Abstract
Person Re-identification (ReID), a critical technology in intelligent surveillance, aims to accurately match specific individuals across non-overlapping camera networks. However, factors in real-world scenarios such as variations in illumination, viewpoint, and pose continuously challenge the matching accuracy of existing models. Although Transformer-based models like TransReID have demonstrated a strong capability for capturing global context in feature extraction, the features they produce still have room for optimization at the metric matching stage. To address this issue, this study proposes a hybrid framework that combines advanced feature extraction with post-processing optimization. We employed a fixed, pre-trained TransReID model as the feature extractor and introduced a camera-aware Jaccard distance re-ranking algorithm (CA-Jaccard) as a post-processing module. Without retraining the main model, this framework refines the initial distance metric matrix by analyzing the local neighborhood topology among feature vectors and incorporating camera information. Experiments were conducted on two major public datasets, Market-1501 and MSMT17. The results show that our framework significantly improved the overall ranking quality of the model, increasing the mean Average Precision (mAP) on Market-1501 from 88.2% to 93.58% compared to using TransReID alone, achieving a gain of nearly 4% in mAP on MSMT17. This research confirms that advanced post-processing techniques can effectively complement powerful feature extraction models, providing an efficient pathway to enhance the robustness of ReID systems in complex scenarios. Additionally, it is the first-ever to analyze how the modified distance metric improves the ReID task when used specifically with the ViT-based feature extractor TransReID.
1. Introduction
With the evolution of deep learning, Person Re-identification (ReID) has become a core technology in fields such as smart cities, public safety, and retail analytics. Its primary task is to achieve cross-scene identity matching and tracking within a network of cameras with non-overlapping views, relying solely on an individual’s appearance features. However, the complexity of real-world environments, which involves challenges like illumination variations, viewpoint differences, diverse human poses, and occlusions, causes the same individual to exhibit significant appearance discrepancies across different camera feeds. These factors pose a severe challenge to the robustness of ReID models.
Current mainstream ReID research can be broadly categorized into two primary directions: first, designing more discriminative deep learning models to extract invariant features, and second, developing more effective post-processing techniques to optimize matching results. In terms of model design, researchers have strived to enhance the ability of models to capture both global and local features, evolving from early Convolutional Neural Networks (CNNs) to the recently outstanding Vision Transformers (ViTs). In particular, Transformer-based models like TransReID [1] have achieved remarkable success in global context modeling by leveraging their self-attention mechanisms.
Nevertheless, even with a powerful feature extractor, the high-dimensional feature vectors it produces can still lead to ranking errors during distance measurement due to subtle feature perturbations. Consequently, the research community has increasingly turned its attention to post-processing or re-ranking techniques, which aim to refine the initial distance-based ranking by leveraging the contextual or topological relationships among samples. The core idea behind such methods is that “a good match should not only be similar to the query target but should also share a similar neighborhood structure”.
This study is situated within this context, aiming to investigate the performance gains achievable by combining a high-performance feature extraction model with an advanced post-processing algorithm. We propose a hybrid framework that utilizes a fixed TransReID model as its feature extraction foundation and incorporates the camera-aware Jaccard distance (CA-Jaccard) [2] re-ranking algorithm. Our research objective was not to design a novel end-to-end model but rather to validate the extent to which post-processing optimization alone can enhance the system’s overall matching performance, particularly its overall ranking quality, without modifying the existing powerful feature extractor. Furthermore, it is the first analysis of how the modified distance metric enhances the ReID task when specifically applied to the ViT-based feature extractor, TransReID.
The main contributions of this paper are as follows:
- We successfully integrated and validated a “feature extraction + post-processing” framework, demonstrating that the CA-Jaccard [2] algorithm can significantly improve the mAP metric of the TransReID [1] model.
- We conducted a systematic analysis of the key hyperparameters of CA-Jaccard [2], specifically the number of neighbors and the expansion range , providing an empirical basis for parameter settings when applying this method to different datasets.
- We utilized Feature Vector Normalization and Feature Space Compression to jointly enhance Person Re-identification performance. Together, they enable robust and efficient cross-camera feature matching while maintaining high accuracy.
