
Leveraging Machine Learning for Weed Management and Crop Enhancement: Vineyard Flora Classification




Abstract
:1. Introduction
2. Related Work
2.1. Neural Network Architectures
2.2. Experimental Studies—Flora Classification
3. Materials and Methods
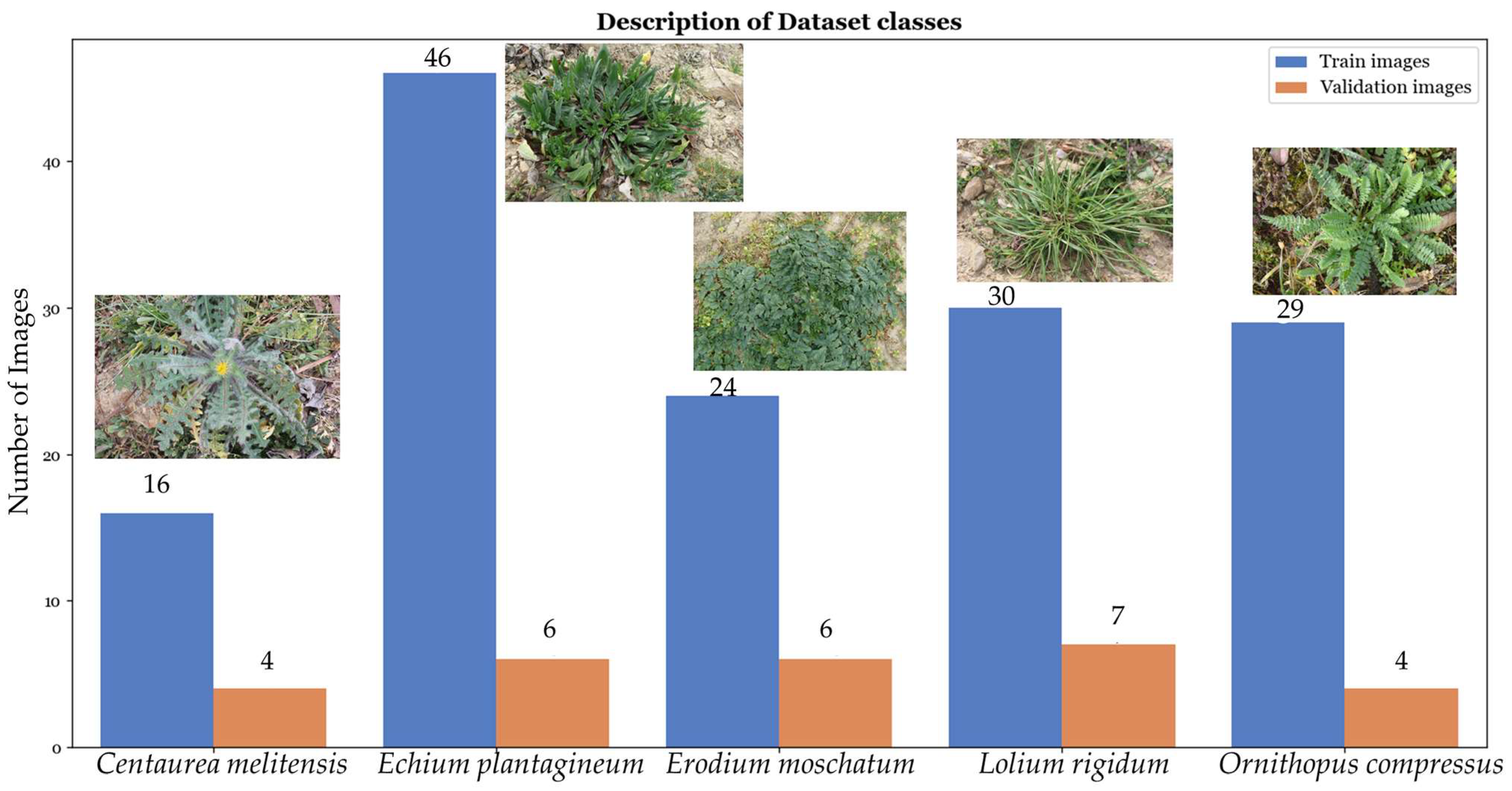
3.1. Data Collection and Sample Preparation
3.2. Algorithm Execution
4. Results
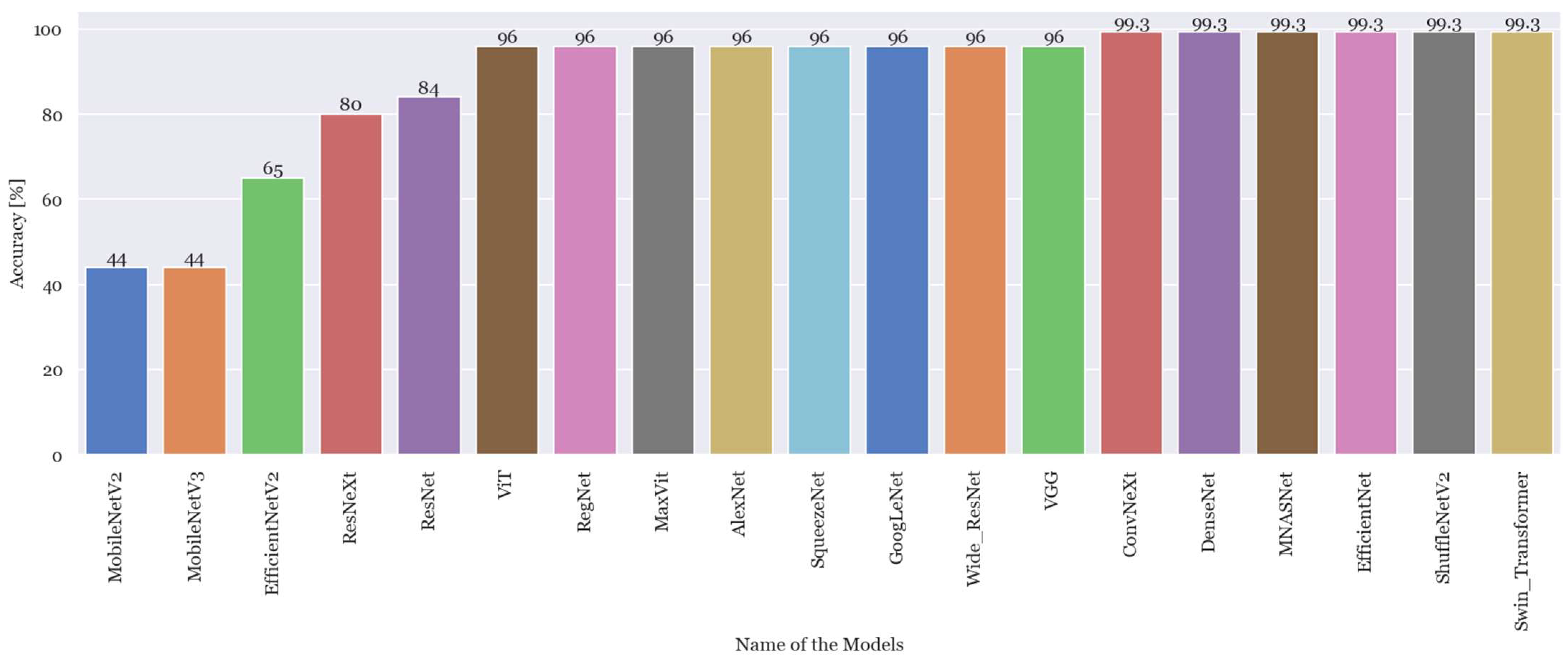
4.1. Experiment 1: Testing PyTorch Classification Architectures Using Different Combinations of Hyperparameters
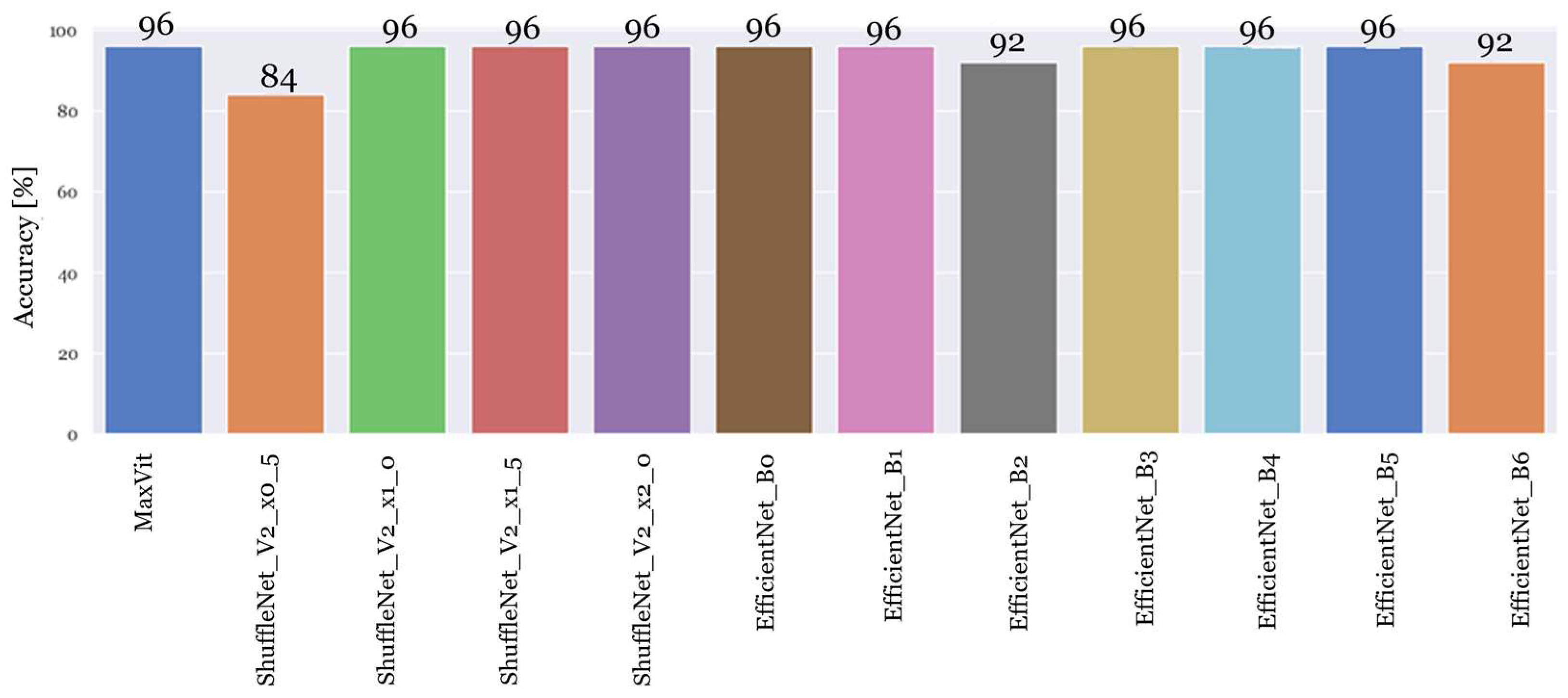
