1. Introduction
State space models represent an extremely well-established framework for the predictive modelling of time series, which has found countless applications in statistics, engineering, econometrics, neuroscience, and other fields [
1,
2,
3,
4,
5,
6]. If both the dynamical processes within the system to be studied and the observation process can be assumed to be linear, the optimal algorithm for recursively estimating the current state of the system is given by the widely used Kalman filter [
7]; for estimating past states, smoothing algorithms are available, many of which themselves are based on the results of Kalman filtering. A well-known example of a recursive smoothing algorithm is given by the Rauch–Tung–Striebel (RTS) smoother [
8].
There are numerous ways to derive the equations of the Kalman filter and the RTS smoother. This paper starts with an approach that was introduced by Duncan and Horn in 1972 [
9]. Their approach is based on expressing the problem of state estimation as a weighted least-squares problem. The first purpose of the present paper is to generalise the weighted least-squares approach to the case of correlations being present between the two noise terms arising in state space models, i.e., the dynamical noise term and the observation noise term; in the paper by Duncan and Horn, it was assumed that these noise terms are uncorrelated.
Duncan and Horn’s approach to state estimation corresponds with estimating the states for all time points simultaneously by inverting a single matrix, usually of large dimensions; Kalman filtering and RTS smoothing can be interpreted as a recursive approach to inverting this matrix. However, non-recursive approaches would also be possible, and some authors actually advocate for replacing Kalman filtering and RTS smoothing with other inversion algorithms. As an example, Chan and Jeliazkov [
10] are mentioned, who have “rediscovered” the weighted least-squares approach to state estimation, based on earlier work by Fahrmeir and Kaufmann [
11], apparently without noticing the much earlier paper by Duncan and Horn.
Aravkin [
12,
13] has reformulated and extended the original work of Duncan and Horn in various directions, but excluding the case of correlated noise terms. He approaches the aforementioned task of inverting a large matrix through a blockwise LDL decomposition of that matrix; Chan and Jeliazkov [
10], in contrast, employ Cholesky decomposition. Aravkin has shown that by applying a recursive inversion algorithm for one-block-banded matrices, originally formulated by Bell [
14], to the LDL decomposition, the Kalman filter (in its “information filter” variant) and the RTS smoother can be retrieved. The derivation of square-root information filters via the Duncan–Horn approach has been discussed by Paige and Saunders [
15] and by Hammarling [
16].
The second purpose of this paper is to discuss the fact that for the task of state estimation in the case of correlated noise terms, two different generalised Kalman filter algorithms exist that are not equivalent. Most available textbooks on state space modelling and Kalman filtering present either one or the other of these algorithms; Harvey [
2] is a rare example of an author presenting both algorithms. As also mentioned by Harvey, these two algorithms correspond to two slightly different forms of defining the underlying state space model. The difference between these two forms is given solely by the time index of the dynamical noise term, relative to the time index of the state vector; Harvey labels these two forms the “contemporaneous form” and the “future form” [
17]. While in control engineering, the “future form” is used almost exclusively, in statistics, the “contemporaneous form” is also frequently used due to its relationship with autoregressive moving-average (ARMA) modelling, which represents an important tool for time series analysis [
18].
While, as mentioned, generalisations of the Kalman filter for the case of correlated noise terms are available, generalisations of the RTS smoother for this case are rarely discussed in the literature. In the present paper, these generalisations will be derived using the weighted least-squares approach, both for contemporaneous-form and future-form state space models. It will also be pointed out that by switching between the contemporaneous form and future form, lag-zero cross-correlations between the two noise terms become lag-one cross-correlations, and vice versa; this will explain the fact that the corresponding generalised Kalman filter algorithms are not equivalent.
The next step will then be to define a further generalised state estimation problem that contains both lag-zero and lag-one cross-correlations; it will be demonstrated that for this case, through the weighted least-squares approach, no optimal recursive filtering and smoothing algorithms can be derived. Instead, an approximate recursive algorithm will be presented, which can be obtained by merging the available Kalman filter algorithms for contemporaneous-form and future-form state space models. Related work has been presented recently by Linares-Pérez and coauthors [
19], although these authors arrive at a different recursive algorithm.
