1. Introduction
Neurological disorders are common and predicted to affect one in six people [
1]. Scientists constantly work to find more effective methods of diagnosing and treating these devastating conditions. Animal subjects are invaluable in neuroscience, as they allow researchers to induce diseases and their pathogenesis [
2]. Small animals, most commonly mice, led to the development of many important animal models [
3]. However, small animals lack the brain complexity and biological scale found in humans, resulting in many therapies failing to translate to human trials [
4,
5]. This issue led to an increased focus on developing large animal models. Animals such as sheep, pigs, and non-human primates resulted in more robust findings [
6]. Recently, minipigs have emerged at the forefront of neuroscience, as they present multiple advantages over other large animals, such as a relatively large gyrencephalic brain that is similar to the human brain’s anatomy, neurophysiological processes, and white-to-gray matter ratio (60:40) [
7]. Furthermore, the minipig’s use presents a considerably lower cost and fewer ethical issues [
8] when compared with its alternatives.
Medical imaging, such as magnetic resonance (MR) imaging, provides researchers with non-invasive access to the brain. MRI produces higher-quality images compared with computed tomography without radiation risks, making it suitable for research. Medical image processing is a crucial part of research, as it allows researchers to monitor their experiments and understand disease development. Processes such as image registration, skull stripping, tissue segmentation, and landmark detection are necessary for many experiments.
In recent years, deep learning has overtaken the field by outperforming virtually all previous algorithms and allowing for solving entirely new problems. Nowadays, most new AI developments, such as general adversarial networks and transformers, also succeed in medical imaging [
9,
10]. However, many algorithms are created and optimized for MR analysis of human data and are not directly applicable or sufficiently sensitive to measure large-animal data. For example, due to differences in the size and shape of the head, highly successful tools such as SynthStrip [
11] fail on minipig images. This forces researchers into laborious, expensive, and error-prone manual processing. Therefore, there is an urgent need for accurate and automated tools to analyze minipig data.
In this work, we propose PigSNIPE, a pipeline for the automated processing of minipig MR images similar to software available for humans [
12]. This is an extension of our previous work [
13] and allows for image registration, AC-PC alignment, brain mask segmentation, skull stripping, tissue segmentation, caudate-putamen brain segmentation, and landmark detection in under two minutes. To the best of our knowledge, this is the first tool aimed at animal images which will dramatically reduce the time and resources needed to analyze minipig data and accelerate the scientific discovery process. Our tool is open source and can be found at
https://github.com/BRAINSia/PigSNIPE (accessed on 6 February 2023).
2. Data
In this study, we used two large-animal minipig datasets. The first (Germany) dataset consists of 106 scanning sessions from 33 Libechov minipigs [
14] collected using a 3T Philips Achieva scanner. Each scanning session contained single T1 and T2 weighted scans. The T1w images were acquired at the acquisition resolution of
mm
3 and a spatial size of
voxels. The T2w images have a
mm
3 resolution and a spatial size of
voxels.
The second (Iowa) dataset was collected for a study investigating CLN2 gene mutation at the University of Iowa [
15]. The Iowa dataset consisted of 38 scanning sessions from 23 Yucatan minipigs using a 3.0T GE SIGNA Premier scanner. Many scanning sessions contain more than one T1w and T2w image, resulting in a total of 178 T1w and 134 T2w images. Both the T1w and T2w images were acquired at a resolution of
mm
3 and a spatial size of
voxels.
Based on our data, we created two training datasets. The first dataset was used for the brainmask training models. As both low-resolution and high-resolution brainmask models worked on either the T1w or T2w images, we took advantage of all available data, as shown in
Table 1. The second dataset was used to train the intracranial volume, white and gray matter and CSF, and caudate-putamen segmentation models, which require as input the registered T1w and T2w images. We computed a Cartesian product of all T1w and T2w images for each scanning session to maximize our training dataset and obtain all possible pairs. The range of all possible pairs per scanning session was between 1 and 28. Therefore, to avoid the overrepresentation of some subjects, we limited the number of T1w-T2w pairs to four. The resulting training split is in
Table 2. For each dataset, we split the data by subject into training, validation, and test sets (80%, 10%, and 10%, respectively) on the subject basis to ensure data from the same animal appeared only in one subset.
