First, the input data are pre-processed. The Topographic module processes the terrain data to generate the terrain data file. The PREinter module reads the preprocessed data and generates the data required by the Inter module, which interpolates the input data. The Background module analyzes the background field data at the barometric layer. The VERinter module reads the background field data and generates the initial grid data and boundary conditions. The MM5 module produces its forecast using the data obtained from other modules. Finally, the Post module generates visual graphics based on the forecast results.
3.1. Number of Component Instances Completed and Effective Working Time Test
Table 2 lists the location statistics of the parallel components in each module. For example, in the first row of
Table 2, within the Pre module, there are nine component calls that appear in the for loops, eight component calls in the while loops, three component calls in the recursive call structures, and five component calls that are not included in these three structures. As
Table 2 reveals, most component calls in the application appear in the code structures with simple dependencies. Therefore, these components are highly suitable for parallel execution, aligning well with the load-balancing strategy proposed in this paper.
The execution platform we used is a heterogeneous cluster. This platform consists of thirty dual-core servers (Intel Pentium G4520 @ 3.60 GHz, 8 GB memory; nodes 1–30), three 8-core servers (Intel Xeon Silver 4110 @ 2.10 GHz, 64 GB memory; nodes 31–33), and three 10-core servers (Intel Xeon Silver 4114 @ 2.20 GHz, 256 GB memory; nodes 34–36). The input data included weather information such as altitude, temperature, relative humidity, air pressure, and wind field within 48 h from 7 August to 8 August 2021, in Sichuan, China. The output was 48 h of precipitation data from 9 August to 10 August 2021.
Table 3 presents the results of node aggregation on this heterogeneous cluster. Based on the results of the aggregation operation, we deployed a component application on Sc2. For the initial threshold values, we set LT = 2, MT = 10 for a single-core node, LT = 4, MT = 20 for a dual-core node, and LT = 16, MT = 80 for an 8-core node. Node 33 was selected as the startup node. During the application execution, the task information of the component instances was sent to the low-load nodes in Sc2, which generated the corresponding component instances and executed them. In multicore nodes, the CPU core is the basic unit that performs the tasks of the component instances. We counted the number of component instances completed on each CPU core and the time required to complete these tasks.
In
Figure 8, the 52 points on the
x-axis each represent a CPU core. Points 1–28 represent the CPU cores on the first 14 dual-core nodes of sub-cluster Sc
2. For example, points 1 and 2 represent the two CPU cores of node 8 (the first dual-core node in Sc
2). Points 29–52 represent the CPUs of the last three 8-core nodes on Sc2; that is, the twenty-four CPU cores on nodes 31, 32, and 33. The
y-axis represents the number of component instances completed by each CPU core. For the first 14 dual-core nodes, the CPU frequency is 3.60 GHZ, the average number of component instances completed by each CPU core is 34, and the variance is 3.6. As shown in
Figure 8, the number of component instances completed on these CPU cores is approximately evenly distributed, which reflects the effect of our load-balancing mechanism. For the last three 8-core nodes, the average number of component instances completed by each CPU core is 28, which is slightly lower than that for the dual-core nodes. This is because the CPU frequency of the 8-core nodes is low (2.10 GHz). The variance in the number of component instances completed by the CPU cores of the 8-core nodes is 5.02, which is approximately evenly distributed. Our load-balancing mechanism embodies the principle of “able people should do more work”.
A CPU core with a strong processing capacity can quickly complete its existing tasks, thus returning to a low load status and becoming able to accept more new tasks. Meanwhile, our approximately even distribution does not imply that the numbers of component instances completed by the cores with the same frequency are identical. As
Figure 8 reveals, CPU cores with the same frequency complete different numbers of instances. This is because the component instances vary in size. For CPU cores with the same frequency, over the same period, a core may be able to complete multiple small instances, whereas another core with large instances may only be able to complete one large instance.
Figure 9 shows the statistics of the effective working time on each node. The effective working time refers to the total time spent running all component instances assigned to a CPU core.
A comparison of
Figure 8 and
Figure 9 reveals that there is a small gap in the number of component instances executed in the different CPU cores that is due to the difference in the size of the component instances. However, from the perspective of effective working time, each CPU core completed nearly the same amount of work, demonstrating the effect of our load-balancing mechanism.
