



Integrating Machine Learning Techniques and the Theory of Planned Behavior to Assess the Drivers of and Barriers to the Use of Generative Artificial Intelligence: Evidence in Spain

 ,
,  and
and
Abstract
1. Introduction
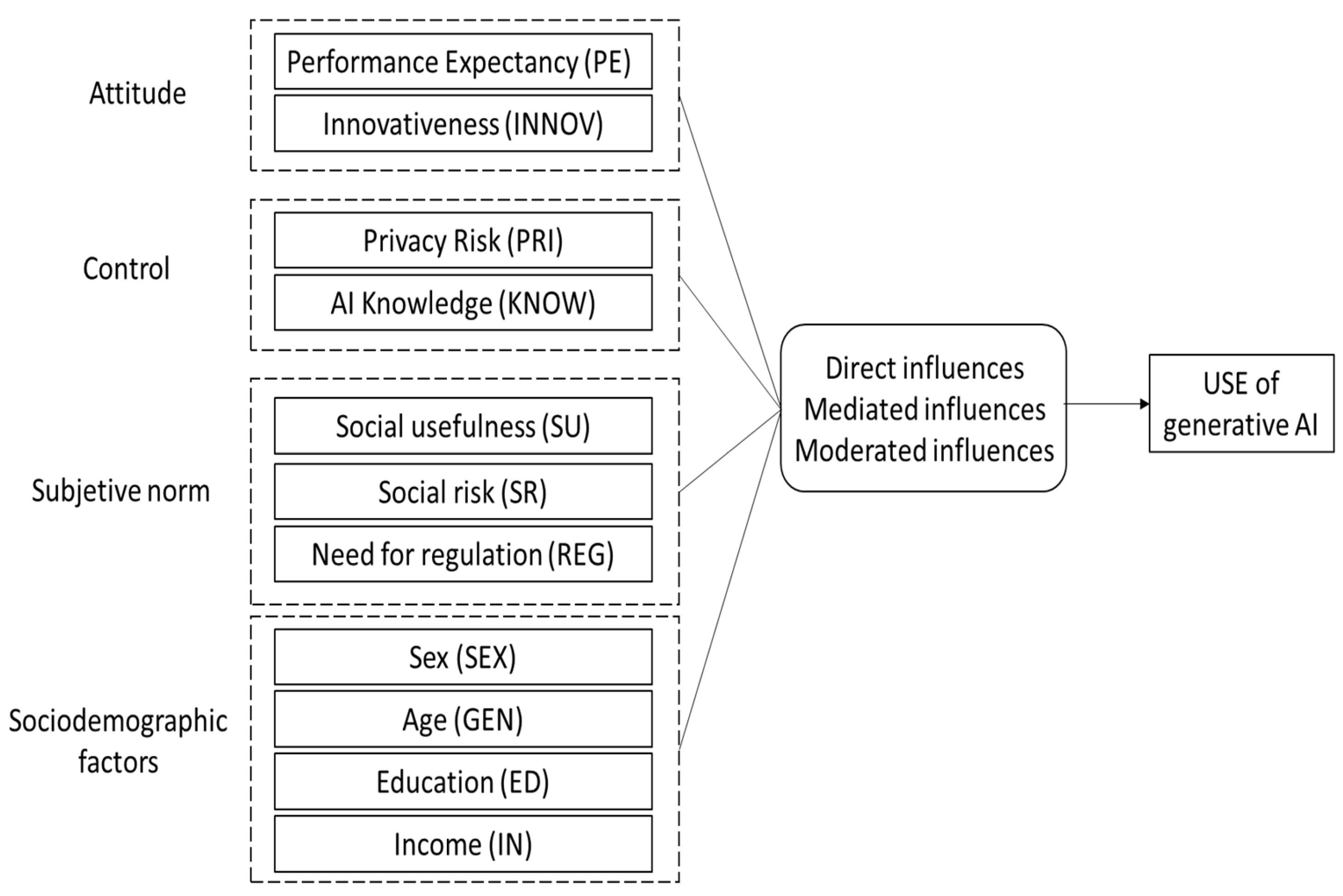
- RO1: To develop a theoretical framework based on TPB to explain and predict the use of GAI. The proposed theoretical model was tested using a national survey conducted in Spain by Centro de Investigaciones Sociológicas titled “Artificial Intelligence” [15].
- RO2: To identify the most relevant variables in explaining GAI use.
