1. Introduction
Expiration date recognition is an important technology for visually impaired individuals, contributing positively to their daily routines. Globally, there are millions of people with visual impairments [
1] who face challenges in identifying critical information on product packaging, such as expiration dates. This limitation can lead to the consumption of expired products, posing health risks and reducing their quality of life. Europe, with its diverse population, has made significant strides in developing advanced technologies. However, the accessibility of expiration date recognition for visually impaired people continues to hold importance. The integration of this technology into everyday tools and devices is vital for enhancing the independence and safety of these individuals. As the continent continues to progress in various sectors, it is important to prioritize the development and implementation of accessible technologies, such as expiration date recognition, to assist visually impaired individuals.
Researchers and developers are increasingly dedicating their efforts to creating fast, accurate, and reliable methods for expiration date detection. These innovations not only improve the lives of visually impaired individuals but also contribute to the broader goal of inclusive technology that benefits everyone. In the computer vision field, notably, the convolutional neural network (CNN) yields promising results in practical applications: Ref. [
2] developed a deep learning framework with 97.74% accuracy for recognizing expiration dates on product packages. The framework includes three networks: a date detection network, a day–month–year (DMY) detection network, and a recognition network, and it handles 13 date formats and challenging conditions like varying fonts and blurring using a publicly available dataset called ExpDate. Ref. [
3] proposed a novel system to help visually impaired individuals recognize expiration dates on beverage packages. The system captures an image of the product taken by the user, processes it using a Spatial Transformer Network (STN) to handle skewed, misaligned, or partially missing date images, and then utilizes a dedicated convolutional neural network (CNN) for final recognition. The system achieved high recognition rates of 99.42% for images without spaces and 98.44% for images with spaces. Ref. [
4] proposed an enhanced method for optical character recognition (OCR) to detect and recognize expiry dates on food packages. This method uses an improved DBNet combined with a Convolutional Block Attention Module (CBAM) to better extract character features in complex contexts. The improved model shows high accuracy and robustness, achieving a character detection accuracy of 97.9% and a recognition accuracy of 97.8%. The system has been successfully deployed on the NVIDIA Jetson Nano, enhancing its practical applicability in the food packaging industry.
While the algorithms mentioned above yield excellent detection results, they are characterized by large model sizes, numerous parameters, and significant computational requirements. Consequently, many studies have shifted their focus towards developing lightweight target-detection algorithms. Ref. [
5] proposed an advanced method for detecting Litchi leaf diseases and pests. This method employs an improved fully convolutional one-stage object detection network (FCOS) named FCOS-FL, which incorporates G-GhostNet-3.2 as the backbone to create a lightweight model. The model enhances feature extraction using the Central Moment Pooling Attention (CMPA) mechanism, improving the center sampling and central loss by utilizing real target dimensions. FCOS-FL demonstrates high detection accuracy, with specific accuracy rates of 93.2% for
Mayetiola sp. and 92% for Litchi algal spot. The system is designed for deployment on embedded devices, offering practical applications in agriculture. Ref. [
6] presented an enhanced coral bleaching detection model named FCOS_EfficientNET. The model uses EfficientNet as its backbone and integrates the Bidirectional Feature Pyramid Network (BiFPN) for better feature extraction. FCOS_EfficientNET demonstrates high accuracy and real-time performance, with FCOS_EfficientNETb3 achieving a mean average precision (mAP) of 48.5% on the MS COCO dataset [
7] and 81.5% accuracy on a custom coral bleaching detection dataset. The study demonstrates the potential of this model for real-time and large-scale monitoring tasks in assessing coral reef health. Ref. [
8] proposed a compact and highly accurate real-time edge–AI detector for monitoring chicken health. The detector leverages an improved FCOS-Lite model with MobileNet as the backbone, incorporating a gradient weighting loss function and Complete Intersection over Union (CIoU) loss function to enhance classification and localization accuracy. Knowledge distillation is used to transfer critical information from a larger teacher model to the FCOS-Lite detector, maintaining its compactness without compromising performance. The experimental results demonstrate that the proposed detector achieves a mean average precision (mAP) of 95.1% and an F1-score of 94.2%, operating efficiently at over 20 FPS on a resource-constrained edge–AI-enabled device. The innovative approach ensures low power consumption and minimal bandwidth costs, making it suitable for practical applications in automated poultry health monitoring.