In practical applications, it is often assumed that, from prior knowledge, it would be known that the noise terms were uncorrelated. In many cases, this assumption may actually be justified, while in other cases, it has to be regarded as an unwarranted constraint. Sometimes, the same source of randomness affects both the dynamical process itself and the observation process; as an example, Chui and Chen [
20] mention aircraft inertial navigation. There are also applications where the state space model is used mainly as a device for a quantitative description of the temporal correlation structure present in the original data and not as a model of an underlying physical reality, and, in such cases, it would be difficult to justify the constraint of uncorrelated noise terms. If it is decided to set the cross-correlation to zero, this should be the result of a corresponding model comparison step, i.e., by proving that a model with vanishing cross-correlation displays the best performance in modelling the data.
The structure of the present paper is as follows. In
Section 2, linear state space models are discussed. In
Section 3, Kalman filters are discussed for the case of correlated noise terms, including the corresponding information filters. In
Section 4, a recursive approach to solving a certain class of linear equations is reviewed; later, this approach is employed to solve the weighted least-squares problem.
Section 5 contains the main results of the paper, including the discussion and generalisation of the weighted least-squares approach to state estimation. In
Section 6, the case of both lag-zero and lag-one cross-correlations being present simultaneously is discussed. In
Section 7, an example of the application of the proposed algorithms to simulated data is presented, while in
Section 8 an example of their application to real-world data follows. The paper closes in
Section 9 with a final discussion and conclusions. The
Appendix A contains a somewhat lengthy derivation, which establishes the equivalence of the two equations arising in
Section 5.
2. State Space Models
Let
denote a given time series of data vectors, where the subscript
denotes a discrete time; let
n denote the dimensions of the data vectors. The given time series shall be modelled by a linear state space model given by a pair of equations, the first of which is known as the observation equation, given by
where
denotes a series of state vectors, with
m denoting the dimensions of the state vectors,
denotes an
-dimensional matrix, known as the observation matrix, and
denotes a series of noise vectors, known as observation noise, which are assumed to be drawn from a Gaussian distribution with a mean vector of zero and an
-dimensional covariance matrix,
. As the subscript
t indicates, the observation matrix and the covariance matrix of the observation noise may depend on time.
The second equation is known as the dynamical equation; it can be formulated in two different variants [
17], the first, known as the “contemporaneous form”, being given by
while the second variant, known as the “future form”, is given by
where
denotes an
-dimensional matrix, known as the state transition matrix, and
denotes a series of noise vectors, known as dynamical noise, which are assumed to be drawn from a Gaussian distribution with a mean vector of zero and an
-dimensional covariance matrix,
. As the subscript
t indicates, the state transition matrix and the covariance matrix of the dynamical noise may also depend on time. In the future-form dynamical equation, Equation (
3), many authors choose to write the time dependence of the state transition matrix as
instead of
, but this is merely a matter of definition.
The two noise terms,
and
, may be correlated, i.e., the expectation of the product,
, may not vanish, such that an
-dimensional cross-covariance matrix needs to be defined by
where the symbol
denotes the expectation (over time
); this cross-covariance matrix may also depend on time. Then, the covariance matrix of the stacked vector of both noise terms is given by
For later use, this cross-covariance matrix will now be inverted. First, new symbols for the inverses of the covariance matrices
and
are introduced:
Note that
and
represent information matrices. The desired inverse matrix is formulated as
where
3. Kalman Filter Algorithms for the Case of Correlated Noise Terms
The task of state estimation consists of estimating the series of state vectors,
,
, for given data,
, and given model parameter matrices,
,
,
,
, and
; an estimate of the initial state should also be available, e.g., at time
, denoted as
. The classical solution to this task is given by a twofold recursive algorithm consisting of a forward pass through the data by the Kalman filter, followed by a backward pass by a smoother, such as the Rauch–Tung–Striebel (RTS) smoother [
3,
21]. The estimates are given by a sequence of mean vectors and covariance matrices, corresponding to multivariate Gaussian distributions.
The Kalman filter consists of a recursion in the forward direction through time. At each time point, first the predicted states, , and the corresponding covariance matrices, , are computed. Then, second, the filtered states, , and the corresponding covariance matrices, , are computed. The notation is defined as an “estimate of based on the information available at time ”.
