
DRFAN: A Lightweight Hybrid Attention Network for High-Fidelity Image Super-Resolution in Visual Inspection Applications

 , ,
, , 
Abstract
1. Introduction
- We propose the DRFAN, a novel lightweight SISR framework that innovatively integrates the MLLA module and GAB into a unified hybrid architecture. This design enables dynamic multi-scale feature selection through parallel processing mechanisms, reduces channel redundancy, and establishes cross-layer global context modeling pathways, ensuring robust global representation capabilities.
- We introduce the GAB module to extend pixel interaction beyond local regions via a hierarchical interaction strategy. By leveraging structural similarity priors between image patches, it optimizes spatial information aggregation efficiency, significantly enhancing the reconstruction of high-frequency textures and fine-grained details.
- We design a tightly coupled residual framework to synergize the advantages of convolutional local feature extraction, the long-range dependency modeling capability of self-attention, and the efficient computational characteristics of Mamba. This complementary feature fusion mechanism achieves the coordinated optimization of these three core operations.
- Experimental results on multiple benchmark SR datasets demonstrate that the DRFAN shows significant advantages in SISR tasks and industrial inspection scenarios, offering an efficient and reliable solution for practical applications.
2. Related Work
2.1. Lightweight Single-Architecture Super-Resolution Network
2.2. Lightweight Hybrid Architecture Super-Resolution Network
3. Materials and Methods
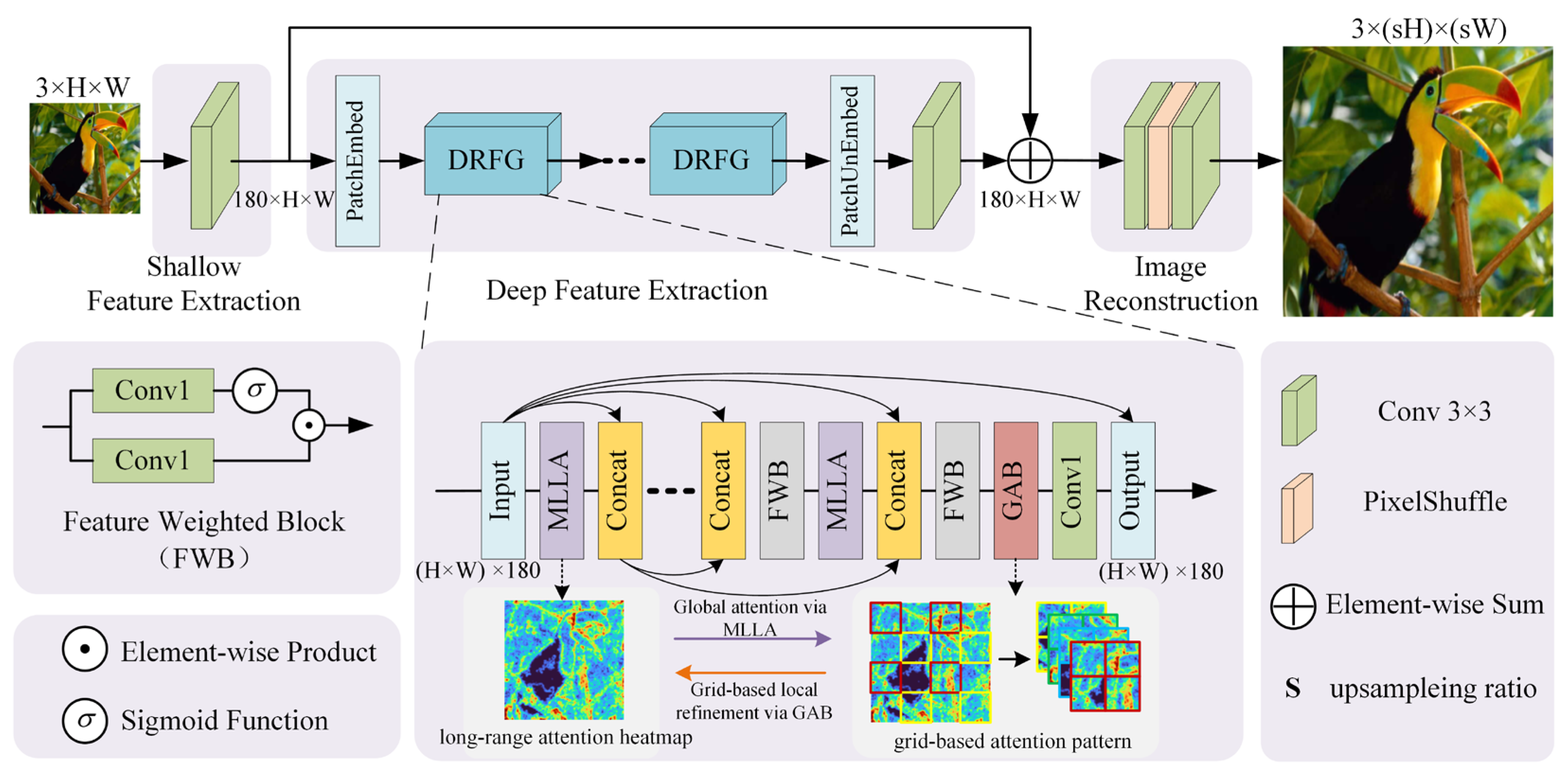
3.1. Overall Architecture
3.2. Dense Residual Fused Group (DRFG)
3.3. Mamba-like Linear Attention (MLLA) Block
3.3.1. Unified SSM Gating and Linear Attention Framework
3.3.2. Computational Optimization and Spatial Gating Enhancement
3.4. Grid Attention Block (GAB)
3.4.1. Local Attention Enhancement via GAB
3.4.2. Complexity Analysis and Efficiency Optimization
4. Experiments
4.1. Datasets
4.2. Metrics
4.3. Implementation Details
4.4. Training Setting
4.5. Ablation Study
- (1)
- Efficacy of SGFN Module
- (2)
- Efficacy of GAB Module
- (3)
- Qualitative Analysis and Error Map Visualization
4.6. Benchmark Comparisons on Public Datasets
4.6.1. Quantitative Analysis
4.6.2. Qualitative Experiments
4.6.3. Parameter Analysis
4.7. Comparative Experiments on Rice Grain Dataset
4.7.1. Quantitative Analysis
4.7.2. Qualitative Experiments
4.7.3. Statistical Validation
5. Discussion
5.1. Efficiency–Accuracy Trade-Off and Linear Complexity Advantage
5.2. Limitations on Scalability to Higher Magnification
5.3. Generalization to Motion Blur and Real-World Degradations
