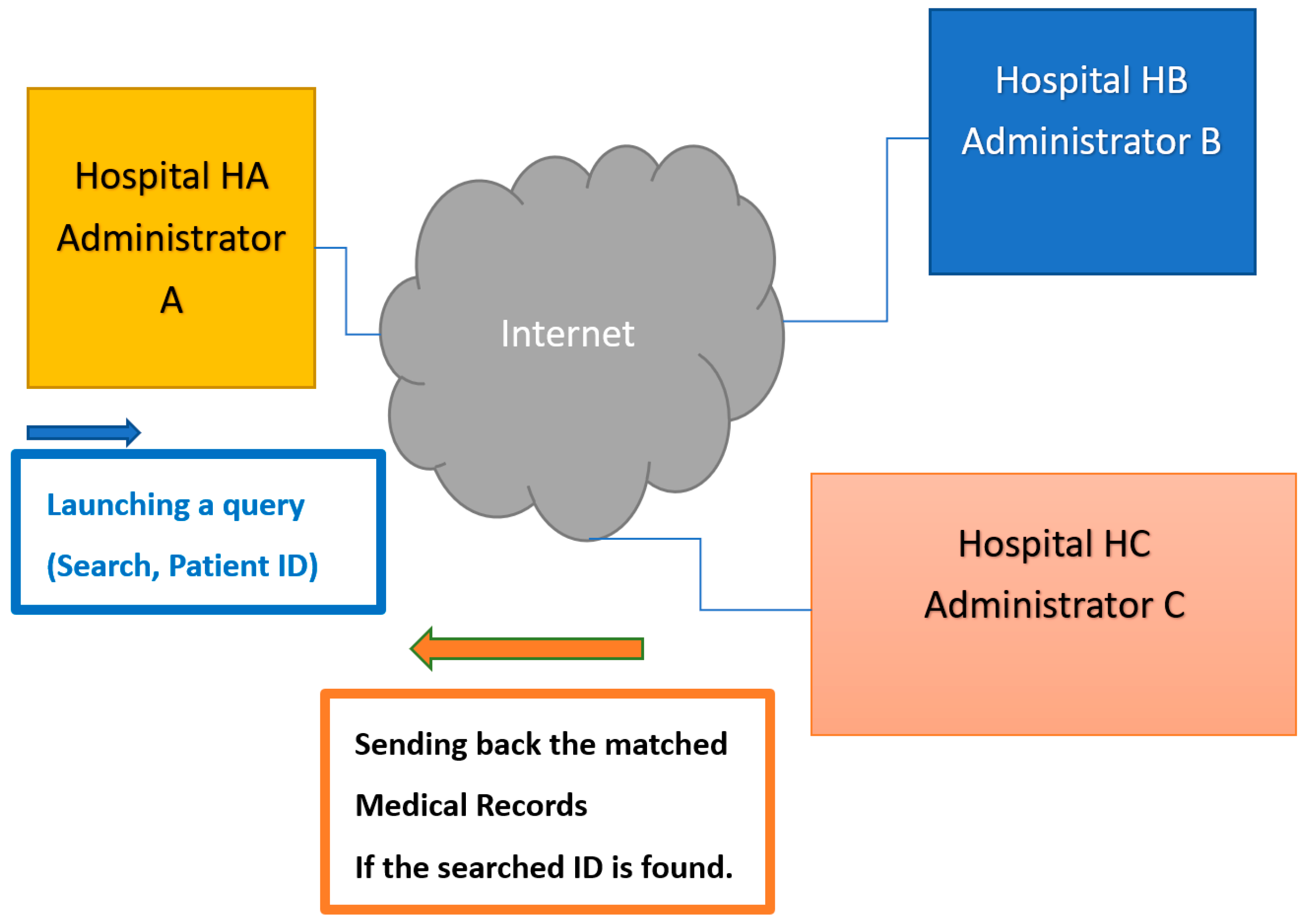
For convenience, in the following, we treat EMRSs of other hospitals as the Server side and the administrator of the EMRS of Hospital HA who initiates the request as the Client side. Moreover, we denote the Servers as X and the Clients as Y.