2. Theoretical Background
2.1. Attitudinal Variables
2.2. Variables Associated with Behavioral Control
2.3. Subjective Norms
2.4. Influence of Sociodemographic Variables
3. Materials and Methods
3.1. Sampling
3.2. Sample
3.3. Measurement of Variables
3.4. Data Analysis
3.4.1. Operationalizing the Variables
3.4.2. The Use of Machine Learning Instruments to Assess Drivers of GAI Use
4. Results
4.1. Descriptive Statistics and Linear Regression Estimation
4.2. Results of Research Objective 1
4.3. Results of Research Objective 2
5. Discussion
5.1. General Issues
5.2. Theoretical and Analytical Implications
5.3. Practical Implications
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| GAI | Generative Artificial Intelligence |
| RO | Research Objective |
| DTR | Decision tree regression |
| RF | Random Forest |
| XGBoost | Extreme Gradient Boosting |
| TPB | Theory of Planned Behavior |
| TAM | Technology Acceptance Model |
| UTAUT | Unified Theory of Acceptance and Use of Technology |
| PE | Performance expectancy |
| INNOV | Innovativeness |
| PRI | Perceived privacy risk |
| KNOW | Knowledge |
| SU | Social utilities |
| SR | Social risk |
| REG | Need for regulation |
| SEX | Sex |
| GEN | Generation (X and Baby Boom) |
| ED | Education level |
| IN | Income level |
| SHAP | Shapley additive explanations measure |
| RMSE | Rooted mean squared error |
| MAE | Mean average error |
References
- Polak, P.; Anshari, M. Exploring the multifaceted impacts of artificial intelligence on public organizations, business, and society. Humanit. Soc. Sci. Commun. 2024, 11, 1373. [Google Scholar] [CrossRef]
- Tamvada, J.P.; Narula, S.; Audretsch, D.; Puppala, H.; Kumar, A. Adopting new technology is a distant dream? The risks of implementing Industry 4.0 in emerging economy SMEs. Technol. Forecast. Soc. Change 2022, 185, 122088. [Google Scholar] [CrossRef]
- Soni, N.; Sharma, E.K.; Singh, N.; Kapoor, A. Artificial intelligence in business: From research and innovation to market deployment. Procedia Comput. Sci. 2020, 167, 2200–2210. [Google Scholar] [CrossRef]
- Almusaed, A.; Yitmen, I.; Almssad, A. Enhancing smart home design with AI models: A case study of living spaces implementation review. Energies 2023, 16, 2636. [Google Scholar] [CrossRef]
- Alowais, S.A.; Alghamdi, S.S.; Alsuhebany, N.; Alqahtani, T.; Alshaya, A.I.; Almohareb, S.N.; Aldairem, A.; Alrashed, M.; Bin Saleh, K.; Badreldin, H.A.; et al. Revolutionizing healthcare: The role of artificial intelligence in clinical practice. BMC Med. Educ. 2023, 23, 689. [Google Scholar] [CrossRef]
- Pérez, J.; Castro, M.; López, G. Serious games and AI: Challenges and opportunities for computational social science. IEEE Access 2023, 11, 62051–62061. [Google Scholar] [CrossRef]
- Lo, C.K. What is the impact of ChatGPT on education? A rapid review of the literature. Educ. Sci. 2023, 13, 410. [Google Scholar] [CrossRef]
- Feuerriegel, S.; Hartmann, J.; Janiesch, C.; Zschech, P. Generative AI. Bus. Inf. Syst. Eng. 2024, 66, 111–126. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Kshetri, N.; Hughes, L.; Slade, E.L.; Jeyaraj, A.; Kar, A.K.; Baabdullah, A.M.; Koohang, A.; Raghavan, V.; Ahuja, M.; et al. Opinion paper: ‘So what if ChatGPT wrote it?’ Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int. J. Inf. Manag. 2023, 71, 102642. [Google Scholar] [CrossRef]
- Zhou, J.; Müller, H.; Holzinger, A.; Chen, F. Ethical ChatGPT: Concerns, challenges, and commandments. Electronics 2024, 13, 3417. [Google Scholar] [CrossRef]
- Shaw, D. The digital erosion of intellectual integrity: Why misuse of generative AI is worse than plagiarism. AI Soc. 2025. [Google Scholar] [CrossRef]
- Sharma, R. AI copyright and intellectual property. In AI and the Boardroom: Insights into Governance, Strategy, and the Responsible Adoption of AI.; Apress: Berkeley, CA, USA, 2024; pp. 47–57. [Google Scholar] [CrossRef]
- Mahmoud, A.B.; Kumar, V.; Spyropoulou, S. Identifying the Public’s Beliefs About Generative Artificial Intelligence: A Big Data Approach. IEEE Trans. Eng. Manag. 2025, 72, 827–838. [Google Scholar] [CrossRef]
- Taeihagh, A. Governance of generative AI. Policy Soc. 2025, 44, 1–22. [Google Scholar] [CrossRef]
- Centro de Investigaciones Sociológicas. Inteligencia artificial. Estudio 3495. Available online: https://www.cis.es/documents/d/cis/es3495mar-pdf (accessed on 7 May 2025).
- Ajzen, I. The theory of planned behavior. Organ. Behav. Hum. Decis. Process. 1991, 50, 179–211. [Google Scholar] [CrossRef]
- Al-Emran, M.; Abu-Hijleh, B.; Alsewari, A.A. Exploring the Effect of Generative AI on Social Sustainability Through Integrating AI Attributes, TPB, and T-EESST: A Deep Learning-Based Hybrid SEM-ANN Approach. IEEE Trans. Eng. Manag. 2024, 71, 14512–14524. [Google Scholar] [CrossRef]
- Davis, F.D. User acceptance of information technology: System characteristics, user perceptions and behavioral impacts. Int. J. Man. Mach. Stud. 1993, 38, 475–487. [Google Scholar] [CrossRef]
- Dell’Acqua, F.; McFowland, E., III; Mollick, E.R.; Lifshitz-Assaf, H.; Kellogg, K.; Rajendran, S.; Krayer, L.; Candelon, F.; Lakhani, K.R. Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality. Harvard Business School Technology & Operations Management Unit Working Paper 2023, No. 24-013. Available online: https://ssrn.com/abstract=4573321 (accessed on 12 May 2025). [CrossRef]
- Gansser, O.A.; Reich, C.S. A new acceptance model for artificial intelligence with extensions to UTAUT2: An empirical study in three segments of application. Technol. Soc. 2021, 65, 101535. [Google Scholar] [CrossRef]
- Ajzen, I. Perceived behavioral control, self-efficacy, locus of control, and the theory of planned behavior. J. Appl. Soc. Psychol. 2002, 32, 665–683. [Google Scholar] [CrossRef]
- Sparks, P.; Guthrie, C.A.; Shepherd, R. The Dimensional Structure of the Perceived Behavioral Control Construct. J. Appl. Soc. Psychol. 1997, 27, 418–438. [Google Scholar] [CrossRef]
- Zhang, D.; Xia, B.; Liu, Y.; Xu, X.; Hoang, T.; Xing, Z.; Staples, M.; Lu, Q.; Zhu, L. Privacy and copyright protection in generative AI: A lifecycle perspective. In Proceedings of the IEEE/ACM 3rd International Conference on AI Engineering—Software Engineering for AI, Lisbon, Portugal, 14–5 April 2024; pp. 92–97. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Venkatesh, V.; Bala, H. Technology Acceptance Model 3 and a Research Agenda on Interventions. Decis. Sci. 2008, 39, 273–315. [Google Scholar] [CrossRef]
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. User acceptance of information technology: Toward a unified view. MIS Q. 2003, 27, 425–478. [Google Scholar] [CrossRef]
- Loh, W.-Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Chung, D.; Jeong, P.; Kwon, D.; Han, H. Technology acceptance prediction of roboadvisors by machine learning. Intell. Syst. Appl. 2023, 18, 200197. [Google Scholar] [CrossRef]
- Cuc, L.D.; Rad, D.; Cilan, T.F.; Gomoi, B.C.; Nicolaescu, C.; Almași, R.; Dzitac, S.; Isac, F.L.; Pandelica, I. From AI Knowledge to AI Usage Intention in the Managerial Accounting Profession and the Role of Personality Traits—A Decision Tree Regression Approach. Electronics 2025, 14, 1107. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf (accessed on 12 May 2025).
