1. Introduction
The global incidence of Cardio Vascular Diseases (CVD) has been steadily rising, reaching an estimated prevalence of 523 million cases worldwide in 2019. This figure represents a nearly twofold increase over a span of 30 years [
1]. In comparison to other CVD, ischemic heart diseases stand out as the leading cause of mortality, accounting for more than 9 million deaths in 2021 [
2].
In this context, Cardiac Magnetic Resonance Imaging (CMRI) has emerged as a significant aid for the visualization and diagnosis of myocardial diseases. Its proficiency lies in accurately imaging anatomical regions, all while posing minimal risks to the patient [
3]. Meanwhile, deep learning approaches for classification, detection and segmentation have garnered increasing attention and have been actively employed and investigated in the medical-image-analysis domain since the mid 2010s [
4].
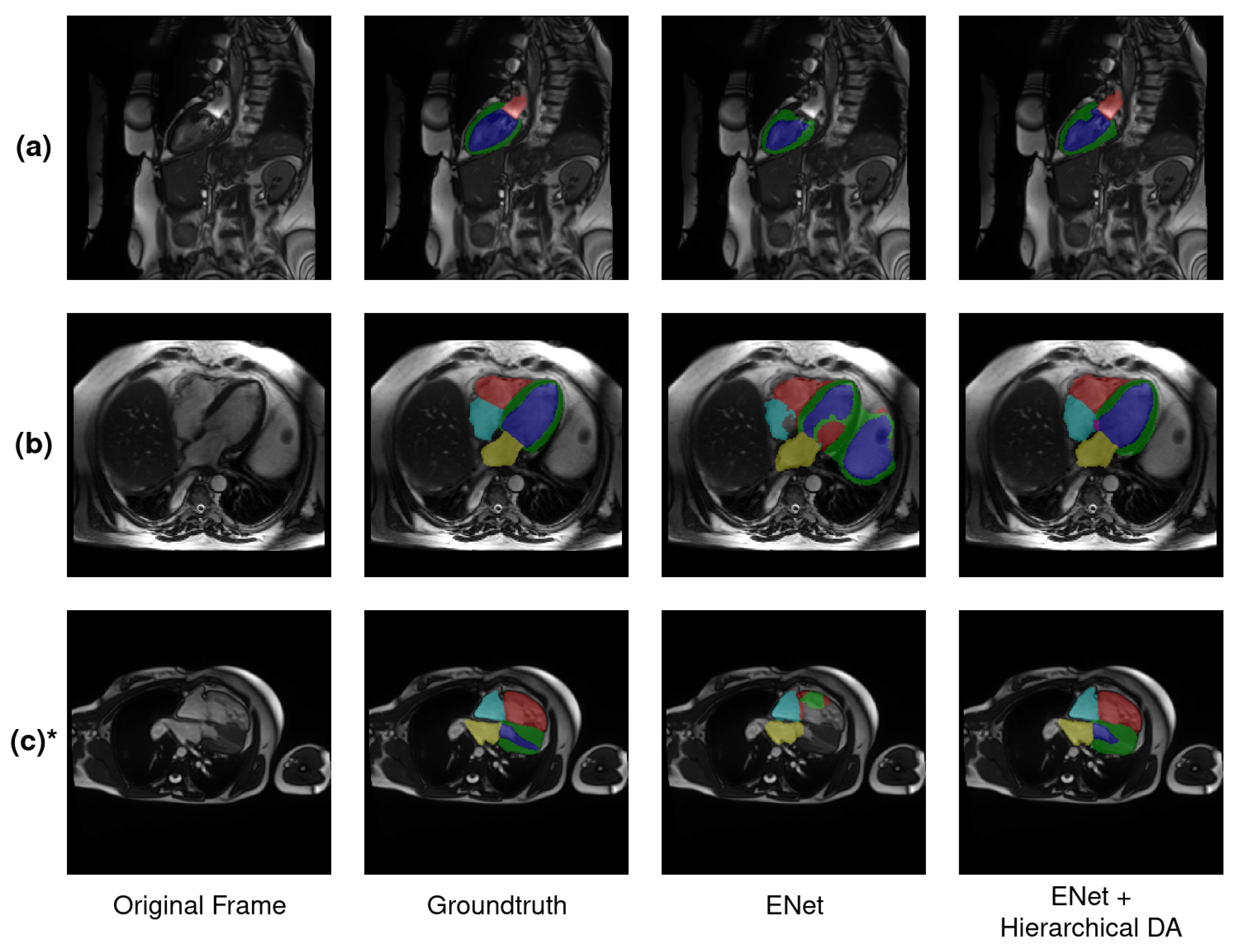
Multiplanar Cine-MRI sequences are extensively used in clinical practice for CMRI, providing the capability to quantify cardiac function and movement while encompassing the entire heart. This quantification is performed with the help of the short-axis (SAX) and multiple long-axis (LAX) views. The SAX view acquisition usually incorporates 8 to 12 spatial slices across multiple cardiac phases, while each LAX view acquisition covers two, three and four cardiac chambers in a single spatial slice. The intersections of their respective spatial plans are centered on the left ventricle cavity.
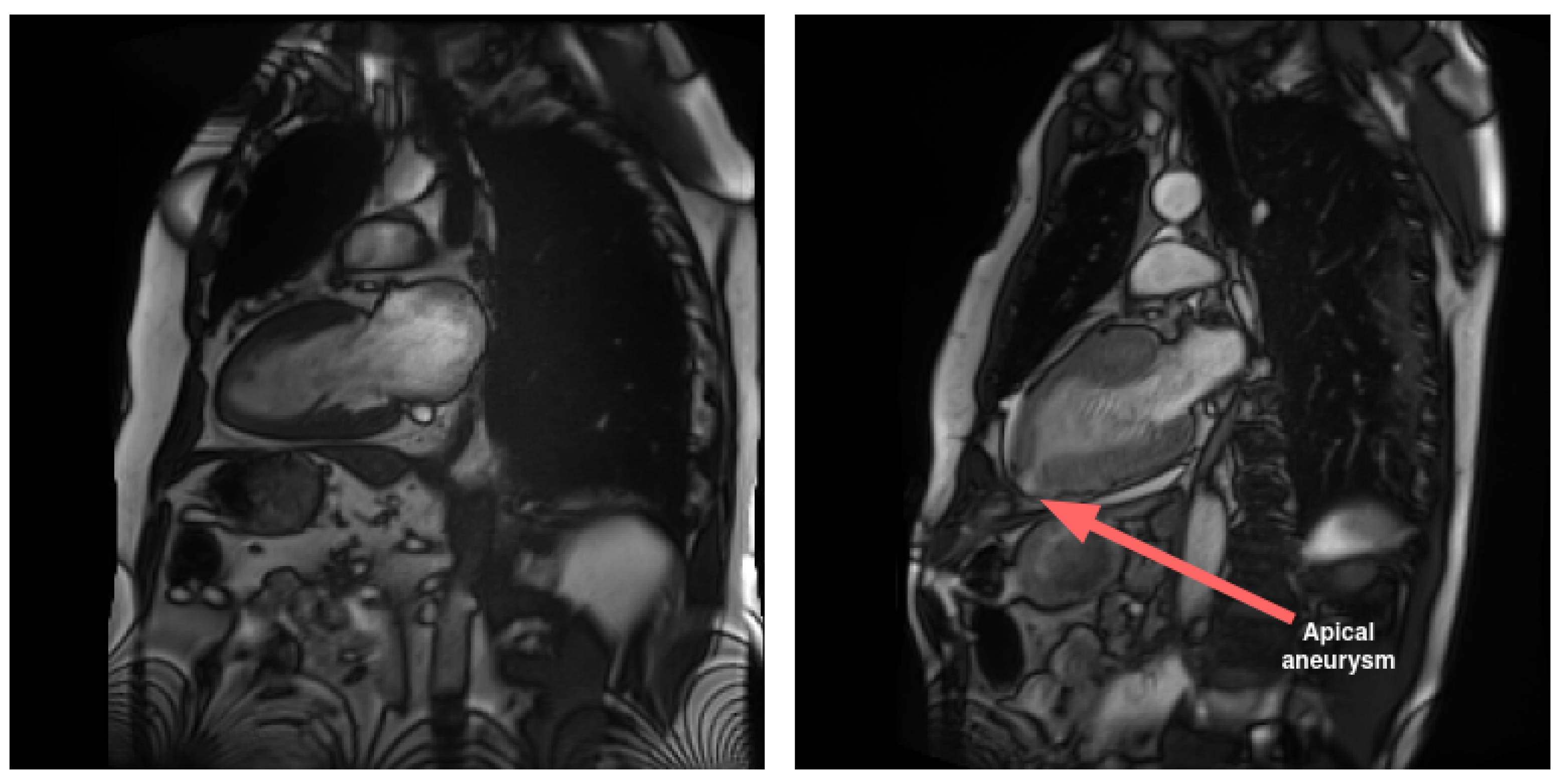
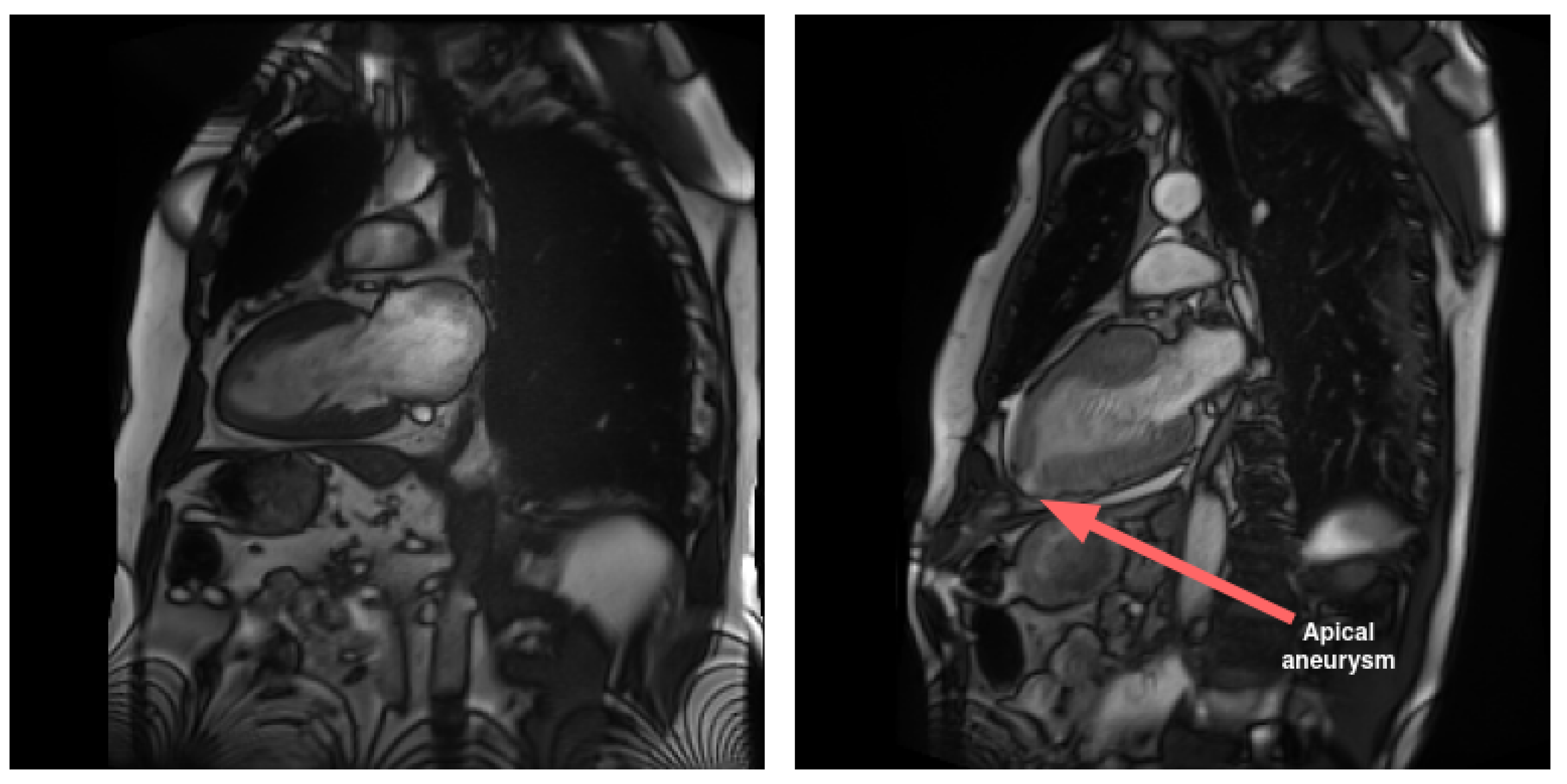
