1. Introduction
Fog computing is an extended part of cloud computing that uses edge devices to carry out computation, communication, and storage. The data, applications, and resources of the cloud are moved closer to the end users. Even the workload generated by IoT devices is decentralized to reduce the latency incurred and to increase the efficiency of operation. The fog computing market is increasing as there is a need for developing low-latency solutions and real-time processing of applications. The market size of fog computing at the global level is expected to reach USD 12,206 million by 2033. The growing market size is because of the increasing number of IoT devices which demand the need to process and analyze data closer to the source of the applications [
1,
2].
The distributed nature of fog computing poses significant challenges with respect to accessibility, resource provisioning, security, privacy, load balancing, and many other factors. Fog computing extends support for millions of IoT requests, and their demands are heterogeneous and stringent in nature. Resource provisioning is one of the prominent challenges in a fog environment as the user exhibits high demands for resources like bandwidth, throughput, response time, and availability. Improper provisioning of resources has a greater impact on performance by increasing the latency and also causes inefficiency for services within the fog network. Hence, there is a need to formulate a proper resource management policy for a better user experience [
3,
4].
Q learning is a basic form of reinforcement learning that determines the optimal action policy for a finite Markov Decision Process through interaction with the environment in repetition. In a computing environment with a large state space, the learning process is slow and often requires several episodes of training and ends up with suboptimal solutions. With the increase in the state space, the size of the Q-table keeps growing, which leads to high memory usage and results in inefficient exploitation of the state space. The success of the Q-learning model is determined by the reward function, which reflects the ability of the Q-learning agent to reach the goal state with minimum episodes of training. Proper reward shaping enhances the effectiveness of the Q-learning algorithm [
5,
6].
A typical large language model (LLM) represents a world model for planning and control operation. It enables autonomous state exploration and directly outputs rewards and states. LLMs are lightweight in nature, which makes them suitable for deployment in fog environments. The models are further optimized to reduce the size of the model and speed up the arrival of inference using the Generative Pre-trained Transformer Quantized (GPTQ) method. The use of edge accelerators like NVIDIA JavaScript Object Notation (JSON) and a Tensor Processing Unit (TPU) helps in efficient execution of LLM models at edge devices by preserving the privacy of the data. The LLM-guided Q-learning algorithm uses the LLM’s action probability as a heuristic value to influence the Q function. Here, the LLM model is employed to guide the Q-learning agent for reward shaping using the heuristic value. It modulates the Q-value function by implicitly inducing the desired resource provisioning policy in it. The reshaped Q function prevents the over and under estimation of the policies and converges to an optimal solution [
7,
8].
In this paper, a novel LLM-guided Q-learning framework is designed to address the resource provisioning problem. The action bonus form of the heuristic, i.e., maximum entropy, is generated by the LLM model, which encourages exploration of the large state space fog environment. The heuristic value generated by the LLM provides navigation guidance to a Q-learning agent at every iteration step, which results in the formulation of the desired policy in the upcoming iterations of training. The expected value analysis under a finite and infinite fog environment is performed towards objective functions to arrive at the desired resource provisioning policies [
9,
10].
The objectives of this paper are as follows:
Mathematical representation of the fog computing system model and objective functions considered for evaluation purposes.
Design of a novel framework for resource provisioning using an LLM-guided Q-learning model.
Illustration of algorithms for each of the components in the LLM-guided Q-learning model.
Expected value analysis of the proposed framework in a finite and infinite fog environment.
Simulation of the proposed framework using the iFogSim 3.3 simulator by considering the ChatGPT classic model as a large language model and synthetic workload.
The remaining sections of the paper are organized as follows:
Section 2 deals with the related work,
Section 3 presents the system model,
Section 4 discusses the proposed framework,
Section 5 presents expected value analysis of the proposed framework under a finite and infinite fog environment,
Section 6 discusses the results, and finally
Section 7 arrives at the conclusion.
2. Related Work
In this section, some of the potential recent papers on scalable resource provisioning for fog computing are discussed and their limitations are identified.
