
Developing Analytical Tools for Arabic Sentiment Analysis of COVID-19 Data


Abstract
1. Introduction
- Building of an ArSentiCOVID lexicon, a first lexical resource for Arabic SA about COVID-19.
- Developing a lexicon-based sentiment analyzer tool that can properly handle both negation and emoji.
- Constructing an extensive list of Arabic negation.
- Scraping a large Arabic corpus from Twitter about COVID-19.
- Annotating an Arabic sentiment corpus about COVID-19, a new Arabic reference corpus for SA, automatically annotated by based mainly on the constructed lexicon.
- Conducting an in-depth study using lexicon-based approach to investigate the usefulness and quality of the ArSentiCOVID lexicon.
- Introducing an ensemble method that combines lexicon-based sentiment features (negation, polarity, and emojis) as input features for a ML classifier to generate a more precise Arabic SA procedure.
2. Related Works
2.1. Arabic Lexicon Construction
2.2. Arabic COVID-19 Corpus
3. Research Methodology
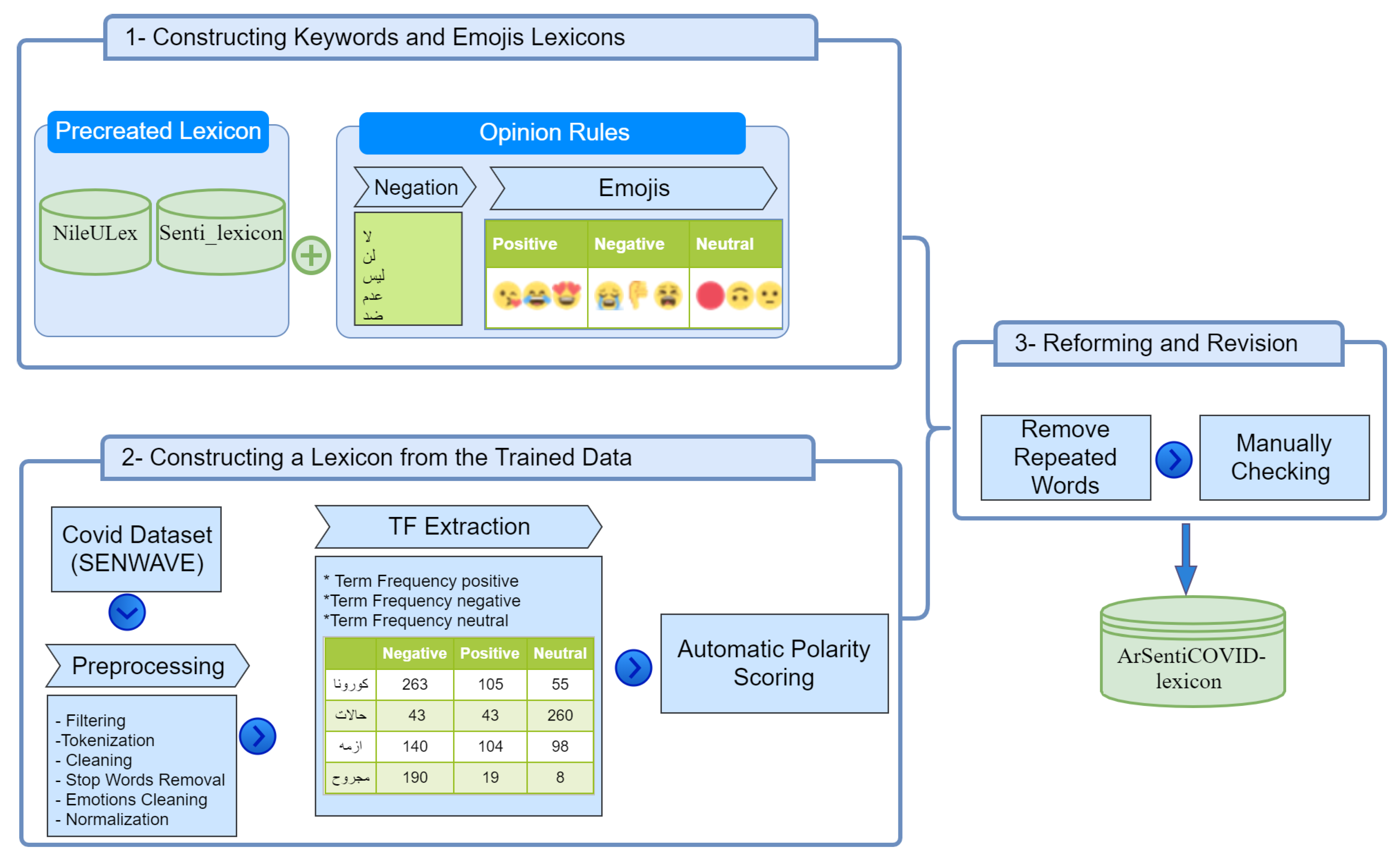
3.1. Lexicon Construction
3.1.1. Constructing Keyword and Opinion Rules Lexicons
3.1.2. Constructing a Lexicon Using the Trained Data
| Algorithm 1: Constructing a lexicon using the trained data. |
 |
3.1.3. Reforming and Revision
3.2. Sentiment Analyzer
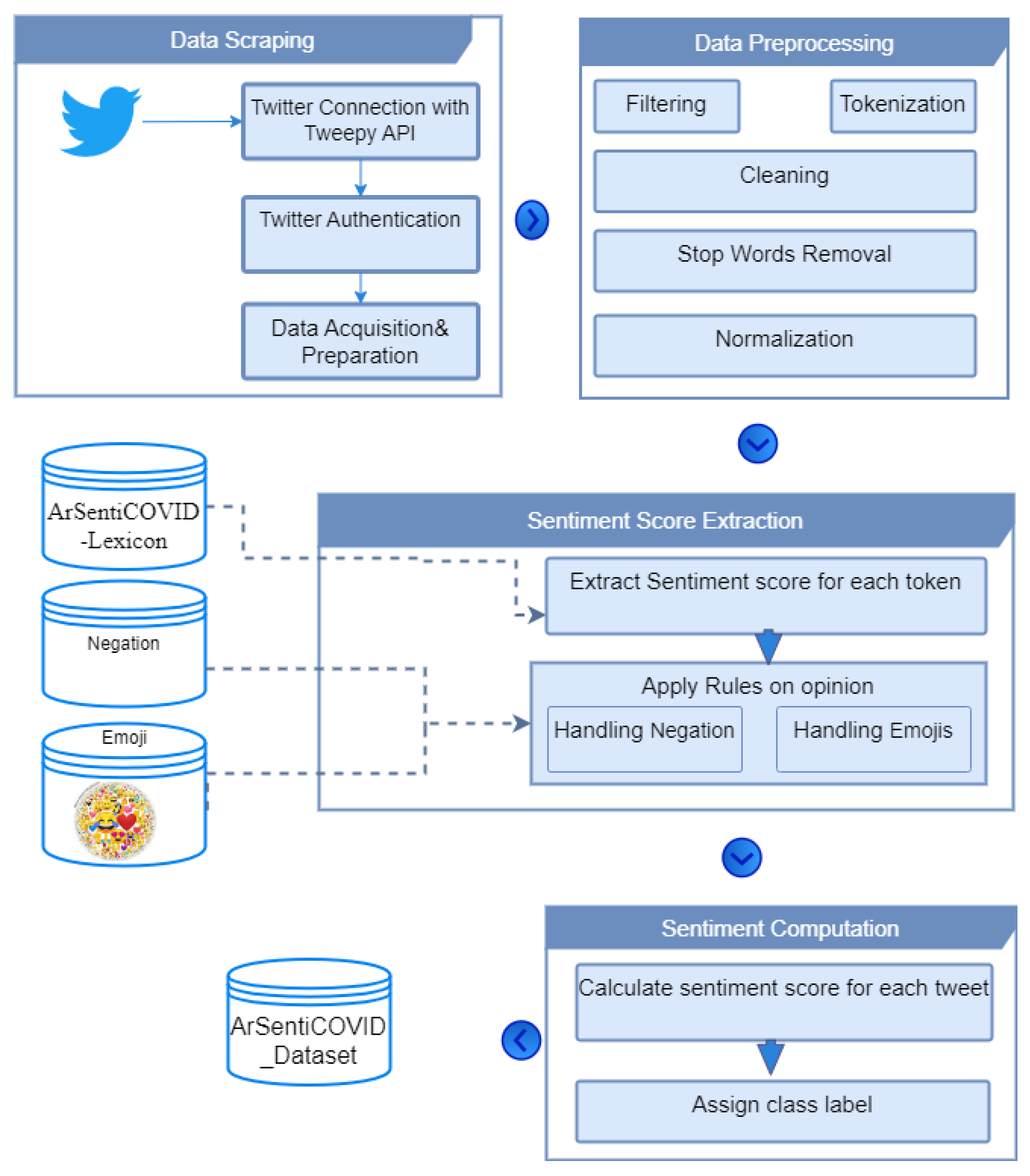
3.2.1. Scraping Tweets
3.2.2. Data Preprocessing
- -
- Substitute “أ”,“إ” , and “آ” for bare alif “ا” regardless of where in the word it appears.
- -
- Substitute the final “ة” for “ه”.
- -
- Substitute the final “ى” for “ي”.
- -
- Substitute the final “ئ” and “ؤ” for “ء”.
