
Deep Machine Learning of MobileNet, Efficient, and Inception Models



Abstract
1. Introduction
2. Materials and Methods
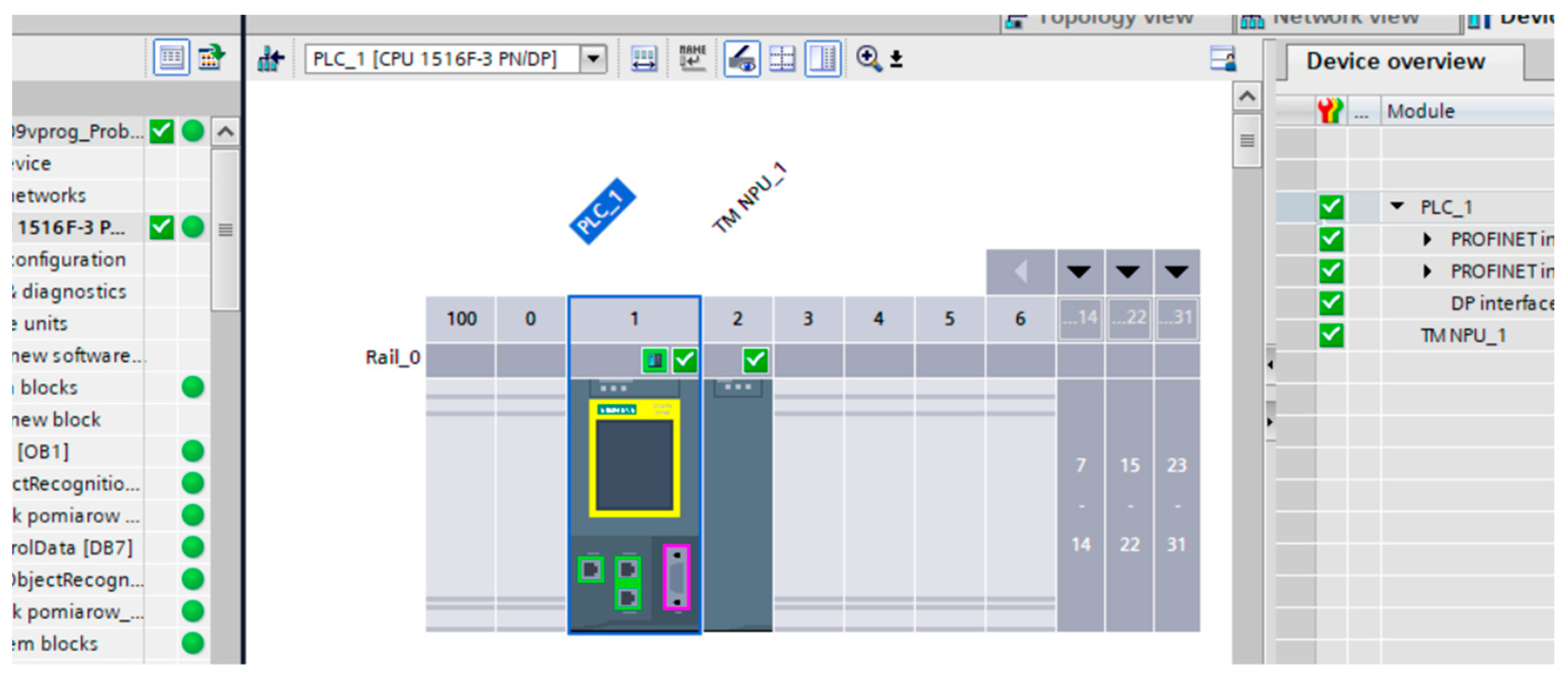
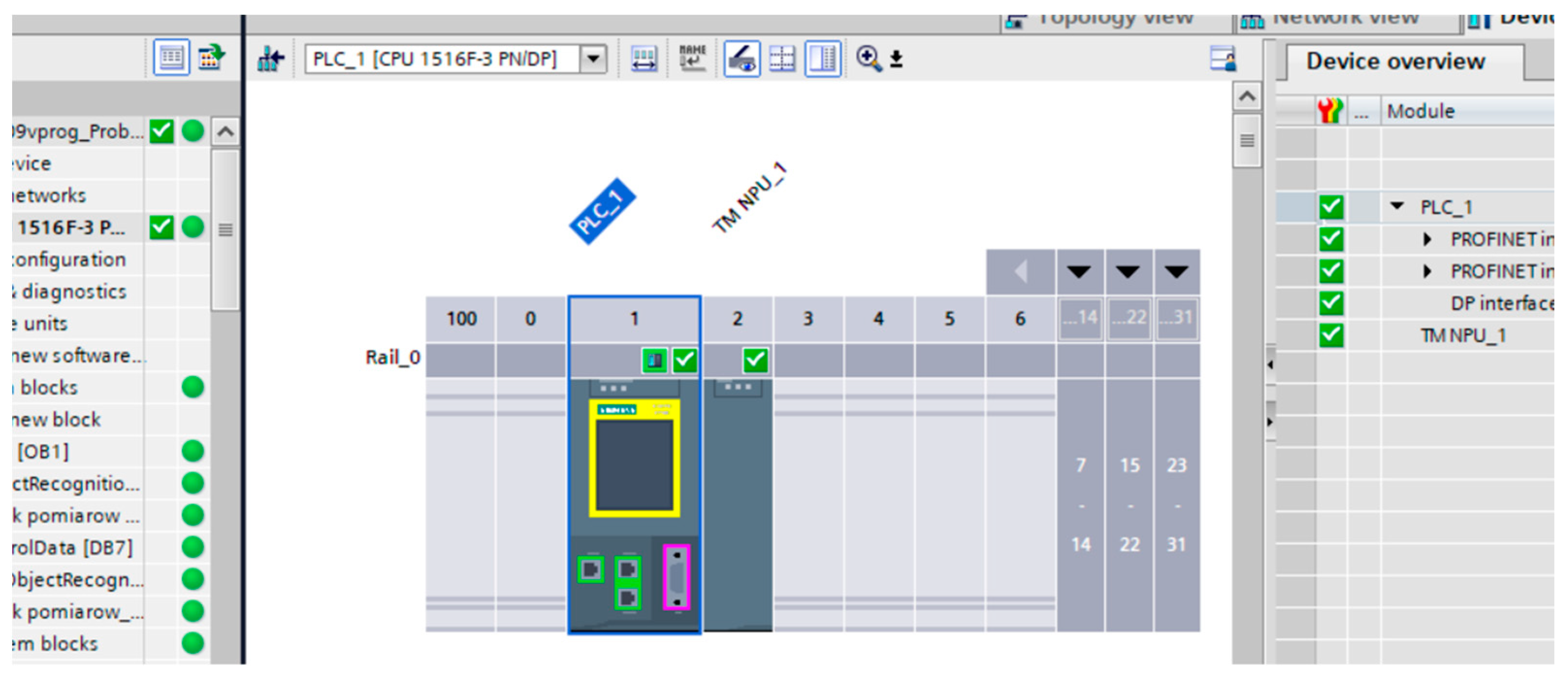
2.1. Research Station
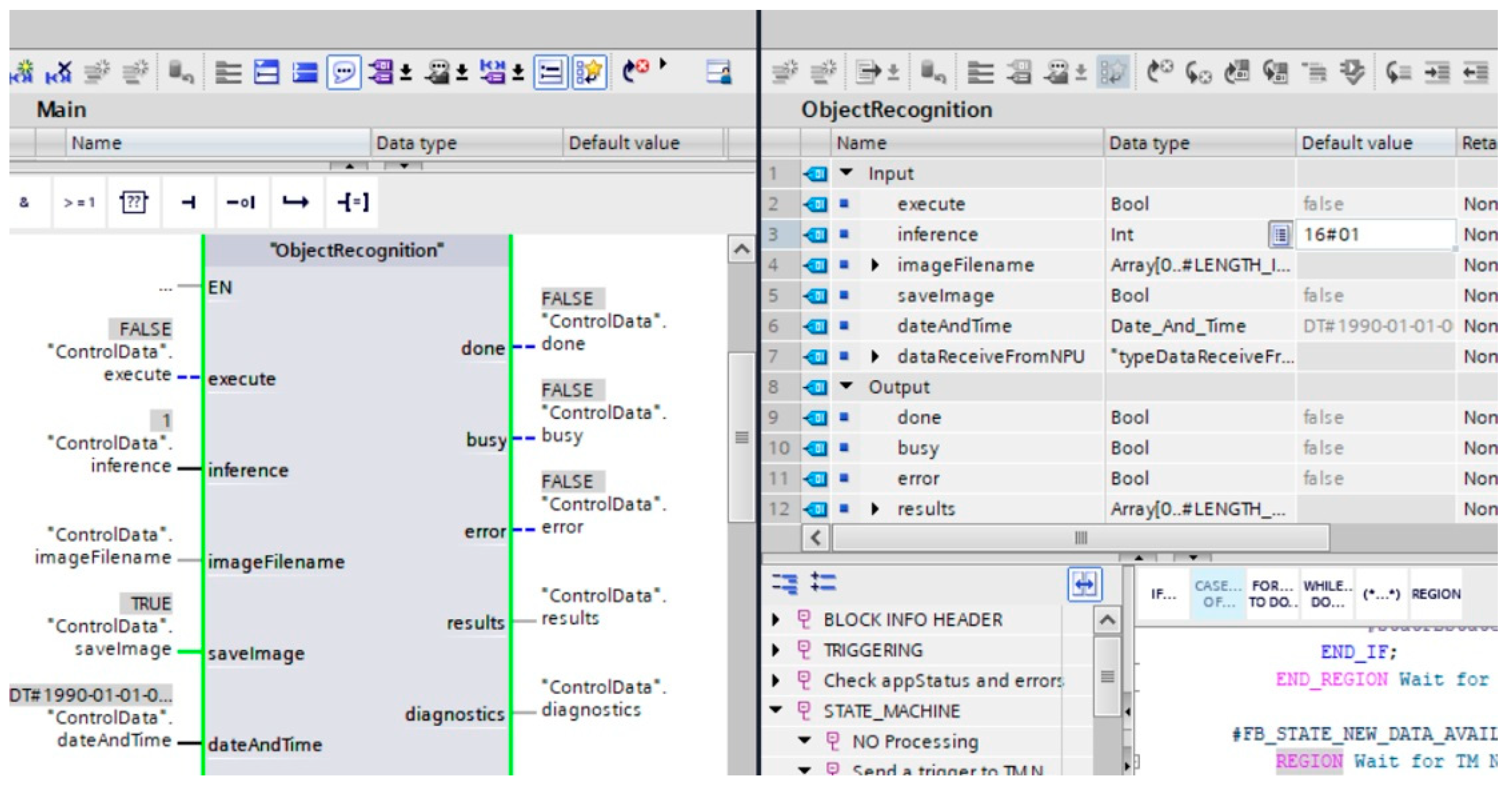
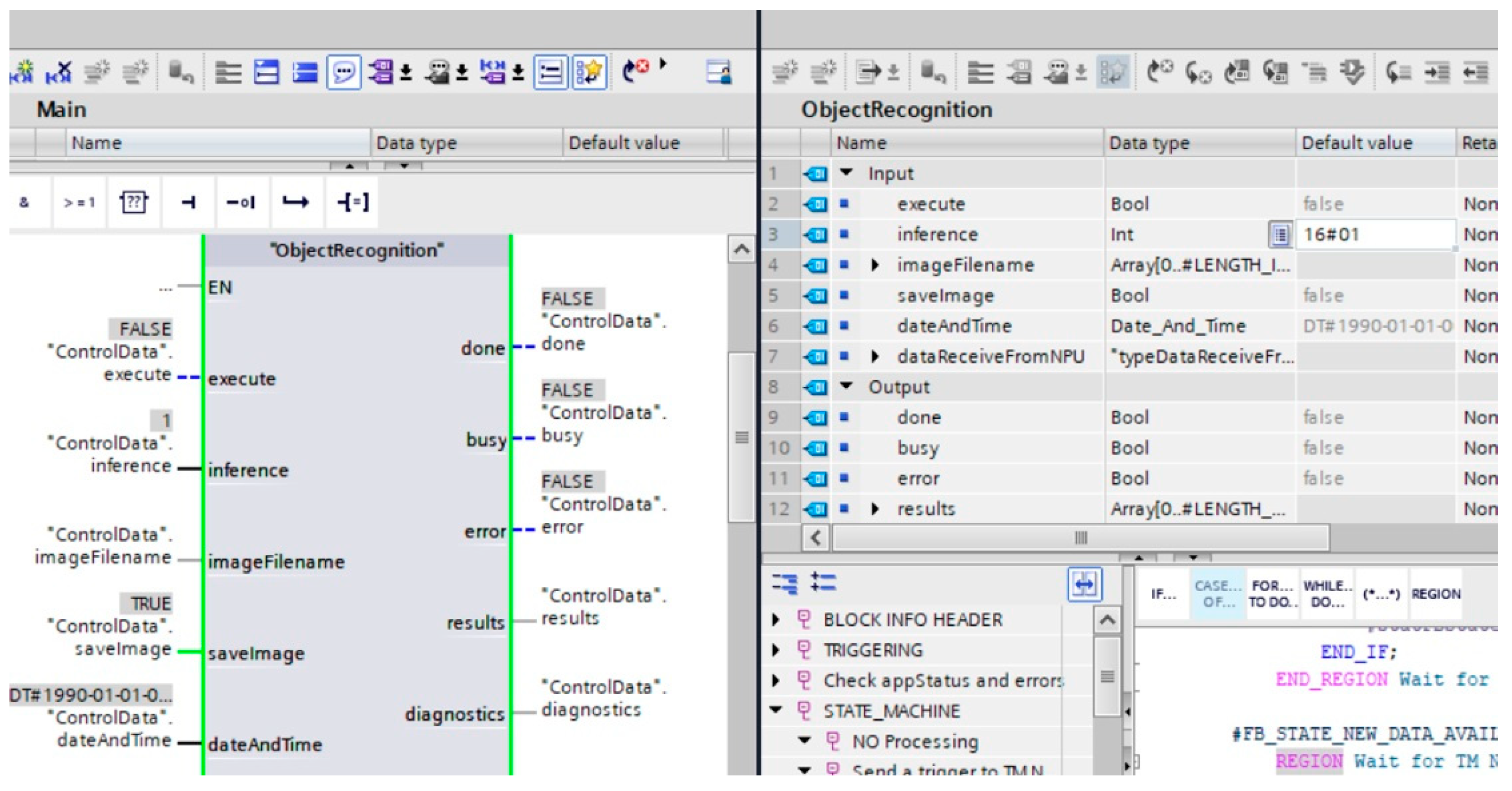
2.2. Converting the CNN Artificial Intelligence Model to the SMC Card
- Python programming using TensorFlow and Keras libraries to create and teach an artificial intelligence model;
- Models to be produced according to research needs;
- Conversion of artificial neural networks for use in the test bench.
3. Method—MobileNet, Efficient, and Inception
- First, in the form of coloured squares made in a graphics programme by the authors. The training images were simple and uniform. From these images, the relationship between the number of epochs and the effectiveness of artificial intelligence models is investigated. Additionally, the rationale for selecting the correct number of epochs is determined.
- The second relates to images of a cuboid, called container in the paper, in one of two colours, red or blue.
