1. Introduction
Predicting stock prices on stock exchanges is a complex problem due to the highly nonlinear and non-stationary behavior of financial markets. Accurate predictions require extensive expertise and deep knowledge from professionals [
1]. Accurate predictions can yield substantial economic benefits. For example, in 2024, 20% of the world’s 200 richest individuals will accumulate their wealth through finance and investments [
2]. This financial potential motivates investors to seek methods for estimating future stock prices to maximize profits and reduce losses.
To date, research on daily stock-exchange price prediction can be grouped into five main lines of inquiry. First, studies that focus on stock indices—indicators of the aggregated value of the whole market or of specific sectors [
3]—have sought to anticipate whether an index will rise or fall [
4,
5,
6], its closing level [
7,
8,
9], and even its intraday peak [
10]. Second, a substantial body of work targets individual stock prices, forecasting their closing quotations [
7,
10,
11,
12,
13,
14] as well as their daily minima and maxima [
15]. Third, researchers address stock price trends, classifying whether a given share is likely to appreciate or depreciate in the following session [
12,
16,
17,
18]. Fourth, a set of decision-support models for investors has emerged: some aggregate return, profit, and risk into a weighted score [
19], while others generate buy/hold/sell signals over horizons of one to six days [
20]. Finally, attention has turned to cryptocurrencies, with Bitcoin in particular inspiring models that predict its future USD exchange rate and trend direction [
21]. While most existing studies focus on predicting closing prices or general market direction, [
15] is one of the few that targets both maximum and minimum daily prices, which aligns closely with the objective of this study.
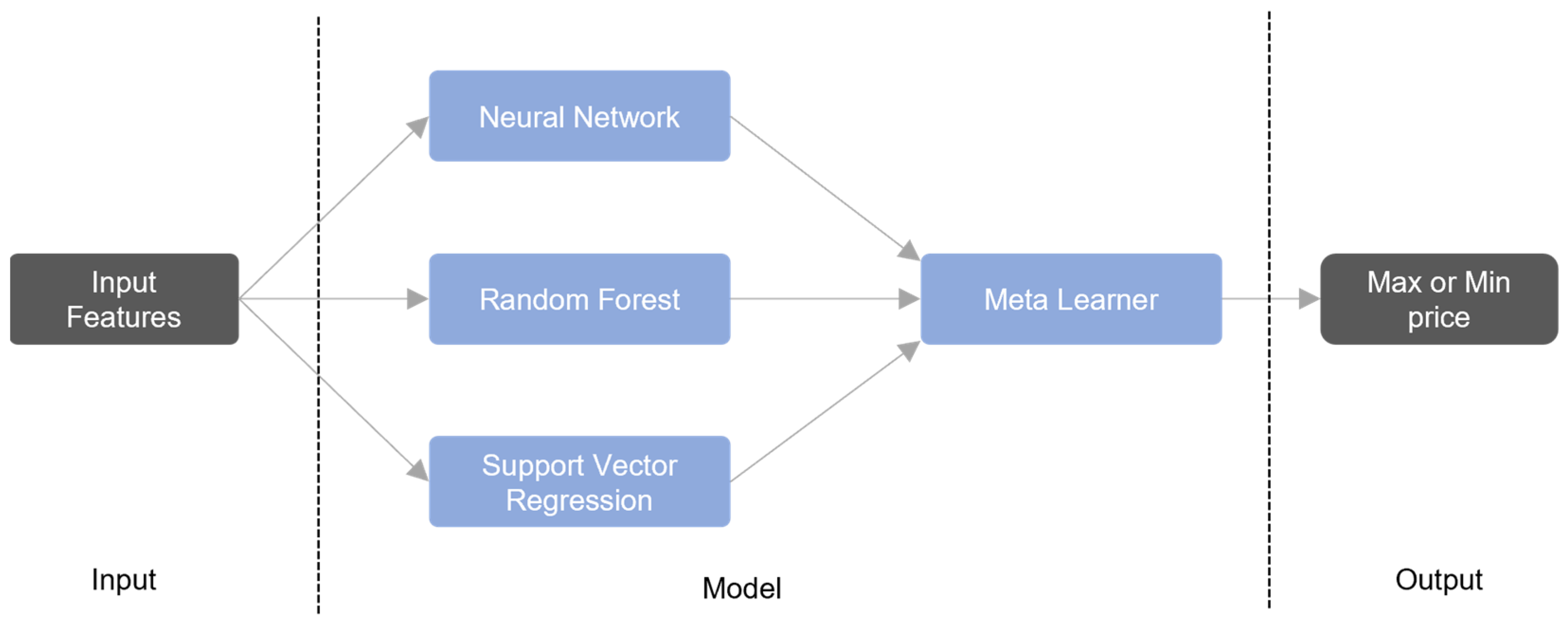
