1. Introduction
Practical text data classification and comprehension [
1,
2,
3] are crucial to a range of applications, such as social media analysis [
4,
5,
6,
7,
8], recommendation systems, and automated content moderation [
9,
10,
11]. During the last decade, extensive efforts have been made towards developing methods to process and extract data from short texts with restricted and condensed information. Among the most potent approaches in this area are BERT, TF + IDF, and the integrated LDA + BERT + AE method. BERT (Bidirectional Encoder Representations from Transformers) is a groundbreaking method in deep learning that allows models to learn contextual relations within the text more efficiently. TF + IDF, an ancient statistical technique, is used to quantify the importance of words in a document and is thus a valuable asset for information filtering and identification of essential topics. The combined LDA + BERT + AE method promises to combine the depth and width of text understanding using LDA (Latent Dirichlet Allocation) topic modeling, BERT contextual understanding, and AE (Autoencoder) data dimensionality reduction and optimization. The importance of the analysis of short texts with the help of intelligent clustering methods [
12] stems from the growing need for the rapid processing and understanding of vast amounts of compressed text data, characteristic of modern digital communication. With the growth of social networks, websites, and mobile applications, the number of short messages such as tweets, statuses, and comments is increasing, for which natural language processing systems must improve the speed and accuracy of analysis. These messages contain valuable information about public opinion, user preference, and current trends, and therefore, their analysis is crucial in marketing, brand management, political analysis, and many other fields. Hence, developing and optimizing models such as BERT, TF + IDF, and LDA + BERT + AE to deal with such texts efficiently and accurately is of the topmost priority in artificial intelligence and NLP [
13,
14,
15].
This study aims to improve the quality and hasten the processing of text clustering data so that intelligent clustering methods can be employed for more precise and efficient retrieval of helpful information. Particular emphasis is placed on their flexibility and utility across applications where traditional approaches would face difficulties because of the paucity of data quantity or heterogeneity. The results of this work can offer significant improvements in the field of short text analysis, providing a deeper and more accurate understanding of the content and helping to implement more effective NLP systems. The importance of this topic is increased in the digital era, with data volumes growing exponentially. Short texts such as tweets, user reviews, and social media comments represent a significant portion of this content. Traditional analysis methods [
16,
17,
18] are often ineffective for working with such formats due to their brevity and high concentration of meaning in a limited number of words. This challenges researchers to select suitable data processing tools and adapt them to the specific requirements of short text formats. The impact of contextual analysis on the quality and accuracy of clustering is also considered. Modern technologies such as BERT [
19,
20] offer a revolutionary approach to understanding language, allowing systems to better deal with the ambiguities and complexities of natural language. Integrating BERT with LDA [
21,
22] and AE [
23,
24,
25] within a single solution opens up new opportunities to improve analysis accuracy through a deeper understanding of text structures and semantics. This work aims to demonstrate how such combined approaches can enhance short texts’ clustering and classification processes, considering their unique characteristics and needs. Thus, the study offers a comprehensive view of the problem of analyzing short texts and examines promising directions for developing clustering technologies based on data mining. The results obtained in this work suggest a significant contribution to natural language processing. They can be used to create more efficient and adaptive NLP systems, capable of coping with a wide range of tasks in the modern information world.
In [
26], the authors discuss the importance of analyzing short texts such as social media posts for clustering and knowledge extraction. They review different approaches to short text clustering (STC) to overcome the problems of sparsity, high dimensionality, and lack of information and analyze and summarize research results from five authoritative databases. In [
27], the authors of the Chinese Co-Learning Clustering (COTC) method use the advantages of BERT and TF-IDF to cluster working texts. This approach uses the mutual training of two models, which can improve the clustering quality to combine semantic and keyword information. In [
28], the researchers propose the GloCOM model, which uses global context clustering to improve topic study in text retrieval. This approach can effectively solve the problem of data sparsity inherent in certain texts. In [
29], the POTA method is developed, which uses the attention and traffic mechanism to generate reliable pseudo-labels. This can improve the learning of the presented materials and increase the accuracy of clustering the necessary texts. The authors of [
30] investigated the possibility of using large language models (LLMs) for clustering sufficient texts. They applied generative models to create interpretable clusters, which can achieve greater consistency between the clustering effects and human resources. In [
31], the author proposed the AECL method, which uses the attention mechanism and contrast learning to create more discriminative representations. This makes it possible to effectively solve the problem of false negative examples and improve the quality of text clustering.
The main contributions of this study include the development of a hybrid architecture (LDA + BERT + AE) that integrates topic modeling, contextual embedding, and dimensionality reduction into a unified framework specifically designed for short text clustering. A weighted concatenation mechanism is introduced, with a tunable parameter γ, which balances the contribution of topic-based and semantic features. The proposed method is extensively compared with traditional models such as TF-IDF and standalone BERT using multiple clustering quality metrics (Silhouette, Adjusted Rand Index, V-Measure) and demonstrates significantly improved performance. The approach is validated on a real-world dataset of categorized news articles, achieving a high accuracy (98%) and F1-score (0.9), confirming its practical effectiveness. Furthermore, the implementation is made publicly available to support reproducibility and further research in the field of hybrid embeddings for natural language processing. Despite the high popularity of individual methods such as BERT, TF-IDF, and LDA, each has certain limitations in the task of short text clustering. In particular, TF-IDF does not take into account the context, LDA does not reflect the semantic relationships between words, and BERT weakly separates topics. In this paper, we propose a hybrid method, LDA + BERT + AE, which can overcome these limitations by combining the methods and utilizing a learnable feature combination.
