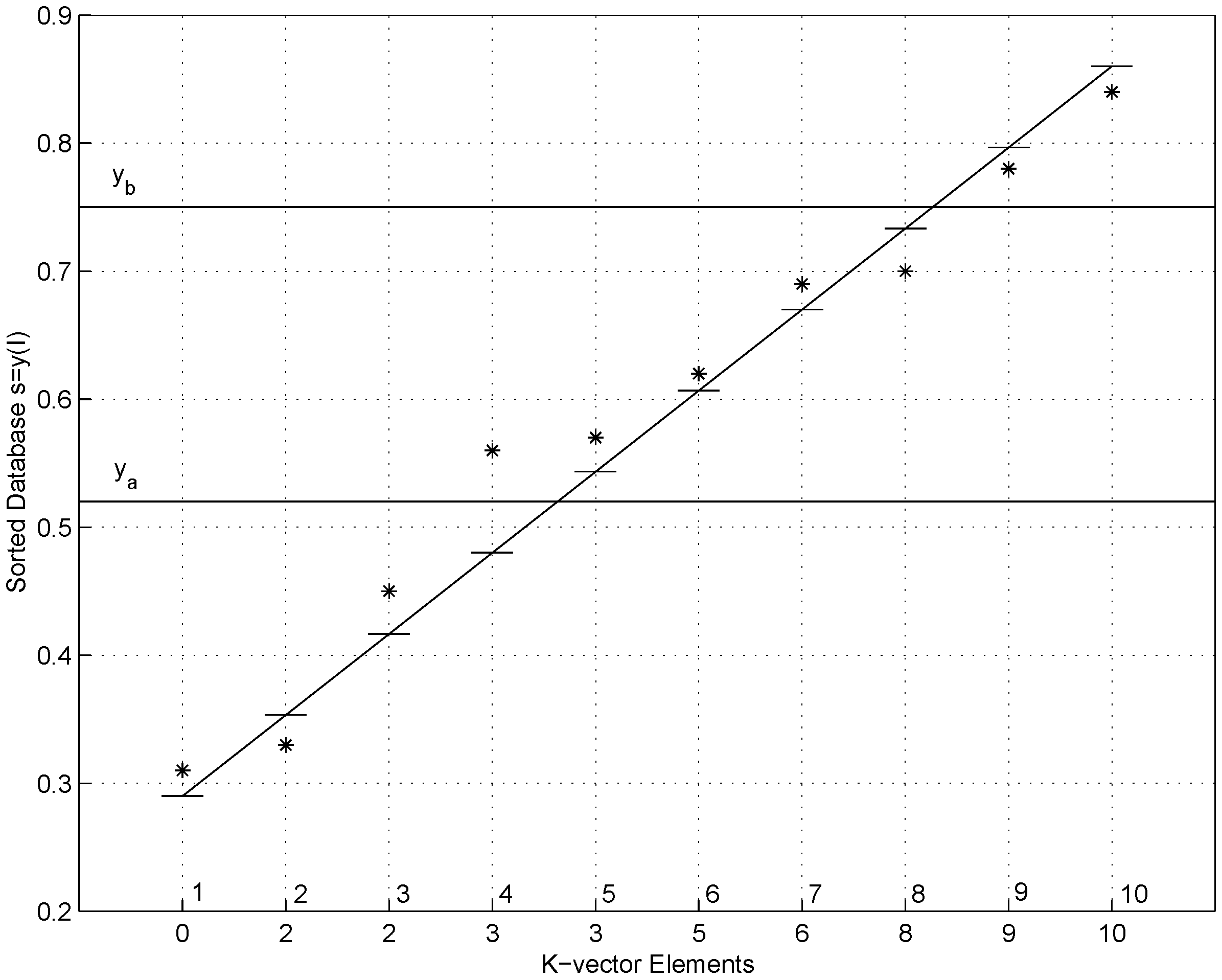
3.1. Search Time Dramatically Reduced

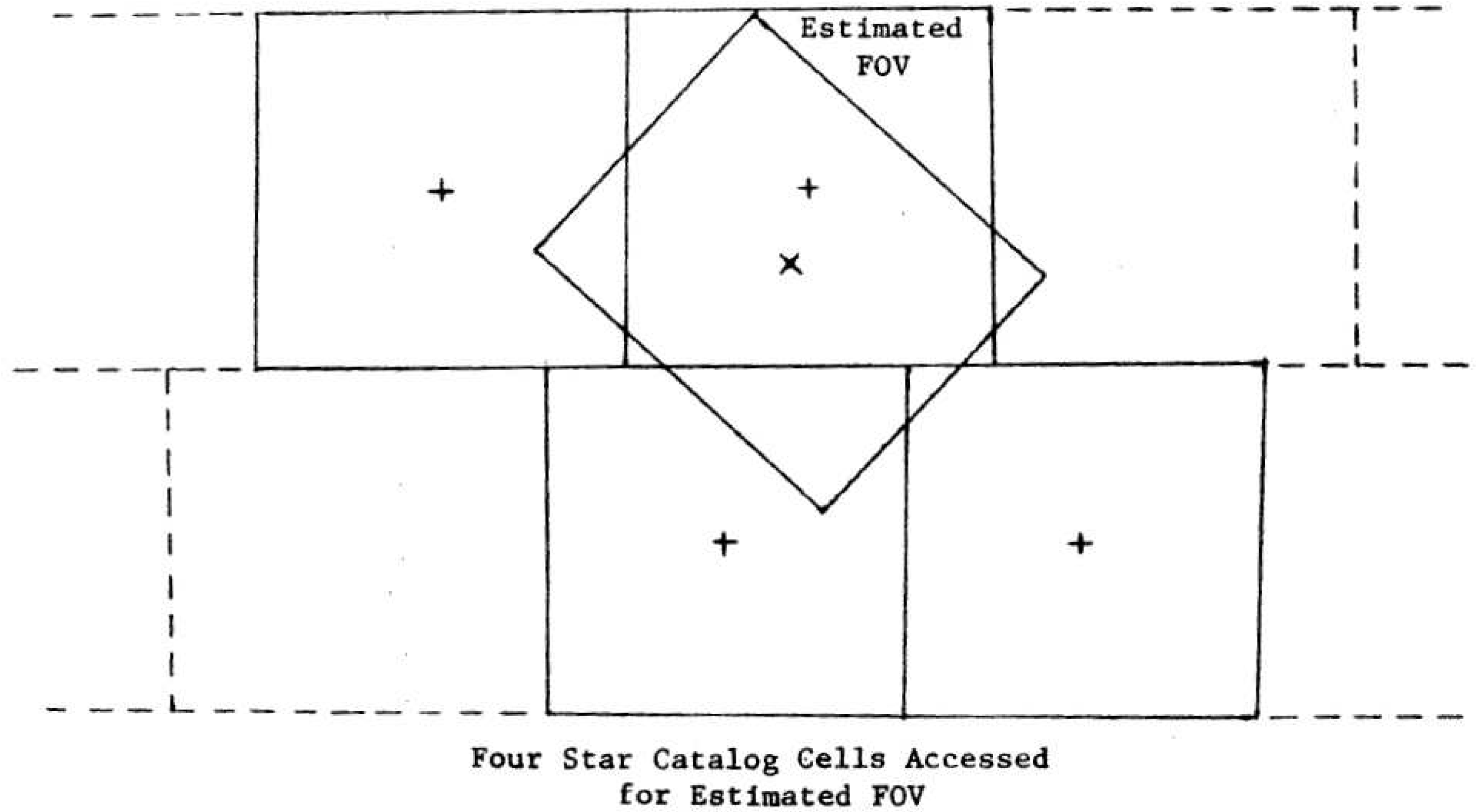
3.2. Novel Grid Algorithm
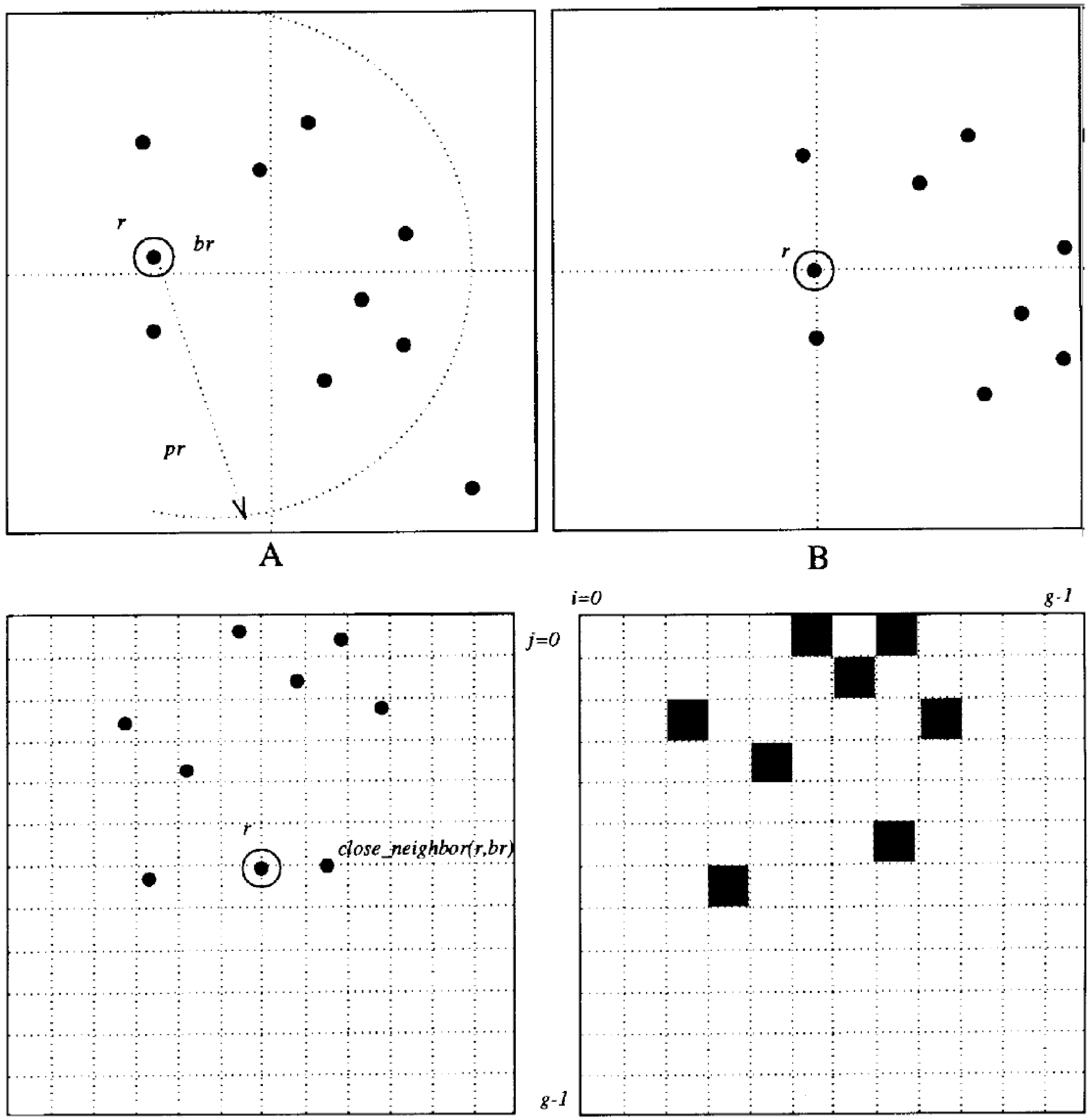
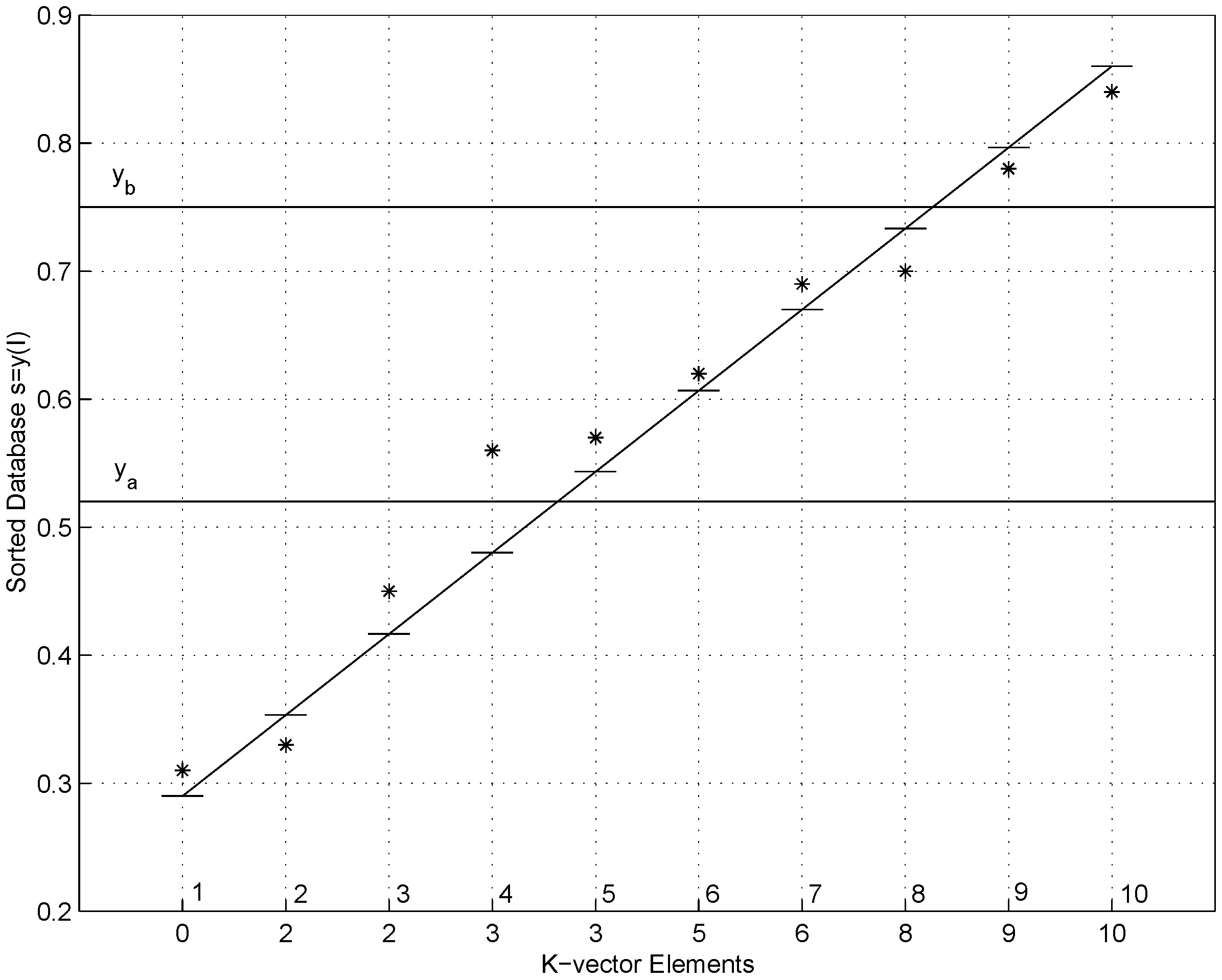
3.3. Search Time Reduced Much Further

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Feature | Database | Database | Validation | Used |
|---|---|---|---|---|---|---|
