1. Introduction
Statistical projection estimates in the Monte Carlo method were first proposed by N.N. Chentsov [
1]. He developed a general technique for optimizing such estimates; this technique, however, requires clarification in specific problems [
2]. In the paper [
3], projection estimates based on the Legendre polynomials for marginal probability densities of solutions to stochastic differential equations were proposed. The mean square error of the estimates was studied, and a comparison of both the obtained projection estimates and the histogram was carried out with examples. The analysis of the results showed that for the same sample size, the projection estimate approximates the density more accurately. In addition, such an estimate is specified analytically, and it is a smooth function. So, it is preferable in, e.g., filtering problems and the control of nonlinear systems [
4,
5,
6,
7].
This paper presents two statistical algorithms, based on algorithms using Legendre polynomials from [
3], for jointly obtaining projection estimates of the density and distribution function of a random variable.
When solving different problems by statistical estimation algorithms, it is important to make an optimal (consistent) choice of their parameters for finding the mathematical expectation of a certain functional that depends on a random variable. Therefore, this paper analyzes the mean square error of the projection estimate from this point of view. Such parameters are the projection expansion length and sample size. We solve a conditional optimization problem considered by G.A. Mikhailov [
8]. The objective of this problem is to minimize the algorithm complexity while achieving the required level of approximation accuracy. We study how to minimize the mean square error of the projection estimates of the density and distribution function by the equalization of its deterministic and stochastic components. The accuracy of the projection estimates also depends on the degree of smoothness of the density; therefore, in this paper, we consider the dependence of error not only on the projection expansion length but also on the degree of smoothness of the approximated function.
The obtained theoretical results are confirmed with examples using a two-parameter family of densities that allows one both to choose the degree of smoothness and to perform a simple calculation of the expansion coefficients with respect to Legendre polynomials.
The rest of this paper has the following structure:
Section 2 contains the necessary information on the Fourier–Legendre series and the definition of projection estimates of the density and distribution function; in this section, relations for expansion coefficients of the density and distribution function with respect to Legendre polynomials are obtained.
Section 3 presents algorithms for jointly obtaining randomized projection estimates of the density and distribution function. The analysis and conditional optimization of randomized projection estimates are carried out in
Section 4.
Section 5 proposes a two-parameter family of densities with different degrees of smoothness and related distribution functions; it presents an algorithm for modeling the corresponding random variables, gives the expansion coefficients of the considered densities and distribution functions, and studies the convergence rate of their expansions. Numerical experiments and their analysis are discussed in
Section 6. In
Section 7, a projection estimate of the density is compared with a histogram. Brief conclusions on the paper are given in
Section 8.
3. Algorithms for Jointly Obtaining Randomized Projection Estimates of Density and Distribution Functions
The randomization of the projection estimate of the density
g is obtained by the first equation of Formula (
14) as a result of calculating linear functional (
15) for the Legendre polynomials (
6) by the Monte Carlo method with independent realizations of the random variable
:
where
is the
lth realization and
N is the sample size (number of realizations).
Estimates
can also be obtained from expression (
16) as
where
are statistical estimates of initial moments of the random variable
,
and
. Using Formulae (
4) and (
5), we can write the expressions for the estimates of the density expansion coefficients separately for even indices (
), as
and for odd indices (
), as
The randomization of the projection estimate of the distribution function
f is obtained by the second equation of Formula (
14) and recurrence relations (
20):
Here and below, the dependence of the estimates of both expansion coefficients and functions on the sample size N is not indicated for simplicity.
Remark 3. To obtain a projection estimate of the distribution function f based on the first Legendre polynomials, it is necessary to find estimates of the expansion coefficients of the density g with respect to the first Legendre polynomials.
Further, we present Algorithm 1 for jointly obtaining randomized projection estimates of the density and distribution function of the random variable
.
| Algorithm 1: Jointly obtaining projection estimates of the density and distribution function using explicit formulae for the Legendre polynomials. |
0. Set the projection expansion length n and the sample size N.
1. Simulate N realizations of the random variable , .
2. Find statistical estimates of initial moments of the random variable using Formula (23), . Set .
3. Find estimates of expansion coefficients of the density g using Formula (22) or Formulae (24) and (25), .
4. Find estimates of expansion coefficients of the distribution function f using Formula (26), .
5. Find randomized projection estimates and of the density and distribution function, respectively, using Formula (14).
|
In step 3 in Algorithm 1, errors can occur due to the peculiarities of machine arithmetic when calculating expansion coefficients
. To avoid this, it is recommended to use Formula (
21) together with recurrence relation (
1) and expression (
6).