2. Materials and Methods
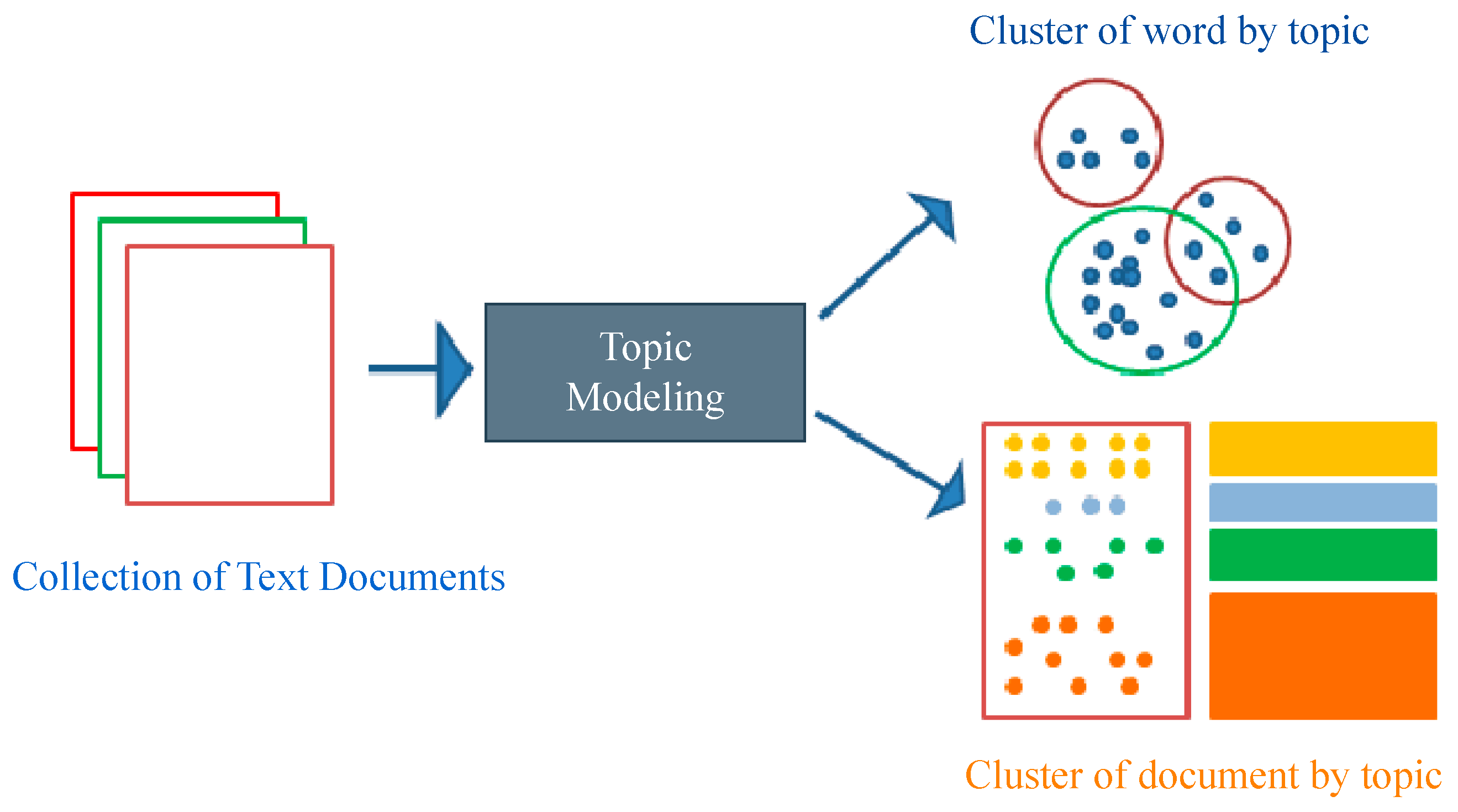
TF-IDF achieves high accuracy in keyword detection but loses grammatical and contextual information. LDA models topics but ignores word order and context. BERT captures contextual dependencies but does not provide explicit topic features. Therefore, using these methods in isolation does not ensure reliable clustering of short, semantically rich texts. To address these limitations, this study proposes an end-to-end approach to text data analysis and clustering that integrates two advanced natural language processing technologies: LDA and BERT. This hybrid method, referred to as dependent embedding, is specifically designed to combine the strengths of each model while compensating for their individual weaknesses. In addition, TF-IDF is incorporated to improve the estimation of word importance in texts. The LDA method (
Figure 1), as a statistical approach to topic modeling, enables the identification of common topics in large text collections. However, its main disadvantage lies in its inability to capture word order and meaning, which significantly limits its applicability for tasks requiring semantic understanding.
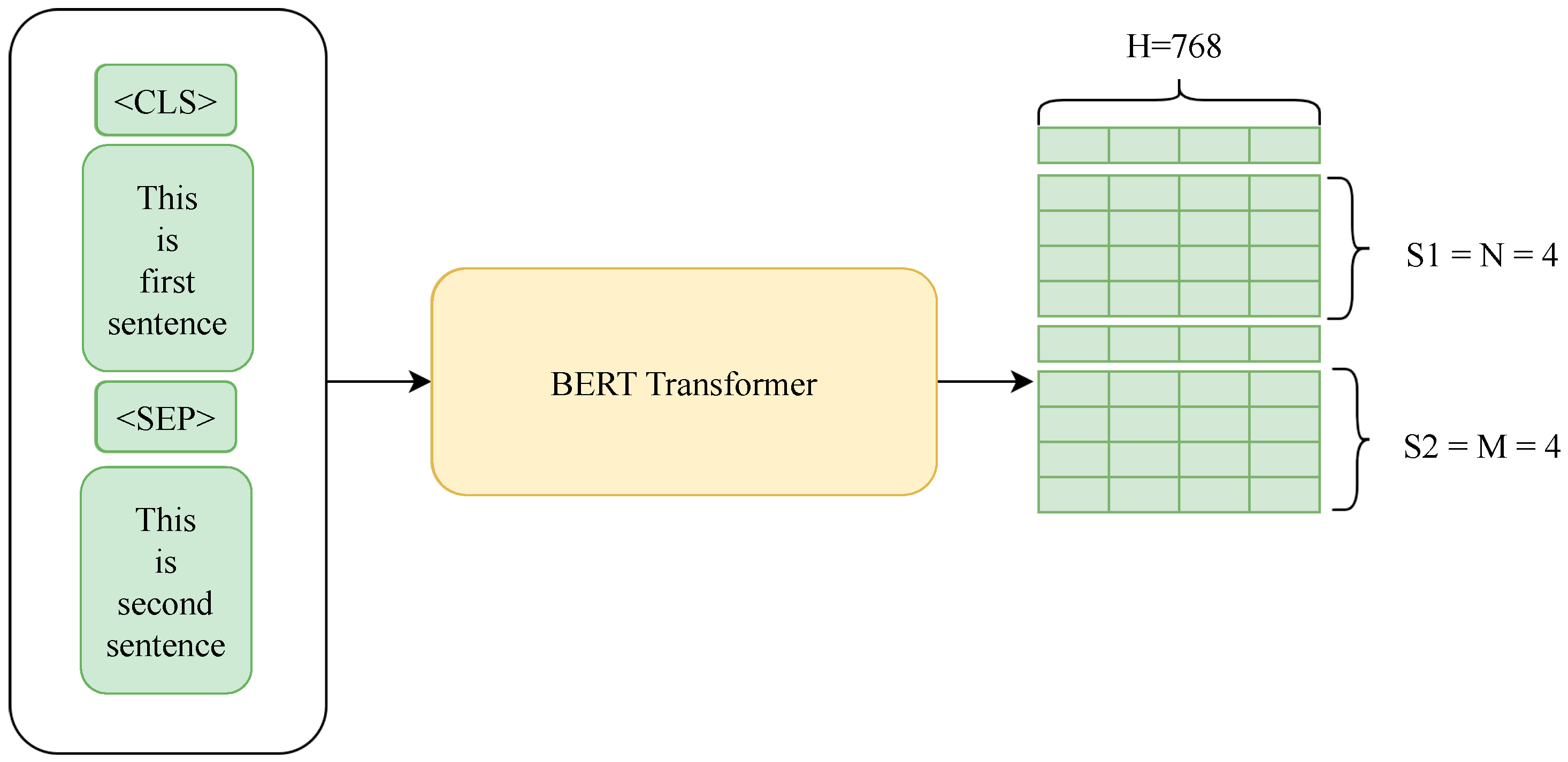
In response to this limitation, BERT was introduced, a deep learning model based on the transformer architecture, which can analyze each word in all other words in a sentence, thereby capturing the contextual nuances of language. The analysis begins with data preprocessing, including removing text noise, such as special characters and stop words, and tokenizing and lemmatizing words. LDA is then applied to identify broad topic clusters, which helps identify common themes in a collection of texts. BERT is then used to create vectors of each word, allowing for a deeper understanding of the semantic relationships and nuances present in the texts (
Figure 2).
