1. Introduction
Portfolio optimization constitutes a substantial challenge within the realm of financial engineering, leading to the proliferation of various methodologies. Among these, the foundational mean variance (MV) model, as articulated by Markowitz [
1], holds a position of paramount importance and lasting influence. The MV model addresses portfolio optimization by minimizing the portfolio risk subject to a target return or maximizing portfolio return subject to a defined risk tolerance. Building on this framework, Markowitz et al. [
2] introduced the semivariance risk measure, arguing that its application results in the creation of portfolios that exhibit better performance relative to those constructed using variance. Subsequent research has focused on extending the mean semivariance (MSV) model to incorporate diverse real-world complexities. Huang [
3] examined portfolio selection within a fuzzy environment, comparing fuzzy MV and MSV models and employing genetic algorithms for solution. Tsai and Wang [
4] proposed the MSV model designed to manage uncertainty in both upside and downside risk and return. Qin et al. [
5] modeled portfolio returns as fuzzy random variables, developed the MSV model with random returns, and implemented a hybrid solution algorithm. Gökgöz and Atmaca [
6] optimized energy portfolios in the Turkish financial market, highlighting the influence of investor risk aversion on optimal solutions. Chen et al. [
7] considered uncertain returns, transaction costs, cardinality, and boundary constraints within the MSV framework, and utilized evolutionary algorithms for solution. Hamdi et al. [
8] addressed portfolio optimization under conditional value-at-risk (CVaR) by incorporating short selling, cardinality constraints, and transaction costs, and solved the resulting problem using penalty decomposition methods.
Traditional portfolio selection models primarily address unsystematic risk, exhibiting limitations in mitigating systematic risk. The beta criterion, which measures systematic risk, serves as a valuable complement to other risk measures, enhancing the overall risk management when used in combination. This is particularly relevant within the context of the capital asset pricing model (CAPM), which relates the expected return of a security to its beta risk. Researchers, including Chochola et al. [
9], Chochola et al. [
10], Hur and Chung [
11], and Cenesizoglu and Reeves [
12], have applied the CAPM model to analyze the dynamic of financial markets.
Given the vast number of assets in stock markets, the selection of efficient assets presents a significant challenge. Scientific methodologies are therefore imperative. The DEA method introduced by Charnes et al. [
13] offers a non-parametric approach to assess the relative efficiency of decision-making units (DMUs) by comparing the ratio of their weighted outputs to weighted inputs. This methodology has been increasingly used in portfolio optimization. Morey and Morey [
14] modeled the MV model using DEA, with variance as the input and the expected return as the output. Lamb and Tee [
15] designed a skewness-MV model with DEA, evaluating mutual fund performance using variance as the input and return as the output. Branda [
16] applied DEA to portfolio optimization, considering risk and return as the input and output, respectively. Xiao et al. [
17] tackled the issue of uncertainty in stock returns and employed DEA for optimizing portfolios in the context of the American stock market. Zhou et al. [
18] integrated DEA with multiple data sources to provide optimal portfolio support vector machines. Hamdi et al. [
19] formulated a conditional risk model utilizing DEA and subsequently employed meta-heuristic algorithms for its resolution. Their research culminated in the presentation of an optimized portfolio within the Iranian stock market, demonstrating a propensity for efficient assets to receive maximal weighting within the portfolio construction.
This study aims to construct an optimal portfolio composed of efficient stocks from automotive companies while simultaneously managing the systematic risk. To this end, the MSV model is developed by integrating DEA with beta risk metrics. In contrast to traditional portfolio optimization approaches—such as mean variance or mean semivariance models that mainly depend on historical returns and risk measures like variance or semivariance—the proposed methodology assesses assets within a multidimensional analytical framework.
DEA incorporates multiple financial indicators, treating risk and financial leverage as inputs and metrics like return on equity, earnings per share, and the inverse price-to-earnings ratio as outputs. This approach provides a more comprehensive perspective on asset performance and financial health, facilitating the identification of assets that have not only generated favorable returns but are also fundamentally robust. When an asset (typically a company’s stock) is deemed fundamentally robust, it signifies that the issuing company possesses sound financial characteristics and indicators that suggest long-term stability, profitability, and growth potential. These attributes pertain to the company’s operational performance and intrinsic value, rather than solely its stock price in the market.
By allowing investors to prioritize criteria aligned with their objectives (e.g., earnings quality, valuation metrics, or capital structure), DEA enhances the portfolio selection process. As a result, the integration of DEA with the MSV model enables the construction of portfolios that excel not only in risk–return performance but also in foundational strength. This methodology transcends traditional optimization techniques by incorporating fundamental and operational factors, ensuring that selected assets operate efficiently and possess long-term growth potential.
Portfolio optimization problems highlight the limitations of traditional analytical techniques, which struggle to address non-linear objective functions, multiple constraints, and high-dimensional search spaces. These challenges render conventional approaches computationally inefficient or impractical in real-world scenarios. To overcome these shortcomings, the proposed methodology employs neural networks and multi-objective evolutionary algorithms (NSGA2 and SPEA2). Neural networks excel by learning intricate patterns in financial data, while evolutionary algorithms—inspired by natural selection—systematically explore vast solution spaces to identify near-optimal portfolios. This synergy enables the model to navigate the complexities of portfolio construction, prioritizing risk–return trade-offs and investor-specific criteria with greater adaptability and precision.
The remainder of this paper is organized as follows.
Section 2 establishes the mathematical foundations of the DEA-
-MSV framework, detailing its components and theoretical principles.
