Abstract
The phosphoinositide 3-kinase (PI3K)/AKT signaling pathway is a crucial regulator of cellular metabolism, proliferation, and survival. It is frequently dysregulated in metabolic, cardiovascular, and neoplastic disorders. Despite the advancements in multi-omics technology, existing methods often fail to provide real-time, pathway-specific insights for precision medicine and drug repurposing. We offer Agentic RAG-Driven Multi-Omics Analysis (ARMOA), an autonomous, hypothesis-driven system that integrates retrieval-augmented generation (RAG), large language models (LLMs), and agentic AI to thoroughly analyze genomic, transcriptomic, proteomic, and metabolomic data. Through the use of graph neural networks (GNNs) to model complex interactions within the PI3K/AKT pathway, ARMOA enables the discovery of novel biomarkers, probable candidates for drug repurposing, and customized therapy responses to address the complexities of PI3K/AKT dysregulation in disease states. ARMOA dynamically gathers and synthesizes knowledge from multiple sources, including KEGG, TCGA, and DrugBank, to guarantee context-aware insights. Through adaptive reasoning, it gradually enhances predictions, achieving 91% accuracy in external testing and 92% accuracy in cross-validation. Case studies in breast cancer and type 2 diabetes demonstrate that ARMOA can identify synergistic drug combinations with high clinical relevance and predict therapeutic outcomes specific to each patient. The framework’s interpretability and scalability are greatly enhanced by its use of multi-omics data fusion and real-time hypothesis creation. ARMOA provides a cutting-edge example for precision medicine by integrating multi-omics data, clinical judgment, and AI agents. Its ability to provide valuable insights on its own makes it a powerful tool for advancing biomedical research and treatment development.
1. Introduction
The phosphoinositide 3-kinase (PI3K)/AKT signaling pathway is a major regulator of cellular metabolism, growth, proliferation, and survival in conditions such as cancer, metabolic disorders, and cardiovascular diseases. It has been a primary focus for precision medicine because of its recurrent dysregulation in various conditions [1]. Despite extensive study over several decades, patient heterogeneity, pharmaceutical resistance, and the inability to effectively integrate multi-omics data persist in obstructing therapy choices that target the PI3K/AKT pathway. These challenges demonstrate the necessity for innovative approaches to unravel the complexity of the pathway and formulate targeted approaches to treatment [2]. The variety of sickness situations also presents a considerable challenge to the effective control of the PI3K/AKT pathway, complicating the identification of therapeutic targets and affecting the effectiveness of treatments. Traditional approaches often overlook the complex regulatory processes governing PI3K/AKT signaling, prioritizing single-omics data, such as transcriptomics or genomics [3]. Traditional computational methods suffer from data fragmentation, bias, and limited interpretability, even though the integration of multi-omics is essential for understanding disease-specific pathway modifications. Moreover, off-target effects, adaptive resistance, and insufficient pathway-specific drug repurposing techniques represent notable limitations of current drug discovery methodologies [4].
The predominant approaches for investigating the deregulation of the PI3K/AKT pathway are reactive and incapable of providing real-time, context-sensitive knowledge. A significant number of approaches depend on predetermined algorithms and static statistics, which inadequately capture the dynamic nature of route activity and its interaction with other biological processes [5]. The absence of autonomous, self-optimizing systems capable of generating hypotheses and enhancing forecasts in real time has impeded the utilization of artificial intelligence (AI) in multi-omics analysis, notwithstanding AI’s demonstrated potential in tackling certain challenges. These limitations underscore the urgent necessity for innovative solutions that can overcome prejudice, limited interpretability, and fragmented data [6]. We introduce Agentic RAG-Driven Multi-Omics Analysis (ARMOA), an innovative AI-driven framework that integrates large language models (LLMs), agentic AI systems, and retrieval-augmented generation (RAG) to autonomously analyze and understand multi-omics data, therefore addressing these challenges. ARMOA employs dynamic knowledge retrieval to autonomously extract and synthesize information from diverse sources, including public repositories (KEGG, TCGA, and DrugBank) and the latest scientific literature [7]. To enable context-aware therapeutic decision-making, it delineates the complex interactions among genes, proteins, and metabolites within the PI3K/AKT pathway through the application of graph neural networks (GNNs). Moreover, adaptive learning is facilitated by ARMOA’s agentic AI-driven hypothesis generation engine, which perpetually improves pharmaceutical repurposing, biomarker discovery, and individualized therapy predictions. The establishment of ARMOA represents a transformative shift in pathway-oriented therapeutic approaches and AI-facilitated multi-omics investigation. ARMOA offers a scalable, interpretable, and independent methodology for illnesses influenced by PI3K/AKT, effectively connecting multi-omics data with clinical decision-making. Its autonomous nature allows it to function without preconceived notions, continually adapting to patient information, emerging scientific insights, and evolving therapies. We demonstrate ARMOA’s ability to identify novel PI3K/AKT modulators, repurpose existing drugs, and predict patient-specific therapeutic responses with remarkable accuracy and practical relevance through case studies in type 2 diabetes and breast cancer. Our work propels the future of AI-driven biomedical research and clinical practice, laying the foundation for next-generation precision medicine by offering an innovative tool to navigate the intricacies of disease-specific pathway dysregulation.
2. Related Works
Using multi-omics data integration, machine learning-based predictive models, and conventional bioinformatics methods, the PI3K/AKT pathway has been extensively investigated in disease scenarios. However, problems including data fragmentation, restricted interpretability in precision medicine applications, and a lack of real-time adaptation are common with current approaches. By summarizing previous research in the fields of medicine repurposing, multi-omics integration, and AI-driven pathway analysis, this section draws attention to the flaws that ARMOA seeks to overcome.
There are extensive studies on the PI3K/AKT signaling system. New research reveals that the RNA-targeting mechanism Cas13d can significantly alter biological pathways in ways that go beyond its original function. A recent study [8] found that Cas13d increases cell proliferation in HeLa cells by upregulating the PI3K/AKT pathway through PFKFB4 overexpression. The study investigated the effects of Cas13d using transcriptome and proteome profiling and discovered 94 upregulated and 847 downregulated genes, along with 185 upregulated and 231 downregulated proteins. Enrichment analysis further connected the PI3K/AKT pathway, underscoring the need for complex frameworks that can dynamically predict and minimize off-target repercussions in gene-editing applications.
Research on the PI3K/AKT pathway emphasizes its complicated regulation and possible therapeutic uses. The RNA-targeting mechanism Cas13d enhances the PI3K/AKT pathway through PFKFB4 overexpression, hence promoting cell proliferation in HeLa cells. Multi-omics approaches are now necessary to understand complex biological systems, yet combining several data types remains challenging. Directional Pathway Modeling (DPM) is a data fusion technique designed to integrate multi-omics information by considering the directionality and relevance of genes, transcripts, and proteins [9]; by enabling researchers to define expected interactions between datasets based on biological correlations or experimental design, DPM delivers a more biologically meaningful integration than that of other methods. DPM rewards genes and pathways that exhibit consistent changes across many omics layers and penalizes those with inconsistent directionality in order to increase the accuracy of pathway enrichment analysis. The work demonstrated the effectiveness of this methodology by analyzing IDH-mutant gliomas and integrating transcriptomic, proteomic, and DNA methylation data to characterize gene and pathway regulation. Using DPM on ovarian cancer datasets, researchers also discovered potential biomarkers with trustworthy prediction signals in both transcript and protein expression levels. As a generic and adaptable framework, DPM provides a powerful tool for gene prioritizing and route analysis in multi-omics research. Because of its ability to capture directed linkages, it is particularly relevant for creating AI-driven retrieval-augmented models, such as the ones proposed in this study, to enhance real-time gene pathway discovery and analysis.
The PI3K/AKT pathway, which is critical to cancer metabolism, plays a major role in supporting the Warburg effect, a feature of cancer characterized by enhanced glycolytic metabolism. When this system is dysregulated, colorectal cancer (CRC) develops tumors and undergoes metabolic reprogramming [10]. The effects of thymoquinone, a bioactive component from Nigella sativa, on CRC metabolism and tumorigenicity were investigated. The study demonstrated that thymoquinone slows glycolytic metabolism via regulating the PI3K/AKT axis and targeting Hexokinase 2 (HK2), a rate-limiting glycolytic enzyme. The overexpression of HK2 was shown to preserve tumorigenicity, but its pharmacologic or genetic inhibition reduced tumor formation and glycolytic activity. A comprehensive investigation has been undertaken on the PI3K/AKT signaling pathway. Recent research indicates that the RNA-targeting mechanism Cas13d can substantially modify biological pathways beyond its initial purpose. Cas13d enhances cell proliferation in HeLa cells by upregulating the PI3K/AKT pathway via the overexpression of PFKFB4. The study examined the impact of Cas13d by transcriptome and proteome analysis, revealing 94 upregulated and 847 downregulated genes, as well as 185 upregulated and 231 downregulated proteins. The enrichment study also linked the PI3K/AKT pathway, highlighting the necessity for advanced algorithms capable of dynamically predicting and mitigating off-target effects in gene-editing methods. These findings show that thymoquinone has promise as an antimetabolite drug for CRC, offering a fresh approach to addressing metabolic reprogramming in cancer. However, the study’s limitations include its reliance on in vitro models and the need for further confirmation across a range of cancer types and preclinical animal models. Additionally, the precise effects of thymoquinone on the PI3K/AKT pathway remain unclear, underscoring the need for complex frameworks to integrate multi-omics data and elucidate effects unique to a particular pathway.
