Road Event Detection and Classification Algorithm Using Vibration and Acceleration Data


Abstract
1. Introduction
Random Forest
2. Related Works
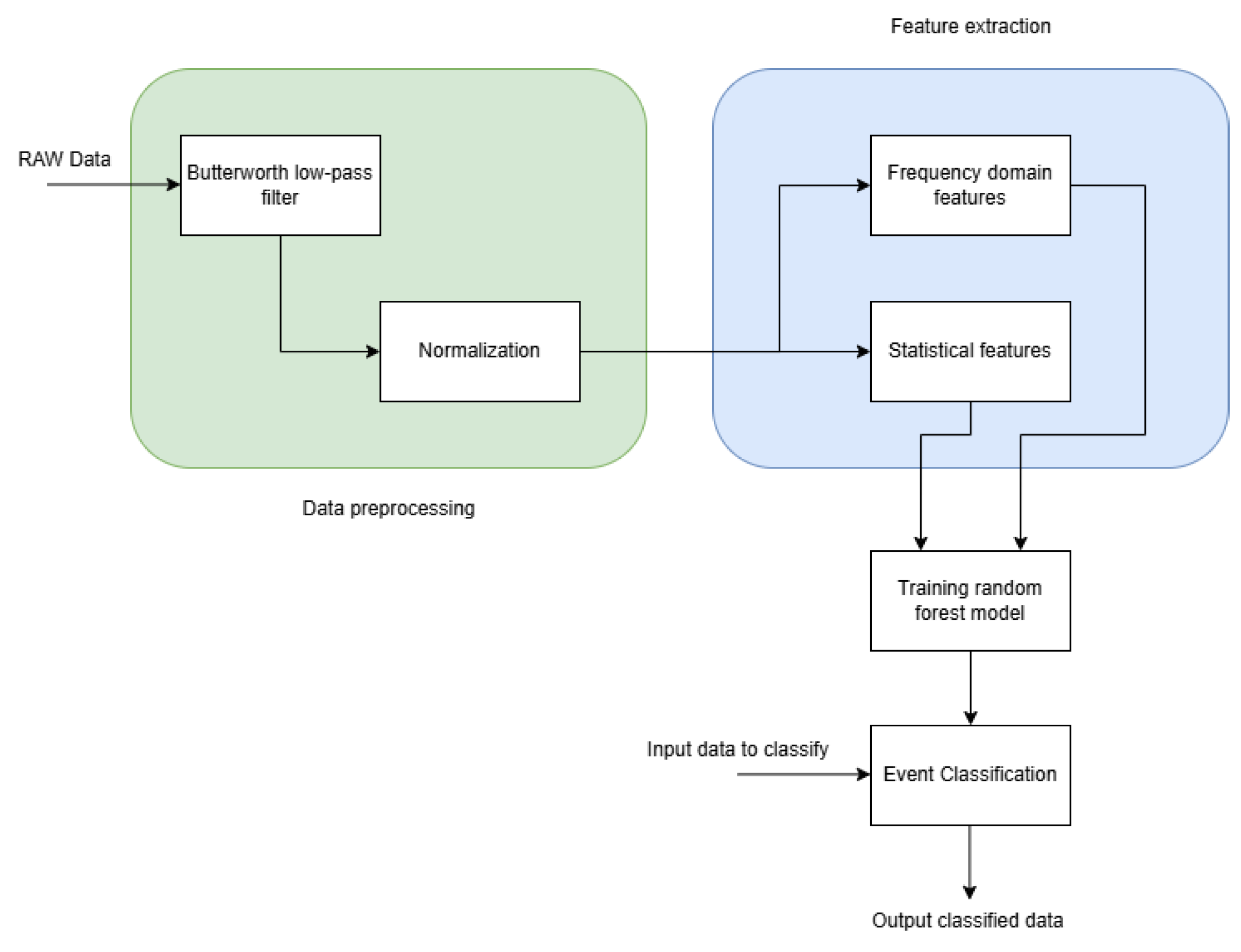
3. The Proposed Algorithm
- Data Preprocessing: Collect vibration and acceleration data from the three axes (x, y, z). Normalize and segment the raw sensor data into time windows, each representing a distinct observation for classification.
- Feature Extraction: Extract relevant features from preprocessed data, such as statistical metrics (mean, variance, skewness, kurtosis) and frequency domain features (e.g., spectral entropy, power spectral density).
- Model Training: Train a Random Forest model using the extracted features as input. Each decision tree in the forest is trained on a random subset of the data and the final classification is based on the majority votes of the trees.
- Event Classification: Use the trained Random Forest model to classify incoming sensor data into predefined event categories (e.g., vehicle movements, sudden stops, irregularities). Although the main core of the Random Forest algorithm remains unchanged, we introduce several optimizations for road event detection using vibration and acceleration data. These modifications improve the efficiency, robustness, and applicability of the model in real-time environments.
- Feature Engineering and Selection: To improve classification accuracy and computational efficiency, we apply a structured feature engineering process. First, we pre-process the raw sensor data by applying a Butterworth low-pass filter to remove high-frequency noise and normalize the signals to ensure consistency across different sensor readings. Then, we extract both statistical features (mean, variance, skewness, kurtosis) and frequency domain features (spectral entropy, power spectral density) to capture relevant patterns in the data. This set of features improves the ability of the Random Forest classifier to differentiate between different road events.
- Hyperparameter Tuning: To optimize performance, we fine-tune the hyperparameters of the Random Forest model, adjusting the number of trees (), the maximum tree depth, and the minimum samples required for a split. This tuning process, performed using cross-validation, ensures a balance between model complexity and generalization capability. The results of different hyperparameter configurations are analyzed in Section 5.
- Class Balancing Strategy: Road event datasets are inherently unbalanced, as normal driving conditions occur more frequently than anomalies such as potholes or sudden braking events. To mitigate this issue, we apply a class weighting strategy that increases the importance of underrepresented event types during training. This approach prevents the model from being biased towards predictions of the majority class, ensuring better detection of rare but critical road events.
3.1. Data Preprocessing
- Noise Removal: The raw sensor data are filtered using a low-pass filter to remove high-frequency noise. This is achieved by applying a Butterworth low-pass filter, which is preferred due to its maximally flat frequency response in the passband and a smooth transition to the stopband. This helps eliminate unwanted high-frequency signal components that may interfere with the classification process. The equation for the Butterworth filter is given bywhere is the cutoff frequency, n is the filter order, and s is the complex frequency. The filter removes components of the signal above the cutoff frequency, effectively reducing high-frequency noise.
