1. Introduction
Matrices have an important role in current engineering problems like artificial intelligence [
1], biomedicine [
2], machine learning [
3], neural networks [
4], etc. It could be said that they are, in fact, an interface between mathematics and the real world. Spectral matrix theory is closely related to big data and statistics, graph theory, networking, cryptography, search engines, optimization, convexity and, of course, the resolution of all kinds of linear equations.
An open problem of spectral theory is the sought-for eigenvalues and eigenvectors of a matrix. For this purpose, iterative methods are especially appropriate when the matrices have a large size and they are sparse, because the iteration matrix does not change during the process.
The classical power method of R. von Mises and H. Pollaczek-Geiringer [
5] assumes the existence of a dominant eigenvalue. One of the main contributions of this paper is the proposal of an algorithm to compute the eigenvalues of matrices and operators that do not have a dominant eigenvalue. The algorithm is based on the iterative averaged methods for fixed-point approximation proposed initially by Mann [
6] and Krasnoselskii [
7] and, subsequently, by Ishikawa [
8], Noor [
9], Sahu [
10] and others. There are recent articles on this topic (references [
11,
12,
13,
14,
15,
16,
17,
18,
19], for instance). In general, these papers deal with the problem of approximation of fixed points of non-expansive, asymptotically non-expansive and nearly asymptotically non-expansive mappings that are particular cases of Lipschitz and near-Lipschitz maps [
20,
21]. However, this article aims to prove that the usefulness of iterative averaged methods goes beyond fixed-point approximation.
In reference [
22], the author proposed a new algorithm of this type called N-iteration. The method has proved useful for the iterative resolution of Fredholm integral equations of the second kind and of the Hammerstein type [
23] (see, for instance, references [
24,
25]).
The above procedure is used in this article to compute eigenvalues and eigenvectors of matrices and linear operators (
Section 2 and
Section 3) and for the resolution of systems of linear equations (
Section 4). All these techniques are applied to solving Fredholm integral equations [
26,
27,
28,
29,
30] of the first kind by means of orthogonal polynomials (
Section 5). In
Section 6, we review some properties of compact and Fredholm integral operators, while
Section 7 presents the solution of a Fredholm integral equation of the first kind in a particular case where the kernel of the operator is separable.
Section 8 deals with a particular case of a Fredholm integral equation of the second kind. Several examples with tables and figures illustrate the performance and convergence of the algorithms proposed.
2. Averaged Power Method for Finding Eigenvalues and Eigenvectors of a Matrix
Given a matrix , where denotes the set of real or complex matrices of size , the power method is a well-known procedure for finding the dominant eigenvalue of matrix A. Let represent the spectrum of A, that is to say, the set of eigenvalues of A.
Definition 1. A matrix A has a dominant eigenvalue if for any , If (or ) is non-null and then v is a dominant eigenvector of
It is well known that if the matrix
A is diagonalizable and it has a dominant eigenvalue, then the sequence defined by
and the recurrence
for
converges with high probability to a dominant eigenvector (i.e., if the component of
with respect to the dominant eigenvector is non-null). The dominant eigenvalue can be approximated by means of the so-called Rayleigh quotient:
when
k is sufficiently large. The formula comes, obviously, from the definition of an eigenvector associated with the eigenvalue
We shall see, with an example, that if the matrix has no dominant eigenvalue then the power method may not converge.
Example 1. The matrix has the eigenvalue with eigenvectors and with eigenvectors The power method does not work in general sincefor k being odd andfor k being even. The sequence () does not converge except for the starting point The present section is devoted to proposing an algorithm to find eigenvalues and eigenvectors of matrices that do not have a dominant eigenvalue.
In reference [
22], an algorithm for the approximation of a fixed point of
where
C, is a nonempty, closed and convex subset of a proposed normed space
E. This is given by the following recurrence:
for
and
This iterative scheme was called N-algorithm. The procedure generalizes the Krasnoselskii–Mann method, defined in references [
6,
7], obtained in the case where
. If, additionally,
one has the usual Picard–Banach iteration.