Najwa et al. discuss a Quality of Service (QoS) aware resource provisioning approach for fog environments. Two crucial challenges are involved in designing the resource provisioning framework for maximizing the throughput and minimizing the latency [
11]. Low latency applications prefer the fog paradigm, as delay and congestion in service are overcome by bringing the cloud services to the edge of the network. An application placement strategy based on a greedy approach was designed to minimize the latency of IoT applications. Here, the incoming requests are distributed among the fog nodes using a greedy edge placement strategy. The approach is composed of two stages: the first stage is proper placement of requests across fog nodes to satisfy the high QoS needs of the real-time applications; and the second stage is depth-first search logic, which is used to identify the fog nodes that satisfy the bandwidth requirement of the incoming application requests. Each of the incoming requests is assigned priority during the placement process according to its processing requirements. The requests having higher processing requirements are sent to the nearest IoT devices for servicing. Here, resource provisioning latency requirement of the incoming requests is addressed. The evaluation was performed by considering the Distributed Camera Network (DCN) as a benchmark application. The DCN applications are mounted onto the fog nodes using a variable-sized tree network topology. From the results it was inferred that the end-to-end delay is minimized. However, the chances of getting stuck in an infinite loop is greater as the approach does not keep track of the visited fog nodes during placement of the application requests.
Masoumeh et al. present an autonomic approach to efficiently allocate the resources for IoT requests [
12]. The IoT requests experience heavy workload variation with respect to time, which needs to be addressed to prevent over/under provisioning of the resources. A Bayesian learning-inspired automated computing model was designed to make dynamic scaling decisions about whether to increase/decrease the resources for fog nodes. The Bayesian learning model is dependent on conditional probability for deciding the occurrence or non-occurrence of the event. A time-series prediction model was used to perform planning and analysis of the control loop. The autonomic system is composed of four major components: monitor, analyze, plan, and execute (MAPE). The MAPE module was further enriched with a knowledge database (MAPE-k). The MAPE-k computing model was introduced by IBM and executes MAPE modules automatically to calculate the number of fog nodes to be deployed for executing the IoT services. The time-series model is used to predict the future demand for resources. A three-tier fog computing architecture was considered for implementation purposes comprising a IoT device tier, fog tier, and cloud tier. The proposed MAPE-k module sits at the fog tier, which does automatic resource provisioning. The MAPE-k control module is executed in a loop through several iterations at regular intervals of time to allocate the fog nodes as per the dynamic changes in the IoT services workloads. However, the practical applicability of the approach is limited, as the Bayesian learning expects the computing environment to be static. In a static computing environment, sufficient information on the computing environment is known in advance; however, the fog environment is totally unpredictable, complex, heterogeneous, and highly dynamic in nature.
Nguyen et al. present an elastic form of resource provisioning framework for container-based applications in the fog computing paradigm [
13]. Kubernetes is one of the most widely used orchestration platforms for container-based applications. The framework is designed to execute over the Kubernetes computing platform to deliver resources in real-time. The ongoing traffic information is gathered in real-time and resources are allocated in proportion to the traffic distribution. Here, the Kubernetes platform is used for the purpose of orchestration, and the IoT applications are kept in the form of a container and deployed inside the fog nodes. Fog nodes situated in the nearby vicinity operate together in the form of a cluster. Two important limitations of traditional Kubernetes are that it does not consider network traffic status for application scheduling and it does not monitor the changing popularity of the applications over time. Here, the real-time traffic information is gathered at frequent time intervals. Affinity-based priority rules are formulated that specify the intended location for the fog nodes. The relocation decisions about the fog nodes are made as per the formulated affinity-based priority rules. To determine the best-fit node for the application, several factors are considered, including the health of the node, node affinity, location of the node, and application spreading statistics. The filtering and scoring steps of Kubernetes are completed first. Then the scheduler determines the bandwidth requirement and distributes them among the fog nodes in the nearest vicinity. The performance is tested by considering the small-scale and medium-scale applications. Compared to the traditional Kubernetes performance, the proposed framework achieves an improvement in terms of enhanced throughput and reduced latency. However, the performance considering large-scale applications with dynamic changes in the network traffic is not achieved. This limits its practical application for providing the resources considering computation-intensive applications.