3.2.3. Sentiment Score Extraction
3.2.4. Sentiment Computation
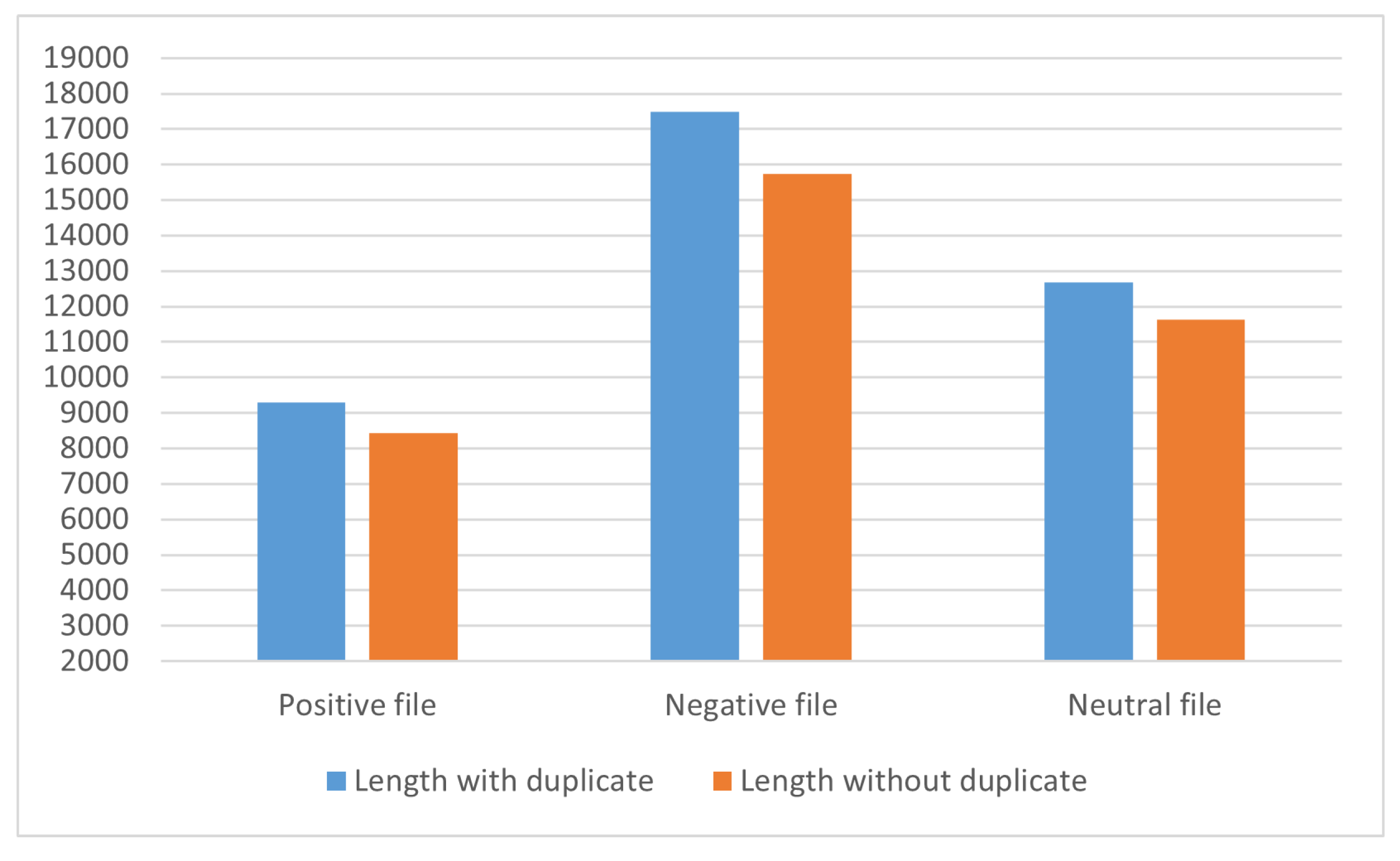
3.2.5. Dataset Description
4. Experimentation and Simulation
4.1. Experimental Setup
4.1.1. Dataset Description
4.1.2. Feature Representation
4.1.3. Classification Algorithms
4.1.4. Evaluation Metrics
4.2. Experimental Results
4.2.1. Lexicon Construction Approach Results
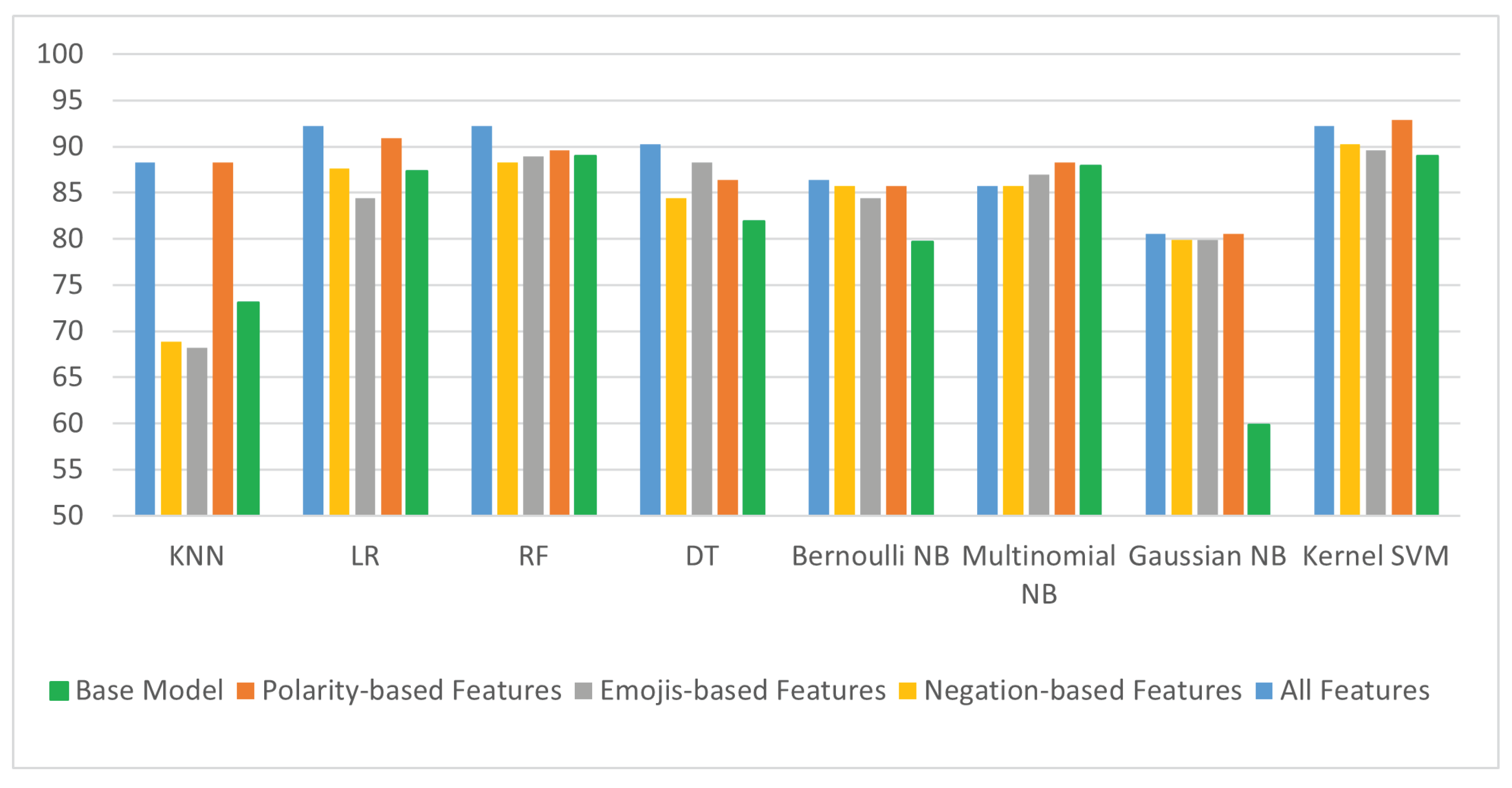
4.2.2. ML Classification Models Results
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guellil, I.; Azouaou, F.; Mendoza, M. Arabic sentiment analysis: Studies, resources, and tools. Soc. Netw. Anal. Min. 2019, 9, 56. [Google Scholar] [CrossRef]
- El-Beltagy, S.R.; Ali, A. Open issues in the sentiment analysis of Arabic social media: A case study. In Proceedings of the 2013 9th International Conference on Innovations in Information Technology (IIT), IEEE, Al Ain, United Arab Emirates, 17–19 March 2013; pp. 215–220. [Google Scholar]
- Al-Moslmi, T.; Albared, M.; Al-Shabi, A.; Omar, N.; Abdullah, S. Arabic senti-lexicon: Constructing publicly available language resources for Arabic sentiment analysis. J. Inf. Sci. 2018, 44, 345–362. [Google Scholar] [CrossRef]
- Ballesteros, M.; Francisco, V.; Díaz, A.; Herrera, J.; Gervás, P. Inferring the scope of negation in biomedical documents. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, New Delhi, India, 11–17 March 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 363–375. [Google Scholar]
- Assiri, A.; Emam, A.; Al-Dossari, H. Towards enhancement of a lexicon-based approach for Saudi dialect sentiment analysis. J. Inf. Sci. 2018, 44, 184–202. [Google Scholar] [CrossRef]
- Alharbi, O. Negation Handling in Machine Learning-Based Sentiment Classification for Colloquial Arabic. Int. J. Oper. Res. Inf. Syst. (IJORIS) 2020, 11, 33–45. [Google Scholar] [CrossRef]
- Al-Twairesh, N.; Al-Khalifa, H.; Al-Salman, A. Arasenti: Large-scale twitter-specific Arabic sentiment lexicons. In Proceedings of the Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 697–705. [Google Scholar]
- Gamal, D.; Alfonse, M.; El-Horbaty, E.S.M.; Salem, A.B.M. Twitter benchmark dataset for Arabic sentiment analysis. Int. J. Mod. Educ. Comput. Sci. 2019, 11, 33. [Google Scholar] [CrossRef]
- Al-Laith, A.; Shahbaz, M.; Alaskar, H.F.; Rehmat, A. AraSenCorpus: A Semi-Supervised Approach for Sentiment Annotation of a Large Arabic Text Corpus. Appl. Sci. 2021, 11, 2434. [Google Scholar] [CrossRef]
- Haouari, F.; Hasanain, M.; Suwaileh, R.; Elsayed, T. Arcov-19: The first arabic COVID-19 twitter dataset with propagation networks. arXiv 2020, arXiv:2004.05861. [Google Scholar]
- Yang, Q.; Alamro, H.; Albaradei, S.; Salhi, A.; Lv, X.; Ma, C.; Alshehri, M.; Jaber, I.; Tifratene, F.; Wang, W.; et al. SenWave: Monitoring the global sentiments under the COVID-19 pandemic. arXiv 2020, arXiv:2006.10842. [Google Scholar]
