
An Adaptive Moving Window Kriging Based on K-Means Clustering for Spatial Interpolation


Abstract
1. Introduction
2. Theoretical Background
2.1. Ordinary Kriging
| Algorithm 1 Ordinary kriging algorithm |
| Input: observed data at positions ;
target points for |
| Output: estimated values of at the target points for |
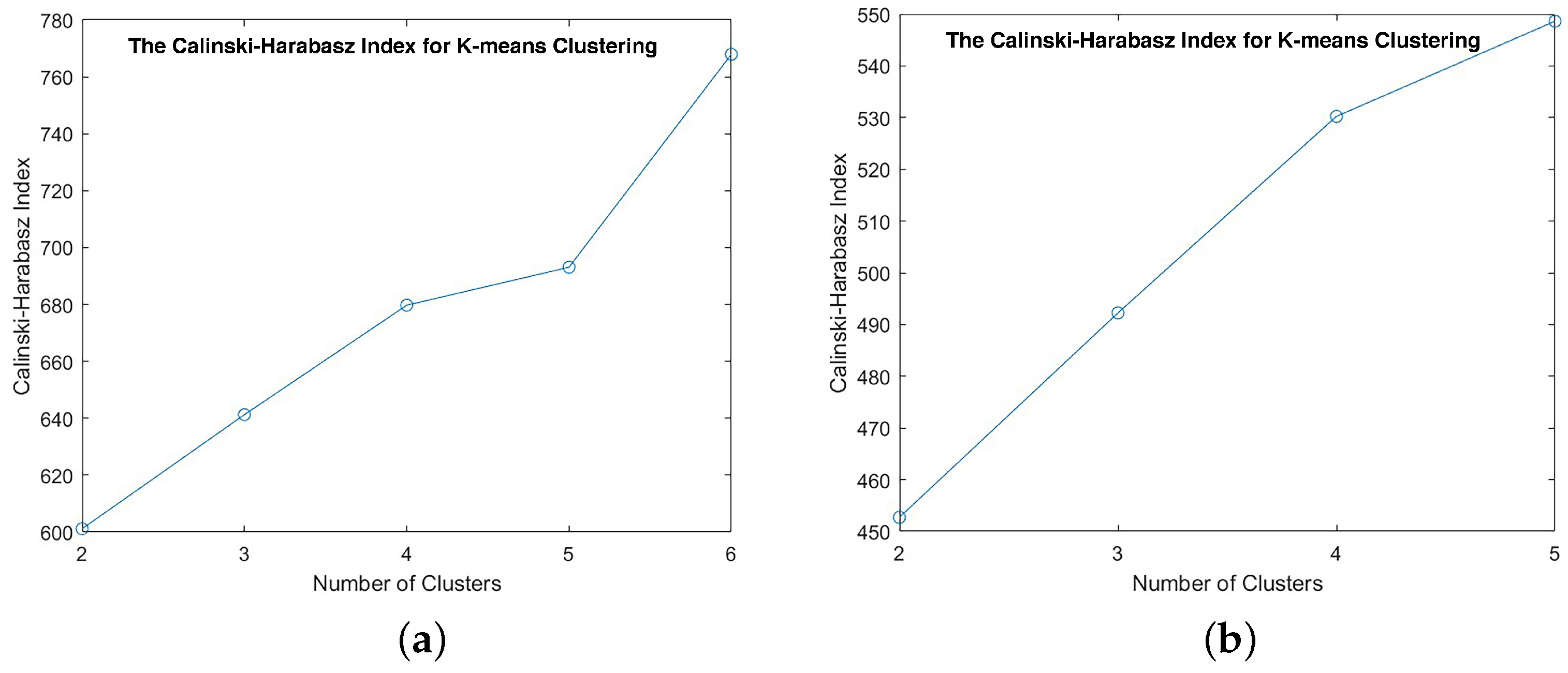
2.2. K-Means Clustering
| Algorithm 2 K-means clustering algorithm |
| Input: dataset of points ;
number of clusters k |
Output: k clusters with its centroid
|
3. Methodology
3.1. Moving Window Kriging
| Algorithm 3 Moving window kriging algorithm |
| Input: observed data at positions ;
target points for |
Output: estimated values of at the target points for
|
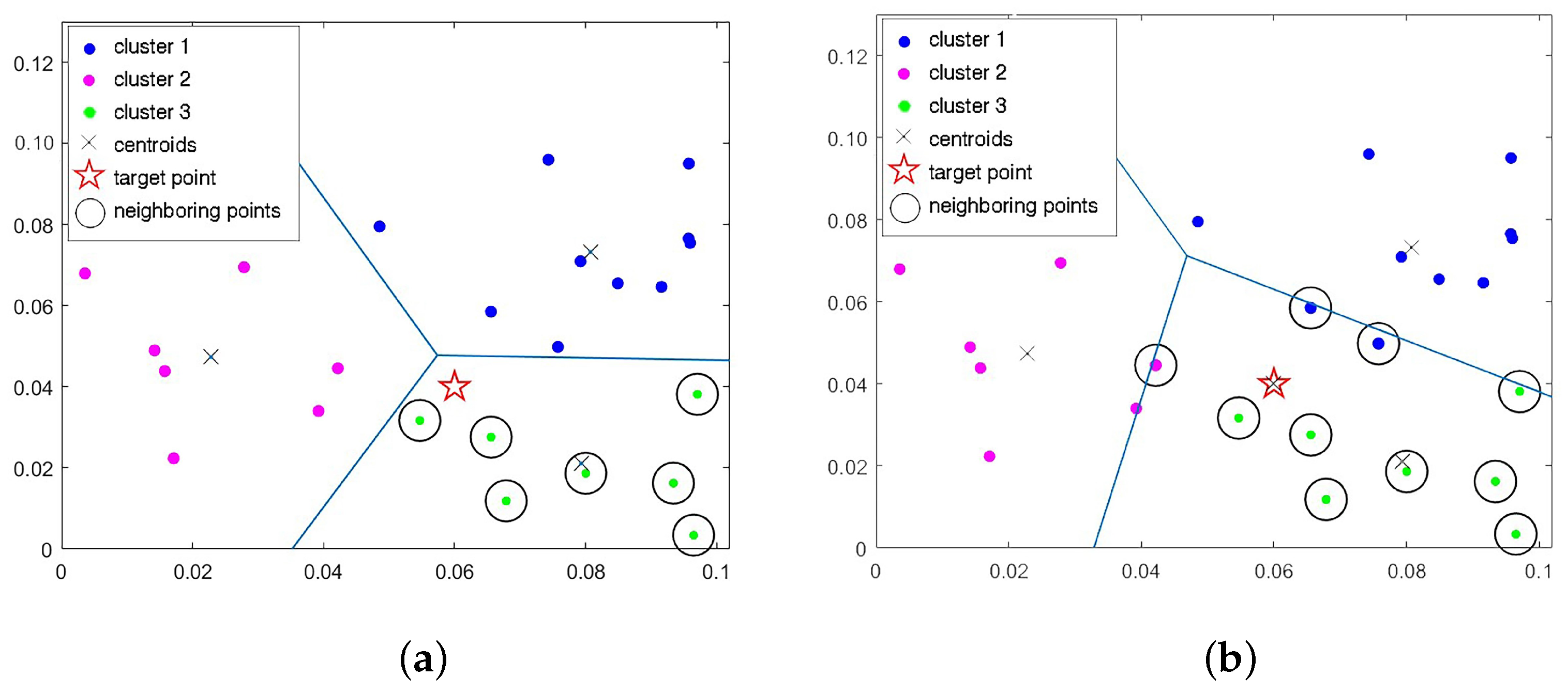
3.2. Window Selection Based on K-Means Clustering
| Algorithm 4 Window selection based on the K-means clustering algorithm |
| Input: sampling positions ;
number of clusters k; target points for |
Output: windows of the points for
|
4. Case Study: Spatial Interpolation of Meteorological Data in Thailand
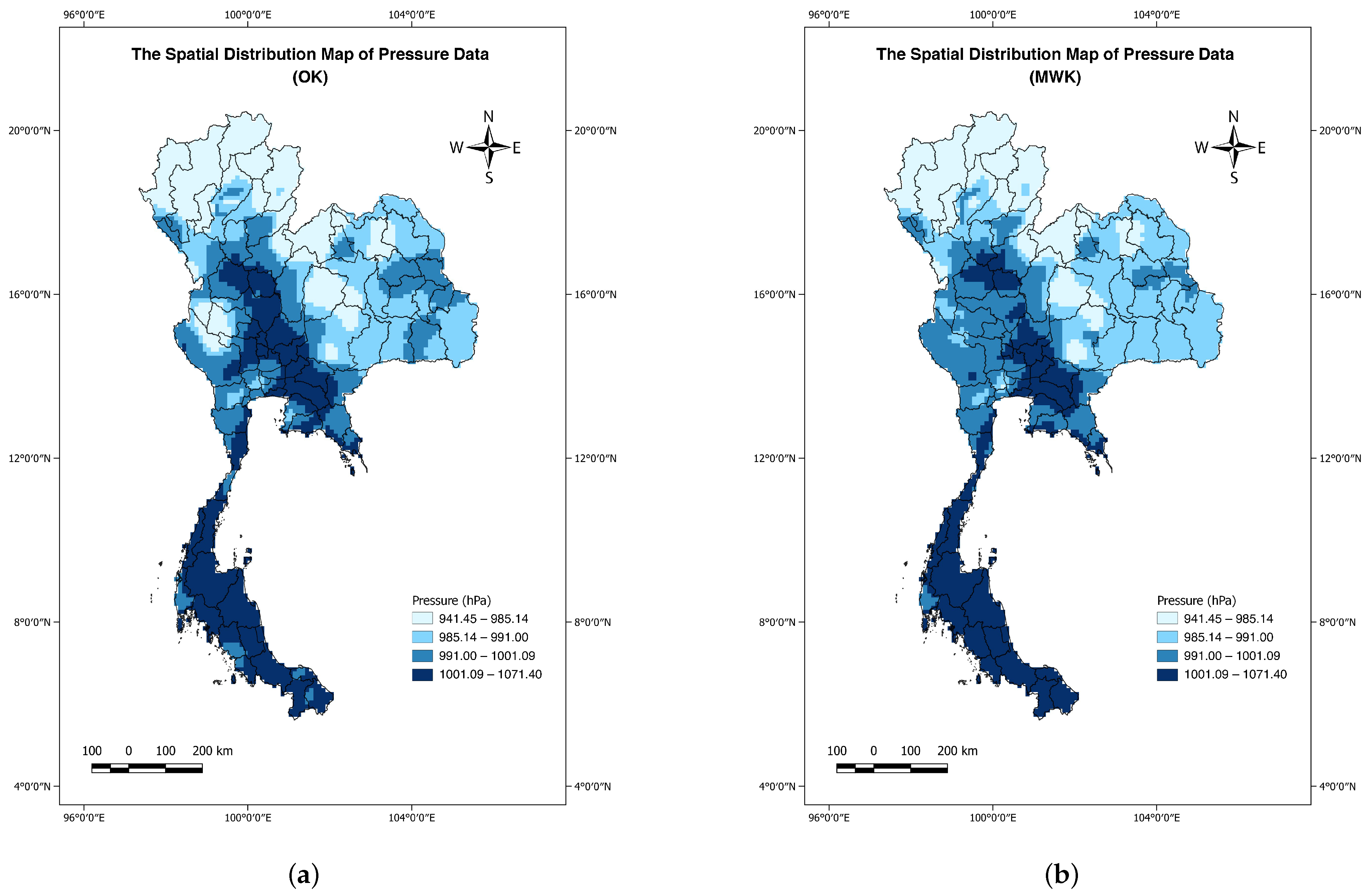
4.1. Data Description
4.2. Accuracy Assessment
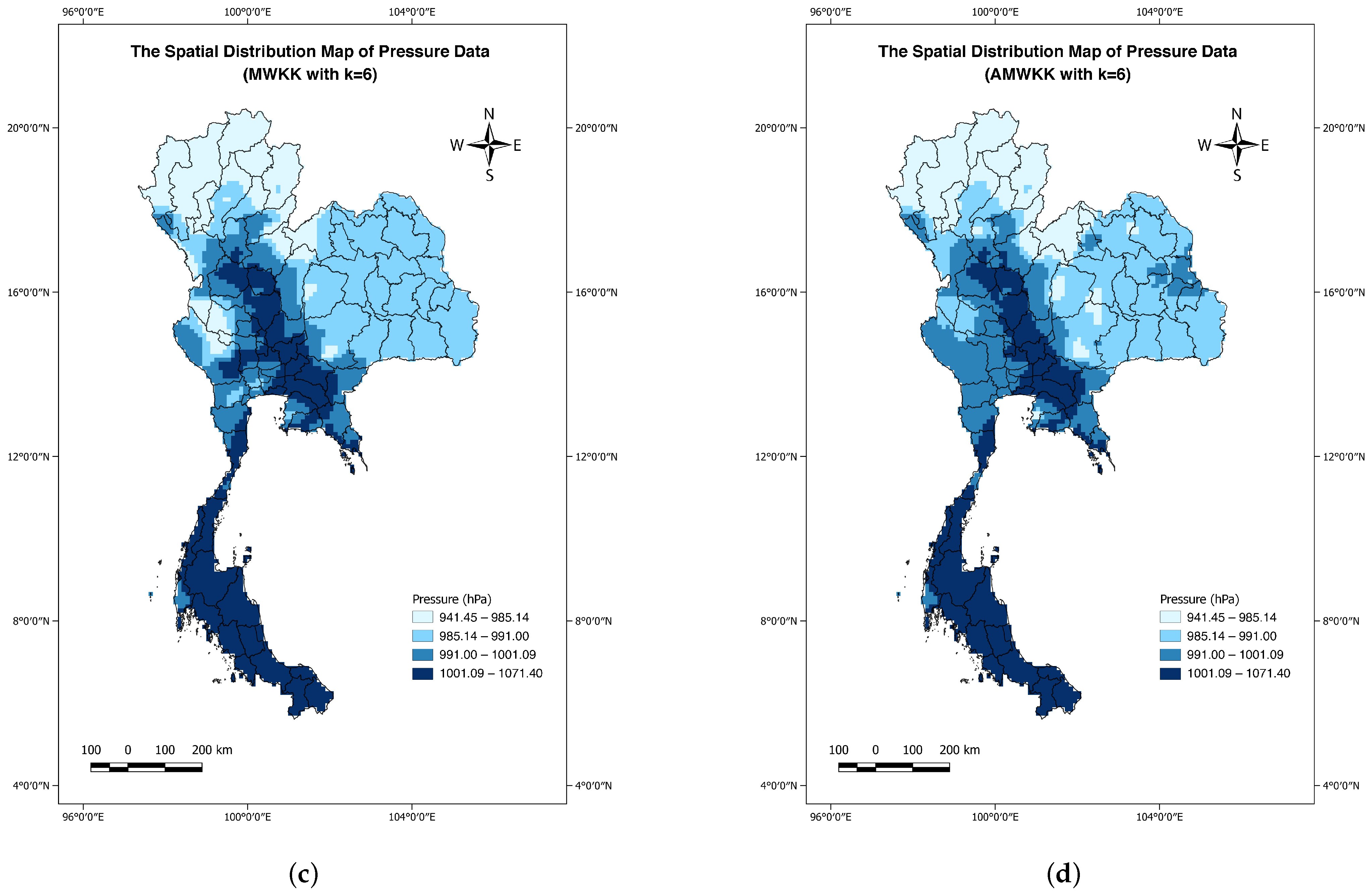
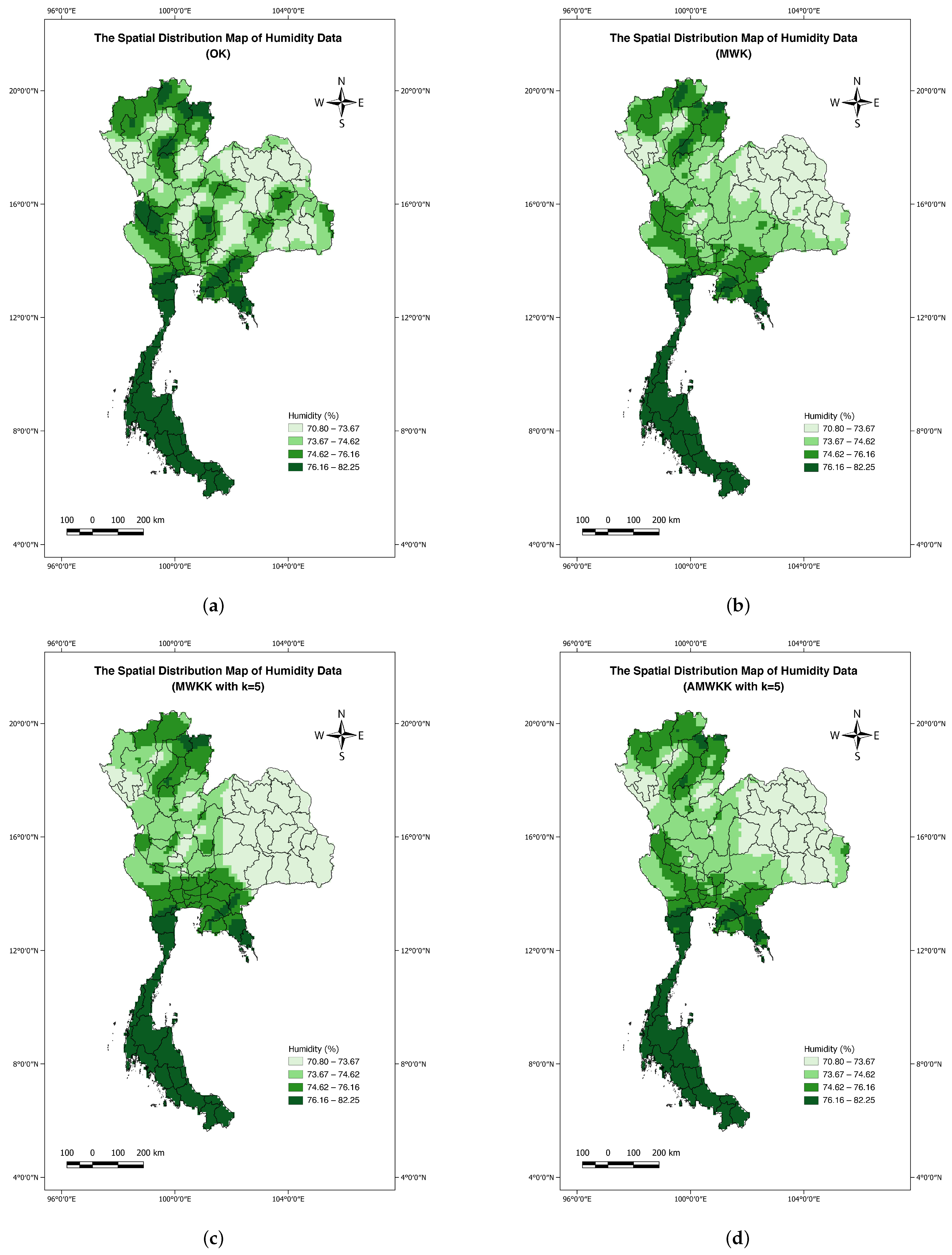
4.3. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krige, D.G. A statistical approach to some basic mine valuation problems on the Witwatersrand. J. S. Afr. Inst. Min. Metall. 1951, 52, 119–139. [Google Scholar]
- Matheron, G. Principles of geostatistics. Econ. Geol. 1963, 58, 1246–1266. [Google Scholar] [CrossRef]