- We leveraged Neighborhood Expansion Structure Optimization and Cross-camera Penalty Weight Tuning to synergistically enhance Person Re-identification by improving cross-camera feature matching. Together, they enhance the robustness and accuracy of cross-camera feature matching.
2. Related Work
The research trajectory of Person Re-identification (ReID) is intricate, evolving from early methods that relied on low-level visual cues to data-driven deep learning models, and has since branched out into numerous subfields addressing specific challenges.
2.1. Paradigm Shift from Handcrafted Features to Deep Learning
Early research in ReID focused on designing robust handcrafted features. Researchers attempted to describe pedestrians using low-level visual attributes such as color, texture, and shape. For instance, Gray et al. [3] utilized color histograms for matching, while Farenzena et al. [4] proposed the Symmetry-Driven Accumulation of Local Features (SDALF) method, which combines color and symmetry. Subsequently, more complex descriptors like the Scale-Invariant Feature Transform (SIFT) [5] and Histogram of Oriented Gradients (HOG) [6] were also applied to this task. However, these handcrafted features had limited tolerance to variations in illumination, viewpoint, and pose, exhibiting significant performance bottlenecks in complex scenarios.
The advent of deep learning brought a revolutionary breakthrough to ReID. Methods based on Convolutional Neural Networks (CNNs) can automatically learn high-level and more discriminative semantic features from large-scale data. Research during this period primarily revolved around designing more effective CNN architectures to tackle the core challenges of ReID. Among these, part-based methods emerged as a significant research branch. The Part-based Convolutional Baseline (PCB) proposed by Sun et al. [7] effectively addresses the issue of partial occlusion by horizontally partitioning a pedestrian image into multiple stripes and learning features for each region independently. Building on this, the Multiple Granularity Network (MGN) proposed by Wang et al. [8] further developed a multi-branch network to simultaneously learn global features and local features at different granularities (scales), which significantly enhanced the model’s ability to recognize fine details.
2.2. Introduction and Development of the Transformer Architecture
In recent years, the Transformer architecture has been introduced into the ReID field due to its exceptional capability for global context modeling. Unlike the limited receptive fields of CNNs, the self-attention mechanism in a Transformer can capture long-range dependencies between any two patches of an image within a single layer. TransReID [1] stands as a representative work in this area; it not only uses a Transformer to extract powerful global features, but also ingeniously integrates a Jigsaw Patch Matching module to learn discriminative local features in a supervised manner. To address the misalignment issues caused by pose variations, Zhu et al. proposed Auto-Aligned Transformer (AAformer) [9], which introduces learnable “part tokens” to automatically locate human body parts. Meanwhile, Hierarchical Aggregation Transformers (HATs) [10], proposed by Zhang et al., explore the hierarchical aggregation of CNNs and Transformers, combining the strengths of both architectures.
2.3. Auxiliary Technologies and Specialized Research Directions
In addition to innovations in backbone networks, numerous auxiliary technologies and studies targeting specific scenarios have also greatly advanced the development of ReID. These include the following directions:
- Distance Metric and Re-ranking: The distance matching process after feature extraction is equally crucial, as the traditional Euclidean distance cannot fully reflect the semantic similarity between features. To address this, Zhong et al. [11] proposed k-reciprocal re-ranking, which utilizes the neighborhood relationships among samples to refine the initial ranking. The CA-Jaccard [2] method adopted in our study builds upon this foundation by further incorporating Jaccard distance and camera information to tackle the domain shift problem across cameras.
- Data Augmentation: To enhance model robustness, data augmentation techniques are widely applied. Random Erasing, proposed by Zhong et al. [12], simulates occlusion by randomly erasing regions of an image. Meanwhile, methods based on Generative Adversarial Networks (GANs), such as PTGAN proposed by Wei et al. [13] and CamStyle proposed by Zhong et al. [14], can generate samples in different styles to bridge the domain gap between cameras.
- Unsupervised and Cross-Domain Learning: Due to the high cost of data annotation, unsupervised ReID has become a prominent research area. MMT (Mutual Mean-Teaching), proposed by Ge et al. [15], employs a framework where two models learn from each other to effectively leverage unlabeled data. In the context of cross-domain adaptation, SPGAN, proposed by Deng et al. [16], and HH-ReID, proposed by Zhong et al. [17] are dedicated to preserving identity similarity during style transfer and addressing adaptation challenges with heterogeneous data modalities, respectively.
