


A Survey of Visual SLAM Based on RGB-D Images Using Deep Learning and Comparative Study for VOE


Abstract
1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Year | Methods | Type of Datasets | Survey of DL |
|---|---|---|---|---|
| [14] | 2017 | Visual SLAM, VOE | RGB-D | No |
| [15] | 2019 | Visual-inertial SLAM, VOE | Stereo, RGB-D | No |
| [16] | 2020 | Visual SLAM, VOE | RGB-D | Yes |
| [17] | 2020 | Visual SLAM | RGB-D | Yes |
| [18] | 2020 | Semantic SLAM, Visual SLAM | Monocular, RGB-D, Stereo | Yes |
| [19] | 2021 | Visual SLAM | RGB-D | Yes |
| [20] | 2022 | Embedded SLAM, Visual-inertial SLAM, Visual-SLAM, VOE | RGB-D | Yes |
| [6] | 2022 | Visual SLAM, VOE | Sonar, Laser, LiDAR, RGB-D, Monocular, Stereo | Yes |
| [21] | 2022 | Visual SLAM | RGB-D | Yes |
| [22] | 2022 | Visual SLAM | RGB-D | Yes |
| [23] | 2022 | Visual SLAM, VOE | RGB-D | Yes |
| [24] | 2022 | Semantic Visual SLAM | Sonar, Laser, LiDAR, RGB-D, Monocular, Stereo | Yes |
| [25] | 2022 | Visual SLAM, VOE | RGB-D, GPS | No |
| [26] | 2022 | Visual SLAM | RGB-D | Yes |
| [27] | 2022 | VOE | LiDAR, RGB-D, Point cloud | Yes |
| [28] | 2023 | Visual SLAM, VOE | RGB-D | Yes |
| [29] | 2023 | Visual SLAM | Monocular, RGB-D, Stereo | Yes |
| [7] | 2023 | Visual SLAM, VOE | Monocular, RGB-D, Stereo | Yes |
| [30] | 2024 | Visual SLAM, VOE | Monocular, RGB-D | Yes |
| [31] | 2024 | Visual SLAM, VOE | Monocular, RGB, Stereo, LiDAR | No |
| [32] | 2024 | Visual SLAM, Visual-Inertial SLAM | RGB-D, IMU | No |
| [33] | 2024 | Visual SLAM, Visual-Inertial SLAM | RGB-D | Yes |
| [34] | 2024 | VOE | Monocular, RGB | Yes |
- A taxonomy for investigating DL-based methods to perform Visual SLAM and VOE from data acquired from RGB-D image sensors is proposed. We conducted a complete survey based on three methods to construct Visual SLAM and VOE from RGB-D images (1) using DL for modules of the Visual SLAM and VOE systems; (2) using DL to supplement the modules of Visual SLAM and VOE systems; and (3) using end-to-end DL to build Visual SLAM and VOE systems.
- The surveyed studies were examined in detail and are presented in the following order: methods, evaluation dataset, evaluation measures, results, and discussion analysis. We also present the challenges in implementing DL-based Visual SLAM and VOE with input data obtained from RGB-D sensors.
- We collected and published the TQU-SLAM benchmark dataset, including devices and equipment for data collection, data collection environment, data collection process, data synchronization/data correction and data labeling, and annotation/ground truth (GT) data preparation, and fine-tuned a VOE model with the MLF-VO framework for a comparative study. The VOE results are presented in detail and visually, and analysis and discussion are also presented.
2. Related Work
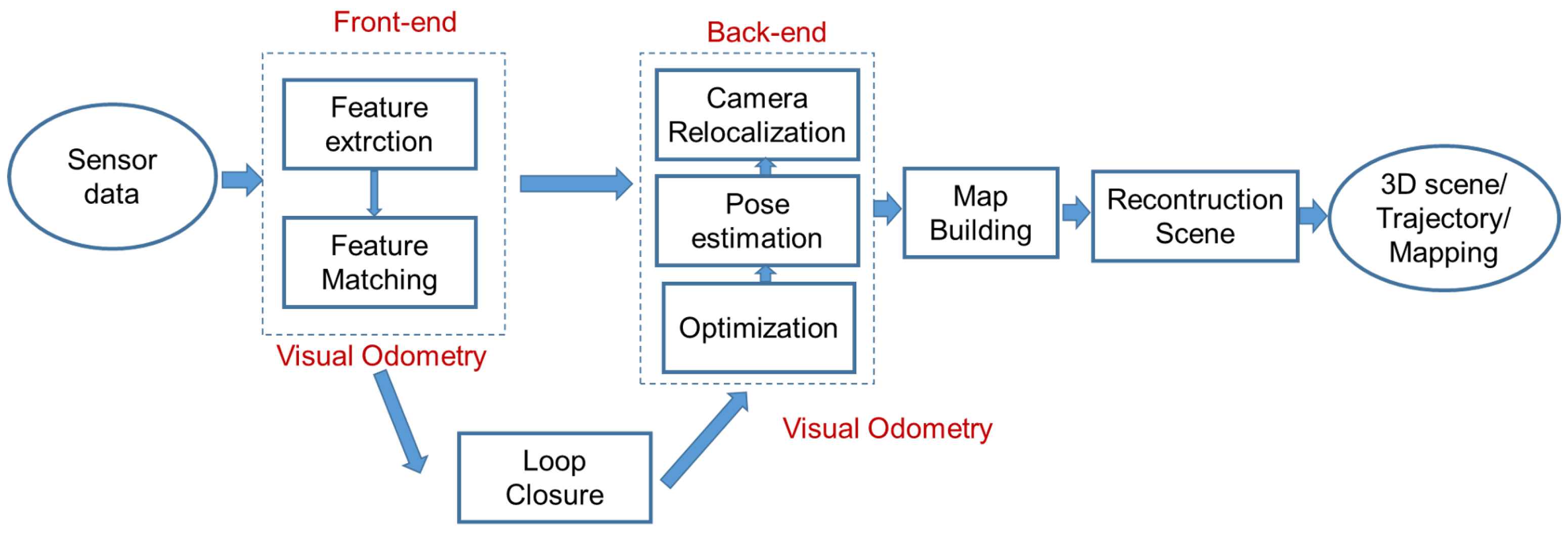
3. Visual SLAM and Visual Odometry Using Deep Learning: Survey
3.1. Deep Learning-Based Module for Visual SLAM and Visual Odometry
3.1.1. Depth Estimation
3.1.2. Optical Flow Estimation
| Authors/Years | Dataset/ Measu./ Methods | NYUDepth | KITTI 2012 Dataset | Make3D Dataset | Cityscapes Dataset | TUM RGB-D SLAM Dataset | ICL-NUIM Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Linear | Log | Linear | Log | Linear | Log | Linear | Log | Linear | Log | Linear | Log | ||
| [40]/2014 | Multi-Scale DN | 2.19 | 0.285 | 5.246 | 0.248 | 8.325 | 0.409 | - | - | - | - | - | - |
| [59]/2015 | CRF_ CNN | 0.82 | - | - | - | - | - | - | - | - | - | - | - |
| [60]/2015 | Ordinal Relationships DN | 1.2 | 0.42 | - | - | - | - | - | - | - | - | - | - |
| [61]/2015 | HCRF_CNN | 0.75 | 0.26 | - | - | - | - | - | - | - | - | - | - |
| [62]/2015 | SGD_DN | 0.64 | 0.23 | - | - | - | - | - | - | 1.41 | 0.37 | 0.83 | 0.43 |
| [63]/2016 | CRF_ CNN_N | 0.73 | 0.33 | - | - | - | - | - | - | 0.86 | 0.29 | 0.81 | 0.41 |
| [41]/2016 | Pixel-wise_ ranking DN | 0.24 | 0.38 | - | - | - | - | - | - | - | - | - | - |
| [64]/2016 | Deeper FCRN | 0.51 | 0.22 | - | - | - | - | - | - | 1.07 | 0.39 | 0.54 | 0.28 |
| [45]/2016 | Unsupervised CNN | - | - | 5.104 | 0.273 | 9.635 | 0.444 | - | - | - | - | - | - |
| [46]/2017 | Unsupervised CNN_D | - | - | 6.125 | 0.217 | 8.86 | 0.142 | 14.445 | 0.542 | - | - | - | - |
| [42]/2017 | SfMLearner | - | - | 4.975 | 0.258 | 10.47 | 0.478 | - | - | - | - | - | - |
| [54]/2017 | PE_S | 0.52 | 0.21 | - | - | - | - | - | - | 0.69 | 0.25 | 0.32 | 0.18 |
| [54]/2017 | PE_N | 0.45 | 0.17 | - | - | - | - | - | - | 0.65 | 0.24 | 0.22 | 0.12 |
| [65]/2018 | StD | 0.48 | 0.17 | - | - | - | - | - | - | 0.7 | 0.27 | 0.36 | 0.18 |
| [66]/2018 | RSS | 0.45 | 0.18 | - | - | - | - | - | - | 0.65 | 0.24 | 0.33 | 0.19 |
| [67]/2018 | Pre-trained KITTI + Cityscapes | - | - | 6.641 | 0.248 | - | - | - | - | - | - | - | - |
| [43]/2018 | DVO_CNN | - | - | 5.583 | 0.228 | 8.09 | 0.204 | - | - | - | - | - | - |
| [67]/2018 | Pre-trained KITTI | - | - | 6.5 | 0.27 | - | - | - | - | - | - | - | - |
| [68]/2018 | Pre-trained KITTI | - | - | 6.22 | 0.25 | - | - | - | - | - | - | - | - |
| [69]/2018 | Geonet-VGG pre-trained KITTI | - | - | 6.09 | 0.247 | - | - | - | - | - | - | - | - |
| [69]/2018 | Geonet-Resnet Pre-trained KITTI | - | - | 5.857 | 0.233 | - | - | - | - | - | - | - | - |
| [70]/2018 | DF-Net Pre-trained KITTI | - | - | 5.507 | 0.223 | - | - | - | - | - | - | - | - |
| [68]/2018 | Pre-trained KITTI + Cityscapes | - | - | 5.912 | 0.243 | - | - | - | - | - | - | - | - |
| [69]/2018 | Geonet-Resnet Pre-trained KITTI + Cityscapes | - | - | 5.737 | 0.232 | - | - | - | - | - | - | - | - |
| [70]/2018 | DF-Net Pre-trained KITTI + Cityscapes | - | - | 5.215 | 0.213 | - | - | - | - | - | - | - | - |
| [65]/2018 | StD- RGB | 0.51 | 0.21 | - | - | - | - | - | - | - | - | - | - |
| [66]/2018 | RSS-RGB | 0.73 | 0.19 | - | - | - | - | - | - | - | - | - | - |
| [71]/2019 | Pre-trained KITTI + Cityscapes | - | - | 5.199 | 0.213 | - | - | - | - | - | - | - | - |
| [71]/2019 | Pre-trained KITTI | - | - | 5.326 | 0.217 | - | - | - | - | - | - | - | - |
| [48]/2019 | Pre-trained KITTI | - | - | 5.439 | 0.217 | - | - | - | - | - | - | - | - |
| [48]/2019 | Pre-trained KITTI + Cityscapes | - | - | 5.234 | 0.208 | - | - | - | - | - | - | - | - |
| [47]/2019 | Struct2depth | - | - | 5.291 | 0.215 | - | - | - | - | - | - | - | - |
| [72]/2019 | Monodepth2 | - | - | 4.701 | 0.19 | - | - | - | - | - | - | - | - |
| [52]/2020 | DRM- SLAM_F | 0.42 | 0.16 | - | - | - | - | - | - | 0.62 | 0.23 | 0.3 | 0.13 |
| [73]/2020 | Packnet-sfm | - | - | 4.601 | 0.189 | - | - | - | - | - | - | - | - |
| [52]/2020 | DRM- SLAM_C | 0.5 | 0.19 | - | - | - | - | - | - | 0.7 | 0.28 | 0.36 | 0.18 |
| [74]/2020 | EPC++ | - | - | 5.35 | 0.216 | - | - | - | - | - | - | - | - |
| [75]/2021 | Faster R-CNN AVN | - | - | 4.772 | 0.191 | - | - | - | - | - | - | - | - |
| [53]/2022 | Cowan-GGR | - | - | 3.923 | 0.188 | - | - | - | - | - | - | - | - |
| [53]/2022 | Cowan | - | - | 4.916 | 0.212 | - | - | - | - | - | - | - | - |
3.1.3. Keypoint Detection and Feature Matching
| Datasets/ Authors/ Years | Sintel Clean Dataset [85] | Sintel Final Dataset [85] | KITTI 2012 [9] | KITTI 2015 Dataset [11] | Middlebury Dataset [86] | Flying Chairs Dataset [55] | Foggy Dataset [83] |
|---|---|---|---|---|---|---|---|
| Train/Test () | Train/Test () | Train/Test () | Train/Test () | Train/Test () | Train/Test () | Train/Test () | |
| [55]/2015 | 3.20/6.08 | 4.83/7.88 | 6.07/7.6 | - | 3.81/4.52 | - | - |
| [56]/2017 | 1.45/4.16 | 2.01/5.74 | 1.28/1.8 | 2.30/- | 0.35/0.52 | - | - |
| [57]/2017 | 3.17/6.64 | 4.32/8.36 | 8.25/10.1 | 0.33/0.58 | -/3.07 | - | |
| [77]/2017 | 4.17/5.30 | 5.45/6.16 | 3.29/4.0 | 0.36/0.39 | - | - | - |
| [78]/2017 | -/3.01 | -/7.96 | -/9.5 | - | - | -/3.01 | - |
| [58]/2018 | 2.02/4.39 | 2.08/5.04 | 1.45/1.7 | 2.16/- | - | - | - |
| [79]/2018 | 4.03/7.95 | 5.95/9.15 | 3.55/4.2 | 8.88/- | - | -/3.76 | - |
| [80] (Hard) /2018 | 5.38/8.35 | 6.01/9.38 | - | 8.8/- | - | - | - |
| [80] (Hard-ft) /2018 | 6.05/- | 7.09/- | - | 7.45/- | - | - | - |
| [80] (None-ft) /2018 | 4.74/- | 5.84/- | - | 3.24/- | - | - | - |
| [80] (Soft-ft) /2018 | 3.89/7.23 | 5.52/8.81 | - | 3.22/- | - | - | - |
| [81] (baseline) /2019 | 6.72/- | 7.31/- | 3.23/- | 4.21/- | - | - | - |
| [81] (gtF) /2019 | 6.15/- | 6.71/- | 2.61/- | 2.89/- | - | - | - |
| [81] (F) /2019 | 6.21/- | 6.73/- | 2.56/- | 3.09/- | - | - | - |
| [81] (low-rank) /2019 | 6.39/- | 6.96/- | 2.63/- | 3.03/- | - | - | - |
| [81] (sub) /2019 | 6.15/- | 6.83/- | 2.62/- | 2.98/- | - | - | - |
| [81] (sub-test-ft) /2019 | 3.94/6.84 | 5.08/8.33 | 2.61/1.1 | 2.56/- | - | - | - |
| [81] (sub-train-ft) /2019 | 3.54/7.0 | 4.99/8.51 | 2.51/1.3 | 2.46/- | - | - | - |
| [88]/2019 | -/3.748 | -/5.81 | -/3.5 | - | -/0.33 | -/2.45 | - |
| [83] /2020 | - | - | -/1.6 | - | - | - | -/4.32 |
| [82] (PWC-Net-ft) /2021 | 2.02/4.39 | 2.08/5.04 | 1.45/1.7 | - | - | - | -/6.10 |
| [82] (FlowNet2-ft) /2021 | 1.45/4.16 | 2.01/5.74 | 1.28/1.8 | - | - | - | -/4.74 |
| [82] (FlowNet2-IA) /2021 | 1.52/4.11 | 5.51/1.4 | 1.4/1.8 | - | - | - | -/4.72 |
