
Audio Anti-Spoofing Based on Audio Feature Fusion
Abstract
:1. Introduction
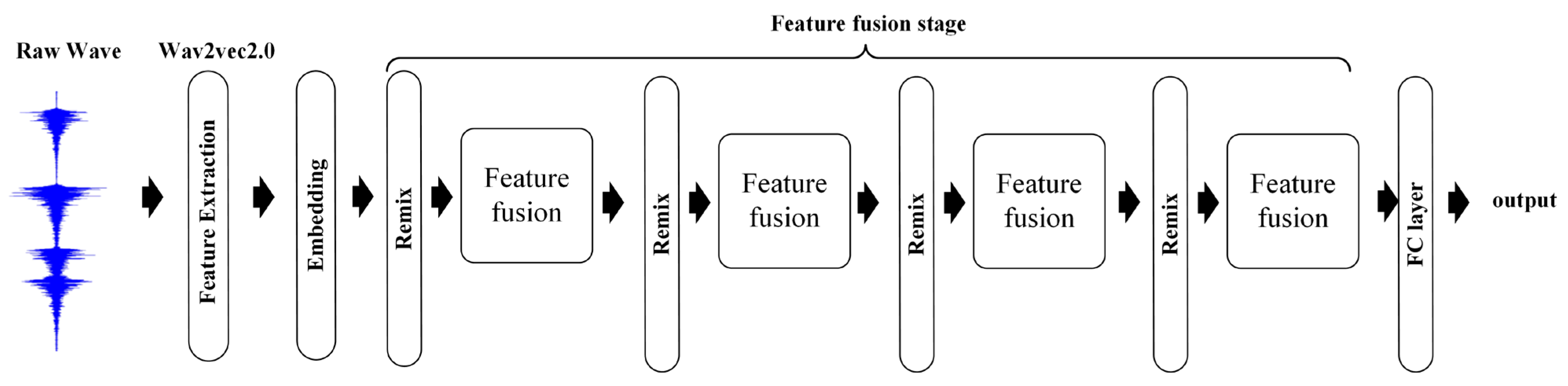
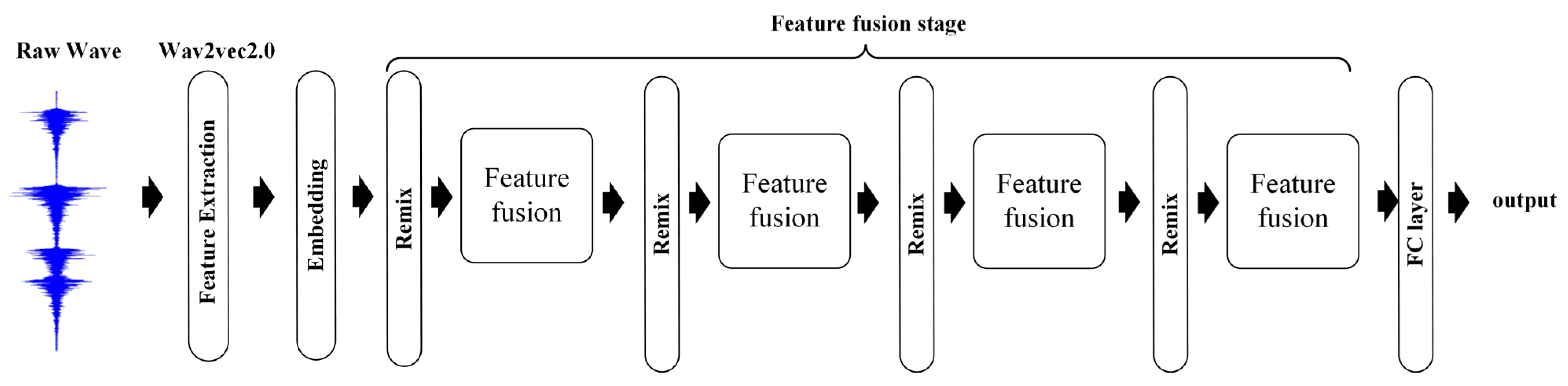
2. Methods
2.1. Wav2vec 2.0
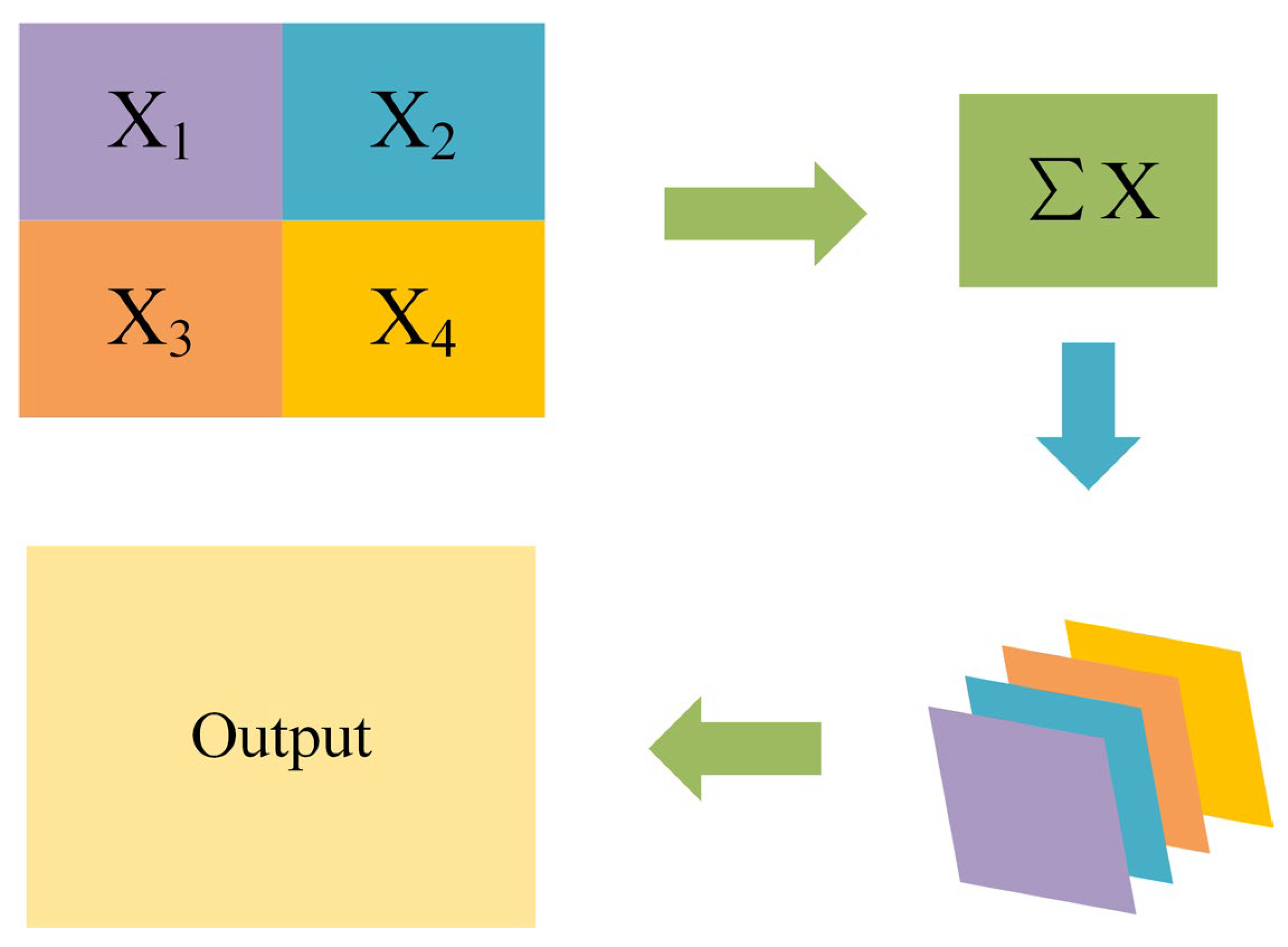
2.2. Remix
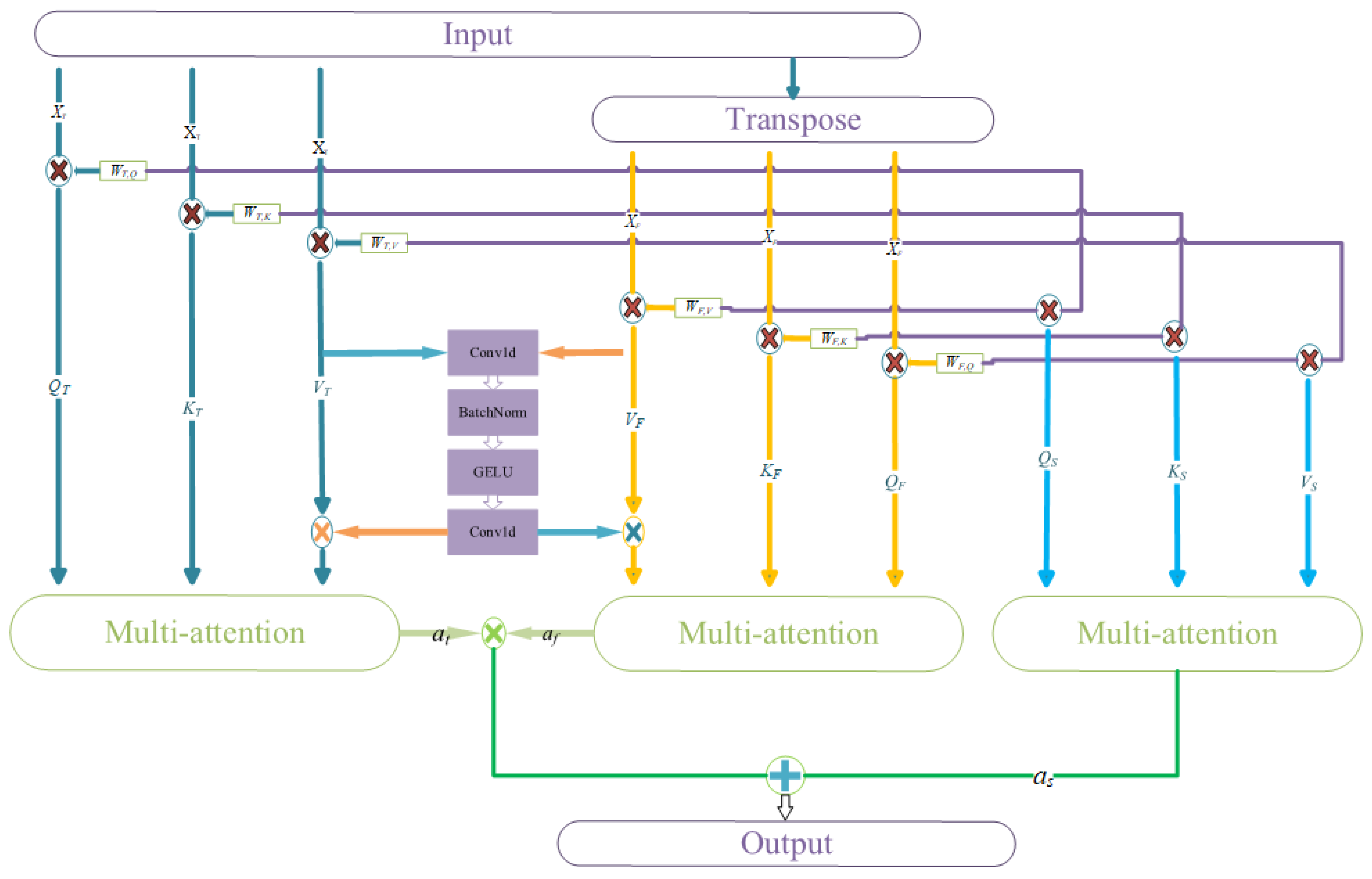
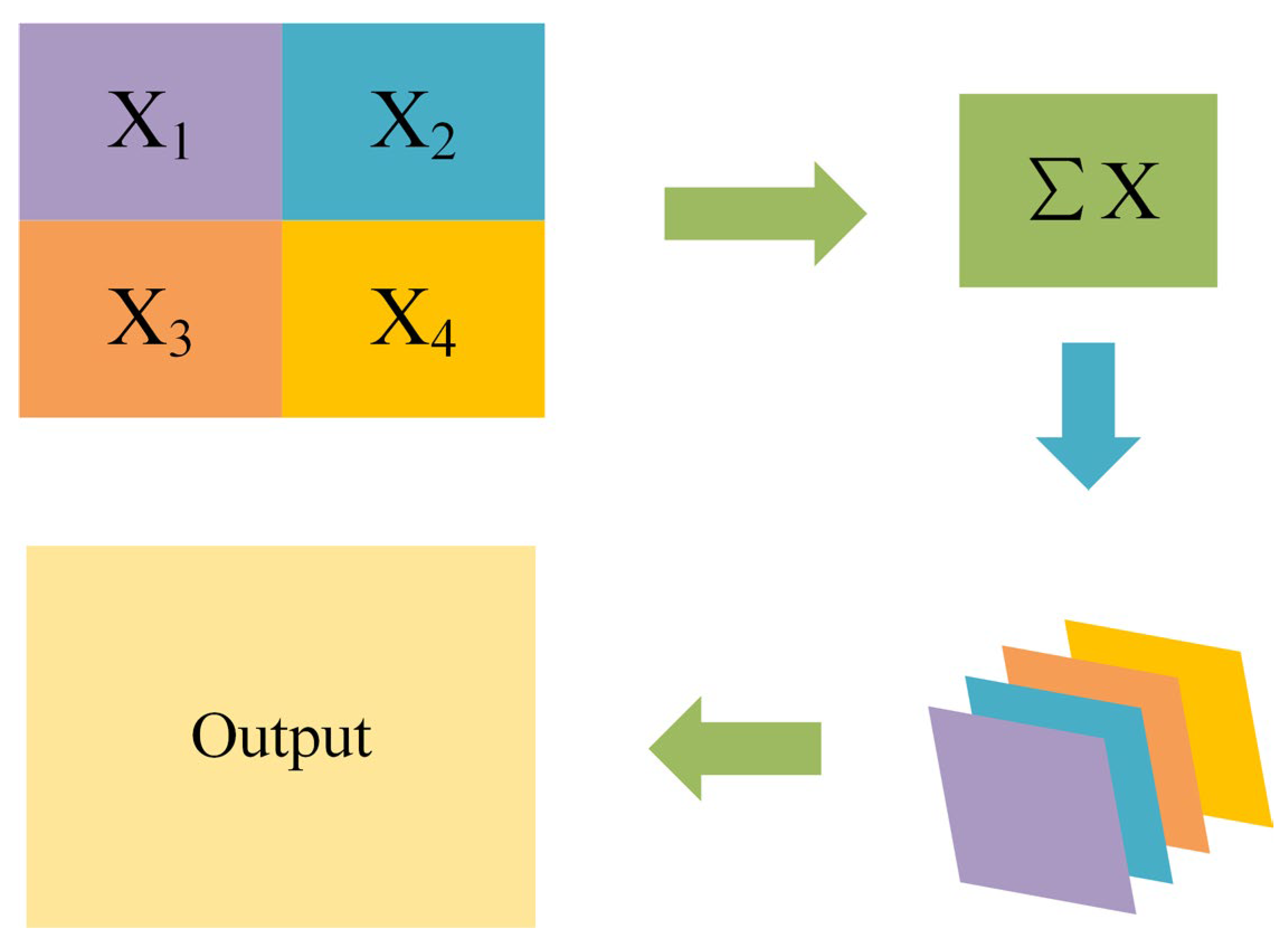
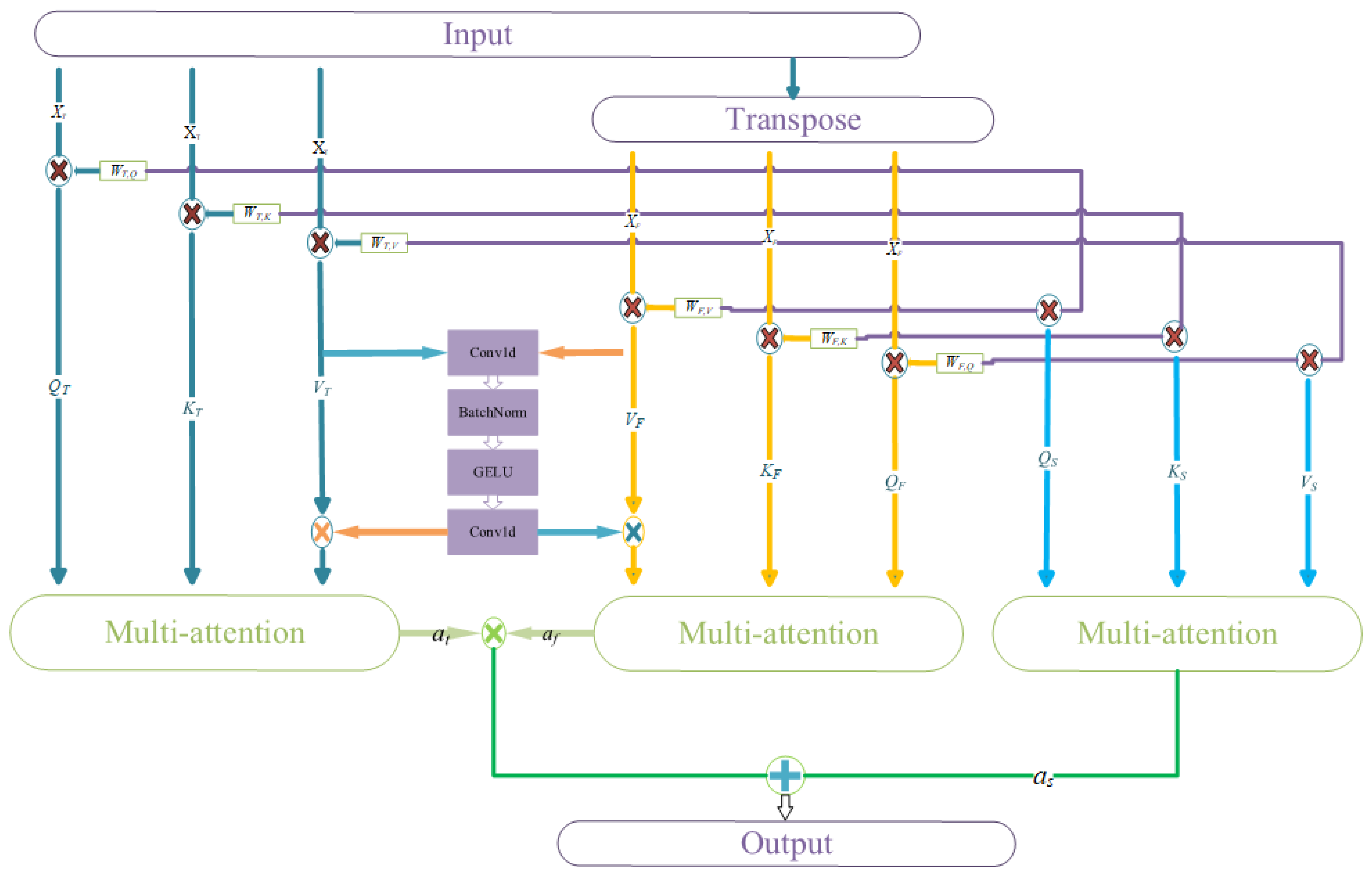
2.3. Feature Fusion
2.4. Data Augmentation
3. Experimental Setup and Details
3.1. Dataset and Evaluation Criteria
3.2. Experimental Details
3.3. Simple Back-End Classification Model
4. Results
4.1. Data Augmentation Results
4.2. Comparison with Models That Do Not Use the Pre-Trained Model
4.3. Comparison with Models Using the Pre-Trained Model
4.4. Results of the Simple Back-End Classification Model
4.5. Results of a Model without Back-End Classification
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) IEEE, Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.O.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep voice 3: Scaling text-to-speech with convolutional sequence learning. arXiv 2017, arXiv:171007654. [Google Scholar]
- Li, N.; Liu, S.; Liu, Y.; Zhao, S.; Liu, M. Neural speech synthesis with transformer network. In Proceedings of the AAAI Conference on Artificial Intelligence 2019, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6706–6713. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. Fastspeech 2: Fast and high-quality end-to-end text to speech. arXiv 2020, arXiv:200604558. [Google Scholar]
