
Hybrid RFSVM: Hybridization of SVM and Random Forest Models for Detection of Fake News

Abstract
1. Introduction
1.1. Knowledge-Based Study
1.2. Style-Based Study
1.3. Propagation-Based Study of Fake News
- How are the propagation patterns of false news represented?
- What will be the measuring parameters for the characterization of dissemination of false news?
- How do we differentiate the dissemination of fake news from news that is verified?
- How do we analyze the pattern of fake news in various domains like politics, economy, and education?
- How does fake news propagate differently for topics like presidential elections and health, for various platforms like Instagram, Facebook, and X (Twitter), in different languages like English, Hindi, Mandarin Chinese, and Spanish?
2. Related Work and Motivation
2.1. Proposed Framework
- Data Acquisition: Authors acquired the dataset about fake news on COVID-19 on X (Twitter) from dataworld.com.
- Data Labelling: Data containing tweets from X (Twitter). After cleaning the records, we labeled them 1 (fake news) and 0 (true news). The training set contains 60% data, and the test set contains 40% data containing fake news related to COVID-19.
- Defining the Feature Set: The set of features that authors used consisted of a TFIDF feature vector [22].
- Evaluation Parameters for Fake News Detection: Various evaluation parameters are used by the author in the manuscript, as follows.
2.2. Proposed Algorithm
- (a)
- For each tree in the forest, simply sample n data points. Further, for each node in a tree, we will randomly select m attributes by calculating variance. This leads to the new dataset d’ from the dataset d using the random replacement method along with the assignments of weights against each attribute.
- (b)
- For each subset having a random feature of dataset d’, apply SVMs for each feature subset and generate the output of the classification as one class of SVM, which can further be used to update the weights of all the vectors on the basis of the outcomes of classification. The weights of the vectors can further be increased in case of misclassification and decrease in other cases.
- (c)
- Repeat step (a) and (b), by generating different random datasets till all input vectors are further classified.
- (d)
- The output of the complete dataset is computed using the majority voting process, from the final outputs of each of the random feature subsets Di. Proposed Algorithm is shown in Algorithm 1.
| Algorithm 1: Hybrid RFSVM Fake News Detection Algorithm. |
| Input: Dataset Output: Classification of news as fake/real & evaluation metrics // Phase 1: Data Set Creation // Download the Dataset For each data belonging to the dataset do Data pre-processing return Processed Data // Phase 2: Fake Dataset Text Augmentation // For each data in the Dataset FW ← extract (Bag of words) MS ← cosine similarity (FW, FW) If max (MS) AFT ← combine fake text // (Augmented Fake Text) // Phase 3: Text Classification // // For Machine Learning: tfidf (t, x, X) ← tf (t, x).idf (t, X) tf (t, x) ← Log(1+freq (t, x)) idf (t, X) ← Log (N/count d belongs to D, t belongs to d) TF, IDF ← tfidf (Dataset) // Feature Extraction // Accuracy ← Random Forest + SVMs |
3. Implementation and Results
- (a)
- Analysis of different types of news categories with five different models in terms of accuracy: naïve Bayes (NB), Random Forest (RF), XGBOOST, SVMs, and RFSVM. A comparative analysis of different models in terms of accuracy, with different types of news categories, is presented in Table 6.