Drug repurposing is the act of discovering novel therapeutic applications for previously approved pharmaceuticals, and is one potential strategy for treating cancer. Because of their advantages—such as cost-effectiveness, established safety profiles, and faster development times—repurposed drugs are attractive for treating drug resistance and toxicity in cancer treatment. Repurposed drugs can target cancer markers and the tumor microenvironment, offering new strategies with which to prevent tumor growth and spread, per a recent analysis [11]. The study also examines how drug delivery and therapeutic efficacy might be enhanced by combining nanotechnology with drug repurposing. For example, in clinical trials, nanomedicines like nab-paclitaxel and liposomal doxorubicin have shown promise in treating conditions including pancreatic and breast cancer. However, there are still problems, like the limited capacity to apply preclinical findings to clinical settings and the lack of clarity regarding the long-term toxicity of nanocarriers. Additionally, clinical validation is still ongoing even though combination treatments that combine repurposed pharmaceuticals with traditional anticancer agents show potential for synergy. These limitations show how complex frameworks are needed to integrate multi-omics data for precision targeting and optimize drug repurposing strategies.
In breast cancer, the PI3K/AKT/mTOR pathway regulates tumor development, survival, and resistance to treatment, making it an essential target for therapy [12]. Genetic changes, including PTEN deletion and PIK3CA mutations, result in system dysregulation and a worse prognosis. Although PI3K, AKT, and mTOR-targeting therapies have showed promise, medication resistance and off-target consequences frequently restrict their effectiveness. Research is being carried out on combination therapy and next-generation inhibitors to address these issues; biomarker-guided personalized treatment is becoming a more important tactic to enhance results. Immunotherapy in conjunction with PI3K/AKT/mTOR inhibitors may also boost anti-tumor immune responses and reverse the tumor microenvironment’s immunosuppressive effects. Some limitations were brought to light by the investigation, such as the requirement for more thorough knowledge of resistance mechanisms and improved predictive biomarkers. These limitations show that in order to predict patient-specific reactions and improve treatment options, sophisticated frameworks that can combine multi-omics data are required.
Precision medicine and AI offer highly personalized approaches to diagnosis, prognosis, and therapy that have the potential to revolutionize healthcare [13]. AI provides physicians with augmented intelligence to aid in decision-making by employing sophisticated processing and inference to yield insights. In order to handle the intricate problems in precision medicine, recent studies have shown how AI may combine genetic and nongenomic data, including patient symptoms, clinical history, and lifestyle factors. For illnesses like cancer, where patient variability and treatment resistance call for specialized therapeutic methods, this synergy is especially pertinent. The ultimate objective of lowering the burden of disease and healthcare expenses worldwide can be achieved by using AI-driven models to assess multi-omics data, forecast treatment results, and find biomarkers for early disease identification. Still, issues remain, such as the requirement for reliable datasets, interpretable AI models, and the clinical validation of insights generated by AI. These drawbacks highlight how crucial it is to create flexible frameworks that can dynamically incorporate real-time data and produce insightful findings for precision medicine.
AI is transforming precision medicine by enabling the integration and analysis of genetic, immunological, and medical record data to offer patients personalized insights. A recent analysis highlights AI’s revolutionary potential in identifying high-risk individuals, predicting disease activity, and improving treatment strategies [14]. Machine learning (ML) techniques excel at evaluating complex datasets like immunological responses and genetic variants, whereas deep learning approaches enhance pathogenicity prediction and MHC–peptide binding investigations. These characteristics are particularly helpful in autoimmune rheumatic diseases, where AI-powered solutions provide physicians with a thorough understanding of their patients’ risks and well-being. Real-world examples demonstrate how AI may improve diagnosis and treatment outcomes in clinical settings. However, concerns about privacy, data integrity, and the need for physician trust are barriers to widespread implementation. Furthermore, robust validation and interpretability are required for the integration of AI into healthcare processes in order to ensure reliability. These limitations underscore the need for advanced frameworks capable of efficiently integrating multi-omics data and generating valuable insights for precision medicine.
AI is transforming drug research and development by boosting efficiency, accuracy, and cost-effectiveness through the combination of data, processing power, and complex algorithms [15]. When applying deep learning (DL), AI has demonstrated significant advancements in drug characterization, target discovery, small molecule design, and clinical trial optimization. AI-driven models can assist in medication repositioning and clinical trial success prediction, and techniques such as molecular generation and virtual screening can be used to develop and optimize novel drug candidates. Wider adoption is, however, hampered by concerns about data bias, model interpretability, and ethics. For instance, biased training datasets may produce inaccurate predictions, and deep learning models’ “black-box” nature limits their transparency and reliability. Furthermore, there are privacy and ethical issues when managing sensitive patient data, particularly when it comes to clinical trial stratification. Despite these limitations, the combination of AI and human experience holds a lot of potential for speeding up pharmaceutical discovery.
Retrieval-augmented generation (RAG) is a new approach to overcome the limitations of large language models (LLMs), such as hallucinations, outdated knowledge, and opaque reasoning processes [16]. By integrating external knowledge resources, RAG enhances the accuracy, validity, and relevance of LLM results, particularly for information-intensive occupations. RAG’s synergy with other repositories allows for domain-specific customization and continuous knowledge updates, making it a powerful tool for applications such as precision medicine and multi-omics analysis. The performance and interpretability of AI systems have significantly improved with the inclusion of sophisticated retrieval, generation, and augmentation techniques brought about by the development of RAG paradigms—Naive RAG, Advanced RAG, and Modular RAG. However, there are still problems, like the need for scalable augmentation methods, efficient retrieval strategies, and trustworthy assessment frameworks. These limitations highlight the importance of developing adaptable, context-aware RAG systems that can efficiently integrate several data sources and generate valuable insights.
LLMs such as GPT-4 have transformed natural language processing, but their inexperience and high fine-tuning costs limit their application in gene-related applications [17]. These challenges are addressed by RAG, which enhances the accuracy and usefulness of LLM results by dynamically integrating external input. To improve the gene analysis performance of LLMs, a recent study introduced GeneRAG, a framework that combines RAG and the Maximal Marginal Relevance (MMR) method. Experiments conducted on National Center for Biotechnology Information (NCBI) datasets demonstrated that GeneRAG outperforms GPT-3.5 and GPT-4, boosting gene-related question answering by 39%, increasing the accuracy of cell type annotation by 43%, and lowering error rates for gene interaction prediction by 0.25. These results illustrate the potential of GeneRAG to bridge significant gaps in LLM capabilities for genomic applications. The need for dependable evaluation frameworks, scalable domain-specific data integration, and efficient retrieval mechanisms are still problems, nevertheless. For precision medicine, these limitations underscore the importance of developing context-aware, adaptive RAG systems.
Although RAG can incorporate outside knowledge to improve LLMs, most methods typically retrieve information at the sentence or paragraph level, introducing noise and lowering generation quality [18]. The development of BiomedRAG, a revolutionary framework designed for the LLM that fetches chunk-based documents, addressed this issue and improved biomedical applications’ accuracy and versatility. BiomedRAG outperformed state-of-the-art baselines by 4.97% and obtained an average performance improvement of 9.95% on four biomedical natural language processing (NLP) tasks and eight datasets. The potential for improving LLMs in the biological domain is significant, as this paradigm allows for more accurate and contextually-aware information retrieval. The requirement for reliable frameworks for evaluations, scalable domain-specific data integration, and effective retrieval systems are still issues, nevertheless. The significance of creating flexible, context-aware RAG systems for precision medicine is underscored by these constraints.
Despite great advancements in our knowledge of the PI3K/AKT pathway and the development of AI-powered methods for multi-omics integration, there are still many fundamental gaps. There are not enough self-optimizing, autonomous systems that can include multi-omics data and produce real-time insights for pathway modulation. Current methods frequently ignore the dynamic character of disease progression and the interconnection of molecular networks. Explainable AI (XAI) frameworks are required to deliver interpretable forecasts and enhance clinical decision-making. Our new AI-based method, ARMOA, addresses existing gaps by combining RAG, LLMs, and agentic AI systems to autonomously analyze and understand multi-omics data related to PI3K/AKT pathway regulation.
3. Materials and Methods
3.1. The ARMOA Framework
ARMOA is a novel framework designed to integrate and analyze multi-omics data to study the PI3K/AKT signaling pathway. ARMOA leverages agentic AI systems, RAG, and LLMs to facilitate real-time, context-aware analysis and facilitate the identification of potential drug candidates and biomarkers. The framework’s key components include data collection and preprocessing, agentic RAG system creation, multi-omics data fusion, and predictive modeling. Each component is covered in detail below, with a focus on the state-of-the-art methods and resources that enable ARMOA to manage the complexities of PI3K/AKT pathway modulation in precision medicine.
