
A Novel Equivariant Self-Supervised Vector Network for Three-Dimensional Point Clouds

Abstract
1. Introduction
- We propose an equivariant self-supervised vector network for point clouds. The network with a novel structure has better robustness to rotated data and can reconstruct the point cloud under arbitrary rotation in 3D space.
- Our network can deal with more rotation-equivariant tasks like pose change estimation and rotation-invariant tasks like classification, segmentation, and few-shot learning. It means our network has high generalization ability.
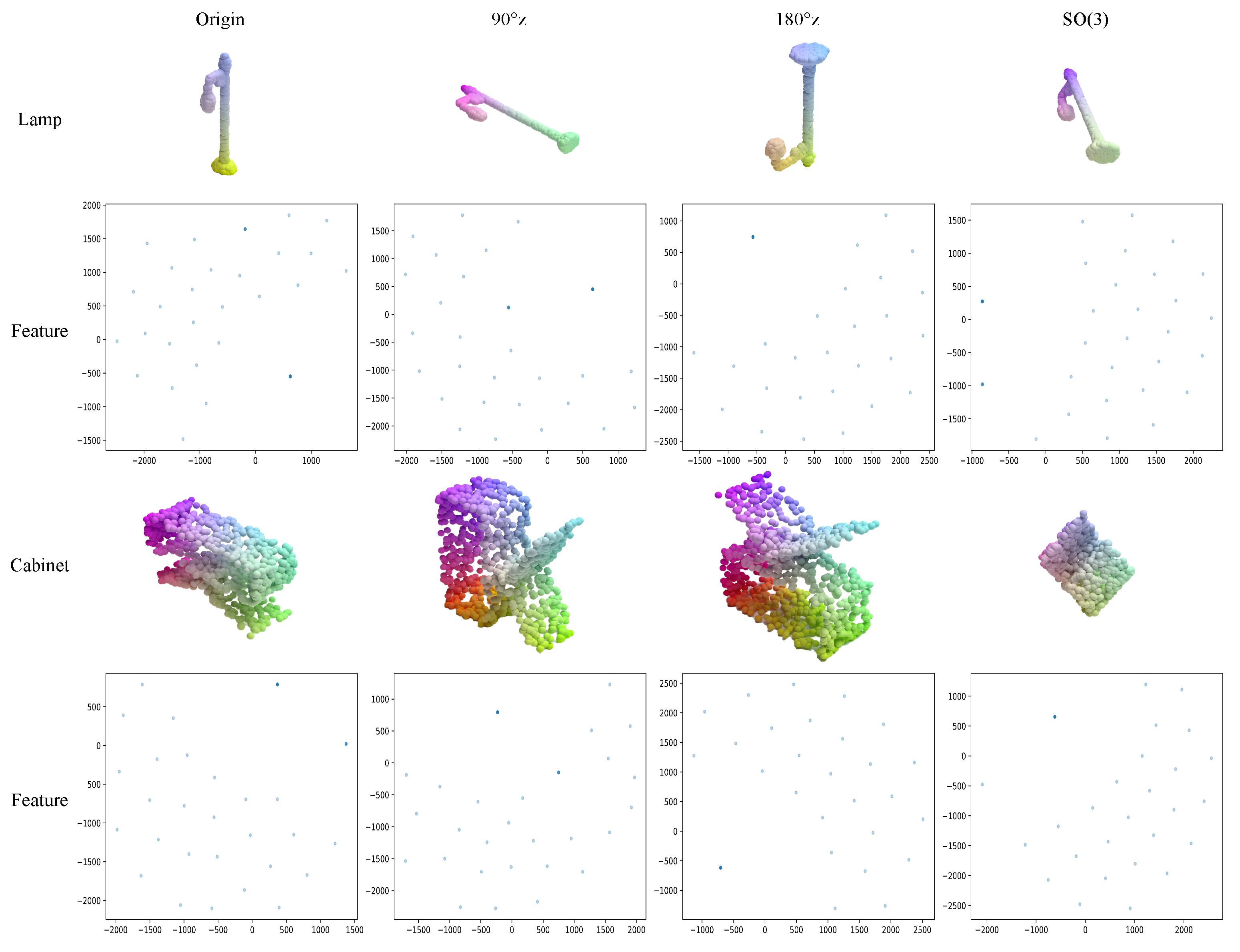
- We perform an interpretability analysis of equivariant and self-supervised learning architectures in the network and visualizations to demonstrate that it is equivariant.