- Third, a collection of images of various elements, including electrical parts, where the model is supposed to learn correct and incorrect elements in order to possibly select the correct element in a further work.
- ReLU: Rectified Linear Unit activation function in neural networks. Mathematical notation:
- Convolution2D refers to a two-dimensional convolution operation, which is a fundamental element in convolutional networks (CNNs) that process images. Convolution is the mathematical operation of combining two functions to produce a third function as a result. In the context of image processing, convolution involves moving a ‘filter’ or ‘kernel’ through an image and calculating the sum of the products of the filter elements and the corresponding image elements. Mathematical notation:where I—image; K—convolution kernel. The convolution process allows the network to detect local features in the image: texture, shape, and edges. In practice, image and kernel are finite-dimensional matrices, so the sum is conducted only by finite dimensions. In the example presented here, the convolution kernel has a matrix of (3 × 3).
- Maxpooling2D: a technique that allows for the selection of a maximum value from a specific region in the input matrix otherwise known as a feature map. Mathematical notation:where input (i,j) is the value of a pixel at position (i,j) of the input feature map, output (i,j) is the value of a pixel at position (i,j) of the output feature map; k—kernel size; and pooling “stride” is the step by which the window is moved during the “pooling” operation. Stride can be equal to the size of the kernel (window), leading to non-overlapping windows and reduced dimensionality in each dimension. The example shown here has a set value of (2,2).
- Dropout is a regularisation technique which helps to prevent overfitting of the model to training data. During training for each iteration, Dropout selects a certain random percentage of neurons in the stratum set to zero. The percentage of neurons is a parameter and has the name ‘dropout rate’. Mathematical notation:where xi is an input neuron, yi is the output from the neuron after the application of Dropout, di is a random Bernoulli variable that takes the value of 1 with probability p (the probability of the neuron’s behaviour); and p is the ‘dropout rate’, the probability of each neuron’s behaviour.