- Nautsch, A.; Wang, X.; Evans, N.; Kinnunen, T.H.; Vestman, V.; Todisco, M.; Delgado, H.; Sahidullah, M.; Yamagishi, J.; Lee, K.A. ASVspoof 2019: Spoofing countermeasures for the detection of synthesized, converted and replayed speech. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 252–265. [Google Scholar] [CrossRef]
- Wu, Z.; Kinnunen, T.; Evans, N.; Yamagishi, J.; Hanilçi, C.; Sahidullah, M.; Sizov, A. ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Kinnunen, T.; Sahidullah, M.; Delgado, H.; Todisco, M.; Evans, N.; Yamagishi, J.; Lee, K.A. The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection. In Proceedings of the 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Yamagishi, J.; Wang, X.; Todisco, M.; Sahidullah, M.; Patino, J.; Nautsch, A.; Liu, X.; Lee, K.A.; Kinnunen, T.; Evans, N.; et al. ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection. arXiv 2021, arXiv:210900537. [Google Scholar]
- Ma, Y.; Ren, Z.; Xu, S. RW-Resnet: A novel speech anti-spoofing model using raw waveform. arXiv 2021, arXiv:210805684. [Google Scholar]
- Tak, H.; Jung, J.; Patino, J.; Kamble, M.; Todisco, M.; Evans, N. End-to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection. arXiv 2021, arXiv:210712710. [Google Scholar]
