
A Piecewise Linear Regression Model Ensemble for Large-Scale Curve Fitting

Abstract
1. Introduction
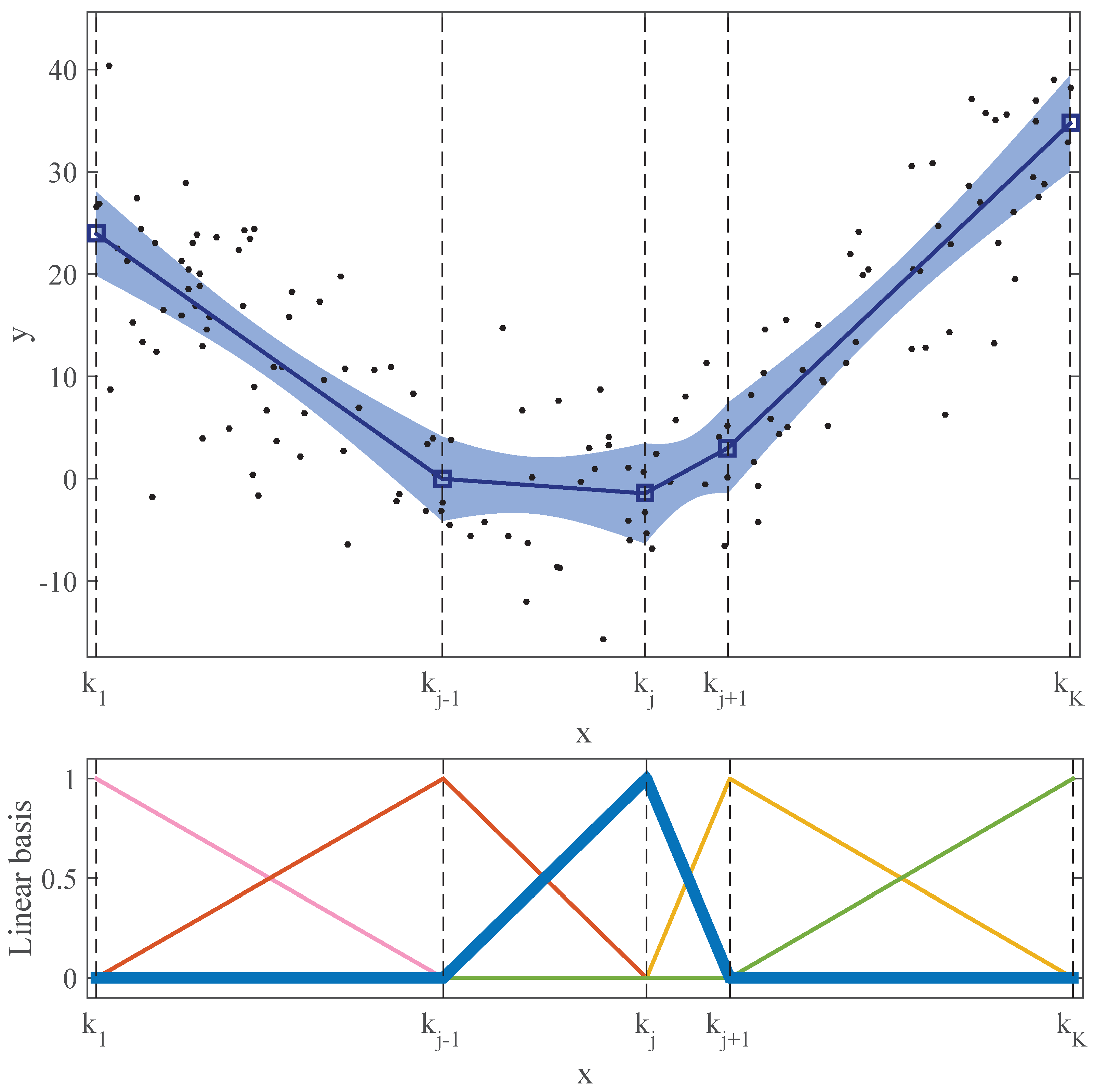
2. Continuous Piecewise Linear Regression
Model Definition
3. Parameter Estimation from Small Datasets
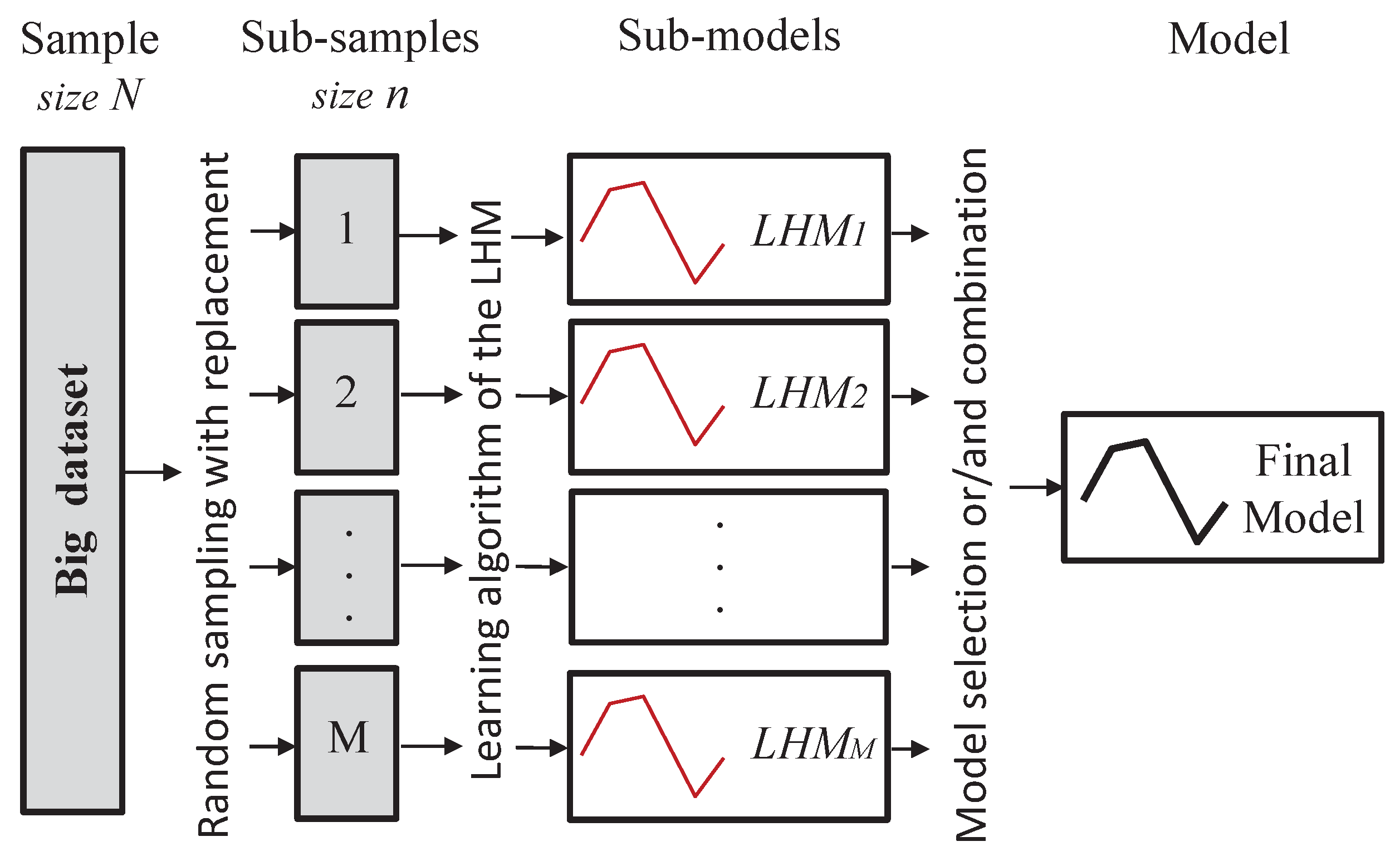
4. Parameter Estimation from Large-Scale Datasets
5. Proposed Methods
5.1. Model Selection (MS)
5.2. Model Combination (MC)
5.2.1. Output Averaging (MC1)
5.2.2. Model Averaging with Complexity Reduction and Refitting (MC2)
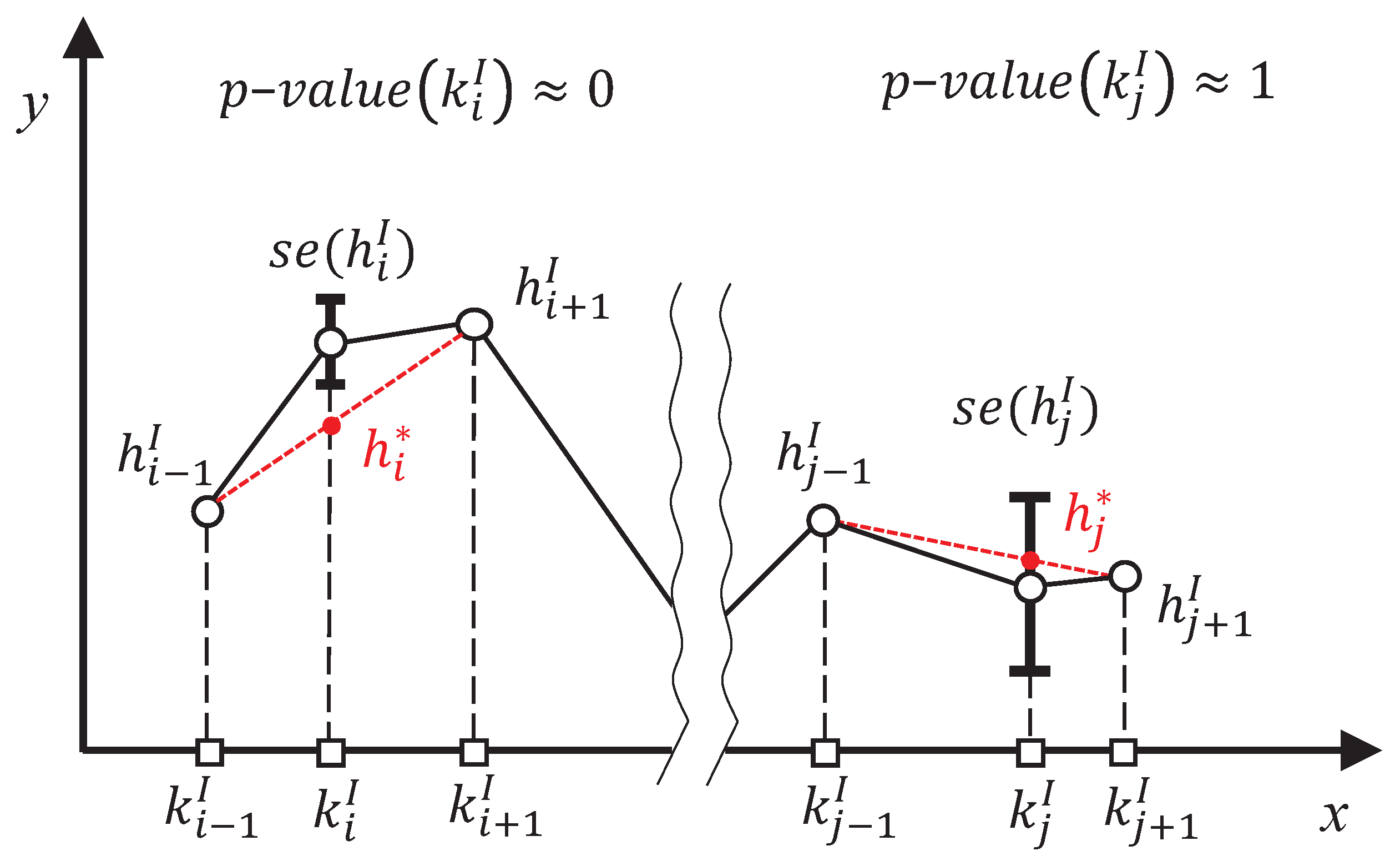
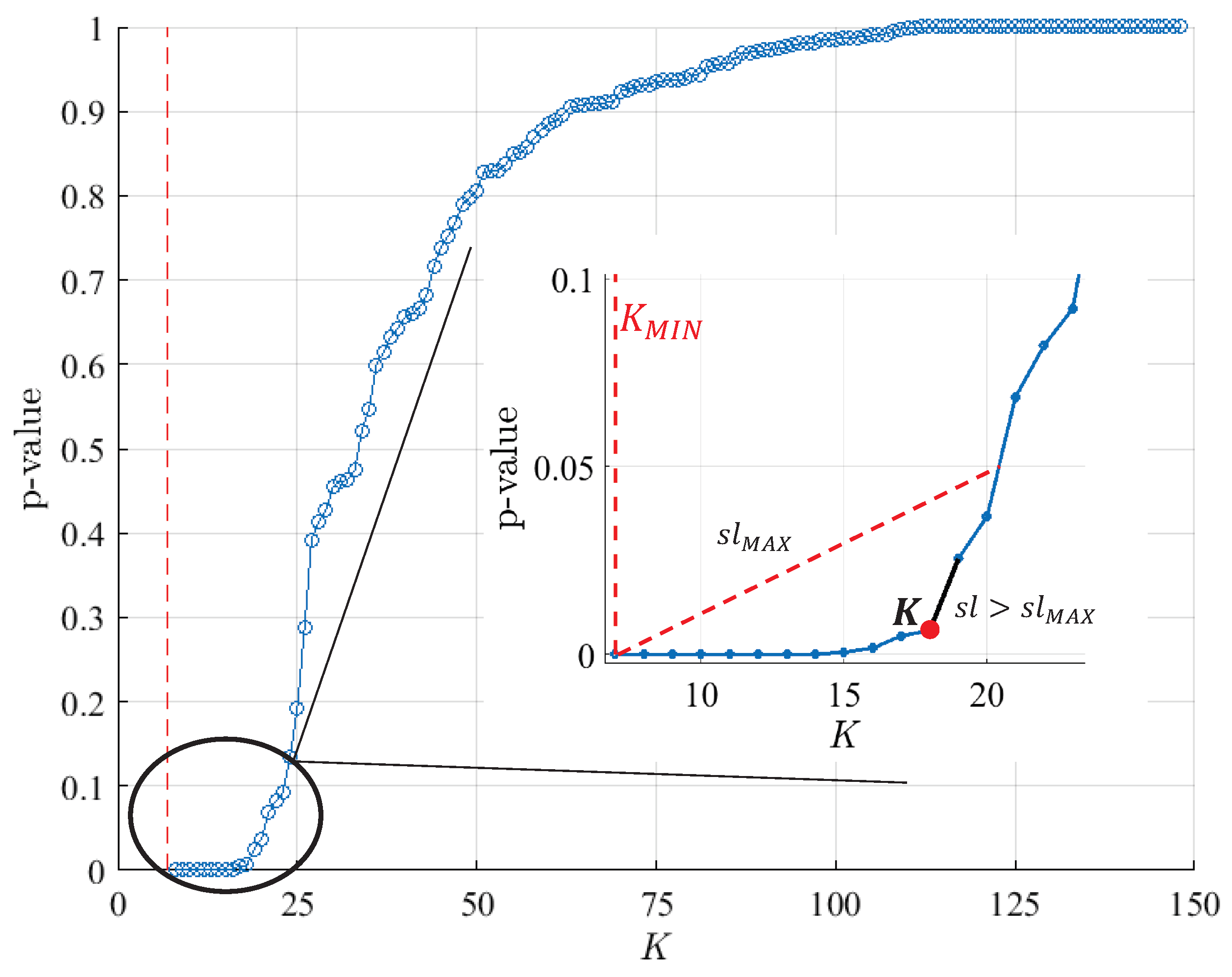
| Algorithm 1 Pruning algorithm of MC2. |
PART I: Generate the pruning sequence (a) initialisation , , for down to do (b) calculate the p-value of each knot for to do ▹ for all the internal knots with end for (c) prune the knot with the highest p-value , where (d) save the p-value of the pruned knot () and , (e) calculate the slope of the p-value curve in m end for PART II: Select the final PM and K (a) calculate the maximum slope that is allowed (b) find the elbow of the p-value curve (c) select the final K and |
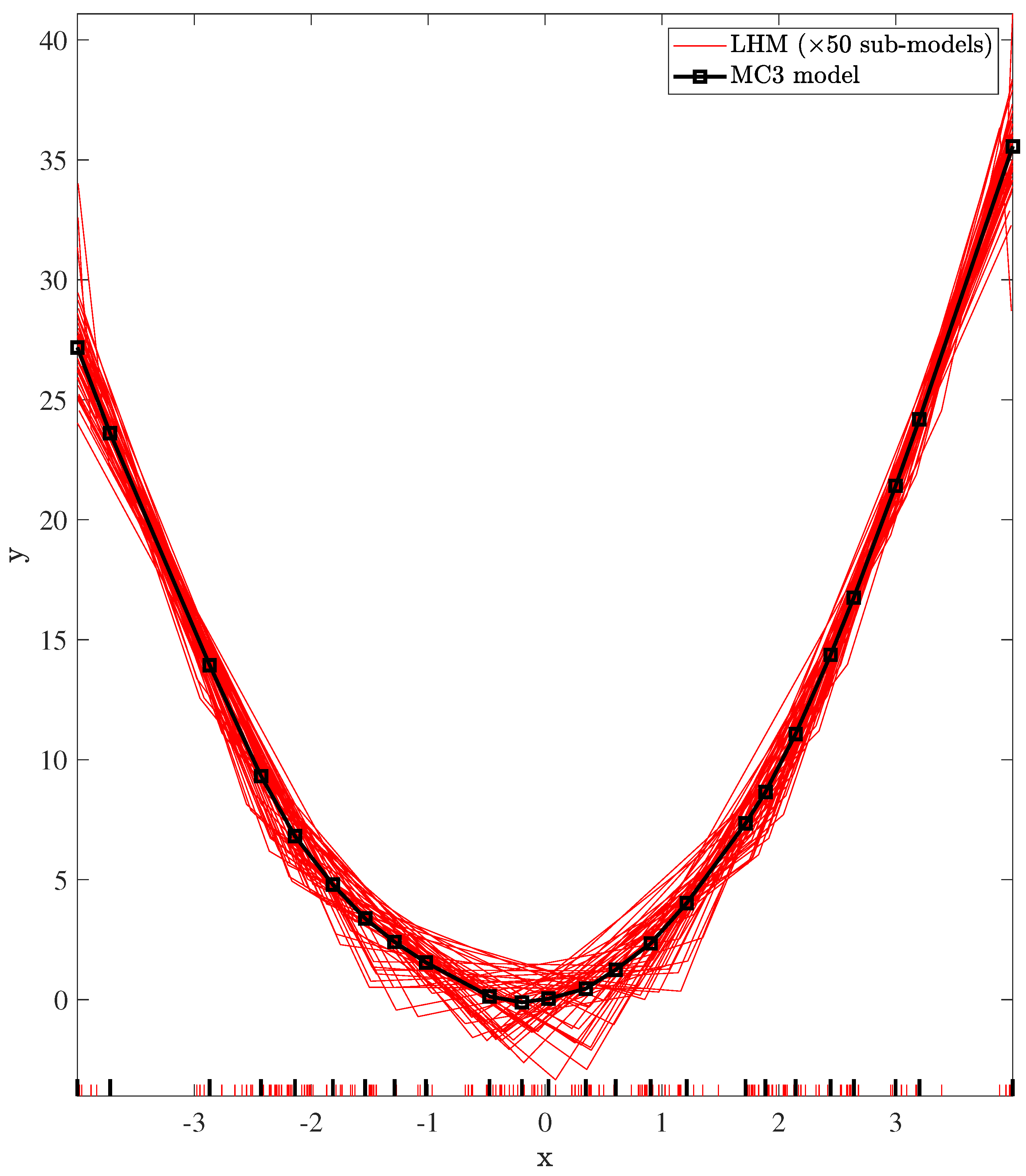
5.2.3. Applying the Learning Algorithm of the LHM to the Set of Sub-Models (MC3)
5.3. Improving MC by Means of OLS
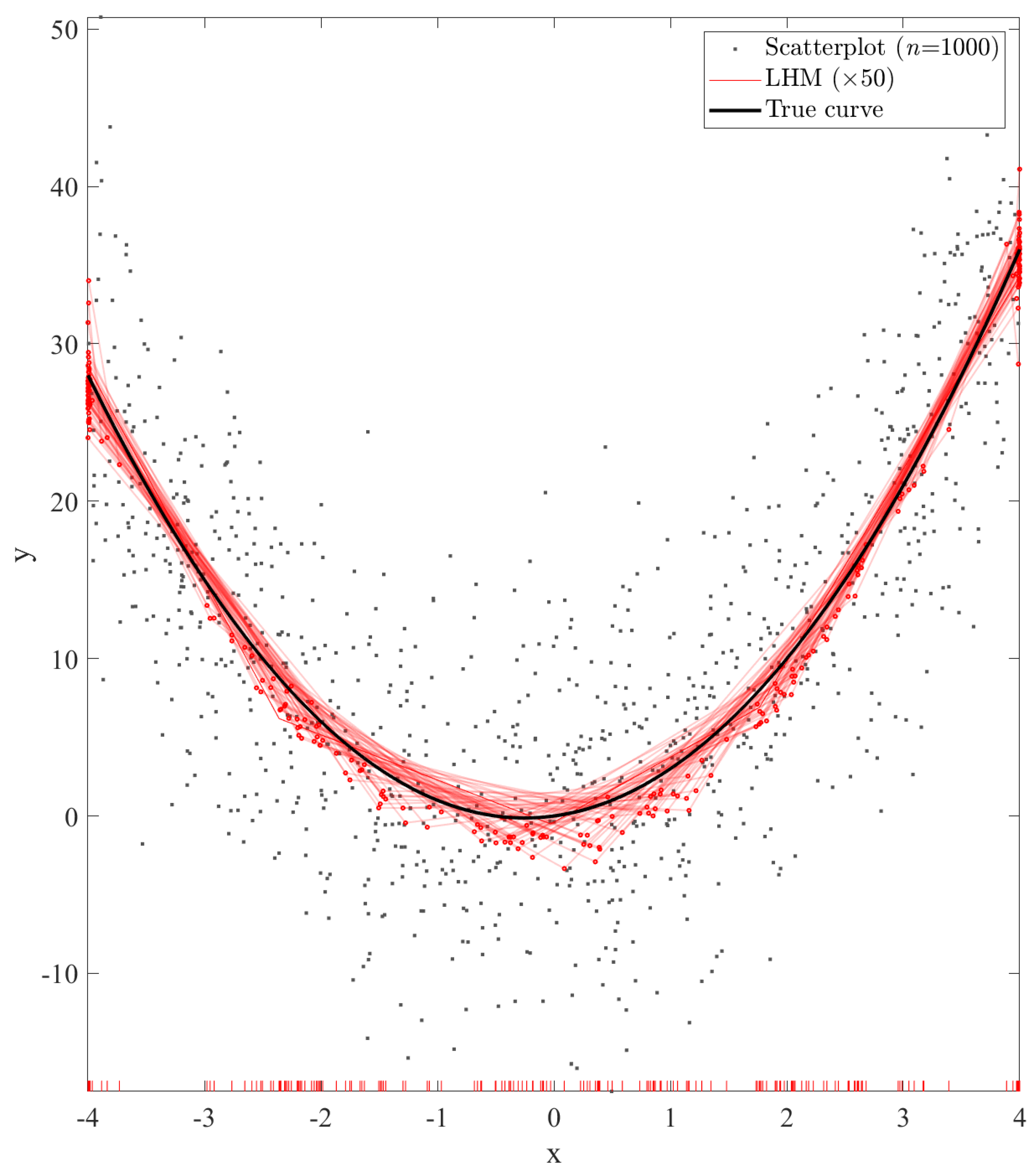
6. Empirical Results
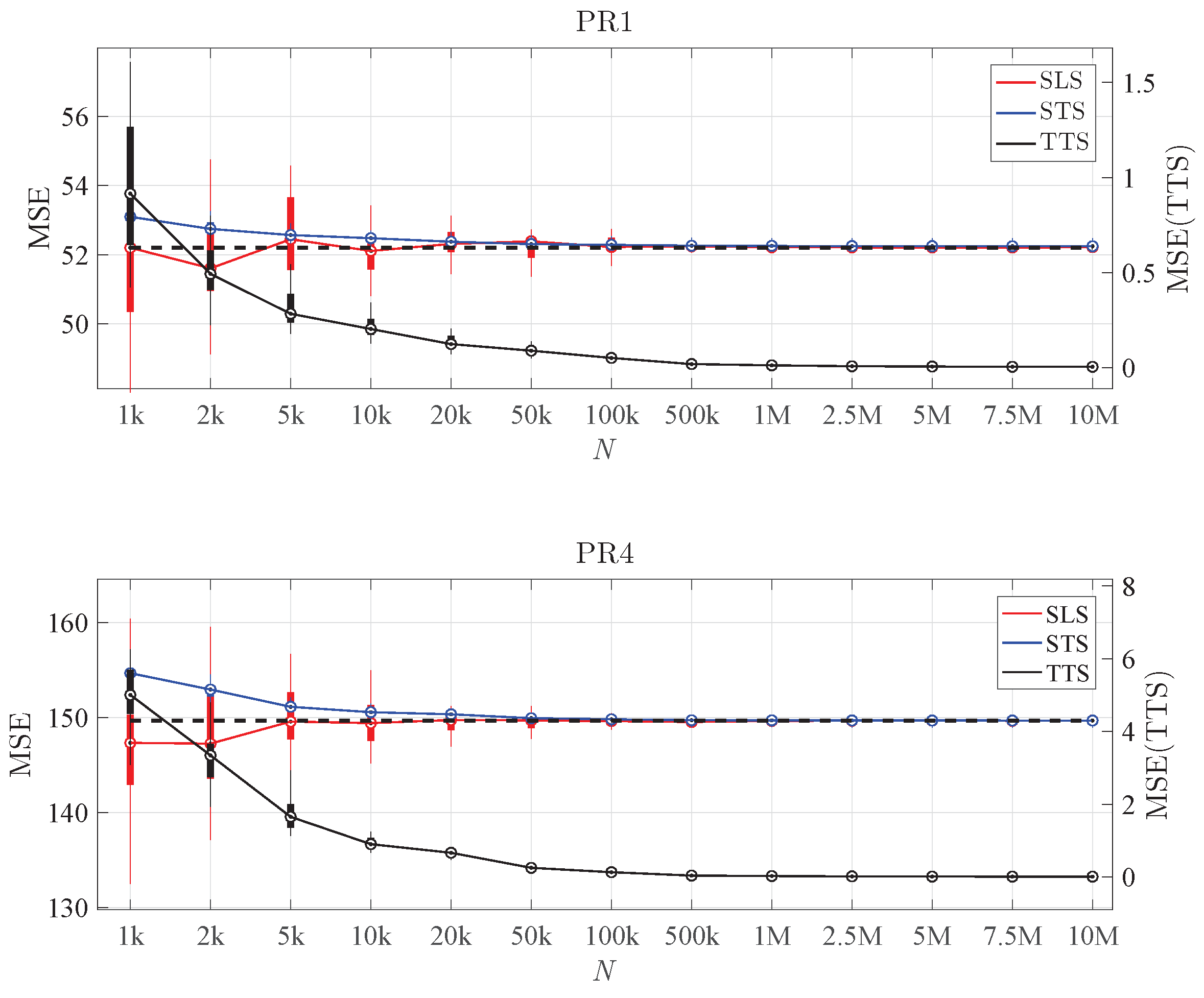
6.1. Performance of the Reference Algorithm
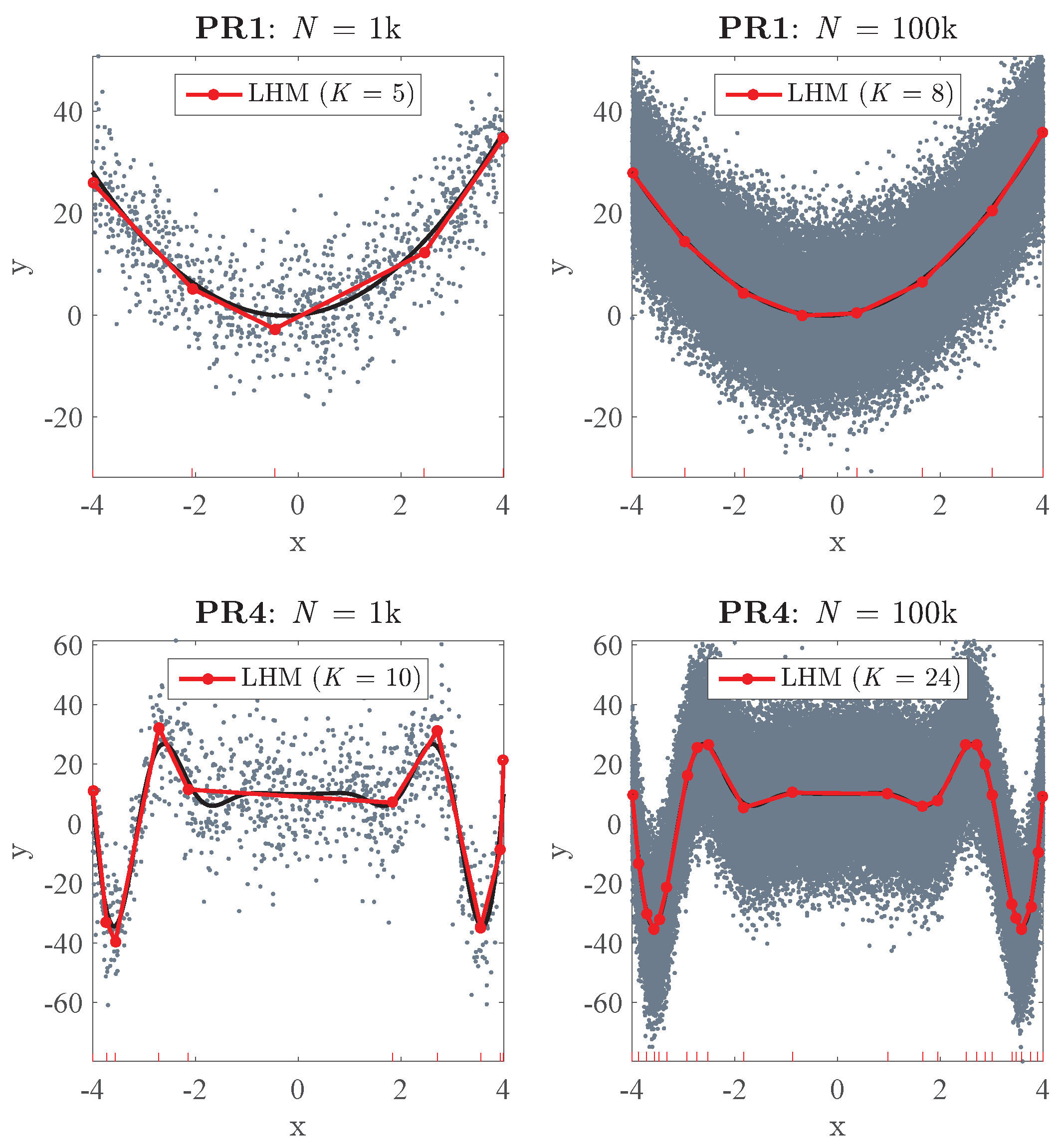
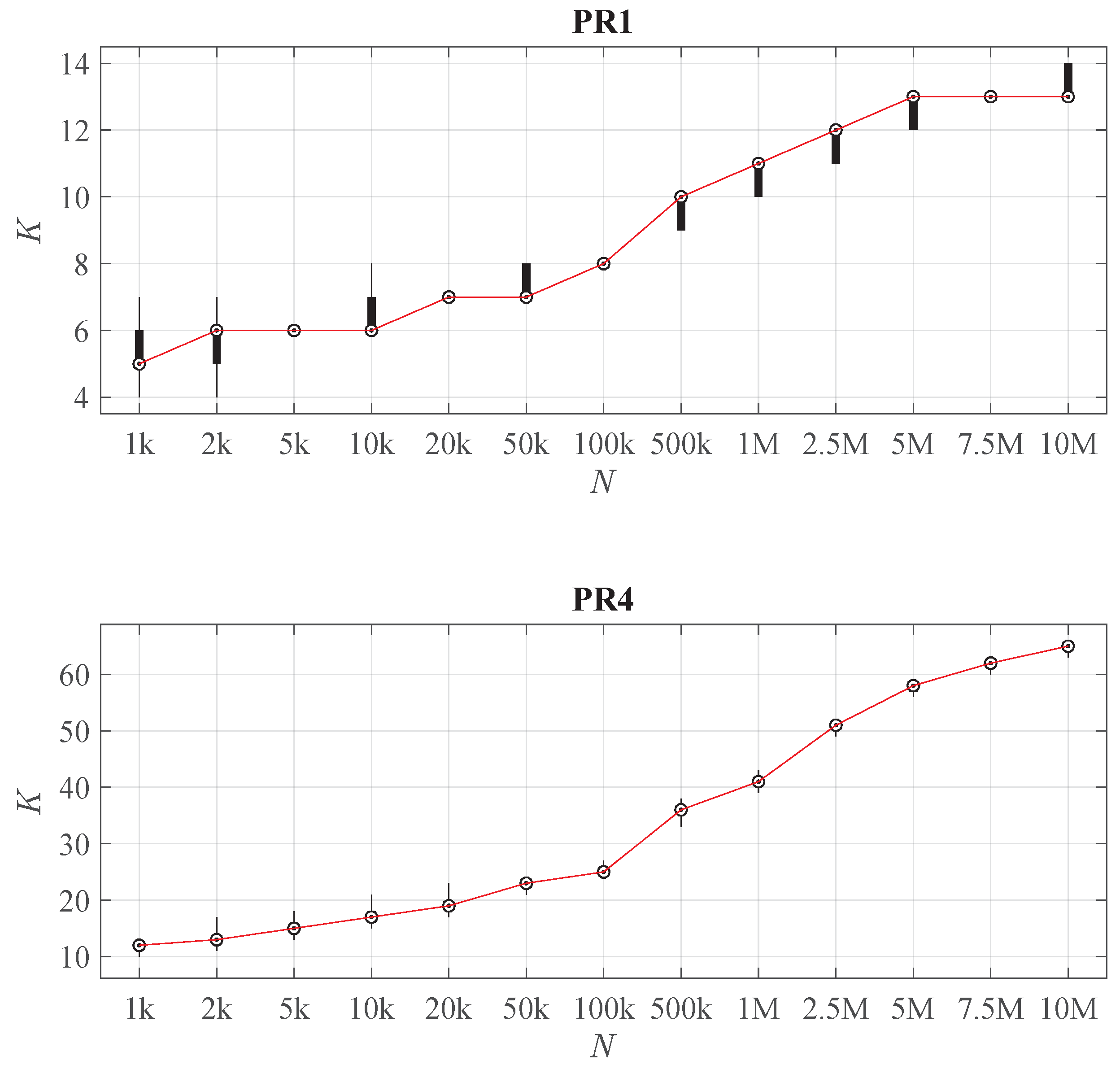
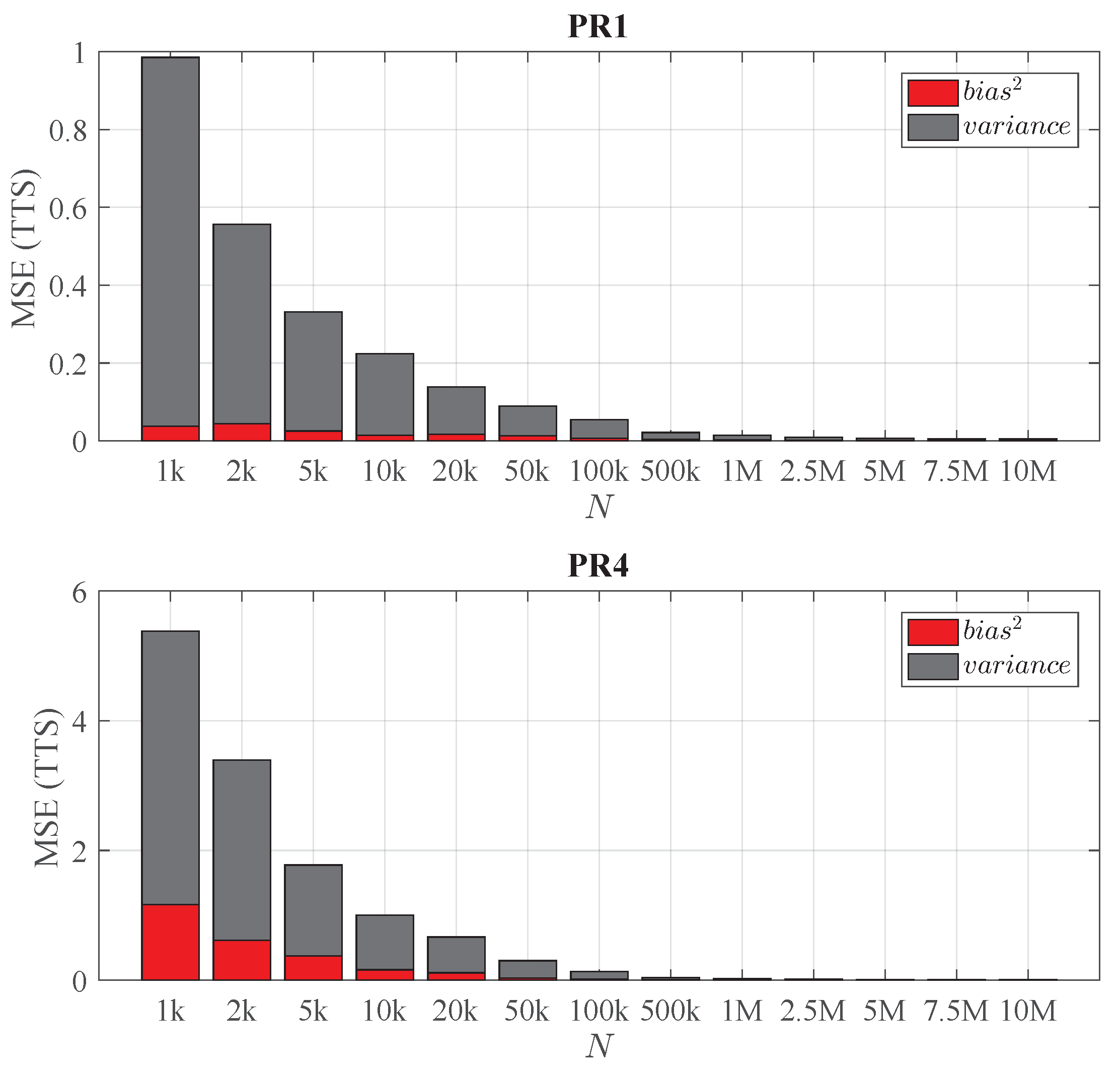
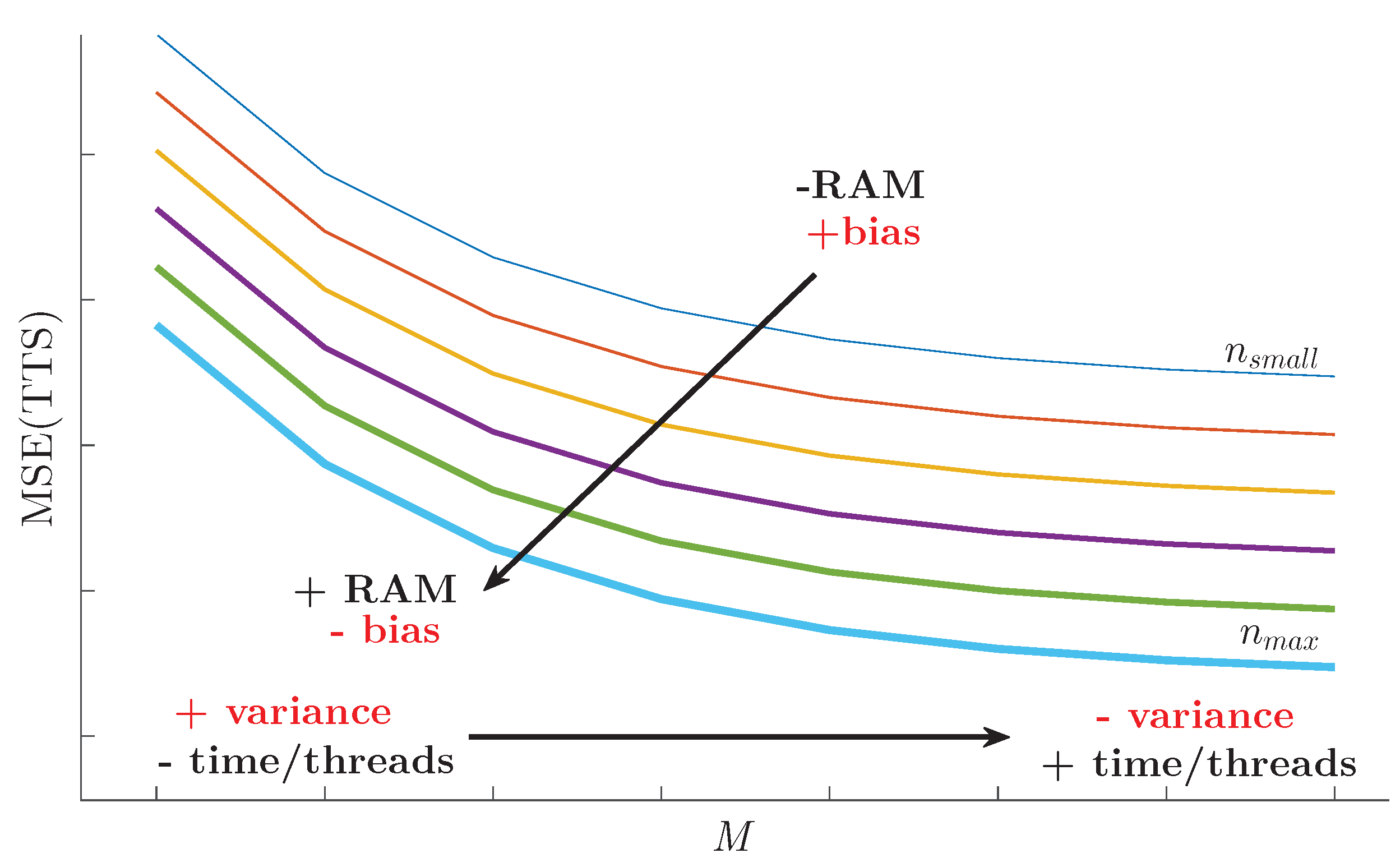
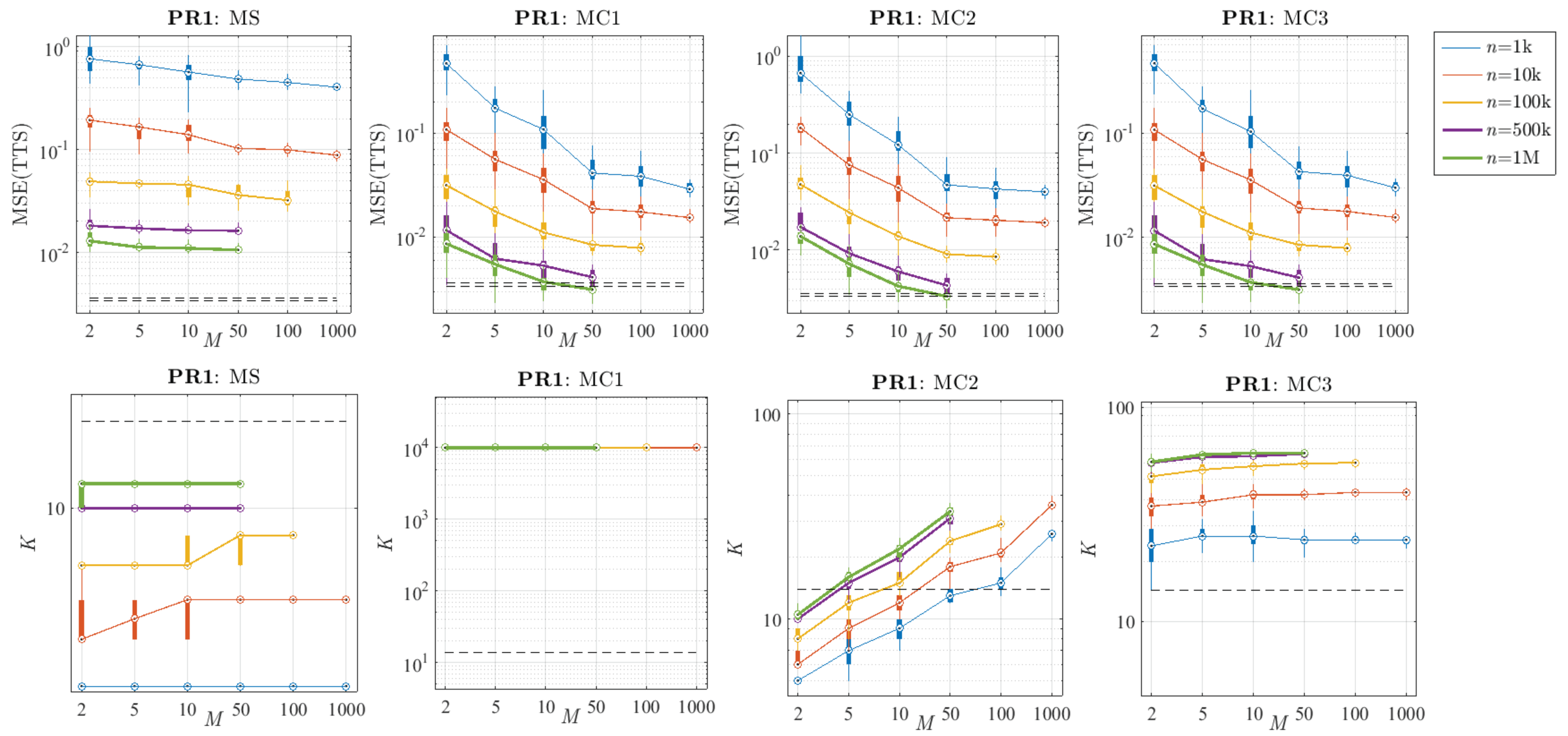
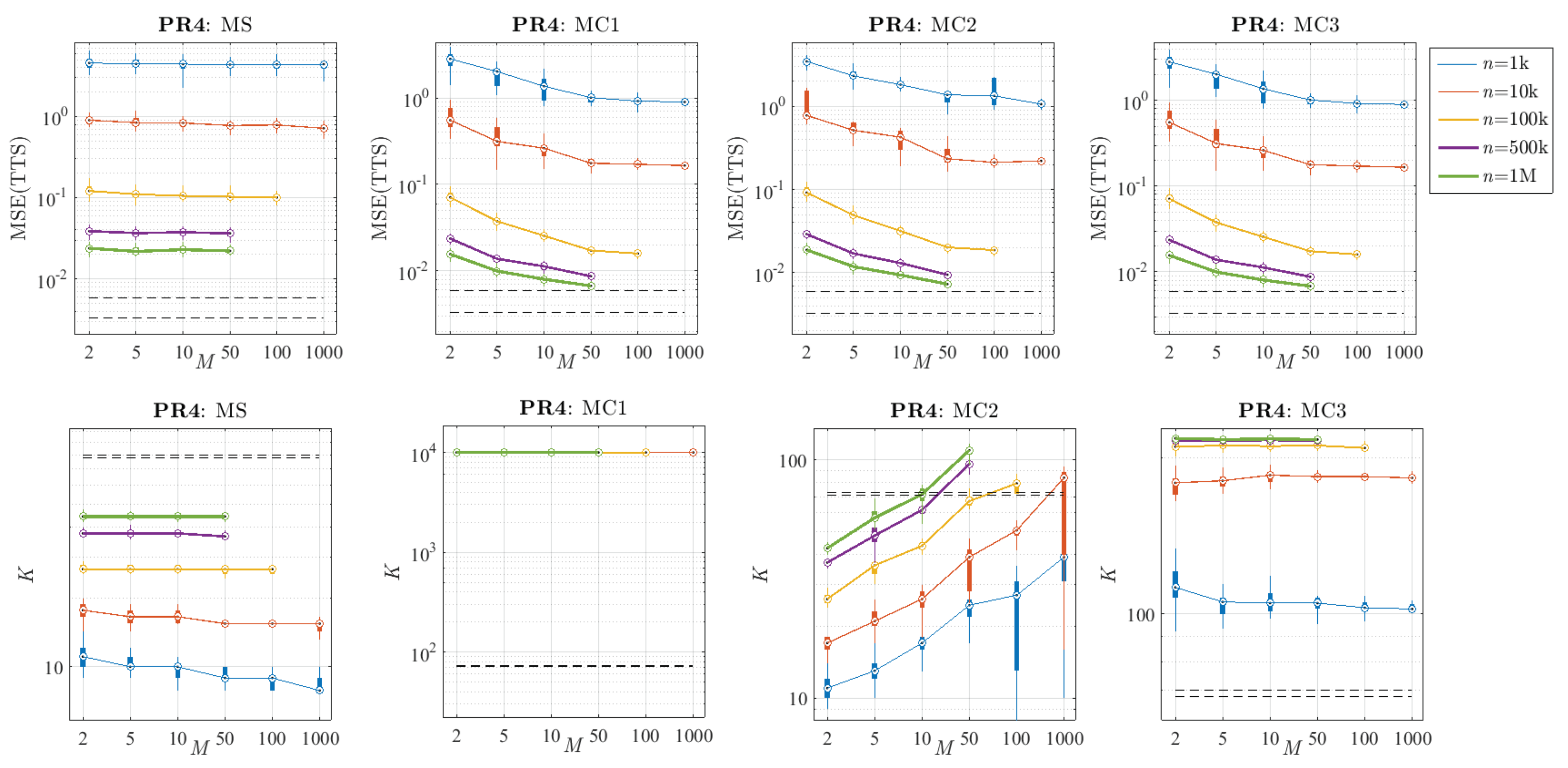
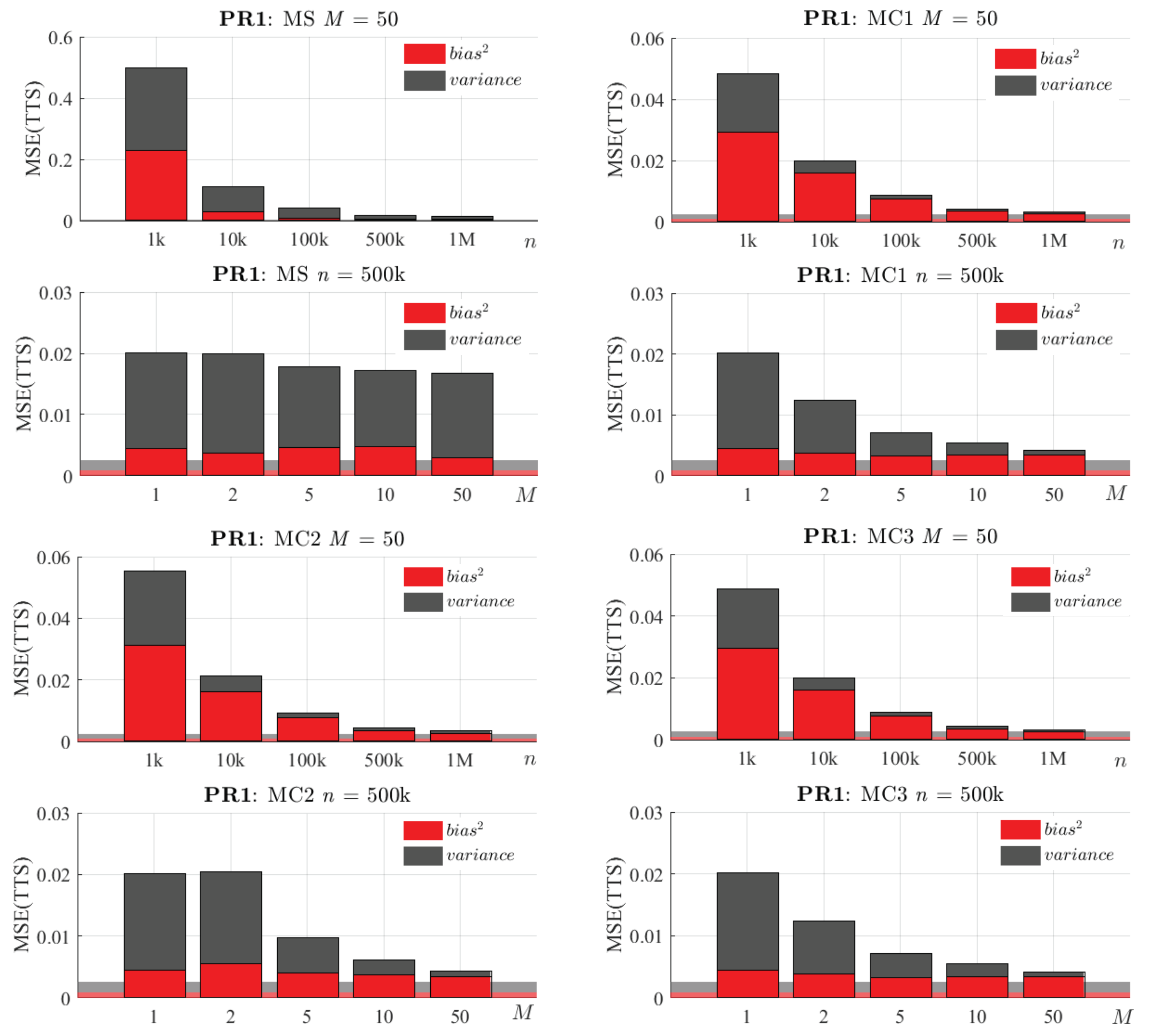
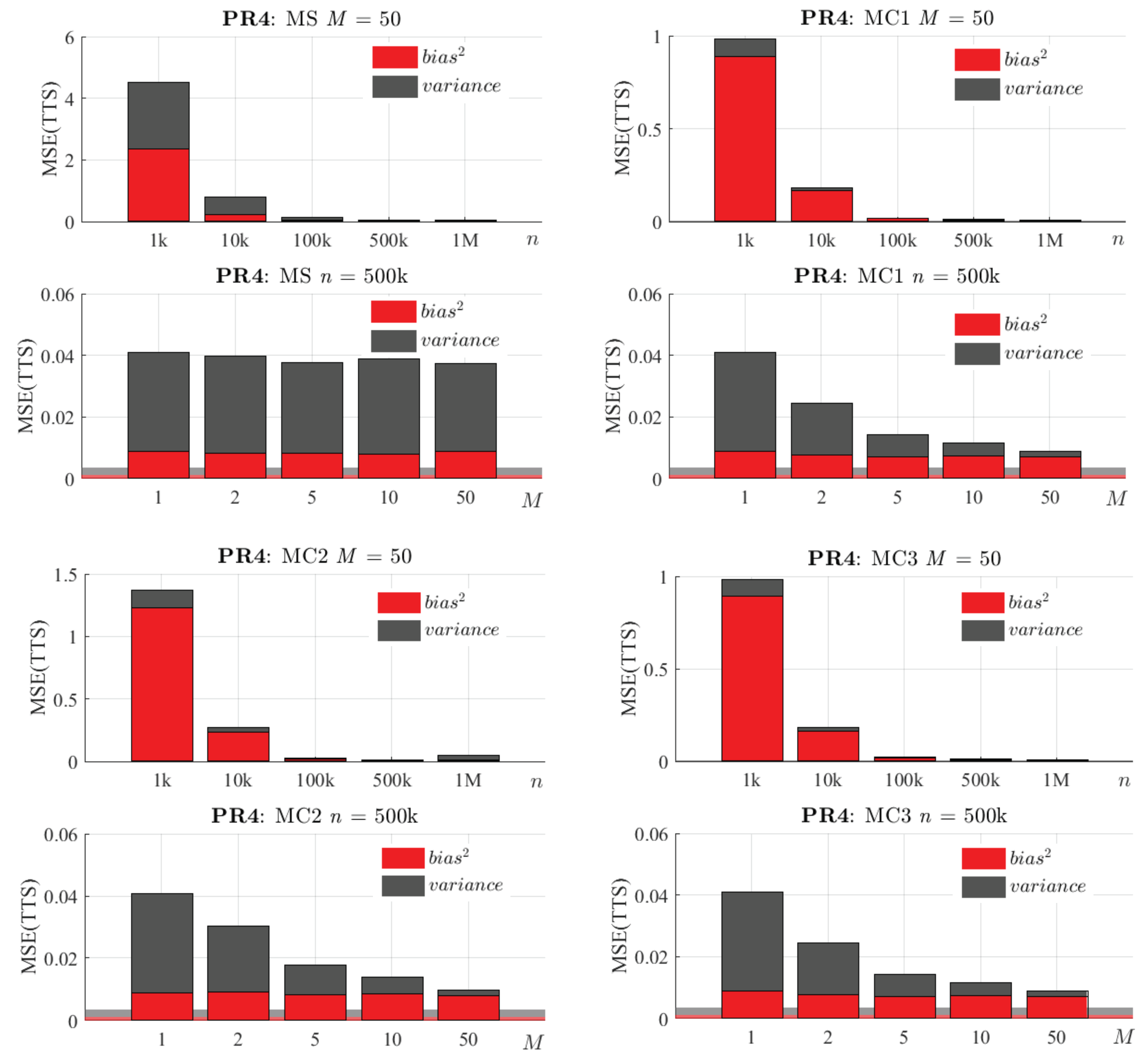
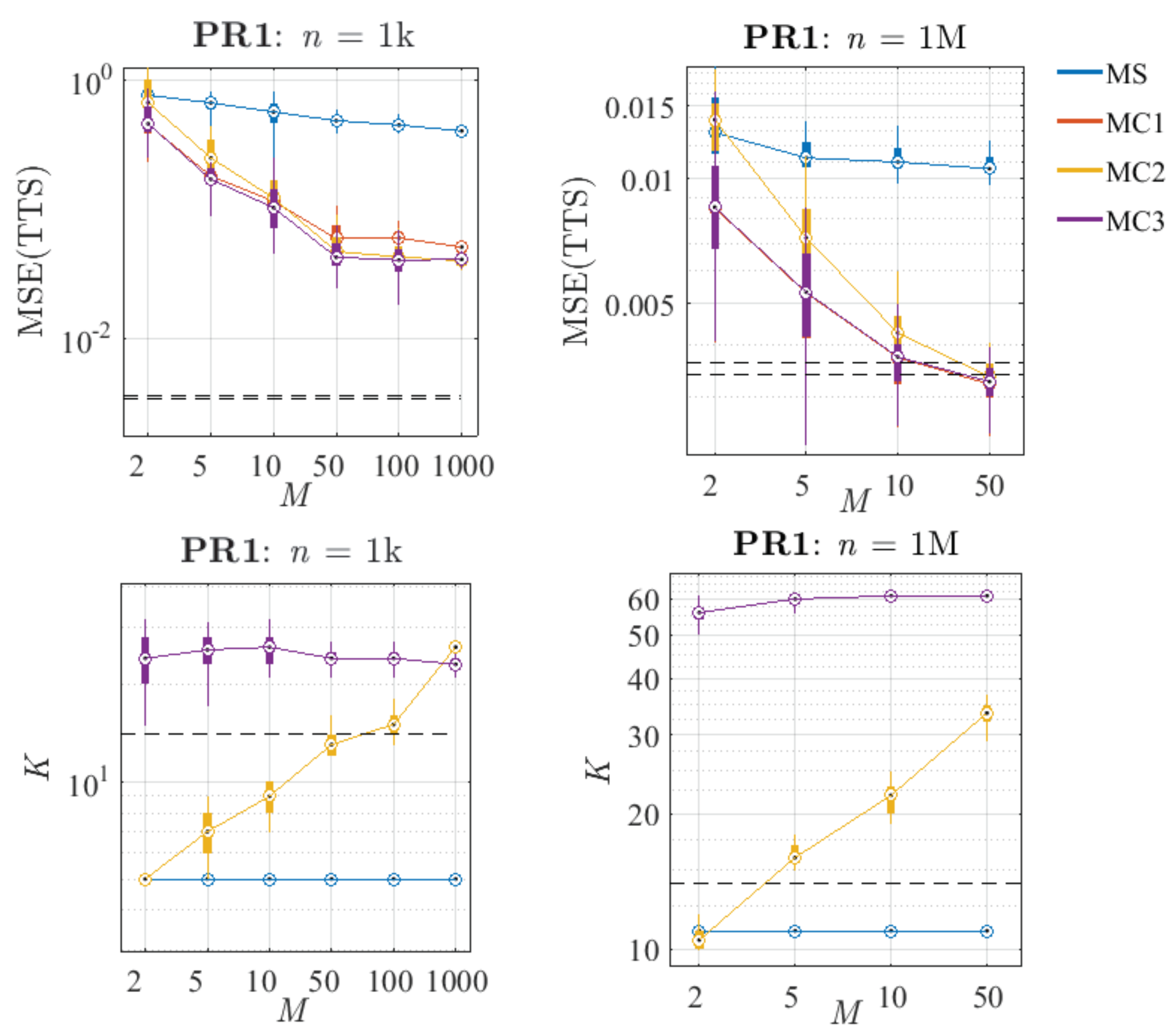
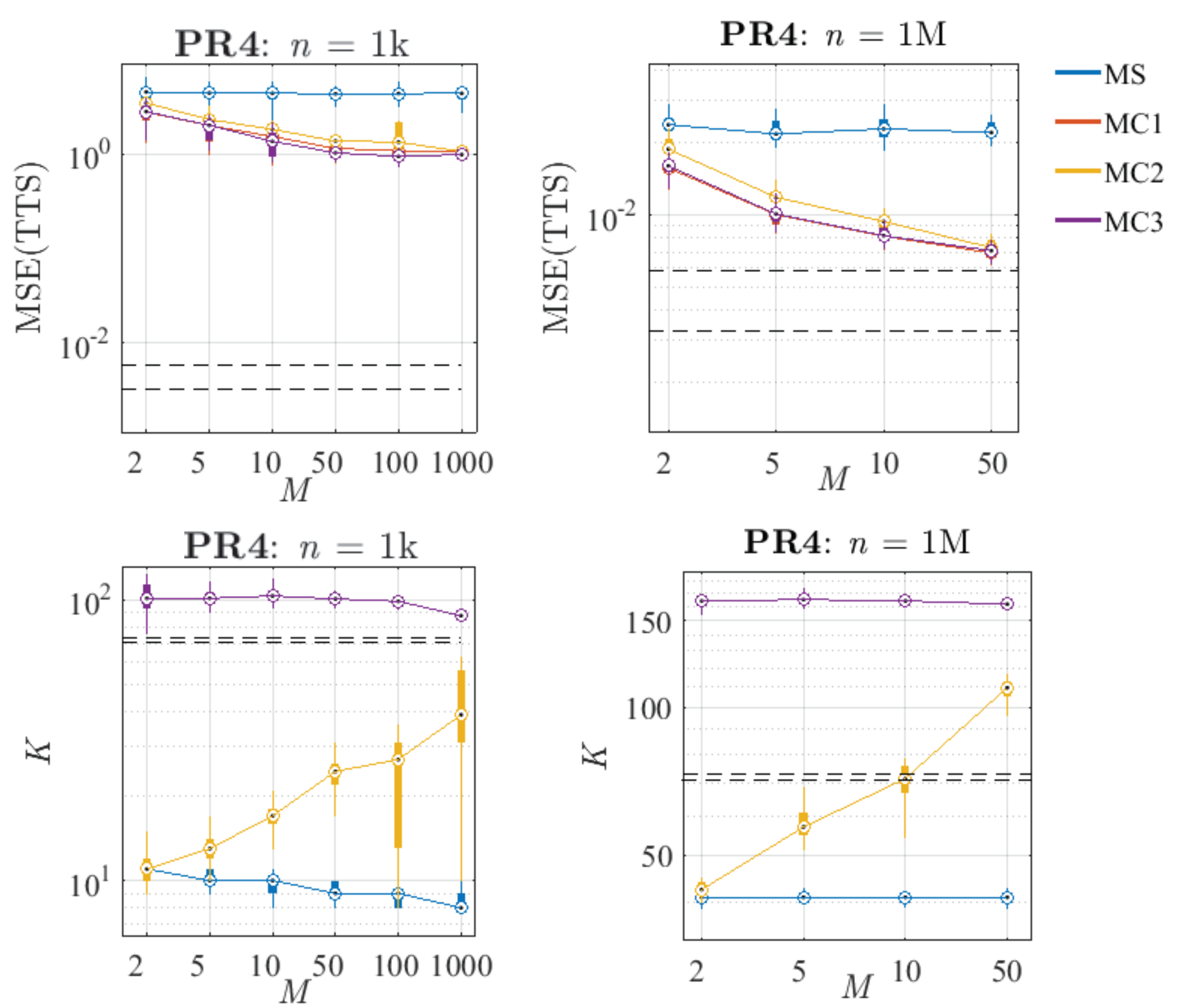