Instead of formulating the recursion for the states
and
and the corresponding covariance matrices,
and
, it may also be formulated for the information states,
and
, and the corresponding information matrices,
and
, leading to information filters. Again, new symbols shall be introduced:
Depending on whether covariance matrices or information matrices are employed, there are covariance Kalman filters or information Kalman filters (the latter usually simply called information filters).
3.1. Contemporaneous Form and Future Form
In Equations (
2) and (
3), the “contemporaneous form” and the “future form” of the dynamical equation of a state space model are defined. The names of these forms refer to the question of whether the state vector,
, on the left-hand side of the dynamical equation is contemporaneous to the dynamical noise term,
, on the right-hand side or whether it has advanced by one time step into the future relative to that noise term; this terminology was introduced by Harvey [
17].
The fact that two variants for the dynamical equation can be formulated is a consequence of using discrete-time dynamics; in continuous-time dynamics, there would be no such distinction. The relative choice of the time indices of these two terms may seem like an insignificant technical detail, and in many situations, this is indeed the case. If the two noise terms, and , are uncorrelated, exactly the same Kalman filter algorithm is valid for both the contemporaneous form and the future form.
However, if the two noise terms are correlated, this no longer holds true. In this case, two different Kalman filter algorithms exist that are not equivalent; these two algorithms will be reviewed below in
Section 3.2 and
Section 3.3. Most papers and textbooks present only one of the two possible algorithms without discussing the issue further; the only exception known to this author is the textbook by Harvey [
2].
3.2. Contemporaneous-Form Kalman Filter
Derivations of this version of the Kalman filter can be found in the textbook by Jazwinski [
1], based on orthogonal projection, or the textbook by Brown and Hwang [
22], based on a least-mean-squares approach; the algorithm is also given by several other authors, such as Harvey [
2], Gibbs [
23], and Grewal and Andrews [
21]. Its equations are given as follows:
Compared to the standard Kalman filter with uncorrelated noise terms, only the expressions for the innovation covariance, Equation (14), and for the optimal Kalman gain, Equation (15), contain additional terms. It should be emphasised that for the computation of the innovation likelihood, Equation (14) is not to be used for the innovation covariance; rather, the standard expression, , has to be used.
Also the contemporaneous form information filter is needed:
where
denotes the
-dimensional unity matrix, and the quantities denoted by the symbols
,
, and
have been introduced in order to simplify the equations.
The information filter algorithm in Equations (
18)–(24) can be condensed into two equations (plus the two equations defining
and
), directly describing the update of the filtered information state estimate and its information matrix:
3.3. Future-Form Kalman Filter
This version of the Kalman filter is given in numerous textbooks, such as those by Anderson and Moore [
24], Kailath et al. [
3], Chui and Chen [
20], and Gómez [
25]. It can be derived by decorrelating the noise terms, such that, formally, the standard Kalman filter for uncorrelated noise terms can be applied. Its equations are given as follows:
In this filter,
, as defined by Equation (
27), represents a
modified state transition matrix, and
, as defined by Equation (28), represents a
modified dynamical noise covariance matrix. Note that
where
is defined in Equation (
8). As a further modification to the standard Kalman filter for uncorrelated noise terms, a new term,
, arises in the equation for the predicted state estimate, Equation (29); however, since this term is precisely known, it does not cause any further changes to the standard Kalman filter. As another subtle difference, in the case of the future-form Kalman filter, in Equation (30), the time index of the modified dynamical noise covariance matrix has to be chosen as
in contrast to Equation (13).
Also, the future-form information filter is needed:
where the quantity denoted by the symbol
has been introduced in order to simplify the equations.
Again, the information filter algorithm in Equations (
36)–(40) can be condensed into two equations:
It has to be emphasised that the filter algorithm in Equations (
12)–(17) is not equivalent to the filter algorithm in Equations (
27)–(34), and this applies likewise to the information filter algorithms. This is obvious from a direct comparison of the equations and can readily be confirmed by numerical examples.
4. Recursive Solution of a Linear Equation with a Symmetric One-Block-Banded Matrix
Before embarking on the actual discussion of the weighted least-squares approach to state estimation, an algorithm for the recursive solution of a linear equation needs to be briefly reviewed. Let the linear equation be given by
where the square matrix,
, has a particular structure, known as symmetric one-block-banded matrix structure. This structure is given by
where
,
, denotes a set of invertible symmetric positive definite
-dimensional square matrices, and
,
, denotes another set of
-dimensional square matrices. For the vectors
and
, a similar partitioning as for
shall be defined:
where the dimensions of the subvectors
and
,
, shall be
m.
