1. Introduction
The emergence of large language models (LLMs) has generated significant enthusiasm in higher education due to their demonstrated ability to generate and analyze text, thereby potentially transforming academic tasks ranging from content creation to academic assessment. The authors in [
1,
2] acknowledge this potential of LLMs to transform higher education. Despite the promising opportunities that LLMs offer to streamline teaching and engage students, their deployment in educational settings, such as exam question generation, poses substantial challenges in terms of alignment, reliability, and fairness [
3]. Unlike many general-purpose applications where broad knowledge is an advantage, university courses are built on carefully curated content—such as instructor-prepared notes, concise lecture summaries, and tailored presentations, and are particularly sensitive to even slight discrepancies or biases in AI-generated content. Such misalignment can undermine academic integrity and significantly affect student performance. This specificity demands that any AI-generated exam questions not only be accurate and clear but also align precisely with course objectives, maintain appropriate difficulty levels, and uphold strict standards of fairness.
A number of studies have reviewed the evolutionary potential of AI in education [
1,
4] and have examined automated question generation techniques and evaluations [
5,
6,
7]. Existing studies tend to focus on broad trends or isolated tasks without critically examining the specific challenges that arise when integrating LLMs into the domain of academic assessment. In particular, prior research has rarely addressed the dual need for (i) ensuring that generated questions are rigorously aligned with course objectives and pedagogical standards, and (ii) providing interpretable justifications for the AI’s decisions. This lack of a holistic framework means that, even when automated question generation appears technically sound, educators are left uncertain about the quality, fairness, and contextual relevance of the output.
In response to these gaps, our study proposes a comprehensive methodological framework specifically tailored for higher education. Our approach centers on three interrelated tasks:
Alignment Evaluation —assessing how accurately an existing exam question reflects a course’s learning objectives.
Question Improvement—refining suboptimal exam questions to enhance clarity, specificity, and appropriate difficulty.
New Question Generation—creating entirely new exam questions that conform to intended learning outcomes.
These tasks are applied across multiple university courses that span both theory-oriented and application-oriented domains and cover various cognitive levels as delineated in Bloom’s Taxonomy [
8].
On top of this, our framework integrates a meta-evaluation layer that is supervised by human experts. In this setup, a specialized LLM that is augmented by rigorous human oversight assigns ground-truth scores and evaluates the quality of explanations underlying each AI agent’s decision. This dual-level evaluation not only enables robust comparisons among different AI architectures (VectorRAG, VectorGraphRAG, and a Fine-Tuned LLM), but also produces detailed explanations that help identify sources of potential biases and/or misalignment. By offering detailed, empirically validated insights, our study contributes a set of best practices and actionable guidelines for the responsible and context-aware integration of AI in academic assessments.
Our goal is not to compete solely on the generation of quality metrics but rather to ensure that LLM-based agents are finely tuned to the specific demands of higher education, safeguarding academic integrity and enhancing assessment effectiveness. Ultimately, our work is designed to serve as a meticulous guide for educators and technology developers. It ensures that AI implementations are not only evaluated on traditional quality metrics but are also carefully aligned with the unique demands of higher education, thereby safeguarding academic integrity and supporting effective teaching and learning outcomes.
By addressing these specific gaps, the lack of targeted evaluation on alignment, the absence of human-supervised meta-assessment, and the limited discussion of actionable guidelines, our study tends to enhance both academic insights and the practical implementation of responsible, context-aware AI in higher education.
2. Related Work
The recent expansion of AI applications in education has led to a diverse body of research, ranging from general analyses to domain-specific implementations. However, a deeper examination reveals critical gaps that our study aims to address, with a focus on developing best practices for AI-enabled assessment.
2.1. AI in Education: Overviews and Trends
A number of comprehensive studies have been concluded towards exploring AI’s broad potential in higher education. The authors in [
9] provide a meta-systematic review that calls for heightened ethical standards, interdisciplinary collaboration, and methodological rigor in deploying AI. In addition, the authors in [
1,
4] further discuss how AI, and LLMs in particular, are reshaping educational landscapes by enhancing content creation and personalization, while [
10] presents a systematic review in science education that highlights AI’s capacity for personalized feedback and automated assessments while underscoring privacy and bias concerns. Moving towards practical implementation, the authors in [
11] investigated the usage of knowledge graphs (KGs) to enhance curriculum alignment and employability outcomes, while the authors in [
12] presented recommender systems as an AI tool that can personalize resource suggestions by accounting for learner preferences.
Despite these valuable conclusions, these studies tend to discuss general trends without analyzing the challenges of aligning AI outputs with the specific curricular objectives of university courses. Moreover, while discussions on AI integration in learning management systems [
13] and ethical frameworks [
14,
15,
16] have raised important issues of bias and transparency, they generally lack a rigorous, multi-dimensional evaluation framework that focuses on providing concrete, task-specific guidelines that address exam question generation, evaluation, and alignment.
2.2. LLM-Based Exam Question Generation
Several studies have explored the automated generation of exam questions using LLMs. The authors in [
5] provided one of the initial insights into automated exam content creation, implying that the research on question generation predominantly employed syntax-based or template-driven methods. More recent studies have leveraged state-of-the-art LLMs—such as GPT-3, GPT-4, and T5—to generate a wide array of question types. For instance, the authors in [
17] demonstrated that few-shot prompt engineering with ChatGPT4 models can be effective for generating reading comprehension questions, while the authors in [
18] demonstrated the application of LLMs to create multiple-choice questions for computing courses. Although these studies showcase the technical feasibility of automated question generation, they often evaluate the generated questions on isolated quality metrics without a deeper analysis of alignment with course objectives or the provision of human-understandable explanations. Our work distinguishes itself by systematically assessing alignment and improvement tasks and by quantifying performance variations across different course types.
Other research efforts have sought to refine question generation by integrating domain-specific strategies. The authors in [
19] introduced a method that fine-tunes LLMs in accordance with Bloom’s Taxonomy to generate questions across various cognitive levels, and the authors in [
20] incorporated knowledge graphs to improve domain specificity in cybersecurity education. Specialized approaches, such as domain-adapted training on scientific texts, demonstrate the scalability of QG methods [
7,
21], and modular QG pipelines that separate question stem generation from distractor formulation further enhance reliability [
22,
23]. Furthermore, an AI–educator workflow for generating math multiple-choice questions was presented in [
24], while distractor quality through topic modeling was presented in [
25] or ontology-based methods presented in [
26]. Some recent work evaluates ChatGPT-generated assessments in probability and engineering statistics, noting mismatches in scoring schemes and inadequate coverage of higher-level cognitive domains [
27]. Another study validates multi-task learning techniques for producing high-quality question–answer pairs in diverse subjects [
28]. Yet, these studies typically consider question generation as a stand-alone task, rather than as part of an integrated framework that includes post-generation evaluation and iterative improvement.
2.3. Improving and Evaluating Automated Content
In addition to generation, a number of studies have sought to enhance the quality of AI-produced questions. For example, the authors in [
29,
30] highlight the role of prompt engineering and teacher feedback in improving question quality. Additionally, retrieval-augmented approaches have been used to reduce factual errors [
20], while reinforcement learning has shown promise in refining AI-generated feedback [
31]. Ontology-based approaches appear especially effective in conceptual domains like biology [
26]. Large datasets such as SQuAD [
32] have served as benchmarks for reading comprehension and question-answering, guiding the development and evaluation of LLM-driven generation. Even though these studies contribute important techniques for improving output quality, they rarely combine these methods into a unified evaluation framework that improves the content and the reasoning behind it.Our framework introduces a meta-evaluator, supervised by domain experts, which not only scores questions on multiple dimensions (such as alignment, clarity, and fairness) but also offers explanation quality ratings. This dual approach allows us to identify where and why certain agents may be biased or misaligned, a gap largely overlooked in prior research.
2.4. Alignment with Curriculum and Learning Objectives
Many studies have acknowledged the importance of aligning educational content with curriculum standards. Knowledge graphs have been used to map course content to industry-required skills by the authors in [
11], and personalized tutoring systems have demonstrated the benefits of tailoring educational resources to individual learning trajectories explored in [
12,
33]. However, these approaches primarily focus on content recommendation rather than on ensuring that exam questions accurately reflect curricular goals. Our work directly addresses this shortfall by systematically evaluating alignment as a distinct task within our comprehensive framework.
2.5. Automated Grading and Feedback Mechanisms
Automated grading has evolved from simple scoring algorithms to more sophisticated, LLM-based methods that aim to replicate human grading, presented in [
34,
35,
36]. While these studies demonstrate promising techniques for reducing grading workloads and increasing consistency, they often lack transparency; few provide detailed explanations for the assigned scores. This opacity makes it difficult to diagnose and correct biases in the grading process—a critical limitation that our meta-evaluation layer is specifically designed to overcome.
2.6. Ethical Considerations: Fairness and Bias in AI-Assisted Education
Ethical considerations, particularly regarding fairness and bias, are the center of discussions on AI in education. Various studies have outlined various fairness metrics [
15] and ethical frameworks [
13,
14,
16] aimed at guiding the responsible use of AI tools. Despite the fact that these contributions are essential, they often stop at general recommendations without addressing the detailed, practical challenges of implementing such frameworks in exam question generation and evaluation. Our framework explicitly incorporates human oversight to ensure that even subtle biases are identified and corrected, thereby ensuring that the AI outputs meet the high standards required in academic assessments.
2.7. Current Research Gaps and Our Contributions
Despite considerable progress across these areas, significant gaps remain. Most existing research addresses individual components—such as question generation, grading, or feedback—in isolation, without offering a comprehensive framework that integrates these elements under a unified evaluative rubric. Moreover, there is a notable lack of systematic guidelines that consider both the technical quality and the pedagogical alignment of AI-generated exam questions, especially in the context of higher education where even minor errors can have severe consequences.
To overcome these gaps, our study introduces a multi-purpose AI framework that:
Proposes a three-task framework (Alignment Evaluation, Question Improvement, and New Question Generation) that reflects real-world academic assessment needs.
Incorporates a human-supervised meta-evaluator to provide both numerical scores and detailed explanations.
Utilizes mixed-effects modeling to rigorously quantify agent performance and isolate sources of bias or misalignment.
Offers a set of best practices and actionable guidelines for educators and developers seeking to integrate LLMs into higher-education assessments.
While the previous work has provided an important groundwork in both automated question generation and AI in education, our study bases its uniqueness in its meticulous, multi-dimensional evaluation of LLM-based agents, to offer practical, actionable guidelines for educators seeking to implement responsible, context-aware AI in their assessment processes. By addressing the specific needs of higher education, where even minor misalignment can have severe impacts, we provide a framework that is not only scientifically rigorous but also practically valuable for safeguarding academic integrity and enhancing learning outcomes.
3. Materials and Methods
This section presents a comprehensive methodological framework that aims to systematically explore how large language models (LLMs) can evaluate, refine, and generate exam questions in a higher-education context.