- Journel, A.G.; Huijbregts, C.J. Mining Geostatistics; Academic Press: London, UK, 1978. [Google Scholar]
- Lamamra, A.; Neguritsa, D.L.; Mazari, M. Geostatistical modeling by the Ordinary Kriging in the estimation of mineral resources on the Kieselguhr mine, Algeria. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2019; Volume 362, p. 012051. [Google Scholar]
- Singh, R.K.; Ray, D.; Sarkar, B. Mineral deposit grade assessment using a hybrid model of kriging and generalized regression neural network. Neural Comput. Appl. 2022, 34, 10611–10627. [Google Scholar] [CrossRef]
- Schorr, J.; Cudmani, R.; Nübel, K. Interpretation of field tests using geo-statistics and Kriging to assess the deep vibratory compaction of the Dike A21, Diavik Diamond Mine. Acta Geotech. 2023, 18, 1391–1405. [Google Scholar] [CrossRef]
- Kingsley, J.; Lawani, S.O.; Esther, A.O.; Ndiye, K.M.; Sunday, O.J.; Penížek, V. Predictive mapping of soil properties for precision agriculture using geographic information system (GIS) based geostatistics models. Mod. Appl. Sci. 2019, 13, 60–77. [Google Scholar] [CrossRef][Green Version]
- Aryafar, A.; Khosravi, V.; Karami, S. Groundwater quality assessment of Birjand plain aquifer using kriging estimation and sequential Gaussian simulation methods. Environ. Earth Sci. 2020, 79, 210. [Google Scholar] [CrossRef]
- Munyati, C.; Sinthumule, N. Comparative suitability of ordinary kriging and Inverse Distance Weighted interpolation for indicating intactness gradients on threatened savannah woodland and forest stands. Environ. Sustain. Indic. 2021, 12, 100151. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Spatio-Temporal Characteristics of PM2.5 Concentrations in China Based on Multiple Sources of Data and LUR-GBM during 2016–2021. Int. J. Environ. Res. Public Health 2022, 19, 6292. [Google Scholar] [CrossRef]
- Zhang, Z.; Du, Q. A bayesian kriging regression method to estimate air temperature using remote sensing data. Remote Sens. 2019, 11, 767. [Google Scholar] [CrossRef]
- Zhang, G.; Tian, G.; Cai, D.; Bai, R.; Tong, J. Merging radar and rain gauge data by using spatial–temporal local weighted linear regression kriging for quantitative precipitation estimation. J. Hydrol. 2021, 601, 126612. [Google Scholar] [CrossRef]
- Das, S.; Islam, A.R.M.T. Assessment of mapping of annual average rainfall in a tropical country like Bangladesh: Remotely sensed output vs. kriging estimate. Theor. Appl. Climatol. 2021, 146, 111–123. [Google Scholar] [CrossRef]
- He, Q.; Zhang, K.; Wu, S.; Lian, D.; Li, L.; Shen, Z.; Wan, M.; Li, L.; Wang, R.; Fu, E.; et al. An investigation of atmospheric temperature and pressure using an improved spatio-temporal Kriging model for sensing GNSS-derived precipitable water vapor. Spat. Stat. 2022, 51, 100664. [Google Scholar] [CrossRef]
- Cressie, N. Spatial prediction and ordinary kriging. Math. Geol. 1988, 20, 405–421. [Google Scholar] [CrossRef]
- Wackernagel, H. Multivariate Geostatistics: An Introduction with Applications; Springer Science & Business Media: New York, NY, USA, 2003. [Google Scholar]
- Chiles, J.P.; Delfiner, P. Geostatistics: Modeling Spatial Uncertainty; John Wiley and Sons: Hoboken, NJ, USA, 2012; Volume 713. [Google Scholar]
