Abstract
This paper proposes a multi-granularity retrieval algorithm based on an unsupervised image augmentation network. The algorithm designs a feature extraction method (AugODNet_BRA) rooted in image augmentation, which efficiently captures high-level semantic features of images with few samples, small targets, and weak features through unsupervised learning. The Omni-Dimensional Dynamic Convolution module and Bi-Level Routing Attention mechanism are introduced to enhance the model’s adaptability to complex scenes and variable features, thereby improving its capability to capture details of small targets. The Omni-Dimensional Dynamic Convolution module flexibly adjusts the dimensions of convolution kernels to accommodate small targets of varying sizes and shapes. At the same time, the Bi-Level Routing Attention mechanism adaptively focuses on key regions, boosting the model’s discriminative ability for targets in complex backgrounds. The optimized loss function further enhances the robustness and distinctiveness of features, improving retrieval accuracy. The experimental results demonstrate that the proposed method outperforms baseline algorithms on the public dataset CUB-200-2011 and exhibits great potential for application and practical value in scenarios such as carrier-based aircraft tail hook recognition.
1. Introduction
In the era of rapid development of information and intelligence, data retrieval technology has become increasingly important in fields such as image retrieval and object recognition. It can efficiently and accurately extract information related to the query target from vast amounts of data. This technology is of great significance for improving work efficiency, optimizing decision-making processes, and promoting technological innovation in relevant fields. However, with the increasing complexity of application scenarios and the diversification of data characteristics, the limitations of traditional data retrieval methods have gradually become apparent. This is especially true when dealing with data that have few samples and weak features, where the performance and effectiveness of retrieval algorithms face significant challenges. These types of data are often characterized by a small number of samples, inconspicuous features, low signal-to-noise ratios, small targets, and complex backgrounds. These characteristics make it difficult for existing algorithms to extract effective information, thereby affecting the accuracy and efficiency of retrieval.
Data with few samples and weak features are widely found in many fields, such as medical image analysis, object detection, remote sensing image recognition, and underwater sonar image localization. In these fields, obtaining samples is often difficult or costly, resulting in small-scale datasets that cannot meet the demand for large-scale training data required by traditional machine learning or deep learning methods. Moreover, the weak feature characteristics of the data, such as low resolution, high noise, and complex backgrounds, further increase the difficulty of feature extraction and pattern recognition. Therefore, developing efficient retrieval algorithms that can effectively deal with data with few samples and weak features is of great theoretical and practical significance for advancing technological progress and practical applications in these fields.
To address the challenges of retrieving data with few samples and weak features, this paper proposes a multi-granularity retrieval algorithm based on an unsupervised image augmentation network. The algorithm designs a feature extraction method (AugODNet_BRA) based on image augmentation, which efficiently captures the high-level semantic features of images with few samples, small targets, and weak features. By introducing the Omni-Dimensional Dynamic Convolution module and the Bi-Level Routing Attention mechanism, the model’s adaptability to complex scenes and multi-scale features is enhanced. An optimized loss function further improves the robustness and distinctiveness of features. Experimental results show that the proposed method outperforms baseline methods on the public dataset CUB-200-2011 and the Carrier-based Aircraft Tail Hook Recognition Dataset (SubCATHR-DET), demonstrating good application potential and practical value.
The main contributions of this paper are as follows:
- A multi-granularity retrieval algorithm for data with few samples and weak features is proposed, effectively addressing the shortcomings of traditional methods in these scenarios.
- The Omni-Dimensional Dynamic Convolution module and Bi-Level Routing Attention mechanism are introduced, significantly enhancing the model’s adaptability to complex scenes and small targets.
- An optimized loss function was designed to improve the robustness and distinctiveness of features, thereby increasing retrieval accuracy.
- Experiments on the public dataset CUB-200-2011 and the SubCATHR-DET dataset helped to verify the effectiveness and practicality of the proposed method.
The structure of this paper is as follows: Section 2 reviews the related work; Section 3 details the proposed model architecture; Section 4 introduces the experimental design and evaluation metrics; Section 5 presents the experimental results and discussion; and, finally, Section 6 summarizes the main contributions and outlines future work directions.
2. Related Studies
In recent years, few-shot learning has made notable advances, primarily focusing on three directions: data augmentation [1], metric learning [2], and meta-learning [3].
Data augmentation enhances model generalization by transforming and expanding datasets. Traditional techniques include rotation, translation, scaling, and cropping, which effectively mitigate overfitting [4]. With the advent of GANs [5], augmentation based on generative model has become mainstream, such as the GAN-based image classification augmentation method proposed by Zhang et al. [6]. Unsupervised learning approaches, including image rotation augmentation [7] and AugNet [8], further improve data diversity through self-supervised learning.
Metric learning optimizes the distance relationships between samples, bringing similar samples closer while pushing dissimilar ones apart, thereby enhancing model performance [9]. Representative methods include Siamese networks [10] and Facenet [11]. Recent advancements, such as metric learning based on angular loss [12], prototypical network based on hierarchical representation [13], and methods combining global and local features [14], have further refined few-shot learning performance.
Meta-learning enables models to quickly adapt to new tasks through multi-task learning [15]. Finn et al’s model-agnostic meta-learning (MAML) [16] optimizes model initialization parameters for rapid convergence. Other approaches, such as matching networks [17], Latent Embedding Optimization (LEO) [18], and a self-supervised meta-prompt learning framework with meta-gradient regularization for few-shot generalization (SUPMER) [19], have improved the generalization and adaptability of few-shot learning.