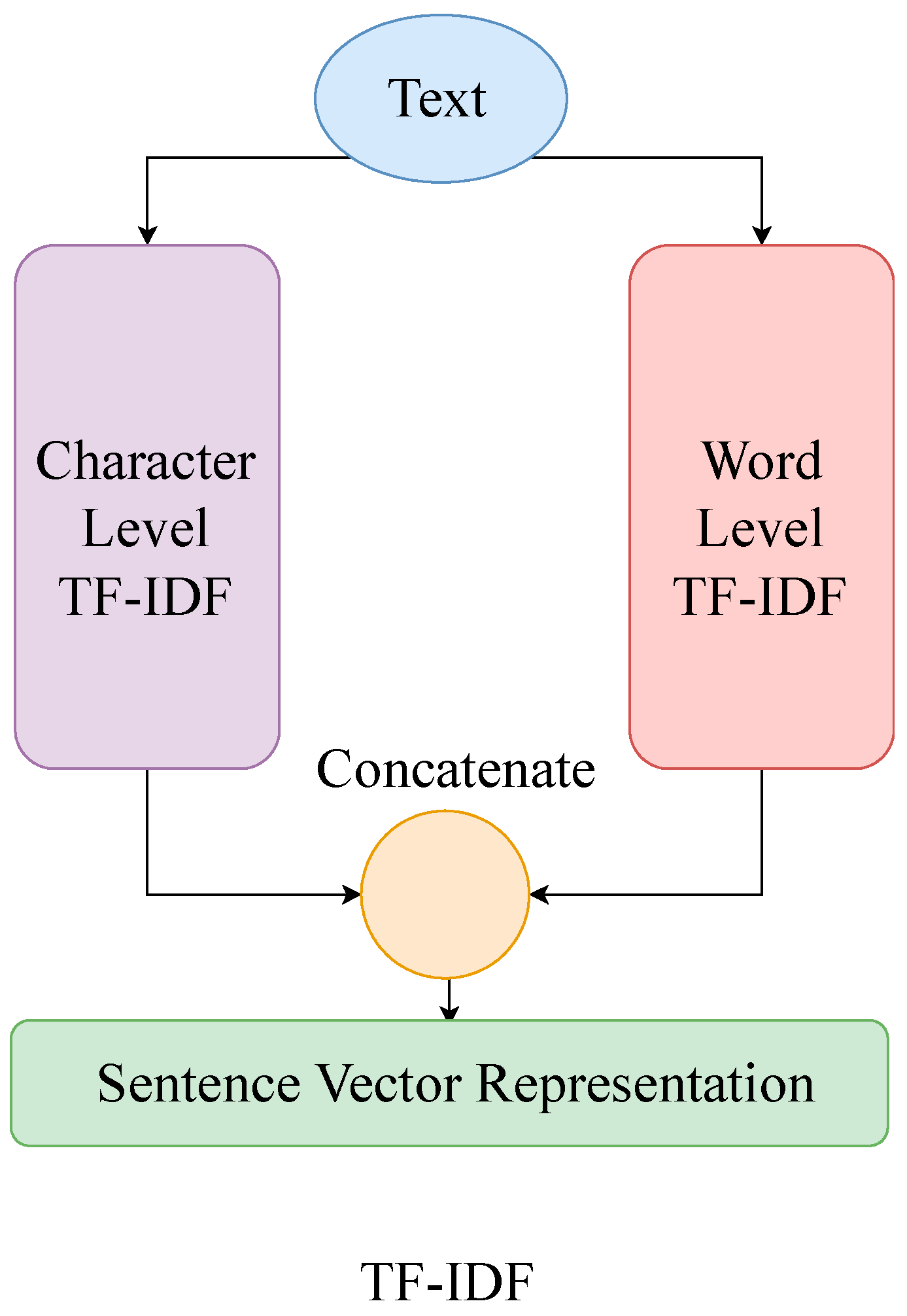
This study uses the TF + IDF method to further improve the quality of analysis and clustering. This method estimates the importance of each word in a single document based on its frequency of occurrence compared to its overall frequency across all documents in the corpus. This approach to weighting terms makes it possible to identify the most significant keywords for specific texts. It provides a more accurate and informative representation of texts for subsequent stages of clustering (
Figure 3).
The metrics used to evaluate clustering quality include the following: silhouette—indicates how objects are separated from each other during clustering (the higher, the better); calinski_harabasz index—evaluates intra-cluster and inter-cluster variation (the higher, the better); davies_bouldin—an averaged measure of cluster “similarity” (the lower, the better); adjusted_rand (ARI)—compares predicted clusters with ground truth labels (the higher, the better); homogeneity—shows how well each cluster contains objects from only one accurate category; completeness—reflects how well objects of the same category fall into one cluster; v_measure—a harmonic mean between homogeneity and completeness (the higher, the better). The parameter γ controls the relative weight of “topic” features (LDA vector) compared to “contextual” features (BERT vector), where increasing γ increases the contribution of topic-based features (LDA) when forming the feature space (1):
where
—concatenates two arrays: (LDA * γ) and BERT. We selected γ = 15 based on a series of preliminary experiments (values ranging from 1 to 20), as gamma = 15 achieved the best balance between topic-based and semantic information (
Table 1).