- Tan, Q.; Xu, X. Comparative analysis of spatial interpolation methods: An experimental study. Sens. Transducers 2014, 165, 155. [Google Scholar]
- Marwanza, I.; Nas, C.; Azizi, M.; Simamora, J. Comparison between moving windows statistical method and kriging method in coal resource estimation. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2019; Volume 1402, p. 033016. [Google Scholar]
- Haas, T.C. Kriging and automated variogram modeling within a moving window. Atmos. Environ. Part A 1990, 24, 1759–1769. [Google Scholar] [CrossRef]
- Alkhaled, A.A.; Michalak, A.M.; Kawa, S.R.; Olsen, S.C.; Wang, J.W. A global evaluation of the regional spatial variability of column integrated CO2 distributions. J. Geophys. Res. Atmos. 2008, 113. [Google Scholar] [CrossRef]
- Hammerling, D.M.; Michalak, A.M.; Kawa, S.R. Mapping of CO2 at high spatiotemporal resolution using satellite observations: Global distributions from OCO-2. J. Geophys. Res. Atmos. 2012, 117, D06306. [Google Scholar] [CrossRef]
- Haas, T.C. Multivariate spatial prediction in the presence of non-linear trend and covariance non-stationarity. Environmetrics 1996, 7, 145–165. [Google Scholar] [CrossRef]
- Lloyd, C.D.; Atkinson, P.M. Non-stationary approaches for mapping terrain and assessing prediction uncertainty. Trans. GIS 2002, 6, 17–30. [Google Scholar] [CrossRef]
- Pardo-Igúzquiza, E.; Dowd, P.A.; Grimes, D.I. An automatic moving window approach for mapping meteorological data. Int. J. Climatol. 2005, 25, 665–678. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships; John Wiley & Sons: Chichester, UK, 2003. [Google Scholar]