6.2. Selection of n and M
6.3. Comparative Analysis of the Proposed Methods
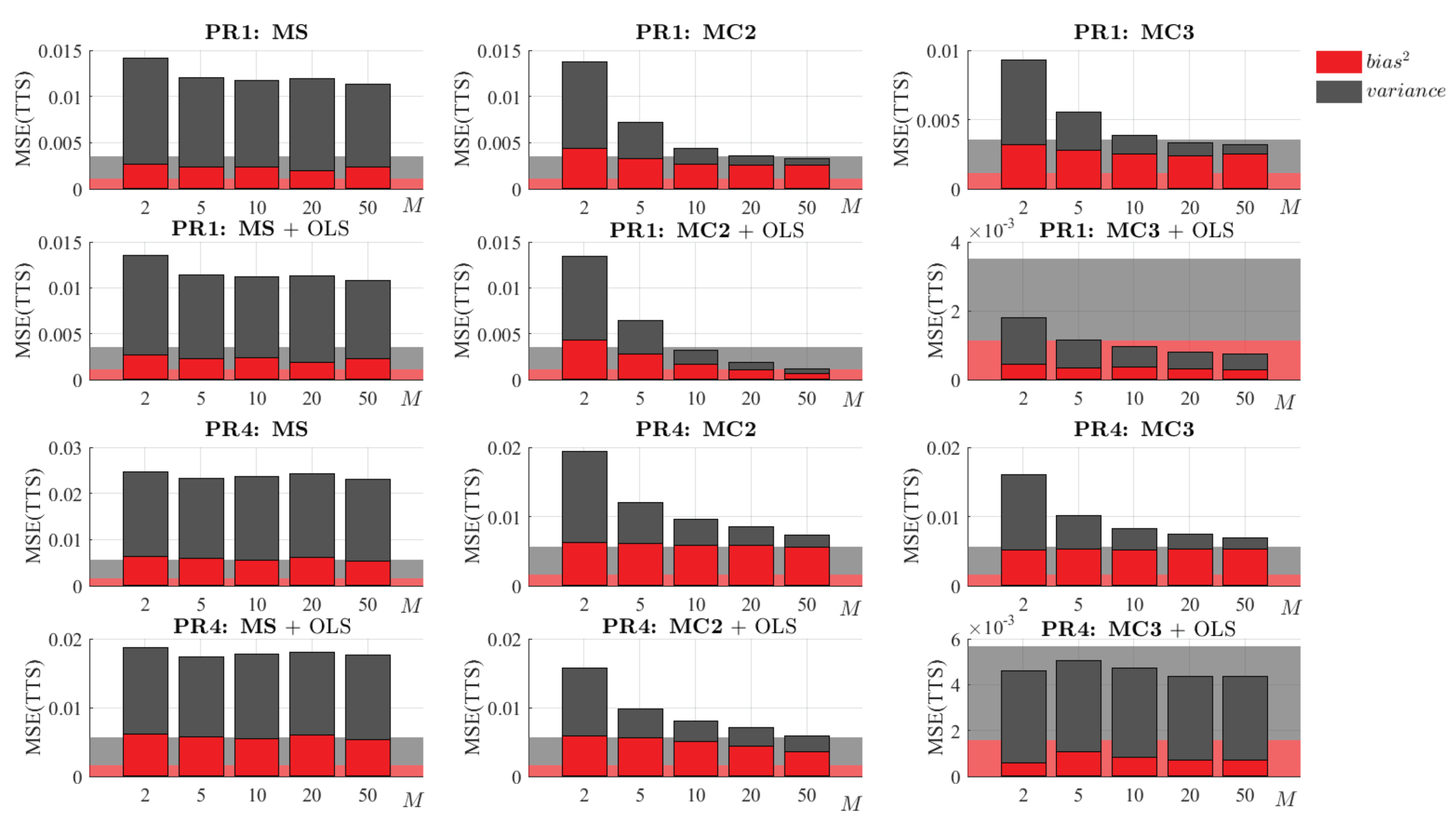
6.4. Impact of Carrying out a Final OLS
6.5. CPU-Time versus Accuracy
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AIC | Akaike information criterion |
| BIC | Bayesian information criterion |
| LHM | Linear Hinges Model |
| MS | Model selection |
| MC | Model combination |
| MSE | Mean squared error |
| OLS | Ordinary least squares |
| PM | Pruned model |
| RA | Reference algorithm |
| SLS | Scattered learning set |
| STS | Scattered test set |
| TTS | True test set |
| WLS | Weighted least squares |
Appendix A. Learning Algorithm of the LHM
References
- Hand, D.J. Statistics and computing: The genesis of data science. Stat. Comput. 2015, 25, 705–711. [Google Scholar] [CrossRef][Green Version]
- Diaz, J.; Munoz-Caro, C.; Nino, A. A Survey of Parallel Programming Models and Tools in the Multi and Many-Core Era. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 1369–1386. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R.; Taylor, J. An Introduction to Statistical Learning: With Applications in Python; Springer International Publishing: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2001; Volume 1. [Google Scholar]
- Bekkerman, R.; Bilenko, M.; Langford, J. Scaling Up Machine Learning: Parallel and Distributed Approaches; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Xing, S.; Sun, J.Q. Separable Gaussian Neural Networks: Structure, Analysis, and Function Approximations. Algorithms 2023, 16, 453. [Google Scholar] [CrossRef]
- Merino, Z.D.; Farmer, J.; Jacobs, D.J. Probability Density Estimation through Nonparametric Adaptive Partitioning and Stitching. Algorithms 2023, 16, 310. [Google Scholar] [CrossRef]