- Davis, F.D. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 1989, 13, 319–340. [Google Scholar] [CrossRef]
- Shirali-Shahreza, S. Set up my smart home as I want. Computer 2024, 57, 65–73. [Google Scholar] [CrossRef]
- Daungsupawong, H.; Wiwanitkit, V. Correspondence: Generative artificial intelligence in healthcare. Int. J. Med. Inform. 2024, 189, 105498. [Google Scholar] [CrossRef]
- Barros, A.; Prasad, A.; Sliwa, M. Generative artificial intelligence and academia: Implication for research, teaching and service. Manag. Learn. 2023, 54, 597–604. [Google Scholar] [CrossRef]
- Benbya, H.; Strich, F.; Tamm, T. Navigating Generative Artificial Intelligence Promises and Perils for Knowledge and Creative Work. J. Assoc. Inf. Syst. 2024, 25, 23–36. [Google Scholar] [CrossRef]
- Camilleri, M.A. Factors affecting performance expectancy and intentions to use ChatGPT: Using SmartPLS to advance an information technology acceptance framework. Technol. Forecast. Soc. Change 2024, 201, 123247. [Google Scholar] [CrossRef]
- Ibrahim, F.; Münscher, J.-C.; Daseking, M.; Telle, N.-T. The technology acceptance model and adopter type analysis in the context of artificial intelligence. Front. Artif. Intell. 2025, 7, 1496518. [Google Scholar] [CrossRef]
- Yudhistyra, W.I.; Srinuan, C. Exploring the Acceptance of Technological Innovation Among Employees in the Mining Industry: A Study on Generative Artificial Intelligence. IEEE Access 2024, 12, 165797–165809. [Google Scholar] [CrossRef]
- Al Darayseh, A. Acceptance of artificial intelligence in teaching science: Science teachers’ perspective. Comput. Educ. Artif. Intell. 2023, 4, 100132. [Google Scholar] [CrossRef]
- Sobaih, A.E.E.; Elshaer, I.A.; Hasanein, A.M. Examining students’ acceptance and use of ChatGPT in Saudi Arabian higher education. Eur. J. Investig. Health Psychol. Educ. 2024, 14, 709–721. [Google Scholar] [CrossRef] [PubMed]
- Strzelecki, A. To use or not to use ChatGPT in higher education? A study of students’ acceptance and use of technology. Interact. Learn. Environ. 2024, 32, 5142–5155. [Google Scholar] [CrossRef]
- Hsu, W.-L.; Silalahi, A.D.K.; Tedjakusuma, A.P.; Riantama, D. How Do ChatGPT’s Benefit–Risk Paradoxes Impact Higher Education in Taiwan and Indonesia? An Integrative Framework of UTAUT and PMT with SEM & fsQCA. Comput. Educ. Artif. Intell. 2025, 8, 100412. [Google Scholar] [CrossRef]
- Agarwal, R.; Prasad, J. A conceptual and operational definition of personal innovativeness in the domain of information technology. Inf. Syst. Res. 1998, 9, 204–215. [Google Scholar] [CrossRef]
- Lu, J.; Yao, J.E.; Yu, C.-S. Personal innovativeness, social influences and adoption of wireless Internet services via mobile technology. J. Strateg. Inf. Syst. 2005, 14, 245–268. [Google Scholar] [CrossRef]
- Chalutz Ben-Gal, H. Artificial intelligence (AI) acceptance in primary care during the coronavirus pandemic: What is the role of patients’ gender, age and health awareness? A two-phase pilot study. Front. Public Health 2023, 10, 2022. [Google Scholar] [CrossRef] [PubMed]
- Biloš, A.; Budimir, B. Understanding the Adoption Dynamics of ChatGPT among Generation Z: Insights from a Modified UTAUT2 Model. J. Theor. Appl. Electron. Commer. Res. 2024, 19, 863–879. [Google Scholar] [CrossRef]
- Wirtz, J.; Lwin, M.O.; Williams, J.D. Causes and consequences of consumer online privacy concern. Int. J. Serv. Ind. Manag. 2007, 18, 326–348. [Google Scholar] [CrossRef]
- KPMG International. Privacy in the New World of AI: How to Build Trust in AI Through Privacy. Available online: https://kpmg.com/privacyservices (accessed on 7 May 2025).
- Shahriar, S.; Allana, S.; Fard, M.H.; Dara, R. A Survey of Privacy Risks and Mitigation Strategies in the Artificial Intelligence Life Cycle. IEEE Access 2023, 11, 61829–61854. [Google Scholar] [CrossRef]
- Jagtap, P. Artificial Intelligence and Privacy: Examining the Risks and Potential Solutions. Artif. Intell. 2024. Available online: https://www.researchgate.net/publication/378545816 (accessed on 7 May 2025).