LAX views play a crucial role in imaging atria in comparison to SAX views. Specifically, LAX views are instrumental in visualizing pathological conditions that impact this area of the heart, such as malformations and interatrial communications. Additionally, LAX views contribute to the diagnosis of diseases affecting the apical region of the heart. In contrast to the SAX view, the LAX view enables the assessment of the apical region, as illustrated in
Figure 1.
While segmentation for CMRI is a well-investigated domain, the majority of studies predominantly concentrate on SAX segmentation [
5], with a particular emphasis on utilizing Cine-MRI sequences. Conversely, LAX views have received comparatively less attention, with methods developed for other image orientations, particularly in SAX [
6,
7,
8,
9,
10,
11,
12].
Few studies have conducted an in-depth examination of Cine-MRI long-axis cardiac images, as exemplified by the
-net method proposed by Vigneault et al. [
13]. In this work, the authors addressed multiclass segmentation for SAX, LAX two-chamber and four-chamber views by employing a predelineation UNet. The bottom features from this UNet were utilized to train a Spatial Transformer Network [
14], allowing the learning and estimation of rigid affine transformation matrix parameters to achieve a canonical orientation consistent with clinical practices across the dataset. Following this transformation, the output was directed to a second segmentation pipeline comprising multiple chained UNets. For LAX four-chamber images, the authors annotated over five classes in addition to the background class, facilitating whole-heart segmentation. This study involved full cardiac cycle annotation. The reported results include average Intersection over Union (IoU) scores of 0.856 and 0.845 for LAX two-chamber and LAX four-chamber, respectively.
