
An Efficient Approach to Manage Natural Noises in Recommender Systems


Abstract
1. Introduction
- The rules for detecting natural noises are proposed based on the subcategories of users and items. The proposed scheme detects natural noises only depending on historical ratings in the recommendation and does not introduce additional information into the recommender system.
- In the proposed natural noise management scheme, we do not eliminate it directly but correct the natural noise with threshold values weighted by probabilities. Compared with re-predicting methods, our scheme has a much higher efficiency.
- Experimental results on different datasets indicate that our proposed scheme performs better than previous typical methods. It has high potential to be used as a scheme for managing natural noises and provides a great decision support for recommender systems.
2. Related Work
3. The Proposed Approach of Managing Natural Noises
3.1. Detection of Natural Noise
3.1.1. The Classification of Ratings
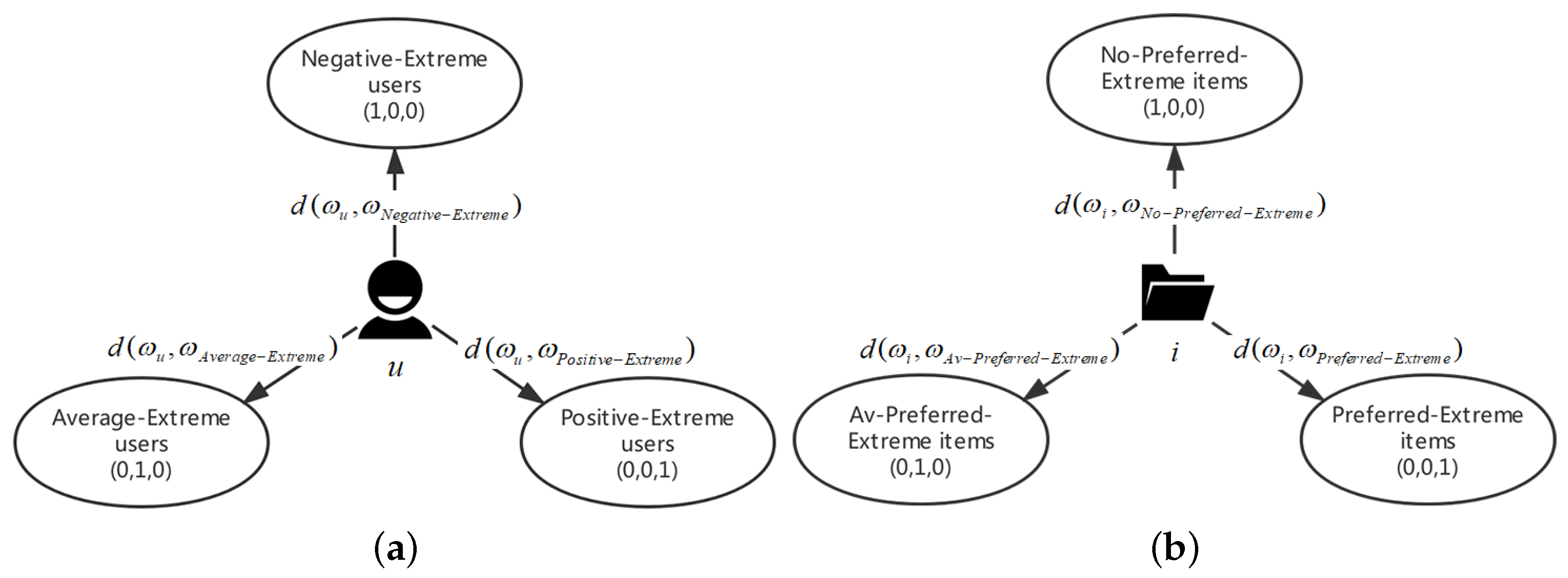
3.1.2. The Subcategories of Users and Items
- If is the minimum value among , d( ) and , the user u is regarded as a Negative user;
- If is the minimum value among , d( ) and , the user u is regarded as an Average user;
- If is the minimum value among , d( ) and , the user u is regarded as a Positive user.
- If is the minimum value among , and , the item i is regarded as a No-Preferred item;
- If is the minimum value among , and , the item i is regarded as a Av-Preferred item;
- If is the minimum value among , and , the item i is regarded as a Preferred item.
3.1.3. The Rules of Detecting Natural Noise
3.2. Correction of the Natural Noise
- 1.
- For the rating of a No-Preferred item from Negative users, the correction strategy is as follows:
- If the score is a low rating, keep it unchanged;
- If the score is a medium rating, it is corrected by
- If the score is a high rating, it is corrected by
- 2.
- For the rating of an Av-Preferred item from Average users, the correction strategy is as follows:
- If the score is a low rating, it is corrected by
- If the score is a medium rating, keep it unchanged;
- If the score is a high rating, it is corrected by Equation (16).
- 3.
