1. Introduction
Wind energy is essential in the global transition to sustainable energy, as it harnesses the power of wind, a renewable and abundant resource, to produce clean electricity without harmful emissions. Wind is a global phenomenon that countries around the world can tap into, and the versatility of wind production permits wind turbines to be deployed offshore as well as on land [
1]. Wind energy is produced by wind turbines, which convert kinetic energy from wind into electrical power by using large blades that rotate a generator [
2,
3]. As one of the fastest-growing sources of renewable energy, wind turbines play a significant role in reducing reliance on fossil fuels, lowering greenhouse gas emissions, and mitigating climate change [
4,
5]. In the world energy arena, wind energy is the predominant renewable energy source, and wind power production more than tripled between 2010 and 2020, increasing from 198 gigawatts (GW) to 743 GW in that span [
6]. Wind energy is sourced from wind farms, which feature scores of wind turbines spread out across a large area. Any effort to predict wind power production must consider the dynamics of every single wind turbine in a wind farm, which involves an immense amount of data [
7]. However, several challenges must be overcome to successfully predict wind power production. Among the most significant obstacles to wind power forecasting is the variability of wind [
8]. Wind power is inconsistent regardless of the characteristics of the wind farm. Even if a location with a high average wind volume is selected, power output remains susceptible to factors such as the weather and the season, which can prove disruptive to the power grid supplied by the wind farm [
9]. This is a significant drawback of wind energy, as the power grid relies on a consistent power input to meet the regular power needs of the customers. Furthermore, fluctuations in wind volume decrease the efficiency of the integration of wind energy into the power grid, increasing operating costs compared with those of fossil fuels [
10]. However, adjustments can be made to manage changes in operating conditions if the wind power can be predicted in advance [
11]. Accordingly, the ability to accurately forecast wind power production is of immense value to the wind energy sector.
Accurate wind power prediction is challenging because the conditions of each wind farm are different. Wind power parameters, such as geography, wind turbine type, number of wind turbines, and weather patterns, differ between wind farms, which makes creating a single rigid prediction model impractical [
10]. Prediction methods can be physical or statistical in nature. Physical models are supplied with weather data, including air pressure, humidity, water vapor concentrations, and air speed. These inputs are used to generate wind power output using thermodynamics, but the utility of these models is limited due to the need for up-to-date conditions and a high cost of local and imprecise data [
12,
13]. Statistical methods involve supplying the model with historical wind conditions and power data. These data are used to train the model to forecast site-specific wind power production based on trends and patterns identified over time [
13,
14]. Statistical wind power prediction methods are most effective when employing intelligent artificial intelligence (AI) algorithms featuring deep learning [
15]. Those deep learning models are artificial neural networks (ANN), which include multiple hidden layers that allow the model to process inputs and determine outputs of interest, such as future wind power outputs [
16]. Those deep learning models can analyze large datasets of historical weather patterns, real-time meteorological data, and turbine performance to forecast wind conditions more accurately, allowing wind farms to dynamically adjust turbine settings [
17]. This approach to wind power prediction is not new, as statistical time series models, such as autoregressive integrated moving average (ARIMA) and kernel extreme learning machine (KELM), are frequently used for process prediction. More recently, deep learning models, e.g., long short-term memory (LSTM), with elements, e.g., gated recurrent units (GRU), have become more prevalent in the prediction of wind power [
9]. As a special case of recurrent neural networks (RNN), LSTM has greater accuracy and fewer errors in wind power prediction relative to other methods. Convolutional neural networks (CNNs) are also used in time series prediction, although limitations include CNNs’ tendency to consider only ordinary feature extraction, while neglecting to capture time series modeling characteristics [
18]. This results in maximum efficiency, improved grid integration, and reduced downtime of each turbine, which stabilizes energy production, enhances reliability of the grid, and reduces operational costs, which would help to fully unlock the potential of wind energy [
19]. These AI models offer the potential for long-term wind power prediction, but limitations of existing models limit their utility.