- Alqurashi, S.; Alhindi, A.; Alanazi, E. Large arabic twitter dataset on COVID-19. arXiv 2020, arXiv:2004.04315. [Google Scholar]
- Mataoui, M.; Zelmati, O.; Boumechache, M. A proposed lexicon-based sentiment analysis approach for the vernacular Algerian Arabic. Res. Comput. Sci. 2016, 110, 55–70. [Google Scholar] [CrossRef]
- Al-Thubaity, A.; Alqahtani, Q.; Aljandal, A. Sentiment lexicon for sentiment analysis of Saudi dialect tweets. Procedia Comput. Sci. 2018, 142, 301–307. [Google Scholar] [CrossRef]
- Badaro, G.; Jundi, H.; Hajj, H.; El-Hajj, W.; Habash, N. Arsel: A large scale arabic sentiment and emotion lexicon. OSACT 2018, 3, 26. [Google Scholar]
- Guellil, I.; Adeel, A.; Azouaou, F.; Hussain, A. Sentialg: Automated corpus annotation for algerian sentiment analysis. In Proceedings of the International Conference on Brain Inspired Cognitive Systems, Xi’an, China, 7–8 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 557–567. [Google Scholar]
- Badaro, G.; Baly, R.; Hajj, H.; Habash, N.; El-Hajj, W. A large scale Arabic sentiment lexicon for Arabic opinion mining. In Proceedings of the EMNLP 2014 workshop on arabic natural language processing (ANLP), Doha, Qatar, 25–29 October 2014; pp. 165–173. [Google Scholar]
- Alam, F.; Shaar, S.; Dalvi, F.; Sajjad, H.; Nikolov, A.; Mubarak, H.; Martino, G.D.S.; Abdelali, A.; Durrani, N.; Darwish, K.; et al. Fighting the COVID-19 infodemic: Modeling the perspective of journalists, fact-checkers, social media platforms, policy makers, and the society. arXiv 2020, arXiv:2005.00033. [Google Scholar]
- Alsudias, L.; Rayson, P. COVID-19 and Arabic Twitter: How can Arab world governments and public health organizations learn from social media? In Proceedings of the Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020, Online, 9 July 2020. [Google Scholar]
- Mubarak, H.; Hassan, S. Arcorona: Analyzing arabic tweets in the early days of coronavirus (COVID-19) pandemic. arXiv 2020, arXiv:2012.01462. [Google Scholar]
- El-Beltagy, S.R. Nileulex: A phrase and word level sentiment lexicon for egyptian and modern standard arabic. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portoroz, Slovenia, 23–28 May 2016; pp. 2900–2905. [Google Scholar]
- Abdulla, N.A.; Ahmed, N.A.; Shehab, M.A.; Al-Ayyoub, M. Arabic sentiment analysis: Lexicon-based and corpus-based. In Proceedings of the 2013 IEEE Jordan conference on applied electrical engineering and computing technologies (AEECT), Amman, Jordan, 3–5 December 2013; pp. 1–6. [Google Scholar]
- Kolchyna, O.; Souza, T.T.; Treleaven, P.; Aste, T. Twitter sentiment analysis: Lexicon method, machine learning method and their combination. arXiv 2015, arXiv:1507.00955. [Google Scholar]
- Ihnaini, B.; Mahmuddin, M. Valence Shifter Rules for Arabic Sentiment Analysis. Int. J. Multidiscip. Sci. Adv. Technol. 2020, 1, 167–184. [Google Scholar]
