





Risk-Sensitive Policy with Distributional Reinforcement Learning


Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Theoretical Background
3.1.1. Markov Decision Process
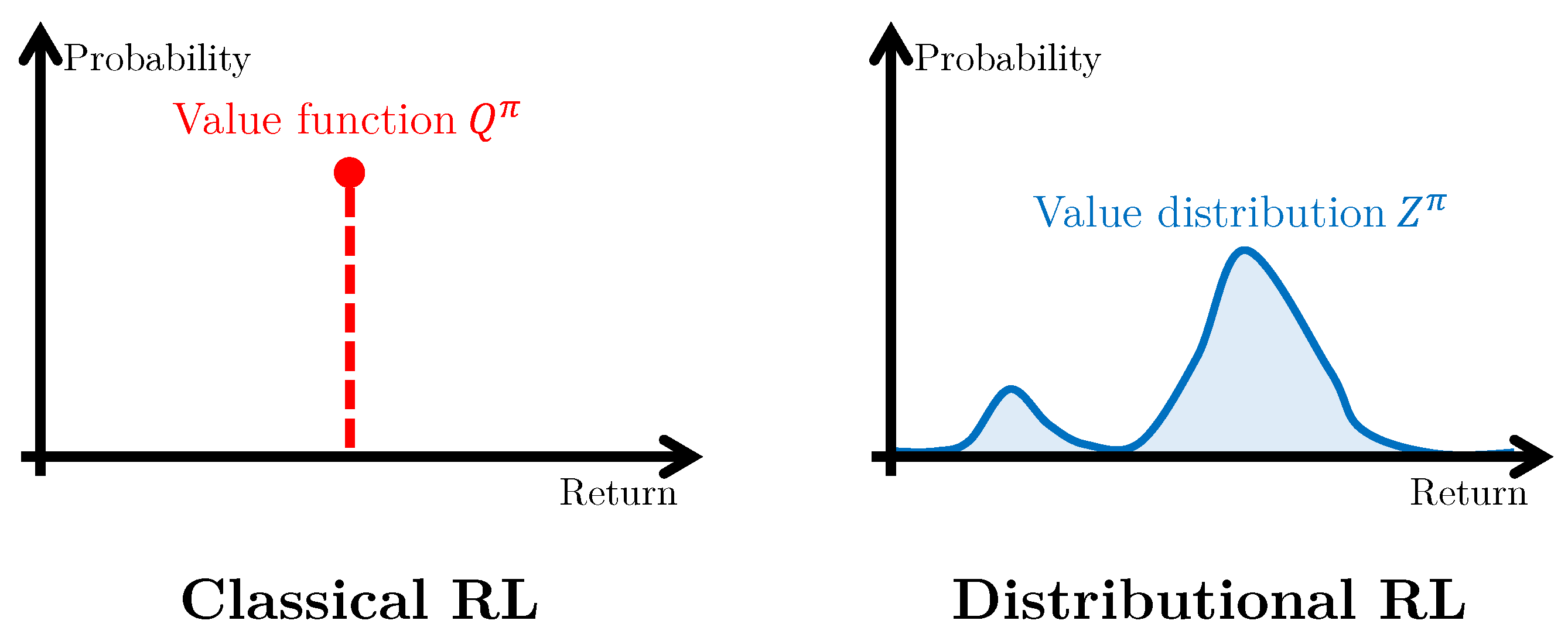
3.1.2. Distributional Reinforcement Learning
3.2. Methodology