Numerous wind power prediction methodologies using the models introduced previously have been published, each of which has made valuable contributions to advance the field. One study exploring this area is the development of a CNN-LSTM deep learning model to perform 2-D regional short-term wind speed forecasting. This study combined a CNN and LSTM to develop a model capable of forecasting wind speed more accurately than other similar models. The geographic data from the wind farm was used to train the CNN component, while the chronological data were used to train the LSTM module. The feature extraction of the CNN and historical prediction of the LSTM were input back into the CNN to predict wind speed components, with very accurate results [
20]. Another study involved developing a novel genetic LSTM (GLSTM) model for wind power forecasting. This study created a GLSTM framework that combined LSTM with a genetic algorithm (GA) for short-term wind power prediction. GA is an optimization algorithm that helps address the limitations of computing power and time that wind energy prediction models require to obtain accurate results. This added optimization increases the capability of LSTM layers, which bolsters the sequential data learning capability of the existing LSTM model. Results from this study indicated average improvements between 6% and 30% compared with existing wind power prediction models, including standard LSTM [
14]. Both of these models, as well as countless others, considerably bolstered the quality of wind power forecasting in the short term. However, short-term predictions only provide a wind power output outlook of days at best, whereas accurate long-range prediction of wind power would allow turbine operators to better optimize the production of power. While traditional models, such as LSTM, GRU, RNN, and ARIMA, are effective for time series prediction, they have limitations in handling highly complex, multistep forecasting tasks of the nature needed for wind power prediction [
21,
22]. Classic RNNs suffer from the vanishing gradient problem, hindering their ability to learn long-term dependencies in sequential data [
23,
24].
Beyond the above studies, some Transformer-based architectures have been used for wind power forecasting as well. A Transformer-based deep neural network incorporating wavelet transform showed promising results in 6 h ahead wind power prediction [
25]. Another Transformer-based model was developed to capture long-term dependencies and key information within wind data, enabling the extraction of correlations between wind farms and wind power forecasting [
26]. Wu et al. [
27] used ensemble empirical mode decomposition to convert the original wind speed sequence from one to sixteen dimensions and a Transformer model to directly model the multidimensional wind speed data. A multihead attention mechanism within Transformer neural networks was developed in [
28] to learn sequential dependencies between wind turbines to qualify spatial information. Xiang et al. [
29] combined LSTM with a vision Transformer model to better utilize the relationship between extracted characteristics and the desired output for accurate prediction. While the above Transformer-based models represent improvements from traditional LSTM and GRU architectures, their high computational cost for large quantities of wind power data is a concern. The input to the prediction model is enormous, and while performing a time series analysis, further data are produced that must also be stored and remembered. Mechanisms, e.g., GRUs [
30] and empirical mode decomposition [
16], permit previous information to be discarded and decomposited, and while the LSTM architecture does not permit the complete discarding of past information, losses do occur, which affects the quality of the prediction. To improve the performance of LSTM, particularly for memory and data storage concerns, further modification of the LSTM model is required, which introduces the need for extended LSTM (xLSTM).
xLSTM improves upon these models by incorporating additional layers and mechanisms, such as attention mechanisms, to capture more intricate temporal dependencies and better handle non-linear relationships in the data. This results in improved accuracy, particularly for long-range predictions in energy systems. The proposed xLSTM architecture further extends this paradigm by implementing a dual-pathway approach that combines scalar and matrix memory structures, thereby addressing the inherent limitations of conventional recurrent models in capturing multiscale temporal patterns in wind energy data. Moreover, the empirical validation conducted across diverse seasonal conditions demonstrates the xLSTM model’s robustness and adaptability to varying meteorological phenomena, establishing a foundation for more reliable integration of intermittent renewable energy sources into existing power grid infrastructures.
The remainder of this paper is organized as follows:
Section 2 presents the xLSTM architecture, including detailed formulations of both sLSTM and mLSTM components.
Section 3 outlines the SCADA data processing methodology for wind power forecasting, encompassing data preprocessing, quality control procedures, and hyperparameter optimization strategies.
Section 4 presents the empirical results of the xLSTM model implementation, with detailed analyses of prediction accuracy across various wind speed regimes and seasonal patterns. Finally,
Section 5 summarizes the major findings, discusses the implications for wind energy forecasting applications, and proposes directions for future research development.