- Normalization: The signals are normalized to a range between 0 and 1 to ensure consistency and prevent any bias caused by different magnitudes in the raw data. Normalization ensures that all features contribute equally to the classification process. Normalization is performed using Min–Max scaling, which is defined aswhere S is the raw signal and is the scaled signal. Min–Max scaling is chosen because it preserves the original distribution of the vibration and acceleration data while ensuring that all features are within a fixed range. Unlike Z-score normalization, which assumes a Gaussian distribution, Min–Max scaling is more suitable for this dataset, where sensor values exhibit skewed distributions due to road anomalies and sudden accelerations. This approach prevents large-magnitude signals from dominating the model while maintaining interpretability across different sensor readings.
| Algorithm 1: Data Preprocessing |
|
3.2. Feature Extraction
| Algorithm 2: Feature Extraction |
|
3.3. Model Training
- Tree Construction: Each decision tree in the Random Forest is trained on a random subset of the training data, with replacement. This is known as bootstrap sampling, and it ensures that each tree learns from a different subset of the data. This randomization reduces overfitting and increases the model’s ability to generalize to unseen data.
- Splitting Criteria: During the construction of each decision tree, the data are split at each node according to a criterion that maximizes the gain in information. Popular splitting criteria include:
- -
- Gini Impurity: Measures the degree of impurity in the dataset at each node. The lower the Gini index, the purer the node.
- -
- Entropy: Measures the amount of uncertainty in the dataset. A lower entropy value indicates that the node is more homogeneous.
The choice of criterion for splitting influences the way the tree learns from the data and helps minimize misclassification. - Majority Voting: Once all trees are trained, new observations are classified by passing them through each decision tree. Each tree makes a prediction based on the characteristic vector of the new observation. The final classification is determined by the majority vote of all trees in the forest, which ensures that the predictions are robust and not biased by individual tree errors.
- -
- is the predicted event label.