| [82] (FlowNet2-IAER) /2021 | 1.46/4.06 | 2.13/1.37 | 1.37/1.8 | - | - | - | -/5.19 |
| [93] (OFPoint) /2025 | -/- | -/- | -/0.065 | - | - | - | -/- |
| Authors/Years | Datasets/ Measu./ Methods | Webcam Dataset | Oxford Dataset | EF | HP- Viewpoint Dataset | HP- Illumination Dataset | |||
|---|---|---|---|---|---|---|---|---|---|
| 2% | Stand. | 2% | Stand. | 2% | Average Match Score | Average Match Score | Average Match Score | ||
| [104]/2004 | SIFT | 20.7 | 46.5 | 43.6 | 32.2 | 23 | 0.296 | 0.49 | 0.494 |
| [101]/2006 | Fast | 26.4 | 53.8 | 47.9 | 39 | 28 | - | - | - |
| [105]/2006 | SURF | 29.9 | 56.9 | 57.6 | 43.6 | 28.7 | 0.235 | 0.493 | 0.481 |
| [102]/2009 | SFOP | 22.9 | 51.3 | 39.3 | 42.2 | 21.2 | - | - | - |
| [99]/2011 | EdgeFoci | 30 | 54.9 | 47.5 | 46.2 | 31 | - | - | - |
| [103]/2013 | SIFER | 25.7 | 45.1 | 40.1 | 27.4 | 17.6 | - | - | - |
| [106]/2013 | WADE | 27.5 | 44.3 | 51 | 25.6 | 28.6 | - | - | - |
| [90]/2015 | TILDE-GB | 33.3 | 54.5 | 32.8 | 43.1 | 16.2 | - | - | - |
| [90]/2015 | TILDE-CNN | 36.8 | 51.8 | 49.3 | 43.2 | 27.6 | - | - | - |
| [90]/2015 | TILDE-P24 | 40.7 | 58.7 | 59.1 | 46.3 | 33 | - | - | - |
| [90]/2015 | TILDE-P | 48.3 | 58.1 | 55.9 | 45.1 | 31.6 | - | - | - |
| [107]/2017 | L2-Net+DoG | - | - | - | - | - | 0.189 | 0.403 | 0.394 |
| [107]/2017 | L2-Net+SURF | - | - | - | - | - | 0.307 | 0.627 | 0.629 |
| [107]/2017 | L2-Net+FAST | - | - | - | - | - | 0.229 | 0.571 | 0.431 |
| [107]/2017 | L2-Net+ORB | - | - | - | - | - | 0.298 | 0.705 | 0.673 |
| [107]/2017 | L2-Net+Zhang et al. | - | - | - | - | - | 0.235 | 0.685 | 0.425 |
| [108]/2017 | Hard-Net+DoG | - | - | - | - | - | 0.206 | 0.436 | 0.468 |
| [108]/2017 | Hard-Net+SURF | - | - | - | - | - | 0.334 | 0.65 | 0.668 |
| [108]/2017 | Hard-Net+FAST | - | - | - | - | - | 0.29 | 0.617 | 0.63 |
| [108]/2017 | Hard-Net+ORB | - | - | - | - | - | 0.238 | 0.616 | 0.632 |
| [108]/2017 | Hard-Net+Zhang et al. | - | - | - | - | - | 0.273 | 0.671 | 0.557 |
| [109]/2018 | LF-Net | - | - | - | - | - | 0.251 | 0.617 | 0.566 |
| [91]/2019 | RF-Net | - | - | - | - | - | 0.453 | 0.783 | 0.808 |
| [93]/2025 | OFPoint | - | - | - | - | - | - | 0.617 | 0.678 |
3.1.4. DL Modules Add to the Visual SLAM Algorithm
| Authors/Years | Dataset/ Measu./ Methods | TUM RGB-D SLAM Dataset | KITTI 2012 Dataset | Euroc Dataset | ||
|---|---|---|---|---|---|---|
| (m) | (%) | (deg/100 m) | (m) | (m) | ||
| [118]/2017 | ORB-SLAM2 (stereo) | - | 0.727 | 0.22 | - | - |
| [119]/2019 | GCN-SLAM | 0.05 | - | - | - | - |
| [110]/2020 | SP-Flow SLAM | 0.03 | - | - | - | - |
| [110]/2020 | Stereo LSD-SLAM | - | 0.942 | 0.272 | - | - |
| [110]/2020 | SP-Flow SLAM(stereo) | - | 0.76 | 0.19 | - | - |
| [111]/2020 | LIFT-SLAM | - | - | - | 9.19 | 0.573 |
| [111]/2021 | LIFT-SLAM (fine-tune KITI) | - | - | - | 11.33 | 0.08 |
| [111]/2021 | LIFT-SLAM (fine-tune Euroc) | - | - | - | 8.94 | 0.07 |
| [111]/2021 | Adaptive LIFT-SLAM | - | - | - | 8.56 | 0.04 |
| [111]/2021 | Adaptive LIFT-SLAM (fine-tune KITI) | - | - | - | 11.24 | 0.28 |
| [111]/2021 | Adaptive LIFT-SLAM (fine-tune Euroc) | - | - | - | 11.3 | 0.048 |
| [120]/2023 | Point-SLAM | 0.0892 | - | - | - | - |
| [121]/2023 | ESLAM | 0.0211 | - | - | - | - |
| [122]/2023 | Co-SLAM | 0.0274 | - | - | - | - |
| [113]/2024 | SplaTAM | 0.0339 | - | - | - | - |
| [112]/2024 | RTG-SLAM | 0.0106 | - | - | - | - |
| [123]/2024 | SG-Init+ DROID(L) | - | - | 9.07 | - | |
| [123]/2024 | SG-Init+ DROID (O) | - | - | 9.39 | - | |
| [123]/2024 | SG-Init+ DROID (N/A) | - | - | 14.92 | - | |
| [124]/2024 | LGU-VO | - | - | 0.139 | ||
| [124]/2024 | LGU-SLAM | 0.031 | - | - | 0.018 | |
| [124]/2024 | LGU (w/o SSL) | - | - | 0.142 | ||
| [124]/2024 | LGU (w/o SM) | - | - | 0.146 | ||
| Authors/Year | Methods/ Datasets/ Matrix | CARLA | TUM RGB-D SLAM Dataset | Object Fusion Dataset I | Object Fusion Dataset II | Object Fusion Dataset III | Object Fusion Dataset IV | ICL- NUIM Dataset | ADVIO Dataset | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
(%)/ (m) | Mean / Mean / | Mean / Mean / | Mean / Mean / | Mean / Mean / | (Tabs) | Mean Error | for Trans. | ||||
| [114]/2017 | MR-SLAM | - | 0.085 | - | - | - | - | - | - | - | - |
| [115]/2018 | Mask-SLAM | 58.2/ 13.7 | - | - | - | - | - | - | - | - | - |
| [117]/2018 | DS-SLAM | - | 0.103 | - | - | - | - | - | - | - | - |
| [135]/2018 | VINS-Mono | - | - | - | - | - | - | - | 5.037 | 4.71 | 1.68 |
| [125]/2018 | DynaSLAM | - | 0.019 | - | - | - | - | - | - | - | - |
| [126]/2018 | Detect-SLAM | - | 0.113 | - | - | - | - | - | - | - | - |
| [127]/2019 | ObjectFusion- FCN-VOC8s | - | - | 0.52/ 0.62/ 0.729 | 0.5169/ 0.5966/ 0.7103 | 0.5775/ 0.6559/ 0.6708 | 0.3529/ 0.4168/ 0.7361 | - | - | - | - |
| [127]/2019 | ObjectFusion- CRF-RNN | - | - | 0.59/ 0.63/ 0.938 | 0.4769/ 0.4899/ 0.5633 | 0.5618/ 0.6058/ 0.4115 | 0.273/ 0.2989/ 0.5955 | - | - | - | - |
| [127]/2019 | ObjectFusion- Mask-RCNN | - | - | 0.59/ 0.64/ 0.895 | 0.4855/ 0.5021/ 0.7125 | 0.4946/ 0.5397/ 0.4489 | 0.3433/ 0.3938/ 0.716 | - | - | - | - |
| [127]/2019 | ObjectFusion- Deeplabv3+ | - | - | 0.58/ 0.63/ 0.856 | 0.4849/ 0.4927/ 0.719 | 0.4869/ 0.537/ 0.4458 | 0.3484/ 0.3952/ 0.7351 | - | - | - | - |
| [127]/2019 | ObjectFusion- SORS (GLOBAL) | - | - | 0.71/ 0.726/ 0.954 | 0.5889/ 0.6438/ 0.7989 | 0.6063/ 0.6764/ 0.872 | 0.4012/ 0.4261/ 0.7806 | - | - | - | - |
| [127]/2019 | ObjectFusion- SORS (ACTIVATE) | - | - | 0.702/ 0.724/ 0.936 | 0.5301/ 0.5765/ 0.8626 | 0.5528/ 0.6106/ 0.902 | 0.3728/ 0.3878/ 0.7873 | - | - | - | - |
| [128]/2019 | OFB-SLAM | - | 0.082 | - | - | - | - | - | - | - | - |
| [129]/2020 | Semantic Filter_ RANSAC_ Faster R-CNN | - | 0.19 | - | - | - | - | - | - | - | - |
| [130]/2020 | Offline Deep SAFT | - | 0.0179 | - | - | - | - | 0.057 | - | - | - |
| [130]/2020 | Continuous Deep SAFT | - | 0.168 | - | - | - | - | 0.043 | - | - | - |
| [130]/2020 | Discrete Deep SAFT | - | 0.0235 | - | - | - | - | 0.065 | - | - | - |
| [131]/2020 | EF-Razor | - | 0.0168 | - | - | - | - | - | - | - | - |
| [132]/2020 | RoomSLAM | - | 0.205 | - | - | - | - | - | - | - | - |
| [133]/2020 | USS-SLAM with ALT | - | 0.01702 | - | - | - | - | - | - | - | - |
| [133]/2020 | USS-SLAM without ALT | - | 0.019 | - | - | - | - | - | - | - | - |
| [134]/2020 | Visual-inertial _SS | - | - | - | - | - | - | - | 4.84 | 4.51 | 1.61 |
| [136]/2020 | DM-SLAM | - | 0.034 | - | - | - | - | - | - | - | - |
| [137]/2021 | RDS-SLAM | - | 0.065 | - | - | - | - | - | - | - | - |
| [138]/2022 | ORB-SLAM2 _PST | - | 0.019 | - | - | - | - | - | - | - | - |
| Authors/Years | Datasets/ Measu./ Methods | SceneNet RGB-D [145] | KITTI 2012 Dataset | 7-Scenes Dataset [146] |
|---|---|---|---|---|
|
of (cm) |
of (cm) | Dense Correspondence Reprojection Error (DCRE) (cm) | ||
| [150]/2015 | InfiniTAM(IM)_S1 | 22.486 | - | - |
| [150]/2015 | InfiniTAM(IM)_S2 | 28.08 | - | - |
| [150]/2015 | InfiniTAM(IM)_S3 | 13.824 | - | - |
| [150]/2015 | InfiniTAM(IM)_S4 | 34.846 | - | - |
| [151]/2017 | BundleFusion (BF)_S3 | 4.164 | - | - |
| [151]/2017 | BundleFusion (BF)_S1 | 5.2 | - | - |
| [151]/2017 | BundleFusion (BF)_S2 | 5.598 | - | - |
| [151]/2017 | BundleFusion (BF)_S4 | 7.742 | - | - |
| [152]/2017 | PoseNet17 | - | - | 24 |
| [147]/2018 | Maskfusion(MF)_S4 | 18.972 | - | - |
| [147]/2018 | Maskfusion (MF)_S1 | 20.856 | - | - |
| [147]/2018 | Maskfusion (MF)_S2 | 22.71 | - | - |
| [153]/2018 | PoseNet + log q | - | - | 22 |
| [147]/2018 | Maskfusion (MF)_S3 | 14.824 | - | - |
| [153]/2018 | MapNet | - | - | 21 |
| [68]/2018 | Vid2Depth | - | 1.25 | - |
| [142]/2019 | MID-fusion (MID)_S1 | 5.98 | - | - |
| [142]/2019 | MID-fusion (MID)_S2 | 4.132 | - | - |
| [142]/2019 | MID-fusion (MID)_S3 | 5.1675 | - | - |
| [142]/2019 | MID-fusion (MID)_S4 | 5.3825 | - | - |
| [71]/2019 | CC | - | 1.2 | - |
| [47]/2019 | Struct2Depth | - | 1.1 | - |
| [72]/2019 | Monodepth2 | - | 1.6 | - |
| [74]/2020 | EPC++ | - | 1.2 | - |
| [143]/2021 | NeuralR-Pose | - | - | 21 |
| [75]/2021 | Insta-DM | - | 1.05 | - |
| [141]/2022 | ObjectFusion_S3 | 0.79 | - | - |
| [141]/2022 | ObjectFusion_S1 | 0.964 | - | - |
| [144]/2022 | ORGPoseNet | - | - | 21 |
| [141]/2022 | ObjectFusion_S4 | 1.132 | - | - |
| [144]/2022 | ORGMapNet | - | - | 20 |
| [53]/2022 | Cowan | - | 1.15 | - |
| [53]/2022 | Cowan-GGR | - | 1.05 | - |
| Authors/ Years | Methods/ Datasets/ Measu. | KITTI 2012 Dataset | NYU RGB-D V2 Dataset | TUM RGB-D SLAM Dataset | ICL-NUIM Dataset | Mask-RCNN MC Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
(%) | (Degrees) | (log) | (abs. rel) | (log) | (abs. rel) | (log) | (abs. rel) | |||||||
| [164]/ 2011 | VISO-S | 2.05 | 1.19 | - | - | - | - | - | - | - | - | - | - | - |
| [164] /2011 | VISO-M | 19 | 3.23 | - | - | - | - | - | - | - | - | - | - | - |
| [165] /2016 | BKF | 18.04 | 5.56 | - | - | - | - | - | - | - | - | - | - | - |
| [63]/ 2016 | - | - | 0.73 | 0.33 | 0.33 | 0.86 | 0.29 | 0.25 | 0.81 | 0.41 | 0.45 | - | - | |
| [63]/ 2016 | + Fusion | - | - | 0.65 | 0.3 | 0.29 | 0.81 | 0.28 | 0.24 | 0.64 | 0.32 | 0.34 | - | - |
