
A Review of Machine Learning’s Role in Cardiovascular Disease Prediction: Recent Advances and Future Challenges
 , , and
, , and
Abstract
1. Introduction
1.1. Motivation and Paper Contributions
1.2. Papers Selection Strategy
1.3. Organization of the Paper
2. The Role of Machine Learning in Cardiovascular Disease Prediction
2.1. Background
2.2. Significance of Feature Selection in Cardiovascular Disease Prediction and Related State-of-the-Art Research
3. Machine Learning Models for Cardiovascular Disease Prediction and Related State-of-the-Art Research
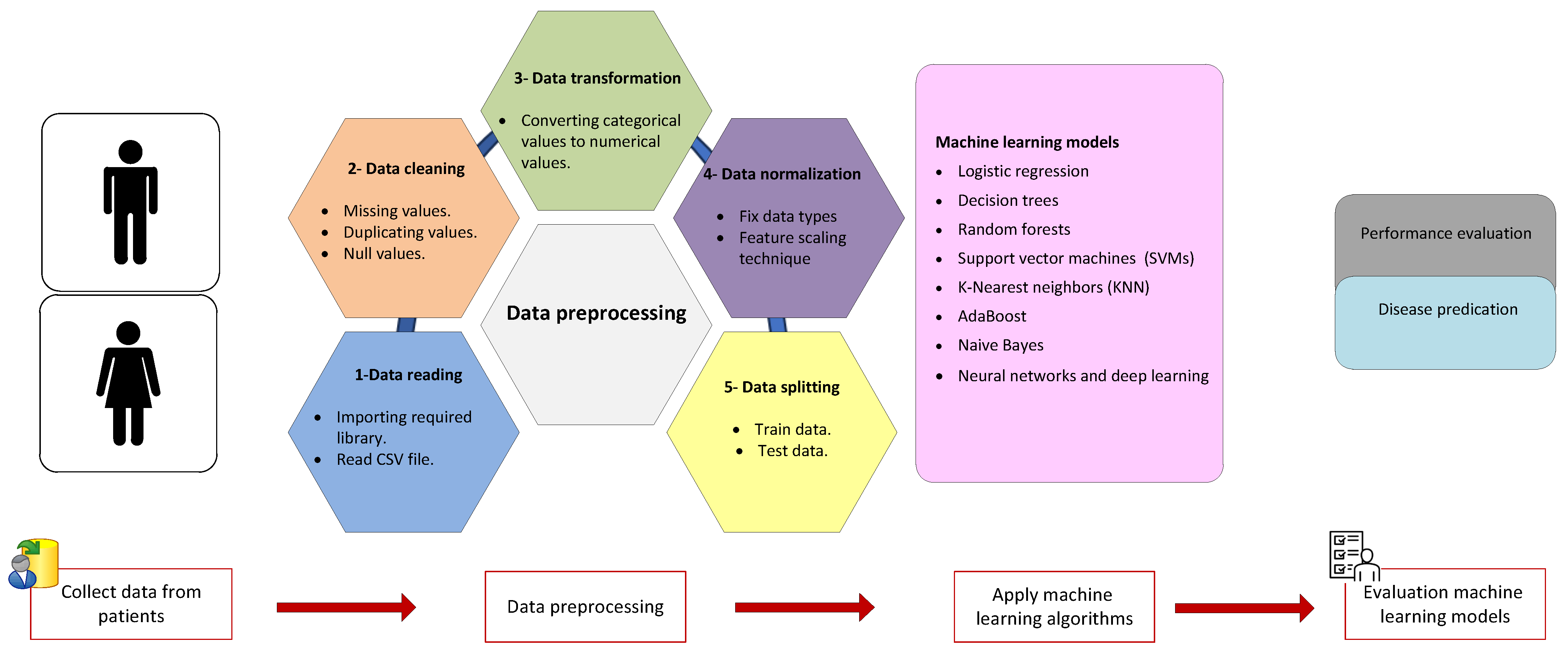
4. Data Collection and Preprocessing
4.1. Data Collection
4.2. Data Preprocessing Techniques
5. Evaluation Metrics and Cross-Validation for Cardiovascular Disease Prediction
5.1. Evaluation Metrics
5.2. Model Validation and Cross-Validation
5.3. Model Interpretability and Explainability
6. Recent Trends in Machine Learning for Cardiovascular Disease Prediction and Future Works
- Delays in diagnosing cardiac disease continue to have a major impact on the treatment of patients [123]. More efficient classification and early prediction of cardiovascular disease methods are required.
- Deep learning techniques have gained prominence in medical image analysis and ECG data interpretation due to their significant role in providing more accurate diagnosis and prediction of diseases [31]. However, the adoption of such techniques in clinical practice comes with some challenges. These challenges include data privacy, the need for large and diverse datasets, regulatory compliance, model robustness, and generalization issues [203]. Therefore, future research should address these challenges. Furthermore, the interpretability of deep learning models remains an ongoing research topic, as understanding the inner workings of complex neural networks is crucial for clinical acceptance.
- Explainable AI (XAI) is essential in cardiovascular disease prediction, attracting significant research attention [204]. XAI techniques empower clinicians by elucidating the importance of each feature in predictions, enabling informed decision-making and building trust [187]. Collaboration between healthcare providers and AI-driven systems can be facilitated through XAI, translating complex model outputs into actionable insights and enhancing clinicians’ diagnostic and treatment capabilities. Further research studies in this essential direction are needed.
- The transformative impact of IoT technology on healthcare is evident, enabling remote patient monitoring and facilitating telemedicine through wireless sensors [205,206,207]. The integration of machine learning models with wearable devices, IoT sensors, and mobile health applications for continuous cardiovascular disease monitoring represents a compelling research avenue [32,208]. Exploring the efficiency of remote medical applications by employing machine learning algorithms is crucial for enhancing data analysis, increasing reliability, and achieving fast and accurate decision-making. Further research in this domain is essential for advancing healthcare systems.
- Machine learning can enhance risk assessment and treatment recommendations by analyzing the historical data of patients [209,210]. As such, machine learning can identify early warning signs of cardiovascular disease, enabling timely interventions [211,212]. Therefore, future works should focus on developing more accurate models to enhance risk assessment and treatment recommendations.
- The Generative Adversarial Network (GAN) stands out as a widely embraced technique in the machine learning domain [73,213]. Leveraging this method enables the creation of synthetic data closely resembling real data, making GAN a promising solution for addressing challenges associated with data scarcity in cardiovascular discussions. Hence, understanding the intricate connections between GAN and data privacy could be explored in future studies. Besides, utilizing GAN to classify unbalanced signals in fetal cardiovascular rate data can be investigated in future [214].
- Efforts are being made to improve interoperability and data sharing among healthcare systems and institutions [215]. The ability to access and share medical data is crucial for training efficient machine learning models. Research is ongoing to improve the robustness and generalization of machine learning models in healthcare systems. Future research could involve further investigation into interoperability and data sharing among healthcare systems.
- Aggregating larger data at a central server confronts issues. To address these issues, the idea of federated learning is introduced, where the focus is on sharing model knowledge instead of sharing raw data [216]. Federated learning establishes a more secure system by enabling model training on decentralized devices, preserving privacy, and minimizing the risk of centralized data breaches [217]. This approach results in a robust system with enhanced security and data access controls that safeguard privacy [218]. A suggested future work would involve the development and implementation of a standardized, interoperable, and secure federated learning framework for data sharing. This framework would allow multiple healthcare institutions and researchers to collaborate while preserving patient privacy [219].
- The management of vast historical data and the constant influx of streaming data in healthcare services pose a formidable challenge for conventional database storage and machine learning approaches. Addressing this challenge in real-time data processing has led researchers to explore big data approaches [220,221,222]. Further research studies in this direction are needed.
- Machine learning involves predictive models that analyze patient data for early detection. Future research should refine predictive models for early anomaly detection and develop advanced algorithms for more accurate predictions. Efforts should be focused on creating personalized care plans and improving machine learning integration into telemedicine platforms for informed decisions during remote consultations.
- Future work should address the ethical concerns issue in healthcare systems. In particular, Strategies to mitigate bias and enhance fairness in healthcare systems should be developed. This includes the development of novel algorithms and methodologies that prioritize equity and fairness.
- Achieving the best possible level of security and privacy protection is important, which need to be considered in the future [223]. Data sharing and collaboration among healthcare institutions are crucial for building large, diverse datasets. This collaboration allows the development of more accurate and robust machine-learning models for medical applications. However, ensuring data privacy, handling data heterogeneity, and addressing issues like missing values and imbalanced datasets is crucial, and should be investigated in the future. In addition, collecting and preprocessing healthcare data for cardiovascular disease prediction is still a challenging issue that needs to be addressed.
- As contemporary technology continues to advance, the acquisition of high-resolution and multidimensional data becomes increasingly feasible. In dealing with such high-quality data, the conventional machine-learning approaches may exhibit some limitations. Exploring the potential of employing a blend of multiple machine learning models could prove to be a promising avenue for addressing the challenges posed by high-dimensional data in future research.
- To advance the application of machine learning in healthcare systems, future work should focus on establishing strong collaborative networks between data scientists, clinicians, and domain experts [224]. This collaboration will ensure that machine learning models are designed and tuned to enhance patient care and decision-making.
- Future research should emphasize the potential of machine learning to address cardiovascular disease on a global scale, with a specific focus on regions with limited access to healthcare resources.
- Future research should also aim to bridge healthcare disparities by providing accessible and effective cardiovascular disease prediction and management tools to underserved populations.