- For the rating of a Preferred item from Positive users, the correction strategy is as follows:
4. Experimental Analyses
4.1. Evaluation Metrics
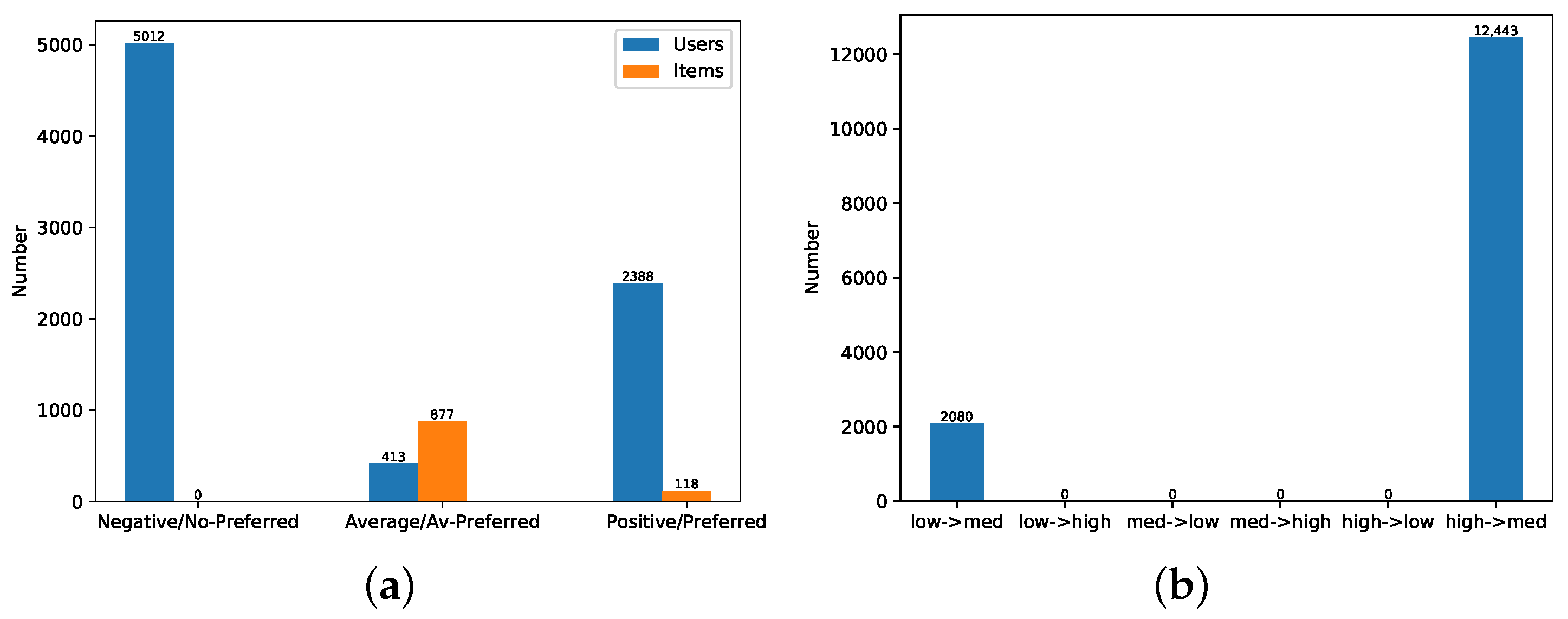
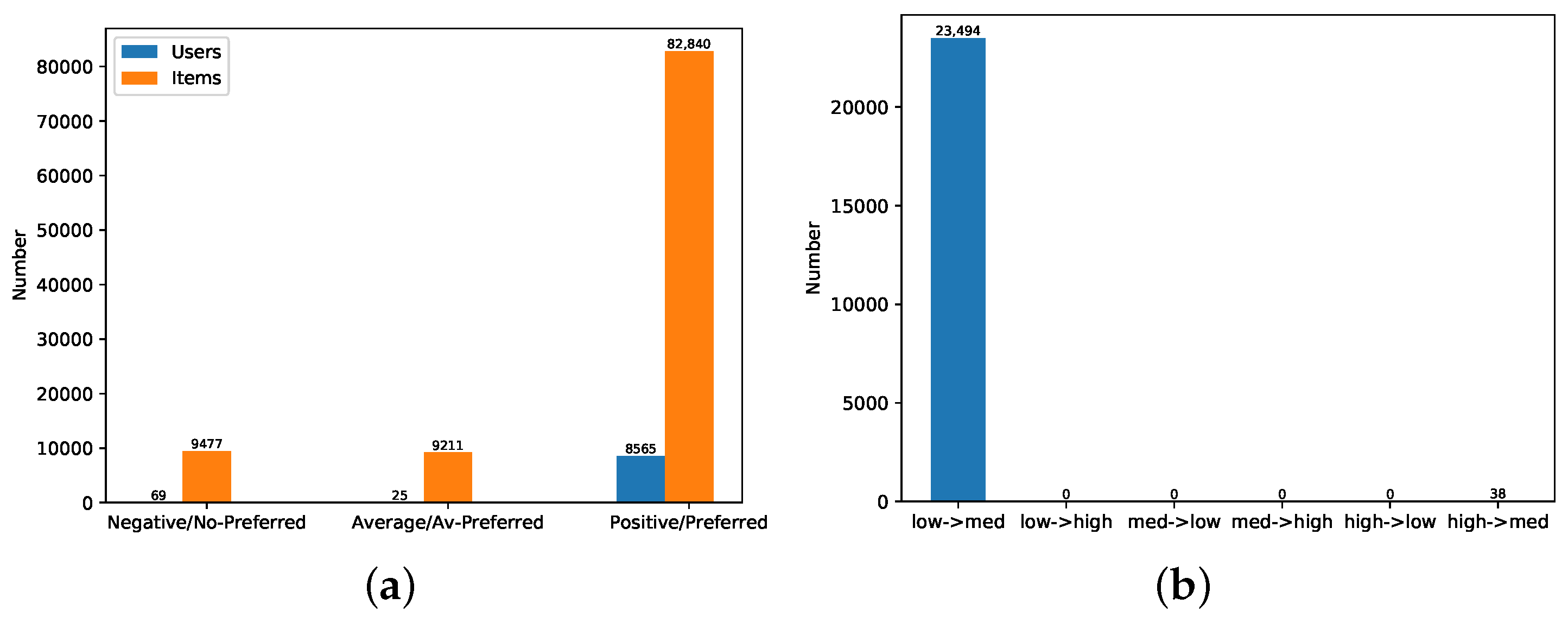
4.2. Datasets
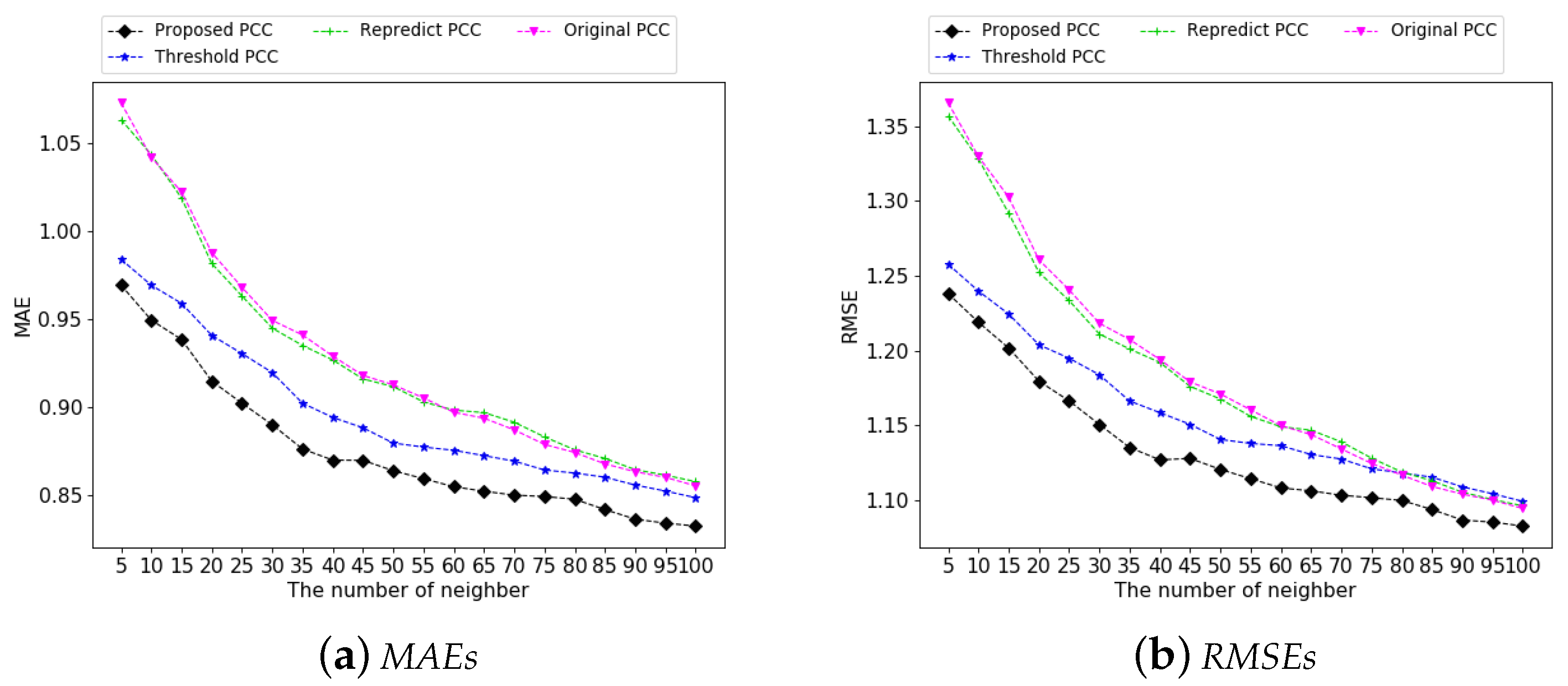
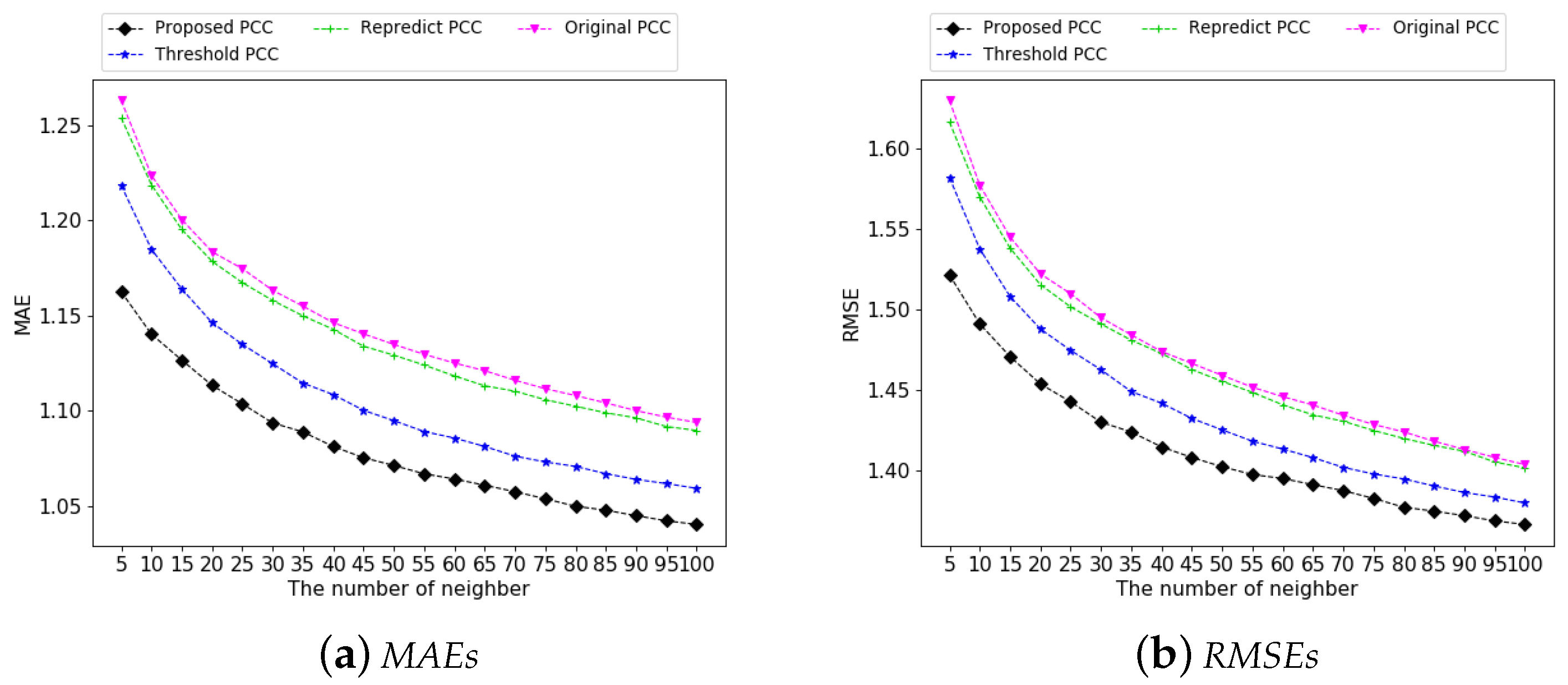
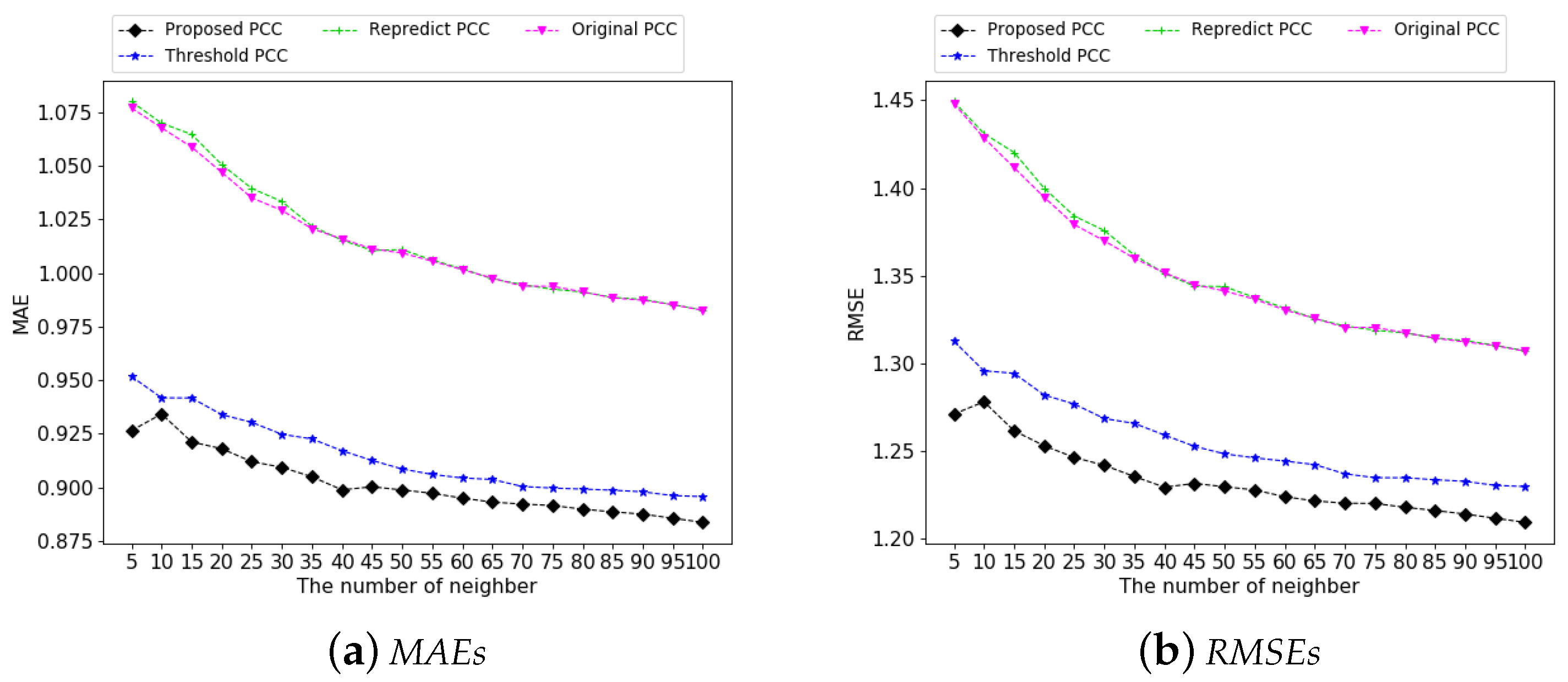
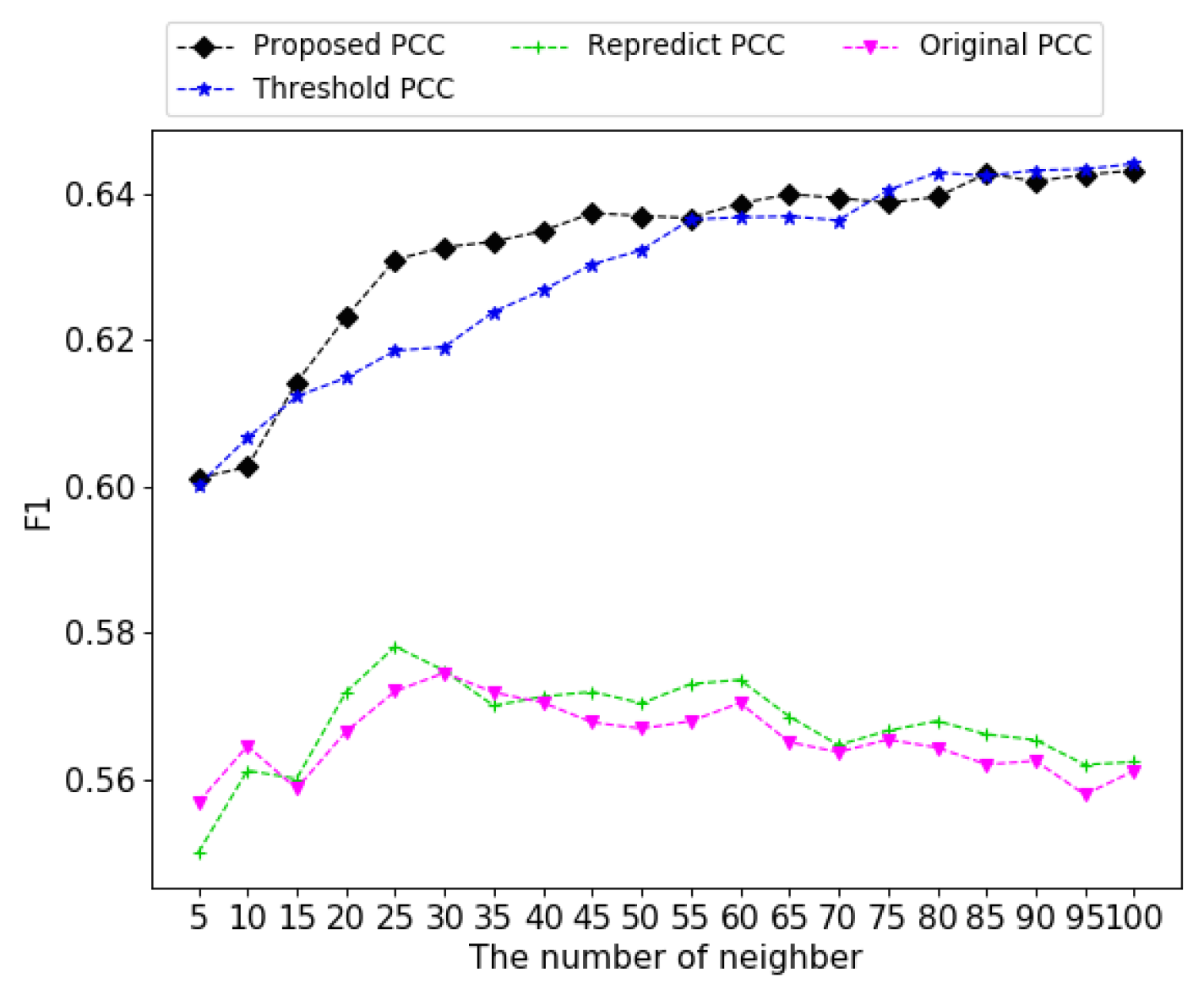
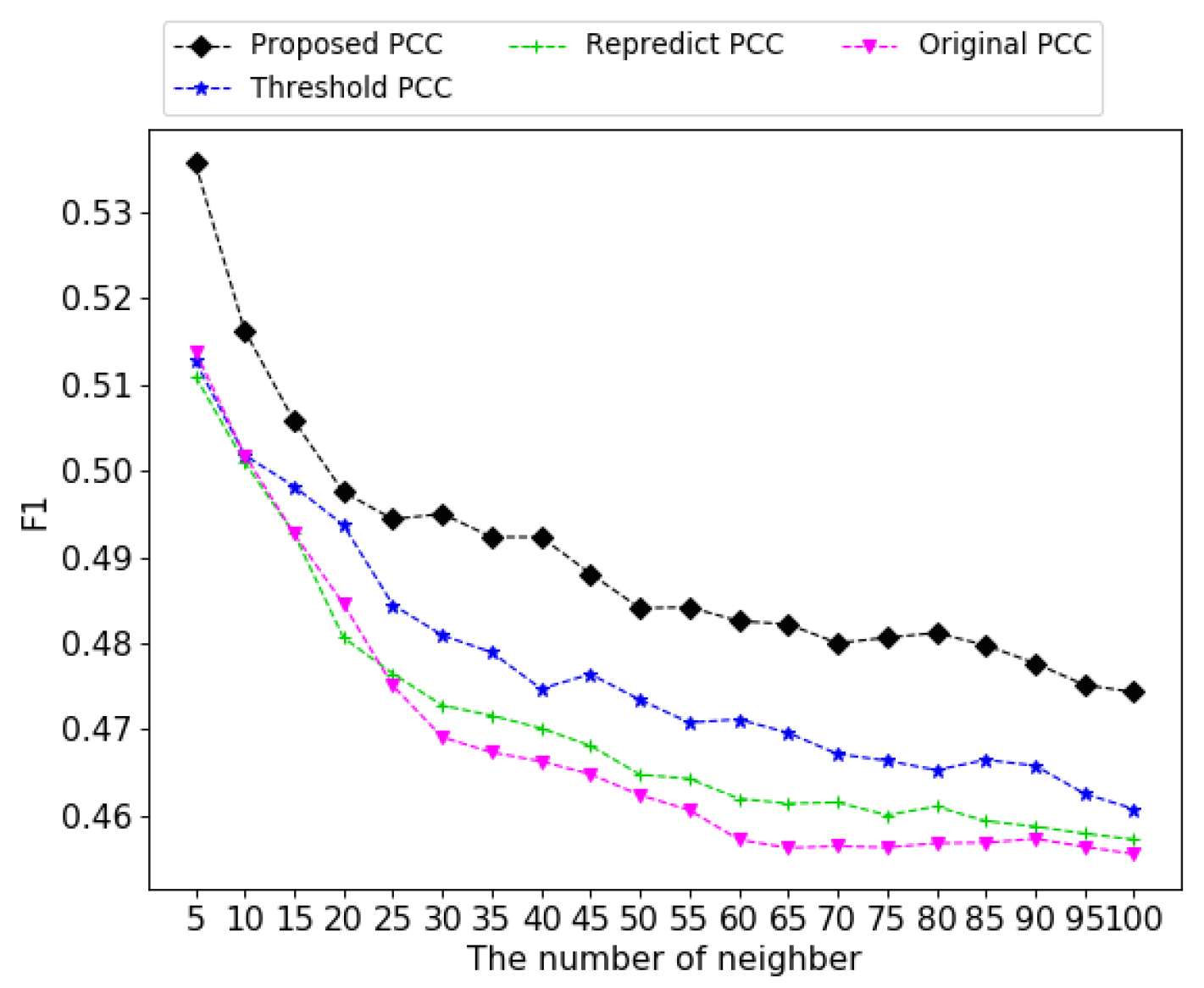
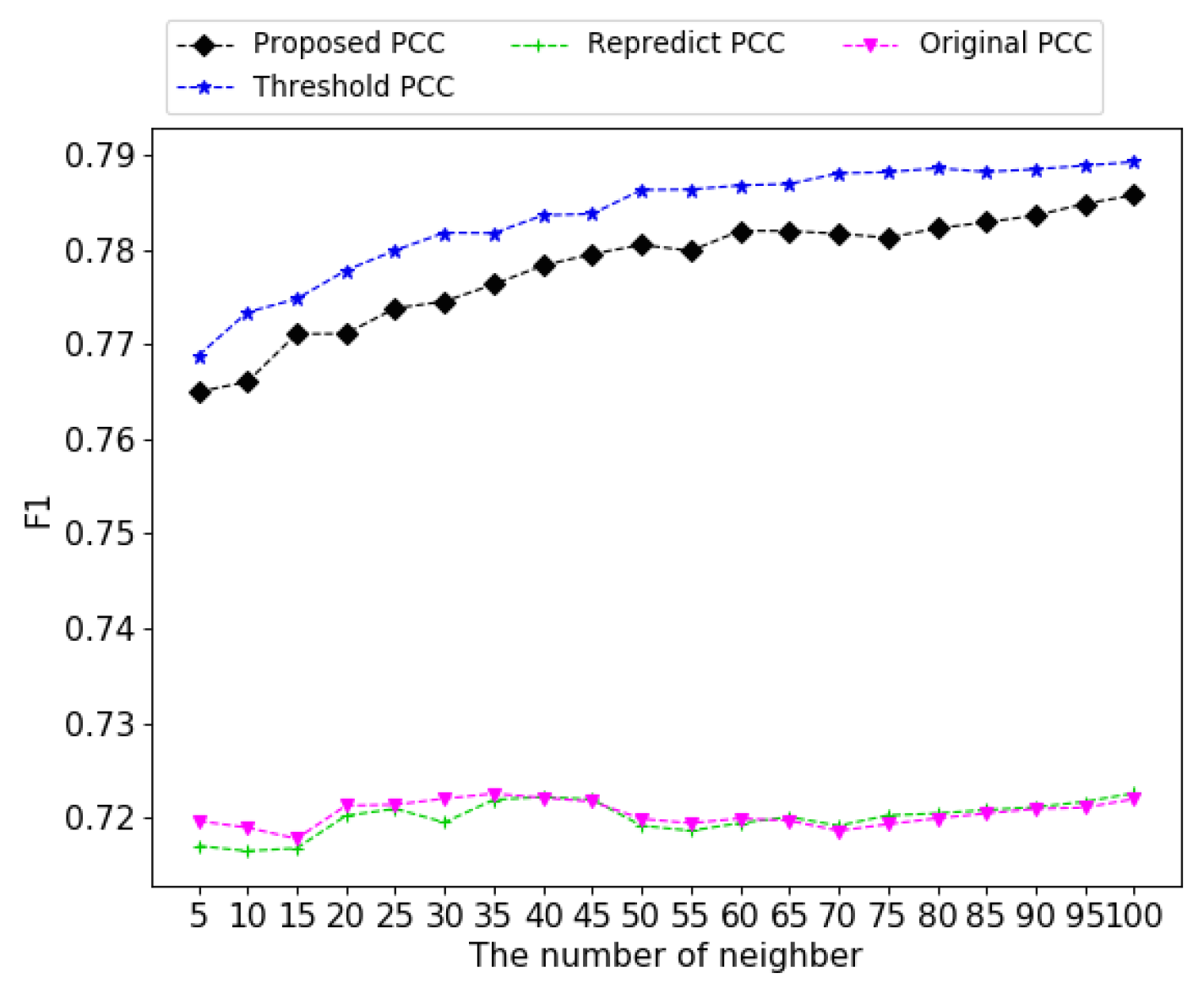
4.3. Experimental Results in Similarity Based Models
4.3.1. Correction of Natural Noises
4.3.2. Performance Analysis
4.4. Experimental Results in Learning Based Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Eppler, M.J.; Mengis, J. The Concept of Information Overload—A Review of Literature from Organization Science, Accounting, Marketing, MIS, and Related Disciplines (2004). In Kommunikationsmanagement im Wandel; Springer: Berlin/Heidelberg, Germany, 2008; pp. 271–305. [Google Scholar]
- Khan, Z.Y.; Niu, Z.D.; Sandiwarno, S.; Prince, R. Deep learning techniques for rating prediction: A survey of the state-of-the-art. Artif. Intell. Rev. 2021, 54, 95–135. [Google Scholar] [CrossRef]
- Ahmadian, S.; Joorabloo, N.; Jalili, M.; Ahmadian, M. Alleviating data sparsity problem in time-aware recommender systems using a reliable rating profile enrichment approach. Expert Syst. Appl. 2022, 187, 115849. [Google Scholar] [CrossRef]
- Lü, L.Y.; Medo, M.; Yeung, C.H.; Zhang, Y.C.; Zhang, Z.K.; Zhou, T. Recommender systems. Phys. Rep. 2012, 519, 1–49. [Google Scholar] [CrossRef]