- Ameur, M.S.H.; Aliane, H. AraCOVID19-SSD: Arabic COVID-19 Sentiment and Sarcasm Detection Dataset. arXiv 2021, arXiv:2110.01948. [Google Scholar]
- Aljabri, M.; Chrouf, S.M.B.; Alzahrani, N.A.; Alghamdi, L.; Alfehaid, R.; Alqarawi, R.; Alhuthayfi, J.; Alduhailan, N. Sentiment analysis of Arabic tweets regarding distance learning in Saudi Arabia during the COVID-19 pandemic. Sensors 2021, 21, 5431. [Google Scholar] [CrossRef] [PubMed]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 137–142. [Google Scholar]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In On the Move to Meaningful Internet Systems, Proceedings of the OTM Confederated International Conferences; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Swain, P.H.; Hauska, H. The decision tree classifier: Design and potential. IEEE Trans. Geosci. Electron. 1977, 15, 142–147. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kwok, S.W.; Carter, C. Multiple decision trees. In Machine Intelligence and Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 1990; Volume 9, pp. 327–335. [Google Scholar]
- Dietterich, T.G. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Jovanovic, B.; Lemeshow, S. Best subsets logistic regression. Biometrics 1989, 45, 1265–1270. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #Positive | #Negative | Total | |
|---|---|---|---|
| NileULex | 1281 | 3693 | 4974 |
| Arabic senti-lexicon | 1176 | 2704 | 3880 |
| Emoji Group | Emoji | Emoji Sentiment | Number of Emojis (320) |
|---|---|---|---|
| Smileys Happiness Love |  | Positive | 69 |
| Straight face No expression Hesitation Surprise Shock Flags Animals Job |  | Neutral | 199 |
| Sadness Cry Anger Annoyed worry Disappointed Great dismay Horror Frowning |  | Negative | 52 |
| Tweet Text | Polarity |
|---|---|
 | Positive |
| Positive | |
| Positive | |
| Negative | |
| Negative | |
| Neutral | |
| Neutral |
| Total tweets in original SenWave dataset | 9999 |
| Total Tweets after removing joking sentiment tweets | 8581 |
| Total number of positive tweets | 1562 |
| Total number of negative tweets | 2750 |
| Total number of neutral tweets | 4269 |
| Total number of words | 122,005 |
| Total number of characters | 678,915 |
| Average words per tweet | 14.2 |
| Word | Positive_Score | Negative_Score | Neutral_Score |
|---|---|---|---|
| ازمه/crisis | 104 | 140 | 98 |
| العالم/world | 27 | 5 | 67 |
| الصبر/patience | 130 | 5 | 48 |
| Tweet | Label |
|---|---|
 | Positive |
| Positive | |
| Positive | |
| Neutral | |
| Neutral | |
| Neutral | |
| Negative | |
| Negative | |
| Negative |
| Positive | Negative | Neutral | |
|---|---|---|---|
| Total tweets | 8672 | 5946 | 27,843 |
| Total Words | 63,885 | 46,195 | 205,856 |
| Total Characters | 363,710 | 276,724 | 1,264,083 |
| Average words in each tweet | 7.36 | 7.76 | 7.39 |