Traditional ML and deep-learning (DL) approaches often perform inconsistently across data sets. To mitigate this limitation, recent studies employ stacking ensembles instead of a single ML or DL model [
22,
23,
24,
25]. In stacking, several base (“weak”) learners are trained in parallel, and their predictions, together with the true labels, feed a meta-learner that learns how to combine them optimally, thereby improving overall accuracy [
26,
27]. Although stacking has been used in financial forecasting, most studies focus on predicting closing prices or binary movement direction. In contrast, this study focuses on predicting both the maximum and minimum daily stock prices using a structured hybrid ensemble. Furthermore, we combine neural networks, SVR, and decision trees in a specific configuration optimized for performance consistency across multiple datasets. This design, combined with the cross-market application to both Brazilian stocks and a U.S. index, represents a novel empirical contribution.
This research builds upon the results presented in the bachelor’s thesis of Sebastian Tuesta, defended at the Universidad Nacional Mayor de San Marcos (UNMSM) in 2025. The current study extends his preliminary work by incorporating additional financial indicators, refining the hybrid model architecture based on stacking techniques, and evaluating its predictive performance across different stock markets, including both national and international indices.
5. Discussion and Conclusions
This paper introduces a stacking-based hybrid model to forecast a stock’s highest and lowest prices by employing three ML models as base learners and a meta-model for the final prediction. This method typically produces more consistent and precise outcomes than single ML models. While the current approach avoids sector-specific influences to simplify analysis, future research should explore the impact of industry-specific volatility on model performance. Including sectoral classification or volatility measures may provide deeper insights into how models generalize across heterogeneous financial environments.
