1. Introduction
Feature selection is a fundamental challenge in analyzing high-dimensional data, where datasets often contain numerous irrelevant or redundant features. Removing these features enhances predictive accuracy, reduces computational complexity, and improves model interpretability. By selecting the most relevant subset, models can focus on informative data, leading to more efficient and accurate predictions.
In bioinformatics, feature selection helps identify key biological markers or genes associated with specific processes or diseases, enabling deeper insights into biological mechanisms while improving predictive reliability. It is also widely applied in fields such as finance, healthcare, and text classification, where efficient handling of high-dimensional data is essential.
As a crucial step in data preprocessing, feature selection reduces overfitting, enhances generalization, and decreases computational costs. Methods for feature selection are typically categorized into filter, wrapper, and embedded approaches [
1,
2].
Filter-based feature selection methods utilize statistical measures in order to rank features or to give various features in a dataset a numerical rank in order to be able to discard irrelevant features with a low statistical score. Filter-based methods are often computationally efficient, but they sacrifice accuracy due to the fact that they look at the features individually without taking into account the relationships between features. For example, two features may be insignificant on their own, but when paired together, they might heavily affect the data.
Wrapper methods are often referred to as trial-and-error methods because they take into account every possible combination of features and choose the best one. As a result, wrapper methods for feature selection are often the most computationally expensive, but yield the most accurate results. The work being performed focuses on performing feature selection for highly dimensional data (large number of features), so wrapper-based approaches take an incredibly long time to run; thus, testing them has proven to be difficult.
Embedded methods perform feature selection during the model training process. The benefit of these methods is that they take into account interactions between features, something that filter-based approaches completely ignore. Embedded methods often provide a good balance between computational cost and accuracy.
A hybrid method can be any combination of two types of feature selection methods or even a feature selection method and another algorithm that may not generally be used for feature selection.
2. Related Work
Feature selection is a critical process in data mining and machine learning, aiming to identify the most relevant features from large datasets to improve model performance and reduce dimensionality. Nature-inspired algorithms have shown significant promise in optimizing feature selection [
3]. This section expands on recent advancements and related work in this area.
A comprehensive study focused on the scalability of feature selection algorithms in the context of dynamic data generated by web-based applications and the Internet of Things (IoT) [
4]. The research emphasized the limitations of existing dimensionality reduction techniques when dealing with noisy and rapidly inflating datasets. The study concluded that feature selection methods are essential for reducing data load and avoiding overfitting, thereby improving the efficiency of machine learning models.
Another comprehensive survey examined various nature-inspired metaheuristic methods for feature selection [
5]. The study focused on the representation and search algorithms, highlighting their potential for global search and optimization. The survey provided an analysis of the advantages and disadvantages of different approaches, offering guidance for future research to address unresolved issues in the literature.
Looking at particular nature-inspired algorithms, the Genetic Algorithm (GA) is one of the most widely used algorithms for feature selection. GA mimics the process of natural selection by generating a population of candidate solutions and iteratively evolving them to find the optimal feature subset. A study applied GAs for feature selection in medical diagnosis, demonstrating significant improvements in classification accuracy and computational efficiency [
6].
In [
7], a feature selection method using the Ant Colony Optimization (ACO) algorithm, aiming to address the challenges posed by high-dimensional data. By employing a heuristic distance directly in the probability function, the algorithm avoids the need for subattribute sets and iteratively creates a frequency order list to determine feature importance. The technique’s effectiveness is validated through experiments that compare it with fifteen other algorithms, using identical datasets, classifiers, and performance metrics. The paper also demonstrates how feature selection improves classification performance and evaluates the convergence performance of the proposed method, highlighting its effectiveness in managing complex, multidimensional data.
In [
8], a novel feature selection architecture integrating metaheuristic techniques with evolutionary algorithms and chaos theory is introduced. The proposed method leverages evolutionary concepts, such as mutation and crossover operators from Genetic Algorithms, to enhance search space exploration and exploitation. Additionally, a chaotic map function generates new random feature subsets to improve the optimization process. The method was tested on 10 datasets across various machine learning models, showing significant performance improvements compared to existing methods.