Despite these breakthroughs, challenges remain. Data augmentation struggles to fully exploit the latent information in few-shot and weak-feature data. Metric learning still faces difficulties in distinguishing between similar and dissimilar samples. Meta-learning’s reliance on task migration and adaptability to task structures requires further enhancement.
Image retrieval technology aims to identify the most similar images from a vast database for a given query. Traditional methods rely on handcrafted features, like color histograms, texture features, and shape description, but their performance is limited in complex scenes as they fail to comprehensively capture multi-layer and multi-scale image information. With the rise of deep learning, CNN-based feature learning has replaced handcrafted features as the mainstream paradigm for image retrieval. Deep learning’s hierarchical structure automatically extracts abstract features, better adapting to specific datasets and application requirements. Deep learning-based image retrieval methods fall into two categories: supervised and unsupervised learning. Supervised learning has been widely applied in image retrieval. Xia et al. [20] used CNNs for feature learning to obtain image representation tailored to hashing, as well as a set of hash functions. Liu et al. [21] proposed Deep Supervised Hashing (DSH), which learns binary codes from similar and dissimilar image pairs. Jiang et al. [22] demonstrated the applicability of supervised training for asymmetric hashing. Ng et al. [23] introduced a multi-layer supervised hashing method with deep features. In recent years, Chaudhuri et al. [24] proposed a data-free (DF) sketch-based image retrieval method, addressing the issue of retrieving photos from hand-drawn sketches without paired data. Huang et al. [25] introduced the Cross-modal and Uni-modal Soft-label Alignment (CUSA) method, effectively solving cross-modal matching and uni-modal semantic loss issues in image-text retrieval.
Despite the success of supervised models, acquiring large-scale labeled data remains a challenge. Consequently, unsupervised models that do not rely on category labels have gained attention. Erin et al. [26] proposed a deep hashing method that learns compact binary codes through multi-layer non-linear transformations. DeepBit [27] achieves efficient visual object matching by learning compact binary descriptors, but its binarization overlooks data distribution, leading to significant quantization loss. To address this, Duan et al. [28] introduced the Deep Binary Descriptor with Multi-Quantization (DBD-MQ) method, which synchronously optimizes parameters and binarization function maps via K-AutoEncoders (KAEs) to reduce quantization loss. Huang et al. [29] proposed Unsupervised Triplet Hashing (UTH), leveraging triplets of anchor images, rotated images, and random images to learn binary codes. Shen et al. [30] presented Unsupervised Similarity-Adaptive Deep Hashing (SADH), which updates similarity graphs and optimizes binary codes. Xu et al. [31] introduced a semantic part-based weighting aggregation. Liu et al. [32] successfully applied similarity-based unsupervised deep transfer learning to remote sensing image retrieval. Jang et al. [33] proposed the Self-Supervised Product Quantization (SPQ) method, which trains in a self-supervised manner. Qiu et al. [34] developed Hashing with Contrastive Information Bottleneck (CIBHash), combining contrastive learning with deep binary hashing. Wang et al. [35] proposed Contrastive Quantization with Code Memory (MeCoQ), employing contrastive learning to acquire unsupervised binary descriptors. Qiu et al. [36] introduced Hierarchical Hyperbolic Product Quantization (HiHPQ), focusing on the multi-layer semantic similarities in images.
In summary, image retrieval has achieved remarkable progress driven by deep learning models, but challenges persist in few-shot and weak-feature scenarios. Supervised methods rely on large-scale labeled data, limiting their applicability in data-scarce environments. Unsupervised methods partially address the lack of labels but still exhibit limited performance in weak-feature and complex-background retrieval. In light of the limitations of the related work discussed earlier, this paper proposes a multi-granularity retrieval algorithm based on an unsupervised image augmentation network. By incorporating the Omni-Dimensional Dynamic Convolution module and the Bi-Level Routing Attention mechanism, this method integrates multi-scale feature extraction and a key area that focuses into the model architecture, thereby achieving end-to-end efficient feature learning.
3. Model Architecture
To address the challenges of retrieving few-shot, small-target, and weak-feature images, this paper proposes a multi-granularity retrieval algorithm based on unsupervised image augmentation. The framework consists of a feature extraction module and an image retrieval module. In the feature extraction stage, this paper designs the AugODNet_BRA algorithm, which efficiently captures high-level semantic features of images through unsupervised learning. The core idea of AugODNet_BRA is image augmentation, where the embedding space is optimized so that enhanced representations of the same source image cluster closely while those of different source images remain distant, thereby enhancing feature discriminability.
To improve the model’s adaptability in complex scenes and its ability to capture small-target details and multi-scale features, this study employed a Deep Convolutional Neural Network (DCNN) as the foundational architecture, with ResNet18 serving as the backbone network. ResNet18 was chosen for its relatively shallow network depth and robust feature extraction capabilities, which excel in few-shot learning scenarios. To adapt to the processing needs of small targets and weak features, this paper introduces targeted improvements to ResNet18. Firstly, Omni-Dimensional Dynamic Convolution modules are incorporated into the second residual stage (Res2) and the third residual stage (Res3) of ResNet18, replacing traditional convolutional layers to enhance the model’s adaptive feature extraction capabilities for targets of varying scales. Secondly, a Bi-Level Routing Attention (BRA) mechanism is added after Stages Res2 and Res3 to strengthen the association between mid-level and high-level features, thereby increasing the model’s focus on key areas. Additionally, to optimize the robustness and discriminability of feature representation, this research designed a loss function that integrates boundary margins, class center regularization, and dynamic loss weights. The training process of the model adopts an unsupervised learning approach, learning feature embeddings from image pairs generated through data augmentation without reliance on class labels.