- Koenigstein, N.; Dror, G.; Koren, Y. Yahoo! music recommendations: Modeling music ratings with temporal dynamics and item taxonomy. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 165–172. [Google Scholar]
- Smith, B.; Linden, G. Two Decades of Recommender Systems at Amazon.com. IEEE Internet Comput. 2017, 21, 12–18. [Google Scholar] [CrossRef]
- Gomez-Uribe, C.A.; Hunt, N. The Netflix Recommender System: Algorithms, Business Value, and Innovation. ACM Trans. Manag. Inf. Syst. (TMIS) 2015, 6, 1–19. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep Neural Networks for YouTube Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar]
- Margaris, D.; Vassilakis, C.; Spiliotopoulos, D. On Producing Accurate Rating Predictions in Sparse Collaborative Filtering Datasets. Information 2022, 13, 302. [Google Scholar] [CrossRef]
- Singh, P.K.; Sinha, S.; Choudhury, P. An improved item-based collaborative filtering using a modified Bhattacharyya coefficient and user–user similarity as weight. Knowl. Inf. Syst. 2022, 64, 665–701. [Google Scholar] [CrossRef]
- Liu, N.; Li, M.X.; Qiu, H.Y.; Su, H.L. A hybrid user-based collaborative filtering algorithm with topic model. Appl. Intell. 2021, 51, 7946–7959. [Google Scholar]
- O’Mahony, M.P.; Hurley, N.J.; Silvestre, G.C. Detecting noise in recommender system databases. In Proceedings of the 11th International Conference on Intelligent User Interfaces, Sydney, Australia, 29 January–1 February 2006; pp. 109–115. [Google Scholar]
- Pham, H.X.; Jung, J.J. Preference-based user rating correction process for interactive recommendation systems. Multimed. Tools Appl. 2013, 65, 119–132. [Google Scholar] [CrossRef]