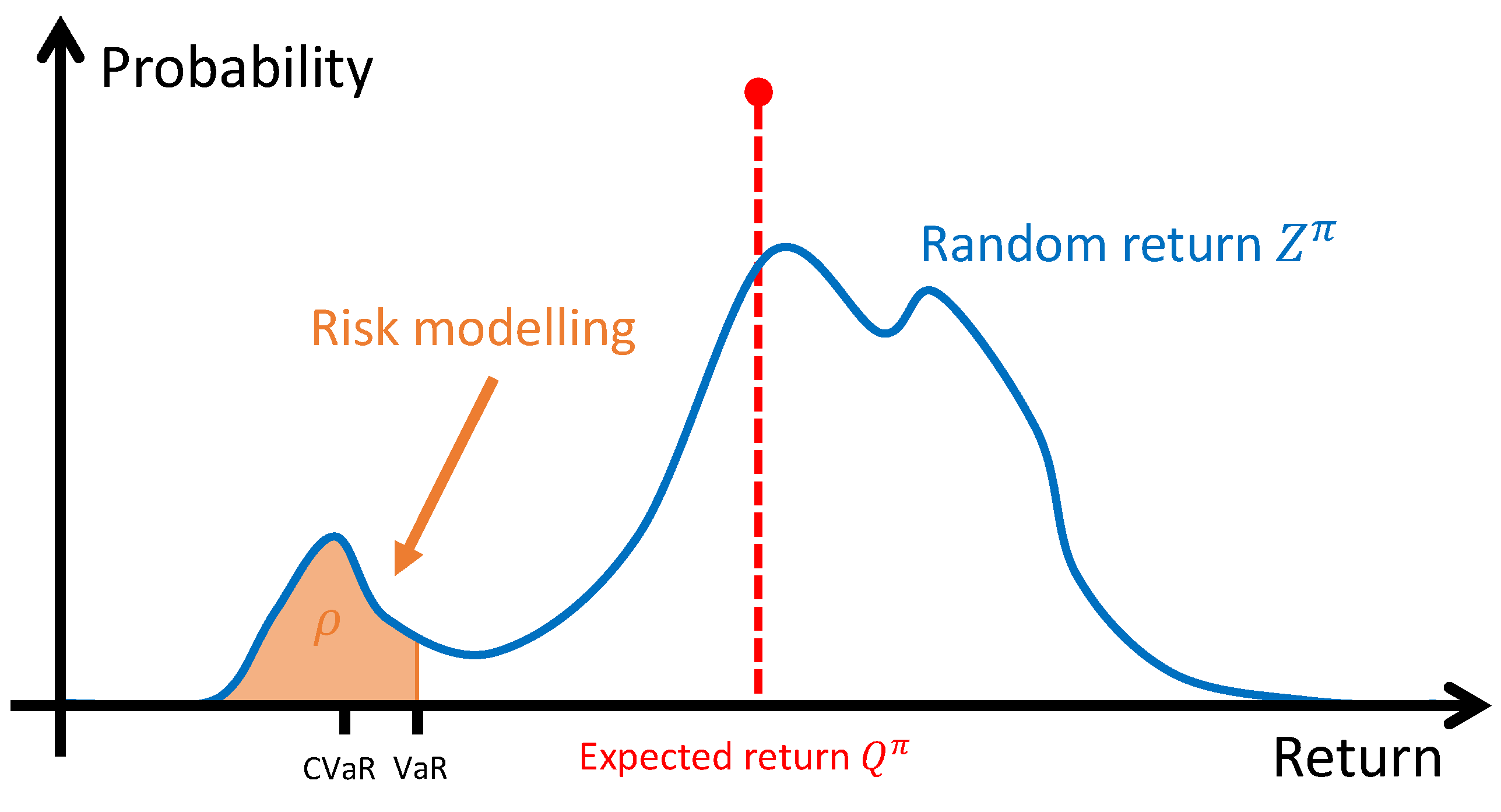
3.2.1. Objective Criterion for Risk-Sensitive RL
- •
- denotes the probability of the event ⋆,
- •
- is the minimum acceptable return (from the perspective of risk mitigation),
- •
- is the threshold probability that is not to be exceeded.
