

A Two-Stage Multi-Objective Optimization Algorithm for Solving Large-Scale Optimization Problems


Abstract
1. Introduction
- (1)
- The decision variable clustering strategy effectively categorizes all variables into two distinct groups: those related to diversity and those related to convergence, thereby facilitating the evolutionary process. This approach employs the angle between the convergence direction and the sampled solution as a distinguishing feature, subsequently clustering these features using the k-means method. Variables associated with smaller angles contribute more significantly to convergence, whereas those with larger angles play a more substantial role in enhancing diversity.
- (2)
- By employing the non-dominated dynamic weight aggregation method, Pareto optimal solutions are identified in multi-objective optimization problems (MOPs) with varying Pareto front shapes. Subsequently, the optimization problem involving reference lines is addressed by leveraging these solutions within the Pareto optimal subspace, thereby resolving the population diversity issue.
- (3)
- To assess the efficacy of the proposed algorithm, comprehensive empirical evaluations were performed on a range of benchmark problems. These evaluations involved comparisons with several advanced MOEAs designed for addressing both multi-objective optimization problems and large-scale optimization challenges. The experimental results conclusively demonstrate that the algorithm introduced in this study is capable of effectively solving large-scale optimization problems characterized by numerous decision variables, achieving commendable performance outcomes.
2. Background
2.1. Multi-Objective Optimization
2.2. Large-Scale Multi-Objective Optimization
3. Proposed Algorithm
| Algorithm 1 Main Framework of LSMOEA-VT |
|
| 1. P ← Initialize(N); |
| 2. [DV, CV] ← VariableClustering (P, nSel, nPer); |
| 3. subCVs ←InteractionAnalysis (P, CV, nCor); |
| 4. while termination criterion not fulfilled do |
| 5. P′ ← ConvergenceOptimization(P, subCVs); |
| 6. Q ← Find some Pareto-optimal solutions of |
| 7. Ω ← Learn the subspace based on Q; |
| 8. Update the given reference lines ; |
| 9. P ← Diversity maintaining with in Ω; |
| 10. Return P. |
3.1. Clustering of Decision Variables
| Algorithm 2 Clustering of Decision Variables | |
| Input: pop, number of candidate solutionsSelNum, number of perturbationPerNum Output: [Diver,Conver] | |
| 1. | for i = 1:n do |
| 2. | C ← Choose SelNum solutions from pop randomly; |
| 3. | for j = 1:SelNum do |
| 4. | Make perturbation for the i-th variable of C[j] for PerNum times to bring a generation SP and then normalize it; |
| 5. | Generate a line L for SP in objective space; |