Another study involving fully annotated LAX four-chamber was conducted by Bai et al. [
15]. In this work, the authors compared a semisupervised learning pipeline to a baseline UNet by using a small amount of annotated data. They reached average respective Dice scores of 0.934 ± 0.029 and 0.930 ± 0.032 by using 200 training slices corresponding to ED and ES timeframes for 100 examinations. Their approach introduces a distinct starting postulate, considering the various axes of view as entangled. The idea is that these axes can be learned through shared anatomical features at their intersections, thereby enhancing segmentation by incorporating surrounding features. The most promising outcomes were attained by employing a multitask pipeline that simultaneously addressed both anatomical intersection detection and segmentation.
In previous work, Bai et al. [
16] used a VGG16 [
17] architecture to automatically segment atria from LAX four- and two-chamber Cine-MRI images. They attained respective Dice scores of 0.93 ± 0.05 on the LAX two-chamber left atrium and 0.95 ± 0.02 and 0.96 ± 0.02 for the LAX four-chamber left atrium and right atrium, respectively. It is worth mentioning that they achieved inference times of approximately 0.2 s for the ED and ES LAX images and 1.4 s when the entire sequence was included.
Other notable works involve the integration of Statistical Models of Deformation (SMOD) with UNet-based segmentation, as proposed by Acero et al. [