In addition to the original T1w and T2w scan data, we generated inter-cranial volume (ICV) mask, caudate-putamen (CP), and gray and white matter and cerebrospinal fluid (GWC) segmentations. The ICV masks served as the ground truth for low-resolution, high-resolution, and ICV models. The CP segmentations were manually traced and used to train the CP segmentation model. The GWC masks were generated using Atropos software [
16] and used for training the GWC model. The physical landmark data consisted of 19 landmarks used for training the landmark detection models. Detailed information on the data and implementation of landmark detection can be found in our previous work [
13].
3. Materials and Methods
3.1. Pipeline Overview
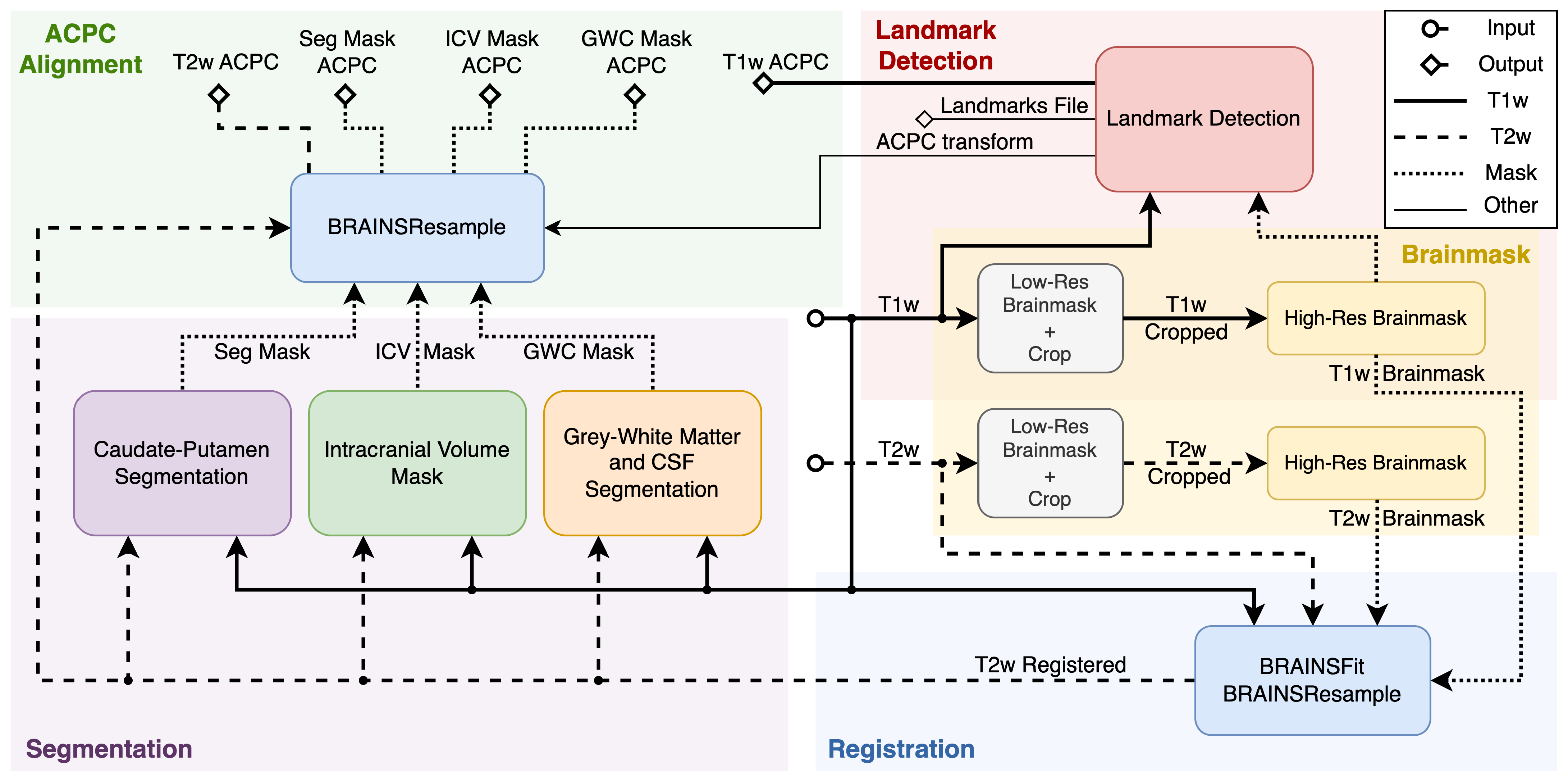
Figure 1 displays the simplified view of the PigSNIPE pipeline. The pipeline consists of five main parts, and the flow of the different data types is indicated by the line styles described in the legend. The pipeline’s inputs are T1w and T2w images (middle of the figure) in their original physical spaces. The starting step (Brainmask) is to compute the image brainmasks as other processes require them. First, we compute a low-resolution brainmask to crop the original image around the brain. This step then allows for computing a high-resolution brainmask. Then, the original T1w and T2w images and their corresponding high-resolution brainmasks are used in the registration process (Registration). The co-registered T1w and T2w images are used in the Segmentation part to compute the intracranial volume mask (ICV), gray