- Wang, J.; Tong, W.; Zhi, X. Model Parallelism Optimization for CNN FPGA Accelerator. Algorithms 2023, 16, 110. [Google Scholar] [CrossRef]
- Sánchez-Úbeda, E.F.; Wehenkel, L. The Hinges model: A one-dimensional continuous piecewise polynomial model. In Proceedings of the Information Processing and Management of Uncertainty in Knowledge-Based Systems, IPMU, Milan, Italy, 11–15 July 1998; pp. 878–885. [Google Scholar]
- Koenker, R.; Ng, P.; Portnoy, S. Quantile smoothing splines. Biometrika 1994, 81, 673–680. [Google Scholar] [CrossRef]
- Eilers, P.H.C.; Marx, B.D. Flexible smoothing with B-splines and penalties. Statist. Sci. 1996, 11, 89–121. [Google Scholar] [CrossRef]
- Ruppert, D.; Carroll, R.J. Theory & Methods: Spatially-adaptive Penalties for Spline Fitting. Aust. New Zealand J. Stat. 2000, 42, 205–223. [Google Scholar]
- Rehab, M.A.; Boufares, F. Scalable Massively Parallel Learning of Multiple Linear Regression Algorithm with MapReduce. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015; Volume 2, pp. 41–47. [Google Scholar] [CrossRef]
- Bell, N.; Garland, M. Efficient Sparse Matrix-Vector Multiplication on CUDA; Technical Report; Nvidia Technical Report NVR-2008-004; Nvidia Corporation: Santa Clara, CA, USA, 2008. [Google Scholar]
- Ezzatti, P.; Quintana-Orti, E.S.; Remon, A. High performance matrix inversion on a multi-core platform with several GPUs. In Proceedings of the Parallel, Distributed and Network-Based Processing (PDP), 2011 19th Euromicro International Conference, Ayia Napa, Cyprus, 9–11 February 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 87–93. [Google Scholar]
- Golub, G.H.; Van Loan, C.F. Matrix computations; JHU Press: Baltimore, MD, USA, 2012; Volume 3. [Google Scholar]
- Sharma, G.; Martin, J. MATLAB®: A language for parallel computing. Int. J. Parallel Program. 2009, 37, 3–36. [Google Scholar] [CrossRef]