18]. Their study focused on hypertrophic cardiomyopathy and normal examinations, incorporating LAX two- and four-chamber views, with the right atrium being the sole missing class. Al Khalil et al. [
19] used SPADE-GAN image generation in conjunction with VAE-based label deformation by interpolation over LAX four-chamber images to perform data augmentation prior to segmentation. The augmentation generated by the GAN improved their results compared to the use of more traditional morphological alterations [
20]. Additionally, Pei et al. [
21] and Wang et al. [
22] utilized images from the LAX four-chamber view to implement domain adaptation with feature differentiation between CT and MR modalities. The M&M2 challenge incorporated images from the LAX four-chamber view as part of the segmentation task, with a specific focus on right ventricle segmentation [
23]. Various methods were developed by participants, employing the four-chamber view in independent pipelines [
6,
7,
8] or through shared information pipelines, with LAX data often utilized to refine SAX segmentation [
9,
10,
11,
12]. Notably, among the top-performing methods for the LAX four-chamber segmentation task, excluding the approach proposed by Li et al. [
9], separate pipelines were employed, with no information sharing between SAX and LAX.
Most other works have primarily focused on LAX segmentation targeting one or two anatomical structures. These encompass various deep learning approaches [
24,
25,
26] or hybrid pipelines combining deep learning, as exemplified by Zhang et al. [
27]. Additionally, Sinclair et al. [
25] and Leng et al. [
26] also included the LAX three-chamber view, an orientation that is less often studied in segmentation tasks compared to LAX two-chamber and four-chamber views. Notably, Gonzales et al. [
28] introduced an automated left atrium segmentation method utilizing active contours on a polar grid. Their approach involves employing a residual network for extracting mitral-valve-insertion points in a preprocessing step. Subsequently, edge reconstruction and Cartesian mapping are applied to obtain the final segmentation.
Over recent years, several deep learning architectures have been applied to tasks related to medical-imaging segmentation. The most notable, UNet, introduced by Ronneberger et al. [
29], has been used in numerous works, with various adaptations and modifications [
30,
31]. This architecture and its derived variants have consistently achieved state-of-the-art performances when applied to medical-image segmentation [
23,
32]. Additionally, both prior to and concurrently with UNet, Fully Convolutional Networks (FCNs) have also been employed, yielding acceptable results [
16].
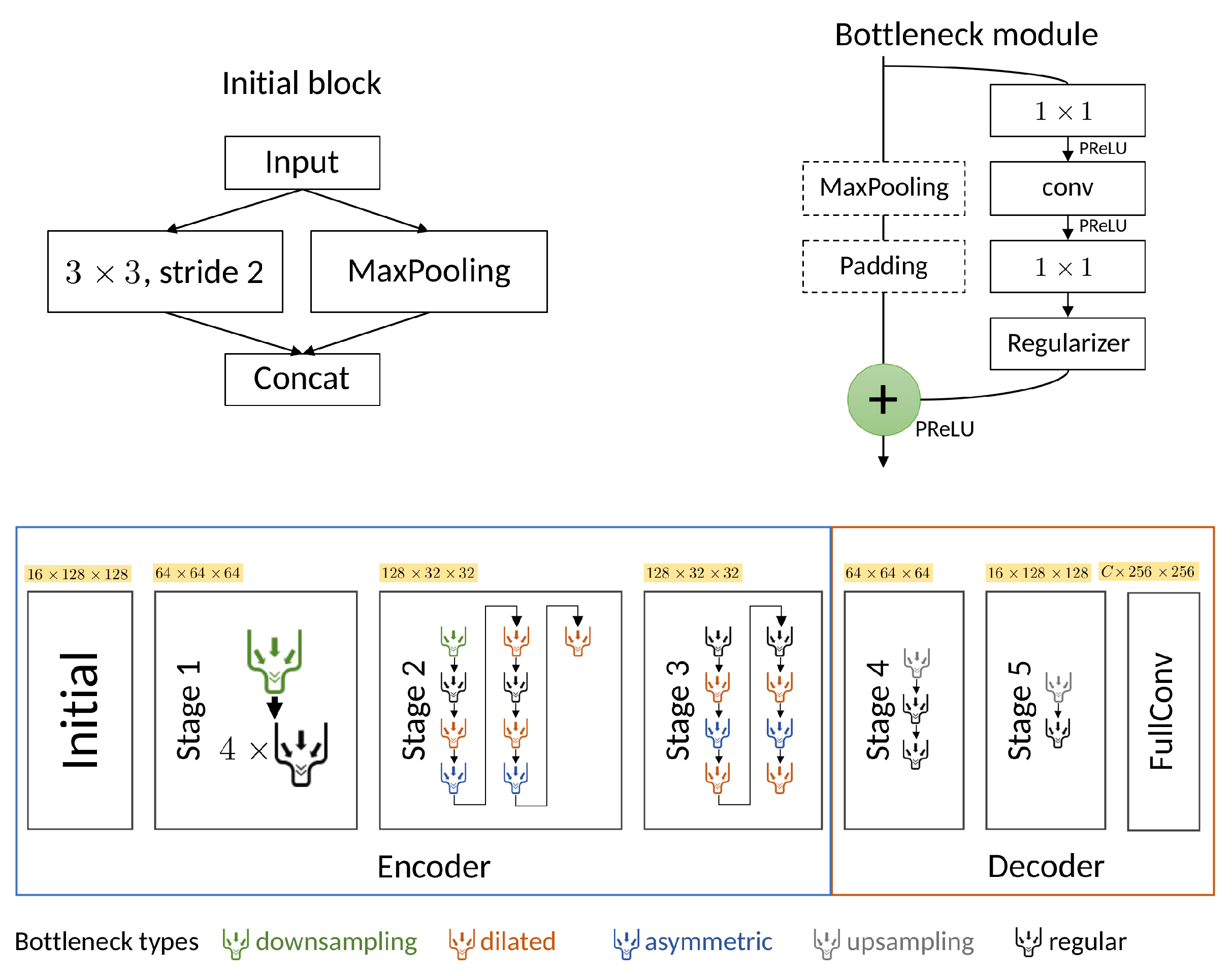
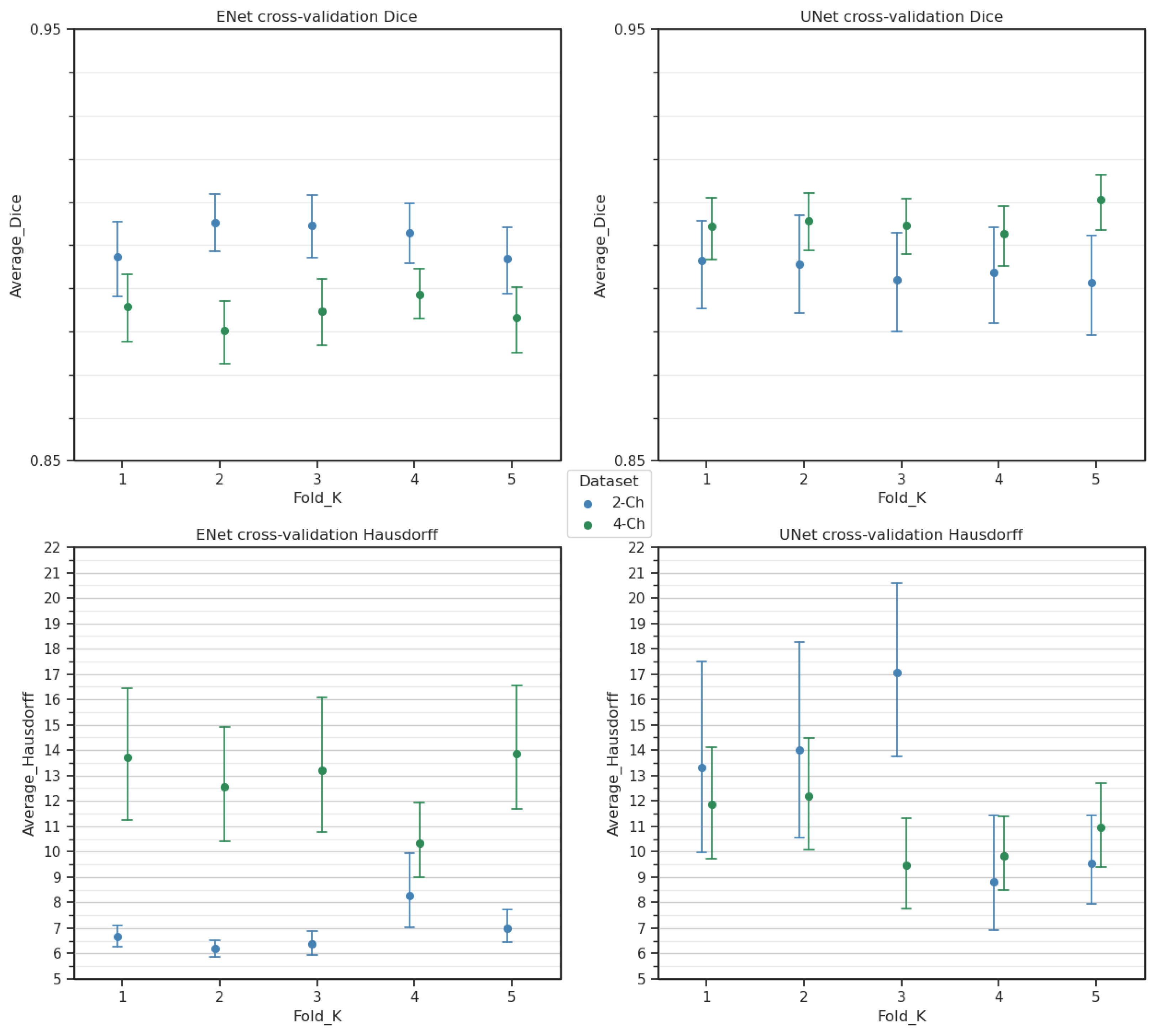
We employed the ENet architecture by Paszke et al. [