In three out of four instances, the results from the proposed model exceed those found in the reference study [
15]. In the other case [
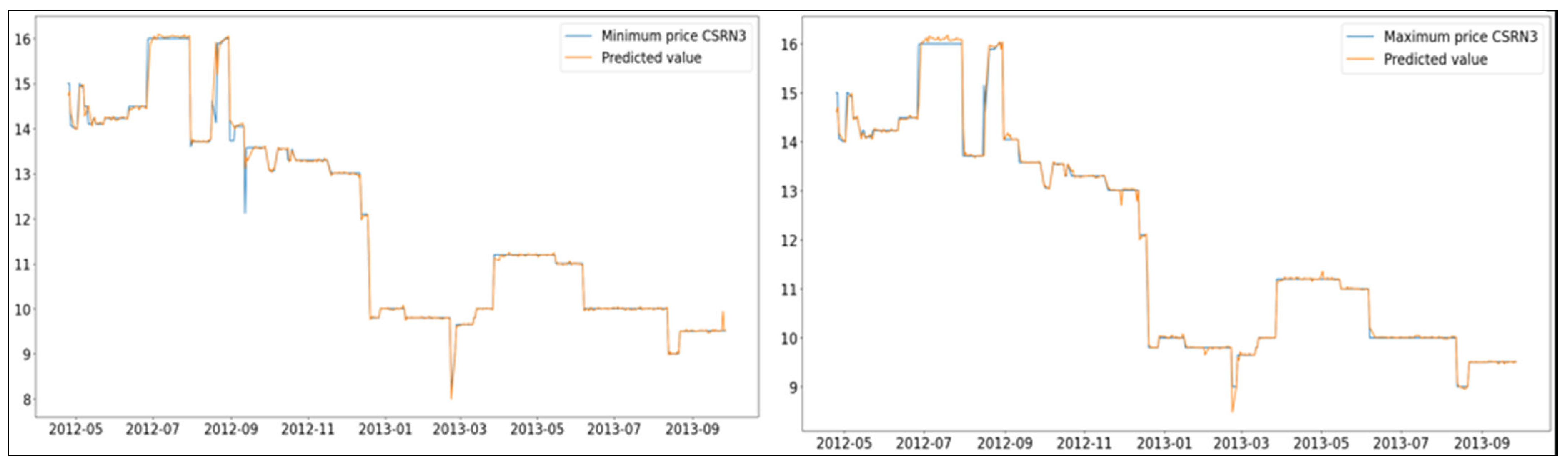
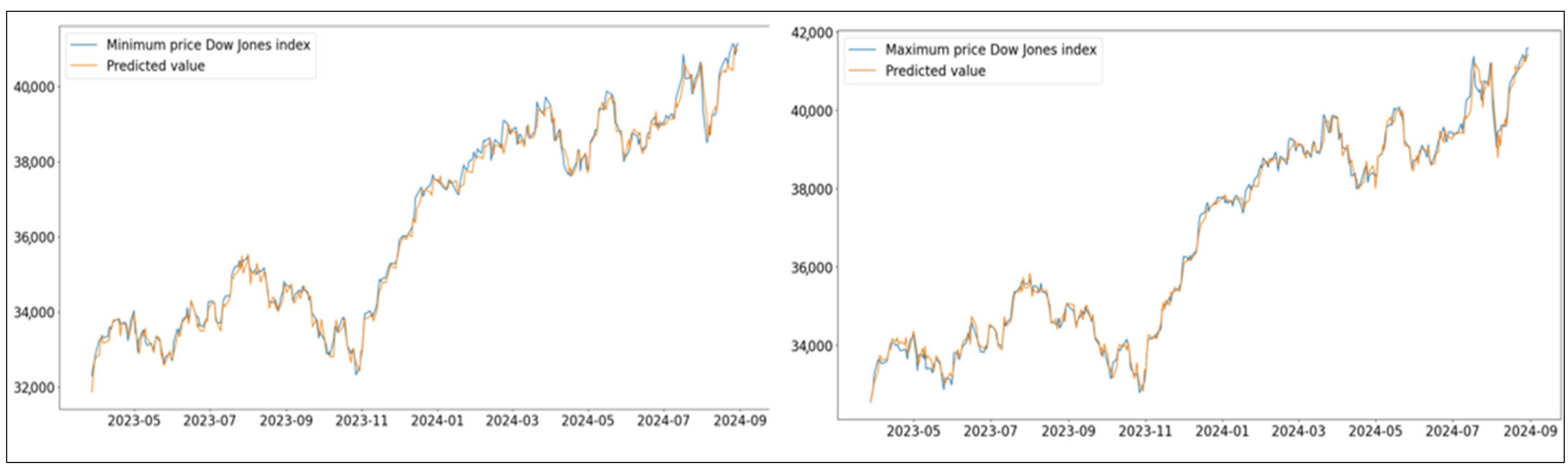
15], its performance is similar to those of the state-of-the-art methods. Additionally, a further experiment validated the model’s competitiveness, attaining MAPEs < 1 for every stock and index examined (
Figure 4,
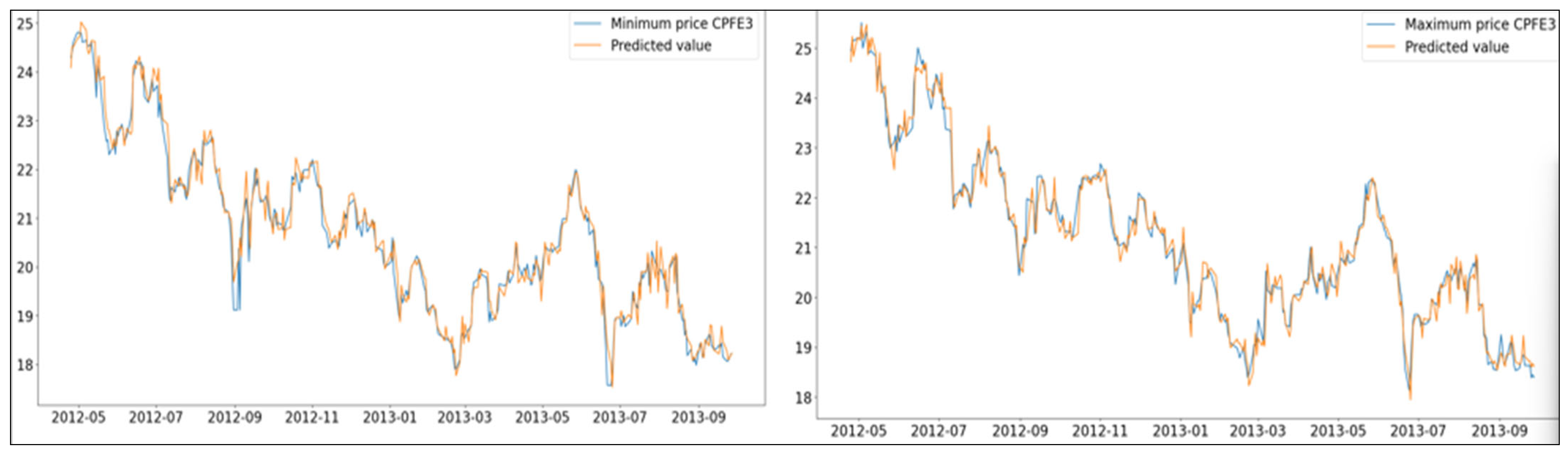
Figure 5 and
Figure 6).In addition to MAPE, the model’s performance was also evaluated using RMSE, MAE, and directional accuracy, as reported in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8. These metrics provide complementary perspectives on prediction quality. RMSE and MAE assess the magnitudes of the prediction errors, while directional accuracy evaluates whether the predicted price movement direction (up or down) matches the actual movement. These results suggest that the hybrid model is capable of effectively adapting to the specific characteristics of the analyzed stock data and market index; however, due to the limited number of datasets, further validation is required to confirm its general applicability across a broader range of financial assets.
It is also important to note that this study did not include a direct comparison with recent deep-learning-based forecasting models such as long short-term memory (LSTM) networks or the Temporal Fusion Transformer (TFT). These methods have demonstrated strong predictive capabilities in time series tasks but were excluded here due to their considerably higher computational requirements. Future research should consider benchmarking the proposed hybrid model against such architectures to assess relative performance in terms of both accuracy and resource efficiency.