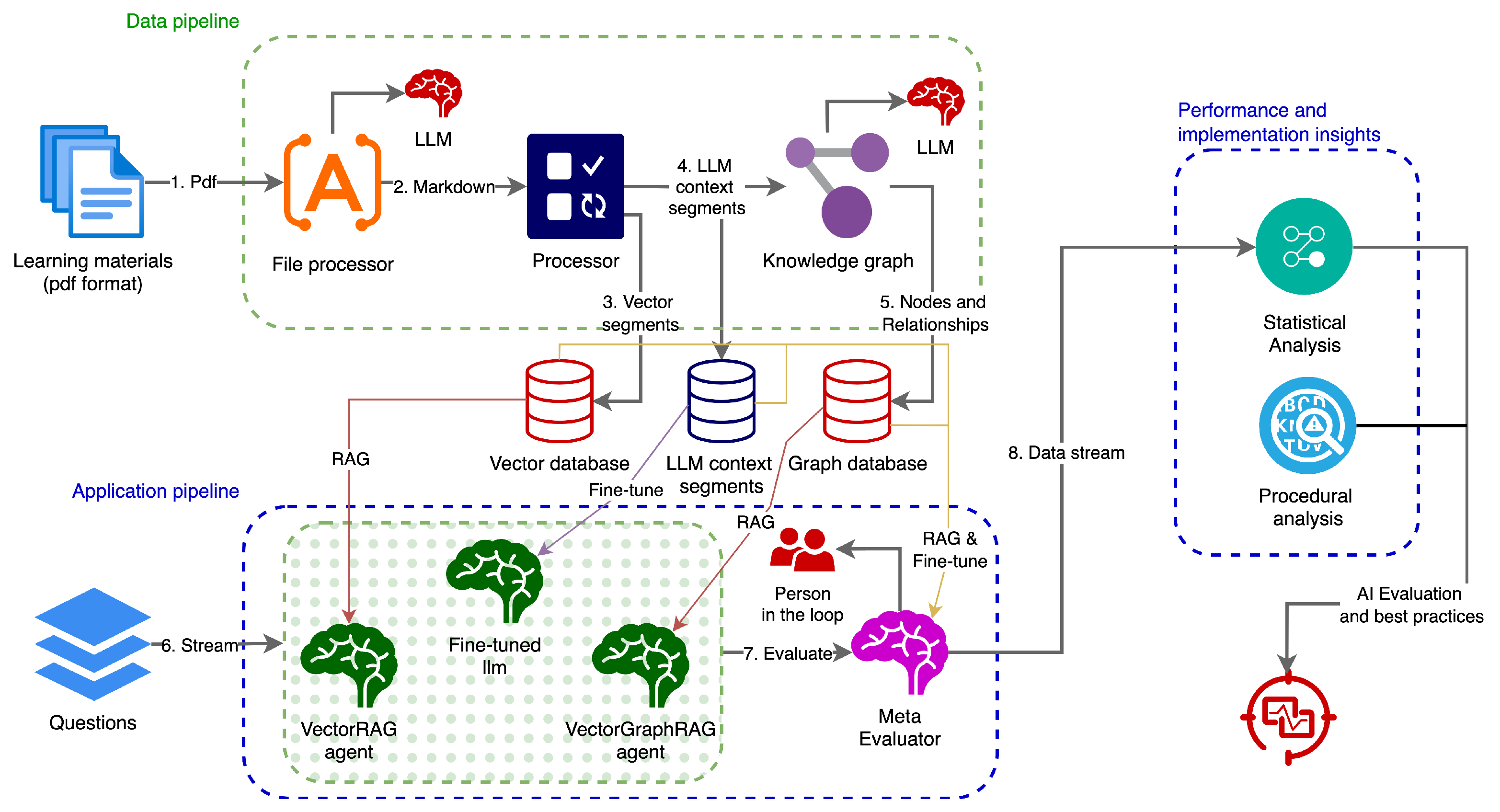
Figure 1 provides an overview of the complete workflow, beginning with the processing of partially condensed course materials and concluding with a structured comparative analysis of different LLM-based agents. In addition, our approach aims not only to assess these approaches from a purely statistical standpoint but also to provide guidelines and best practices for safely and effectively adopting AI in academic assessments. By acknowledging that most university courses in our dataset rely on distilled materials, such as instructor-curated notes, slides, and condensed summaries, our framework is designed to handle the alignment sensitivities and domain-specific constraints that characterize real-world higher education settings.
We pay special attention to how the nature of distilled course materials (versus entire textbook chapters), the design of retrieval-augmented databases, and supervised fine-tuning all interact to ensure precise alignment with learning objectives. Human experts play a crucial role throughout this pipeline, validating data pre-processing steps, monitoring potential biases, and supervising the meta-evaluator.
3.1. Workflow Pipeline Overview
Figure 1 shows the global process in three interconnected layers: the Data Pipeline, the Application Pipeline, and the Performance and Implementation Insights. Each layer builds upon the outputs of the previous one, creating a unified framework for generating, refining, and evaluating exam questions. Ultimately, the Performance and Implementation Insights identifies the best-performing agent configurations and best practices under varied pedagogical conditions.
3.1.1. Data Pipeline
The pipeline begins with converting original course materials (such as PDF slides and notes) into an enhanced Markdown format, producing structured and consistent text for subsequent processing. A central Processor then cleans, chunks, and embeds the text into two complementary forms: (i) smaller segments optimized for vector databases and hybrid (dense + sparse) retrieval [
38], and (ii) larger segments aligned with an LLM context window. From these enriched materials, a customized knowledge graph is constructed to capture key conceptual relationships. In parallel, a Fine-Tune Processor compiles a domain-specific dataset from the processed text, enabling the fine-tuning of a baseline LLM on course-relevant content.
3.1.2. Application Pipeline
Three distinct agents leverage these prepared resources. The VectorRAG agent utilizes a vector database to retrieve contextually relevant passages before generating or scoring questions [
39]. The VectorGraphRAG agent adds a knowledge-graph layer to model interlinked concepts for improved retrieval [
40], while the Fine-Tuned LLM agent employs a pre-trained model refined on curated question data [
41]. An agent evaluator orchestrates the three core tasks (see
Section 3.3), while a Meta Evaluator assigns ground-truth scores and explanation-quality ratings. Human experts oversee the meta-evaluation to safeguard correctness and alignment with course goals.
3.1.3. Performance and Implementation Insights
The final layer consolidates numerical scores, textual justifications, and any expert-driven corrections into a comprehensive dataset for analysis. Primary and secondary statistical analyses are then applied to examine how each agent’s performance varies by question type, Bloom’s level, course category, and other factors. This includes linear mixed-effects models that account for correlations within the same question and specialized secondary analyses (e.g., self-reflection accuracy, over-/under-grading). These models help identify the most effective agent configurations under diverse pedagogical conditions.
3.2. Datasets
This study relies on three primary datasets: (1) Course Materials, (2) Exam Questions and (3) Fine-Tuning Datasets. By combining both theoretical and application-oriented resources from four university-level courses (Data Science, Web Design, Integrated Systems, and Operating Systems), the data collection process ensures a robust representation of each course’s objectives and content.
3.2.1. Course Materials and Processing
Faculty and teaching assistants provided official documents such as lecture notes, slides, textbook excerpts, coding examples, laboratory guides, and supplementary readings. These materials, carefully curated to align with academic standards, capture both foundational theories and practical insights. The resulting corpus allows LLM-based agents to retrieve or generate exam questions that accurately reflect course-level learning outcomes.
These materials were initially converted from PDF and slide formats into Markdown by leveraging a multi-modal LLM [
42] that could handle text blocks, embedded images, and tables. To ensure correctness and clarity, human reviewers supervised and corrected the resulting Markdown files, particularly focusing on accurate handling of diagrams, special characters, and spacing inconsistencies. Next, each Markdown file was chunked into segments with a maximum of 1000 characters and a maximum token count of 1024. The chunking process was guided by logical structures, such as whole topics or paragraphs, ensuring that splits preserved meaningful context. This threshold was established through an iterative process with human supervision, where different chunk sizes were tested and evaluated to balance retrieval efficiency, context retention, and minimizing partial overlaps between content blocks. The established threshold offered a practical balance: it minimized partial overlaps between content blocks yet retained enough context for meaningful retrieval.
Ultimately, these segments were embedded into a Qdrant [
43] vector database for dense retrieval. In parallel, a domain-specific semantic knowledge graph was constructed in Neo4j [
44]. The knowledge-graph layer mainly focuses on linking relevant entities and topics, but its detailed architecture is beyond the scope of this study and is described in a separate publication.
3.2.2. Exam Questions and Processing
Table 1 shows the distribution of the original exam questions, a wide range of open-ended (essay-style) questions spanned across different cognitive levels according to Bloom’s taxonomy [
8] and categorized by question design into: single-step questions—generally require students to address one primary concept or task; and multi-step questions—involve multiple, interlinked sub-tasks or a sequence of reasoning steps. These items reflect theory-oriented or application-oriented course content. Instructors contributed an initial set of questions, particularly single-step ones, which were further expanded through generative strategies. Using a fine-tuned LLM (detailed in
Section 3.4), three variant forms of each original single-step item were created, each emphasizing different alignment aspects of the course materials. A second cycle then added multi-step questions by integrating vector-based and graph-based content, producing two new multi-step variations per original question. These added variations exhibited deliberately asymmetric alignments (one strongly matched vector-based content but loosely aligned with graph-based materials, and the other the reverse), thus probing how each LLM architecture handles partially overlapping or conflicting retrieval cues.
Once aggregated, these original and generatively varied items served as inputs for the three tasks executed by each LLM-based agent. In Tasks 2 and 3, the agent itself generates two new questions (an improved question and an entirely new one), effectively increasing the total number of question-based responses well beyond the original items shown in
Table 1. After discarding 37 invalid responses that did not meet minimum quality or consistency checks, the final dataset for this study included 3605 valid agent responses (covering Tasks 1, 2, and 3 across all conditions). The final exam-question dataset therefore encompassed both human-curated items and partially augmented versions. This balanced dataset supported robust evaluation of each LLM agent’s ability to score, refine, and generate questions. Example questions are given in the
Appendix A.2.
3.3. Core Tasks and Two-Part Evaluations
The study’s experimental design encompassed three main tasks, each requiring two outputs from the agent: a numeric score (1–10) and a concise textual explanation. This approach ensures that an agent’s performance can be evaluated not only on quantitative measures (e.g., alignment or clarity) but also on the reasoning reflected in its justifications.
Task 1 (Alignment Evaluation) has agents receive an existing exam question and evaluate its alignment with course objectives. They provide numeric ratings (e.g., concept coverage, specificity/relevance, and accuracy/correctness) and a textual rationale. Comparisons with ground-truth scores reveal where the agent might over- or under-grade alignment.