- GlobalAveragePooling2D is a layer often used before the last densely connected layer (Dense) in CNN models; it reduces dimensionality and prevents overfitting. Mathematical notation:where output (c) is the output value for feature channel c; input (i,j,c) is the value under the heading (i,j) for feature channel c. It should be noted that the sums are calculated by all spatial positions (i,j).
| Algorithm 1: Trenning AI model for image |
| IMPORT TensorFlow, compact version 1 |
Convvolution2D, MaxPooling2D, BlobalAveragePooling2D, Dropout, ReLU
|
3.1. First Training Database—Simple Database
3.2. Second Training Database—Database with Cuboid
3.3. Third Training Database—Database with Different Objects
4. Results—Verification of Tree CNN Models
4.1. Artificial Intelligence Models Built with MobileNet
4.1.1. First Training Database—Simple Data Base
4.1.2. Second Training Database—Database with Cuboid
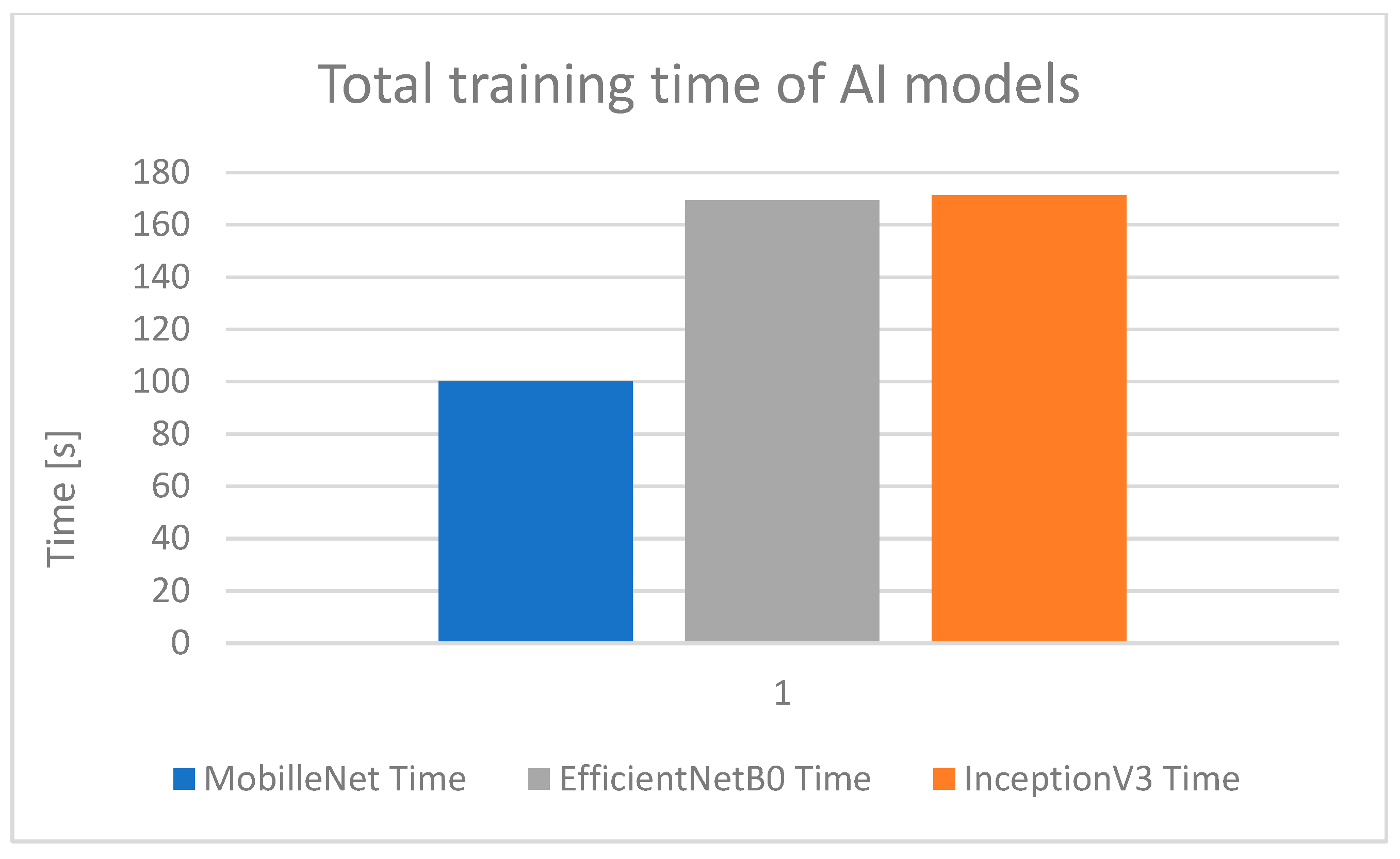
4.2. Three Models: MobileNet, EfficientNetB0, and InceptionV3
Third Training Database—Database with Different Objects
- MobileNet;
- EfficieNetB0;
- InceptionV3.
4.3. Verification of InceptionV3 Model on the PLC Testbed
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolution neural network |
| FPGA | Field-programmable gate array |
| GRU | Gated recurrent unit |
| HPC | High-performance computing |
| MAPE | Mean absolute percentage of error |
| MAE | Mean absolute error |
| LSTM | Long short-term memory |
| PLC | Programable Logical Control |
| RMSE | Root mean square error |
| RGB | Red, green, blue |
| VGG | Very deep convolution networks |
| SMC | Simatic memory card |
| SVR | Support vector regression |
References
- Available online: https://typeset.io/ (accessed on 19 October 2023).