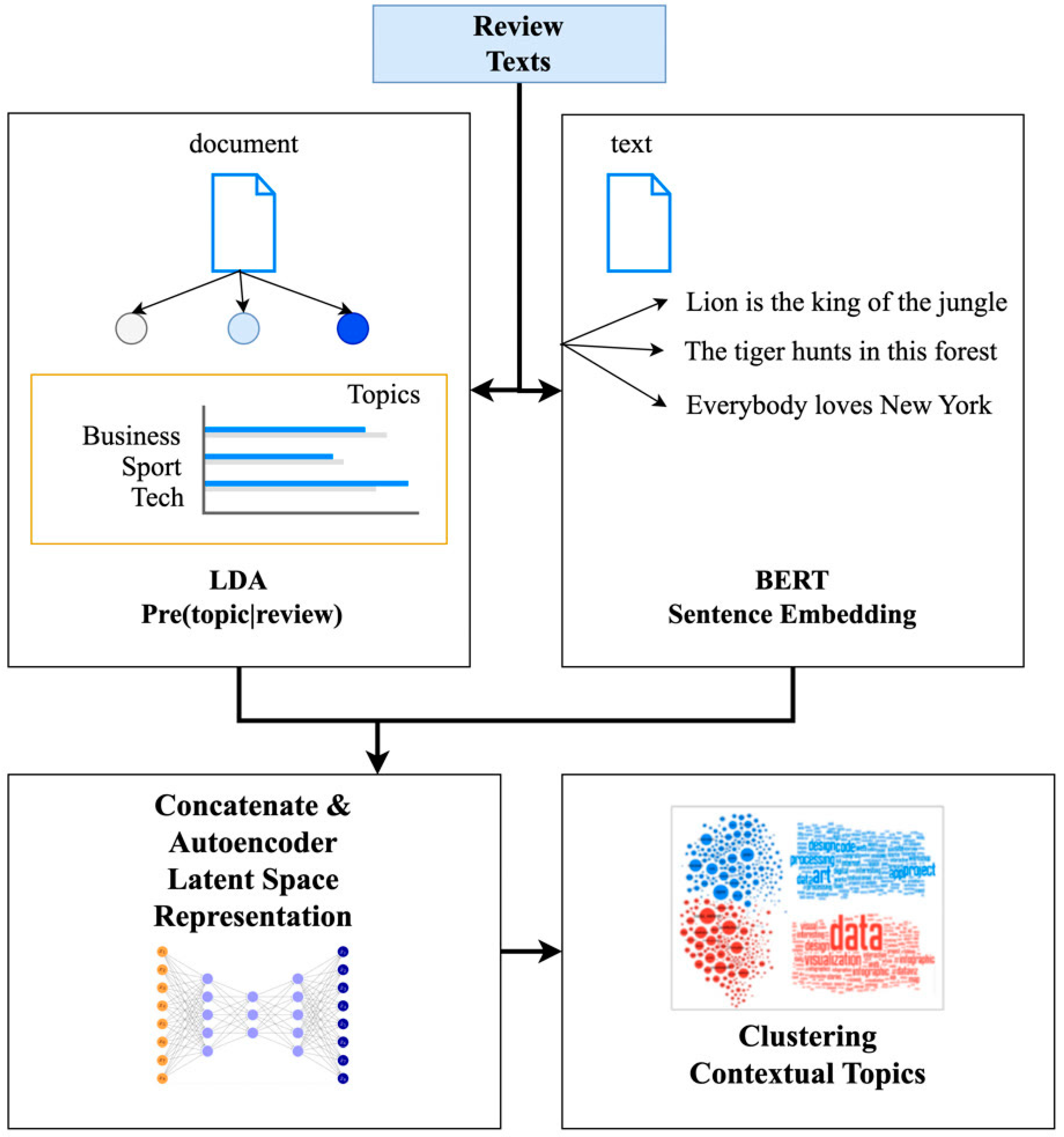
The hybrid LDA + BERT + AE method is an advanced approach to text data analysis, combining LDA for topic modeling, deep learning with BERT, and dimensionality reduction using autoencoders (AEs). This combination effectively identifies main topics from large text arrays while accounting for contextual relationships between words, capturing subtle nuances of language.
Figure 4 illustrates the general structure of this method. The input to the model is a collection of documents (D). The LDA module generates topic distributions
p (topic∣document) of dimensionality
, where
is the predefined number of topics used in LDA. BERT provides the contextual embeddings of 768 dimensions. These outputs are concatenated into a single vector
and passed to the autoencoder, compressing the vector into a lower-dimensional latent space and reconstructing it. The latent representation produced by the autoencoder is then used for clustering with the K-Means algorithm. The results include cluster labels, the trained LDA model (for interpretability), and the autoencoder (for reuse). This method enhances the quality of clustering and visualization. It provides a deeper semantic understanding of the text, making it particularly effective for analyzing complex short texts and supporting various NLP tasks (
Figure 4).
Several stages of data preprocessing were used to work on the short text clustering problem. First, all texts were cleared of noise, including removing special characters, links, numbers, and stop words. Then, the texts were tokenized and lemmatized to bring words to their original form, which improved the quality of the input data for the models. A grid search method was used to optimize the parameters of the BERT and LDA models to find the best hyperparameters. This included adjusting the number of topics for the LDA model and the length of sequences for BERT. The architecture of the hybrid LDA + BERT + AE model is presented in the following stages. First, the LDA model was used to identify topic clusters, after which BERT was used to extract vector representations of words, taking into account the category types. AE performed dimensionality reduction of the vector space, improving the clustering accuracy. The results of this integrated approach are evaluated by comparison with traditional text clustering methods. Integrating LDA + BERT + AE is expected to significantly enhance clustering accuracy, providing a deeper understanding of texts and more efficient extraction of helpful information. This research shows the significant potential of the “context-aware embedding” approach to improve the processing and analysis of text data, which has important implications for a wide range of applications in natural language processing. In the study, several works are referenced that validate the effectiveness of advanced techniques such as BERT, TF + IDF, and the hybrid LDA + BERT + AE approach in short text clustering. Notably, the methodologies outlined by Manias et al. (2023) [
1] and Fu et al. (2023) [
2] are considered. These studies emphasize the advantages of multilingual strategies and ensemble methods, particularly in text categorization and sentiment analysis. The integration of these approaches is demonstrated to significantly enhance the accuracy and efficiency of clustering tasks in the study of short texts.
3. Results and Discussion
The training dataset used in our study, presented on the Kaggle platform, includes 2225 entries classified into five categories: sports, technology, business, entertainment, and politics. The data collected from news articles on the website represents a balanced and diverse set, making it an excellent basis for studying and comparing different clustering methods. The dataset structure is ideal for machine learning and projects aimed at understanding text data and classifying it into predefined categories. The dataset is divided into two primary columns: category and text. The category column assigns each article to one of the categories mentioned, with the category “sports” being the most common. The text column contains the full text of the news article. The texts of the articles vary in length and content, covering a wide range of topics within their categories, which adds uniqueness to each article. However, there are also duplicates with identical text. This dataset provides a rich opportunity for developing and testing text classification models, allowing algorithms to learn to identify categories of texts based on their content. This is especially true for natural language processing (NLP) applications such as topic modeling, keyword analysis, or developing systems to automatically sort news articles into appropriate sections on a website. The structure and content of this dataset make it ideal for research projects aimed at understanding the language used in different types of news articles and developing effective methods for classifying and analyzing text data. First, we show how different vectorization methods (TF-IDF [
2], BERT [
1], LDA_BERT) affect document clustering in Uniform Manifold Approximation and Projection (UMAP) plots. The UMAP method transformed text data into a two-dimensional space after feature extraction using TF-IDF, BERT, or hybrid LDA + BERT + AE [
23,
24]. The UMAP method provides a non-linear dimensionality reduction while preserving the topological structure of the data. The accuracy of the UMAP method directly depends on the tuning parameters (n_neighbors, min_dist, etc.) and the complexity of the data. The primary purpose of using UMAP in this case is to visualize the clustering results, not to assess the accuracy of the classification. Each document in the 2D space is represented as a point, and its color corresponds to the cluster (obtained by the K-Means method). These visualizations demonstrate to what extent objects are grouped (or, conversely, mixed) by a particular feature variant: TF-IDF, pure BERT embeddings, or a hybrid combination of LDA and BERT. However, the concatenation of LDA and BERT alone may not be enough to provide the most straightforward structure of the vector space. We introduce an autoencoder (AE)—a self-learning neural network that can compress (encode) the combined LDA + BERT vector to a more compact latent representation and decode it back. In this form, the model learns to eliminate redundant information and capture the most relevant factors of variation. The K-Means algorithm with the number of clusters k is used to cluster the transformed documents. K-Means iteratively minimizes the sum of squared distances between points and centroids of clusters, forming groups of similar documents in the resulting vector space. The choice of K-Means is due to its simplicity, widespread use, and sufficiency in the initial assessment of the effectiveness of various vectorization methods (TF-IDF, BERT, LDA_BERT).