| Extraction | Size | Search | measurements | |||
| /Available | ||||||
| Junkins | 1981 | N/A | 3/3 | |||
| Liebe | 1992 | N/A | 3/3 | |||
| Baldini | 1993 | 9/12 | ||||
| Scholl | 1995 | 6/6 | ||||
| Quine | 1996 | N/A | 6/6 | |||
| Padgett | 1997 | N/A | ||||
| Mortari | 1997 | 6/6 | ||||
| Kolomenkin | 2008 | 6/6 |
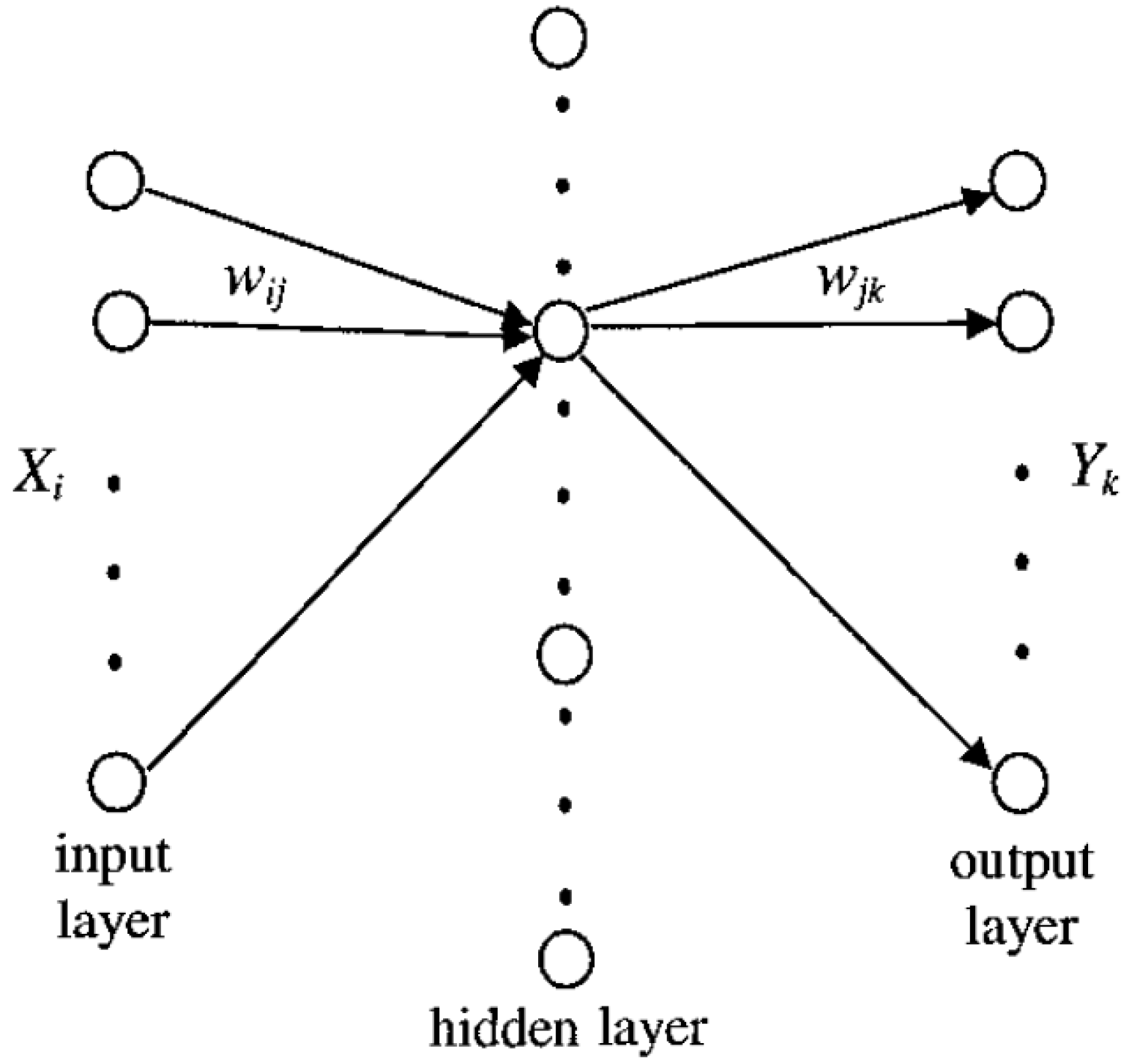
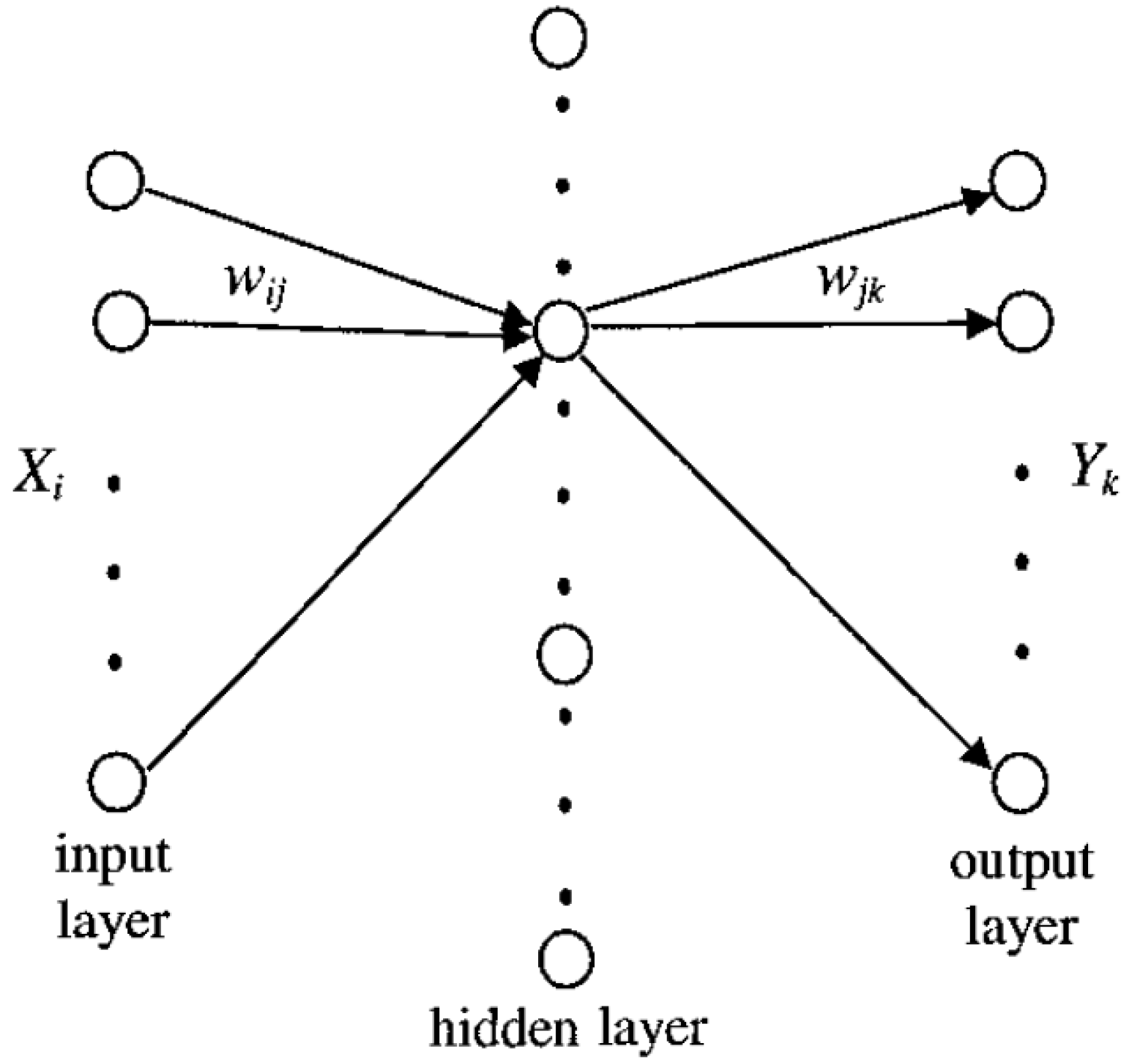