Section 3 follows with a comprehensive description of the feedforward neural network, emphasizing its architecture, training methodology, and adaptability to non-linear financial data for solving the optimization model.
Section 4 then introduces the NSGA2 and SPEA2 algorithms, explaining their evolutionary mechanisms, parameter configurations, and integration into the multi-objective optimization workflow.
Section 5 subsequently analyzes the empirical results derived from applying the proposed hybrid model to automotive sector portfolios, comparing the performance metrics across methodologies to evaluate their effectiveness. Finally,
Section 6 synthesizes the key findings, discusses practical implications for portfolio management, and outlines potential directions for future research, reinforcing the study’s contributions to adaptive and robust investment strategies.
5. Application: Iran Stock Market
This research employs an applied methodology, utilizing quantitative data within a post-event framework and drawing upon historical data from automotive enterprises. Data was collected via archival retrieval from stock exchange repositories. The statistical sample comprises data from 21 automotive firms over the period of 2017 to 2021. The selection of the Iranian automotive industry for this study was driven by several compelling factors. It represents a large and strategically important sector within Iran’s economy, characterized by substantial transaction volumes and a rich availability of data, including stock prices, returns, and financial information. Furthermore, the industry’s inherent high volatility and considerable susceptibility to economic policies present a challenging yet fertile ground for the rigorous testing of financial models. This dynamism provides a realistic scenario for evaluating model performance under complex market conditions. Finally, the chosen period of 2017–2021 was critical as it yielded a robust and comprehensive dataset suitable for both model training and testing, unlike preceding or subsequent periods, which contained incomplete or less pertinent data.
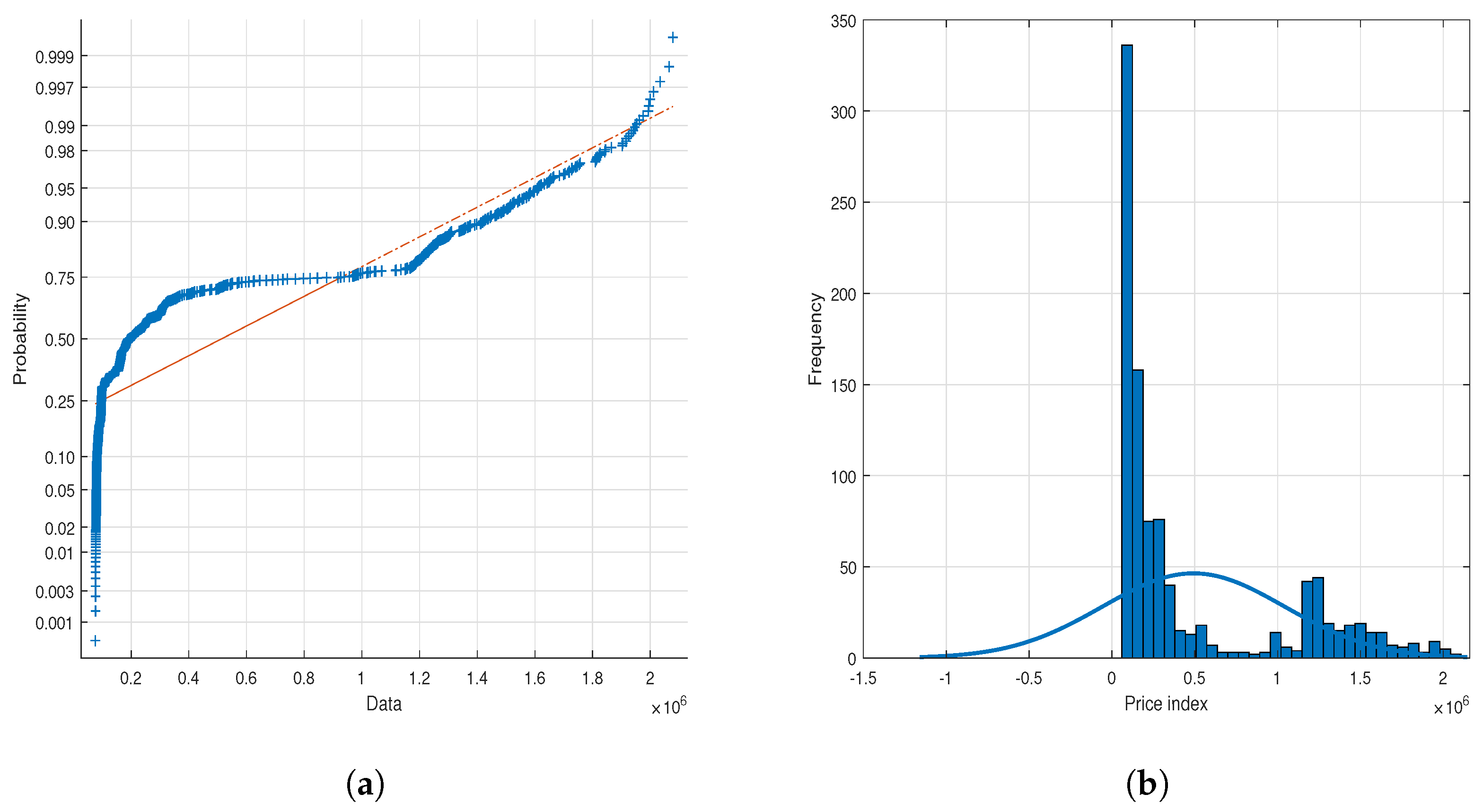
Statistical computations and model implementation were performed utilizing MATLAB software. Market evaluation commenced with an analysis of the automotive market index, as illustrated in
Figure 2. Observations indicate a non-normal distribution of the market index. Further analysis, through the construction of a histogram, revealed a positive skew, as evidenced in
Figure 2. This positive skewness suggests a potential for future appreciation in the automotive price index, implying opportunities for substantial returns for market participants. Subsequently, the statistical sample underwent analysis to ascertain the beta risk, semivariance risk, and expected returns for each stock.