The solution to Equation (
43) can be based on the blockwise LDL decomposition of
according to
where
and
Then, in the first step, the equation
is recursively solved for
, which is defined by
while in the second step, Equation (
49) is recursively solved for
. The corresponding recursions were given by Bell [
14], as follows:
It is not hard to see that the “forward” recursion leads to a Kalman filter, while the “backward” recursion leads to a smoother.
In addition to the equations given by Bell, another equation needs to be added to the “backward” recursion. For this purpose, the task of computing the inverse of the matrix explicitly is studied, which can be carried out by inverting the matrices and separately.
has a block-diagonal structure, with blocks , where the index t refers to blocks. Its inverse also has a block-diagonal structure, with blocks .
has a block-bidiagonal structure, with blocks
and
. Its inverse has a lower block-triangular structure, with blocks
where the indices
s and
t refer to blocks.
Then, if the product
is formed, it is found that the blocks on the diagonal of
can be computed by a “backward” recursion over
t from
to
, according to
The idea of inverting the matrix
via blockwise LDL decomposition, in the context of state estimation, has also been proposed by Fahrmeir and Kaufmann [
11], while Chan and Jeliazkov [
10] prefer to employ Cholesky decomposition for this purpose.
5. Weighted Least-Squares Approach to State Estimation
Various authors have noticed that the state estimation problem can be cast as a regression problem; a good review of the earlier literature has been provided by Solo [
26]. A particularly influential paper was published in 1972 by Duncan and Horn [
9], who showed that the linear state estimation problem can be solved by weighted least squares. Later, the same approach was “rediscovered” by Chan and Jeliazkov [
10]; see also the related work by Fahrmeir and Kaufmann [
11]. The derivation given in the paper by Duncan and Horn will now briefly be reproduced, but it will be generalised for the case
.
5.1. Contemporaneous Form
First, the contemporaneous form of the state space model is considered, which is also the form employed by Duncan and Horn. The starting point is given by writing down the equations of the state space model, Equations (
1) and (
2), for all time points,
:
Note that in the first of these equations, the term
can be interpreted as the prediction of the state at time
, denoted as
. Then, the set of Equation (58) may be rearranged as
By defining
and
the set of Equation (59) can be rewritten as
The vector
contains the known data, including the prediction of the state at
. The vector
contains the unknown noise terms, for which the covariance matrix is given by
The inverse of
is given by
where the matrices
,
, and
have been defined in Equations (
8)–(10).
Equations (60)–(63) represent a weighted least-squares problem to be solved for
, i.e., the sequence of the states. The solution,
, to this problem has to fulfil the equation
If the matrix product
has full rank, the estimated solution is given by
The covariance matrix of the estimated solution
is given by
By comparing with Equation (
43), the following correspondences can be found:
By evaluating the matrix product
, using Equation (
7), it can easily be confirmed that a symmetric one-block-banded matrix is produced, with a shape given by Equation (
44) and blocks given by
such that the algorithm in Equations (50)–(55) can be applied to solve Equation (65).
The vector
, corresponding to the “given-data” vector,
, in Equation (
43), consists of stacked
m-dimensional subvectors, given by
By inserting Equations (68) and (69) into Equation (52), it follows, for
, that
By inserting Equations (69) and (70) into Equation (53), it follows, for
, that
By inserting Equation (69) into Equations (55) and (57), it follows, for
, that
Equations (71) and (72) represent an algorithm for forward recursive filtering, in the case of contemporaneous-form models, to be applied for ; the modifications for the limit cases and follow accordingly from Equations (50), (51), (69), and (70).
Equations (73) and (74) represent an algorithm for backward recursive smoothing, in the case of contemporaneous-form models, to be applied for ; the modifications for the limit case follow accordingly from Equations (54) and (56), using , as provided by the forward filter. Note that replacing in Equation (57) with is justified due to Equation (67).