| Average characters in each tweet | 41.94 | 46.53 | 45.40 |
| Total tweets in original AraCOVID19-SSD dataset | 4548 |
| Total number of positive tweets | 1762 |
| Total number of negative tweets | 955 |
| Total number of neutral tweets | 1831 |
| Total number of words | 72,122 |
| Total number of characters | 493,356 |
| Average words per tweet | 15.85 |
| Feature Set Name | Feature Name |
|---|---|
| Baseline model | Unigram |
| Sentiment based feature | F1. The frequency of positive words |
| F2. The frequency of negative words | |
| F3. The frequency of neutral words | |
| F4. F1 + F2 + F3 | |
| Emoji based features | F5. The frequency of positive emojis |
| F6. The frequency of negative emojis | |
| F7. The frequency of neutral emojis | |
| F8. F5 + F6 + F7 | |
| Negation based features | F9. The frequency of negation words |
| F10. Absence/presence of negation | |
| F11. F9 + F10 | |
| All Features | F12. F4 + F8 + F11 |
| Lexicon | Setting | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| NileULex | Average without Applying Any Rule | 40.27% | 40.27% | 40.27% | 40.27% |
| senti-lexicon | 40.27% | 40.27% | 40.27% | 40.27% | |
| ArSentiCOVID | 76.87% | 76.87% | 76.87% | 76.87% | |
| NileULex | Average with Applying Negation Rules | 55.57% | 55.57% | 55.57% | 55.57% |
| senti-lexicon | 55.46% | 55.46% | 55.46% | 55.46% | |
| ArSentiCOVID | 81.00% | 81.00% | 81.00% | 81.00% | |
| NileULex | Average with Applying Emoji Rule | 40.27% | 40.27% | 40.27% | 40.27% |
| senti-lexicon | 40.27% | 40.27% | 40.27% | 40.27% | |
| ArSentiCOVID | 79.00% | 79.00% | 79.00% | 79.00% | |
| NileULex | Average with Applying Negation and Emoji Rules | 55.57% | 55.57% | 55.57% | 55.57% |
| senti-lexicon | 55.46% | 55.46% | 55.46% | 55.46% | |
| ArSentiCOVID | 83.00% | 83.00% | 83.00% | 83.00% |
| Feature | Classifier | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| Unigram | SVM | 89.01 | 89.51 | 89.01 | 88.86 |
| GNB | 59.89 | 74.43 | 59.89 | 62.03 | |
| MNB | 87.91 | 88.13 | 87.91 | 87.74 | |
| BNB | 79.67 | 80.60 | 79.67 | 79.11 | |
| DT | 81.87 | 81.78 | 81.87 | 81.81 | |
| RF | 89.01 | 89.13 | 89.01 | 88.89 | |
| LR | 87.36 | 88.11 | 87.36 | 87.11 | |
| KNN | 73.08 | 79.79 | 73.08 | 69.92 |
| Feature | Classifier | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| bigram | SVM | 89.01 | 89.76 | 89.01 | 88.82 |
| GNB | 66.48 | 78.03 | 66.48 | 68.67 | |
| MNB | 88.46 | 88.86 | 88.46 | 88.33 | |
| BNB | 79.12 | 81.64 | 79.12 | 78.28 | |
| DT | 85.16 | 85.18 | 85.16 | 84.94 | |
| RF | 86.81 | 86.94 | 86.81 | 86.70 | |
| LR | 85.71 | 87.10 | 85.71 | 85.30 | |
| KNN | 67.03 | 76.93 | 67.03 | 61.74 | |
| trigram | SVM | 89.01 | 89.76 | 89.01 | 88.82 |
| GNB | 68.68 | 80.59 | 68.68 | 70.80 | |
| MNB | 87.91 | 88.40 | 87.91 | 87.76 | |
| BNB | 76.37 | 79.69 | 76.37 | 75.17 | |
| DT | 83.52 | 83.59 | 83.52 | 83.3 | |