| [64]/ 2016 | - | - | 0.51 | 0.22 | 0.18 | 1.07 | 0.39 | 0.25 | 0.54 | 0.28 | 0.23 | - | - | |
| [64]/ 2016 | + Fusion | - | - | 0.44 | 0.19 | 0.16 | 0.91 | 0.32 | 0.22 | 0.41 | 0.23 | 0.19 | - | - |
| [166]/ 2017 | LSTM-KF | 3.24 | 1.55 | - | - | - | - | - | - | - | - | - | - | - |
| [166]/ 2017 | LSTMs | 3.07 | 1.38 | - | - | - | - | - | - | - | - | - | - | - |
| [148]/ 2019 | LKN | 1.79 | 0.87 | - | - | - | - | - | - | - | - | - | - | - |
| [52]/ 2020 | DRM- SLAM_C | - | - | 0.5 | 0.19 | 0.16 | 0.7 | 0.28 | 0.2 | 0.36 | 0.18 | 0.16 | - | - |
| [52]/ 2020 | F w/o Confidence | - | - | 0.48 | 0.2 | 0.16 | 0.67 | 0.26 | 0.18 | 0.35 | 0.17 | 0.16 | - | - |
| [52]/ 2020 | DRM- SLAM_F | - | - | 0.44 | 0.16 | 0.09 | 0.62 | 0.23 | 0.1 | 0.3 | 0.13 | 0.14 | - | - |
| [149]/ 2020 | Nonsemantic maps without moving objects | - | - | - | - | - | - | - | - | - | - | - | 0.0068 ± (0.0029) | 0.0138 ± (0.0057) |
| [149]/ 2020 | Semantic maps without moving objects | - | - | - | - | - | - | - | - | - | - | - | 0.0045 ± (0.0029) | 0.0127 ± (0.0057) |
| [149]/ 2020 | Nonsemantic maps with moving objects | - | - | - | - | - | - | - | - | - | - | - | 0.0071 ± (0.0029) | 0.0145 ± (0.0057) |
| [149]/ 2020 | Semantic maps with moving objects | - | - | - | - | - | - | - | - | - | - | - | 0.0057 ± (0.0029) | 0.0134 ± (0.0057) |
| Authors/Years | Datasets/ Measu. Methods | KITTI 2012 Dataset (Seq.00, Seq.02, Seq.05) | City Centre | GPW [163] | TUM RGB-D SLAM Dataset (fr1_desk, fr2_desk, fr3_ long _office) | KITTI 2012 Dataset (Seq.00, Seq.02, Seq.08) | KITTI 2012 Dataset (Seq.00) | ||
|---|---|---|---|---|---|---|---|---|---|
| Avg. Good Match (%) | |||||||||
| [172]/2012 | DBoW2_ORB | 0.067 | 0.22 | 0.092 | - | - | - | - | - |
| [172]/2012 | DBoW2_BRISK | 0.318 | 0.186 | 0.088 | - | - | - | - | - |
| [172]/2012 | DBoW2_SURF | 0.175 | 0.177 | 0.086 | - | - | - | - | - |
| [172]/2012 | DBoW2_AKAZE | 0.413 | 0.444 | 0.199 | - | - | - | - | - |
| [173]/2017 | DBoW3_ORB | 0.274 | 0.217 | 0.182 | - | - | - | - | - |
| [173]/2017 | DBoW3_BRISK | 0.169 | 0.187 | 0.098 | - | - | - | - | - |
| [173]/2017 | DBoW3_SURF | 0.12 | 0.019 | 0.0197 | - | - | - | - | - |
| [173]/2017 | DBoW3_AKAZE | 0.46 | 0.174 | 0.147 | - | - | - | - | - |
| [174]/2018 | iBoW | 0.88 | 0.94 | 0.95 | - | - | - | - | - |
| [175]/2019 | HF-Net | - | - | - | - | - | - | - | - |
| [167]/2020 | Impro_BoW _Without AE | 0.912 | 0.96 | 0.94 | - | - | - | - | - |
| [167]/2020 | Impro_BoW _With AE | 0.96 | 0.97 | 0.97 | - | - | - | - | - |
| [168]/2021 | Triplet Loss _BoW | - | - | - | 0.014 | 0.016 | 5.416705 | 6.74 | - |
| [168]/2021 | Triplet Loss _Metric _Learning | - | - | - | 0.012 | 0.0135 | 2.92 | 3.46 | - |
| [169]/2022 | CNN_DFM | - | - | - | - | - | - | - | 63 |
| Authors | Dataset/ Measu./ Methods | KITTI 2012 Dataset (03, 04, 05, 06, 07,10) | KITTI 2012 Dataset (09,10) | ScanNet++ [171] Dataset | |||||
|---|---|---|---|---|---|---|---|---|---|
| [176]/2015 | ORB-SLAM-mono | 7.4623 | 0.0221 | 0.0368 | - | - | - | - | |
| [177]/2016 | DSO-mono | 7.3854 | 0.0241 | 0.0452 | - | - | - | - | - |
| [178]/2017 | PMO | 0.7463 | 0.7183 | 0.9633 | - | - | - | - | - |
| [179]/2017 | DSO-stereo | 0.0756 | 0.9387 | 1 | - | - | - | - | |
| [69]/2018 | GeoNet | - | - | - | 6.2302 | 0.0306 | 0.0544 | - | - |
| [180]/2019 | SRNN | 0.6754 | 0.6121 | 0.9667 | - | - | - | - | - |
| [180]/2019 | SRNN-se | 0.6526 | 0.5801 | 0.9727 | - | - | - | - | - |
| [180]/2019 | SRNN-point | 0.5234 | 0.6267 | 0.9822 | - | - | - | - | - |
| [180]/2019 | SRNN-channel | 0.5033 | 0.6487 | 0.9873 | - | - | - | - | - |
| [181]/2019 | DistanceNet-FlowNetS | 0.5544 | 0.6292 | 0.9752 | - | - | - | - | - |
| [181]/2019 | DistanceNet-Reg | 0.5315 | 0.6848 | 0.9855 | - | - | - | - | - |
| [181]/2019 | DistanceNet-LSTM | 0.4167 | 0.6871 | 0.9896 | - | - | - | - | - |
| [181]/2019 | DistanceNet-BCE | 0.3925 | 0.7158 | 0.993 | - | - | - | - | - |
| [181]/2019 | DistanceNet | 0.3901 | 0.6984 | 0.9916 | 0.4624 | 0.6669 | 0.9841 | - | - |
| [48]/2019 | SfMLearner | - | - | - | 7.5671 | 0.0216 | 0.0505 | - | - |
| [182]/2022 | NICE-SLAM | - | - | - | - | - | - | 0.0445 | 0.7449 |
| [122]/2023 | Co-SLAM | - | - | - | - | 0.0526 | 0.7886 | ||
| [121]/2023 | ESLAM | - | - | - | - | 0.0443 | 0.7451 | ||
| [120]/2023 | Point-SLAM | - | - | - | - | - | - | 0.0067 | 0.9912 |
| [113]/2024 | SplaTAM | - | - | - | - | - | - | 0.0132 | 0.9531 |
| [112]/2024 | RTG-SLAM | - | - | - | - | - | - | 0.0095 | 0.9641 |
| Authors/Year | Dataset/ Measu./ Methods | NYU RGB-D V2 Dataset [49] | NYU RGB-D V2 Dataset | KITTI 2012 Dataset | Make3D [50] Dataset | ||||
|---|---|---|---|---|---|---|---|---|---|
| RGB | Depth | RGB | RGB | ||||||
| [183]/2008 | Samples_0 | - | - | - | - | - | - | 16.7 | 0.53 |
| [50]/2009 | Samples_0 | - | - | - | - | 8.374 | 0.28 | - | 0.698 |
| [40]/2014 | Samples_0 | - | - | - | - | 7.156 | 0.19 | - | - |
| [62]/2015 | Samples_0 | 0.641 | 0.158 | - | - | - | - | - | - |
| [64]/2016 | Samples_0 | 0.573 | 0.127 | - | - | - | - | - | - |
| [184]/2016 | Samples_0 | 0.744 | 0.187 | - | - | - | - | - | - |
| [185]/2016 | Samples_0 | - | - | - | - | 7.508 | - | - | - |
| [186]/2016 | Samples_650 | - | - | - | - | 7.14 | 0.179 | - | - |
| [187]/2017 | Samples_0 | 0.586 | 0.121 | - | - | - | - | - | - |
| [188]/2017 | Samples_225 | 0.442 | 0.104 | - | - | - | - | - | - |
| [188]/2017 | Samples_225 | - | - | - | - | 4.5 | 0.113 | - | - |
| [189]/2018 | Samples_0 | 0.593 | 0.125 | - | - | - | - | - | - |
| [189]/2018 | Samples_0 | 0.582 | 0.12 | - | - | - | - | - | - |
| [65]/2018 | Samples_0 | 0.514 | 0.143 | - | - | 6.266 | 0.208 | - | - |
| [65]/2018 | Samples_20 | 0.351 | 0.078 | 0.461 | 0.11 | - | - | - | - |
| [190]/2018 | (L2 loss) | 0.943 | 0.572 | - | - | - | - | ||
| [190]/2018 | L1 loss | 0.256 | 0.046 | 0.68 | 0.24 | - | - | - | - |
| [65]/2018 | Samples_200 | 0.23 | 0.044 | 0.259 | 0.054 | - | - | - | - |
| [190]/2018 | L1 loss Samples_50 | - | - | 0.44 | 0.13 | - | - | - | - |
| [65]/2018 | Samples_50 | - | - | 0.347 | 0.076 | - | - | - | - |
| [65]/2018 | Samples_500 | - | - | - | - | 3.378 | 0.073 | 5.525 | 0.14 |
| [190]/2018 | L1 loss samples_200 | - | - | 0.39 | 0.1 | - | - | - | - |
| [191]/2018 | Samples_0 | - | - | - | - | 6.298 | 0.18 | - | - |
| [192]/2019 | Samples_0 | 0.583 | 0.164 | - | - | 5.191 | 0.145 | 10.281 | 0.594 |
| [193]/2019 | Samples_0 | 0.766 | 0.254 | - | - | 5.187 | 0.141 | ||
| [194]/2019 | Samples_0 | 0.579 | 0.108 | - | - | - | - | - | - |
| [195]/2019 | Samples_0 | 0.547 | 0.152 | - | - | - | - | - | - |
| [196]/2019 | Samples_100 | 0.502 | - | - | - | - | - | - | - |
| [197]/2019 | Samples_20 | 0.526 | - | 1.369 | - | - | - | - | - |
| [192]/2019 | Samples_20 | 0.385 | 0.086 | 0.462 | 0.106 | - | - | - | - |
| [197]/2019 | Samples_200 | 0.495 | - | 1.265 | - | - | - | - | - |
| [192]/2019 | Samples_200 | 0.292 | 0.068 | 0.289 | 0.062 | - | - | - | - |
| [195]/2019 | Samples_20 | - | - | 0.457 | 0.107 | - | - | - | - |
| [197]/2019 | Samples_50 | - | - | 1.31 | - | - | - | - | - |
| [192]/2019 | Samples_50 | - | - | 0.35 | 0.075 | - | - | - | - |
| [197]/2019 | Samples_0 | - | - | - | - | 5.437 | - | - | - |
| [197]/2019 | Samples_500 | - | - | - | - | 5.389 | - | - | - |
| [196]/2019 | Samples_500 | - | - | - | - | 5.14 | - | - | - |
| [192]/2019 | Samples_500 | - | - | - | - | 3.033 | 0.051 | 5.658 | 0.135 |
| [198]/2020 | DEM_ samples_0 | 0.49 | 0.135 | - | - | 4.433 | 0.101 | 10.003 | 0.529 |
| [198]/2020 | w/o pre-trained weights samples_0 | 0.637 | 0.187 | - | - | - | - | - | - |
| [198]/2020 | DEM_samples_20 | 0.314 | 0.069 | 0.443 | 0.1 | - | - | - | - |
| [198]/2020 | DEM_samples_200 | 0.194 | 0.036 | 0.223 | 0.041 | - | - | - | - |
| [198]/2020 | w/o pre-trained weights | 0.226 | 0.042 | 0.23 | 0.043 | - | - | - | - |
| [198]/2020 | DEM_samples_50 | - | - | 0.342 | 0.07 | - | - | - | - |
| [198]/2020 | DEM_samples_500 | - | - | - | - | 2.485 | 0.04 | 5.455 | 0.104 |
3.1.5. End-to-End for the Visual SLAM Algorithm
| Authors/Years | Methods | Dataset/ Measu./ Output | KITTI 2012 Dataset (00, 02, 05, 07, 08) | KITTI 2012 Dataset (09, 10) | KITTI 2012 Dataset (Seq.03, Seq.04, Seq.05, Seq.06, Seq.07,Seq.10) | |||
|---|---|---|---|---|---|---|---|---|
| (%) | (Degrees) | (%) | (Degrees) | (%) | (Degrees) | |||
| [207]/2015 | OKVIS | Trajectory estimation | - | - | 13.535 | 2.895 | - | - |
| [42]/2017 | SFMLearner | Trajectory estimation | 36.232 | 4.562 | 21.085 | 7.25 | - | - |
| [208]/2017 | ROVIO | Trajectory estimation | - | - | 20.11 | 2.165 | - | - |
| [200]/2017 | DeepVO | Trajectory estimation | - | - | - | - | 5.96 | 6.12 |
| [204]/2018 | VIOLearner | Trajectory estimation | 5.574 | 2.31 | 1.775 | 1.135 | - | - |
| [202]/2018 | UnDeepVO | Trajectory estimation | 4.07 | 2.026 | - | - | - | - |
| [202]/2018 | VISO2-M | Trajectory estimation | 17.924 | 2.798 | - | - | 17.48 | 16.52 |
| [202]/2018 | ORB-SLAM-M | Trajectory estimation | 27.0575 | 10.2375 | - | - | - | - |
| [202]/2018 | VISO2-M | Trajectory estimation | - | - | - | - | 1.89 | 1.96 |