- Zhang, Q. Convolutional Neural Networks. In Proceedings of the 3rd International Conference on Electromechanical Control Technology and Transportation: ICECTT, Chongqing, China, 19–21 January 2018; Volume 1, pp. 434–439, ISBN 978-989-758-312-4. [Google Scholar] [CrossRef]
- Yao, X.; Wang, X.; Wang, S.H.; Zhang, Y.D. A comprehensive survey on convolutional neural network in medical image analysis. Multimed. Tools Appl. 2020, 81, 41361–41405. [Google Scholar] [CrossRef]
- Zhai, J.H.; Zang, L.G.; Zhang, S.F. Some Insights into Convolutional Neural Networks. In Proceedings of the 2017 International Conference on Machine Learning and Cybernetics (ICMLC), Ningbo, China, 9–12 July 2017. [Google Scholar]
- Zhao, K.; Di, S.; Li, S.; Liang, X.; Zhai, Y.; Chen, J.; Ouyang, K.; Cappello, F.; Chen, Z. FT-CNN: Algorithm-Based Fault Tolerance for Convolutional Neural Networks. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1677–1689. [Google Scholar]
- Kalbande, M.; Bhavsar, P. Performance Comparison of Deep Spiking CNN with Artificial Deep CNN for Image Classification Tasks. In Proceedings of the 2022 IEEE Region 10 Symposium (TENSYMP), Mumbai, India, 1–3 July 2022. [Google Scholar]
- Kavitha, M. Analysis of DenseNet-MobileNet-CNN Models on Image Classification using Bird Species Data. In Proceedings of the 2023 International Conference on Disruptive Technologies (ICDT), Greater Noida, India, 11–12 May 2023. [Google Scholar]
- Sabanci, K. Benchmarking of CNN Models and MobileNet-BiLSTM Approach to Classification of Tomato Seed Cultivars. Sustainability 2023, 15, 4443. [Google Scholar] [CrossRef]
- Masykur, F.; Setyawan, M.B.; Winangun, K. Epoch Optimization on Rice Leaf Image Classification Using Convolutional Neural Network (CNN) MobileNet. CESS (J. Comput. Eng. Syst. Sci.) 2022, 7, 581–591. [Google Scholar] [CrossRef]
- Rafay, A.; Hussain, W. EfficientSkinDis: An EfficientNet-based classification model for a large manually curated dataset of 31 skin diseases. Biomed. Signal Process. Control 2023, 85, 104869. [Google Scholar] [CrossRef]
- Amruthamsh, A.; Amrutesh, A.; CG, G.B.; KP, A.R.; Gowrishankar, S. EfficientNet Models for Detection of Anemia Disorder using Palm Images. In Proceedings of the 2023 7th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–13 April 2023; pp. 1437–1443. [Google Scholar]
- SivaRao, B.S.S.; Rao, B.S. EfficientNet—XGBoost: An Effective White-Blood-Cell Segmentation and Classification Framework. Nano Biomed. Eng. 2023, 15, 126–135. [Google Scholar] [CrossRef]
- ZainEldin, H.; Gamel, S.A.; El-Kenawy, E.-S.M.; Alharbi, A.H.; Khafaga, D.S.; Ibrahim, A.; Talaat, F.M. Brain Tumor Detection and Classification Using Deep Learning and Sine-Cosine Fitness Grey Wolf Optimization. Bioengineering 2023, 10, 18. [Google Scholar] [CrossRef] [PubMed]
- Sharma, N.; Gupta, S.; Koundal, D.; Alyami, S.; Alshahrani, H.; Asiri, Y.; Shaikh, A. U-Net Model with Transfer Learning Model as a Backbone for Segmentation of Gastrointestinal Tract. Bioengineering 2023, 10, 119. [Google Scholar] [CrossRef] [PubMed]
- Ning, W.X.; Zhang, H.X.; Wang, D.Z.; Fan, F.; Shu, L. EfficientNet-based electromagnetic attack on AES cipher chips. In Proceedings of the International Conference on Cryptography, Network Security, and Communication Technology (CNSCT 2023), Changsha, China, 12 May 2023. [Google Scholar] [CrossRef]
- Lindow, S.E. Deep CNN-Based Facial Recognition for a Person Identification System Using the Inception Model. In Proceedings of the International Conference on Cryptography, Network Security, and Communication Technology (CNSCT 2023), Changsha, China, 6–8 January 2023. [Google Scholar] [CrossRef]
- Amin, S.U.; Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Abdul, W. Attention based Inception model for robust EEG motor imagery classification. In Proceedings of the 2021 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Glasgow, UK, 17–20 May 2021. [Google Scholar] [CrossRef]
- Pradana, I.C.; Mulyanto, E.; Rachmadi, R.F. Deteksi Senjata Genggam Menggunakan Faster R-CNN Inception V2. J. Tek. ITS 2022, 11, A110–A115. [Google Scholar] [CrossRef]
- Piratelo, P.H.M.; de Azeredo, R.N.; Yamao, E.M.; Bianchi Filho, J.F.; Maidl, G.; Lisboa, F.S.M.; de Jesus, L.P.; Penteado Neto, R.d.A.; Coelho, L.d.S.; Leandro, G.V. Blending Colored and Depth CNN Pipelines in an Ensemble Learning Classification Approach for Warehouse Application Using Synthetic and Real Data. Machines 2022, 10, 28. [Google Scholar] [CrossRef]
- Rani, D.S.; Burra, L.R.; Kalyani, G.; Rao, B. Edge Intelligence with Light Weight CNN Model for Surface Defect Detection in Manufacturing Industry. J. Sci. Ind. Res. 2023, 82, 178–184. [Google Scholar]
- Venkatesan, D.; Kannan, S.K.; Arif, M.; Atif, M.; Ganeshan, A. Sentimental Analysis of Industry 4.0 Perspectives Using a Graph-Based Bi-LSTM CNN Model. Mob. Inf. Syst. 2022, 2022, 5430569. [Google Scholar] [CrossRef]
- Miao, S.; Zhou, C.; AlQahtani, S.A.; Alrashoud, M.; Ghoneim, A.; Lv, Z. Applying machine learning in intelligent sewage treatment: A case study of chemical plant in sustainable cities. Sustain. Cities Soc. 2021, 72, 103009. [Google Scholar] [CrossRef]
- Cicceri, G.; Maisano, R.; Morey, N.; Distefano, S. A Novel Architecture for the Smart Management of Wastewater Treatment Plants. In Proceedings of the 2021 IEEE International Conference on Smart Computing (SMARTCOMP), Irvine, CA, USA, 23–27 August 2021; pp. 392–394. [Google Scholar] [CrossRef]
- Turay, T.; Vladimirova, T. Toward Performing Image Classification and Object Detection With Convolutional Neural Networks in Autonomous Driving Systems: A Survey. IEEE Access 2022, 10, 14076–14119. [Google Scholar] [CrossRef]
- Yadav, P.; Madur, N.; Rajopadhye, V.; Salatogi, S. Review on Case Study of Image Classification using CNN. Int. J. Adv. Res. Sci. Commun. Technol. 2022, 2, 683–687. [Google Scholar] [CrossRef]
- Solowjow, E.; Ugalde, I.; Shahapurkar, Y.; Aparicio, J.; Mahler, J.; Satish, V.; Goldberg, K.; Claussen, H. Industrial Robot Grasping with Deep Learning using a Programmable Logic Controller (PLC). In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 97–103. [Google Scholar]
- Available online: https://docs.openvino.ai/2023.1/home.html (accessed on 2 April 2023).