A feature selection architecture designed to enhance machine learning model performance by selecting relevant features and eliminating redundancy was introduced in [
9]. The architecture combines metaheuristic techniques, evolutionary algorithms, and chaos theory to address high-dimensional data challenges. Key elements include Genetic-Algorithm-inspired mutation and crossover operators for efficient search and a chaotic map function for generating random feature subsets. Testing on 10 datasets demonstrated significant performance improvements compared to existing methods.
The study in [
10] improved feature selection (FS) in hyperspectral image (HSI) classification by proposing a new filter–wrapper (F-W) framework to enhance swarm intelligence and evolutionary algorithms (SIEAs). The performance of ten SIEAs under this framework is evaluated using three HSIs, focusing on accuracy, selected bands, convergence rate, and runtime. Results show that overall, the SIEAs outperform traditional FS methods, achieving higher accuracy and efficiency, especially in complex scenes.
Particle Swarm Optimization (PSO) is also a popular evolutionary computation (EC) method that has been widely applied to feature selection problems. For example, an adaptive Particle Swarm Optimization (PSO) method for feature selection that overcomes the limitations of traditional PSO by incorporating adaptive parameter updating and leadership learning strategies is presented in [
11]. Experimental results on 10 UCI datasets show that the proposed method outperforms other algorithms in both exploration and exploitation, selecting fewer than 8% of the original features while achieving more effective feature subsets than six traditional feature selection methods.
Binary Particle Swarm Optimization (BPSO) is a discrete variant of the Particle Swarm Optimization (PSO) algorithm, designed to handle optimization problems where variables are binary (i.e., they can take on values of 0 or 1). In traditional PSO, particles adjust their positions and velocities in a continuous search space to find optimal solutions. However, BPSO modifies this approach to operate within a binary search space. In BPSO, each particle represents a candidate solution as a binary string. The concept of velocity is reinterpreted as the probability of each bit in the string flipping from 0 to 1 or vice versa. This probability is typically determined using a sigmoid function applied to the velocity component, ensuring that updates remain within the binary constraints [
12].
A Stick Binary PSO (BPSO), redefining momentum as stickiness and velocity as flipping probability, was introduced in [
13]. The stickiness factor considers the stability of particle states, encouraging particles that have remained unchanged for a long period to flip, thereby increasing population diversity. However, unconstrained flipping in the time dimension expands the search space, increasing computational costs and slowing population convergence.
An applied PSO within an evolutionary multitasking framework Is featured in [
14]. The first task involved selecting from all original features, while the second focused on choosing from only the top-ranked features. Similarly, authors in [
15] employed BPSO for spam detection, introducing mutation operators to mitigate premature convergence and improve algorithm performance. Their experimental results demonstrated superior performance compared to other methods.
The ChaoticMap algorithm integrates two types of chaotic maps (logistic maps and tent maps) into the Binary PSO (BPSO) [
16]. The chaotic maps are used to determine the inertia weight of the BPSO. The Chaotic Binary Particle Swarm Optimization (CBPSO) for feature selection employs the K-nearest neighbor (K-NN) method with leave-one-out cross-validation (LOOCV) as a classifier to evaluate classification accuracy. The proposed feature selection method yields promising results in terms of reducing the number of feature subsets while achieving superior classification accuracy compared to other methods in the literature.
VLPSO, a PSO variant with dynamic and variable-length feature selection, which achieved higher classification accuracy in less time, was introduced in [
17]. Additionally, the Competitive Swarm Optimization (CSO) algorithm was introduced to explore novel optimization strategies [
18]. Nguyen et al. further enhanced CSO by incorporating performance constraints and the Relief algorithm to improve population diversity and local search efficiency [
19]. They also employed SVM as a surrogate model to accelerate evaluations. Their results showed that adaptive performance constraints guided particles toward high-quality solutions, but this approach increased exploitation tendencies, making the population more prone to local optima.
From this review, so far, it is evident that existing PSO-based feature selection algorithms largely rely on mathematical and evolutionary computation methods for population initialization and update strategies. However, these approaches struggle to provide effective initialization and guided updates when applied to large-scale datasets.