- Multi-Modal and Emerging Data Sources: To overcome the limitations of RGB imagery, research has begun to explore multi-modal fusion. Wu et al. [18] combined RGB and infrared data to handle scenes with insufficient illumination. More recently, Guo et al. [19] pioneered an ReID method based on LiDAR point clouds, which leverages 3D geometric structural information to counteract appearance variations and has opened a new direction for the field.
- Video-based ReID: For video data, the research focus lies in effectively utilizing temporal information. Early works, such as that by McLaughlin et al. [20], used LSTMs for sequence modeling. Subsequent methods like TRL [21] and TMN [22] have designed more complex spatiotemporal modeling mechanisms to capture dynamic cues.
- Lightweight Models: To deploy ReID models on resource-constrained edge devices, lightweight design has also garnered significant attention. The classic MobileNetV2 [23] architecture is widely used, while MetaGON [24], proposed by Zhang et al., combines meta-learning and GANs to design an efficient domain generalization model specifically for edge devices.
- Camera-aware k-reciprocal Nearest Neighbors (CK-RNNs) [2]: Traditional k-RNNs consider only the mutual proximity of image features, but ignore camera-related factors. On the other hand, CK-RNNs prioritize neighbors captured under the same or similar camera conditions when computing k-reciprocal neighbors, filtering out noisy neighbors caused by camera variations.
- Camera-aware Local Query Expansion (CLQE) [2]: This is an auxiliary module designed to leverage camera variations as a strong constraint. During the query expansion stage, it mines reliable samples from related neighbors and assigns higher weights based on camera similarity, further refining the overlap computation. This helps reduce cross-camera mismatches.
There are many recent techniques for person re-identification are present in [25,26]. Overall, the field of Person Re-identification has evolved from a singular task of feature extraction into a comprehensive research area that encompasses multiple directions, including model architecture, metric learning, data augmentation, and multi-modal fusion. It is against this backdrop that our study focuses on the integration of two critical stages—feature extraction and post-processing—aiming to explore an optimization path that balances both performance and efficiency.
3. Proposed Method
This study proposes a hybrid framework for Person Re-identification that integrates advanced feature extraction with post-processing optimization. The core idea of this framework is to enhance identification robustness in complex cross-camera environments without retraining a powerful pre-trained feature extractor. This is achieved by applying a series of optimization processes to its output features and then utilizing an advanced, camera-aware re-ranking algorithm to refine the initial matching results.
3.1. System Framework
As illustrated in Figure 1, the framework in this study primarily consists of the following two sequential stages. The left side illustrates the feature extraction stage, while the right side details the post-processing re-ranking stage. The modules enclosed in red boxes indicate the primary modifications introduced in this study.
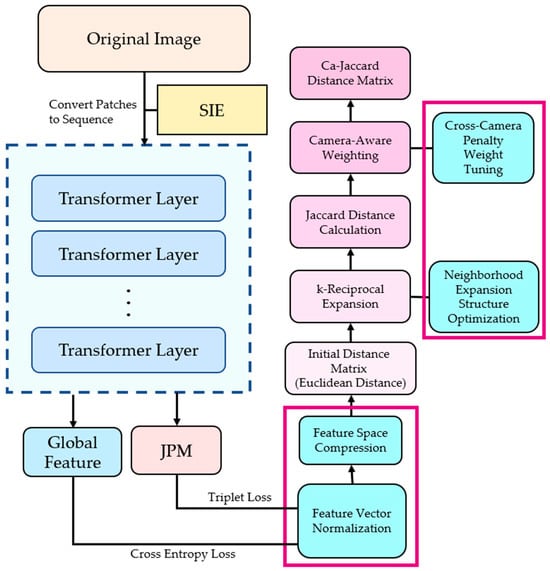
Figure 1.
The architecture of our proposed framework.