- Available online: https://cache.industry.siemens.com/dl/files/877/109765877/att_979771/v2/S71500_tm_npu_manual_en-US_en-US.pdf (accessed on 10 January 2023).
- Rybczak, M.; Popowniak, N.; Kozakiewicz, K. Applied AI with PLC and IRB1200. Appl. Sci. 2022, 12, 12918. [Google Scholar] [CrossRef]
- Parisi, L.; Ma, R.; RaviChandran, N.; Lanzillotta, M. hyper-sinh: An accurate and reliable function from shallow to deep learing in TensorFlow and Keras. Mach. Learn. Appl. 2021, 6, 100112. [Google Scholar] [CrossRef]
- Haghighat, E.; Juanes, R. SciANN: A Keras/TensorFlow wrapper for scientific computations and physics-informed deep learning using artificial neural networks. Comput. Methods Appl. Mech. Eng. 2021, 373, 113552. [Google Scholar] [CrossRef]
- Janardhanan, P.S. Project repositories for machine learning with TensorFlow. Procedia Comput. Sci. 2020, 171, 188–196. [Google Scholar] [CrossRef]
- Khan, S.; Rahmani, H.; Shah SA, A.; Bennamoun, M.; Medioni, G.; Dickinson, S. A Guide to Convolutional Neural Networks for Computer Vision; Morgan & Claypool Publishers: San Rafael, CA, USA, 2018. [Google Scholar]
- Aghdam, H.H.; Heravi, E.J. Guide to Convolutional Neural Networks; Springer: New York, NY, USA, 2017; pp. 973–978. [Google Scholar]
- Available online: https://keras.io/api/applications/ (accessed on 10 September 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter: | Value: |
|---|---|
| Kernel size | 3 × 3 |
| Image size | 224 × 224 |
| Batch size | 256 |