One research study addressed this issue introducing an importance-guided Particle Swarm Optimization based on MLP (IGPSO) to enhance feature selection for high-dimensional datasets [
20]. The approach leverages a neural network-generated importance vector to guide both population initialization and evolution, ensuring that optimization focuses on the most relevant features. A two-stage training process refines this importance vector by first identifying useful features from positive samples and then filtering out irrelevant ones using negative samples. To further improve performance, IGPSO replaces traditional PSO acceleration factors and inertia weight with importance-guided updating, where more critical features receive stronger influence while less important ones are de-emphasized. This strategy balances exploration and exploitation, leading to efficient feature selection with fewer features and improved classification accuracy on large-scale datasets.
However, EC-based feature selection methods are generally effective for small-scale problems with feature dimensions ranging from tens to hundreds [
21,
22]. When dealing with large-scale datasets containing thousands of dimensions, these methods become computationally expensive and struggle to achieve satisfactory performance. Additionally, the effectiveness of swarm-intelligence-based algorithms is highly dependent on population initialization [
23].
Thus, our approach enables the exploration of large datasets with high-dimensional feature spaces by introducing a new feature selection method based on PSO. By incorporating a guided particle scheme with three filter-based methods, the proposed algorithm effectively tackles critical challenges in high-dimensional data analysis, such as premature convergence to suboptimal solutions, which often hinder the performance of traditional PSO-based techniques. This advancement is particularly important for complex, high-dimensional datasets, where the large number of features typically poses significant challenges. The algorithm’s ability to efficiently navigate large search spaces and identify the most relevant features makes it a robust and promising algorithm for enhancing the accuracy and efficiency of data analysis across diverse applications.
3. Approach
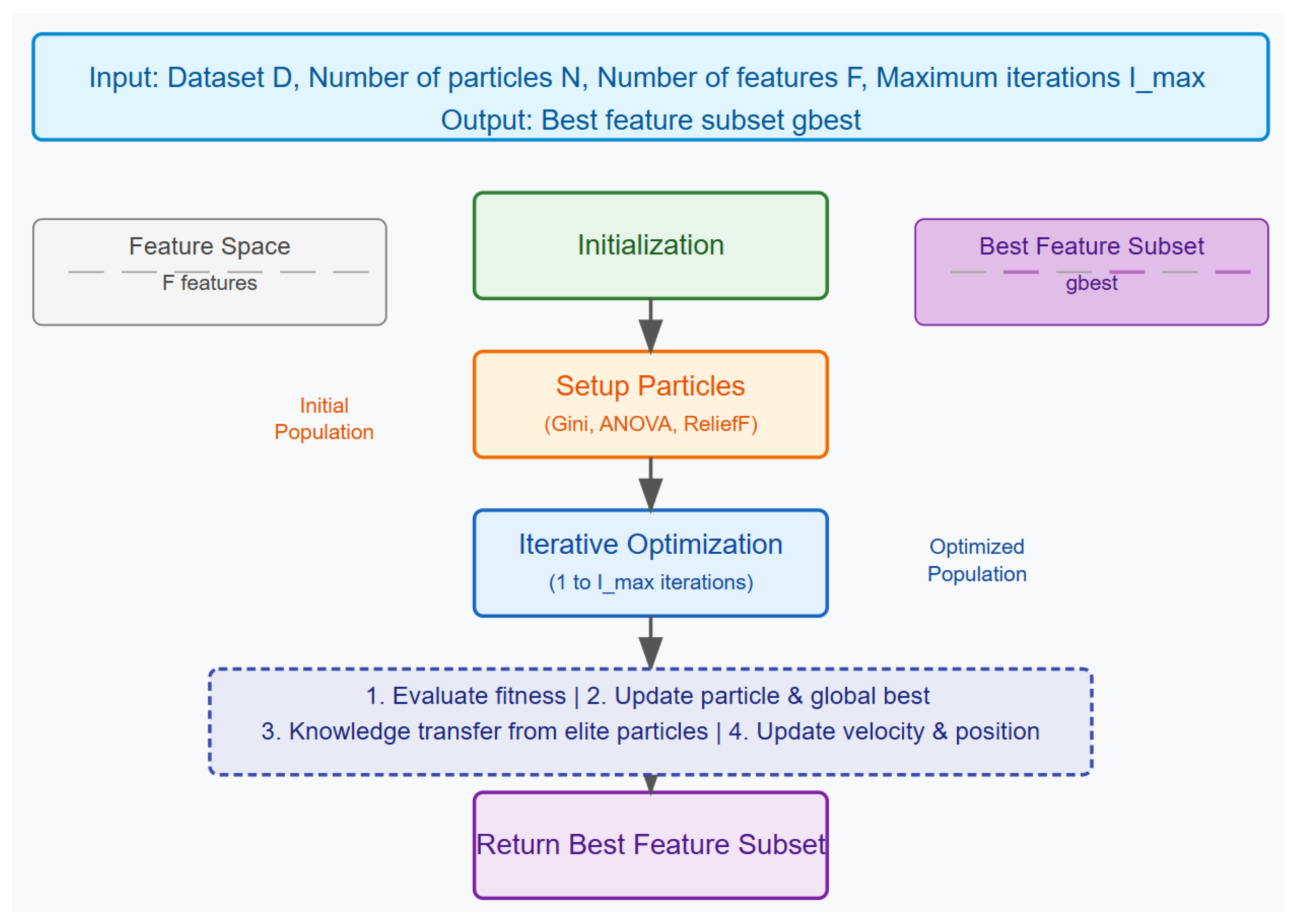
An overview of the proposed approach is shown in
Figure 1. The two proposed algorithms have two goals in mind: (1) expansion of the search space using three filter-based methods to generate the particles and (2) using a fitness factor that weights accuracy and size of a feature set, including knowledge transfer, in order to prevent premature convergence. The figure as well as Algorithm 1 describe the approach.