| [203]/2018 | Depth-VO-Feat | Trajectory estimation | - | - | 12.27 | 3.52 | - | - |
| [206]/2022 | SelfVIO | Trajectory estimation | 0.9 | 0.44 | 1.88 | 1.23 | - | - |
| [206]/2022 | SelfVIO (no IMU) | Trajectory estimation | - | - | 2.41 | 1.62 | - | - |
| [206]/2022 | SelfVIO (LSTM) | Trajectory estimation | - | - | 2.07 | 1.32 | - | - |
4. Challenges and Discussion
4.1. Performances of Visual SLAM and VOE Systems
4.2. Energy Consumption and Computing Space
4.3. Generalize and Adaptive
| Authors/Years | Dataset/ Measu./ Methods | 7-Scenes Dataset [146] | |
|---|---|---|---|
| Ang. Error (Degrees) | Trans. Error (m) | ||
| [222,223]/2016 | PoseNet | 10.4 | 0.44 |
| [222,223]/2016 | Bayesian PoseNet | 9.81 | 0.47 |
| [222,223]/2016 | PoseNet-Euler6 | 9.83 | 0.38 |
| [222,223]/2016 | PoseNet-Euler6-Aug | 8.58 | 0.34 |
| [222,223]/2016 | BranchNet-Euler6 | 9.82 | 0.3 |
| [222,223]/2016 | BranchNet-Euler6-Aug | 8.3 | 0.29 |
| [152]/2017 | Geometric PoseNet | 8.1 | 0.23 |
| [224]/2017 | Hourglass | 9.5 | 0.23 |
| [225]/2017 | LSTM-Pose | 9.9 | 0.31 |
| [226]/2017 | BranchNet | 8.3 | 0.29 |
| [227]/2019 | MLFBPPose | 9.8 | 0.2 |
| [228]/2019 | ANNet | 7.9 | 0.21 |
| [229]/2019 | GPoseNet | 10.0 | 0.31 |
| [230]/2019 | AnchorPoint | 7.5 | 0.13 |
| [231]/2020 | AttLoc | 7.6 | 0.2 |
| [232]/2021 | GNN-RPS | 5.2 | 0.16 |
4.4. Actual Implementation

5. Comparative Study for VOE
5.1. Data Collection
5.2. Preparing GT Trajectory for Evaluating VOE
5.3. Fine-Tuning VOE Model Based on DL
5.4. Comparative Study of VOE Results
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhai, Z.M.; Moradi, M.; Kong, L.W.; Glaz, B.; Haile, M.; Lai, Y.C. Model-free tracking control of complex dynamical trajectories with machine learning. Nat. Commun. 2023, 14, 5698. [Google Scholar] [CrossRef] [PubMed]
- Zhai, Z.M.; Moradi, M.; Glaz, B.; Haile, M.; Lai, Y.C. Machine-learning parameter tracking with partial state observation. Phys. Rev. Res. 2024, 6, 13196. [Google Scholar] [CrossRef]
- Ajagbe, S.A.; Adigun, M.O. Deep learning techniques for detection and prediction of pandemic diseases: A systematic literature review. Multimed. Tools Appl. 2024, 83, 5893–5927. [Google Scholar] [CrossRef] [PubMed]
- Gbadegesin, A.T.; Akinwole, T.O.; Ogundepo, O.B. Statistical Analysis of Stakeholders Perception on Adoption of AI/ML in Sustainable Agricultural Practices in Rural Development. In Proceedings of the Ninth International Congress on Information and Communication Technology. ICICT 2024; Lecture Notes in Networks and Systems. Springer: Singapore, 2024; Volume 1003. [Google Scholar] [CrossRef]
- Taiwo, G.A.; Saraee, M.; Fatai, J. Crime Prediction Using Twitter Sentiments and Crime Data. Informatica 2024, 48, 35–42. [Google Scholar] [CrossRef]
- Abaspur Kazerouni, I.; Fitzgerald, L.; Dooly, G.; Toal, D. A survey of state-of-the-art on visual SLAM. Expert Syst. Appl. 2022, 205, 117734. [Google Scholar] [CrossRef]
- Favorskaya, M.N. Deep Learning for Visual SLAM: The State-of-the-Art and Future Trends. Electronics 2023, 12, 2006. [Google Scholar] [CrossRef]
- Phan, T.D.; Kim, G.W. Toward Specialized Learning-based Approaches for Visual Odometry: A Comprehensive Survey. J. Intell. Robot. Syst. Theory Appl. 2025, 111, 44. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Menze, M.; Geiger, A. Object Scene Flow for Autonomous Vehicles. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; Volume 32, pp. 315–326. [Google Scholar] [CrossRef]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar] [CrossRef]
- Taketomi, T.; Uchiyama, H.; Ikeda, S. Visual SLAM algorithms: A survey from 2010 to 2016. Ipsj Trans. Comput. Vis. Appl. 2017, 9, 16. [Google Scholar] [CrossRef]
- Jinyu, L.; Bangbang, Y.; Danpeng, C.; Nan, W.; Guofeng, Z.; Hujun, B. Survey and evaluation of monocular visual-inertial SLAM algorithms for augmented reality. Virtual Real. Intell. Hardw. 2019, 1, 386–410. [Google Scholar] [CrossRef]
- Lai, D.; Zhang, Y.; Li, C. A Survey of Deep Learning Application in Dynamic Visual SLAM. In Proceedings of the 2020 International Conference on Big Data and Artificial Intelligence and Software Engineering, ICBASE 2020, Bangkok, Thailand, 30 October–1 November 2020; pp. 279–283. [Google Scholar] [CrossRef]
- Azzam, R.; Taha, T.; Huang, S.; Zweiri, Y. Feature-based visual simultaneous localization and mapping: A survey. Appl. Sci. 2020, 2, 224. [Google Scholar] [CrossRef]
- Xia, L.; Cui, J.; Shen, R.; Xu, X.; Gao, Y.; Li, X. A survey of image semantics-based visual simultaneous localization and mapping: Application-oriented solutions to autonomous navigation of mobile robots. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420919185. [Google Scholar] [CrossRef]
- Fang, B.; Mei, G.; Yuan, X.; Wang, L.; Wang, Z.; Wang, J. Visual SLAM for robot navigation in healthcare facility. Pattern Recognit. 2021, 113, 107822. [Google Scholar] [CrossRef] [PubMed]
- Barros, A.M.; Michel, M.; Moline, Y.; Corre, G.; Carrel, F. A Comprehensive Survey of Visual SLAM Algorithms. Robotics 2022, 11, 24. [Google Scholar] [CrossRef]
- Qin, J.; Li, M.; Li, D.; Zhong, J.; Yang, K. A Survey on Visual Navigation and Positioning for Autonomous UUVs. Remote Sens. 2022, 14, 3794. [Google Scholar] [CrossRef]
- Zhang, Z.; Zeng, J. A Survey on Visual Simultaneously Localization and Mapping. Front. Comput. Intell. Syst. 2022, 1, 18–21. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. The Revisiting Problem in Simultaneous Localization and Mapping: A Survey on Visual Loop Closure Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19929–19953. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, J.; Liu, J.; Tong, Q.; Liu, R.; Chen, S. Semantic Visual Simultaneous Localization and Mapping: A Survey. arXiv 2022. [Google Scholar] [CrossRef]
- Tian, Y.; Yue, H.; Yang, B.; Ren, J. Unmanned Aerial Vehicle Visual Simultaneous Localization and Mapping: A Survey. J. Physics Conf. Ser. 2022, 2278, 012006. [Google Scholar] [CrossRef]
- Tourani, A.; Bavley, H.; Sanchez-Lopez, J.L.; Voos, H. Visual SLAM: What are the Current Trends and What to Expect? Sensors 2022, 22, 9297. [Google Scholar] [CrossRef]
- Agostinho, L.R.; Ricardo, N.M.; Pereira, M.I.; Hiolle, A.; Pinto, A.M. A Practical Survey on Visual Odometry for Autonomous Driving in Challenging Scenarios and Conditions. IEEE Access 2022, 10, 72182–72205. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, J.; Wang, D. A Review of Common Techniques for Visual Simultaneous Localization and Mapping. J. Robot. 2023, 8872822. [Google Scholar] [CrossRef]
- Mokssit, S.; Licea, D.B.; Guermah, B.; Ghogho, M. Deep Learning Techniques for Visual SLAM: A Survey. IEEE Access 2023, 11, 20026–20050. [Google Scholar] [CrossRef]
- Herrera-Granda, E.P.; Torres-Cantero, J.C.; Peluffo-Ordóñez, D.H. Monocular visual SLAM, visual odometry, and structure from motion methods applied to 3D reconstruction: A comprehensive survey. Heliyon 2024, 10, e37356. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, X.; Sier, H.; Zhang, H.; Westerlund, T. Event-based Sensor Fusion and Application on Odometry: A Survey. arXiv 2024. [Google Scholar] [CrossRef]
- Svishchev, N.; Lino, P.; Maione, G.; Azhmukhamedov, I. A comprehensive survey of advanced SLAM techniques. E3s Web Conf. 2024, 541, 8–11. [Google Scholar] [CrossRef]
- Al-Tawil, B.; Hempel, T.; Abdelrahman, A.; Al-Hamadi, A. A review of visual SLAM for robotics: Evolution, properties, and future applications. Front. Robot. 2024, 11, 1–18. [Google Scholar] [CrossRef]
- Neyestani, A.; Picariello, F.; Ahmed, I.; Daponte, P.; De Vito, L. From Pixels to Precision: A Survey of Monocular Visual Odometry in Digital Twin Applications. Sensors 2024, 24, 1274. [Google Scholar] [CrossRef]
- Jiang, Z.; Taira, H.; Miyashita, N.; Okutomi, M. Self-Supervised Ego-Motion Estimation Based on Multi-Layer Fusion of RGB and Inferred Depth. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 23–27. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Schubert, D.; Goll, T.; Demmel, N.; Usenko, V.; Stuckler, J.; Cremers, D. The TUM VI Benchmark for Evaluating Visual-Inertial Odometry. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 1680–1687. [Google Scholar] [CrossRef]
- Cortes, S.; Solin, A.; Rahtu, E.; Kannala, J. ADVIO: An Authentic Dataset for Visual-Inertial Odometry; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11214, pp. 425–440. [Google Scholar] [CrossRef]
- Theodorou, C.; Velisavljevic, V.; Dyo, V.; Nonyelu, F. Visual SLAM algorithms and their application for AR, mapping, localization and wayfinding. Array 2022, 15, 100222. [Google Scholar] [CrossRef]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inf. Process. Syst. 2014, 3, 2366–2374. [Google Scholar]
- Chen, W.; Fu, Z.; Yang, D.; Deng, J. Single-image depth perception in the wild. Adv. Neural Inf. Process. Syst. 2016, 29, 730–738. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 6612–6621. [Google Scholar] [CrossRef]