| Pool size | (2,2) |
| Stride | 2 |
| Optimizer | Adam |
| Activation function | ReLU |
| Learning rate | 8 × 103 |
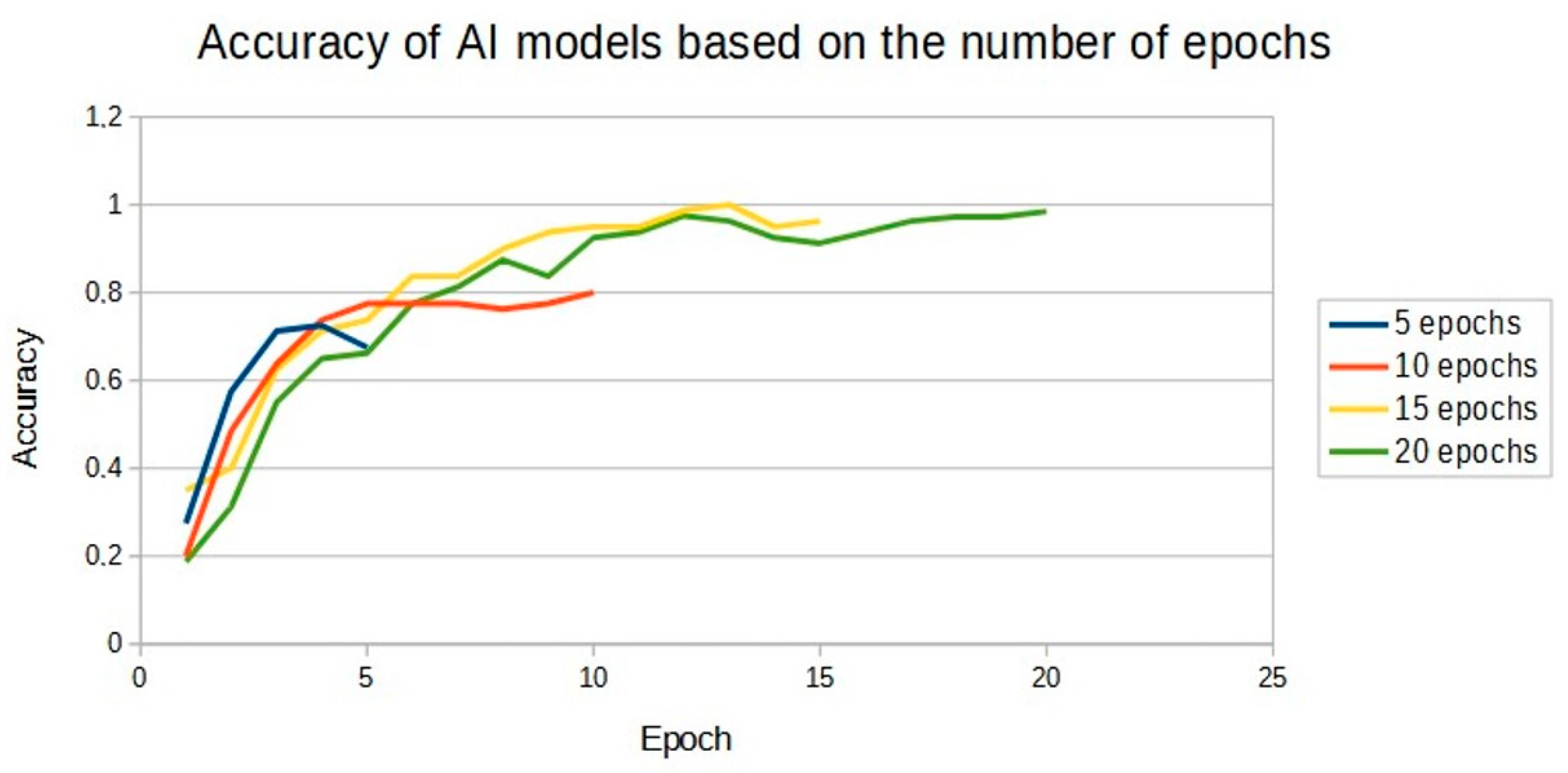
| Epoch | Accuracy of Learned Model 10 Epochs | Accuracy of Learned Model 15 Epochs | Accuracy of Learned Model 20 Epochs |
|---|---|---|---|
| 1 | 0.20 | 0.35 | 0.19 |
| 2 | 0.49 | 0.40 | 0.31 |
| 3 | 0.64 | 0.63 | 0.55 |
| 4 | 0.74 | 0.71 | 0.65 |
| 5 | 0.78 | 0.74 | 0.66 |
| 6 | 0.78 | 0.84 | 0.78 |
| 7 | 0.78 | 0.84 | 0.81 |
| 8 | 0.76 | 0.90 | 0.88 |
| 9 | 0.78 | 0.94 | 0.84 |
| 10 | 0.80 | 0.95 | 0.93 |
| 11 | - | 0.95 | 0.94 |
| 12 | - | 0.99 | 0.98 |
| 13 | - | 1.00 | 0.96 |
| 14 | - | 0.95 | 0.93 |
| 15 | - | 0.96 | 0.91 |
| 16 | - | - | 0.94 |
| 17 | - | - | 0.96 |
| 18 | - | - | 0.97 |
| 19 | - | - | 0.97 |
| 20 | - | - | 0.99 |
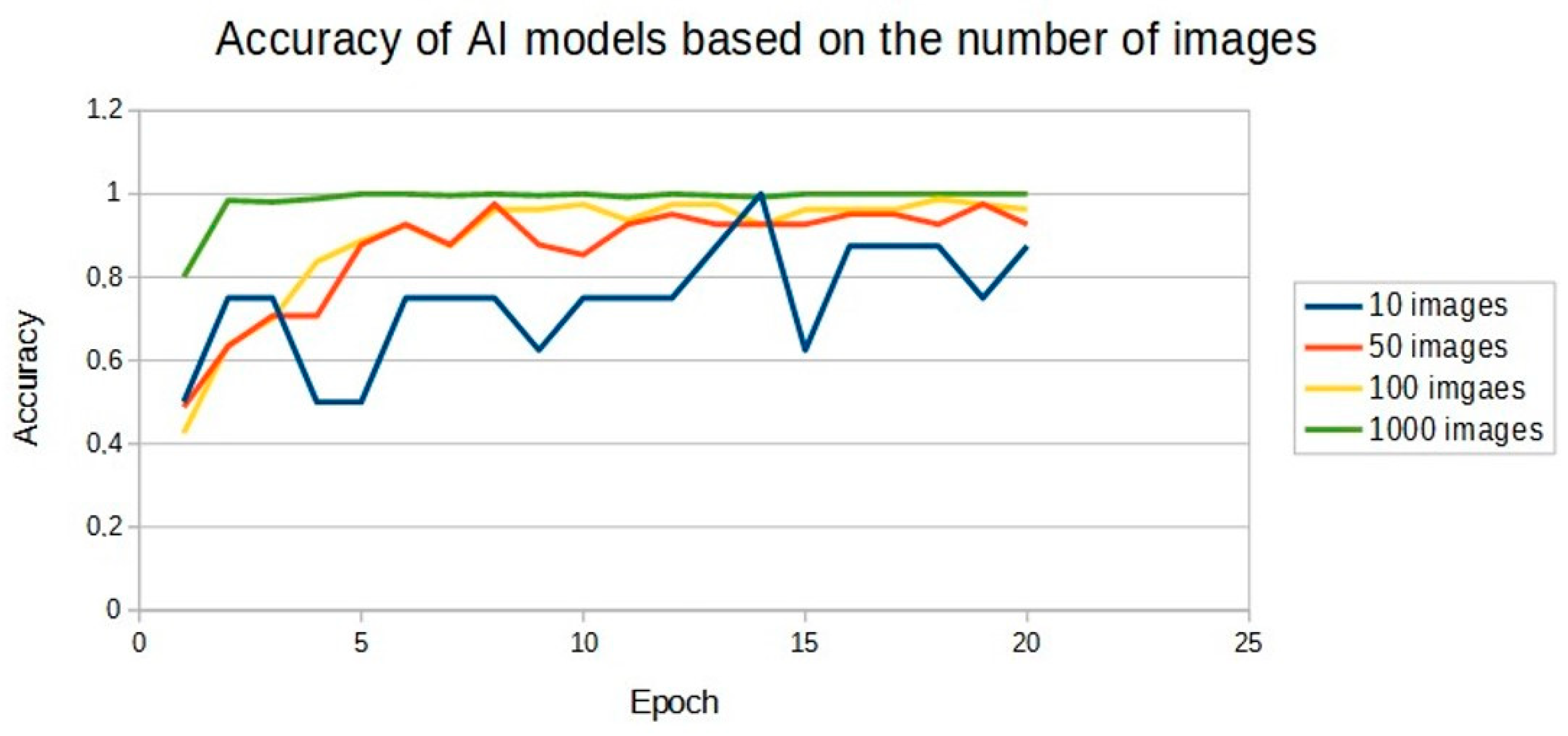
| Epoch | Accuracy of Learned Model 10 Images | Accuracy of Learned Model 50 Images | Accuracy of Learned Model 100 Images | Accuracy of Learned Model 1000 Images |
|---|---|---|---|---|
| 1 | 0.50 | 0.49 | 0.43 | 0.80 |
| 2 | 0.75 | 0.63 | 0.64 | 0.98 |
| 3 | 0.75 | 0.71 | 0.70 | 0.98 |
| 4 | 0.50 | 0.71 | 0.84 | 0.99 |
| 5 | 0.50 | 0.88 | 0.89 | 1.00 |
| 6 | 0.75 | 0.93 | 0.93 | 1.00 |
| 7 | 0.75 | 0.88 | 0.88 | 1.00 |
| 8 | 0.75 | 0.98 | 0.96 | 1.00 |
| 9 | 0.63 | 0.88 | 0.96 | 1.00 |
| 10 | 0.75 | 0.85 | 0.98 | 1.00 |
| 11 | 0.75 | 0.93 | 0.94 | 0.99 |
| 12 | 0.75 | 0.95 | 0.98 | 1.00 |
| 13 | 0.88 | 0.93 | 0.98 | 1.00 |