- (b)
- Analysis of different types of news categories with five different models in terms of precision in Table 7:
- (c)
- Analysis of different types of news categories with five different models in terms of precision in Table 8:
- (d)
- Analysis of different types of news categories with five different models in terms of precision in Table 9:
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, X.; Zafarani, R. Fake news: A survey of research, detection methods, and opportunities. arXiv 2018, arXiv:1812.00315. [Google Scholar]
- Reddy, H.; Raj, N.; Gala, M.; Basava, A. Text-mining-based Fake News Detection Using Ensemble Methods. Int. J. Autom. Comput. 2020, 17, 210–221. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, Y.F.B. FNED: A Deep Network for Fake News Early Detection on Social Media. ACM TOIS 2020, 38, 25. [Google Scholar] [CrossRef]
- Alkhodair, S.A.; Ding, S.H.; Fung, B.C.; Liu, J. Detecting breaking news rumors of emerging topics in social media. Inf. Process. Manag. 2020, 57, 102018. [Google Scholar] [CrossRef]
- Meel, P.; Vishwakarma, D.K. Fake News, Rumor, Information Pollution in Social Media and Web: A Contemporary Survey of State-of-the-arts, Challenges and Opportunities. Expert Syst. Appl. 2019, 153, 112986. [Google Scholar] [CrossRef]
- Sharma, K.; Qian, F.; Jiang, H.; Ruchansky, N.; Zhang, M.; Liu, Y. Combating fake news: A survey on identification and mitigation techniques. ACM TIST 2019, 10, 21. [Google Scholar] [CrossRef]
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Ozbay, F.A.; Alatas, B. Fake news detection within online social media using supervised artificial intelligence algorithms. Phys. A Stat. Mech. Appl 2020, 540, 123174. [Google Scholar] [CrossRef]
- Monti, F.; Frasca, F.; Eynard, D.; Mannion, D.; Bronstein, M.M. Fake News Detection on Social Media Using Geometric Deep Learning. arXiv 2019, arXiv:1902.06673. [Google Scholar]
- Vishwakarma, D.K.; Varshney, D.; Yadav, A. Detection and veracity analysis of fake news via scrapping and authenticating the web search. Cogn. Syst. Res. 2019, 58, 217–229. [Google Scholar] [CrossRef]
- Alzanin, S.M.; Azmi, A.M. Detecting rumors in social media: A survey. Procedia Comput. Sci. 2018, 142, 294–300. [Google Scholar] [CrossRef]
- Cybenko, A.K.; Cybenko, G. AI and fake news. IEEE Intell. Syst. 2018, 33, 1–5. [Google Scholar] [CrossRef]
- Jang, S.M.; Geng, T.; Li, J.Y.Q.; Xia, R.; Huang, C.T.; Kim, H.; Tang, J. A computational approach for xamining the roots and spreading patterns of fake news: Evolution tree analysis. Comput. Hum. Behav. 2018, 84, 103–113. [Google Scholar] [CrossRef]
- Pérez-Rosas, V.; Kleinberg, B.; Lefevre, A.; Mihalcea, R. Automatic Detection of Fake News. arXiv 2017, arXiv:1708.07104. [Google Scholar]
- Wang, W.Y. “Liar, liar pants on fire”: A new benchmark dataset for fake news detection. arXiv 2017, arXiv:1705.0064. [Google Scholar]
- Ruchansky, N.; Seo, S.; Liu, Y. CSI: A hybrid deep model for fake news detection. In Proceedings of the 26th ACM International Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 797–806. [Google Scholar]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Al Amrani, Y.; Lazaar, M.; El Kadiri, K.E. Random forest and support vector machine based hybrid approach to sentiment analysis. Procedia Comput. Sci. 2018, 127, 511–520. [Google Scholar] [CrossRef]
- Garg, N.; Gupta, R.; Kaur, M.; Ahmed, S.; Shankar, H. Efficient Detection and Classification of Orange Diseases using Hybrid CNN-SVM Model. In Proceedings of the 2023 International Conference on Disruptive Technologies (ICDT), Greater Noida, India, 11–12 May 2023; pp. 721–726. [Google Scholar]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Dedeepya, P.; Yarrarapu, M.; Kumar, P.P.; Kaushik, S.K.; Raghavendra, P.N.; Chandu, P. Fake News Detection on Social Media Through a Hybrid SVM-KNN Approach Leveraging Social Capital Variables. In Proceedings of the 2024 3rd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 5–7 June 2024; pp. 1168–1175. [Google Scholar]
- Ramos, J. Using TF-IDF to determine word relevance in document queries. In Proceedings of the 1st Instructional Conference on Machine Learning. 2003; Volume 242, pp. 133–142. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1;type=pdf;doi=b3bf6373ff41a115197cb5b30e57830c16130c2c (accessed on 11 August 2024).