Amina et al. present a centralized controller approach combined with a distributed computing model for resource provisioning in a fog environment [
14]. The fog computing architecture is made up of heterogeneous fog nodes, which represent high mobility, complex distribution, and sporadic availability of the resources. The computing model of the fog environment is modeled as a Markov Decision Process (MDP) to satisfy the end users with minimum latency. At first, a centralized fog controller was designed, which acquires global knowledge about the fog environment. Then, collaborative reinforcement learning agents are deployed, which manage the fog nodes by satisfying the user requirements. Proper resource coordination is carried out to provide continuous Quality of Service (QoS) satisfaction to end users. Flawless resource provisioning is guaranteed by accurately tracking the resources. The number of satisfied users is enhanced within the predefined latency requirement through distributed computation. The centralized fog controller along with the set of Q-learning agents and market actors formulate a multiple agent-based system. The integral number of fog instances is enumerated, which ensures a lower cost from fog users. The Q-learning agents that are deployed are capable of sharing the resource information among each other to arrive at common resource provisioning policies. No agent has complete knowledge of the fog computing model, and hence the decentralized learning approach is depended on to make better decisions. A real-world mobility-based dataset is considered for experiment purposes, and the higher efficiency is achieved using a collaborative learning approach. Dynamic allocation of resources is performed based on the real-time workload demands. It guarantees better resource utilization without over provisioning or under provisioning of the resources. However, if synchronization does not happen between the Q-learning agents, significant communication overhead occurs. The size of the Q-table increases exponentially and prevents the scalability of the system due to state space explosion.
Mohammad et al. present an autonomic resource provisioning approach for IoT applications using fuzzy Q-learning methodology [
15]. The optimal states of the fog nodes are represented using the MAPE-k, loop which is composed of five major components; these are monitoring, analysis, planning, and execution, which are enriched with a knowledge database. All incoming user requests enter the admission control unit, which decides whether the requests need to be sent to the cloud based on their deadline requirement. Otherwise, the requests are processed at fog nodes for quicker responses. The controller is responsible for scheduling the requests to the nearest fog nodes that have sufficient resources for execution. A feedback loop is added for the autonomic component, which does real-time gathering of data typically representing the variation in the monitored system. The monitoring component takes charge of gathering the response time, power requirement, and container productivity. The main goal is to meet the service level agreement (SLA) and reduce the response time incurred. The analysis component does the job of data preprocessing and the planning component performs an action to adapt the monitoring system to attain the desired state. The set of control inputs is mapped onto control outputs using fuzzy inference mechanisms. It helps in handling the nonlinearity in the system by approximation of nonlinear problems using knowledge expression similar to human reasoning. The uncertainty involved in the workload is handled effectively using fuzzy rules. The self-learning-enabled fuzzy algorithm is responsible for automatically scaling the resource provisioning policies. The computation overhead is less due to limited static fuzzy rules and the resource classification is enhanced by incorporating the signals from the environment. However, due to formulation of static rules, the fuzzy system becomes poorly tuned and leads to inefficient resource allocation. Even though fuzzy inference systems are capable of handling vagueness, they require extensive reconfiguration of rules to adapt to the rapidly changing state of fog nodes.
Masoumeh et al. present a learning-based approach for resource provisioning in the fog paradigm [
16]. The varying workload demands of the IoT applications are managed very well by formulating appropriate scaling decisions about whether to provision the resources. Nonlinear autoregressive neural networks embedded with a Hidden Markov Model (HMM) are used to predict the resource requirement of the applications. An autoregressive model is used to determine the probability-based correlation between the workload demands of the incoming IoT applications. Then, that knowledge is used to determine the next workload for a new/unknown IoT application. It operates with the assumption that the current value is a function of a past value in a time-series model. The proposed framework is composed of a control module, monitor module, prediction module, and decision module. The control module receives the incoming IoT application and if the deadline is less than the threshold set, corresponding information is stored in the shared memory. Otherwise, it is transferred to the cloud for processing. The prediction module is responsible for predicting the future workload demands of the IoT applications. The quantity of fog resources required for deployment is determined by the prediction module. Finally, the decision module takes up the decision of whether to scale up or scale down the resources, which is transferred to actuator as output. The performance is evaluated over the real-time dataset and is found to achieve a significant reduction in the delay and cost. However, the controller module operates by setting a threshold value, which is not suitable for highly varying dynamic situations. The threshold method does not penalize for false positive classifications; as a result, arriving at a stable threshold value becomes highly difficult.