| 14 | 1.00 | 0.93 | 0.93 | 0.99 |
| 15 | 0.63 | 0.93 | 0.96 | 1.00 |
| 16 | 0.88 | 0.95 | 0.96 | 1.00 |
| 17 | 0.88 | 0.95 | 0.96 | 1.00 |
| 18 | 0.88 | 0.93 | 0.99 | 1.00 |
| 19 | 0.75 | 0.98 | 0.98 | 1.00 |
| 20 | 0.88 | 0.93 | 0.96 | 1.00 |
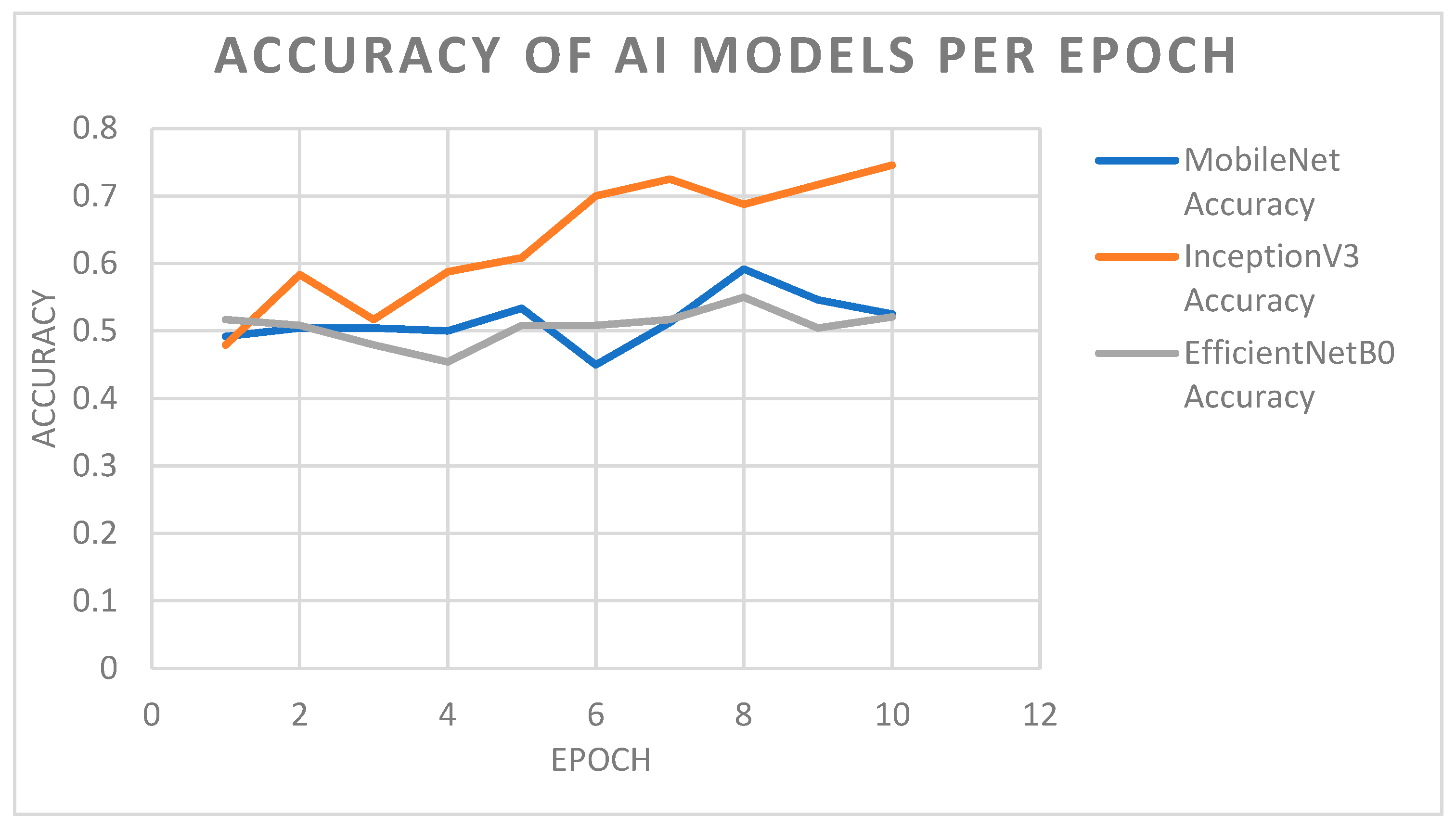
| Epoch | Accuracy of MobileNet Model | Accuracy of EfficientNetB0 Model | Accuracy of InceptionV3 Model |
|---|---|---|---|
| 1 | 0.4916 | 0.5166 | 0.4791 |
| 2 | 0.5041 | 0.5083 | 0.5833 |
| 3 | 0.5041 | 0.4791 | 0.5166 |
| 4 | 0.5000 | 0.4541 | 0.5875 |
| 5 | 0.5333 | 0.5083 | 0.6083 |
| 6 | 0.4500 | 0.5083 | 0.7000 |
| 7 | 0.5125 | 0.5166 | 0.7250 |
| 8 | 0.5916 | 0.5500 | 0.6875 |
| 9 | 0.5458 | 0.5041 | 0.7166 |
| 10 | 0.5250 | 0.5208 | 0.7458 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rybczak, M.; Kozakiewicz, K. Deep Machine Learning of MobileNet, Efficient, and Inception Models. Algorithms 2024, 17, 96. https://doi.org/10.3390/a17030096
Rybczak M, Kozakiewicz K. Deep Machine Learning of MobileNet, Efficient, and Inception Models. Algorithms. 2024; 17(3):96. https://doi.org/10.3390/a17030096
Chicago/Turabian StyleRybczak, Monika, and Krystian Kozakiewicz. 2024. "Deep Machine Learning of MobileNet, Efficient, and Inception Models" Algorithms 17, no. 3: 96. https://doi.org/10.3390/a17030096
APA StyleRybczak, M., & Kozakiewicz, K. (2024). Deep Machine Learning of MobileNet, Efficient, and Inception Models. Algorithms, 17(3), 96. https://doi.org/10.3390/a17030096