3.1.1. Feature Extraction and Optimization
This stage is responsible for extracting highly discriminative feature vectors from input pedestrian images. We selected a pre-trained TransReID model as the base extractor. Diverging from the original method, we additionally designed feature vector normalization and feature space compression modules. These aim to provide more stable and compact feature representations for the subsequent distance measurement stage.
3.1.2. Camera-Aware Re-Ranking
This stage receives the optimized feature vectors and applies the CA-Jaccard algorithm for post-processing. By analyzing the local neighborhood topology among feature vectors and incorporating camera information, this algorithm refines the initial distance metric matrix and ultimately outputs a more reliable ranked list of matches.
3.2. Stage One: Feature Extraction and Optimization
3.2.1. TransReID-Based Feature Extraction
We employed TransReID as the backbone network for feature extraction. This model is a pure Transformer-based architecture whose core self-attention mechanism enables it to capture long-range dependencies within an image. This allows it to learn features rich in global context, which is crucial for overcoming partial occlusions and pose variations.
For each input image, TransReID generates a global feature vector, (from the CLS token), representing the entire image, along with a set of local features, , produced by its Jigsaw Patch Module (JPM), corresponding to different body regions. To create a comprehensive feature vector that contains both global and local information, we fuse them through averaging and concatenation, as shown in Equation (1):
In Equation (1), is the resulting raw feature vector after fusion, represents the feature vector of the -th local region, is the total number of local features, and the operator denotes the vector concatenation operation.
3.2.2. Feature Space Optimization
Directly using the high-dimensional for distance calculation can affect ranking stability and efficiency due to issues like inconsistent vector magnitudes and the curse of dimensionality. To mitigate this, we designed two key optimization steps:
L2 Normalization
We applied L2 normalization to each raw feature vector , projecting it onto a unit hypersphere. This step eliminates the influence of vector magnitude, allowing subsequent distance calculations to focus solely on the similarity of feature directions, thereby enhancing metric stability. The normalized feature is calculated as shown in Equation (2):
In Equation (2), represents the L2-normalized feature vector, and is the L2 norm (Euclidean norm) of the vector , defined as .
PCA Compression
To filter out redundant information and noise from the features and improve the efficiency of subsequent computations, we used Principal Component Analysis (PCA) to reduce the dimensionality of the normalized features . After multiple experimental tests, we decided to compress the original 768-dimensional features to 256 dimensions, forming the final feature vector used for re-ranking. This helped to construct a more compact and discriminative feature space.
3.3. Stage Two: Camera-Aware Re-Ranking
After obtaining the optimized feature vectors , we employed the CA-Jaccard algorithm to re-rank the initial Euclidean distances for all sample pairs. The core innovation of CA-Jaccard lies in its use of camera information to overcome the bias of traditional Jaccard distance in cross-camera matching. It primarily consists of two well-designed modules: Camera-aware K-Reciprocal Nearest Neighbors (CK-RNNs) [2] and Camera-aware Local Query Expansion (CLQE) [2]. The method first calculates the Jaccard distance based on an expanded neighborhood set to measure the similarity of the neighborhood structures of two samples, as shown in Equation (3):
In Equation (3), is the Jaccard distance between a query sample and a gallery sample , calculated based on their k-reciprocal nearest neighbor sets, where k is a parameter determining the size of the neighbor set. and represent the expanded k-reciprocal nearest neighbor sets for the query sample and gallery sample , respectively. The notation denotes the number of elements in a set.
Next, to alleviate the domain gap problem in cross-camera matching, CA-Jaccard introduces a camera-aware adjustment mechanism. It integrates the Jaccard distance with camera ID information through a weighted fusion to obtain the final distance metric , as shown in Equation (4):
In Equation (4), is the final distance after the camera-aware adjustment. It is a Jaccard distance adjusted by incorporating camera ID information. is a balancing parameter used to regulate the weights of the Jaccard distance and camera information, which we set to 0.5 in this study. and represent the camera IDs of the query sample and the gallery sample , respectively. is an indicator function that equals 1 if the condition is true (i.e., the two samples are from different cameras), and 0 otherwise. This term acts as a penalty to prioritize cross-camera matches.