- Hua, G.; Teoh, A.B.J.; Zhang, H. Towards end-to-end synthetic speech detection. IEEE Signal Process. Lett. 2021, 28, 1265–1269. [Google Scholar] [CrossRef]
- Wang, X.; Yamagishi, J. Investigating self-supervised front ends for speech spoofing countermeasures. arXiv 2021, arXiv:211107725. [Google Scholar]
- Tak, H.; Todisco, M.; Wang, X.; Jung, J.; Yamagishi, J.; Evans, N. Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation. arXiv 2022, arXiv:220212233. [Google Scholar]
- Kinnunen, T.; Lee, K.A.; Delgado, H.; Evans, N.; Todisco, M.; Sahidullah, M.; Yamagishi, J.; Reynolds, D.A. t-DCF: A detection cost function for the tandem assessment of spoofing countermeasures and automatic speaker verification. arXiv 2018, arXiv:180409618. [Google Scholar]
- Liu, X.; Wang, X.; Sahidullah, M.; Patino, J.; Delgado, H.; Kinnunen, T.; Todisco, M.; Yamagishi, J.; Evans, N.; Nautsch, A.; et al. ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild. arXiv 2022, arXiv:221002437. [Google Scholar] [CrossRef]
- Ma, K.; Feng, Y.; Chen, B.; Zhao, G. End-to-End Dual-Branch Network Towards Synthetic Speech Detection. IEEE Signal Process. Lett. 2023, 30, 359–363. [Google Scholar] [CrossRef]
- Ilyas, H.; Javed, A.; Malik, K.M. Avfakenet: A Unified End-to-End Dense Swin Transformer Deep Learning Model for Audio-Visual Deepfakes Detection. Appl. Soft Comput. 2023, 136, 110124. [Google Scholar] [CrossRef]