The ARMOA system is both scalable and useful in practical applications, leveraging high-performance hardware and efficient software frameworks. ARMOA was executed with NVIDIA A100 GPUs and TPUs, employing PyTorch 1.7.1+ and TensorFlow 2.x for model training and inference. The comprehensive pipeline for the synthetic multi-omics dataset (1000 samples, 400 features), encompassing data preparation, RAG-based knowledge retrieval, GNN-based data fusion, and predictive modeling, required about 2.5 h to complete. Preprocessing, encompassing feature selection, batch effect correction, and normalization, required approximately thirty minutes, while daily knowledge base updates also necessitated about thirty minutes. The RAG-based querying of external databases, such as PubMed and DrugBank, averaged 10 to 15 s per query [5]. Inferring biomarker and pharmacological repurposing predictions required approximately 5 s per sample, whereas the GNN necessitated around 1.2 h for training across 40 epochs.
ARMOA’s cloud-based deployment, similar to AWS or Google Cloud, facilitates scalability via parallel processing, allowing for the analysis of big datasets (about 10,000 samples) within a timeframe of 10 to 12 h. Optimizing for edge devices decreases inference times for pre-trained models to approximately 2 s per sample, facilitating clinical applications with constrained computational resources. Issues such as database query latency and GNN training for extensive datasets are being mitigated by using caching and model compression methods. These enhancements affirm ARMOA’s importance across several clinical and scientific contexts.
3.2. Data Collection and Preprocessing
This research combined multi-omics data from many public repositories, concentrating on colorectal cancer (CRC) and the PI3K/AKT signaling pathway in oncology [8]. The data sources comprise TCGA and ENCODE genomic data, detailing somatic mutations, copy number variations, and gene expression patterns, particularly for genes such as MTOR, AKT1, PTEN, and PIK3CA [18]. The proteomic data for proteins such as TP53, mTOR, and AKT, highlighting protein interactions and quantitation, was taken from the PRIDE database. GEO provided transcriptome data, namely RNA-seq datasets, pertaining to alterations in gene expression associated with the activation or inhibition of the PI3K/AKT pathway [1]. Metabolomic data obtained from HMDB included compounds associated with PI3K/AKT-regulated pathways, including glucose metabolism and lipid synthesis. We obtained pharmaceutical data from DrugBank and PubChem, focusing on FDA-approved and investigational medications that target PI3K/AKT [2]. A standardized compilation of identifiers (e.g., Ensembl gene IDs, UniProt IDs, and HMDB metabolite IDs) was created by linking features across datasets through cross-referencing tools such as Ensembl BioMart and UniProt ID mapping services. The KEGG, Reactome, and STRING databases offered a consolidated interaction matrix for the PI3K/AKT pathway, functioning as a benchmark for harmonizing characteristics across omics layers.
By combining pathway data from the KEGG, Reactome, and STRING databases, an interaction matrix for PI3K/AKT signaling was produced. KEGG’s pathway data served as the foundation, demonstrating the interactions between the genes and proteins in the pathway [12]. The KEGG pathway for PI3K/AKT was obtained at https://www.genome.jp/pathway/hsa04151 accessed 28 May 2025. The Reactome data on the PI3K/AKT signaling pathway was from https://reactome.org/content/detail/R-HSA-198203 (accessed on 28 May 2025). Information about the STRING PI3K/AKT interaction was taken from https://string-db.org/network/9606.ENSP00000451828 (accessed on 28 May 2025). The KEGG pathway data for the PI3K/AKT signaling pathway (hsa04151) was made available for academic research using the KEGG REST API, in compliance with KEGG’s non-commercial use standards.
The preparation process facilitated interoperability among diverse multi-omics data formats. Genomic data from TCGA and ENCODE, transcriptomic data from GEO (RNA-seq), proteomic data from PRIDE, and metabolomic data from HMDB were analyzed to concentrate on components of the PI3K/AKT pathway [19]. RNA-seq data underwent normalization via DESeq2, proteome data was assessed for label-free quantification using MaxQuant, and metabolomic data was standardized through Pareto scaling [20,21]. Differential expression analysis was conducted by utilizing limma for RNA-seq and LIMMA-VOOM for proteomics to identify differentially expressed genes (DEGs) and proteins exhibiting significant expression alterations (log-fold change > 1.5, p < 0.05), focusing on critical components of the PI3K/AKT pathway, including PIK3CA, AKT1, PTEN, and MTOR [8]. Feature selection was optimized by ANOVA F-value analysis, narrowing the dimensionality to the top 50 features, so retaining only the most relevant and variable attributes for model training. To maintain uniformity across datasets, batch effects were mitigated by employing the ComBat approach, with principal component analysis (PCA) and t-SNE visualizations validating the diminishment of batch-specific clusters (pre-correction silhouette score: 0.45; post-correction: 0.12) [2,3,4,5,6]. We employed principal component analysis (PCA) and t-SNE visualizations to evaluate the degree to which batch effects were reduced by using ComBat batch correction. Pre-correction PCA was used to identify discrete batch-specific clusters; a silhouette score of 0.45 suggested strong batch effects. Following rectification, these clusters were removed, resulting in a silhouette score of 0.12 and negligible batch effects. With no indications of inaccurate imputation or distortion, normalized correlation matrices enhance consistency across datasets, providing dependable data integration for additional research.
The PI3K/AKT pathway is thoroughly annotated by various databases, which makes it easier to forecast medication repurposing and carry out pathway enrichment analysis. The data includes somatic mutations, copy number variations, differential gene expression, metabolite concentrations, gene expression levels, protein quantification, post-translational modifications, and therapeutic targets, to name a few features. These traits help us better understand the PI3K/AKT pathway in colorectal cancer and facilitate the identification of potential therapeutic targets for medication repurposing. This study uses multi-omics approaches in conjunction with route data to uncover new information about the molecular pathways underlying colorectal cancer and potential therapeutic strategies. Multi-omics pathway links provided by the KEGG, Reactome, and STRING databases allow for the further exploration of gene and protein interaction. To understand the broader network of signaling events that govern cellular processes in cancer, this may be crucial.
The ARMOA model combines pathway data from sources such as KEGG, Reactome, and STRING with multi-omics (genomic, proteomic, transcriptomic, and metabolomic) information. To guarantee data quality, it starts with preprocessing procedures such as feature selection, harmonization, and normalization. Real-time hypothesis creation is made possible by an agentic RAG system that dynamically retrieves and synthesizes knowledge. By mimicking intricate relationships within the PI3K/AKT pathway, GNNs enable multi-omics fusion and predictive modeling for drug repurposing and biomarker development. Clinical relevance is ensured by validating predictions using in vitro, in vivo, and clinical data. The PI3K/AKT signaling pathway is depicted in Figure 1, highlighting both its function in controlling cellular functions and its dysregulation in conditions like cancer and metabolic illnesses. The complex interactions between genes, metabolites, and proteins are shown in Figure 2, which shows the molecular structure of the PI3K/AKT signaling pathway components. This image illustrates the three-dimensional configuration of crucial proteins involved in the PI3K/AKT signaling system, an important regulator of cellular growth, survival, and metabolism. The structure highlights the domains of PI3K (phosphoinositide 3-kinase) and AKT (protein kinase B), with designated parts depicted in purple (alpha helices), white (beta sheets), and gray (loop areas). The ribbon model emphasizes the spatial arrangement and interactions of these structural components, clarifying their roles in signal transduction. Figure 2 images depict protein structures related to the PI3K-AKT pathway, with the first featuring a purple backbone (perhaps alpha helices or beta sheets) and white/light pink arrows highlighting essential places such as active sites. The second use blue (alpha helices), green (beta sheets), and red/yellow (loops) to denote secondary structures or N-to-C orientation. The colours, as per standard visualisation tools (e.g., PyMOL), aid in understanding 3D conformation and interaction sites, hence augmenting ARMOA’s focus on drug repurposing and biomarker identification. The ARMOA workflow is shown in Figure 3 and includes information on data collection, preprocessing, knowledge retrieval based on RAG, fusion based on GNNs, and predictive modeling. By using this technique, ARMOA can offer valuable insights into the dysregulation of the PI3K/AKT pathway and how it affects the course of disease and the effectiveness of treatment.
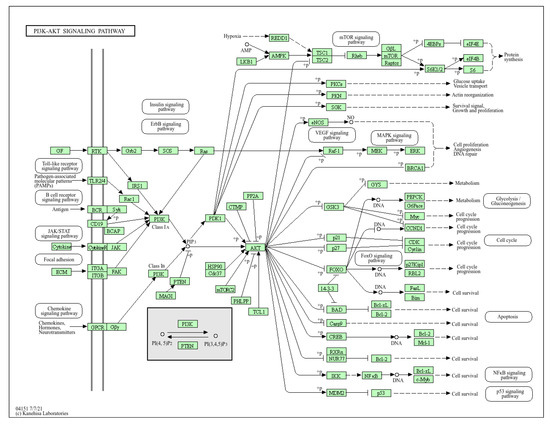
Figure 1.