- Haas, T.C. Local prediction of a spatio-temporal process with an application to wet sulfate deposition. J. Am. Stat. Assoc. 1995, 90, 1189–1199. [Google Scholar] [CrossRef]
- Van Stein, B.; Wang, H.; Kowalczyk, W.; Emmerich, M.; Bäck, T. Cluster-based Kriging approximation algorithms for complexity reduction. Appl. Intell. 2020, 50, 778–791. [Google Scholar] [CrossRef]
- Abedini, M.; Nasseri, M.; Ansari, A. Cluster-based ordinary kriging of piezometric head in West Texas/New Mexico–Testing of hypothesis. J. Hydrol. 2008, 351, 360–367. [Google Scholar] [CrossRef]
- Yasojima, C.; Protázio, J.; Meiguins, B.; Neto, N.; Morais, J. A new methodology for automatic cluster-based kriging using K-nearest neighbor and genetic algorithms. Information 2019, 10, 357. [Google Scholar] [CrossRef]
- Cressie, N.; Hawkins, D.M. Robust estimation of the variogram: I. J. Int. Assoc. Math. Geol. 1980, 12, 115–125. [Google Scholar] [CrossRef]
- Cressie, N. Statistics for Spatial Data; John Wiley & Sons: New York, NY, USA, 1993. [Google Scholar]
- Cressie, N. Fitting variogram models by weighted least squares. J. Int. Assoc. Math. Geol. 1985, 17, 563–586. [Google Scholar] [CrossRef]
- Syakur, M.; Khotimah, B.; Rochman, E.; Satoto, B.D. Integration k-means clustering method and elbow method for identification of the best customer profile cluster. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2018; Volume 336, p. 012017. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 411–423. [Google Scholar] [CrossRef]