4. Experiments
4.1. Experimental Setup
The hardware and software configurations for our experiments are detailed in Table 1. The key parameters used for model training and evaluation are listed in Table 2.

Table 1.
A list of the experimental environment configurations.
Table 2.
A list of the experimental parameters.
4.2. Experimental Results
The main phase of our experiments focused on validating the identification performance of the global feature vectors generated by TransReID [1] when combined with the CA-Jaccard [2] feature metric method under various hyperparameter combinations. In this stage, our experimental design centered on adjusting the first two neighborhood parameters, and , of the CA-Jaccard [2] algorithm. We conducted tests on two common cross-camera Person ReID datasets: Market-1501 [27] and MSMT17 [13].
The evaluation metrics included the mean Average Precision (mAP) and Rank-1 accuracy. The mAP metric represents the model’s stability in overall identity matching, while Rank-1 offers the most direct observation of whether the model makes a correct match at its first attempt.
As observed from the results on Market-1501 [27], detailed in Table 3, the original TransReID [1] model without re-ranking achieved an mAP of 88.2% and a Rank-1 accuracy of 95%. When CA-Jaccard [2] was applied, the mAP significantly increased to over 93%, while the Rank-1 accuracy showed a slight decrease of 0.02%. A possible reason for this is that improving the overall ranking precision may adversely affect the Rank-1 metric. Furthermore, the experimental results for -values, variations in affected both the mAP and Rank-1 metrics, as shown in Figure 2 and Figure 3.
Table 3.
Experimental results with different k-value combinations on the Market-1501 dataset.
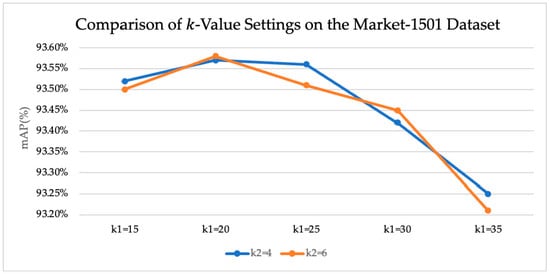
Figure 2.
Comparison of mAP with different k-value settings on the Market-1501 dataset.
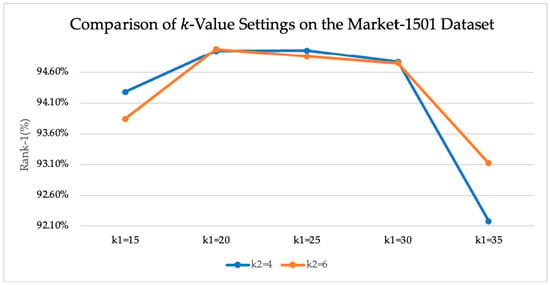
Figure 3.
Comparison of Rank-1 accuracy with different k-value settings on the Market-1501 dataset.
Further comparing different values while keeping fixed, a slight improvement was observed at (mAP 93.56%, Rank-1 94.96%). However, setting led to a decrease in accuracy (mAP dropped to 93.42%, Rank-1 to 94.77%). This suggests that an overly large k-value may cause the k-reciprocal set to include too many irrelevant samples, thereby degrading the re-ranking quality. Overall, the optimal parameter combination was and , which substantially boosted mAP while maintaining a high Rank-1 level. The charts indicate that regardless of whether was fixed or varied, the mAP performance exhibited a trend of first increasing and then decreasing, highlighting the need to carefully select an appropriate range for the neighborhood parameters.
On the more challenging MSMT17 [13] dataset, the original TransReID [1] model achieved a mAP of 64.9% and a Rank-1 accuracy of 83.3%. By introducing the CA-Jaccard [2] method, a similar significant performance improvement was observed in Table 4. For example, with and , the mAP increased to 68.76%. Adjusting to 6 further raised the mAP to 68.81%, while the Rank-1 accuracy remained at 83.3%. This demonstrates that the camera-aware re-ranking strategy can effectively mitigate the cross-camera matching problem in this dataset.
Table 4.
Experimental results with different k-value combinations on the MSMT17 dataset.