5.2. Future Form
Now, it shall be assumed that the state space model is formulated in the future form; see Equations (
1) and (
3). The corresponding temporal shift in the dynamical noise term, as compared to the state space model in the contemporaneous form, has the effect that, within the matrix
, the cross-covariance matrix
moves to different block positions:
The inverse of
is given by
Also, in this case, the matrix product
yields a one-block-banded matrix, according to Equation (
44), with blocks given by
The vector
consists of stacked
m-dimensional subvectors, given by
By inserting Equations (77) and (78) into Equation (52), it follows, for
, that
By inserting Equations (78) and (79) into Equation (53), it follows, for
, that
By inserting Equation (78) into Equations (55) and (57), it follows, for
, that
Equations (80) and (81) represent an algorithm for forward recursive filtering, in the case of future-form models, to be applied for ; the modifications for the limit cases and follow accordingly from Equations (50), (51), (77), and (79).
Equations (82) and (83) represent an algorithm for backward recursive smoothing, in the case of future-form models, to be applied for ; the modifications for the limit case follow accordingly from Equations (54) and (56), using , as provided by the forward filter.
5.3. Interpretation of the Filters and Smoothers
The next required task is interpreting the filters and smoothers that were derived in the previous section. By construction, the output of the backward smoothing recursions, simply denoted by in Equations (73) and (82), represents the smoothed state estimates, , and from Equation (67), it is also clear that the recursion of Equations (74) and (83) describes the covariance matrix of the smoothed state estimates. However, the meaning of the intermediate quantities and , to be computed by Equations (71), (72), (80), and (81), is not immediately obvious. In the case of non-correlated noise terms, would directly correspond to the filtered information state, , but in the general case, this is no longer true.
The condition for interpreting the quantities
and
is that the known information filters, as reviewed above in
Section 3, be reproduced. This condition leads to the following interpretations: for the contemporaneous form,
and for the future form,
Equation (84) has already been given by Fahrmeir and Kaufmann [
11], although only for the non-correlated case,
.
Then, in the case of the contemporaneous form, the information filter becomes, for
,
and the smoother becomes, for
,
In the case of future form, the information filter becomes, for
,
and the smoother becomes, for
,
The modifications for the limit case follow accordingly from Equations (50), (51), (77), and (79); the case requires no modifications to the forward filter pass.
It therefore follows that the contemporaneous-form filter in Equations (88) and (89) is equivalent to the filter in Equations (
25) and (26) and that the future-form filter in Equations (92) and (93) is equivalent to the filter in Equations (
41) and (42), although these equivalences are far from obvious; however, they can be verified either through their application to numerical examples, or—preferably—by explicit algebraic manipulation. As an example of the latter approach, it is shown in the
Appendix A how Equation (88) can be transformed into Equation (
25). The transformation for the corresponding expressions for the covariance matrix
could probably be performed in a similar way; the same remark also applies to the expressions for the conditional mean vector and covariance matrix of the future-form filter.
Finally, both the contemporaneous-form smoother algorithm in Equations (90) and (91) and the future-form smoother algorithm in Equations (94) and (95) represent generalisations of the standard RTS smoother algorithm.
5.4. The Origin of the Non-Equivalence of the two Kalman Filters
In
Section 3, the covariance Kalman and information filter algorithms were reviewed for the case of correlated noise terms, both for the contemporaneous-form and future-form state space models, and it was stated that they are not equivalent. The reason for this lack of equivalence is not hard to find: depending on whether the contemporaneous form or future form is used, the statement that the cross-correlation matrix,
, does not vanish has different meaning. If in the contemporaneous form,
is defined by
then in future form, it would have to be defined by
and this is precisely the definition for
chosen by Brown and Hwang [
22] since these authors use the future form but at the same time present the algorithm in Equations (
12)–(17), which in the present paper, is listed as a contemporaneous-form algorithm.
Then, it becomes obvious that actually two cross-correlation matrices should be defined, one for lag-zero (instantaneous) correlation and one for lag-one correlation:
Swapping the two noise terms in the definition of
would give
However, in the definition of
, the two noise terms may not be swapped since
From the viewpoint of the contemporaneous form, the Kalman filter in Equations (
12)–(17) is valid for the case
(with
to be replaced by
), while the Kalman filter in Equations (
27)–(34) is valid for the case
(with
to be replaced by
). Naturally, both filters are valid for the case
6. Merging the Contemporaneous Form and Future Form
In the discussion of the previous section, one case has not yet been addressed:
Is there a Kalman filter for this case?