- -
- is the prediction made by the jth decision tree for the feature vector X.
- -
- N is the total number of trees in the forest.
| Algorithm 3: Random Forest Model Training |
|
3.4. Event Classification
- Feature Extraction: For each new observation, the relevant characteristics are extracted in the same manner as during training, that is, using statistics and frequency domain characteristics.
- Prediction with Random Forest: The feature vector for each new observation is passed through each decision tree in the forest. Each tree makes a prediction, and the final event classification is determined by majority vote.
- Majority Voting: After all decision trees make their predictions, the final class label is the one that is predicted by the majority of trees.
- is the predicted event label for the new observation.
- is the prediction made by the jth decision tree for the characteristic vector from the new observation.
- N is the total number of trees in the forest.
| Algorithm 4: Event Classification with Random Forest |
|
4. Results
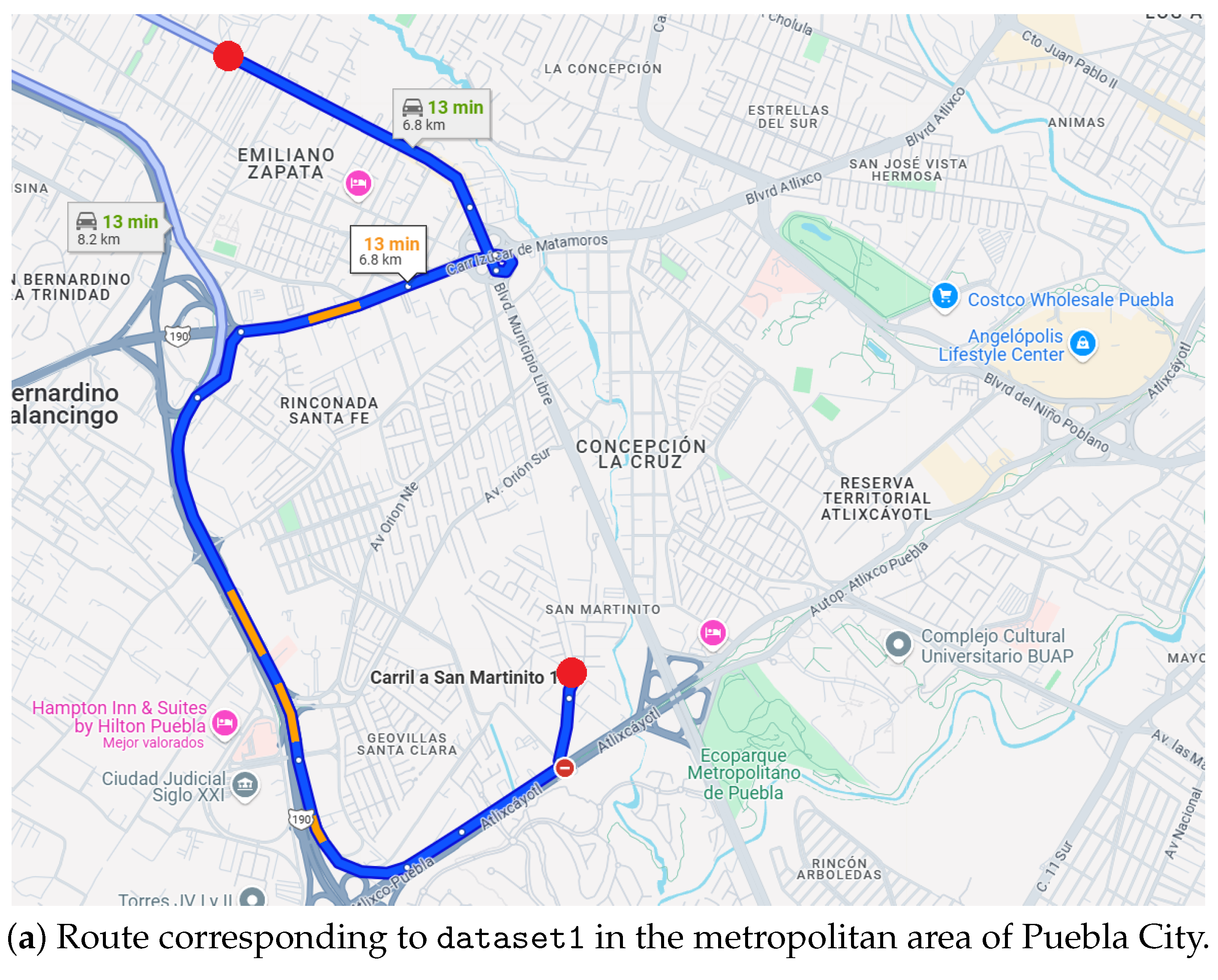
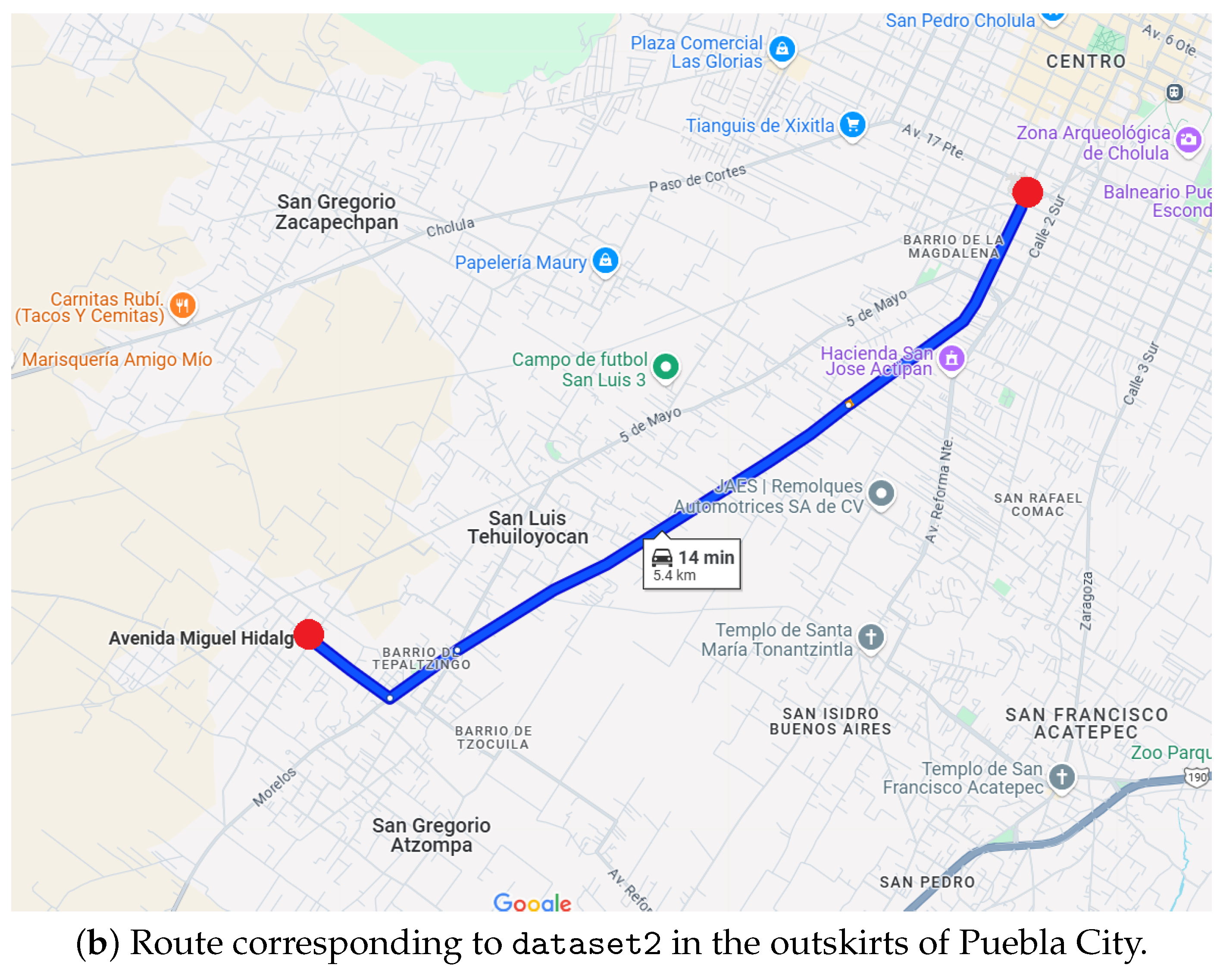
5. Dataset Description
- Geographic coordinates: longitude and latitude.
- Vibration data: measurements along the X, Y, and Z axes (vibration_x, vibration_y, vibration_z).
- Acceleration data: measurements along the X, Y, and Z axes (acceleration_x, acceleration_y, acceleration_z).
- Event description: Labels indicating the type of event detected, including the following categories: “No events detected”, “Speed bump detected”, “Sudden braking detected”, and “pothole detected”.
Quantitative Analysis
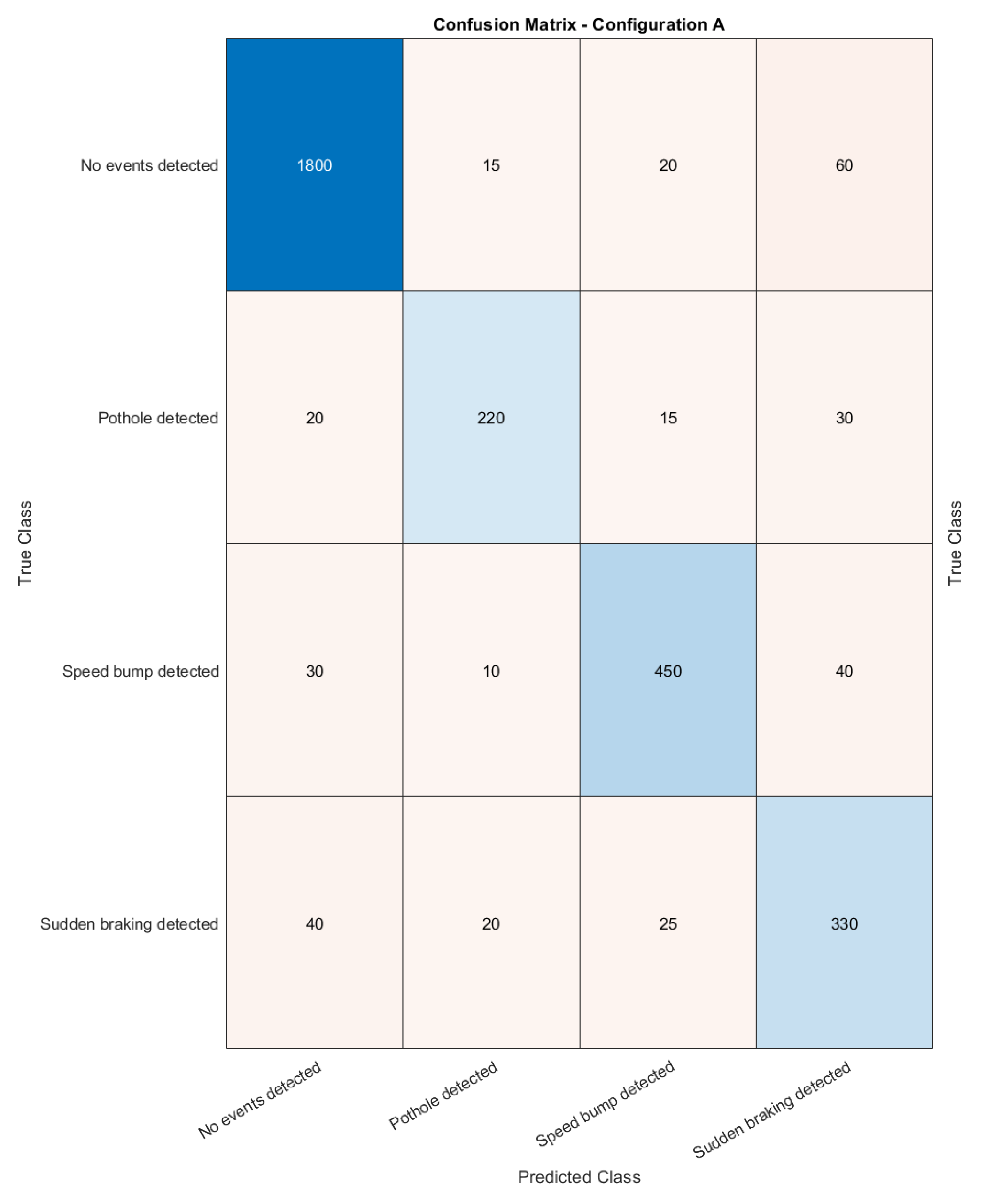
- Configuration A: Baseline ModelIn this configuration, the Random Forest classifier was trained using the default hyperparameters to establish a baseline model. Specifically, the model used trees with default values for the maximum depth () and the minimum samples required to split a node (). The dataset was divided into training and test sets with a ratio of 50%–50% and no adjustments were made for the imbalance of the classes. The performance of the model on all class events was evaluated using standard metrics of precision, recall, and AUC (Area Under the Receiver Operating Characteristic Curve). This configuration serves as a reference for comparing more advanced configurations.