The overall framework of the multi-granularity retrieval algorithm based on unsupervised image enhancement designed in this study is shown in Figure 1.
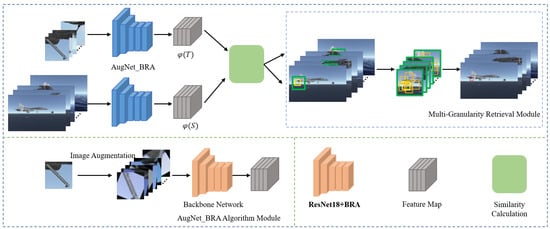
Figure 1.
The overall framework of the model.
3.1. AugNet Algorithm
The AugNet algorithm [8] trains a deep convolutional neural network to extract image features in an unsupervised manner, and it represents images as low-dimensional vectors while preserving inter-image similarities. The method is based on the intuition that, in a parameterized embedding space, variants generated from the same source image via data augmentation should exhibit compact feature distributions, while those from different sources should maintain sufficient dissimilarity.
This study employed a batch processing method, where each batch comprises images derived from N distinct source images, with each source image enhanced to generate M variants. Each enhanced view retains only partial regions of the source image, encouraging the network to learn the relationships between different regions (e.g., foreground and background) rather than merely learning the augmentation methods. The embedding vector is defined as follows:
where the output of the entire neural network is denoted as , where w represents all parameters of the network, denotes the image data, and is the embedding vector of the i-th enhanced image from the j-th source image.
The contrastive loss is defined using positive and hardest negative pairs:
where represents the distance.
For datasets with few samples, small targets, and weak features, the following image augmentation techniques were applied.
- Rotation: Targets in real-world scenarios often exhibit diverse orientations due to viewpoint changes or motion. To address this, this paper adopted a rotation augmentation method, which enhances the model’s generalization to varying target angles and mitigates the overfitting caused by uneven angle distributions in training data. The rotation angle is randomly sampled from a uniform distribution ;
- Noise: Noise is a common factor affecting image data, particularly under low-light, low-contrast, or high-compression conditions. By deliberately adding noise during training, the model learns to separate signals from background interference, reducing noise’s negative impact on accuracy and improving generalization. This paper focused on superimposing noise from a Gaussian distribution onto the input images;
- Cropping: Targets in real images may not always occupy central or specific regions. Random cropping enhances the model’s adaptability to positional variations and scale changes, improving performance for small targets in low-resolution scenarios. A square sub-region is cropped from the original image and resized to the target dimensions (e.g., 224 × 224). The side length ratio of the square to the shorter edge of the original image is sampled from a uniform distribution , where the lower bound is specified by the minimum crop ratio parameter ;
- Resolution: Image resolution is often affected by device performance and shooting conditions. Downsampling strategies simulate resolution degradation, training the model to recognize targets under incomplete information and improving robustness to compression or blur. Images are first downsampled by a ratio randomly selected from and then resized back to their original dimensions;
- Hue: As an attribute of image color, hue is susceptible to lighting and environmental conditions. To enhance the model’s adaptability to color variations, a hue adjustment strategy is proposed. The hue is dynamically adjusted by randomly sampling from a uniform distribution , simulating diverse lighting conditions and improving robustness;
- Saturation: Saturation fluctuations occur in real-world images due to varying shooting environments. A saturation adjustment strategy is introduced, where saturation is modified by sampling from . The distribution is designed asymmetrically near zero to ensure robustness for low-saturation or grayscale images;
- Brightness: Image brightness is influenced by lighting conditions. A brightness augmentation strategy multiplies the brightness by a random value sampled from and adjusts it with a bias sampled from , improving performance in extreme lighting scenarios;
- Occlusion: Target occlusion is a critical challenge in real-world detection. To enhance the model’s adaptability to such situations, rectangular mask regions with dimensions 15% of the original image’s height and width are randomly generated and filled with gray to simulate occlusion. The number of regions is sampled from .
To further diversify the data, all of the enhanced samples were horizontally flipped with a 50% probability. Figure 2 compares the original input images with their augmented counterparts. In experiments, each original sample was expanded into 64 resized training samples.

Figure 2.
Image augmentation example.
3.2. Omni-Dimensional Dynamic Convolution Module
For feature extraction of small-target, weak-feature, and multi-angle data, static convolution employs an invariant convolutional kernel to process all inputs, limiting its ability to adapt to variations in target size, orientation, or viewpoint. This may result in inadequate capture of fine local details. In few-shot learning scenarios, traditional CNNs struggle to learn effective features, leading to overfitting, underfitting, and poor generalization.
Dynamic convolution addresses this by adjusting kernel parameters based on input characteristics, enabling adaptive processing of diverse target features. This adaptability is particularly valuable for small targets and weak features, allowing kernels to refine their focus. Thus, this study integrated a dynamic convolution module into the feature extraction network.
Recent advances in dynamic convolution include Conditionally Parameterized Convolutions (CondConv) [37] and Dynamic Convolution (DyConv) [38], which primarily adjust the number of kernels. YAO et al. [39] proposed Omni-Dimensional Dynamic Convolution (ODConv), which dynamically adapts spatial dimensions, input channels, output channels, and kernel counts, enhancing flexibility and expressiveness. The implementation is illustrated in Figure 3.