and white matter and cerebrospinal fluid mask (GWC), and caudate-putamen segmentation (Seg). On the other side of the pipeline, the Landmark Detection step uses the T1w image with its high-resolution brainmask. This process produces the ACPC transform and ACPC-aligned T1w image, and it computes 19 physical landmarks saved in both the original T1w and ACPC spaces. The last part of the pipeline is ACPC alignment. At this point, the computed ICV, GWC, Seg, and T2w registered images are in the original T1w space. Therefore, we can reuse the ACPC transform computed during the Landmark Detection process to resample the data into the ACPC space. The figure displays the full configuration of the pipeline. However, the user can choose the configuration, such as not running the landmark detection and AC-PC alignment, which greatly reduces the runtime. The user can also decide to skull-strip the data (not shown in the figure).
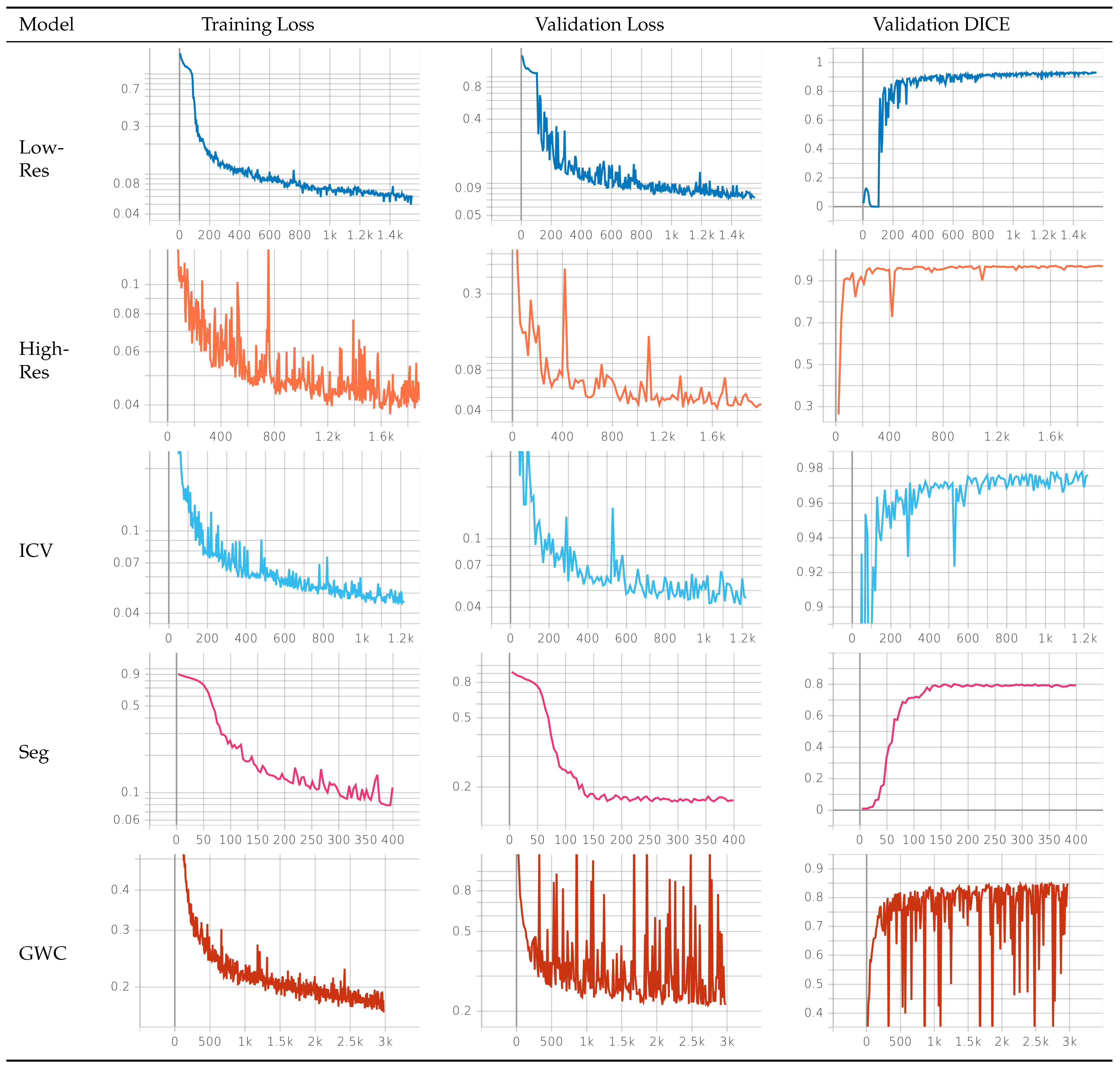
3.2. Deep Learning Segmentation Model
All brainmasks and segmentations are based on the same model architecture: the 3D ResUNet architecture [
17] (see the citation for the architecture details). Each model uses the Adam optimizer, a learning rate of 0.001, and the DiceCE loss, which combines the Dice and cross-entropy losses. The implementation leveraged the existing MONAI [
18], PyTorch [
19], and Lightning [
20] libraries.
All models used 5 layers with 16, 32, 64, 128, and 256 channels per layer (with the low-resolution model being an exception, having 128 channels in the last layer) and 3 residual connections. The only variations between the models were in image voxel size. In the low-resolution model, we resampled a
voxel region with a 3 mm isotropic spacing from the center of the image. This dramatically decreased the image size by over 95%, allowing for easy model training. All other models used an isotropic spacing of 0.5 mm. The high-resolution model used a
region, the ICV and GWC models used a
region, and the Seg model used a
voxel region. Those regions were resampled around the centroid of the low-resolution brainmask for the high-resolution model, high-resolution brainmask for the ICV model, and ICV mask for the GWC and Seg models. The centroids were computed using ITK’s ImageMomentsCalculator [
21]. Additionally, to make the high-resolution brainmask model robust to errors in the centroid position resulting from the inaccuracy of the low-resolution model, we added a random vector to the computed centroid position during training.
For preprocessing, all models used intensity value scaling from −1.0 to 1.0 with truncation on the 1% and 99% percentiles and implemented standard data augmentation techniques: random rotation, zoom, noise, and flip (except for the Seg model). Additionally, for the ICV, GWC, and Seg models, we passed both T1w and T2w images on two channels.
For post-processing during inference, we applied the FillHoles transform, which would fill all holes that could randomly occur in the predicted masks for all models. Additionally, all models except for the GWC model used KeepLargestConnectedComponent, which removed the noise outside the predicted mask.