The Guided Particle Swarm Optimization (PSO) algorithm for feature selection begins by initializing a swarm of particles, where each particle represents a potential subset of features. The goal of the algorithm is to identify the best feature subset that maximizes a fitness function, which likely measures the subset’s ability to accurately classify or predict outcomes based on the dataset provided.
Each particle in the swarm is assigned a random position (corresponding to a feature subset) and velocity, while the global best position, denoted as , is initialized with an extremely high score, ensuring that any better solution will replace it. The initial positions of the particles are informed by three feature selection methods: Gini index, ANOVA, and ReliefF. Particles are divided equally among the positions computed by these methods, and their feature subsets are initialized using the knee point method, which balances the number of features with their relevance.
The algorithm then enters an iterative process, where it repeatedly evaluates and updates the particles over a series of iterations. During each iteration, the fitness of each particle’s feature subset is calculated. Fitness is calculated according to Equation (3):
where
is the weighting factor,
is the classification error rate,
is the selected feature set, and
is the total feature set.
If a particle’s current subset yields a better fitness score than its previously best-known score, the particle updates its best-known position. Similarly, if a particle’s fitness score is better than the global best score across the entire swarm, the global best position is updated.
The following velocity and position update equations are used:
where
is the updated velocity of particle
i at time step
;
is the inertia weight;
is the previous velocity of the particle;
and
are the cognitive and social coefficients;
are random numbers sampled from a uniform distribution;
is the personal best position of particle
i;
is the global best position;
is the current position of particle
i;
is the sigmoid function applied to the velocity;
is a random number sampled from a uniform distribution; and
is the updated binary position of the particle.
After evaluating all particles, the swarm is sorted based on their best scores. A subset of elite particles—those with the best performance—is identified, and knowledge from these elite particles is transferred to others in the swarm to guide the search towards more promising areas of the solution space; this is what we refer to as the knowledge transfer mechanism. Finally, each particle’s velocity and position are updated, allowing the swarm to explore new subsets of features while being influenced by both individual and collective experiences.