The above discussions have proved that the detection models could be deployed on edge devices, whereas the recognition models are not deployed yet. Ref. [
9] presented a novel approach for scene text recognition using a single visual model, named SVTR. This method dispenses with sequential modeling and decomposes image text into small patches called character components. The model then employs hierarchical stages of component-level mixing, merging, and combining to recognize characters through a simple linear prediction. Ref. [
10] presented a novel approach called PARSeq for scene text recognition (STR). The method leverages Permutation Language Modeling (PLM) to train an ensemble of autoregressive (AR) models with shared weights. PARSeq unifies context-free non-AR and context-aware AR inference, offering state-of-the-art (SOTA) results on various STR benchmarks with an accuracy of 96.0% when trained on real data. Ref. [
11] proposed SwinTextSpotter, an end-to-end scene text spotting framework leveraging a Transformer-based architecture. The framework introduces Recognition Conversion (RC) to integrate detection and recognition features, enhancing performance through joint optimization. SwinTextSpotter eliminates the need for character-level annotations or rectification modules and achieves state-of-the-art results across six benchmarks, including multi-oriented, arbitrarily shaped, and multilingual datasets. The discussed recognition models show excellent results in scene text recognition; however, the model size is huge when deploying on computation-constrained devices.
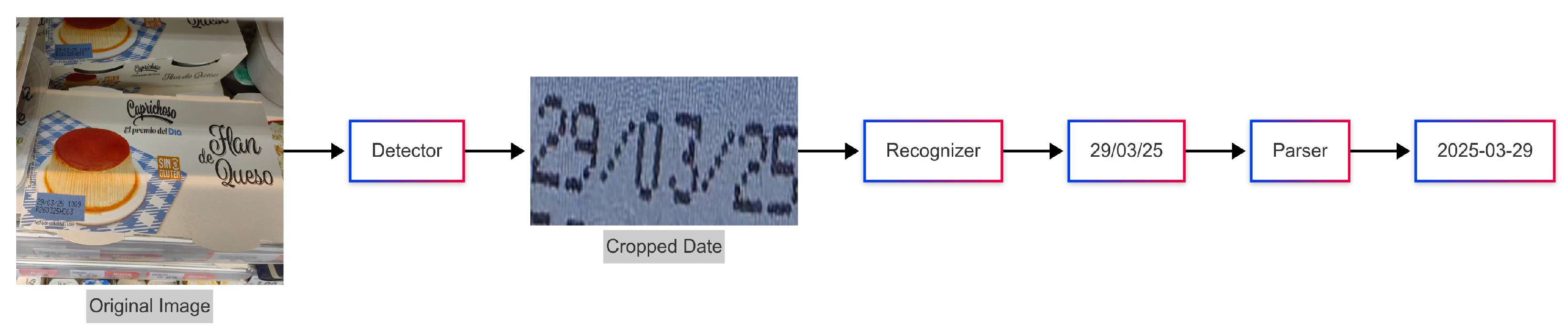
In this study, we propose that our optical character recognition (OCR) system operates in two phases: text detection and text recognition. The text detection network employs modified fully convolutional one-stage object detection (FCOS) [
12] to locate characters on packages, enclosing them in rectangular boxes. The character recognition network uses a convolutional recurrent neural network (CRNN) [
13] trained with CTC loss to recognize characters within these boxes. To address date time format, a date time parser is applied after the date is recognized in the original date format. The experimental results demonstrate that our method achieves high accuracy and fast inference. We propose using this OCR system to tackle the challenge of recognizing expiration dates in daily scenarios. The system, combined with edge devices, is portable, easy to deploy in daily life, and energy efficient.
The main contributions of our work are as follows:
We propose a lightweight backbone network for detection models, which addresses the challenges presented regarding real-time performance on computationally constrained devices, thereby significantly enhancing the model’s performance on edge devices.
We design a date time parser to parse up to 17 different date formats for a better understanding of the dates.
We implement a quantized model on edge devices to reduce hardware power consumption, shrink the model size, and enhance portability.