- Eom, Y.; Lee, Y.; Um, J.S.; Kim, H. Anti-spoofing using transfer learning with variational information bottleneck. arXiv 2022, arXiv:220401387. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Xu, X.; Kang, Y.; Cao, S.; Lin, B.; Ma, L. Explore wav2vec 2.0 for Mispronunciation Detection. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 4428–4432. [Google Scholar]
- Peng, L.; Fu, K.; Lin, B.; Ke, D.; Zhang, J. A Study on Fine-Tuning wav2vec2. 0 Model for the Task of Mispronunciation Detection and Diagnosis. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 4448–4452. [Google Scholar]
- Vaessen, N.; Van Leeuwen, D.A. Fine-tuning wav2vec2 for speaker recognition. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7967–7971. [Google Scholar]
- Fan, Z.; Li, M.; Zhou, S.; Xu, B. Exploring wav2vec 2.0 on speaker verification and language identification. arXiv 2020, arXiv:201206185. [Google Scholar]
- Pepino, L.; Riera, P.; Ferrer, L. Emotion recognition from speech using wav2vec 2.0 embeddings. arXiv 2021, arXiv:210403502. [Google Scholar]
- Xie, Y.; Zhang, Z.; Yang, Y. Siamese Network with wav2vec Feature for Spoofing Speech Detection. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 4269–4273. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), London, UK, 4–9 December 2017. [Google Scholar]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. Mixformer: End-to-end tracking with iterative mixed attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 13608–13618. [Google Scholar]
- Jung, J.; Heo, H.-S.; Tak, H.; Shim, H.; Chung, J.S.; Lee, B.-J.; Yu, H.-J.; Evans, N. AASIST: Audio anti-spoofing using integrated spectro-temporal graph attention networks. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6367–6371. [Google Scholar]
- Lavrentyeva, G.; Novoselov, S.; Tseren, A.; Volkova, M.; Gorlanov, A.; Kozlov, A. STC antispoofing systems for the ASVspoof2019 challenge. arXiv 2019, arXiv:190405576. [Google Scholar]
- Cáceres, J.; Font, R.; Grau, T.; Molina, J.; SL, B.V. The Biometric Vox system for the ASVspoof 2021 challenge. In Proceedings of the ASVspoof 2021 Workshop, Online, 16 September 2021. [Google Scholar]
- Das, R.K. Known-unknown data augmentation strategies for detection of logical access, physical access and speech deepfake attacks: ASVspoof 2021. In Proceedings of the ASVspoof 2021 Workshop, Online, 16 September 2021. [Google Scholar]
- Tak, H.; Kamble, M.; Patino, J.; Todisco, M.; Evans, N. Rawboost: A Raw Data Boosting and Augmentation Method Applied to Automatic Speaker Verification Anti-Spoofing. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6382–6386. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:190408779. [Google Scholar]