For other values on MSMT17 (such as 25 and 30), the change in mAP was relatively small, centering around 68.79%. This indicates that the dataset’s sensitivity to adjustments in was less pronounced than that of Market-1501 [27]. The line charts shown in Figure 4 and Figure 5 also show that when exceeded 30, the mAP consistently trended downward, suggesting that excessive neighborhood expansion dilutes the discriminative power of the features. The results demonstrate that the best performance, in terms of both accuracy and mAP, was achieved when and . This aligns with the settings recommended in the original CA-Jaccard [2] paper, indicating the algorithm’s stability and generalization capability under specific parameters. The experimental results on both datasets confirm that without end-to-end training, CA-Jaccard [2] can robustly improve the stability of the entire Person ReID system.
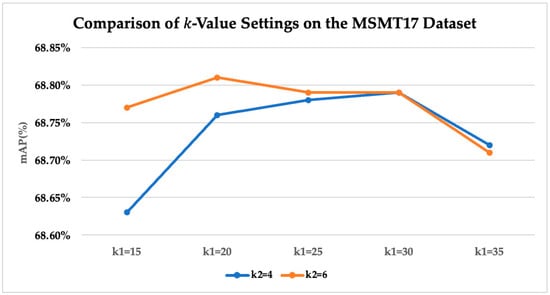
Figure 4.
Comparison of mAP with different k-value settings on the MSMT17 dataset.
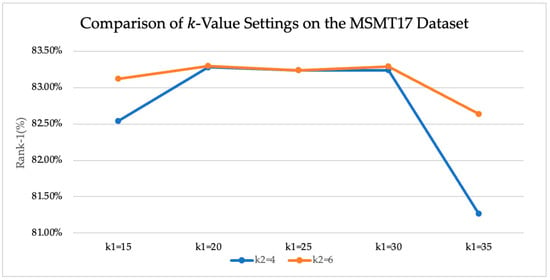
Figure 5.
Comparison of Rank-1 accuracy with different k-value settings on the MSMT17 dataset.
A comparison of our experimental method with other recent models on the same datasets is presented in Table 5. The highest and second-highest values are marked in red and blue, respectively. Our method achieved the most impressive performance on the Market-1501 dataset, with a mAP 2.5% higher than the top-performing MGN + UP-ReID [28]. On the MSMT17 dataset, our method also reached the second-highest mAP at 68.8%. This highlights the stability and potential of the combined TransReID [1] and CA-Jaccard [2] system. Although there is still room for improvement in the Rank-1 metric, this system can substantially increase mAP without significantly compromising Rank-1 accuracy. In practical applications, different identification methods can be selected based on specific needs.
Table 5.
Comparison with other state-of-the-art models on the Market-1501 and MSMT17 datasets.
5. Conclusions
In this study, we integrated the Transformer-based TransReID [1] model with the semantic-driven re-ranking mechanism CA-Jaccard [2] to propose an identification pipeline for the cross-camera Person ReID task, characterized by high discriminative power and strong robustness. Additionally, we are the first to investigate how the modified distance metric enhances the ReID task when used with the ViT-based feature extractor, TransReID. Through experimental evaluations on the Market-1501 and MSMT17 datasets, we tested and compared the performance difference between TransReID [1] operating alone and when integrated with CA-Jaccard [2].
The experimental results demonstrate that after incorporating DBSCAN and camera-encoded information, CA-Jaccard [2] significantly improved the mean Average Precision (mAP). On the Market-1501 [27] dataset, using the optimal parameter combination (, ), the mAP increased to 93.58%, an improvement of over 5 percentage points compared to the 88.2% of the original TransReID [1]. Although the Rank-1 accuracy was slightly lower than that of TransReID [1] (a decrease of approximately 0.02%), the overall ranking quality was superior.
This phenomenon can be attributed to the differences in the retrieval logic of the two methods. TransReID [1] focuses on high-precision exact matching. Its feature design and global modeling capabilities make it easier for the target ID to be ranked first, which is suitable for scenarios requiring real-time identification and single-best-match retrieval.
In contrast, CA-Jaccard [2], through its k-reciprocal neighborhood expansion and camera-aware weighted adjustments, can more effectively cover the true ID among multiple candidate samples. This leads to improvements in both overall recall and the distribution of ranked results, making it suitable for practical scenarios where a list of candidates is considered, such as forensic investigations by law enforcement or backend intelligent surveillance retrieval tasks.