- Moon, W.-K.; Xiaofan, W.; Holly, O.; Kim, J.K. Between Innovation and Caution: How Consumers’ Risk Perception Shapes AI Product Decisions. J. Curr. Issues Res. Advert. 2025, 1–23. [Google Scholar] [CrossRef]
- Chung, J.; Kwon, H. Privacy fatigue and its effects on ChatGPT acceptance among undergraduate students: Is privacy dead? Educ. Inf. Technol. 2025, 30, 12321–12343. [Google Scholar] [CrossRef]
- Compeau, D.R.; Higgins, C.A. Computer self-efficacy: Development of a measure and initial test. MIS Q. 1995, 19, 189–210. [Google Scholar] [CrossRef]
- Venkatesh, V. Determinants of perceived ease of use: Integrating control, intrinsic motivation, and emotion into the technology acceptance model. Inf. Syst. Res. 2000, 11, 342–365. [Google Scholar] [CrossRef]
- Araujo, T.; Helberger, N.; Kruikemeier, S.; de Vreese, C.H. In AI We Trust? Perceptions About Automated Decision-Making by Artificial Intelligence. AI Soc. 2020, 35, 611–623. [Google Scholar] [CrossRef]
- Alshutayli, A.A.M.; Asiri, F.M.; Abutaleb, Y.B.A.; Alomair, B.A.; Almasaud, A.K.; Almaqhawi, A. Assessing Public Knowledge and Acceptance of Using Artificial Intelligence Doctors as a Partial Alternative to Human Doctors in Saudi Arabia: A Cross-Sectional Study. Cureus 2024, 16, e64461. [Google Scholar] [CrossRef]
- Lokaj, B.; Pugliese, M.; Kinkel, K.; Lovis, C.; Schmid, J. Barriers and Facilitators of Artificial Intelligence Conception and Implementation for Breast Imaging Diagnosis in Clinical Practice: A Scoping Review. Eur. Radiol. 2023, 34, 2096–2109. [Google Scholar] [CrossRef]
- Kansal, R.; Bawa, A.; Bansal, A.; Trehan, S.; Goyal, K.; Goyal, N.; Malhotra, K. Differences in Knowledge and Perspectives on the Usage of Artificial Intelligence Among Doctors and Medical Students of a Developing Country: A Cross-Sectional Study. Cureus 2022, 14, e21434. [Google Scholar] [CrossRef] [PubMed]
- Gado, S.; Kempen, R.; Lingelbach, K.; Bipp, T. Artificial intelligence in psychology: How can we enable psychology students to accept and use artificial intelligence? Psychol. Learn. Teach. 2021, 21, 37–56. [Google Scholar] [CrossRef]
- Kelly, S.; Kaye, S.-A.; Oviedo-Trespalacios, O. What factors contribute to the acceptance of artificial intelligence? A systematic review. Telemat. Inform. 2023, 77, 101925. [Google Scholar] [CrossRef]
- Elshaer, I.A.; Hasanein, A.M.; Sobaih, A.E.E. The Moderating Effects of Gender and Study Discipline in the Relationship between University Students’ Acceptance and Use of ChatGPT. Eur. J. Investig. Health Psychol. Educ. 2024, 14, 1981–1995. [Google Scholar] [CrossRef]
- Strzelecki, A.; ElArabawy, S. Investigation of the moderation effect of gender and study level on the acceptance and use of generative AI by higher education students: Comparative evidence from Poland and Egypt. Br. J. Educ. Technol. 2024, 55, 1209–1230. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Yenduri, G.; Kaluri, R.; Rajput, D.S.; Lakshmanna, K.; Fang, K.; Chen, J.; Wang, W. The role of GPT in promoting inclusive higher education for people with various learning disabilities: A review. PeerJ Comput. Sci. 2025, 11, e2400. [Google Scholar] [CrossRef]