- Toledo, R.Y.; Mota, Y.C.; Martínez, L. Correcting noisy ratings in collaborative recommender systems. Knowl.-Based Syst. 2015, 76, 96–108. [Google Scholar] [CrossRef]
- Turk, A.M.; Bilge, A. Robustness analysis of multi-criteria collaborative filtering algorithms against shilling attacks. Expert Syst. Appl. 2019, 115, 386–402. [Google Scholar] [CrossRef]
- Chung, C.Y.; Hsu, P.Y.; Huang, S.H. βP: A novel approach to filter out malicious rating profiles from recommender systems. Decis. Support Syst. 2013, 55, 314–325. [Google Scholar] [CrossRef]
- Cai, Y.F.; Zhu, D. Trustworthy and profit: A new value-based neighbor selection method in recommender systems under shilling attacks. Decis. Support Syst. 2019, 124, 113112. [Google Scholar] [CrossRef]
- Xia, H.; Fang, B.; Gao, M.; Ma, H.; Tang, Y.Y.; Wen, J. A novel item anomaly detection approach against shilling attacks in collaborative recommendation systems using the dynamic time interval segmentation technique. Inf. Sci. 2015, 306, 150–165. [Google Scholar] [CrossRef]
- Castro, J.; Yera, R.; Martínez, L. An empirical study of natural noise management in group recommendation systems. Decis. Support Syst. 2017, 94, 1–11. [Google Scholar] [CrossRef]
- Bag, S.; Kumar, S.; Awasthi, A.; Tiwari, M.K. A noise correction-based approach to support a recommender system in a highly sparse rating environment. Decis. Support Syst. 2019, 118, 46–57. [Google Scholar] [CrossRef]