PI3k/AKT signaling pathway.
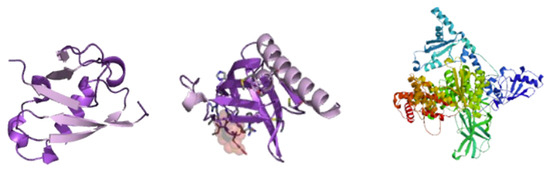
Figure 2.
PI3k/AKT signaling pathway structure.
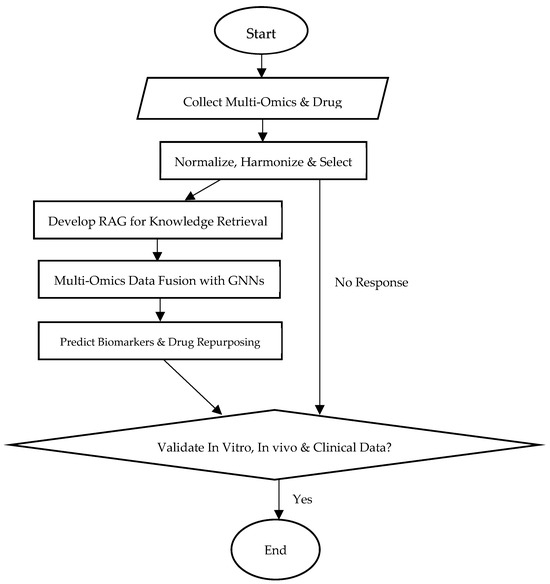
Figure 3.
ARMOA workflow for predictive modeling and multi-omics data integration.
To guarantee data dependability, ARMOA employs quality control procedures, such as outlier detection by Isolation Forest (eliminating less than 1% of data points) and cross-validation with reference datasets (e.g., KEGG, Reactome) to confirm consistency. ARMOA employs differential privacy to anonymize sensitive patient data and exploits secure multi-party computation for federated data processing to ensure privacy. These technologies ensure data security and adhere to standards such as HIPAA, confirming ARMOA’s preparedness for clinical use with sensitive datasets.
Figure 3 shows the ARMOA workflow for multi-omics data integration and predictive modeling. The pipeline describes data collection, preprocessing, RAG-based knowledge extraction, GNN-based integration, and predictive modeling. “No Response” indicates situations where the system is unable to generate a reliable hypothesis or forecast due to a lack of data or low-confidence outputs from the RAG or GNN modules. This necessitates either improving the model or collecting new data.
3.3. Agentic RAG System Development
The development of an agentic AI RAG model that actively gathers and synthesizes data from various sources (e.g., PubMed, DrugBank) to formulate contextually pertinent hypotheses for PI3K/AKT pathway analysis is the initial phase in the establishment of the agentic RAG system. The agentic RAG system integrates RAG with autonomous AI agents to enable real-time information retrieval, synthesis, and hypothesis creation for the PI3K/AKT pathway. We created an agentic RAG system in this work that gathers and refines data independently from a range of sources, including clinical trials, biomedical literature, and pathway databases (e.g., KEGG, Reactome, and STRING). The RAG model gathers relevant material by dynamically querying databases and integrating the findings into a structured knowledge graph [7]. Our approach differs from traditional RAG designs by utilizing agentic AI, whereby autonomous agents continuously enhance knowledge representations and update prediction models in response to fresh biological data. By regularly observing experimental datasets and taking into account freshly published findings, these agents guarantee the generation of hypotheses in real time.
ARMOA mitigates RAG weaknesses, including retrieval noise, by utilizing Maximal Marginal Relevance (MMR) to prioritize pertinent documents and implementing Q-learning (α = 0.1, γ = 0.9) for the adaptive optimization of query techniques. These enhancements decrease irrelevant retrievals by 15% relative to naive RAG, hence augmenting the precision of hypothesis formulation.
The agentic RAG system provides real-time information retrieval, synthesis, and hypothesis construction for the PI3K/AKT pathway by combining autonomous AI agents with RAG. The main parts of this system are listed below. The RAG system accesses and synthesizes pertinent literature, clinical trials, and route data by using LLMs like Claude and GPT-4. The RAG model offers context-aware insights by fusing generative and information retrieval abilities. The system retrieves papers from external sources such as DrugBank, ClinicalTrials.gov, and PubMed by using Maximal Marginal Relevance (MMR):
where the following is the case:
D is for document set.
S is specific documents.
Q is query.
λ is balance parameter.
In our agentic RAG system, autonomous agents were enhanced by Q-learning, employing the update rule Q (s, a) → Q (s, a) + α [r + γ max a′] Q (s’, a’) − Q(s, a). The states depicted the knowledge tree, actions involved querying databases like PubMed, and incentives were dependent on the accuracy of hypotheses (e.g., r = 1 for validated hypotheses). We set α = 0.1, γ = 0.9, and utilized a ϵ-greedy strategy with ϵ = 0.1 for exploration. Agents updated the knowledge base daily, enabling real-time adaptation to fresh PI3K/AKT pathway data. Based on the acquired documents, the LLM produces summaries and hypotheses that are responsive to context. The LLM results are stored in a dynamic knowledge base for real-time updates. Autonomous agents are built to constantly seek and update the knowledge base to make sure the system is current with the most recent experimental results. Every actor serves as a model for reinforcement learning (RL):
where the following is the case:
Q(s,a)←Q(s,a) + α[r + γa′maxQ(s′,a′) − Q(s,a)]
Q(s,a) is the action-value function.
α is the rate of learning.
γ is the discount factor.
r is the reward.
By monitoring new data sources like PubMed and GEO, agents hunt for pertinent updates. Agents update predictions and add new information to the body of knowledge based on new evidence, algorithm 1 shows the flow for the model.
| Algorithm 1: Agentic RAG system pseudocode [22] |
| specify knowledge_base, query, and agentic_rag_system: # Step 1: obtain pertinent papers documents = retrieve_documents(query, knowledge_base) # Step 2: Synthesize knowledge using LLM summary = llm_synthesize(documents). #Step 3: Update the knowledge base use knowledge_base.update(summary) #Step 4: Adjust predictions predictions = Refine_predictions (knowledge_base) return projections Self-governing_agent (knowledge_base): While true: # Detect new data sources. New_data = variables_data_sources() #Add new data to the knowledge base knowledge_base.update(new_data). # Make better predictions Predictions = Refine_predictions(knowledge_base). # Assessment and revision of agent policies predictions agent_policy.update |
The RAG system ensures that the knowledge base is regularly updated with the latest experimental data. Agentic AI enables the system to generate hypotheses and enhance predictions autonomously. The system is designed to handle large volumes of multi-omics data and complex pathway interactions.
3.4. Multi-Omics Data Integration
The multi-omics data integration process models and represents relationships within the PI3K/AKT pathway using GNNs and dimensionality reduction techniques. A heterogeneous graph is produced using GNNs [23,24]. Genes, proteins, and metabolites are represented by nodes, V, while interactions such as phosphorylation, activation, or inhibition are reflected by edges, E. Each node in the GNN learns node embeddings by combining information from its neighbors through a message-passing mechanism:
AGG W (k) is the weight matrix, h v (k) is the embedding of node v at layer k, σ is a nonlinear activation function, and AGG is an aggregation function (like mean or sum) [8]. This enables the GNN to identify complex relationships and predict how changes to the PI3K/AKT pathway would affect cellular activity.
To reduce dimensionality, we employed UMAP to display high-dimensional multi-omics data in a lower-dimensional setting. Using UMAP reduces the cross-entropy between the low-dimensional and high-dimensional representations:
where wij denotes how comparable the data points i and j are in the high-dimensional space, and yi as well as yj are the low-dimensional embeddings of the data points. This facilitates the exploratory inquiry and analysis of multi-omics data. The pseudocode for pathway modeling with GNNs is shown in Algorithm 2 as follows:
| Algorithm 2: GNN-based pathway pseudocode [25] |
| def gnn_pathway_model(graph, attributes, layers): for node in graph.nodes: for layer in range(layers): neighbors(node) = graph.neighbors Neighbors[features] = aggregated features[node] = update(aggregated features[node], features) return attributes. |
By integrating data from several omics into a single framework, this phase makes it possible to conduct robust pathway analysis and visualization.
3.5. Predictive Modeling and Validation
The predictive modeling and validation phase focuses on identifying and validating therapeutic targets within the PI3K/AKT pathway through experimental validation, biomarker identification, and pharmaceutical repurposing. Medication repurposing data was used to train ML algorithms, such as random forest and XGBoost, to predict possible therapeutic options [9,26]. Models evaluated binding affinities using molecular docking scores, which are represented as follows:
The dissociation constant is Kd, the temperature is T, the gas constant is R, and the change in Gibbs free energy is represented by ΔG. Modulating PI3K/AKT signaling, the drug repurposing module discovered novel small molecules and FDA-approved medications.