- Seo, S.; Yoon, E.J.; Kim, J.; Jin, S.; Kim, J.S.; Maeng, S. Hama: An efficient matrix computation with the mapreduce framework. In Proceedings of the Cloud Computing Technology and Science (CloudCom), 2010 IEEE Second International Conference, Indianapolis, IN, USA, 30 November–3 December 2010; IEEE: New York, NY, USA, 2010; pp. 721–726. [Google Scholar]
- Qian, Z.; Chen, X.; Kang, N.; Chen, M.; Yu, Y.; Moscibroda, T.; Zhang, Z. MadLINQ: Large-scale distributed matrix computation for the cloud. In Proceedings of the 7th ACM european conference on Computer Systems, Bern, Switzerland, 10–13 April 2012; ACM: New York, NY, USA, 2012; pp. 197–210. [Google Scholar]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Akaike, H. A Bayesian extension of the minimum AIC procedure of autoregressive model fitting. Biometrika 1979, 66, 237–242. [Google Scholar] [CrossRef]
- Yuan, Z.; Yang, Y. Combining Linear Regression Models. J. Am. Stat. Assoc. 2005, 100, 1202–1214. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the ICML, Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]
- Friedman, J.H. A Variable Span Smoother; Technical Report; DTIC Document: Fort Belvoir, VA, USA, 1984. [Google Scholar]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Sánchez-Úbeda, E.F. Models for Data Analysis: Contributions to Automatic Learning. Ph.D. Thesis, Universidad Pontificia Comillas, Madrid, Spain, 1999. [Google Scholar]
- Sánchez-Úbeda, E.F.; Wehenkel, L. Automatic fuzzy-rules induction by using the ORTHO model. In Proceedings of the Information Processing and Management of Uncertainty in Knowledge-based Systems (IPMU 2022), Milan, Italy, 11–15 July 2000; pp. 1652–1659. [Google Scholar]