Sabiha et al. [
17] discuss deep Q-learning-enabled frameworks, which mainly work on optimizing the Quality of Experience (QoE) and reducing the energy consumption. Mixed-integer linear programming is employed to perform effective resource utilization. It considers both continuous variables and discrete variables to formulate global optimum task scheduling policies. It approximates the Q-value function, which helps in handling the large state space environment. It begins by initializing the Q network, target network, and replay buffer. An epsilon greedy policy is employed to perform actions based on experience replay. The target network is updated using the gradient descent methodology. A proper balance between exploration and exploitation is achieved through sampling past experiences. However, the chance of overestimation of the Q value is higher and random experience replay leads to poor prioritization of important transitions of the agent.
To summarize, most of the existing works exhibit the following drawbacks. Most of the approaches are not suitable for a highly dynamic and heterogeneous fog computing environment as they use a static set of rules. They also suffer from scalability problems, which results in over provisioning or under provisioning of resources for computation-intensive applications. Improper handling of fog nodes’ state space explosion results in increased computational complexity. The vagueness or uncertainty in the request and resource parameters is not handled efficiently, which affects the stability of the system.
3. System Model
The system model inputs the set of requests coming from various IoT devices that are capable of being executed among the fog nodes in the fog tier.
Every request is composed of varying resource requirements in terms of Deadline (Ddl), Computational power (Cp), Memory (Mem), Storage (St), and Bandwidth (Bw).
The set of fog nodes is distributed across the fog tier.
The following end Objective Functions (OFs) are set for the proposed LLM-guided Q-learning (LLM_QL) framework.
OF1: Processing Delay (PD(LLM_QL)): This is the time required to service the requests sent by the IoT devices over the fog layer.
where
stands for requests processing rate across fog nodes (million instructions per second),
represents the size of the requests (million instructions), and
i represents the index term to traverse through the number of requests. The objective of the LLM_QL is to minimize the processing delay involved in servicing the requests.
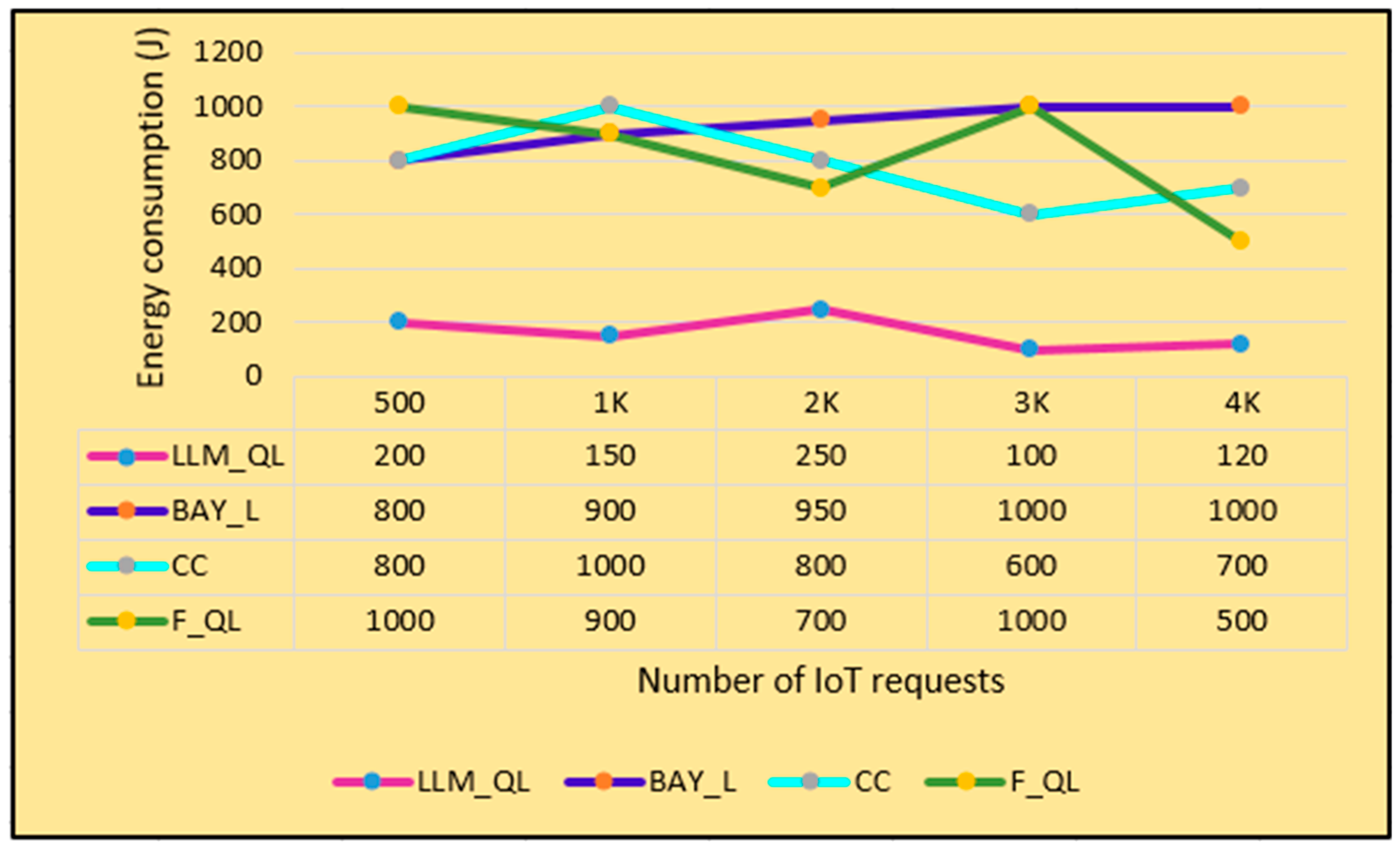
OF2: Energy Consumption (EC(LLM_QL)): This is the amount of energy required for input request pre-processing, computation, and transmission over the fog layer.
where
represents the power required to process the input requests,
is the total workload allocated, which is measured in terms of Floating Point Operations Per Second (FLOPS),
is the computational capacity of the fog node in Operations Per Second (OPS), and i represents the index term to traverse through the number of requests.
OF3: Load (LD(LLM_QL)): This is the measure of a large quantity of work put on fog nodes for execution.
where
represents the mean number of fog nodes that process the requests from IoT devices for their successful execution,
is the number of requests from IoT devices which are up and running,
is the total number of fog nodes,
is the computational capacity of the fog node measured in terms of Million Instructions Per Second (MIPS), and
i represents the index term to traverse through the number of fog nodes.