3.3. Landmark Detection
A fundamental step in neuroimage analysis is anatomical landmark detection. Landmarks have many uses in medical imaging, including morphometric analysis [
22], image-guided surgery [
23], or image registration [
24]. In addition, many analysis tools require landmarks to co-register different imaging sets.
The landmark detection is a two-stage process involving four deep reinforcement learning models [
25]. All models detect multiple landmarks simultaneously through the multi-agent, hard parameter-sharing [
26,
27] deep Q network [
28]. The models are optimized by Huber loss [
29] and an Adam optimizer [
30] and controlled by an
-greedy exploration [
31] policy.
The first step was to crop the T1w image and compute the brain mask’s center of gravity, which is used for reinforcement learning initialization. In the first two models, we computed three landmarks, allowing AC-PC alignment of the T1w image. After that, the image in the standard AC-PC space allowed for accurate computation of the remaining 16 landmarks.
Detailed information about the models’ architecture, training, and results can be found in our previous work [
13].
3.4. Image Registration and AC-PC Alignment
Despite images from the same scanning session being taken minutes apart, many sources for possible image misalignment exist. For example, the animal might move during the scanning session, resulting in poor alignment of the images. As the ICV, GWC, and Seg models use both T1w and T2w images simultaneously, it is crucial to ensure proper image registration.
For all registrations, we used the BRAINSFit and BRAINSResample algorithms from the BRAINSTools package [
32]. The algorithms use high-resolution masks to ensure that the registration samples data points from the region of interest. By default, the pipeline uses Rigid registration with ResampleInPlace. This allows for image registration without interpolation errors. However, the user has the option to use the Rigid+Affine transform, which allows for nonlinear transformation.