- Artificial General Intelligence (AGI), or strong AI, mimics human intelligence by learning, reasoning, generalizing, and exhibiting self-awareness [225,226]. AGI may have a significant impact on cardiovascular disease, due to its adaptability in accomplishing diverse tasks, integrating medical knowledge, and personalizing treatment planning [227]. AGI can achieve continuous learning and adaptability to ensure up-to-date information for managing cardiovascular disease. Research efforts should aim to enhance AGI cognitive abilities and reasoning.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| ID | Attribute | Type of Attribute | Values |
|---|---|---|---|
| 1 | Id | Discrete | Unique identifier |
| 2 | Age | Discrete | Age of patient in days |
| 3 | Gender | Discrete | Female = 1, male = 2 |
| 4 | Height | Discrete | In cm |
| 5 | Weight | Continuous | In kg |
| 6 | Ap hi | Discrete | Systolic blood pressure |
| 7 | Ap low | Discrete | Diastolic blood pressure |
| 8 | Cholesterol | Discrete | 1 = normal, 2 = above normal, 3 = well above normal |
| 9 | Gluc | Discrete | 1 = normal, 2 = above normal, 3 = well above normal |
| 10 | Smoke | Binary | Whether patient smokes or not (yes = 1, no = 0) |
| 11 | Alcohol | Binary | Whether patient drinks or not (yes = 1, no = 0) |
| 12 | Active | Binary | Physical activity (yes = 1, no = 0) |
| 13 | Cardio | Binary | Presence or absence of cardiovascular disease (yes = 1, no = 0) |
| ID | Attribute | Type of Attribute | Values |
|---|---|---|---|
| 1 | Sex/gender | Discrete | Male = 1 or female = 0 |
| 2 | Age | Continuous | Age of patient in years |
| 3 | Cp (chest pain) | Discrete | 1 = typical angina, 2 = atypical angina, 3 = non-anginal pain, 4 = asymptomatic |
| 4 | RestBP (resting blood pressure) | Continuous | 90–200 |
| 5 | Chol (cholesterol level) | Continuous | 126–564 |
| 6 | Fbs (fasting blood sugar) | Discrete | Fasting blood sugar > 120 mg/dL 1 = true, 0 = false |
| 7 | Restecg (resting Electrocardiography results) | Discrete | 0 = normal, 1 = ST-T wave abnormality, 2 = showing probable or defined left ventricular hypertrophy by Estes criteria |
| 8 | Thalach (maximum heart rate achieved) | Continuous | 71–202 |
| 9 | Exang (exercise-induced angina) | Discrete | Yes = 1 or no = 0 |
| 10 | Old peak ST (depression level) | Continuous | 0 to 6.2 |
| 11 | Slope (slope of the peak exercise segment) | Discrete | 1 = upward sloping, 2 = flat, 3 = downward sloping |
| 12 | Ca (fluoroscopy value) | Discrete | 0 to 3 |
| 13 | Thal (severity of chest pain or trouble breathing) | Discrete | 3 = normal, 6 = fixed defect, 7 = reversible defect |
| 14 | Target | Discrete | Yes = 1 or no = 0 |
| ID | Attribute | Type of Attribute | Values |
|---|---|---|---|
| 1 | Sex | Nominal | Male = l or female = 0 |
| 2 | Age | Continuous | Age of patient in the whole number |
| 3 | Education | Continuous | Values = 1–4. Some High School = 1, High School or GED = 2, Some College or Vocational School = 3, College = 4 |
| 4 | Current Smoker | Nominal | Yes = 1 or no = 0 |
| 5 | Cigarettes per day | Continuous | Number of cigarettes smoked per day |
| 6 | BP Meds | Nominal | Yes = 1 or no = 0 was BP patient or not |
| 7 | Prevalent Stroke | Nominal | Yes = 1 or no = 0 was stroke patient or not |
| 8 | Prevalent Hyp | Nominal | Yes = 1 or no = 0, whether the patient was hypertensive |
| 9 | Diabetes | Nominal | Yes = 1 or No = 0 was diabetes patient or not |
| 10 | Tot Chol | Continuous | Total cholesterol level |
| 11 | Sys BP | Continuous | Systolic blood pressure |
| 12 | Dia BP | Continuous | Diastolic blood Pressure |
| 13 | BMI | Continuous | Body mass index |
| 14 | Heart Rate | Continuous | Heart rate or pulse rate |
| 15 | Glucose | Continuous | Glucose level |
| 16 | Ten-Year CHD (Target) | Nominal | Yes = 1 or no = 2, the 10-year risk of coronary heart disease (CHD) |
Appendix B
| Paper | Year | Dataset Used | Algorithms Used | ACC% | Pr% | Re% | F1% |
|---|---|---|---|---|---|---|---|
| [228] | 2023 | Cleveland | LR, KNN, DT, XGB, SVM, RF | 79.12% | 79% | 79% | 79% |
| [228] | 2023 | Comprehensive UCI datasets | LR, KNN, DT, XGB, SVM, RF | 99.03% | 99% | 99% | 99% |
| [29] | 2023 | Cleveland | Soft voting ensemble based on (RF, KNN, LR, NB, GB, AB) | 93.44% | NP | NP | NP |
| [29] | 2023 | IEEE Dataport | Soft voting ensemble based on (RF, KNN, LR, NB, GB, AB) | 95.00% | NP | NP | NP |
| [229] | 2023 | IEEE Dataport | CART | 87.25% | 88.24% | 84.51% | NP |
| [230] | 2023 | Cardiovascular Disease dataset | RF, DT, MLP, and XGB | 87.28% | 88.70% | 84.85% | 86.71% |
| [147] | 2023 | Cleveland | Quine McCluskey Binary Classifier (QMBC) (LR, DT, RF, KNN, NB, SVM, and MLP) | 98.36% | 100% | 97.22% | 98.59% |
| [147] | 2023 | Comprehensive UCI datasets | Quine McCluskey Binary Classifier (QMBC) (LR, DT, RF, KNN, NB, SVM, and MLP) | 98.31% | 96.89% | 100% | 98.42% |
| [147] | 2023 | Cardiovascular Disease dataset | Quine McCluskey Binary Classifier (QMBC) (LR, DT, RF, KNN, NB, SVM, and MLP) | 99.95% | 100% | 99.91% | 99.95% |
| [231] | 2023 | Cleveland | Deep ANN, LSTM, CNN, and hybrid CNN with LSTM | 97.75% | 98.57% | 97.87% | 97.18% |
| [231] | 2023 | IEEE Dataport | Deep ANN, LSTM, CNN, and hybrid CNN with LSTM | 98.86% | 99.13% | 99.42% | 90.83% |
| [232] | 2022 | Cleveland | Stochastic Gradient Descent Classifiers, LR, SVM, NB, ConvSGLV, and ensemble methods | 93.00% | NP | NP | NP |
| [233] | 2022 | IEEE Dataport | NN, MLPNN, AB, SVM, LR, ANN, RF | 93.39% | NP | NP | NP |
| [234] | 2022 | Cleveland | NB, SVM, LR, DT, RF, and KNN | 94.1% | 97.1% | 94.8% | 90.8% |
| [235] | 2022 | Cleveland | NB, DT, LR KNN, SVM, GB, and RF algorithms | 85.18% | 0.83% | 90% | 86% |
| [236] | 2022 | Cleveland and Statlog | NB with weighted approach, 2 SVMs with XGBoost, an improved SVM (ISVM) based on duality optimization (DO) technique, and an XGBoost | 95.9% | 97.1% | 94.67% | 95.35% |
| [237] | 2022 | Heart disease dataset (IEEE Dataport) | Stacking-Based Ensemble Learning (XGB, ETs, RF, GB) | 92.34% | 92.00% | 93.49% | 92.74% |
| [238] | 2021 | PhysioNet’s arrhythmia Dataset | SVM, KNN, RF, ETs, Bagging, DT, LR, and Adaptive Boosting | 99.8% | 100% | 100% | 100% |
| [238] | 2021 | UCI’s Arrhythmia Dataset | SVM, KNN, RF, ETs, Bagging, DT, LR, and Adaptive Boosting | 95.6% | 93% | 93% | 93% |
| [239] | 2021 | Framingham | MaLCaDD using ensemble algorithm (10 fold) | 99.1% | NP | NP | NP |
| [239] | 2021 | Cardiovascular Disease dataset | MaLCaDD using ensemble algorithm (10 fold) | 98.0% | NP | NP | NP |
| [148] | 2021 | Cleveland | RF, DT, and hybrid model between RF and DT | 88.7% | NP | NP | NP |
| [240] | 2021 | Cleveland, Hungary, Switzerland, and VA Long Beach and Statlog | Hybrid classifiers like (DTBM), (RFBM), (KNNBM), (ABBM), (GBBM) | 99.05% | 99% | 98% | 99% |
| [239] | 2021 | Cleveland | MaLCaDD using ensemble algorithm (10 fold) | 95.5% | NP | NP | NP |
| [142] | 2021 | Comprehensive datasets (1025) | LR, ABM1, MLP, KNN, DT, RF | 100% | 100% | 100% | 100% |
| [140] | 2020 | StatLog | Two-tier ensemble PSO-based feature selection | 93.55% | NP | NP | 91.67% |
| [140] | 2020 | Hungarian | Two-tier ensemble PSO-based feature selection | 91.18% | NP | NP | 90.91% |
| [140] | 2020 | Cleveland | Two-tier ensemble PSO-based feature selection | 85.71% | NP | NP | 86.49% |
| [140] | 2020 | Z-Alizadeh Sani | Two-tier ensemble PSO-based feature selection | 98.13% | NP | NP | 96.90% |
| [139] | 2020 | Cleveland | LR, KNN, DT, SVM, RF | 91.80% | 93.55% | 90.62% | 92.06% |
| [57] | 2020 | Cardiovascular Disease dataset | DT, NB, LR, RF, SVM, and KNN | 73% | 75% | 68% | 73% |
| [141] | 2020 | Comprehensive dataset (1025) | RF, SVM, NB, and DT | 99% | 97.1% | 99.7% | 99.7% |
| [80] | 2019 | Cleveland | HRFLM | 88.4% | 90.1% | 92.8% | 90% |
| [125] | 2018 | Cleveland and Hungarian | NB, ANN, SVM, RF, LR | 98.13% | 98.1% | NP | 98.1% |
| [3] | 2017 | Cleveland | Multi-Layer Perceptron Neural Network (hidden layer size = 8) | 95.55% | 95.45% | NP | 95.45% |
References
- Atun, R. Transitioning health systems for multimorbidity. Lancet 2015, 386, 721–722. [Google Scholar] [CrossRef]
- Panch, T.; Szolovits, P.; Atun, R. Artificial intelligence, machine learning and health systems. J. Glob. Health 2018, 8, 020303. [Google Scholar] [CrossRef]
- Karayılan, T.; Kılıç, Ö. Prediction of heart disease using neural network. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; pp. 719–723. [Google Scholar]
- Nagendra, K.; Ussenaiah, M. A study on various data mining techniques used for heart diseases. Int. J. Recent Sci. Res. 2018, 9, 24350–24354. [Google Scholar]
- Ahmed, H.; Younis, E.M.; Hendawi, A.; Ali, A.A. Heart disease identification from patients’ social posts, machine learning solution on Spark. Future Gener. Comput. Syst. 2020, 111, 714–722. [Google Scholar] [CrossRef]
- Kelly, B.B.; Fuster, V. (Eds.) Promoting Cardiovascular Health in the Developing World: A Critical Challenge to Achieve Global Health; National Academies Press: Washington, DC, USA, 2010. [Google Scholar]
- Anjaneyulu, M.; Degala, D.P.; Devika, P.; Hema, V. Effective heart disease prediction using hybrid machine learning techniques. AIP Conf. Proc. 2023, 2492, 030070. [Google Scholar]
- Ansarullah, S.I.; Kumar, P. A systematic literature review on cardiovascular disorder identification using knowledge mining and machine learning method. Int. J. Recent Technol. Eng. 2019, 7, 1009–1015. [Google Scholar]
- Nazir, S.; Shahzad, S.; Mahfooz, S.; Nazir, M. Fuzzy logic based decision support system for component security evaluation. Int. Arab J. Inf. Technol. 2018, 15, 224–231. [Google Scholar]
- Dritsas, E.; Trigka, M. Efficient data-driven machine learning models for cardiovascular diseases risk prediction. Sensors 2023, 23, 1161. [Google Scholar] [CrossRef]
