1. Introduction
For some years now, interest in so-called edge computing has been growing continuously [
1,
2]. Edge computing is an application deployment model based on the use of computing infrastructure positioned close to the user. This infrastructure is also connected to the cloud, of which it could be considered the closest frontier to the user. Edge devices can be specialized electronic tools—such as gateways, cameras or other IoT (internet of things) devices [
3]—with data collection and processing capabilities or they can be servers, personal computers or minicomputers.
There are many reasons that have determined the success of edge computing [
4]. The main ones consist of (i) low latency in accessing services, (ii) the possibility of processing large volumes of data close to their production, avoiding resorting to expensive and time-consuming cloud storage services, and the possibility of keeping sensitive data in limited and protected portions of the network.
However, these benefits are accompanied by problems that have promoted intense research activity in recent years. The common matrix of these problems is the limitation of available computing, storage, and connectivity resources, and the localized nature of the edge infrastructure, which can only be considered as such by users located in the surrounding area.
The limited resources have repercussions on the number of instances of services that can be deployed in the edge. Some results, known for years, obtained through queuing theory rigorously show how the resource utilization coefficient is closely linked to system time [
5], i.e., the latency observed by users requesting a service. Therefore, if it is necessary to maintain low latency—and this is essential, otherwise it would be worth deploying the services in the core cloud—then it is necessary to have an adequately low service utilization coefficient. However, a low utilization coefficient of a limited amount of resources results in a low number of deployable instances. Clearly, the process of service request arrivals depends on the number of potential users who are near the edge. However, for particular services, such as IoT and vehicular services in the metropolitan area, various instances of refusal of service can occur [
6]. For this reason, much of the recent research on edge computing has focused on guaranteeing performance values linked to the probability of rejection, such as, for example, its average value per minute or its peak value, and also on guaranteeing satisfactory values of latency, while maximizing the number of requests that can be served per unit of time. To ensure a tolerable latency value, the value of the resource utilization coefficient is capped high, and this is a fixed point that cannot be violated. Therefore, the problem to be solved becomes a problem of maximizing the number of service instances completed in a unit of time while maintaining a predefined utilization coefficient of the computing resources in the edge.
To address this problem, a recently defined methodology for deploying cloud services, known as function as a service (FaaS), has proven to be particularly promising [
2,
6,
7,
8,
9]. This methodology, based on events, consists in instantiating in the cloud—in the edge, in this case—portions of the code that can be invoked in stateless mode, called functions, which implement the service only for the time necessary for their execution. At the end of the execution the function is removed and the resources freed. If developers are able to create applications by organizing them into elementary functions, ideally implementing a single task, the actual amount of resources used is minimized. Furthermore, the execution environment for these functions, made available by cloud providers, allows them to be executed without managing the underlying computing and storage architecture. This mode of application development is known as serverless. Therefore, no infrastructure management issues, such as file system operations, horizontal autoscaling of functions, load balancing, and system monitoring, need be addressed by developers. They can, therefore, focus solely on the application code.
To optimize the performance obtainable through the serverless model, it is necessary to configure some parameters that determine its operation. In particular, the horizontal autoscaling of functions, typical of serverless platforms, must adapt to the edge system and its current state. In this paper, we use the concept of state to describe the essential configuration of the edge system and the value of the operational parameters, such as the current occupancy of resources.
The main objective of this paper was to compare reinforcement learning algorithms capable of adapting to the state of the system, in order to determine the optimal operating parameters that determine the horizontal autoscaling events of the functions. In particular, these algorithms are able to learn how to configure the threshold value on CPU occupancy to trigger autoscaling events, in order to maximize the number of functions that can be instantiated in the edge, guaranteeing adequate latency and success rate values in accessing services.
Some papers have already addressed related problems. For example, in [
10], a comparison of OpenFaaS, AWS Greengrass, and Apache OpenWhisk with different workloads is shown. The edge computing cluster is based on Raspberry Pis. In [
8], a performance comparison of FaaS platforms is shown, namely, OpenFaaS, Kubeless, Fission, and Knative. By using different runtimes written in Python, NodeJS, and Golang the authors evaluate the latency for accessing compute-intensive and I/O-intensive functions. A serverless model is considered in [
9], where function invocation on the edge is based on a multi-armed bandit problem. In a recent paper [
7], we propose the use of a reinforcement learning algorithm for minimizing the average observed latency for accessing a serverless function by using a Q-learning agent to learn the optimal HPA threshold.
Nevertheless, the need to carry out the analysis shown in this paper depends on the fact that the results of the previous research activities, illustrated also in what follows, are often difficult to compare. The different characteristics of the systems, their different configuration, the service request arrival processes, and the deployed functions are so different as to make it difficult to understand what is the best choice to make in a real edge computing system. Moreover, different objective functions and differentiability properties, due to the use of different reward functions, can significantly influence the achievable performance. For this reason, we focused on three different algorithms inspired by different principles: value-based, policy-based, and a combination of both. These principles bring together almost all the proposals present in the literature. In particular, we compared the performance of the deep Q-network (DQN), advantage actor–critic (A2C), and proximal policy optimization (PPO) algorithms in an edge computing cluster orchestrated using Kubernetes. This choice was based on the fact that Kubernetes is currently the most popular open-source container orchestration and management technology. On this platform, we installed OpenFaas, which is one of the most popular serverless technologies. We used this integrated platform to deploy functions that emulate the behavior of an IoT-oriented edge system.
In summary, the main contributions of this paper are as follows:
We provide insights into the typical problems of edge systems when they are managed with the considered technologies.
We compare the learning capabilities of different, popular reinforcement learning algorithms, based on system configuration and desired results.
We critically review the results, based on the type of algorithm—value-based, policy-based or mixed—and on the basis of the actual function invocation process.
The paper is organized as follows.
Section 2 illustrates the serverless computing technologies, the related FaaS model, and the components typically found in a serverless computing system. In
Section 3, we survey works dealing with the adoption of serverless computing for IoT services and artificial intelligence to control it. The serverless control model is introduced in
Section 4, along with some insights on the system dynamics related to the control capabilities due to the underlying Kubernetes mechanism. Some background on reinforcement learning and a synthetic description of the employed algorithms is presented in
Section 5.
Section 6 includes the experimental setup and numerical results obtained through lab experiments. Finally,
Section 7 reports our conclusions.
2. Background on Serverless Computing
The model for using cloud resources commonly referred to as serverless requires the cloud provider to take care of all the management activities of the physical servers and dynamically allocate the resources necessary for the operation of the costumer software. This frees up application developers to focus only on developing the code and deploying it directly into the production environment.
To take advantage of the potential of serverless computing, applications must be organized into elementary functions that can be invoked in stateless mode. For this reason, serverless services are offered according to the
function as a service (FaaS) model. Ideally, each function should implement a single task, such that each function is short-lived and recyclable. This particular access to cloud services, if well executed, tends to minimize the use of resources by the customer and to maximize the number of applications deployed by the provider. Therefore, the use of the serverless model determines mutual benefit, which has led to its considerable success in recent years [
2,
6,
7,
8,
9,
11,
12].