This study is structured as follows:
Section 2 presents the network composition, detector, recognizer, and parser;
Section 3 details the datasets, model training, model quantization, and deployment; and
Section 4 provides the results of the proposed work.
3. Datasets and Implementation Details
3.1. Datasets
The detection model dataset is used from the
ExpDate of Seker et al. [
2]. It consists of two datasets, which are a dataset
Products-Real that contains 1767 real-world expiration date images from food, beverage, and medicine packages and a dataset
Products-Syn that has more than 12 thousand synthetic images that were used to train the network. For the recognition model, the dataset consists of self-labeled expiration date images, which contain 510 samples [
19].
3.2. Model Training
The proposed models are trained with the PyTorch CUDA 11.8 framework. They are trained on a single NVIDIA GeForce GTX 1080 GPU with 8 GB of memory.
Table 2 shows the parameters of the detection model and the recognition model, respectively.
Detection Model: AdamW optimizer is chosen because it can achieve faster convergence compared to the standard Adam optimizer by decoupling weight decay from the gradient update and making it more resilient to variations in the training data. The input size is 800 in width and 1280 in height, and the initial learning rate is 0.001 with warm-up changes. The batch size is 6 per GPU and a total of 20 training epochs. Data augmentation is applied to make more training samples; the augmentation techniques include scale, stretch, translate, random rotation no more than 5°, random brightness, random saturation, random contrast, and normalized with mean [103.53, 116.28, 123.675] and variance [0.017429, 0.017507, 0.017125] in BGR order.
Recognition Model: the optimizer is Adam; the input size is resized to 32 width and 128 height. The initial learning rate is 7 × 10−4; the batch size per GPU is 384 with a total of 20 training epochs. The data augmentation used includes Gaussian blur, motion blur, random rotation no more than 30°, shear, translate, and normalized with mean [127.5, 127.5, 127.5] and variance [1/127.5, 1/127.5, 1/127.5] in RGB order.
3.3. Android Deployment
Neural networks have significantly pushed forward the limits in various applications; however, they frequently require considerable computational resources. To incorporate modern networks into edge devices that have stringent power and compute constraints, it is crucial to minimize the power consumption and latency of neural network inference. Quantizing neural networks stands out as a highly effective method for achieving these reductions, although it may introduce additional noise that could result in decreased accuracy [
20].
NCNN is a high-performance neural network inference computing framework optimized for mobile platforms [
21]. This research employed the NCNN framework to quantify the model and construct a real-time expiration date identification and character recognition application utilizing the quantized model.
Figure 4 illustrates the quantization procedure.
The Android implementation is verified on an Oppo Find X5 running with Android version 13 with processor Qualcomm Snapdragon 888, a Realme GT Neo2 running Android 13 with Snapdragon 870, and Redmi 10 Pro running Android 13 with Snapdragon 732G. The smartphones have an application that was developed based on Java Development Kit 21.0.3, NCNN 20241226-android-vulkan, and Android Studio 2024.2.2 Patch 1.
The expiration date real-time recognition application created in this study is composed of three main components (
Figure 5): the video acquisition module, the processing module, and the result display module. The video acquisition module uses the smartphone’s camera to capture food packages in real time; the processing module inputs these video streams into the detection model frame by frame while keeping the resolution size of the image fixed at
, and the detected area is cropped out; then, it preprocesses the cropped image and sends it to the recognition model; after the recognition receives the correct date, the date time parser tries to transform the date format into a unified format; the result display module then shows the predicted bounding boxes and the parsed characters in real time, providing the non-maximum suppression (NMS) threshold bar and the confidence threshold bar to adjust in the expiration date recognition app developed in this research. As shown in
Figure 6, the app’s overall interface features an image with working unit CPU or GPU of the smartphone, the size of the image, the inference time, frames per second (FPS), and the average FPS. Users can adjust the NMS threshold bar and the confidence threshold bar to change how the detected area would be shown on the interface.
4. Results
This part provides an assessment of each network separately, as well as an analysis of the overall effectiveness of the proposed work and the Android application.
4.1. Detector Results
In this evaluation, a confusion matrix serves as the primary metric. This matrix is an effective means of assessing a classification model’s performance, including its application in detection scenarios. It supplies a detailed comparison of the model’s predictions versus the true labels, enabling the identification of areas where the model may falter. This particular study focuses on a classification task involving a single class, the expiration date.