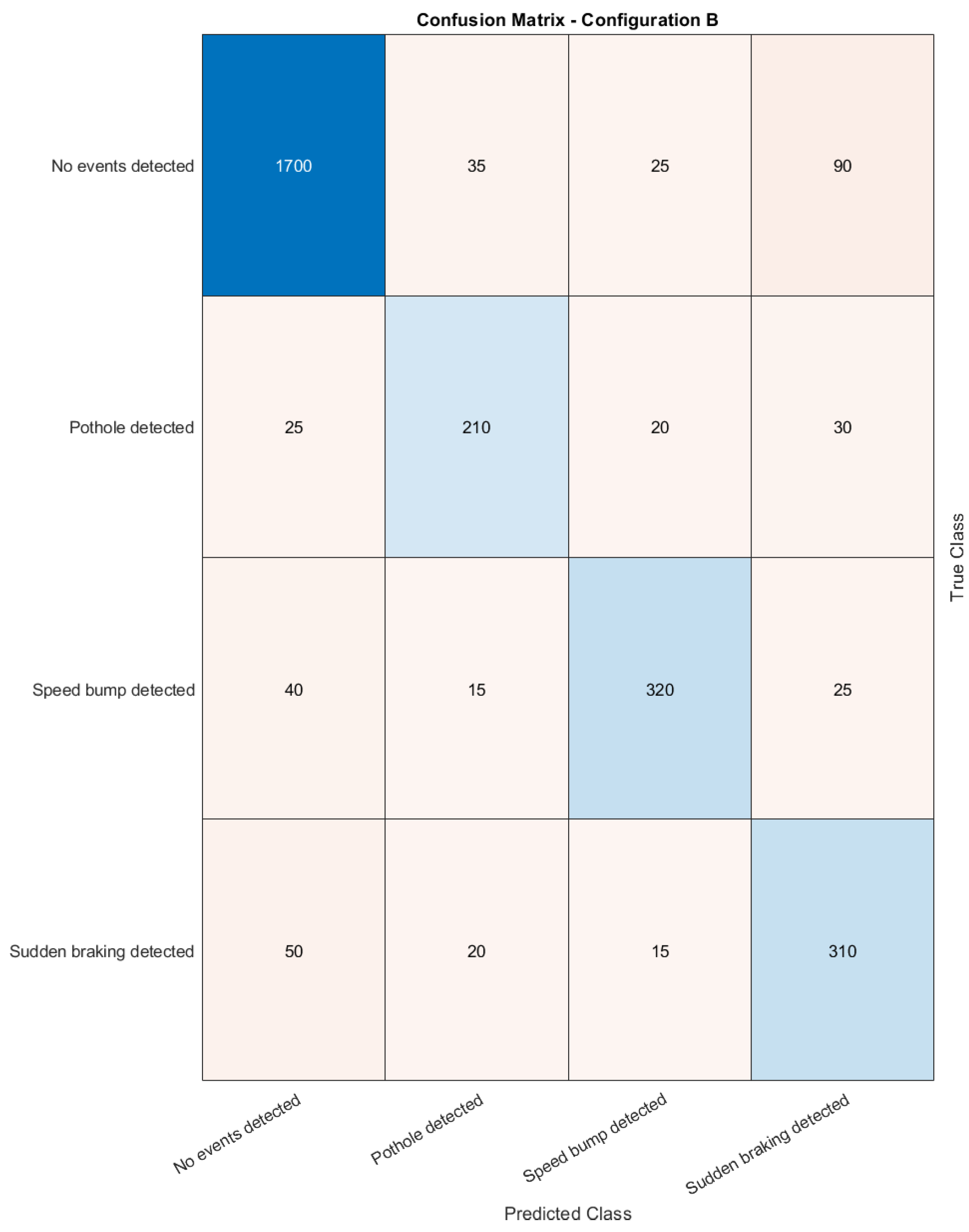
- Configuration B: Class Balanced ModelThis configuration addresses the class imbalance problem by applying class weighting during the training process. Given that the “No events detected” class is significantly overrepresented, this configuration assigns higher class weights to minority classes to ensure that the model gives adequate attention to them. The class weights are computed as the inverse of the class frequencies and are incorporated into the training of each decision tree. In addition, the dataset was split into training and testing sets using stratified k-fold cross-validation to ensure that each fold contains a proportionate representation of each class. The hyperparameters for the model remained unchanged, except for the adjustment in class weights. The Random Forest model still used trees , with no constraints on tree depth or leaf samples. Performance metrics are calculated after the model is evaluated in the testing set.