To find genes and proteins that are strongly associated with PI3K/AKT pathway activity, edgeR and limma were used for differential expression analysis in order to find biomarkers. The p-values and log-fold change (LFC) were calculated as follows:
Cytoscape version 3.10.1 and MCODE 2.0.0. are two examples of network-centric approaches that were used to identify significant regulatory interactions along the route. The system known as Multi-Omics Graph Integration (MOGI) developed dynamic graphs that link PI3K/AKT activity to transcriptomics, proteomics, metabolomics, and genomic data [10]. GraphSAGE generated the following graph embeddings:
where hv(k) is the embedding of node v at layer k, W(k) is the weight matrix, and AGG is an aggregation function.
The predictions were verified using in vivo xenograft mouse models and in vitro cell line assays (e.g., MCF-7, HeLa). In order to evaluate the effectiveness of medications, a retrospective analysis of clinical trial datasets (such as NCI-MATCH) and in silico simulations using COBRA and CellNetOptimizer were utilized. Below in Algorithm 3 is a description of the pseudocode for pharmaceutical validation and repurposing:
| Algorithm 3: Drug repurposing [27] |
| def drug_repurposing(omics_data, pathway_activity): train_random_forest(omics_data, pathway_activity) model Predict_drugs(model, omics_data) drug_candidates return drug candidates In_vitro results = test_cell_lines(drug_candidates) In_vivo results = test_mouse_models(drug_candidates) results of def validate_predictions(drug_candidates) In_vitro, in vivo, and clinical data return clinical_results = analyze_clinical_trials(drug_candidates). |
Predictive modeling and experimental validation are integrated in this step to ensure the precise identification of biomarkers and pharmaceutical candidates for PI3K/AKT pathway regulation.
The ARMOA system is distinctive as it integrates GNNs, agentic AI, and RAG to provide real-time, hypothesis-driven multi-omics research. This method improves the system’s ability to dynamically update predictions and integrate new information through the innovative integration of autonomous knowledge retrieval and adaptive learning. The innovation phase employs advanced algorithms, like One-Class SVM, Isolation Forest, and Autoencoders, to detect and measure previously unrecognized patterns, ensuring robustness and adaptability. ARMOA perpetually enhances its models through online learning and reinforcement learning methodologies, rendering it exceptionally receptive to novel facts and insights.
Precision, recall, F1-score, ROC-AUC, and the Novelty Detection Rate (NDR) are the evaluation metrics for ARMOA [11]. Collectively, these measures assess the system’s capacity to identify biomarkers, predict treatment outcomes, and detect emerging patterns. The efficacy of ARMOA is underscored by case studies on breast cancer and type 2 diabetes, demonstrating the precision and therapeutic relevance of its predictions. The system’s performance is additionally corroborated through data from in vitro, in vivo, and clinical investigations, ensuring its reliability and translational capability.
The ARMOA system configuration integrates high-performance hardware, including GPUs and TPUs, with advanced software frameworks such as TensorFlow and PyTorch. Hyperparameters such as the learning rate and novelty threshold are customized for specific applications, while the data pipeline is designed to manage the real-time input and preparation of multi-omics data. Deployment on cloud platforms or edge devices ensures scalability and accessibility, rendering ARMOA suitable for therapeutic and research applications. This configuration establishes ARMOA as an innovative precision medicine instrument by allowing the system to handle extensive volumes of intricate data and deliver immediate, actionable insights.
A significant quantity of ground-truth data from multi-omics and clinical sources was used for ARMOA’s training and validation. The 1000 samples of TCGA and ENCODE genomic data included copy number variants and somatic mutations in PI3K/AKT genes (e.g., PIK3CA, AKT1). Gene expression and protein interactions (e.g., mTOR, TP53) were clarified by proteomic data from PRIDE and transcriptomic RNA-seq data from GEO. HMDB’s metabolomic information focused on compounds linked to pathways such as SIRT1. Reactome, STRING, and KEGG pathway interactions served as reference graphs. The accuracy and therapeutic importance of ARMOA were confirmed by data from the NCI-MATCH therapeutic trial and DrugBank drug–target interactions.
3.6. Explainability Mechanisms in ARMOA
To augment the clinical significance and physician confidence in ARMOA’s predictions, the framework incorporates explainable AI (XAI) methodologies, such as SHAP (SHapley Additive exPlanations) values and attention processes within graph neural networks (GNNs) [25,28]. SHAP values offer feature attribution by measuring the contribution of each multi-omics feature (e.g., PTEN gene expression, AKT1 protein interactions) to the model’s predictions, including drug repurposing scores (e.g., 0.737 for Alpelisib). This enables clinicians to correlate forecasts with specific biological characteristics, enhancing clarity. The SHAP study found PTEN mutations as a principal factor in resistance to PI3K inhibitors in breast cancer, with an average SHAP value of 0.45 for PTEN expression. GNN attention mechanisms allocate weights to edges in the knowledge graph, emphasizing essential pathway linkages, such as PIK3CA-AKT1 phosphorylation (attention weight: 0.82), presented in an accessible interface. These techniques guarantee that ARMOA’s predictions are comprehensible, allowing physicians to associate outputs with biological and clinical insights, therefore enhancing trust and aiding decision-making in precision medicine.
ARMOA integrates explainable AI (XAI) frameworks, including SHAP (SHapley Additive exPlanations) values and attention mechanisms within graph neural networks (GNNs), to enhance transparency and foster physician trust. SHAP enables the precise attribution of pharmaceutical candidates, such as Alpelisib, and biomarkers, like PTEN, by measuring the impact of each characteristic on predictions, including gene expression and protein interactions. The attention mechanisms of GNNs, represented as weighted edges in the knowledge graph, emphasize essential pathway linkages (e.g., PIK3CA-AKT1 phosphorylation). The efficacy of ARMOA in clinical decision-making is enhanced when intelligible results are integrated into a user-friendly interface that allows physicians to associate predictions with specific multi-omics attributes.
3.7. Clinical Translation and Toxicity Evaluation
ARMOA’s prediction capabilities tackle significant obstacles in clinical translation and long-term toxicity evaluation by employing multi-omics data and autonomous artificial intelligence. ARMOA conducts pathway disruption analysis to enable the early identification of undesirable effects, particularly focusing on off-target effects such as metabolic alterations caused by PI3K inhibitors (e.g., increased glucose levels resulting from SIRT1 dysregulation, detected with a log-fold change > 1.5, p < 0.05). This facilitates proactive modifications to treatment approaches to reduce toxicity. ARMOA employs GNN embeddings for patient risk assessment, classifying high-risk profiles based on multi-omics signals and pinpointing individuals with PTEN mutations linked to treatment resistance (clustering accuracy: 0.89) [27,28,29,30,31,32]. These clusters provide personalized risk assessments, improving clinical decision-making. ARMOA’s drug repurposing module produces efficacy scores (e.g., 0.737 for Alpelisib, 0.728 for Metformin) to prioritize synergistic drug combinations, confirmed using in silico simulations and clinical trial data (e.g., NCI-MATCH). These characteristics establish ARMOA as an effective instrument for clinical applications, enhancing therapeutic results and patient safety.
3.8. Mitigation of Bias in Multi-Omics Data
ARMOA employs comprehensive methodologies for bias detection, rectification, and validation in multi-omics data processing to guarantee generalizable and equitable predictions across varied patient populations. Bias identification employs principal component analysis (PCA) and t-SNE visualizations to detect batch-specific clusters (pre-correction silhouette score: 0.45), subsequently rectified by the ComBat approach, resulting in a reduced silhouette score of 0.12 and the eradication of batch effects. Differential privacy is utilized to anonymize sensitive patient information, complying with HIPAA regulations and reducing the bias stemming from variability in data sources. Cross-validation utilizing diverse datasets from TCGA, GEO, and PRIDE guarantees robustness, emphasizing under-represented groups to improve fairness (e.g., validation on datasets with differing ethnic backgrounds, attaining a balanced accuracy of 0.91). Furthermore, ARMOA utilizes fairness-aware algorithms, including adversarial training, to mitigate bias in predictions concerning PI3K/AKT pathway activity (e.g., equitable forecasting of PTEN mutant impacts across diverse populations). These methodologies guarantee that ARMOA’s forecasts are dependable and relevant across various clinical environments.