- Liu, F.; Liang, C. Analyzing wealth distribution effects of artificial intelligence: A dynamic stochastic general equilibrium approach. Heliyon 2025, 11, e41943. [Google Scholar] [CrossRef]
- Doshi, A.R.; Hauser, O.P. Generative AI enhances individual creativity but reduces the collective diversity of novel content. Sci. Adv. 2024, 10, eadn5290. [Google Scholar] [CrossRef] [PubMed]
- Sebastian, G. Privacy and Data Protection in ChatGPT and Other AI Chatbots: Strategies for Securing User Information. Int. J. Secur. Priv. Pervasive Comput. 2024, 15, 1–14. [Google Scholar] [CrossRef]
- Alkamli, S.; Alabduljabbar, R. Understanding privacy concerns in ChatGPT: A data-driven approach with LDA topic modeling. Heliyon 2024, 10, e39087. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Duan, R.; Ni, J. Unveiling Security, Privacy, and Ethical Concerns of ChatGPT. arXiv 2023, arXiv:2307.14192. Available online: https://arxiv.org/abs/2307.14192 (accessed on 7 May 2025). [CrossRef]
- Venkatesh, V.; Thong, J.Y.L.; Xu, X. Consumer Acceptance and Use of Information Technology: Extending the Unified Theory of Acceptance and Use of Technology. MIS Q. 2012, 36, 157–178. [Google Scholar] [CrossRef]
- Rahman, M.M.; Babiker, A.; Ali, R. Motivation, Concerns, and Attitudes Towards AI: Differences by Gender, Age, and Culture. In Proceedings of the International Conference on Human-Computer Interaction, Doha, Qatar, 2–5 December 2024. [Google Scholar] [CrossRef]
- Armutat, S.; Wattenberg, M.; Mauritz, N. Artificial Intelligence: Gender-Specific Differences in Perception, Understanding, and Training Interest. In Proceedings of the International Conference on Gender Research, Barcelona, Spain, 25–26 April 2024; Academic Conferences and Publishing International Limited: Reading, UK, 2024; pp. 36–43. [Google Scholar] [CrossRef]
- Kozak, J.; Fel, S. How Sociodemographic Factors Relate to Trust in Artificial Intelligence Among Students in Poland and the United Kingdom. Sci. Rep. 2024, 14, 28776. [Google Scholar] [CrossRef]
- Pellas, N. The Influence of Sociodemographic Factors on Students’ Attitudes Toward AI-Generated Video Content Creation. Smart Learn. Environ. 2023, 10, 57. [Google Scholar] [CrossRef]
- Otis, N.G.; Cranney, K.; Delecourt, S.; Koning, R. Global Evidence on Gender Gaps and Generative AI; Harvard Business School: Boston, MA, USA, 2024. [Google Scholar] [CrossRef]
- Liengaard, B.D.; Sharma, P.N.; Hult, G.T.M.; Jensen, M.B.; Sarstedt, M.; Hair, J.F.; Ringle, C.M. Prediction: Coveted, yet forsaken? Introducing a cross-validated predictive ability test in partial least squares path modeling. Decis. Sci. 2021, 52, 362–392. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Categories |
|---|---|
| Sex | Male (48.5%), female (51.5%) |
| Age | 18–24 years (8.5%), 25–34 years (13.6%), 35–44 years (18.3%), 45–54 years (19.5%), 55–64 years (16.4%), 65–74 years (11.9%), 75+ years (11.8%) |
| Nationality | Spanish (91.3%), Spanish and others (3.1%), others (5.6%) |
| Education degree | Less than primary (4.7%), primary (11.4%), secondary (43.1%), vocational education and training (14.1%), University degree, master and PhD (26.7%) |
| Monthly income level | ≤EUR 300 (0.5%), EUR 301–600 (5.0%), EUR 601–900 (6.0%), EUR 901–1200 (14.0%), EUR 1201–1800 (16.8%), EUR 1801–2400 (15.3%), EUR 2401–3000 (13.1%), EUR 3001–4500 (15.4%), EUR 4501–6000 (5.5%), >EUR 6000 (3.7%), not answered (3.9%) |
