

Issues on a 2–Dimensional Quadratic Sub–Problem and Its Applications in Nonlinear Programming: Trust–Region Methods (TRMs) and Linesearch Based Methods (LBMs)

Abstract
1. Introduction
- represents an approximate Newton-type direction, at the current feasible point ;
- represents a negative curvature direction for the nonlinear function , at the current feasible point ;
- represents the exact/approximate Hessian matrix of at ;
- represents the exact/approximate Gradient vector of at ;
- and are steplengths along the directions (i.e., following the taxonomy of Table 1, we have and ), with and . The constraint potentially plays a multi-purpose role, modeling for instance the gradient-related property for the search direction at , i.e.,
- reverse the directions and ;
2. Feasibility Issues for Our Quadratic Problem
- Cond. I: and .
- Cond. II: and ; moreover,
- –
- if , then
- –
- if , then
- Cond. III: and ; moreover,
- –
- if , then
- –
- if , then
- Cond. IV: , , , moreover,
- –
- if and , then
- –
- if and , then .
- Cond. V: , , , moreover,
- –
- if and , then
- –
- if and , then .
3. On the Use of Quadratic Sub-Problems Within TRMs and LBMs, in Large-Scale Optimization
- can be computed by either an exact (small- and medium-scale problems) or an approximate (large-scale problems) procedure;
- In order to prove the global convergence of the sequence to stationary limit points satisfying either first- or second-order necessary optimality conditions, is required to provide a sufficient reduction of the quadratic model , i.e., the difference is asked to satisfy a condition like ()
- can be computed by an approximate procedure, e.g., by adopting a Cauchy step or using the Steihaug conjugate gradient (see [22,23]), regardless of signature. Then, the approximate solution of (4) is merely sought on a linear manifold of a dimension of one or at most two, rather than on the entire subset ;
- Depending on a number of additional assumptions, TRMs can prove to be globally convergent to either a simple stationary limit point, or to a point which satisfies second-order necessary optimality conditions [2];
- Finding the exact/accurate solution of the sub-problem (4) is in general quite a cumbersome task in large-scale problems, representing a difficult goal that is often (when possible) skipped.
- when (or for any k), then represents a Newton-type direction, being typically computed by approximately solving Newton’s equation at the current iterate . Then, an Armijo-type linesearch procedure is applied along to compute , provided that is gradient-related (see e.g., [3]) at ;
- when , then represents a Newton-type direction again, while is typically a negative curvature direction for at , which approximates an eigenvector associated with the least negative eigenvalue of . The vector plays an essential role, when LBMs’ convergence to stationary points satisfying the second-order necessary optimality conditions needs to be proved. In the last case, the computation of the steplengths and is often carried out at once, (as in curvilinear linesearch procedures—see [24]), or the steplength computation is carried out by pursuing independent tasks (see, for example, [25]). We highlight that in (5), when both and , we may experience difficulties related to properly scaling the two search directions.
- Unlike trust-region based TNMs, at iterate , the search of a stationary point for a quadratic polynomial model of (i.e., Newton’s equation) is performed on , so that the quadratic expansion is not trusted on a more reliable compact subset (trust-region) of . Thus, the search direction might show poor performance when the iterates in the sequence are far from a stationary limit point . More specifically, note that in case ; then, solving Newton’s equation and the trust-region sub-problemfor any yields the same solutions. Conversely, when is indefinite, then Newton’s equation provides a saddle point for , that might be interpreted as a solution to a trust-region sub-problem (the interested reader may consider the paper [26] for some extensions). Furthermore, from this perspective, we remark that in LBMs, solving (2) where , , and , is to a to large extent equivalent to computing the Cauchy step when solving (4). Indeed, in the last case, the trust-region constraint in (4), in principle, can be equivalently replaced by the compact feasible set (box constraints) in (2), after setting . On the other hand, in case , and setting (2) and , along with , then, with similar reasoning, the solution to (2) closely resembles the application of the dogleg method when solving (4). Finally, since the coefficients in (2) may have negative values, we may potentially reverse the directions and when solving (2). Thus, following the idea behind (3), the scheme (2) suggests that, in case is also indefinite, (2) easily generalizes the proposals in [27]. In fact, following (3), we are able to exactly compute a global minimum for (2), regardless of the signature of Q, so that the resulting direction is gradient-related at .