- Wang, P.Y.; Wang, Y.; Zhang, L.Y.; Zhu, H. An effective and efficient fuzzy approach for managing natural noise in recommender systems. Inf. Sci. 2021, 570, 623–637. [Google Scholar] [CrossRef]
- Amatriain, X.; Pujol, J.M.; Tintarev, N.; Oliver, N. Rate it again: Increasing recommendation accuracy by user re-rating. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 22–25 October 2009; pp. 173–180. [Google Scholar]
- Yera, R.; Castro, J.; Martínez, L. A fuzzy model for managing natural noise in recommender systems. Appl. Soft Comput. 2016, 40, 187–198. [Google Scholar] [CrossRef]
- Choudhary, P.; Kant, V.; Dwivedi, P. Handling Natural Noise in Multi Criteria Recommender System utilizing effective similarity measure and Particle Swarm Optimization. Procedia Comput. Sci. 2017, 115, 853–862. [Google Scholar] [CrossRef]
- Castro, J.; Yera, R.; Martinez, L. A fuzzy approach for natural noise management in group recommender systems. Expert Syst. Appl. 2018, 94, 237–249. [Google Scholar] [CrossRef]
- Li, B.; Chen, L.; Zhu, X.Q.; Zhang, C.Q. Noisy but non-malicious user detection in social recommender systems. World Wide Web 2013, 16, 677–699. [Google Scholar] [CrossRef]
- Shani, G.; Gunawardana, A. Evaluating Recommendation Systems. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 257–297. [Google Scholar]
- MovieLens 100K Dataset. Available online: https://grouplens.org/datasets/movielens/ (accessed on 14 January 2022).
- Yahoo Music Dataset. Available online: https://webscope.sandbox.yahoo.com/ (accessed on 14 January 2022).
- Epinions Dataset. Available online: http://www.trustlet.org/downloaded_epinions.html (accessed on 14 January 2022).