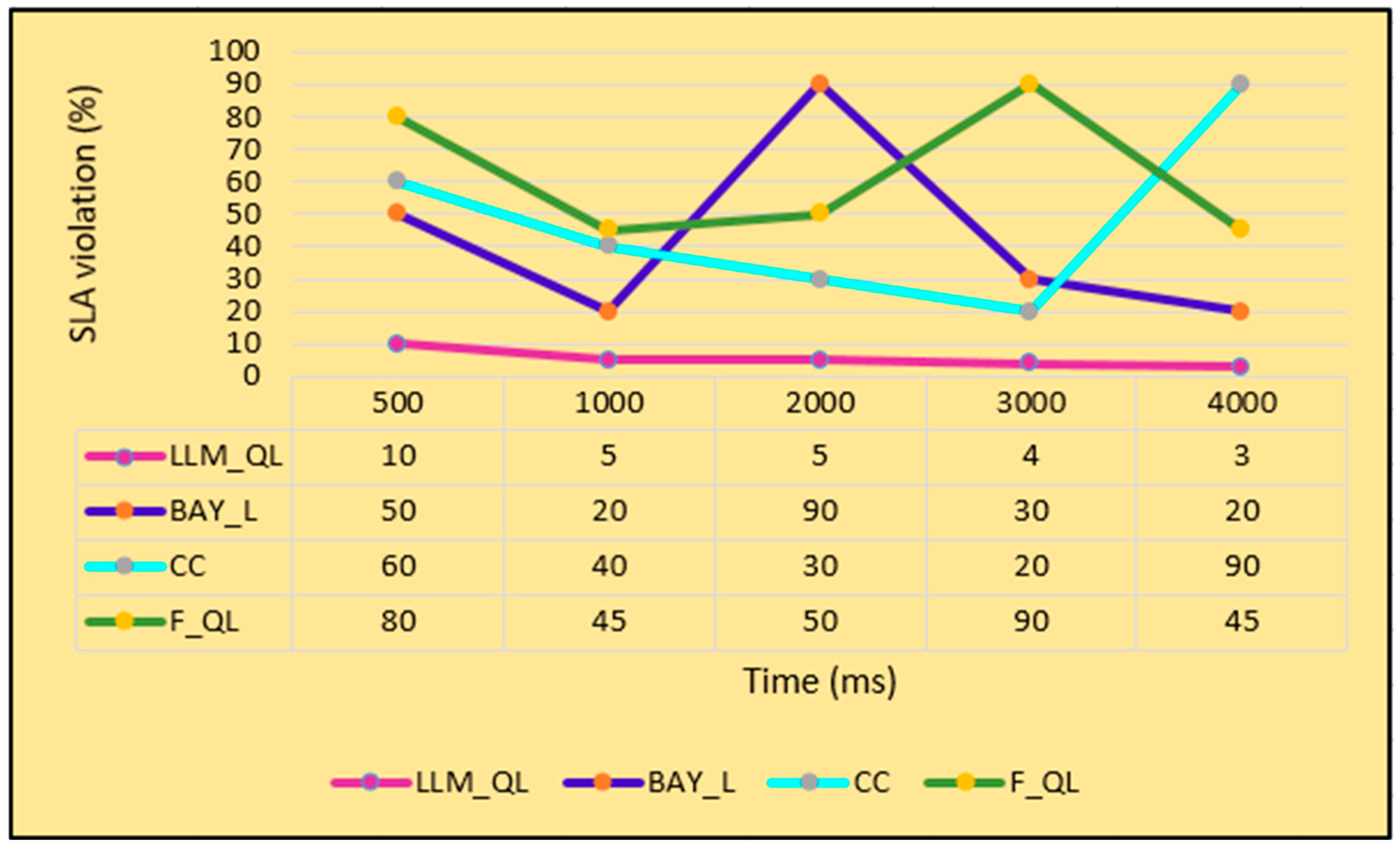
OF4: Service Level Agreement Violation (SLAV(LLM_QL)): This is the measure of violation that occurs when the agreed standards of service are not provided by the fog service provider.
The SLAV has happened when the value exceeds zero, and similarly the SLAV has not happened when becomes lesser than or equal to zero.
4. Proposed Work
The high-level architecture of the proposed LLM-guided Q-learning framework for task scheduling is shown in
Figure 1. The architecture is divided into three compartments: IoT requests, the fog node resource pool, and the LLM-powered Q-learning agent. The resource requirements of the IoT devices include temporary storage, bandwidth, processing power, and energy. The fog nodes represent an essential component of the architecture, and include virtual computers, switches, gateways, and routers. These nodes are tightly coupled and provide a rich set of computing resources to the IoT devices as per their requirement. Basically, the Q-learning agent undertakes a representative form of learning, which keeps continuously improving the agent’s action according to the response of the operating environment. One of the significant challenges encountered by the Q-learning agent is overestimation of the bias as it tries to approximate the action value by considering the maximum estimated value of the action. The computed Q value is greater than the true value of one or more actions. The maximum operator applied over the action’s value is more likely to be inclined towards the overestimated Q value. The effectiveness of the learning is limited as it does not provide the correct heuristic value for each state action pair. Hence, in this framework the Q-learning is enriched with the heuristics of the LLM model, leading to high inference speed and also overcomes the impact of bias introduced.