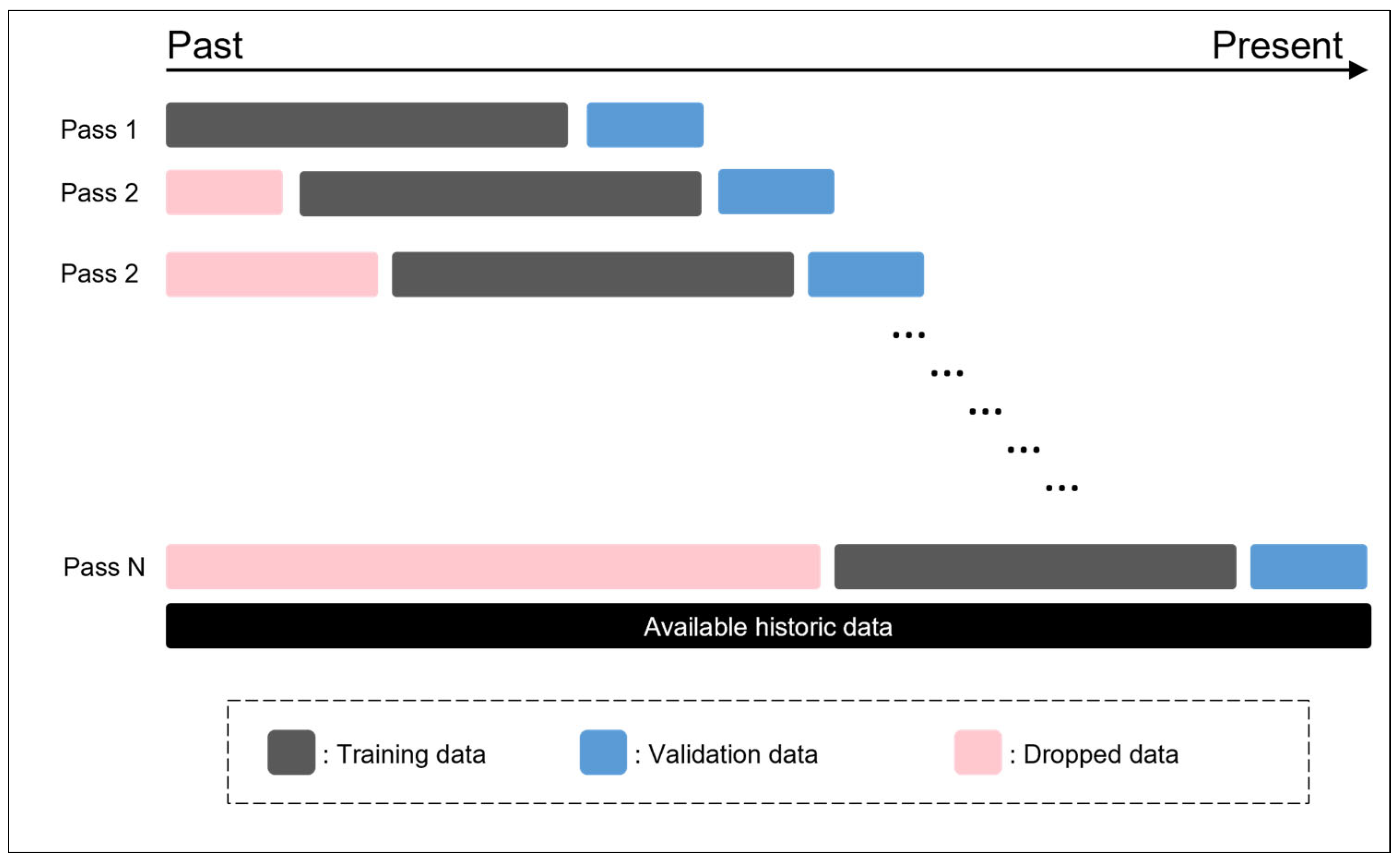
A key limitation of this study lies in the relatively narrow scope of the datasets used. Only two individual stocks (CSRN3.SA and CPFE3.SA) and one market index (DJI) were analyzed. Although these were selected based on their uses in prior benchmark studies to ensure methodological comparability, the limited dataset reduces the generalizability of the findings. Additionally, the time spans of the datasets are inconsistent: CSRN and CPFE cover the period from 2008 to 2013, while DJI spans 2018 to 2024. This temporal gap introduces macroeconomic and structural differences that may affect comparability and the interpretation of model performance across datasets. To partially address this, the DJI index was included to represent a broader international market context. Nevertheless, future research should incorporate a more diverse set of stocks from various sectors and global markets to further evaluate the robustness and scalability of the proposed hybrid model.
Another important consideration relates to the assumptions inherent in the proposed approach. The model assumes that short-term price dynamics can be effectively captured using only historical price data (five previous days) and weighted moving averages without incorporating technical indicators or external features. While this choice simplifies implementation and helps prevent overfitting, it also limits the model’s ability to capture sudden structural changes or external shocks. Future versions could benefit from integrating additional features, such as trading volume, volatility indices, or sectoral risk indicators.