- Breese, J.S.; Heckerman, D.; Kadie, C.M. Empirical Analysis of Predictive Algorithms for Collaborative Filtering. arXiv 2013, arXiv:1301.7363. Available online: http://xxx.lanl.gov/abs/1301.7363 (accessed on 19 August 2022).
- Yang, L.; Liu, Z.; Dou, Y.; Ma, J.; Yu, P.S. ConsisRec: Enhancing GNN for Social Recommendation via Consistent Neighbor Aggregation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’21, Virtual Event, 11–15 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2141–2145. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]











{kind=link}
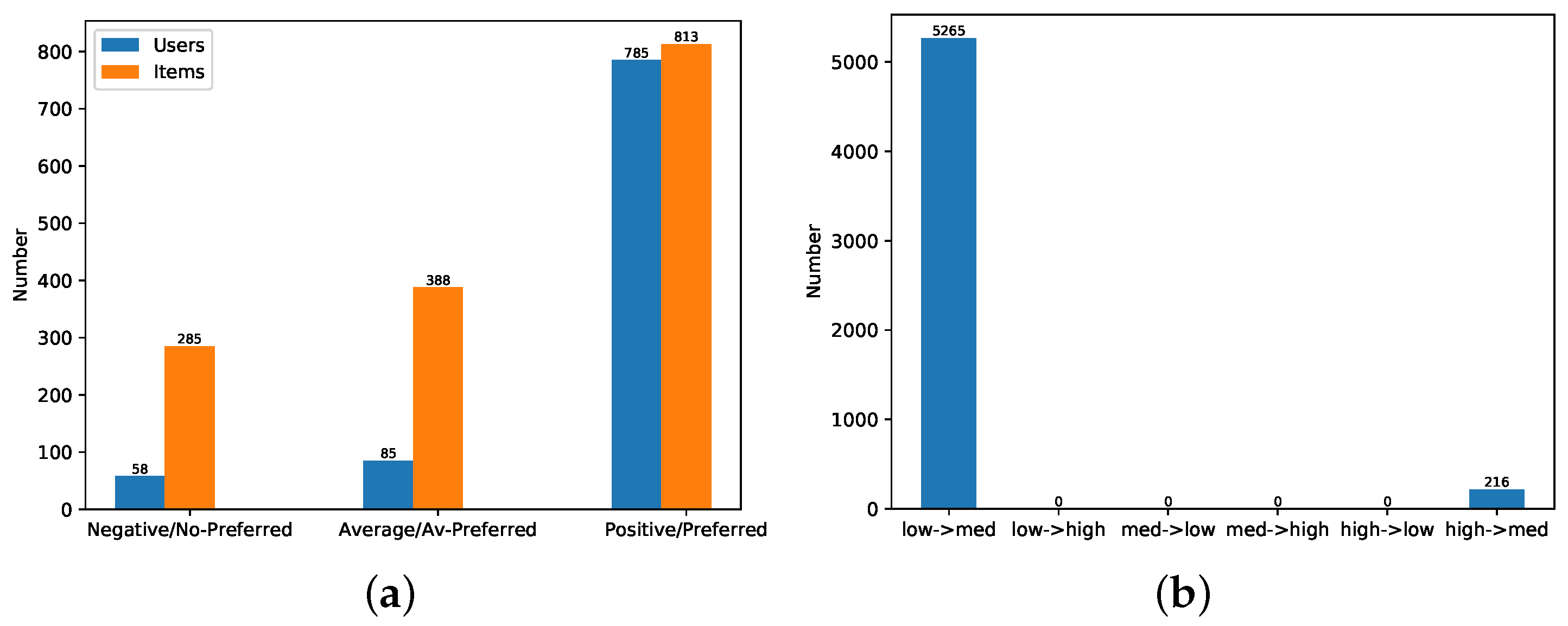{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Manage Natural Noises | Author | Problem | Main Work |
|---|---|---|---|
| Remove noises | O’Mahony et al. (2006) [12] | Data sparsity | Detect noises and remove them |
| Li et al. (2013) [26] | Data sparsity | Detect noises and remove them | |
| Correct noises | Amatriain et al. (2009) [22] | Depending on additional information | Re-rating |
| Pham and Jung (2013) [13] | Depending on additional information | Interactive recommender systems | |
| Toledo et al. (2014) [14] | Time-consuming | Re-predicting | |
| Yera et al. (2016) [23] | Time-consuming | Re-predicting | |
| Castro et al. (2017) [19] | Time-consuming | Re-predicting | |
| Choudhary et al. (2017) [24] | Time-consuming | Re-predicting | |
| Castro et al. (2018) [25] | Time-consuming | Re-predicting | |
| Bag et al. (2019) [20] | - | Threshold value |
| Special virtual users | Negative-Extreme | Only provides low ratings for items | |