| Variables | Responses | Operationalization |
|---|---|---|
| Output variable: frequency of using GAI (USE) | ||
| USE1 = Chat GPT USE2 = Gemini USE3 = Microsoft copilot USE4 = Perplexity USE5 = Other | Never = 0; Once = 1; Several times in a year = 2; Several times in a month = 3; Several times in a week = 4; Every day = 5 | The standardized value of the maximum of USE1, USE2,…, USE5 |
| Input variables (Attitude) | ||
| Performance expectancy (PE): Indicate your agreement respect the following consequences of using GAI: PE1 = Progress PE2 = Wealth PE3 = Efficiency PE4 = Well-being | From completely disagreement = 1 to completely agreement = 10 | The standardized value of the first principal component of the items |
| Innovativeness (INNOV): Indicate your level of comfort in the following situations INNOV1 = Undergoing a medical operation performed by a robot INNOV2 = Traveling in a self-driving car INNOV3 = Talking to an artificial intelligence, for example, a customer service or information service assistant | From completely disagreement = 1 to completely agreement = 10 | The standardized value of the first principal component of the items |
| Input variables (Behavioral control) | ||
| Privacy risk (PRI): When someone provides personal data on the Internet, do you think it is very likely, somewhat likely, not very likely, or not at all likely that...? PRI1 = Their data may be used without their knowledge PRI2 = Their identity may be stolen PRI3 = Their personal safety may be at risk PRI4 = They may become a victim of fraud PRI5 = Their reputation may be damaged | From not possible = 1 to very possible = 4 | The standardized value of the first principal component of the items |
| Knowledge (KNOW) = Assess your knowledge and familiarity with artificial intelligence. | From complete lack of knowledge = 1 to complete knowledge = 10. | The standardized value of the item |
| Input variables (Subjective norms) | ||
| Social usefulness (SU): AI may promote SU1 = The protection of people’s rights SU2 = Culture, values, and ways of life SU3 = Humanity as a whole | Harmful = 1 Neutral = 2; Beneficial = 3 | The standardized value of the first principal component of the items |
| Social risks (SR): AI SR1 = may be used to spread misinformation and fake news SR2 = may facilitate the commission of crimes or illegal acts SR3 = may lead to greater global inequality SR4 = may pose a threat to humanity | From completely disagree = 1 to completely agree = 5. Neutral value = 3. | The standardized value of the first principal component of the items |
| Regulation (REG). Indicate your degree of agreement REG1 = The programming and training of artificial intelligence should be regulated REG2 = Companies and organizations should disclose when they use artificial intelligence instead of humans REG3 = The use of artificial intelligence should be regulated REG4 = Artificial intelligence poses a threat to intellectual property REG5 = Implementing stricter ethical standards and legal safeguards for artificial intelligence is one of the most important challenges humanity currently faces | From completely disagree = 1 to completely agree = 5. Neutral value = 3. | The standardized value of the first principal component of the items |