- Dai, W.; Brisimi, T.S.; Adams, W.G.; Mela, T.; Saligrama, V.; Paschalidis, I.C. Prediction of hospitalization due to heart diseases by supervised learning methods. Int. J. Med. Inform. 2015, 84, 189–197. [Google Scholar] [CrossRef]
- Bakar, W.A.W.A.; Josdi, N.L.N.B.; Man, M.B.; Zuhairi, M.A.B. A Review: Heart Disease Prediction in Machine Learning & Deep Learning. In Proceedings of the 2023 19th IEEE International Colloquium on Signal Processing & Its Applications (CSPA), Kedah, Malaysia, 3–4 March 2023; pp. 150–155. [Google Scholar]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Kwak, D.; Ali, A.; Imran, M.; Kwak, K.S. A smart healthcare monitoring system for heart disease prediction based on ensemble deep learning and feature fusion. Inf. Fusion 2020, 63, 208–222. [Google Scholar] [CrossRef]
- Xiao, F.; Miao, Q.; Xie, X.; Sun, L.; Wang, R. Indoor anti-collision alarm system based on wearable Internet of Things for smart healthcare. IEEE Commun. Mag. 2018, 56, 53–59. [Google Scholar] [CrossRef]
- Tian, S.; Yang, W.; Le Grange, J.M.; Wang, P.; Huang, W.; Ye, Z. Smart healthcare: Making medical care more intelligent. Glob. Health J. 2019, 3, 62–65. [Google Scholar] [CrossRef]
- Shah, T.; Yavari, A.; Mitra, K.; Saguna, S.; Jayaraman, P.P.; Rabhi, F.; Ranjan, R. Remote health care cyber-physical system: Quality of service (QoS) challenges and opportunities. IET Cyber-Phys. Syst. Theory Appl. 2016, 1, 40–48. [Google Scholar] [CrossRef]
- Li, J.P.; Haq, A.U.; Din, S.U.; Khan, J.; Khan, A.; Saboor, A. Heart disease identification method using machine learning classification in e-healthcare. IEEE Access 2020, 8, 107562–107582. [Google Scholar] [CrossRef]
- Li, W.; Chai, Y.; Khan, F.; Jan, S.R.U.; Verma, S.; Menon, V.G.; Kavita, f.; Li, X. A comprehensive survey on machine learning-based big data analytics for IoT-enabled smart healthcare system. Mob. Netw. Appl. 2021, 26, 234–252. [Google Scholar] [CrossRef]
- Methaila, A.; Kansal, P.; Arya, H.; Kumar, P. Early heart disease prediction using data mining techniques. Comput. Sci. Inf. Technol. J. 2014, 24, 53–59. [Google Scholar]
- Chaithra, N.; Madhu, B. Classification models on cardiovascular disease prediction using data mining techniques. Cardiovasc. Dis. Diagn. 2018, 6, 1–4. [Google Scholar]
- Pazos-López, P.; Peteiro-Vázquez, J.; Carcía-Campos, A.; García-Bueno, L.; de Torres, J.P.A.; Castro-Beiras, A. The causes, consequences, and treatment of left or right heart failure. Vasc. Health Risk Manag. 2011, 7, 237–254. [Google Scholar]
- Sadaka, M.; Aboelela, A.; Arab, S.; Nawar, M. Electrocardiogram as prognostic and diagnostic parameter in follow up of patients with heart failure. Alex. J. Med. 2013, 49, 145–152. [Google Scholar] [CrossRef][Green Version]
- Steinberg, Z.L.; Singh, H.S. How to plan and perform a diagnostic catheterisation in adult patients with congenital heart disease. Heart 2023, 109, 151–157. [Google Scholar] [CrossRef]
- Ye, G.; Gamage, P.T.; Balasubramanian, V.; Li, J.K.J.; Subasi, E.; Subasi, M.M.; Kaya, M. Short-Term Risk Estimation and Treatment Planning for Cardiovascular Disease Patients after First Diagnostic Catheterizations with Machine Learning Models. Appl. Sci. 2023, 13, 5191. [Google Scholar] [CrossRef]
- Chatterjee, P.; Cymberknop, L.J.; Armentano, R.L. IoT-based decision support system for intelligent healthcare—Applied to cardiovascular diseases. In Proceedings of the 2017 7th International Conference on Communication Systems and Network Technologies (CSNT), Nagpur, India, 11–13 November 2017; pp. 362–366. [Google Scholar]
- Alzubi, J.; Nayyar, A.; Kumar, A. Machine learning from theory to algorithms: An overview. J. Phys. Conf. Ser. 2018, 1142, 012012. [Google Scholar] [CrossRef]
- Elsayed, M.; Erol-Kantarci, M. AI-enabled future wireless networks: Challenges, opportunities, and open issues. IEEE Veh. Technol. Mag. 2019, 14, 70–77. [Google Scholar] [CrossRef]
- Gacanin, H. Autonomous wireless systems with artificial intelligence: A knowledge management perspective. IEEE Veh. Technol. Mag. 2019, 14, 51–59. [Google Scholar] [CrossRef]
- Chandrasekhar, N.; Peddakrishna, S. Enhancing Heart Disease Prediction Accuracy through Machine Learning Techniques and Optimization. Processes 2023, 11, 1210. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Mahmud, M.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Luna, S.A.; Siddique, Z. Machine-learning-based disease diagnosis: A comprehensive review. Healthcare 2022, 10, 541. [Google Scholar] [CrossRef]
- Yu, K.H.; Beam, A.L.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.R. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef]
- Peltonen, E.; Bennis, M.; Capobianco, M.; Debbah, M.; Ding, A.; Gil-Castiñeira, F.; Jurmu, M.; Karvonen, T.; Kelanti, M.; Kliks, A.; et al. 6G White Paper on Edge Intelligence. arXiv 2020, arXiv:2004.14850. [Google Scholar]
- Aljanabi, M.; Qutqut, M.H.; Hijjawi, M. Machine learning classification techniques for heart disease prediction: A review. Int. J. Eng. Technol. 2018, 7, 5373–5379. [Google Scholar]
- Xie, R.; Khalil, I.; Badsha, S.; Atiquzzaman, M. An intelligent healthcare system with data priority based on multi vital biosignals. Comput. Methods Programs Biomed. 2020, 185, 105126. [Google Scholar] [CrossRef] [PubMed]
- Pustokhina, I.V.; Pustokhin, D.A.; Gupta, D.; Khanna, A.; Shankar, K.; Nguyen, G.N. An effective training scheme for deep neural network in edge computing enabled Internet of medical things (IoMT) systems. IEEE Access 2020, 8, 107112–107123. [Google Scholar] [CrossRef]
- Vennemann, B.; Obrist, D.; Rösgen, T. Automated diagnosis of heart valve degradation using novelty detection algorithms and machine learning. PLoS ONE 2019, 14, e0222983. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Jiménez, M.A.; Ramirez-GarciaLuna, J.L.; Kolosovas-Machuca, E.S.; Drager, J.; González, F.J. Development and validation of an algorithm to predict the treatment modality of burn wounds using thermographic scans: Prospective cohort study. PLoS ONE 2018, 13, e0206477. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Liu, F.; Zhi, X.; Zhang, T.; Huang, C. An integrated deep learning algorithm for detecting lung nodules with low-dose CT and its application in 6G-enabled internet of medical things. IEEE Internet Things J. 2020, 8, 5274–5284. [Google Scholar] [CrossRef]
- Khan, M.A.; Algarni, F. A healthcare monitoring system for the diagnosis of heart disease in the IoMT cloud environment using MSSO-ANFIS. IEEE Access 2020, 8, 122259–122269. [Google Scholar] [CrossRef]
- Wang, S.; Summers, R.M. Machine learning and radiology. Med. Image Anal. 2012, 16, 933–951. [Google Scholar] [CrossRef]
- Ravì, D.; Wong, C.; Deligianni, F.; Berthelot, M.; Andreu-Perez, J.; Lo, B.; Yang, G.Z. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 2016, 21, 4–21. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Alam, T.E.; Trafalis, T.; Huebner, P. Deep MLP-CNN model using mixed-data to distinguish between COVID-19 and Non-COVID-19 patients. Symmetry 2020, 12, 1526. [Google Scholar] [CrossRef]
- Degerli, A.; Zabihi, M.; Kiranyaz, S.; Hamid, T.; Mazhar, R.; Hamila, R.; Gabbouj, M. Early detection of myocardial infarction in low-quality echocardiography. IEEE Access 2021, 9, 34442–34453. [Google Scholar] [CrossRef]
- Alloghani, M.; Al-Jumeily, D.; Mustafina, J.; Hussain, A.; Aljaaf, A.J. A systematic review on supervised and unsupervised machine learning algorithms for data science. In Supervised and Unsupervised Learning for Data Science; Springer: Cham, Switzerland, 2020; pp. 3–21. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Libbrecht, M.W.; Noble, W.S. Machine learning applications in genetics and genomics. Nat. Rev. Genet. 2015, 16, 321–332. [Google Scholar] [CrossRef]
- Fatima, M.; Pasha, M. Survey of machine learning algorithms for disease diagnostic. J. Intell. Learn. Syst. Appl. 2017, 9, 1–16. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- De Lannoy, G.; François, D.; Delbeke, J.; Verleysen, M. Weighted conditional random fields for supervised interpatient heartbeat classification. IEEE Trans. Biomed. Eng. 2011, 59, 241–247. [Google Scholar] [CrossRef] [PubMed]
- Dutta, A.; Batabyal, T.; Basu, M.; Acton, S.T. An efficient convolutional neural network for coronary heart disease prediction. Expert Syst. Appl. 2020, 159, 113408. [Google Scholar] [CrossRef]
- Banerjee, A.; Mohanta, B.K.; Panda, S.S.; Jena, D.; Sobhanayak, S. A secure IoT-fog enabled smart decision making system using machine learning for intensive care unit. In Proceedings of the 2020 International Conference on Artificial Intelligence and Signal Processing (AISP), Amaravati, India, 10–12 January 2020; pp. 1–6. [Google Scholar]
- Mamun, M.; Farjana, A.; Al Mamun, M.; Ahammed, M.S.; Rahman, M.M. Heart failure survival prediction using machine learning algorithm: Am I safe from heart failure? In Proceedings of the 2022 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 6–9 June 2022; pp. 194–200. [Google Scholar]
- Princy, R.J.P.; Parthasarathy, S.; Jose, P.S.H.; Lakshminarayanan, A.R.; Jeganathan, S. Prediction of cardiac disease using supervised machine learning algorithms. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 570–575. [Google Scholar]
- Choudhury, R.P.; Akbar, N. Beyond diabetes: A relationship between cardiovascular outcomes and glycaemic index. Cardiovasc. Res. 2021, 117, e97–e98. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Qureshi, M.; Daniyal, M.; Tawiah, K. A Novel Study on Machine Learning Algorithm-Based Cardiovascular Disease Prediction. Health Soc. Care Community 2023, 2023, 1406060. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Kevin, I.; Wang, K.; Wang, H.; Yang, L.T.; Jin, Q. Deep-learning-enhanced human activity recognition for Internet of healthcare things. IEEE Internet Things J. 2020, 7, 6429–6438. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Haq, A.U.; Li, J.P.; Memon, M.H.; Nazir, S.; Sun, R. A hybrid intelligent system framework for the prediction of heart disease using machine learning algorithms. Mob. Inf. Syst. 2018, 2018, 3860146. [Google Scholar] [CrossRef]