This process continues until the maximum number of iterations is reached, after which the algorithm returns the global best feature subset found, representing the most optimal selection of features according to the fitness function used.
| Algorithm 1 Guided Particle Swarm Optimization for Feature Selection |
- 1:
Input: Dataset , Number of particles N, Number of features F, Maximum iterations - 2:
Output: Best feature subset - 3:
Initialize particles with positions and velocities - 4:
Initialize global best position and score to infinity - 5:
for each particle i in the swarm do - 6:
Compute Gini, ANOVA, and ReliefF positions for the dataset - 7:
Divide particles equally among these positions - 8:
Initialize feature subset using the knee point method - 9:
end for - 10:
for each iteration t from 1 to do - 11:
for each particle i in the swarm do - 12:
Evaluate fitness of using the fitness function - 13:
if fitness is better than particle’s best score then - 14:
Update particle’s best position and score - 15:
end if - 16:
if fitness is better than global best score then - 17:
Update global best position and score - 18:
end if - 19:
end for - 20:
Sort swarm based on particle best scores - 21:
Update elite particles - 22:
Transfer knowledge from elite particles to others - 23:
for each particle i in the swarm do - 24:
Update velocity and position of the particle - 25:
end for - 26:
end for - 27:
return
|
In terms of the complexity analysis, the time complexity is as follows:
and the space complexity is as follows:
where
N is the number of particles in the swarm,
F is the number of features in the dataset,
M is the number of samples in the dataset, and
is the maximum number of iterations.
The algorithm is computationally intensive for large datasets (large M and F) and large swarm sizes (N), but its linear scaling with respect to and N makes it manageable for large dataset sizes.
4. Experiments and Setup
This section first describes the datasets used followed by the descriptions of the comparison algorithms. Then, the evaluation measures are listed, and the experiments and results are shown and discussed.
4.1. Dataset Description
Twelve datasets have been used for the experiments. These have been extracted from the Cancer Genome Atlas (TCGA) [
24]. TCGA is a pioneering cancer genomics initiative, and has molecularly characterized more than 20,000 primary cancer samples and corresponding normal tissues across 33 cancer types. This collaborative project, launched in 2006 by the National Cancer Institute (NCI) and the National Human Genome Research Institute, brought together experts from various fields and institutions.
Over the course of twelve years, TCGA produced more than 2.5 petabytes of data, encompassing genomic, epigenomic, transcriptomic, and proteomic information. This vast dataset, which has already contributed to advancements in cancer diagnosis, treatment, and prevention, continues to be publicly accessible to the research community.
The twelve datasets used are given in
Table 1. As one can see, the number of features vary between 35,924 to 44,909. Since we are investigating feature selection, these datasets are considered to be very large and appropriate for our experiments. The dataset abbreviations stand for Cholangiocarcinoma (CHOL), Colon Adenocarcinoma (COAD), Head and Neck Squamous Cell Carcinoma (HNSC), Kidney Renal Clear Cell Carcinoma (KIRC), Kidney Renal Papillary Cell Carcinoma (KIRP), Liver Hepatocellular Carcinoma (LIHC), Lung Squamous Cell Carcinoma (LUSC), Prostate Adenocarcinoma (PRAD), Stomach Adenocarcinoma (STAD), Thyroid Carcinoma (THCA), and Uterine Corpus Endometrial Carcinoma (UCEC). All datasets are binary with two classes: cancer or not cancer.
4.2. Comparison Approaches
The following comparison approaches have been used to select the best features. As for the classification portion, the K-Nearest Neighbor (KNN) has been used.
ANOVA (Analysis of Variance): ANOVA is a statistical method used to analyze the differences among group means among each other [
25]. It determines whether there are any statistically significant differences between the means of independent groups by comparing the variability within groups to the variability between groups. Within feature selection, the ANOVA F-test identifies features that have significant differences across different classes and how different a feature is within its own class, helping to select the most relevant features for improving model performance. It uses ANOVA to select the top 10% of features based on their statistical significance, while retaining important features despite reducing dimensionality.
EN (Elastic Net): Elastic Net is an embedded method that combines both L1 (Lasso) and L2 (Ridge) embedded methods to enhance the performance of regression models [
26], specifically their penalty coefficients. Elastic Net will be typically used in scenarios when the number of predictors exceeds the number of observations or when predictors are highly correlated. By linearly combining the penalties, Elastic Net encourages sparsity like lasso, which helps in variable selection, while also stabilizing the solution like ridge regression, which improves prediction accuracy.
BPSO (Binary PSO): BPSO was described in
Section 2.