The detailed working of the LLM_QL framework is as follows. The state space of the Q-learning agent represents a set of all possible states that a Q-learning agent encounters in the environment. It is an important component of Q-learning agent as it learns to formulate the optimal action depending on the prevailing states. The state space indicates all possible combinations of configurations that the environment is composed of. Each state is used to provide a unique experience for the agent. The state typically represents the condition of the system, i.e., resource usage, task load, latency, and energy consumption. The fog nodes are made to learn best resource allocation policies by consequently interacting with the environment. The Q values are updated using the Bellman equation. The agent performs actions, which include allocation of resources, migration of tasks from fog node to the cloud, and queuing of the task for execution at later stages. A positive reward is provided for actions such as less processing delay, effective load balance, and lesser service level violations. Similarly, a negative reward is provided for actions such as higher processing delay, frequent load imbalance, and higher service level violations. Traditional Q-learning agents suffer from dimensionality problems and they cannot update the state action pairs for all possible combinations. However, the Q-learning agent enriched with the heuristic guidance of LLM helps in easy generalization and can operate efficiently in large and continuous state space environments.
The environment setup for the Q-learning agent involves the state space, action space, reward function, and transition dynamics. A pre-built environment is used for implementation using Application Programming Interfaces (APIs) like OpenAI Gym and unity machine learning agents. The Q-learning process inputs the IoT device requests and processes them using the Bellman equation to determine the optimal fog node for servicing.
Algorithm 1 provides the working of the LLM-guided Q-learning framework in detail. The IoT device requests are mapped onto the best fit fog nodes by considering the action value computed by the LLM-guided Q-learning agent. The heuristic value encourages the thinking ability of the agent in reaching the goal state. While navigating the Q-learning agent, the landmark positions are given highest heuristic values, which makes the traversal easier. It converges rapidly to appropriate promising solutions instead of searching for the perfect solution. By performing limited sampling and putting constraints over the responses, LLMs are made capable enough to perform zero-shot learning in varying computing scenarios of the fog environment. The actor–critic Q-learning algorithm usually finds it difficult to derive the policies through the implicit exploration process. Just by applying sample efficiency, proper reward reshaping is not possible and often ends up with the wrong heuristic value. Hence, the use of LLMs represents a promising approach for reward reshaping through autonomous state space exploration for Q-learning agents. Any possible inaccuracies in the learning steps are handled through fine tuning of the learning steps, which enhances the speed of inference and minimizes the impact of hallucination.
| Algorithm 1: Working of LLM-guided Q-learning framework |
1: Start
2: Input: IoT device request set: ,
Markov Decision Process MDP, Large Language Model G, Prompt P
3: Output: Resource provisioning policies i.e., R
4: Training phase of LLM_QL
5: Initialize the Heuristic Q buffer: MDP(G(P)), actor-critic , and target actor-critic
6: Generate Q buffer: , where = state of the agent at time step i, action performed at time step i, and Q value for action in state .