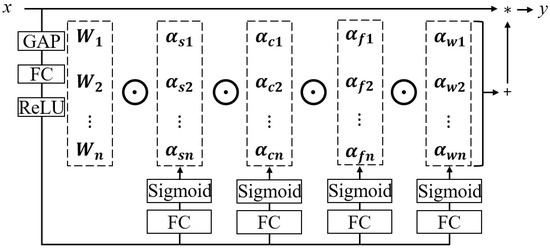
Figure 3.
The ODConv implementation process.
The input data undergoes a global average pooling (GAP), which is followed by a fully connected (FC) layer and ReLU activation function for feature transformation [39]. A four-branch module then computes four types of attention , , , and in the kernel space . ODConv is defined as follows:
where , , , and represent the attention weights for spatial, input channel, output channel, and kernel space, respectively. The symbol ⊙ denotes multiplicative operations along kernel space, and * denotes convolution.
3.3. Bi-Level Routing Attention Mechanism
Attention mechanisms play a pivotal role in deep learning, particularly for small-target, weak-feature, and few-shot data. Inspired by human vision, they enable neural networks to focus on critical regions while suppressing irrelevant information. For small targets and weak features, attention acts as an intelligent filter, allocating computational resources efficiently to capture essential details and improve feature extraction.
Standard self-attention mechanism faces challenges with small targets and weak features due to its global dependency computation, which incurs high computational overhead and disperses attention weights. Multi-Head Self-Attention (MHSA) [40] enhances feature modeling through parallel attention heads, but its fixed attention range struggles with sparse features in small-target and weak-feature data. Additionally, MHSA’s equivalent computation wastes resources on irrelevant regions, reducing efficiency.
Zhu et al. [41] proposed the Bi-Level Routing Attention (BRA) mechanism, which employs dynamic query-aware sparse attention to address these challenges. For small targets and weak features, BRA first performs coarse-grained region screening to locate relevant key-value pairs, reducing computational complexity. It then conducts fine-grained attention calculations within these regions to precisely extract local details. As shown in Figure 4, BRA selects the top candidate windows for attention computation, balancing efficiency and precision.
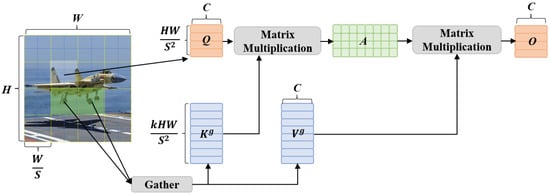
Figure 4.
The Bi-Level Routing Attention mechanism.
Figure 4 illustrates a hierarchical attention mechanism framework that was used for visual feature processing, and it shows significant advantages in sparse feature scenarios. The input image is divided into multiple candidate windows, with a window size of , where S is an adjustable step size parameter. By selecting the key-value pairs ( and ) with the highest relevance within these regions, the mechanism achieves a balance between computational efficiency and feature precision. The query vector Q (with dimensions ) is matrix-multiplied with the key-value matrix (with dimensions ) to generate the attention matrix A, whose elements represent the correlation strength between the query and key-value features. After normalization processing, the attention matrix is combined with the value matrix to ultimately produce the feature matrix O (with dimensions ). Compared to traditional methods, this hierarchical strategy only performs in-depth calculations on highly relevant regions, thereby avoiding redundant computations in the sparse feature background and significantly improving model performance. The figure clearly demonstrates the complete process from image segmentation, feature extraction, and attention weighting to the final feature fusion, reflecting the delicate balance of computational efficiency and feature precision achieved by this mechanism.
The 2D input feature map was divided into non-overlapping regions, each containing feature vectors. Reshaping X into , linear projections generated query, key, and value tensors and V, respectively:
where , , and are projection weights for queries, keys, and values, respectively.
A directed graph determines the inter-region attention relationships. Region-level queries and the keys are obtained by averaging, and the adjacent matrix is computed as follows:
To prune the association graph, only the top k connections per region are retained, yielding the routing index matrix :
This function selects the indices of the top k most relevant regions for each region from the adjacency matrix . Specifically, it performs a row-wise top-k operation and returns an index matrix , where each row contains the indices of the k most relevant regions for that particular region. Using , token-to-token attention is confined to the top k regions. The gathered key-value tensors and are reconstructed as follows:
This function collects key-value pairs from the original key K and value V tensors according to the index matrix . It extracts the keys and values specified by from the entire feature map, enabling the application of the attention mechanism on these regions.
The output feature map O is computed as follows:
where the function implements the standard attention mechanism, and [42] is a local context augmentation term.
For few-shot and weak-feature datasets, although deep residual structures can effectively alleviate the vanishing gradient problem and ensure effective feature extraction with limited data, overly deep residual networks are prone to overfitting. Thus, ResNet18 was chosen as the backbone for AugNet. AugODNet_BRA further optimizes AugNet by integrating dynamic convolution and BRA modules. As shown in Figure 5, traditional convolutions in the Res-2 and Res-3 stages were replaced with ODConv, enabling adaptive feature learning. BRA modules were added after Res-2 and Res-3 to enhance cross-scale information flow, particularly for small targets and weak features.