For this paper, we considered an edge computing system accessed using serverless technologies. Using this system, we analyzed and compared the ability of some machine learning algorithms to control the horizontal autoscaling events of functions. To understand some architectural choices and the expected performance, it is necessary to focus on the technical characteristics of the system and the technologies used in it.
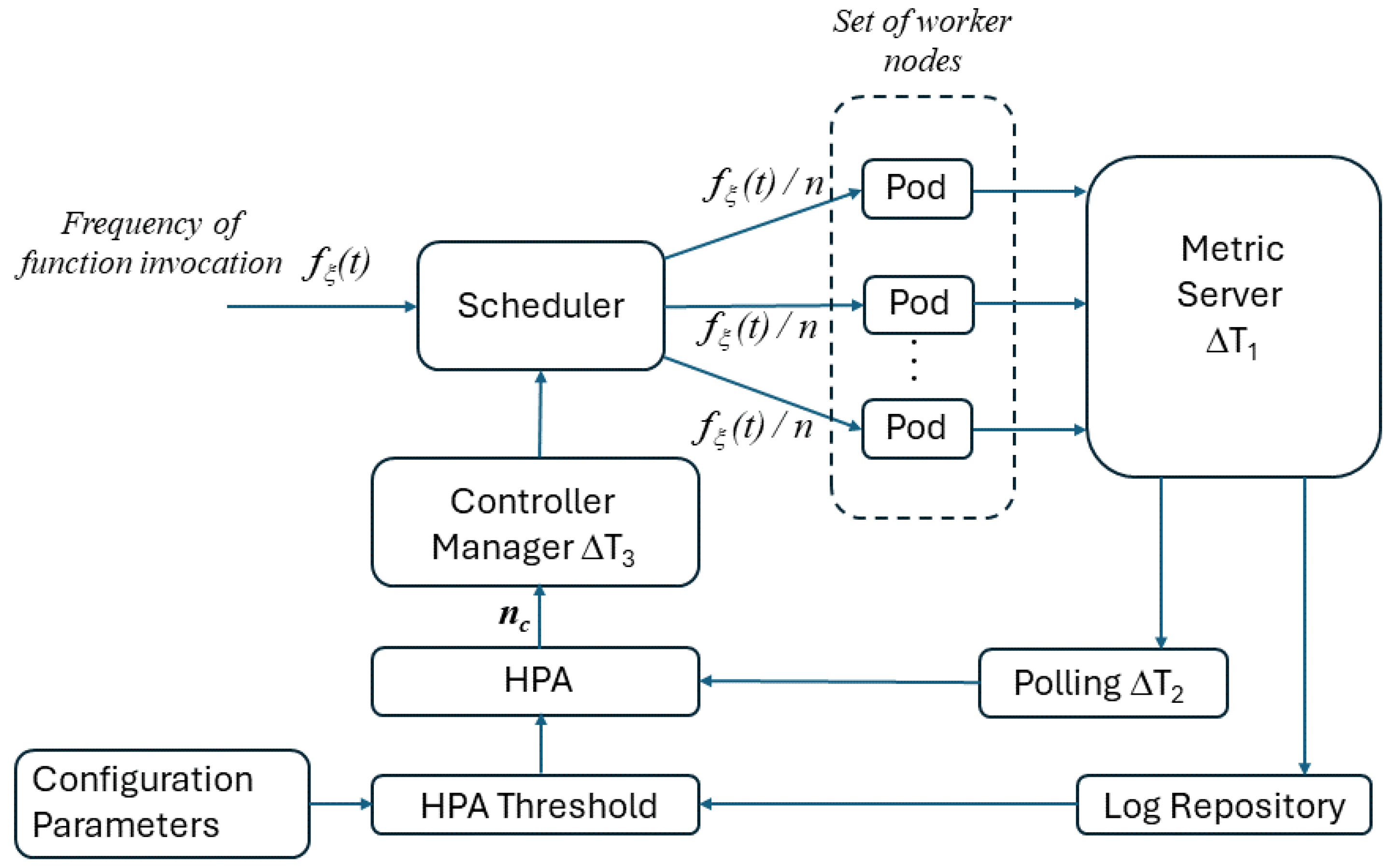
The schematic model of the serverless computing system used for our experimantal campaign is depicted in
Figure 1. Before focusing on the individual elements, we point out the key element of the model, namely, the parameter
. This parameter ideally represents the minimum number of instances of a single function generated by the platform autoscaling algorithm to satisfy the required performance, in terms of latency and losses, referred to, in short, as the service level agreement (SLA).
The system is composed of the following functional elements, which the expert reader will be able to map onto the functional elements of the most popular commercial and open serverless platforms, such as OpenFaas (
https://www.openfaas.com/, accessed on 1 July 2024) and OpenWhisk (
https://openwhisk.apache.org/, accessed on 1 July 2024):
Scheduler: This component receives at time t incoming requests to access a function with an arrival rate equal to .
Computing cluster: This cluster can be composed of a generic number of physical servers. In this case, we use a single server, which represents the edge system. Since the functions must be instantiated, ensuring an adequate degree of isolation, they are implemented in containers. Furthermore, in line with a very popular practice today, the containers are orchestrated using Kubernetes. For this reason, in the computing cluster shown
Figure 1 there are
, which include the containerized code of functions. We assume that
function instances are currently deployed in the computing cluster. For this reason, we can reasonably assume that each pod receives requests for execution of the considered function by the scheduler at an average frequency of
.
Metric server: This component collects resource metrics, such as CPU load, and makes them available to the scaling control mechanism by storing them in a log repository. Clearly, the collection of metrics cannot be a continuously running process; rather, it is carried out periodically, with a period that in
Figure 1 is indicated by
.
Horizontal pod autoscaler (HPA): This component automatically updates the number of active pods associated with the workload resource that implements the function. Using the terminology of Kubernetes, such a resource could be, for example, a deployment (
https://kubernetes.io/docs/concepts/workloads/controllers/deployment/, accessed on 1 July 2024). The aim of the horizontal autoscaling is to control the workload of each pod, to match the incoming demand according to predefined metrics, such as the CPU occupation. Thus, when the load increases, the HPA response is to increase the number of pods until a configured maximum, while if the load decreases then the HPA instructs the resource controller to scale back down until the configured minimum. In this case, reading the metrics in the log repository is not a continuous process, and it happens periodically, with a period that in
Figure 1 is indicated by
, and asynchronously, with respect to the writing to the log repository by the metric server. The behavior of the HPA is also influenced by a number of configuration parameters, such as the value of the thresholds for scaling the number of instantiated functions up and down and their maximum and minimum numbers. To highlight this behavior, we included a configuration parameters box in
Figure 1.
Controller manager: This element indicates the workload resource controller that supervises the life cycle of the pods, verifies their status and, if necessary, instantiates new ones, to comply with the indications received from the HPA. The Kubernetes health checks proactively ensure service availability for avoiding service disruptions. In the horizontal autoscaling process, it is also necessary to consider that updating does not lead to the immediate availability of further instantiated functions. For this reason, an entire setup process must be completed with the verification of the healthy status of the relevant pods. We indicate the time needed to complete this process with .