In order to investigate this case, the covariance matrices in Equations (63) and (75) have to be merged as follows:
This covariance matrix is no longer block-diagonal, and as a consequence, the matrix
is not a one-block-banded matrix; rather, it will generically be a full matrix, such that its inverse will also be a full matrix. Consequently, no recursive algorithm for optimally solving this state estimation problem can be derived through the approach presented above in
Section 5.1 and
Section 5.2.
However, recursive algorithms for
non-optimally solving this problem may exist. As an example, the Kalman filter algorithms in Equations (
12)–(17) and Equations (
27)–(34) are considered again. Since the generalisations with respect to the standard Kalman filter without correlated noise terms occur in different equations, these algorithms may, in a purely heuristical way, be merged as follows:
It is less obvious how the smoother algorithms for the contemporaneous form and for the future form may be merged, and in this paper, this problem will not be considered further.
Here, it should be mentioned that recently Linares-Pérez and coauthors [
19] also presented a generalised recursive filter algorithm for state estimation, which contains the Kalman filters in Equations (
12)–(17) and Equations (
27)–(34) as special cases. However, for the case
, their recursive filter differs from the generalised Kalman filter in Equations (97)–(104). The exact relationship between the two filter algorithms still needs to be investigated.
7. Application Example: Simulated Data
Now, an example for the application of the generalised Kalman filter in Equations (97)–(104) to simulated data will be presented. The state and data dimensions are chosen as
, and the model parameters are chosen as
i.e., the parameters do not depend on time. From a state space model employing these parameters, 1000 simulated time series are created, each of length
points, using different sets of dynamical and observation noise values. The noise values are created such that they approximately fulfil the following constraints:
using the chosen values for
q,
r,
, and
, as given above.
Since this is a simulation, the true states are known. Then, the same state space model that was used to create the simulated time series is used to estimate the states, either using the weighted least-squares approach, i.e., solving Equation (65) non-recursively, or the generalised Kalman filter algorithm in Equations (97)–(104). While the former algorithm provides smoothed state estimates, the latter provides filtered state estimates, but nevertheless, these two sets of estimates shall be compared.
In the particular setting of this simulation, state estimation is equivalent to noise reduction with respect to the observational noise term. Therefore, the performance of the two algorithms for state estimation may be compared by quantifying the achieved level of noise reduction; this is possible since the true states are known. The result is shown via histograms in
Figure 1. Note that a value of 0 dB on the horizontal axis corresponds to failure in noise reduction.
In the figure, it can be seen that for the 1000 time series created, both algorithms achieve values for noise reduction between 5 dB and 7 dB; if the distributions are fitted by Gaussians, for the weighted least-squares algorithm, a mean of 6.3234 and a standard deviation of 0.1624 are obtained, while for the generalised Kalman filter algorithm, a mean of 5.8242 and a standard deviation of 0.2079 are obtained. Thus, at least in this simulation example, the generalised Kalman filter achieves almost as good performance as the weighted least-squares algorithm, despite representing a non-optimal algorithm for state estimation.
8. Application Example: Real-World Data
Next, an example of the application of the generalised Kalman filter in Equations (97)–(104) to a real-world dataset is presented. A hydroacoustic recording is chosen that was obtained in the Baltic Sea by a floating hydrophone while a ship was passing at a distance of a few hundred metres. The original sampling rate was 20 kHz, but the data have been subsampled to 5 kHz. From a much longer time series, a short window of 0.4096 s in length is selected, corresponding to 2048 samples. The selected data are transformed into a mean of zero and a variance of one. Within the selected window, the underwater sound emission of the passing ship is dominated by a single line at a frequency of approx. 498.5 Hz. The aim of the analysis is to extract this line from background noise and other signal components.
The data dimension is
, while the state dimension is chosen as
. Since it is intended to model a single stochastic oscillation, the structure of the state space model is chosen such that it corresponds to an autoregressive moving-average (ARMA) model with model orders
and
:
From this model, the state transition matrix and the dynamical noise covariance matrix of the state space model, in
observer canonical form, are as follows:
In a pure ARMA model, the additional parameter should be zero; however, in order to avoid a singular covariance matrix, , it is necessary to allow this parameter to be non-zero; it is constrained to be positive.