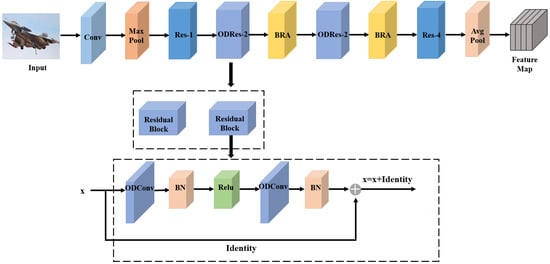
Figure 5.
The AugODNet_BRA backbone network structure.
3.4. Loss Function Optimization
Traditional contrastive loss functions inadequately control the similarity differences between positive (same-class) and negative (different-class) sample pairs, potentially causing overlapping or adjacent embeddings. Additionally, imbalanced gradient contributions from positive and negative pairs during training hinder convergence and performance. To address this, an optimized strategy incorporating margin intervals, class-center regularization, and dynamic loss weight is proposed.
Margin Interval: To enhance class separability, a margin parameter enforces a minimum distance between positive and negative pairs, preventing class confusion in the embedding space. The optimized loss function is as follows:
Class-Center Regularization: This maximizes the distances between class centers to avoid overlap, improving separability. The class-center regularization loss function is
where is the minimum inter-class margin, and denotes the distance between classes i and k.
Dynamic Loss Weight: The weights of the positive and negative pairs are adjusted adaptively during training. Initially, negative sample pairs typically generate larger gradients, which have a more significant impact on model updates, while positive pairs contribute less. Dynamic weight balances their influence, enhancing training efficiency and stability.
The final loss function is as follows:
where and are weight factors for positive and negative pairs, respectively.
Combining these, the optimized loss function is
where is a hyperparameter adjusting the regularization term R.
3.5. Multi-Granularity Retrieval Algorithm
For object recognition tasks involving few-shot and weak-feature data, traditional methods based on large-scale training samples are difficult to meet the application needs of scarce data scenarios. This study transforms recognition into a retrieval task, enabling accurate identification (even with one-shot matches).
A multi-granularity retrieval algorithm, comprising coarse-grained and fine-grained stages, is proposed. During the coarse-grained retrieval phase, the similarity between the target image and the database images is calculated to identify high-similarity regions and compress the candidate search space; subsequently, in the fine-grained retrieval phase, multiple refined samples are generated within the reduced region to conduct high-precision feature matching; and, finally, by integrating the retrieval results of the sub-samples, the precise localization and recognition of the target are achieved. Figure 6 illustrates the workflow using a carrier-based aircraft tail hook recognition as an example.
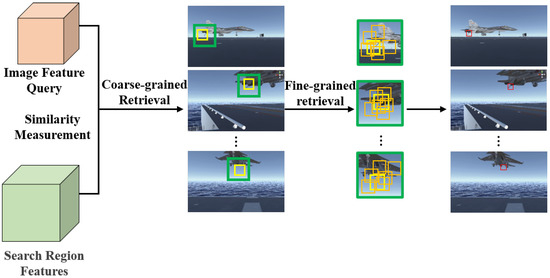
Figure 6.
The multi-granularity retrieval algorithm workflow.
4. Experimental Design
To systematically evaluate the effectiveness of the proposed method, this study designed a series of comparative and ablation experiments. The comparative experiments aim to verify the performance differences between the algorithm presented in this paper and existing methods (including AugNet, SPQ, HiHPQ, CIBHash, and MeCoQ) on the SubCATHR-DET and CUB-200-2011 datasets; the ablation experiments were used to analyze the contribution of each core component (Omni-Dimensional Dynamic Convolution module, Bi-Level Routing Attention mechanism, and optimized loss function) in this algorithm to the model performance. All the experiments were conducted under the same hardware environment and software configuration to ensure the comparability and reliability of the results.
4.1. Datasets
- SubCATHR-DET Dataset: A subset of the Carrier-based Aircraft Tail Hook Recognition Dataset (CATHR-DET) [43]. The CATHR-DET dataset consists of 400 real samples and 3600 synthetic samples, with an image resolution of 1300 × 600 pixels. It encompasses various weather conditions, including sunny, cloudy, and rainy days. The dataset is characterized by small targets, weak features, and complex backgrounds. Small targets refer to the fact that the tail hook occupies an extremely small area in the image, with a size of only 50 × 50 pixels, accounting for merely 0.32% of the entire image (1300 × 600 pixels). Compared to the overall structure of the aircraft, the tail hook is even more insignificant. Weak features indicate that the contours and textures of the tail hook are faint, making it difficult to distinguish from other parts of the aircraft and background elements. Moreover, the shape and position of the tail hook vary significantly due to the different angles and perspectives during landing, which further increases the difficulty of distinguishing the tail hook from the background. Complex backgrounds mean that the signal-to-noise ratio (SNR) between the tail hook and background elements (such as the flight deck, sea surface, and clouds) is low. Particularly under adverse weather conditions (such as cloudy or rainy days), the visibility of the tail hook is further reduced, which may interfere with target recognition. Therefore, the carrier-based aircraft tail hook recognition data are classified as weak-feature, small-target data. For this study, 260 images (30 real samples and 230 synthetic samples) were randomly selected from the CATHR-DET dataset to form the SubCATHR-DET dataset. The training set comprises 1600 images with a resolution of 50 × 50 pixels, which were cropped from 10 images of carrier-based aircraft landing with a resolution of 1300 × 600 pixels. To avoid data redundancy, images with high similarity were removed. The test set includes 200 images of carrier-based aircraft landing. The query images consist of 50 images with a resolution of 50 × 50 pixels containing tail hooks, which were cropped from images of carrier-based aircraft landing that include tail hooks.