4. Non-dimensional Algorithms
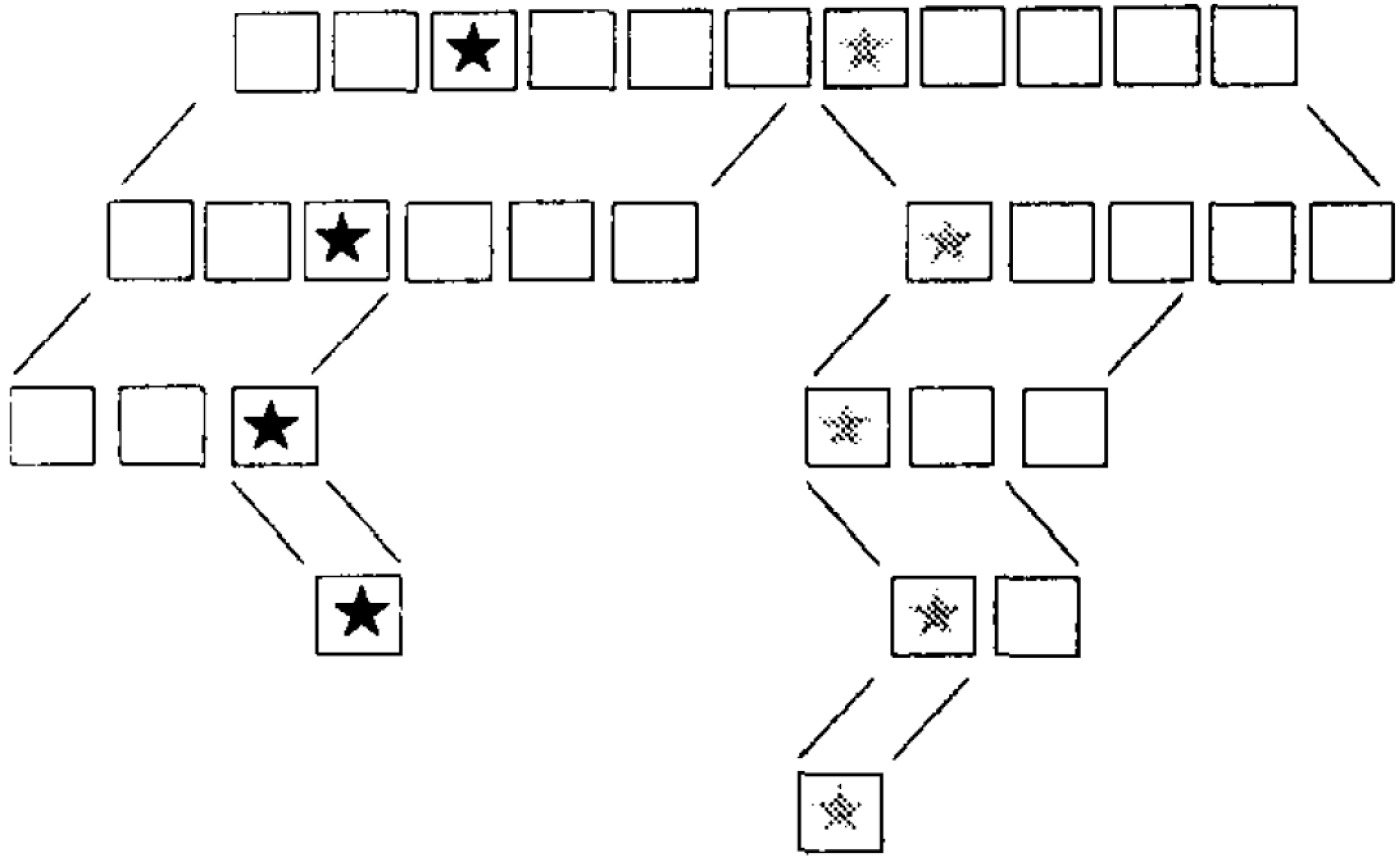
5. Recursive Star Identification
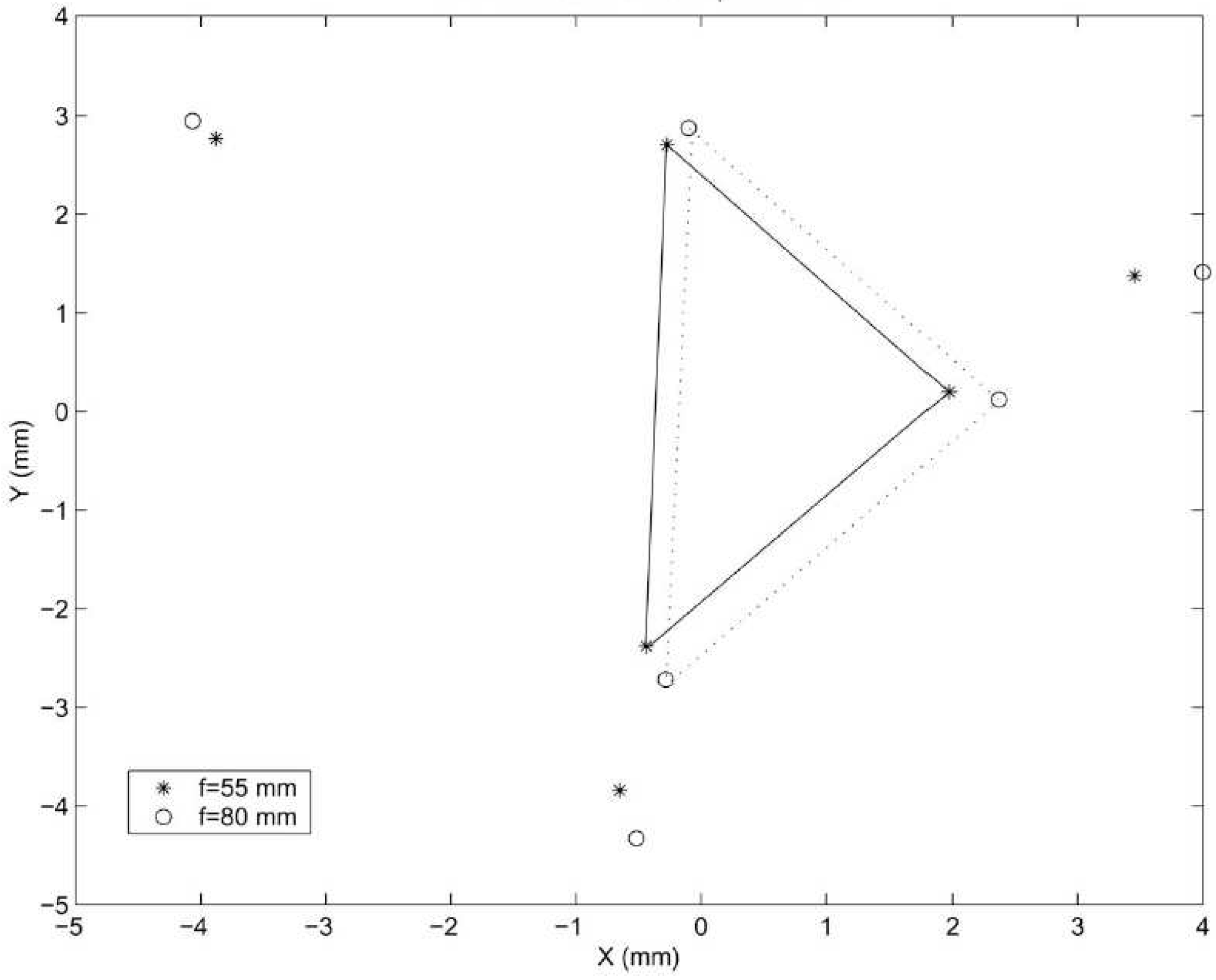
Star Trackers for Different Applications
- Star Gyros. With appropriate algorithms, images from star cameras may also be used for estimating the angular velocity of the spacecraft [32].
- Multiple Fields-of-View system. While attitude determination from a single star camera image produces very accurate information about the direction of the camera boresight, the estimate of the rotation about the camera’s boresight axis is less accurate. In order to solve this problem, a second star camera is sometimes used. There is another method, which uses a single star camera to record a combination of multiple star images simultaneously. For a two fields-of-view camera the light are preferentially smeared by the optics (e.g., by adding astigmatism) so that stars from one aperture are smeared in a horizontal direction in the image plane, while light from the other aperture is smeared in the vertical direction [38,39]. Image filtering algorithms can detect the direction of the smearing and separate the stars according to which aperture they entered. If, however, the Star-ID technique is very robust to the presence of non-stars, the Star-ID algorithm may be run many times on the same image, perhaps on stars from three apertures, all in orthogonal directions [40,41,42]. In these cases it is possible to separate the stars without the need for smearing the stars in a given direction.
- Techniques requiring multiple images as well as attitude maneuvers have been implemented [43].