7: Q Bootstrapping
8:
9: For each IoT device request in request task set do
10: Perform sampling of the Q state from the fog state space, = reward received for the action
11: Compute Q buffer
12: Perform sampling over the computed value of the Q buffer
13: where
14: ))
15: Update the critic
16: if t mod == 0 then
17: Update actor
18: Update the target networks
19:
20:
21: End if
22: End for
23: End Training phase of LLM_QL
24: Testing phase of LLM_QL
25: For each testing iteration t of IoT device request in request task set do
26: Re-compute Q buffer , where represent the memory buffer
27: Compute the updated value of the critic
28: Update the critic
29: Update the target networks
30:
31:
32: End For
33: End Testing phase of LLM_QL
34: Output
35: Stop |
5. Expected Value Analysis
The expected value analysis of the proposed LLM_QL is performed by considering four objective functions, i.e., processing delay, energy consumption, load imbalance, and service level agreement violation. Two types of fog computing scenarios are considered for analysis purposes, i.e., finite fog computing scenarios and infinite fog computing scenarios. The four objective functions (OFs) considered for analysis purpose are Processing Delay (PD(LLM_QL)), Energy Consumption (EC(LLM_QL)), Load (LD(LLM_QL)), and Service Level Agreement Violation (SLAV(LLM_QL)). The performance of the proposed LLM_QL is compared with three of the recent existing works, i.e., Bayesian Learning (BAY_L) [
12], Centralized Controller (CC) [
14], and Fuzzy Q Learning (F_QL) [
15].
5.1. Finite Fog Computing Scenario
The finite fog computing scenario consists of N number of IoT device requests , K fog computing nodes , and P resource provisioning policies . The probability of the outcome of the objective functions varies between low, medium, or high .
OF1: Processing Delay (PD(LLM_QL)): The expected value of the processing delay of the proposed LLM_QL, i.e., EV(PD(LLM_QL)) is influenced by the expected value of the processing rate of the requests
and the expected value of the size of the requests
.
PD(LLM_QL): PD(BAY_L) =
where
f(x(t),r(t),P) = System state, Desired setpoint, and system parameters.
PD(CC) =
PD(F_QL) =
OF2: Energy Consumption (EC(LLM_QL)): The expected value of the energy consumption of the proposed LLM_QL, i.e.,
EV(EC(LLM_QL)) is influenced by the expected value of the power required to process the input requests
, workload allocated
, and computational capacity of the fog node
.
EC(LLM_QL): EC(BAY_L) =
EC(CC) =
EC(F_QL) =
OF3: Load (LD(LLM_QL)): The expected value of the load on the proposed LLM_QL, i.e.,
EV(LD(LLM_QL)) is influenced by the expected value of the request processing time
)) and number of requests generated
LD(LLM_QL): LD(BAY_L) =
LD(CC) =
LD(F_QL) =
OF4: Service Level Agreement Violation (SLAV(LLM_QL)): The expected value of the Service Level Agreement Violation of the proposed LLM_QL, i.e.,
EV(SLAV(LLM_QL)) is influenced by the expected value of the request processing time
)).
SLAV(LLM_QL): SLAV(BAY_L) =
SLAV(CC) =
SLAV(F_QL) =
5.2. Infinite Fog Computing Scenario
The infinite fog computing scenario consists of an infinite number of IoT device requests , K fog computing nodes , and resource provisioning policies .
OF1: Processing Delay (PD(LLM_QL)): The EV(PD(LLM_QL)) during the infinite scenario remained less compared to EV(PD(LLM_QL)) during the finite scenario.
PD(LLM_QL): PD(BAY_L) =
PD(CC) =
PD(F_QL) =
OF2: Energy Consumption (EC(LLM_QL)): The EV(EC(LLM_QL)) during the infinite scenario is found to be less compared to EV(EC(LLM_QL)) during the finite scenario.
EC(LLM_QL): EC(BAY_L) =
EC(CC) =
EC(F_QL) =
OF3: Load (LD(LLM_QL)): The EV(LD(LLM_QL)) during the infinite scenario is very much balanced compared to EV(LD(LLM_QL)) during the finite scenario.
LD(LLM_QL):
LD(BAY_L) =
LD(CC) =
LD(F_QL) =
OF4: Service Level Agreement Violation (SLAV(LLM_QL)): The EV(SLAV(LLM_QL)) during the infinite scenario is found to be consistently lower compared to EV(SLAV(LLM_QL)) during the finite scenario.
SLAV(LLM_QL):
SLAV(BAY_L) =
SLAV(CC) =
SLAV(F_QL) =






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}