- Khemphila, A.; Boonjing, V. Heart disease classification using neural network and feature selection. In Proceedings of the 2011 21st International Conference on Systems Engineering, Las Vegas, NV, USA, 16–18 August 2011; pp. 406–409. [Google Scholar]
- Takci, H. Improvement of heart attack prediction by the feature selection methods. Turk. J. Electr. Eng. Comput. Sci. 2018, 26, 1–10. [Google Scholar] [CrossRef]
- Awan, S.M.; Riaz, M.U.; Khan, A.G. Prediction of heart disease using artificial neural network. VFAST Trans. Softw. Eng. 2018, 6, 51–61. [Google Scholar]
- Gárate-Escamila, A.K.; El Hassani, A.H.; Andrès, E. Classification models for heart disease prediction using feature selection and PCA. Inform. Med. Unlocked 2020, 19, 100330. [Google Scholar] [CrossRef]
- Martis, R.J.; Acharya, U.R.; Mandana, K.; Ray, A.K.; Chakraborty, C. Application of principal component analysis to ECG signals for automated diagnosis of cardiac health. Expert Syst. Appl. 2012, 39, 11792–11800. [Google Scholar] [CrossRef]
- Dolatabadi, A.D.; Khadem, S.E.Z.; Asl, B.M. Automated diagnosis of coronary artery disease (CAD) patients using optimized SVM. Comput. Methods Programs Biomed. 2017, 138, 117–126. [Google Scholar] [CrossRef] [PubMed]
- Arabasadi, Z.; Alizadehsani, R.; Roshanzamir, M.; Moosaei, H.; Yarifard, A.A. Computer aided decision making for heart disease detection using hybrid neural network-Genetic algorithm. Comput. Methods Programs Biomed. 2017, 141, 19–26. [Google Scholar] [CrossRef] [PubMed]
- Long, N.C.; Meesad, P.; Unger, H. A highly accurate firefly based algorithm for heart disease prediction. Expert Syst. Appl. 2015, 42, 8221–8231. [Google Scholar] [CrossRef]
- Sudarshan, V.K.; Acharya, U.R.; Oh, S.L.; Adam, M.; Tan, J.H.; Chua, C.K.; Chua, K.P.; San Tan, R. Automated diagnosis of congestive heart failure using dual tree complex wavelet transform and statistical features extracted from 2 s of ECG signals. Comput. Biol. Med. 2017, 83, 48–58. [Google Scholar] [CrossRef]
- Ramalingam, V.; Dandapath, A.; Raja, M.K. Heart disease prediction using machine learning techniques: A survey. Int. J. Eng. Technol. 2018, 7, 684–687. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, Y.; Peng, J.; Zhang, L.; Xu, L.; Yan, K.; Li, L. DML-GANR: Deep metric learning with generative adversarial network regularization for high spatial resolution remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8888–8904. [Google Scholar] [CrossRef]
- Ghorbani, R.; Ghousi, R.; Makui, A.; Atashi, A. A new hybrid predictive model to predict the early mortality risk in intensive care units on a highly imbalanced dataset. IEEE Access 2020, 8, 141066–141079. [Google Scholar] [CrossRef]
- Ding, J.; Errapotu, S.M.; Guo, Y.; Zhang, H.; Yuan, D.; Pan, M. Private empirical risk minimization with analytic gaussian mechanism for healthcare system. IEEE Trans. Big Data 2020, 8, 1107–1117. [Google Scholar] [CrossRef]
- Jabeen, F.; Maqsood, M.; Ghazanfar, M.A.; Aadil, F.; Khan, S.; Khan, M.F.; Mehmood, I. An IoT based efficient hybrid recommender system for cardiovascular disease. Peer-to-Peer Netw. Appl. 2019, 12, 1263–1276. [Google Scholar] [CrossRef]
- Muzammal, M.; Talat, R.; Sodhro, A.H.; Pirbhulal, S. A multi-sensor data fusion enabled ensemble approach for medical data from body sensor networks. Inf. Fusion 2020, 53, 155–164. [Google Scholar] [CrossRef]
- Paul, A.K.; Shill, P.C.; Rabin, M.R.I.; Murase, K. Adaptive weighted fuzzy rule-based system for the risk level assessment of heart disease. Appl. Intell. 2018, 48, 1739–1756. [Google Scholar] [CrossRef]
- Ahmad, W.; Ahmad, A.; Iqbal, A.; Hamayun, M.; Hussain, A.; Rehman, G.; Khan, S.; Khan, U.U.; Khan, D.; Huang, L. Intelligent hepatitis diagnosis using adaptive neuro-fuzzy inference system and information gain method. Soft Comput. 2019, 23, 10931–10938. [Google Scholar] [CrossRef]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Jothi Prakash, V.; Karthikeyan, N. Enhanced evolutionary feature selection and ensemble method for cardiovascular disease prediction. Interdiscip. Sci. Comput. Life Sci. 2021, 13, 389–412. [Google Scholar] [CrossRef] [PubMed]
- Samir, A.A.; Rashwan, A.R.; Sallam, K.M.; Chakrabortty, R.K.; Ryan, M.J.; Abohany, A.A. Evolutionary algorithm-based convolutional neural network for predicting heart diseases. Comput. Ind. Eng. 2021, 161, 107651. [Google Scholar] [CrossRef]
- Srinivas, P.; Katarya, R. hyOPTXg: OPTUNA hyper-parameter optimization framework for predicting cardiovascular disease using XGBoost. Biomed. Signal Process. Control 2022, 73, 103456. [Google Scholar] [CrossRef]
- Ay, Ş.; Ekinci, E.; Garip, Z. A comparative analysis of meta-heuristic optimization algorithms for feature selection on ML-based classification of heart-related diseases. J. Supercomput. 2023, 79, 11797–11826. [Google Scholar] [CrossRef] [PubMed]
- Cocianu, C.L.; Uscatu, C.R.; Kofidis, K.; Muraru, S.; Văduva, A.G. Classical, Evolutionary, and Deep Learning Approaches of Automated Heart Disease Prediction: A Case Study. Electronics 2023, 12, 1663. [Google Scholar] [CrossRef]
- Villamil, H.C.; Espitia, H.E.; Bejarano, L.A. Multiobjective Optimization of Fuzzy System for Cardiovascular Risk Classification. Computation 2023, 11, 147. [Google Scholar] [CrossRef]
- Karthikeyan, G.; Komarasamy, G.; Daniel Madan Raja, S. Design of an efficient decision support system using evolutionary deep forward network model. J. Intell. Fuzzy Syst. 2023, 44, 7027–7042. [Google Scholar] [CrossRef]
- Al Bataineh, A.; Manacek, S. MLP-PSO hybrid algorithm for heart disease prediction. J. Pers. Med. 2022, 12, 1208. [Google Scholar] [CrossRef]
- Ahmad, Z.; Li, J.; Mahmood, T. Adaptive Hyperparameter Fine-Tuning for Boosting the Robustness and Quality of the Particle Swarm Optimization Algorithm for Non-Linear RBF Neural Network Modelling and Its Applications. Mathematics 2023, 11, 242. [Google Scholar] [CrossRef]
- Bashir, S.; Khan, Z.S.; Khan, F.H.; Anjum, A.; Bashir, K. Improving heart disease prediction using feature selection approaches. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 619–623. [Google Scholar]
- Fassnacht, F.E.; Neumann, C.; Förster, M.; Buddenbaum, H.; Ghosh, A.; Clasen, A.; Joshi, P.K.; Koch, B. Comparison of feature reduction algorithms for classifying tree species with hyperspectral data on three central European test sites. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2547–2561. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. A comprehensive comparison on evolutionary feature selection approaches to classification. Int. J. Comput. Intell. Appl. 2015, 14, 1550008. [Google Scholar] [CrossRef]
- Tan, F.; Fu, X.; Zhang, Y.; Bourgeois, A.G. A genetic algorithm-based method for feature subset selection. Soft Comput. 2008, 12, 111–120. [Google Scholar] [CrossRef]
- Nyathi, T.; Pillay, N. Comparison of a genetic algorithm to grammatical evolution for automated design of genetic programming classification algorithms. Expert Syst. Appl. 2018, 104, 213–234. [Google Scholar] [CrossRef]
- Gokulnath, C.B.; Shantharajah, S. An optimized feature selection based on genetic approach and support vector machine for heart disease. Clust. Comput. 2019, 22, 14777–14787. [Google Scholar] [CrossRef]
- Kalamkar, S.; A, G.M. Clinical data fusion and machine learning techniques for smart healthcare. In Proceedings of the 2020 International Conference on Industry 4.0 Technology (I4Tech), Pune, India, 13–15 February 2020; pp. 211–216. [Google Scholar]
- Ghazal, T.M.; Hasan, M.K.; Alshurideh, M.T.; Alzoubi, H.M.; Ahmad, M.; Akbar, S.S.; Al Kurdi, B.; Akour, I.A. IoT for smart cities: Machine learning approaches in smart healthcare—A review. Future Internet 2021, 13, 218. [Google Scholar] [CrossRef]
- Nusinovici, S.; Tham, Y.C.; Yan, M.Y.C.; Ting, D.S.W.; Li, J.; Sabanayagam, C.; Wong, T.Y.; Cheng, C.Y. Logistic regression was as good as machine learning for predicting major chronic diseases. J. Clin. Epidemiol. 2020, 122, 56–69. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Ross Quinlan, J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Haq, A.U.; Li, J.; Khan, J.; Memon, M.H.; Parveen, S.; Raji, M.F.; Akbar, W.; Ahmad, T.; Ullah, S.; Shoista, L.; et al. Identifying the predictive capability of machine learning classifiers for designing heart disease detection system. In Proceedings of the 2019 16th International Computer Conference on Wavelet Active Media Technology and Information Processing, Chengdu, China, 14–15 December 2019; pp. 130–138. [Google Scholar]
- Enriko, I.K.A.; Suryanegara, M.; Gunawan, D. Heart disease prediction system using k-Nearest neighbor algorithm with simplified patient’s health parameters. J. Telecommun. Electron. Comput. Eng. (JTEC) 2016, 8, 59–65. [Google Scholar]
- Palimkar, P.; Shaw, R.N.; Ghosh, A. Machine learning technique to prognosis diabetes disease: Random forest classifier approach. In Advanced Computing and Intelligent Technologies: Proceedings of ICACIT 2021; Springer: Singapore, 2022; pp. 219–244. [Google Scholar]
- Haq, A.U.; Li, J.; Memon, M.H.; Memon, M.H.; Khan, J.; Marium, S.M. Heart disease prediction system using model of machine learning and sequential backward selection algorithm for features selection. In Proceedings of the 2019 IEEE 5th International Conference for Convergence in Technology (I2CT), Bombay, India, 29–31 March 2019; pp. 1–4. [Google Scholar]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers—A Tutorial. ACM Comput. Surv. (CSUR) 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining adaboost. In Empirical Inference: Festschrift in Honor of Vladimir N. Vapnik; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Schölkopf, B.; Luo, Z.; Vovk, V. Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Berrar, D. Bayes’ theorem and naive Bayes classifier. Encycl. Bioinform. Comput. Biol. ABC Bioinform. 2018, 403, 412. [Google Scholar]