- Uniform Star Catalog. In order to develop optimized star sensing and star identification with respect to continuous operation and reliability, the concept of star catalogs with near uniform angular spacing between stars has been proposed [44]. These catalogs are not characterized by constant magnitude cutoffs. They are reference star catalogs where the expectation of the number of stars that fall in a given field of view is approximately constant (i.e. 5 or 6) (minimum standard deviation), independently which region of the sky the sensor optical axis is pointing.
6. Conclusion
References and Notes
- Gottlieb, D. M. Star Identification Techniques. In Spacecraft Attitude Determination and Control; Kluwer: Dordrecht, The Netherlands, 1978; Chapter 7.7; pp. 259–266. [Google Scholar]
- Bezooijen, R. W. H. V. Automated Star Pattern Recognition. Ph.D. Thesis, Stanford University, 1989. [Google Scholar]
- Samaan, M. A.; Mortari, D.; Junkins, J. L. Nondimensional star identification for uncalibrated star cameras. J. Astronaut. Sci. 2006, 54, 95–111. [Google Scholar] [CrossRef]
- Salomon, P. H. A microprocessor controlled ccd star tracker. In AIAA 14th Aerospace Sciences Meeting; AIAA: Washington, DC, USA, 1976. [Google Scholar]
- Junkins, J. L.; White, C.; Turner, J. Star pattern recognition for real-time attitude determination. J. Astronaut. Sci. 1977, 25, 251–270. [Google Scholar]
- Junkins, J. L.; Strikwerda, T. E. Autonomous star sensing and attitude estimation. In Proc. Annual Rocky Mountain Guidance and Control Conference, February 1979. No. 79-013.
- Strikwerda, T. E.; Junkins, J. L. Star pattern recognition and spacecraft attitude determination. Technical Report ETL-0260; U.S Army Engineer Topographic Laboratories: Fort Belvoir, VA, USA, 1981. [Google Scholar]
- Groth, E. J. A pattern matching algorithm for two-dimensional coordinates lists. Astronom. J. 1986, 91, 1244–1248. [Google Scholar] [CrossRef]
- Sasaki, T. A star identification method for satellite attitude determination using star sensors. In Proc. 15th International Symposium on Space Technology and Sciences, May 1986; pp. 1125–1130.
- Anderson, D. Autonomous Star Sensing and Pattern Recognition for Spacecraft Attitude Determination. Ph.D. Thesis, Texas A&M University, May 1991. [Google Scholar]
- Liebe, C. C. Pattern recognition of star constellations for spacecraft applications. IEEE Aeronaut. Electron. Syst. Mag. 1992, 10, 2–12. [Google Scholar] [CrossRef]
- Baldini, D.; Barni, M.; Foggi, A.; Benelli, G.; Mecocci, A. A new star-constellation matching algorithm for satellite attitude determination. ESA Journal 1993, 17, 185–198. [Google Scholar]
- Ketchum, E. A.; Tolson, R. H. Onboard star identification without a priori attitude information. J. Guidance, Control & Dynamics 1995, 18, 242–246. [Google Scholar]
- Scholl, M. S. Star-field identification for autonomous attitude determination. J. Guidance, Control & Dynamics 1995, 18, 61–65. [Google Scholar]
- Quine, B. M.; Whyte, H. F. D. A fast autonomous star-acquisition algorithm for spacecraft. Control Engin. Pract. 1996, 4, 1735–1740. [Google Scholar] [CrossRef]
- Padgett, C.; Delgado, K. K. A grid algorithm for autonomous star identification. IEEE Trans. Aerospace Electron. Syst. 1997, 33, 202–213. [Google Scholar] [CrossRef]
- Mortari, D. A fast on-board autonomous attitude determination system based on a new star-id technique for a wide fov star tracker. Adv. Astronaut. Sci. 93, 893–903.
- Mortari, D. Search-less algorithm for star pattern recognition. J. Astronaut. Sci. 1997, 45, 179–194. [Google Scholar]
- Mortari, D. K-vector range searching techniques. Adv. Astronaut. Sci. 2000, 105, 449–464. [Google Scholar]
- Solaiappan, A.; Pandiyan, R.; Ramachandran, M.; Vighhnesam, N. Attitude determination using an experimental fast recovery star sensor (frss) for a geostationary spacecraft. In Proc. 2nd International Astronautical Congress, October 2001; Flight Dynamics Division, ISRO Satellite Centre: Bangalore, India, 2001. [Google Scholar]
- Mortari, D.; Samaan, M. A.; Bruccoleri, C. The pyramid star identification technique. Navigation 2004, 51, 171–183. [Google Scholar] [CrossRef]
- Brady, T.; Tillier, C.; Brown, R.; Jimenez, A.; Kourepenis, A. The inertial stellar compass: A new direction in spacecraft attitude determination. In Proc. 16th Annual USU Conference on Small Satellites; 2002. [Google Scholar]
- Crew, G. B.; Vanderspek, R.; Doty, J. Hete experience with the pyramid algorithm. Technical Report 02139; MIT Center for Space Research: Cambridge, MA, 2002. [Google Scholar]
- Alveda, P. Neural network star pattern recognition of spacecraft attitude determination and control. In Advances in Neural Information Processing System; Denver, CO, 1989; pp. 213–322. [Google Scholar]