| 6. | Angle[i][j] ← the angle between L and normal line of hyperplane; |
| 7. | MSE[i][j] ← the mean square error of the fitting; |
| 8. | end for |
| 9. | end for |
| 10. | CV ← {mean(MSE[i]) < 1 × 10−2}; |
| 11. | [C1, C2] ← apply k-means to group all variables into two categories adopting Angle as feature; |
| 12. | if CV⋂C1 ≠ ∅ and CV⋂C2 ≠ ∅ then |
| 13. | CV ← CV⋂C, C is either C1 or C2 depending on which of the average of Angle is smaller; |
| 14. | end if |
| 15. | DV ← {j ∉ CV } |
3.2. Interaction Analysis
| Algorithm 3 Interaction Analysis | |
| Input: pop, Conver, number of chosen solutions CorNum Output: subCVs | |
| 1. set subCVs as ∅; | |
| 2. for all the ν ∈ CV do | |
| 3. set CorSet as ∅; | |
| 4. for all the Group ∈ subCVs do | |
| 5. for all the u ∈ Group do | |
| 6. flag ← False; | |
| 7. for i = 1: CorNum do | |
| 8. Choose an individual p from pop randomly; | |
| 9. if ν has interaction with u in individual p then | |
| 10. flag ← True; | |
| 11. CorSet = {Group} cupCorSet; | |
| 12. Break; | |
| 13. end if | |
| 14. end for | |
| 15. if flag is True then | |
| 16. Break; | |
| 17. end if | |
| 18. end for | |
| 19. end for | |
| 20. if CorSet = ∅ then | |
| 21. subCVs = subCVs∪{{ν}}; | |
| 22. else | |
| 23. subCVs = subCVs/CorSet; | |
| 24. Group ← all variables in CorSet and ν; | |
| 25. subCVs = subCVs∪{Group}; | |
| 26. end if | |
| 27. end for | |
3.3. Pareto Optimal Subspace Learning
| Algorithm 4 Pareto-Optimal Subspace Learning | |
| 1. | Input: The Pareto-optimal solutions Q, a threshold value ε, the lower bound = , the upper bound = . Output: The learned Pareto-optimal subspace Ω |
| 2. | Let a matrix M ∈ R|P|×n denote the solutions in Q |
| 3. | mean ← Calculate the mean values of M; |
| 4. | M′ ← Update M by subtracting mean; |
| 5. | ← Calculate the eigenvalues of the covariance matrix of M′; |
| 6. | ← Record the positions of the eigenvalues with the descending order; |
| 7. | |
| 8 | While < ε do |
| 9. | |
| 10. | end |
| 11. | median ← Calculate the median value of each column in M; |
| 12. | for i ← j + 1 to n do |
| 13. | ← Copy the component of median; |
| 14. | ← Copy the component of median; |
| 15. | end |
| 16. | Ω ← All points in ; |
| 17. | Return Ω. |
3.4. Maintaining Population Diversity
| Algorithm 5 Diversity Maintaining | |
| Input: The Pareto-optimal subspace Ω, the updated reference lines ; Output: P | |
| 1. | ← ∅ |
| 2. | for i ← 1 to m do |
| 3. | ← Initialize a vector of m elements with zeros except for the i-th element with one; |
| 4. | ← Solve the single-objective optimization problem |
| 5. | ; |
| 6. | end |
| 7. | ← ∅ |
| 8. | ← ∅ |
| 9. | for i ← 1 to m do |
| 10. | ← The maximal element at the i-th component of ; |