3.2. Performance and Speedup Test
In addition to the proposed PCDDB method, we tested two other cases in the performance and speedup tests. One is a case in which a static load-balancing mechanism is used; that is, all components are assigned to each computing node only at the beginning of the application, and the distribution does not change during the process. The other is a dynamic centralized load-balancing method, which arranges monitoring agents on each computing node, collects the load information of the computing node, and sends it to a central scheduler, which uniformly generates a load migration strategy and assigns the component instances to nodes with light load.
We first compared the performances of the three methods through experiments. The PCDDB version MM5 application was deployed on cluster Sc
2. We set LT = 2 and MT = 10 as the initial threshold values of the corresponding threshold on a single-core node. The values on the dual-core nodes and the 8-core nodes were multiplied by the corresponding number of cores. The applications using the other two load-balancing methods were deployed on a cluster composed of fourteen randomly selected dual-core nodes and three 8-core nodes. The size of the input data was varied, and the execution times of the applications using the three different load-balancing methods were recorded. The input data range spans from 0 to 400 M, with measurements taken at regular intervals of 10 (i.e., 0, 10, 20, 30, …, 400), resulting in a total of 41 experimental trials for each method. The results are presented in
Figure 10. The static load-balancing decision was made prior to application execution and thus cannot account for the load conditions of nodes during runtime. It assigns components to different nodes before execution based solely on the application’s component definitions and process requirements, which results in inferior performance compared to the other two methods. The dynamic, centralized load-balancing method, on the other hand, deployed component instance tasks to nodes with lighter loads during application execution, based on real-time load conditions of the computing nodes. This approach outperforms the static method. However, it is entirely dependent on a single central scheduler for generating and executing load scheduling decisions, which places a significant burden on the management node hosting the scheduler and incurs a relatively high load-balancing overhead. In contrast, the PCDDB method’s dynamic, distributed load-balancing decision-making captured the load conditions of computing nodes in real time and distributed the load-balancing overhead across various computing nodes within a sub-cluster that enjoyed good communication conditions. This approach has demonstrated the best performance compared to the other two methods.
To further evaluate the advantages of the proposed node aggregation in reducing the communication overhead of the load-balancing mechanism, we deployed the MM5 component application on sub-cluster SC
5. A cluster was composed of eighteen randomly selected dual-core nodes and three 10-core nodes. We set LT = 4, MT = 20 on the dual-core node and LT = 20, MT = 100 on the 10-core node. While changing the size of the input data, we recorded the communication costs of load-balancing. The communication cost includes the transmission of the low-load status from the computing node to the startup node in the load-balancing algorithm, transmission of the component instance task allocation requests between nodes, and replies sent by nodes accepting certain component instances to the startup node. Experiments were conducted across a range of 0 to 400 M in increments of 10 (0, 10, 20, …, 400), totaling 41 data points.
Figure 11 shows the result of the communication cost test, revealing that when the proposed load-balancing mechanism was taken, deploying the application on a sub-cluster generated by our aggregation algorithm lowered the communication cost.
To test the scalability of the PCDDB method, we selected several dual-core nodes in cluster Sc5 to deploy the weather forecasting application. There are 18 dual-core nodes in Sc5. We tested 1, 2, 4, 8, and 16 nodes, which correspond to the cases of 2, 4, 8, 16, and 32 cores, respectively. We used the three load-balancing methods defined above to calculate the corresponding speedup with respect to a single core (without any load-balancing strategy). For the PCDDB method, we tested both LT = 4, MT = 12 and LT = 4, MT = 20 for the dual-core nodes.
Table 4 presents the result of the speedup test. As the number of cores increases, the PCDDB method achieved better speedup results than the static and centralized methods. When using the PCDDB method, if the number of computing nodes is large and the number of applications running on the sub-cluster is small, that is, the overall load of the sub-cluster is light and there are many low-load nodes, we should reduce the value of MT appropriately so that each low-load node is assigned fewer new tasks. This enables more low-load nodes to be utilized to achieve better performance. In
Table 4, the speedup using MT = 12 is higher than that using MT = 20 for 8, 16, and 32 cores. On the contrary, if there are fewer nodes in a sub-cluster and the value of MT is small, some tasks will not be assigned in time. These tasks will be returned to the startup node for reallocation. If this occurs more than once, the system performance will be compromised. As
Table 4 reveals, the speedup obtained using MT = 12 on the 2- and 4-core nodes is relatively poor compared with that obtained using MT = 20. Before performing the PCDDB method, appropriate values of LT and MT should be set according to the number of nodes in a sub-cluster and the overall workload of the sub-cluster, which will improve the load-balancing result.