2. Related Work
2.1. Transformer for Point Clouds
2.2. Self-Supervised Learning
2.3. Equivariant Network
3. The Equivariant Vector Network with Self-Supervised Learning
3.1. The Theory of Equivariant Networks
3.2. Information Theory in Masked Autoencoder
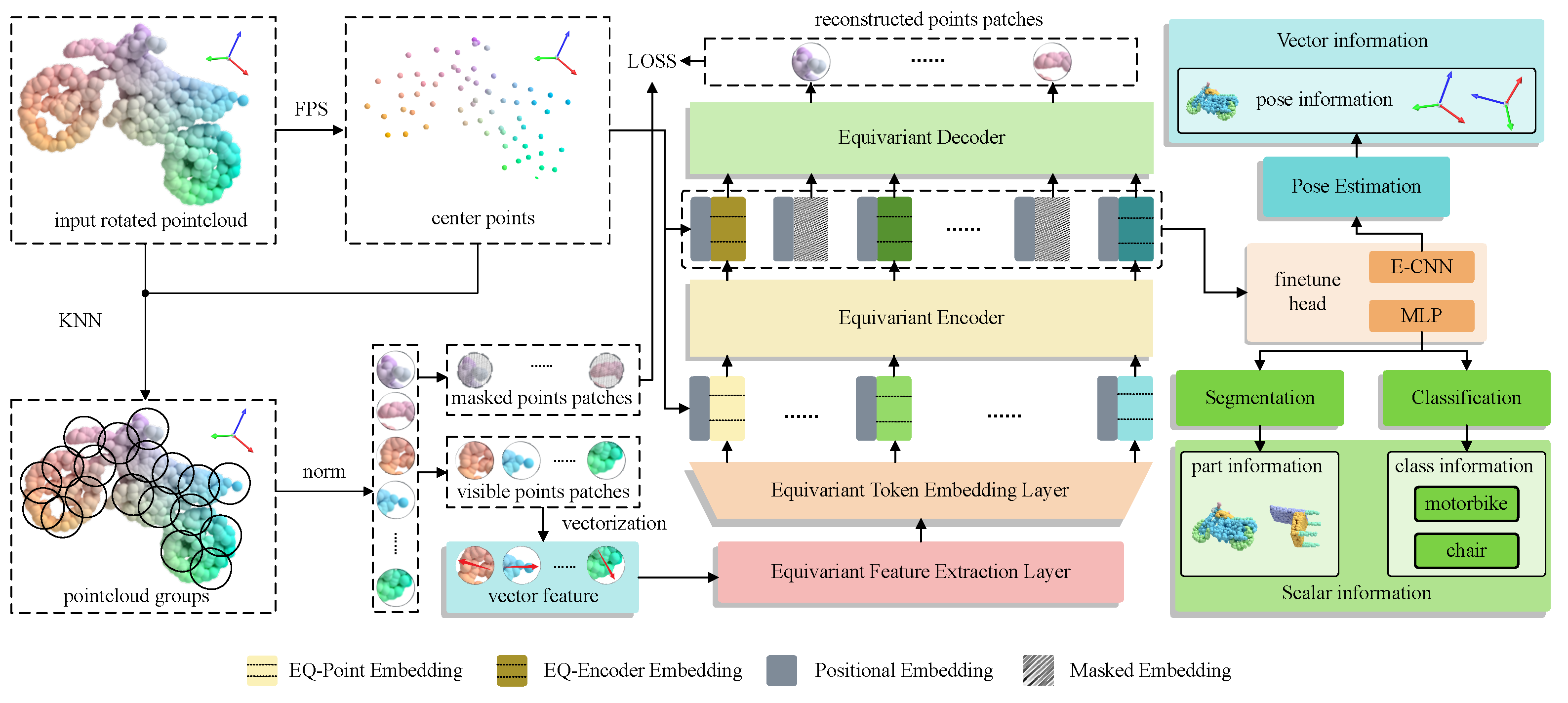
3.3. Network Overview
3.4. Network Backbone
3.4.1. Patch Generation of Point Clouds
3.4.2. Initialization of Vector Features
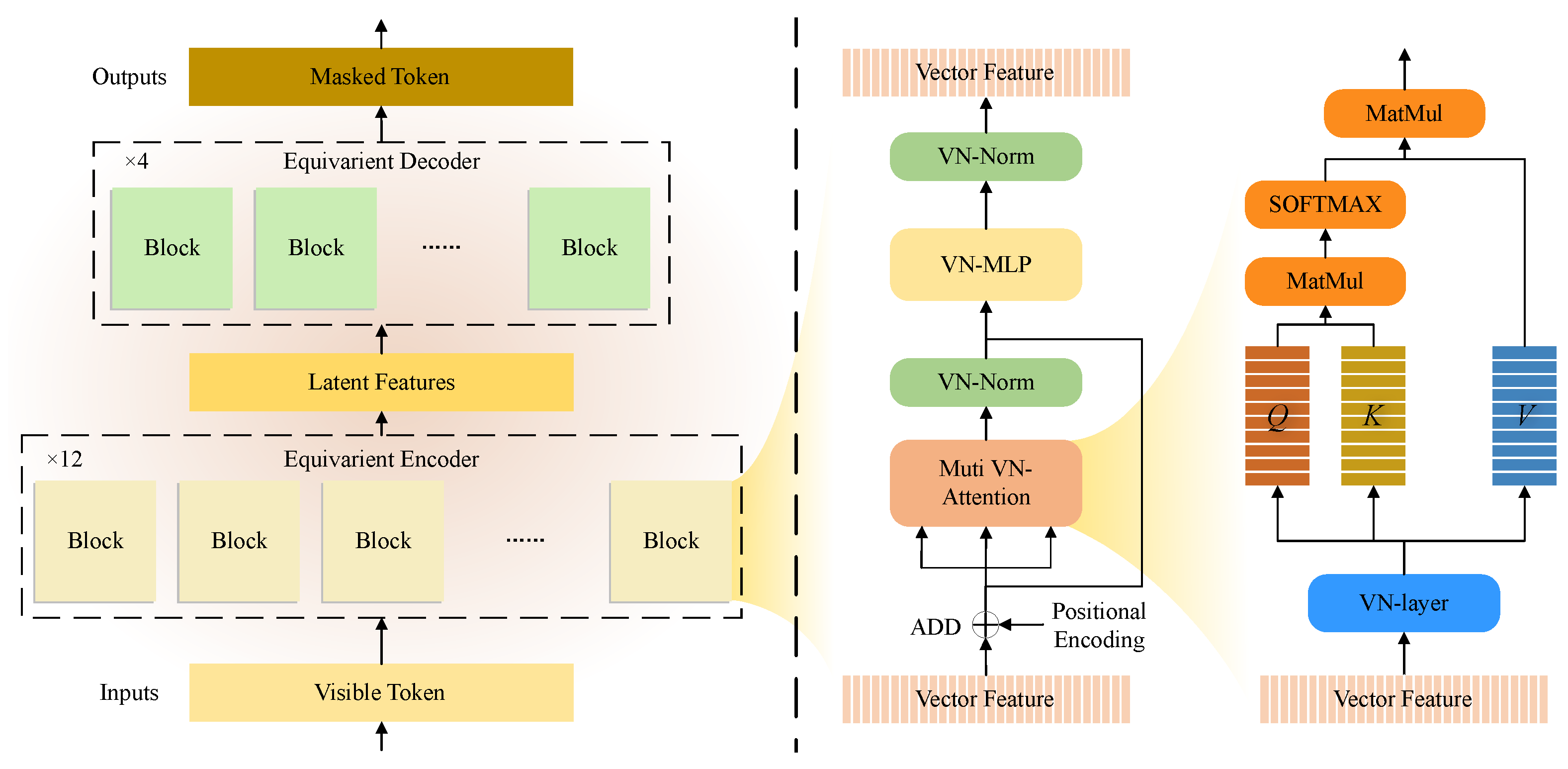
3.4.3. Equivariant Layers
3.4.4. Autoencoder Backbone
3.5. Implementation
3.5.1. Pre-Training Tasks
3.5.2. Fine-Tuning Tasks
4. Experiment
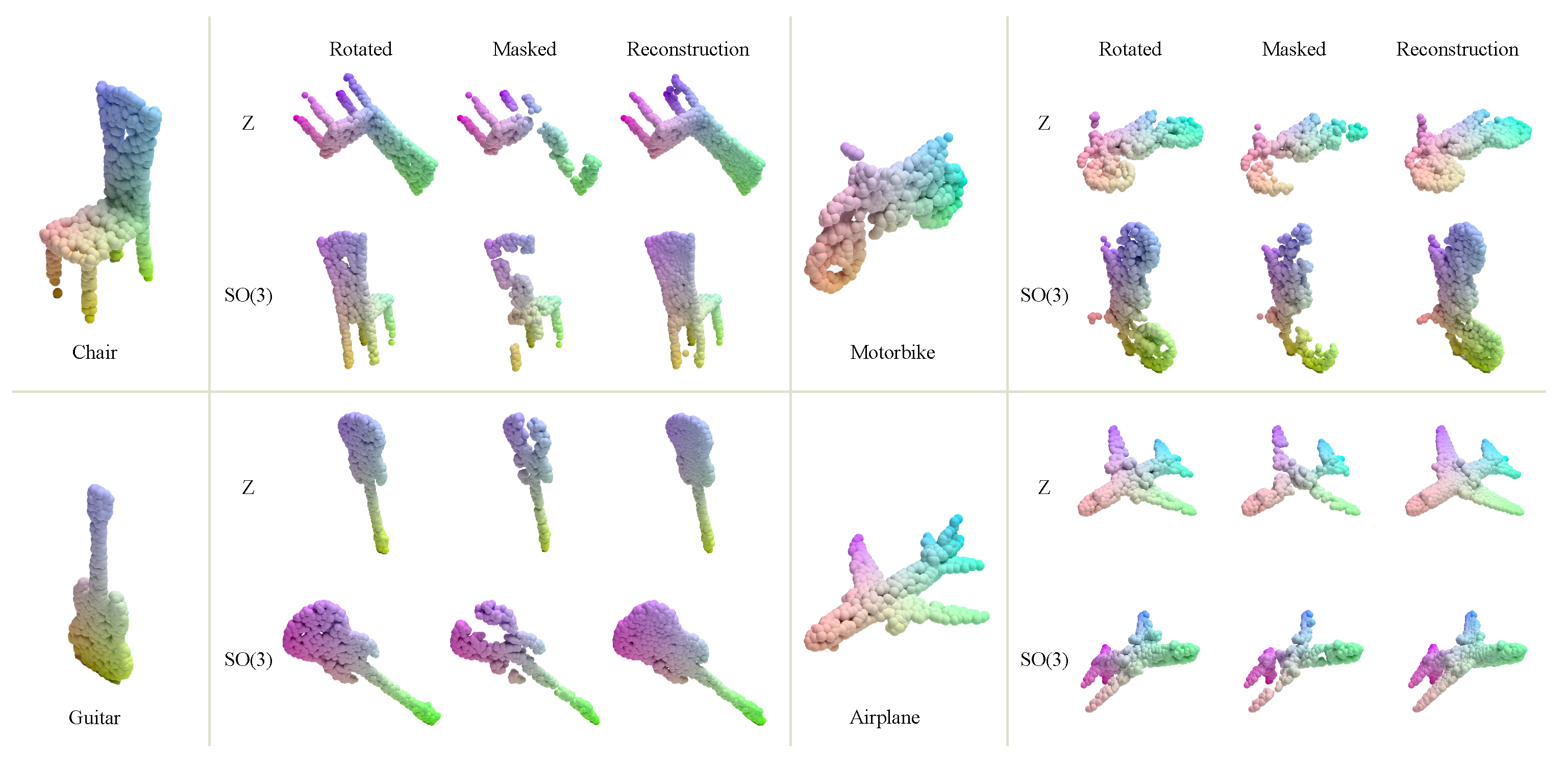
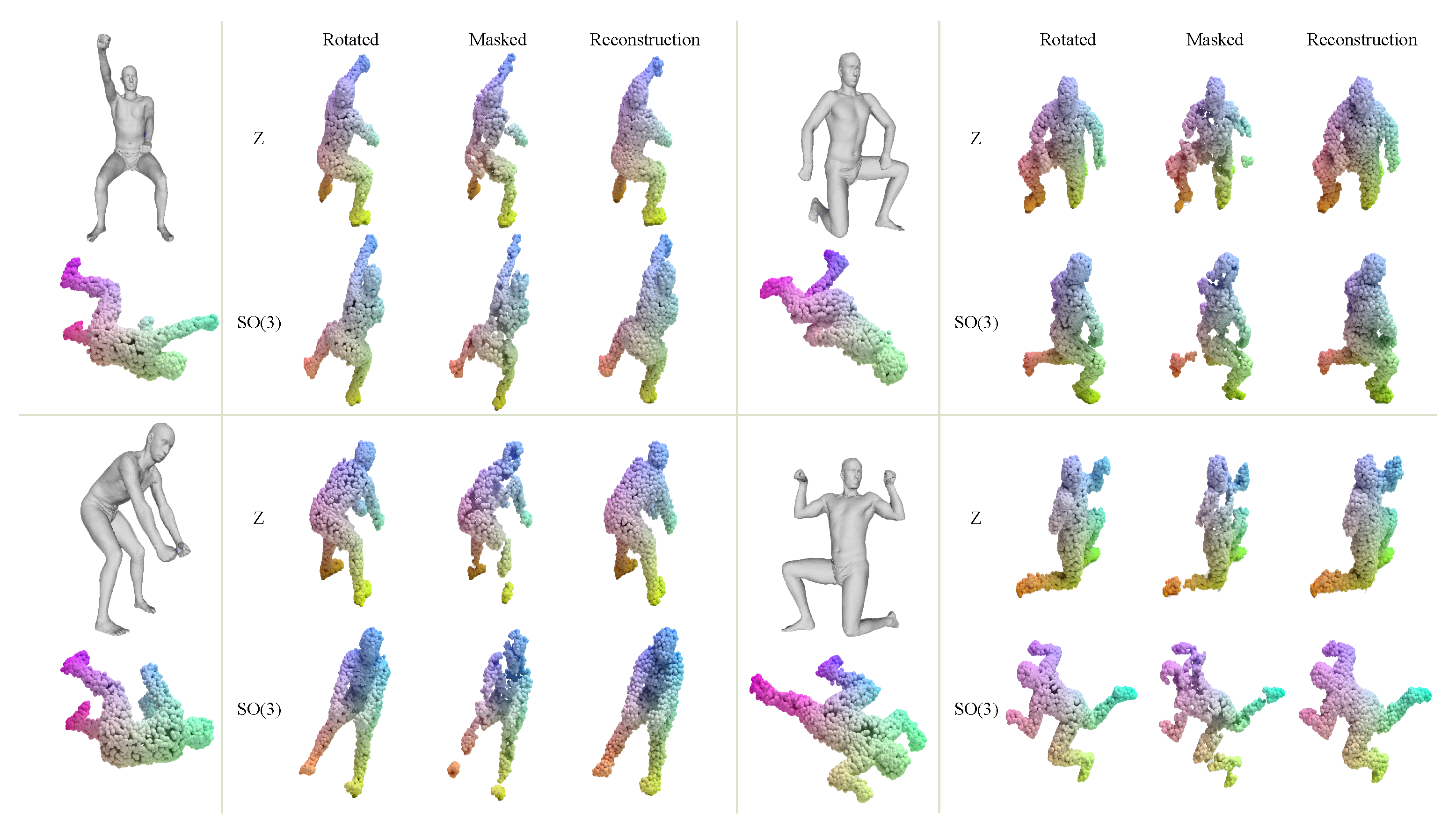
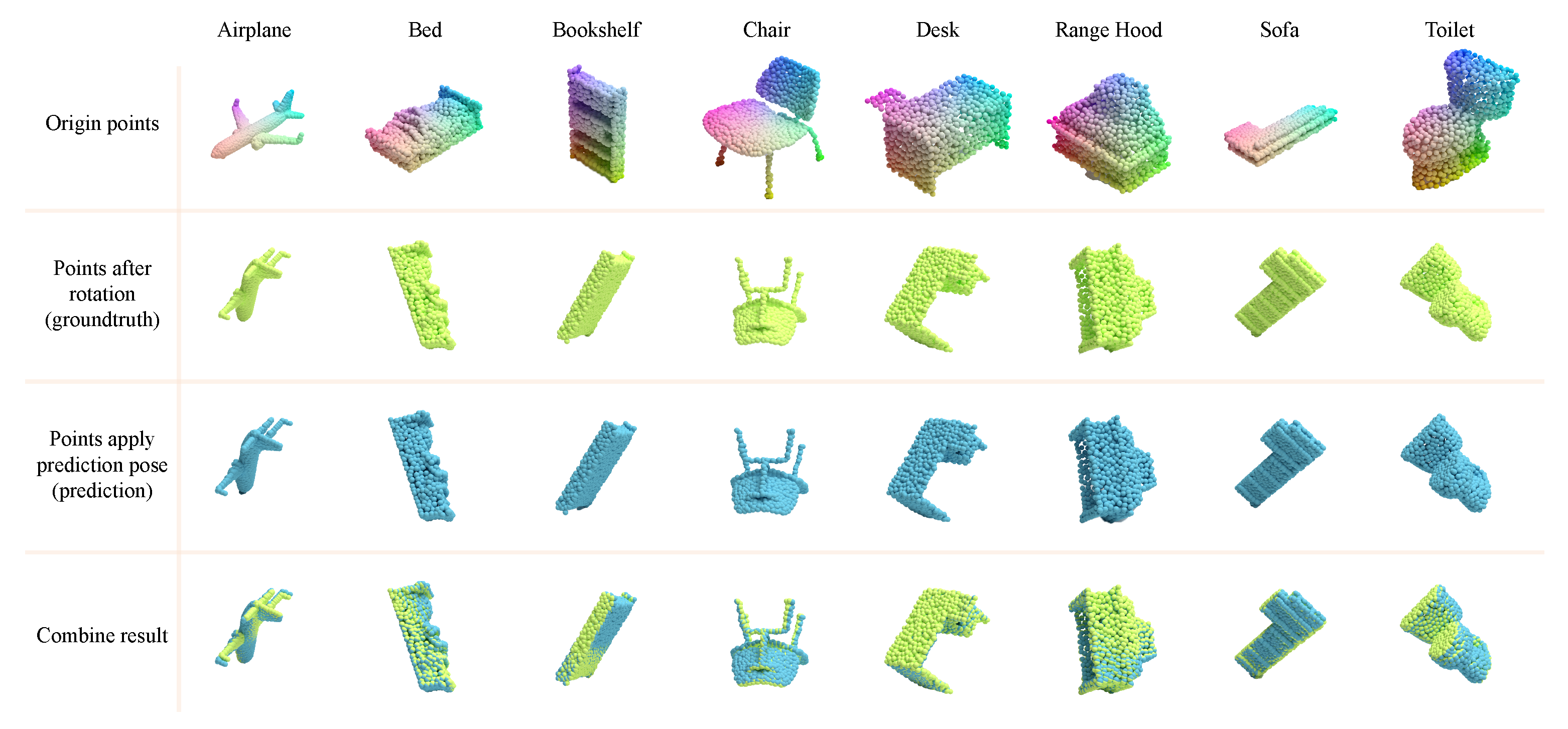
4.1. Reconstruction
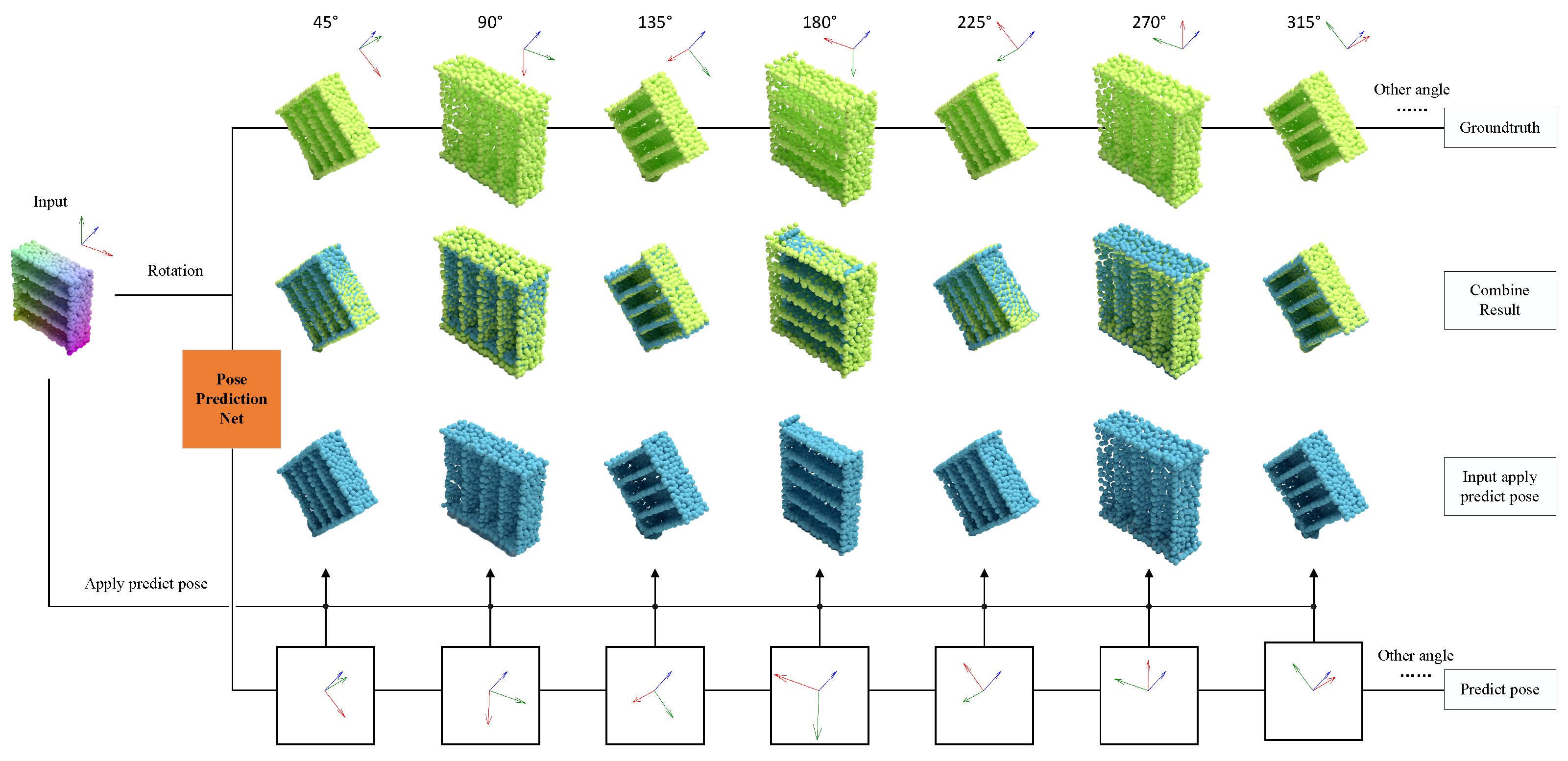
4.2. Pose Change Estimation
4.3. Classification
4.4. Segmentation
4.5. Few-Shot Learning
4.6. Summary
5. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, J.; Zhao, W.; Deng, B.; Wang, Z.; Zhang, F.; Zheng, W.; Cao, W.; Nan, J.; Lian, Y.; Burke, A.F. Autonomous driving system: A comprehensive survey. Expert Syst. Appl. 2024, 242, 122836. [Google Scholar] [CrossRef]
- Chen, Z.; Ye, M.; Xu, S.; Cao, T.; Chen, Q. Ppad: Iterative interactions of prediction and planning for end-to-end autonomous driving. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany; pp. 239–256. [Google Scholar]
- Liebers, C.; Prochazka, M.; Pfützenreuter, N.; Liebers, J.; Auda, J.; Gruenefeld, U.; Schneegass, S. Pointing it out! Comparing manual segmentation of 3D point clouds between desktop, tablet, and virtual reality. Int. J. Hum.-Interact. 2024, 40, 5602–5616. [Google Scholar] [CrossRef]