| Input variables (sociodemographic) | ||
| Sex (SEX) | Male = 0 and Female = 1 | Dummy variable |
| Generation (GEN) | Gen Z and Y (age less than 45 years) = 0, Gen X or baby Boomers(at least 45 years) = 1 | Dummy variable |
| Education (ED) | Primary school or less = 1; secondary school or vocational education = 2, University degree or higher = 3 | The standardized value of the item |
| Monthly Income (IN) | By following the scales in Table 1, from the lower income (< EUR 300) = 1 to the higher degree (>EUR 6000) = 10 | The standardized value of the item |
| Mean | SD | FL | AVE | |
|---|---|---|---|---|
| Output Variable (USE) | ||||
| USE1 = ChatGPT | 1.58 | 1.81 | --- | --- |
| USE2 = Gemini | 0.385 | 1.07 | --- | --- |
| USE3 = Microsoft Copilot | 0.571 | 1.29 | --- | --- |
| USE4 = Perplexity | 0.099 | 0.56 | --- | --- |
| USE5 = Other | 0.632 | 1.37 | --- | --- |
| USEINT | 1.87 | 1.87 | 1 | 100% |
| Input Variables | ||||
| Mean | SD | FL | AVE | |
| Performance expectancy (PE) | ||||
| PE1 | 7.88 | 1.91 | 0.79 | 55.60% |
| PE2 | 6.28 | 2.32 | 0.69 | |
| PE3 | 7.56 | 1.93 | 0.78 | |
| PE4 | 6.41 | 2.1 | 0.72 | |
| Innovativeness (INNOV) | ||||
| INNOV1 | 4.63 | 3.07 | 0.73 | 56.10% |
| INNOV2 | 4.1 | 2.79 | 0.82 | |
| INNOV3 | 4.52 | 2.94 | 0.68 | |
| Privacy risk (PRI) | ||||
| PRI1 | 3.44 | 0.654 | 0.62 | 50.02% |
| PRI2 | 3.06 | 0.762 | 0.75 | |
| PRI3 | 2.72 | 0.851 | 0.72 | |
| PRI4 | 3.23 | 0.705 | 0.76 | |
| PRI5 | 2.74 | 0.863 | 0.67 | |
| Knowledge (KNOW) | ||||
| KNOW | 4.36 | 2.23 | 1.00 | 100% |
| Social usefulness (SU) | ||||
| SU1 | 1.63 | 0.753 | 0.74 | 54.10% |
| SU2 | 1.62 | 0.763 | 0.74 | |
| SU3 | 1.78 | 0.837 | 0.73 | |
| Social risks (SR) | ||||
| SR1 | 4.37 | 1 | 0.71 | 50.04% |
| SR2 | 4.1 | 1.18 | 0.75 | |
| SR3 | 3.79 | 1.33 | 0.72 | |
| SR4 | 3.57 | 1.35 | 0.64 | |
| Regulation (REG) | ||||
| REG1 | 4.42 | 0.905 | 0.84 | 55.40% |
| REG2 | 4.54 | 0.824 | 0.70 | |
| REG3 | 4.52 | 0.843 | 0.86 | |
| REG4 | 4.01 | 1.15 | 0.64 | |
| REG5 | 4.36 | 0.95 | 0.77 | |
| Education (ED) | ||||
| ED | 2.53 | 0.543 | 1.00 | 100% |
| Income (IN) | ||||
| IN | 3.46 | 1.92 | 1.00 | 100% |
| Variable | β | SD | η2 | t-Ratio | p-Value |
|---|---|---|---|---|---|
| PE→USE | 0.083 | 0.0253 | 0.0816 | 3.287 | 0.001 |
| INNOV→USE | 0.228 | 0.0268 | 0.0987 | 8.5 | <0.001 |
| PRI→USE | 0.083 | 0.0240 | 0.0081 | 3.469 | <0.001 |
| KNOW→USE | 0.709 | 0.0262 | 0.2494 | 27.082 | <0.001 |
| SU→USE | 0.140 | 0.0255 | 0.0117 | 5.49 | <0.001 |
| SR→USE | −0.036 | 0.0281 | 0.0050 | −1.284 | 0.1993 |
| REG→USE | −0.153 | 0.0284 | 0.0108 | −5.376 | <0.001 |
| SEX→USE | −0.156 | 0.0490 | 0.0024 | −3.177 | 0.002 |
| GEN→USE | −0.730 | 0.0511 | 0.0522 | −14.274 | <0.001 |
| ED→USE | 0.199 | 0.0244 | 0.0170 | 8.178 | <0.001 |
| IN→USE | 0.054 | 0.0240 | 0.0013 | 2.273 | 0.023 |
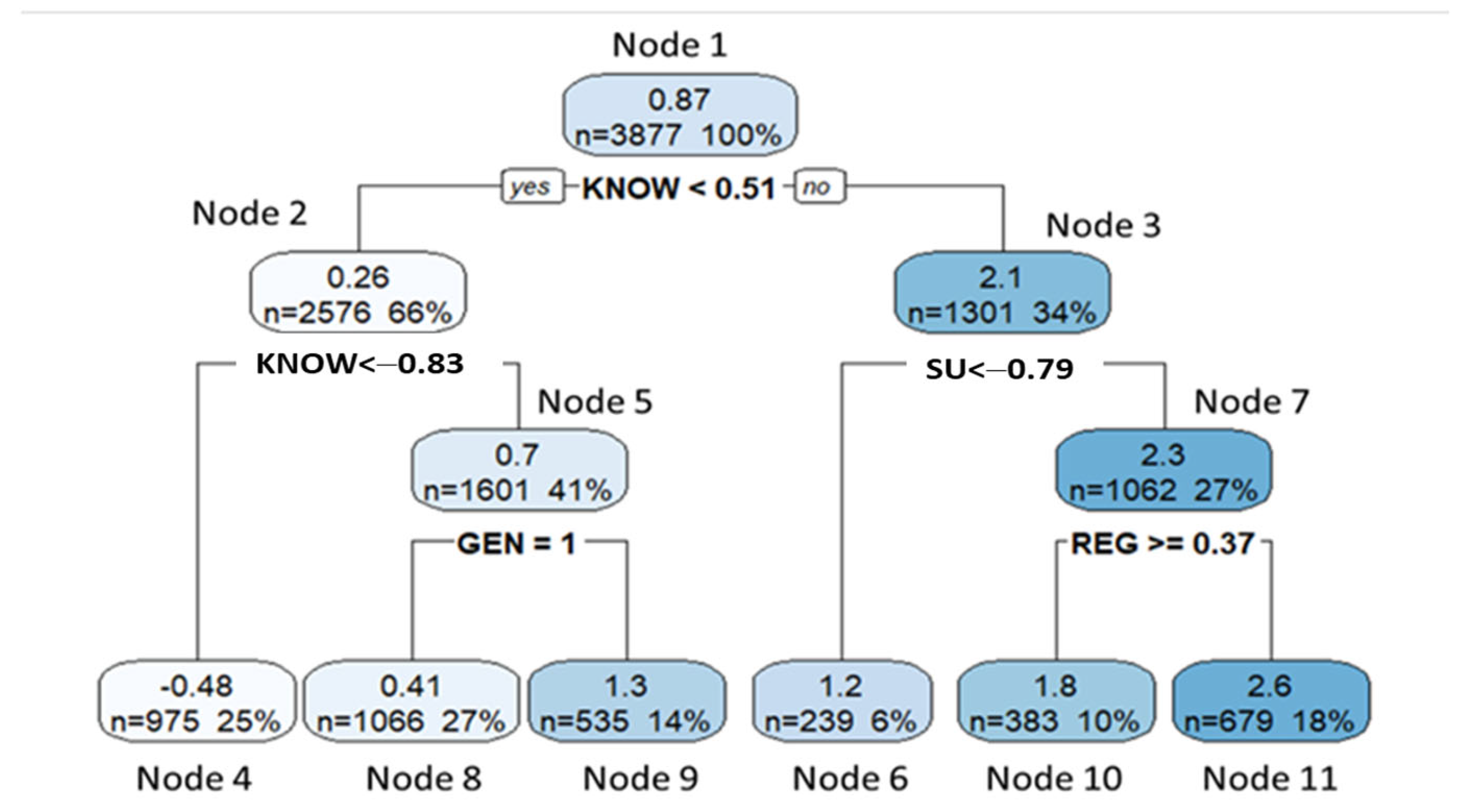
| Node 1 | Node 2 | Node 3 | Node 5 | Node 7 |
|---|---|---|---|---|
| KNOW < 0.511 | KNOW < −0.834 | SU < −0.787 | GEN = 1.000 | REG > 0.369 |
| GEN = 1.000 | GEN = 1.000 | REG > 0.369 | INNOV < 0.076 | GEN = 1 |