| 11. | ← The minimal element at the i-th component of ; |
| 12. | end |
| 13. | for each do |
| 14. | r ← |
| 15. | end |
| 16. | P ← ∅ |
| 17. | for i ← 1 to N do |
| 18. | ; |
| 19. | P ← P∪; |
| 20. | end |
| 21. | Return P. |
4. Experiments and Results
4.1. Experimental Setting
4.2. Experiments and Analysis
4.2.1. Results of Problems with 30 Variables
4.2.2. Performance Comparison Between LMEA and Existing MOEAs on Large-Scale MaOPs
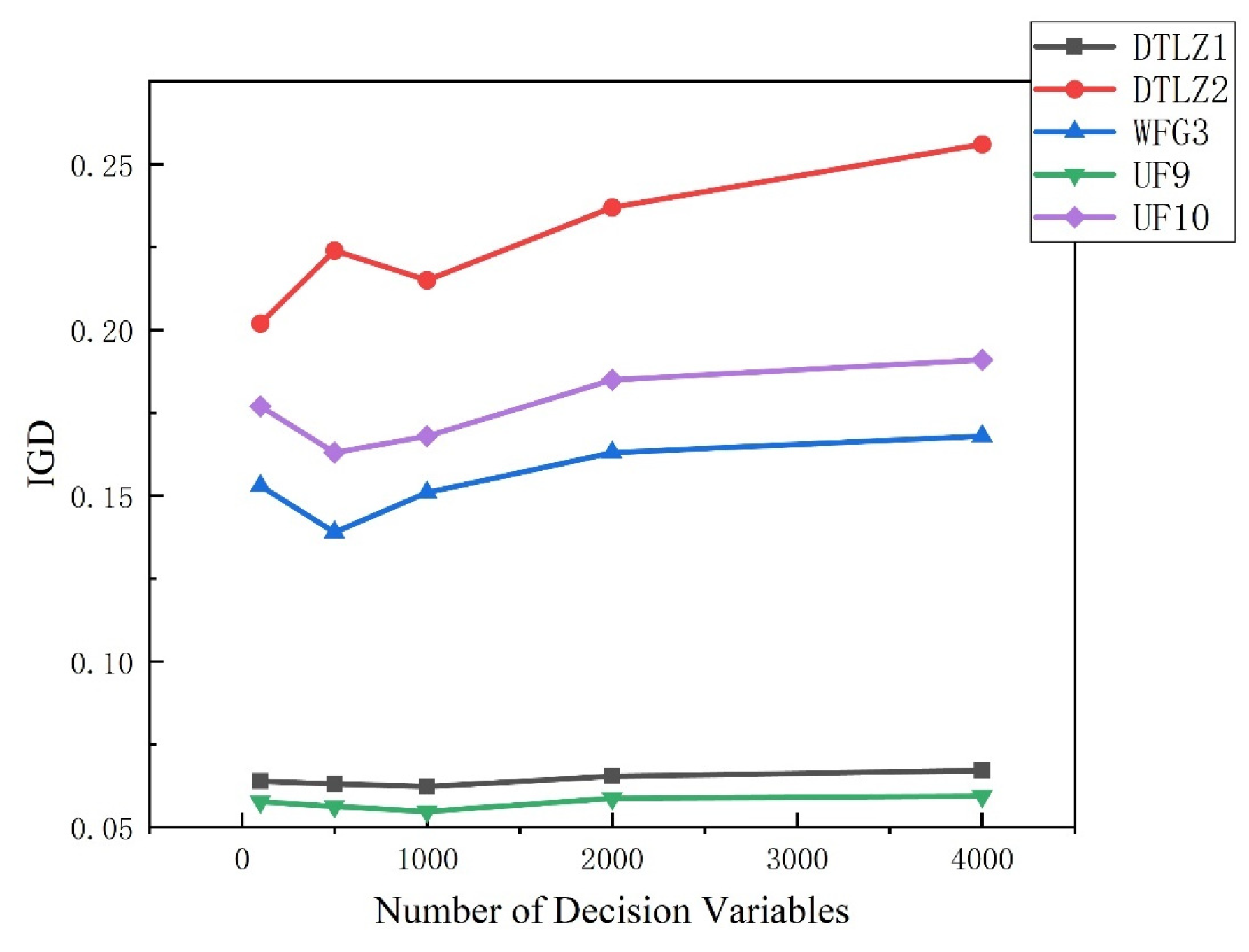
4.2.3. Performance of LMEA on Large-Scale MaOPs with 2000 and 4000 Decision Variables
4.2.4. Efficiency Comparison Between LSMOEA-VT and Other Algorithms
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part i: Solving problems with box constraints. IEEE Trans. Evol. Comput. 2014, 18, 577–601. [Google Scholar] [CrossRef]
- Liu, C.; Liu, J.; Jiang, Z. A multiobjective evolutionary algorithm based on similarity for community detection from signed social networks. IEEE Trans. Cybern. 2014, 44, 2274–2287. [Google Scholar]
- Zhu, H.; Shi, Y. Brain storm optimization algorithm for full area coverage of wireless sensor networks. In Proceedings of the 2016 Eighth International Conference on Advanced Computational Intelligence (ICACI), Chiang Mai, Thailand, 14–16 February 2016; pp. 14–20. [Google Scholar]
- Guo, Y.; Liu, D.; Chen, M.; Liu, Y. An energy-efficient coverage optimization method for the wireless sensor networks based on multi-objective quantum-inspired cultural algorithm. In Proceedings of the Advances in Neural Networks ISNN 2013, Dalian, China, 4–6 July 2013; pp. 343–349. [Google Scholar]
- Fleming, P.J.; Purshouse, R.C.; Lygoe, R.J. Many-objective optimization: An engineering design perspective. In Proceedings of the 3rd International Conference on Evolutionary Multi-Criterion Optimization, Guanajuato, Mexico, 9–11 March 2005; pp. 14–32. [Google Scholar]
- Garcia, J.; Berlanga, A.; López, J.M.M. Effective evolutionary algorithms for many-specifications attainment: Application to air traffic control tracking filters. IEEE Trans. Evol. Comput. 2009, 13, 151–168. [Google Scholar]
- Kollat, J.B.; Reed, P.M.; Maxwell, R.M. Many-objective groundwater monitoring network design using bias-aware ensemble Kalman filtering, evolutionary optimization, and visual analytics. Water Resour. Res. 2011, 47, 1–18. [Google Scholar] [CrossRef]
- Potter, M.A.; Jong, K.A.D. A cooperative coevolutionary approach to function optimization. Third Parallel Prob. Solving Form Nat. 1994, 866, 249–257. [Google Scholar]
- Li, X.; Mei, Y.; Yao, X.; Omidvar, M.N. Cooperative co-evolution with differential grouping for large scale optimization. IEEE Trans. Evol. Comput. 2014, 18, 378–393. [Google Scholar]