- Ding, X.; Qiao, J.; Liu, N.; Yang, Z.; Zhang, R. Robotic grinding based on point cloud data: Developments, applications, challenges, and key technologies. Int. J. Adv. Manuf. Technol. 2024, 131, 3351–3371. [Google Scholar] [CrossRef]
- Li, L.; Zhang, X. A robust assessment method of point cloud quality for enhancing 3D robotic scanning. Robot. Comput.-Integr. Manuf. 2025, 92, 102863. [Google Scholar] [CrossRef]
- Chen, K.X.; Zhao, J.Y.; Chen, H. A vector spherical convolutional network based on self-supervised learning. Acta Autom. Sin. 2023, 49, 1354. [Google Scholar] [CrossRef]
- Simeonov, A.; Du, Y.; Tagliasacchi, A.; Tenenbaum, J.B.; Rodriguez, A.; Agrawal, P.; Sitzmann, V. Neural Descriptor Fields: SE(3)-Equivariant Object Representations for Manipulation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar] [CrossRef]
- Cohen, T.; Welling, M. Steerable CNNs. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Lin, C.E.; Song, J.; Zhang, R.; Zhu, M.; Ghaffari, M. Se (3)-equivariant point cloud-based place recognition. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023; PMLR: New York, NY, USA, 2023; pp. 1520–1530. [Google Scholar]
- Zhu, M.; Ghaffari, M.; Clark, W.A.; Peng, H. E2PN: Efficient SE (3)-equivariant point network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1223–1232. [Google Scholar]
- Yu, H.X.; Wu, J.; Yi, L. Rotationally equivariant 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1456–1464. [Google Scholar]
- Wu, H.; Wen, C.; Li, W.; Li, X.; Yang, R.; Wang, C. Transformation-equivariant 3D object detection for autonomous driving. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2795–2802. [Google Scholar]