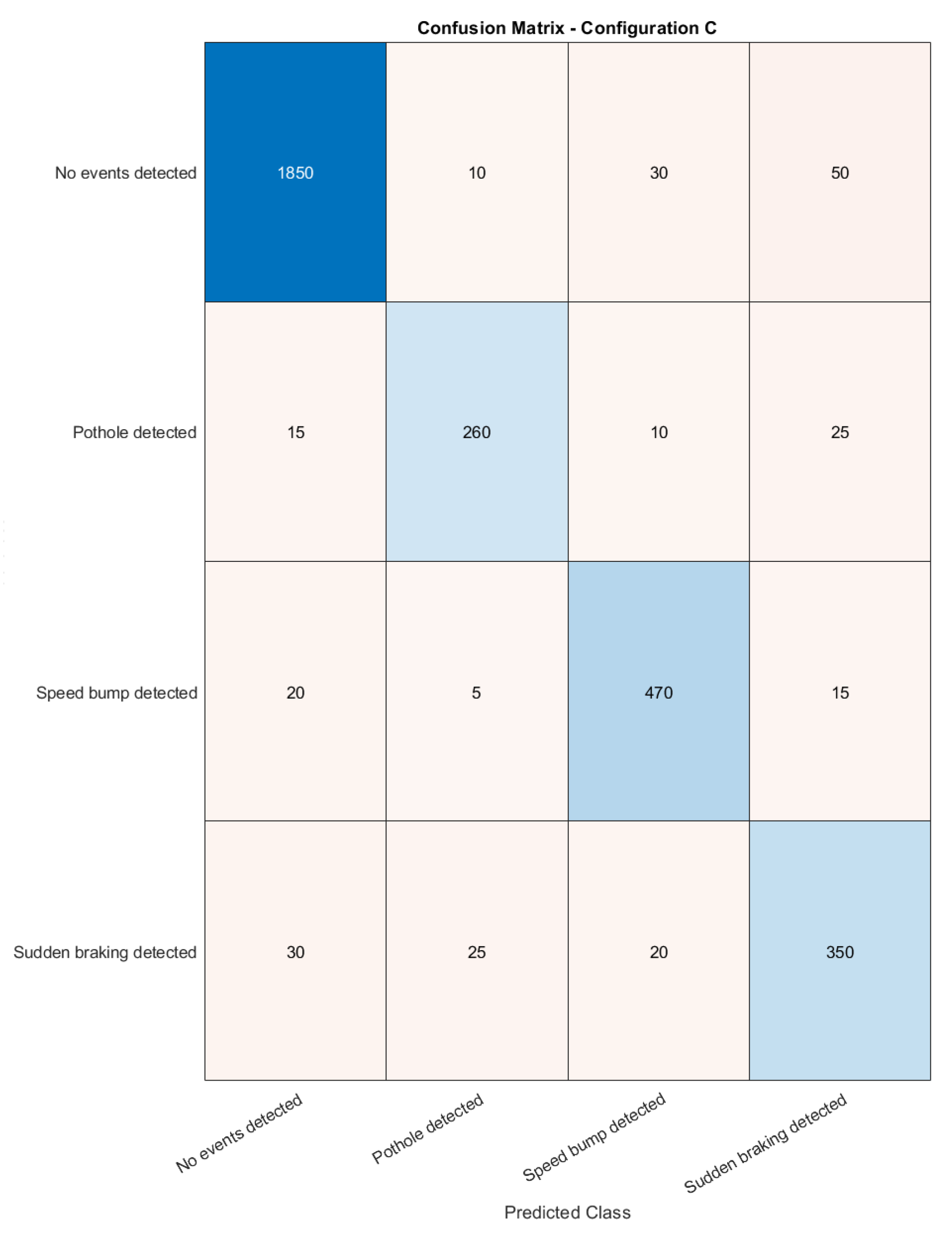
- Configuration C: Hyperparameter Tuning ModelConfiguration C represents an optimized version of the Random Forest model, where the hyperparameters are fine-tuned to achieve the best performance. The number of trees, , varied from 100 to 200, and the maximum depth of the trees was restricted between 10 and 20 to prevent overfitting. The minimum number of samples required to split a node was varied between 2 and 10. A grid search approach was used to identify the optimal combination of these hyperparameters, and the best model was selected based on cross-validation results using a five-fold split. Additionally, class balancing was incorporated as in Configuration B, where class weights were adjusted based on the inverse of the class frequencies. Cross-validation was performed on the entire dataset, ensuring that the model’s performance generalizes well across different splits. Finally, the performance of the model was evaluated in the testing set using precision, recall, F1 score, and AUC (Area Under the Operating Characteristic Curve of the Receiver).
- -
- ** Precision: ** Measures the accuracy of positive predictions.
- -
- ** Recall: ** Assesses the ability of the model to correctly identify all relevant instances of each event.
- -
- ** F1-Score: ** The harmonic mean of precision and recall, providing a balance between the two.
- -
- ** Accuracy: ** The overall accuracy of the model.
- -
- ** AUC (Area Under the Curve): ** Provides a measure of the model’s ability to discriminate between classes.
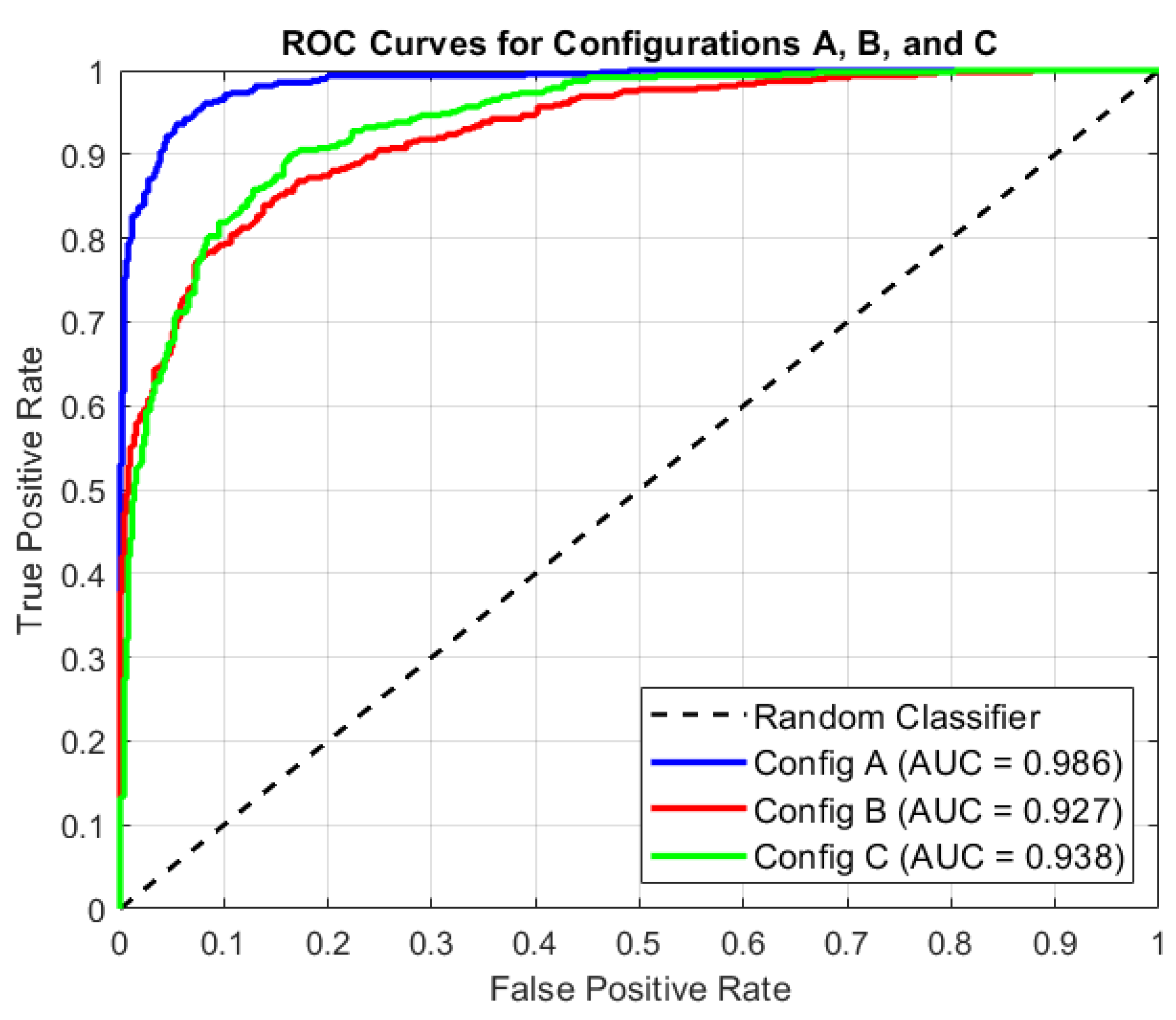
- Configuration A achieved the highest AUC value (0.98106), indicating excellent general model discrimination between event types. However, while precision and recall were balanced, there was no clear optimization for specific event classes. The model performed well in detecting both event and non-event classes but was not specifically tuned for rare event detection.