Next, we formulate Algorithm 2 for jointly obtaining randomized projection estimates of the density and distribution function.
| Algorithm 2: Jointly obtaining projection estimates of the density and distribution function using the recurrence relation for the Legendre polynomials. |
0. Set the projection expansion length n and the sample size N.
1. Simulate N realizations of the random variable , .
2. Find estimates of expansion coefficients of the density g using Formula (21) together with recurrence relation (1) and expression (6), .
3. Find estimates of expansion coefficients of the distribution function f using Formula (26), .
4. Find randomized projection estimates and of the density and distribution function, respectively, using Formula (14).
|
4. Analysis and Conditional Optimization of Randomized Projection Estimates
In this section, we analyze the error of the projection estimate
relative to the density
g of the random variable
in
. Let
; then,
due to Jensen’s inequality [
21]. Further, we consider the following expression:
Functions
and
are orthogonal in
since they belong to different subspaces. The first one is formed by the Legendre polynomials
for
, and the second one is formed by the Legendre polynomials
for
. This is a consequence of the equalities
hence,
According to Parseval’s identity [
9], we have
and
Therefore, taking into account that the unbiased estimate of mathematical expectation is used [
18], namely,
, we obtain
where
denotes the variance.
The equality
is satisfied since
, i.e.,
. For
, the variance of estimates
and the sample size
N are inversely proportional [
22]; therefore, using additionally inequality (
9) under the condition
(see Remark 1), we find
where
are constants independent of
n and
N.
The error of the projection estimate
relative to the distribution function
f of the random variable
in
is analyzed similarly:
where
are constants independent of
n and
N.
From the obtained estimates, it is clear how the mean square error depends on the projection expansion length n and the sample size N.
Further, we consider a problem of the optimal (consistent) choice of parameters for statistical algorithms to obtain projection estimates of the density and distribution function: the projection expansion length n and the sample size N. For jointly obtaining these estimates by Algorithms 1 and 2, it is sufficient to consider the optimal choice of parameters for density estimation only and use them for distribution function estimation. This is because the degree of smoothness of f is greater than the degree of smoothness of g, so the sequence converges to f faster than the sequence converges to g.
The main result is stated using the symbol “≍”. The expression for suitable functions u and v means that and for ; i.e., there exist constants such that , where n and are natural numbers.
Theorem 1. Let the density g of the random variable ξ belong to , and let be the randomized projection estimate of the density obtained by Algorithms 1 or 2 with the projection expansion length n and the sample size N. Then, the minimum complexity of obtaining the estimate is achieved with the parameters and that satisfy relationswhere γ is the required approximation accuracy for the density g in , i.e., . Proof. To find the optimal parameters
and
for the estimate
, it is sufficient to equate terms [
8] in Formula (
28) and express the required approximation accuracy
from the relation
From the equality
we obtain the relationship for the optimal parameters, i.e.,
, as well as expressions
and consequently,
and
. □
Theorem 1 establishes the relationship between parameters in Algorithms 1 and 2,
n and
N, as well as the dependence of approximation accuracy on parameter
s. By choosing parameters in this way, we have
where
is a constant independent of
n and
N.
Remark 4. The error (
28)
of the randomized projection estimate relative to the density g is based on inequality (
9)
, but inequality (
10)
can also be used. Then, taking into account Remark 1, we have It is possible to formulate an analogue of Theorem 1 and show that the following relationship between parameters for estimating the density g is conditionally optimal: Remark 5. If the distribution function f of the random variable ξ belongs to (this condition holds if the density g of the random variable ξ belongs to , i.e., if the conditions of Theorem 1 are satisfied), then the minimum complexity of obtaining randomized projection estimate by Algorithms 1 or 2 is achieved with parameters and that satisfy relationswhere γ is the required approximation accuracy for the function f in , i.e., . The proof is similar to the proof of Theorem 1. Another relationship between parameters can be found if we take inequality (
10)
instead of inequality (
9)
(see Remark 4). 5. Two-Parameter Family of Densities with Different Degrees of Smoothness
In this section, a special example is proposed to test statistical algorithms for obtaining projection estimates depending on the projection expansion length, sample size, and smoothness of the estimated function.