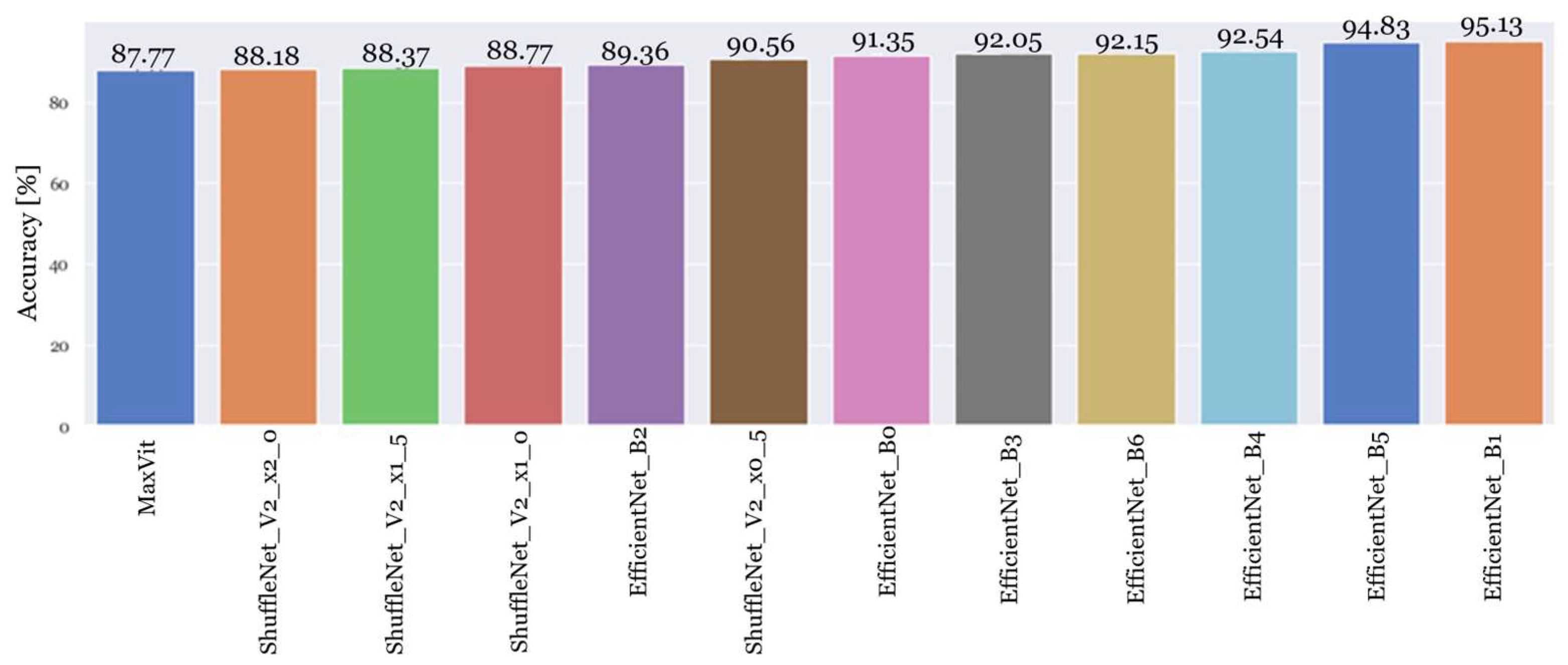
4.2. Experiment 2: Testing the Best-Performing PyTorch Classification Architectures
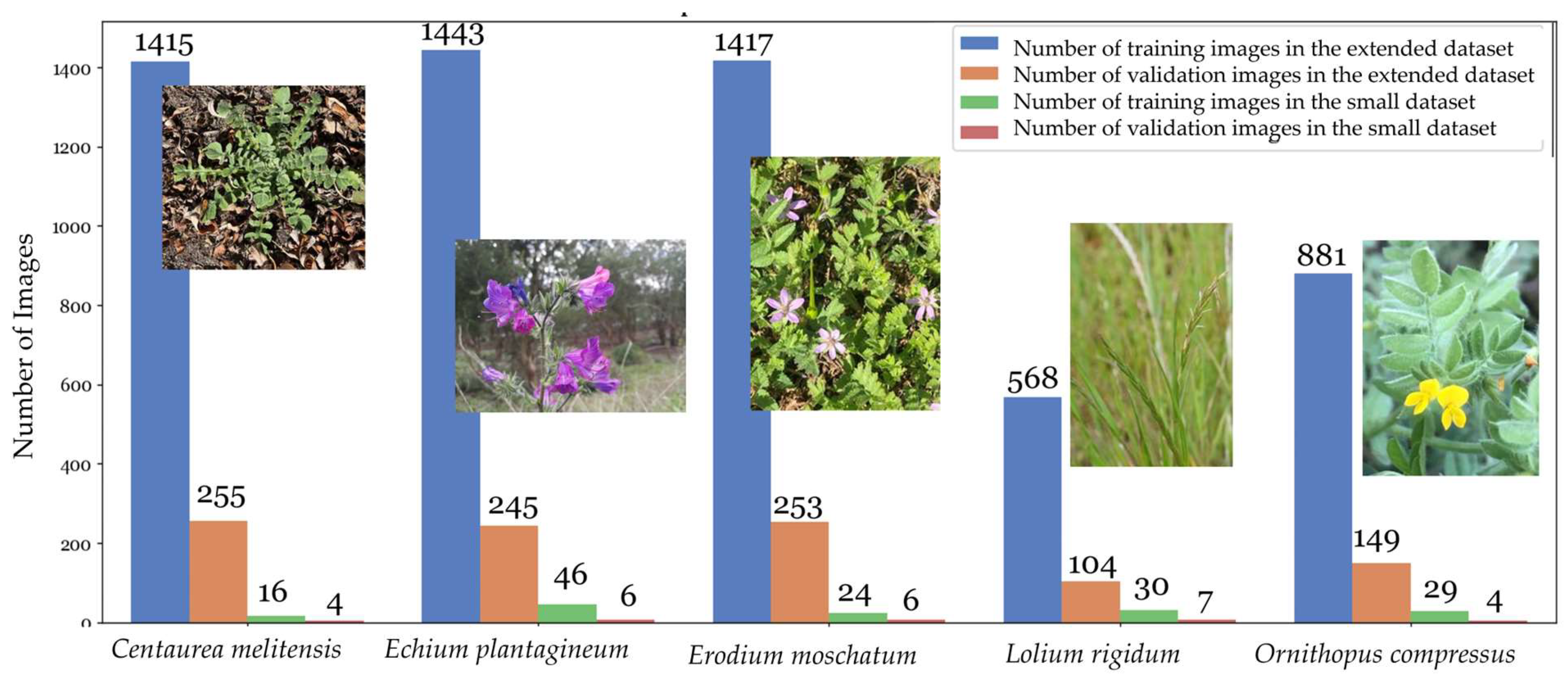
4.3. Experiment 3: Testing a New Dataset with Re-Trained PyTorch Classification Architectures
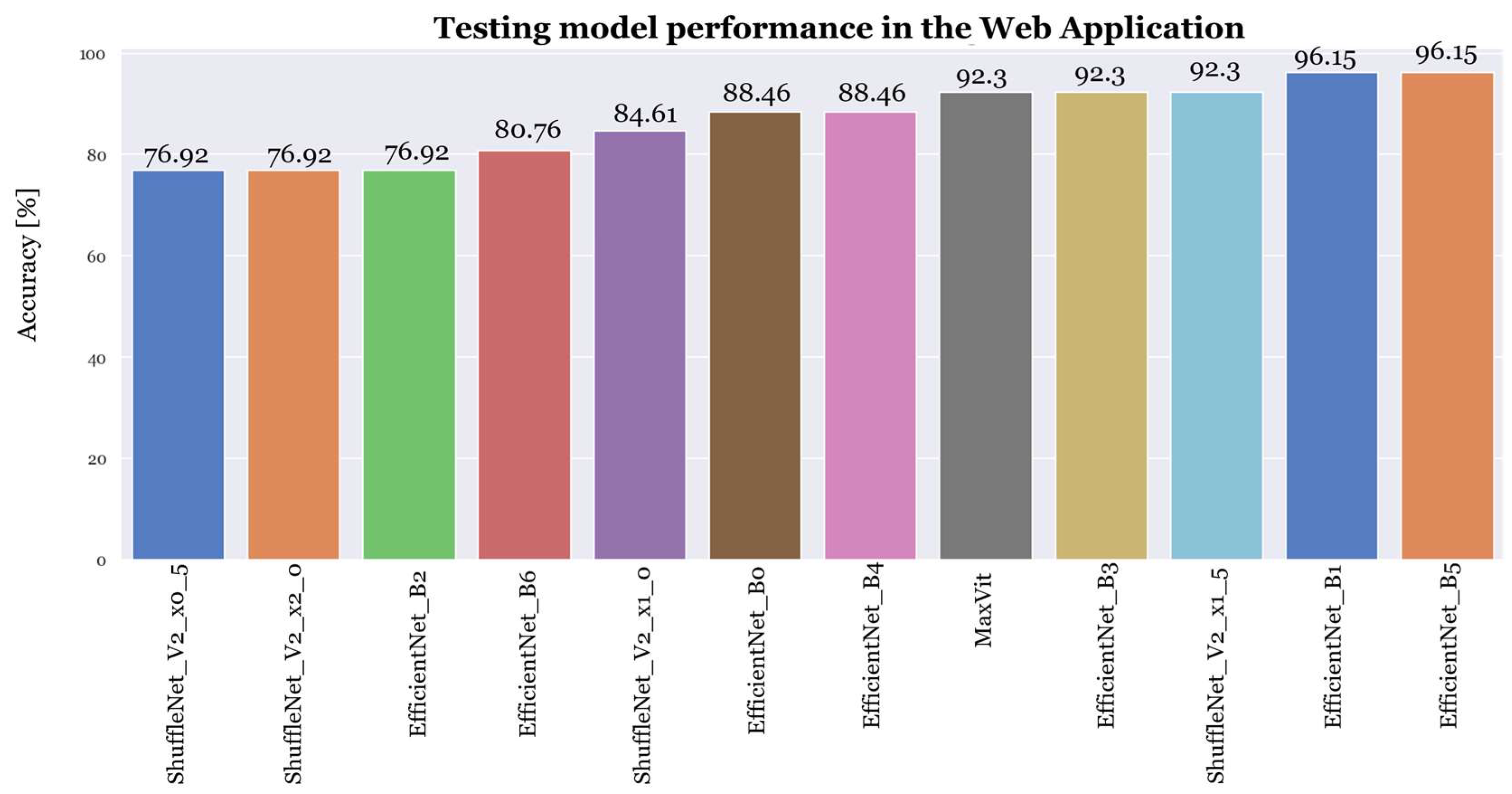
4.4. Experiment 4: Testing Best-Performing Models of PyTorch Classification Architectures with New Images
5. Discussion of Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hasan, A.S.M.M.; Sohel, F.; Diepeveen, D.; Laga, H.; Jones, M.G.K. A survey of deep learning techniques for weed detection from images. Comput. Electron. Agric. 2021, 184, 106067. [Google Scholar] [CrossRef]