- Hong, J.; Dickerson, J. A. Neural-network-based autonomous star identification algorithm. J. Guidance, Control & Dynamics 2000, 23, 728–735. [Google Scholar]
- Guangjun, Z.; Wei, X.; Jiang, J. Full-sky autonomous star identification based on radial and cyclic features of star pattern. Image Vision Comput. 2008, 26, 891–897. [Google Scholar]
- Kolomenkin, M.; Pollak, S.; Shimshoni, I.; Lindenbaum, M. Geometric voting algorithm algorithm for star trackers. IEEE Trans. Aerospace Electron. Syst. 2008, 44, 441–456. [Google Scholar] [CrossRef]
- au Rousseau, G. L.; Bostel, J.; Mazari, B. Star recognition algorithm for aps star tracker: Oriented triangles. IEEE Aerospace Electron. Syst. Mag. 2005, 27–31. [Google Scholar] [CrossRef]
- Samaan, M. A.; Mortari, D.; Junkins, J. L. Recursive mode star identification algorithms. IEEE Trans. Aerospace Electron. Syst. 2005, 41, 1246–1254. [Google Scholar] [CrossRef]
- Parish, J. J.; Parish, A. S.; Swanzy, M.; Woodbury, D.; Mortari, D.; Junkins, J. L. Stellar positioning system (part i): Applying ancient theory to a modern world. In Astrodynamics Specialist Conference, Honolulu HI, August 2008; AIAA/AAS, 2008. [Google Scholar]
- Woodbury, D.; Parish, J. J.; Parish, A. S.; Swanzy, M.; Mortari, D.; Junkins, J. L. Stellar positioning system (part ii): Overcoming error during implementation. In Astrodynamics Specialist Conference, Honolulu HI, August 2008; AIAA/AAS, 2008. [Google Scholar]
- Katake, A. B.; Ochoa, J. O.; Zbranek, J.; Day, B.; Bruccoleri, C.; Goodsell, D. Development and testing of the starcam sg100: A stellar gyroscope. In AIAA Guidance and Control Conference Exhibit, Honolulu HI, August 2008; AIAA/AAS, 2008. No. 2008-6650. [Google Scholar]
- Junkins, J. L.; Mortari, D.; Pollock, T. C.; Boyle, D.; Carron, I.; Abdelkhalik, O. O.; Ettouati, I.; Hill, C.; Cantrell, J. Feasibility study and system concept development for the space situational awareness camera system. Contract SC-03A-22-08, Shafer. October 2005. [Google Scholar]
- Ettouati, I.; Mortari, D.; Pollock, T. C. Space surveillance with star trackers. part i: Simulation. In Space Flight Mechanics Meeting Conference, January 2006; AAS: Tampa, FL, 2006. No. 06-231. [Google Scholar]
- Abdelkhalik, O. O.; Mortari, D.; Junkins, J. L. Space surveillance with star trackers. Part ii: Orbit estimation. In Space Flight Mechanics Meeting Conference, January 2006; AAS: Tampa, FL, 2006. No. 06-231. [Google Scholar]
- Mortari, D. Planet and time estimation using star trackers. In Space Flight Mechanics Meeting Conference, January 2006; AAS: Tampa, FL, 2006. No. 09-160. [Google Scholar]
- Karimi, R. R.; Mortari, D. Designing an interplanetary autonomous navigation system (ians) using visible planets. In Space Flight Mechanics Meeting Conference, February 2009; AAS: Savannah, GA, 2009. No. 09-160. [Google Scholar]
- Junkins, J. L.; Pollock, T. C.; Mortari, D. Multiple field of view optical imaging system and method. U.S. Patent Pending No. 60/239,559, January 2001. [Google Scholar]
- Mortari, D.; Pollock, T. C.; Junkins, J. L. Towards the most accurate attitude determination system using star trackers. Adv. Astronaut. Sci. 1998, 99, 839–850. [Google Scholar]
- Mortari, D.; Angelucci, M. Star pattern recognition and mirror assembly misalignment for digistar ii and iii multiple fovs star sensors. Adv. Astronaut. Sci. 1999, 102, 1175–1184. [Google Scholar]
- Mortari, D.; Romoli, A. Navstar iii: A three fields of view star tracker. In Proc. IEEE Aerospace Conference, March 2002.
- Samaan, M. A. Research on Multiple FOVs Star Sensor Data Processing. Ph.D. Thesis, Texas A&M University, June 2003. [Google Scholar]
- Udomkesmalee, S.; Alexander, J. W.; Tolivar, A. F. Stochastic star identification. J. Guidance, Control & Dynamics 1994, 17, 1283–1286. [Google Scholar]
- Samaan, M. A.; Bruccoleri, C.; Mortari, D.; Junkins, J. L. Novel techniques for the creation of a uniform star catalog. In Proc. AAS/AIAA Astrodynamics Specialist Conference, August 2003; AAS/AIAA, 2003. No. 03-609. [Google Scholar]
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Spratling, B.B., IV; Mortari, D. A Survey on Star Identification Algorithms. Algorithms 2009, 2, 93-107. https://doi.org/10.3390/a2010093
Spratling BB IV, Mortari D. A Survey on Star Identification Algorithms. Algorithms. 2009; 2(1):93-107. https://doi.org/10.3390/a2010093
Chicago/Turabian StyleSpratling, Benjamin B., IV, and Daniele Mortari. 2009. "A Survey on Star Identification Algorithms" Algorithms 2, no. 1: 93-107. https://doi.org/10.3390/a2010093
APA StyleSpratling, B. B., IV, & Mortari, D. (2009). A Survey on Star Identification Algorithms. Algorithms, 2(1), 93-107. https://doi.org/10.3390/a2010093