3.1. Transform the PSI Problem into a HE-Operatable Form
Reference [
22] converts the PSI problem into the following polynomial form to meet the types of operable operations (addition and multiplication) supported by HE and asks the Server to calculate it on the encryption domain:
where
∈ Y is an element on the Client side, and
∈ X is an element on the Server side. If the result of
is 0, it indicates that
is also one of the elements on the server side (i.e., there is an intersection between X and Y). If the result is not 0,
does not belong to the Intersection Set. It is worth noting that for the Server when calculating
,
is the plaintext form, while
is in the ciphertext form transmitted by the Client after conducting the HE operations.
However, when the result of
is not 0, the Client could infer the elements on the Server by initiating multiple PSI requests to the Server, resulting in indirect leakage of the elements on the Server. To eliminate the concerns about leaking elements on the Server, multiplying the above polynomial by a random number
is an ingenious way, that is:
This simple operation can ensure that the Client cannot speculate the data on the Server. We can now learn whether the two sets have an intersection through the evaluation of
Fx (
y;
r) on Y by the similar expounds associated with
. That is, we regard the
the Client requests the Server to evaluate the encryption domain as a PSI-checking request. Next, if there is an intersection between X and Y, we hope to obtain the corresponding labels of the intersected elements. As suggested in [
23], a new polynomial
could be created based on
to fulfill this requirement. That is
In Equation (5),
is used to determine whether there is an intersection, and
is a curve-fitting polynomial passing through a sequence of given data points which is used to retrieve the corresponding labels of the intersected elements. Taking the two-dimensional space as an example, given the coordinates of k points, we can use the well-known Lagrange Interpolation Formula to find the polynomial that passes through all the given k points on the plane. Therefore, we can transform the server’s database into the coordinate and retrieve the corresponding data label by polynomial interpolation. Suppose there are three data on the server, say 1, 2, and 3, and the corresponding labels are 6, 11, and 18. Then, we can regard the data and the corresponding labels as three points (1, 6), (2, 11), (3, 18) in the two-dimensional space. Then, through the polynomial-based curve-fitting, we can find the desired polynomial. Taking the Lagrange interpolation as an example,
can be written as:
It can be easily checked that generated above does satisfy , , .
So far, we can use
to complete Task 1 (by
) and Task 2 (by
) mentioned at the end of
Section 2.2. Moreover, we can regard the Server’s evaluation of
based on the request sent from the Client in the homomorphic encryption domain as a labeled PSI, which retrieves the corresponding labels of the intersected data on both sides of the databases without leaking any sensitive information.
Let us focus on the situation of the pre-described symptom retrieval system. Suppose that the administrator of the EMRS has a set of patient ID numbers Y = {A123456789, X298659978, Z297466383, and so on}, and another hospital, say Hospital HA, has the patient ID numbers and the associated symptoms set X = {(A123456789, hypertension), (T203584780, heart disease, diabetes), (B119641539, asthma), and so on}. The administrator of the EMRS initiates a labeled PSI request to the hospital HA to retrieve the patient’s symptoms, ensuring that the remaining patient information stored in the hospital HA’s database will not be known to the requester. Moreover, the administrator of hospital HA’s EMRS cannot know which patients’ symptoms are being retrieved. Nonetheless, there are still some issues to be resolved.
In HE schemes, there is noise associated with each ciphertext, and sequence operations on the ciphertext will increase the noise progressively. The nature of HE has the operation (whether it is addition or multiplication) on a ciphertext always be a ciphertext. Therefore, we can regard
as multiplication operations among the server’s ciphertexts. Further note, that when the noise is too loud, the ciphertext cannot be decrypted correctly. Adding ciphertext and ciphertext, multiplying ciphertext and plaintext, and adding ciphertext and plaintext will not enlarge the noise too much. However, if two ciphertexts are multiplied, the noise will be amplified quickly. Notice that the larger the noise is, the slower the calculation of the ciphertext will be. Therefore, we must resolve these issues; otherwise, when the number of
reaches an application-dependent threshold, say more than 10 million items, it will be difficult for the Server to calculate the polynomial correctly within a short period. Therefore, we must optimize the server’s polynomial calculation in the HE domain. The following Section briefly introduces the optimization methods proposed in [
22].