| INNOV < −0.265 | INNOV < 0.074 | INNOV < −0.265 | SU < −0.196 | KNOW < 0.960 |
| SU < −0.185 | ED < −0.056 | GEN = 1 | PE < 0.636 | PE < 0.708 |
| ED < −0.056 | SU < 0.100 | SR > 0.687 | ED < −0.056 | SR > −0.106 |
| INNOV < 1.324 | PE < −1.714 | PE < −2.589 | PRI > −4.298 | SU < −0.175 |
| REG > −2.262 | ED < −1.897 | PRI < −4.332 | REG > −4.461 | INNOV < −0.676 |
| PE < 1.504 | PRI < −2.565 | |||
| SU < 1.497 | SR < −3.448 | |||
| PRI > −10.588 |
| Method | R2 | RMSE | MAE |
|---|---|---|---|
| Linear regression | 39.12% | 1.455 | 1.176 |
| Decision tree regression | 32.55% | 1.532 | 1.260 |
| Random Forest | 92.30% | 0.652 | 0.528 |
| XGBoost | 92.85% | 0.535 | 0.396 |
| Method | Q2 | RMSE | MAE |
|---|---|---|---|
| Linear regression | 38.81% | 1.465 | 1.175 |
| Decision tree regression | 31.53% | 1.548 | 1.267 |
| Random Forest | 41.26% | 1.437 | 1.170 |
| XGBoost | 32.44% | 1.566 | 1.231 |
| Method | Q2 | RMSE | MAE |
|---|---|---|---|
| DTR | 31.52% | 1.56 | 1.28 |
| RF | 41.36% | 1.46 | 1.2 |
| XGBoost | 33.21% | 1.57 | 1.24 |
| ANOVA | F = 385.8 (<0.001) | F = 314.6 (<0.001) |
| RMSE | MAE | |||
|---|---|---|---|---|
| Mean Difference | p-Value | Mean Difference | p-Value | |
| RF vs. DTR | −0.097 | <0.001 | −0.089 | <0.001 |
| XGBoost vs. DTR | 0.010 | 0.038 | −0.047 | <0.001 |
| XGBoost vs. RF | 0.107 | <0.001 | 0.041 | <0.001 |
| Mean | 95% Confidence Interval | ||
|---|---|---|---|
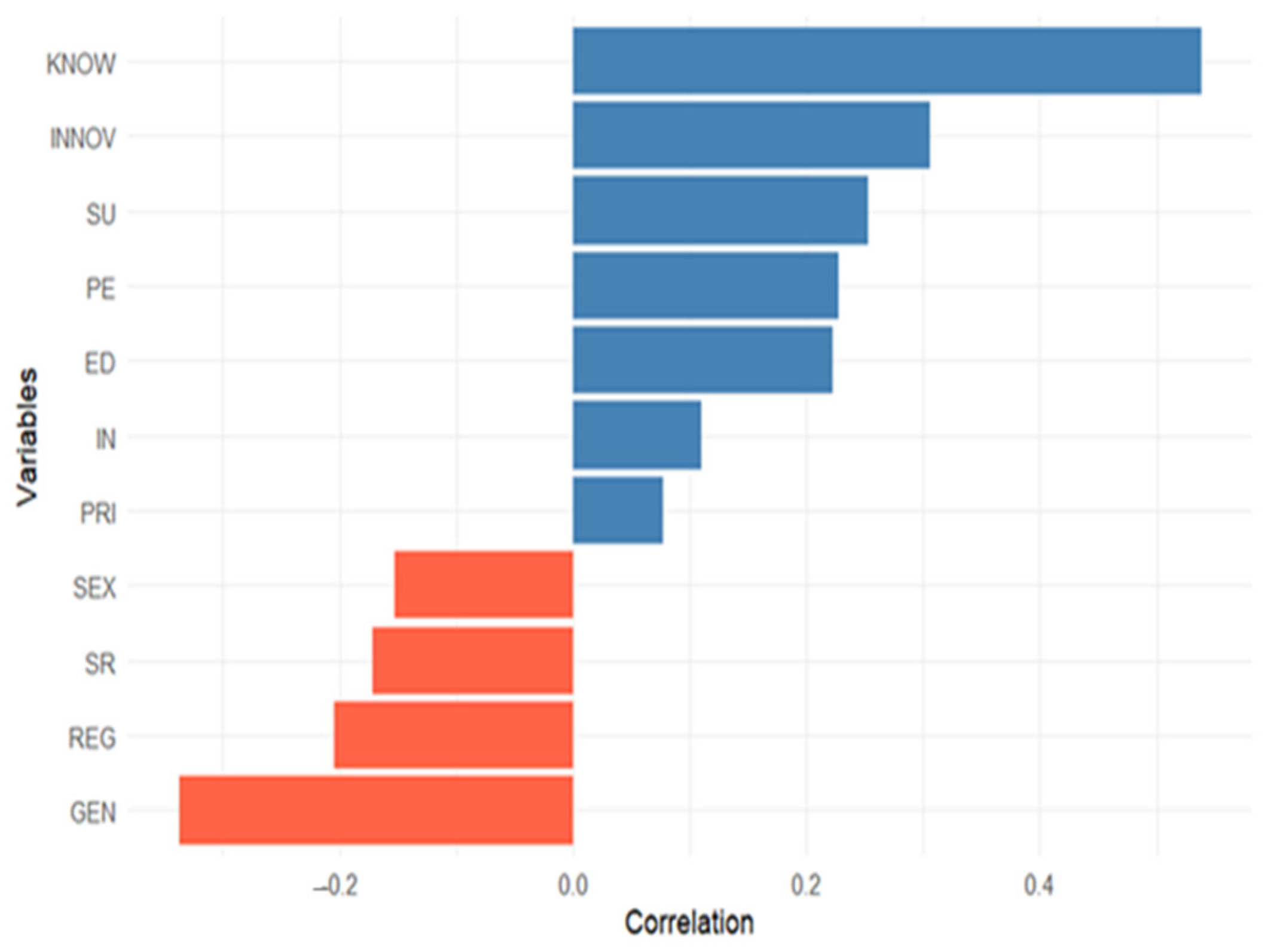
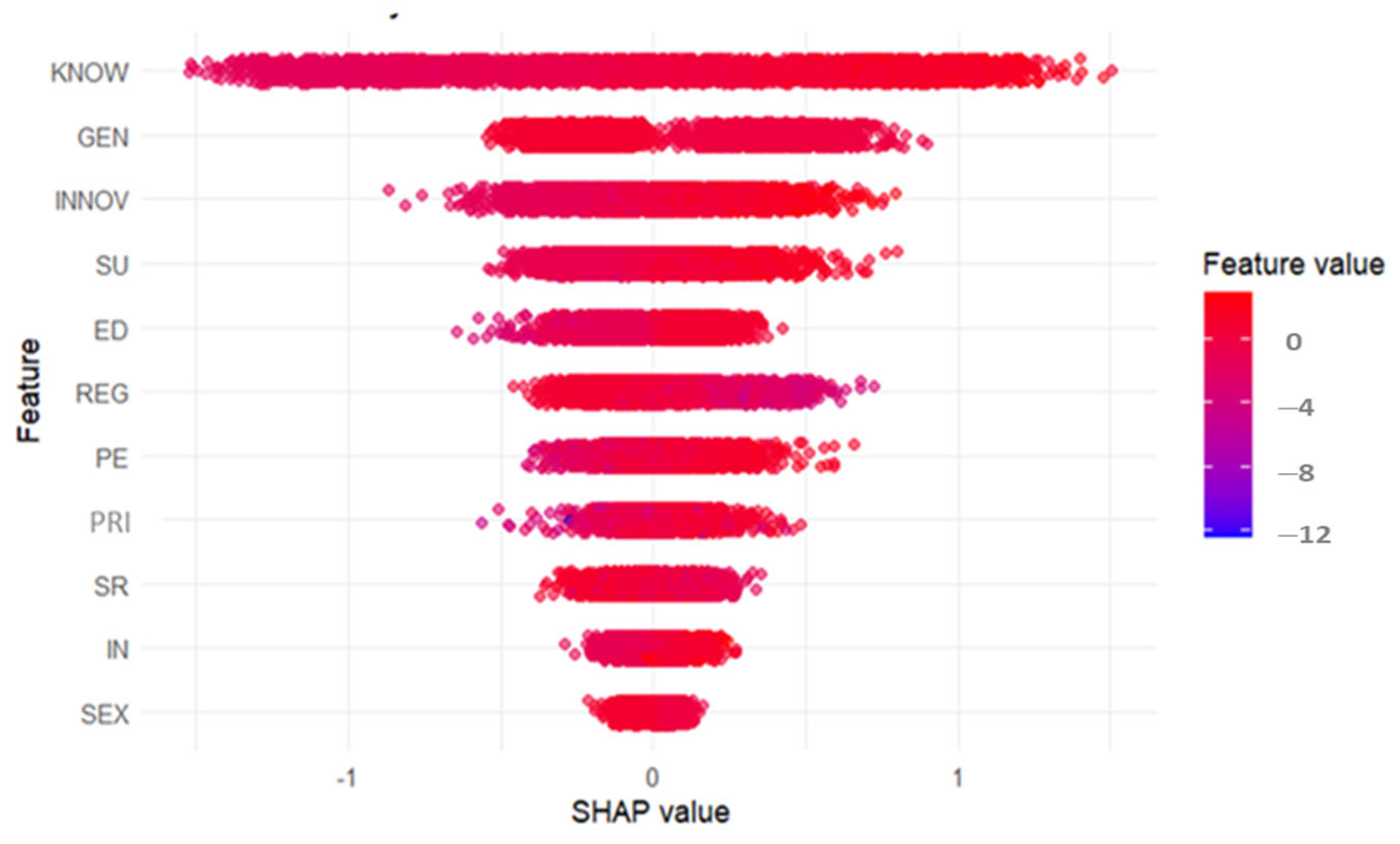
| Variable | SHAP | SHAP_Lower | SHAP_Upper |
| KNOW | 0.559 | 0.547 | 0.571 |
| GEN | 0.297 | 0.293 | 0.301 |
| INNOV | 0.193 | 0.189 | 0.197 |
| SU | 0.154 | 0.150 | 0.158 |
| ED | 0.136 | 0.134 | 0.138 |
| REG | 0.117 | 0.113 | 0.120 |
| PE | 0.102 | 0.099 | 0.104 |
| PRI | 0.074 | 0.072 | 0.076 |
| SR | 0.073 | 0.071 | 0.075 |
| IN | 0.053 | 0.051 | 0.054 |
| SEX | 0.039 | 0.038 | 0.040 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez-Portabella, A.; Andrés-Sánchez, J.d.; Arias-Oliva, M.; Souto-Romero, M. Integrating Machine Learning Techniques and the Theory of Planned Behavior to Assess the Drivers of and Barriers to the Use of Generative Artificial Intelligence: Evidence in Spain. Algorithms 2025, 18, 410. https://doi.org/10.3390/a18070410
Pérez-Portabella A, Andrés-Sánchez Jd, Arias-Oliva M, Souto-Romero M. Integrating Machine Learning Techniques and the Theory of Planned Behavior to Assess the Drivers of and Barriers to the Use of Generative Artificial Intelligence: Evidence in Spain. Algorithms. 2025; 18(7):410. https://doi.org/10.3390/a18070410
Chicago/Turabian StylePérez-Portabella, Antonio, Jorge de Andrés-Sánchez, Mario Arias-Oliva, and Mar Souto-Romero. 2025. "Integrating Machine Learning Techniques and the Theory of Planned Behavior to Assess the Drivers of and Barriers to the Use of Generative Artificial Intelligence: Evidence in Spain" Algorithms 18, no. 7: 410. https://doi.org/10.3390/a18070410
APA StylePérez-Portabella, A., Andrés-Sánchez, J. d., Arias-Oliva, M., & Souto-Romero, M. (2025). Integrating Machine Learning Techniques and the Theory of Planned Behavior to Assess the Drivers of and Barriers to the Use of Generative Artificial Intelligence: Evidence in Spain. Algorithms, 18(7), 410. https://doi.org/10.3390/a18070410