For what concerns the container startup latency for instantiating new functions, a particular problem must be considered, which is known as
cold start [
13]. A cold start happens when it is necessary to start a new container, configure the runtime environment for its execution, and deploy the requested function, possibly after downloading it from a repository if not locally available. Some values of cold start delay times are reported in [
13]. Their values are in the order of hundreds of ms up to a few seconds. Therefore, cold starts can also significantly affect
and the responsiveness of applications. A typical approach for mitigating this problem consists of keeping a number of instances in the idle state and using them when needed. This approach is known as
warm start, and it takes much less time than instantiating a new function from scratch. However, while the cost of storage to maintain unused pods is affordable in the core of a cloud, it cannot be supported on a resource-constrained edge system. Some proposals explore the use of artificial intelligence (AI) techniques to predict new requests and the relevant instantiation of functions [
1,
7]. However, these approaches rely on the existence of good autocorrelation properties in the arrival process. To avoid making assumptions that could compromise the applicability of the research results, our analysis was based on temporal profiles of requests to FaaS services captured by an operational system [
14].
4. Dynamics of HPA Control
From
Section 2, it is clear that every HPA control action on the computing cluster is affected by a latency, due to
,
, and
. In particular, given some configuration parameters, the value of
can be expressed as a function of the arrival process and these delays: that is,
, where
T, in the worst case, is equal to
+
+
. The resulting load for each pod is ideally
Equation (
3) highlights the first type of error that affects the control of the HPA, namely,
. The effects of this error are as follows:
We refer to
as a
latency error type. The magnitude of the latency error essentially depends on the autocorrelation properties of the request arrival process. If this process produced almost constant arrival rates, this error would be negligible. However, as will be evident from the use of FaaS request traces, this is not always the case. More formally, given the autocorrelation function
, the worst situation for the latency error is
. On the other hand, if
, with at least
, the latency error effects could be neglected. Regardless of the latency error, the estimation of the optimal value of
is a problem that must be addressed. As shown in what follows, this problem is addressed using reinforcement learning techniques. The output of the algorithms considered, as shown below, determines the configuration parameters of the HPA; therefore, it determines the estimated value of
, which we indicate as
. This leads to the second type of error, namely,
estimation error . In summary, the resulting load for each pod isFurthermore, assuming the reinforcement learning algorithm has been adequately trained, even with the limitations shown above it is necessary to consider that the arrival process may not be stationary. In this case, a further type of error has to be considered, which is the so-called
generalization error , where the subscripts
and
refer to two different arrival processes. In this case, the resulting load for each pod becomes
5. Reinforcement Learning Algorithms
Reinforcement learning algorithms have the general objective of allowing an agent to learn through interaction with the environment with which it can interact. Learning consists of allowing the agent to make subsequent decisions and receive a reward, positive or negative, based on the results resulting from the actions. The general objective, therefore, is learning an optimal strategy that maximizes the final reward. Each learning iteration is organized into consecutive steps, i.e., elementary interactions between the agent and the environment. Each interaction, with the related reward, is associated with the state of the system, i.e., a collection of the value of a set of parameters that are sufficient to describe the evolution of the system. The reward of each action is then associated with state transitions. In summary, during each iteration, the agent makes decisions, interacts with the environment, observes the states assumed by the system and the rewards, and adapts its own behavior, based on past experiences. The iterations are repeated over time, to improve the agent’s performance until it reaches a certain objective. For this purpose, reinforcement learning algorithms make use of policy functions. Such functions represent strategies that map the states of the environment to the actions the agent takes. In other words, the policy defines the agent behavior in every possible state of the environment. Policies may be deterministic or statistic. For this paper, we considered statistic policies referred to as that represent the probability of selecting the action a in the state s. The parameters in the vector represent the tuning knobs to find the optimal policy during training.
The purpose of our analysis was to compare some of the most popular reinforcement learning algorithms, regarding their ability to adapt to the edge computing environment, to handle the horizontal scaling functions of serverless functions. The comparison concerned deep Q-network (DQN), proximal policy optimization (PPO), and advantage actor–critic (A2C).
The reason for this choice was the need to use mechanisms to ensure stable updates and prevent drastic changes to the policy, which helps maintain learning stability and efficiency. This leads to more robust performance in a wide range of environments. Some proposals in the literature [
1], to which we have also contributed [
7], are based on Q-learning [
48]. Although Q-learning is intuitive and is suitable for a discrete state space, it has been shown that it may suffer from instability issues [
49,
50]. In addition, these approaches are also those mostly adopted in the recent literature for driving resource autoscaling applied to serverless deployment on Kubernetes (see the state-of-the-art analysis in recent works, like [
51,
52]).
For the sake of completeness, in the following subsections we report the main concepts and equations describing the selected algorithms. The interested reader can find additional details in [
49,
50,
53,
54].
5.1. Deep Q-Network
Deep Q-network (DQN) is a reinforcement learning algorithm that uses a neural network to approximate the action-value function
Q. DQN was introduced by Mnih et al. in 2013 [
49,
50]. It was introduced to address several significant challenges in reinforcement learning, particularly when dealing with complex environments characterized by high-dimensional environment states. It can be regarded as the evolution of the value-based Q-learning approach. In particular, this algorithm approximates the action-value function
through a neural network with parameters
. The action-value function represents the expected value of future rewards obtained by taking action
a in state
s.
The parameters of the neural network are updated by minimizing the mean squared error (MSE) between the current Q-value and the target Q-value, as follows:
where the target
y is defined as
and
r is the reward received after taking action
a in state
s;
is the discount factor that determines the importance of future rewards;
is the target action-value obtained using the parameters
of the target network, a copy of the Q-network that is periodically updated to stabilize training.
5.2. Advantage Actor–Critic
Advantage actor–critic (A2C) is a reinforcement learning algorithm that combines both value-based and policy-based methods. It is defined by the use of two components, namely, the actor, which updates the policy distribution in the direction suggested by the other component, the so-called critic. The latter evaluates the action taken by the actor, using the value function.
The policy (actor) update is expressed by the expected return
, as follows:
where
is the policy (probability of taking action
given state
) and
is the advantage estimate at time
t, which is expressed as
where
is the return (cumulative future reward) from time
t and
is the value function, which estimates the expected return from state
.
Finally, the value (critic) update is given by
where
is the value function parameterized by
, which represents the parameters of the value network (critic). These are adjusted to minimize the value function loss.
5.3. Proximal Policy Optimization
Proximal policy optimization is a reinforcement learning algorithm that directly optimizes a policy without making significant changes to parameters due to high advantage estimates that could induce unstable behavior. In addition, it maintains a good balance between exploration and exploitation phases. For this purpose, the basic formulation of PPO includes an objective function to optimize, including clipping operations to ensure that no drastic changes are made. The so-called surrogate objective function of PPO can be expressed as
where
is the objective function. The parameters in the vector
are adjusted to maximize this objective while preventing large updates through clipping. This function takes into account the ratio between the new policy and the old policy, aiming to improve the current policy without making drastic changes.
is the expectation over time
t, i.e., an average over the various time steps considered in the training process;
is the probability ratio (importance ratio) between the new policy
and the old policy
:
This ratio indicates how much the new policy differs from the old policy for a given action
in a state
.
is the estimated advantage at time
t, representing the difference between the actual return and the estimated value of the state. It indicates how good the action was compared to the average;
is a clipping function that limits the ratio
, to keep policy changes under control. The interval
limits how much the new policy can deviate from the old policy;
is a hyperparameter that determines the width of the clipping. Typical values are small, such as 0.1 or 0.2.