- Sánchez-Úbeda, E.F.; Berzosa, A. Modeling and forecasting industrial end-use natural gas consumption. Energy Econ. 2007, 29, 710–742. [Google Scholar] [CrossRef]
- Sánchez-Úbeda, E.F.; Berzosa, A. Fuzzy Reference Model for Daily Outdoor Air Temperature; Proceedings of TAMIDA, Granada; Dialnet: Sioux Falls, SD, USA, 2005; pp. 271–278. [Google Scholar]
- de Andrade Vieira, R.J.; Sanz-Bobi, M.A.; Kato, S. Wind turbine condition assessment based on changes observed in its power curve. In Proceedings of the Renewable Energy Research and Applications (ICRERA), 2013 International Conference, Madrid, Spain, 20–23 October 2013; IEEE: New York, NY, USA, 2013; pp. 31–36. [Google Scholar]
- Gascón, A.; Sánchez-Úbeda, E.F. Automatic specification of piecewise linear additive models: Application to forecasting natural gas demand. Stat. Comput. 2018, 28, 201–217. [Google Scholar] [CrossRef]
- Moreno-Carbonell, S.; Sánchez-Úbeda, E.F.; Muñoz, A. Time Series Decomposition of the Daily Outdoor Air Temperature in Europe for Long-Term Energy Forecasting in the Context of Climate Change. Energies 2020, 13, 1569. [Google Scholar] [CrossRef]
- Sánchez-Úbeda, E.F.; Sánchez-Martín, P.; Torrego-Ellacuría, M.; Rey-Mejías, A.D.; Morales-Contreras, M.F.; Puerta, J.L. Flexibility and Bed Margins of the Community of Madrid’s Hospitals during the First Wave of the SARS-CoV-2 Pandemic. Int. J. Environ. Res. Public Health 2021, 18, 3510. [Google Scholar] [CrossRef] [PubMed]
- Mestre, G.; Sánchez-Úbeda, E.F.; Muñoz San Roque, A.; Alonso, E. The arithmetic of stepwise offer curves. Energy 2022, 239, 122444. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
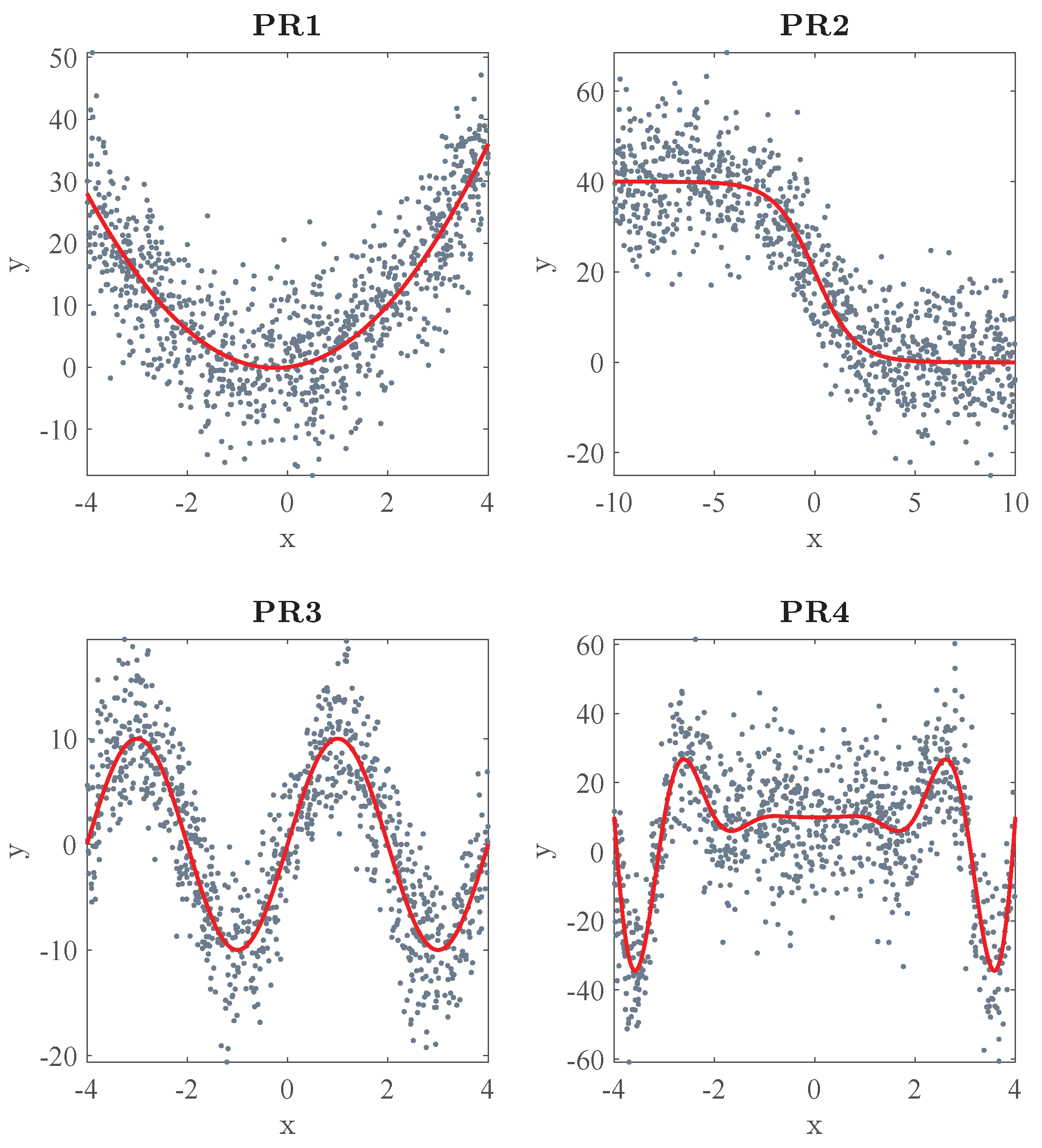
| Problem | True Function |
|---|---|
| PR1 | |
| PR2 | |
| PR3 | |
| PR4 |
| PR1 (MSE) | PR2 (MSE) | PR3 (MSE) | PR4 (MSE) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SLS | STS | TTS | SLS | STS | TTS | SLS | STS | TTS | SLS | STS | TTS | ||