Task 2 (Question Improvement) asks agents to take a “suboptimal” exam question and propose an improved version, assigning scores for criteria such as alignment, clarity, fairness, or difficulty. This tests the agent’s ability to refine prompts while adhering to curricular standards and is a practical scenario for real-world educational revision.
Task 3 (Question Generation) instructs agents to create a new question at a given Bloom’s level and self-score it on alignment, clarity/fairness, difficulty, and originality. This tests the agent’s capacity to synthesize novel items that remain pedagogically sound and balanced in complexity.
3.4. LLM Agents and Architectures
Three distinct LLM-based agents were developed for the study: VectorRAG, VectorGraphRAG, and a Fine-Tuned LLM. Each agent performs the same three tasks, alignment evaluation, question improvement, and new question generation, but is equipped with a unique approach to retrieving and processing domain-specific information.
3.4.1. VectorRAG
This agent is a retrieval-augmented model that queries the Qdrant [
43] vector database to identify the most relevant text segments from the embedded course materials. Once these relevant context chunks are retrieved (e.g., top-5 or top-20, depending on the experimental setting), they are fed into a language model that uses Google Gemini 2.0 [
42] as its backbone to produce a final output for alignment scores, improved questions, or newly generated questions.
3.4.2. VectorGraphRAG
This agent extends the retrieval-augmented approach by incorporating a knowledge graph (Neo4j [
44]). In addition to standard vector retrieval, this agent leverages relationships stored in the knowledge graph, such as conceptual links or sentiment edges, to enrich its context. This approach is particularly useful for multi-step questions or cases where cross-topic reasoning is needed. The final text output is generated by the same backbone language model as VectorRAG [
42] but is grounded by the graph-based insights.
3.4.3. Fine-Tuned LLM
The Fine-Tuned LLM is a specialized model built on top of Meta-Llama-3.1-8B [
45]. It was refined using supervised fine-tuning (SFTTrainer) on a custom dataset derived from the course materials and exam questions. In an initial attempt (Fine-Tuned LLMv1 [
46]), the model’s outputs did not meet the quality criteria set by human reviewers. Consequently, the fine-tuning datasets were cleaned, noise was removed, and domain-distilled samples were added—resulting in a second version (Fine-Tuned LLMv2). This updated model (named vlada22/Meta-Llama-3.1-8B-Instruct-finki-edu-4courses) [
47] was approved by human experts based on consistency, alignment with course concepts, and clarity.
Below is a high-level summary of the fine-tuning parameters used for the second version. Two main configurations (v1 and v2) differed in learning rate, epoch count, and batch size, among other settings. Both leveraged QLoRA and LoRA-based training modules, focusing on the query, key, value, and projection components of the model:
Configuration v1:
- –
learning_rate = , num_train_epochs = 3, per_device_train_batch_ size = 4
Lower batch sizes and fewer epochs.
Configuration v2:
- –
learning_rate = , num_train_epochs = 5, per_device_train_batch_ size = 128
Larger batch sizes, more epochs, and a carefully curated dataset.
Through human-in-the-loop experimentation, Fine-Tuned LLM v2 was ultimately selected for the final experiments due to its superior alignment and generation quality.
3.5. Meta Evaluator, Human Oversight, and Score Integration
A specialized
Meta Evaluator, implemented as GPT4o [
48] with strict evaluation policies, assigns ground-truth (reference) scores for each subdimension in Tasks 1–3 by referencing the original course materials. It also reviews each agent’s justifications and produces a rating for explanation quality, emphasizing coherence, factual integrity, and logical clarity. Human experts resolve domain-specific nuances to ensure that all finalized ground-truth scores accurately reflect the intended learning objectives. Task 1 comparisons rely on an absolute error metric between the agent’s subgrades and the meta-evaluator’s ground-truth, whereas Tasks 2 and 3 treat the meta-evaluator’s subgrades as
true for measuring how closely the agent’s improved or newly generated question aligns with course standards. The structured dataset ultimately captures all numeric outputs (agent and meta scores) plus explanation-quality ratings, providing a transparent record of agent performance and justifications across a range of question types.
Senior faculty members and domain experts from each course oversaw all critical stages, from data pre-processing (Markdown conversion, chunking, question selection) to the final meta-evaluation. Their role was to (1) review the correctness and fairness of auto-generated or refined questions, (2) validate the performance of the Fine-Tuned LLM during the iterative SFT process, and (3) supervise the meta-evaluator’s final scoring to mitigate biases and address any missing context. The final meta scores (averaged or sub-dimensional) were thus the product of LLM-based evaluation plus domain-expert supervision, ensuring both consistency and reliability.
3.6. Data Parsing and Final Dataset Preparation
Once each LLM agent (VectorRAG, VectorGraphRAG, Fine-Tuned LLM) completed its assigned tasks, providing alignment scores, improved questions, and newly generated items, these outputs were consolidated into a single dataset. During this process, multiple versions of both the agent outputs and the meta-evaluation were created to refine quality and ensure final decisions were based on robust data:
Agents1 (Version 1)—VectorRAG with a top-20 retrieval setting, VectorGraphRAG with top-50, and Fine-Tuned LLM v1 (the initial fine-tuned model).
Agents2 (Version 2)—VectorRAG with top-5 retrieval, VectorGraphRAG with top-20, and Fine-Tuned LLM v2 (the improved fine-tuned model).
Meta_auto—The “raw” outputs of the meta-evaluator (LLM-based) when scoring Agents2 responses.
Meta_human—The final ground-truth dataset after human experts supervised and corrected the meta-evaluator’s judgments from Meta_auto.
In the first version (Agents1) dataset, a preliminary human review of these outputs identified several issues with alignment, clarity, and difficulty, leading the team to conclude that they were insufficient for final analysis. To address these shortcomings, both the retrieval parameters and the fine-tuning process were refined. In the second version (Agents2) dataset, human experts conducted another review of the outputs and deemed them acceptable for statistical modeling and further study.
Following the collection of Agents2 responses, a Meta Evaluator was employed to produce meta_auto dataset: initial “ground-truth” scores generated automatically by an LLM-based system. However, because the study implies rigorous human supervision to mitigate biases or factual inaccuracies, domain experts manually examined and corrected the meta_auto outputs, creating a final reference dataset known as meta_human. Consequently, meta_human represents the combined product of automated scoring and expert oversight.
With Agents2 outputs serving as the primary agent-based dataset and meta_human as the authoritative set of ground-truth evaluations, several comparative analyses were performed. This multi-stage workflow ensured that each iteration of data collection and evaluation was systematically validated, ultimately enabling robust conclusions about agent performance, fairness, and real-world applicability of the proposed LLM-based exam-question framework.
The final datasets (agents1, agents2, meta_auto, and meta_human) contain 3605 valid agent and meta responses, encompassing both original question evaluations and newly generated items.
3.7. Statistical Modeling and Analysis
After producing a final dataset from the Agents2 outputs and matching them to the Meta_human ground truth, several targeted analyses were performed to evaluate agent performance, detect biases, and validate the system’s real-world applicability. The following subsections outline each analytical step in a structured but narrative style.
3.7.1. Main Analysis (Mixed-Effects Model)
A primary goal was to quantify how accurately each agent (VectorRAG, VectorGraphRAG, and Fine-Tuned LLM v2) performed across the three tasks (alignment evaluation, question improvement, and new question generation) under varying instructional contexts. To achieve this, a linear mixed-effects model (LMM) was fitted for each task. The model accounted for repeated measures on the same question by incorporating random intercepts, thereby mitigating potential correlations. Agent type, course orientation, question design, question category, and explanation-quality subdimensions were entered as fixed effects.
In Task 1, the outcome variable consisted of absolute alignment errors between the agent’s subgrades and the Meta_human reference. For Tasks 2 and 3, the outcome was the Meta_human subgrade assigned to the improved or newly generated questions (e.g., averaged scores for alignment, clarity, difficulty, and originality). By including the same set of fixed effects in these models, the study systematically examined the circumstances under which particular agents excelled or struggled and assessed the impact of explanation clarity on overall performance.
3.7.2. Self-Reflection and Over-/Under-Grading
An additional focus was on the consistency between an agent’s self-assessment and the external ground truth. In Tasks 2 and 3, each agent scored its own outputs for alignment or clarity, among other dimensions, and these self-scores were then compared with the Meta_human reference. The difference between the two scores revealed whether the agent tended to overestimate or underestimate its own quality.
In Task 1, a signed-error approach was taken by comparing the agent’s alignment subgrades (concept coverage, specificity/relevance, accuracy/correctness) with the Meta_human scores, thereby highlighting any systematic over-grading or under-grading patterns. These self-reflection and over-/under-grading measures helped identify calibration gaps that could affect downstream decisions if agents were used unsupervised.
3.7.3. Bias Identification and Removal (Meta_auto vs. Meta_human)
To assess the robustness of the meta-evaluator itself, a bias analysis compared its initial automated assessments (Meta_auto) against the expert-supervised ground truth (Meta_human). The same Agents2 responses were used in both sets of evaluations, facilitating a clear measurement of discrepancies. Wilcoxon signed-rank and error distribution analyses were applied to ascertain whether the automated evaluator displayed systematic biases for particular question designs or content domains. Where biases were detected, human supervision played a crucial corrective role, providing adjustments to the meta-evaluator’s evaluation policies. This process underscored the advantages of a hybrid system that combines LLM-based automation with expert oversight in high-stakes academic settings.
3.7.4. Real-World Validation on 100 Human-Created Exam Questions (Task 1)
To evaluate the practical applicability of the proposed framework, a set of 100 human-created exam questions was compiled. These questions were specifically chosen to be theory-oriented (course_category), application-based (question_category), and multi-step (question_design), reflecting a more complex examination style. The best-performing agent, as identified by the earlier analyses, was then used to evaluate the alignment of these questions with the intended course objectives under Task 1 only. Subsequently, human experts assigned comparable alignment scores to each of the same 100 questions, forming a basis for a direct comparison. A paired t-test and Bland–Altman analysis were conducted to assess whether the agent’s alignment evaluations significantly differed from human judgments. If the differences are minimal and not statistically significant, it would indicate that the system’s reliability extends to real exam scenarios.
3.8. Workflow Implementation and Data Availability
All workflow modules were implemented in Python (version 3.12). Data cleaning and organization utilized pandas [
49], with statsmodels [
50] supporting the mixed-effects analyses. Retrieval and knowledge-graph components were managed by LangChain [
51], gte-Embegginds model based on [
52], Qdrant [
43], and Neo4j [
44]. The VectorRAG and VectorGraphRAG agents used Google Gemini 2.0 [
42], and the Fine-Tuned LLM relied on Meta-Llama-3.1-8B-Instruct-finki-edu-4courses [
47]. The Meta Evaluator was GPT4o [
48], supplemented by human experts to ensure alignment with genuine course standards.
Appendix A.2 (
Table A4) shows example questions generated by agents for Task 3.