- MacLaren, C.; Storkey, J.; Menegat, A.; Metcalfe, H.; Dehnen-Schmutz, K. An ecological future for weed science to sustain crop production and the environment. A review. Agron. Sustain. Dev. 2020, 40, 24. [Google Scholar] [CrossRef]
- Dyrmann, M.; Karstoft, H.; Midtiby, H.S. Plant species classification using deep convolutional neural network. Biosyst. Eng. 2016, 151, 72–80. [Google Scholar] [CrossRef]
- Shaikh, T.A.; Rasool, T.; Rasheed Lone, F. Towards leveraging the role of machine learning and artificial intelligence in precision agriculture and smart farming. Comput. Electron. Agric. 2022, 198, 107119. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, High-performance Deep Learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Lv, Q.; Zhang, S.; Wang, Y. Deep Learning model of image classification using Machine Learning. Adv. Multimed. 2022, 2022, 3351256. [Google Scholar] [CrossRef]
- Models and Pre-Trained Weights—Torchvision 0.16 Documentation. Available online: https://pytorch.org/vision/stable/models.html#classification (accessed on 30 October 2023).
- Rahman, A.; Lu, Y.; Wang, H. Performance evaluation of deep learning object detectors for weed detection for cotton. Smart Agric. Technol. 2023, 3, 100126. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical guidelines for efficient CNN architecture design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. arXiv 2020, arXiv:2003.13678. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Boesch, G. Deep Residual Networks (ResNet, ResNet50)—2023 Guide. viso.ai, 1 January 2023. Available online: https://viso.ai/deep-learning/resnet-residual-neural-network/ (accessed on 28 February 2023).
