
Specification Mining Based on the Ordering Points to Identify the Clustering Structure Clustering Algorithm and Model Checking
Abstract
1. Introduction
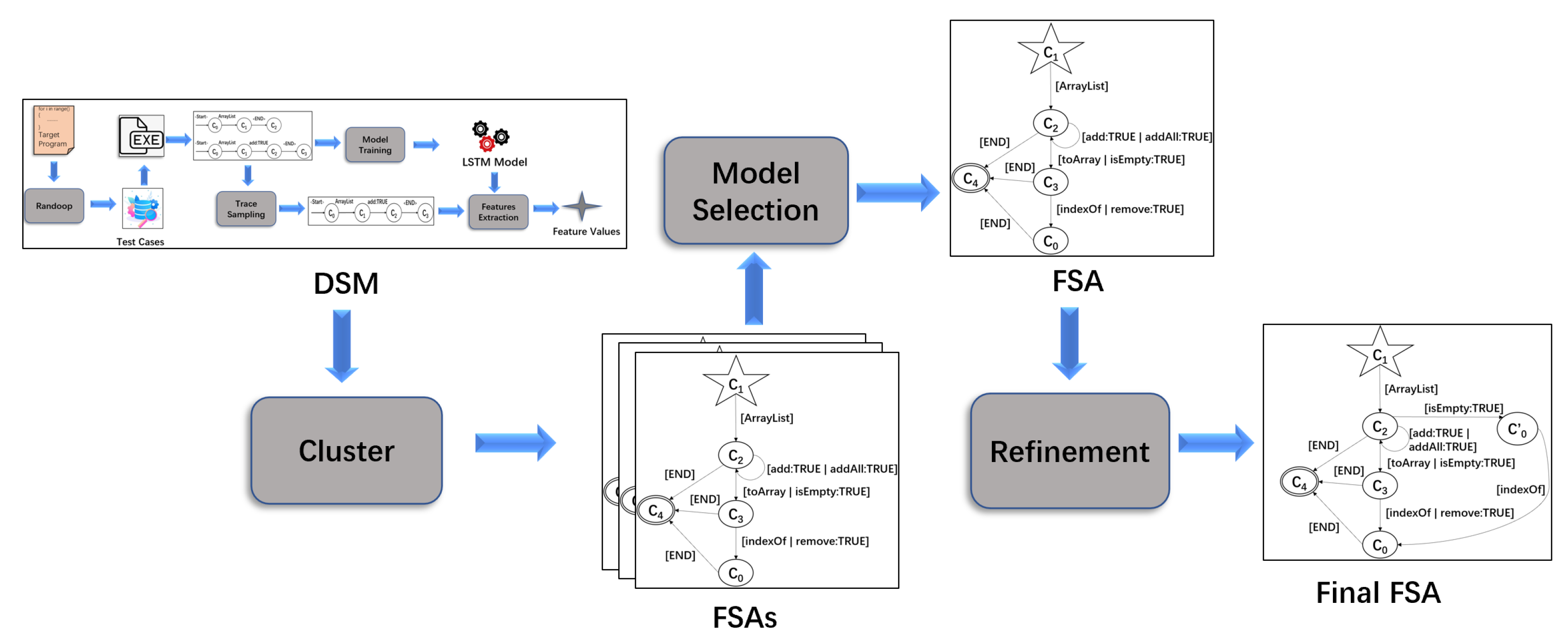
- DSM is employed to generate the feature values of states in the traces of the program;
- The OPTICS clustering algorithm first generates a reachability plot based on the feature values. Then, the range of the clustering radius is determined according to the reachability plot, and several suitable radii are selected within this range to cluster the feature values to obtain the FSAs;
- A model selection algorithm is used to select the FSA with the highest F-measure from the generated FSAs. Specifically, the F-measure is defined in Section 3.2;
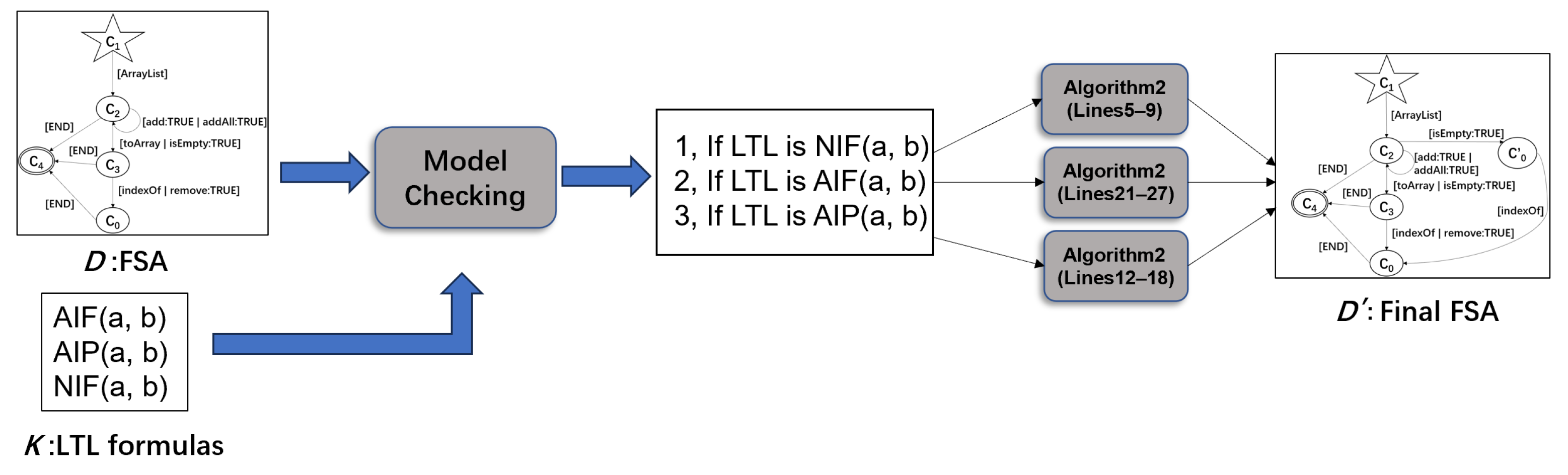
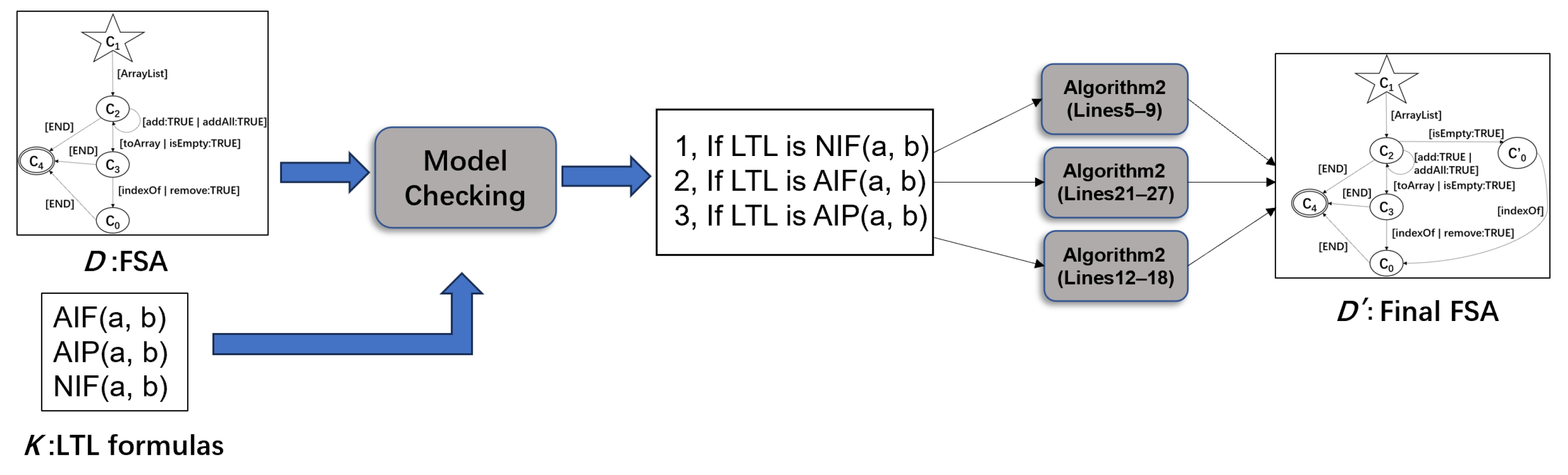
- Texada [6] is employed to generate LTL properties specifying the desired behaviors of the system. Then, model checking of the FSA is performed to verify whether the selected FSA satisfies these properties. If not, we refine the FSA by adding and deleting the corresponding states and transitions in it according to the type of the property which the FSA violates, so that the traces that violate the property are removed from the FSA.