- As in (5), the search directions and might be suitably combined in a curvilinear framework (see, for example, [24]). However, to our knowledge, the selection of and in the literature is seldom performed with a joint procedure to separately assess and , i.e., and are rarely chosen as independent parameters. Hence, in the literature of linesearch-based TNMs, the linesearch procedure that starts from and yields explores a one-dimensional manifold (regular curve), rather than considering as a two-dimensional manifold with independent real coefficients and .
- Adaptively updates the parameters , , , in (2), when the iterate changes, following the rationale behind the update of in (4), and retaining the strong convergence properties of TRMs. This fact is of remarkable interest, since in (2) the information associated with the search directions and is suitably trusted in a compact subset of (namely, the box constraints , );
- Exactly computes a cheap global minimum for (2), so that the vector is then provided to a standard linesearch procedure such as the Armijo rule, to ensure that the global convergence of the sequence to stationary (limit) points is preserved;
- Allows for the convergence of subsequences of the iterates to stationary limit points, where either first- or second-order necessary optimality conditions are fulfilled;
- Preserves generality within a wide range of optimization frameworks, as reported in the next Section 4;
- Combines the effects of and , skipping all the drawbacks related to a possible different scaling between these directions. We recall that since and are generated through the application of different methods, then the comparison of their performances may be biased by the latter generating methods.
4. How General Is the Model (2) in Nonlinear Programming Frameworks?
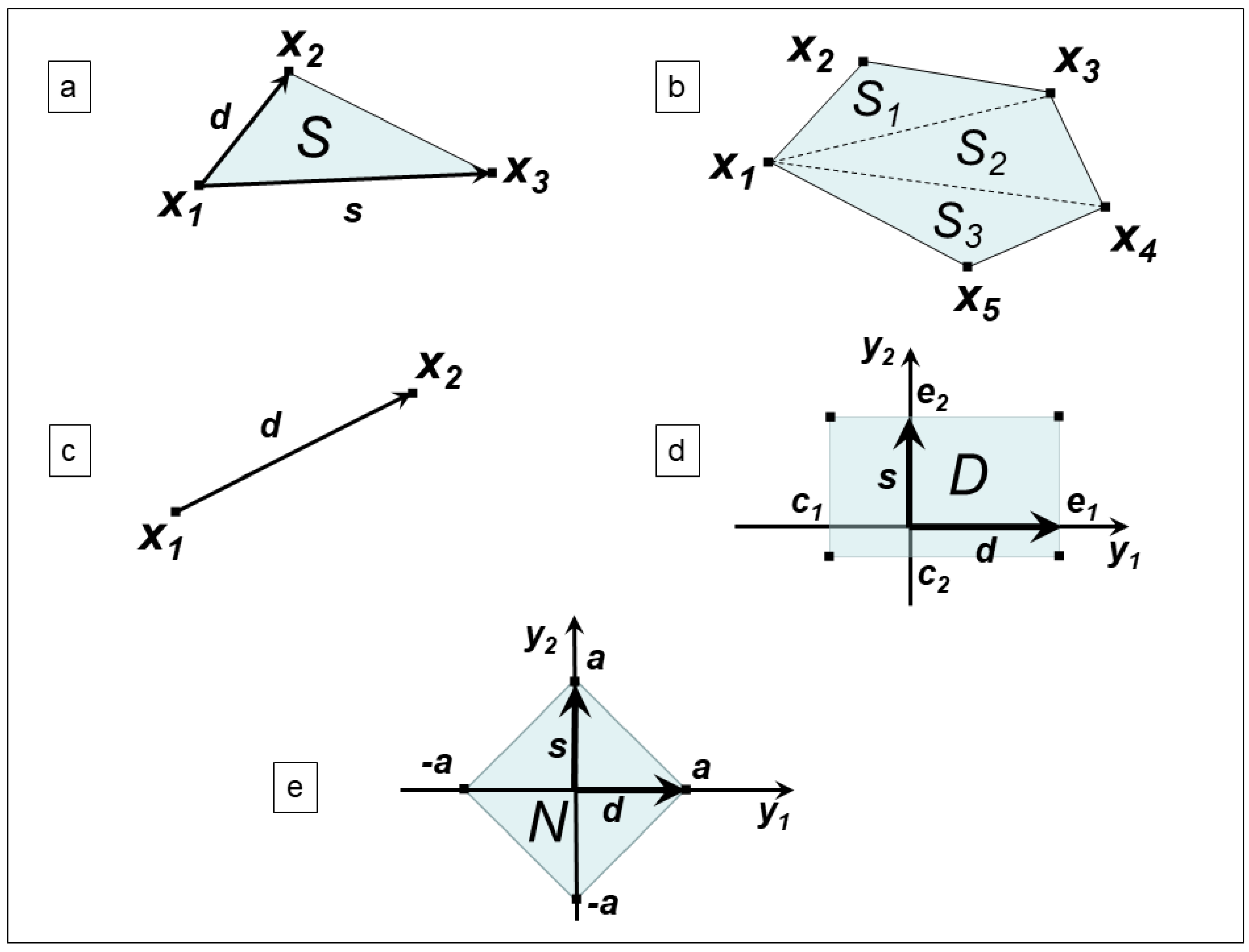
4.1. Minimization over a Bounded Simplex
- , ,
- ,
- , , , ,
- ,
4.2. Minimization over a Bounded Polygon
4.3. Minimization over a Bounded Segment
- , ,
- ,
- , , , ,
- ,
4.4. Minimization over a Bounded Box in
- ,
- , , , ,
- ,
- ,
- , , , ,
- .