| MS | 2 | 52.22 | 52.27 | 63.99 | 64.03 | 16.00 | 16.00 | 149.71 | 149.64 | ||||
| 5 | 52.22 | 52.27 | 63.99 | 64.03 | 16.00 | 16.00 | 149.71 | 149.64 | |||||
| 10 | 52.21 | 52.27 | 63.99 | 64.03 | 16.00 | 16.00 | 149.71 | 149.64 | |||||
| 20 | 52.22 | 52.27 | 63.99 | 64.03 | 16.00 | 16.00 | 149.71 | 149.64 | |||||
| 50 | 52.21 | 52.27 | 63.99 | 64.03 | 16.00 | 16.00 | 149.71 | 149.63 | |||||
| MC1 | 2 | 52.21 | 52.27 | 63.99 | 64.03 | 16.00 | 16.00 | 149.70 | 149.64 | ||||
| 5 | 52.21 | 52.26 | 63.99 | 64.03 | 16.00 | 16.00 | 149.70 | 149.63 | |||||
| 10 | 52.21 | 52.26 | * | 63.98 | 64.03 | 16.00 | 16.00 | 149.70 | 149.63 | ||||
| 20 | 52.21 | 52.26 | 63.98 | 64.03 | 16.00 | 16.00 | 149.70 | 149.63 | |||||
| 50 | 52.21 | 52.26 | 63.98 | 64.03 | 16.00 | 16.00 | 149.70 | 149.63 | |||||
| MC2 | 2 | 52.22 | 52.27 | 63.99 | 64.03 | 16.00 | 16.00 | 149.70 | 149.64 | ||||
| 5 | 52.21 | 52.26 | 63.98 | 64.03 | 16.00 | 16.00 | 149.70 | 149.63 | |||||
| 10 | 52.21 | 52.26 | * | 63.98 | 64.02 | 16.00 | 16.00 | 149.70 | 149.63 | ||||
| 20 | 52.21 | 52.26 | 63.98 | 64.02 | * | 16.00 | 16.00 | * | 149.70 | 149.63 | * | ||
| 50 | 52.21 | 52.26 | 63.98 | 64.02 | 16.04 | 16.04 | 149.69 | 149.63 | |||||
| MC3 | 2 | 52.21 | 52.26 | ( *) | 63.98 | 64.02 | ( *) | 16.00 | 16.00 | ( *) | 149.69 | 149.63 | ( *) |
| 5 | 52.20 | 52.26 | 63.98 | 64.02 | 16.00 | 16.00 | 149.69 | 149.63 | |||||
| 10 | 52.20 | 52.26 | 63.98 | 64.02 | 16.00 | 16.00 | 149.69 | 149.63 | |||||
| 20 | 52.20 | 52.26 | 63.98 | 64.02 | 16.00 | 16.00 | 149.69 | 149.63 | |||||
| 50 | 52.20 | 52.26 | 63.98 | 64.02 | 16.00 | 16.00 | 149.69 | 149.63 | |||||
| RA | - | 52.21 | 52.26 | 63.98 | 64.02 | 16.00 | 16.00 | 149.68 | 149.63 | ||||