5.4. Embedded Deployability and Future Evaluation
5.5. Broader Industrial Applicability and Future Dataset Expansion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, K.; Yang, S.; Dong, R.; Wang, X.; Huang, J. Survey of single image super—Resolution reconstruction. IET Image Process. 2020, 14, 2273–2290. [Google Scholar] [CrossRef]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN variants for computer vision: History, architecture, application, challenges and future scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 391–407. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th Acm International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual feature distillation network for lightweight image super-resolution. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; pp. 41–55, Proceedings, Part III 16. [Google Scholar]
- Arun, P.V.; Buddhiraju, K.M.; Porwal, A.; Chanussot, J. CNN-based super-resolution of hyperspectral images. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 6106–6121. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Choi, H.; Lee, J.; Yang, J. N-gram in swin transformers for efficient lightweight image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2071–2081. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 457–466. [Google Scholar]
- Qu, M.; Wu, Y.; Liu, W.; Gong, Q.; Liang, X.; Russakovsky, O.; Zhao, Y.; Wei, Y. Siri: A simple selective retraining mechanism for transformer-based visual grounding. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 546–562. [Google Scholar]
- Lin, H.; Zou, J.; Wang, K.; Feng, Y.; Xu, C.; Lyu, J.; Qin, J. Dual-space high-frequency learning for transformer-based MRI super-resolution. Comput. Methods Programs Biomed. 2024, 250, 108165. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020; pp. 5156–5165. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023. [Google Scholar] [CrossRef]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Zhang, H.; Zhu, Y.; Wang, D.; Zhang, L.; Chen, T.; Wang, Z.; Ye, Z. A survey on visual mamba. Appl. Sci. 2024, 14, 5683. [Google Scholar] [CrossRef]
- Qu, H.; Ning, L.; An, R.; Fan, W.; Derr, T.; Liu, H.; Xu, X.; Li, Q. A survey of mamba. arXiv 2024, arXiv:2408.01129. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Mienye, I.D.; Swart, T.G.; Obaido, G. Recurrent neural networks: A comprehensive review of architectures, variants, and applications. Information 2024, 15, 517. [Google Scholar] [CrossRef]