The loss of the critical value function can be expressed as
This function measures how much the value estimate of the state by the model
differs from the target value
. The latter is the estimate of the value of state
given by the value function parameterized by
;
is a scaling factor for the quadratic loss used to compensate with the derivative coefficient.
The total combined loss that is minimized during training by its empirical average is
where
and
are coefficients that balance the three loss terms, and
is the entropy term that encourages additional exploration. Entropy measures the uncertainty or randomness of the policy, encouraging exploration. Increasing entropy can help avoid overfitting and promote the discovery of new strategies. These parameters and terms are designed in order to gradually improve the policy while maintaining training stability and efficiency. The actual values used in our experiments were the default values of the library Stable-Baselines3, reported in
Table 1:
6. Experimental Setup and Results
6.1. System Architecture and Technologies
This section includes a detailed overview of the experimental setup, to allow the interested reader to reproduce the experiments.
The edge computing system was implemented by using an HP Omen server 45L GT22-1013nl with an Intel® i9 14900k processor at 5.8 GHz (eight hyperthreaded performance cores + 16 efficient cores, for a total of 32 threads) and 64 GB RAM. By using the Hyper-V hypervisor, we instantiated two Ubuntu 22.04.2 virtual machines for implementing a two-nodes computing cluster managed by Kubernetes (k8s). The two nodes implemented the master node and a worker node of the Kubernetes cluster. The master node was configured with 4 virtual CPU cores (vcpus) and 12 GB of RAM. The worker node was configured with 24 vcpus and 32 GB of RAM. The decision to use a single computer node was made in order to emulate a single-node edge system, a fairly common situation. However, this did not compromise the generality of the results. In fact, regardless of the number of nodes used, the resources, in terms of CPU cores and RAM, were abstracted by Kubernetes and managed as a whole. Thus, what really impacted on performance was the volume of available resources.
The FaaS capabilities were introduced by using OpenFaas. This is a serverless platform that enables creation and deployment of applications through serverless computing. Its architecture is container-based and makes use of Docker containers to execute functions. Every function is packaged within a self-contained image, allowing developers to use the desired programming language. The OpenFaas integration with Kubernetes allows deploying functions quickly on Kubernetes clusters, leveraging its scalability capabilities. The interaction with this tool is mediated by a built-in API Gateway that exposes the cluster functionality. The API Gateway manages the routing of requests to the corresponding functions and manages security policies. In the experimental system, we installed the Community Edition of OpenFaaS, which is the only open-source distribution of OpenFaaS. Although the Community Edition offers a wide range of features and tools, it has some limitations compared to the commercial version. In particular, the HPA allows replicating only five instances of the same function. For this reason, in our experiments we used the Kubernetes HPA for scaling functions. The reinforcement learning algorithms were implemented by using the Stable-Baselines3 library (
https://stable-baselines3.readthedocs.io/en/master/, accessed on 1 July 2024), which is a Python library that provides implementations of different reinforcement learning algorithms. It is compatible with PyTorch (
https://pytorch.org/, accessed on 1 July 2024) and Gymnasium (
https://gymnasium.farama.org/index.html, accessed on 1 July 2024). The latter is a tool that allows implementing a personalized environment through a set of open APIs. The environment that we implemented included the action space, the state definition, the reward function, and any details needed to allow interaction with the reinforcement learning agent.
The requests sent to the edge computing system were generated via the Hey traffic generator (
https://github.com/rakyll/hey, accessed on 1 July 2024). This is a tool used to generate and simulate load towards an application, facilitating the testing and development process. Hey allows sending customized HTTP requests by generating output information on the status of the requests and response times. It also allows some simple forms of concurrent generation of parallel requests as well as the control of the generation rate.
Data from the Azure Public Dataset was used for both training and tests, in particular the Azure Functions Trace 2019 (
https://github.com/Azure/AzurePublicDataset, accessed on 1 July 2024), by selecting one of the functions characterized by a greater frequency of invocation.
In the invocation dataset used, each row, which represents a day of requests, presents an almost periodic trend. In other words, there is a pattern of requests that highlight a sort of daily periodicity. Furthermore, during a day, sometimes rapid changes in the frequency of requests occur, while in other intervals there are none at all. The peaks of the request frequency are around the value of 1800 requests/minute.
The experimental tests were carried out with a compute-intensive function. Specifically, the function factored a given input number in the HTTP request. The reason we used a compute-intensive function was that the horizontal autoscaling policy is based on CPU occupancy. If we had used a different autoscaling policy—for example, based on memory occupancy—to carry out a similar analysis, we would have had to use a memory-bound function.
For training, we set a maximum acceptable latency threshold
s for this service, i.e., the SLA. If the observed service latency exceeded this threshold, the quality of service was assumed to be compromised. Therefore, the reward function
used took into account both the observed latency and the losses. We assumed a loss when the HTTP response code was different from “200 OK”. Thus, we formalized this performance metric as a combination of the latency reward
and the loss reward
, as follows:
where
was the average response latency in one minute and
was the weight of different contributions, set to
.
The reward represented the numerical value that returned to the agent based on its actions. When the agent took optimal actions, it was rewarded with the best achievable reward in the state; otherwise, it was assigned a negative or zero reward. In this way, the reward served as a performance measure for the agent during the training process. The reward formulation was developed gradually, to avoid making the system unstable. This function was piecewise differentiable, with a discontinuity on the latency threshold. Therefore, gradient ascent algorithms could converge the policy parameters towards the threshold from both directions. Before defining the final formulation, we conducted an in-depth base case analysis, to identify the weaknesses of each case. In more detail, we should not keep the service latency as low as possible, but just within the SLA value. In fact, the other fundamental key performance indicator (KPI) for an edge system is resource utilization efficiency. Since the considered function was CPU-intensive, we were interested to keep high the utilization efficient of the processor. This led to the current version of the reward. It has a strong penalty when a single HTTP request is not satisfied. In addition, it considers an increasing reward for a service latency approaching the SLA but lower than it (i.e., ). In fact, from queuing theory, when increasing the utilization of the service node, we observe an increase in the service time. However, if the SLA is violated (i.e., ), we set the reward equal to a negative, decreasing function of the service latency.
The agent action space was a discrete set corresponding to the set of actions changing the HPA threshold values of the cpu load, to trigger autoscaling operations. The set of the CPU percentage threshold values were the following: . The granularity of this set was established experimentally. Essentially, the level of granularity was fixed when no appreciable results were observed by using more levels. Thus, the action space corresponded to the set of the following increments and decrements of the threshold value: . Clearly, the actions available in a state are those compatible with the values in .
6.2. Numerical Results
In this section, we illustrate the numerical results that allowed us to draw conclusions regarding the compared algorithms. Results of our experiment are provided as
Supplementary Materials, see the relevant section.