5. Conclusions
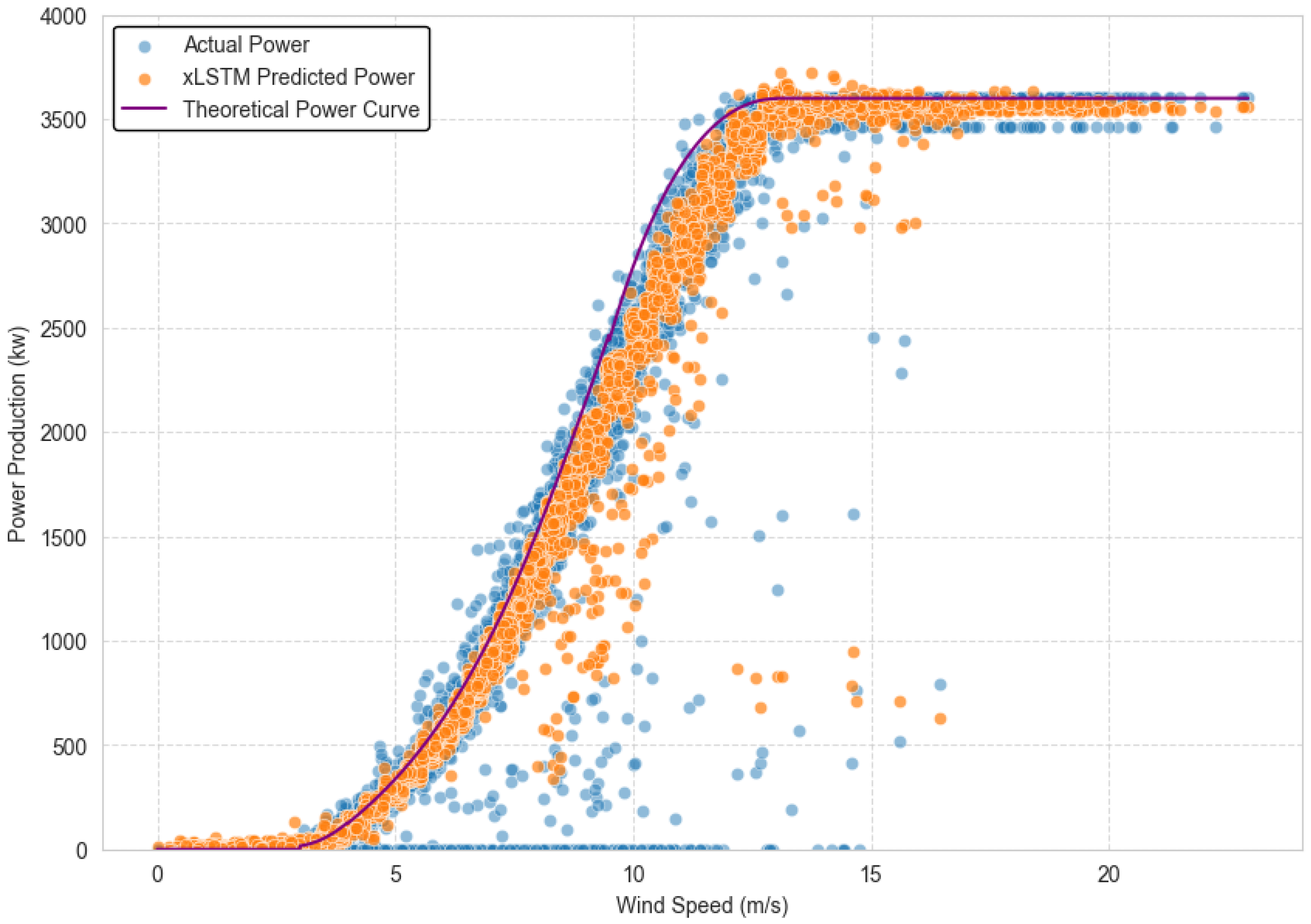
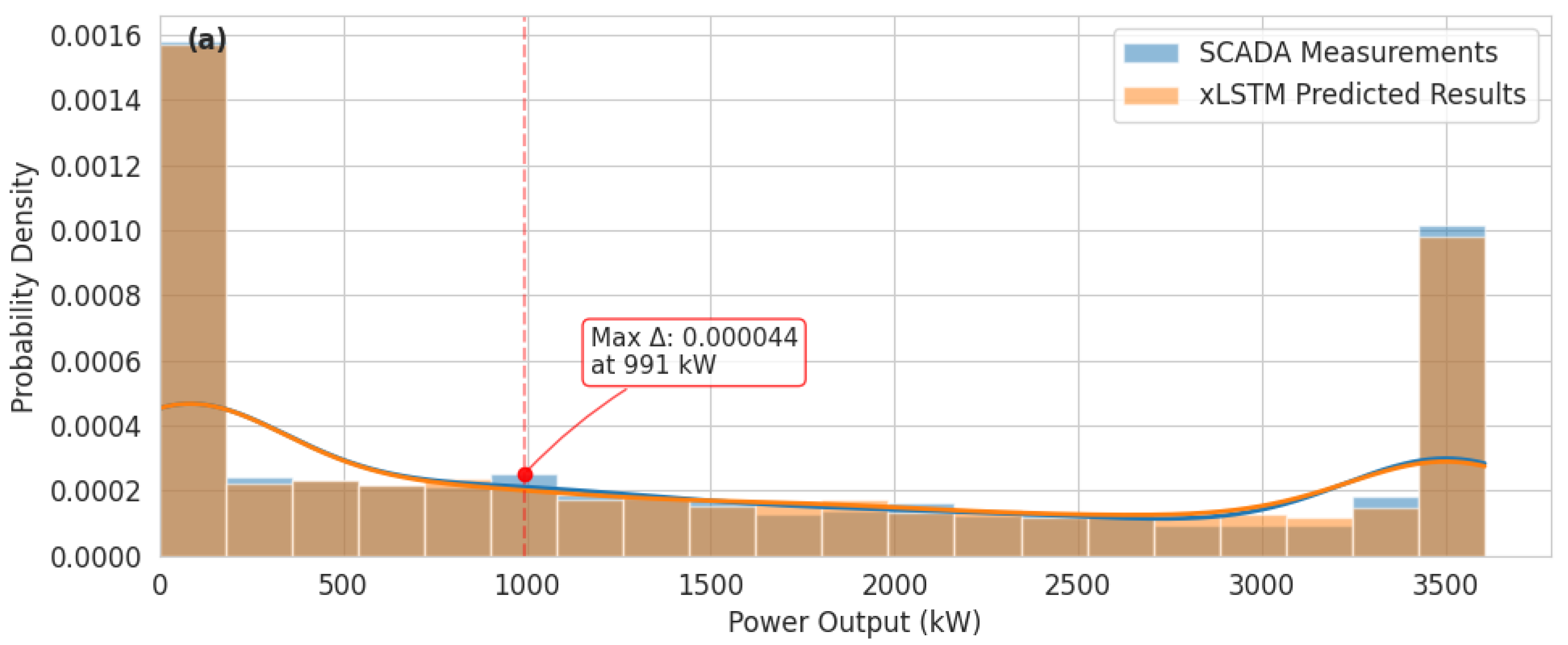
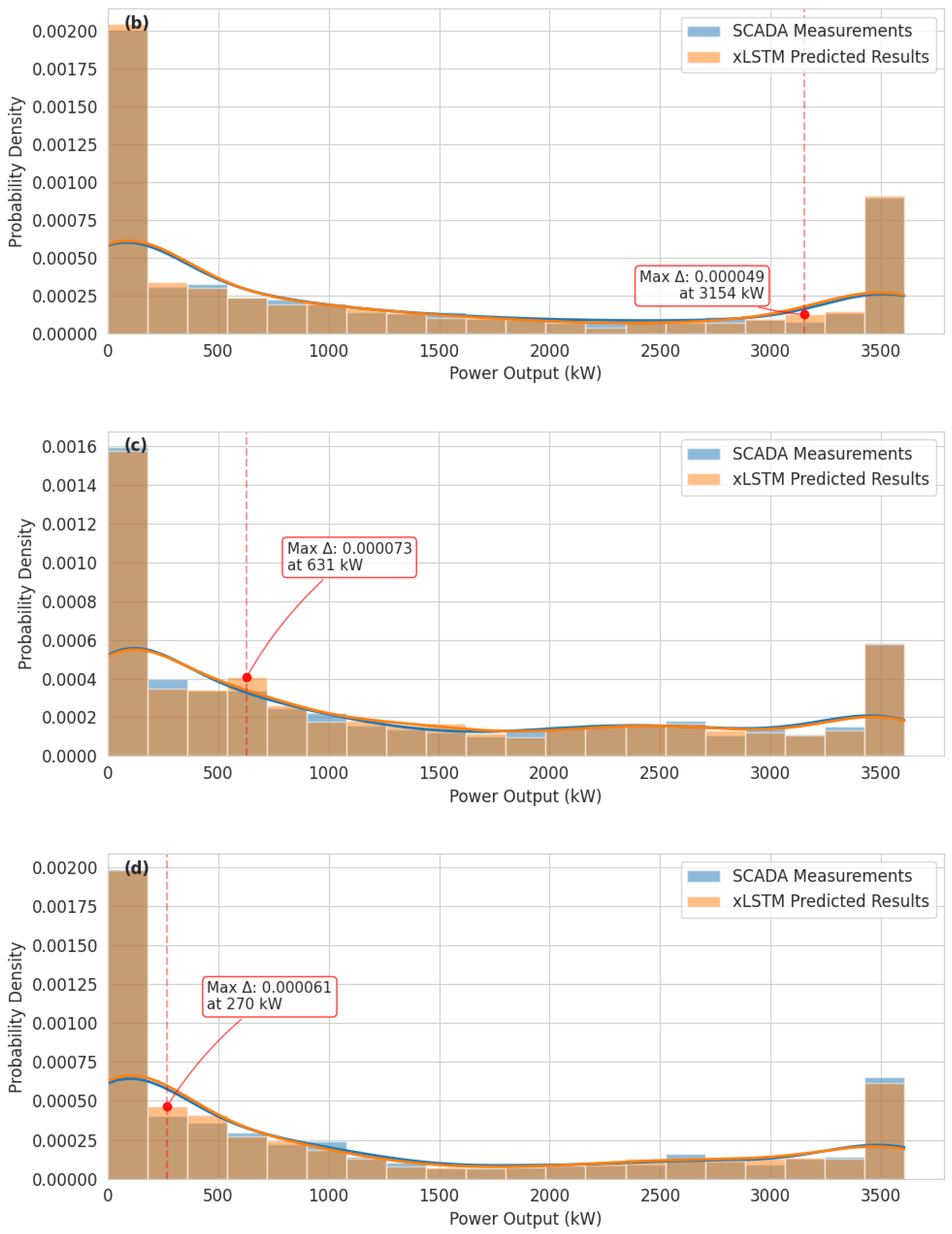
This study introduces a novel xLSTM architecture for wind power forecasting that addresses fundamental limitations in conventional recurrent neural networks. The xLSTM model’s key innovations, which are exponential gating with memory mixing and matrix memory structures, enable more effective processing of temporal dependencies in wind power data. Empirical evaluation using wind turbine SCADA data demonstrates the xLSTM model’s superior predictive performance across diverse operational conditions, achieving comprehensive metrics of = 0.923, MAPE = 8.47%, RMSE = 34.6 kW, and MAE = 36.2 kW across all wind speed regimes.