Averaged power method
If the matrix
has no dominant eigenvalue, that is to say,
for any
, the power method may not converge. The algorithm proposed here is the use of the N-iteration of the matrix
A instead of computing the powers of
A. The sequence of vectors obtained by the power or the averaged power method may produce a divergent sequence (even though the iterates may be good approximations of an eigenvector). To avoid this fact, a scaling of the output vector is sometimes performed at every step of the algorithm. Thus, the procedure is described by the following recurrence:
for
such that
and
The notation
represents any norm in
and
is the inner product in the
m-dimensional Euclidean space.
A useful criterion to stop the algorithm is to check that for some tolerance or .
The last value is an approximation of an eigenvalue of A and is the corresponding eigenvector.
In order to justify the suitability of the algorithm, we will consider the simplest case of the Krasnoselskii iteration:
for
Let us denote
It is easy to check that
and the eigenvectors of
B and
A agree, that is to say,
X is an eigenvector of
A with respect to an eigenvalue
, if and only if
X is an eigenvector of
B with eigenvalue
Let us assume that A has positive and negative eigenvalues with the same absolute value. Then, for the positive eigenvalue
For a negative eigenvalue and, consequently, is a dominant eigenvalue of B. Hence, the power method applied to the matrix B will converge to an eigenvector of B (and thus of A), if the component of with respect to this eigenvector is non-null.
The power method is based on the product of a matrix and a vector. This operation has a complexity If the number of iterations is , the complexity is For a large matrix, the averaging operations of the N-algorithm proposed are negligible, and the complexity is Though the operations involved are about twice as many as in the original power method, the type of convergence (polynomial of degree 2) is not modified. If one wishes to reduce the total number of operations, the use of constant weight coefficients is advisable, and the algorithm is able to be conveniently optimized.
The speed of convergence of the power method (and consequently the number of iterations required to give a good approximation) depends on the ratio where are the greatest eigenvalues in magnitude. The smaller is this quotient, while the faster is the convergence. In the averaged Mann–Krasnoselskii method, this “spectral gap” is where is the positive eigenvalue. For instance, if , minimum quotients are reached for values of close to
Example 2. Considering the matrix of Example 1,we obtain that for the Krasnoselskii method with gives as first approximationand the rest of iterations agree with the eigenvector The positive eigenvalue is computed as Example 3. The spectrum of the matrixis The N-iteration, with starting at , with Euclidean scaling produces the sequence of approximations collected in Table 1. The eigenvalue computed is The stopping criterion was
Example 4. Let us consider the following matrix:The set of eigenvalues of A is The algorithm described with starting at with Euclidean scaling produces the sequence of approximations and distances as between those collected in Table 2. The eigenvalue computed is The stopping criterion was
Remark 1. Let us notice that the matrices of these examples do not have a dominant eigenvalue but, nevertheless, the N-iterated power algorithm is convergent.
Averaged Power Method for Finding Eigenvalues and Eigenfunctions of a Linear Operator
The algorithm proposed in this section can be applied to find eigenvalues and eigenvectors/eigenfunctions of a linear operator defined in an infinite-dimensional normed linear space
in case of existence (see, for instance, Theorem 2). Starting at
, we would follow the steps
for
such that
and
Let us note that a structure of inner product space in E for computing the eigenvalue by means of the Rayleigh quotient is required. Otherwise, we should solve the equation
The stop criteria of the algorithm are similar to the given for matrices, using the norm of the space E or the modulus in the case of employing the approximations of the eigenvalue.