All the model parameters are fitted to the selected data through numerical maximisation of the innovation likelihood. The innovation likelihood is computed with the generalised Kalman filter in Equations (97)–(104). The resulting estimates of the model parameters are
The estimates of
and
correspond to a frequency of 498.5751 Hz. Also, an estimate of the initial state,
, is obtained by maximising the innovation likelihood. It should be noted that these estimates of the model parameters may represent only a local maximum of the innovation likelihood.
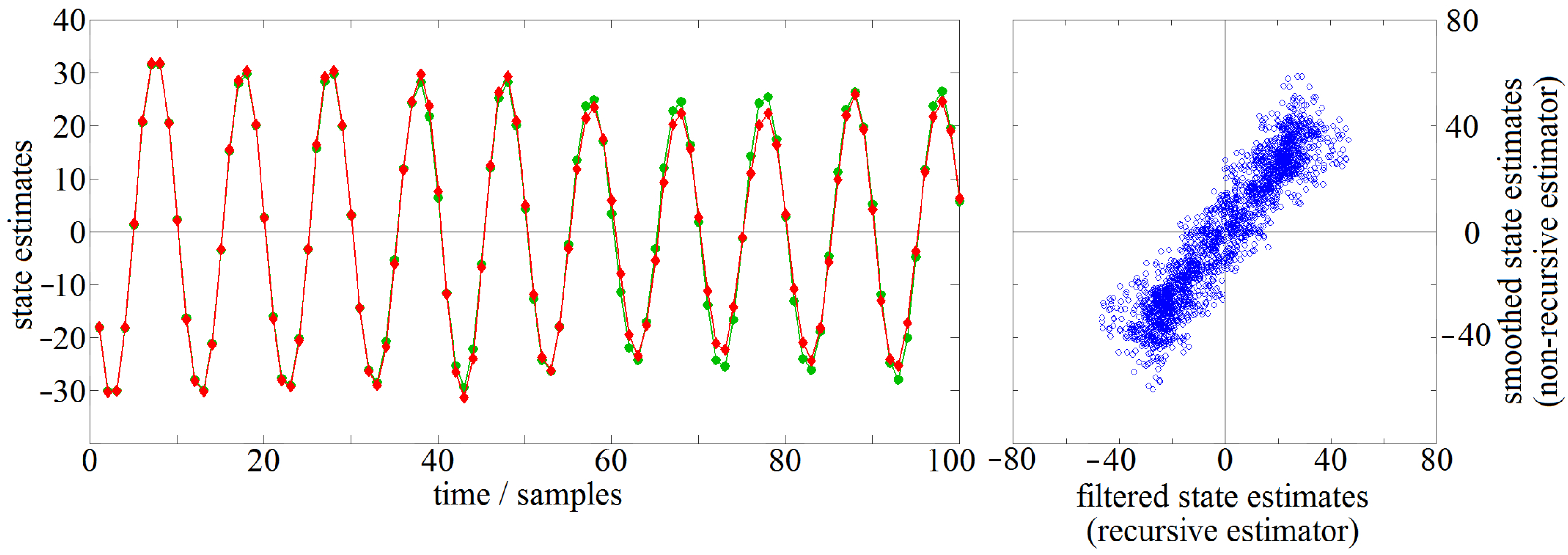
Then, the optimised state space model is employed to estimate the states that correspond to the selected data, using either the non-recursive weighted least-squares approach of solving Equation (65) directly or the generalised Kalman filter in Equations (97)–(104). While the first approach yields smoothed estimates, the latter yields filtered estimates. Both time series of state estimates are displayed in
Figure 2, either versus time or as a perpendicular scatter plot. At each time point, the state is a two-dimensional vector, but only the first component is displayed.
In the figure, it can be seen that both time series of state estimates are very similar. The smoothed state estimates obtained by the non-recursive approach (denoted by lines and symbols in red colour) represent the correct estimates by definition. Differences between the two time series of state estimates arise for two reasons: first, smoothed estimates will always differ somewhat from filtered estimates, and second, as has been shown above, the estimates obtained by the non-recursive approach represent only an non-optimal approximation of the correct estimates. The numerical results shown in the figure illustrate the good quality achieved by this approximation.