- Han, D.; Wang, Z.; Xia, Z.; Han, Y.; Pu, Y.; Ge, C.; Song, J.; Song, S.; Zheng, B.; Huang, G. Demystify mamba in vision: A linear attention perspective. Adv. Neural Inf. Process. Syst. 2025, 37, 127181–127203. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 191–207, Proceedings, Part XII 16. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.-T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Luo, X.; Xie, Y.; Zhang, Y.; Qu, Y.; Li, C.; Fu, Y. Latticenet: Towards lightweight image super-resolution with lattice block. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 272–289, Proceedings, Part XXII 16. [Google Scholar]
- Sun, L.; Dong, J.; Tang, J.; Pan, J. Spatially-adaptive feature modulation for efficient image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 13190–13199. [Google Scholar]
- Lei, X.; Zhang, W.; Cao, W. Dvmsr: Distillated vision mamba for efficient super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 6536–6546. [Google Scholar]
- Urumbekov, A.; Chen, Z. Contrast: A Hybrid Architecture of Transformers and State Space Models for Low-Level Vision. arXiv 2025, arXiv:2501.13353. [Google Scholar]
- Wen, J.; Hou, W.; Van Gool, L.; Timofte, R. Matir: A hybrid mamba-transformer image restoration model. arXiv 2025, arXiv:2501.18401. [Google Scholar]
- Xiao, Y.; Yuan, Q.; Jiang, K.; Chen, Y.; Zhang, Q.; Lin, C. Frequency-assisted mamba for remote sensing image super-resolution. IEEE Trans. Multimedia 2024, 27, 1783–1796. [Google Scholar] [CrossRef]
- He, Y.; He, Y. MPSI: Mamba enhancement model for pixel-wise sequential interaction Image Super-Resolution. arXiv 2024. [Google Scholar] [CrossRef]
- Ren, Y.; Li, X.; Guo, M.; Li, B.; Zhao, S.; Chen, Z. Mambacsr: Dual-interleaved scanning for compressed image super-resolution with ssms. arXiv 2024, arXiv:2408.11758. [Google Scholar]
- Chu, S.-C.; Dou, Z.-C.; Pan, J.-S.; Weng, S.; Li, J. Hmanet: Hybrid multi-axis aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 6257–6266. [Google Scholar]
- Chen, Z.; Zhang, Y.; Gu, J.; Kong, L.; Yang, X.; Yu, F. Dual aggregation transformer for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12312–12321. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.-H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Guildford, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the Curves and Surfaces: 7th International Conference, Avignon, France, 24–30 June 2010; Revised Selected Papers 7. 2012; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimedia Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Li, W.; Zhou, K.; Qi, L.; Jiang, N.; Lu, J.; Jia, J. Lapar: Linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond. Adv. Neural Inf. Process. Syst. 2020, 33, 20343–20355. [Google Scholar]
- Zhu, X.; Guo, K.; Ren, S.; Hu, B.; Hu, M.; Fang, H. Lightweight image super-resolution with expectation-maximization attention mechanism. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1273–1284. [Google Scholar] [CrossRef]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring sparsity in image super-resolution for efficient inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4917–4926. [Google Scholar]