Subsequently, the statistical sample underwent analysis to calculate the beta risk, semivariance risk, and expected returns for each stock from Equations (
1), (
8), and (
13).
Additional details on the computation of daily returns and semivariance can be found in
Appendix A.
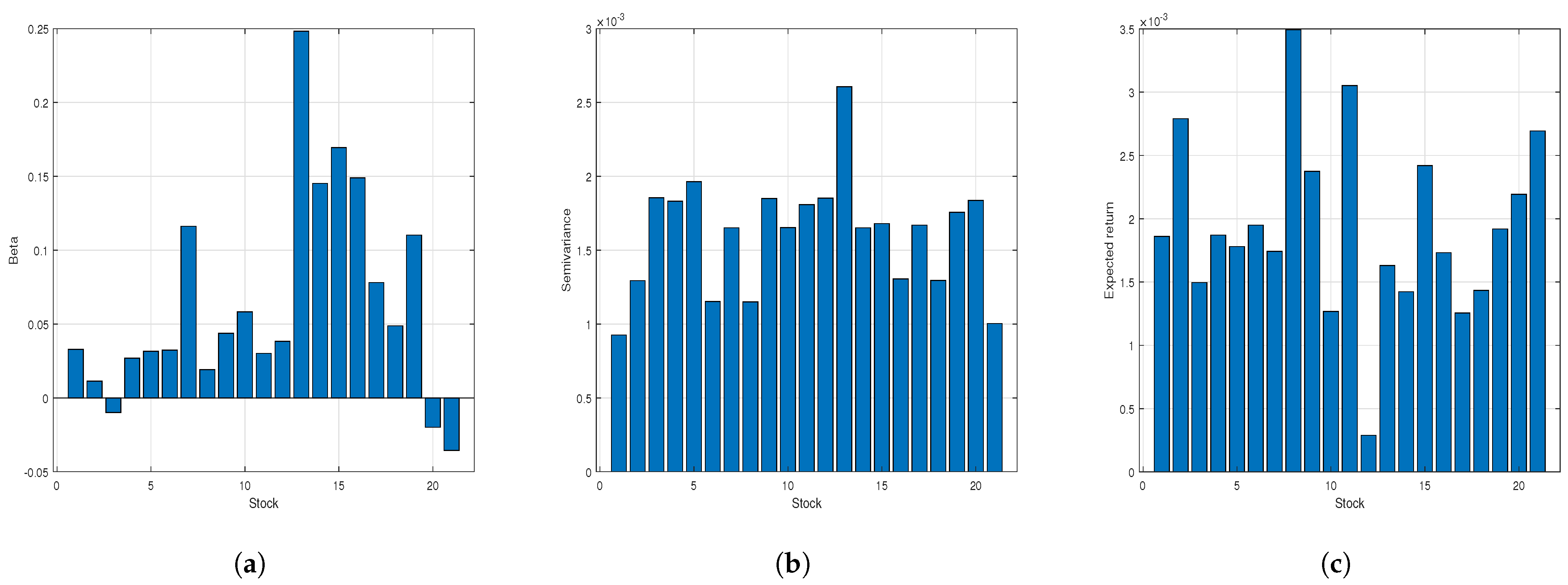
The respective values for
, semivariance, and expected returns are presented in
Figure 3. In
Figure 3, the negative beta observed in certain stocks within automotive companies indicates a negative covariance between the returns of these stocks and the automotive market index. In other words, these stocks tend to move in the opposite direction of the automotive market. Consequently, the inclusion of such stocks in an automotive investment portfolio can mitigate the portfolio’s systematic risk. Furthermore, according to
Figure 3, stock #21 exhibits the lowest beta risk, while stock #1 demonstrates the lowest semivariance. Conversely, stock #8 presents the highest expected return.
The proposed model (
10) introduces a new parametric optimization approach, building on DEA. Its input parameters include
(expected return),
(semivariance risk), and
(market risk). This model uniquely applies DEA to conceptualize risk as a consumed resource (input) and return as a generated product (output), enabling an evaluation of individual assets’ relative efficiency in converting risk into return. The utilization of beta risk, in conjunction with semivariance risk, facilitates a more nuanced assessment of an asset’s efficiency by incorporating systematic market risk. Assets demonstrating superior return generation for a given level of risk, or conversely, exhibiting lower risk for a given level of return, are identified as relatively more efficient and consequently receive higher efficiency scores, approaching unity. Conversely, assets exhibiting comparatively lower returns relative to their incurred risk, when juxtaposed with other assets within the dataset, are deemed inefficient and are assigned lower efficiency scores. The application of DEA efficiency scores enables the identification and subsequent exclusion of inefficient assets from a portfolio. After solving model (
10), its results were presented in Table 2.