IG (Information Gain): Information gain is a criterion used in feature selection to measure how much information a given feature contributes to reducing uncertainty in a classification task. It is based on the concept of entropy from information theory, where entropy represents the amount of randomness or impurity in the dataset. The information gain of a feature is computed as the reduction in entropy achieved by partitioning the data based on that feature. A higher information gain indicates that the feature is more informative and useful for classification [
27].
CS (Chi-Square Test): The Chi-Square Test is a filter type of the feature selection method. It evaluates each feature individually without considering a specific model. This method is effective across different models, as it is model-agnostic. The Chi-Square Test assigns each feature a Chi value based on its statistical relevance to the target variable. This approach is fast and efficient, particularly suitable for high-dimensional datasets. It works well with categorical datasets but can also handle qualitative data points [
28].
CSA (ChiSimAnneal): ChiSimAnneal is a hybrid feature selection algorithm that combines the Chi-Square statistical test with a simulated annealing optimization strategy. The Chi-Square test evaluates the dependency between categorical features and the target variable, selecting features that exhibit strong statistical associations. Simulated annealing, a probabilistic optimization technique inspired by the annealing process in metallurgy, is then applied to refine the feature subset by exploring different combinations and avoiding local optima. This approach enhances the selection process by balancing exploration and exploitation, leading to an optimal subset of features that improve model performance [
29].
PSO (4-2): PSO (4-2) allows particles to vary in length, reducing search space and improving PSO’s performance by focusing on relevant features. This technique enhances PSO’s ability to avoid local optima and produce high classification performance with fewer features in shorter time frames, as shown in tests on high-dimensional datasets [
17], and was also described in
Section 2.
RR (Ridge Regression): Ridge Regression integrates feature selection within the training process of a model. It is an example of an embedded method. During model training, Ridge Regression calculates coefficients for each feature, indicating their importance. Features with coefficients above a specified threshold (e.g., 0.2) are selected. This method is efficient and leverages the model’s learning process for feature selection. However, it may not eliminate irrelevant features entirely and requires careful parameter tuning to identify the most relevant features accurately [
30].
GA (Genetic Algorithm): GA was described in
Section 2.
ChaoticMap: ChaoticMap was described in
Section 2.
VLPSO (Variable-length PSO): VLPSO was described in
Section 2.
The last two algorithms listed, ChaoticMap and Variable-length PSO, were implemented for the comparison experiments; however, given the large dataset sizes, neither could be run due to their time complexity. However, all other comparison algorithms were included.
4.3. Algorithm Parameters
Table 2 lists the parameters used for the experiments for the different algorithms. Please note that for IGPSO, the parameter values were set to those of GPSO as well as the other nature-inspired algorithms, in order to make sure that the same search effort was used.
4.4. Computing Infrastructure for Experiments
The experiments were conducted using the infrastructure of the Center for Computationally Assisted Science and Technology (CCAST), which offers advanced cyberinfrastructure for research and education at NDSU and beyond. CCAST manages and operates high-performance, cloud, and interactive computing resources, while also educating researchers on the effective and efficient utilization of these resources and other relevant topics in the computational science and engineering fields.
5. Results
This section presents the results of the experiments conducted.
Table 3 shows the accuracy results obtained running all algorithms on all datasets. The best values achieved for each dataset is highlighted in bold. As can be seen, our proposed algorithm as well as the BPSO obtains the highest accuracy for four datasets, the ANOVA, EN, and IG algorithms achieve the highest accuracy for three dataset, the CSA and GA algorithms for two datasets, and the CS and RR algorithms score best for one dataset.
As for the precision results given in
Table 4, the proposed algorithm scores highest for seven datasets, BPSO scores best for five datasets, ANOVA and EN for three datasets, IG, CSA, and IGPSO for two datasets, and CS and RR for one dataset.