- Huang, Y.; Li, J.; Gao, X.; Hu, Y.; Lu, W. Interpretable detail-fidelity attention network for single image super-resolution. IEEE Trans. Image Process. 2021, 30, 2325–2339. [Google Scholar] [CrossRef]
- Sun, L.; Pan, J.; Tang, J. Shufflemixer: An efficient convnet for image super-resolution. Adv. Neural Inf. Process. Syst. 2022, 35, 17314–17326. [Google Scholar]
- Yu, L.; Li, X.; Li, Y.; Jiang, T.; Wu, Q.; Fan, H.; Liu, S. Dipnet: Efficiency distillation and iterative pruning for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1692–1701. [Google Scholar]
- Wang, H.; Zhang, Y.; Qin, C.; Van Gool, L.; Fu, Y. Global aligned structured sparsity learning for efficient image super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10974–10989. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MLP | SGFN | GAB | Params (K) | Set5 PSNR (dB) /SSIM | Set14 PSNR (dB) /SSIM | BSD100 PSNR (dB) /SSIM | Urban100 PSNR (dB) /SSIM | Manga109 PSNR (dB) /SSIM |
|---|---|---|---|---|---|---|---|---|---|
| A | √ | 1035 | 32.19/0.8944 | 28.58/0.7809 | 27.58/0.7362 | 25.95/0.7811 | 30.37/0.9064 | ||
| B | √ | 1087 | 32.30/0.8959 | 28.67/0.7830 | 27.61/0.7374 | 26.14/0.7863 | 30.62/0.9089 | ||
| C | √ | √ | 952 | 32.16/0.8944 | 28.54/0.7806 | 27.56/0.7356 | 25.89/0.7789 | 30.34/0.9058 | |
| D | √ | √ | 1057 | 32.30/0.8960 | 28.65/0.7831 | 27.63/0.7381 | 26.19/0.7882 | 30.67/0.9100 |
| Methods | Params (K) | FLOPs (G) | Set5 PSNR (dB)/ SSIM | Set14 PSNR (dB)/ SSIM | BSD100 PSNR (dB)/ SSIM | Urban100 PSNR (dB)/ SSIM | Manga109 PSNR (dB)/ SSIM |
|---|---|---|---|---|---|---|---|
| SRCNN [3] | 57 | 52.7 | 30.48/0.8628 | 27.49/0.7503 | 26.90/0.7101 | 24.52/0.7221 | 27.66/0.8505 |
| FSRCNN [4] | 12 | 4.6 | 30.71/0.8657 | 27.59/0.7535 | 26.98/0.7150 | 24.62/0.7280 | 27.90/0.8517 |
| VDSR [5] | 665 | 612.6 | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 | 28.83/0.8809 |
| EDSR-baseline [6] | 1518 | 114.0 | 32.09/0.8938 | 28.58/0.7813 | 27.57/0.7357 | 26.04/0.7849 | 30.35/0.9067 |
| CARN [7] | 1592 | 90.9 | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | -/- |
| IMDN [8] | 715 | 40.9 | 32.21/0.8948 | 28.58/0.7811 | 27.56/0.7353 | 26.04/0.7838 | 30.45/0.9075 |
| RFDN [9] | 550 | 23.9 | 32.24/0.8952 | 28.61/0.7819 | 27.57/0.7360 | 26.11/0.7858 | 30.58/0.9089 |
| LatticeNet [31] | 777 | 43.6 | 32.18/0.8943 | 28.61/0.7812 | 27.57/0.7355 | 26.14/0.7844 | 30.54/0.9075 |
| LAPAR-A [48] | 659 | 94.0 | 32.15/0.8944 | 28.61/0.7818 | 27.61/0.7366 | 26.14/0.7871 | 30.42/0.9074 |
| EMASRN [49] | 546 | - | 32.17/0.8948 | 28.57/0.7809 | 27.55/0.7351 | 26.01/0.7938 | 30.41/0.9076 |