- CUB-200-2011 Dataset: A fine-grained bird dataset with 200 subcategories that has a total of 11,788 images [44]. Each subcategory contains approximately 60 images. For experiments, 100 bird species were randomly selected, with 80% for training, 2 images per class for queries (200 total), and the remainder as the retrieval database.
4.2. Parameter Settings
The feature extraction used ResNet18, with each image augmented 8 times (M = 8) and resized to 50 × 50. The margin interval = 0.1, minimum class-center distance = 0.1, positive weight = 1, negative weight = 0.2, and regularization weight = 0.01 were set. The Adam optimizer was used with an initial learning rate of for 100 epochs (coarse-grained retrieval step = 30 px; fine-grained step = 8 px).
4.3. Evaluation Metrics
Performance was evaluated using precision, recall, F1 score, and the mean average precision (mAP).
5. Experiments
This section evaluates the impact of replacing different modules in AugODNet_BRA and validates their effectiveness.
5.1. Comparative Experiments
First, ODConv modules were integrated into ResNet18’s Res2 and Res3 stages (individually and jointly) to analyze their impact. Res1 was unchanged to preserve low-level feature extraction, and Res4 remained unmodified for stability. The experiments on SubCATHR-DET (Table 1) showed that replacing both Res2 and Res3 yielded the best performance (mAP: 76.3%).

Table 1.
Performance with ODConv modules.
The experimental results demonstrate that replacing the conventional convolutional layers with ODConv modules in both the Res2 and Res3 stages of ResNet18 (denoted as Res2+Res3) achieved optimal model performance, as quantified in Table 1. This enhancement originates from ODConv’s strengthened capability to capture fine-grained feature representations during intermediate hierarchical processing. For BRA module evaluation, systematic configurations were implemented by integrating BRA modules after Res2, Res3, or both stages within the ResNet18 backbone. To safeguard low-level feature extraction integrity, the BRA modules were excluded from the initial residual stage, while their omission in the final stage mitigated computational redundancy given diminishing performance returns. Comparative analyses (Table 2) confirmed that dual BRA module deployment (Res2+Res3) yielded peak performance, aligning with theoretical expectations of hierarchical feature refinement.
Table 2.
Performance with BRA modules.
Building upon the experimental findings, this study developed the AugODNet_BRA algorithm by replacing convolutional layers in the Res2 and Res3 of the ResNet18 backbone with ODConv modules and then integrating BRA modules post these stages. The proposed algorithm, coupled with a multi-granularity retrieval framework, was applied to carrier-based aircraft tail hook recognition tasks for performance evaluation. Comparative validation against the baseline model AugNet and other methods (SPQ, HiHPQ, CIBHash, and MeCoQ) on the SubCATHR-DET dataset demonstrated superior retrieval performance, the results of which are detailed in Table 3.
Table 3.
SubCATHR-DET results.
As shown in Table 3, the proposed method surpassed all compared methods across metrics, attaining 82.3% precision, 79.1% recall, 80.7% F1 score, and 78.7% mAP. This represents an 8.6% mAP improvement over the baseline method AugNet, confirming the effectiveness of multi-granularity strategies and feature extraction network optimizations. The performance enhancement stems from the Bi-Level Routing Attention mechanism and ODConv modules, which collectively enhanced the fine-grained feature representation capabilities. Concurrently, the integration of coarse-to-fine retrieval strategies improved both local feature discrimination and global structural perception, demonstrating particular efficacy in small object recognition tasks like carrier-based aircraft tail hook recognition (where multi-scale feature preservation is critical).
To gain a deeper understanding of the model’s performance in retrieval tasks, this paper conducted a meticulous error type analysis of the retrieval errors. The results indicate that the main error types include background interference misjudgment (e.g., where the carrier-based aircraft tail hook’s texture and color are highly similar to complex backgrounds, such as the aircraft carrier deck and other parts of the carrier-based aircraft, causing the model to misidentify background elements as tail hooks). Additionally, there is the issue of the weakened features of small targets as the feature details of the tail hook are severely lost in images captured at low resolution or from a distance, making it difficult for the model to effectively capture its key features. Lastly, there is insufficient adaptability to multi-pose variations, where the tail hook exhibits significant morphological differences under various landing angles and the model’s generalization capability for certain rare poses is limited.
The SPQ method was suboptimal as though its precision and mAP was close to the method proposed in this paper, it also produced a lower recall rate. This was due to the loss of some local detail information. HiHPQ had lower precision and mAP, and this was attributed to the information loss due to high-dimensional space quantization, which particularly introduces false positives in small-target data. CIBHash showed poor performance, likely because it loses effective features when compressing image representations under few-shot conditions.
Figure 7 illustrates the object recognition performance of the proposed model on the SubCATHR-DET dataset. The first two columns present the detection results of the tail hook in simulated aircraft carrier landing images, while the third column corresponds to the detection results in real aircraft carrier landing images. The results demonstrate that the proposed method can effectively identify the tail hook in both real and simulated scenarios, showing robust recognition performance.

Figure 7.
Tail hook detection examples from SubCATHR-DET.
On CUB-200-2011, AugODNet_BRA outperformed other methods in Recall@K (K = 1, 2, 4), surpassing suboptimal method HiHPQ by 3.1%, 4.4%, and 4.6%, respectively (Figure 8).