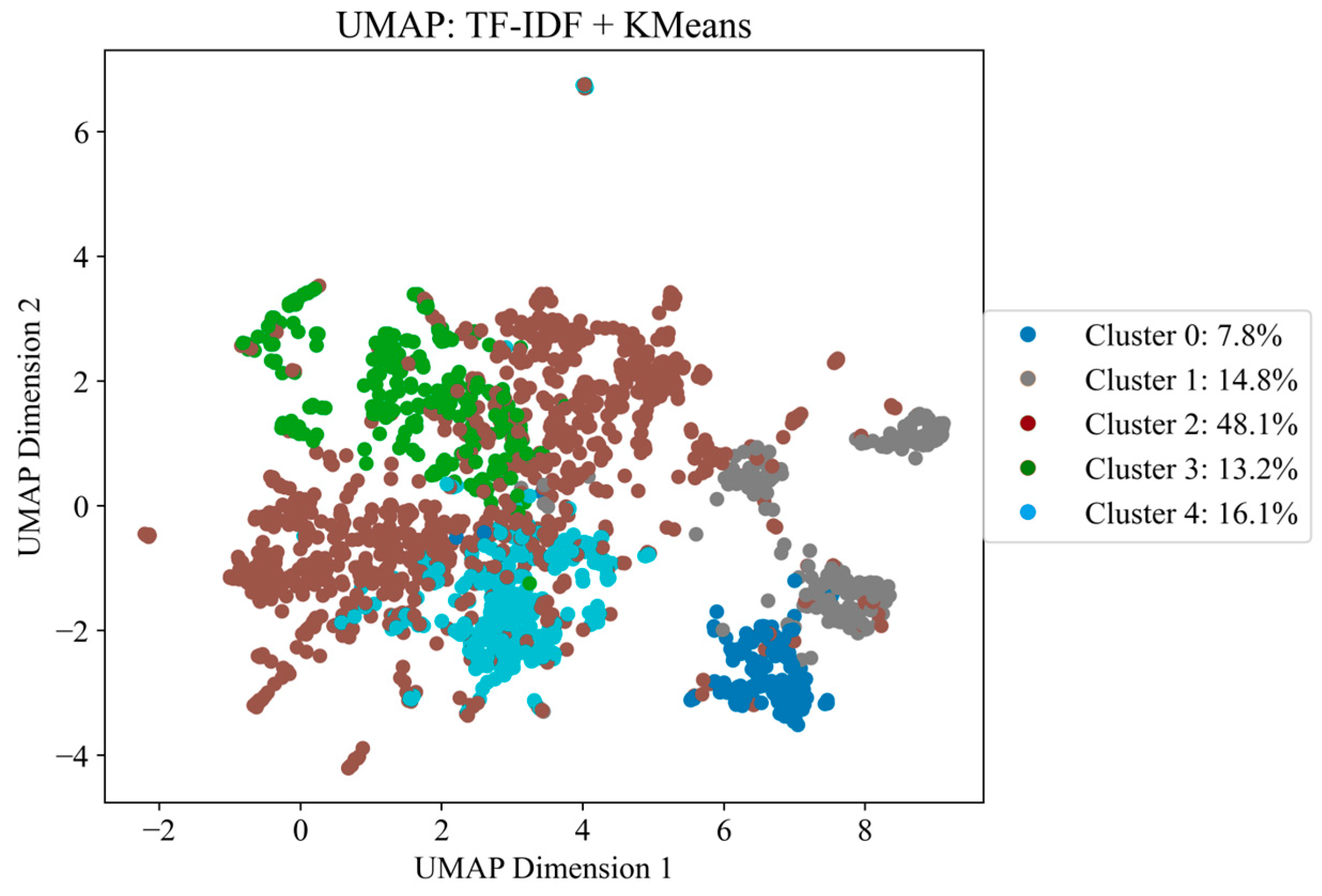
Figure 5 shows the result of data clustering performed using the TF-IDF method. This method transforms texts into a vector space where each dimension corresponds to a single word in the document, allowing the degree of content similarity between different documents to be measured. The graph finds the five clusters, and the distribution of each cluster shows how much percentage the cluster has compared to the total data. The TF-IDF method has disadvantages, mainly if used with short texts such as reviews or comments. The first problem is that TF-IDF loses context because it does not consider the text’s grammar and word order. This can render the approach ineffective for handling loosely coupled and unstructured data where semantic word relations are significant.