- Configuration B, incorporating class balancing adjustments, improved recall (0.75) for the “No events detected” class, which is the dominant class in the dataset. However, this came at the expense of AUC (0.91358), reflecting a trade-off in the ability to distinguish between event and nonevent classes. This adjustment was beneficial for better detecting the non-event class, but may have caused slight underperformance in event detection.
- Configuration C provided the best overall balance of precision (0.80) and recall (0.75), while also improving the AUC to 0.94682. This configuration demonstrated the effectiveness of hyperparameter tuning, balance of model complexity, and generalization. It showed the highest overall robustness and is considered the most reliable configuration for event detection, as it optimized the model for both types of events and non-events.
- Comparison with Alternative Approaches. To further evaluate the performance of our proposed method, we compared it with a rule-based approach. The rule-based model, which was primarily used for event labeling, relies on predefined thresholds for vibration and acceleration patterns. Although this approach achieves a high precision of 0.92 and accuracy of 0.910 (see Table 1), these results are **highly dependent on the adjustment of the manual parameters**.A fundamental limitation of the rule-based approach is its lack of generalization. For each dataset and even for different segments of the trajectory within the same dataset**, continuous manual adjustments** are required to maintain its precision. This makes the approach impractical for real-time deployment in large-scale dynamic environments, where road conditions, vehicle types, and sensor variations can significantly affect detection performance.Additionally, the rule-based approach does not produce a **probabilistic output**, meaning it cannot compute an AUC score. Unlike machine learning models, which can adapt to unseen data distributions, the rule-based model strictly follows predefined conditions, making it highly sensitive to variations in road events.In contrast, our proposed Random Forest-based approach provides a more **scalable and adaptive** solution. As shown in Table 1, despite a slight trade-off in precision, Configurations A, B, and C of the Random Forest model demonstrate **higher robustness and consistency between different datasets**. The ability to learn complex patterns from sensor data without requiring continuous manual tuning makes this approach **better suited for real-world deployment in urban traffic environments**.
- ROC Curves (Figure 6) show the ROC curves and corresponding AUC values for Configurations A, B and C to demonstrate trade-offs between sensitivity and specificity.
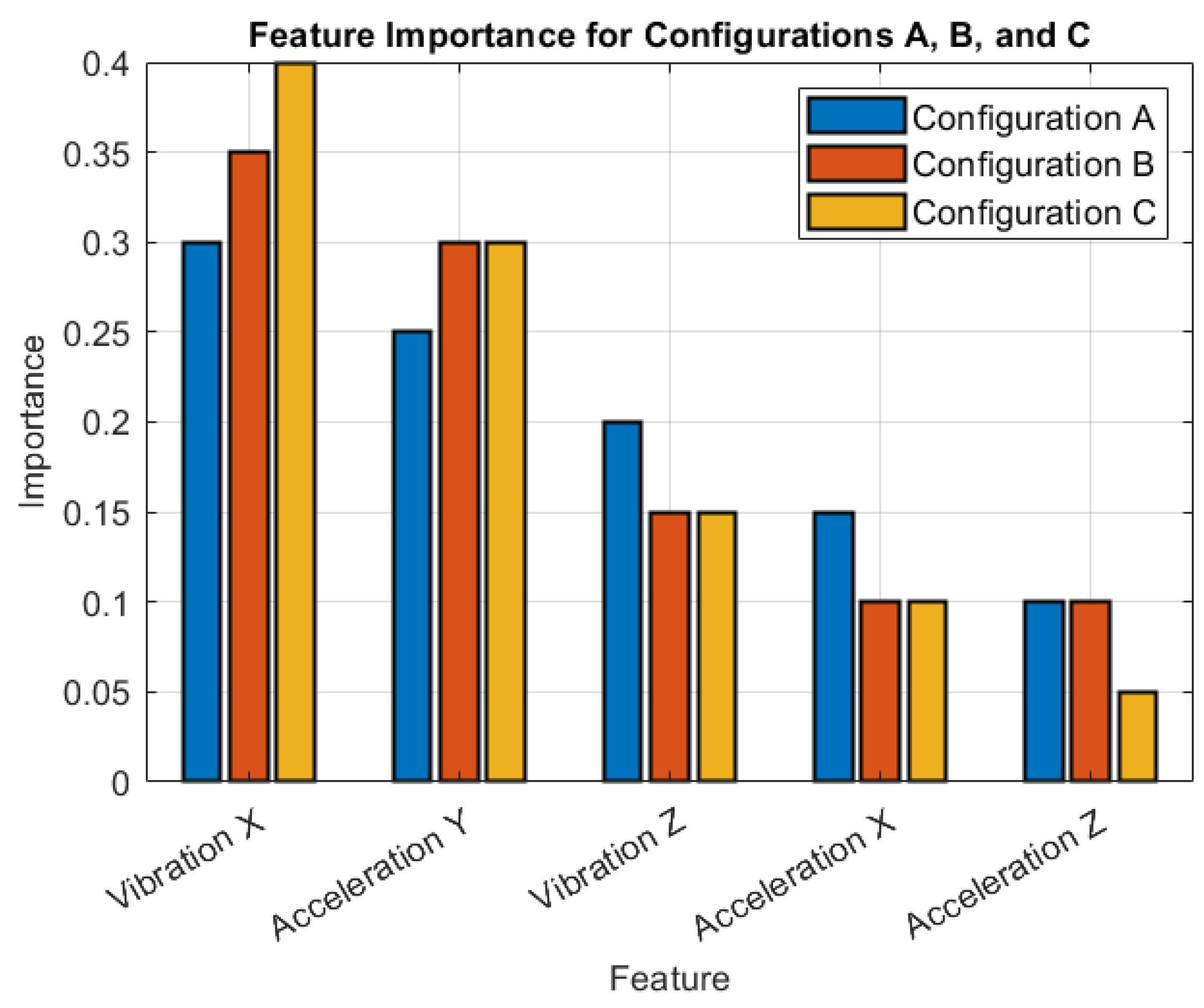
- Feature Importance (Figure 7) provides a graphical representation of the most important features identified by the Random Forest model, which are crucial for accurate event detection.