- We propose a specification mining approach based on the OPTICS clustering algorithm and model checking. Specifically, during the generation of FSAs, we employ the OPTICS clustering algorithm to improve the clustering effect and solve the parameter setting problem so that the parameters can be intuitively set. In addition, we refine the generated FSAs based on model checking to alleviate the problem of incorrect merging among states in FSAs generated by clustering feature values and improve the quality of specifications;
- We implemented our approach in a tool called MCLSM;
- We conducted experiments on 13 target library classes from [8,9,13,14] to evaluate the performance of our tool, and the results show that the average F-measure of the FSAs generated by MCLSM reaches 92.19%, which is 175.85%, 197.67%, 66.95%, 177.17%, 233.41%, 367.49%, and 28.48% higher than that of FSAs generated by the most related tools, i.e., 1-tails [7], 2-tails [7], SEKT 1 [13], SEKT 2 [13], CONTRACTOR++ [13], TEMI [13], and DSM [8,9], respectively.
2. Preliminary
2.1. Model Checking
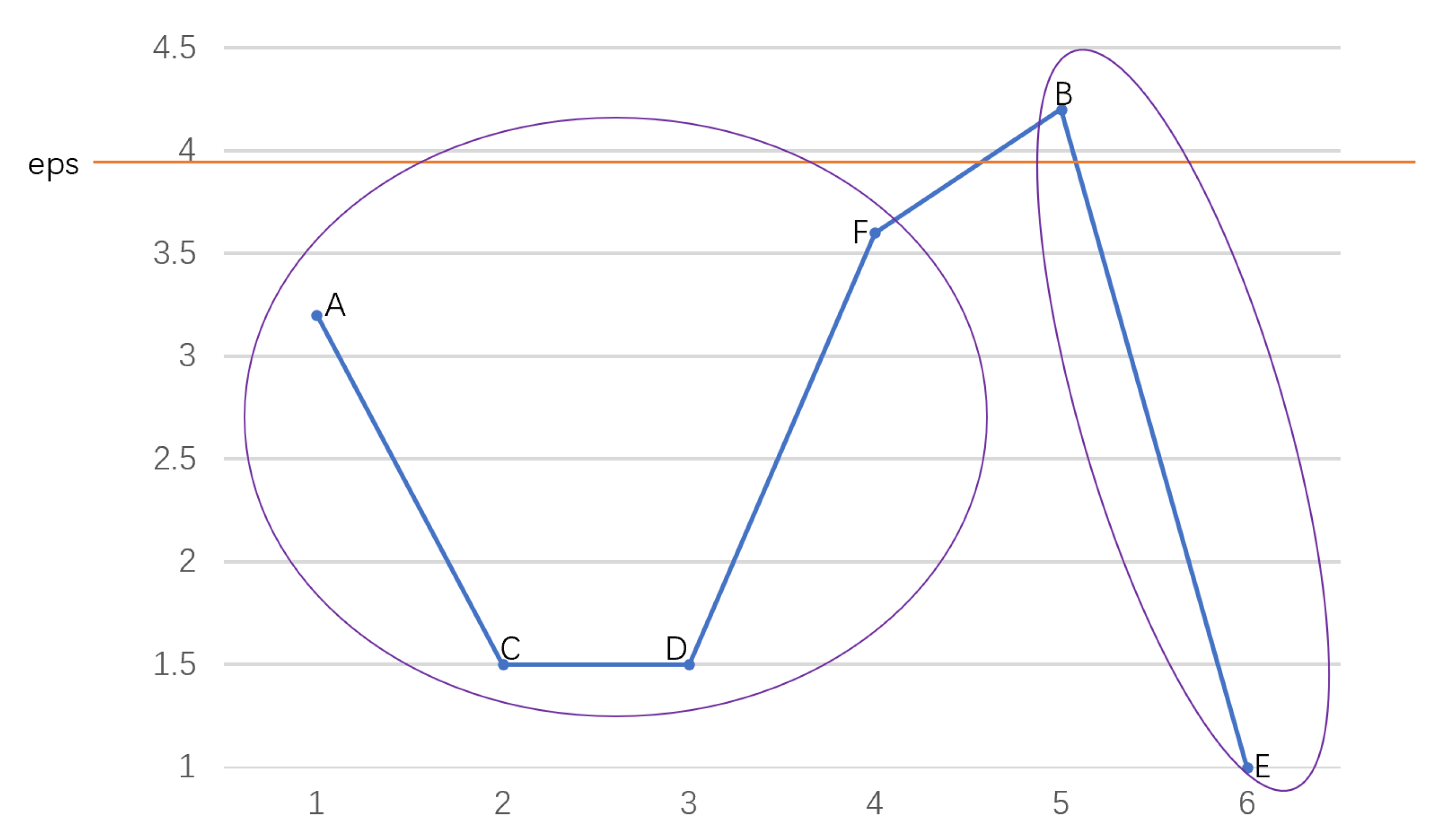
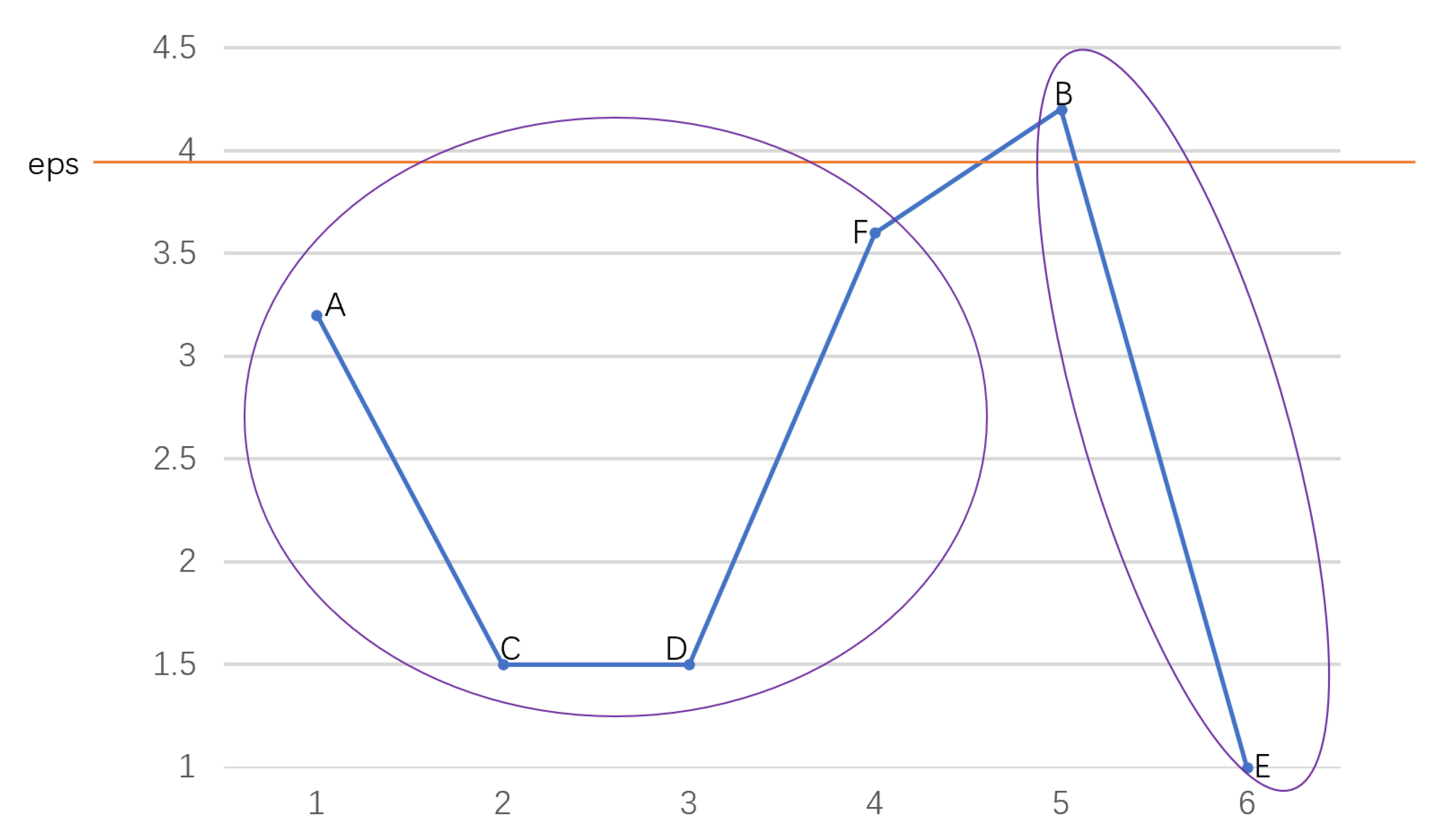
2.2. OPTICS Clustering Algorithm
- − : For ∈ O, its − is a subset of O containing objects whose distance from is not greater than . That is, ) = {∈O| distance(, ) ≤}. The number of objects in is noted as . Usually, is used to represent the clustering radius ;
- Core object: for any ∈ O, is a core object if , where is an integer constant;
- Core distance: the minimum radius that makes an object o a core object is called the core distance of o;
- Reachability distance: the reachability distance of an object p with respect to a core object o denoted as is the maximum value between the actual distance of o to p and the core distance of o.