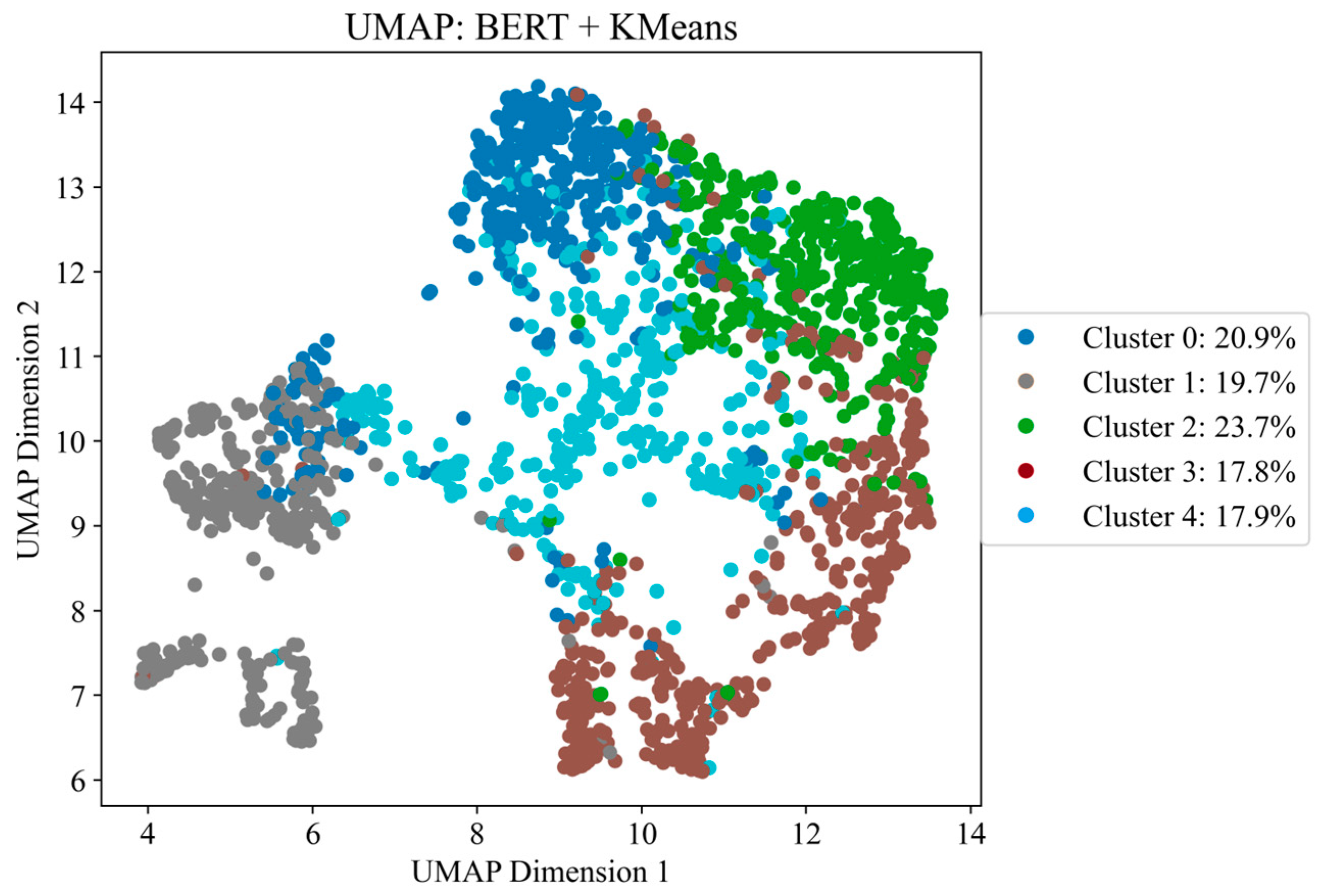
Figure 6 demonstrates the clustering results using vector clause join obtained from the BERT (Bidirectional Encoder Representations from Transformers) model. As a result of clustering, the BERT method, unlike TF-IDF, which processes each word separately and across the entire document corpus, takes into account the bidirectional meaning of words in a sentence, providing rich and differentiated vector representations, which is especially important for the analysis of sentences and paragraphs where understanding the meaning critically influences the meaning of words and phrases.
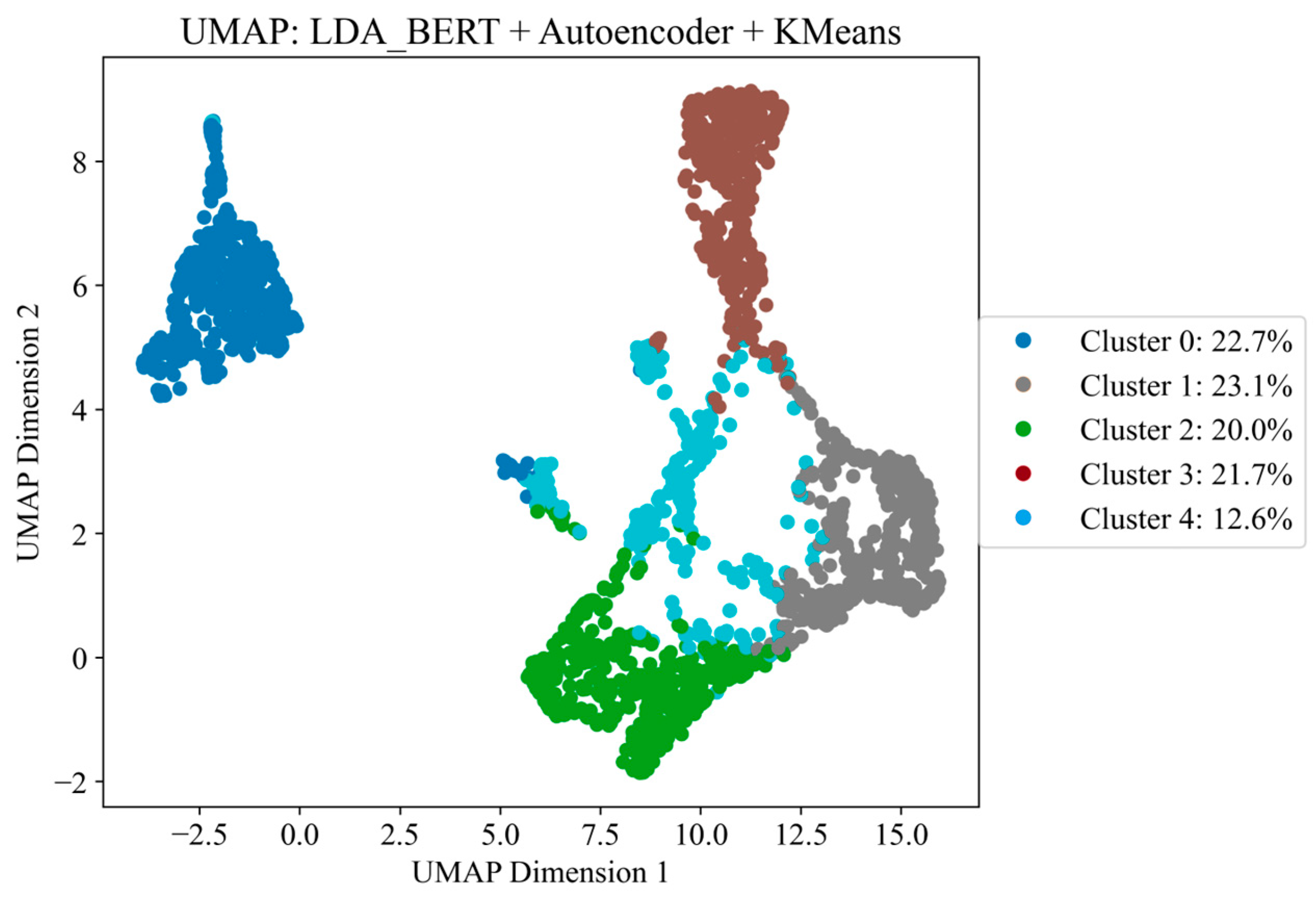
Figure 7 presents the results of clustering performed using a synthesized approach that combines two powerful text analysis methods—LDA and BERT, known as “context-thematic anchoring”. This hybrid approach aims to overcome the main limitations of using each method individually by combining LDA statistical topic modeling with a deep contextual understanding of language. This integration allows one to more fully explore text data’s semantics and contextual aspects, providing a more profound and accurate knowledge of the content, which is critical for effective clustering and subsequent analysis.
Figure 8 displays the hybrid LDA + BERT + AE model training process in which the model was trained for 200 epochs.