| PR1 (Bias–Var) | PR2 (Bias–Var) | PR3 (Bias–Var) | PR4 (Bias–Var) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MS | 2 | ||||||||
| 5 | |||||||||
| 10 | |||||||||
| 20 | |||||||||
| 50 | |||||||||
| MC1 | 2 | ||||||||
| 5 | |||||||||
| 10 | |||||||||
| 20 | |||||||||
| 50 | |||||||||
| MC2 | 2 | ||||||||
| 5 | |||||||||
| 10 | |||||||||
| 20 | |||||||||
| 50 | |||||||||
| MC3 | 2 | ||||||||
| 5 | |||||||||
| 10 | |||||||||
| 20 | |||||||||
| 50 | |||||||||
| RA | - | ||||||||
| PR1 (Time (s)) | PR2 (Time (s)) | PR3 (Time (s)) | PR4 (Time (s)) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MS | 2 | 18.55 | 3.44 | 21.99 | 16.38 | 3.09 | 19.47 | 22.34 | 6.83 | 29.17 | 33.39 | 9.56 | 42.95 |
| 5 | 54.87 | 3.54 | 58.41 | 46.87 | 3.18 | 50.05 | 61.54 | 6.83 | 68.37 | 95.32 | 9.57 | 104.89 | |
| 10 | 138.56 | 3.55 | 142.11 | 117.97 | 3.16 | 121.13 | 151.43 | 6.82 | 158.26 | 224.60 | 9.51 | 234.11 | |
| 20 | 283.71 | 3.58 | 287.28 | 245.99 | 3.18 | 249.17 | 311.64 | 6.74 | 318.39 | 455.19 | 9.42 | 464.61 | |
| 50 | 788.09 | 3.58 | 791.67 | 662.48 | 3.23 | 665.71 | 797.61 | 6.79 | 804.40 | 1156.44 | 9.52 | 1165.95 | |
| MC1 | 2 | 18.55 | 0.00 | 18.55 | 16.38 | 0.00 | 16.38 | 22.34 | 0.00 | 22.34 | 33.39 | 0.00 | 33.39 |
| 5 | 54.87 | 0.00 | 54.87 | 46.87 | 0.00 | 46.87 | 61.54 | 0.00 | 61.54 | 95.32 | 0.00 | 95.32 | |
| 10 | 138.56 | 0.00 | 138.57 | 117.97 | 0.00 | 117.97 | 151.43 | 0.00 | 151.44 | 224.60 | 0.00 | 224.60 | |
| 20 | 283.71 | 0.01 | 283.72 | 245.99 | 0.01 | 246.00 | 311.64 | 0.01 | 311.65 | 455.19 | 0.01 | 455.20 | |
| 50 | 788.09 | 0.02 | 788.11 | 662.48 | 0.02 | 662.49 | 797.61 | 0.02 | 797.62 | 1156.44 | 0.02 | 1156.45 | |
| MC2 | 2 | 18.55 | 8.61 | 27.15 | 16.38 | 7.67 | 24.05 | 22.34 | 17.27 | 39.61 | 33.39 | 22.55 | 55.94 |
| 5 | 54.87 | 11.30 | 66.17 | 46.87 | 10.47 | 57.35 | 61.54 | 23.19 | 84.72 | 95.32 | 28.90 | 124.22 | |