- Chen, W.; Weise, T.; Yang, Z.; Tang, K. Large-scale global optimization using cooperative coevolution with variable interaction learning. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Krakow, Poland, 11–15 September 2010; pp. 300–309. [Google Scholar]
- Sun, Y.; Kirley, M.; Halgamuge, S.K. Extended differential grouping for large scale global optimization with direct and indirect variable interactions. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation, Madrid, Spain, 11–15 July 2015; pp. 313–320. [Google Scholar]
- Omidvar, M.N.; Li, X.; Yao, X. Cooperative co-evolution with delta grouping for large scale non-separable function optimization. In Proceedings of the IEEE Congress on Evolutionary Computation, New Orleans, LA, USA, 5–8 June 2011; pp. 1–8. [Google Scholar]
- Yang, Z.; Tang, K.; Yao, X. Multilevel cooperative coevolution for large scale optimization. In Proceedings of the IEEE Congress on Evolutionary Computation, Hong Kong, China, 1–6 June 2008; pp. 1663–1670. [Google Scholar]
- Zhang, X.; Tian, Y.; Cheng, R.; Jin, Y. A decision variable clustering-based evolutionary algorithm for large-scale many-objective optimization. IEEE Trans. Evol. Comput. 2016, 22, 97–112. [Google Scholar] [CrossRef]
- Hajikolaei, K.H.; Pirmoradi, Z.; Cheng, G.H.; Wang, G.G. Decomposition for large-scale global optimization based on quantified variable correlations uncovered by metamodeling. Eng. Optim. 2015, 47, 429–452. [Google Scholar] [CrossRef]
- Ghorpadeaher, J.; Metre, V.A. Clustering multidimensional data with PSO based algorithm. arXiv 2014, arXiv:1402.6428. [Google Scholar]
- Chen, W.N.; Zhang, J.; Chung, H.S.H.; Zhong, W.L.; Wu, W.G.; Shi, Y.H. A novel set-based particle swarm optimization method for discrete optimization problems. IEEE Trans. Evol. Comput. 2010, 14, 278–300. [Google Scholar] [CrossRef]
- Chen, W.N.; Zhang, J.; Lin, Y.; Chen, N.; Zhan, Z.H.; Chung, S.H.; Li, Y.; Shi, Y.H. Particle swarm optimization with an aging leader and challengers. IEEE Trans. Evol. Comput. 2013, 17, 241–258. [Google Scholar] [CrossRef]
- Yu, W.J.; Shen, M.; Chen, W.N.; Zhan, Z.H.; Gong, Y.J.; Lin, Y.; Liu, O.; Zhang, J. Differential evolution with two-level parameter adaptation. IEEE Trans. Cybern. 2014, 44, 1080–1099. [Google Scholar] [CrossRef]
- Ma, X.; Liu, F.; Qi, Y.; Wang, X.; Li, L.; Jiao, L. A multiobjective evolutionary algorithm based on decision variable analyses for multiobjective optimization problems with large-scale variables. IEEE Trans. Evol. Comput. 2015, 20, 275–298. [Google Scholar] [CrossRef]
- Wolfe, D.A.; Hollander, M. Nonparametric statistical methods. In Biostatistics and Microbiology: A Survival Manual; Springer: New York, NY, USA, 2009. [Google Scholar]