Figure 8 also shows how the model, throughout the training process, has a tremendous loss reduction, which indicates its appropriateness to learn and adapt effectively. The abscissa axis indicates the number of epochs, and the ordinate axis shows the values of the loss function of the epochs. Since the beginning of training, loss values for both the training and validation sets are approximately 1.25 during the zero-th epoch. This is a typical sign of the initial phases of training, where the model has not been optimized yet and its parameters are still being calibrated. However, during the initial 25 epochs, the model exhibits a sharp decline in loss up to the value of about 0.9. This stage can be referred to as the rapid progression of the model during training, when it balances its weights and parameters. Between 25–75 epochs, training and validation loss graphs level off and stabilize with minor fluctuations. These fluctuations may indicate the model fine-tuning stage, when the model acclimates to the idiosyncrasies of the data and resists overfitting. By the 200th epoch, both curves reach stable values of about 0.4, which indicates the successful completion of the training process. The same behavior of the curves on the training and validation sets confirms that the LDA + BERT + AE model has excellent generalization ability and can work effectively on new data. This efficiency of the model is confirmed by the subsequent results of its application, presented in the images. Examples of text clustering using the hybrid LDA + BERT + AE model demonstrate high prediction accuracy, almost identical to the actual values. For instance, for a case, the model accurately identifies the subject of the text as “sports” with 98.20% precision, which is entirely consistent with the actual subject. Similarly, the model accurately classifies texts into other subjects, such as “business” and “politics”, which confirms its high validity and reliability for text data analysis and clustering activities. Therefore, this hybrid model completed the training process efficiently and demonstrated outstanding performance on real-life tasks and thus could be extremely beneficial in short text analysis and other natural language processing applications.
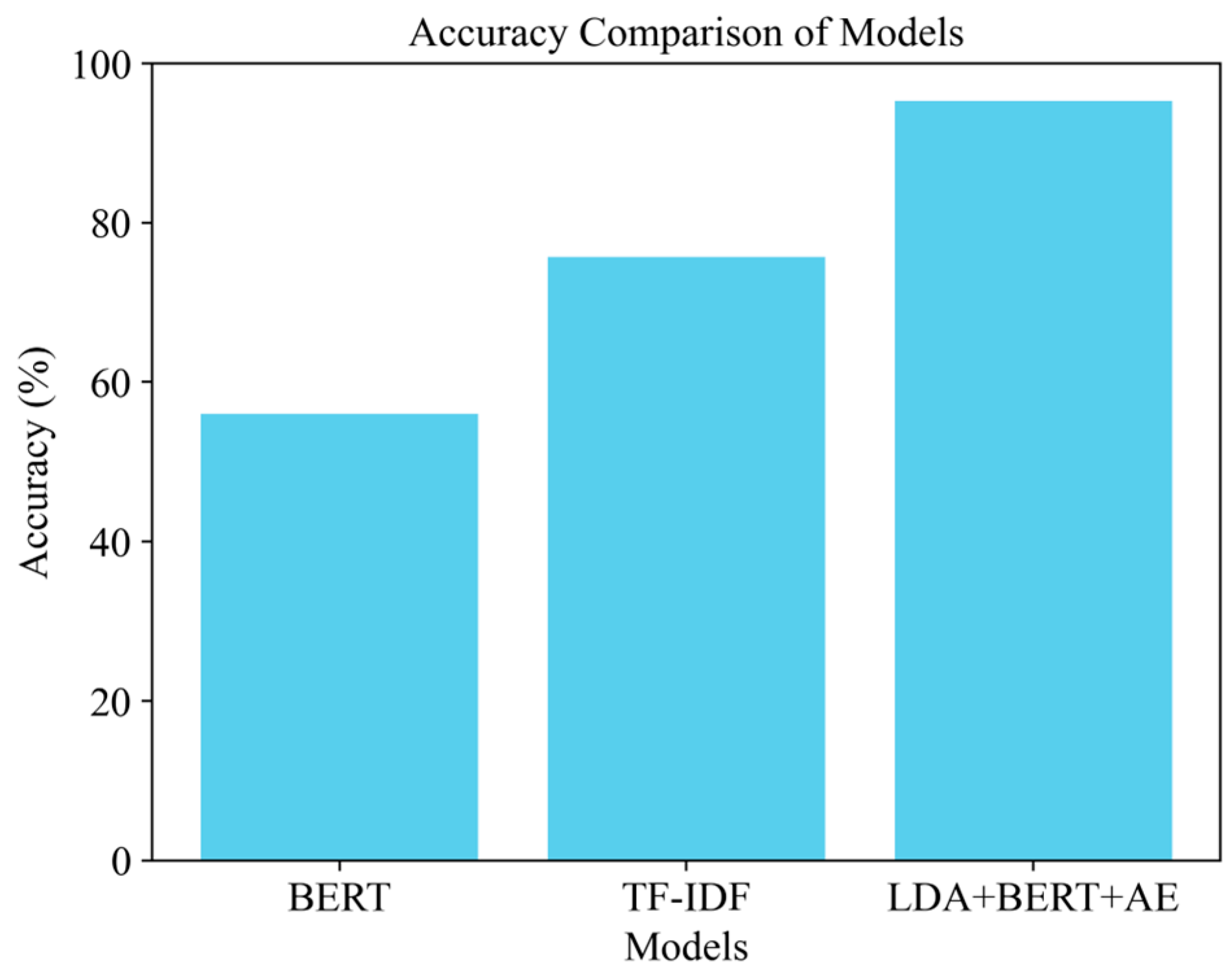
Figure 9 shows the accuracy comparison of three models: BERT, TF-IDF, and LDA + BERT + AE. The BERT model shows an accuracy of about 60%. Although it can cope with contextual relationships between words, its limitations in classifying texts that require precise topic extraction reduce the overall effectiveness. The TF-IDF model shows higher accuracy, about 75%. It is based on the frequency of words in the document and their significance, which improves its accuracy compared to BERT. However, the lack of consideration of contextual relationships between words is the main limitation of the method, especially when working with texts that require a deep understanding of the semantics. The hybrid LDA + BERT + AE model shows a significantly better result, with an accuracy of about 98%. This is explained by the fact that this model uses the strengths of LDA for topic modeling, BERT for contextual analysis, and Autoencoder for data dimensionality reduction. The result is a model with high classification accuracy, especially effective when analyzing texts with a clearly expressed topic focus.