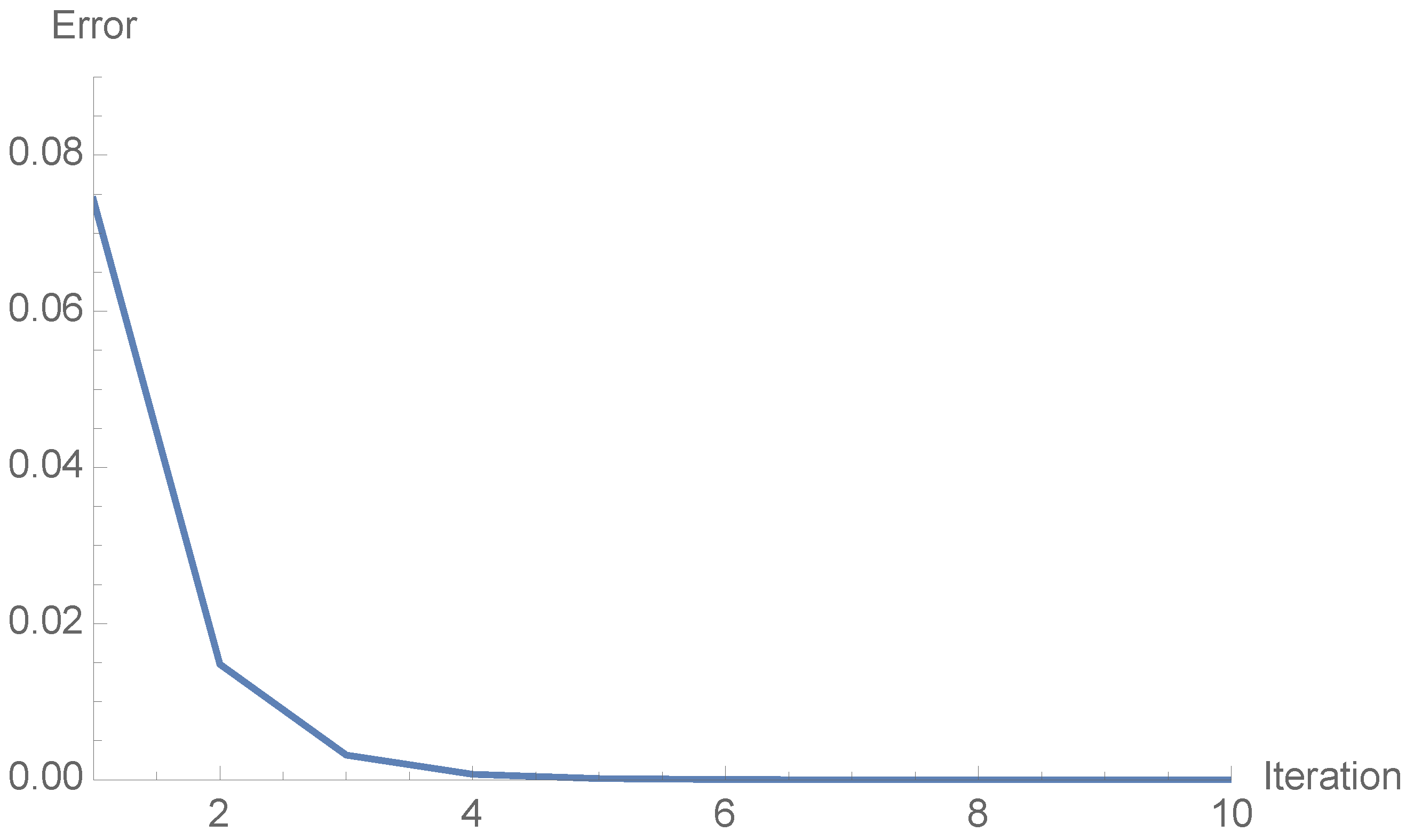
Example 5. Let us compute an eigenvalue of a Fredhom integral operator on defined, for asFor the sequence of approximate dominant eigenvalues () generated by the N-algorithm with is collected in Table 3. The norm is computed as follows:and the inner product is given byTable 3 collects the number of iterations (n), the approximate eigenvalue (), the -distance between and (where is the n-th approximation of the eigenfunction) and the successive distances between the eigenvalue approximations (). The tenth outcome of the eigenfunction iswith eigenvalue The stopping criterion was Figure 1 represents the number of iterations (x-axis) and corresponding magnitude (y-axis). 3. Computation of an Eigenvector of a Known Eigenvalue of a Linear Operator
This section is devoted to studying the convenience of using the N-iteration to find an eigenvector/eigenfunction corresponding to a non-null known eigenvalue of a linear operator in finite or infinite dimensions.