- Zille, H.; Ishibuchi, H.; Mostaghim, S.; Nojima, Y. A framework for large-scale multiobjective optimization based on problem transformation. IEEE Trans. Evol. Comput. 2018, 22, 260–275. [Google Scholar] [CrossRef]
- He, C.; Li, L.; Tian, Y.; Zhang, X.; Cheng, R.; Jin, Y.; Yao, X. Accelerating Large-Scale Multiobjective Optimization via Problem Reformulation. IEEE Trans. Evol. Comput. 2019, 23, 949–961. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, X.; Cheng, R.; Qiu, J.; Jin, Y. A competitive mechanism based multi-objective particle swarm optimizer with fast convergence. Inf. Sci. 2018, 427, 63–76. [Google Scholar] [CrossRef]
- Cheng, R.; Jin, Y. A competitive swarm optimizer for large scale optimization. IEEE Trans. Cybern. 2015, 45, 191–204. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, G.-G.; Li, K.; Yeh, W.-C.; Jian, M.; Dong, J. Enhancing MOEA/D with information feedback models for large-scale many-objective optimization. Inf. Sci. 2020, 522, 1–16. [Google Scholar] [CrossRef]
- Cheng, R.; Jin, Y.; Narukawa, K.; Sendhoff, B. A multiobjective evolutionary algorithm using gaussian process-based inverse modeling. IEEE Trans. Evol. Comput. 2015, 19, 838–856. [Google Scholar] [CrossRef]
- Deb, K.; Thiele, L.; Laumanns, M.; Zitzler, E. Scalable Test Problems for Evolutionary Multiobjective Optimization; Springer: London, UK, 2005. [Google Scholar]
- Huband, S.; Hingston, P.; Barone, L.; While, L. A review of multiobjective test problems and a scalable test problem toolkit. IEEE Trans. Evol. Comput. 2006, 10, 477–506. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhou, A.; Zhao, S.; Suganthan, P.N.; Liu, W.; Tiwari, S. Multiobjective Optimization Test Instances for the CEC 2009 Special Session and Competition; Nanyang Technological University: Singapore, 2008; Volume 264, pp. 1–30. [Google Scholar]
- Cheng, R.; Jin, Y.; Olhofer, M.; Sendhoff, B. Test problems for largescale multi- and many-objective optimization. IEEE Trans. Cybern. 2017, 47, 4108–4121. [Google Scholar] [CrossRef] [PubMed]
- Zhou, A.; Jin, Y.; Zhang, Q.; Sendhoff, B.; Tsang, E. Combining model-based and genetics-based offspring generation for multi-objective optimization using a convergence criterion. In Proceedings of the IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 892–899. [Google Scholar]
- While, L.; Hingston, P.; Barone, L.; Huband, S. A faster algorithm for calculating hypervolume. IEEE Trans. Evol. Comput. 2006, 10, 29–38. [Google Scholar] [CrossRef]

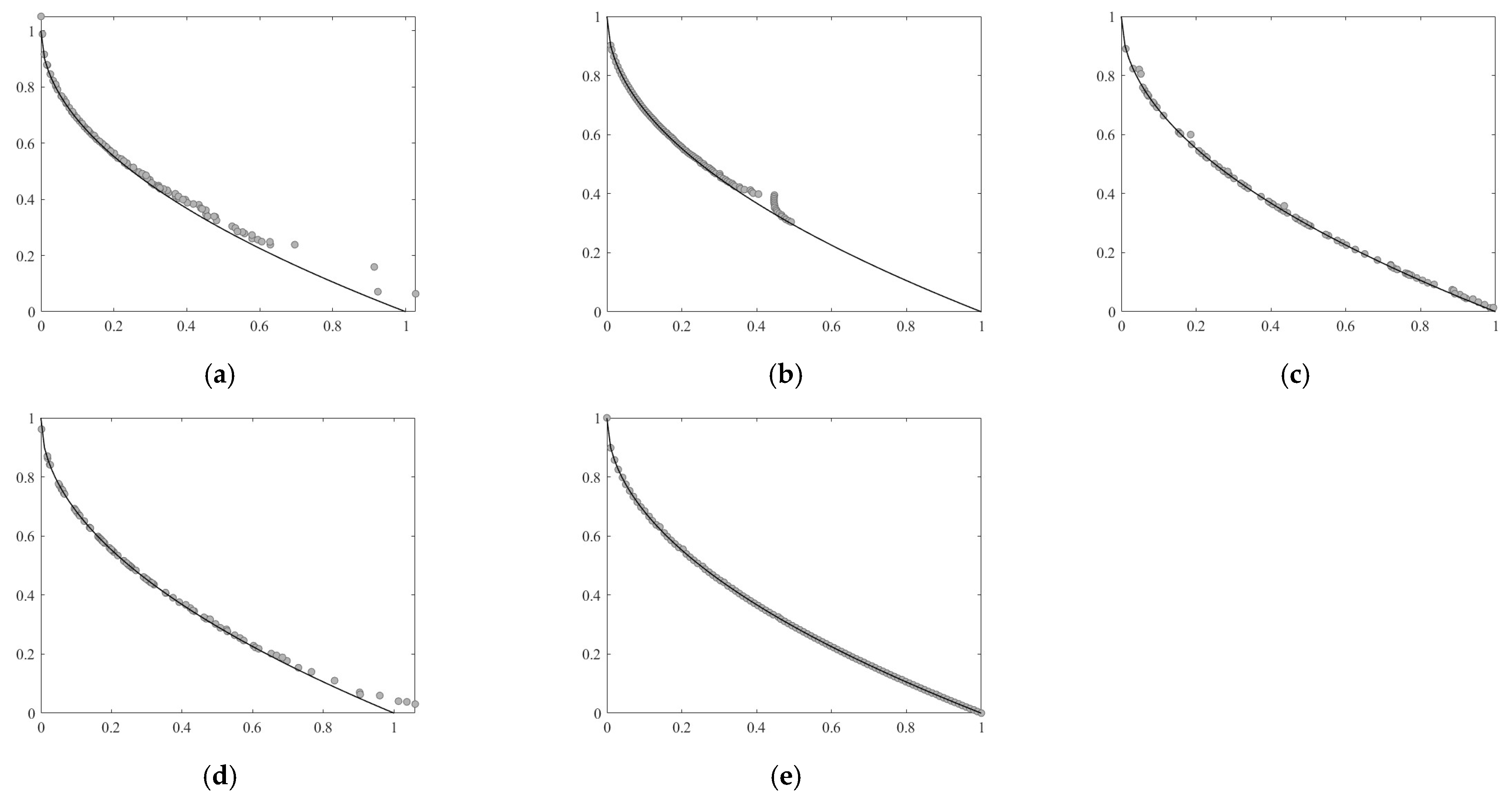
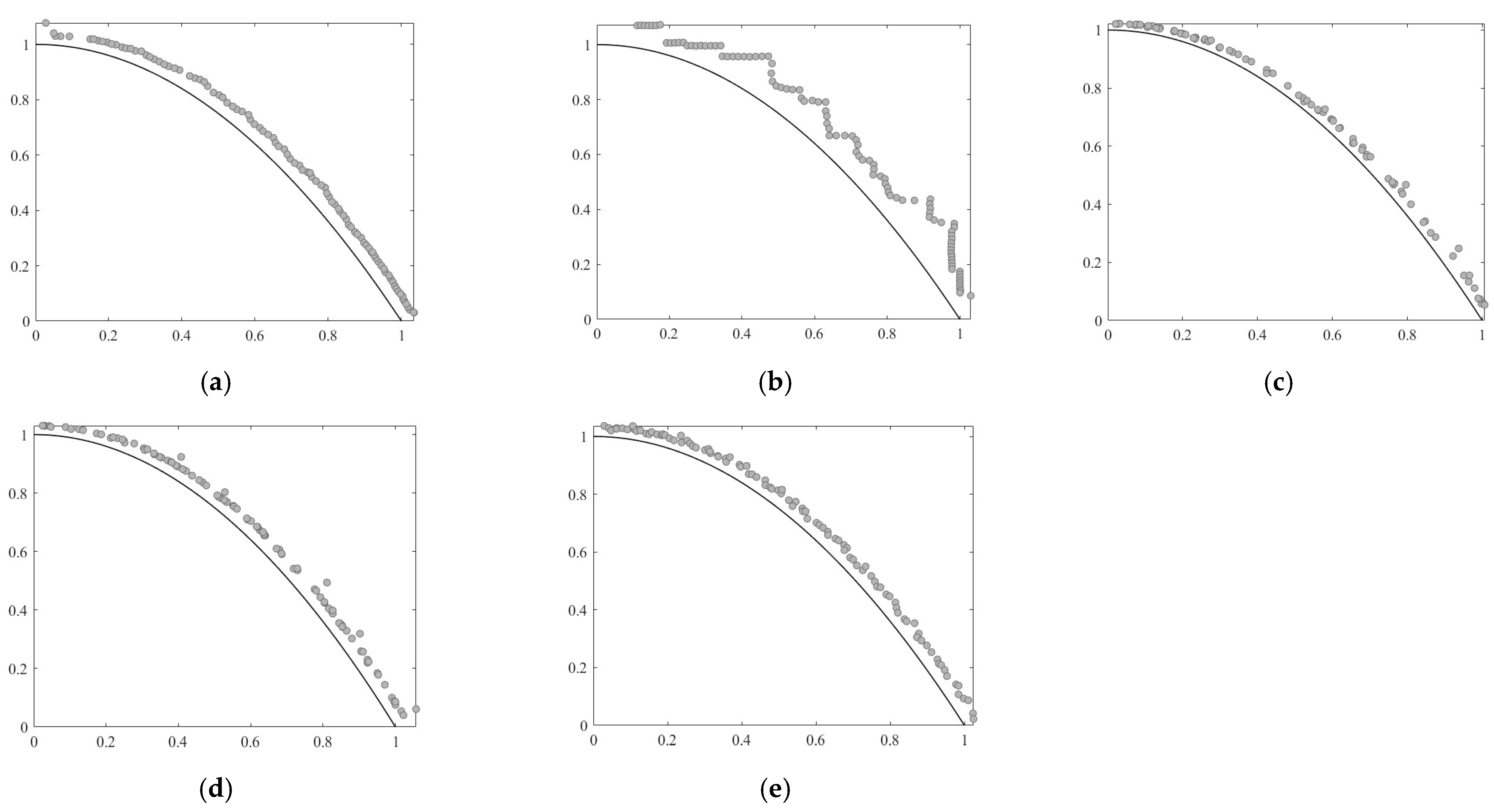

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem | Obj. | Dec. | NSGA-III | MOEA/D | MOEA/DVA | LMEA | LSMOEA-VT |
|---|---|---|---|---|---|---|---|