Furthermore, by integrating the DBSCAN clustering algorithm with well-designed distance thresholds (e.g., ) and neighborhood parameters (, ), the model exhibits enhanced fault tolerance for outliers in the data. Many visually ambiguous edge cases are effectively classified or excluded during the re-ranking stage, which further reduces the risk of false matches and improves the system’s practicality and stability under non-end-to-end training conditions. CA-Jaccard [2] not only significantly compensates for the deficiencies of TransReID [1] in terms of recall and sample coverage, but also provides a practical path to enhance overall retrieval quality through post-processing without retraining the main model. Future work will further explore generalization capabilities across different scenarios, the fusion of multi-modal signals, and the integration of spatiotemporal trajectory information to expand the potential of this research in real-world intelligent surveillance applications.
Author Contributions
Conceptualization, C.-H.C. and T.-C.H.; methodology, C.-H.C. and T.-C.H.; software, T.-C.H.; validation, C.-H.C., T.-C.H. and C.-L.L.; formal analysis, C.-H.C., J.-H.L. and C.-L.L.; investigation, C.-H.C. and T.-C.H.; resources, C.-H.C.; data curation, T.-C.H. and C.-W.W.; writing—original draft preparation, C.-H.C. and T.-C.H.; writing—review and editing, C.-H.C., C.-W.W., J.-H.L. and C.-L.L.; visualization, T.-C.H. and C.-W.W.; supervision, C.-H.C., T.-C.H. and C.-L.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The market-1501dataset is available at https://www.kaggle.com/datasets/pengcw1/market-1501 (accessed on 4 September 2025) and msmt17 dataset is available at https://www.pkuvmc.com/dataset.html (accessed on 4 September 2025).
Acknowledgments
The authors would like to acknowledge the anonymous reviewers for their valuable and constructive feedback, which greatly enhanced the quality of this paper. They would also thank the Wei Hao Chen for his assistance in revising and editing the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. TransReID: Transformer-Based Object Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15013–15022. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, Z.; Chen, Z.; Zhu, Y. CA-Jaccard: Camera-Aware Jaccard Distance for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 17532–17541. [Google Scholar] [CrossRef]
- Gray, D.; Tao, H. Viewpoint Invariant Pedestrian Recognition with an Ensemble of Localized Features. In Proceedings of the European Conference on Computer Vision (ECCV 2008), Marseille, France, 12–18 October 2008; LNCS 5302. Springer: Berlin/Heidelberg, Germany, 2008; pp. 262–275. [Google Scholar] [CrossRef]
- Farenzena, M.; Bazzani, L.; Perina, A.; Murino, V.; Cristani, M. Person re-identification by symmetry-driven accumulation of local features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2360–2367. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; LNCS 11211. pp. 501–518. [Google Scholar] [CrossRef]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning discriminative features with multiple granularities for person re-identification. In Proceedings of the ACM Multimedia Conference (ACM MM), Seoul, Republic of Korea, 22–26 October 2018; pp. 274–282. [Google Scholar] [CrossRef]
- Zhu, K.; Guo, H.; Zhang, S.; Wang, Y.; Liu, J.; Wang, J.; Tang, M. AAformer: Auto-aligned transformer for person re-identification. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 17307–17317. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Zhang, P.; Qi, J.; Lu, H. HAT: Hierarchical Aggregation Transformers for Person Re-Identification. In Proceedings of the 29th ACM International Conference on Multimedia (ACM MM 2021), Chengdu, China, 20–24 October 2021; pp. 516–525. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3652–3661. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020; pp. 13001–13008. [Google Scholar] [CrossRef]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 79–88. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Zheng, Z.; Li, S.; Yang, Y. Camera Style Adaptation for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5157–5166. [Google Scholar] [CrossRef]
- Ge, Y.; Chen, D.; Li, H. Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-Identification. In Proceedings of the Eighth International Conference on Learning Representations (ICLR 2020), Virtual Event, 26–30 April 2020; Available online: https://openreview.net/forum?id=rJlnOhVYPS (accessed on 4 September 2025).