Table 1 lists the main common hyperparameters of the algorithms that generated the bests results in our experiments. The Kubernetes cluster was configured by using a downscale stabilization of 60 s, in order to be more reactive with respect to the default configuration of 5 min. In fact, in a Kubernetes cluster this parameter is used to prevent the flapping of replicas, in case of fluctuating metrics. Given the analysis in
Section 4, combining all the delay contributions determining the value of
T in Equation (
4), we opted for a value that slightly overcame the maximum
T value.
The state features included the parameters affecting the evolution of the system. They modeled the environment in the global sense, including the technical parameters of the infrastructure, the process parameters of the incoming service requests, and the operative parameters of the running system logic. The state of the environment was defined through the following quantities:
Average latency of the response to a request made to the function;
Number of function replicas within the cluster;
Average CPU usage in percent;
Average RAM usage in percent;
Number of requests in one minute;
Total CPU usage by all instantiated replicas in one minute;
Total RAM usage by all instantiated replicas in one minute;
Success rate;
HPA CPU threshold value in percent;
Cosine of the angle associated with a certain minute of the day;
Sine of the angle associated with a certain minute of the day.
The last two values in the list were used to introduce periodic time values, to represent the daily cycle.
The Kubernetes manifest file that instantiates the deployment associated with the function instances was configured with the following values of requests and limits:
requests: memory: “100 Mi”, cpu: “100 m”;
limits: memory: “500 Mi”, cpu: “500 m”.
For all algorithms, the first test carried out consisted in using a constant and high frequency of function invocations, which was equal to 1000 invocations per minute. In this way, both the convergence capacity of the algorithms and the training stabilization time were analyzed.
What immediately emerged in our tests was a significant difference between the performance obtained with DQN and those relating to the other algorithms. For this reason, this section is organized into the following two subsections.
6.2.1. DQN
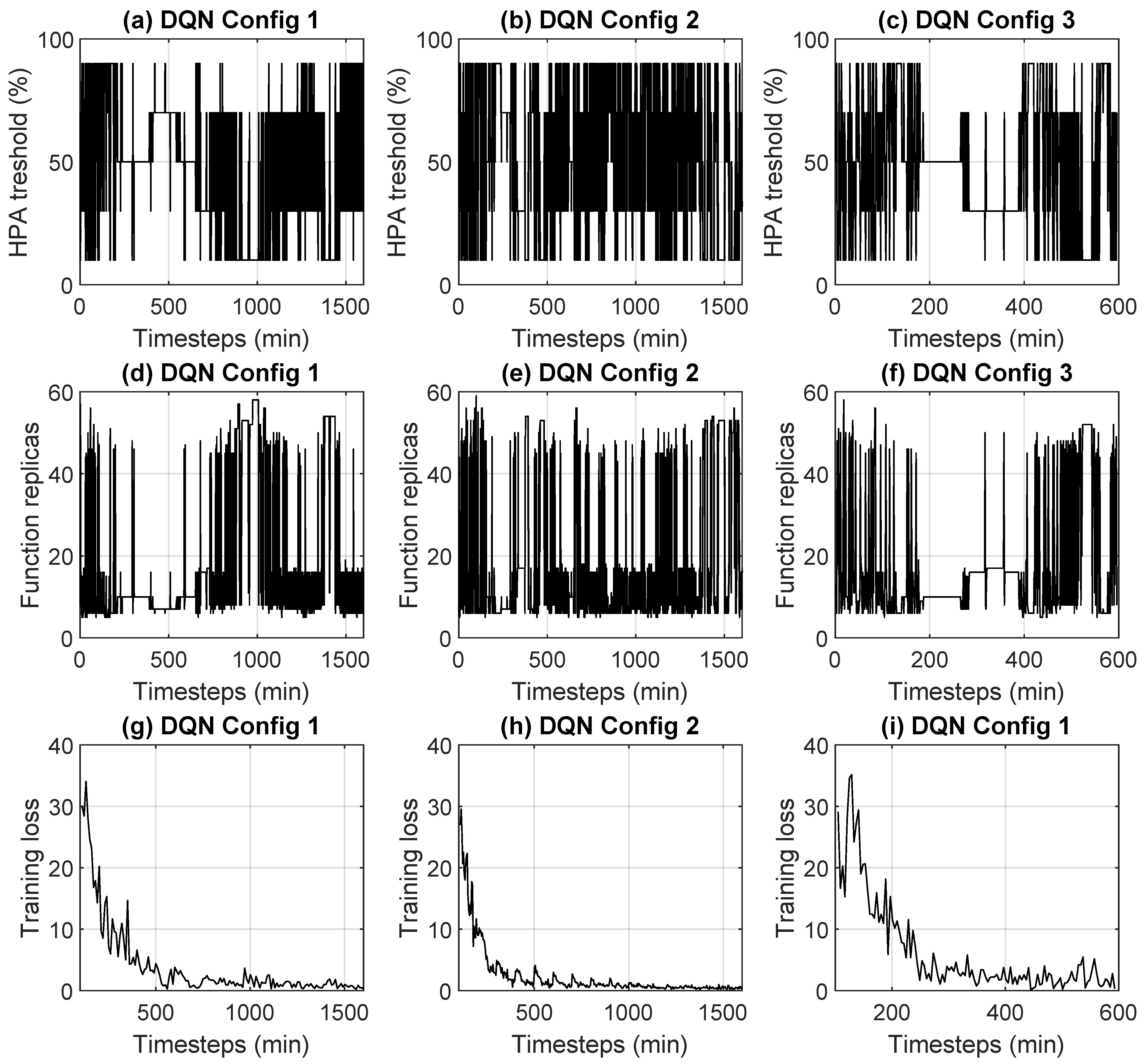
Regarding the DQN,
Figure 2 shows performance in three different configurations. The performance figures were the HPA threshold over time, the number of replicas over time, and the training loss over time, respectively. The three different configurations differed by the following parameters:
batch_size: Minibatch size for each gradient update.
train_freq: Number of steps between model updates.
target_update_interval: Number of steps between target network updates.
The values used in the three different configurations are reported in
Table 2.