- Kim, G.; Han, D.K.; Ko, H. SpecMix: A mixed sample data augmentation method for training with time-frequency domain features. arXiv 2021, arXiv:210803020. [Google Scholar]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-End anti-spoofing with RawNet2. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2021, Toronto, ON, Canada, 6–11 June 2021; pp. 6369–6373. [Google Scholar]
- Martín-Doñas, J.M.; Álvarez, A. The Vicomtech Audio Deepfake Detection System Based on Wav2vec2 for the 2022 ADD Challenge. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 9241–9245. [Google Scholar]
- Cohen, A.; Rimon, I.; Aflalo, E.; Permuter, H.H. A study on data augmentation in voice anti-spoofing. Speech Commun. 2022, 141, 56–67. [Google Scholar] [CrossRef]
- Jung, J.; Tak, H.; Shim, H.; Heo, H.-S.; Lee, B.-J.; Chung, S.-W.; Kang, H.-G.; Yu, H.-J.; Evans, N.; Kinnunen, T. SASV challenge 2022: A spoofing aware speaker verification challenge evaluation plan. arXiv 2022, arXiv:220110283. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Partition | EER (%) | Min t-DCF |
|---|---|---|
| LA (3) | 3.71 | 0.2880 |
| LA (5) | 1.18 | 0.2171 |
| DF (3) | 2.62 | |
| DF (5) | 4.72 |
| Model | EER (%) | Min t-DCF |
|---|---|---|
| SSL_Anti-spoofing [13] | 0.82 | 0.2066 |