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. arXiv 2017, arXiv:1611.05431. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2017, arXiv:1605.07146. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. MaxViT: Multi-axis vision transformer. arXiv 2022, arXiv:2204.01697. [Google Scholar]
- Liu, H.; Yao, D.; Yang, J.; Li, X. Lightweight Convolutional Neural Network and its application in rolling bearing fault diagnosis under variable working conditions. Sensors 2019, 19, 4827. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Alibabaei, K.; Gaspar, P.D.; Lima, T.M.; Campos, R.M.; Girão, I.; Monteiro, J.; Lopes, C.M. A review of the challenges of using deep learning algorithms to support decision-making in agricultural activities. Remote Sens. 2022, 14, 638. [Google Scholar] [CrossRef]
- Alibabaei, K.; Gaspar, P.D.; Assunção, E.; Alirezazadeh, S.; Lima, T.M. Irrigation optimization with a deep reinforcement learning model: Case study on a site in Portugal. Agric. Water Manag. 2022, 263, 107480. [Google Scholar] [CrossRef]
- Andrea, C.-C.; Daniel, B.B.M.; Jose Misael, J.B. Precise weed and maize classification through convolutional neuronal networks. In Proceedings of the 2017 IEEE Second Ecuador Technical Chapters Meeting (ETCM), Salinas, Ecuador, 16–20 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Gao, J.; Nuyttens, D.; Lootens, P.; He, Y.; Pieters, J.G. Recognising weeds in a maize crop using a random forest machine-learning algorithm and near-infrared snapshot mosaic hyperspectral imagery. Biosyst. Eng. 2018, 170, 39–50. [Google Scholar] [CrossRef]
- Bakhshipour, A.; Jafari, A. Evaluation of support vector machine and artificial neural networks in weed detection using shape features. Comput. Electron. Agric. 2018, 145, 153–160. [Google Scholar] [CrossRef]
- Sa, I.; Chen, Z.; Popovic, M.; Khanna, R.; Liebisch, F.; Nieto, J.; Siegwart, R. weedNet: Dense semantic weed classification using multispectral images and MAV for smart farming. IEEE Robot. Autom. Lett. 2018, 3, 588–595. [Google Scholar] [CrossRef]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.K.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar] [CrossRef]
- Yashwanth, M.; Chandra, M.L.; Pallavi, K.; Showkat, D.; Kumar, P.S. Agriculture automation using deep learning methods implemented using Keras. In Proceedings of the 2020 IEEE International Conference for Innovation in Technology (INOCON), Bangluru, India, 6–8 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Jin, X.; Che, J.; Chen, Y. Weed identification using deep learning and image processing in vegetable plantation. IEEE Access 2021, 9, 10940–10950. [Google Scholar] [CrossRef]
- El-Kenawy, E.-S.M.; Khodadadi, N.; Mirjalili, S.; Makarovskikh, T.; Abotaleb, M.; Karim, F.K.; Alkahtani, H.K.; Abdelhamid, A.A.; Eid, M.M.; Horiuchi, T.; et al. Metaheuristic optimization for improving weed detection in wheat images captured by drones. Mathematics 2022, 10, 4421. [Google Scholar] [CrossRef]
- Sunil, G.C.; Koparan, C.; Ahmed, M.R.; Zhang, Y.; Howatt, K.; Sun, X. A study on deep learning algorithm performance on weed and crop species identification under different image background. Artif. Intell. Agric. 2022, 6, 242–256. [Google Scholar] [CrossRef]
- Sunil, G.C.; Zhang, Y.; Koparan, C.; Ahmed, M.R.; Howatt, K.; Sun, X. Weed and crop species classification using computer vision and deep learning technologies in greenhouse conditions. J. Agric. Food Res. 2022, 9, 100325. [Google Scholar] [CrossRef]
- Solawetz, J. Train, Validation, Test Split for Machine Learning. Roboflow Blog. Available online: https://blog.roboflow.com/train-test-split/ (accessed on 24 August 2023).
- Brownlee, J. Difference between A Batch and an Epoch in a Neural Network. Available online: https://machinelearningmastery.com/difference-between-a-batch-and-an-epoch/ (accessed on 28 August 2023).
- Nabi, J. Hyper-Parameter Tuning Techniques in Deep Learning. Medium. Available online: https://towardsdatascience.com/hyper-parameter-tuning-techniques-in-deep-learning-4dad592c63c8 (accessed on 28 August 2023).
- Zhao, G.; Liu, G.; Fang, L.; Tu, B.; Ghamisi, P. Multiple convolutional layers fusion framework for hyperspectral image classification. Neurocomputing 2019, 339, 149–160. [Google Scholar] [CrossRef]
- Flora-On|Flora de Portugal. Available online: https://flora-on.pt/ (accessed on 19 April 2023).
- Uma Comunidade Para Naturalistas · iNaturalist. Available online: https://www.inaturalist.org/ (accessed on 9 September 2023).
- Jardim Botânico UTAD. Available online: https://jb.utad.pt (accessed on 9 September 2023).
- GBIF. Available online: https://www.gbif.org/ (accessed on 9 September 2023).
- Gradio: UIs for Machine Learning. Available online: https://gradio.app (accessed on 21 September 2023).
- Unzueta, D. Convolutional Layers vs. Fully Connected Layers. Medium. Available online: https://towardsdatascience.com/convolutional-layers-vs-fully-connected-layers-364f05ab460b (accessed on 23 September 2023).