As evidenced in
Table 1, with the exception of stock #8, the expected returns of the remaining stocks exhibit relative homogeneity. Consequently, as illustrated in
Table 2, the DEA model identifies this particular stock as efficient due to its comparatively high return. Notably, this elevated return is achieved in conjunction with low semivariance, indicative of the stock’s inherent quality. In
Table 1, stock #1 demonstrates a markedly low semivariance; hence, it attains an efficiency score of 1.0 in
Table 2. Furthermore, stock #21 achieves an efficiency score of 1.0 in
Table 2, owing to its simultaneously low market risk and semivariance. This concurrent low level of both risk metrics for this specific stock suggests a robust underlying company performance. In environments characterized by market uncertainty, the prediction of future returns becomes increasingly complex, and risk profiles can exhibit rapid fluctuations. DEA, by evaluating the efficiency of assets in converting contemporaneous risk into contemporaneous return, offers a relatively dynamic analytical perspective. This facilitates the identification of assets that have, historically, demonstrated a superior performance relative to their accepted risk under prevailing market conditions. Moreover, the integration of beta risk alongside semivariance assists investors in considering systematic market risk in addition to downside volatility risk (semivariance). In uncertain market conditions, systematic risk can assume a more prominent role, rendering its consideration crucial for comprehensive portfolio risk management.
Furthermore, the selection of assets that exhibit efficiency in converting risk into return can indirectly lead to the inclusion of companies with stronger fundamental characteristics. Entities demonstrating greater stability and profitability are more likely to exhibit resilient performance in uncertain market conditions. Additionally, in volatile market environments, the identification and subsequent removal of assets characterized by low returns relative to their associated risk assumes heightened importance. DEA, through the provision of a quantitative efficiency score, offers investors a valuable tool for this specific purpose.
While DEA evaluates contemporaneous performance, its computation of risk and return is inherently predicated on historical data. Given the potential for past efficiency to become an unreliable predictor of future outcomes due to abrupt market shifts, it is crucial to recognize DEA as a tool for ex-post performance evaluation rather than a mechanism for forecasting. This methodology lacks the inherent capacity to directly anticipate future market fluctuations. The DEA method serves to delineate the relative efficiency of assets; however, it does not directly furnish optimal weightings for portfolio construction.
Our analysis successfully identifies efficient assets; however, allocating capital among them necessitates additional methodologies. Consequently, our subsequent goal is to determine optimal weights for these efficient stocks by solving model (
12) through two different techniques: neural networks and evolutionary algorithms. The specific parameter configurations for the NSGA2 and SPEA2 algorithms can be found in
Table 3 and
Table 4, respectively. It is crucial to distinguish that while the previous step established efficient shares considering all input and output constraints, we now simplify the problem by applying only the
constraint, thereby solving a dedicated portfolio optimization problem using these advanced methods.
Neural networks, particularly multilayer perceptrons, exhibit substantial efficacy in discerning non-linear patterns and intricate interrelationships within financial datasets. They can effectively exploit the stock efficiency metrics derived from DEA to discern underlying regularities.
We address the semivariance model for three efficient stocks using a neural network. We designed a feedforward neural network with three hidden layers. The input layer handles 1000 prospective weight vectors, while the output layer estimates portfolio semivariance. The mapping function from 1000 probable weight vectors to a portfolio’s semivariance is inherently complex and non-linear. Consequently, the accurate learning of this function necessitates a network architecture beyond one or two hidden layers. This intrinsic complexity, rather than input dimensionality, determines the requisite network depth. Insufficient depth, evidenced by unsatisfactory performance, signals underfitting, for which augmenting network depth by adding more hidden layers is a suitable solution. Three hidden layers were employed, providing sufficient depth to extract abstract features from weight combinations. Neuron counts of 30, 20, and 10 were selected for these layers, respectively. This decision stemmed from suboptimal performance with fewer neurons, as lower counts reduce model capacity, hindering accurate approximations of the semivariance function. A decreasing neuron count across layers is a common and effective neural network architecture. To prevent overfitting, early stopping was implemented; training halted if the validation error worsened for six consecutive epochs without improvement.