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 994–1003. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Generalizing a Person Retrieval Model Hetero- and Homogeneously. In Computer Vision—ECCV 2018, Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 172–188. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.-S.; Yu, H.-X.; Gong, S.; Lai, J. RGB-Infrared Cross-Modality Person Re-Identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5390–5399. [Google Scholar] [CrossRef]
- Guo, W.; Pan, Z.; Liang, Y.; Xi, Z.; Zhong, Z.; Feng, J.; Zhou, J. LiDAR-Based Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 19–21 June 2024; pp. 17437–17447. [Google Scholar] [CrossRef]
- McLaughlin, N.; Martinez del Rincon, J.; Miller, P. Recurrent Convolutional Network for Video-Based Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1325–1334. [Google Scholar] [CrossRef]
- Dai, J.; Zhang, P.; Lu, H.; Wang, H. Video Person Re-Identification by Temporal Residual Learning. arXiv 2018, arXiv:1802.07918. [Google Scholar] [CrossRef] [PubMed]
- Eom, C.; Lee, G.; Lee, J.; Ham, B. Video-Based Person Re-Identification with Spatial and Temporal Memory Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12036–12045. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Peng, X.; Zhao, H.; Zhang, X.; Zhang, C.; Chen, C. MetaGON: A Lightweight Pedestrian Re-Identification Domain Generalization Model Adapted to Edge Devices. IEEE Open J. Commun. Soc. 2024, 5, 690–699. [Google Scholar] [CrossRef]
- Yan, J.; Wang, Y.; Luo, X.; Tai, Y.W. Fusionsegreid: Advancing person re-identification with multimodal retrieval and precise segmentation. arXiv 2025, arXiv:2503.21595. [Google Scholar]
- Asperti, A.; Fiorilla, S.; Nardi, S.; Orsini, L. A review of recent techniques for person re-identification. Mach. Vis. Appl. 2025, 36, 25. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-Identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar] [CrossRef]
- Yang, Z.; Jin, X.; Zheng, K.; Zhao, F. Unleashing Potential of Unsupervised Pre-Training with Intra-Identity Regularization for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 14298–14307. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-Scale Feature Learning for Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3702–3712. [Google Scholar] [CrossRef]
- Zhu, K.; Guo, H.; Liu, Z.; Tang, M.; Wang, J. Identity-Guided Human Semantic Parsing for Person Re-Identification. In Computer Vision—ECCV 2020; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12348, pp. 346–363. [Google Scholar] [CrossRef]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-Aware Global Attention for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3186–3195. [Google Scholar] [CrossRef]
- Li, H.; Wu, G.; Zheng, W.-S. Combined Depth Space Based Architecture Search for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6729–6738. [Google Scholar] [CrossRef]
- Zhang, A.; Gao, Y.; Niu, Y.; Liu, W.; Zhou, Y. Coarse-to-Fine Person Re-Identification with Auxiliary-Domain Classification and Second-Order Information Bottleneck. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 598–607. [Google Scholar]
- Wang, P.; Zhao, Z.; Su, F.; Meng, H. LTReID: Factorizable Feature Generation with Independent Components for Long-Tailed Person Re-Identification. IEEE Trans. Multimed. 2022, 25, 4610–4622. [Google Scholar] [CrossRef]
- Jia, M.; Cheng, X.; Lu, S.; Zhang, J. Learning Disentangled Representation Implicitly via Transformer for Occluded Person Re-Identification. IEEE Trans. Multimed. 2022, 25, 1294–1305. [Google Scholar] [CrossRef]
- Wang, T.; Liu, H.; Song, P.; Guo, T.; Shi, W. Pose-Guided Feature Disentangling for Occluded Person Re-Identification Based on Transformer. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-22), Virtual Event, 22 February–1 March 2022; pp. 2540–2549. [Google Scholar] [CrossRef]
- Zhu, H.; Ke, W.; Li, D.; Liu, J.; Tian, L.; Shan, Y. Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4692–4702. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, Y.; Zhang, T.; Li, B.; Pu, S. PHA: Patch-Wise High-Frequency Augmentation for Transformer-Based Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 14133–14142. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).