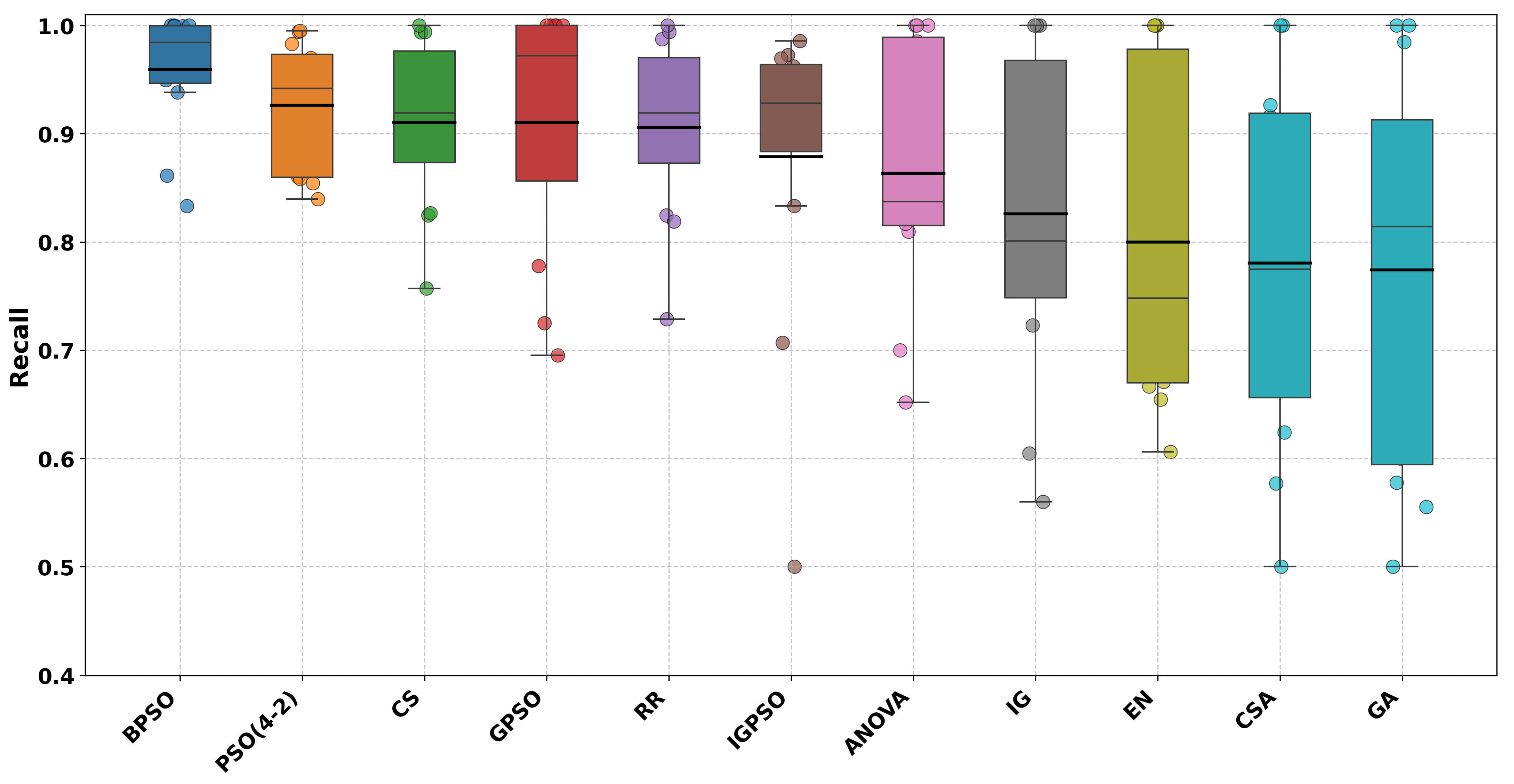
Next up are the recall results given in
Table 5. As can be seen from the results in the table, GPSO again scores best for six datasets, followed by BPSO for five datasets, ANOVA for four datasets, EN and IG for three datasets, CSA and GA for two datasets, and PSO(4-2), CS, and RR for one dataset.
F1-scores are displayed in
Table 6. The table shows that the proposed algorithm, GPSO, obtains the best results for seven datasets followed by BPSO for five datasets, ANOVA, EN, and IG for three datasets, CSA and GA for two datasets, and PSO(4-2), CS, RR, and IGPSO for one dataset.