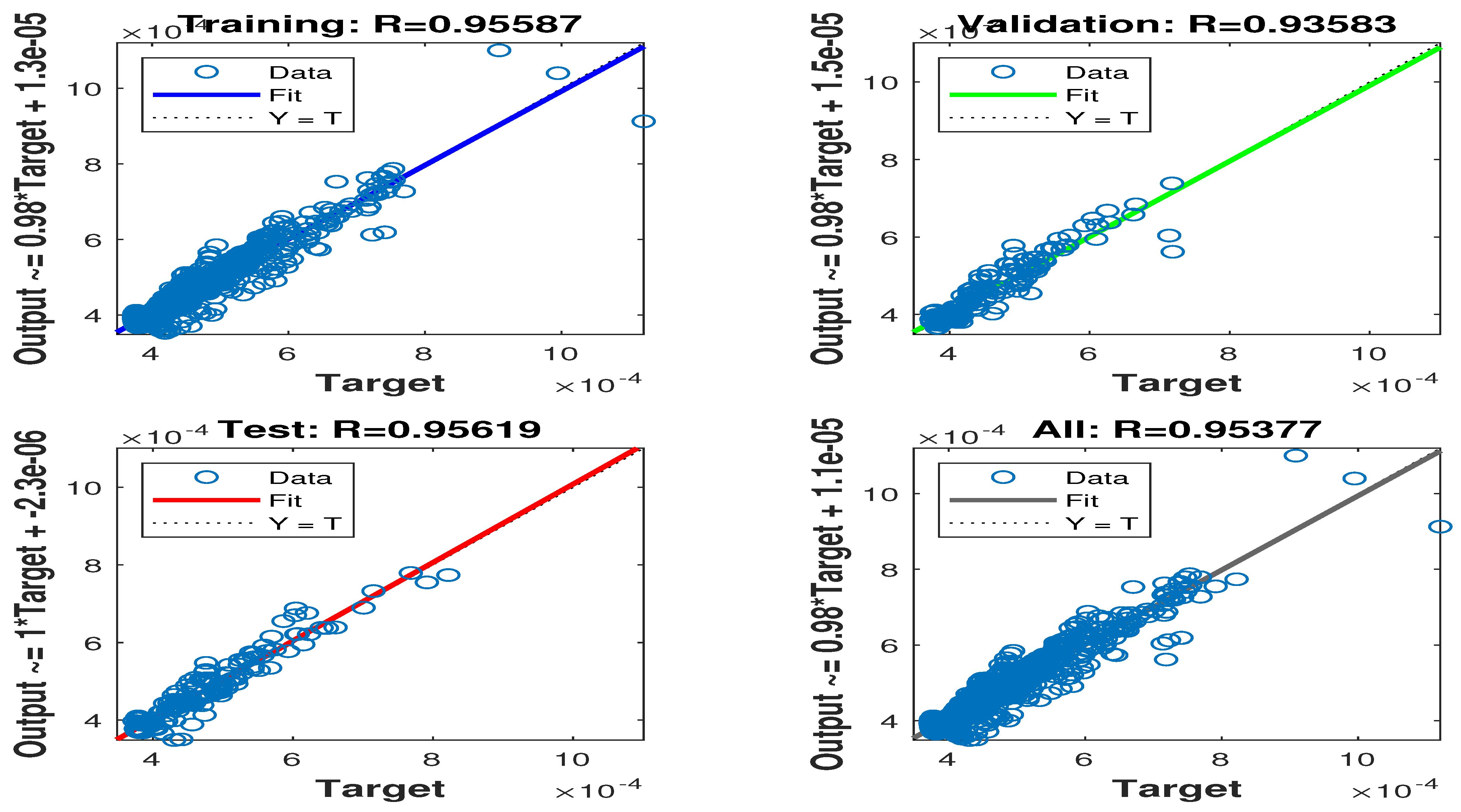
Inherent in this design is the neural network’s capacity to learn an approximation of the functional relationship between the input weights and the resultant semivariance, predicated on the provided 1000 data samples. Thus, rather than engaging in the direct computation of semivariance within the optimization process, we leverage a machine learning model to execute this task. Specifically, our aim is to utilize the neural network to approximate the objective function (semivariance) and subsequently perform a minimization procedure on this approximation to ascertain the optimal weight allocations. Fundamentally, the training of the neural network in this design entails learning a non-linear mapping function that transforms the stock weights to the corresponding semivariance value. As is visually represented in
Figure 4, the attainment of a coefficient of determination (R) of 0.95 in the regression analysis conducted within the internal layers of the neural network’s learning process signifies a remarkably robust model fit. This indicates that the regression model trained within these internal layers has successfully accounted for 95 percent of the variance observed in the target variable, which is likely an intermediate feature intrinsically linked to portfolio semivariance.
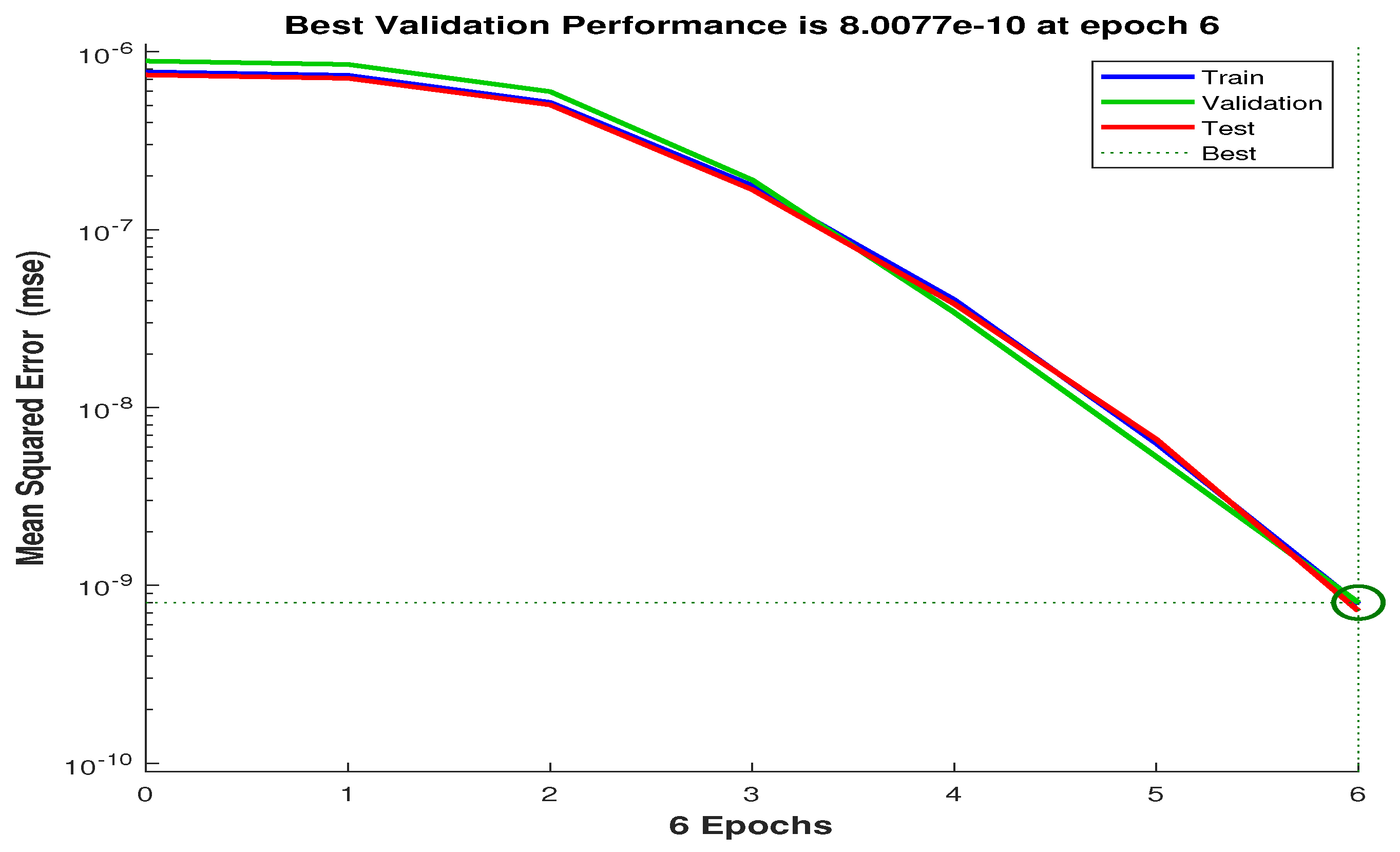
The neural network, in its preceding layers, has demonstrated a proficiency in extracting salient and pertinent features from the input data. These extracted features exhibit a strong correlative relationship with the target variable within the internal layers. The regression model (which may be a straightforward linear regression or a more complex non-linear formulation) trained on these extracted features has effectively modeled the relationship between these features and the target variable. This substantial goodness-of-fit within the internal layers underscores the considerable potential of the neural network to learn intricate data patterns and generate precise outputs, such as portfolio risk assessments. The declining trajectory of the mean squared error (MSE) throughout the training regimen constitutes a highly favorable and indispensable indicator of model performance.
Figure 5 illustrates the model’s ongoing learning and performance enhancement; with each training epoch or iteration, the neural network adaptively adjusts its internal weights to bring its output predictions (portfolio semivariance) closer to the actual or target values. A lower MSE value directly corresponds to a higher degree of accuracy in the model’s predictive or generative capabilities. A consistently decreasing MSE trend signifies a continuous improvement in the model’s precision. Furthermore, a stable descent in MSE suggests that the training process is converging towards an optimal (or at least a locally optimal) solution where the prediction error is minimized. The results thus obtained underscore the promising nature of employing neural networks for portfolio optimization within the capital market. The model has exhibited a notable capacity to learn complex data relationships, and its performance has demonstrably improved over the course of its training.