| Average-Extreme | Only provides medium ratings for items | ||
| Positive-Extreme | Only provides high ratings for items | ||
| Special virtual items | No-Preferred-Extreme | Only get low ratings from users | |
| Av-Preferred-Extreme | Only get medium ratings from users | ||
| Preferred-Extreme | Only get high ratings from users |
| Subcategory | Remark | |
|---|---|---|
| Users categories | Negative | Tend to provide high ratings for items |
| Average | Tend to provide medium ratings for items | |
| Positive | Tend to provide low ratings for items | |
| Items categories | No-Preferred | Tend to get high ratings from users |
| Av-Preferred | Tend to get medium ratings from users | |
| Preferred | Tend to get low ratings from users |
| Low Ratings | Medium Rating | High Ratings | |
|---|---|---|---|
| (Negative users, No-Preferred items) | - | Natural noise | Natural noise |
| (Average users, Av-Preferred items) | Natural noise | - | Natural noise |
| (Positive users, Preferred items) | Natural noise | Natural noise | - |
| Dataset | Ratings | Users | Items | Sparsity | Rating Scale |
|---|---|---|---|---|---|
| Movielens-100K | 100,000 | 943 | 1682 | 6.30% | 1–5 |
| Yahoo Music | 270,121 | 8089 | 1000 | 3.33% | 1–5 |
| Epinions | 482,850 | 8693 | 123,330 | 0.45% | 1–5 |
| Scheme | Description |
|---|---|
| Original PCC/ConsisRec/MF | Apply PCC/ConsisRec/MF to the original dataset |
| Repredict PCC/ConsisRec/MF | Apply PCC/ConsisRec/MF to the dataset which is denoised by the scheme in [14] |
| Threshold PCC/ConsisRec/MF | Apply PCC/ConsisRec/MF to the dataset which is denoised by the scheme in [20] |