4.5. Minimization Including a 1-Norm Inequality Constraint in
- , , , , ,
- so that four instances of the problem (2) need to be solved.
4.6. Minimization Including an ∞-Norm Inequality Constraint in
- ,
- , , , ,
- ,
4.7. Minimization Including a 2-Norm Inequality Constraint in
- –
- ,
- –
- –
- , , , ,
- –
- ,
- UPPER bound: to the solution of (13), as long as we follow the indications in Section 4.5, i.e., we recast and solve (11) as in (8), where
- –
- –
- –
- , , , , ,
so that four instances of the problem (2) need to be solved.
5. KKT Conditions and the Fast Solution of Problem (2)
- Cases (I), (II), (III), (IV) are associated with possible solutions in the vertices of the box constraints;
- Cases (V), (VI), (VII), (VIII) are associated with possible solutions on the edges of the box constraints;
- Case (IX) represents a possible feasible unconstrained minimizer for the objective function in (2);
- Cases (X), (XI), (XII) are associated with possible solutions, making the last inequality constraint in (14) active.
- Case (I): We set , . If , then set
- Case (II): We set , . If , then set
- Case (III): We set , . If , then set
- Case (IV): We set , . If , then set
- Case (V): We set and possibly compute the solution of the equationso that:
- –
- if , then set
- –
- if , then there is no solution for Case (V);
- –
- if , then set as any value satisfying , and compute as in (20);
- Case (VI): We set and possibly compute the solution of the equationso that:
- –
- if , then set
- –
- if , then there is no solution for Case (VI);
- –
- if , then set as any value satisfying , and compute as in (21);
- Case (VII): We set and possibly compute the solution of the equationso that:
- –
- if , then set
- –
- if , then there is no solution for Case (VII);
- –
- if , then set as any value satisfying , and compute as in (22);
- Case (VIII): We set and possibly compute the solution of the equationso that:
- –
- if , then set
- –
- if , then there is no solution for Case (VIII);
- –
- if , then set as any value satisfying , and compute as in (23);
- Case (IX): If , we compute the solutionof the linear systemotherwise, in case , then there is no solution for Case (IX);otherwise, in case , then we have three sub-cases:
- : then, recalling that we are in the sub-case where equations and yield the same information, we exploit equation and we set . Thus, from the bounds and the last inequality in (14), we obtainwhich yield the next three cases:
- –
- : admitting other three sub-cases, namely
- ∗
- , so that we set
- ∗
- , so that we set
- ∗
- , so that we set
- –
- : admitting no solution for Case (IX) as long as the condition holds. Conversely, in case , we have the three cases:
- ∗
- , so that we set
- ∗
- , so that we set
- ∗
- , so that we set
- –
- : corresponding to the three cases:
- ∗
- , so that we set
- ∗
- , so that we set
- ∗
- , so that we set
- : then, recalling that we are in the sub-case where equations and yield the same information, with , we exploit equation with . Therefore, we havewhich yield the next two cases:
- –
- This case implies that the objective function is constant (i.e., ), so that we set
- –
- : admitting no solution for Case (IX)
- : then, recalling that we are again in the sub-case where equations and yield the same information, we exploit equation and we set . Thus, from the bounds and the last inequality in (14), we obtainwhich yield the next three cases:
- –
- : admitting other three cases, namely
- ∗
- , so that we set
- ∗
- , so that is always fulfilled and we set
- ∗
- , so that we set
- –
- : admitting no solution for Case (IX) as long as the condition holds. Conversely, in case we have the three cases:
- ∗
- , so that we set
- ∗
- , so that we set
- ∗
- , so that we set
- –
- : corresponding to the three cases
- ∗
- , so that we set
- ∗