Upon meticulous examination of
Table 5, it becomes evident that the neural network demonstrates precisely the behavior anticipated from a rational portfolio optimization process. The empirical observation that assets exhibiting the lowest semivariance (a measure of downside risk) and the highest returns ultimately receive the most substantial weight allocations within the optimized portfolio underscores the efficacy of the proposed methodology in synergistically integrating machine learning (specifically, the neural network for the explicit modeling of portfolio semivariance) with a robust optimization algorithm (in this instance, the interior-point method). In essence, the optimization algorithm, leveraging the risk predictions generated by the neural network as its objective function, has operated judiciously by preferentially allocating a greater weight to those assets that offer superior returns commensurate with lower levels of risk exposure. This principle constitutes the bedrock of a judicious investment strategy.
Furthermore, the proposed neural network has demonstrably acquired a robust understanding of the intricate relationship between the specific weight allocations assigned to individual stocks and the resultant overall risk profile of the composite portfolio. Consequently, the optimization algorithm has been effectively guided, through the informed outputs of the neural network, towards asset allocations predominantly comprising stocks characterized by desirable attributes, namely, a low risk and high return potential. This outcome is fundamentally congruent with established investment tenets that advocate for either the maximization of returns for a given, predetermined level of risk tolerance or, conversely, the minimization of risk exposure for a specified target level of return. The strategic allocation of a greater weight to assets exhibiting lower risk profiles coupled with higher return prospects represents a demonstrably rational investment heuristic that can significantly assist investors in the pursuit and attainment of their articulated financial objectives. A portfolio meticulously optimized according to these well-established principles is demonstrably more likely to exhibit superior performance over extended investment horizons when contrasted with portfolios constructed through either stochastic weight allocations or those predicated solely on intuitive judgments. This anticipated outperformance is directly attributable to the explicit focus on assets possessing both a substantial return potential and comparatively modest levels of risk. Conversely, the application of evolutionary algorithms and the traditional optimization method resulted in the predominant allocation of weight to the individual stock exhibiting the highest absolute return (stock # 8).