| DTLZ1 | 5 | 100 | 4.2683 × 10+0 (1.03 × 10+0) − | 1.3858 × 10−1 (2.26 × 10−3) − | 7.6881 × 10−2 (4.73 × 10−4) − | 6.2269 × 10−2 (3.87 × 10−4) + | 6.3955 × 10−2 (5.62 × 10−4) |
| 500 | 7.3485 × 10+1 (8.54 × 10+0) − | 1.7756 × 10−1 (5.21 × 10−2) − | 7.8375 × 10−2 (2.74 × 10−3) − | 6.3324 × 10−2 (6.25 × 10−4) − | 6.3173 × 10−2 (6.17 × 10−4) | ||
| 1000 | 2.2688 × 10+2 (6.17 × 10+0) − | 1.9744 × 10−1 (5.07 × 10−2) − | 8.0133 × 10−2 (1.57 × 10−3) − | 6.1723 × 10−2 (5.18 × 10−4) | 6.2387 × 10−2 (6.33 × 10−4) | ||
| DTLZ2 | 5 | 100 | 3.5217 × 10−1 (5.72 × 10−4) − | 3.5226 × 10−1 (2.45 × 10−7) − | 2.7182 × 10−1 (5.62 × 10−6) − | 2.1687 × 10−1 (2.97 × 10−3) − | 2.0285 × 10−1 (3.15 × 10−3) |
| 500 | 3.5217 × 10−1 (8.98 × 10−5) − | 3.5226 × 10−1 (5.76 × 10−7) − | 2.7184 × 10−1 (4.27 × 10−6) − | 2.1695 × 10−1 (3.23 × 10−3) + | 2.2481 × 10−1 (4.26 × 10−3) | ||
| 1000 | 3.5217 × 10−1 (7.75 × 10−4) − | 3.5226 × 10−1 (2.57 × 10−6) − | 2.7184 × 10−1 (8.35 × 10−6) − | 2.1733 × 10−1 (3.38 × 10−1) − | 2.1538 × 10−1 (3.76 × 10−1) | ||
| DTLZ3 | 5 | 100 | 7.0742 × 10+1 (5.12 × 10+0) − | 3.6673 × 10−1 (3.52 × 10−3) − | 2.8249 × 10−1 (2.05 × 10−4) − | 2.0842 × 10−1 (4.14 × 10−3) − | 1.9827 × 10−1 (5.49 × 10−3) |
| 500 | 3.2149 × 10+2 (4.52 × 10+0) − | 4.8663 × 10+2 (2.16 × 10−1) − | 2.8286 × 10−1 (2.13 × 10−3) + | 2.8596 × 10−1 (3.24 × 10−3) + | 2.8771 × 10−1 (4.75 × 10−3) | ||
| 1000 | 8.9137 × 10+2 (6.71 × 10+1) − | 4.9681 × 10+2 (3.11 × 10+2) − | 2.8111 × 10−1 (4.71 × 10−3) + | 2.8235 × 10−1 (4.11 × 10−3) + | 2.8354 × 10−1 (5.82 × 10−3) | ||
| DTLZ4 | 5 | 100 | 2.8751 × 10−1 (1.30 × 10−1) − | 7.7852 × 10−1 (2.17 × 10−1) − | 3.7593 × 10−1 (1.29 × 10−1) − | 2.0692 × 10−1 (2.57 × 10−2) + | 2.7738 × 10−1 (4.26 × 10−2) |
| 500 | 2.0469 × 10−1 (1.42 × 10−2) + | 6.8635 × 10−1 (2.28 × 10−1) − | 4.4421 × 10−1 (1.28 × 10−1) − | 3.1322 × 10−1 (2.65 × 10−2) − | 3.0395 × 10−1 (3.61 × 10−2) | ||
| 1000 | 2.5829 × 10−1 (1.28 × 10−1) + | 5.1757 × 10−1 (2.03 × 10−1) − | 4.4537 × 10−1 (1.31 × 10−1) − | 3.2145 × 10−1 (2.73 × 10−2) − | 3.2077 × 10−1 (3.94 × 10−2) | ||
| DTLZ7 | 5 | 100 | 6.8754 × 10−1 (2.50 × 10−2) − | 5.6271 × 10−1 (3.17 × 10−2) − | 5.7549 × 10−1 (5.15 × 10−5) − | 3.6496 × 10−1 (2.15 × 10−2) − | 3.5785 × 10−1 (3.37 × 10−2) |
| 500 | 3.8837 × 10+0 (2.74 × 10−1) − | 5.4342 × 10−1 (4.64 × 10−3) − | 5.7677 × 10−1 (4.58 × 10−4) − | 3.7924 × 10−1 (8.74 × 10−3) − | 3.6955 × 10−1 (6.69 × 10−2) | ||
| 1000 | 3.9533 × 10+0 (2.46 × 10−1) − | 5.5189 × 10−1 (2.81 × 10−2) − | 5.8372 × 10−1 (4.33 × 10−4) − | 3.6842 × 10−1 (7.26 × 10−3) − | 3.6693 × 10−1 (4.38 × 10−3) | ||
| WFG3 | 5 | 100 | 7.8146 × 10−1 (4.74 × 10−2) − | 2.5807 × 10+0 (7.93 × 10−2) − | 2.5671 × 10+0 (7.85 × 10−3) − | 1.5692 × 10−1 (3.29 × 10−2) − | 1.5349 × 10−1 (5.16 × 10−2) |