The reason why all these configurations were tested was to find a solution that would make the DQN work. Despite this, as can be seen from
Figure 2a–c, even when the training phase seemed to stabilize with a decreasing training loss (
Figure 2g–i) the algorithm was unable to identify an optimal HPA threshold in all configurations. This implied a continuous oscillation of the number of replicas instantiated to serve a constant load (
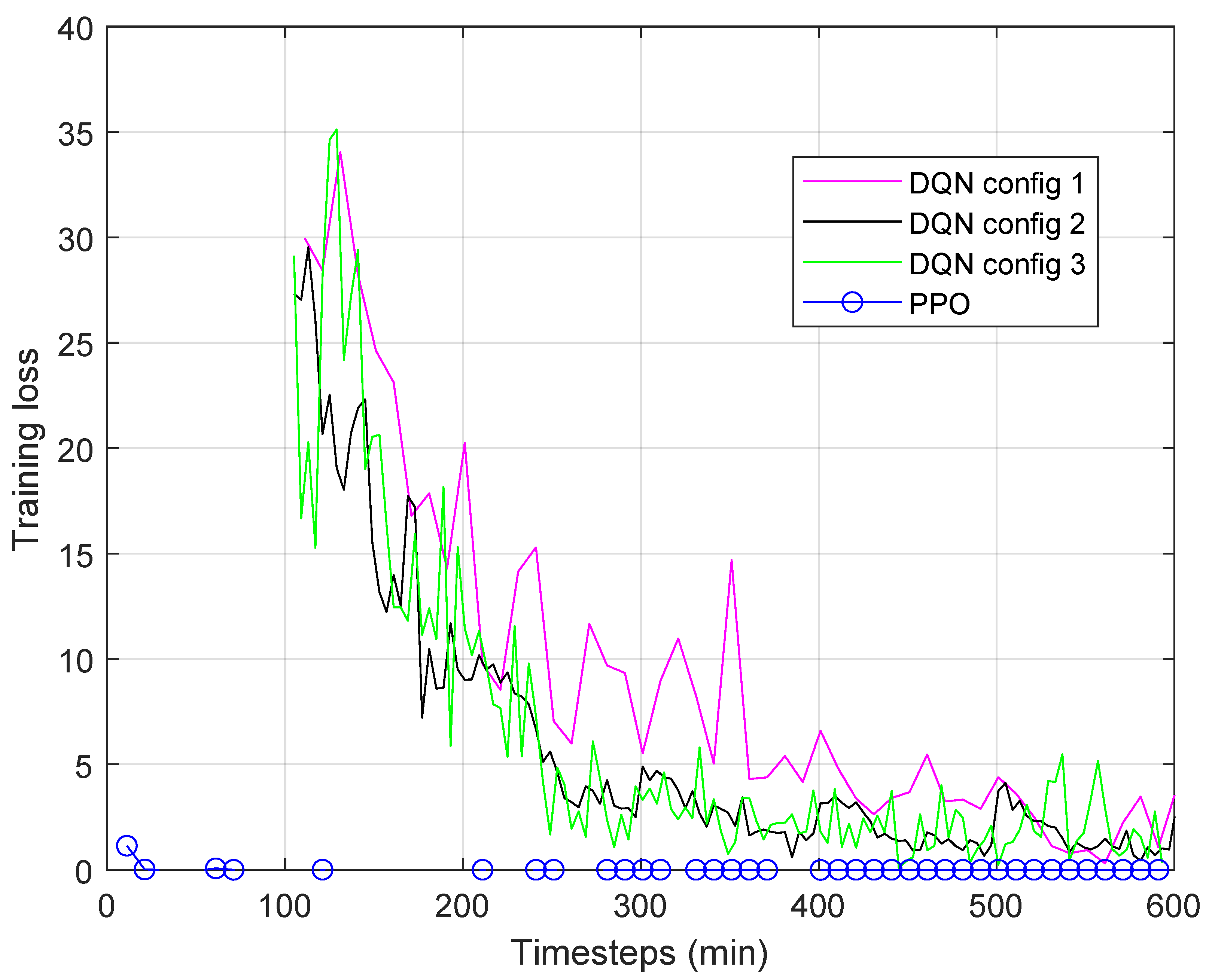
Figure 2d–f). The reduced time interval for DQN Config 3 is to illustrate in detail the behavior of the DQN. As already mentioned above, the DQN is affected by estimates of the gradient of parameters, which can take on excessive values and make it unstable. This behavior, already observed in other contexts, also emerged in our tests relating to the environment considered in this paper. To better highlight the problems of the DQN, in
Figure 3 the training loss in the three cases was compared with that of the PPO, which will be better illustrated in the next
Section 6.2.2. The marked differences that emerged undoubtedly confirm the inadequacy of DQN:
In summary, the DQN was considered unsuitable in the analyzed scenario, and the A2C and PPO algorithms will be compared from now on.
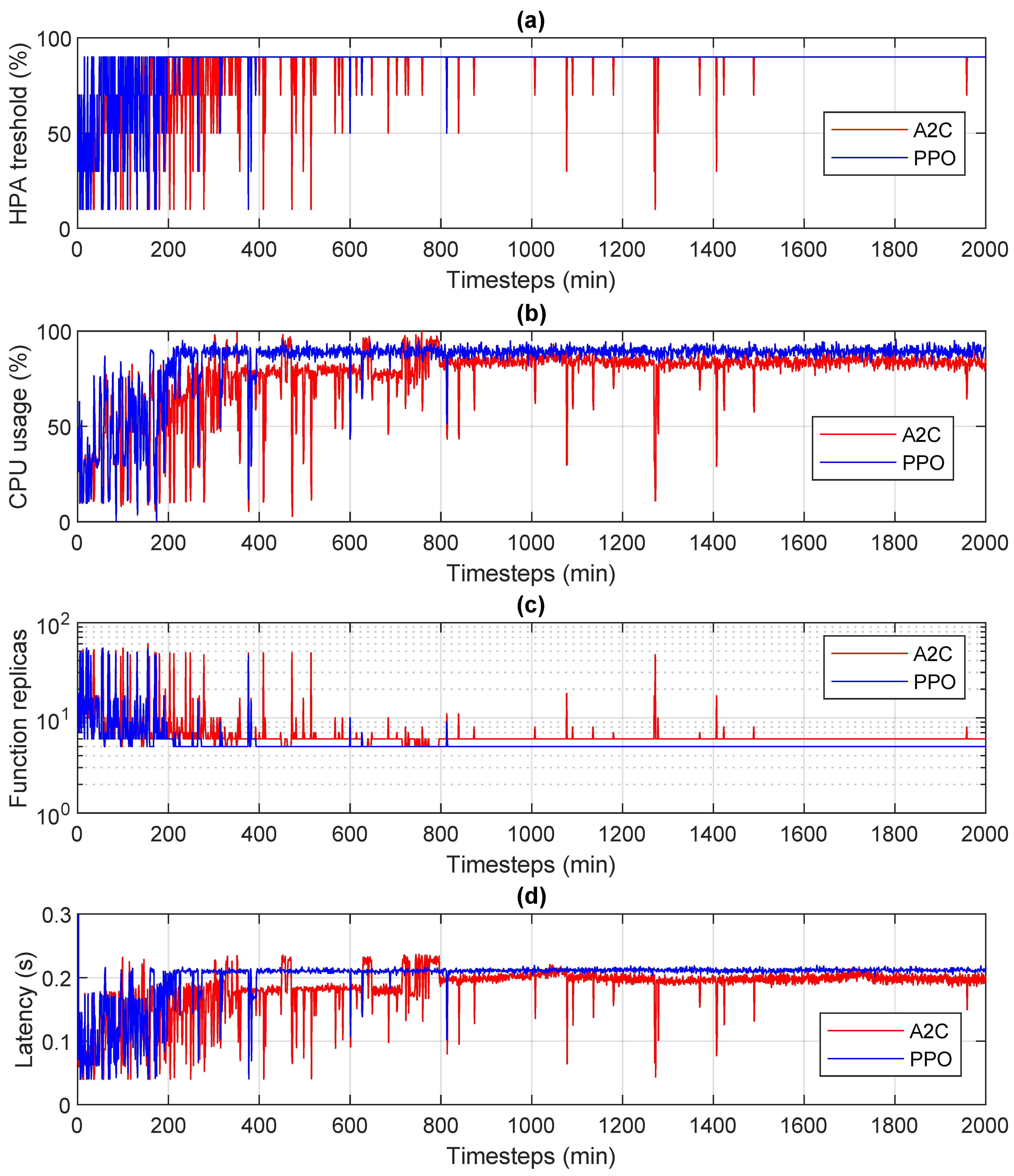
6.2.2. A2C and PPO
Figure 4 shows a direct comparison of the CPU usage and the number of replicas over time for both A2C and PPO. For both algorithms, the ability to converge towards a stable operating condition is evident. This corresponds to a CPU threshold value of 90% used by the HPA. However, the dynamic behavior of the PPO seemed to be better, as the number of steps needed to converge was smaller:
Some differences were also present when convergence had been achieved. While the PPO was practically stable, A2C showed some peaks in the creation of additional instances, which had a negative impact on the percentage of CPU usage.