5.1. Densities with Different Degrees of Smoothness and Related Distribution Functions
Let
be the random variable defined by the density
:
where
and
are parameters (natural numbers) and
is a normalizing constant, with
because
Further, we assume that . The function has the following properties:
(a) is continuous on the set of real numbers;
(b) The support of is the set ;
(c) The normalization condition holds:
(d)
is differentiable at
only
r times:
(e) The derivative
exists almost everywhere on
; if the derivative is understood in a generalized sense, then
Next, we determine the distribution function
for the random variable
with density (
30):
It is easy to see that
for
and
for
. Moreover,
and consequently,
The function
is differentiable
times at
since
due to relationship (
31). Thus,
If we do not restrict ourselves to the space with natural s (see Remark 1), then we can show that and .
Consider the case
. Then, the generalized derivative
is represented as a linear combination of functions
and
, where
is the indicator of
. It suffices to find a condition for parameter
which ensures that
, where
is defined by Formula (
11) and
.
If
x and
y have the same sign, then
, and if
x and
y have different signs, then
. Hence,
The integrals on the right-hand side of the latter equality coincide since the integrand does not change when the signs of
x and
y change simultaneously. The convergence condition for them is
. Indeed, for
, we have
and
For , these integrals obviously diverge. Therefore, for , and for .
The case is similar to the considered case, so finally, and , provided that and .
5.2. Modeling Random Variables with Given Test Distributions Using Monte Carlo Method
The modeling formula for the random variable
with distribution function
for parameters
and
can be derived using the inverse function method [
22]:
, where
is the inverse function to
and
is the random variable having a uniform distribution on
.
Given the distribution function
, we can obtain the Algorithm 3 for modeling the random variable
.
| Algorithm 3: Modeling the random variable with given test density and distribution function. |
|
0. Set parameters , , calculate and :
|
| 1. Obtain a realization of the random variable having a uniform distribution on . |
| 2. If , then is a root of the algebraic equation
|
| from , otherwise is a root of the algebraic equation
|
| from . |
For small and , roots can be found analytically. Next, we obtain the modeling formulae for two cases used below.
Proposition 1. For the random variable ξ with densitythe modeling formula is as follows:where Proof. The density
g of the random variable
is included in a two-parameter family (
30) for
,
, and
:
. For given parameters, we have
First, we consider the case
; i.e., we should solve Equation (33). This is the quadratic equation
where
,
.
The function
has a minimum at
since
,
and
. This means that the quadratic equation has two real roots (the discriminant is positive) and the largest of them determines
:
Second, we consider the case
; i.e., we should solve Equation (34). This is the cubic equation
where
,
.
The function
has extrema at
:
. A minimum is reached at
:
and
. A maximum is reached at
:
and
. This means that the cubic equation has three real roots (the discriminant is positive) and
is determined by the root that lies between the smallest and the largest roots. By using Cardano’s formulae for roots [
23], we have
where
and
, which corresponds to the positive discriminant; therefore,
A and
B are complex conjugate numbers:
Let
. Since
and
, we obtain
; therefore,
and
Thus,
i.e., Formula (
35) is valid. □
Proposition 2. For the random variable ξ with densitythe modeling formula is as follows:where Proof. The density
g of the random variable
is included in a two-parameter family (
30) for
,
, and
:
. In this case,
The proof is the same as for Proposition 1, so some details are omitted. We only note that for
, Equation (33) is the quartic equation
where
,
, the polynomial
has a minimum at
, and
. The quartic equation has two real roots, and the largest of them determines
. It is convenient to find roots using Ferrari’s formulae [
23].