- The core object queue , ordered queue , result queue , and reachability distance queue are initialized to empty;
- All core objects in O are chosen based on and , and then added to ;
- If there is an element in that has not been processed, jump to 4, and otherwise 8.
- An unprocessed object o is randomly taken out from and placed in . Then, it is marked as processed. Further, each object p satisfying is selected from and added to in an ascending order of the reachability distance with respect to o;
- If is not empty, jump to 6, and otherwise 3;
- The reachability distance of the first object in , with respect to the last object in , is stored in . Then, is removed from both and , and added into ;
- Each object whose reachability distance with respect to the last object r in is not greater than is selected from . Then, these objects are sorted in ascending order of the reachability distance with respect to r and replace the objects in . Finally, jump to 5;
- The reachability plot is plotted based on and .
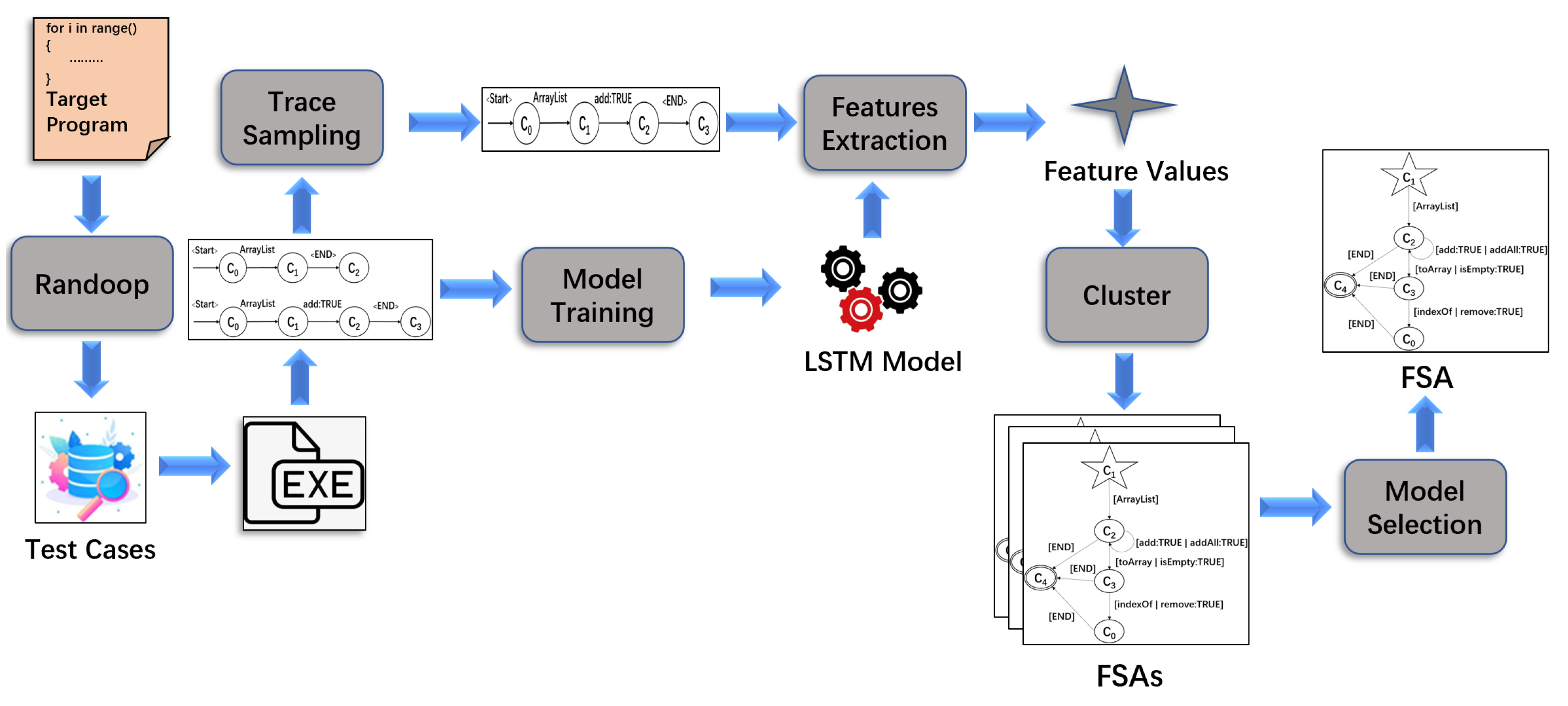
2.3. DSM
- DSM uses Randoop [21] to generate a large number of test cases. Then, it executes the target program with these cases and stores the traces (the methods calls) of the program in a trace set;
- The LSTM model is trained by all execution traces;
- In order to improve the efficiency of specification mining, a subset of traces that can cover all adjacent method pairs of execution traces is extracted;
- Two types of features, i.e., and , are extracted in each state based on the subset of traces and the LSTM model, where captures information of previously invoked methods before , and captures information about methods immediately after state using the LSTM model. For instance, suppose that all