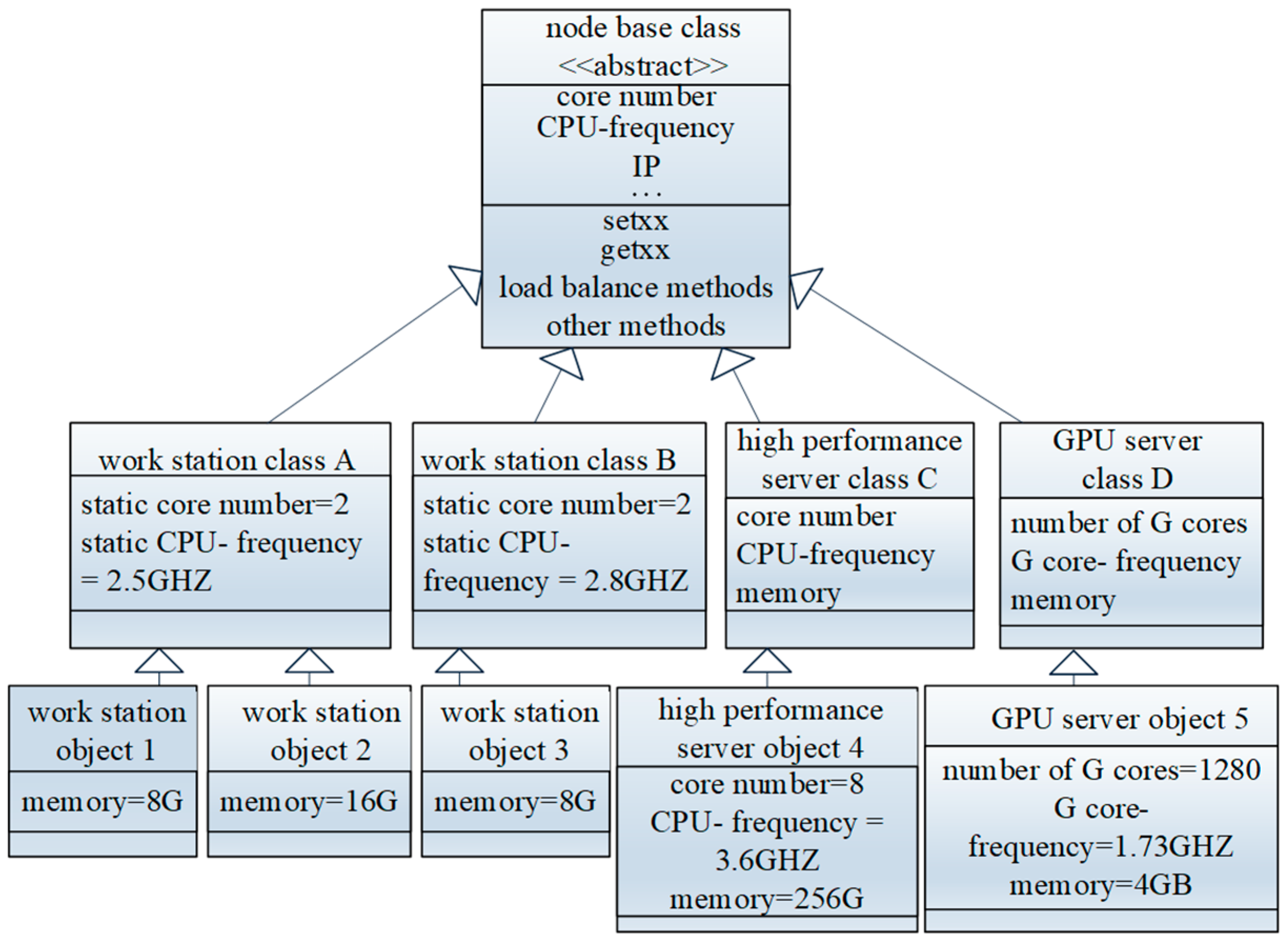










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}