- Wang, C.; Buenaposada, J.M.; Zhu, R.; Lucey, S. Learning Depth from Monocular Videos using Direct Methods. In Proceedings of the The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2022–2030. [Google Scholar] [CrossRef]
- Steinbrücker, F.; Sturm, J.; Cremers, D. Real-time visual odometry from dense RGB-D images. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 719–722. [Google Scholar] [CrossRef]
- Garg, R.; Vijay Kumar, B.G.; Carneiro, G.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9912, pp. 740–756. [Google Scholar] [CrossRef]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the he IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Unsupervised monocular depth and ego-motion learning with structure and semantics. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; Volume 2019, pp. 381–388. [Google Scholar] [CrossRef]
- Bian, J.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.; Reid, I. Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video. arXiv 2019, arXiv:1908.10553. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 1–14. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3D: Learning 3D scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 824–840. [Google Scholar] [CrossRef]
- Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Roth, S. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the The IEEE CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Ye, X.; Ji, X.; Sun, B.; Chen, S.; Wang, Z.; Li, H. DRM-SLAM: Towards dense reconstruction of monocular SLAM with scene depth fusion. Neurocomputing 2020, 396, 76–91. [Google Scholar] [CrossRef]
- Mumuni, F.; Mumuni, A.; Amuzuvi, C.K. Deep learning of monocular depth, optical flow and ego-motion with geometric guidance for UAV navigation in dynamic environments. Mach. Learn. Appl. 2022, 10, 100416. [Google Scholar]
- Weerasekera, C.S.; Latif, Y.; Garg, R.; Reid, I. Dense monocular reconstruction using surface normals. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 2524–2531. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazırbas, C.; Golkov, V. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. In Proceedings of the The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1–9. [Google Scholar]
- Ranjan, A.; Black, M.J. Optical Flow Estimation using a Spatial Pyramid Network. In Proceedings of the Psychologie Schweizerische Zeitschrift Für Psychologie Und Ihre Andwendungen, Honolulu, HI, USA, 21–26 July 2017; pp. 4161–4170. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.y.; Kautz, J. PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume. In Proceedings of the The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Liu, F.; Shen, C.; Lin, G. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5162–5170. [Google Scholar] [CrossRef]
- Zoran, D.; Isola, P.; Krishnan, D.; Freeman, W.T. Learning ordinal relationships for mid-level vision. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 388–396. [Google Scholar] [CrossRef]
- Wang, P.; Shen, X.; Lin, Z.; Cohen, S.; Price, B.; Yuille, A. Towards unified depth and semantic prediction from a single image. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2800–2809. [Google Scholar] [CrossRef]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar] [CrossRef]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper Depth Prediction with Fully Convolutional Residual Networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 696–698. [Google Scholar]
- Mal, F.; Karaman, S. Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image. In Proceedings of the Proceedings—IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; pp. 4796–4803. [Google Scholar] [CrossRef]
- Chen, Z.; Badrinarayanan, V.; Drozdov, G.; Rabinovich, A. Estimating Depth from RGB and Sparse Sensing; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11208, pp. 176–192. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, P.; Xu, W.; Zhao, L.; Nevatia, R. Unsupervised Learning of Geometry from Videos with Edge-Aware Depth-Normal Consistency. In Proceedings of the The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018; Volume 1, pp. 7493–7500. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2018, 15, 695–697. [Google Scholar] [CrossRef]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. arXiv 2018. [Google Scholar] [CrossRef]
- Zou, Y.; Luo, Z.; Huang, J.B. DF-Net: Unsupervised Joint Learning of Depth and Flow Using Cross-Task Consistency; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11209, pp. 38–55. [Google Scholar] [CrossRef]
- Ranjan, A.; Jampani, V.; Balles, L.; Kim, K.; Sun, D.; Wulff, J.; Black, M.J. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12232–12241. [Google Scholar] [CrossRef]
- Godard, C.; Aodha, O.M.; Firman, M.; Brostow, G. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Volume 2019, pp. 3827–3837. [Google Scholar] [CrossRef]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Raventos, A.; Gaidon, A. 3D packing for self-supervised monocular depth estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2482–2491. [Google Scholar] [CrossRef]
- Luo, C.; Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R.; Yuille, A. Every Pixel Counts ++: Joint Learning of Geometry and Motion with 3D Holistic Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2624–2641. [Google Scholar] [CrossRef]
- Lee, H.Y.; Ho, H.W.; Zhou, Y. Deep Learning-based Monocular Obstacle Avoidance for Unmanned Aerial Vehicle Navigation in Tree Plantations: Faster Region-based Convolutional Neural Network Approach. J. Intell. Robot. Syst. Theory Appl. 2021, 101, 5. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. RAFT: Recurrent All-Pairs Field Transforms for Optical Flow. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 4839–4843. [Google Scholar] [CrossRef]
- Ren, Z.; Yan, J.; Ni, B.; Liu, B.; Yang, X.; Zha, H. Unsupervised deep learning for optical flow estimation. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, AAAI 2017, San Francisco, CA, USA, 4–9 February 2017; pp. 1495–1501. [Google Scholar] [CrossRef]
- Zhu, Y.; Lan, Z.; Newsam, S.; Hauptmann, A.G. Guided Optical Flow Learning. arXiv 2017. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, Y.; Yang, Z.; Zhao, L.; Wang, P.; Xu, W. Occlusion Aware Unsupervised Learning of Optical Flow. In Proceedings of the The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; Volume 4, p. 1. [Google Scholar] [CrossRef]
- Janai, J.; Güney, F.; Ranjan, A.; Black, M.; Geiger, A. Unsupervised Learning of Multi-Frame Optical Flow with Occlusions; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11220, pp. 713–731. [Google Scholar] [CrossRef]
- Zhong, Y.; Ji, P.; Wang, J.; Dai, Y.; Li, H. Unsupervised deep epipolar flow for stationary or dynamic scenes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 12087–12096. [Google Scholar] [CrossRef]
- Liao, B.; Hu, J.; Gilmore, R.O. Optical flow estimation combining with illumination adjustment and edge refinement in livestock UAV videos. Comput. Electron. Agric. 2021, 180, 105910. [Google Scholar] [CrossRef]
- Yan, W.; Sharma, A.; Tan, R.T. Optical flow in dense foggy scenes using semi-supervised learning. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13256–13265. [Google Scholar] [CrossRef]
- Dai, Q.; Patii, V.; Hecker, S.; Dai, D.; Van Gool, L.; Schindler, K. Self-supervised object motion and depth estimation from video. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 4326–4334. [Google Scholar] [CrossRef]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A Naturalistic Open Source Movie for Optical Flow Evaluation; Springer: Berlin/Heidelberg, Germany, 2012; pp. 611–625. [Google Scholar]
- Baker, S.; Scharstein, D.; Roth, S.; Black, M.J.; Szeliski, R. A Database and Evaluation Methodology for Optical Flow. Int. J. Comput. Vis. 2009, 92, 1–31. [Google Scholar] [CrossRef]
- Berman, D.; Treibitz, T.; Avidan, S. Single Image Dehazing Using Haze-Lines. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 720–734. [Google Scholar] [CrossRef]
- Bailer, C.; Taetz, B.; Stricker, D. Flow Fields: Dense Correspondence Fields for Highly Accurate Large Displacement Optical Flow Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1879–1892. [Google Scholar] [CrossRef]
- Hartmann, W. Predicting Matchability. In Proceedings of the The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Verdie, Y.; Yi, K.M.; Fua, P.; Lepetit, V. TILDE: A Temporally Invariant Learned DEtector. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 7–12 June 2015; pp. 5279–5288. [Google Scholar] [CrossRef]
- Shen, X.; Wang, C.; Li, X.; Yu, Z.; Li, J.; Wen, C.; Cheng, M.; He, Z. RF-net: An end-to-end image matching network based on receptive field. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 8124–8132. [Google Scholar] [CrossRef]
- Liu, Y. SuperPoint and SuperGlue for Feature Tracking: A Good Idea for Robust Visual Inertial Odometry? 2024. Available online: https://www.researchgate.net/publication/380480837_SuperPoint_SuperGlue_for_Feature_Tracking_A_Good_Idea_for_Robust_Visual_Inertial_Odometry (accessed on 20 May 2024).