These alternative methodologies assigned comparatively minimal weight to stocks characterized by lower semivariance, a decision that consequently led to elevated levels of overall portfolio risk within the optimized portfolios, as explicitly detailed in
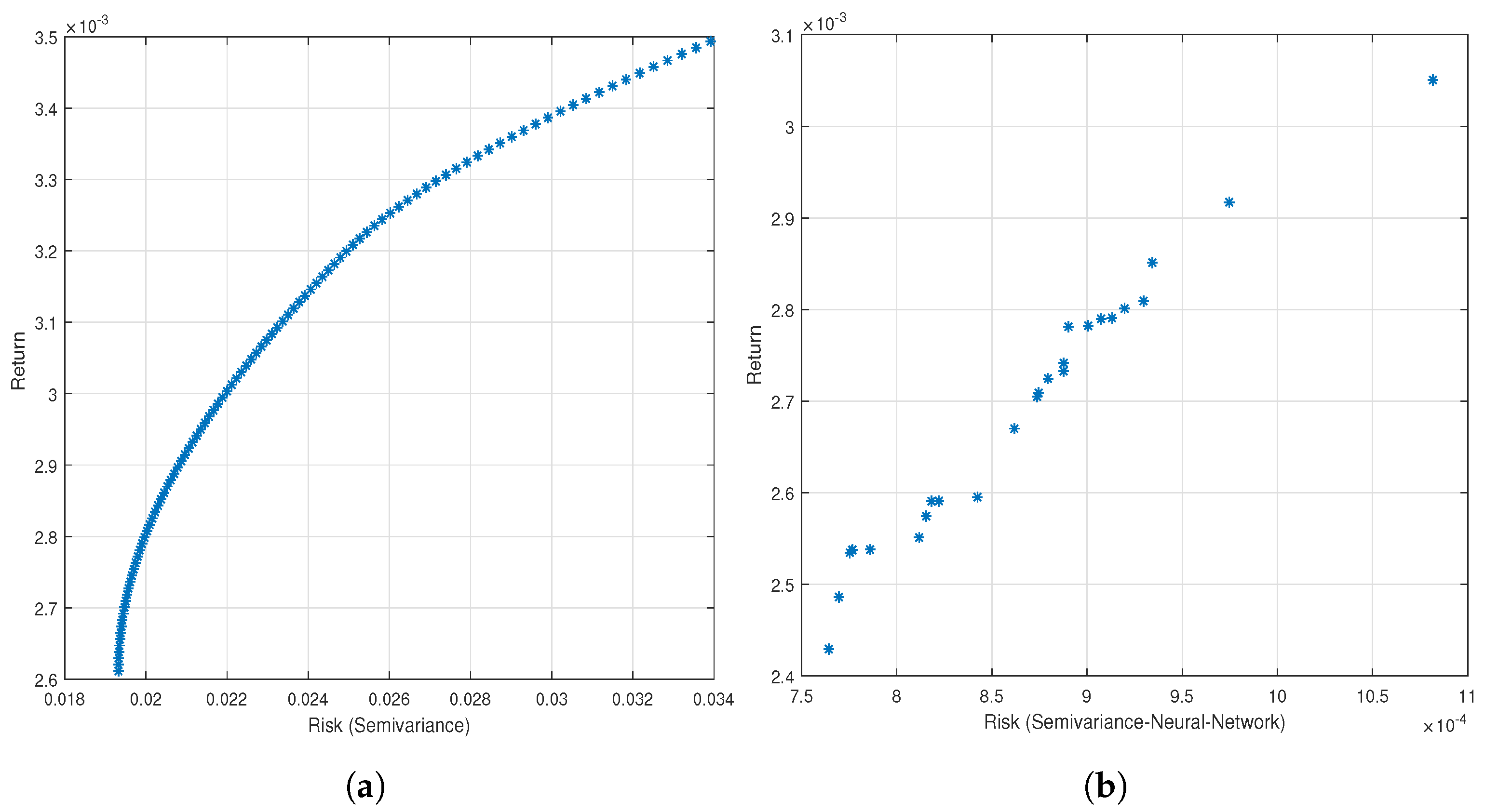
Table 6. In stark contrast, the aggregate risk associated with the portfolio constructed through the informed application of the neural network is demonstrably and significantly lower. Moreover, as visually elucidated in
Figure 6 and
Figure 7, the portfolios generated through the neural network approach consistently exhibit lower levels of risk exposure when directly compared to those portfolios derived from the implementation of evolutionary algorithms and the traditional method. By way of concrete illustration, for a comparable level of portfolio return approximating
, the neural network-optimized portfolio exhibits a markedly lower risk level of
, whereas the risk levels associated with portfolios generated by the alternative methodologies are substantially higher, approximating
.
To further examine the portfolios generated by the introduced methods, their efficiency was evaluated using DEA in
Table 7 and
Table 8. As observed, the neural network produced a greater number of efficient portfolios compared to the other two methods. The superior performance of the neural network in generating a larger number of efficient portfolios likely indicates its enhanced capability in learning the complex relationships between input variables (weights) and output variables (risk) within the capital market. The neural network may have identified non-linear and subtle patterns that the evolutionary algorithms were not readily able to discover, leading to the generation of portfolios that offer lower risk relative to the accepted return.
The second-place ranking of NSGA2 in terms of the number of efficient portfolios suggests that this evolutionary algorithm also demonstrated a respectable performance in identifying a set of pareto-optimal portfolios (trade-off between risk and return). NSGA2 is well-recognized for its efficacy in searching the solution space and identifying a set of non-dominated solutions (where no other solution is superior in all objectives). The last-place ranking of the SPEA2 algorithm in terms of the number of efficient portfolios may indicate that this algorithm, in comparison to the neural network and NSGA2, was less successful in identifying portfolios that simultaneously performed well across all efficiency criteria (DEA inputs and outputs). This could be attributed to the algorithm’s structure, parameter settings, or its search strategy within the solution space.