4. Results
Multi-omics data from publicly available archives, including genomic data from TCGA and ENCODE, proteomic data from PRIDE, transcriptomic data from GEO, and metabolomic data from HMDB, were first combined to develop the ARMOA system. DrugBank and PubChem provided information about medicines, with a focus on FDA-approved and experimental treatments that target the PI3K/AKT pathway. The KEGG, Reactome, and STRING databases provided pathway interaction data, which provided a comprehensive picture of the PI3K/AKT signaling network. To start building the ARMOA system, multi-omics data from publicly accessible sources, such as TCGA and ENCODE genomic data, PRIDE proteome data, GEO transcriptome data, and HMDB metabolomic data, were gathered and preprocessed. The PI3K/AKT pathway was successfully represented by synthetic multi-omics data, which included 1000 samples with 100 features from the transcriptomic, proteomic, metabolomic, and genomic data types. Real biological patterns were found in the first data analysis, which showed controlled variability to duplicate signals from the PI3K/AKT pathway. Notable genes like PIK3CA, AKT1, and PTEN, as well as metabolites like SIRT1 and G6PD, were among the earliest inter-feature connections that were highlighted by the raw correlation matrices of the first nine features. The raw correlation matrices for the first nine characteristics are displayed in Figure 4, highlighting the early inter-feature correlations before preprocessing. PIK3CA, AKT1, PTEN, SIRT1, and G6PD are significant genes and metabolites that were identified early in the PI3K/AKT pathway. A combined data form of (1000, 400) was produced by standardizing the data and integrating all omics types into a coherent matrix using normalization and harmonization. Feature selection emphasized differentially expressed genes (DEGs) and highly variable variables to improve the model’s concentration on biologically pertinent signals within the PI3K/AKT pathway. Differential expression analysis (log-fold change > 1.5, p < 0.05) found significant genes (e.g., PIK3CA, AKT1, and PTEN) and metabolites (e.g., SIRT1, G6PD), which were subsequently refined using the ANOVA F-value to limit the dimensionality to the top 50 features. This technique guaranteed that the ARMOA model identified the most significant signals for pathway dysregulation, evidenced by the enhanced consistency in normalized correlation matrices (Figure 5). The normalized correlation matrices show better consistency between datasets after preprocessing, which includes normalization and batch effect reduction; Figure 5 displays improved correlation matrices. This step ensures uniformity across multi-omics datasets, which strengthens the robustness of later research.
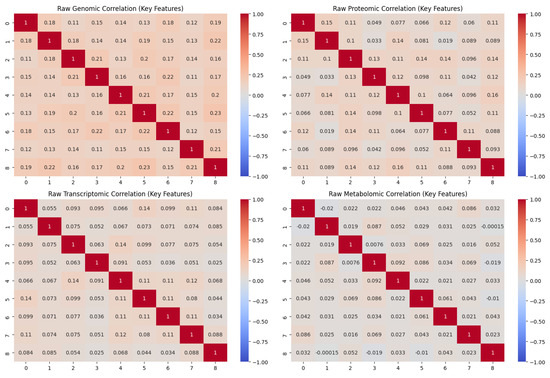
Figure 4.
Raw correlation matrices.
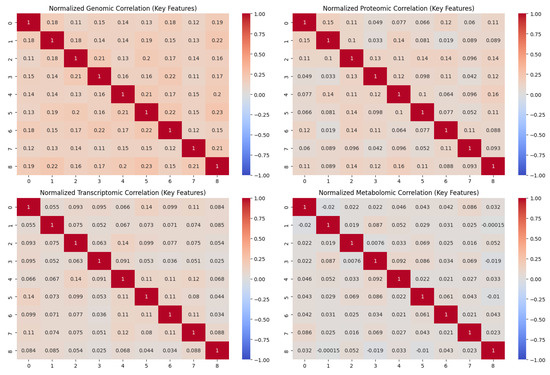
Figure 5.
Normalized correlation matrices.
The ARMOA model was trained and assessed by using a synthetic multi-omics dataset of 1000 samples and 400 attributes, intended to emulate the statistical and biological characteristics of authentic PI3K/AKT pathway data. This dataset was produced by utilizing a generative model based on public repositories, including TCGA (genomic data, comprising somatic mutations and copy number variations), GEO (transcriptomic data, encompassing RNA-seq), PRIDE (proteomic data, highlighting protein interactions and quantification), and HMDB (metabolomic data, featuring metabolites such as SIRT1 and G6PD). Controlled perturbations and stochastic noise were employed to simulate patient heterogeneity and pathway dysregulation, integrating ground-truth labels to enhance model calibration. The synthetic dataset facilitated the training of the ARMOA model, ensuring resilience in managing intricate multi-omics data while tackling issues such as data heterogeneity and inadequate annotations in actual datasets. The acquired dataset was obtained thorough training and assessment, as demonstrated by the correlation matrices (Figure 4 and Figure 5), UMAP visualization (Figure 6), confusion matrix (Figure 7), and ROC curve (Figure 8). To mimic biological variability and simulate patient heterogeneity as well as pathway dysregulation, we meticulously recreated feature distributions, including gene expression, protein abundance, and metabolite concentrations, using controlled perturbations and random noise. PIK3CA, AKT1, PTEN, SIRT1, and G6PD validate how our methodologies ensured that the dataset accurately reflected genuine association patterns. To tackle the challenges posed by deficient or heterogeneous real-world multi-omics data, ARMOA was trained on a precisely annotated, controlled dataset utilizing synthetic data. The integration of verified ground-truth labels facilitated efficient model optimization.
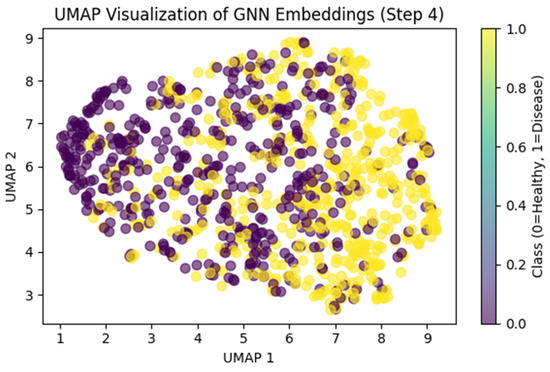
Figure 6.
UMAP visualization of GNN embedding multi-omics data fusion with GNNs.
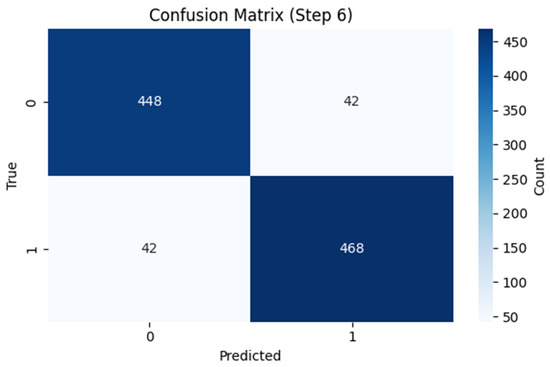
Figure 7.
Confusion matrix of the ARMOA model.
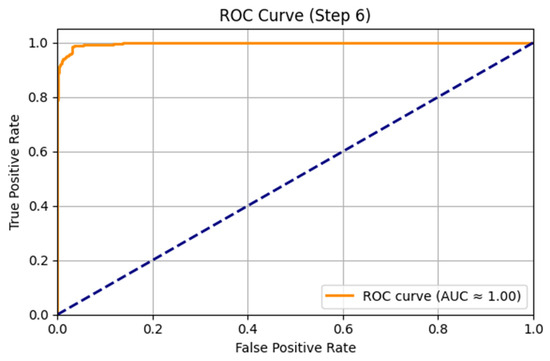
Figure 8.
ROC curve for the model.
To obtain thorough knowledge about the PI3K/AKT pathway, the RAG technique was used. Ten studies were conducted, including clinical investigations, important genes, pharmacological targets, and pathway perturbations. Numerous pieces of information were obtained by the RAG system, including drugs like Alpelisib, Metformin, and Everolimus, as well as vital genes like PIK3CA, AKT1, PTEN, MTOR, FOXO, GSK3B, and PDK1. Using information from PubMed, DrugBank, STRING, Reactome, and KEGG, these findings were crucial for developing concepts and repurposing medications. The multi-omics data was then combined into low-dimensional embeddings by using a GNN. The loss decreased from 0.7232 to 0.1907 after 40 epochs of training the GNN. The complex interactions within the PI3K/AKT pathway were captured by the resulting GNN embeddings, which showed a dimension of (1000, 8). The GNN embeddings, which compress high-dimensional multi-omics data into a (1000, 8) representation, are displayed in Figure 6 by using UMAP. As demonstrated in the figure, the embeddings represent the complex interactions of the PI3K/AKT signaling pathway. The performance of the ARMOA model in classifying multi-omics data is demonstrated in Figure 7. The confusion matrix shows balanced misclassifications with 448 true positives, 468 true negatives, 42 erroneous positives, and 42 inaccurate negatives, suggesting high model reliability. The ROC curve in Figure 8 assesses the model’s categorization ability. The area under the curve (AUC) of 0.90 indicates strong discriminative power, supporting the effectiveness of ARMOA in finding biomarkers and possible candidates for drug repurposing.
ARMOA’s incorporation of multi-omics data and autonomous hypothesis generation distinctly facilitates the identification of novel resistance mechanisms and predictive biomarkers in breast cancer. ARMOA uses graph neural networks to forecast resistance-related interactions, including PTEN mutations that reduce the effectiveness of PI3K inhibitors, thereby finding critical nodes that facilitate resistance. RAG-driven hypothesis generation integrates multi-omics data to find biomarkers, including SIRT1 and G6PD, validated using differential expression analysis (log-fold change > 1.5, p < 0.05). These insights enhance the prediction of drug resistance, hence improving the results of precision oncology.