- , so that we set
- ∗
- , so that we set
Thus, overall, for Case (IX), if , we setalong withotherwise, if , there is no solution for Case (IX); - Case (X): We set with , and we distinguish among three cases:
- –
- if , then set ;
- –
- if , then there is no solution for Case (X);
- –
- if , then set
Set with - Case (XI): We distinguish among the next four cases:
- –
- if , then set , ; otherwise, there is no solution for Case (XI);
- –
- if , then and we analyze three sub-cases:
- If , then set
- If , then set ;
- If , then set
- –
- if , then set , ; if ( OR ), then there is no solution for Case (XI);
- –
- if , then and we analyze three sub-cases:
- If , then set
- If , then set ;
- If , then set
Set and ; if , then setotherwise, there is no solution for Case (XI); - Case (XII): We set with , and we distinguish among three cases:
- –
- if , then set ;
- –
- if , then there is no solution for Case (XII);
- –
- if , then set
Set with
6. Conclusions and Future Work
- Developing novel iterative LBMs (e.g., linesearch-based TNMs), where the search direction (e.g., a Newton-type direction) is possibly combined with another direction (e.g., the steepest descent at , a negative curvature direction at , etc.) through the use of (14). Then, comparing the efficiency of the novel methods with more standard linesearch-based approaches from the literature could give indications of the reliability of the ideas in this paper;
- Developing novel hybrid methods where the rationale behind alternating trust-region or linesearch-based techniques is exploited. In particular, the iterative scheme (respectively, ) might be considered, where the search directions and , along with the steplengths and (respectively, and ), are alternatively computed by solving
- A trust-region sub-problem like (4), so that a sufficient reduction in the quadratic model is ensured;
- A sub-problem like (14), so that the solution is a promising gradient-related direction to be used within a linesearch procedure.
In order to preserve the global convergence to stationary points satisfying either first- or second-order necessary optimality conditions; - Specifically, comparing the use of dogleg methods (within TRMs) vs. the application of (14) coupled with a linesearch technique. This issue is tricky, since dogleg methods are applied to trust-region sub-problems like (4), including a general quadratic constraint (i.e., the trust-region constraint), while in (14) all the constraints are linear, so that the exact global solution of (14) is easily computed. Moreover, the last issue might shed light also on the opportunity (possibly) of privileging an efficient linesearch procedure applied to a (coarsely computed) gradient-related search direction, in place of a precise computation of the search direction in LBMs, using an inexpensive linesearch procedure. In other words, it is at present questionable if coupling a coarse computation of the vectors and with an accurate linesearch procedure would be more preferable than coupling the accurately computed vectors and with a cheaper linesearch procedure;
- Introducing nonmonotone stabilization techniques (see e.g., [28]) combining nonmonotonicity with any of the above ideas, for both TRMs and LBMs.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ben-Tal, A.; Nemirovski, A. Lectures on Modern Convex Optimization: Analysis, Algorithms, and Engineering Applications. In MPS-SIAM Series on Optimization; SIAM: Philadelphia, PA, USA, 2001. [Google Scholar]
- Conn, A.R.; Gould, N.I.M.; Toint, P.L. Trust-region methods. In MPS-SIAM Series on Optimization; SIAM: Philadelphia, PA, USA, 2000. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Micchelli, C.A. Interpolation of scattered data: Distance matrices and conditionally positive definite functions. Constr. Approx. 1986, 2, 11–22. [Google Scholar] [CrossRef]