33] due to its capability to produce effective segmentation results with lower computational costs and faster inference. A detailed description of the architecture is provided in
Section 2.2. The ENet architecture has previously found application in the medical-imaging domain [
34,
35,
36,
37]. For instance, Salvaggio et al. achieved favorable results in prostate-volume estimation by using ENet [
34]. Furthermore, Karimov et al. conducted a performance evaluation of ENet, comparing it against UNet by using histological slices [
37]. Their findings indicated that ENet achieved a Dice performance comparable to UNet but demonstrated a superior computational efficiency, with performance gains of up to 15 times.
In the realm of cardiac Cine-MRI segmentation, ENet has primarily been utilized for SAX when applied to the MRI modality [
35,
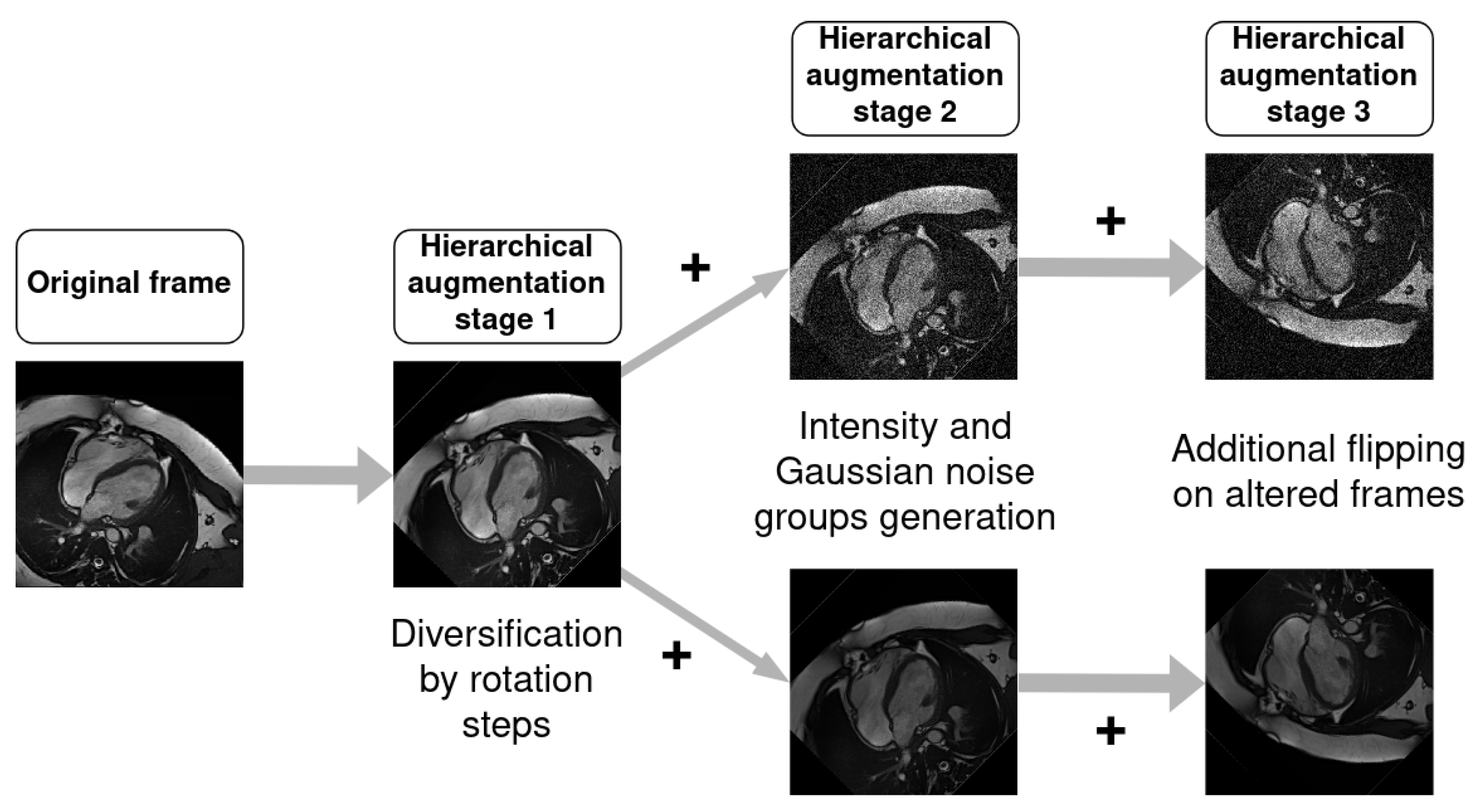
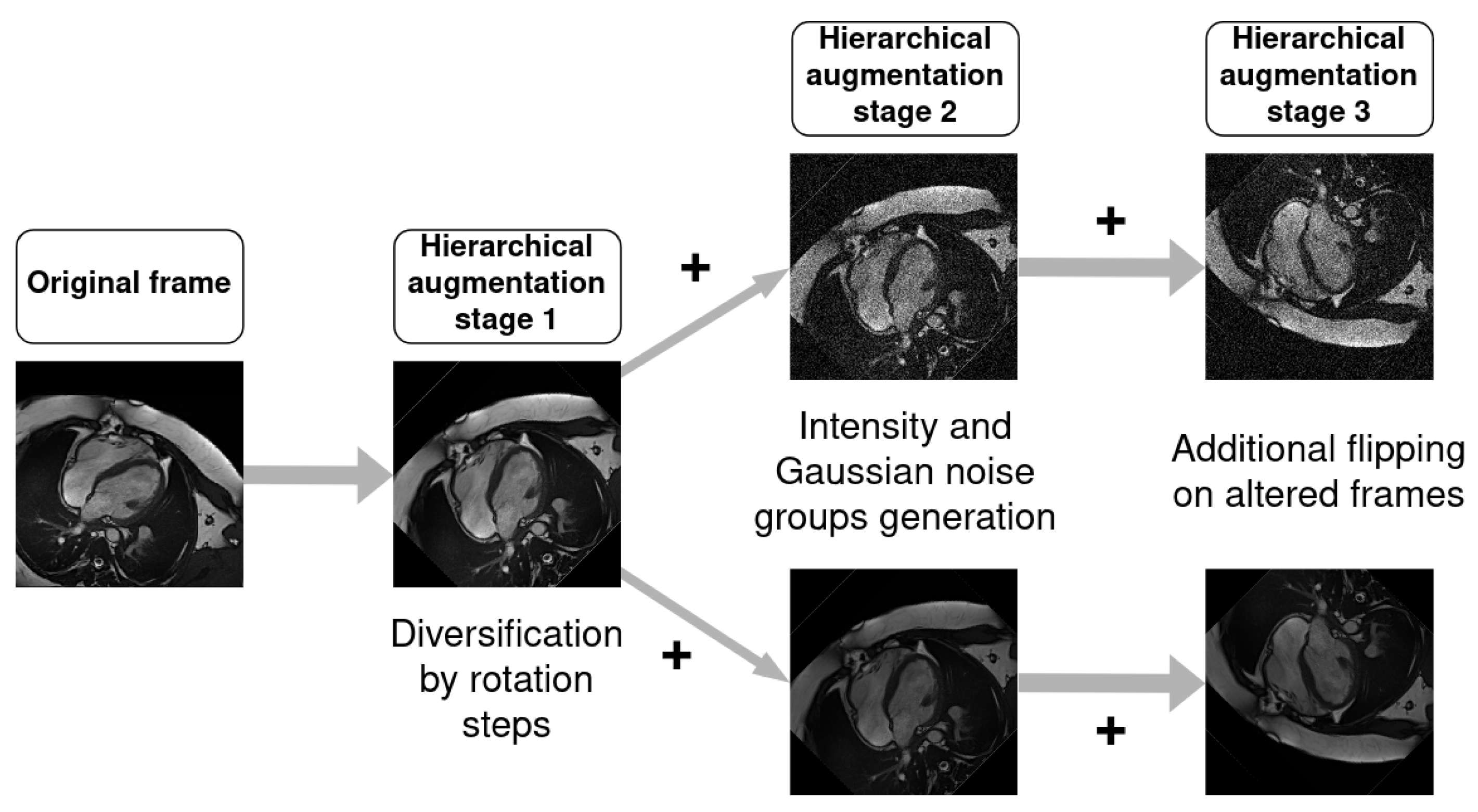
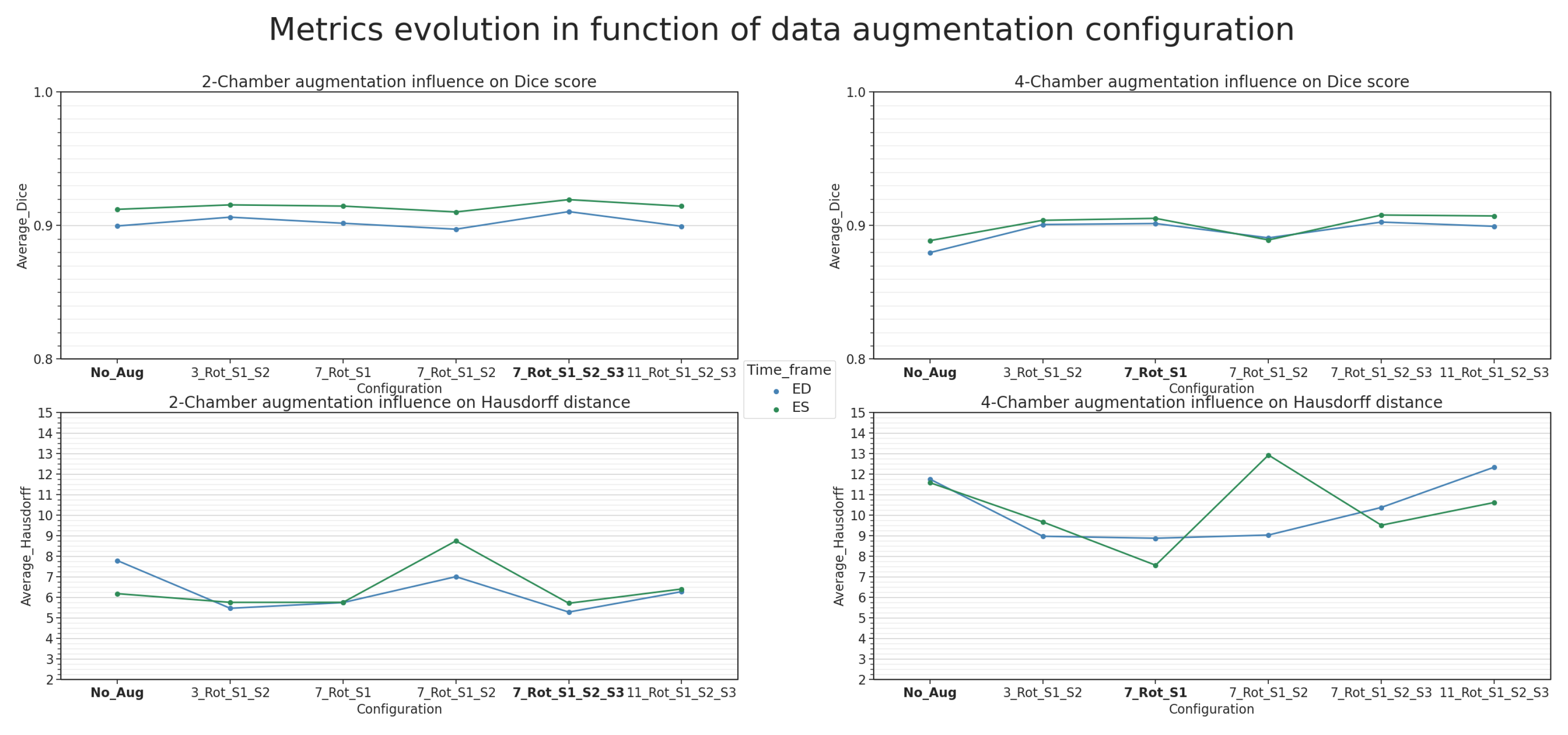
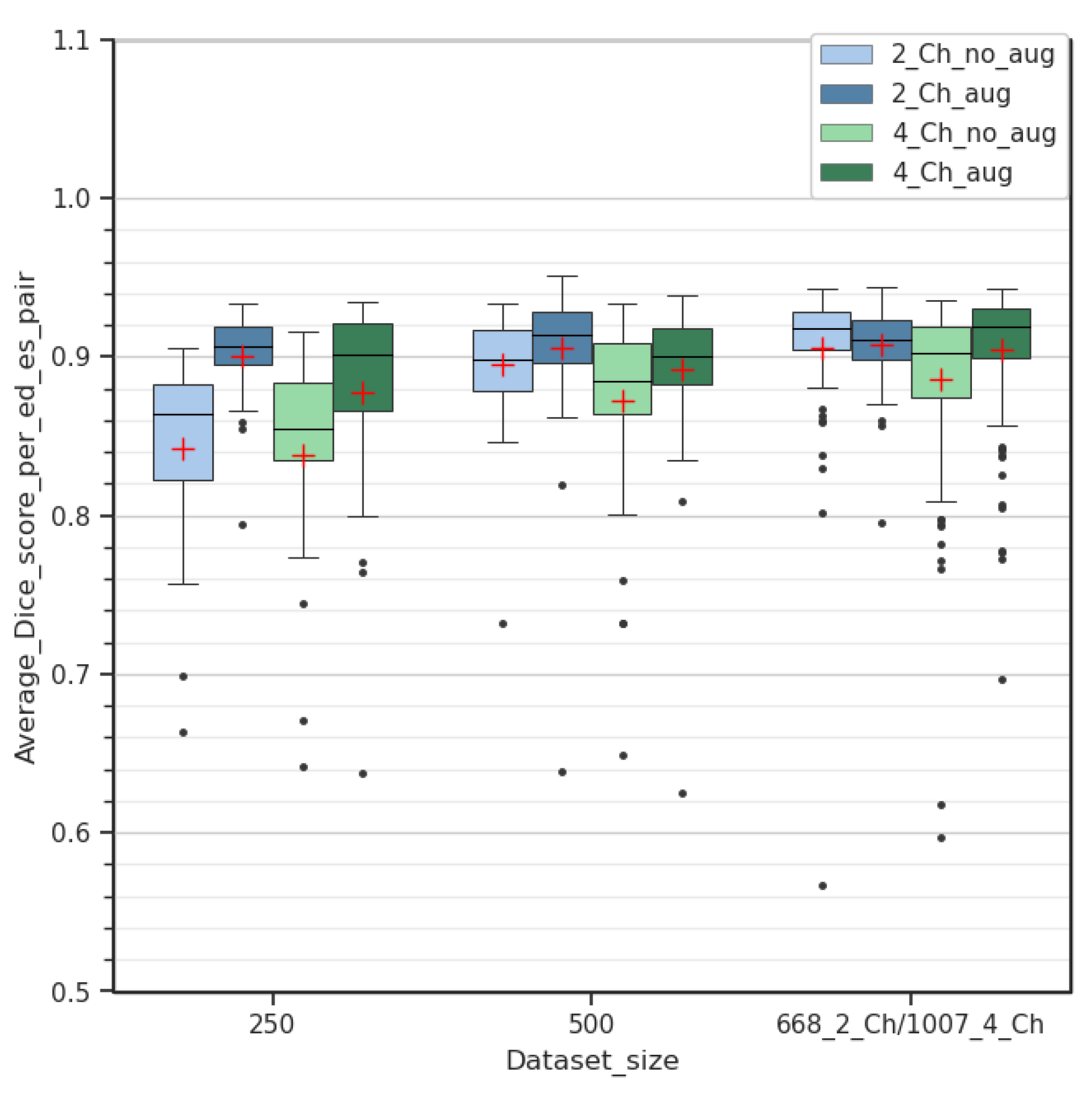
36]. To the best of our knowledge, our study represents the first instance of using the ENet architecture for long-axis two- and four-chamber segmentation in Cine-MRI. In contrast to the previously mentioned works, the current article concentrates on whole-heart segmentation in both LAX two- and four-chamber views and does not involve a SAX study. Our assessment specifically explores the impact of hierarchical data augmentation on segmentation improvement, with an additional focus on extrapolating the Left Ventricular Ejection Fraction (LVEF).