| Proposed PCC/ConsisRec/MF | Apply PCC/ConsisRec/MF to the dataset which is denoised by our scheme |
| Dataset | MF | ConsisRec | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | F1 | RMSE | MAE | F1 | |
| Movielens 100K denoised by our scheme | 0.9523 | 0.7510 | 0.6657 | 0.9287 | 0.7319 | 0.6667 |
| Original Movielens 100K | 0.9499 | 0.7571 | 0.6586 | 0.9264 | 0.7287 | 0.6989 |
| YahooMusic denoised by our scheme | 1.2630 | 0.9562 | 0.5767 | 1.2760 | 0.9897 | 0.5728 |
| Original YahooMusic | 1.2205 | 0.9650 | 0.6040 | 1.2822 | 1.0371 | 0.5195 |
| Epinions denoised by our scheme | 1.9925 | 1.3505 | 0.6612 | 1.1024 | 0.8607 | 0.5669 |
| Origianl Epinions | 1.9900 | 1.3661 | 0.6580 | 1.1025 | 0.8642 | 0.6274 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, C.; Wang, Y.; Li, B.; Liu, H.; Wang, P.; Zhang, L.Y. An Efficient Approach to Manage Natural Noises in Recommender Systems. Algorithms 2023, 16, 228. https://doi.org/10.3390/a16050228
Luo C, Wang Y, Li B, Liu H, Wang P, Zhang LY. An Efficient Approach to Manage Natural Noises in Recommender Systems. Algorithms. 2023; 16(5):228. https://doi.org/10.3390/a16050228
Chicago/Turabian StyleLuo, Chenhong, Yong Wang, Bo Li, Hanyang Liu, Pengyu Wang, and Leo Yu Zhang. 2023. "An Efficient Approach to Manage Natural Noises in Recommender Systems" Algorithms 16, no. 5: 228. https://doi.org/10.3390/a16050228
APA StyleLuo, C., Wang, Y., Li, B., Liu, H., Wang, P., & Zhang, L. Y. (2023). An Efficient Approach to Manage Natural Noises in Recommender Systems. Algorithms, 16(5), 228. https://doi.org/10.3390/a16050228