| RF | 87.36 | 87.73 | 87.36 | 87.22 | |
| LR | 84.62 | 86.31 | 84.62 | 84.14 | |
| KNN | 65.38 | 76.31 | 65.38 | 59.50 | |
| fourgram | SVM | 86.26 | 87.27 | 86.26 | 85.98 |
| GNB | 68.68 | 80.59 | 68.68 | 70.80 | |
| MNB | 87.36 | 87.92 | 87.36 | 87.18 | |
| BNB | 76.37 | 80.58 | 76.37 | 74.77 | |
| DT | 84.07 | 84.03 | 84.07 | 83.92 | |
| RF | 86.26 | 86.53 | 86.26 | 86.09 | |
| LR | 82.97 | 85.17 | 82.97 | 82.37 | |
| KNN | 64.84 | 78.99 | 64.84 | 58.44 |
| Feature | Classifier | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| F1 | SVM | 88.46 | 88.55 | 88.46 | 88.37 |
| GNB | 59.34 | 73.46 | 59.34 | 61.45 | |
| MNB | 78.02 | 81.88 | 78.02 | 76.51 | |
| BNB | 80.22 | 80.85 | 80.22 | 79.70 | |
| DT | 87.91 | 87.90 | 87.91 | 87.89 | |
| RF | 86.81 | 86.67 | 86.81 | 86.64 | |
| LR | 85.71 | 85.96 | 85.71 | 85.41 | |
| KNN | 83.52 | 83.28 | 83.52 | 83.19 | |
| F2 | SVM | 90.11 | 90.45 | 90.11 | 89.92 |
| GNB | 59.34 | 73.46 | 59.34 | 61.45 | |
| MNB | 86.26 | 86.95 | 86.26 | 86.05 | |
| BNB | 80.77 | 81.61 | 80.77 | 80.22 | |
| DT | 85.16 | 85.09 | 85.16 | 85.01 | |
| RF | 89.01 | 89.20 | 89.01 | 88.84 | |
| LR | 90.11 | 90.45 | 90.11 | 89.92 | |
| KNN | 84.07 | 84.56 | 84.07 | 83.68 | |
| F3 | SVM | 89.56 | 89.97 | 89.56 | 89.43 |
| GNB | 59.34 | 73.46 | 59.34 | 61.45 | |
| MNB | 82.97 | 85.33 | 82.97 | 81.86 | |
| BNB | 79.12 | 79.87 | 79.12 | 78.52 | |
| DT | 84.62 | 84.65 | 84.62 | 84.43 | |
| RF | 88.46 | 88.48 | 88.46 | 88.33 | |
| LR | 87.91 | 88.55 | 87.91 | 87.68 | |
| KNN | 82.97 | 83.18 | 82.97 | 82.66 | |
| F4 | SVM | 92.86 | 92.93 | 92.86 | 92.86 |
| GNB | 80.52 | 81.25 | 80.52 | 80.28 | |
| MNB | 88.31 | 88.97 | 88.31 | 88.45 | |
| BNB | 85.71 | 85.69 | 85.71 | 85.64 | |
| DT | 86.36 | 86.5 | 86.36 | 86.41 | |
| RF | 89.61 | 89.67 | 89.61 | 89.62 | |
| LR | 90.91 | 90.92 | 90.91 | 90.89 | |
| KNN | 88.31 | 88.51 | 88.31 | 88.35 |
| Feature | Classifier | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| F5 | SVM | 90.66 | 90.79 | 90.66 | 90.55 |
| GNB | 59.34 | 73.46 | 59.34 | 61.45 | |
| MNB | 89.56 | 89.60 | 89.56 | 89.37 | |
| BNB | 81.87 | 82.43 | 81.87 | 81.54 | |
| DT | 85.16 | 85.13 | 85.16 | 85.07 | |
| RF | 89.56 | 89.67 | 89.56 | 89.55 | |
| LR | 86.81 | 87.13 | 86.81 | 86.50 | |
| KNN | 78.57 | 81.39 | 78.57 | 75.92 | |
| F6 | SVM | 89.01 | 89.33 | 89.01 | 88.84 |
| GNB | 59.34 | 73.46 | 59.34 | 61.45 | |
| MNB | 87.91 | 88.12 | 87.91 | 87.79 | |
| BNB | 80.22 | 81.11 | 80.22 | 79.67 | |
| DT | 83.52 | 83.34 | 83.52 | 83.35 | |
| RF | 89.01 | 89.21 | 89.01 | 88.95 | |
| LR | 87.36 | 87.92 | 87.36 | 87.09 | |
| KNN | 76.92 | 82.22 | 76.92 | 75.35 | |
| F7 | SVM | 89.01 | 89.33 | 89.01 | 88.84 |
| GNB | 59.34 | 73.46 | 59.34 | 61.45 | |
| MNB | 88.46 | 88.7 | 88.46 | 88.19 | |
| BNB | 79.67 | 80.60 | 79.67 | 79.11 | |
| DT | 82.42 | 82.32 | 82.42 | 82.34 | |