- OpenData. Available online: https://data.hii.or.th (accessed on 27 October 2020).
- Valjarević, A.; Srećković-Batoćanin, D.; Valjarević, D.; Matović, V. A GIS-based method for analysis of a better utilization of thermal-mineral springs in the municipality of Kursumlija (Serbia). Renew. Sustain. Energy Rev. 2018, 92, 948–957. [Google Scholar] [CrossRef]
- Valjarević, A.; Živković, D.; Gadžić, N.; Tomanović, D.; Grbić, M. Multi-criteria GIS analysis of the topography of the Moon and better solutions for potential landing. Open Astron. 2019, 28, 85–94. [Google Scholar] [CrossRef]
- Sansare, D.A.; Mhaske, S.Y. Natural hazard assessment and mapping using remote sensing and QGIS tools for Mumbai city, India. Nat. Hazards 2020, 100, 1117–1136. [Google Scholar] [CrossRef]
- Muller, A.; Gericke, O.; Pietersen, J. Methodological approach for the compilation of a water distribution network model using QGIS and EPANET. J. S. Afr. Inst. Civ. Eng. 2020, 62, 32–43. [Google Scholar] [CrossRef]
- Elangovan, K.; Krishnaraaju, G. Mapping and Prediction of Urban Growth using Remote Sensing, Geographic Information System, and Statistical Techniques for Tiruppur Region, Tamil Nadu, India. J. Indian Soc. Remote Sens. 2023, 51, 1657–1671. [Google Scholar] [CrossRef]
- Geng, Z.; Chengchang, Z.; Huayu, Z. Improved K-means Algorithm Based on Density Canopy. Knowl.-Based Syst. 2018, 145, 289–297. [Google Scholar]
- Zhong, X.; Kealy, A.; Duckham, M. Stream Kriging: Incremental and recursive ordinary Kriging over spatiotemporal data streams. Comput. Geosci. 2016, 90, 134–143. [Google Scholar] [CrossRef]