As regards latency (sub-figure (d)), in the case of A2C temporary deviations were noted that did not correspond to variations of the same duration in the HPA threshold. After careful evaluation, we concluded that they were due to the presence of some CPU cores in the server used, which were managed for energy saving (CPU efficient cores). This information is not available to the Kubernetes scheduler, so slight performance differences are observed when these cores are selected to instantiate new functions.
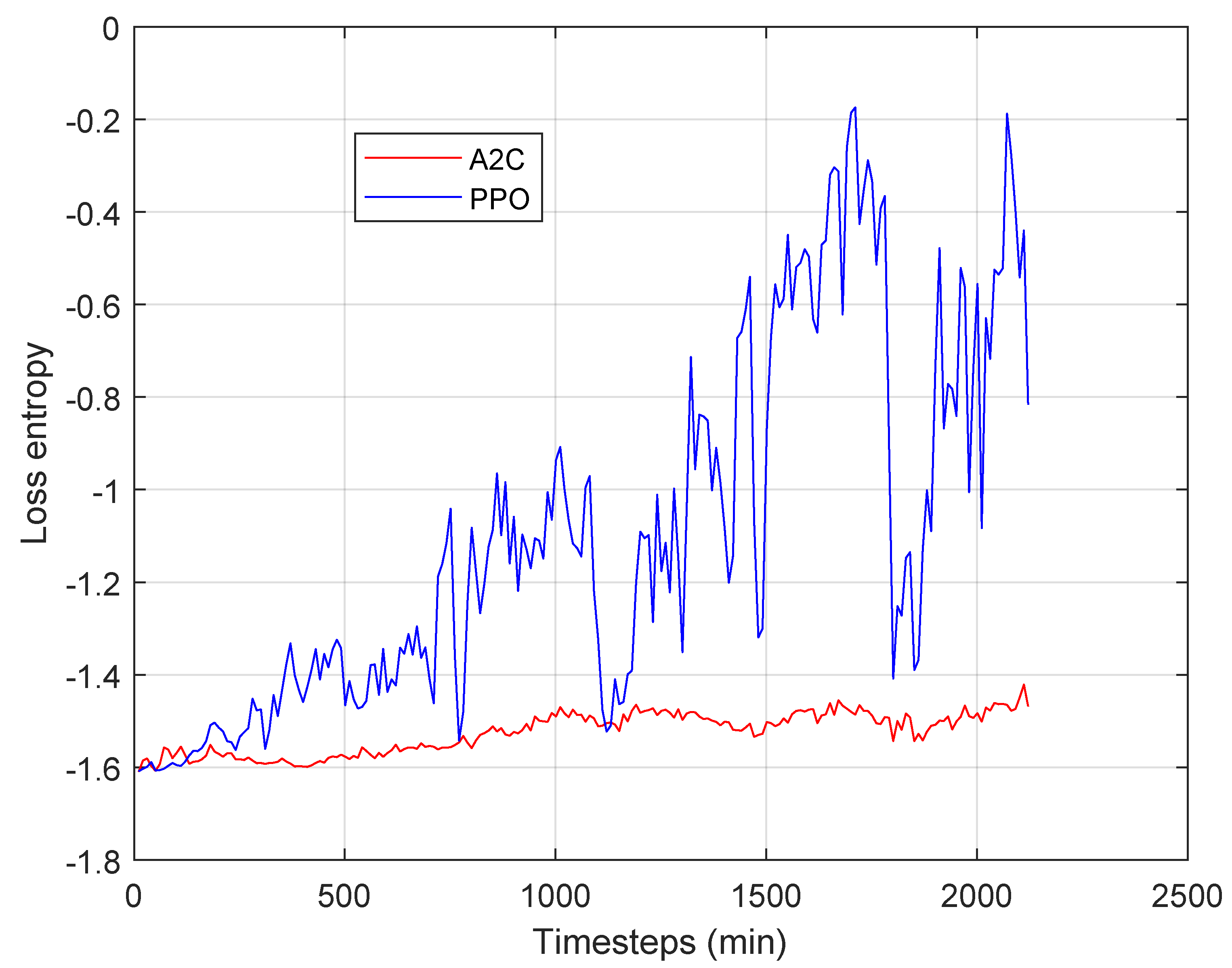
Observing the figure, however, it emerges that to fully converge both algorithms requires more than 200 steps. This is also evident in
Figure 5, which shows the entropy loss for both algorithms over time. It is clear that PPO showed lower losses and faster convergence values, although a significant number of steps to converge were required. We believe that this was due to the training time of the algorithms, which certainly took time, but also to the effects of the latencies of the processes identified in
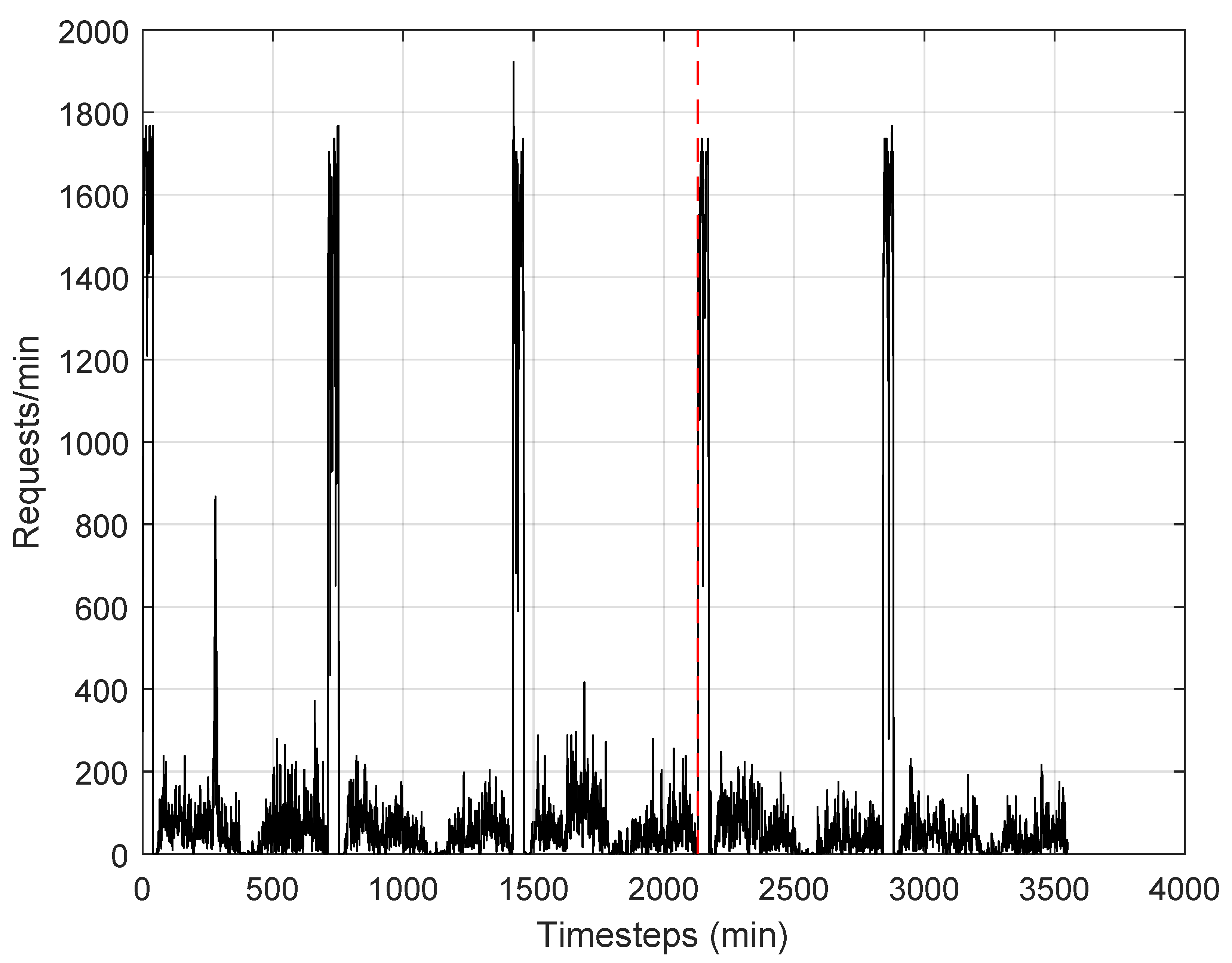
Section 4. This could affect performance when the temporal pattern of invocations is variable over time. For this reason, we used the measured pattern of one of the most challenging functions of the Azure database. The number of requests over time is shown in
Figure 6. It appears that the pattern of requests alternated intervals of low and high demand, even with abrupt variations. This trace has been divided into two intervals, highlighted by the vertical dotted red line in the figure. The first interval was used for training, the second for testing.
For this analysis, in addition to presenting the performance obtained from A2C and PPO, we also report that obtained by using a baseline system. This baseline consisted of the same cluster used for the experiments shown above, eliminating the reinforcing learning. The CPU occupancy threshold was set at 0.5 and was kept constant for the entire duration of the tests. The experimental results are summarized in
Figure 7 and
Figure 8. The former shows the boxplot of the service time during training and testing for the A2C and PPO algorithms and the test results for the baseline system. The horizontal dashed line indicates the considered latency threshold (SLA), equal to 500 ms. We can observe that, beyond some outliers, all the algorithms show substantial compliance with the SLA, with the baseline exhibiting the lowest latency values. However, we recall that the desired effect of introducing the reinforcement learning techniques was to increase resource utilization while respecting SLA values. Therefore, if it turns out that CPU utilization has increased, the values shown in
Figure 7 are absolutely satisfactory, as latency is well below the SLA limit. The CPU utilization is shown in
Figure 8. It can be seen that the best use was that relating to the PPO, slightly better than the A2C case, and appreciably better than the baseline. This means that it was able to keep service time under control, and, at the same time, to improve the utilization of computing resources, which is of paramount importance in an edge system.
Finally, we report the experimental loss rate of PPO, A2C, and the baseline system in
Table 3. In this case, we can observe a negligible difference between the PPO and the baseline system in terms of the best performance obtained.
In summary, it can be concluded that PPO is preferable to A2C. However, it also appears that the difference is rather modest. This is attributable to the convergence time of the algorithms, which can be slower than the variations in the frequency of function invocation. This phenomenon is well visible in
Figure 9, where we show the entropy loss over time measured when the system is fed with the Azure trace. It is evident that the entropy loss is sensitive to the oscillation in the input process due to the variability of the number of requests per minute. The results is that PPO is able to converge even in this experiment, characterized by high input variability, whereas A2C is much slower. Therefore, the algorithms operate predominantly in a transient stage, and they are affected by the control latency modeled in