To illustrate the impact of model conversion and quantization, the configurations remain unchanged. Although the IoU metric might not ensure that all the digits are encapsulated within the detected region—since it can be considered a true positive even when missing some digits, potentially leading to varied date interpretation—it serves as a useful parameter for assessing the performance of different models.
The same datasets are used by this work and [
2] regarding the evaluation of the
Products-Real dataset. It is worth noting that the date label is only selected since the other labels would be redundant. The numerical results are taken from [
2] for comparing the differences in our proposed work with theirs. From
Table 3, the precision, recall, and F1-score are 0.9850, 0.8814, and 0.9303, respectively, in this work; by contrast, the metrics are 0.9758, 0.9905, and 0.9831, respectively, in the previous work. While our model excels in precision, it sacrifices recall, which results in an overall F1-score that is lower than the previous work’s. The precision, recall, and F1-score are calculated as follows,
Precision: ;
Recall (Sensitivity): ;
F1-Score: .
The tests were conducted in the same environment on a single GeForce GTX 1080 GPU. The detection model of [
2] took 239 ms per image on average, while the proposed detection model can infer with 53 ms per image on average. The Torch Script model offers the best overall performance in terms of precision and F1-score but is also the largest in size for the PC platform. The FP32 and FP16 models have similar performance with slightly reduced precision and F1-score but are significantly smaller in size for edge devices. The INT8 model has a significant drop in precision and F1-score.
4.2. Recognizer Results
After fine-tuning the model, the accuracy can reach 97.06%. To build statistical confidence, k-fold cross validation is performed. Due to the small amount of real data, k is selected as 5. The validation accuracy interval is [94.35%, 99.76%]. The fine-tuning accuracy, 97.06%, falls in the interval. The accuracy is calculated by comparing each output character and the ground truth character, which consists of letters and symbols. The recognition inference in this work is 10 ms per image, while, in the work of [
2], it is 92 ms per image; both are tested in the same environment on a single NVIDIA GTX 1080 GPU.
Table 3 shows that the Torch Script, FP32, and FP16 models all have a similar high accuracy of 97.06%, indicating that they perform almost identically in terms of prediction accuracy, and the INT8 model has a significantly lower accuracy of 44.12%, which suggests a substantial loss in performance. As for the model size, the FP32 and Torch Script models have similar sizes, both around 31.8 MB, and the FP16 model, using half-precision floating points, has a significantly smaller size of 15.9 MB while maintaining the same accuracy, which is beneficial for scenarios where storage or memory efficiency is crucial without compromising on performance. While the INT8 model is the smallest, at 8.54 MB, this shows that it has been heavily quantized. However, this quantization comes at the cost of accuracy.
4.3. The Overall Performance
Figure 7 illustrates the functionality of the proposed method on local product packages. It shows that the area indicating the expiration date can be detected, with the date subsequently recognized and converted into a standardized format. Dates lacking a specific day are automatically adjusted to the start of the month; for instance, in the first row of
Figure 7, 01 2025 is translated to 2025-01-01. The second row in
Figure 7 depicts that dates including the full year are accurately processed. The third row demonstrates that dates using a two-digit format for the year can also be correctly interpreted, as seen with 30.03.25, which is processed as 2025-03-30.
4.4. Android Deployment
Figure 8 shows the different quantized detection and recognition models run 100 times to obtain the mean inference time and the standard deviation.
Observations across phone models indicate that the Oppo phone generally performs well across all the tests, with lower inference times on both the CPU and GPU. Notably, the GPU times are consistently better than the CPU times, particularly for detection. The Realme phone is slightly slower than Oppo in most tests, especially for GPU detection times. However, its CPU performance is fairly competitive in recognition. The Redmi phone is significantly slower than the other phones across all the models, especially in GPU detection times. The CPU detection and recognition are also notably higher. The processors of the three phones can be ranked in descending order of performance as Oppo, Realme, and Redmi. Consequently, on the whole, the Oppo phone delivered the best performance.