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4 August 2001; Volume 3, pp. 41–46. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM TIST 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Yager, R.R. An extension of the naive Bayesian classifier. Inf. Sci 2006, 176, 577–588. [Google Scholar] [CrossRef]
- Cortes, V.; Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake news detection using machine learning ensemble methods. Complexity 2020, 1, 8885861. [Google Scholar] [CrossRef]
- Hamsa, H.; Indiradevi, S.; Kizhakkethottam, J.J. Student academic performance prediction model using decision tree and fuzzy genetic algorithm. Proc. Technol. 2016, 25, 326–332. [Google Scholar] [CrossRef]
- Malhotra, P.; Malik, S.K. Fake News Detection Using Ensemble Techniques. Multimed. Tools Appl. 2024, 83, 42037–42062. [Google Scholar] [CrossRef]
- Sharma, U.; Saran, S.; Patil, S.M. Fake news detection using machine learning algorithms. IJCRT 2020, 8, 509–518. [Google Scholar]
- Khanam, Z.; Alwasel, B.N.; Sirafi, H.; Rashid, M. Fake news detection using machine learning approaches. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1099, 012040. [Google Scholar] [CrossRef]
- Pandey, S.; Prabhakaran, S.; Reddy, N.S.; Acharya, D. Fake news detection from online media using machine learning classifiers. J. Phys. Conf. Ser. 2022, 2161, 012027. [Google Scholar] [CrossRef]
- Mallick, C.; Mishra, S.; Senapati, M.R. A cooperative deep learning model for fake news detection in online social networks. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 4451–4460. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topics Covered | Content Analysed | |
|---|---|---|
| PolitiFact | American Politics | Statements |
| FactCheck | American Politics | TV ads, Debates, Speeches, Interviews and News |
| Snopes | Politics and other Social Issues | News Articles and Videos |
| TruthorFiction | Politics, Religion, Nature, Food and Medical | Email Rumours |
| HoaxSlayer | Ambiguity | Articles and Messages |
| FullFact | Economy, Health, Education, Crime, Immigration, Law | Articles |
| Support Vector Machine + Random Forest | RFSVM |
| Support Vector Machine | SVM |
| Random Forest | RF |
| XGBoost | XGB |
| Naïve Bayes | NB |
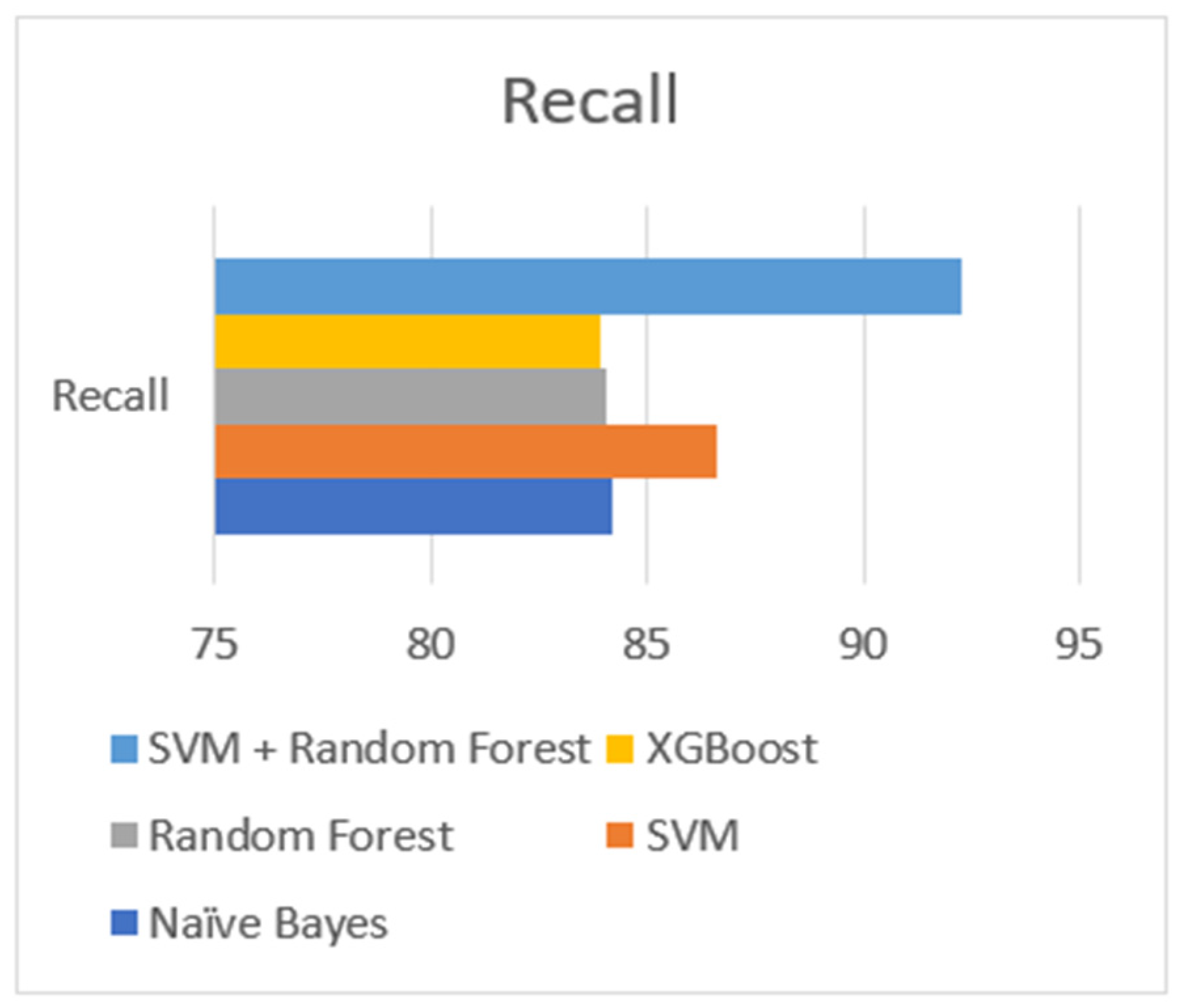
| Model | Accuracy | Precision | Recall | F1-score |