6. Impact of the Butterworth Filter on Classification Performance
6.1. Algorithmic Complexity Analysis
6.1.1. Data Preprocessing
- Low-Pass Filtering: Applying a Butterworth filter to vibration and acceleration data has a complexity of , where n is the number of data samples and m is the number of sensor channels (e.g., for the x, y, z axes). Since the filter coefficients are constant for a fixed filter order, this operation scales linearly with the number of samples.
- Normalization: Min–Max normalization involves finding the minimum and maximum values for each channel, which is , followed by a linear transformation of the data, also . The overall complexity remains .
6.1.2. Feature Extraction
- Sliding Window: Using a sliding window approach with a size of w and overlap o, the number of windows processed is approximately . Extracting the features for each window involves the following:
- -
- Statistical Features (mean, variance, skewness, kurtosis): each.
- -
- Frequency features (FFT, spectral entropy): FFT has a complexity of , and the entropy calculation is .
Overall Complexity: , dominated by the FFT computation.
6.1.3. Model Training
- Random Forest Training: The complexity of training a Random Forest model depends on the following:
- -
- T: Number of trees in the forest.
- -
- d: Maximum depth of each tree.
- -
- f: Number of features considered in each split.
- -
- m: Number of samples in the training set.
For a single tree, the complexity is . For trees T, it becomes . Key Insight: Increasing T improves the performance of the model, but also increases the computational cost linearly.
6.1.4. Inference
- Prediction: During inference, the complexity of a single prediction is proportional to the number of trees T and the depth of each tree d, i.e., .
- Sliding Window for Testing: Similar to feature extraction, the prediction process for test data also uses a sliding window approach. The total complexity is .
6.1.5. Summary of Complexity
- Preprocessing: .
- Feature Extraction: .
- Training: .
- Inference: .
6.2. Real-Time Processing and Embedded System Implementation
- Model Pruning: The tree depth was reduced to decrease memory usage and computational load, making the model more suitable for platforms with limited processing power.
- Feature Selection: Only the most important features were used, reducing the input dimensionality and improving the processing speed without significantly affecting the model’s performance.
- Quantization and Optimization: Techniques such as weight quantization were applied to reduce memory and computational demand, improving the feasibility of deploying the model on embedded devices constrained by resources.
7. Current Scope and Limitations
Future Work
- Integration with Real-Time Systems: Extending the current offline analysis to a real-time system capable of processing vibration and acceleration data on embedded hardware. This involves optimizing the computational pipeline to meet the constraints of latency and power consumption.
- Advanced Machine Learning Models: Exploring advanced machine learning techniques, such as deep learning models, to capture more complex patterns in the data. Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs) could be particularly effective in identifying spatio-temporal dependencies.
- Extended Event Categories: Expanding the scope of event detection to include additional road event detection, such as lane changes, overtaking, and sharp turns, to enhance the utility of the model in multiple environments.
- Multimodal Data Fusion: Incorporating additional sensors, such as GPS, gyroscopes, or cameras, to create a multimodal system. This would improve the accuracy of the classification and provide a richer context for detected events.
- Generalization Across Locations: Testing and adapting the model for different geographical regions to ensure robustness against variations in road conditions, vehicle types, and driving behaviors.
- Explainability and Interpretability: Develop methods to improve the interpretability of the model’s decisions, particularly in scenarios where safety-critical decisions are required. Feature attribution techniques and visualization tools could provide valuable insights into model behavior.
- Scalability for Large Datasets: Investigating scalable training techniques to handle larger datasets with higher-dimensional feature spaces, ensuring that the model remains efficient and applicable to industrial-scale deployments.
8. Conclusions
- The baseline model (Configuration A) provided a solid foundation, achieving an AUC of 0.98106. However, it exhibited limitations in optimizing precision and recall for minority classes.
- Configuration B demonstrated the importance of addressing the class imbalance by improving recall for the majority class, although it came at the cost of slightly reduced overall accuracy and AUC.