| 500 | 8.9773 × 10−1 (2.58 × 10−2) − | 2.7678 × 10+0 (7.14 × 10−2) − | 2.7785 × 10+0 (9.95 × 10−3) − | 1.4847 × 10−1 (4.61 × 10−2) − | 1.3965 × 10−1 (5.31 × 10−2) | ||
| 1000 | 9.3544 × 10−1 (2.84 × 10−2) − | 2.8471 × 10+0 (9.36 × 10−2) − | 2.7513 × 10+0 (3.82 × 10−2) − | 1.5483 × 10−1 (2.74 × 10−2) − | 1.5194 × 10−1 (1.47 × 10−2) | ||
| UF9 | 3 | 100 | 2.5245 × 10−1 (9.69 × 10−2) − | 3.1762 × 10−1 (1.68 × 10−2) − | 4.4526 × 10−2 (3.71 × 10−5) + | 5.9225 × 10−2 (9.31 × 10−3) − | 5.7736 × 10−2 (4.22 × 10−3) |
| 500 | 2.7972 × 10−1 (8.47 × 10−2) − | 3.3365 × 10−1 (3.11 × 10−2) − | 4.4528 × 10−2 (8.49 × 10−6) + | 5.7626 × 10−2 (7.14 × 10−3) − | 5.6315 × 10−2 (6.83 × 10−3) | ||
| 1000 | 3.1644 × 10−1 (4.65 × 10−2) − | 3.2554 × 10−1 (7.48 × 10−2) − | 4.4526 × 10−2 (9.13 × 10−6) + | 5.5243 × 10−2 (5.10 × 10−3) − | 5.4827 × 10−2 (7.47 × 10−3) | ||
| UF10 | 3 | 100 | 3.7573 × 10−1 (8.36 × 10−2) − | 6.4471 × 10−1 (1.67 × 10−1) − | 1.2125 × 10−1 (3.13 × 10−3) + | 1.7623 × 10−1 (1.69 × 10−2) + | 1.7748 × 10−1 (2.29 × 10−2) |
| 500 | 4.0668 × 10−1 (8.58 × 10−2) − | 6.7228 × 10−1 (1.83 × 10−1) − | 1.1268 × 10−1 (9.25 × 10−4) + | 1.6658 × 10−1 (5.35 × 10−3) − | 1.6356 × 10−1 (4.03 × 10−3) | ||
| 1000 | 4.2155 × 10−1 (1.41 × 10−1) − | 5.9265 × 10−1 (2.57 × 10−1) − | 1.1477 × 10−1 (2.85 × 10−3) + | 1.81× 1042 × 10−1 (8.57 × 10−3) − | 1.6836 × 10−2 (6.20 × 10−3) | ||
| +/−/≈ | 2/22/0 | 0/24/0 | 8/16/0 | 6/18/0 | |||
| Problem | NSGA-III | MOEA/D | MOEA/DVA | LMEA | LSMOEA-VT |
|---|---|---|---|---|---|
| LSMOP1 | 2.3421 × 10−1 (3.12 × 10−3) − | 3.6152 × 10−1 (2.57 × 10−2) − | 1.9591 × 10−1 (6.74 × 10−3) − | 1.8182 × 10−1 (8.99 × 10−3) − | 1.7651 × 10−1 (8.99 × 10−3) |
| LSMOP2 | 1.6871 × 10−1 (2.51 × 10−3) − | 2.4541 × 10−1 (8.98 × 10−4) − | 1.6212 × 10−1 (2.61 × 10−3) − | 1.5644 × 10−1 (2.54 × 10−3) ≈ | 1.5537 × 10−1 (1.45 × 10−3) |
| LSMOP3 | 4.7176 × 10−1 (1.30 × 10−1) − | 8.0682 × 10−1 (5.37 × 10−1) − | 7.1024 × 10−1 (4.81 × 10−2) − | 6.1232 × 10−1 (5.68 × 10−2) − | 3.6852 × 10−1 (4.12 × 10−2) |
| LSMOP4 | 2.4222 × 10−1 (9.23 × 10−3) − | 3.6237 × 10−1 (5.44 × 10−3)− | 1.9776 × 10−1 (3.29 × 10−3) + | 2.1585 × 10−1 (2.44 × 10−3) + | 2.2274 × 10−1 (1.28 × 10−3) |
| LSMOP5 | 3.5893 × 10−1 (1.82 × 10−1) ≈ | 7.9303 × 10−1 (6.23 × 10−2) − | 4.1494 × 10−1 (3.83 × 10−2) − | 3.7932 × 10−1 (1.65 × 10−2) − | 3.5402 × 10−1 (3.97 × 10−2) |
| LSMOP6 | 1.4049 × 10+0 (2.52 × 10−1) + | 1.6947 × 10+0 (4.22 × 10−1) + | 2.7213 × 10−1 (1.97 × 10−1) − | 2.5820 × 10+4 (3.71 × 10+3) − | 1.6651 × 10+3 (4.33 × 10+3) |
| LSMOP7 | 3.0012 × 10+0 (3.31 × 10−1) − | 9.9436+0 (1.15 × 10−1) − | 9.8291 × 10−1 (2.81 × 10−2) − | 1.7422 × 10−1 (3.02 × 10−2) + | 2.8983 × 10+0 (7.58 × 10−1) |