Let
be a linear operator defined on a normed space
E. If
where
is the point spectrum of
T, the search for an eigenvector (or eigenfunction if
E is a functional space) associated with
consists in finding an element
non-null such that
. The solution of this equation can be reduced to a fixed-point problem considering that this equality is equivalent to
assuming that
is non-null. The following result gives sufficient conditions for the convergence of the N-iteration applied to
to find an eigenvector associated to a non-null eigenvalue.
The next result was given in reference [
22].
Proposition 1. Let E be a normed space and be nonempty, closed and convex. Let be a nonexpansive operator such that the set of fixed points is nonempty; then, the sequence of N-iterates () for is such that the sequence () is convergent for any fixed point of T. If E is a uniformly convex Banach space and the scalars are chosen such that and , then the sequence () tends to zero for any .
Theorem 1. Let E be a uniformly convex Banach space, and be a linear and compact operator. If is non-null, such that , then the N-iteration with the scalars described in the previous proposition applied to the map converges strongly to an eigenvector associated with
Proof. Since there exists , such that . Then, is a fixed point of .
The latter operator is nonexpansive since
for any
due to the hypotheses on
Regarding invariance, if
then
and
Let
, and (
)
be the sequence of N-iterates of
. Since
is compact, there exists a convergent subsequence (
). Let
f be the limit of this subsequence. Then,
because
due to the properties of the N-iteration (Proposition 1). The continuity of
implies that
and
The fact that
exists (see Proposition 1) implies that the sequence of N-iterates (
) converges strongly to the fixed point
f (that is to say, to an eigenvector of
K associated with
). □
Corollary 1. Let λ be a non-null eigenvalue of the real or complex matrix A. If, for some subordinate matrix norm, , then the N-iteration applied to is convergent to an eigenvector associated with
Proof. This is a trivial consequence of Theorem 1 considering that, in finite dimensional spaces, all the linear operators are compact. □
Example 6. The matrixhas an eigenvalue equal to 10 and The computation of an eigenvector associated with by means of the N-iteration with starting at as described in Corollary 1, has produced the approximations collected in Table 4. The seventh approximation of the estimated eigenvalue isThe stop criterion was 4. Solution of a Linear System of Equations by an Averaged Iterative Method
If we need to solve a linear system of equations such as
where
,
and
we can transform (
1) into an equation of the following type:
where
and
It is clear that
T is a Lipschitz operator:
, and
are a subordinate matrix norm of
Let us note that we use the same notation for vector and subordinate matrix norms.
If
then
T is nonexpansive. Let us assume that the system (
1) has some solution
. Then, for any
and any ball
is invariant under
T. If
,
then the restriction of
T to the ball
is a continuous map on a compact set. The N-iteration is such that
(Proposition 1). At the same time, due to the compactness of
, for
there exists a subsequence
such that
By continuity,
tends to
and consequently
is a fixed point of
T. The fact that
is convergent (Proposition 1) implies that the whole sequence
converges to the fixed point
that is to say, it approximates a solution of the equation
Remark 2. If , T is contractive on a complete space, and there exists a unique solution which can be approximated by means of the Picard iteration.
If T is nonexpansive and the N-iteration where and can be used to find a solution, according to the arguments exposed.
Remark 3. The complexity of this iterative algorithm is similar to that given for the averaged power method, since the core of the procedure is the product of a matrix (which remains constant over the process) and a vector.
Example 7. Let us consider the equation , whereand The spectral radius of is and the typical fixed-point method does not converge. The N-iteration has been applied to the map with the values of the parameters equal to and starting point Table 5 collects ten approximations of the solution along with their relative errors, computed as The stop criterion was Figure 2 represents the number of iteration (x-axis) along with (y-axis) 5. Solution of a Fredholm Integral Equation of the First Kind by Means of Orthogonal Polynomials
This section is devoted to solving integral equations of the Fredholm type of the first kind, given by the following expression:
assuming that
,
and the function
u is known. The notation
means the space of square-integrable real functions defined on a compact real interval
We must notice that the solution of this equation is not unique, since if
is a solution of (
3) and
h belongs to the null space of the operator
K defined as follows:
then
is a solution as well.