- Fuchs, F.; Worrall, D.; Fischer, V.; Welling, M. SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; 33, pp. 1970–1981. [Google Scholar]
- Zhu, M.; Han, S.; Cai, H.; Borse, S.; Ghaffari, M.; Porikli, F. 4D panoptic segmentation as invariant and equivariant field prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 22488–22498. [Google Scholar]
- Deng, C.; Litany, O.; Duan, Y.; Poulenard, A.; Tagliasacchi, A.; Guibas, L. Vector Neurons: A General Framework for SO(3)-Equivariant Networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5100–5109. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. Acm Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.; Koltun, V. Point Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Yu, X.; Tang, L.; Rao, Y.; Huang, T.; Zhou, J.; Lu, J. Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 19291–19300. [Google Scholar] [CrossRef]
- Pang, Y.; Wang, W.; Tay, F.E.; Liu, W.; Tian, Y.; Yuan, L. Masked autoencoders for point cloud self-supervised learning. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2022; pp. 604–621. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2022, arXiv:2106.08254. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 3–5 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Chan, K.H.R.; Yu, Y.; You, C.; Qi, H.; Wright, J.; Ma, Y. ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction. J. Mach. Learn. Res. 2022, 23, 1–103. [Google Scholar]
- Yu, Y.; Chan, K.; You, C.; Song, C.; Ma, Y. Learning Diverse and Discriminative Representations via the Principle of Maximal Coding Rate Reduction. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 9422–9434. [Google Scholar]