3.2.2. Practical Modelling of the Risk
- •
- is a function extracting risk features from the random return probability distribution , such as or ,
- •
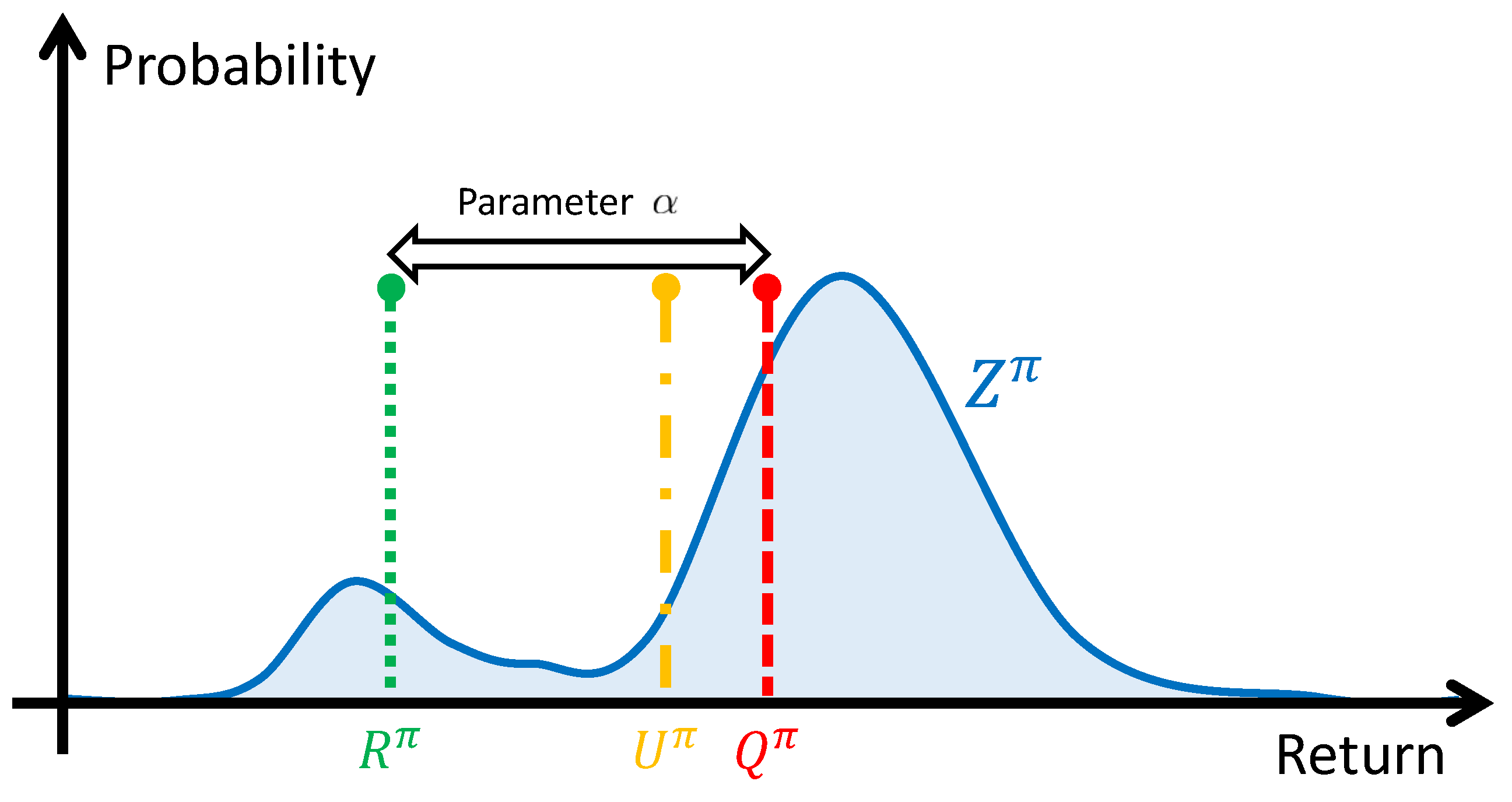
- is a parameter corresponding to the cumulative probability associated with the worst returns, generally between and . In other words, this parameter controls the size of the random return distribution tail from which the risk is estimated.