For
, Equation (34) is the cubic equation that is solved similarly to the cubic equation from the proof of Proposition 1. Such reasoning leads to Formula (
36). □
5.3. Expansion Coefficients of Test Functions (Fourier–Legendre Series)
To exactly calculate the second term of the projection estimate error (
27) in examples, we find expansion coefficients
of the density
, as well as expansion coefficients
of the distribution function
with respect to Legendre polynomials (
6):
First, we obtain the following values:
We multiply the left-hand and right-hand sides of relation (
1) by
and integrate over the interval
:
or
Similarly, by multiplying the left-hand and right-hand sides of relation (
1) by
and integrating over the interval
, we obtain
These relations can be formally applied for
when
but not for
. Therefore, we should consider the case
separately:
For
and
, we have
and then we use relation (
17):
If
is even, then
according to Formula (
5), and
. If
i is odd, then we can apply the explicit Formula (
4) or obtain an additional recurrence relation. We choose the latter way and take into account relation (
1) for
:
The same reasoning leads to the following results:
and
where
for even
. For odd
i, we have
Thus, we obtain the general expression for calculating
and
with arbitrary non-negative integers
and
i:
so that the expansion coefficients of the density
with respect to Legendre polynomials (
6) are expressed as follows (relation (
37) is also used here):
Expressions for the expansion coefficients of the distribution function
are similarly obtained:
These expressions for the expansion coefficients of the density
and distribution function
are used for their approximation as
and for the approximation error:
5.4. Analysis of Convergence Rate for Expansions of Test Functions
Consider the function
where
is a parameter (natural number). Its expansion coefficients
with respect to Legendre polynomials (
6) are expressed through the previously found values
:
Further, we derive the recurrence relation for
, different from relation (
38). We multiply the left-hand and right-hand sides of relation (
1) by
and integrate over the interval
:
Next, we use the rule of integration by parts:
and consequently, taking into account equality (
17), we obtain
therefore,
or
i.e.,
The series formed by the squared expansion coefficients
converges since
. It can be represented as a sum of two series:
The Raabe–Duhamel test [
24] implies that the first series (similarly for the second one) converges in the same way as the series
since the sequence
has the limit
, but the convergence of this series is equivalent to the convergence of the integral
which takes place under the condition
, or
.
As a result, using Parseval’s identity, we find
where
and this corresponds to estimate (
9) with the limit value
(see Remark 1).
The obtained result can be transferred to the function
and its expansion coefficients
with respect to Legendre polynomials (
6). The easiest way to prove this is the use of the equality
, which follows from the relation between expansion coefficients of an arbitrary function from
and its reflection [
25]. Therefore, the same result holds for the function
. This result can be extended to the function
due to its degree of smoothness is greater by one than the degree of smoothness of
.
Thus,
where
are some constants. Moreover, we can assume that
and
are real positive numbers, and if we consider
not to be a density but some function not bound by the probability theoretical framework, then the condition
is admissible. Such a convergence reflects that
and
subject to
and
. It corresponds to estimate (
9).
6. Numerical Experiments
In this section, we present the results of the joint estimation of the density and distribution function for two examples that use a two-parameter family (
30) of densities with different degrees of smoothness. In these examples, the results are presented in the tables that contain the errors of the projection estimates of the density and distribution function in
. We study the dependence of error on the projection expansion length (for the maximum degree
n of the Legendre polynomials, values 4, 8, 16, 32, and 64 are used, i.e.,
for
), on the sample size
for
, and on the degree of smoothness of the approximated density (see Examples 1 and 2 below). Algorithm 2 is applied for estimation.
These examples show the approximation errors
and
, which are calculated using Formula (
39), i.e., deterministic components of projection estimate errors. In the tables, they are in rows marked by the symbol “∗”. The remaining rows contain errors that include deterministic and stochastic components. The formulae for these errors follow from Parseval’s identity:
where
and
are estimates of expansion coefficients
and
, respectively. For an arbitrary density
g, a similar formula was used to obtain estimate (
27).