- Myers, D.E. Kriging, cokriging, radial basis functions and the role of positive definiteness. Comput. Math. Appl. 1992, 24, 139–148. [Google Scholar] [CrossRef]
- Conn, A.R.; Gould, N.I.M.; Sartenaer, A.; Toint, P.L. On Iterated-Subspace Minimization Methods for Nonlinear Optimization. In Proceedings on Linear and Nonlinear Conjugate Gradient-Related Methods; Adams, L., Nazareth, L., Eds.; SIAM: Philadelphia, PA, USA, 1996; pp. 50–78. [Google Scholar]
- Shea, B.; Schmidt, M. Why line search when you can plane search? SO-friendly neural networks allow per-iteration optimization of learning and momentum rates for every layer. arXiv 2024, arXiv:2406.17954. [Google Scholar]
- Caliciotti, A.; Fasano, G.; Nash, S.; Roma, M. An adaptive truncation criterion for Newton-Krylov methods in large scale nonconvex optimization. Oper. Res. Lett. 2018, 46, 7–12. [Google Scholar] [CrossRef]
- McCormick, G.P. A modification of Armijo’s step-size rule for negative curvature. Math. Program. 1977, 13, 111–115. [Google Scholar] [CrossRef]
- Moré, J.J.; Sorensen, D.C. On the use of directions of negative curvature in a modified Newton method. Math. Program. 1979, 16, 1–20. [Google Scholar] [CrossRef]
- Nash, S.G. A survey of truncated-Newton methods. J. Comput. Appl. Math. 2000, 124, 45–59. [Google Scholar] [CrossRef]
- Fasano, G.; Roma, M. Iterative computation of negative curvature directions in large scale optimization. Comput. Optim. Appl. 2007, 38, 81–104. [Google Scholar] [CrossRef]
- De Leone, R.; Fasano, G.; Roma, M.; Sergeyev, Y.D. Iterative Grossone-Based Computation of Negative Curvature Directions in Large-Scale Optimization. J. Optim. Theory Appl. 2020, 186, 554–589. [Google Scholar] [CrossRef]
- Curtis, F.E.; Robinson, D.P. Exploiting negative curvature in deterministic and stochastic optimization. Math. Program. 2019, 176, 69–94. [Google Scholar] [CrossRef]
- Gill, P.E.; Wong, E. Sequential Quadratic Programming Methods. In Mixed Integer Nonlinear Programming; Lee, J., Leyffer, S., Eds.; The IMA Volumes in Mathematics and Its Applications; Springer: New York, NY, USA, 2012; Volume 154. [Google Scholar]
- Fletcher, R.; Gould, N.I.; Leyffer, S.; Toint, P.; Wächter, A. Global convergence of a trust-region SQP-filter algorithm for general nonlinear programming. SIAM J. Optim. 2002, 13, 635–659. [Google Scholar] [CrossRef]
- Wang, J.; Petra, C.G. A Sequential Quadratic Programming Algorithm for Nonsmooth Problems with Upper-Objective. SIAM J. Optim. 2023, 33, 2379–2405. [Google Scholar] [CrossRef]
- Nocedal, J.; Yuan, Y. Combining trust-region and line-search techniques. In Advances in Nonlinear Programming; Yuan, Y., Ed.; Kluwer: Boston, MA, USA, 1998; pp. 157–175. [Google Scholar]
- Tong, X.; Zhou, S. Combining Trust Region and Line Search Methods for Equality Constrained Optimization. Numer. Funct. Anal. Optim. 2006, 24, 143–162. [Google Scholar] [CrossRef]
- Waltz, R.A.; Morales, J.L.; Nocedal, J.; Orban, D. An interior algorithm for nonlinear optimization that combines line search and trust region steps. Math. Program. 2006, 107, 391–408. [Google Scholar] [CrossRef]
- Pei, Y.; Zhu, D. A trust-region algorithm combining line search filter technique for nonlinear constrained optimization. Int. J. Comput. Math. 2014, 91, 1817–1839. [Google Scholar] [CrossRef]
- Dembo, R.S.; Eisenstat, S.C.; Steihaug, T. Inexact Newton methods. SIAM J. Numer. Anal. 1982, 19, 400–408. [Google Scholar] [CrossRef]
- Steihaug, T. The Conjugate Gradient method and Trust Regions in large scale optimization. SIAM J. Numer. Anal. 1983, 20, 626–637. [Google Scholar] [CrossRef]
- Lucidi, S.; Rochetich, F.; Roma, M. Curvilinear stabilization techniques for truncated Newton methods in large scale unconstrained optimization. SIAM J. Optim. 1998, 8, 916–939. [Google Scholar] [CrossRef]