The map is called the kernel of the Fredholm operator K. The following are interesting particular cases of k:
If is the Fourier Transform of f.
For we have the Hilbert Transform of f.
When the Laplace Transform of f is obtained.
We consider in this section an arbitrary kernel .
Assuming that
, we consider the expansions of
u and
v in terms of an orthogonal basis of the space
in order to find a solution of (
3). In this case we have chosen the polynomials of Legendre, which compose an orthogonal basis of
. They are defined for
as
Legendre polynomials satisfy the following equalities:
We have considered here orthonormal Legendre polynomials
, that is to say,
in order to facilitate the calculus of the coefficients of a function with respect to the basis. In this way, for
where
The convergence of the sum holds with respect to the norm
in
If the domain of the integral of the Equation (
3) is a different interval, a simple change of variable transforms
into a system of orthogonal polynomials defined on it.
To solve the Equation (
3), let us consider Legendre expansions of the maps
up to the
q-th term:
The discretization of the integral Equation (
3) becomes
Thus,
Denoting
we obtain a system of linear equations whose unknowns are the coefficients
of the sought function
for
The linear system can be written as
where
and
The system can be transformed into the fixed-point problem
as explained in the previous section. This equation can be solved using the described method whenever
for some subordinate norm of the matrix
Example 8. In order to solve the following Fredholm integral equation of the first kindwe used the Legendre polynomials defined in the interval :We have considered an expansion with and obtained a system of linear equations with matrix ,The unknowns are the coefficients of v with respect to () and is the vector of coefficients of u with respect to the same basis. The system has been transformed into Since (close to 1), we have applied the N-algorithm with all the parameters equal to Starting at , we obtain at the 18-th iteration the approximate solution:with an error ofand stop criterion Figure 3 displays the 6th, 12th and 18th approximation function to the solution of the equation. For the 18th Picard iteration, , the error is as follows:Consequently, the N-iteration may be better even if the Picard method can be applied. 6. Spectrum of a Compact Operator and General Solution of Fredholm Integral Equations of the First Kind
In this section we explore the relationships between spectral theory and the resolution of a Fredholm integral equation of the first kind given by following the expression:
where
and
is defined as
where
It is well known that
K is a linear and compact operator.
A linear map where E is a normed space, is self-adjoint if where is the adjoint of K. The set of eigenvalues of a linear operator is called the point spectrum of K, , and if there exists such that In this case v is an eigenvector of K (or an eigenfunction, in the case where E is a functional space). The set is the eigenspace associated with
The next theorems describe the spectrum of compact operators (see the references [
26,
27], for instance), and provide a kind of “diagonalization” of these maps.
Theorem 2. Let be a linear, compact and self-adjoint operator. Then K has an orthonormal basis of eigenvectors and
If the cardinal of is not finite then the spectrum is countably infinite and the only cluster point of is that is to say, where
The eigenspaces corresponding to different eigenvalues are mutually orthogonal.
For , has finite dimension.
According to this theorem, the eigenvalues of a compact self-adjoint operator can be ordered as follows:
and the action of
K on every element
can be expressed as follows:
where
is an orthonormal basis of eigenvectors of
K. If
is finite, then
K has a finite range. If additionally
K is positive, then the eigenvalues also are. If
K is strictly positive, then the inverse operator admits the following expression:
and, in general,
K is a densely defined unbounded operator, because the range of
K is dense in
E.
For a compact operator, the map is positive and self-adjoint and the positive square roots of the eigenvalues of are the singular values of For a not necessarily self-adjoint operator, we have the following result, known as Singular Value Decomposition of a compact operator K.