Section 4. This is a stimulus for future research activities aimed at improving the dynamic features of algorithms.
For completeness,
Figure 10 shows the performance of the PPO algorithm, selected for its best performance, when the
limits parameter of the Kubernetes deployment associated with the function pods varied. This figure shows the average service time, the average HPA target threshold, the CPU utilization, and the request loss ratio when the limits parameter varied between 250 and 1000 millicores. This parameter is of paramount importance in computing clusters, since it determines the user perceived quality when the system is far from saturation. It is evident that best values are those characterized by highest CPU efficiency, thus 500 and 750 millicores as CPU limits applied to a single pod.
7. Conclusions
This paper addresses the issue of maximizing the efficiency of resource usage in edge computing systems. The application scenario considered was compatible with the IoT and the resource control action was based on the use of serverless technologies orchestrated using reinforcement learning techniques. The considered learning algorithms were DQN, A2C, and PPO. These algorithms were essentially selected as being representative of the different algorithmic approaches that have inspired the vast majority of research contributions, often difficult to compare because they are applied to systems with different features. These algorithms were employed to determine the CPU occupancy threshold value, which was used to trigger the horizontal autoscaling of the serverless functions that implemented the requested services.
The first contribution of the work consisted in identifying the intrinsic limitations of the system that compromised the effectiveness of the control action. These limits determined three types of errors, classified as latency error, estimation error, and generalization error.
The further analysis consisted of evaluating the convergence capacity of the algorithms, using a constant frequency of request arrivals. This allowed us to observe the problems of the instability of the DQN due to the absence of mechanisms to contain the variation in the updating of the algorithm parameters. Regarding A2C and PPO, even though a convergence was achieved, it appeared to be rather slow, due to the intrinsic limitations mentioned above. PPO appeared to be preferable, with a limited but appreciable difference compared to A2C.
Finally, the impact of this slowness was analyzed by considering a challenging case, which consisted in loading the system with one of the most demanding arrival patterns among those measured in a real serverless system. The result of the analysis was twofold: PPO continued to be preferable to A2C and outperformed a baseline system that made use of autoscaling mechanisms within the default parameters of the technology used.
In summary, the findings suggest that the reinforcement learning approach is promising, but that there is considerable room for further research. The next steps will be aimed at addressing the limitations that have emerged. The problem is quite challenging because from the first statistical analysis on the arrival patterns of the serverless functions it appears that they lack the statistic autocorrelation properties to be exploited through inference. A possible approach to improving performance consists of classifying the applications according to the number of functions implemented. From the trace dataset used, it appears that some applications continue to be monolithic, i.e., implemented with one or very few functions. Other applications are very well structured in different functions. Introducing this information into the state could hopefully bring benefits. Another possible research direction would be to resort to completely new approaches, starting from including graph neural networks in the loop or, more challengingly, leveraging the interplay with upper-layer protocols for taking advantage of context information and different types of functions, in particular I/O-bound functions.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}