3.2.3. Risk-Based Utility Function
3.2.4. Risk-Sensitive Distributional RL Algorithm
3.3. Performance Assessment Methodology
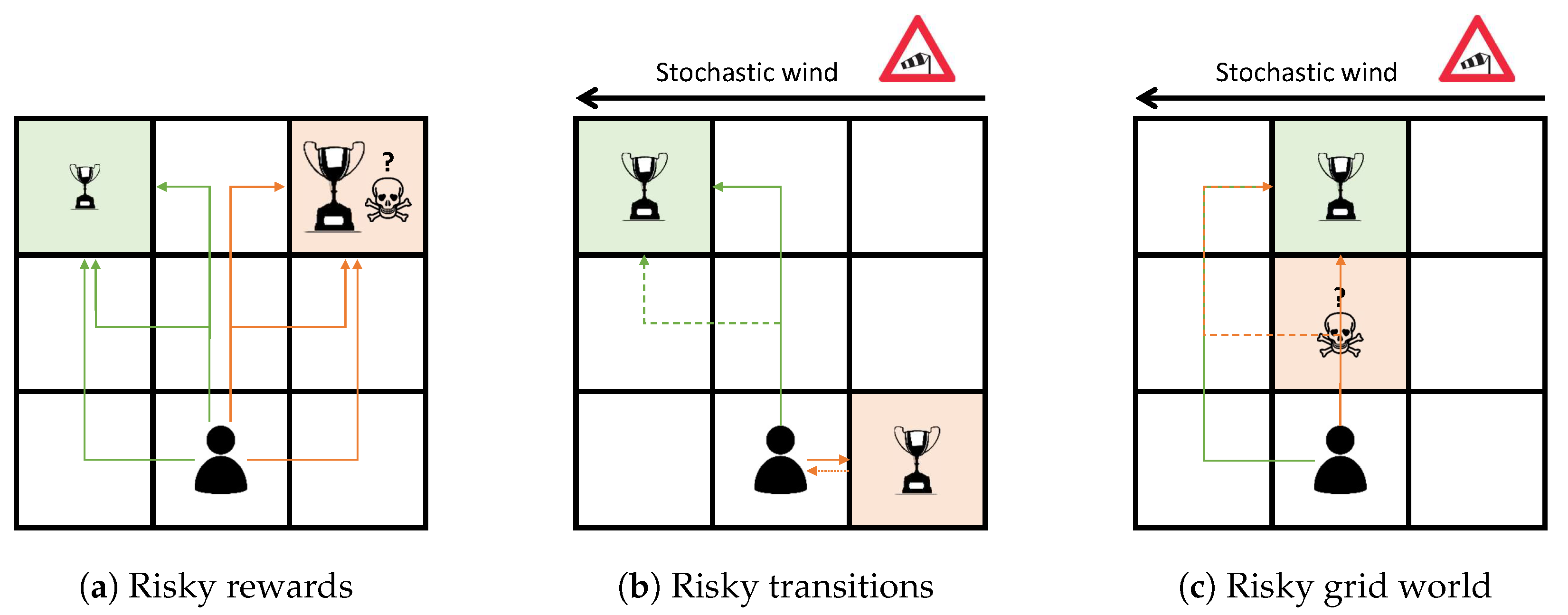
3.3.1. Benchmark Environments
| Algorithm 1 Risk-sensitive distributional RL algorithm. |
|
3.3.2. Risk-Sensitive Distributional RL Algorithm Analysed
4. Results and Discussion
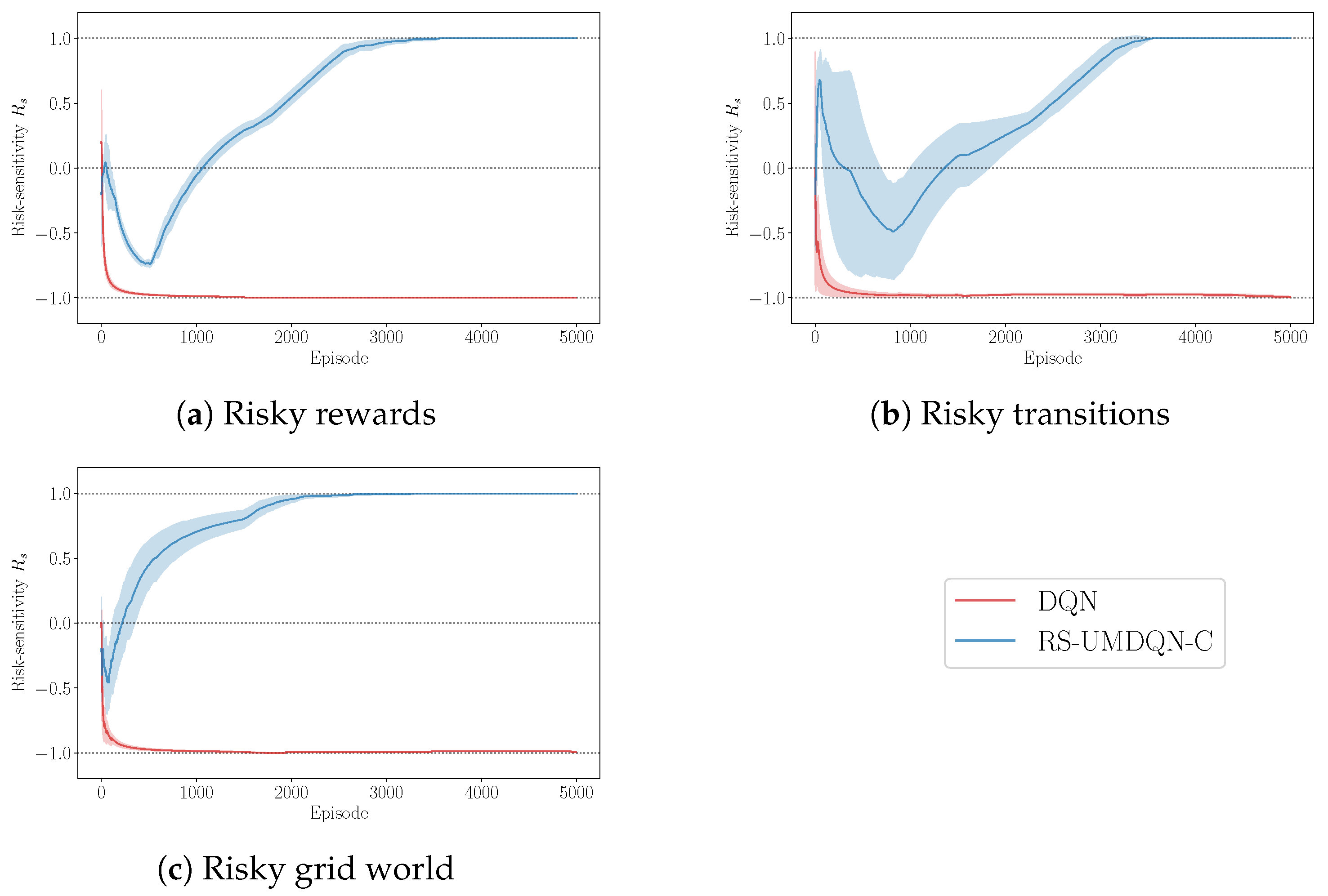
4.1. Decision-Making Policy Performance
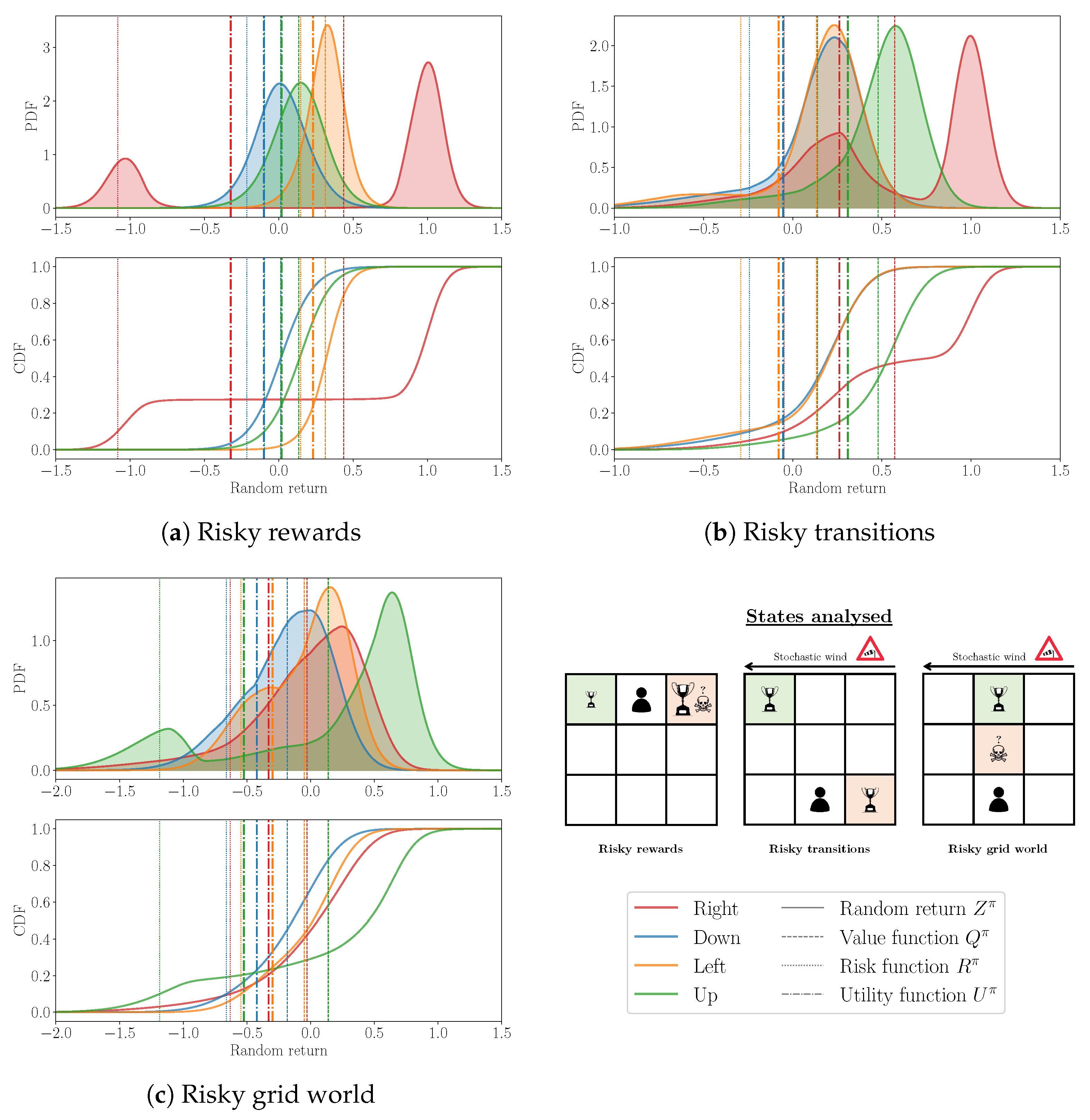
4.2. Probability Distribution Visualisation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Benchmark Environments
- , a state s being composed of the two coordinates of the agent within the grid,
- , with an action a being a moving direction,
- where:
- –
- and if the agent reaches the first objective location (terminal state),
- –
- and with a 75% chance, and and with a 25% chance if the agent reaches the second objective location (terminal state),
- –
- and otherwise,
- associates a 100% chance to move once in the chosen direction, while keeping the agent within the grid world (crossing a border is not allowed),
- associates a probability of 1 to the state , which is the position of the agent in Figure 4,
- .
- , a state s being composed of the two coordinates of the agent within the grid,
- , with an action a being a moving direction,
- where:
- –
- and if the agent reaches one of the objective locations (terminal state),
- –
- and otherwise,
- associates a 100% chance to move once in the chosen direction AND a 50% chance to get pushed once to the left by the stochastic wind, while keeping the agent within the grid world,
- associates a probability of 1 to the state , which is the position of the agent in Figure 4,
- .