| SMSR [50] | 1006 | 57.2 | 32.12/0.8932 | 28.55/0.7808 | 27.55/0.7351 | 26.11/0.7868 | -/- |
| DeFiAN [51] | 1065 | 12.8 | 32.16/0.8942 | 28.63/0.7810 | 27.58/0.7363 | 26.10/0.7862 | 30.59/0.9084 |
| ShuffleMixer [52] | 411 | 28.0 | 32.21/0.8953 | 28.66/0.7827 | 27.61/0.7366 | 26.08/0.7835 | 30.65/0.9093 |
| SAFMN [32] | 240 | 14.0 | 32.18/0.8949 | 28.60/0.7813 | 27.58/0.7359 | 25.97/0.7809 | 30.43/0.9063 |
| DIPNet [53] | 543 | 72.97 | 32.20/0.8950 | 28.58/0.7811 | 27.59/0.7364 | 26.16/0.7879 | 30.53/0.9087 |
| DVMSR [33] | 424 | 19.67 | 32.19/0.8955 | 28.61/0.7823 | 27.58/0.7379 | 26.03/0.7838 | 30.48/0.9084 |
| GASSL-B [54] | 694 | 39.9 | 32.17/0.8950 | 28.66/0.7835 | 27.62/0.7377 | 26.16/0.7888 | 30.70/0.9100 |
| DRFAN (ours) | 1057 | 65.1 | 32.30/0.8960 | 28.65/0.7831 | 27.63/0.7381 | 26.19/0.7882 | 30.67/0.9100 |
| Scale | Methods | Params (K) | PSNR (dB)/SSIM | Inference Time (ms) |
|---|---|---|---|---|
| ×4 | CARN [7] | 1592 | 34.91/0.8370 | 57.7 |
| IMDN [8] | 715 | 36.54/0.8944 | 26.0 | |
| SAFMN [32] | 240 | 37.65/0.9122 | 8.9 | |
| ShuffleMixer [52] | 411 | 37.86/0.9137 | 17.8 | |
| SwinIR-S [12] | 897 | 37.90/0.9150 | 31.5 | |
| DRFAN (ours) | 1057 | 38.09/0.9165 | 41.3 |
| Comparison | Metric | p-Value | Significance (p < 0.01) |
|---|---|---|---|
| DRFAN vs. CARN | PSNR | 0 | Yes |
| SSIM | 0.00195 | Yes | |
| DRFAN vs. IMDN | PSNR | 0 | Yes |
| SSIM | 0.00195 | Yes | |
| DRFAN vs. SAFMN | PSNR | 0 | Yes |
| SSIM | 0.00195 | Yes | |
| DRFAN vs. ShuffleMixer | PSNR | 0 | Yes |
| SSIM | 0.00195 | Yes | |
| DRFAN vs. SwinIR-S | PSNR | 0 | Yes |
| SSIM | 0.00195 | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.-L.; Jiang, B.; Xu, L.; Lu, Z.; Wang, Z.-T.; Liu, B.; Jia, S.-Y.; Liu, H.-D.; Li, B. DRFAN: A Lightweight Hybrid Attention Network for High-Fidelity Image Super-Resolution in Visual Inspection Applications. Algorithms 2025, 18, 454. https://doi.org/10.3390/a18080454
Li Z-L, Jiang B, Xu L, Lu Z, Wang Z-T, Liu B, Jia S-Y, Liu H-D, Li B. DRFAN: A Lightweight Hybrid Attention Network for High-Fidelity Image Super-Resolution in Visual Inspection Applications. Algorithms. 2025; 18(8):454. https://doi.org/10.3390/a18080454
Chicago/Turabian StyleLi, Ze-Long, Bai Jiang, Liang Xu, Zhe Lu, Zi-Teng Wang, Bin Liu, Si-Ye Jia, Hong-Dan Liu, and Bing Li. 2025. "DRFAN: A Lightweight Hybrid Attention Network for High-Fidelity Image Super-Resolution in Visual Inspection Applications" Algorithms 18, no. 8: 454. https://doi.org/10.3390/a18080454
APA StyleLi, Z.-L., Jiang, B., Xu, L., Lu, Z., Wang, Z.-T., Liu, B., Jia, S.-Y., Liu, H.-D., & Li, B. (2025). DRFAN: A Lightweight Hybrid Attention Network for High-Fidelity Image Super-Resolution in Visual Inspection Applications. Algorithms, 18(8), 454. https://doi.org/10.3390/a18080454