Theorem 3. Let be a non-null linear and compact operator. Let be the sequence of singular values of K, considered according to their algebraic multiplicities and in decreasing order. Then there exist orthonormal sequences and on E and , respectively, such that, for andFor every where , and denotes the null space of K. Moreover Remark 4. According to the equalities (7) and (8), for ,andthat is to say, is an eigenvector of with respect to the eigenvalue and is an eigenvector of with respect to the same eigenvalue. Let us consider the equation quoted above
for
where
is the data function and
is the unknown. We will assume that the kernel
of
K satisfies the following:
so that
K is linear and compact.
Let us assume that
g can be expanded in terms of the following system
:
According to (
8) and the definition of adjoint operator,
and
Let us assume also that
Then, using the equality (
7),
and by (
12),
If
f is expanded in terms of the system
,
and, by (
11), there exists a solution of
if
We can conclude that if
g admits an expansion in terms of the system
the Fredholm integral equation of the first kind has a solution.
7. Solution of a Fredholm Integral Equation of the First Kind with Separable Kernel
We consider now the case where
K has a separable kernel
k, that is to say,
k can be expressed as
for some
Spectrum of K:
As suggested by the equality (
13), we can guess that
K has eigenfunctions of type
In order to find
, we consider that
where
and the problem is reduced to solving the eigenvalue issue:
where
is the vector of coefficients of
with respect to (
).
Null space of K:
Let us consider now the null space of the operator
K. If
,
If the maps
are linearly independent, a characterization of the functions belonging to the null space is as follows:
for
Let us consider an orthogonal system of functions
for
defined following a Gram–Schmidt process from
If
is any function,
belongs to the null space of
K since
for
. In order to define an orthonomal basis of the kernel, let us consider a system of functions
such that
is linearly independent and complete. Then, we define
A Gram–Schmidt process on
provides an orthonormal basis (
) of the null space of
K.
General solution of :
The general solution of the equation
has the following form:
where
are the eigenfunctions, the coefficients
are to be computed and the
are arbitrary. To find
let us consider that
and we have a linear system of
r equations with unknown
’s,
Example
Consider the following Fredholm integral equation of the first kind:
Let us study the characteristics of the operator
K.
Spectrum of K:
The first eigenvalue of the operator was computed in Example 5, obtaining a value of
The second eigenvalue was found by applying the averaged power method, but subtracting at every step the component of the approximation with respect to the first eigenfunction (
. The value obtained is
The maps of the kernel
k are as follows:
Let us define the matrix
A as in (
14),
The spectrum of the matrix is
Two eigenfunctions associated with these eigenvalues were computed as follows:
and
Since the map
, the equation has a solution.
Null space of K:
As explained previously, the maps
h belonging to the null space of
K are characterized by the following equations:
for
An orthogonal system defined from
is as follows:
In order to construct an orthonormal basis of the null space, we consider the following functions:
First, define
Then, by means of a Gram–Schmidt process, we obtain an orthogonal basis of the null space:
General solution of :
Let the solution of the equation be
where
are the eigenfunctions of
K and
Solving the system (
15), we obtain the coefficients
and
Substituting in the previous equality we find the approximate general solution of the equation:
where
are arbitrary coefficients. An exact solution is
8. Solving the Equation
Let us consider now the following equation:
where the kernel is separable:
It is obvious that this equation has a non trivial solution if
belongs to the point spectrum of
In this case the solution is any eigenfunction
associated with
For instance, let us solve the following equation:
where
is a separable kernel with
In this case the eigenvalue is
The matrix associated with the operator,
is as follows:
We look for an eigenfunction of the form:
The system of equations to find the coefficients is as follows:
The spectral radius of
A is
Consequently, the usual iterative methods to solve this system do not converge. We apply the N-iteration to the matrix
A starting at
and we obtain a sequence of vectors for the approximate solutions of
in terms of the maps
The results are collected in
Table 6. The last outcome is
providing the approximate solution:
with stop criterion
where
is the vector of coefficients computed at the
n-th iteration. An exact solution is
Remark 5. All the computations have been performed using Mathematica software.







{kind=link}
{kind=link}
{kind=link}