- , a state s being composed of the two coordinates of the agent within the grid,
- , with an action a being a moving direction,
- where:
- –
- and if the agent reaches the objective location (terminal state),
- –
- and with a 75% chance, and and with a 25% chance if the agent reaches the stochastic trap location (terminal state),
- –
- and otherwise,
- associates a 100% chance to move once in the chosen direction AND a 25% chance to get pushed once to the left by the stochastic wind, while keeping the agent within the grid world,
- associates a probability of 1 to the state , which is the position of the agent in Figure 4,
- .
Appendix B. RS-UMDQN-C Algorithm
| Algorithm A1 RS-UMDQN-C algorithm |
|
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Technical Note: Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Levine, N.; Mankowitz, D.J.; Li, J.; Paduraru, C.; Gowal, S.; Hester, T. Challenges of real-world reinforcement learning: Definitions, benchmarks and analysis. Mach. Learn. 2021, 110, 2419–2468. [Google Scholar] [CrossRef]
- Gottesman, O.; Johansson, F.D.; Komorowski, M.; Faisal, A.A.; Sontag, D.; Doshi-Velez, F.; Celi, L.A. Guidelines for reinforcement learning in healthcare. Nat. Med. 2019, 25, 16–18. [Google Scholar] [CrossRef] [PubMed]
- Théate, T.; Ernst, D. An application of deep reinforcement learning to algorithmic trading. Expert Syst. Appl. 2021, 173, 114632. [Google Scholar] [CrossRef]
- Thananjeyan, B.; Balakrishna, A.; Nair, S.; Luo, M.; Srinivasan, K.; Hwang, M.; Gonzalez, J.E.; Ibarz, J.; Finn, C.; Goldberg, K. Recovery RL: Safe Reinforcement Learning with Learned Recovery Zones. IEEE Robot. Autom. Lett. 2021, 6, 4915–4922. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhao, H. A Survey of Deep RL and IL for Autonomous Driving Policy Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14043–14065. [Google Scholar] [CrossRef]
- Bellemare, M.G.; Dabney, W.; Munos, R. A Distributional Perspective on Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 449–458. [Google Scholar]
- García, J.; Fernández, F. A comprehensive survey on safe reinforcement learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Castro, D.D.; Tamar, A.; Mannor, S. Policy Gradients with Variance Related Risk Criteria. In Proceedings of the 29th International Conference on Machine Learning, ICML 2012, Edinburgh, UK, 26 June–1 July 2012. [Google Scholar]
- La, P.; Ghavamzadeh, M. Actor-Critic Algorithms for Risk-Sensitive MDPs. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 252–260. [Google Scholar]
- Zhang, S.; Liu, B.; Whiteson, S. Mean-Variance Policy Iteration for Risk-Averse Reinforcement Learning. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; AAAI Press: Washington, DC, USA, 2021; pp. 10905–10913. [Google Scholar]
- Rockafellar, R.T.; Uryasev, S. Conditional Value-at-Risk for General Loss Distributions. Corp. Financ. Organ. J. 2001, 7, 1443–1471. [Google Scholar] [CrossRef]
- Chow, Y.; Tamar, A.; Mannor, S.; Pavone, M. Risk-Sensitive and Robust Decision-Making: A CVaR Optimization Approach. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 1522–1530. [Google Scholar]
- Chow, Y.; Ghavamzadeh, M.; Janson, L.; Pavone, M. Risk-Constrained Reinforcement Learning with Percentile Risk Criteria. J. Mach. Learn. Res. 2017, 18, 167:1–167:51. [Google Scholar]
- Tamar, A.; Glassner, Y.; Mannor, S. Optimizing the CVaR via Sampling. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; AAAI Press: Washington, DC, USA, 2015; pp. 2993–2999. [Google Scholar]