Additionally, the pipeline can transform all data into a standardized anterior commissure-posterior commissure ( AC-PC) aligned space. This process combines the ACPC transform generated during the landmark detection process and the T2w-to-T1w transform in native space to achieve a T2w image in ACPC space. As all computed segmentations were in the T1w image, we could apply the ACPC transform to generate ACPC-aligned masks.
5. Discussion
We present MinipigBrain, a deep learning-based pipeline for minipig MRI processing. Trained on heterogeneous datasets, the pipeline can perform multiple operations commonly used in human neurodegenerative research for application in minipig models.
5.1. Deep Learning Models
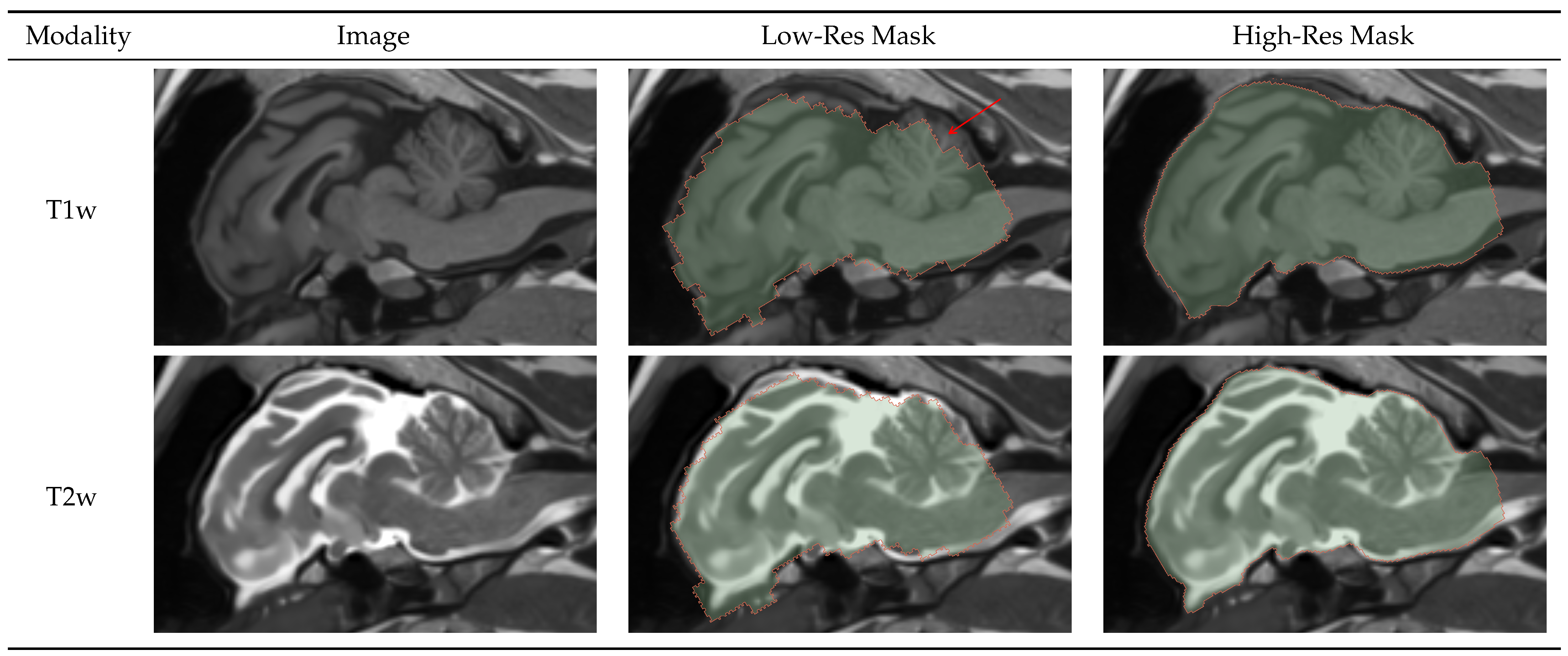
Splitting the initial brainmask process into low- and high-resolution masks was necessary to extract a region of interest from the original image space. The low-resolution masks proved robust and sufficiently accurate for preparing the data for the subsequent processes.
The caudate-putamen segmentation model accuracy was worse than those of the high-resolution and ICV models, which produced highly precise masks. The caudate and putamen are small, hard-to-distinguish regions. Even minor errors in segmenting of such small regions could lead to a higher impact on the DICE metric. Additionally, we predicted that the worse quality of the T2w images in the Germany dataset harmed the training process, and we are investigating ways to improve the model’s performance.
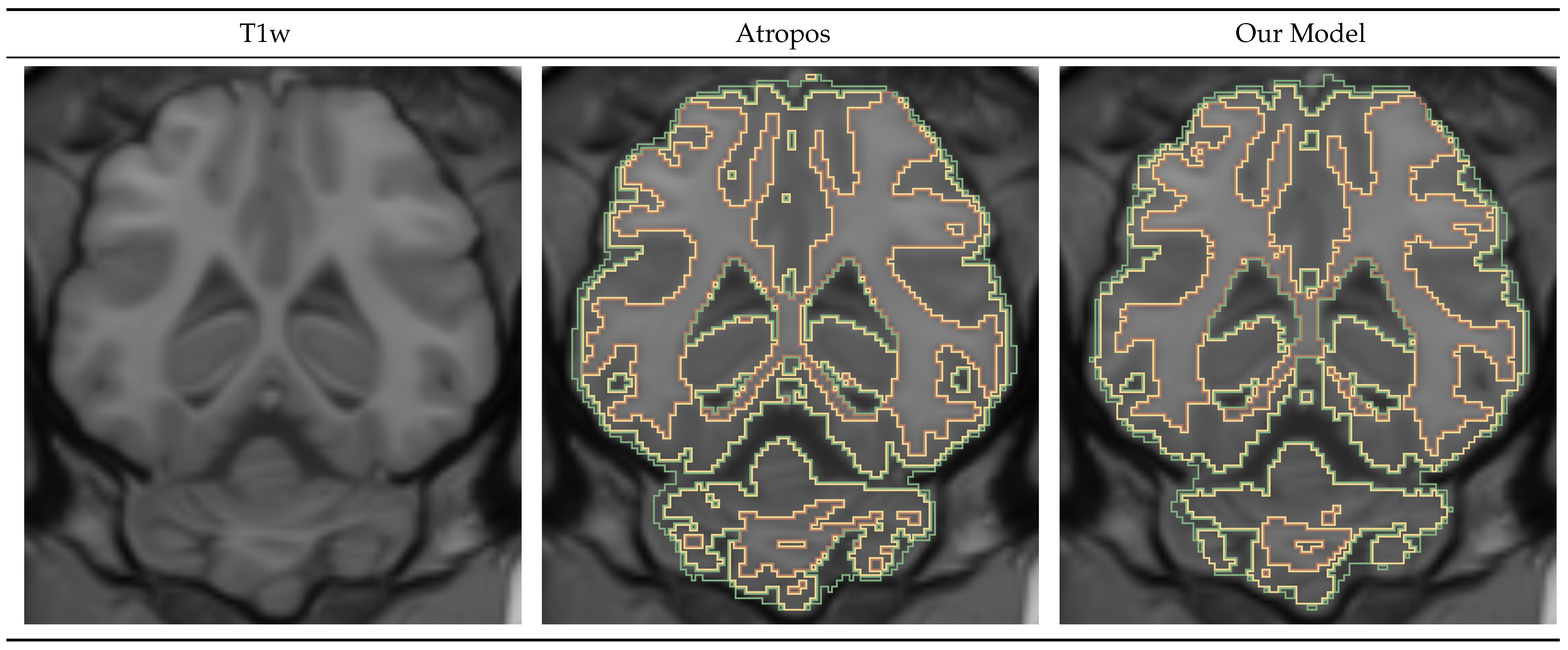
The evaluation of the tissue classification model was more complicated. We did not have the resources to obtain high-quality manual labels for the gray and white matter and cerebrospinal fluid segmentation problem and therefore used the Atropos results as the “ground truth”. However, Atropos is a tool aimed at human data rather than minipigs, and it produced suboptimal results. During visual qualitative analysis, we found examples of mistakes in the Atropos images. This negatively impacted the evaluation of our model, as the DICE metric only measures the overlap between the masks and not the quality of the masks. However, despite the suboptimal labels, during the training process, the model was able to generalize and produce arguably better results than the “ground truth” masks in many cases. During the visual qualitative review, a