- Yu, Y.; Buchanan, S.; Pai, D.; Chu, T.; Wu, Z.; Tong, S.; Haeffele, B.D.; Ma, Y. White-Box Transformers via Sparse Rate Reduction. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Volume 36, pp. 9422–9457. [Google Scholar]
- Chen, C.; Li, G.; Xu, R.; Chen, T.; Wang, M.; Lin, L. ClusterNet: Deep Hierarchical Cluster Network with Rigorously Rotation-Invariant Representation for Point Cloud Analysis. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Li, X.; Li, R.; Chen, G.; Fu, C.W.; Cohen-Or, D.; Heng, P.A. A Rotation-Invariant Framework for Deep Point Cloud Analysis. IEEE Trans. Vis. Comput. Graph. 2022, 28, 4503–4514. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Hua, B.S.; Chen, W.; Tian, Y.; Yeung, S.K. Global Context Aware Convolutions for 3D Point Cloud Understanding. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 210–219. [Google Scholar] [CrossRef]
- Yongming, R.; Jiwen, L.; Jie, Z. Spherical Fractal Convolutional Neural Networks for Point Cloud Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 452–460. [Google Scholar]
- Wiersma, R.; Nasikun, A.; Eisemann, E.; Hildebrandt, K. Deltaconv: Anisotropic operators for geometric deep learning on point clouds. ACM Trans. Graph. (TOG) 2022, 41, 1–10. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Awais, M.; Naseer, M.; Khan, S.; Anwer, R.M.; Cholakkal, H.; Shah, M.; Yang, M.H.; Khan, F.S. Foundation Models Defining a New Era in Vision: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2025. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. ShellNet: Efficient Point Cloud Convolutional Neural Networks Using Concentric Shells Statistics. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Rpublic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Wu, X.; Jiang, L.; Wang, P.S.; Liu, Z.; Liu, X.; Qiao, Y.; Ouyang, W.; He, T.; Zhao, H. Point Transformer V3: Simpler Faster Stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4840–4851. [Google Scholar]