These results can be interpreted as corroborating evidence for the significant potential of neural networks as a powerful tool in portfolio optimization. Their ability to learn intricate patterns may render them superior in identifying optimal asset allocations that establish a more favorable equilibrium between risk and return. The results demonstrate that the selection of the optimization algorithm has a significant impact on the efficiency of the final portfolios. Depending on the characteristics of the market and the investor’s objectives, one method may outperform another. The performance of evolutionary algorithms such as NSGA2 and SPEA2 is highly dependent on the tuning of their parameters. It is plausible that with more precise parameter adjustments, their performance could be improved. These findings could provide impetus for exploring the combination of different optimization methods (such as utilizing the neural network’s output as an initial population for a genetic algorithm) to leverage the inherent strengths of each approach.
Computational Complexity
This section provides a detailed analysis of the computational resources and time required for each component of our integrated methodology. Understanding these execution times is crucial for evaluating the practical applicability and scalability of our approach, and it clearly highlights the trade-off between solution quality and computational cost.
In portfolio optimization using a neural network, where we employed a two-stage method, the neural network training time was merely 2 s (it should be noted that early stopping was employed to prevent overfitting), and the time to find optimal weights based on the predicted semivariance was 0.5 s. Cumulatively, solving this problem with the neural network took only 2.5 s. In contrast, when solving the same problem with the NSGA2 and the SPEA2 (both configured with 100 iterations (generations) and a population size of 50), finding the optimal weights required 40 and 45 s, respectively. This direct comparison clearly demonstrates the inherent trade-off between solution quality and computational cost across the different methodologies.
The most significant advantage of our neural network-based approach emerges in its extraordinary operational speed during the second stage. After the initial neural network training (which was completed at a negligible cost of 2 s), the process of finding an optimal portfolio for a specified return is remarkably fast, typically taking only milliseconds. This unparalleled speed makes our approach highly suitable for real-time portfolio adjustments or high-frequency decision-making scenarios, where the iterative and inherently slower nature of evolutionary algorithms would be prohibitive. This highlights a clear trade-off: a very low initial training cost for the neural network, but in return, a negligible operational cost for each decision.
This characteristic provides superior speed and deterministic results compared to the stochastic nature of evolutionary algorithm executions. Among the two evolutionary algorithms tested, NSGA2 demonstrated a superior performance in terms of both solution quality and computational efficiency. NSGA2 completed its optimization on average in 40 s, indicating a slight computational advantage over SPEA2, which took approximately 45 s. Consequently, our two-stage approach, which utilizes a neural network as a semivariance surrogate model, significantly enhances the speed and scalability of portfolio optimization after initial training, making it ideal for dynamic market environments.
6. Conclusions
This study introduces a novel approach to portfolio optimization by integrating the DEA model with the MSV framework. Initially, the DEA model assesses asset efficiency using semivariance and beta as risk inputs and expected return as the output. Subsequently, an optimal portfolio is constructed from the identified efficient stocks. To determine the optimal weights of these stocks within the portfolio, the MSV model is solved using both a neural network and evolutionary algorithms (NSGA2 and SPEA2). In the neural network-based optimization method, random weights are fed into the neural network, with the portfolio’s semivariance serving as the output. This output then acts as the objective function to determine the optimal asset weights. Conversely, in the evolutionary algorithm-based optimization, the MSV model is solved for the efficient stocks using the NSGA2 and SPEA2 algorithms, and their respective outcomes are compared. The findings indicate that optimizing efficient stocks with a neural network significantly reduces the portfolio risk and yields higher efficiency compared to both evolutionary algorithm-based methods. Notably, the NSGA2 algorithm outperforms SPEA2 in this context. These results suggest that neural networks are effective in discerning the inherent non-linear behavior within market data, thus offering investors a valuable tool for both forecasting and optimizing their investment portfolios. The success of the neural network in solving the semivariance model underscores its robust learning capabilities. Furthermore, the favorable performance of genetic algorithms in generating efficient portfolios opens promising avenues for future research, particularly in integrating the neural network’s objective function with these algorithms for enhanced optimization and analysis.
The findings of this research are derived from data pertaining to the Iranian automotive sector over a specific period. Consequently, the unique fluctuations of the Iranian market may have influenced the model’s performance. Therefore, the proposed model’s performance requires further testing and validation in other markets such as developed markets with different regulatory frameworks or additional emerging markets—as well as across different asset classes, including bonds, commodities, and currencies. Additionally, generalizing these results to markets experiencing lower returns, recessionary conditions, or crises requires further validation. Hence, to further develop the DEA--MSV framework and broaden its applicability in more intricate market scenarios, several promising avenues for future research exist. In illiquid and noisy data markets (e.g., small-cap stocks), robust optimization can be employed to effectively manage the inherent uncertainties in return and risk estimations.
It will be crucial to integrate liquidity constraints and transaction cost models into the optimization problem, while also leveraging robust DEA models for more reliable asset filtering in such volatile conditions. For bond portfolios, the concept of downside risk can be redefined using yield spread semivariance, necessitating re-training the ANN on bond-specific data and incorporating bond-specific constraints (like duration and credit rating) into the optimization model. Furthermore, DEA inputs and outputs will require updates to accurately assess the bond efficiency. Finally, to ensure the framework’s adaptability to dynamic market conditions (e.g., during crises), implementing a rolling-window strategy is vital. This involves periodic updates of the DEA, re-training or fine-tuning the ANN, and re-executing the optimization process. Moreover, regime-switching models can be utilized to dynamically adjust parameters and strategies in response to evolving market states.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}