| ours | 1.18 | 0.2171 |
| T23 [8] | 1.32 | 0.2177 |
| wav2+FF layer [37] | 3.54 | 0.2780 |
| fusion [38] | 4.66 | 0.2882 |
| wav2+LLGF [12] | 7.18 | 0.3590 |
| LFCC-LCNN | 8.90 | 0.3152 |
| Rawnet2 [36] | 9.49 | 0.4192 |
| AASIST [29] | 11.47 | 0.5081 |
| CQCC-GMM | 15.80 | 0.4948 |
| LFCC-GMM | 21.13 | 0.5836 |
| Model | EER (%) |
|---|---|
| ours | 2.62 |
| SSL_Anti-spoofing | 2.85 |
| wav2+FF layer [37] | 4.98 |
| Rawnet2 [36] | 6.10 |
| T23 [8] | 15.64 |
| Partition | EER (%) | Min t-DCF |
|---|---|---|
| LA (5) | 1.58 | 0.2286 |
| DF (3) | 3.18 |
| Partition | EER (%) | Min t-DCF |
|---|---|---|
| LA (5) | 24.84 | 0.8038 |
| DF (3) | 16.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Tu, G.; Liu, S.; Cai, Z. Audio Anti-Spoofing Based on Audio Feature Fusion. Algorithms 2023, 16, 317. https://doi.org/10.3390/a16070317
Zhang J, Tu G, Liu S, Cai Z. Audio Anti-Spoofing Based on Audio Feature Fusion. Algorithms. 2023; 16(7):317. https://doi.org/10.3390/a16070317
Chicago/Turabian StyleZhang, Jiachen, Guoqing Tu, Shubo Liu, and Zhaohui Cai. 2023. "Audio Anti-Spoofing Based on Audio Feature Fusion" Algorithms 16, no. 7: 317. https://doi.org/10.3390/a16070317
APA StyleZhang, J., Tu, G., Liu, S., & Cai, Z. (2023). Audio Anti-Spoofing Based on Audio Feature Fusion. Algorithms, 16(7), 317. https://doi.org/10.3390/a16070317