methods that appear in the program are in a set and a trace is = , …, , …, , where ( and ) in is the invoked method at state . At state , methods from to in are invoked. Thus, () and for other methods in M, . All feature values of all states in all traces belonging to the subset are stored in a set O = {=, , …, = , }, where h is the number of states in all traces and for each , = , …, , and = , …, ;
- The K-means [11] and hierarchical clustering algorithms are used to cluster the feature values and generate FSAs. An FSA can be represented as a five-tuple D = (Q, , , , F), where Q is a finite set of states, is a table of input characters, is a transition function mapping Q × to Q, ∈ Q is the initial state, and F ⊂ Q is the set of acceptable states;
- The FSA with the highest F-measure is selected from the generated FSAs.
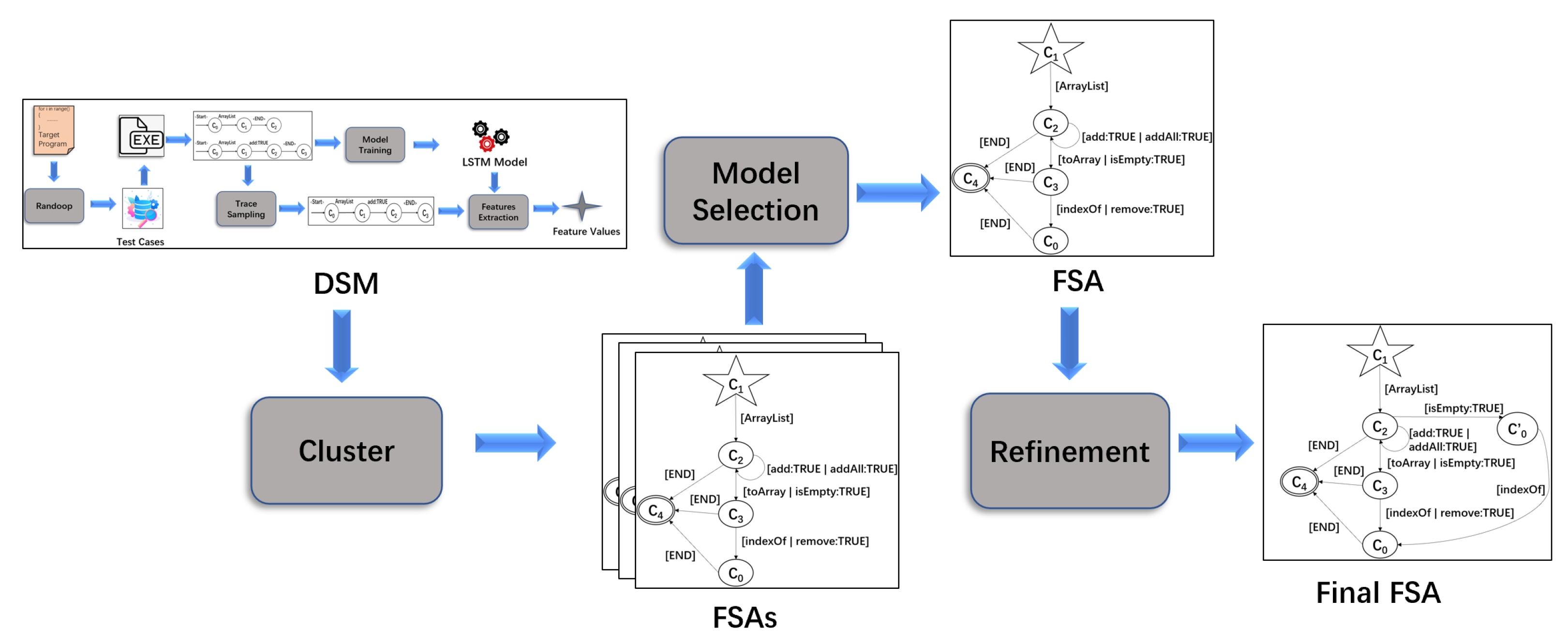
3. Specification Mining Based on the OPTICS Clustering Algorithm and Model Checking
- We cluster feature values obtained by DSM based on in the reachability plot, which is drawn according to the OPTICS clustering algorithm [12];
- The FSAs with the highest F-measure are selected during the model selection;
- We perform model checking on the selected FSAs and refine the FSAs based on the verification result to obtain the final FSAs.
3.1. Clustering
- , , and are defined as in Section 2.2;
- is used to store objects of the same class as a given object;
- K is used to mark the category to which the current objects belong;
- The map is used to map the category K to the corresponding core objects at one clustering;
- is used to store after each clustering;
- The variable is used to control the increment of at each clustering;
- represents the reachability plot generated by the OPTICS clustering algorithm.