Example 1. Let be the density from a two-parameter family (
30)
, and let be the related distribution function described by Formula (
32)
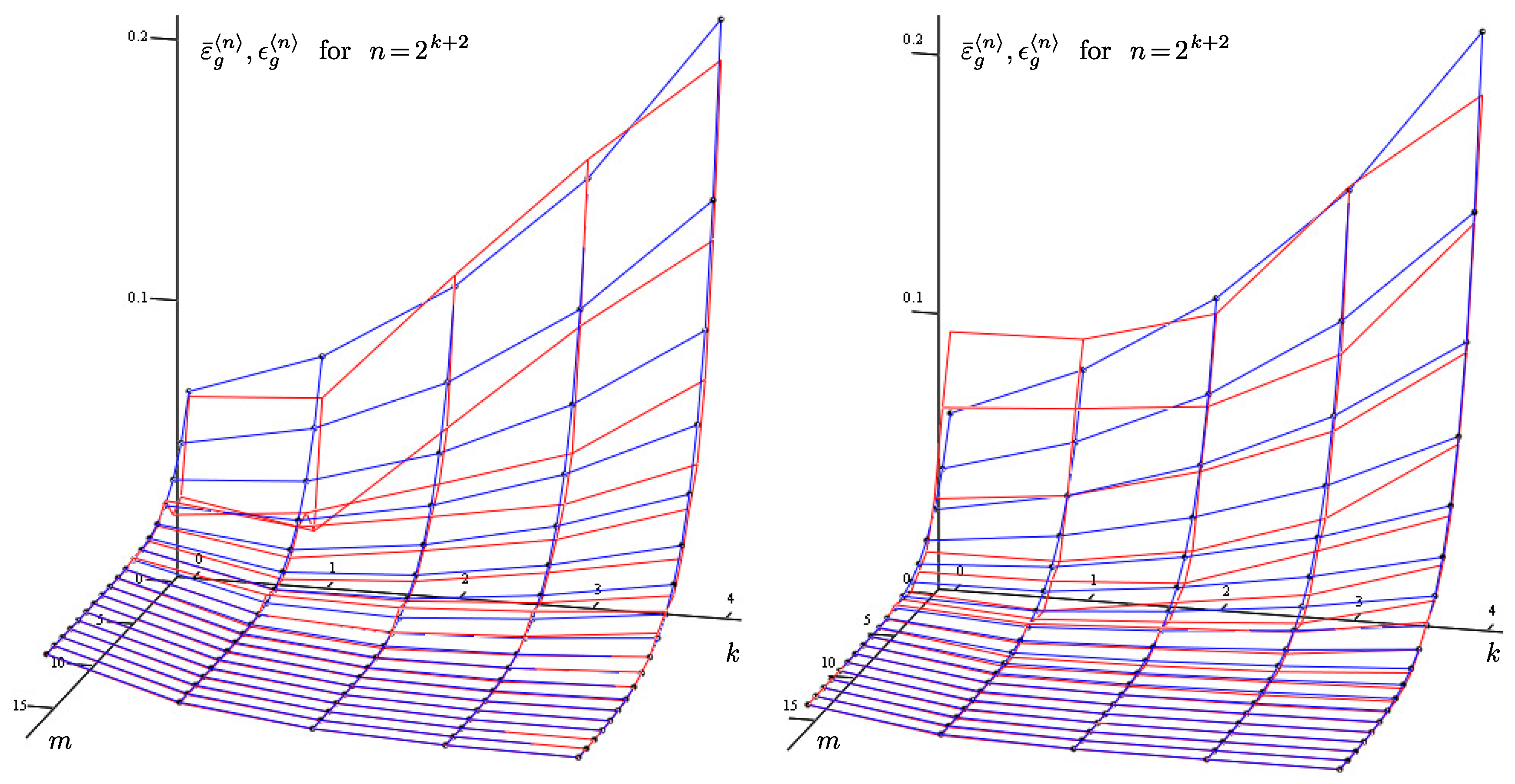
, with the following parameters: , for . The modeling formula is given in Proposition 1. The function is continuous, non-differentiable at , but its first-order derivative exists almost everywhere on Ω: , , i.e., . However, if we do not restrict ourselves to the space with natural s (see Remark 1), then for (). The degree of smoothness of is greater, and . This corresponds to Formulae (40), which take the formfor given parameters and . According to Theorem 1, for the limit value , to achieve the required approximation accuracy , , the conditionally optimal parameters should be as follows: ; this is confirmed by the statistical modeling results (see Table 1 and Table 2). In the row “∗” of Table 1, the deterministic component of error decreases by approximately times (in Table 2, by approximately times) when the projection expansion length n is doubled. In the rest of this table, errors corresponding to optimal parameters and are highlighted in bold, and they are consistent with the relationship . Table 2 demonstrates higher accuracy of distribution function estimation. In our calculations with the formulae for errors, the following values are used (squared norms of the functions and ): For clarity, Figure 1 contains the approximation errors in graphical form. One axis shows , which determines the projection expansion length, , and another axis shows , which determines the sample size, . The vertical axis corresponds to the density approximation errors. The example under consideration corresponds to the left part of Figure 1, which presents two surfaces. The first one (red) corresponds to the obtained computational error, it is formed on data from Table 1. The second one (blue, with marked nodes) corresponds to the theoretical error according to Formula (28) with : Constants and are approximately determined based on the condition of a minimum sum of squared deviations between the theoretical error and computational error.