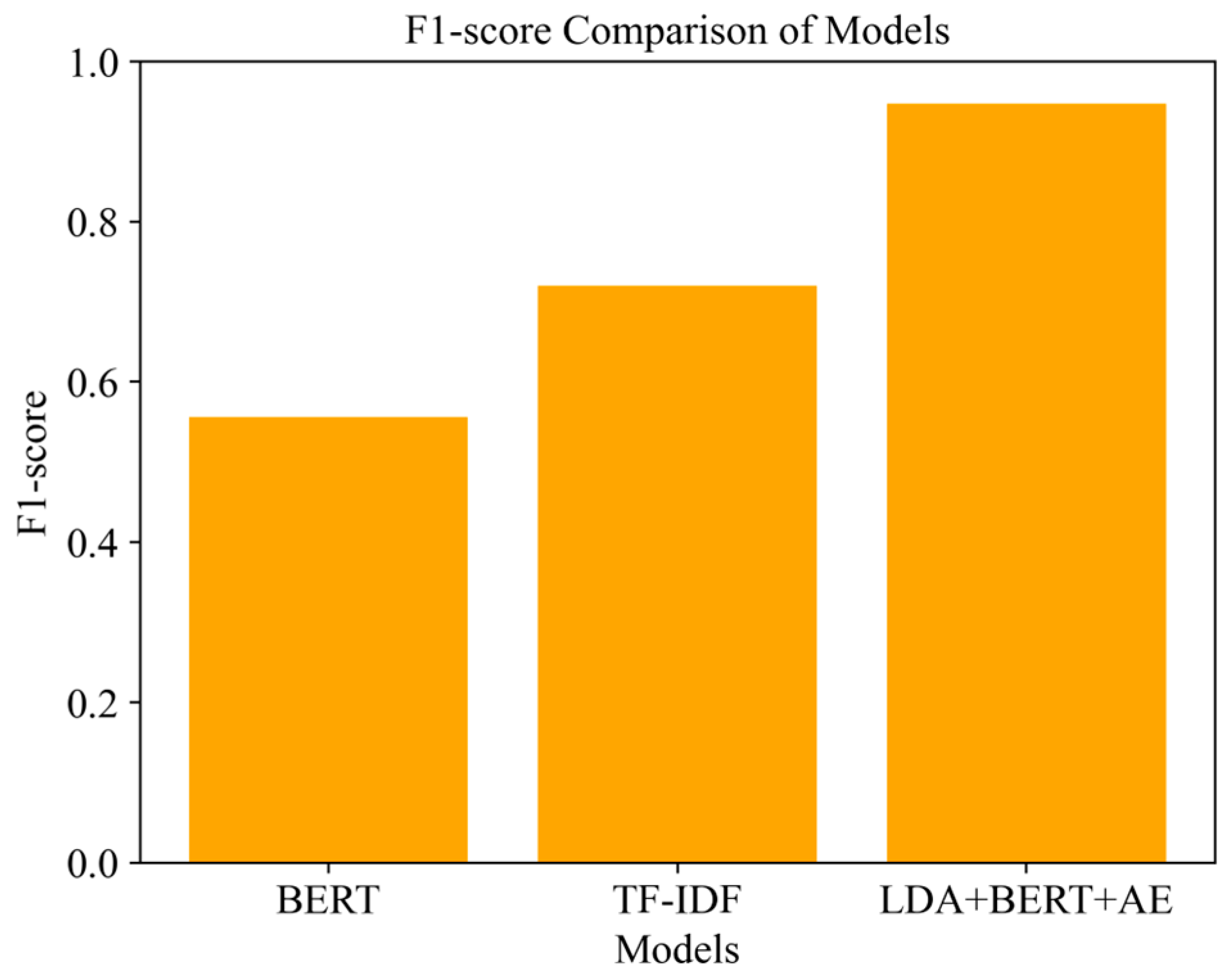
Figure 10 displays the comparison of the F1 scores of the same models. The measure considers precision and recall, providing a balanced view of the model’s performance. The BERT model possesses an F1-score of around 0.55, which shows its ability to interpret context, but it falls short in accurately classifying texts, especially when dealing with specific categories. The TF-IDF model shows a better result, with an F1-score of about 0.7, and has a more suitable precision–recall ratio than BERT. However, the lack of understanding of deep semantic relationships limits the classification of complex texts. Compared with the other four models, the hybrid LDA + BERT + AE model achieves an F1-score of around 0.9, confirming that it performs very well in accurately classifying texts. Extracting topic aspects and contextual nuances achieves higher precision and recall, so it is a good choice for short text analysis tasks. In conclusion, in both cases, the LDA + BERT + AE model significantly outperforms the BERT and TF-IDF models regarding both accuracy and F1-score. Although BERT provides contextual understanding and TF-IDF effectively handles keyword importance, its limitations become apparent when classifying texts that require deep semantic analysis. The hybrid LDA + BERT + AE model, combining the best features of different methods, provides maximum accuracy and efficiency in context-rich text analysis tasks.
Figure 11 shows the text analysis results regarding Kanye West using various text processing methods: BERT, TF-IDF, and LDA + BERT + AE. The BERT method identifies “entertainment” as the dominant theme (32.11%), corresponding to the text’s central theme of music and entertainment. TF-IDF and LDA + BERT + AE distribute weights more evenly between categories, although LDA + BERT + AE is more accurate in identifying “entertainment” (51.51%) as the top category. This shows how integrating contextual understanding with topic modeling can improve text classification.
We used measures such as the Jaccard Index, Matthus Correlation Coefficient (MCC), Foulkes–Mallows Index (FM), and Cohen’s Kappa Coefficient to quantify the performance of models. These measures helped us compare and evaluate the classification performance of different methods in depth, providing a comprehensive understanding of their performance and accuracy. The metrics results show that the LDA + BERT + AE method performs better on most metrics, indicating its superiority in classifying texts (
Table 2).
Table 2 summarizes the performance metrics of LDA + BERT + AE and TF-IDF methods, indicating the superiority of LDA + BERT + AE over the Jaccard Index, Matthews Correlation Coefficient (MCC), and Cohen’s Kappa Coefficient. These metrics indicate better classification performance and accuracy. The analyses demonstrate that the combined approach of LDA + BERT + AE significantly outperforms BERT and TF-IDF methods in text processing and classification tasks, particularly when precise classification of thematically rich texts is required. Integrating LDA for topic modeling with BERT’s deep contextual understanding and autoencoder capabilities for vector space optimization enables high accuracy in determining the topical content of text. This approach enhances classification quality and provides deeper insights into semantic relationships within the text, which is crucial for various natural language processing applications. Experiments were conducted in supervised mode (Random Forest, SVM) to highlight the advantages of hybrid representations, training them on the same feature vectors. Metrics such as accuracy, F1-score, and others were obtained (
Table 3).
The results showed that supervised classification achieves higher ARI/homogeneity values. However, the unsupervised clusterer gives comparable results. This indicates that the obtained vectors (especially LDA_BERT) contain qualitative information about the data structure. To ensure the reproducibility and transparency of the study, the source code of the hybrid model and analysis methods was placed in the public domain. The code is available in the repository at the following link [
32]. The posted code contains all stages of the model implementation, including data preprocessing, selection of significant features, parameter analysis, and deviation prediction. This allows researchers and practitioners to use the proposed approach for their tasks and, if necessary, make improvements and adapt the methodology to different conditions. This approach helps increase scientific transparency and supports open scientific discussion.
To further enhance the evaluation, future work will include validation on multiple benchmark datasets, such as 20 Newsgroups, AG News, and TweetEval, which cover diverse linguistic and topical structures. Moreover, the proposed method will be compared with recent deep representation models, including SBERT, SimCSE, and Universal Sentence Encoder, to assess its performance relative to state-of-the-art techniques. These extensions aim to provide a more comprehensive understanding of the model’s strengths and limitations across varied contexts and domains.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}