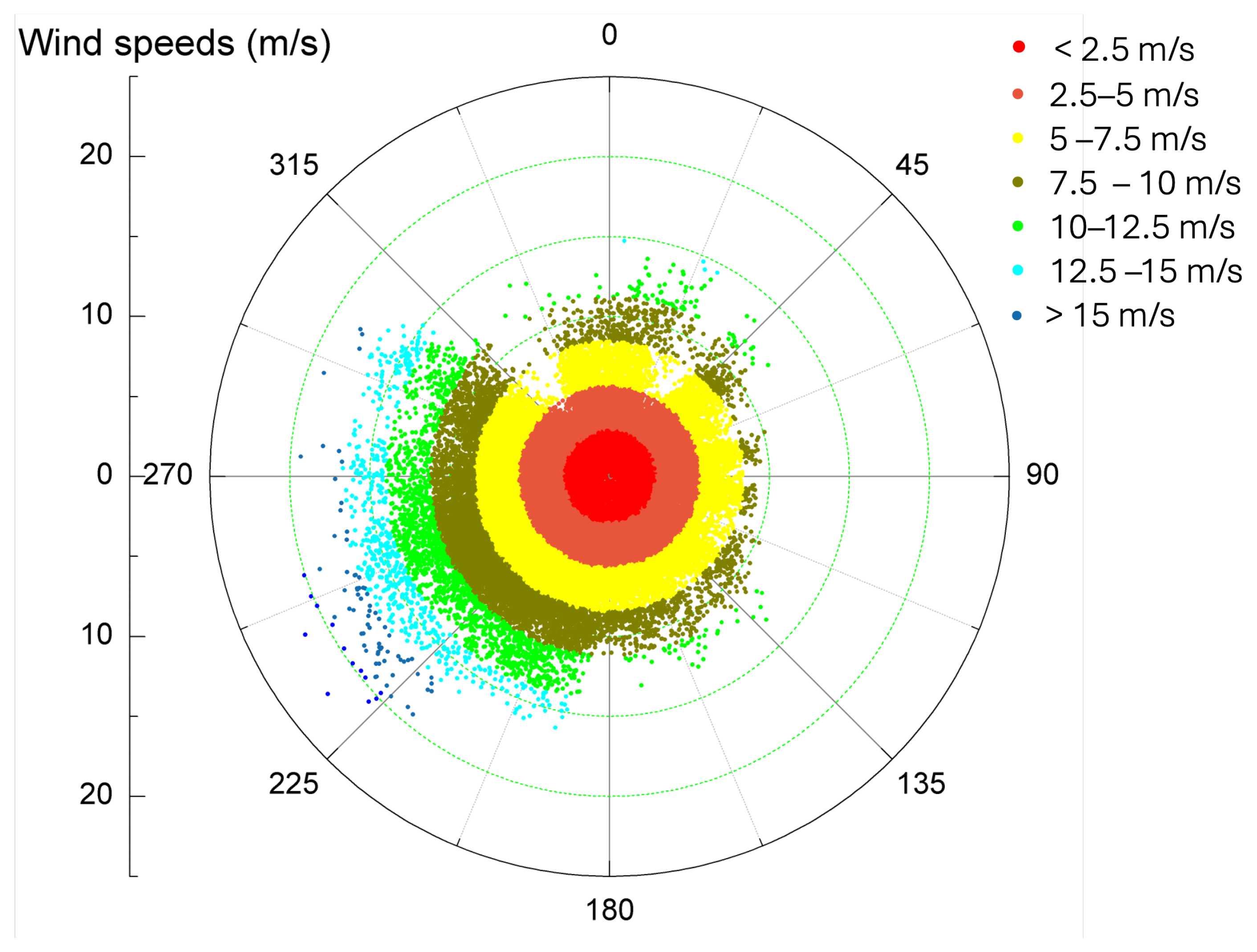
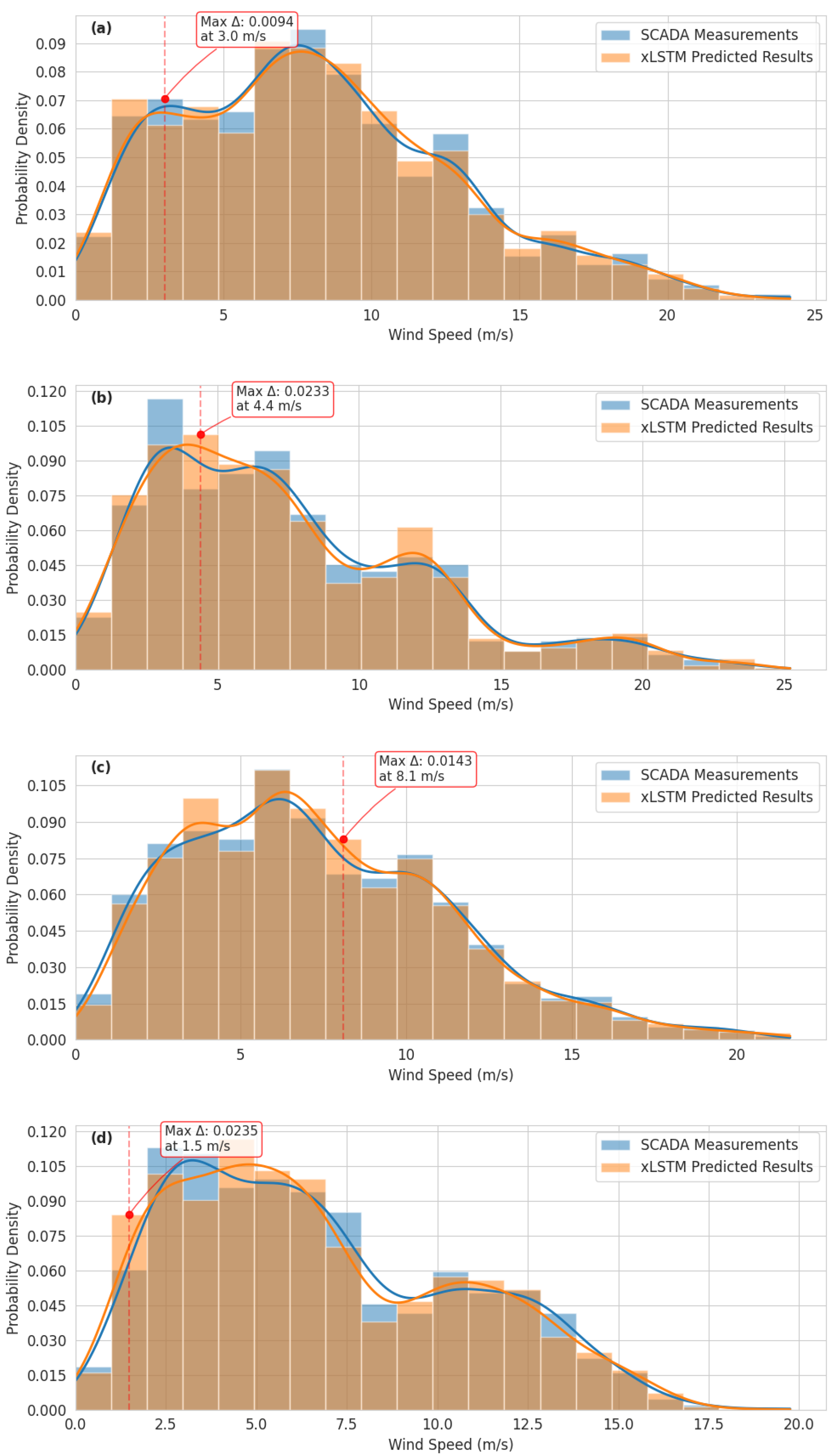
The xLSTM architecture demonstrates particularly strong performance in high wind speed conditions (>12 m/s), attaining an value of 0.954 and MAPE of 4.21%. This enhanced accuracy in the power curve’s plateau region provides significant value for operational planning and grid integration during periods of maximum generation. Seasonal analysis confirms the model’s robust temporal pattern recognition capabilities, with consistently strong predictive performance across all seasons ( values: 0.963–0.987) and effective modeling of both unimodal winter distributions and more complex bimodal patterns characteristic of transitional seasons.