| Algorithm 1: Clustering Process | ||||
| Input: O | ||||
| Output: | ||||
| 1 | Initialize: , , , , = ∅, ; | |||
| 2 | = ; | |||
| 3 | Determine the range of and the value of according to ; | |||
| 4 | ; | |||
| 5 | while do | |||
| 6 | ← Find all core objects in O based on and ; | |||
| 7 | ; | |||
| 8 | while ≠ ∅ do | |||
| 9 | ← Take out from ; | |||
| 10 | ← Take out all objects o satisfying from ; | |||
| // n represents the number of objects in | ||||
| 11 | while ≠ ∅ do | |||
| 12 | ← Take out all objects satisfying from ; | |||
| 13 | ← Take out of ; | |||
| 14 | end | |||
| 15 | ← Grouping objects in into K category; | |||
| 16 | = ∅; | |||
| 17 | K = K + 1; | |||
| 18 | end | |||
| 19 | ←; | |||
| 20 | = ∅; | |||
| 21 | = ; | |||
| 22 | end | |||
| 23 | return ; | |||
3.2. Model Selection
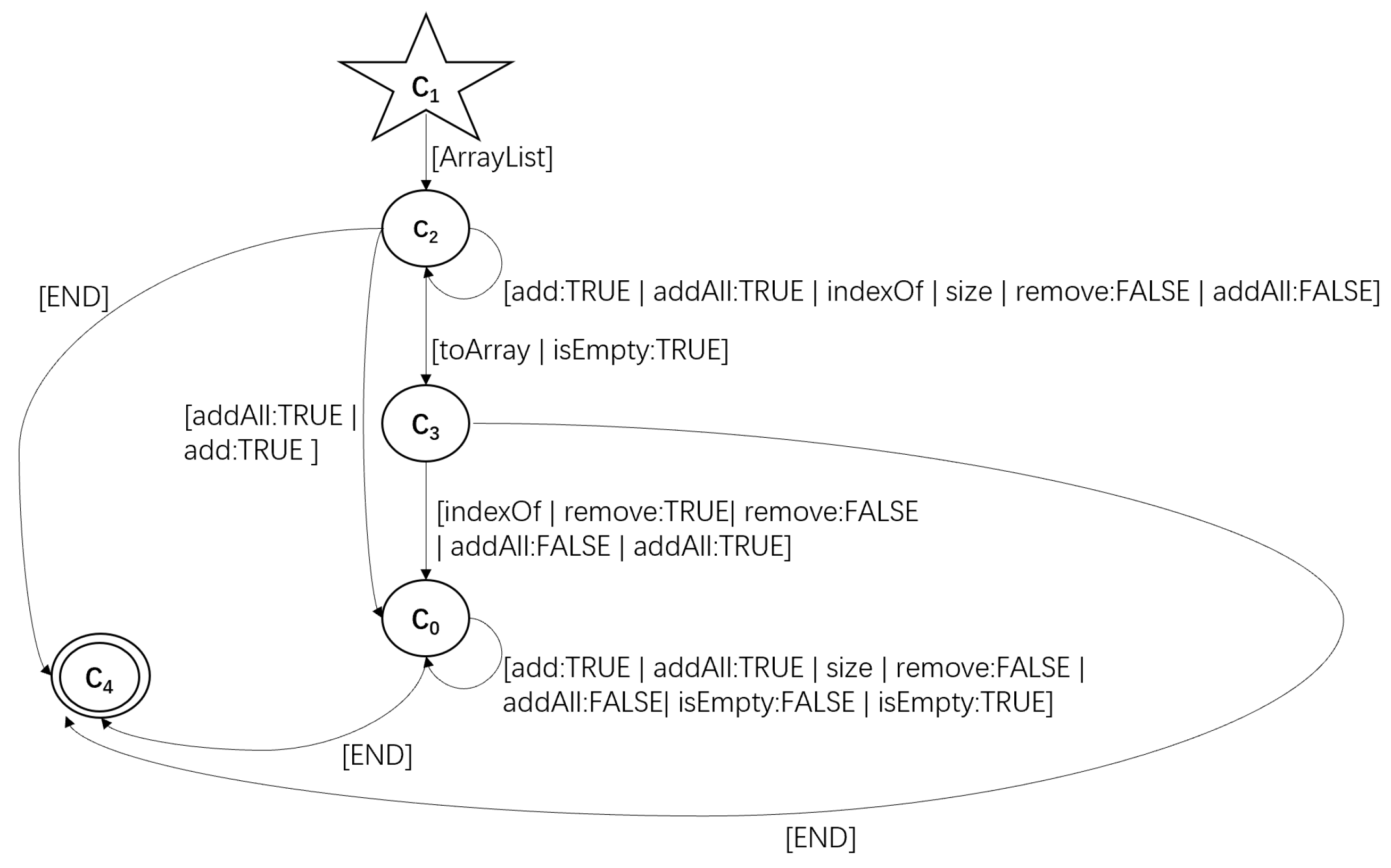
3.3. FSA Refinement Based on Model Checking
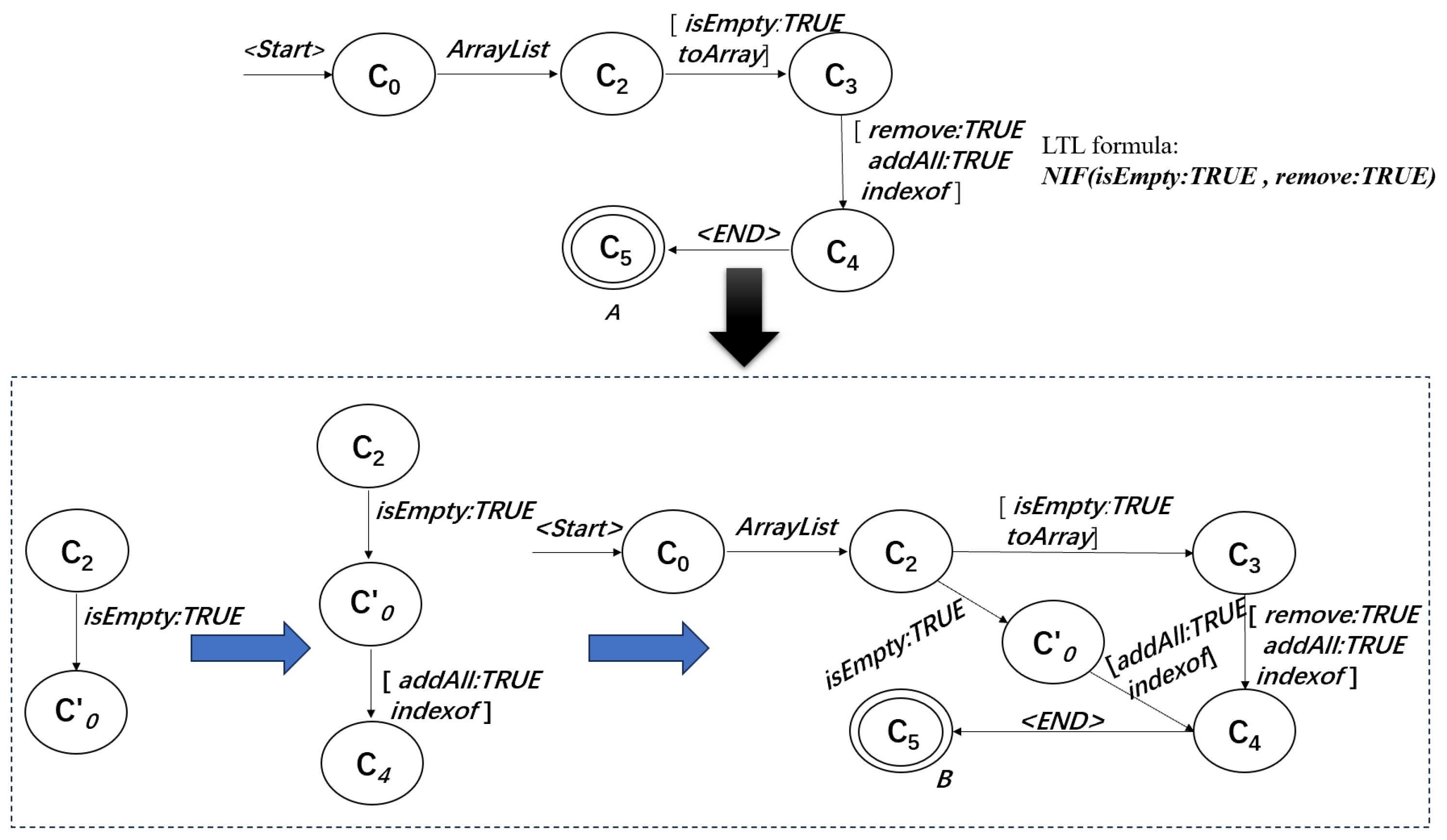
- : an occurrence of event a must be immediately followed by event b, i.e., G (a→Xb);
- : an occurrence of event a must be immediately preceded by event b, i.e., F→ (¬a∪ (b∧Xa));
- : an occurrence of event a is never immediately followed by event b, i.e., G (a→X (¬b)).