| LSMOP8 | 3.2336 × 10−1 (1.02 × 10−2) + | 6.1604 × 10−1 (1.76 × 10−2) − | 3.5637 × 10−1 (6.92 × 10−2) + | 3.1677 × 10−1 (5.54 × 10−3) + | 3.9824 × 10−1 (4.66 × 10−3) |
| LSMOP9 | 2.5286+0 (9.52 × 10−2) − | 1.3600+0 (4.32 × 10−1) − | 6.7058 × 10−1 (1.31 × 10−1) − | 6.5163 × 10−1 (7.54 × 10−3) − | 6.3776 × 10−1 (2.77 × 10−2) |
| +/−/≈ | 2/6/1 | 1/7/1 | 3/6/0 | 3/5/1 |
| Problem | Obj. | 2000-Variable | 4000-Variable |
|---|---|---|---|
| DTLZ1 | 5 | 9.3525 × 10−1 (7.37 × 10−3) | 9.3571 × 10−1 (5.36 × 10−3) |
| DTLZ2 | 5 | 6.2454 × 10−1 (5.17 × 10−3) | 6.2331 × 10−1 (4.65 × 10−3) |
| DTLZ3 | 5 | 6.2466 × 10−1 (4.94 × 10−3) | 6.2370 × 10−1 (1.53 × 10−2) |
| DTLZ4 | 5 | 5.7154 × 10−1 (4.53 × 10−2) | 5.8147 × 10−1 (2.34 × 10−2) |
| DTLZ5 | 5 | 3.3281 × 10−2 (2.87 × 10−4) | 3.2918 × 10−2 (3.49 × 10−4) |
| DTLZ6 | 5 | 3.3110 × 10−2 (1.41 × 10−3) | 3.4250 × 10−2 (1.37 × 10−4) |
| DTLZ7 | 5 | 1.2547 × 10−1 (4.85 × 10−3) | 1.2963 × 10−1 (3.10 × 10−3) |
| WFG3 | 5 | 5.8532 × 10−1 (2.54 × 10−3) | 5.8791 × 10−1 (3.76 × 10−3) |
| UF9 | 3 | 7.0363 × 10−1 (1.49 × 10−2) | 7.1057 × 10−1 (1.22 × 10−2) |
| UF10 | 3 | 1.6887 × 10−1 (7.96 × 10−3) | 1.6449 × 10−1 (1.60 × 10−2) |
| Problem | NSGA-III | MOEA/D | MOEA/DVA | LMEA | LSMOEA-VT |
|---|---|---|---|---|---|
| DTLZ1 | 5.4198 × 10+1 | 4.5699 × 10+2 | 2.8743 × 10+2 | 5.9040 × 10+1 | 5.3691 × 10+1 |
| DTLZ2 | 6.6541 × 10+1 | 6.0568 × 10+2 | 3.5147 × 10+2 | 5.5374 × 10+1 | 5.1817 × 10+1 |
| WFG3 | 6.6261 × 10+1 | 6.4752 × 10+2 | 3.5863 × 10+2 | 5.2783 × 10+1 | 5.0770 × 10+1 |
| UF9 | 6.9655 × 10+1 | 6.3372 × 10+2 | 3.5215 × 10+2 | 5.5708 × 10+1 | 4.9766 × 10+1 |
| UF10 | 6.7915 × 10+1 | 6.3627 × 10+2 | 3.6118 × 10+2 | 6.2106 × 10+1 | 5.2047 × 10+1 |
| LSMOP1 | 7.9914 × 10+1 | 8.2347 × 10+2 | 2.5079 × 10+2 | 1.60002× 10+2 | 3.4328 × 10+2 |
| LSMOP2 | 8.6011 × 10+1 | 8.1857 × 10+2 | 2.4873 × 10+2 | 1.4634 × 10+2 | 3.4029 × 10+2 |
| LSMOP3 | 8.9809 × 10+1 | 8.3215 × 10+2 | 2.7383 × 10+2 | 1.3938 × 10+2 | 3.4699 × 10+2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Liu, T. A Two-Stage Multi-Objective Optimization Algorithm for Solving Large-Scale Optimization Problems. Algorithms 2025, 18, 164. https://doi.org/10.3390/a18030164
Liu J, Liu T. A Two-Stage Multi-Objective Optimization Algorithm for Solving Large-Scale Optimization Problems. Algorithms. 2025; 18(3):164. https://doi.org/10.3390/a18030164
Chicago/Turabian StyleLiu, Jiaqi, and Tianyu Liu. 2025. "A Two-Stage Multi-Objective Optimization Algorithm for Solving Large-Scale Optimization Problems" Algorithms 18, no. 3: 164. https://doi.org/10.3390/a18030164
APA StyleLiu, J., & Liu, T. (2025). A Two-Stage Multi-Objective Optimization Algorithm for Solving Large-Scale Optimization Problems. Algorithms, 18(3), 164. https://doi.org/10.3390/a18030164