- Kapoor, R.; Sharma, D.; Gulati, T. State of the art content based image retrieval techniques using deep learning: A survey. Multimed. Tools Appl. 2021, 80, 29561–29583. [Google Scholar] [CrossRef]
- Taye, M.M. Understanding of machine learning with deep learning: Architectures, workflow, applications and future directions. Computers 2023, 12, 91. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N. | Models | Learning Rate | Weight Decay | N.er of Layers | Best Acc (%) | Test Accuracy (%) | Inference Time (sec) | N. | Models | Learning Rate | Weight Decay | N.er of Layers | Best Acc (%) | Test Accuracy (%) | Inference Time (sec) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | MobileNetV2 | 0.0001 | 0.0001 | Seq. | 44.0 | 16.67 | 0.005 | 39 | ShuffleNet_v2_x0_5 | 0.0001 | 0 | Lin. | 99.3 | 46.66 | 0.004 |
| 2 | MobileNetV3_Large | 0.0001 | 0 | Lin. | 44.0 | 16.67 | 0.006 | 40 | ShuffleNet_v2_x1_0 | 0.001 | 0 | Lin. | 99.3 | 66.67 | 0.034 |
| 3 | MobilenetV3_Small | 0.001 | 0.0001 | Seq. | 44.0 | 26.67 | 0.005 | 41 | ShuffleNet_v2_x1_5 | 0.001 | 0.0001 | Lin. | 99.3 | 16.67 | 0.005 |
| 4 | MaxVit | 0.001 | 0.0001 | Lin. | 96.0 | 76,67 | 0.055 | 42 | ShuffleNet_v2_x2_0 | 0.001 | 0.0001 | Lin. | 96.0 | 66.67 | 0.005 |
| 5 | AlexNet | 0.0001 | 0 | Seq. | 96.0 | 33.33 | 0.001 | 43 | EfficientNet_b0 | 0.001 | 0 | Lin. | 99.3 | 63.33 | 0.008 |
| 6 | GoogLeNet | 0.01 | 0 | Lin. | 96.0 | 10.00 | 0.007 | 44 | EfficientNet_b1 | 0.0001 | 0 | Lin. | 99.3 | 86.66 | 0.010 |
| 7 | Vit_b_16 | 0.0001 | 0 | Seq. | 96.0 | 56.67 | 0.006 | 45 | EfficientNet_b2 | 0.001 | 0.0001 | Seq. | 99.3 | 50.00 | 0.011 |
| 8 | Vit_b_32 | 0.0001 | 0.0001 | Lin. | 96.0 | 60 | 0.029 | 46 | EfficientNet_b3 | 0.001 | 0 | Lin. | 99.3 | 60.00 | 0.012 |
| 9 | ResNeXt50_32x4d | 0.0001 | 0.0001 | Lin. | 80.0 | 13.33 | 0.006 | 47 | EfficientNet_b4 | 0.001 | 0.0001 | Lin. | 99.3 | 73.33 | 0.014 |
| 10 | ResNeXt101_32x8d | 0.01 | 0.0001 | Seq. | 48.0 | 16.67 | 0.013 | 48 | EfficientNet_b5 | 0.0001 | 0 | Seq. | 99.3 | 83.33 | 0.017 |
| 11 | ResNeXt101_64x4d | 0.0001 | 0.0001 | Seq. | 76.0 | 46.67 | 0.014 | 49 | EfficientNet_b6 | 0.001 | 0 | Lin. | 99.3 | 23.33 | 0.020 |
| 12 | ResNet18 | 0.0001 | 0 | Lin. | 84.0 | 43.33 | 0.002 | 50 | EfficientNet_b7 | 0.001 | 0 | Seq. | 96.0 | 53.33 | 0.056 |
| 13 | ResNet34 | 0.0001 | 0 | Seq. | 84.0 | 46.67 | 0.004 | 51 | SqueezeNet1_0 | 0.0001 | 0 | Lin. | 96.0 | 20.00 | 0.034 |
| 14 | ConvNeXt_Tiny | 0.0001 | 0 | Seq. | 99.3 | 70.00 | 0.005 | 52 | SqueezeNet1_1 | 0.0001 | 0 | Lin. | 96.0 | 46.67 | 0.002 |
| 15 | ResNet50 | 0.0001 | 0 | Lin. | 80.0 | 43.33 | 0.021 | 53 | VGG11 | 0.0001 | 0 | Seq. | 96.0 | 63.33 | 0.020 |
| 16 | Convnext_small | 0.001 | 0.0001 | Lin. | 99.3 | 26.67 | 0.038 | 54 | RegNet_y_400mf | 0.001 | 0 | Seq. | 96.0 | 66.66 | 0.022 |
| 17 | Wide_ResNet50_2 | 0.0001 | 0.0001 | Lin. | 64.0 | 50.00 | 0.008 | 55 | VGG11_bn | 0.001 | 0 | Lin. | 96.0 | 63.33 | 0.034 |
| 18 | Wide_ResNet101_2 | 0.0001 | 0 | Seq. | 96.0 | 33.33 | 0.014 | 56 | RegNet_y_800mf | 0.001 | 0 | Seq. | 96.0 | 56.66 | 0.032 |
| 19 | Convnext_base | 0.0001 | 0 | Seq. | 96.0 | 86.67 | 0.010 | 57 | VGG_13 | 0.0001 | 0 | Seq. | 96.0 | 70.00 | 0.004 |
| 20 | Convnext_large | 0.0001 | 0 | Seq. | 96.0 | 90.00 | 0.041 | 58 | RegNet_Y_1_6GF | 0.001 | 0 | Seq. | 96.0 | 63.33 | 0.021 |