- Rajeswaran, A.; Ghotra, S.; Ravindran, B.; Levine, S. EPOpt: Learning Robust Neural Network Policies Using Model Ensembles. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hiraoka, T.; Imagawa, T.; Mori, T.; Onishi, T.; Tsuruoka, Y. Learning Robust Options by Conditional Value at Risk Optimization. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 2615–2625. [Google Scholar]
- Shen, Y.; Tobia, M.J.; Sommer, T.; Obermayer, K. Risk-Sensitive Reinforcement Learning. Neural Comput. 2014, 26, 1298–1328. [Google Scholar] [CrossRef] [PubMed]
- Dabney, W.; Ostrovski, G.; Silver, D.; Munos, R. Implicit Quantile Networks for Distributional Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 1104–1113. [Google Scholar]
- Tang, Y.C.; Zhang, J.; Salakhutdinov, R. Worst Cases Policy Gradients. In Proceedings of the 3rd Annual Conference on Robot Learning, CoRL 2019, Osaka, Japan, 30 October–1 November 2019; Volume 100, pp. 1078–1093. [Google Scholar]
- Urpí, N.A.; Curi, S.; Krause, A. Risk-Averse Offline Reinforcement Learning. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Yang, Q.; Simão, T.D.; Tindemans, S.; Spaan, M.T.J. Safety-constrained reinforcement learning with a distributional safety critic. Mach. Learn. 2022, 112, 859–887. [Google Scholar] [CrossRef]
- Pinto, L.; Davidson, J.; Sukthankar, R.; Gupta, A. Robust Adversarial Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 2817–2826. [Google Scholar]
- Qiu, W.; Wang, X.; Yu, R.; Wang, R.; He, X.; An, B.; Obraztsova, S.; Rabinovich, Z. RMIX: Learning Risk-Sensitive Policies for Cooperative Reinforcement Learning Agents. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 23049–23062. [Google Scholar]
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Théate, T.; Wehenkel, A.; Bolland, A.; Louppe, G.; Ernst, D. Distributional Reinforcement Learning with Unconstrained Monotonic Neural Networks. Neurocomputing 2023, 534, 199–219. [Google Scholar] [CrossRef]
- Wehenkel, A.; Louppe, G. Unconstrained Monotonic Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 1543–1553. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Symbol | Value |
|---|---|---|
| DNN structure | - | |
| Learning rate | ||
| Deep learning optimiser epsilon | - | |
| Replay memory capacity | C | |
| Batch size | 32 | |
| Target update frequency | ||
| Random return resolution | 200 | |
| Random return lower bound | ||
| Random return upper bound | ||
| Exploration -greedy initial value | - | |
| Exploration -greedy final value | - | |
| Exploration -greedy decay | - | |
| Risk coefficient | ||
| Risk trade-off |
| Benchmark Environment | DQN | RS-UMDQN-C | ||||
|---|---|---|---|---|---|---|
| Risky rewards | 0.3 | −1.246 | −0.474 | 0.1 | −0.126 | −0.013 |
| Risky transitions | 0.703 | 0.118 | 0.411 | 0.625 | 0.346 | 0.485 |
| Risky grid world | 0.347 | −1.03 | −0.342 | 0.333 | 0.018 | 0.175 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Théate, T.; Ernst, D. Risk-Sensitive Policy with Distributional Reinforcement Learning. Algorithms 2023, 16, 325. https://doi.org/10.3390/a16070325
Théate T, Ernst D. Risk-Sensitive Policy with Distributional Reinforcement Learning. Algorithms. 2023; 16(7):325. https://doi.org/10.3390/a16070325
Chicago/Turabian StyleThéate, Thibaut, and Damien Ernst. 2023. "Risk-Sensitive Policy with Distributional Reinforcement Learning" Algorithms 16, no. 7: 325. https://doi.org/10.3390/a16070325
APA StyleThéate, T., & Ernst, D. (2023). Risk-Sensitive Policy with Distributional Reinforcement Learning. Algorithms, 16(7), 325. https://doi.org/10.3390/a16070325