- Detrano, R.; Janosi, A.; Steinbrunn, W.; Pfisterer, M.; Schmid, J.J.; Sandhu, S.; Guppy, K.H.; Lee, S.; Froelicher, V. International application of a new probability algorithm for the diagnosis of coronary artery disease. Am. J. Cardiol. 1989, 64, 304–310. [Google Scholar] [CrossRef]
- Gudadhe, M.; Wankhade, K.; Dongre, S. Decision support system for heart disease based on support vector machine and artificial neural network. In Proceedings of the 2010 International Conference on Computer and Communication Technology (ICCCT), Allahabad, India, 17–19 September 2010; pp. 741–745. [Google Scholar]
- Kadhim, M.A.; Radhi, A.M. Heart disease classification using optimized Machine learning algorithms. Iraqi J. Comput. Sci. Math. 2023, 4, 31–42. [Google Scholar] [CrossRef]
- Kahramanli, H.; Allahverdi, N. Design of a hybrid system for the diabetes and heart diseases. Expert Syst. Appl. 2008, 35, 82–89. [Google Scholar] [CrossRef]
- Das, R.; Turkoglu, I.; Sengur, A. Effective diagnosis of heart disease through neural networks ensembles. Expert Syst. Appl. 2009, 36, 7675–7680. [Google Scholar] [CrossRef]
- Jabbar, M.A.; Deekshatulu, B.; Chandra, P. Classification of heart disease using artificial neural network and feature subset selection. Glob. J. Comput. Sci. Technol. Neural Artif. Intell. 2013, 13, 4–8. [Google Scholar]
- Sa, S. Intelligent heart disease prediction system using data mining techniques. Int. J. Healthc. Biomed. Res. 2013, 1, 94–101. [Google Scholar]
- Olaniyi, E.O.; Oyedotun, O.K.; Adnan, K. Heart diseases diagnosis using neural networks arbitration. Int. J. Intell. Syst. Appl. 2015, 7, 72. [Google Scholar] [CrossRef]
- Samuel, O.W.; Asogbon, G.M.; Sangaiah, A.K.; Fang, P.; Li, G. An integrated decision support system based on ANN and Fuzzy_AHP for heart failure risk prediction. Expert Syst. Appl. 2017, 68, 163–172. [Google Scholar] [CrossRef]
- Liu, X.; Wang, X.; Su, Q.; Zhang, M.; Zhu, Y.; Wang, Q.; Wang, Q. A hybrid classification system for heart disease diagnosis based on the RFRS method. Comput. Math. Methods Med. 2017, 2017, 8272091. [Google Scholar] [CrossRef]
- Geweid, G.G.; Abdallah, M.A. A new automatic identification method of heart failure using improved support vector machine based on duality optimization technique. IEEE Access 2019, 7, 149595–149611. [Google Scholar] [CrossRef]
- Mondéjar-Guerra, V.; Novo, J.; Rouco, J.; Penedo, M.G.; Ortega, M. Heartbeat classification fusing temporal and morphological information of ECGs via ensemble of classifiers. Biomed. Signal Process. Control 2019, 47, 41–48. [Google Scholar] [CrossRef]
- Yıldırım, Ö.; Pławiak, P.; Tan, R.S.; Acharya, U.R. Arrhythmia detection using deep convolutional neural network with long duration ECG signals. Comput. Biol. Med. 2018, 102, 411–420. [Google Scholar] [CrossRef] [PubMed]
- Kiranyaz, S.; Ince, T.; Gabbouj, M. Real-time patient-specific ECG classification by 1-D convolutional neural networks. IEEE Trans. Biomed. Eng. 2015, 63, 664–675. [Google Scholar] [CrossRef] [PubMed]
- Dixit, S.; Kala, R. Early detection of heart diseases using a low-cost compact ECG sensor. Multimed. Tools Appl. 2021, 80, 32615–32637. [Google Scholar] [CrossRef]
- Bemando, C.; Miranda, E.; Aryuni, M. Machine-learning-based prediction models of coronary heart disease using naïve bayes and random forest algorithms. In Proceedings of the 2021 International Conference on Software Engineering & Computer Systems and 4th International Conference on Computational Science and Information Management (ICSECS-ICOCSIM), Pekan, Malaysia, 24–26 August 2021; pp. 232–237. [Google Scholar]
- Jan, M.; Awan, A.A.; Khalid, M.S.; Nisar, S. Ensemble approach for developing a smart heart disease prediction system using classification algorithms. Res. Rep. Clin. Cardiol. 2018, 9, 33–45. [Google Scholar] [CrossRef]
- Ram Kumar, R.; Polepaka, S. Performance comparison of random forest classifier and convolution neural network in predicting heart diseases. In Proceedings of the Third International Conference on Computational Intelligence and Informatics: ICCII 2018; Springer: Singapore, 2020; pp. 683–691. [Google Scholar]
- Singh, H.; Navaneeth, N.; Pillai, G.N. Multisurface proximal SVM based decision trees for heart disease classification. In Proceedings of the TENCON 2019–2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 13–18. [Google Scholar]
- Desai, S.D.; Giraddi, S.; Narayankar, P.; Pudakalakatti, N.R.; Sulegaon, S. Back-propagation neural network versus logistic regression in heart disease classification. In Proceedings of the Advanced Computing and Communication Technologies: Proceedings of the 11th ICACCT 2018; Springer: Singapore, 2019; pp. 133–144. [Google Scholar]
- Patil, D.D.; Singh, R.; Thakare, V.M.; Gulve, A.K. Analysis of ECG arrhythmia for heart disease detection using SVM and cuckoo search optimized neural network. Int. J. Eng. Technol. 2018, 7, 27–33. [Google Scholar] [CrossRef]
- Liu, N.; Lin, Z.; Cao, J.; Koh, Z.; Zhang, T.; Huang, G.B.; Ser, W.; Ong, M.E.H. An intelligent scoring system and its application to cardiac arrest prediction. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 1324–1331. [Google Scholar] [CrossRef] [PubMed]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adam, M.; Gertych, A.; San Tan, R. A deep convolutional neural network model to classify heartbeats. Comput. Biol. Med. 2017, 89, 389–396. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Si, Y.; Wang, D.; Guo, B. Automatic recognition of arrhythmia based on principal component analysis network and linear support vector machine. Comput. Biol. Med. 2018, 101, 22–32. [Google Scholar] [CrossRef]
- Saxena, R.; Johri, A.; Deep, V.; Sharma, P. Heart diseases prediction system using CHC-TSS Evolutionary, KNN, and decision tree classification algorithm. In Proceedings of the Emerging Technologies in Data Mining and Information Security: Proceedings of IEMIS 2018; Springer: Singapore, 2019; Volume 2, pp. 809–819. [Google Scholar]
- Basheer, S.; Mathew, R.M.; Devi, M.S. Ensembling coalesce of logistic regression classifier for heart disease prediction using machine learning. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 127–133. [Google Scholar] [CrossRef]
- Soni, J.; Ansari, U.; Sharma, D.; Soni, S. Predictive data mining for medical diagnosis: An overview of heart disease prediction. Int. J. Comput. Appl. 2011, 17, 43–48. [Google Scholar] [CrossRef]
- Hinchliffe, R.; Brownrigg, J.; Apelqvist, J.; Boyko, E.; Fitridge, R.; Mills, J.; Reekers, J.; Shearman, C.; Zierler, R.; Schaper, N.; et al. IWGDF guidance on the diagnosis, prognosis and management of peripheral artery disease in patients with foot ulcers in diabetes. Diabetes/Metab. Res. Rev. 2016, 32, 37–44. [Google Scholar] [CrossRef]
- Al-Milli, N. Backpropogation neural network for prediction of heart disease. J. Theor. Appl. Inf. Technol. 2013, 56, 131–135. [Google Scholar]
- Singh, A.; Kumar, R. Heart disease prediction using machine learning algorithms. In Proceedings of the 2020 International Conference on Electrical and Electronics Engineering (ICE3), Gorakhpur, India, 14–15 February 2020; pp. 452–457. [Google Scholar]
- Hashi, E.K.; Zaman, M.S.U. Developing a hyperparameter tuning based machine learning approach of heart disease prediction. J. Appl. Sci. Process Eng. 2020, 7, 631–647. [Google Scholar] [CrossRef]
- Tama, B.A.; Im, S.; Lee, S. Improving an intelligent detection system for coronary heart disease using a two-tier classifier ensemble. BioMed Res. Int. 2020, 2020, 9816142. [Google Scholar] [CrossRef]
- Shah, D.; Patel, S.; Bharti, S.K. Heart disease prediction using machine learning techniques. SN Comput. Sci. 2020, 1, 1–6. [Google Scholar] [CrossRef]
- Ali, M.M.; Paul, B.K.; Ahmed, K.; Bui, F.M.; Quinn, J.M.; Moni, M.A. Heart disease prediction using supervised machine learning algorithms: Performance analysis and comparison. Comput. Biol. Med. 2021, 136, 104672. [Google Scholar] [CrossRef] [PubMed]
- Maji, S.; Arora, S. Decision tree algorithms for prediction of heart disease. In Proceedings of the Information and Communication Technology for Competitive Strategies: Proceedings of Third International Conference on ICTCS 2017; Springer: Singapore, 2019; pp. 447–454. [Google Scholar]
- Nikhar, S.; Karandikar, A. Prediction of heart disease using machine learning algorithms. Int. J. Adv. Eng. Manag. Sci. 2016, 2, 239484. [Google Scholar]
- Patel, S.B.; Yadav, P.K.; Shukla, D. Predict the diagnosis of heart disease patients using classification mining techniques. IOSR J. Agric. Vet. Sci. (IOSR-JAVS) 2013, 4, 61–64. [Google Scholar]
- Nguyen, T.; Khosravi, A.; Creighton, D.; Nahavandi, S. Classification of healthcare data using genetic fuzzy logic system and wavelets. Expert Syst. Appl. 2015, 42, 2184–2197. [Google Scholar] [CrossRef]
- Kapila, R.; Ragunathan, T.; Saleti, S.; Lakshmi, T.J.; Ahmad, M.W. Heart Disease Prediction using Novel Quine McCluskey Binary Classifier (QMBC). IEEE Access 2023, 11, 64324–64347. [Google Scholar] [CrossRef]
- Kavitha, M.; Gnaneswar, G.; Dinesh, R.; Sai, Y.R.; Suraj, R.S. Heart disease prediction using hybrid machine learning model. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 1329–1333. [Google Scholar]
- Mehmood, A.; Iqbal, M.; Mehmood, Z.; Irtaza, A.; Nawaz, M.; Nazir, T.; Masood, M. Prediction of heart disease using deep convolutional neural networks. Arab. J. Sci. Eng. 2021, 46, 3409–3422. [Google Scholar] [CrossRef]
- Ramprakash, P.; Sarumathi, R.; Mowriya, R.; Nithyavishnupriya, S. Heart disease prediction using deep neural network. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 666–670. [Google Scholar]