The remainder of this paper is structured as follows. In
Section 2, we provide details on the datasets, our hierarchical data-augmentation technique and the network architecture used for our comparison. In
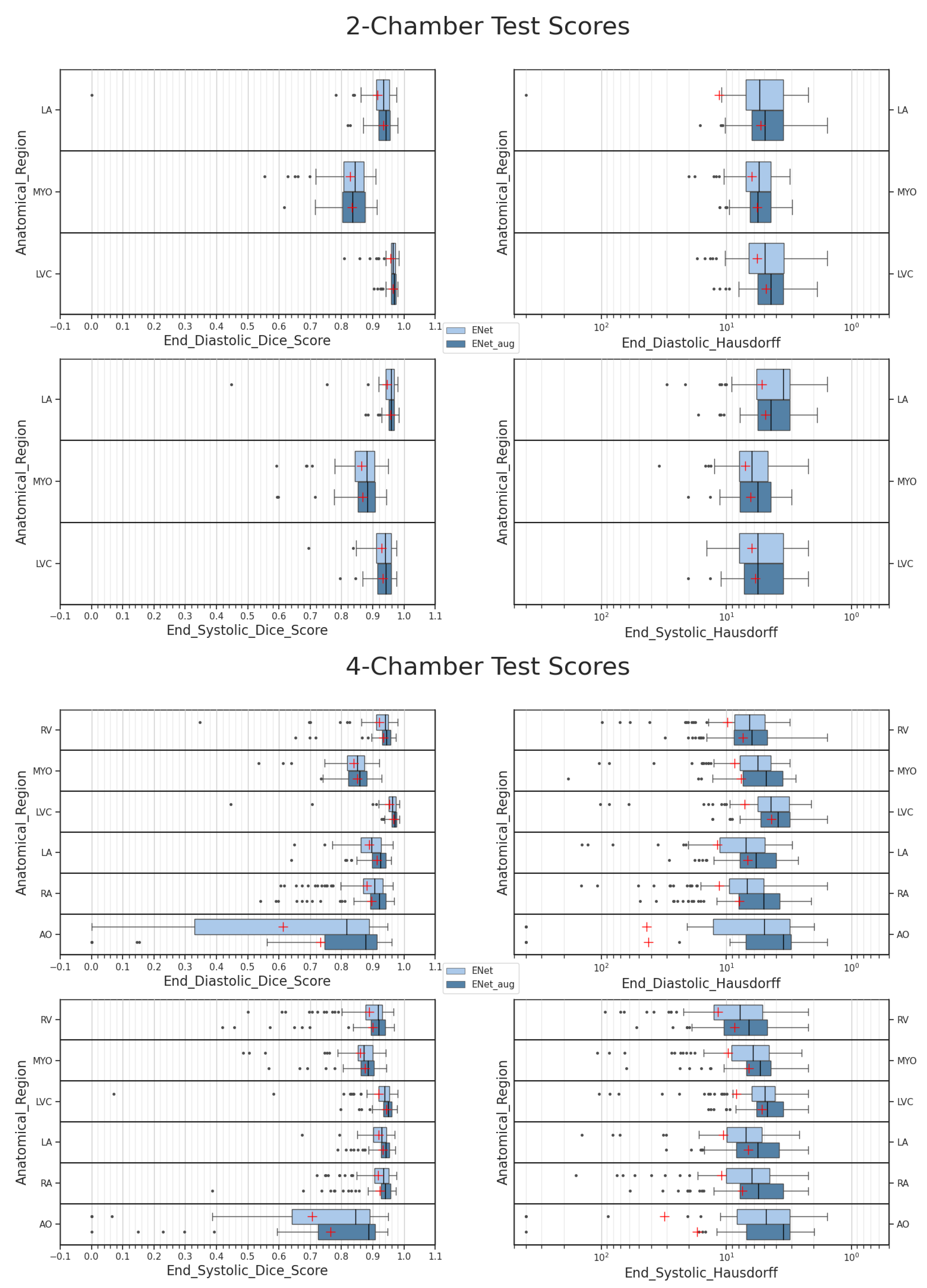
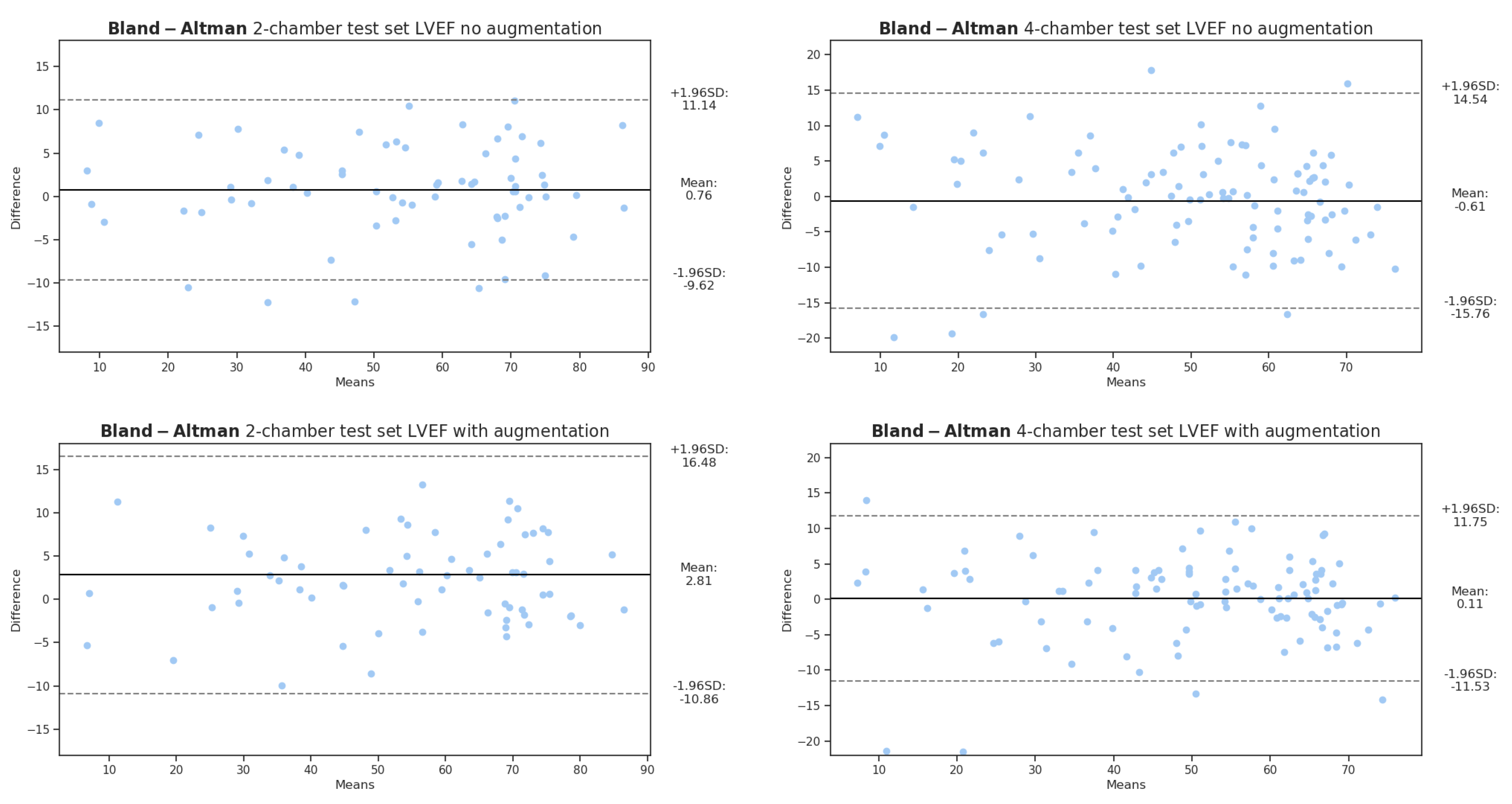
Section 3, the scores with and without data augmentation are presented as well as the clinical metric estimation over the LVEF. In
Section 4, the segmentation results are analyzed along the data-augmentation influence, and finally, in
Section 6, we present our conclusions.