The dataset includes both human-generated exam questions, which represent the actual question pool for the courses, and LLM-generated questions. Since the human-generated questions are actively used for student assessment, they cannot be published. However, all data generated by LLMs—including questions, course materials, fine-tuning datasets with the code for the actual fine-tuning, datasets produced by agents (Agents1 and Agents2), and meta-evaluation datasets with human supervision (Meta1 and Meta2), along with the analysis code, will be shared on the project’s GitHub repository (v1.0.0) [
53] after acceptance, in accordance with the journal’s data-sharing guidelines.
3.9. Methodological Synthesis and Alignment with Research Objectives
Overall, this methodology integrates (i) a data pipeline that enriches course materials; (ii) an application pipeline in which three LLM-based agents evaluate, refine, and create exam questions; and (iii) a meta-evaluation layer that produces ground-truth and explanation-quality scores. The resulting dataset supports a mixed-effects framework capable of capturing agent, task, and question-level variations. By enforcing transparent scoring rubrics and explicit justifications, the study directly addresses its core goals: to measure alignment with course objectives, compare retrieval-based and fine-tuned LLMs, and determine whether high-quality justifications correlate with more reliable self-scoring or improved question quality.
Beyond these immediate research outcomes, the approach serves as a comprehensive guideline and set of best practices for educators and developers aiming to responsibly integrate AI into higher education. It addresses crucial considerations such as fairness, bias mitigation, domain-specific requirements, and the necessity of human oversight. By adopting the methodological steps outlined in this study, educators and developers can deploy LLM-based question generation and evaluation tools with greater confidence, ensuring both pedagogical integrity and equitable student assessment.
4. Results
This section presents the findings from all experimental and analytical procedures described in
Section 3.7. It begins with an overview of the final dataset and initial visualizations, followed by the core mixed-effects models for Tasks 1, 2, and 3. Furthermore, additional analyses are presented, including self-reflection and over-/under-grading, bias identification in meta-evaluation, and real-world validation on new questions.
4.1. Main Analysis (Mixed-Effects Model)
For all tasks, each agent’s explanation quality was scored (1–10) on each relevant subdimension. This led to 108,150 long-format records (3605 questions × 3 agents × 10 task-subdimensions for tasks 1, 2 and 3).
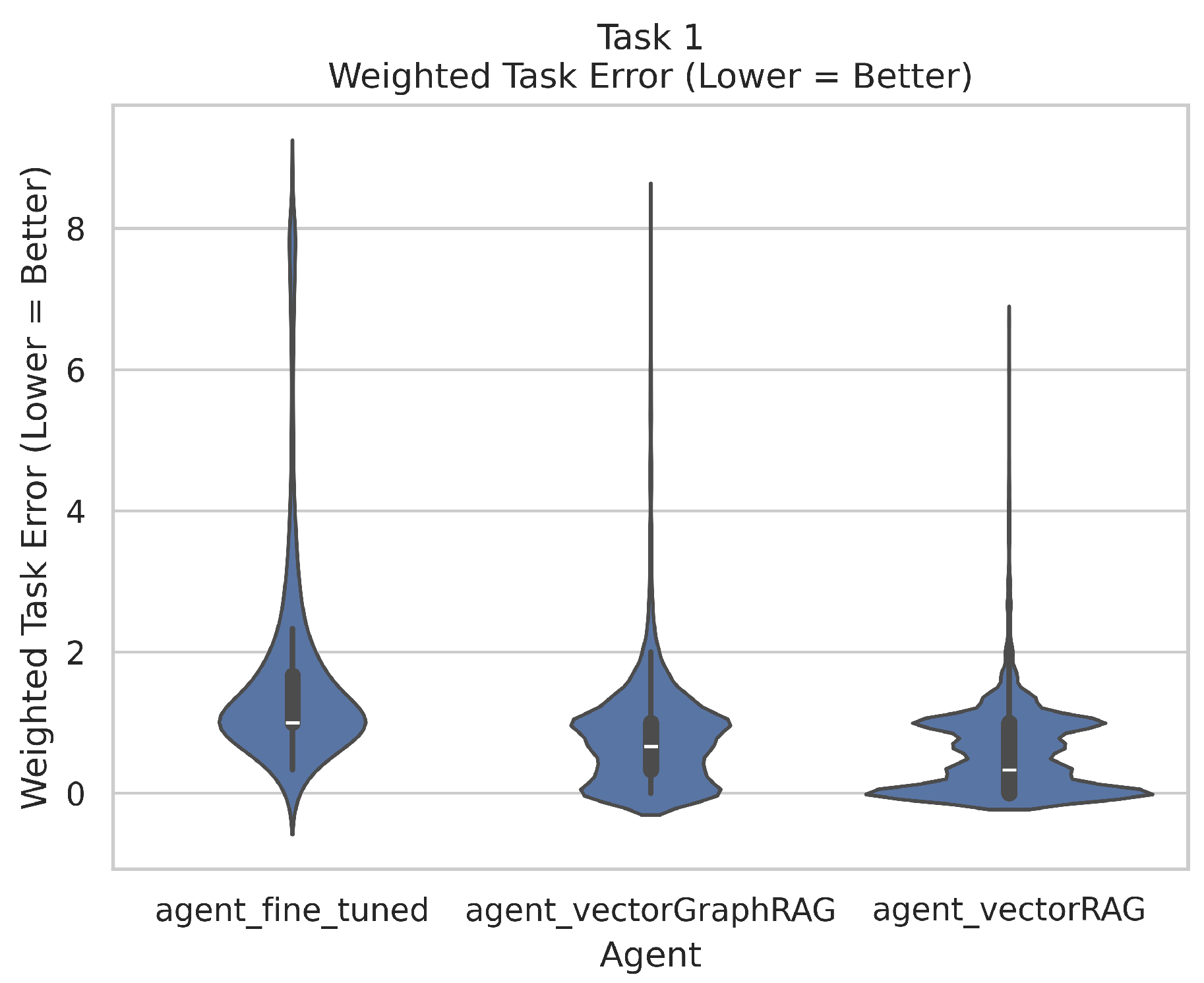
Figure 2 shows the Task 1 distributions of averaged absolute errors (lower is better), while
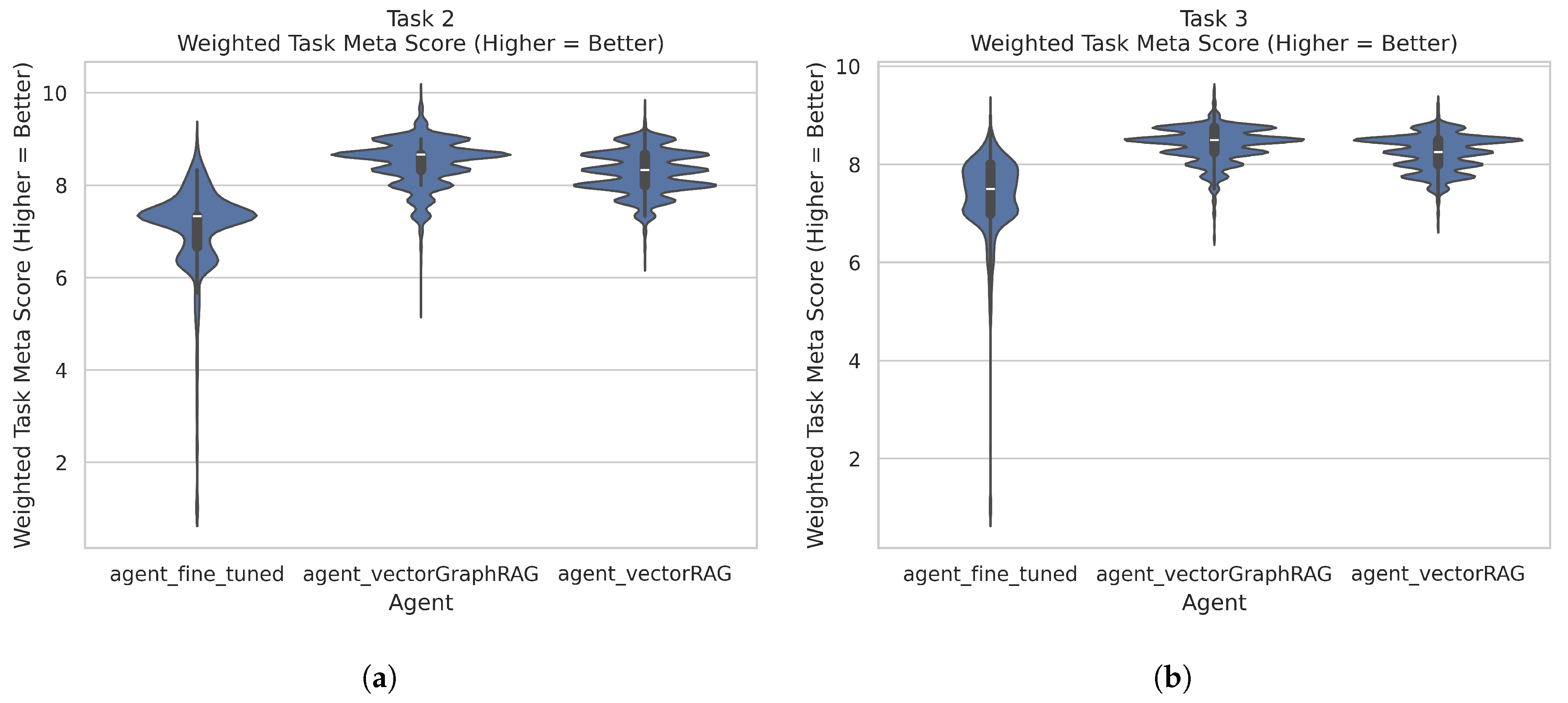
Figure 3 shows Tasks 2 and 3 averaged meta scores (higher is better). These initial visualizations provide a preliminary overview before turning to mixed-effects models.
4.1.1. Mixed-Effects Modeling and Large-Output Tables
A linear mixed-effects model (LMM) was employed for each task to account for the nested data structure. Every question (question_id) can generate multiple observations (one for each agent, each subgrade, etc.), leading to potentially correlated residuals within the same question. Including adds a random intercept for each question, thereby allowing each question to have its own baseline level. This approach reduces bias from unobserved question-level factors (such as difficulty, style, or intrinsic complexity) that could otherwise inflate residuals and obscure true agent or design effects.
The choice of LMM over simpler ANOVA or OLS arises from several considerations:
Repeated Measures on the Same Questions: Each question is seen by multiple agents, so scores from the same question are not independent.
Varying Baseline: Distinct questions may be inherently “easier” or “harder” to align, improve, or recreate, making a random intercept beneficial.
Complex Interactions: Agents interact with question design (single-step vs. multi-step), question category (application, knowledge, or creation/evaluation), and course orientation (application vs. theory), potentially at different slopes.