|---|---|---|---|---|
| Naïve Bayes | 96 | 85 | 84.18 | 84.58 |
| SVM | 96.75 | 86.91 | 86.63 | 86.76 |
| Random Forest | 96.25 | 84.88 | 84.05 | 84.46 |
| XGBoost | 95.75 | 84.56 | 83.90 | 84.63 |
| SVM + Random Forest | 97.56 | 88.21 | 92.30 | 93.50 |
| Accuracy | RFSVM > SVM > RF > NB > XGB |
| Precision | RFSVM > SVM > RF > XGB > NB |
| Recall | RFSVM > SVM > RF > NB > XGB |
| F1-score | RFSVM > SVM > XGB > NB > RF |
| Reference | Classifier Used | Year | Accuracy | Precision | F1-score |
|---|---|---|---|---|---|
| [31] | NB | 2020 | 0.60 | 0.59 | 0.72 |
| RF | 0.59 | 0.62 | 0.67 | ||
| LR | 0.65 | 0.69 | 0.75 | ||
| PAC | 0.92 | 0.93 | 0.9257 | ||
| [32] | XGBOOST | 2020 | 0.75 | - | - |
| SVM | 0.73 | - | - | ||
| RF | 0.73 | - | - | ||
| [33] | SVM | 2021 | 0.8933 | - | - |
| DT | 0.7333 | - | - | ||
| NB | 0.8689 | - | - | ||
| LR | 0.9046 | - | - | ||
| KNN | 0.8998 | - | - | ||
| Proposed Approach | RFSVM | 0.9756 | 0.8821 | 0.9350 |
| Category | Avg. Accuracy [NB] | Avg. Accuracy [XGBoost] | Avg. Accuracy [RF] | Avg. Accuracy [SVMs] | Avg. Accuracy [RFSVM] | Reference [34] |
|---|---|---|---|---|---|---|
| Agriculture | 0.87 | 0.89 | 0.91 | 0.95 | 0.97 | 0.95 |
| Aviation | 0.49 | 0.51 | 0.53 | 0.61 | 0.63 | 0.68 |
| Sports | 0.55 | 0.57 | 0.59 | 0.65 | 0.67 | 0.72 |
| Roads | 0.64 | 0.66 | 0.68 | 0.72 | 0.74 | 0.80 |
| Residential | 0.53 | 0.55 | 0.57 | 0.61 | 0.63 | 0.61 |
| Forest | 0.57 | 0.59 | 0.61 | 0.61 | 0.64 | 0.65 |
| Village | 0.42 | 0.44 | 0.46 | 0.53 | 0.58 | 0.57 |
| Finance | 0.87 | 0.89 | 0.91 | 0.95 | 0.97 | 0.95 |
| Politics | 0.87 | 0.89 | 0.91 | 0.91 | 0.93 | 0.91 |
| Technology | 0.42 | 0.44 | 0.46 | 0.53 | 0.55 | 0.53 |
| Category | Avg. Precision [NB] | Avg. Precision [XGBoost] | Avg. Precision [RF] | Avg. Precision [SVMs] | Avg. Precision [RFSVM] | Reference [34] |
|---|---|---|---|---|---|---|
| Agriculture | 0.90 | 0.92 | 0.94 | 0.98 | 0.98 | 0.98 |
| Aviation | 0.51 | 0.53 | 0.55 | 0.63 | 0.70 | 0.71 |
| Sports | 0.57 | 0.59 | 0.61 | 0.67 | 0.76 | 0.74 |
| Roads | 0.67 | 0.69 | 0.71 | 0.74 | 0.81 | 0.82 |
| Residential | 0.55 | 0.57 | 0.59 | 0.63 | 0.65 | 0.63 |
| Forest | 0.59 | 0.61 | 0.63 | 0.63 | 0.65 | 0.67 |
| Village | 0.43 | 0.45 | 0.47 | 0.55 | 0.56 | 0.59 |
| Finance | 0.90 | 0.92 | 0.94 | 0.98 | 0.98 | 0.98 |