- Wang, Y.; Sun, L.; Qin, W. OFPoint: Real-Time Keypoint Detection for Optical Flow Tracking in Visual Odometry. Mathematics 2025, 13, 1087. [Google Scholar] [CrossRef]
- Burkhardt, Y.; Schaefer, S.; Leutenegger, S. SuperEvent: Cross-Modal Learning of Event-based Keypoint Detection. arXiv 2025. [Google Scholar] [CrossRef]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable CNN for joint description and detection of local features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 8084–8093. [Google Scholar] [CrossRef]
- Li, D.; Shi, X.; Long, Q.; Liu, S.; Yang, W.; Wang, F.; Wei, Q.; Qiao, F. DXSLAM: A robust and efficient visual SLAM system with deep features. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 4958–4965. [Google Scholar] [CrossRef]
- Jacobs, N.; Roman, N.; Pless, R. Consistent temporal variations in many outdoor scenes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Tuytelaars, T.; Schmid, C.; Zisserman, A.; Matas, J.; Schaffalitzky, F.; Kadir, T.; Van Gool, L. A comparison of affine region detectors. Int. J. Comput. Vis. 2005, 65, 43–72. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Ramnath, K. Edge foci interest points. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 359–366. [Google Scholar] [CrossRef]
- Balntas, V.; Lenc, K.; Vedaldi, A.; Mikolajczyk, K. HPatches: A benchmark and evaluation of handcrafted and learned local descriptors. In Proceedings of the The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3852–3861. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Proceedings of the Computer Vision–ECCV 2006, Graz, Austria, 7–13 May 2006; Volume 3951, pp. 1–14. [Google Scholar]
- Forstner, W.; Dickscheid, T.; Schindler, F. Detecting interpretable and accurate scale-invariant keypoints. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2256–2263. [Google Scholar] [CrossRef]
- Mainali, P.; Lafruit, G.; Yang, Q.; Geelen, B.; Gool, L.V.; Lauwereins, R. SIFER: Scale-invariant feature detector with error resilience. Int. J. Comput. Vis. 2013, 104, 172–197. [Google Scholar] [CrossRef]
- Low, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up Robust Features; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 404–417. [Google Scholar] [CrossRef]
- Salti, S.; Lanza, A.; Di Stefano, L. Keypoints from symmetries by wave propagation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2898–2905. [Google Scholar] [CrossRef]
- Tian, Y.; Fan, B.; Wu, F. L2-Net: Deep learning of discriminative patch descriptor in Euclidean space. In >Proceedings of the Proceedings—30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 6128–6136. [Google Scholar] [CrossRef]
- Mishchuk, A.; Mishkin, D.; Radenović, F.; Matas, J. Working hard to know your neighbor’s margins: Local descriptor learning loss. Adv. Neural Inf. Process. Syst. 2017, 30, 4827–4838. [Google Scholar]
- Ono, Y.; Fua, P.; Trulls, E.; Yi, K.M. LF-Net: Learning local features from images. Adv. Neural Inf. Process. Syst. 2018, 31, 6234–6244. [Google Scholar]
- Qin, Z.; Yin, M.; Li, G.; A, F.Y. SP-Flow: Self-supervised optical flow correspondence point prediction for real-time SLAM. Comput. Aided Geom. Des. 2020, 82, 101928. [Google Scholar] [CrossRef]
- Bruno, H.M.S.; Colombini, E.L. LIFT-SLAM: A deep-learning feature-based monocular visual SLAM method. Neurocomputing 2021, 455, 97–110. [Google Scholar] [CrossRef]
- Peng, Z.; Shao, T.; Liu, Y.; Zhou, J.; Yang, Y.; Wang, J.; Zhou, K. RTG-SLAM: Real-time 3D Reconstruction at Scale using Gaussian Splatting. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers; Association for Computing Machinery: New York, NY, USA, 2024; Volume 1. [Google Scholar] [CrossRef]
- Keetha, N.; Karhade, J.; Jatavallabhula, K.M.; Yang, G.; Scherer, S.; Ramanan, D.; Luiten, J. SplaTAM: Splat, Track and Map 3D Gaussians for Dense RGB-D SLAM. In Proceedings of the IEEECVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q. Improving RGB-D SLAM in dynamic environments: A motion removal approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar] [CrossRef]
- Kaneko, M.; Iwami, K.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; Volume 2018, pp. 371–379. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2016, arXiv:1606.00915. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.j.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. Visual-Inertial Monocular SLAM with Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Tang, J.; Ericson, L.; Folkesson, J.; Jensfelt, P. GCNv2: Efficient Correspondence Prediction for Real-Time SLAM. IEEE Robot. Autom. Lett. 2019, 4, 3505–3510. [Google Scholar] [CrossRef]
- Sandstrom, E.; Li, Y.; Van Gool, L.; Oswald, M.R. Point-SLAM: Dense Neural Point Cloud-based SLAM. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 18387–18398. [Google Scholar] [CrossRef]
- Johari, M.M.; Carta, C.; Fleuret, F. ESLAM: Efficient Dense SLAM System Based on Hybrid Representation of Signed Distance Fields. In Proceedings of the IEEE international conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J.; Agapito, L. Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; Volume 2023, pp. 13293–13302. [Google Scholar] [CrossRef]
- Kanai, T.; Vasiljevic, I.; Guizilini, V.; Shintani, K. Self-Supervised Geometry-Guided Initialization for Robust Monocular Visual Odometry. arXiv 2024. [Google Scholar] [CrossRef]
- Huang, Y.; Ji, L.; Liu, H.; Ye, M. LGU-SLAM: Learnable Gaussian Uncertainty Matching with Deformable Correlation Sampling for Deep Visual SLAM. arXiv 2024. [Google Scholar] [CrossRef]
- Bescos, B.; Aci, J.M.F.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Zhong, F.; Wang, S.; Zhang, Z.; Zhou, C.; Wang, Y. Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1001–1010. [Google Scholar] [CrossRef]
- Tian, G.; Liu, L.; Ri, J.H.; Liu, Y.; Sun, Y. ObjectFusion: An object detection and segmentation framework with RGB-D SLAM and convolutional neural networks. Neurocomputing 2019, 345, 3–14. [Google Scholar] [CrossRef]
- Cheng, J.; Sun, Y.; Meng, M.Q.H. Improving monocular visual SLAM in dynamic environments: An optical-flow-based approach. Adv. Robot. 2019, 33, 576–589. [Google Scholar] [CrossRef]
- Shao, C.; Zhang, C.; Fang, Z.; Yang, G. A Deep Learning-Based Semantic Filter for RANSAC-Based Fundamental Matrix Calculation and the ORB-SLAM System. IEEE Access 2020, 8, 3212–3223. [Google Scholar] [CrossRef]
- Xua, L.; Feng, C.; Kamata, V.R.; Menassaa, C.C. A scene-adaptive descriptor for visual SLAM-based locating applications in built environments. Autom. Constr. 2020, 112, 103067. [Google Scholar] [CrossRef]
- Liu, W.; Mo, Y.; Jiao, J.; Deng, Z. EF-Razor: An effective edge-feature processing method in visual SLAM. IEEE Access 2020, 8, 140798–140805. [Google Scholar] [CrossRef]
- Rusli, I.; Trilaksono, B.R.; Adiprawita, W. RoomSLAM: Simultaneous localization and mapping with objects and indoor layout structure. IEEE Access 2020, 8, 196992–197004. [Google Scholar] [CrossRef]
- A, S.J.; Chen, L.; A, R.S.; McLoone, S. A novel vSLAM framework with unsupervised semantic segmentation based on adversarial transfer learning. Appl. Soft Comput. J. 2020, 90, 106153. [Google Scholar]
- Zhao, X.; Wang, C.; Ang, M.H. Real-Time Visual-Inertial Localization Using Semantic Segmentation towards Dynamic Environments. IEEE Access 2020, 8, 155047–155059. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Cheng, J.; Wang, Z.; Zhou, H.; Li, L.; Yao, J. DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes. ISPRS Int. J. Geo-Inf. 2020, 9, 202. [Google Scholar] [CrossRef]
- Liu, Y.; Miura, J.U.N. RDS-SLAM: Real-time Dynamic SLAM using Semantic Segmentation Methods. IEEE Access 2021, 9, 1–15. [Google Scholar] [CrossRef]
- Su, P.; Luo, S.; Huang, X. Real-Time Dynamic SLAM Algorithm Based on Deep Learning. IEEE Access 2022, 10, 87754–87766. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. arXiv 2017. [Google Scholar] [CrossRef]
- Grupp, M. evo: Python Package for the Evaluation of Odometry and SLAM. 2017. Available online: https://github.com/MichaelGrupp/evo (accessed on 20 May 2024).