trained professional preferred our model’s prediction over that of Atropos. We acknowledge the shortcomings of our algorithm in the tissue segmentation problem, and we are actively exploring ways to improve the model’s performance. Nonetheless, we believe that our model still presents scientifically valuable results that can be useful to researchers.
5.2. Pipeline Performance
To the best of our knowledge, PigSNIPE is the first medical imaging tool aimed at large animals that allows for many of the most common processes. Its current form can deliver consistent results in under five minutes per scanning session. Currently, researchers are forced to analyze datasets manually. Performing all the operations available in PigSNIPE can easily take a trained professional a full day of work per pair of T1w and T2w images. Therefore, our tool can drastically decrease the time to perform minipig image analysis, significantly reducing research costs and accelerating scientific discovery.
5.3. Limitations
PigSNIPE is aimed at neuroscientists using large animal subjects in their research. As clinical interventions for animals are minimal, our tool has no immediate clinical utility.
We designed PigSNIPE for ease of use by providing the set-up steps and execution through a Docker container, which further simplified the configuration on the user side. However, using PigSNIPE requires a Linux environment, Docker, and basic skills with the bash shell.
The pipeline is constructed to apply to similarly shaped large quadrupeds (sheep, goats, etc.), but lack of access to those data prevented validation across species.
5.4. Future Work
To improve the performance of segmentation and tissue classification, we plan to experiment with transfer learning. By leveraging a large human dataset and nonlinear transformation, we expect to improve the models’ accuracy.
Additionally, we plan to add a batch execution capability to the pipeline. Loading a model onto the GPU takes more time than the inference time. We have nine different deep learning models, and being able to execute images from different subjects in a batch should significantly speed up the execution time.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}