- D and represent the FSAs before and after refinement, respectively;
- K is a set of LTL formulas generated by Texada;
- is a set of tuples , where is a set of tuples , is a set of tuples , , , , and are states, and , , , and are methods;
- represents newly added states in the FSA.
| Algorithm 2: Refinement Process | ||||
| Input: D = (Q, , , , F), K = {, …, } | ||||
| Output: = (, , , , F) | ||||
| 1 | Initialize: , , ; | |||
| 2 | while and there exists a property violated by do | |||
| 3 | ; | |||
| 4 | for each do | |||
| 5 | if is then | |||
| 6 | Delete (, ) = ; | |||
| 7 | }; | |||
| 8 | Add transition rules to : (, ) = and (, ) = for | |||
| each ; | ||||
| 9 | = + 1; | |||
| 10 | end | |||
| 11 | if is then | |||
| 12 | Delete (, ) = ; | |||
| 13 | ; | |||
| 14 | Add transition rules to : (, ) = for each ; | |||
| 15 | = + 1; | |||
| 16 | ; | |||
| 17 | Add transition rules to : (, a) = and (, ) = ; | |||
| 18 | = + 1; | |||
| 19 | end | |||
| 20 | if is then | |||
| 21 | Delete (, ) = ; | |||
| 22 | ; | |||
| 23 | Add a transition rule to : (, ) = ; | |||
| 24 | = + 1; | |||
| 25 | }; | |||
| 26 | Add transition rules to : (, b) = and (, ) = | |||
| for each ; | ||||
| 27 | = + 1; | |||
| 28 | end | |||
| 29 | end | |||
| 30 | = (, , , , F); | |||
| 31 | end | |||
- If the violated property is , it returns all segments that satisfy , , containing all tuples satisfying , containing all tuples satisfying , and there is satisfying ;
- If the violated property is , it returns all segments that satisfy , , containing all tuples satisfying , containing all tuples satisfying , and for each , ;
- If the violated property is , it returns all segments that satisfy , , containing all tuples satisfying , containing all tuples satisfying , and for each , .
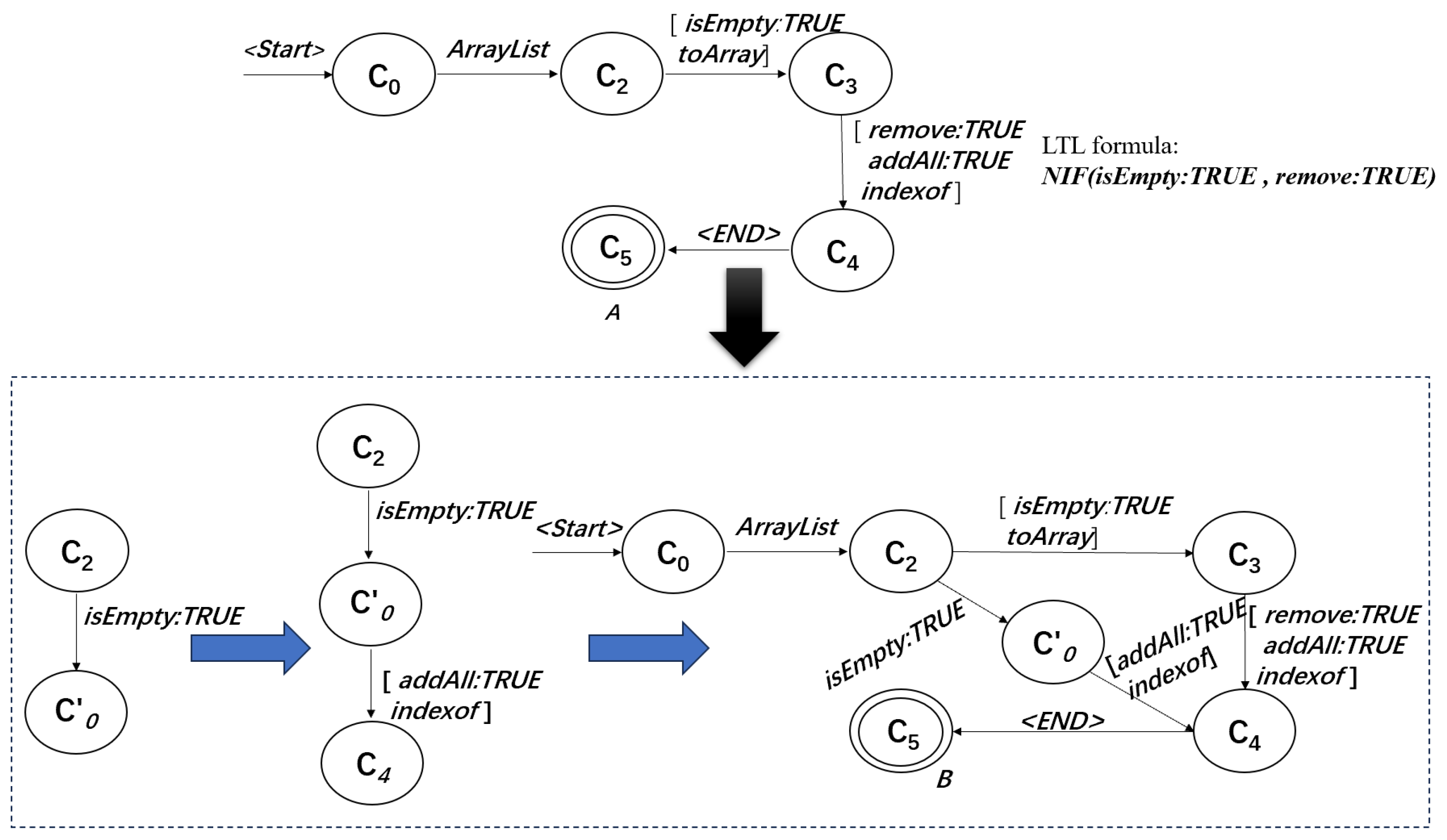
- If it violates , , we first delete the transition rule from state to state using method a, so that the traces violating are removed (Line 6). Then, in order to prevent traces that do not violate from being deleted, we add a state and some transition rules. First, we add a transition rule from state to state using method a. Next, we add transition rules from to each in using the corresponding method (except b) in (Lines 7–8);
- If it violates , , we first delete the transition rule from state to state using method b, so that the traces violating are removed (Line 12). Then, in order to increase the precision of the automaton, we add a state and transition rules from each state in to using the corresponding method in . Next, we update the state subscript and create another new state . Further, we add a transition rule from state to state using method a and a transition rule from state to state using method b (Lines 13–17);
- If it violates , , we first delete the transition rule from state to state using method a, so that the traces violating are removed (Line 21). Then, in order to increase the precision of the automaton, we add a state and some transition rules. First, we add a transition rule from state to state using method a. Next, we update the state subscript and create a new state . We then add a transition rule from to using method b and transition rules from to each state in using the corresponding method in (Lines 23–26).