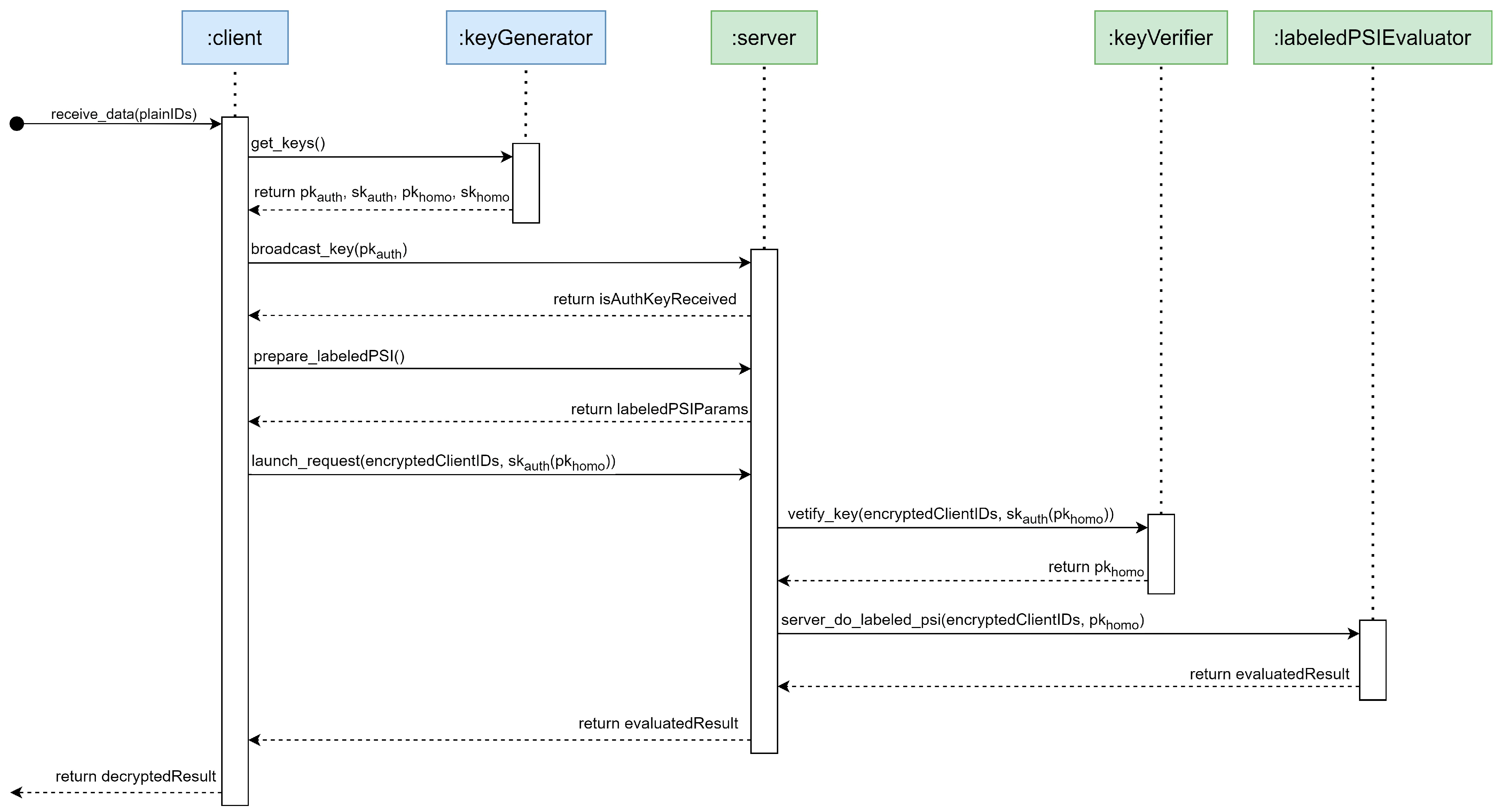
Before applying any optimization process, we summarize the above-mentioned labeled PSI protocol between the Client and the Server as follows:
Step 1: The Client encrypts each element in Y with the homomorphic public key and transmits each encrypted element to the Server one by one.