| RF | 86.26 | 86.27 | 86.26 | 86.05 | |
| LR | 87.36 | 87.92 | 87.36 | 87.09 | |
| KNN | 75.27 | 78.47 | 75.27 | 72.8 | |
| F8 | SVM | 89.61 | 90.08 | 89.61 | 89.69 |
| GNB | 79.87 | 80.72 | 79.87 | 79.66 | |
| MNB | 87.01 | 87.34 | 87.01 | 87.02 | |
| BNB | 84.42 | 84.39 | 84.42 | 84.39 | |
| DT | 88.31 | 88.36 | 88.31 | 88.31 | |
| RF | 88.96 | 88.94 | 88.96 | 88.94 | |
| LR | 84.42 | 85.63 | 84.42 | 84.58 | |
| KNN | 68.18 | 71.93 | 68.18 | 67.28 |
| Feature | Classifier | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| F9 | SVM | 89.01 | 89.51 | 89.01 | 88.86 |
| GNB | 59.89 | 74.43 | 59.89 | 62.03 | |
| MNB | 87.91 | 88.13 | 87.91 | 87.74 | |
| BNB | 79.67 | 80.6 | 79.67 | 79.11 | |
| DT | 81.87 | 81.74 | 81.87 | 81.71 | |
| RF | 87.91 | 88.04 | 87.91 | 87.69 | |
| LR | 87.36 | 88.11 | 87.36 | 87.11 | |
| KNN | 73.08 | 79.79 | 73.08 | 69.92 | |
| F10 | SVM | 90.26 | 90.8 | 90.26 | 90.31 |
| GNB | 79.87 | 80.84 | 79.87 | 79.68 | |
| MNB | 85.71 | 86.16 | 85.71 | 85.80 | |
| BNB | 85.71 | 85.66 | 85.71 | 85.65 | |
| DT | 86.36 | 86.35 | 86.36 | 86.35 | |
| RF | 88.96 | 88.99 | 88.96 | 88.97 | |
| LR | 87.66 | 88.35 | 87.66 | 87.75 | |
| KNN | 68.83 | 74.54 | 68.83 | 67.16 | |
| F11 | SVM | 90.26 | 90.80 | 90.26 | 90.31 |
| GNB | 79.87 | 80.84 | 79.87 | 79.68 | |
| MNB | 85.71 | 86.16 | 85.71 | 85.80 | |
| BNB | 85.71 | 85.66 | 85.71 | 85.65 | |
| DT | 84.42 | 84.38 | 84.42 | 84.39 | |
| RF | 88.31 | 88.30 | 88.31 | 88.29 | |
| LR | 87.66 | 88.35 | 87.66 | 87.75 | |
| KNN | 68.83 | 74.54 | 68.83 | 67.16 |
| Feature | Classifier | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| F12 | SVM | 92.21 | 92.32 | 92.21 | 92.23 |
| GNB | 80.52 | 81.25 | 80.52 | 80.28 | |
| MNB | 85.71 | 86.91 | 85.71 | 85.78 | |
| BNB | 86.36 | 86.34 | 86.36 | 86.27 | |
| DT | 90.26 | 90.34 | 90.26 | 90.25 | |
| RF | 92.21 | 92.32 | 92.21 | 92.23 | |
| LR | 92.21 | 92.24 | 92.21 | 92.22 | |
| KNN | 88.31 | 88.40 | 88.31 | 88.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdelhady, N.; Elsemman, I.E.; Farghally, M.F.; Soliman, T.H.A. Developing Analytical Tools for Arabic Sentiment Analysis of COVID-19 Data. Algorithms 2023, 16, 318. https://doi.org/10.3390/a16070318
Abdelhady N, Elsemman IE, Farghally MF, Soliman THA. Developing Analytical Tools for Arabic Sentiment Analysis of COVID-19 Data. Algorithms. 2023; 16(7):318. https://doi.org/10.3390/a16070318
Chicago/Turabian StyleAbdelhady, Naglaa, Ibrahim E. Elsemman, Mohammed F. Farghally, and Taysir Hassan A. Soliman. 2023. "Developing Analytical Tools for Arabic Sentiment Analysis of COVID-19 Data" Algorithms 16, no. 7: 318. https://doi.org/10.3390/a16070318
APA StyleAbdelhady, N., Elsemman, I. E., Farghally, M. F., & Soliman, T. H. A. (2023). Developing Analytical Tools for Arabic Sentiment Analysis of COVID-19 Data. Algorithms, 16(7), 318. https://doi.org/10.3390/a16070318