9. Discussion and Conclusions
This paper examines the problem of state estimation in linear state space models when non-zero cross-correlations exist between the dynamical noise and observation noise terms. Lag-zero and lag-one cross-correlations are distinguished, and it is highlighted that it depends on which form is chosen for the state space model (the contemporaneous form or the future form) whether a given cross-correlation matrix refers to lag-zero or lag-one cross-correlations. As previously noted by Harvey [
2], the existence of these two forms leads to two distinct, non-equivalent Kalman filtering algorithms for the case of correlated noise.
The main contributions of this paper are as follows: First, the weighted least-squares framework, as developed by Duncan and Horn [
9] for the problem of state estimation in linear state space models, has been generalised to the case of correlated noise terms, thereby obtaining Kalman filter and smoother algorithms, both for the contemporaneous form and the future form. While the resulting generalised Kalman filter algorithms coincide with already known information filter algorithms, the resulting generalised smoother algorithms may be of wider interest, as in the available literature, smoothing in the case of correlated noise terms is rarely discussed. In order to obtain a recursion for the covariance of the smoothed state estimates, the original recursive inversion algorithm by Bell was augmented by two additional expressions, given by Equations (56) and (57).
Second, it has been demonstrated that Bell’s recursive algorithm for inverting one-block-banded matrices via blockwise LDL decomposition, as reviewed in
Section 4, provides a general canonical structure for information filters and RTS smoothers. This structure differs considerably from the structure that is usually chosen; see, e.g., the difference between Equations (
25) and (26) and Equations (88) and (89). As shown in the
Appendix A, by suitable algebraic transformations Equation (88) can be transformed into Equation (
25), and without doubt, the same holds true for the other pairs of corresponding equations for filtered state estimates and their covariance matrices. Actually, in order to prove the equivalence of these pairs of equations, such explicit algebraic transformations are not necessary since the equivalence is already proven by the fact that each pair of equations has been derived from the same underlying state space model. Therefore there is no need to develop a formal proof. It is possible that the equivalence of Equation (26) and Equation (89) has already been established in the theory of Riccati equations, but the author has not verified this.
Third, a generalisation to the case where both lag-zero and lag-one cross-correlations are present simultaneously has been proposed, building upon the previously developed theory for lag-zero and lag-one cross-correlations of the noise terms in state space models. This generalisation offers the potential to merge the filter algorithms for the contemporaneous form and the future form. Strictly speaking, as it has been shown by using the weighted least-squares approach, in this case, no recursive algorithm for optimally solving the corresponding state estimation problem can be derived. Nevertheless, an optimal solution to the state estimation problem can still be obtained through the non-recursive approach of directly solving the weighted least-squares problem. This approach is applicable to any lagged cross-correlation structure for the noise terms that might be chosen. It is important to note, however, that the computational cost of this non-recursive algorithm, in terms of time and memory, scales significantly with the length of the time series being modelled.
For this reason, an approximative recursive algorithm has been proposed that was obtained by merging the recursive Kalman filter algorithms for the contemporaneous-form and future-form state space models; no smoother backward pass was included in this algorithm. The resulting generalised Kalman filter algorithm was obtained using a purely heuristical approach. Nevertheless, it has been demonstrated that, both in a simulation study and in an example of the analysis of real-world data, this approximative recursive algorithm performs almost as well as the optimal non-recursive algorithm.
A further potential benefit of formulating state estimation problems as weighted least-squares problems is given by the possibility of imposing constraints and applying regularisation. If one is willing to perform state estimation using non-recursive algorithms, as suggested by Chan and Jeliazkov [
10], the considerable repertoire of methods and experience that have been accumulated in the least-squares field can be utilised.
Future research directions in this field include the design of approximate recursive smoothers for the case of both lag-zero and lag-one cross-correlations being present simultaneously. Additionally, the development of square-root variants of the information filter and RTS smoother algorithms presented in this paper could be explored. Preliminary experience with modelling real-world data sets using state space models with correlated noise terms indicates that the covariance matrix of the filtered state estimate, given by Equation (104), exhibits a propensity to lose the property of positive definiteness, potentially hindering parameter estimation via maximum likelihood methods; this is a well-known potential effect of forming differences in matrices [
3]. The same problem may arise with the definition of the modified dynamical noise covariance matrix for the future-form Kalman filter; see Equation (28). Square-root filtering algorithms would provide a convenient solution to these kinds of numerical problems.



{kind=link}
{kind=link}