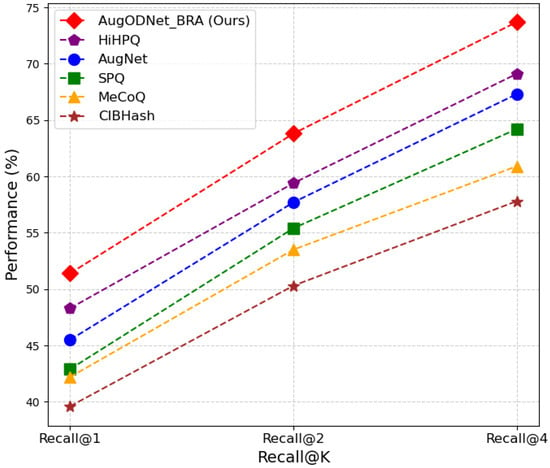
Figure 8.
Recall@K comparison on CUB-200-2011.
Figure 9 presents a comparative visualization of the retrieval results between AugODNet_BRA and the suboptimal method HiHPQ on the CUB-200-2011 dataset. The query image is positioned on the left, while the top-four retrieved images by HiHPQ and AugODNet_BRA are displayed on the right (with erroneous retrievals marked by red bounding boxes). AugODNet_BRA achieved a lower error rate and, critically, its misranked instances were positioned lower in the result sequence compared to HiHPQ, demonstrating its superior discriminative capability in fine-grained feature ranking.

Figure 9.
Retrieval results on CUB-200-2011.
Table 4 shows the training time for 100 epochs of different retrieval models on the SubCATHR-DET dataset. The proposed method trained in 0.4 h (slightly longer than AugNet’s 0.3 h) but achieved an 8.6% higher mAP.
Table 4.
Training time comparison.
5.2. Ablation Studies
To validate the effectiveness of each module, this study conducted ablation experiments on the ODConv, BRA, and GL modules, analyzing their impact on the overall model performance using the SubCATHR-DET dataset. The experimental results are presented in Table 5.
Table 5.
Ablation results.
The ablation results demonstrate that the AugNet model with the ODConv module achieved a 6.2% improvement in mAP, indicating that ODConv enables the network to adaptively process different target features, particularly for few-shot or weak-feature data, by finely adjusting convolutional kernels to better capture targets. The model incorporating the BRA module showed a 3.4% increase in mAP, suggesting that BRA significantly enhances the ability to capture key features and improves the discriminability of weak features, thereby boosting retrieval accuracy and generalization. Replacing the loss function with GL leads to a 1.1% mAP gain, demonstrating that this loss function helps the model extract more robust and discriminative features under few-shot and weak-feature conditions, thereby further optimizing performance.
6. Conclusions
This paper presents a multi-granularity retrieval algorithm based on an unsupervised image augmentation network, and it is designed to tackle the challenge of efficient retrieval of few-shot and weak-feature data. By introducing the AugODNet_BRA feature extraction method, the algorithm employs unsupervised learning to capture high-level semantic features from images with few samples, small targets, and weak features. The inclusion of a Omni-Dimensional Dynamic Convolution module and a Bi-Level Routing Attention mechanism enhances the model’s adaptability to complex scenes and improves its ability to capture fine details of small targets. Furthermore, the optimized loss function boosts the robustness and distinctiveness of the features, leading to more accurate retrieval.
In the comparative experiments, the AugODNet_BRA algorithm demonstrated superior performance over baseline and other classic retrieval algorithms across multiple metrics. On the SubCATHR-DET dataset, it achieved a precision of 82.3%, a recall of 79.1%, an F1 score of 80.7%, and a mAP of 78.7%, representing respective improvements of 10.7%, 18.9%, 15.3%, and 8.6% over the baseline AugNet method. These results highlight the algorithm’s significant advantages in handling small-target and weak-feature data. Additionally, ablation experiments confirm the effectiveness of each component: the Omni-Dimensional Dynamic Convolution module enables the model to adaptively process diverse target features and enhances feature extraction; the Bi-Level Routing Attention mechanism strengthens the model’s ability to capture key features and optimizes the distinguishability of weak features, thereby improving retrieval accuracy and generalization; and the optimized loss function aids in extracting more distinctive and robust features.
In future research, we aim to further refine the existing model and enhance the algorithm’s real-time and scalability to accommodate a broader range of applications and higher real-time demands. Moreover, we plan to apply the algorithm to the recognition of carrier-based aircraft tail hooks and arresting gear engagement states with the goal of achieving human–machine collaborative guidance during aircraft landing. This work is expected to contribute to technological advancements in related fields.
Author Contributions
Conceptualization, A.L.; methodology, A.L., Z.L., Y.L., P.L., and K.W.; software, P.L.; validation, P.L.; investigation, Z.L.; writing—original draft preparation, A.L.; writing—review and editing, Z.L., Y.L., and K.W.; supervision, K.W.; project administration, K.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the China Postdoctoral Science Foundation (No. 2020M682348) and the Innovation Foundation of Ocean Defense Technology (JJ-2022-709-01).