- Zou, Z.X.; Huang, S.S.; Mu, T.J.; Wang, Y.P. ObjectFusion: Accurate object-level SLAM with neural object priors. Graph. Model. 2022, 123, 101165. [Google Scholar] [CrossRef]
- Xu, B.; Li, W.; Tzoumanikas, D.; Bloesch, M.; Davison, A.; Leutenegger, S. MID-fusion: Octree-based object-level multi-instance dynamic SLAM. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5231–5237. [Google Scholar] [CrossRef]
- Zhu, Y.; Gao, R.; Huang, S.; Zhu, S.C.; Wu, Y.N. Learning Neural Representation of Camera Pose with Matrix Representation of Pose Shift via View Synthesis. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9954–9963. [Google Scholar] [CrossRef]
- Qiao, C.; Xiang, Z.; Wang, X. Objects Matter: Learning Object Relation Graph for Robust Camera Relocalization. arXiv 2022. [Google Scholar] [CrossRef]
- McCormac, J.; Handa, A.; Leutenegger, S.; Davison, A.J. SceneNet RGB-D: Can 5M Synthetic Images Beat Generic ImageNet Pre-training on Indoor Segmentation? In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 2017, pp. 2697–2706. [Google Scholar] [CrossRef]
- Shotton, J.; Glocker, B.; Zach, C.; Izadi, S.; Criminisi, A.; Fitzgibbon, A. Scene coordinate regression forests for camera relocalization in RGB-D images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2930–2937. [Google Scholar] [CrossRef]
- Runz, M.; Buffier, M.; Agapito, L. MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality, ISMAR 2018, Munich, Germany, 16–20 October 2018; pp. 10–20. [Google Scholar] [CrossRef]
- Zhao, C.; Sun, L.; Yan, Z.; Neumann, G.; Duckett, T.; Stolkin, R. Learning Kalman Network: A deep monocular visual odometry for on-road driving. Robot. Auton. Syst. 2019, 121, 103234. [Google Scholar] [CrossRef]
- Tao, C.; Gao, Z.; Yan, J.; Li, C.; Cui, G. Indoor 3D Semantic Robot VSLAM based on mask regional convolutional neural network. IEEE Access 2020, 8, 52906–52916. [Google Scholar] [CrossRef]
- Kahler, O.; Prisacariu, V.A.; Ren, C.Y.; Sun, X.; Torr, P.; Murray, D. Very High Frame Rate Volumetric Integration of Depth Images on Mobile Devices. IEEE Trans. Vis. Comput. Graph. 2015, 21, 1241–1250. [Google Scholar] [CrossRef]
- Dai, A.; Nießner, M.; Zollhöfer, M.; Izadi, S.; Theobalt, C. BundleFusion: Real-time Globally Consistent 3D Reconstruction using On-the-fly Surface Re-integration. ACM Trans. Graph. (TOG) 2017, 36, 36–47. [Google Scholar] [CrossRef]
- Kendall, A.; Cipolla, R. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 6555–6564. [Google Scholar] [CrossRef]
- Brahmbhatt, S.; Gu, J.; Kim, K.; Hays, J.; Kautz, J. Geometry-Aware Learning of Maps for Camera Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2616–2625. [Google Scholar]
- Han, X.; Li, S.; Wang, X.; Zhou, W. Semantic mapping for mobile robots in indoor scenes: A survey. Information 2021, 12, 92. [Google Scholar] [CrossRef]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar] [CrossRef]
- Sunderhauf, N.; Pham, T.T.; Latif, Y.; Milford, M.; Reid, I. Meaningful maps with object-oriented semantic mapping. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; Volume 2017, pp. 5079–5085. [Google Scholar] [CrossRef]
- Yang, S.; Huang, Y.; Scherer, S. Semantic 3D occupancy mapping through efficient high order CRFs. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; Volume 2017, pp. 590–597. [Google Scholar] [CrossRef]
- Grinvald, M.; Furrer, F.; Novkovic, T.; Chung, J.J.; Cadena, C.; Siegwart, R.; Nieto, J. Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery. IEEE Robot. Autom. Lett. 2019, 4, 3037–3044. [Google Scholar] [CrossRef]
- Karkus, P.; Angelova, A.; Vanhoucke, V.; Jonschkowski, R. Differentiable Mapping Networks: Learning Structured Map Representations for Sparse Visual Localization. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 4753–4759. [Google Scholar] [CrossRef]
- Hou, Y.; Zhang, H.; Zhou, S. Convolutional Neural Network-Based Image Representation for Visual Loop Closure Detection. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015. [Google Scholar]
- Xia, Y.; Li, J.; Qi, L.; Yu, H.; Dong, J. An Evaluation of Deep Learning in Loop Closure Detection for Visual SLAM. In Proceedings of the 2017 IEEE International Conference on Internet of Things, IEEE Green Computing and Communications, Exeter, UK, 21–23 June 2017; Volume 2018, pp. 85–91. [Google Scholar] [CrossRef]
- Zhang, X.; Su, Y.; Zhu, X. Loop Closure Detection for Visual SLAM Systems Using Convolutional Neural Network. In Proceedings of the 23rd International Conference on Automation and Computing, Huddersfield, UK, 7–8 September 2017; Volume 1063, pp. 54–62. [Google Scholar] [CrossRef]
- Merrill, N.; Huang, G. Lightweight Unsupervised Deep Loop Closure. arXiv 2018. [Google Scholar] [CrossRef]
- Geiger, A.; Ziegler, J.; Stiller, C. StereoScan: Dense 3d Reconstruction in Real-time. 2011 IEEE Intell. Veh. Symp. 2011, 5, 963–968. [Google Scholar]
- Haarnoja, T.; Ajay, A.; Levine, S.; Abbeel, P. Backprop KF: Learning discriminative deterministic state estimators. Adv. Neural Inf. Process. Syst. 2016, 29, 4383–4391. [Google Scholar]
- Coskun, H.; Achilles, F.; Dipietro, R.; Navab, N.; Tombari, F. Long Short-Term Memory Kalman Filters: Recurrent Neural Estimators for Pose Regularization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 2017, pp. 5525–5533. [Google Scholar] [CrossRef]
- Memon, A.R.; Wang, H.; Hussain, A. Loop closure detection using supervised and unsupervised deep neural networks for monocular SLAM systems. Robot. Auton. Syst. 2020, 126, 103470. [Google Scholar] [CrossRef]
- Chang, J.; Dong, N.; Li, D.; Qin, M. Triplet loss based metric learning for closed loop detection in VSLAM system. Expert Syst. Appl. 2021, 185, 115646. [Google Scholar] [CrossRef]
- Duan, R.; Feng, Y.; Wen, C.Y. Deep Pose Graph-Matching-Based Loop Closure Detection for Semantic Visual SLAM. Sustainability 2022, 14, 11864. [Google Scholar] [CrossRef]
- Cummins, M.; Newman, P. FAB-MAP: Probabilistic Localization and Mapping in the Space of Appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Yeshwanth, C.; Liu, Y.C.; Niessner, M.; Dai, A. ScanNet++: A High-Fidelity Dataset of 3D Indoor Scenes. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar] [CrossRef]
- Galvez-Lopez, D.; Tardós, J.D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- rmsalinas. The file orbvoc.dbow3 is the ORB vocabulary in ORBSLAM2 but in binary format of DBoW3 DBoW3, 2017. IEEE Trans. Robot. 2012, 28, 1188–1197. Available online: https://github.com/rmsalinas/DBow3 (accessed on 26 June 2024).
- Garcia-Fidalgo, E.; Ortiz, A. IBoW-LCD: An Appearance-Based Loop-Closure Detection Approach Using Incremental Bags of Binary Words. IEEE Robot. Autom. Lett. 2018, 3, 3051–3057. [Google Scholar] [CrossRef]
- Sarlin, P.E.; Cadena, C.; Siegwart, R.; Dymczyk, M. From coarse to fine: Robust hierarchical localization at large scale. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 12708–12717. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 611–625. [Google Scholar] [CrossRef]
- Fanani, N.; Stürck, A.; Ochs, M.; Bradler, H.; Mester, R. Predictive monocular odometry (PMO): What is possible without RANSAC and multiframe bundle adjustment? Image Vis. Comput. 2017, 68, 3–13. [Google Scholar] [CrossRef]
- Wang, R.; Schworer, M.; Cremers, D. Stereo DSO: Large-Scale Direct Sparse Visual Odometry with Stereo Cameras. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 2017, pp. 3923–3931. [Google Scholar] [CrossRef]
- Xue, F.; Wang, Q.; Wang, X.; Dong, W.; Wang, J.; Zha, H. Guided Feature Selection for Deep Visual Odometry; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11366, pp. 293–308. [Google Scholar] [CrossRef]
- Kreuzig, R.; Ochs, M.; Mester, R. DistanceNet: Estimating Traveled Distance from Monocular Images using a Recurrent Convolutional Neural Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar] [CrossRef]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022, pp. 12776–12786. [Google Scholar] [CrossRef]
- Saxena, A.; Chung, S.H.; Ng, A.Y. 3-D Depth Reconstruction from a Single Still Image. Int. J. Comput. Vis. 2008, 76, 53–69. [Google Scholar] [CrossRef]
- Roy, A.; Todorovic, S. Monocular depth estimation using neural regression forest. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27-30 June 2016; Volume 2016, pp. 5506–5514. [Google Scholar] [CrossRef]
- Mancini, M.; Costante, G.; Valigi, P.; Ciarfuglia, T.A. Fast robust monocular depth estimation for Obstacle Detection with fully convolutional networks. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Daejeon, Republic of Korea, 9–14 October 2016; Volume 2016, pp. 4296–4303. [Google Scholar] [CrossRef]
- Cadena, C.; Dick, A.; Reid, I.D. Multi-modal auto-encoders as joint estimators for robotics scene understanding. Robot. Sci. Syst. 2016, 12. [Google Scholar] [CrossRef]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-scale continuous CRFs as sequential deep networks for monocular depth estimation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 161–169. [Google Scholar] [CrossRef]
- Liao, Y.; Huang, L.; Wang, Y.; Kodagoda, S.; Yu, Y.; Liu, Y. Parse geometry from a line: Monocular depth estimation with partial laser observation. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 5059–5066. [Google Scholar] [CrossRef]
- Xu, D.; Wang, W.; Tang, H.; Liu, H.; Sebe, N.; Ricci, E. Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3917–3925. [Google Scholar] [CrossRef]
- Li, Y.; Qian, K.; Huang, T.; Zhou, J. Depth estimation from monocular image and coarse depth points based on conditional GAN. MATEC Web Conf. 2018, 175, 03055. [Google Scholar] [CrossRef]
- Wang, A.; Fang, Z.; Gao, Y.; Jiang, X.; Ma, S. Depth estimation of video sequences with perceptual losses. IEEE Access 2018, 6, 30536–30546. [Google Scholar] [CrossRef]
- Wofk, D.; Ma, F.; Yang, T.J.; Karaman, S.; Sze, V. FastDepth: Fast monocular depth estimation on embedded systems. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; Volume 2019, pp. 6101–6108. [Google Scholar] [CrossRef]
- Gur, S.; Wolf, L. Single Image Depth Estimation Trained via Depth from Defocus Cues. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7683–7692. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Monocular Depth Estimation Using Multi-Scale Continuous CRFs as Sequential Deep Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1426–1440. [Google Scholar] [CrossRef] [PubMed]
- Tu, X.; Xu, C.; Liu, S.; Xie, G.; Li, R. Real-time depth estimation with an optimized encoder-decoder architecture on embedded devices. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, , 10–12 August 2019; Number 61772185. pp. 2141–2149. [Google Scholar] [CrossRef]
- Wang, T.H.; Wang, F.E.; Lin, J.T.; Tsai, Y.H.; Chiu, W.C.; Sun, M. Plug-and-play: Improve depth prediction via sparse data propagation. In Proceedings of the Proceedings—IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; Volume 2019, pp. 5880–5886. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, Y.; Okatani, T. Visualization of convolutional neural networks for monocular depth estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Volume 2019, pp. 3868–3877. [Google Scholar] [CrossRef]
- Tu, X.; Xu, C.; Liu, S.; Xie, G.; Huang, J.; Li, R.; Yuan, J. Learning Depth for Scene Reconstruction Using an Encoder-Decoder Model. IEEE Access 2020, 8, 89300–89317. [Google Scholar] [CrossRef]