- Wang, C.; Wu, M.; Lam, S.K.; Ning, X.; Yu, S.; Wang, R.; Li, W.; Srikanthan, T. Gpsformer: A global perception and local structure fitting-based transformer for point cloud understanding. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; Springer: Berlin/Heidelberg, Germany, 2025; pp. 75–92. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. PCT: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Gui, J.; Chen, T.; Zhang, J.; Cao, Q.; Sun, Z.; Luo, H.; Tao, D. A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9052–9071. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Liu, Q.; Yue, X.; Lasenby, J.; Kusner, M.J. Unsupervised Point Cloud Pre-Training via Occlusion Completion. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Liu, H.; Cai, M.; Lee, Y.J. Masked discrimination for self-supervised learning on point clouds. In Proceedings of the European Conference on Computer Vision, Tel-Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 657–675. [Google Scholar]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A Survey on Neural Network Interpretability. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 726–742. [Google Scholar] [CrossRef]
- Cohen, T.S.; Welling, M. Group Equivariant Convolutional Networks. In Proceedings of the 33rd International Conference on Machine Learning: ICML 2016, New York, NY, USA, 19–24 June 2016; Volume 6, pp. 4375–4386. [Google Scholar]
- Cohen, T.S.; Geiger, M.; Weiler, M. A general theory of equivariant CNNs on homogeneous spaces. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. Available online: https://dl.acm.org/doi/abs/10.5555/3454287.3455107 (accessed on 10 February 2025).
- Chen, Z.; Chen, Y.; Zou, X.; Yu, S. Continuous Rotation Group Equivariant Network Inspired by Neural Population Coding. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–25 February 2024; Volume 38, pp. 11462–11470. [Google Scholar]
- Penaud-Polge, V.; Velasco-Forero, S.; Angulo-Lopez, J. Group equivariant networks using morphological operators. In Proceedings of the International Conference on Discrete Geometry and Mathematical Morphology, Firenze, Italy, 15–18 April 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 165–177. [Google Scholar]
- Cohen, T.S.; Geiger, M.; Köhler, J.; Welling, M. Spherical CNNs. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Cohen, T.; Weiler, M.; Kicanaoglu, B.; Welling, M. Gauge equivariant convolutional networks and the icosahedral CNN. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 1321–1330. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2011: 21st International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 44–51. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G. Dynamic Routing Between Capsules. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 3859–3869. [Google Scholar]
- Hinton, G.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kosiorek, A.; Sabour, S.; Teh, Y.; Hinton, G. Stacked capsule autoencoders. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. Available online: https://dl.acm.org/doi/abs/10.5555/3454287.3455677 (accessed on 10 February 2025).