- Memarsadeghi, N.; Raykar, V.C.; Duraiswami, R.; Mount, D.M. Efficient kriging via fast matrix-vector products. In Proceedings of the 2008 IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2008; pp. 1–7. [Google Scholar]
- Vlastos, P.G.; Hunter, A.; Curry, R.; Ramirez, C.I.E.; Elkaim, G. Partitioned gaussian process regression for online trajectory planning for autonomous vehicles. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021; IEEE: New York, NY, USA, 2021; pp. 1160–1165. [Google Scholar]
- Kushwaha, M.; Yadav, H.; Agrawal, C. A review on enhancement to standard k-means clustering. In Social Networking and Computational Intelligence: Proceedings of SCI-2018; Springer: Heidelberg, Germany, 2020; pp. 313–326. [Google Scholar]
- Fahim, A.M. An Efficient Parallel K-Means On Multi-Core Processors. Int. J. Sci. Eng. Technol. Res. (IJSETR) 2015, 4, 4234–4241. [Google Scholar]
- Peng, C.; Guiqiong, X. A brief study on clustering methods: Based on the k-means algorithm. In Proceedings of the 2011 International Conference on E-Business and E-Government (ICEE), Shanghai, China, 6–8 May 2011; IEEE: New York, NY, USA, 2011; pp. 1–5. [Google Scholar]
- Hengl, T.; Heuvelink, G.B.; Stein, A. Comparison of Kriging with External Drift and Regression Kriging; ITC Enschede: Enschede, The Netherlands, 2003. [Google Scholar]
- Hengl, T.; Heuvelink, G.B.; Rossiter, D.G. About regression-kriging: From equations to case studies. Comput. Geosci. 2007, 33, 1301–1315. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interpolation Method | Mean MAPE (%) | Mean RMSE | Mean PAEE | Mean NMSE | (%) |