The comparative analysis with established forecasting models demonstrates that xLSTM consistently outperforms traditional approaches like ARIMA (by 35.3%), standard recurrent architectures like LSTM and GRU (by approximately 6–7%), and even advanced models such as Transformers (by 2.3%) across all evaluation metrics. These quantitative improvements, particularly the 21.1% reduction in MAPE compared with conventional LSTM, validate the architectural enhancements of exponential gating and matrix memory structures as significant contributions to the field of wind power forecasting.
The architectural components work synergistically, with mLSTM enhancing parallel sequence processing and information flow while sLSTM with exponential gating enables more effective revision of stored information through scalar cell states. This complementary integration provides a robust framework for modeling the complex, non-linear relationships inherent in wind power generation. The xLSTM model demonstrates significant improvements over conventional approaches in computational efficiency, prediction accuracy, and generalizability across varying temporal and meteorological conditions.
Future work will address the limitations of our current study by expanding both the spatial and temporal dimensions of our analysis. Future work will extend the current forecasting framework of xLSTM to multiturbine wind farm settings, which will enable investigation of inter-turbine interactions, wake effects, and spatial dependencies that affect aggregate power generation. The xLSTM model’s temporal robustness will be enhanced through the incorporation of physics-based constraints and meteorological features that may improve long-term stability and performance under extreme weather conditions. Efficient transfer learning mechanisms will be developed to continuously update model parameters as new operational data becomes available, reducing the need for complete retraining while maintaining prediction accuracy across extended operational periods. The generalizability concerns identified in the current implementation will be collectively addressed by these developments while preserving the computational efficiency advantages of the xLSTM architecture.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}