Regarding analysis by quantized models (FP32, FP16, and INT8), the FP32 detection model on both the CPU and GPU shows relatively consistent performance but falls behind the FP16 model. The FP32 recognition times are moderate and fairly stable. The FP16 model typically exhibits faster inference times compared to FP32, particularly for recognition. This is evident in both the CPU and GPU tests. The FP16 detection on the GPU remains steady across devices. The INT8 model shows mixed results, with faster recognition times on the CPU compared to FP32 and FP16. The INT8 detection on the GPU varies; Oppo handles INT8 models better than Realme and Redmi. Transforming a model from FP32 to INT8 could lead to a reduction in precision because of the less complex numerical representation. This might necessitate additional processing steps like dequantization or reshaping of data, especially in devices that do not natively accommodate INT8. Consequently, the INT8 model might perform slower compared to the FP32 model.
When comparing mobile CPU and GPU performance, GPUs generally expedite detection tasks through parallel processing, although some models defy this trend, with CPUs outperforming GPUs in these scenarios. In recognition tasks, the performance differences are more nuanced, with GPUs sometimes only marginally slower than CPUs. The data transfer overhead between the two further affects the outcomes—especially for tasks involving small datasets or simple computations—often giving the CPU an edge.
When converting a network from full precision to INT8, certain layers tend to be more sensitive than others. Recurrent layers, due to their internal gating mechanisms and the wide dynamic range of activations that occur during sequence processing, recurrent layers, such as the Bidirectional LSTM units in our CRNN, are particularly prone to quantization error. The quantization noise can disrupt the delicate balance between the gating operations (input, forget, and output gates), leading to a significant drop in performance [
22]. Moreover, our testing results demonstrated that the quantization and dequantization operations are introduced after INT8 quantization as the inference is even slower. Experimenting on quantization-aware training (QAT) would also yield slow inference. Overall, the benefits of pursuing advanced methods might not justify the additional complexity.
As
Figure 9 shows, the energy consumption of the application on the Oppo phone reflects its previous performance. The phone is set in flight mode, and the brightness is at maximum while the application is working without any other applications in the background, and the remaining battery energy is recorded every 1 min starting from 100% battery energy, continuously working for 2 h. While the controlled conditions might represent a worst-case or idealized scenario, they serve as an essential baseline for comparing the relative energy efficiency improvements across different model configurations and quantization strategies. Future work will extend these evaluations to more realistic usage conditions; however, establishing a baseline under standardized conditions is a critical step for isolating the performance characteristics of the methods under investigation. The FP32, FP16, and INT8 models are tested in CPU and GPU modes, respectively. In CPU mode, the FP16 model and INT8 model almost consume the same energy, while there is a huge energy drop in GPU mode compared to the same model. Additionally, the INT8 model suffers a significant drop in accuracy after quantization. To take into account the battery of the phone and the accuracy of the model, it is recommendable to use the FP16 model in CPU mode.
Figure 10 shows how the proposed work recognizes the expiration dates in real time. All the images from
Figure 10 are screenshots from the Redmi phone; the average FPS working in CPU mode is around 2. It shows feasibility on computationally constrained devices and a huge advantage in terms of power consumption.
5. Conclusions
In conclusion, this work has demonstrated significant advancements in the recognition and interpretation of expiration dates on product packages, emphasizing the importance of model optimization for edge devices. Among the tested models, the FP16 configuration strikes an ideal balance between performance, accuracy, and energy efficiency, making it particularly suited for deployment in computationally constrained environments. Furthermore, the proposed method’s ability to process a wide variety of date formats and adapt to computational limitations showcases its practicality and versatility. We are particularly grateful to ONCE (Organización Nacional de Ciegos Españoles), the Spanish National Organization of the Blind, for suggesting this concept to us. We intend to carry out evaluations to guarantee the fundamental accessibility of our solution.
Comparing prior research, this study achieves much faster inference and proposes an Android application, emphasizing accessibility for visually impaired users. Exploring alternative quantization methods and expanding the dataset for diverse environments are essential steps for improving robustness and generalizability. Future research could explore rotating box detection while maintaining computational efficiency and accuracy. Here is our open-source model:
https://github.com/AnanasPizzaMigliore/ExpRec (accessed on 1 April 2025).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}