Example 2. Let be the density from a two-parameter family (
30)
, and let be the related distribution function described by Formula (
32)
, with the following parameters: , for . The modeling formula is given in Proposition 2. The function is continuous, differentiable everywhere on Ω, and its second-order derivative exists almost everywhere on Ω: , ; hence, . Considering the space with real non-negative s (see Remark 1), we affirm that for (). The degree of smoothness of is greater, and . This corresponds to Formula (
40)
when substituting given parameters and : Theorem 1 implies that in order to achieve the required approximation accuracy , , with the limit value , the conditionally optimal parameters should satisfy the relationship , and this is illustrated by the statistical modeling results from Table 3 and Table 4. In the row “∗” of Table 3, if the projection expansion length n is doubled, then the deterministic component of error decreases by approximately times (in Table 4, by approximately times). In the rest of this table, errors corresponding to optimal parameters and are shown in bold, and they are consistent with the relationship . Table 4 shows higher accuracy of distribution function estimation. In our calculations with the formulae for errors, the following values are used (squared norms of the functions and ): Figure 1 contains a graphical representation of the numerical experiment. The meaning of different axes is described in Example 1. This example corresponds to the right part of Figure 1 with two surfaces. The first one (red) is constructed from the obtained computational error given in Table 3, and the second one (blue, with marked nodes) corresponds to the theoretical error according to Formula (28) with :where constants and are chosen from the same condition as in Example 1. 7. Comparison of Projection Density Estimate and Histogram
The classical method of estimating the density of a random variable is associated with a histogram [
18], which is very often used in applied problems. We consider a histogram a projection estimate since the main results of this paper are related to projection estimates.
We can define block pulse functions on the set
as
where
L, a natural number, is the number of block pulse functions and
. It is advisable to redefine the function
in such a way that it becomes continuous on the left at
.
Block pulse functions (
41) form an orthonormal system of functions in
. This system is not complete, but it can be used to approximate an arbitrary function
:
where
For
with natural
m, the first
L Walsh or Haar functions on
are exactly expressed through block pulse functions (
41). Therefore, the results of this section can easily be adapted to the projection estimates of the distribution of a random variable using Walsh or Haar functions that form complete orthonormal systems of functions [
26].
The approximation accuracy in
is usually estimated as follows [
27]:
where
does not depend on
L, under the condition
.
As a function
u in the given formulae, we can use the density
g and the distribution function
f. We restrict ourselves to the density
g only (the corresponding expansion coefficients are further denoted by
):
where
Thus, the calculation of expansion coefficients
of the density
from a two-parameter family (
30) is reduced to the calculation of values of the corresponding distribution function
described by Formula (
32), i.e.,
To calculate the approximation error for the density
, we can use the formula similar to the first equation of Formula (
39):
The histogram can be defined by the expression based on approximation (
43):
where
are estimates of expansion coefficients
based on observations of the random variable
,
. For example,
where
is the
lth realization and
N is the sample size (number of realizations). The value
h depending on
L specifies the histogram step.
The error of the histogram
relative to the density
g includes deterministic and stochastic components, and it is estimated from below by the value
:
The results of calculations using Formula (
44) for both densities from Examples 1 and 2 are given in
Table 5 and
Table 6, respectively. They should be compared with the rows “∗” in
Table 1 and
Table 3. Such a comparison shows the undoubted advantage of projection density estimates using Legendre polynomials. The approximation accuracy when using block pulse functions for
corresponds to the approximation accuracy when using Legendre polynomials for
in Example 1 and for
in Example 2. If the number of block pulse functions
L is doubled, then the deterministic component of error decreases by approximately 2 times, and this conclusion does not depend on the degree of smoothness of the estimated density.
The problem of the conditional optimization of the algorithm for obtaining the histogram was solved in [
1]. In this problem, optimal parameters satisfy the relationship
which corresponds to inequality (
42). A generalization of this result in the context of stochastic differential equations can be found in [
3]. Choosing parameters in this way, the computational error
will be approximately twice as large as its deterministic component
, since the conditional optimization of the algorithm for obtaining the histogram assumes the equalization of deterministic and stochastic components.
For densities from Examples 1 and 2, to reduce the approximation error using the histogram by 2 times, it is necessary to increase the number of block pulse functions L by 2 times and the sample size N by times. The projection estimates of densities using Legendre polynomials are more effective in these examples. To reduce the approximation error by 2 times in Example 1, it suffices to increase the projection expansion length n by times and the sample size N by times. In Example 2, it suffices to increase the projection expansion length n by times and the sample size N by times. In this case, increasing n and N implies their subsequent rounding-up.





{kind=link}
{kind=link}