Step 2: The server samples two random numbers, and , for each received ciphertext y and calculates Fx (y; r) and = + in the HE domain.
Step 3: The Server returns the calculated result of and corresponding to each received ciphertext to the Client.
Step 4: The Client decrypts the received results of and with the HE decryption key. If the decrypted result of is 0, is at the intersection of X and Y, and then refer to the decrypted result of as the label associated with . On the contrary, if the decrypted result of is not 0, it means that is not at the intersection of X and Y, so the result of cannot be referred to as the corresponding label.
The complexity of the above-mentioned labeled PSI protocol before applying any optimization process is shown in
Table 2.
For the convenience of explanation, the following complexity analysis of optimized Labeled PSI will take the complexity of its non-optimized version as a benchmark. Starting from
Section 3.2, we will briefly explain each optimization method proposed in [
22,
23]. The prerequisite is that the Server and the Client share the following public information:
|X|: The number of elements in the Server set
|Y|: The number of elements in the Client set
H: a secure Hash function
h: The number of involved hash functions
The bit length of an element in the data set (e.g., 8 bits, 16 bits, or 32 bits).
3.3. The Combined Process of Cuckoo Hashing, Multi-Hashing, and Permutation-Based Hashing
Theoretically, with hashing, the time complexity of data access can be reduced to
O (1); however, the hash collision problem should first be tackled using hashing. When a hash collision occurs frequently, the time complexity of accessing the hash table will increase, and in the worst case, it may degrade the measure to
O (
n). This problem has been solved using Cuckoo hashing [
25], a hashing algorithm that significantly reduces the probability of hash collision. The trick is to use
h (
h > 1) hash functions to improve the usage rate of the Hash-Table (where
h hash functions will make each data corresponding to
h different hashing addresses), and the data access time of
O (1) can be guaranteed. Therefore, with both the Client and Server doing cuckoo hashing, the bucket-wise comparison between the Client and the Server can produce the correct intersection. Among them, the Client’s Hash Table has
m (>|Y|) buckets, and each bucket has one slot, while the Server’s Hash Table has
m (>|Y|) buckets, and each bucket has
s slots.
First, let the Client and the Server agree on the value of h and which hash functions H1, H2, …, Hh to use, then both the Client and the Server insert their data into the Hash Tables by using the Cuckoo hashing. Then, when the Client sends y to the Server to confirm an intersection, we expect the Server also to check whether there is a y in the corresponding bucket through Cuckoo hashing within O (1) time complexity. However, the Server cannot know which Hash function was used to insert the elements in each bucket of the Client’s Hash Table, so we need the Server to do multi-hashing.
Multi-hashing means the Server must insert data into the buckets at the hashing addresses according to the outputs of all hash functions. In this way, no matter which hash function the Client uses to insert the data during Cuckoo hashing; the Server can always find the data in the bucket at the hashing address corresponding to one of the hash functions. After the Server completes multi-hashing, the data may be gathered in the earlier slots of each bucket if no processing is performed. In order to avoid data being located in specific slots and indirectly leaking the Hash Table information on the Server, all the slots in each bucket should be shuffled after all data was inserted into the Hash Table.
The permutation-based hashing proposed by [
26] is a hashing technique that reduces the data bit length that needs to be stored on the Hash Table by encoding a part of the data in the bucket’s index. It can be used to cope with the problem that the bit number of the data is too high and reduce the memory required to store the data. Suppose the bucket size of the Hash Table is
m (here we assume that
m is a power of 2, interested readers can learn how to generalize to other sizes from [
26]), and split the bit representation of the data
x into
xL and
xR, where |
xR| = log (
m). Moreover, we denote the hashing address as Location (
x) =
f (
xL) ⊕
xR, where the actual Hash Table data is represented by |
xL| bits and
f is a random function whose range is in [0,
m). Compared with the original approach, only |
xL| bits are needed to store the entire
x; that is, permutation-based hashing saves log (
m) bits.