|---|---|---|---|---|---|
| OK | 1.0243 | 14.7254 | 0.0101 | 0.6393 | - |
| MWK | 0.9910 | 14.4277 | 0.0098 | 0.6176 | 2.0218 |
| MWKK with k = 6 | 0.9841 | 14.5030 | 0.0097 | 0.6238 | 1.5102 |
| AMWKK with k = 6 | 0.9822 | 14.3834 | 0.0097 | 0.6128 | 2.3226 |
| Interpolation Method | Mean MAPE (%) | Mean RMSE | Mean PAEE | Mean NMSE | (%) |
|---|---|---|---|---|---|
| OK | 2.2915 | 2.2028 | 0.0229 | 0.5170 | - |
| MWK | 2.1813 | 2.1124 | 0.0218 | 0.4770 | 4.1040 |
| MWKK with k = 5 | 2.2087 | 2.1217 | 0.0220 | 0.4833 | 3.6795 |
| AMWKK with k = 5 | 2.1672 | 2.0804 | 0.0216 | 0.4641 | 5.5571 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Supajaidee, N.; Chutsagulprom, N.; Moonchai, S. An Adaptive Moving Window Kriging Based on K-Means Clustering for Spatial Interpolation. Algorithms 2024, 17, 57. https://doi.org/10.3390/a17020057
Supajaidee N, Chutsagulprom N, Moonchai S. An Adaptive Moving Window Kriging Based on K-Means Clustering for Spatial Interpolation. Algorithms. 2024; 17(2):57. https://doi.org/10.3390/a17020057
Chicago/Turabian StyleSupajaidee, Nattakan, Nawinda Chutsagulprom, and Sompop Moonchai. 2024. "An Adaptive Moving Window Kriging Based on K-Means Clustering for Spatial Interpolation" Algorithms 17, no. 2: 57. https://doi.org/10.3390/a17020057
APA StyleSupajaidee, N., Chutsagulprom, N., & Moonchai, S. (2024). An Adaptive Moving Window Kriging Based on K-Means Clustering for Spatial Interpolation. Algorithms, 17(2), 57. https://doi.org/10.3390/a17020057