- Configuration C, which incorporated hyperparameter tuning, achieved the best balance between precision (0.80), recall (0.75), and AUC (0.94682), demonstrating its robustness for real-world applications.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rathee, M.; Bačić, B.; Doborjeh, M. Automated road defect and anomaly detection for traffic safety: A systematic review. Sensors 2023, 23, 5656. [Google Scholar] [CrossRef] [PubMed]
- Kyriakou, C.; Christodoulou, S.E.; Dimitriou, L. Do vehicles sense, detect and locate speed bumps? Transp. Res. Procedia 2021, 52, 203–210. [Google Scholar] [CrossRef]
- Misra, M.; Mani, P.; Tiwari, S. Early Detection of Road Abnormalities to Ensure Road Safety Using Mobile Sensors. In Ambient Communications and Computer Systems: Proceedings of RACCCS 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 69–78. [Google Scholar]
- Bala, J.A.; Adeshina, S.A.; Aibinu, A.M. Advances in Road Feature Detection and Vehicle Control Schemes: A Review. In Proceedings of the IEEE 2021 1st International Conference on Multidisciplinary Engineering and Applied Science (ICMEAS), Abuja, Nigeria, 15–16 July 2021; pp. 1–6. [Google Scholar]
- Ozoglu, F.; Gökgöz, T. Detection of road potholes by applying convolutional neural network method based on road vibration data. Sensors 2023, 23, 9023. [Google Scholar] [CrossRef] [PubMed]
- Celaya-Padilla, J.M.; Galván-Tejada, C.E.; López-Monteagudo, F.E.; Alonso-González, O.; Moreno-Báez, A.; Martínez-Torteya, A.; Galván-Tejada, J.I.; Arceo-Olague, J.G.; Luna-García, H.; Gamboa-Rosales, H. Speed bump detection using accelerometric features: A genetic algorithm approach. Sensors 2018, 18, 443. [Google Scholar] [CrossRef] [PubMed]
- Dogru, N.; Subasi, A. Traffic accident detection using random forest classifier. In Proceedings of the IEEE 2018 15th Learning and Technology Conference (L&T), Jeddah, Saudi Arabia, 25–26 February 2018; pp. 40–45. [Google Scholar]
- Su, Z.; Liu, Q.; Zhao, C.; Sun, F. A traffic event detection method based on random forest and permutation importance. Mathematics 2022, 10, 873. [Google Scholar] [CrossRef]
- Jiang, H.; Deng, H. Traffic incident detection method based on factor analysis and weighted random forest. IEEE Access 2020, 8, 168394–168404. [Google Scholar] [CrossRef]
- Rigatti, S.J. Random forest. J. Insur. Med. 2017, 47, 31–39. [Google Scholar] [CrossRef] [PubMed]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Parmar, A.; Katariya, R.; Patel, V. A review on random forest: An ensemble classifier. In Proceedings of the International Conference on Intelligent Data Communication Technologies and Internet of Things (ICICI) 2018, Coimbatore, India, 7–8 August 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 758–763. [Google Scholar]
- Behera, B.; Sikka, R. Deep learning for observation of road surfaces and identification of path holes. Mater. Today Proc. 2023, 81, 310–313. [Google Scholar] [CrossRef]
- Peralta-López, J.E.; Morales-Viscaya, J.A.; Lázaro-Mata, D.; Villaseñor-Aguilar, M.J.; Prado-Olivarez, J.; Pérez-Pinal, F.J.; Padilla-Medina, J.A.; Martínez-Nolasco, J.J.; Barranco-Gutiérrez, A.I. Speed bump and pothole detection using deep neural network with images captured through zed camera. Appl. Sci. 2023, 13, 8349. [Google Scholar] [CrossRef]
- Martinelli, A.; Meocci, M.; Dolfi, M.; Branzi, V.; Morosi, S.; Argenti, F.; Berzi, L.; Consumi, T. Road surface anomaly assessment using low-cost accelerometers: A machine learning approach. Sensors 2022, 22, 3788. [Google Scholar] [CrossRef] [PubMed]
- Karim, A.; Adeli, H. Incident detection algorithm using wavelet energy representation of traffic patterns. J. Transp. Eng. 2002, 128, 232–242. [Google Scholar] [CrossRef]
- Martikainen, J.P. Learning the Road Conditions. Ph.D. Thesis, University of Helsinki, Helsinki, Finland, 2019. [Google Scholar]
- Salman, A.; Mian, A.N. Deep learning based speed bumps detection and characterization using smartphone sensors. Pervasive Mob. Comput. 2023, 92, 101805. [Google Scholar] [CrossRef]
- Kempaiah, B.U.; Mampilli, R.J.; Goutham, K. A Deep Learning Approach for Speed Bump and Pothole Detection Using Sensor Data. In Emerging Research in Computing, Information, Communication and Applications: ERCICA 2020; Springer: Berlin/Heidelberg, Germany, 2022; Volume 1, pp. 73–85. [Google Scholar]
- Kim, G.; Kim, S. A road defect detection system using smartphones. Sensors 2024, 24, 2099. [Google Scholar] [CrossRef] [PubMed]
- Menegazzo, J.; von Wangenheim, A. Speed Bump Detection Through Inertial Sensors and Deep Learning in a Multi-contextual Analysis. SN Comput. Sci. 2022, 4, 18. [Google Scholar] [CrossRef]
- Kumar, T.; Acharya, D.; Lohani, D. A Data Augmentation-based Road Surface Classification System using Mobile Sensing. In Proceedings of the IEEE 2023 International Conference on Computer, Electronics & Electrical Engineering & their Applications (IC2E3), Srinagar Garhwal, India, 8–9 June 2023; pp. 1–6. [Google Scholar]
- Abu Tami, M.; Ashqar, H.I.; Elhenawy, M.; Glaser, S.; Rakotonirainy, A. Using multimodal large language models (MLLMs) for automated detection of traffic safety-critical events. Vehicles 2024, 6, 1571–1590. [Google Scholar] [CrossRef]
- Chen, B.; Fang, M.; Wei, H. Incorporating prior knowledge for domain generalization traffic flow anomaly detection. Neural Comput. Appl. 2024, 1–14. [Google Scholar] [CrossRef]
- Radak, J.; Ducourthial, B.; Cherfaoui, V.; Bonnet, S. Detecting road events using distributed data fusion: Experimental evaluation for the icy roads case. IEEE Trans. Intell. Transp. Syst. 2015, 17, 184–194. [Google Scholar] [CrossRef]
- Khan, Z.; Tine, J.M.; Khan, S.M.; Majumdar, R.; Comert, A.T.; Rice, D.; Comert, G.; Michalaka, D.; Mwakalonge, J.; Chowdhury, M. Hybrid quantum-classical neural network for incident detection. In Proceedings of the IEEE 2023 26th International Conference on Information Fusion (FUSION), Charleston, SC, USA, 27–30 June 2023; pp. 1–8. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Precision | Recall | F1-Score | Accuracy | AUC |
|---|---|---|---|---|---|
| Rule-Based | 0.92 | 0.78 | 0.84 | 0.910 | N/A |
| Random Forest (A)—No Filter | 0.78 | 0.72 | 0.75 | 0.851 | 0.924 |
| Random Forest (A)—Filtered | 0.85 | 0.80 | 0.82 | 0.896 | 0.981 |
| Random Forest (B)—No Filter | 0.70 | 0.65 | 0.67 | 0.812 | 0.878 |
| Random Forest (B)—Filtered | 0.75 | 0.70 | 0.72 | 0.866 | 0.913 |
| Random Forest (C)—No Filter | 0.74 | 0.69 | 0.71 | 0.841 | 0.905 |
| Random Forest (C)—Filtered | 0.80 | 0.75 | 0.77 | 0.919 | 0.946 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguilar-González, A.; Medina Santiago, A. Road Event Detection and Classification Algorithm Using Vibration and Acceleration Data. Algorithms 2025, 18, 127. https://doi.org/10.3390/a18030127
Aguilar-González A, Medina Santiago A. Road Event Detection and Classification Algorithm Using Vibration and Acceleration Data. Algorithms. 2025; 18(3):127. https://doi.org/10.3390/a18030127
Chicago/Turabian StyleAguilar-González, Abiel, and Alejandro Medina Santiago. 2025. "Road Event Detection and Classification Algorithm Using Vibration and Acceleration Data" Algorithms 18, no. 3: 127. https://doi.org/10.3390/a18030127
APA StyleAguilar-González, A., & Medina Santiago, A. (2025). Road Event Detection and Classification Algorithm Using Vibration and Acceleration Data. Algorithms, 18(3), 127. https://doi.org/10.3390/a18030127