- Hoodbhoy, Z.; Jiwani, U.; Sattar, S.; Salam, R.; Hasan, B.; Das, J.K. Diagnostic accuracy of machine learning models to identify congenital heart disease: A meta-analysis. Front. Artif. Intell. 2021, 4, 708365. [Google Scholar] [CrossRef]
- Jin, B.; Che, C.; Liu, Z.; Zhang, S.; Yin, X.; Wei, X. Predicting the risk of heart failure with EHR sequential data modeling. IEEE Access 2018, 6, 9256–9261. [Google Scholar] [CrossRef]
- McPhee, S.J.; Papadakis, M.A.; Rabow, M.W. (Eds.) Current Medical Diagnosis & Treatment 2010; McGraw-Hill Medical: New York, NY, USA, 2010. [Google Scholar]
- Beyer, M.A.; Laney, D. The Importance of “Big Data”: A Definition; G00235055; Gartner: Stamford, CT, USA, 2012. [Google Scholar]
- Forkan, A.R.M.; Khalil, I. PEACE-Home: Probabilistic estimation of abnormal clinical events using vital sign correlations for reliable home-based monitoring. Pervasive Mob. Comput. 2017, 38, 296–311. [Google Scholar] [CrossRef]
- Jiang, P.; Winkley, J.; Zhao, C.; Munnoch, R.; Min, G.; Yang, L.T. An intelligent information forwarder for healthcare big data systems with distributed wearable sensors. IEEE Syst. J. 2014, 10, 1147–1159. [Google Scholar] [CrossRef]
- Salem, O.; Liu, Y.; Mehaoua, A.; Boutaba, R. Online anomaly detection in wireless body area networks for reliable healthcare monitoring. IEEE J. Biomed. Health Inform. 2014, 18, 1541–1551. [Google Scholar] [CrossRef]
- Teich, J.M.; Osheroff, J.A.; Pifer, E.A.; Sittig, D.F.; Jenders, R.A. Clinical decision support in electronic prescribing: Recommendations and an action plan: Report of the joint clinical decision support workgroup. J. Am. Med. Inform. Assoc. 2005, 12, 365–376. [Google Scholar] [CrossRef]
- UCI. Heart Disease; UCI Machine Learning Repository: Irvine, CA, USA, 1988. [Google Scholar] [CrossRef]
- Framingham. Framingham Heart Disease Study. 2023. Available online: https://www.framinghamheartstudy.org/fhs-for-researchers/ (accessed on 22 May 2023).
- Cardiovascular. Cardiovascular Disease Dataset. 2023. Available online: https://www.kaggle.com/datasets/sulianova/cardiovascular-disease-dataset. (accessed on 22 May 2023).
- ECG. Physikalisch Technische Bundesanstalt Diagnostic ECG Dataset. Available online: https://www.physionet.org/content/ptbdb/1.0.0/ (accessed on 22 May 2023).
- Kaggle. Stroke Prediction Dataset. 2023. Available online: https://www.kaggle.com/datasets/fedesoriano/stroke-prediction-dataset (accessed on 22 May 2023).
- Ras, G.; van Gerven, M.; Haselager, P. Explanation methods in deep learning: Users, values, concerns and challenges. In Explainable and Interpretable Models in Computer Vision and Machine Learning; Springer: Cham, Switzerland, 2018; pp. 19–36. [Google Scholar]
- General Data Protection Regulation. General data protection regulation (GDPR). In Intersoft Consulting; European Union: Brussels, Belgium, 2018; Volume 24. [Google Scholar]
- Alabdulatif, A.; Khalil, I.; Forkan, A.R.M.; Atiquzzaman, M. Real-time secure health surveillance for smarter health communities. IEEE Commun. Mag. 2018, 57, 122–129. [Google Scholar] [CrossRef]
- Narwal, B.; Mohapatra, A.K. A survey on security and authentication in wireless body area networks. J. Syst. Archit. 2021, 113, 101883. [Google Scholar] [CrossRef]
- Benhar, H.; Idri, A.; Fernández-Alemán, J. Data preprocessing for heart disease classification: A systematic literature review. Comput. Methods Programs Biomed. 2020, 195, 105635. [Google Scholar] [CrossRef]
- Ambarwari, A.; Adrian, Q.J.; Herdiyeni, Y. Analysis of the effect of data scaling on the performance of the machine learning algorithm for plant identification. J. RESTI (Rekayasa Sistem Dan Teknologi Informasi) 2020, 4, 117–122. [Google Scholar] [CrossRef]
- Ilyas, I.F.; Chu, X. Data Cleaning; Morgan & Claypool: San Rafael, CA, USA, 2019. [Google Scholar]
- Grampurohit, S.; Sagarnal, C. Disease prediction using machine learning algorithms. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; pp. 1–7. [Google Scholar]
- Ting, D.S.W.; Pasquale, L.R.; Peng, L.; Campbell, J.P.; Lee, A.Y.; Raman, R.; Tan, G.S.W.; Schmetterer, L.; Keane, P.A.; Wong, T.Y. Artificial intelligence and deep learning in ophthalmology. Br. J. Ophthalmol. 2019, 103, 167–175. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Yahaya, L.; Oye, N.D.; Garba, E.J. A comprehensive review on heart disease prediction using data mining and machine learning techniques. Am. J. Artif. Intell. 2020, 4, 20–29. [Google Scholar] [CrossRef]
- Haq, A.U.; Li, J.P.; Khan, J.; Memon, M.H.; Nazir, S.; Ahmad, S.; Khan, G.A.; Ali, A. Intelligent machine learning approach for effective recognition of diabetes in E-healthcare using clinical data. Sensors 2020, 20, 2649. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Idrees, F.; Rajarajan, M.; Conti, M.; Chen, T.M.; Rahulamathavan, Y. PIndroid: A novel Android malware detection system using ensemble learning methods. Comput. Secur. 2017, 68, 36–46. [Google Scholar] [CrossRef]
- Saqlain, M.; Jargalsaikhan, B.; Lee, J.Y. A voting ensemble classifier for wafer map defect patterns identification in semiconductor manufacturing. IEEE Trans. Semicond. Manuf. 2019, 32, 171–182. [Google Scholar] [CrossRef]
- Romdhane, T.F.; Pr, M.A. Electrocardiogram heartbeat classification based on a deep convolutional neural network and focal loss. Comput. Biol. Med. 2020, 123, 103866. [Google Scholar] [CrossRef]
- Pouriyeh, S.; Vahid, S.; Sannino, G.; De Pietro, G.; Arabnia, H.; Gutierrez, J. A comprehensive investigation and comparison of machine learning techniques in the domain of heart disease. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 204–207. [Google Scholar]
- Normawati, D.; Ismi, D.P. K-fold cross validation for selection of cardiovascular disease diagnosis features by applying rule-based datamining. Signal Image Process. Lett. 2019, 1, 62–72. [Google Scholar] [CrossRef]
- Pires, I.M.; Marques, G.; Garcia, N.M.; Ponciano, V. Machine learning for the evaluation of the presence of heart disease. Procedia Comput. Sci. 2020, 177, 432–437. [Google Scholar] [CrossRef]
- Ananey-Obiri, D.; Sarku, E. Predicting the presence of heart diseases using comparative data mining and machine learning algorithms. Int. J. Comput. Appl. 2020, 176, 17–21. [Google Scholar] [CrossRef]
- Wong, T.T.; Yeh, P.Y. Reliable accuracy estimates from k-fold cross validation. IEEE Trans. Knowl. Data Eng. 2019, 32, 1586–1594. [Google Scholar] [CrossRef]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef] [PubMed]
- Wijesinghe, I.; Gamage, C.; Perera, I.; Chitraranjan, C. A smart telemedicine system with deep learning to manage diabetic retinopathy and foot ulcers. In Proceedings of the 2019 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 3–5 July 2019; pp. 686–691. [Google Scholar]
- Shaw, J.; Rudzicz, F.; Jamieson, T.; Goldfarb, A. Artificial intelligence and the implementation challenge. J. Med. Internet Res. 2019, 21, e13659. [Google Scholar] [CrossRef] [PubMed]
- Ghoshal, B.; Tucker, A. Estimating uncertainty and interpretability in deep learning for coronavirus (COVID-19) detection. arXiv 2020, arXiv:2003.10769. [Google Scholar]
- Huynh-Thu, V.A.; Saeys, Y.; Wehenkel, L.; Geurts, P. Statistical interpretation of machine learning-based feature importance scores for biomarker discovery. Bioinformatics 2012, 28, 1766–1774. [Google Scholar] [CrossRef]
- Kumarakulasinghe, N.B.; Blomberg, T.; Liu, J.; Leao, A.S.; Papapetrou, P. Evaluating local interpretable model-agnostic explanations on clinical machine learning classification models. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 7–12. [Google Scholar]
- Neves, I.; Folgado, D.; Santos, S.; Barandas, M.; Campagner, A.; Ronzio, L.; Cabitza, F.; Gamboa, H. Interpretable heartbeat classification using local model-agnostic explanations on ECGs. Comput. Biol. Med. 2021, 133, 104393. [Google Scholar] [CrossRef]
- Assegie, T.A. Evaluation of Local Interpretable Model-Agnostic Explanation and Shapley Additive Explanation for Chronic Heart Disease Detection. Proc. Eng. Technol. Innov. 2023, 23, 48–59. [Google Scholar]
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning-based prediction models in healthcare. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1379. [Google Scholar] [CrossRef]
- Sixian, L.; Imamura, Y.; Ahmed, A. Application of Shapley Additive Explanation towards Determining Personalized Triage from Health Checkup Data. In Proceedings of the International Conference on Pervasive Computing Technologies for Healthcare; Springer: Cham, Switzerland, 2022; pp. 496–509. [Google Scholar]
- Kim, Y.; Kim, Y. Explainable heat-related mortality with random forest and SHapley Additive exPlanations (SHAP) models. Sustain. Cities Soc. 2022, 79, 103677. [Google Scholar] [CrossRef]
- Miranda, E.; Adiarto, S.; Bhatti, F.M.; Zakiyyah, A.Y.; Aryuni, M.; Bernando, C. Understanding Arteriosclerotic Heart Disease Patients Using Electronic Health Records: A Machine Learning and Shapley Additive exPlanations Approach. Healthc. Inform. Res. 2023, 29, 228–238. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Arumugam, K.; Naved, M.; Shinde, P.P.; Leiva-Chauca, O.; Huaman-Osorio, A.; Gonzales-Yanac, T. Multiple disease prediction using Machine learning algorithms. Mater. Today Proc. 2023, 80, 3682–3685. [Google Scholar] [CrossRef]
- Albahri, O.S.; Albahri, A.S.; Zaidan, A.; Zaidan, B.; Alsalem, M.; Mohsin, A.H.; Mohammed, K.; Alamoodi, A.H.; Nidhal, S.; Enaizan, O.; et al. Fault-tolerant mHealth framework in the context of IoT-based real-time wearable health data sensors. IEEE Access 2019, 7, 50052–50080. [Google Scholar] [CrossRef]
- Marcinkevičs, R.; Vogt, J.E. Interpretability and explainability: A machine learning zoo mini-tour. arXiv 2020, arXiv:2012.01805. [Google Scholar]