Hence, the LMM properly captures these within-question correlations and estimates fixed effects for agent, design, category, course orientation, and explanation-quality subdimensions.
Each fitted model can easily produce 20–30 (or more) fixed-effect coefficients due to main effects, interactions, and explanation-quality dimensions. To maintain clarity, full tables with standard errors,
z scores,
p-values, and confidence intervals are placed in
Appendix A.1 (
Table A1,
Table A2 and
Table A3). Summaries of critical effects and forest plots appear in the main text to highlight the most relevant findings. This strategy ensures both accessibility (concise narrative) and reproducibility (complete details in the
Appendix A).
4.1.2. Task 1: Alignment Evaluation of Exam Questions
In Task 1, each agent and the meta-evaluator graded the same original question on three subgrades: Concept Coverage (CC), Specificity/Relevance (SR), and Accuracy/Correctness (AC). The alignment quality is captured by the Averaged_Task_Error:
A lower averaged absolute error indicates closer alignment with the meta-evaluator. The mixed model includes agent, question design (single-step vs. multi-step), question category (application-based, knowledge-based, or creation/evaluation), course category (application-oriented vs. theory-oriented), and the agent’s explanation-quality subgrades (concept_coverage, specificity_relevance, accuracy_correctness). A random intercept for each question captures unobserved variability:
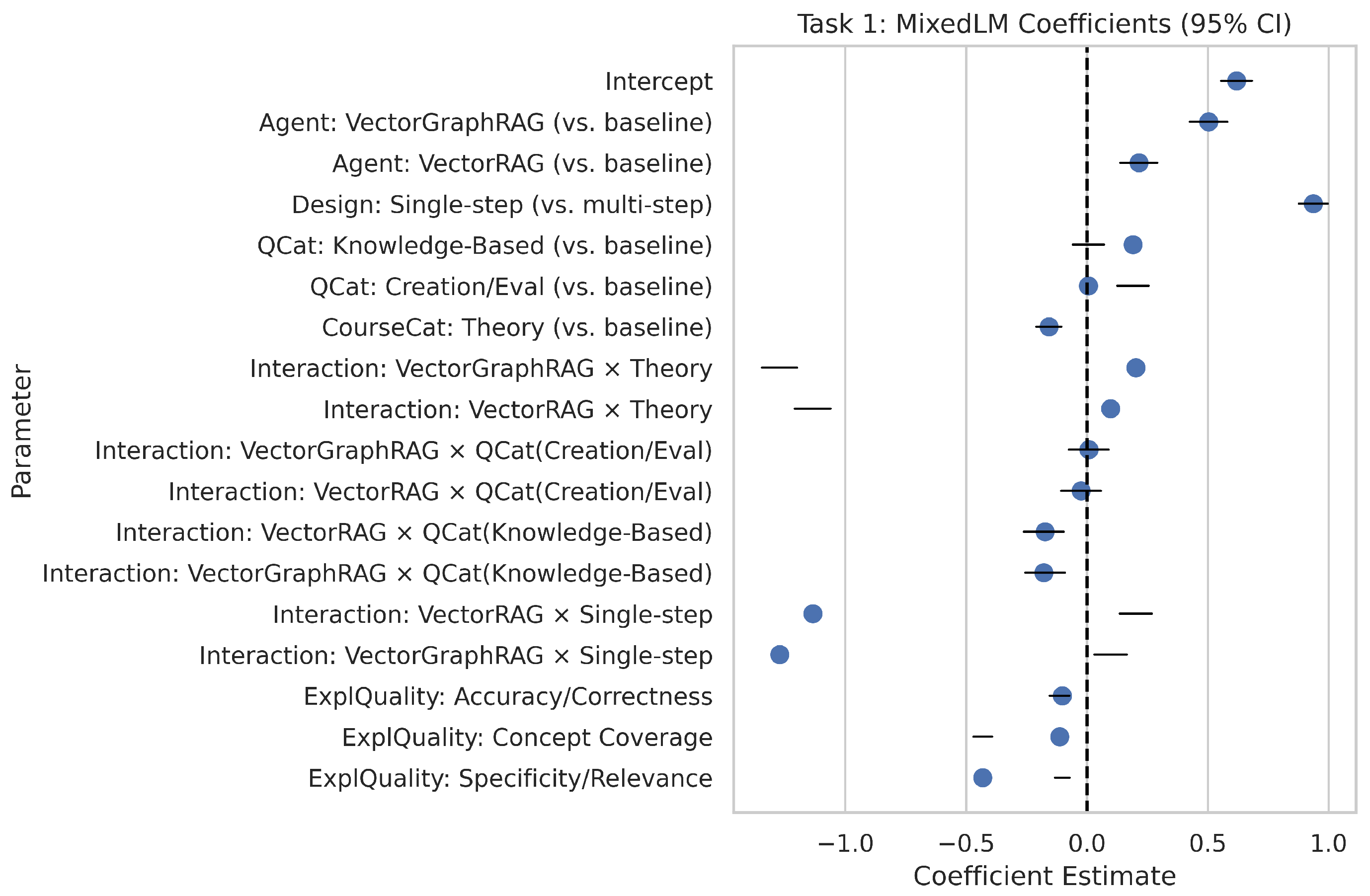
Figure 4 illustrates the fixed effects as point estimates with 95% confidence intervals. The intercept (0.619) represents the fine-tuned LLM under baseline conditions (multi-step, application-based, application-oriented, and mean explanation quality). Single-step design significantly increases error by +0.937. VectorGraphRAG (+0.503) and VectorRAG (+0.215) both raise baseline error, but they also display large negative interactions with single-step (
and
, respectively), indicating they can partially or fully offset the disadvantage of simpler tasks. Explanation-quality subgrades are strongly significant (e.g.,
), suggesting that stronger justifications reduce alignment errors by up to 0.4 or 0.5 points.
Overall, the fine-tuned LLM often achieves relatively low error in multi-step contexts, but VectorRAG or VectorGraphRAG can be more competitive if questions are single-step or if they provide higher-quality explanations in key sub-dimensions such as specificity/relevance.
4.1.3. Task 2: Exam Question Improvement
For Task 2, each agent improved the original question, and the meta-evaluator scored the result on three subgrades: Alignment with Objectives, Clarity, and Appropriate Difficulty (1–10 each). The Averaged_Task_Meta_Score is computed as
Higher values reflect better improvements, from the meta-evaluator’s perspective. The LMM for Task 2 includes similar predictors and a random intercept:
Figure 5 shows the forest plot. The intercept is 7.812, indicating the fine-tuned LLM’s predicted meta score under baseline conditions (multi-step, application-based, application-oriented) with mean explanation quality. VectorRAG (+0.234) and VectorGraphRAG (+0.193) have higher baseline scores than the fine-tuned under these conditions, but they also have negative interactions with single-step (
and
, respectively). Explanation-quality subgrades again exhibit large, significant coefficients (e.g.,
), each adding nearly 0.3–0.4 points to the final meta score when above average.
Under average explanation quality, VectorRAG often achieves top averaged meta scores (reaching or surpassing 8.0) in multi-step, application-oriented improvements. The fine-tuned LLM can, however, catch or exceed those scores in theory-oriented tasks or when it delivers especially strong explanation quality (e.g., high clarity or appropriate difficulty).
4.1.4. Task 3: New Exam Question Generation
In Task 3, each agent produced a new question in the same Bloom’s category, evaluated on four subgrades: Alignment, Clarity, Difficulty, and Originality (1–10 each). The Averaged_Task_Meta_Score is
Higher scores indicate more suitable or creative question generation. The mixed-effects model follows the same pattern:
Figure 6 indicates that the fine-tuned LLM’s baseline intercept is 7.969. Although single-step tasks slightly reduce scores (
), VectorRAG starts slightly above baseline in multi-step tasks (+0.030) but experiences a negative single-step interaction (
). VectorGraphRAG is essentially near the fine-tuned baseline (
), benefiting from large explanation-quality coefficients such as
. It can thus close or exceed gaps if it provides particularly creative or clear justifications.
The fine-tuned LLM generally excels in multi-step, theory-oriented tasks, whereas VectorRAG often thrives in application-oriented contexts. VectorGraphRAG tends to be more sensitive to explanation-quality subgrades, especially originality, allowing it to narrow or overcome baseline disadvantages.
4.2. Self-Reflection Analysis in Tasks 2 and 3
Each agent in Tasks 2 and 3 not only received a meta-evaluator score but also assigned its own self-score to the improved or newly generated question. A Self-Reflection Error was then computed as follows:
where a positive value indicates overestimation (agent scoring itself higher than the meta standard), and a negative value indicates underestimation.
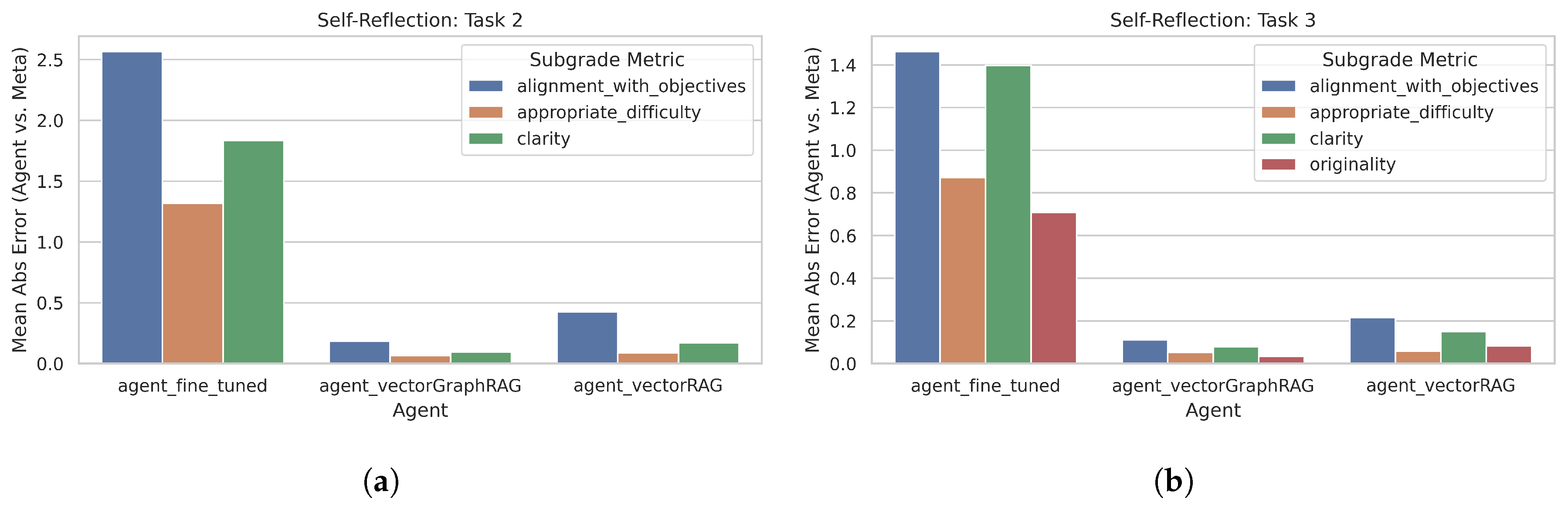
Figure 7 displays the observed distributions for these errors in Tasks 2 and 3.