- Gould, N.I.M.; Lucidi, S.; Roma, M.; Toint, P.L. Solving the trust-region subproblem using the Lanczos method. SIAM J. Optim. 1999, 9, 504–525. [Google Scholar] [CrossRef]
- De Leone, R.; Fasano, G.; Sergeyev, Y.D. Planar methods and Grossone for the Conjugate Gradient breakdown in Nonlinear Programming. Comput. Optim. Appl. 2018, 71, 73–93. [Google Scholar] [CrossRef]
- Grippo, L.; Lampariello, F.; Lucidi, S. A truncated Newton method with nonmonotone linesearch for unconstrained optimization. J. Optim. Theory Appl. 1989, 60, 401–419. [Google Scholar] [CrossRef]
- Grippo, L.; Lampariello, F.; Lucidi, S. A class of nonmonotone stabilization methods in unconstrained optimization. Numer. Math. 1991, 59, 779–805. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Set |
| Set for any k, with |
| OUTER ITERATIONS |
| for |
| Compute and ; if is small then STOP |
| INNER ITERATIONS |
| - Compute , which approximately solves Newton’s equation |
| , i.e., it satisfies the truncation rule |
| - Possibly compute a bounded negative curvature direction at |
| Use a criterion to either combine and , or choose between and |
| If the directions and were combined, set , and |
| use a curvilinear linesearch procedure to select . Otherwise, set |
| with , and use an Armijo-type procedure to select |
| Update |
| endfor |
| Set |
| Set for any k, with |
| OUTER ITERATIONS |
| for |
| Compute and ; if is small then STOP |
| INNER ITERATIONS |
| - Compute , which approximately solves Newton’s equation |
| , i.e., it satisfies the truncation rule |
| - Set |
| Compute and by solving (2); then, update the trust-region |
| parameters |
| Set , and use an Armijo-type procedure to select the |
| steplength along the direction |
| Update |
| endfor |
| Set |
| Set for any k, with . Set |
| OUTER ITERATIONS |
| for |
| Compute and ; if is small then STOP |
| INNER ITERATIONS |
| - Compute , which approximately solves Newton’s equation |
| , i.e., it satisfies the truncation rule |
| - Set |
| Compute and by solving (2); then, set , |
| , |
| If , use an Armijo-type procedure to select the steplength |
| along ; otherwise, skip the linesearch procedure |
| Update the trust-region parameters |
| Update |
| endfor |
| Set |
| Set for any k, with |
| OUTER ITERATIONS |
| for |
| Compute and ; if is small then STOP |
| INNER ITERATIONS |
| - Compute , which approximately solves Newton’s equation |
| , i.e., it satisfies the truncation rule |
| Compute a suitable negative curvature direction for at |
| Compute and by solving (2); then, set . Update the |
| trust-region parameters |
| Use an Armijo-type procedure to select the steplength along |
| Update |
| endfor |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fasano, G.; Piermarini, C.; Roma, M. Issues on a 2–Dimensional Quadratic Sub–Problem and Its Applications in Nonlinear Programming: Trust–Region Methods (TRMs) and Linesearch Based Methods (LBMs). Algorithms 2024, 17, 563. https://doi.org/10.3390/a17120563
Fasano G, Piermarini C, Roma M. Issues on a 2–Dimensional Quadratic Sub–Problem and Its Applications in Nonlinear Programming: Trust–Region Methods (TRMs) and Linesearch Based Methods (LBMs). Algorithms. 2024; 17(12):563. https://doi.org/10.3390/a17120563
Chicago/Turabian StyleFasano, Giovanni, Christian Piermarini, and Massimo Roma. 2024. "Issues on a 2–Dimensional Quadratic Sub–Problem and Its Applications in Nonlinear Programming: Trust–Region Methods (TRMs) and Linesearch Based Methods (LBMs)" Algorithms 17, no. 12: 563. https://doi.org/10.3390/a17120563
APA StyleFasano, G., Piermarini, C., & Roma, M. (2024). Issues on a 2–Dimensional Quadratic Sub–Problem and Its Applications in Nonlinear Programming: Trust–Region Methods (TRMs) and Linesearch Based Methods (LBMs). Algorithms, 17(12), 563. https://doi.org/10.3390/a17120563