4. Empirical Evaluation
4.1. Dataset
4.2. Experience Setting
4.3. Experimental Results and Analyses
4.4. Threats to Validity
4.4.1. Threats to Internal Validity
4.4.2. Threats to External Validity
5. Related Work
5.1. Mining Specifications Expressed in Temporal Logic Formulas
5.2. Mining Specifications Expressed as Models Similar to FSAs
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Symbols | Definition |
| An occurrence of event a must be immediately followed by event b | |
| An occurrence of event a must be immediately preceded by event b | |
| An occurrence of event a is never immediately followed by event b | |
| The error segments in the FSA according to the type of the violated property | |
| Q | The finite set of states in FSA |
| The table of input characters in FSA | |
| The transition function mapping Q × to Q | |
| The initial state in FSA | |
| F | The set of acceptable states in FSA |
| Acronyms | Full Form |
| FSA | Finite-state automaton |
| OPTICS | Ordering points to identify the clustering structure |
| DBSCAN | Density-based spatial clustering of applications with noise |
| CTL | Computing tree logic |
| LTL | Linear-time temporal logic |
| DSM | Deep specification mining |
| LSTM | Long short-term memory |
| DSM-T | Dynamic specification mining based on transformer |
| CPS | Cyber-physical systems |
| TEMI | Trace-enhanced MTS inference |
| GMM | Gaussian mixture model |
| SOC | System-on-chip |
References
- Zhong, H.; Su, Z. Detecting API documentation errors. In Proceedings of the 2013 ACM SIGPLAN International Conference on Object Oriented Programming Systems Languages & Applications, Indianapolis, IN, USA, 29–31 October 2013; pp. 803–816. [Google Scholar] [CrossRef]
- Beschastnikh, I.; Brun, Y.; Schneider, S.; Sloan, M.; Ernst, M.D. Leveraging existing instrumentation to automatically infer invariant-constrained models. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; pp. 267–277. [Google Scholar] [CrossRef]
- Lo, D.; Khoo, S.C. SMArTIC: Towards building an accurate, robust and scalable specification miner. In Proceedings of the 14th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Portland, OR, USA, 5–11 November 2006; pp. 265–275. [Google Scholar] [CrossRef]
- Lo, D.; Mariani, L.; Pezzè, M. Automatic steering of behavioral model inference. In Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT symposium on the Foundations of Software Engineering, Amsterdam, The Netherlands, 24–28 August 2009; pp. 345–354. [Google Scholar] [CrossRef]
- Peleg, H.; Shoham, S.; Yahav, E.; Yang, H. Symbolic automata for static specification mining. In Proceedings of the Static Analysis: 20th International Symposium, SAS 2013, Seattle, WA, USA, 20–22 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 63–83. [Google Scholar]
- Lemieux, C.; Park, D.; Beschastnikh, I. General LTL specification mining (T). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 81–92. [Google Scholar] [CrossRef]
- Biermann, A.W.; Feldman, J.A. On the synthesis of finite-state machines from samples of their behavior. IEEE Trans. Comput. 1972, 100, 592–597. [Google Scholar] [CrossRef]
- Le, T.D.B.; Lo, D. Deep specification mining. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, Amsterdam, The Netherlands, 16–21 July 2018; pp. 106–117. [Google Scholar] [CrossRef]
- Le, T.D.B.; Bao, L.; Lo, D. DSM: A specification mining tool using recurrent neural network based language model. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, 4–9 November 2018; pp. 896–899. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, Makuhari, Japan, 26–30 September 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- MacQueen, J. Classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965; University of California Press: Los Angeles, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. ACM Sigmod Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Krka, I.; Brun, Y.; Medvidovic, N. Automatically Mining Specifications from Invocation Traces and Method Invariants; Technical Report; Citeseer; Center for Systems and Software Engineering, University of Southern California: Los Angeles, CA, USA, 2013. [Google Scholar]
- Le, T.D.B.; Le, X.B.D.; Lo, D.; Beschastnikh, I. Synergizing specification miners through model fissions and fusions (t). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 115–125. [Google Scholar] [CrossRef]
- Pnueli, A. The temporal logic of programs. In Proceedings of the 18th Annual Symposium on Foundations of Computer Science (sfcs 1977), Providence, RI, USA, 31 October–2 November 1977; IEEE: Piscataway, NJ, USA, 1977; pp. 46–57. [Google Scholar] [CrossRef]
- Emerson, E.A.; Clarke, E.M. Characterizing correctness properties of parallel programs using fixpoints. In Proceedings of the Automata, Languages and Programming: Seventh Colloquium, Noordwijkerhout, The Netherlands, 14–18 July 1980; Springer: Berlin/Heidelberg, Germany, 1980; pp. 169–181. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Mahmood, H.; Mehmood, T.; Al-Essa, L.A. Optimizing Clustering Algorithms for Anti-Microbial Evaluation Data: A Majority Score-based Evaluation of K-Means, Gaussian Mixture Model, and Multivariate T-Distribution Mixtures. IEEE Access 2023, 11, 79793–79800. [Google Scholar] [CrossRef]
- Lukauskas, M.; Ruzgas, T. A New Clustering Method Based on the Inversion Formula. Mathematics 2022, 10, 2559. [Google Scholar] [CrossRef]
- Wang, Z. A new clustering method based on morphological operations. Expert Syst. Appl. 2020, 145, 113102. [Google Scholar] [CrossRef]
- Robinson, B.; Ernst, M.D.; Perkins, J.H.; Augustine, V.; Li, N. Scaling up automated test generation: Automatically generating maintainable regression unit tests for programs. In Proceedings of the 2011 26th IEEE/ACM International Conference on Automated Software Engineering (ASE 2011), Lawrence, KS, USA, 6–10 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 23–32. [Google Scholar] [CrossRef]
- Beschastnikh, I.; Brun, Y.; Abrahamson, J.; Ernst, M.D.; Krishnamurthy, A. Using declarative specification to improve the understanding, extensibility, and comparison of model-inference algorithms. IEEE Trans. Softw. Eng. 2014, 41, 408–428. [Google Scholar] [CrossRef]