Analyses reveal that the Fine-Tuned LLM systematically overestimates its performance by around +1.3 to +1.5 points, whereas VectorRAG and VectorGraphRAG hover near +0.1 to +0.2. This discrepancy suggests that, while fine-tuned LLM has strong generation capabilities, it may not be well-calibrated in judging its own improvements or new question quality.
4.3. Over-/Under-Grading Analysis in Task 1
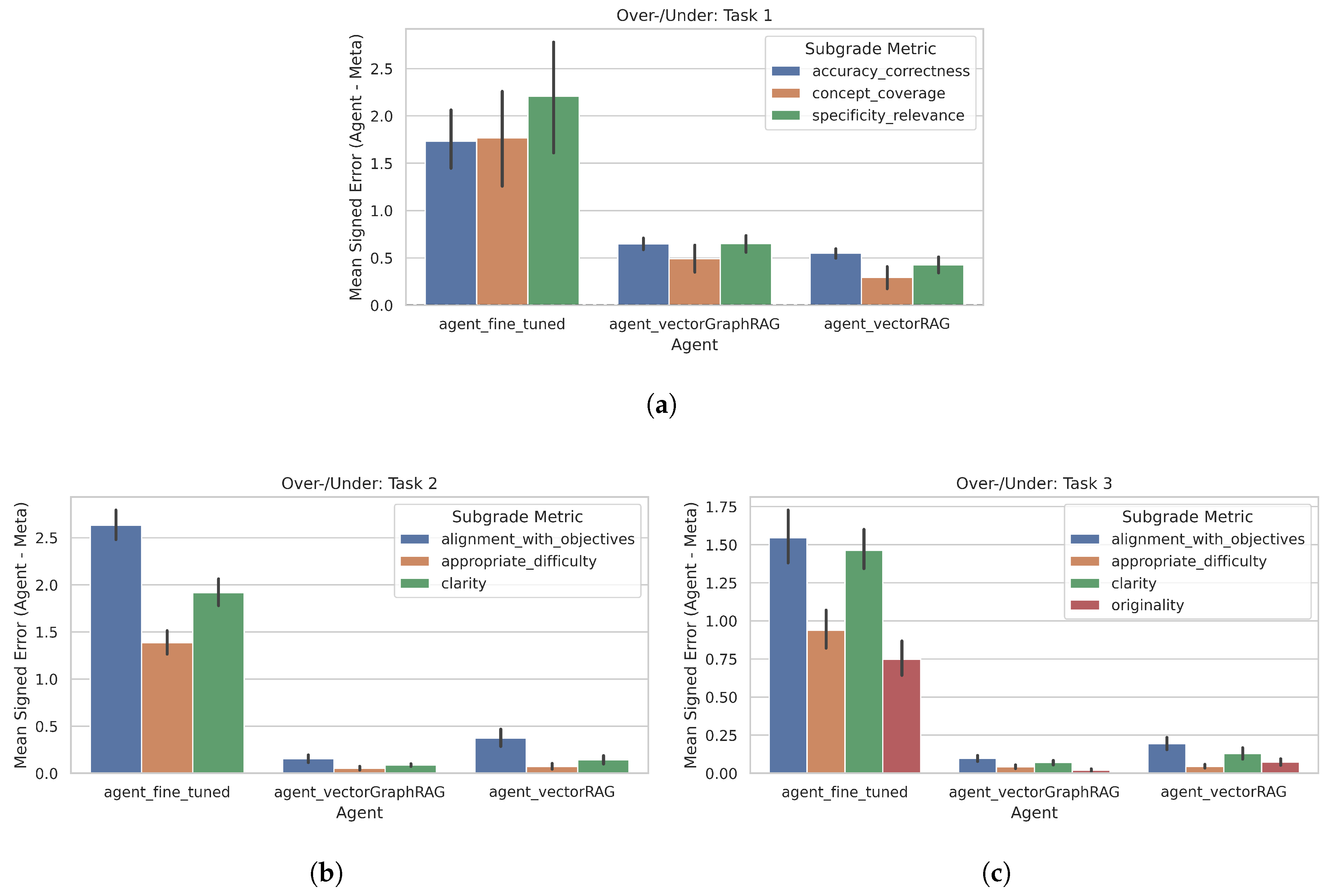
Although Task 1 primarily uses absolute alignment errors, a signed perspective identifies whether agents consistently over-grade or under-grade certain items. The Signed Error in each dimension is
where a positive value indicates over-grading (the agent gave higher subgrades than the meta-evaluator) and a negative value indicates under-grading.
Figure 8 visualizes mean signed errors in Task 1 across Concept Coverage, Specificity/Relevance, and Accuracy/Correctness, grouped by agent and question type.
In Task 1, the fine-tuned LLM tends to over-grade concept coverage for certain categories by ∼+1.3–1.4, consistent with its self-reflection bias in later tasks. VectorRAG has a mild positive bias in creation/evaluation questions, while VectorGraphRAG sometimes underestimates accuracy/correctness. These patterns reinforce the need for a meta-evaluator to mitigate systematic biases.
4.4. Bias Identification (Meta_auto vs. Meta_human)
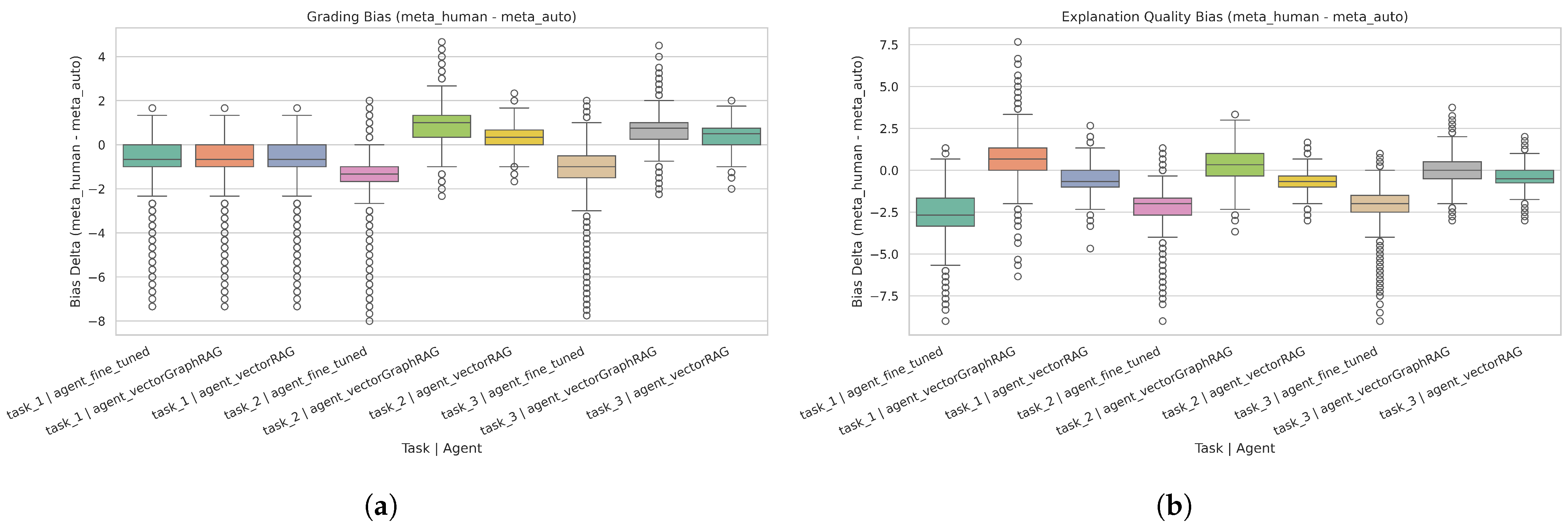
An additional analysis was conducted to showcase how the automated meta-evaluator (Meta_auto) compared to the human-supervised reference (Meta_human), thereby revealing potential biases and the extent to which expert oversight can mitigate them. Specifically, the final dataset was merged to include both the Meta_auto and Meta_human scores for the same items, then grouped by key attributes: task, agent, question_category, question_design, and course_category. Within each group, the difference was computed separately for grading-related scores (e.g., alignment or improved question quality) and for explanation quality subdimensions, by using this formula:
After calculating mean and median differences, the Wilcoxon signed-rank test was used to determine whether these distributions significantly deviated from zero, indicating a systematic gap between the automated evaluator and the human reference. Tables in
Appendix A.3 (
Table A5,
Table A6 and
Table A7) show that, for many combinations of task and agent, the
p-values are extremely small (often lower than
), signifying that Meta_auto and Meta_human consistently differ in their evaluations. In some cases, such as fine-tuned under Task 2 or Task 3, the difference is notably negative, suggesting the human experts tended to provide lower numeric scores than the automated system. On the contrary, the positive mean differences for VectorGraphRAG indicate that Meta_human often rated these outputs higher than Meta_auto evaluations.
These trends apply both to the grading/score dimension (alignment or improved/new question quality) and to explanation quality metrics. Notably, for some agent–task combinations, the Wilcoxon test shows large effect sizes, implying that the discrepancy is not sporadic but rather systematic. This underscores the necessity of human intervention, especially when tasks require nuanced judgments of clarity, correctness, or originality.
Figure 9 illustrates how the differences cluster around negative or positive values depending on the agent and task, reinforcing that the automated meta-evaluator, though helpful, may overestimate or underestimate certain dimensions.
Overall, these results confirm that the Meta Evaluator (Meta_auto) introduces measurable biases in both grading and explanation scores, varying by agent type and question attributes. Human supervision (Meta_human) plays a crucial role in correcting systematic misalignment, especially in high-stakes educational contexts. By identifying where and why biases appear, future iterations of the meta-evaluation system can incorporate targeted calibrations or fine-tuning strategies to narrow the gap between automated judgments and expert assessments.
4.5. Real-World Validation on 100 Human-Created Exam Questions (Task 1)
To assess the framework’s practical utility beyond the experimental conditions, a set of 100 human-authored exam questions was assembled. Each question fell under the theory-oriented course category, was application-based in Bloom’s taxonomy, and had a multi-step design. The recommended agent, identified in earlier sections based on the mixed-effects modeling and subsequent evaluations, was applied to these questions for Task 1. A panel of human experts likewise scored each question’s alignment (averaging concept coverage, specificity/relevance, and accuracy/correctness), thereby generating a reference for comparison.