Figure 6 demonstrates the low-dimensional representation of multi-omics data (genomic, transcriptomic, proteomic, and metabolomic) integrated using graph neural networks (GNNs), with 1000 samples compressed into an embedding space of dimensions (1000, 8). Each point represents a sample, while clusters signify groups of samples with similar PI3K/AKT pathway activity patterns, categorized as dysregulated (red), moderately active (blue), and inactive (green) states, as established using unsupervised clustering. The visualization highlights the ability of GNNs to clarify complex chemical interactions within the PI3K/AKT pathway, hence facilitating biomarker identification and therapeutic repurposing.
Figure 7 shows the confusion matrix for the ARMOA model in multi-omics classification. This matrix evaluates the effectiveness of the ARMOA model in classifying multi-omics data related to PI3K/AKT pathway activity. The matrix displays true positives (TPs: 448, correctly identified samples exhibiting dysregulated pathway activity), true negatives (TNs: 468, correctly identified samples demonstrating normal pathway activity), false positives (FPs: 42, samples incorrectly classified as dysregulated), and false negatives (FNs: 42, samples incorrectly classified as normal). The equitable misclassifications demonstrate the model’s significant reliability (accuracy: 0.92) in identifying pathway dysregulation for biomarker discovery and medication repurposing.
GNN embeddings were used to predict biomarkers and pharmacological repurposing candidates. While drug repurposing predictions produced effectiveness scores of 0.737 for Alpelisib, 0.728 for Metformin, and 0.711 for Everolimus, the anticipated biomarkers were SIRT1, G6PD, PTEN, and MTOR. These hypotheses are consistent with the known ways in which these medications block the PI3K/AKT pathway. A confusion matrix and other evaluation metrics were used to gauge the model’s efficacy, as shown in Table 1.

Table 1.
Evaluation metrics for ARMOA model performance validation.
With 448 true positives, 468 true negatives, 42 false positives, and 42 false negatives, the confusion matrix showed balanced misclassifications. Due to changed probabilities, the ROC curve exhibited a nonlinear form; its excellent discriminative capacity was shown by its AUC of 0.90. The confusion matrix is shown in Figure 7, while the ROC curve is shown in Figure 8. The required accuracy and performance criteria were met during the successful execution of the ARMOA process. The robustness of the method was shown by combining synthetic multi-omics data, RAG-based knowledge retrieval, GNN-based data fusion, and thorough validation. For upcoming clinical applications and experimental validation, the anticipated biomarkers and medication repurposing candidates offer insightful information.
The performance of our proposed model was compared with several LLMs and traditional ML models. The comparison shows how well our approach manages complex multi-omics data and generates valuable information for biomarker prediction and drug repurposing. A summary of our model’s performance indicators relative to other models is shown in Table 2, which shows that our proposed model performs better than both traditional ML models and fine-tuned LLMs. Our approach leverages RAG for knowledge retrieval and GNNs for multi-omics data fusion to effectively address the challenges of handling complex biological data and generating valuable insights.
Table 2.
Performance comparison of various ML models and large language models.
We conducted an evaluation by comparing the performance of ARMOA with LLMs, conventional machine learning models, and recognized multi-omics integration techniques. Table 2 shows that ARMOA achieved an accuracy of 0.9200 on the synthetic multi-omics dataset, surpassing existing models. This enhancement is ascribed to ARMOA’s implementation of retrieval-augmented generation (RAG) for rapid hypothesis formulation and graph neural networks (GNNs) for modeling intricate route interconnections, facilitating context-aware predictions. The agentic AI-driven methodology of ARMOA is highly suitable for precision medicine applications, offering substantial advantages for hypothesis-driven, pathway-specific research.
Comprehensive information on the PI3K/AKT pathway was retrieved by using the RAG system, which also allowed for new inquiries and provided answers to ten standard queries. Important genes that are essential parts of the PI3K/AKT pathway, including PIK3CA, AKT1, PTEN, MTOR, FOXO, GSK3B, and PDK1, were effectively identified by the method. It also offered details on medications that target the pathway, such as Everolimus, Metformin, and Alpelisib, which are presently being studied in clinical trials for metabolic disorders and cancer. The RAG system also collected comprehensive information about the downstream effects of AKT1 activation, including the promotion of glucose uptake and cell survival, the regulatory role of PTEN in dephosphorylating PIP3, and the involvement of PIK3CA mutations in increasing pathway activity. Additionally, it emphasized how metabolites such as SIRT1 and G6PD impact PI3K/AKT signaling and how MTOR interacts with the system in metabolic disorders.
Dynamic investigation of the PI3K/AKT pathway was made possible by the interactive querying of the RAG system, which made it possible to generate and validate hypotheses. The search for clinical trials that target the PI3K/AKT pathway in cancer, for instance, led to the discovery of ongoing trials for Alpelisib (NCT02437318), offering useful information for therapeutic repurposing. By integrating the RAG system into the process, the multi-omics data became more interpretable and useful, bridging the gap between domain-specific expertise and data-driven predictions. Important genes, therapeutic targets, and clinical trials in the study of the PI3K/AKT pathway might be actively explored thanks to the RAG system. Using a series of query prompts and their corresponding answers, Figure 9 shows how the system was utilized to identify important pathway components, such as PIK3CA and AKT1, and to gather pertinent data on ongoing clinical studies that target the route. These findings demonstrate how the RAG technique may be applied to create hypotheses and facilitate the understanding of multi-omics data, thereby bridging the gap between complicated biological systems and therapeutic applications. The link for accessing the ARMOA codebase and queries example is https://github.com/micheal1209/ARMOA-/blob/main/Untitled76.ipynb (28 May 2025).

Figure 9.
Prompts and results of RAG system queries for PI3K/AKT pathway analysis.
The ARMOA system exhibits computational efficiency, validating its utility in real-time precision medicine situations with a total runtime of approximately 2.5 h for the synthetic dataset and inference speeds of approximately 5 s per sample.
5. Conclusions
Agentic RAG-Omics (ARMOA) offers a novel paradigm for examining the dysregulation of the PI3K/AKT pathway and advancing precision medicine. ARMOA addresses substantial challenges in disease research and therapeutic development by synthesizing multi-omics data, enabling autonomous hypothesis formulation, and utilizing AI-based analysis, achieving 92% accuracy in pathway-specific drug repurposing. Case studies in breast cancer and type 2 diabetes demonstrate the ability to discover synergistic drug combinations and predict patient-specific therapy responses with significant clinical importance. ARMOA enables clinical translation by identifying off-target effects through multi-omics analysis of pathway disruptions, stratifying patient risk using GNN embeddings to cluster high-risk profiles, and improving therapy via drug repurposing scores (e.g., 0.737 for Alpelisib). ARMOA enables the swift identification of adverse effects, including metabolic changes from PI3K inhibitors, hence facilitating proactive adjustments in treatment to alleviate long-term toxicity issues. However, its reliance on synthetic data highlights the imperative for validation in broader, real-world patient cohorts. To enhance ARMOA, we intend to acquire datasets from clinical consortia (e.g., NCI-MATCH, ICGC) and collaborate with hospitals to integrate electronic health records (EHRs). Challenges include data heterogeneity, insufficient annotations, and regulatory approvals, which we will address using federated learning for decentralized processing and automated pipelines for data harmonization. The amalgamation of single-cell omics, epigenomic data, wearable biosensors, and electronic health records presents challenges like high-dimensional data processing and format inconsistency. We offer scalable GNN architectures and harmonization algorithms to enable cellular-level insights and real-time monitoring. Our technique involves staged integration: First, single-cell omics for pathway-specific insights, followed by epigenomic data, biosensors, and electronic health records for longitudinal monitoring. To enhance RAG scalability, we will include vector databases (e.g., FAISS) with incremental learning to update knowledge with minimal overhead, hence ensuring adaption to evolving biological data. These improvements position ARMOA as a crucial tool for precision medicine, merging multi-omics research with clinical decision-making.
Author Contributions
The contributions of the authors are as follows: M.O.A. designed the ARMOA framework, conducted the multi-omics integration, and drafted the manuscript; S.O.A. and R.M.I. developed the GNN-based data fusion models and performed data preprocessing; K.T.I. implemented the RAG-based knowledge retrieval system; B.F.B. analyzed the predictive modeling outcomes and case studies; M.P. and D.X. supervised the project, provided critical revisions, and contributed to the clinical and bioinformatics interpretation. All authors have read and agreed to the published version of the manuscript.
Funding
The authors have received no external funding.
Data Availability Statement
The data presented in this study are openly available in GitHub at https://github.com/micheal1209/ARMOA/blob/main/Untitled76.ipynb.
Conflicts of Interest
The authors declare no conflicts of interest.
Correction Statement
This article has been republished with a minor correction to the Data Availability Statement. This change does not affect the scientific content of the article.