This limited feature set is another notable constraint. By relying solely on historical prices and weighted moving averages (WMA), the model excludes potentially informative features such as trading volume, momentum-based indicators (e.g., RSI, MACD), and macroeconomic data. While this decision was made intentionally to control model complexity and focus on the stacking architecture, future studies should explore the effect of incorporating these variables on model accuracy and robustness.
While the proposed stacking model demonstrated strong predictive performance, its interpretability remains limited. As with many ensemble learning approaches, the internal decision logic of the model functions as a black box. This lack of transparency may hinder adoption in practical financial settings in which understanding the rationale behind predictions is essential. In future work, we recommend the use of SHAP (SHapley Additive exPlanations) values or permutation importance to identify the most influential input features and provide more interpretable insights into the model’s decision-making process.
Key factors affecting stock prices consist of news regarding company activities, mergers, and investments, as well as the macroeconomic variables of the nation where the company functions. In upcoming research, we suggest adding these variables to the model after assessing their correlations with stock prices and the trustworthiness of the information sources. Incorporating these variables might enhance prediction accuracy and account for the influence of external factors on stock prices.
In summary, although the proposed hybrid model has shown promising results, its evaluation remains limited to a narrow dataset and simplified input features. More extensive testing and enhancement are required before the model can be broadly applied. There remains considerable work to be accomplished in this field, particularly in improving generalization, interpretability, and real-time applicability across diverse market conditions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}