- Buettner, R.; Kuri, T.; Feist, A.; Hudak, J. Overview of Machine Learning Approaches Applied in Disease Profiling. In Proceedings of the 2020 IEEE Symposium on Industrial Electronics & Applications (ISIEA), Kuala Lumpur, Malaysia, 17–18 July 2020; pp. 1–5. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef]
- Nazir, S.; Ali, Y.; Ullah, N.; García-Magariño, I. Internet of things for healthcare using effects of mobile computing: A systematic literature review. Wirel. Commun. Mob. Comput. 2019, 2019, 1–20. [Google Scholar] [CrossRef]
- Mani, N.; Singh, A.; Nimmagadda, S.L. An IoT guided healthcare monitoring system for managing real-time notifications by fog computing services. Procedia Comput. Sci. 2020, 167, 850–859. [Google Scholar] [CrossRef]
- Selvaraj, S.; Sundaravaradhan, S. Challenges and opportunities in IoT healthcare systems: A systematic review. SN Appl. Sci. 2020, 2, 139. [Google Scholar] [CrossRef]
- Seetharam, K.; Kagiyama, N.; Sengupta, P.P. Application of mobile health, telemedicine and artificial intelligence to echocardiography. Echo Res. Pract. 2019, 6, R41–R52. [Google Scholar] [CrossRef] [PubMed]
- Jagpal, A.; Navarro-Millán, I. Cardiovascular co-morbidity in patients with rheumatoid arthritis: A narrative review of risk factors, cardiovascular risk assessment and treatment. BMC Rheumatol. 2018, 2, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Casalino, G.; Castellano, G.; Kaymak, U.; Zaza, G. Balancing accuracy and interpretability through neuro-fuzzy models for cardiovascular risk assessment. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021; pp. 1–8. [Google Scholar]
- Dhanvijay, M.M.; Patil, S.C. Internet of Things: A survey of enabling technologies in healthcare and its applications. Comput. Netw. 2019, 153, 113–131. [Google Scholar] [CrossRef]
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for Internet of Things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Ding, Y.; Wu, G.; Chen, D.; Zhang, N.; Gong, L.; Cao, M.; Qin, Z. DeepEDN: A deep-learning-based image encryption and decryption network for internet of medical things. IEEE Internet Things J. 2020, 8, 1504–1518. [Google Scholar] [CrossRef]
- Puspitasari, R.D.I.; Ma’sum, M.A.; Alhamidi, M.R.; Jatmiko, W. Generative adversarial networks for unbalanced fetal heart rate signal classification. ICT Express 2022, 8, 239–243. [Google Scholar] [CrossRef]
- Qadri, Y.A.; Nauman, A.; Zikria, Y.B.; Vasilakos, A.V.; Kim, S.W. The future of healthcare internet of things: A survey of emerging technologies. IEEE Commun. Surv. Tutor. 2020, 22, 1121–1167. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 119. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Taha, Z.K.; Yaw, C.T.; Koh, S.P.; Tiong, S.K.; Kadirgama, K.; Benedict, F.; Tan, J.D.; Balasubramaniam, Y.A. A Survey of Federated Learning from Data Perspective in the Healthcare Domain: Challenges, Methods, and Future Directions. IEEE Access 2023, 11, 45711–45735. [Google Scholar] [CrossRef]
- Linardos, A.; Kushibar, K.; Walsh, S.; Gkontra, P.; Lekadir, K. Federated learning for multi-center imaging diagnostics: A simulation study in cardiovascular disease. Sci. Rep. 2022, 12, 3551. [Google Scholar] [CrossRef] [PubMed]
- Sahoo, P.K.; Mohapatra, S.K.; Wu, S.L. SLA based healthcare big data analysis and computing in cloud network. J. Parallel Distrib. Comput. 2018, 119, 121–135. [Google Scholar] [CrossRef]
- Thanigaivasan, V.; Narayanan, S.J.; Iyengar, S.N.; Ch, N. Analysis of parallel SVM based classification technique on healthcare using big data management in cloud storage. Recent Pat. Comput. Sci. 2018, 11, 169–178. [Google Scholar] [CrossRef]
- Wang, Y.; Kung, L.; Wang, W.Y.C.; Cegielski, C.G. An integrated big data analytics-enabled transformation model: Application to health care. Inf. Manag. 2018, 55, 64–79. [Google Scholar] [CrossRef]
- Alsabah, M.; Naser, M.A.; Mahmmod, B.M.; Abdulhussain, S.H.; Eissa, M.R.; Al-Baidhani, A.; Noordin, N.K.; Sait, S.M.; Al-Utaibi, K.A.; Hashim, F. 6G wireless communications networks: A comprehensive survey. IEEE Access 2021, 9, 148191–148243. [Google Scholar] [CrossRef]
- Wenzel, M.; Wiegand, T. Toward global validation standards for health AI. IEEE Commun. Stand. Mag. 2020, 4, 64–69. [Google Scholar] [CrossRef]
- Li, X.; Zhang, L.; Wu, Z.; Liu, Z.; Zhao, L.; Yuan, Y.; Liu, J.; Li, G.; Zhu, D.; Yan, P.; et al. Artificial General Intelligence for Medical Imaging. arXiv 2023, arXiv:2306.05480. [Google Scholar]
- Obaid, O.I. From Machine Learning to Artificial General Intelligence: A Roadmap and Implications. Mesopotamian J. Big Data 2023, 2023, 81–91. [Google Scholar] [CrossRef]
- Kuusi, O.; Heinonen, S. Scenarios from artificial narrow intelligence to artificial general intelligence—Reviewing the results of the international work/technology 2050 study. World Futures Rev. 2022, 14, 65–79. [Google Scholar] [CrossRef]
- Ahamad, G.N.; Shafiullah; Fatima, H.; Imdadullah.; Zakariya, S.; Abbas, M.; Alqahtani, M.S.; Usman, M. Influence of Optimal Hyperparameters on the Performance of Machine Learning Algorithms for Predicting Heart Disease. Processes 2023, 11, 734. [Google Scholar] [CrossRef]
- Ozcan, M.; Peker, S. A classification and regression tree algorithm for heart disease modeling and prediction. Healthc. Anal. 2023, 3, 100130. [Google Scholar] [CrossRef]
- Bhatt, C.M.; Patel, P.; Ghetia, T.; Mazzeo, P.L. Effective heart disease prediction using machine learning techniques. Algorithms 2023, 16, 88. [Google Scholar] [CrossRef]
- Al Reshan, M.S.; Amin, S.; Zeb, M.A.; Sulaiman, A.; Alshahrani, H.; Shaikh, A. A Robust Heart Disease Prediction System Using Hybrid Deep Neural Networks. IEEE Access 2023, 11, 121574–121591. [Google Scholar] [CrossRef]
- Rustam, F.; Ishaq, A.; Munir, K.; Almutairi, M.; Aslam, N.; Ashraf, I. Incorporating CNN Features for Optimizing Performance of Ensemble Classifier for Cardiovascular Disease Prediction. Diagnostics 2022, 12, 1474. [Google Scholar] [CrossRef] [PubMed]
- Doppala, B.P.; Bhattacharyya, D.; Janarthanan, M.; Baik, N. A reliable machine intelligence model for accurate identification of cardiovascular diseases using ensemble techniques. J. Healthc. Eng. 2022, 2022, 2585235. [Google Scholar] [CrossRef] [PubMed]
- Ramesh, T.; Lilhore, U.K.; Poongodi, M.; Simaiya, S.; Kaur, A.; Hamdi, M. Predictive analysis of heart diseases with machine learning approaches. Malays. J. Comput. Sci. 2022, 132–148. [Google Scholar] [CrossRef]
- Boukhatem, C.; Youssef, H.Y.; Nassif, A.B. Heart disease prediction using machine learning. In Proceedings of the 2022 Advances in Science and Engineering Technology International Conferences (ASET), Dubai, United Arab Emirates, 21–24 February 2022; pp. 1–6. [Google Scholar]
- Nagavelli, U.; Samanta, D.; Chakraborty, P. Machine learning technology-based heart disease detection models. J. Healthc. Eng. 2022, 2022, 7351061. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, A.; Chugh, A.; Sharma, A. Ensemble framework for cardiovascular disease prediction. Comput. Biol. Med. 2022, 146, 105624. [Google Scholar] [CrossRef] [PubMed]
- Ketu, S.; Mishra, P.K. Empirical analysis of machine learning algorithms on imbalance electrocardiogram based arrhythmia dataset for heart disease detection. Arab. J. Sci. Eng. 2022, 47, 1447–1469. [Google Scholar] [CrossRef]
- Rahim, A.; Rasheed, Y.; Azam, F.; Anwar, M.W.; Rahim, M.A.; Muzaffar, A.W. An integrated machine learning framework for effective prediction of cardiovascular diseases. IEEE Access 2021, 9, 106575–106588. [Google Scholar] [CrossRef]
- Ghosh, P.; Azam, S.; Jonkman, M.; Karim, A.; Shamrat, F.J.M.; Ignatious, E.; Shultana, S.; Beeravolu, A.R.; De Boer, F. Efficient prediction of cardiovascular disease using machine learning algorithms with relief and LASSO feature selection techniques. IEEE Access 2021, 9, 19304–19326. [Google Scholar] [CrossRef]


| Cardiovascular Disease Type | Description |
|---|---|
| CAD | CAD occurs when the blood vessels (coronary arteries) that supply the heart with oxygen and nutrients become narrowed or blocked due to the buildup of cholesterol and fatty deposits (atherosclerosis). |
| Heart failure | Occurs when the heart cannot pump blood effectively, leading to a reduced supply of oxygen and nutrients to the body’s tissues and organs. It can result from CAD, hypertension, and heart valve diseases. |
| Arrhythmias | This condition involves problems with one or more of the heart’s valves. It can lead to valve stenosis (narrowing) or regurgitation (leakage). Common valve disorders include aortic stenosis and mitral regurgitation. |
| Valvular | This condition involves problems with one or more of the heart’s valves. It can lead to valve stenosis (narrowing) or regurgitation (leakage). Common valve disorders include aortic stenosis and mitral regurgitation. |
| Cardiomyopathy | This is related to the muscle and can weaken the heart’s ability to pump blood effectively. It can be inherited or acquired, and there are different types, such as dilated cardiomyopathy and hypertrophic cardiomyopathy. |
| Congenital | This is present at birth and involves structural abnormalities in the heart. It can affect the heart’s walls, valves, or blood vessels. |
| Infective Endocarditis | This is an infection of the inner lining of the heart (endocardium) and the heart valves. It is typically caused by bacteria or other microorganisms that enter the bloodstream and settle in the heart. |
| Vascular | This refers to conditions or disorders that affect the blood vessels, which include arteries and veins throughout the body, which can disrupt the normal flow of blood. |
| Machine Learning Model | Strengths | Weaknesses |
|---|---|---|