Figure 2,
Figure 3,
Figure 4 and
Figure 5 show the accuracy, precision, recall, and F1-score results as box plots. Please note that numbers in bold indicate the best results.
In order to evaluate the different algorithms fairly, we are investigating their execution times as well.
Table 7 lists the running time/execution time of all algorithms run on all datasets. As can be seen, the fastest algorithms are CS followed by RR taking our proposed algorithm. However, as we have seen, both algorithms do not score very highly in terms of accuracy, precision, recall, and F1-score. The IGPSO takes the longest, with an average of 10,790.84 s (179.85 min), followed by our algorithm, with an average of 2919.84 s (48.66 min). However, our algorithm scores overall better based on the other measures. Not unexpected, the third slowest algorithm is GA followed by PSO(4-2) and BPSO.
In terms of the number of features used and selected during the feature selection process,
Table 8 shows the results. As can be seen, IGPSO uses by far the fewest numbers of features during the process followed by GPSO. All other algorithms select and use more features for the classification task.
Table 9,
Table 10,
Table 11 and
Table 12 show the results of the Mann–Whitney U Test comparing GPSO with all other algorithms in terms of accuracy, precision, recall, and F1-score. The analysis revealed several findings regarding the performance of GPSO compared to other algorithms.
Based on these results, GPSO shows statistically significant differences in accuracy compared to 9 out of the 10 other algorithms, with only BPSO showing a non-significant difference (though still trending toward significance with p = 0.0883). The very low p-values against several algorithms (particularly PSO(4-2) and IGPSO) suggest that GPSO performs either significantly better or significantly worse than these algorithms.
For precision, GPSO shows statistically significant differences compared to 5 out of the 10 other algorithms (PSO(4-2), CS, RR, GA, and IGPSO). The differences with CSA are close to significance (p = 0.0847). The remaining algorithms (ANOVA, EN, BPSO, and IG) do not show statistically significant differences in precision when compared with GPSO.
For recall metrics, GPSO does not show statistically significant differences compared to any of the 10 other algorithms at the conventional significance level of = 0.05. However, three algorithms show trends toward significance (p < 0.10):
EN vs. GPSO (p = 0.0826);
CSA vs. GPSO (p = 0.0575);
GA vs. GPSO (p = 0.0575).
This suggests that while there may be some differences in recall performance between GPSO and these three algorithms, the differences are not strong enough to be considered statistically significant with the current sample size and at the conventional significance threshold.
In summary, GPSO shows a statistically significant difference only when compared to GA (p = 0.0329). It shows marginally significant differences (p < 0.1) when compared to EN, CSA, and IGPSO. For all other algorithms, there are no statistically significant differences in performance based on the provided test results.
6. Conclusions
In this paper, we proposed a feature selection method based on Particle Swarm Optimization. The proposed algorithm makes use of a guided particle scheme whereby three filter-based methods are incorporated. The proposed algorithm addressed the issue of premature convergence to global optima compared to other PSO feature-based methods by the expansion of the search space using three filter-based methods to generate particles, and by using a fitness factor that weights accuracy and size of feature set including knowledge transfer. The proposed method was compared to state-of-the-art feature selection algorithms. ANOVA, EN, BPSO, IG, CSA, PSO(4-2), CS, RR, GA, and IGPSO were implemented and experimented with. The 12 genome datasets we used included up to 44,909 features, which is consider high-dimensional data. The results as well as statistical analysis show that the proposed algorithm compares better to other state-of-the-art feature selection algorithms. In summary, GPSO achieves competitive or better accuracy and precision compared to most algorithms, with similar recall and some variation in F1-score. This indicates its strength in balancing accuracy and precision while maintaining performance on other metrics.
Future work will involve conducting additional experiments to further evaluate the robustness and adaptability of the knowledge-transfer mechanism across diverse datasets and problem domains. This should include fine-tuning the parameters and design of the mechanism to enhance its effectiveness and efficiency. Additionally, a systematic comparison with alternative knowledge-transfer solutions, such as transfer learning frameworks, meta-learning approaches, and domain adaptation techniques, could be performed. Moreover, exploring hybrid approaches that combine multiple knowledge-transfer techniques may lead to improved performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}