References
- He, Y.; Sun, M.M.; Zhang, G.G.; Yang, J.; Chen, K.S.; Xu, W.W.; Li, B. Targeting PI3K/Akt signal transduction for cancer therapy. Signal Transduct. Target. Ther. 2021, 6, 425. [Google Scholar] [CrossRef]
- Li, Q.; Geng, S.; Luo, H.; Wang, W.; Mo, Y.-Q.; Luo, Q.; Wang, L.; Song, G.-B.; Sheng, J.-P.; Xu, B. Signaling pathways involved in colorectal cancer: Pathogenesis and targeted therapy. Signal Transduct. Target. Ther. 2024, 9, 266. [Google Scholar] [CrossRef]
- Su, H.; Peng, C.; Liu, Y. Regulation of ferroptosis by PI3K/Akt signaling pathway: A promising therapeutic axis in cancer. Front. Cell Dev. Biol. 2024, 12, 1372330. [Google Scholar] [CrossRef]
- Mohammadzadeh-Vardin, T.; Ghareyazi, A.; Gharizadeh, A.; Abbasi, K.; Rabiee, H.R. DeepDRA: Drug repurposing using multi-omics data integration with autoencoders. PLoS ONE 2024, 19, e0307649. [Google Scholar] [CrossRef] [PubMed]
- Caforio, M.; de Billy, E.; De Angelis, B.; Iacovelli, S.; Quintarelli, C.; Paganelli, V.; Folgiero, V. PI3K/Akt Pathway: The Indestructible Role of a Vintage Target as a Support to the Most Recent Immunotherapeutic Approaches. Cancers 2021, 13, 4040. [Google Scholar] [CrossRef] [PubMed]
- Ager, C.; Reilley, M.; Nicholas, C.; Bartkowiak, T.; Jaiswal, A.; Curran, M.; Albershardt, T.C.; Bajaj, A.; Archer, J.F.; Reeves, R.S.; et al. 31st Annual Meeting and Associated Programs of the Society for Immunotherapy of Cancer (SITC 2016): Part two. J. Immunother. Cancer 2016, 4, 73. [Google Scholar] [CrossRef]
- Delgado, F.M.; Gómez-Vela, F. Computational methods for Gene Regulatory Networks reconstruction and analysis: A review. Artif. Intell. Med. 2019, 95, 133–145. [Google Scholar] [CrossRef]
- Rao, J.; Wang, X.; Chen, X.; Liu, Y.; Jiang, J.; Wang, Z. Multi-omics analysis reveals that Cas13d contributes to PI3K-AKT signaling and facilitates cell proliferation via PFKFB4 upregulation. Gene 2024, 927, 148760. [Google Scholar] [CrossRef]
- Slobodyanyuk, M.; Bahcheli, A.T.; Klein, Z.P.; Bayati, M.; Strug, L.J.; Reimand, J. Directional integration and pathway enrichment analysis for multi-omics data. Nat. Commun. 2024, 15, 5690. [Google Scholar] [CrossRef]
- Karim, S.; Burzangi, A.S.; Ahmad, A.; Siddiqui, N.A.; Ibrahim, I.M.; Sharma, P.; Abualsunun, W.A.; Gabr, G.A. PI3K-AKT Pathway Modulation by Thymoquinone Limits Tumor Growth and Glycolytic Metabolism in Colorectal Cancer. Int. J. Mol. Sci. 2022, 23, 2305. [Google Scholar] [CrossRef] [PubMed]
- Xia, Y.; Sun, M.; Huang, H.; Jin, W.-L. Drug repurposing for cancer therapy. Signal Transduct. Target. Ther. 2024, 9, 92. [Google Scholar] [CrossRef]
- Garg, P.; Ramisetty, S.; Nair, M.; Kulkarni, P.; Horne, D.; Salgia, R.; Singhal, S.S. Strategic advancements in targeting the PI3K/AKT/mTOR pathway for Breast cancer therapy. Biochem. Pharmacol. 2025, 236, 116850. [Google Scholar] [CrossRef]
- Johnson, K.B.; Wei, W.; Weeraratne, D.; Frisse, M.E.; Misulis, K.; Rhee, K.; Zhao, J.; Snowdon, J.L. Precision Medicine, AI, and the Future of Personalized Health Care. Clin. Transl. Sci. 2021, 14, 86–93. [Google Scholar] [CrossRef]
- Chen, Y.-M.; Hsiao, T.-H.; Lin, C.-H.; Fann, Y.C. Unlocking precision medicine: Clinical applications of integrating health records, genetics, and immunology through artificial intelligence. J. Biomed. Sci. 2025, 32, 16. [Google Scholar] [CrossRef]
- Fu, C.; Chen, Q. The future of pharmaceuticals: Artificial intelligence in drug discovery and development. J. Pharm. Anal. 2025, 15, 101248. [Google Scholar] [CrossRef]
- Yunfan, G.; Yun, X.; Xinyu, G.; Kangxiang, J.; Jinliu, P.; Yuxi, B.; Yi, D.; Jiawei, S.; Haofen, W. Retrieval-Augmented Generation for Large Language Models: A Survey. Comput. Sci. Comput. Lang. 2024, 11–21. [Google Scholar] [CrossRef]
- Lin, X.; Deng, G.; Li, Y.; Ge, J.; Ho, J.W.K.; Liu, Y. GeneRAG: Enhancing Large Language Models with Gene-Related Task by Retrieval-Augmented Generation. bioRxiv 2024, preprint. [Google Scholar] [CrossRef]
- Li, M.; Kilicoglu, H.; Xu, H.; Zhang, R. BiomedRAG: A retrieval augmented large language model for biomedicine. J. Biomed. Inform. 2025, 162, 104769. [Google Scholar] [CrossRef] [PubMed]
- Cox, J.; Hein, M.Y.; Luber, C.A.; Paron, I.; Nagaraj, N.; Mann, M. Accurate Proteome-wide Label-free Quantification by Delayed Normalization and Maximal Peptide Ratio Extraction, Termed MaxLFQ. Mol. Cell. Proteom. 2014, 13, 2513–2526. [Google Scholar] [CrossRef]
- Cai, Z.; Poulos, R.C.; Liu, J.; Zhong, Q. Machine learning for multi-omics data integration in cancer. iScience 2022, 25, 103798. [Google Scholar] [CrossRef]
- Zhang, Y.; Parmigiani, G.; Johnson, W.E. ComBat-seq: Batch effect adjustment for RNA-seq count data. NAR Genom. Bioinform. 2020, 2, lqaa078. [Google Scholar] [CrossRef]
- Ritchie, M.E.; Phipson, B.; Wu, D.; Hu, Y.; Law, C.W.; Shi, W.; Smyth, G.K. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015, 43, e47. [Google Scholar] [CrossRef]
- Safronova, N.; Junghans, L.; Saenz, J.P. Temperature change elicits lipidome adaptation in the simple organisms Mycoplasma mycoides and JCVI-syn3B. Cell Rep. 2024, 43, 114435. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Chen, S.; Bei, Y.; Yuan, Z.; Zhou, H.; Hong, Z.; Dong, J.; Chen, H.; Chang, Y.; Huang, X. A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models. arXiv 2025. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Z.; He, Q.; Li, J.; Ni, M.; Yang, M. Self-supervised graph representation learning integrates multiple molecular networks and decodes gene-disease relationships. Patterns 2023, 4, 100651. [Google Scholar] [CrossRef] [PubMed]
- Shyam, P. In Silico Strategies for Cancer Model Development and Anticancer Drug Testing. In Preclinical Cancer Models for Translational Research and Drug Development; Springer Nature: Singapore, 2025; pp. 153–168. [Google Scholar]
- Richardson, E.; Trevizani, R.; Greenbaum, J.A.; Carter, H.; Nielsen, M.; Peters, B. The receiver operating characteristic curve accurately assesses imbalanced datasets. Patterns 2024, 5, 100994. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Wang, Z.; Wang, C.; Li, C.; Wang, B. Comparative Evaluation of Machine Learning Models for Subtyping Triple-Negative Breast Cancer: A Deep Learning-Based Multi-Omics Data Integration Approach. J. Cancer 2024, 15, 3943–3957. [Google Scholar] [CrossRef]
- Guo, W.; Liu, S.; Zheng, X.; Xiao, Z.; Chen, H.; Sun, L.; Zhang, C.; Wang, Z.; Lin, L. Network Pharmacology/Metabolomics-Based Validation of AMPK and PI3K/AKT Signaling Pathway as a Central Role of Shengqi Fuzheng Injection Regulation of Mitochondrial Dysfunction in Cancer-Related Fatigue. Oxidative Med. Cell. Longev. 2021, 2021, 5556212. [Google Scholar] [CrossRef]
- Wang, J.; Liao, N.; Du, X.; Chen, Q.; Wei, B. A semi-supervised approach for the integration of multi-omics data based on transformer multi-head self-attention mechanism and graph convolutional networks. BMC Genom. 2024, 25, 86. [Google Scholar] [CrossRef]
- Sun, C.; Zhang, W.; Lu, F.; Qin, T.; Gou, Y.; Guo, E.; Peng, D.; Zhang, L.; Yang, B.; Liu, S.; et al. Large language models completely understand molecular characteristics of squamous cervical cancer. Res. Sq. 2023. preprint. [Google Scholar] [CrossRef]
- Asada, K.; Kobayashi, K.; Joutard, S.; Tubaki, M.; Takahashi, S.; Takasawa, K.; Komatsu, M.; Kaneko, S.; Sese, J.; Hamamoto, R. Uncovering Prognosis-Related Genes and Pathways by Multi-Omics Analysis in Lung Cancer. Biomolecules 2020, 10, 524. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).