- Weber, M.; Rist, C.; Zollner, J.M. Learning temporal features with CNNs for monocular visual ego motion estimation. IEEE Conference on Intelligent Transportation Systems, Proceedings, ITSC, Yokohama, Japan, 16–19 October 2017; Volume 2018, pp. 1–6. [Google Scholar] [CrossRef]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Peretroukhin, V.; Clement, L.; Kelly, J. Reducing drift in visual odometry by inferring sun direction using a Bayesian Convolutional Neural Network. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 2035–2042. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVO: Monocular Visual Odometry Through Unsupervised Deep Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I.M. Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 340–349. [Google Scholar] [CrossRef]
- Shamwell, E.J.; Leung, S.; Nothwang, W.D. Vision-Aided Absolute Trajectory Estimation Using an Unsupervised Deep Network with Online Error Correction. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 2524–2531. [Google Scholar] [CrossRef]
- Yang, N.; Von Stumberg, L.; Wang, R.; Cremers, D. D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1278–1289. [Google Scholar] [CrossRef]
- Turan, Y.A.M.; Sarı, A.E.; Saputra, M.R.U.; de Gusmo, P.P.B.; Markham, A.; Trigoni, N. SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation. Neurocomputing 2021, 421, 119–136. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-Based Visual-Inertial Odometry Using Nonlinear Optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Bloesch, M.; Burri, M.; Omari, S.; Hutter, M.; Siegwart, R. IEKF-based Visual-Inertial Odometry using Direct Photometric Feedback. Int. J. Robot. Res. 2017, 36, 106705. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, L.; Li, X.; Yao, J. DeepMLE: A Robust Deep Maximum Likelihood Estimator for Two-view Structure from Motion. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022. [Google Scholar] [CrossRef]
- Zhai, G.; Liu, L.; Zhang, L.; Liu, Y.; Jiang, Y. PoseConvGRU: A Monocular Approach for Visual Ego-motion Estimation by Learning. Pattern Recognit. 2020, 102, 107187. [Google Scholar] [CrossRef]
- Zhu, R.; Yang, M.; Liu, W.; Song, R.; Yan, B.; Xiao, Z. DeepAVO: Efficient pose refining with feature distilling for deep visual odometry. Neurocomputing 2022, 467, 22–35. [Google Scholar] [CrossRef]
- Muhammet, F.A.; Akif, D.; Abdullah, Y.; Alper, Y. HVIOnet: A deep learning based hybrid visual–inertial odometry approach for unmanned aerial system position estimation. Neural Netw. 2022, 155, 461–474. [Google Scholar]
- Haixin, X.; Yiyou, L.; Zeng, H.; Li, Q.; Liu, H.; Fan, B.; Li, C. Robust self-supervised monocular visual odometry based on prediction-update pose estimation network. Eng. Appl. Artif. Intell. 2022, 116, 105481. [Google Scholar]
- Lu, Y.; Chen, Y.; Zhao, D.; Li, D. MGRL: Graph neural network based inference in a Markov network with reinforcement learning for visual navigation. Neurocomputing 2021, 421, 140–150. [Google Scholar] [CrossRef]
- Srivastav, A.; Mandal, S. Radars for Autonomous Driving: A Review of Deep Learning Methods and Challenges. IEEE Access 2023, 11, 97147–97168. [Google Scholar] [CrossRef]
- Islam, S.; Tanvir, S.; Habib, R. Autonomous Driving Vehicle System Using LiDAR Sensor. In Intelligent Data Communication Technologies and Internet of Things; Springer: Singapore, 2022. [Google Scholar] [CrossRef]
- Ali, A.J.; Kouroshli, M.; Semenova, S.; Hashemifar, Z.S.; Ko, S.Y.; Dantu, K. Edge-SLAM: Edge-Assisted Visual Simultaneous Localization and Mapping. ACM Trans. Embed. Comput. Syst. 2022, 22, 1–31. [Google Scholar] [CrossRef]
- Kegeleirs, M.; Grisetti, G.; Birattari, M. Swarm SLAM: Challenges and Perspectives. Front. Robot. 2021, 8, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Lajoie, P.Y.; Ramtoula, B.; Chang, Y.; Carlone, L.; Beltrame, G. DOOR-SLAM: Distributed, Online, and Outlier Resilient SLAM for Robotic Teams. IEEE Robot. Autom. Lett. 2020, 5, 1656–1663. [Google Scholar] [CrossRef]
- Osman Zahid, M.N.; Hao, L.J. A Study on Obstacle Detection For IoT Based Automated Guided Vehicle (AGV). Mekatronika 2022, 4, 30–41. [Google Scholar] [CrossRef]
- Buck, S.; Hanten, R.; Bohlmann, K.; Zell, A. Generic 3D obstacle detection for AGVs using time-of-flight cameras. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Daejeon, Republic of Korea, 9–14 October 2016; Volume 2016, pp. 4119–4124. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 2938–2946. [Google Scholar] [CrossRef]
- Kendall, A.; Cipolla, R. Modelling uncertainty in deep learning for camera relocalization. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; Volume 2016, pp. 4762–4769. [Google Scholar] [CrossRef]
- Melekhov, I.; Ylioinas, J.; Kannala, J.; Rahtu, E. Image-Based Localization Using Hourglass Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops, ICCVW 2017, Venice, Italy, 22–29 October 2017; Volume 2018, pp. 870–877. [Google Scholar] [CrossRef]
- Walch, F.; Leal-taix, C.H.L.; Sattler, T.; Cremers, S.H.D. Image-based localization using LSTMs for structured feature correlation. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 627–637. [Google Scholar]
- Wu, J.; Ma, L.; Hu, X. Delving deeper into convolutional neural networks for camera relocalization. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Wang, C.; Bai, X.; Wu, J. Discriminative Features Matter: Multi-layer Bilinear Pooling for Camera Localization. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Bui, M.; Baur, C.; Navab, N.; Ilic, S.; Albarqouni, S. Adversarial networks for camera pose regression and refinement. In Proceedings of the 2019 International Conference on Computer Vision Workshop, ICCVW 2019, Seoul, Republic of Korea, 27–28 October 2019; pp. 3778–3787. [Google Scholar] [CrossRef]
- Cai, M.; Shen, C.; Reid, I. A hybrid probabilistic model for camera relocalization. In Proceedings of the British Machine Vision Conference 2018, BMVC Newcastle, UK, 3–6 September 2018; pp. 1–12. [Google Scholar]
- Saha, S.; Varma, G.; Jawahar, C.V. Improved visual relocalization by discovering anchor points. In Proceedings of the British Machine Vision Conference 2018, BMVC 2018, Newcastle, UK, 3–6 September 2018; pp. 1–11. [Google Scholar]
- Wang, B.; Chen, C.; Lu, C.X.; Zhao, P.; Trigoni, N.; Markham, A. AtLoc: Attention guided camera localization. In Proceedings of the AAAI 2020—34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 10393–10401. [Google Scholar] [CrossRef]
- Turkoglu, M.O.; Brachmann, E.; Schindler, K.; Brostow, G.J.; Monszpart, A. Visual Camera Re-Localization Using Graph Neural Networks and Relative Pose Supervision. In Proceedings of the 2021 International Conference on 3D Vision, 3DV 2021, London, UK, 1–3 December 2021; pp. 145–155. [Google Scholar] [CrossRef]
- Linear. Linear Regression. 2016. Available online: https://machinelearningcoban.com/2016/12/28/linearregression/ (accessed on 5 April 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. 2015. Available online: https://arxiv.org/pdf/1512.03385 (accessed on 20 June 2024).










| Data Acquisition Times | Direction | Number of RGB-D Frames |
|---|---|---|
| 1ST | FO-D | 21,333 |
| OP-D | 22,948 | |
| 2ND | FO-D | 19,992 |
| OP-D | 21,116 | |
| 3RD | FO-D | 17,995 |
| OP-D | 20,814 | |
| 4TH | FO-D | 17,885 |
| OP-D | 18,548 |
| Dividing Cross-Datasets | Training Data | Testing Data |
|---|---|---|
| Sub1 | 1ST-FO-D, 2ND-FO-D,3RD-FO-D | 4TH-FO-D |
| Sub2 | 1ST-OP-D, 2ND-OP-D,3RD-OP-D | 4TH-OP-D |
| Sub3 | 1ST-FO-D, 2ND-FO-D,4TH-FO-D | 3RD-FO-D |
| Sub4 | 1ST-OP-D, 2ND-OP-D,4TH-OP-D | 3RD-OP-D |
| Sub5 | 1ST-FO-D, 3RD-FO-D,4TH-FO-D | 2ND-FO-D |
| Sub6 | 1ST-OP-D, 3RD-OP-D,4TH-OP-D | 2ND-OP-D |
| Sub7 | 2ND-FO-D, 3RD-FO-D,4TH-FO-D | 1ST-FO-D |
| Sub8 | 2ND-OP-D, 3RD-OP-D,4TH-OP-D | 1ST-OP-D |
| Sub9 | 1ST-FO-D, 2ND-FO-D,3RD-FO-D 1ST-OP-D, 2ND-OP-D,3RD-OP-D | 4TH-FO-D 4TH-OP-D |
| Sub10 | 1ST-FO-D, 2ND-FO-D,4TH-FO-D 1ST-OP-D, 2ND-OP-D,4TH-OP-D | 3RD-FO-D 3RD-OP-D |
| Sub11 | 1ST-FO-D, 3RD-FO-D,4TH-FO-D 1ST-OP-D, 3RD-OP-D,4TH-OP-D | 2ND-FO-D 2ND-OP-D |
| Sub12 | 2ND-FO-D, 3RD-FO-D,4TH-FO-D 2ND-OP-D, 3RD-OP-D,4TH-OP-D | 1ST-FO-D 1ST-OP-D |
| Dividing Cross- Datasets/ Methods | MLF-VO Framework | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Resnet18 | Resnet34 | Resnet50 | Resnet101 | Resnet152 | |||||||||||
(m) | (m) | (m) | (m) | (m) | (m) | (m) | (m) | (m) | (m) | (m) | (m) | (m) | (m) | (m) | |
| Sub1 | 19.95 | 21.67 | 28.95 | 33.70 | 36.29 | 38.93 | 34.38 | 37.14 | 34.74 | 22.38 | 25.01 | 36.51 | 26.90 | 33.07 | 46.36 |
| Sub2 | 38.53 | 49.77 | 41.64 | 30.64 | 32.93 | 31.88 | 29.40 | 39.63 | 32.67 | 18.71 | 22.12 | 30.92 | 26.98 | 34.01 | 29.25 |
| Sub3 | 39.33 | 42.90 | 38.39 | 17.57 | 19.41 | 38.77 | 33.82 | 37.12 | 39.11 | 18.94 | 20.50 | 37.35 | 19.73 | 21.29 | 39.35 |
| Sub4 | 28.80 | 37.28 | 37.84 | 34.74 | 45.31 | 29.60 | 25.80 | 32.94 | 32.90 | 14.78 | 17.41 | 33.51 | 30.63 | 38.29 | 28.96 |
| Sub5 | 18.97 | 20.62 | 29.76 | 26.52 | 28.90 | 33.34 | 18.09 | 20.26 | 27.85 | 30.66 | 33.62 | 32.61 | 19.06 | 21.39 | 30.61 |
| Sub6 | 33.07 | 34.82 | 34.56 | 29.96 | 31.66 | 30.57 | 19.81 | 21.82 | 32.01 | 16.35 | 17.38 | 34.21 | 26.90 | 29.62 | 28.28 |
| Sub7 | 23.77 | 25.26 | 37.11 | 23.28 | 27.28 | 34.15 | 22.03 | 26.08 | 25.58 | 14.32 | 15.70 | 25.52 | 22.39 | 25.91 | 25.83 |
| Sub8 | 39.70 | 42.16 | 30.05 | 52.84 | 57.61 | 30.10 | 46.93 | 50.88 | 29.82 | 56.82 | 61.16 | 32.48 | 36.32 | 39.23 | 30.28 |
| Sub9 | 25.75 | 28.53 | 30.14 | 27.41 | 29.68 | 35.68 | 48.77 | 53.85 | 42.58 | 37.74 | 41.09 | 34.55 | 32.79 | 34.81 | 27.45 |
| 35.16 | 45.45 | 30.20 | 27.22 | 29.09 | 33.28 | 23.32 | 25.37 | 34.08 | 23.89 | 26.85 | 36.45 | 19.67 | 22.45 | 30.77 | |
| Sub10 | 19.26 | 20.91 | 29.20 | 24.37 | 29.84 | 28.96 | 23.00 | 26.35 | 33.85 | 31.18 | 33.43 | 32.19 | 50.63 | 58.73 | 30.42 |
| 20.94 | 26.63 | 30.18 | 17.68 | 20.24 | 29.41 | 21.14 | 24.56 | 31.79 | 29.65 | 41.71 | 28.74 | 38.04 | 48.04 | 36.78 | |
| Sub11 | 17.91 | 19.58 | 29.50 | 39.44 | 42.78 | 29.94 | 63.41 | 71.26 | 39.88 | 18.20 | 19.99 | 34.08 | 28.99 | 31.01 | 32.29 |
| 35.92 | 37.72 | 34.25 | 18.72 | 20.57 | 35.81 | 18.93 | 21.63 | 39.69 | 24.51 | 26.20 | 29.89 | 38.91 | 41.18 | 31.81 | |
| Sub12 | 15.84 | 16.97 | 30.96 | 20.44 | 22.43 | 28.78 | 18.59 | 21.53 | 29.74 | 42.32 | 45.55 | 30.25 | 16.67 | 18.33 | 29.89 |
| 44.45 | 47.58 | 30.00 | 33.61 | 35.66 | 32.31 | 79.56 | 89.46 | 42.07 | 38.91 | 41.18 | 31.81 | 51.14 | 55.11 | 33.40 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, V.-H.; Nguyen, T.-H.-P. A Survey of Visual SLAM Based on RGB-D Images Using Deep Learning and Comparative Study for VOE. Algorithms 2025, 18, 394. https://doi.org/10.3390/a18070394
Le V-H, Nguyen T-H-P. A Survey of Visual SLAM Based on RGB-D Images Using Deep Learning and Comparative Study for VOE. Algorithms. 2025; 18(7):394. https://doi.org/10.3390/a18070394
Chicago/Turabian StyleLe, Van-Hung, and Thi-Ha-Phuong Nguyen. 2025. "A Survey of Visual SLAM Based on RGB-D Images Using Deep Learning and Comparative Study for VOE" Algorithms 18, no. 7: 394. https://doi.org/10.3390/a18070394
APA StyleLe, V.-H., & Nguyen, T.-H.-P. (2025). A Survey of Visual SLAM Based on RGB-D Images Using Deep Learning and Comparative Study for VOE. Algorithms, 18(7), 394. https://doi.org/10.3390/a18070394