| 10 | 138.56 | 13.51 | 152.07 | 117.97 | 11.79 | 129.75 | 151.43 | 27.04 | 178.47 | 224.60 | 31.94 | 256.54 | |
| 20 | 283.71 | 10.48 | 294.19 | 245.99 | 8.65 | 254.64 | 311.64 | 21.24 | 332.89 | 455.19 | 26.53 | 481.72 | |
| 50 | 788.09 | 18.35 | 806.44 | 662.48 | 15.42 | 677.90 | 797.61 | 33.59 | 831.20 | 1156.44 | 44.88 | 1201.32 | |
| MC3 | 2 | 18.55 | 29.12 | 47.66 | 16.38 | 26.79 | 43.17 | 22.34 | 53.24 | 75.58 | 33.39 | 88.24 | 121.63 |
| 5 | 54.87 | 31.03 | 85.90 | 46.87 | 27.43 | 74.30 | 61.54 | 53.33 | 114.87 | 95.32 | 88.01 | 183.34 | |
| 10 | 138.56 | 32.21 | 170.77 | 117.97 | 27.64 | 145.61 | 151.43 | 52.19 | 203.62 | 224.60 | 84.47 | 309.07 | |
| 20 | 283.71 | 21.29 | 304.99 | 245.99 | 17.24 | 263.23 | 311.64 | 35.61 | 347.26 | 455.19 | 60.57 | 515.76 | |
| 50 | 788.09 | 31.87 | 819.96 | 662.48 | 27.52 | 689.99 | 797.61 | 50.69 | 848.30 | 1156.44 | 82.85 | 1239.29 | |
| RA | - | - | - | 114.87 | - | - | 83.82 | - | - | 147.19 | - | - | 180.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreno-Carbonell, S.; Sánchez-Úbeda, E.F. A Piecewise Linear Regression Model Ensemble for Large-Scale Curve Fitting. Algorithms 2024, 17, 147. https://doi.org/10.3390/a17040147
Moreno-Carbonell S, Sánchez-Úbeda EF. A Piecewise Linear Regression Model Ensemble for Large-Scale Curve Fitting. Algorithms. 2024; 17(4):147. https://doi.org/10.3390/a17040147
Chicago/Turabian StyleMoreno-Carbonell, Santiago, and Eugenio F. Sánchez-Úbeda. 2024. "A Piecewise Linear Regression Model Ensemble for Large-Scale Curve Fitting" Algorithms 17, no. 4: 147. https://doi.org/10.3390/a17040147
APA StyleMoreno-Carbonell, S., & Sánchez-Úbeda, E. F. (2024). A Piecewise Linear Regression Model Ensemble for Large-Scale Curve Fitting. Algorithms, 17(4), 147. https://doi.org/10.3390/a17040147