- McIntosh, B.; Duarte, K.; Rawat, Y.S.; Shah, M. Visual-Textual Capsule Routing for Text-Based Video Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Weiler, M.; Geiger, M.; Welling, M.; Boomsma, W.; Cohen, T. 3D steerable CNNs: Learning rotationally equivariant features in volumetric data. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; Volume 31, pp. 10381–10392. [Google Scholar]
- Esteves, C.; Allen-Blanchette, C.; Makadia, A.; Daniilidis, K. Learning SO(3) Equivariant Representations with Spherical CNNs. Int. J. Comput. Vis. 2020, 128, 588–600. [Google Scholar] [CrossRef]
- Kondor, R.; Lin, Z.; Trivedi, S. Clebsch–Gordan Nets: A Fully Fourier Space Spherical Convolutional Neural Network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; Volume 31, pp. 10138–10147. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Maron, H.; Galun, M.; Aigerman, N.; Trope, M.; Dym, N.; Yumer, E.; Kim, V.G.; Lipman, Y. Convolutional neural networks on surfaces via seamless toric covers. ACM Trans. Graph. 2017, 36, 71. [Google Scholar] [CrossRef]
- Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Luo, S.; Hu, W. Diffusion probabilistic models for 3D point cloud generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2837–2845. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | i | z | SO(3) | |
|---|---|---|---|---|
| Traditional network | PointTransformer [18] | 93.7 | - | - |
| Point-BERT [19] | 93.2 | - | - | |
| Point-MAE [20] | 93.8 | - | - | |
| GPSFormer [42] | 94.1 | - | - | |
| ShellNet [37] | 93.1 | 93.1 | 87.8 | |
| PointNet [38] | 89.2 | 85.9 | 74.7 | |
| PointNet++ [16] | 90.7 | 91.8 | 85.0 | |
| DGCNN [17] | 92.9 | 90.3 | 88.6 | |
| Equivariant network | Deltaconv [31] | 93.8 | - | - |
| VN-PointNet [15] | - | 77.5 | 77.2 | |
| VN-DGCNN [15] | - | 89.5 | 90.2 | |
| SFCNN [30] | - | 91.4 | 90.1 | |
| Cluster [27] | - | 87.1 | 87.1 | |
| GC-Conv [29] | - | 89.0 | 89.2 | |
| Ours | 94.2 | 92.8 | 90.6 |
| Methods | i | z | SO(3) | |
|---|---|---|---|---|
| Traditional network | Point-BERT [19] | 84.1 | - | - |
| Point-MAE [20] | 84.2 | - | - | |
| GPSFormer [42] | 85.4 | - | - | |
| ShellNet [37] | 82.8 | - | - | |
| PointNet [38] | 80.4 | 80.4 | 62.3 | |
| PointNet++ [16] | 81.9 | 81.9 | 76.7 | |
| DGCNN [17] | 82.4 | 82.3 | 78.6 | |
| Equivariant network | GC-Conv [29] | - | - | 77.3 |
| VN-PointNet [15] | - | - | 72.8 | |
| VN-DGCNN [15] | - | - | 81.4 | |
| Ours | 84.8 | 82.8 | 81.5 |
| Rotatation | Methods | 5-Way, 10-Shot | 5-Way, 20-Shot | 10-Way, 10-Shot | 10-Way, 20-Shot |
|---|---|---|---|---|---|
| i | DGCNN-rand [17] | 31.6 ± 2.8 | 40.8 ± 4.6 | 19.9 ± 2.1 | 16.9 ± 1.5 |
| DGCNN-OcCo [17] | 90.6 ± 2.8 | 92.5 ± 1.9 | 82.9 ± 1.3 | 86.5 ± 2.2 | |
| Transformer-rand [19] | 87.8 ± 5.2 | 93.3 ± 4.3 | 84.6 ± 5.5 | 89.4 ± 6.3 | |
| Transformer-OcCo [19] | 94.0 ± 3.6 | 95.9 ± 2.3 | 89.4 ± 5.1 | 92.4 ± 4.6 | |
| Point-BERT [19] | 94.6 ± 3.1 | 96.3 ± 2.7 | 91.0 ± 5.4 | 92.7 ± 5.1 | |
| Point-MAE [20] | 96.3 ± 2.5 | 97.8 ± 1.8 | 92.6 ± 4.1 | 95.0 ± 3.0 | |
| GPSFormer [42] | 90.2 ± 2.3 | 91.7 ± 1.1 | 82.5 ± 2.1 | 86.1 ± 3.5 | |
| Ours | 99.8 ± 0.4 | 99.0 ± 0.0 | 88.3 ± 0.9 | 95.5 ± 0.4 | |
| z | Ours | 96.8 ± 1.3 | 96.4 ± 0.7 | 81.3 ± 1.1 | 91.2 ± 0.6 |
| SO(3) | Ours | 94.7 ± 0.8 | 94.3 ± 0.7 | 78.5 ± 1.1 | 91.6 ± 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, K.; Zhao, J.; Xie, M. A Novel Equivariant Self-Supervised Vector Network for Three-Dimensional Point Clouds. Algorithms 2025, 18, 152. https://doi.org/10.3390/a18030152
Shen K, Zhao J, Xie M. A Novel Equivariant Self-Supervised Vector Network for Three-Dimensional Point Clouds. Algorithms. 2025; 18(3):152. https://doi.org/10.3390/a18030152
Chicago/Turabian StyleShen, Kedi, Jieyu Zhao, and Min Xie. 2025. "A Novel Equivariant Self-Supervised Vector Network for Three-Dimensional Point Clouds" Algorithms 18, no. 3: 152. https://doi.org/10.3390/a18030152
APA StyleShen, K., Zhao, J., & Xie, M. (2025). A Novel Equivariant Self-Supervised Vector Network for Three-Dimensional Point Clouds. Algorithms, 18(3), 152. https://doi.org/10.3390/a18030152