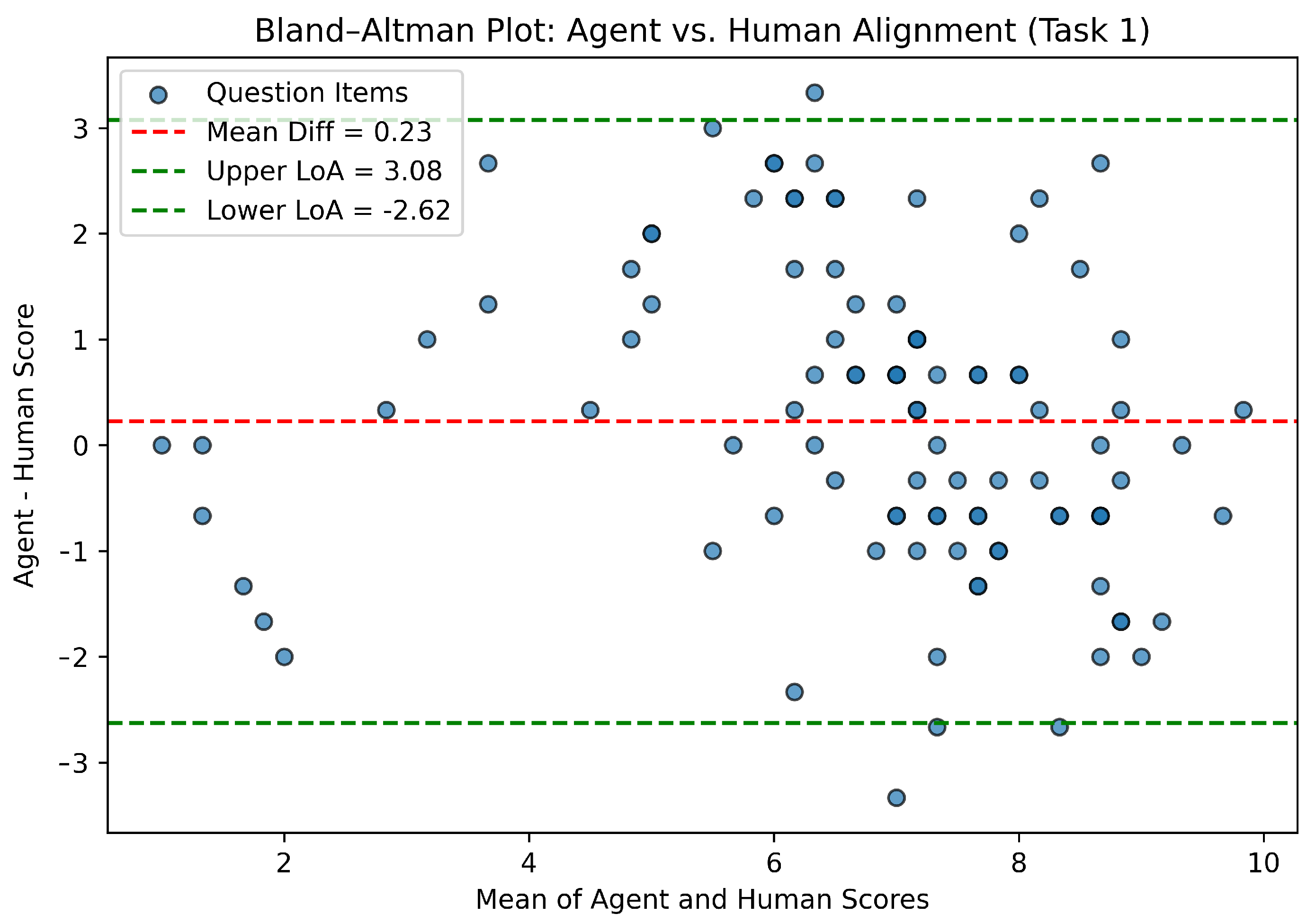
Table 2 presents the key findings, including a paired
t-test of the agent’s average scores against the human scores, along with Bland–Altman statistics. The mean difference (≈0.23) points) is relatively small, and the
p-value (≈0.1224) indicates
no statistically significant difference in overall mean scores. This suggests that, on average, the agent’s alignment evaluations are comparable to those of human experts.
Figure 10 provides a Bland–Altman plot, illustrating each question’s difference (agent minus human) against the mean of the two scores. The “mean difference” (red dashed line) is centered slightly above zero, reflecting the 0.23-point bias. The “95% limits of agreement” (green dashed lines) span from (−2.62) to (3.08), suggesting that, while the agent occasionally overestimates or underestimates certain items, most points fall within a reasonable range of agreement.
These results demonstrate that the discrepancies between the agent and the human experts are generally small and not statistically significant. While occasional outliers remain, the overall trend supports using this best-performing agent to autonomously assess alignment for multi-step, theory-oriented, application-based questions. In practice, instructor oversight continues to play a vital role, particularly for questions lying near the edges of the distribution. Nonetheless, the fact that the system’s outputs do not systematically diverge from human judgments underscores the real-world viability of the proposed framework—indicating that it can be confidently deployed for large-scale alignment tasks while still allowing educators to perform final quality checks as needed.
4.6. Summary of Findings
No single agent dominates under every condition. The fine-tuned LLM often achieves lower error in multi-step, theory-oriented tasks, while VectorRAG excels in application-oriented tasks. VectorGraphRAG, although showing higher baseline error or lower baseline scores, can bridge the gap if it provides high explanation-quality subgrades (e.g., specificity/relevance in Task 1 or originality in Task 3).
Self-reflection
Section 4.2 analysis indicates that the fine-tuned LLM overestimates its performance by more than +1 point, whereas VectorRAG and VectorGraphRAG remain closer to meta-evaluator judgments. Over-/under-grading
Section 4.3 in Task 1 shows parallel biases, suggesting that calibration differences persist across tasks.
By adopting mixed-effects modeling with random intercepts for question_id, these analyses correctly account for within-question correlation, uncovering how agent-type, design, category, and explanation dimensions interact to influence alignment errors or meta scores. Full coefficient tables are in
Appendix A.1, while the forest plots and predicted means presented here highlight the most influential terms and interactions.
5. Discussion
This study aimed to develop and evaluate a systematic framework and provide best practices for integrating large language models (LLMs) into higher-education exam-question design. Three primary tasks: (1) alignment evaluation of original questions, (2) question improvement, and (3) new question generation; were undertaken by three different LLM-based agents. Building on the detailed statistical models and numerical findings presented earlier, this discussion distills the core insights of each task into a cohesive narrative. It offers actionable guidance for selecting the most suitable agents under varying conditions and clarifies why these three LLM-based agents (VectorRAG, VectorGraphRAG, and a fine-tuned LLM) were studied, rather than more complex alternatives. This balanced approach emphasizes both the empirical robustness of the findings and their practical relevance, particularly within the delicate context of higher education, and derives best practices for real-world implementation.
5.1. Main Analysis: Alignment, Improvement, and Generation
The main analysis showcases each agent intrinsic strengths and limitations that deeply depend on the type of question, the nature of the course material, and the cognitive demands of the specific task.
5.1.1. Task 1 (Alignment Evaluation)
In this first task, each agent’s subgrade of the original question was compared to a meta-evaluator’s ground truth, and the discrepancy was measured via weighted absolute error. The fine-tuned LLM generally excelled in multi-step, theory-oriented contexts, especially for higher-level conceptual tasks. Conversely, VectorRAG tended to outperform others for single-step, application-oriented questions, leveraging retrieval-based augmentation. Although VectorGraphRAG started with a somewhat higher baseline error, it could partially close the gap when providing especially strong explanation-quality subgrades—for example, specificity/relevance or accuracy/correctness. Indeed, the regression coefficients indicated that a 1-point increase in specificity_relevance could reduce alignment error by up to 0.4 (e.g., estimate), revealing the tangible impact of deeper, more precise justifications.
5.1.2. Task 2 (Question Improvement)
In this task, each agent generated an improved version of the original question, which the meta-evaluator scored on Alignment with Objectives, Clarity, and Appropriate Difficulty. The fine-tuned LLM tended to excel for theory-heavy or higher-level conceptual refinements, consistent with its domain-focused training. However, it was not always dominant in single-step, practical questions, where VectorRAG often delivered strong results—particularly in multi-step, application-oriented improvement scenarios. VectorGraphRAG’s performance was close to the other agents, but it rarely occupied the top position unless it provided robust explanation-quality subgrades (alignment_with_objectives, clarity, appropriate_difficulty), each of which can raise the meta score by 0.2–0.3 points when above average.
5.1.3. Task 3 (New Question Generation)
For the final task, each agent created an entirely new question in the same Bloom’s category, evaluated on Alignment, Clarity, Difficulty, and Originality. Much like Task 2, the Fine-Tuned LLM often led in theory-oriented or more complex, multi-step tasks. Meanwhile, VectorRAG excelled in application-oriented contexts where retrieval-based expansions offered practical authenticity. VectorGraphRAG generally showed moderate but steady performance, occasionally achieving higher scores when originality was strong (the regression estimate for originality, ≈+0.336, indicates a substantial positive impact). These results highlight the importance of well-substantiated creativity in pedagogical question design.
5.1.4. Guidelines for Agent Selection
Table 3 converts these findings into a practical reference. Each row captures an intersection of (i) Bloom’s category (Knowledge-Based, Application-Based, Creation and Evaluation), (ii) question design (single-step or multi-step), and (iii) course orientation (theory-oriented or application-oriented). For each combination, the table identifies which agent tended to show higher performance in Task 1 (Alignment Evaluation), Task 2 (Question Improvement), and Task 3 (New Question Generation). When no consistent leader emerged, we note “All three agents performed similarly” to reflect minimal or inconsistent differences among the fine-tuned LLM, VectorRAG, and VectorGraphRAG.
While the Fine-Tuned LLM frequently exhibits strong performance in theory-oriented, multi-step tasks across all three tasks, VectorRAG tends to excel in application-oriented conditions for Tasks 2 and 3. Rows labeled “All three agents performed similarly” indicate that neither fine-tuned LLM nor VectorRAG nor VectorGraphRAG consistently outperformed the others, typically reflecting subtler differences that were not clearly resolved by the model predictions.
These findings suggest a task–agent matching approach, with a fine-tuned LLM for conceptual depth, VectorRAG for simpler application-based tasks, and VectorGraphRAG for cross-topic or multi-hop contexts. Certain agents perform better in specific scenarios because their design and training align differently with the nature of the question. The fine-tuned LLM, having absorbed domain-specific patterns from curated datasets, typically excels in multi-step theoretical tasks that require deeper conceptual reasoning. VectorRAG, which dynamically retrieves context from a vector database, tends to outperform others in practical or single-step prompts where references to real-world frameworks or coding snippets are essential. Meanwhile, VectorGraphRAG, enriched by a knowledge-graph layer, can handle multi-topic or cross-linked tasks effectively when it harnesses its graph-based insights and produces sufficiently cohesive explanations.