| 21 | EfficientNet_v2_s | 0.0001 | 0.0001 | Seq. | 65.0 | 20.00 | 0.015 | 59 | VGG13_bn | 0.0001 | 0 | Seq. | 96.0 | 76.67 | 0.004 |
| 22 | EfficientNet_v2_m | 0.0001 | 0.0001 | Lin. | 48.9 | 16.67 | 0.022 | 60 | RegNet_y_3_2gf | 0.001 | 0 | Seq. | 96.0 | 63.33 | 0.005 |
| 23 | EfficientNet_v2_l | 0.0001 | 0 | Seq. | 48.0 | 20.00 | 0.061 | 61 | RegNet_y_8gf | 0.001 | 0 | Lin. | 96.0 | 56.66 | 0.002 |
| 24 | Swin_t | 0.0001 | 0 | Seq. | 68.0 | 16.67 | 0.012 | 62 | RegNet_y_16gf | 0.001 | 0.0001 | Lin. | 96.0 | 53.33 | 0.034 |
| 25 | Swin_s | 0.0001 | 0 | Seq. | 72.0 | 20.00 | 0.024 | 63 | VGG16 | 0.0001 | 0 | Seq. | 96.0 | 46.67 | 0.005 |
| 26 | Swin_b | 0.0001 | 0 | Seq. | 76.0 | 20.00 | 0.023 | 64 | VGG16_bn | 0.0001 | 0 | Seq. | 96.0 | 56.66 | 0.020 |
| 27 | Swin_v2_t | 0.0001 | 0 | Seq. | 99.3 | 36.67 | 0.016 | 65 | VGG19 | 0.0001 | 0.0001 | Lin. | 96.0 | 46.67 | 0.004 |
| 28 | Swin_v2_s | 0.0001 | 0 | Lin. | 64.0 | 36.67 | 0.033 | 66 | VGG19_bn | 0.0001 | 0 | Seq. | 96.0 | 70.00 | 0.005 |
| 29 | Swin_v2_b | 0.0001 | 0 | Seq. | 72.0 | 26.67 | 0.031 | 67 | RegNet_y_32gf | 0.01 | 0 | Lin. | 96.0 | 46.67 | 0.004 |
| 30 | DenseNet201 | 0.001 | 0 | Seq. | 96.0 | 20.00 | 0.034 | 68 | RegNet_y_128gf | 0.01 | 0.0001 | Seq. | 72.0 | 50.00 | 0.034 |
| 31 | DenseNet161 | 0.01 | 0 | Lin. | 96.0 | 16.67 | 0.019 | 69 | RegNet_x_400mf | 0.001 | 0 | Seq. | 96.0 | 56.66 | 0.005 |
| 32 | DenseNet169 | 0.01 | 0 | Seq. | 99.3 | 23.33 | 0.033 | 70 | RegNet_x_800mf | 0.001 | 0 | Seq. | 96.0 | 53.33 | 0.005 |
| 33 | DenseNet121 | 0.01 | 0 | Lin. | 99.3 | 20.00 | 0.013 | 71 | RegNet_x_1_6gf | 0.001 | 0 | Seq. | 96.0 | 46.67 | 0.020 |
| 34 | MNASNet0_5 | 0.001 | 0 | Seq. | 96.0 | 56.67 | 0.005 | 72 | RegNet_x_3_2gf | 0.01 | 0.0001 | Lin. | 96.0 | 50.00 | 0.004 |
| 35 | MNASNet0_75 | 0.0001 | 0 | Seq. | 99.3 | 43.33 | 0.005 | 73 | RegNet_x_8gf | 0.01 | 0 | Lin. | 96.0 | 50.00 | 0.020 |
| 36 | MNASNet1_0 | 0.0001 | 0.0001 | Lin. | 99.3 | 36.67 | 0.004 | 74 | RegNet_x_16gf | 0.01 | 0 | Seq. | 96.0 | 16.67 | 0.013 |
| 37 | MNASNet1_3 | 0.0001 | 0 | Seq. | 96.0 | 40.00 | 0.005 | 75 | RegNet_x_32gf | 0.001 | 0 | Lin. | 96.0 | 33.33 | 0.018 |
| 38 | ResNet101 | 0.0001 | 0 | Lin. | 96.0 | 20.00 | 0.004 | 76 | ResNet152 | 0.0001 | 0 | Seq. | 96.0 | 16.67 | 0.0005 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Corceiro, A.; Pereira, N.; Alibabaei, K.; Gaspar, P.D. Leveraging Machine Learning for Weed Management and Crop Enhancement: Vineyard Flora Classification. Algorithms 2024, 17, 19. https://doi.org/10.3390/a17010019
Corceiro A, Pereira N, Alibabaei K, Gaspar PD. Leveraging Machine Learning for Weed Management and Crop Enhancement: Vineyard Flora Classification. Algorithms. 2024; 17(1):19. https://doi.org/10.3390/a17010019
Chicago/Turabian StyleCorceiro, Ana, Nuno Pereira, Khadijeh Alibabaei, and Pedro D. Gaspar. 2024. "Leveraging Machine Learning for Weed Management and Crop Enhancement: Vineyard Flora Classification" Algorithms 17, no. 1: 19. https://doi.org/10.3390/a17010019
APA StyleCorceiro, A., Pereira, N., Alibabaei, K., & Gaspar, P. D. (2024). Leveraging Machine Learning for Weed Management and Crop Enhancement: Vineyard Flora Classification. Algorithms, 17(1), 19. https://doi.org/10.3390/a17010019