Data Availability Statement
The data will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pengkun, Y.; Jinlong, L.; Runlai, H. Few-shot image data augmentation based on generative adversarial networks. Cyber Secur. Data Gov. 2023, 42. (In Chinese) [Google Scholar]
- Kaya, M.; Bilge, H.Ş. Deep metric learning: A survey. Symmetry 2019, 11, 1066. [Google Scholar] [CrossRef]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, New York, NY, USA, 20–22 June 2016; pp. 1842–1850. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Zhang, H.; Zhang, J.; Koniusz, P. Few-shot learning via saliency-guided hallucination of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2770–2779. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Chen, M.; Chang, Z.; Lu, H.; Yang, B.; Li, Z.; Guo, L.; Wang, Z. Augnet: End-to-end unsupervised visual representation learning with image augmentation. arXiv 2021, arXiv:2106.06250. [Google Scholar]
- Xin, L.; KaiRui, Z.; Yulin, H.; Liping, J.; Jian, Y. Survey of Metric-Based Few-Shot Classification. Pattern Recognit. Artif. Intell. 2021, 34, 909–923. (In Chinese) [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Adv. Neural Inf. Process. Syst. 1993, 6. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Wang, J.; Zhou, F.; Wen, S.; Liu, X.; Lin, Y. Deep metric learning with angular loss. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2593–2601. [Google Scholar]
- Li, Y.; Li, H.; Chen, H.; Chen, C. Hierarchical representation based query-specific prototypical network for few-shot image classification. arXiv 2021, arXiv:2103.11384. [Google Scholar]
- He, J.; Hong, R.; Liu, X.; Xu, M.; Sun, Q. Revisiting local descriptor for improved few-shot classification. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–23. [Google Scholar] [CrossRef]
- Li, F.; Liu, Y.; Wu, P.; Dong, F.; Cai, Q.; Wang, Z. A Survey on Recent Advances in Meta-learning. Chin. J. Comput. 2021, 44, 422–446. (In Chinese) [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D.; Kavukcuoglu, K. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]
- Pan, K.; Li, J.; Song, H.; Lin, J.; Liu, X.; Tang, S. Self-supervised meta-prompt learning with meta-gradient regularization for few-shot generalization. arXiv 2023, arXiv:2303.12314. [Google Scholar]
- Xia, R.; Pan, Y.; Lai, H.; Liu, C.; Yan, S. Supervised hashing for image retrieval via image representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Liu, H.; Wang, R.; Shan, S.; Chen, X. Deep supervised hashing for fast image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2064–2072. [Google Scholar]
- Jiang, Q.Y.; Li, W.J. Asymmetric deep supervised hashing. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Ng, W.W.; Li, J.; Tian, X.; Wang, H.; Kwong, S.; Wallace, J. Multi-level supervised hashing with deep features for efficient image retrieval. Neurocomputing 2020, 399, 171–182. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Bhunia, A.K.; Song, Y.Z.; Dutta, A. Data-free sketch-based image retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12084–12093. [Google Scholar]
- Huang, H.; Nie, Z.; Wang, Z.; Shang, Z. Cross-modal and uni-modal soft-label alignment for image-text retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 18298–18306. [Google Scholar]
- Erin Liong, V.; Lu, J.; Wang, G.; Moulin, P.; Zhou, J. Deep hashing for compact binary codes learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2475–2483. [Google Scholar]
- Lin, K.; Lu, J.; Chen, C.S.; Zhou, J. Learning compact binary descriptors with unsupervised deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1183–1192. [Google Scholar]
- Duan, Y.; Lu, J.; Wang, Z.; Feng, J.; Zhou, J. Learning deep binary descriptor with multi-quantization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1183–1192. [Google Scholar]
- Huang, S.; Xiong, Y.; Zhang, Y.; Wang, J. Unsupervised triplet hashing for fast image retrieval. In Proceedings of the Thematic Workshops of ACM Multimedia 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 84–92. [Google Scholar]
- Shen, F.; Xu, Y.; Liu, L.; Yang, Y.; Huang, Z.; Shen, H.T. Unsupervised deep hashing with similarity-adaptive and discrete optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 3034–3044. [Google Scholar] [CrossRef]
- Xu, J.; Shi, C.; Qi, C.; Wang, C.; Xiao, B. Unsupervised part-based weighting aggregation of deep convolutional features for image retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Liu, Y.; Ding, L.; Chen, C.; Liu, Y. Similarity-based unsupervised deep transfer learning for remote sensing image retrieval. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 7872–7889. [Google Scholar] [CrossRef]
- Jang, Y.K.; Cho, N.I. Self-supervised product quantization for deep unsupervised image retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, USA, 11–17 October 2021; pp. 12085–12094. [Google Scholar]
- Qiu, Z.; Su, Q.; Ou, Z.; Yu, J.; Chen, C. Unsupervised hashing with contrastive information bottleneck. arXiv 2021, arXiv:2105.06138. [Google Scholar]
- Wang, J.; Zeng, Z.; Chen, B.; Dai, T.; Xia, S.T. Contrastive quantization with code memory for unsupervised image retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2468–2476. [Google Scholar]
- Qiu, Z.; Liu, J.; Chen, Y.; King, I. Hihpq: Hierarchical hyperbolic product quantization for unsupervised image retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 4614–4622. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, USA, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Ren, S.; Zhou, D.; He, S.; Feng, J.; Wang, X. Shunted self-attention via multi-scale token aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10853–10862. [Google Scholar]
- Wang, K.; Liu, Y.; Yang, J.; Lu, A.; Li, Z.; Xu, M. Landing State Recognition of Carrier-Based Aircraft Based on Adaptive Feature Enhancement and Fusion. J. Shanghai Jiao Tong Univ. 2025, 59, 274–282. (In Chinese) [Google Scholar] [CrossRef]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The caltech-ucsd birds-200-2011 dataset. 2011. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).