Combined with the permutation-based hashing and the Cuckoo hashing, we can denote the data hashed with the
i-th hash function and its new hashing address as <
xL,
i> and
Locationi (
x) =
Hi (
xL) ⊕
xR, respectively. This approach reduces the size of each data by (log (
m) − ⌈log (
h)⌉) bits, where ⌈.⌉ denotes the ceiling function. Assuming that the bucket size of the Hash Table is
m, and there are
s slots in each bucket, the complexity of the Labeled PSI Protocol after applying all the hashing processes mentioned above is listed in
Table 4.
3.4. The Windowing Process
In HE operations, the addition and multiplication results between a ciphertext and a plaintext will be in the ciphertext domain. If the depth of multiplication between two ciphertexts is too high, it is easy to cause errors in the obtained results. Therefore, if the Server directly performs the item-by-item operation on , it is equivalent to doing |X| times of inter-ciphertext multiplications. When |X| is a large number (e.g., |X| > 220), the Server is prone to miscalculate the result.
Assuming that the Client wants to retrieve the labels corresponding to y on the Server, an optimization method to reduce the multiplication depth is to let the Client send the ciphertexts (y1) encrypted, (y2) encrypted, (y3) encrypted, …, (y|x|) encrypted to a Server. Next, the Server can expand into = Σai yi, where 0 ≤ i ≤ |X| and ai is the coefficient of the corresponding term of y raised to the power of i. From the Server’s perspective, ai is a plaintext, and yi is a ciphertext sent by the Client, so the Server only needs to multiply the plaintext and the ciphertext for each item and adds these items up to obtain the answer. The communication cost after this optimization is O (|Y||X|), and the multiplication depth of HE reduces to O (1). Although the multiplication depth of the Server becomes O (1), the Client must send the ciphertext’s power of one to power of |X| to the Server for each y, which will increase the communication cost of the Client by |X| times. In our case, |Y| is much smaller than |X|, so this approach causes too much burden for the Client.
Instead of having the Client send the ciphertext
y (from the power of one to the power of |X|) to the Server, the above-mentioned communication cost can be mitigated by having the Client only send the
y i∙2^(j𝓁) to the Server, where 𝓁 is the window size, for all 1 ≤
i ≤ 2
𝓁 − 1 and 0 ≤
j ≤ ⌊log2(|X|/𝓁)⌋. After the Server receives these terms, we can calculate the ciphertexts corresponding to
y’s power one to power |X| efficiently and correctly. For example, if 𝓁 is 1, the Client needs to send the encrypted
y,
y2,
y4,
y8,
…,
y2^⌊log2(|X|)⌋ to the Server. This pre-computing process can significantly reduce the multiplication depth of HE operations on the Server, and the extra communication cost paid by the Client will not be too high. The complexity of the labeled PSI protocol after applying the windowing optimization is shown in
Table 5.
3.6. The Modulus Switching Process
When performing homomorphic encryption operations, we will use a set of encryption parameters to encrypt the data, one of which is the modulus
q which defines the algebraic structure of the ciphertext. In general,
q is a product of multiple prime numbers, which determines the ciphertext noise tolerance for correct decryption. The larger the
q value, the greater the noise tolerance, which means that more operations can be performed on the ciphertext, and the size of the ciphertext would be more extensive. When the noise tolerance of the ciphertext is less than or equal to 0, subsequent operations are prone to produce erroneous results. Therefore, at the beginning of encryption, we should choose a larger
q to make the ciphertext capable of performing more operations and producing the correct result. When it is determined that the ciphertext will not be subjected to subsequent operations, the
q value of the ciphertext can be switched to a smaller
q′, thereby reducing the size of the ciphertext and the transmission cost. In addition, replacing
q with
q′ will not affect the correctness of the decrypted ciphertext. The above statement’s correctness is because the ciphertext size is proportional to log (
q). Optimizing this step will reduce the ciphertext size by log (
q)/log (
q′) times. Similarly,
Table 7 depicts the complexity of the Labeled-PSI after applying the Modulus Switching Process.







{kind=link}
{kind=link}