| Politics | 0.90 | 0.92 | 0.94 | 0.94 | 0.96 | 0.94 |
| Technology | 0.43 | 0.45 | 0.47 | 0.55 | 0.54 | 0.55 |
| Category | Avg. Recall [NB] | Avg. Recall [XGBoost] | Avg. Recall [RF] | Avg. Recall [SVMs] | Avg. Recall [RFSVM] | Reference [34] |
|---|---|---|---|---|---|---|
| Agriculture | 0.43 | 0.45 | 0.47 | 0.51 | 0.62 | 0.61 |
| Aviation | 0.23 | 0.25 | 0.27 | 0.35 | 0.52 | 0.53 |
| Sports | 0.51 | 0.53 | 0.55 | 0.61 | 0.78 | 0.78 |
| Roads | 0.10 | 0.12 | 0.14 | 0.18 | 0.33 | 0.35 |
| Residential | 0.25 | 0.27 | 0.29 | 0.33 | 0.41 | 0.43 |
| Forest | 0.53 | 0.55 | 0.57 | 0.57 | 0.72 | 0.71 |
| Village | 0.33 | 0.35 | 0.37 | 0.45 | 0.58 | 0.59 |
| Finance | 0.53 | 0.55 | 0.57 | 0.61 | 0.69 | 0.71 |
| Politics | 0.53 | 0.55 | 0.57 | 0.57 | 0.67 | 0.67 |
| Technology | 0.38 | 0.40 | 0.42 | 0.50 | 0.58 | 0.60 |
| Category | Avg. F1-Score [NB] | Avg. F1-score [XGBoost] | Avg. F1-Score [RF] | Avg. F1-Score [SVMs] | Avg. F1-Score [RFSVM] | Reference [34] |
|---|---|---|---|---|---|---|
| Agriculture | 0.59 | 0.61 | 0.63 | 0.67 | 0.75 | 0.75 |
| Aviation | 0.32 | 0.34 | 0.36 | 0.45 | 0.59 | 0.61 |
| Sports | 0.54 | 0.56 | 0.58 | 0.64 | 0.77 | 0.76 |
| Roads | 0.19 | 0.21 | 0.23 | 0.28 | 0.34 | 0.49 |
| Residential | 0.35 | 0.37 | 0.39 | 0.43 | 0.51 | 0.51 |
| Forest | 0.56 | 0.58 | 0.60 | 0.60 | 0.72 | 0.69 |
| Village | 0.37 | 0.39 | 0.41 | 0.50 | 0.59 | 0.59 |
| Finance | 0.67 | 0.69 | 0.71 | 0.75 | 0.85 | 0.82 |
| Politics | 0.67 | 0.69 | 0.71 | 0.71 | 0.74 | 0.78 |
| Technology | 0.40 | 0.42 | 0.44 | 0.52 | 0.56 | 0.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dev, D.G.; Bhatnagar, V. Hybrid RFSVM: Hybridization of SVM and Random Forest Models for Detection of Fake News. Algorithms 2024, 17, 459. https://doi.org/10.3390/a17100459
Dev DG, Bhatnagar V. Hybrid RFSVM: Hybridization of SVM and Random Forest Models for Detection of Fake News. Algorithms. 2024; 17(10):459. https://doi.org/10.3390/a17100459
Chicago/Turabian StyleDev, Deepali Goyal, and Vishal Bhatnagar. 2024. "Hybrid RFSVM: Hybridization of SVM and Random Forest Models for Detection of Fake News" Algorithms 17, no. 10: 459. https://doi.org/10.3390/a17100459
APA StyleDev, D. G., & Bhatnagar, V. (2024). Hybrid RFSVM: Hybridization of SVM and Random Forest Models for Detection of Fake News. Algorithms, 17(10), 459. https://doi.org/10.3390/a17100459