- Lorenzoli, D.; Mariani, L.; Pezzè, M. Automatic generation of software behavioral models. In Proceedings of the 30th International Conference on Software Engineering, Leipzig, Germany, 10–18 May 2008; pp. 501–510. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, Z. Combinatorial Optimization and Applications: 14th International Conference, COCOA 2020, Dallas, TX, USA, 11–13 December 2020, Proceedings; Springer Nature: Cham, Switzerland, 2020; Volume 12577. [Google Scholar]
- Bingham, J.; Hu, A.J. Empirically efficient verification for a class of infinite-state systems. In Proceedings of the Tools and Algorithms for the Construction and Analysis of Systems: 11th International Conference, TACAS 2005, Held as Part of the Joint European Conferences on Theory and Practice of Software, ETAPS 2005, Edinburgh, UK, 4–8 April 2005; Proceedings 11. Springer: Berlin/Heidelberg, Germany, 2005; pp. 77–92. [Google Scholar]
- Yang, J.; Evans, D.; Bhardwaj, D.; Bhat, T.; Das, M. Perracotta: Mining temporal API rules from imperfect traces. In Proceedings of the 28th International Conference on Software Engineering, Shanghai, China, 20–28 May 2006; pp. 282–291. [Google Scholar] [CrossRef]
- Gabel, M.; Su, Z. Javert: Fully automatic mining of general temporal properties from dynamic traces. In Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Atlanta, GA, USA, 9–14 November 2008; pp. 339–349. [Google Scholar] [CrossRef]
- Gabel, M.; Su, Z. Symbolic mining of temporal specifications. In Proceedings of the 30th International Conference on Software Engineering, Leipzig, Germany, 10–18 May 2008; pp. 51–60. [Google Scholar] [CrossRef]
- Gabel, M.; Su, Z. Online inference and enforcement of temporal properties. In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering-Volume 1, Cape Town, South Africa, 1–8 May 2010; pp. 15–24. [Google Scholar] [CrossRef]
- De Caso, G.; Braberman, V.; Garbervetsky, D.; Uchitel, S. Automated abstractions for contract validation. IEEE Trans. Softw. Eng. 2010, 38, 141–162. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, M.; Yu, B. Dynamic Specification Mining Based on Transformer. In Proceedings of the Theoretical Aspects of Software Engineering: 16th International Symposium, TASE 2022, Cluj-Napoca, Romania, 8–10 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 220–237. [Google Scholar]
- Asarin, E.; Caspi, P.; Maler, O. Timed regular expressions. J. ACM 2002, 49, 172–206. [Google Scholar]
- Cecconi, A.; De Giacomo, G.; Di Ciccio, C.; Maggi, F.M.; Mendling, J. Measuring the interestingness of temporal logic behavioral specifications in process mining. Inf. Syst. 2022, 107, 101920. [Google Scholar] [CrossRef]
- Bartocci, E.; Mateis, C.; Nesterini, E.; Nickovic, D. Survey on mining signal temporal logic specifications. Inf. Comput. 2022, 289, 104957. [Google Scholar] [CrossRef]
- Krka, I.; Brun, Y.; Medvidovic, N. Automatic mining of specifications from invocation traces and method invariants. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, Hong Kong, China, 16–22 November 2014; pp. 178–189. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Rubel Ahmed, M.; Zheng, H. Deep Bidirectional Transformers for SoC Flow Specification Mining. arXiv 2022, arXiv:2203.13182. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Library Class1 | M | Generated Test Case | Recorded Method Calls |
|---|---|---|---|
| ArrayList | 18 | 42,865 | 22,996 |
| LinKedList | 7 | 13,731 | 4847 |
| HashSet | 8 | 23,181 | 257,428 |
| HashMap | 11 | 53,396 | 67,942 |
| Hashtable | 8 | 79,403 | 89,811 |
| Signature | 5 | 79,096 | 205,386 |
| Socket | 21 | 80,035 | 130,876 |
| ZipOutputStream | 5 | 162,971 | 43,626 |
| SringTokenizer | 5 | 148,649 | 336,924 |
| StackAr | 7 | 549,648 | 132,826 |
| NFST | 5 | 158,998 | 95,149 |
| ToHTMLStream | 17 | 103,562 | 278,631 |
| SMTPProtocol | 15 | 57,281 | 136,271 |
| Tools | 1-Tail | 2-Tail | SEKT 1 | SEKT 2 | CON++ | TEMI | DSM | MCLSM | |
|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||
| ArrayList | 13.96 | 13.13 | 36.03 | 13.86 | 13.07 | 16.87 | 22.27 | 81.94 | |
| LinKedList | 27.15 | 25.72 | 86.02 | 26.67 | 24.52 | 07.51 | 32.76 | 98.49 | |
| HashSet | 20.88 | 21.27 | 52.22 | 20.88 | 21.27 | 23.34 | 79.23 | 94.67 | |
| HashMap | 25.41 | 08.71 | 68.94 | - | - | - | 83.53 | 97.02 | |
| Hashtable | 42.39 | 33.58 | 92.78 | - | - | - | 76.82 | 91.42 | |
| Signature | 61.54 | 64.25 | 66.88 | 62.05 | 63.98 | 39.06 | 100.00 | 86.44 | |
| Socket | 35.89 | 31.52 | 55.15 | 34.73 | 28.37 | - | 51.78 | 100.00 | |
| ZipOutputStream | 46.36 | 47.42 | 62.80 | 47.91 | - | - | 87.62 | 91.80 | |
| SringTokenizer | 52.88 | 52.97 | 21.30 | 52.15 | - | - | 100.00 | 94.19 | |
| StackAr | 16.54 | 16.54 | 34.91 | 16.54 | 16.54 | - | 76.27 | 96.55 | |
| NFST | 24.57 | 25.52 | 30.40 | 24.56 | 25.78 | 11.80 | 80.16 | 100.00 | |
| ToHTMLStream | - | - | - | - | - | - | 69.70 | 89.76 | |
| SMTPProtocol | - | - | - | - | - | - | 72.69 | 82.63 | |
| Average | 33.42 | 30.97 | 55.22 | 33.26 | 27.65 | 19.72 | 71.75 | 92.19 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Y.; Wang, M. Specification Mining Based on the Ordering Points to Identify the Clustering Structure Clustering Algorithm and Model Checking. Algorithms 2024, 17, 28. https://doi.org/10.3390/a17010028
Fan Y, Wang M. Specification Mining Based on the Ordering Points to Identify the Clustering Structure Clustering Algorithm and Model Checking. Algorithms. 2024; 17(1):28. https://doi.org/10.3390/a17010028
Chicago/Turabian StyleFan, Yiming, and Meng Wang. 2024. "Specification Mining Based on the Ordering Points to Identify the Clustering Structure Clustering Algorithm and Model Checking" Algorithms 17, no. 1: 28. https://doi.org/10.3390/a17010028
APA StyleFan, Y., & Wang, M. (2024). Specification Mining Based on the Ordering Points to Identify the Clustering Structure Clustering Algorithm and Model Checking. Algorithms, 17(1), 28. https://doi.org/10.3390/a17010028