5.2. Justification for Selecting These Three Agents
Although more advanced LLMs and prompting techniques have emerged, the choice of VectorRAG, VectorGraphRAG, and a fine-tuned LLM was driven by higher education’s unique needs for transparency, reliability, and domain specificity. Retrieval-augmented designs (VectorRAG, VectorGraphRAG) provide interpretable references to course content, which is often essential when validating the correctness or relevance of suggested improvements. Meanwhile, a fine-tuned LLM can specialize deeply in advanced theoretical or conceptual topics without incurring overfitting risks from large, unrelated corpora. VectorGraphRAG, though at times lagging in baseline conditions, can close gaps with high-quality subgrades. Moreover, the simpler retrieval approaches used here (rather than complex multi-hop or large-scale memory) facilitate easier deployment and maintenance within typical university infrastructures.
5.3. Self-Reflection and Over-/Under-Grading Effects
In Tasks 2 and 3, agents provided self-scores on their own question improvements or creations, revealing that the fine-tuned LLM systematically overestimated its quality by about +1 to +1.5 points relative to the meta-evaluator’s ground truth. In contrast, VectorRAG and VectorGraphRAG hovered near +0.1 to +0.2, suggesting more self-awareness. Interestingly, this matches the over-/under-grading
Section 4.3 findings in Task 1, where the fine-tuned LLM displayed a positive bias (e.g., inflating concept coverage by up to 1+ point), while the other two agents showed milder biases. Thus, the same calibration gaps that lead to over-grading in Task 1 resurface in self-reflection errors in Tasks 2 and 3, underscoring the importance of refining how LLMs judge and justify their own outputs if they are to be trusted for real-world educational use.
5.4. Dual Grading System: Granular Scores and Justifications
Across all tasks, each agent used a dual grading system that generated granular numeric sub-scores (e.g., alignment, clarity, correctness) alongside textual justifications. This dual-format output played a crucial role in the following:
Bias Detection: The numeric scores enabled quantitative comparisons, while the explanations revealed how the agent arrived at each rating. Divergences, such as overinflated clarity scores or shallow justifications, were easier to spot.
Transparency and Accountability: Instructors could see not just a final numeric grade but also the reasoning behind it, enabling more precise challenges or corrections.
Enhanced Objectivity: By combining the objectivity of numeric sub-scores with the interpretability of human-readable justifications, the system fostered consistency across varying question categories and course types.
Overall, the dual scoring system added an important layer of insight, improving the detection of bias and reinforcing the trustworthiness of automated assessments.
5.5. Meta Evaluator as a Control Mechanism: Strengths and Limitations
A distinctive contribution of this research is the meta evaluator (Meta_auto), an automated system meant to assess agent outputs in parallel with expert-supervised scoring (Meta_human). Our results show that, while Meta_auto usefully flags questionable outputs, it can also exhibit systematic biases—occasionally overscoring the fine-tuned LLM or underscoring VectorGraphRAG explanations.
From a workflow perspective, a meta evaluator serves as an early warning system, revealing where an agent’s sub-scores or explanations depart from expected norms. Educators can then focus on flagged items rather than manually re-checking every question. However, the meta evaluator itself requires careful prompt-engineering and tuning; routine human oversight remains essential, especially in high-stakes or conceptually complex scenarios.
5.6. Bias Evaluation and Sources of Discrepancy
Comparisons of Meta_auto and Meta_human revealed systematic positive or negative biases under specific agent–task conditions. The data reveal the following: (1) systematic over-scoring of the fine-tuned LLM – The meta evaluator appeared positively influenced by the more verbose or fluent style of the fine-tuned LLM, awarding it +1 to +3 points above human experts’ ratings in many subgroups. This aligns with the fine-tuned LLM’s self-reflection bias, indicating a synergy between the agent’s own “confidence” and the meta-evaluator’s preference for polished text; (2) Systematic under-scoring of retrieval-based agents – VectorRAG and VectorGraphRAG typically received lower automated scores than final human judgments, showing that factual correctness or concise referencing was underappreciated by the meta evaluator. Human experts generate increased scores based on actual content validity, reducing the negative gap.
When the magnitude of these biases exceeded 1.0–2.0 points on a 10-point scale, it underscored the need for targeted corrective strategies, such as revised meta-evaluator prompts or additional training data spotlighting robust justification. Our dual grading system (numeric plus explanation) proved especially helpful for identifying these anomalies, since the mismatch between numeric sub-scores and textual rationales became a clear signal for potential bias.
5.7. Real-World Validation: 100 New Questions
To confirm these patterns beyond controlled tests, we applied the best-performing agent to 100 real, instructor-created exam questions. The agent’s alignment scores did not significantly differ from human expert ratings (p ≈ 0.12), indicating it can effectively handle large-scale alignment tasks once biases are known and mitigated.
This finding underscores that our proposed framework, when carefully tuned and supervised, does not systematically deviate from human standards, boosting confidence in eventual large-scale adoption. Nevertheless, outliers remained, reiterating that full automation is neither recommended nor realistic, especially for high-stakes decisions or intricately nuanced questions.
5.8. Guidelines and Best Practices for Higher Education
Bringing together the insights from the analysis conducted in this study, along with the variety of practical trials for data processing and implementation, we propose a set of best practices for educators and developers:
Match LLM Architecture to Question Type: Select the fine-tuned LLM for conceptually rich or multi-step tasks requiring deep alignment; use VectorRAG for simpler, application-heavy tasks with well-defined chunking and top-k retrieval; deploy VectorGraphRAG for contexts requiring cross-domain or knowledge-graph insights, ensuring it provides robust explanations.
Iterative Tuning and Data Curation: Carefully adjust retrieval parameters (chunk size, top-k), monitor performance, and refine. Fine-tuning benefits from noise-free, domain-distilled datasets. Repeated cycles of training and expert feedback improve alignment and reduce hallucinations.
Leverage a Dual Grading System: Mandate numeric sub-scores for transparency and comparative evaluation. Require textual justifications to reveal the basis for each score, facilitating bias detection and instructor trust. Repeatedly, we see that “better explanations = better scores.” Require the AI to detail alignment decisions, clarity adjustments, or originality elements. This not only helps human reviewers pinpoint errors but also encourages the LLM to scrutinize its own logic more thoroughly.
Automated Meta Evaluation with Human Oversight: While an automated meta-evaluator can drastically reduce instructor workloads, the bias tables prove that purely automated scoring is insufficient for high-stakes decisions. A best practice is to always have a final human check, while the meta evaluator should be used as a guard system that will flag potential discrepancies. Periodic random audits of the meta-evaluator’s judgments can detect drift or emerging biases.
Monitor Agent Self-Reflection: Agents vary in how accurately they self-score. The fine-tuned LLM often inflates its performance by +1 to +1.5 points. If an instructor uses these self-scores directly, students might see inflated question quality or misaligned difficulty levels. Pair self-reflection with external (meta or human) scoring to calibrate the agent’s confidence over time.
Maintain Expert Oversight for High-Stakes Tasks: Although the system can automate a large database of question alignment or generation, final accountability should remain with domain experts. We recommend an 80–20 model, with AI handling most items and experts focusing on random audits or flagged outliers, where this model will balance efficiency and educational precision.
Iterative Review and Calibration: A continuous improvement cycle, ideally at semester boundaries, can keep the system aligned with evolving course objectives.
5.9. Limitations and Future Work
Despite the encouraging results, we note several certain limitations. Expert judgments, despite being thorough, retained elements of subjectivity, and the review process relied on the standards and norms of a single institution. Employing larger reviewer pools, multi-annotator consensus, or multi-institutional replication would help mitigate potential human-bias effects and increase generalizability. Partial real-world validation focused on Task1 with 100 newly created questions, leaving Tasks 2 and 3 to be tested more extensively and in a wider range of academic disciplines or question designs. This study also concentrated largely on text-centric, STEM-based courses; further exploration of humanities or social sciences, where interpretive or highly subjective items are common, could reveal different patterns of performance or bias.
Another limitation concerns the nature of the course materials themselves. The approach hinged on carefully curated lecture notes, slides, and condensed texts rather than raw, unstructured sources. If only dense textbooks or research articles were available, additional pre-processing or fine-tuning may be necessary. The meta-evaluator was similarly tied to a particular large language model and prompt design, so reproducing these results within different LLM ecosystems might introduce new biases or necessitate different calibration strategies. Scalability likewise presents challenges, as fine-tuning large models, maintaining knowledge graphs, and implementing real-time retrieval can require significant computational resources and specialized expertise—constraints that smaller institutions may find difficult to meet.
Finally, the absence of direct student feedback on AI-generated items leaves open questions about the effects on learner motivation, fairness perceptions, and actual educational outcomes. Future work could examine these dimensions by incorporating student perspectives, validating tasks beyond alignment (Tasks 2 and 3) at scale, exploring further refinements to the meta-evaluator prompts, and assessing the viability of more lightweight or distributed infrastructures. Furthermore, future work could also incorporate more sophisticated retrieval (e.g., multi-hop chaining, graph-based expansions, multi-modal models) or advanced multi-agent collaboration, provided that basic transparency and reliability standards are upheld. Such research would not only enrich the understanding of how these AI-driven tools function across diverse contexts but would also advance their integration into real-world academic environments.
6. Conclusions
This work set out to (i) investigate how large language models (LLMs) can evaluate, refine, and generate exam questions in higher education, (ii) establish guidelines and best practices for safely integrating AI into assessment workflows, and (iii) demonstrate the importance of a structured meta-evaluation layer to mitigate bias and maintain academic standards. By systematically analyzing three LLM-based agents (VectorRAG, VectorGraphRAG, and a fine-tuned LLM) across multiple question designs, Bloom’s levels, and course orientations, this study revealed the following:
No single model is universally optimal: each agent excels under different conditions (e.g., theory-oriented, multi-step tasks vs. single-step, application-based tasks). A dual grading system of numeric scores and justifications provides transparency, effectively flags biases, and helps instructors pinpoint where alignment or explanation shortfalls occur. A meta evaluator with embedded guards and safety mechanisms can serve as a powerful control mechanism—identifying discrepancies in agent outputs, but itself requires routine human oversight to address systematic over or underestimation. The educational domain’s high standards, originated from limited and often condensed course materials and the stakes of student assessment, demand that such AI-driven tools be meticulously tuned and regularly audited. Although a real-world test on newly crafted questions demonstrated the feasibility and accuracy of carefully configured AI agents, partial human supervision remains essential, especially when dealing with high-stakes or conceptually complex scenarios, to ensure that any questionable alignments or biases are quickly identified and corrected.
Taken together, these findings underscore the value of selective task–agent matching, iterative fine-tuning and retrieval design, and bias-aware monitoring as a comprehensive roadmap for adopting LLMs in higher-education assessment. By integrating these measures and incorporating partial human oversight through automated safety mechanisms, institutions can harness AI’s potential to streamline question creation and evaluation without compromising the high-standards and the academic success.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}