5. Limitations
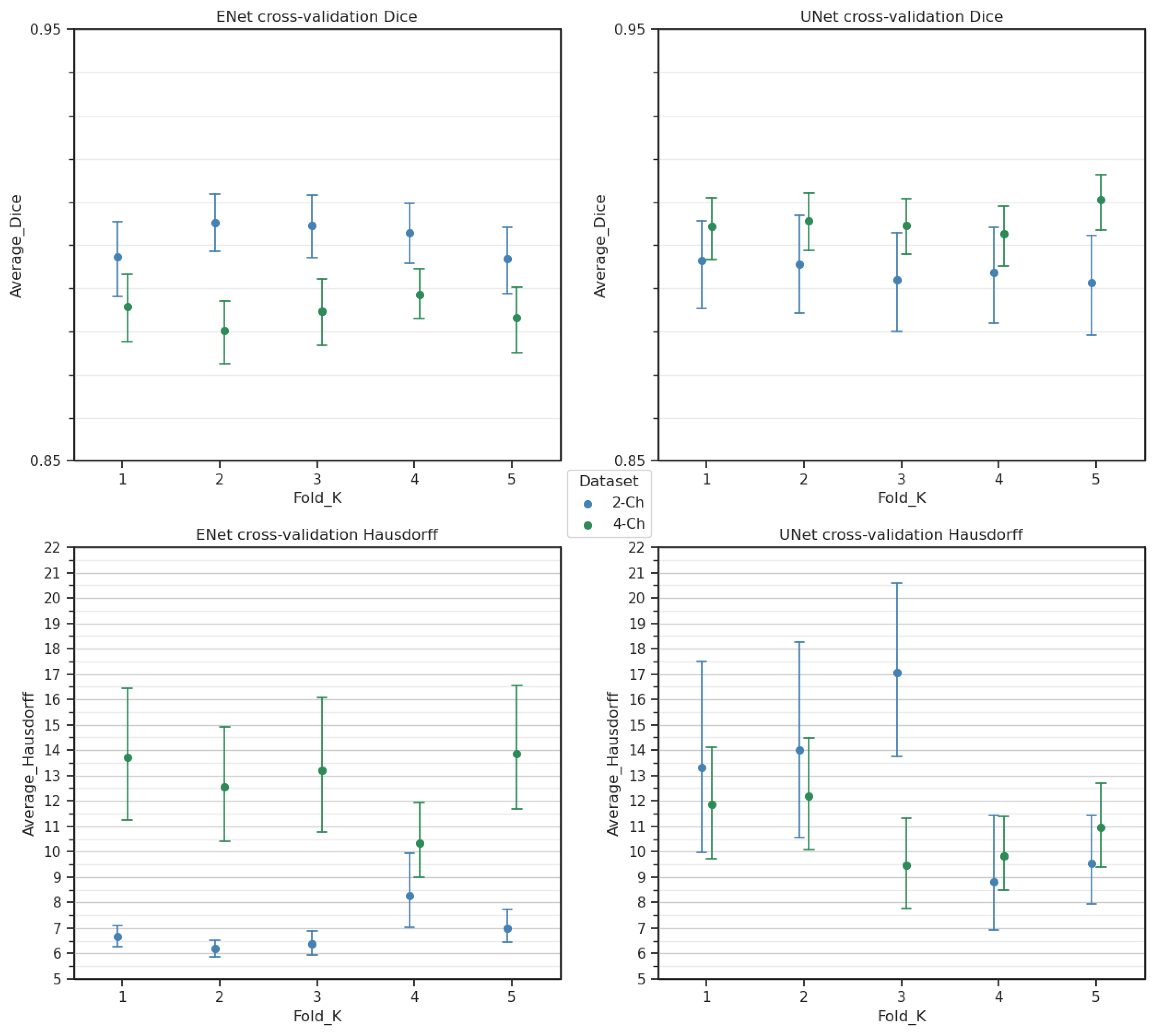
While the present work focuses on whole-heart segmentation in the LAX two- and four-chamber orientation in Cine-MRI, several shortcomings related to the imaging modality and sequence may potentially limit the usage of segmentation. While data augmentation was performed to compensate for these issues, some MRI acquisitions may present extreme degradation related to movement blur, blood flow signals or magnetic field inhomogeneities. Moreover, metric-quality assessments such as with the Hausdorff distance are limited by the spatial resolution, most of the time between 1 and 2 mm per voxel in the plane and often superior to 5 mm out of the plane.
Our database focused only on the ED and ES timeframes of the cardiac cycle. This aspect limits possibilities regarding detailed strain computation since clinical ground truths were not available for other time frames. In addition, only the longitudinal and radial strain can be determined over the LAX plane of view, with the circumferential strain computed from SAX acquisitions. While we demonstrated the feasibility of the acceptable LVEF quantification with the ENet architecture, we did not perform strain computation in this study. A detailed strain analysis can be considered as a major focus of study in future work.
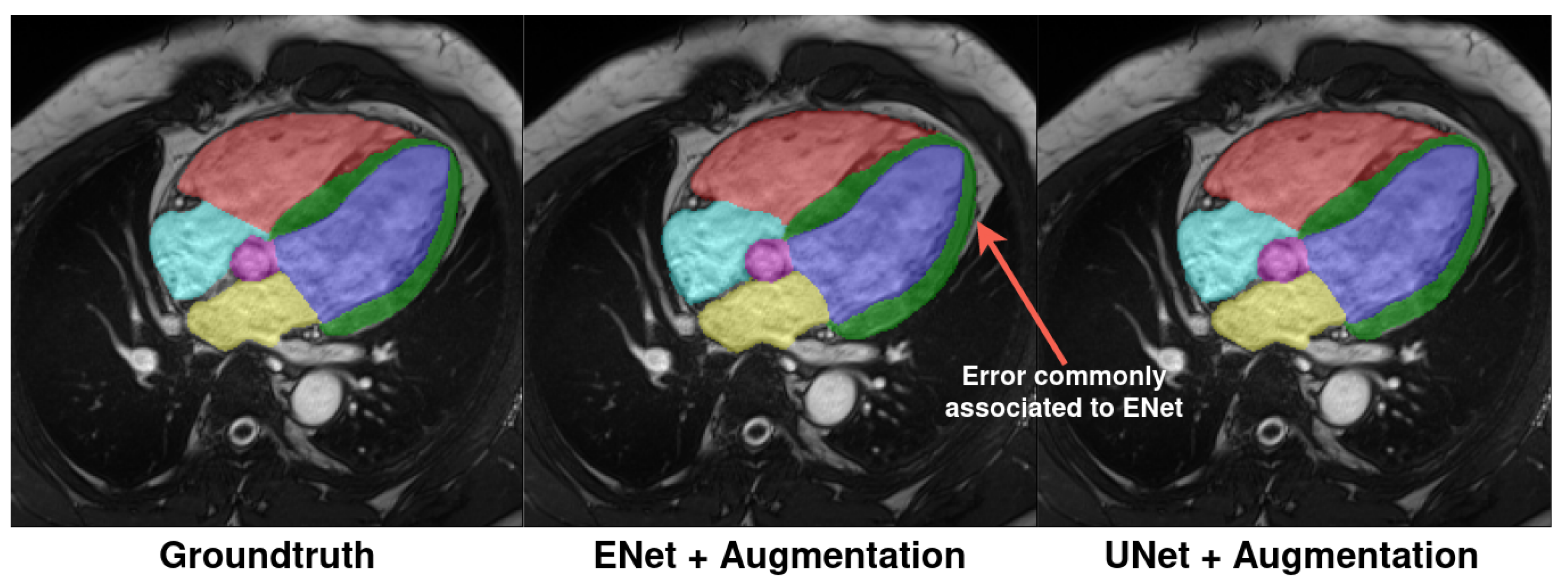
While a short comparison was performed with the state-of-the-art UNet architecture, further hyperparameter optimization, for instance over different loss functions, may provide deeper insights into the performance differences between the architectures.



 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}