| Logistic Regression (LR): A statistical model that assesses the probability of an individual having a cardiovascular disease based on various input features, such as age, cholesterol levels, and blood pressure. | 1. Simplicity and interpretability in disease diagnostics. 2. Computationally efficient for large datasets. 3. Less prone to overfitting, making it robust when working with moderate-sized datasets. | 1. Assumes linear input–outcome relationship. 2. Less flexible in complex medical scenarios. 3. Potential lower predictive accuracy with intricate data patterns. 4. Struggles with non-linear relationships without feature engineering or transformation. |
| Decision Trees (DT): Applicable for both classification and regression problems. It generates a tree-like structure of decision rules by recursively splitting the data according to input attributes. Helps to determine the most important elements or symptoms of cardiovascular disease. | 1. Easy to interpret and hence can explain the decision-making process easily. 2. Handles non-linear relationships in medical data with both categorical and numerical features and identifies key factors for cardiovascular disease. 3. Low computational costs during prediction. | 1. Prone to overfitting, impacting generalization. 2. May not capture complex relationships as well as other models. 3. Less stable, with small data changes leading to different tree structures. |
| Random Forest (RF): An ensemble learning method that combines multiple decision trees to make predictions. It is less prone to overfitting compared to individual decision trees, resulting in the improved generalization of new data. It provides higher predictive accuracy due to the combination of multiple trees and the reduction of bias and variance. | 1. Mitigates decision tree overfitting by averaging predictions. 2. It offers robustness, high accuracy, and handling of non-linearity. 3. Provides accurate and robust results, even in the presence of noisy or complex data. 4. Robust, with effective handling of high-dimensional data. Less sensitive to noisy data. | 1. Computationally intensive, may need more resources. 2. Larger model sizes can be limited in resource-constrained environments. 3. Requires proper hyperparameter tuning for optimization. |
| Support Vector Machines (SVMs): A powerful algorithm that can be used for both classification and regression tasks. It obtains the optimal hyperplane, which seeks the best separation of the data points into different classes. Proficiency in managing high-dimensional data; hence, it is suitable for datasets with many features. | 1. Handles non-linear relationships with kernels. 2. Versatile and effective in complex pattern capture. 3. Find complex decision boundaries in high dimensions. 4. Works well with clear class separation margins. | 1. Computationally expensive, complex in high dimensions. 2. Sensitive to kernel choice. 3. Time-consuming training on large datasets. 4. Essential hyperparameter tuning for optimal performance. 5. May lack interpretability compared to logistic regression or decision trees. |
| K-Nearest Neighbors (KNN): A simple algorithm that finds the k-nearest data points in the training dataset, such as the Euclidean distance. It predicts the class of the new data point by taking a majority vote from the KNN. Effective when similar patients with similar feature profiles are likely to have similar cardiovascular disease outcomes. | 1. Non-parametric algorithm, adapts well to diverse and non-linear patterns of data distributions. 2. Simple to understand and implement. 3. Works well with small datasets, making it applicable in different scenarios. 4. Less sensitive to outliers and noisy data points. | 1. Computationally expensive for large datasets. 2. Sensitive to the choice of k. 3. May struggle with imbalanced datasets. 4. Critical to properly select k for best predictive performance. |
| AdaBoost: Combines several weak classifiers into a unified and robust classifier. Its mechanism involves assigning higher weights to samples that pose greater classification challenges while assigning lower weights to well-categorized samples. It finds application in both categorization and regression analysis. | 1. High accuracy and performance in classification. 2. Versatile with different data types and base classifiers, making it versatile in different machine learning scenarios. 3. Effectively handles noisy data and outliers. 4. Assign higher weights to misclassified instances, allowing it to focus on correcting mistakes. | 1. Handles noisy data but sensitive to outliers or mislabeled instances. 2. Computationally intensive with a large number of weak learners, which may affect training time and resource requirements. 3. Struggles with complex relationships or dependencies in datasets, as it relies on relatively simple weak learners. |
| Naïve Bayes: A probabilistic model that works based on the Bayes theorem. Given the class title, it assumes that features are conditionally independent. It calculates the probability that a patient has cardiovascular disease given their feature values, such as age, cholesterol, and blood pressure. | 1. Computationally efficient with high-dimensional data. 2. Performs well with small to moderately-sized datasets. 3. Its probabilistic nature allows for the simple interpretation of results. 4. Handles a large number of features efficiently. | 1. Assumes feature independence, limiting accuracy in capturing complex dependencies among features. 2. May not capture intricate relationships between features, which can affect predictive accuracy. |
| Deep Learning: It employs various evaluation criteria, including accuracy and specificity, to guide feature extraction inversely. Involves the use of artificial neural networks with multiple hidden layers to learn complex representations from data. Can identify intricate patterns that may be challenging for human interpretation, leading to more accurate diagnosis of diseases. | 1. Automatically discovers relevant features for data, reducing the requirement for manual feature engineering. 2. Effectively handles missing data, providing accurate predictions even when some data are unavailable. 3. Achieves high predictive performance when trained on large and diverse datasets. 4. Handles diverse data types including images, text, and numerical data. | 1. Complex and computationally intensive. 2. Requires substantial computational resources for training and inference. 3. Relies on large amounts of labeled data for effective training. 4. Challenging to interpret, limiting utility in medical diagnostics, where interpretability is essential. |
| Evaluation Metric | Mathematical Equation | Description |
|---|---|---|
| Accuracy | Accuracy is a basic evaluation metric and represents the proportion of correct predictions out of the total predictions. While accuracy is a useful metric, it may not be sufficient for imbalanced datasets, where one class (e.g., healthy patients) dominates the other (e.g., patients with cardiovascular disease). | |
| Recall (Sensitivity) | Sensitivity measures the model’s ability to correctly identify positive cases (individuals with cardiovascular disease). High sensitivity is crucial in healthcare to minimize false negatives, ensuring that individuals with cardiovascular disease are not missed. | |
| Specificity | Specificity measures the model’s ability to correctly identify negative cases (individuals without cardiovascular disease). High specificity is vital to minimize false positives, reducing unnecessary interventions for individuals without cardiovascular disease. | |
| Precision | Precision is the proportion of true positive predictions out of all positive predictions. It measures the model’s accuracy when it predicts positive cases. Higher precision indicates a lower rate of false positives. Precision is important when minimizing false positives is crucial, as in medical diagnosis, where a false positive can lead to unnecessary treatments or anxiety. | |
| F1-score | The F1-score is the harmonic mean of the precision and recall (sensitivity). It provides a balanced measure that considers both false positives and false negatives. It is beneficial when there is an imbalance between the positive and negative classes. | |
| Matthews correlation coefficient (MCC) | Denotes the predictive capacity of a classifier, expressed through values ranging from and . For example, an MCC classifier value of signifies ideal predictions, while indicates entirely inaccurate predictions. A value close to 0 suggests that the classifier is making predictions randomly. | |
| Area under the curve (AUC) | The AUC represents the region beneath the receiver operating characteristic (ROC) curve, a graphical depiction of the true positive rate against the false positive rate. A higher AUC value corresponds to superior model performance, with an ideal model approaching an AUC close to 1. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naser, M.A.; Majeed, A.A.; Alsabah, M.; Al-Shaikhli, T.R.; Kaky, K.M. A Review of Machine Learning’s Role in Cardiovascular Disease Prediction: Recent Advances and Future Challenges. Algorithms 2024, 17, 78. https://doi.org/10.3390/a17020078
Naser MA, Majeed AA, Alsabah M, Al-Shaikhli TR, Kaky KM. A Review of Machine Learning’s Role in Cardiovascular Disease Prediction: Recent Advances and Future Challenges. Algorithms. 2024; 17(2):78. https://doi.org/10.3390/a17020078
Chicago/Turabian StyleNaser, Marwah Abdulrazzaq, Aso Ahmed Majeed, Muntadher Alsabah, Taha Raad Al-Shaikhli, and Kawa M. Kaky. 2024. "A Review of Machine Learning’s Role in Cardiovascular Disease Prediction: Recent Advances and Future Challenges" Algorithms 17, no. 2: 78. https://doi.org/10.3390/a17020078
APA StyleNaser, M. A., Majeed, A. A., Alsabah, M., Al-Shaikhli, T. R., & Kaky, K. M. (2024). A Review of Machine Learning’s Role in Cardiovascular Disease Prediction: Recent Advances and Future Challenges. Algorithms, 17(2), 78. https://doi.org/10.3390/a17020078