
Predicting the Impact of Data Poisoning Attacks in Blockchain-Enabled Supply Chain Networks
 , ,
, ,  ,
,  and
and 
Abstract
:1. Introduction
- A range of machine learning models, including logistic regression, random forest, SVC, and XGB Classifier, were systematically evaluated for network intrusion detection in blockchain-enhanced supply chain networks
- Rigorous evaluation of each model incorporated metrics such as their F1 Score, confusion matrix analysis, and accuracy assessments.
- The robustness of each model against data poisoning attacks was tested by subjecting them to various scenarios, such as no attack, random label flipping with 20% randomness, and distance-based label flipping with a 0.5 distance threshold.
- An eight-layer neural network was also experimented with, and its performance was assessed using accuracy and a classification report library.
- Comprehensive insights were provided into the effects of data poisoning attacks on machine learning models and their implications for network security.
- This research contributed to developing more robust and secure network intrusion detection systems for blockchain-enabled supply chain networks.
2. Related Work
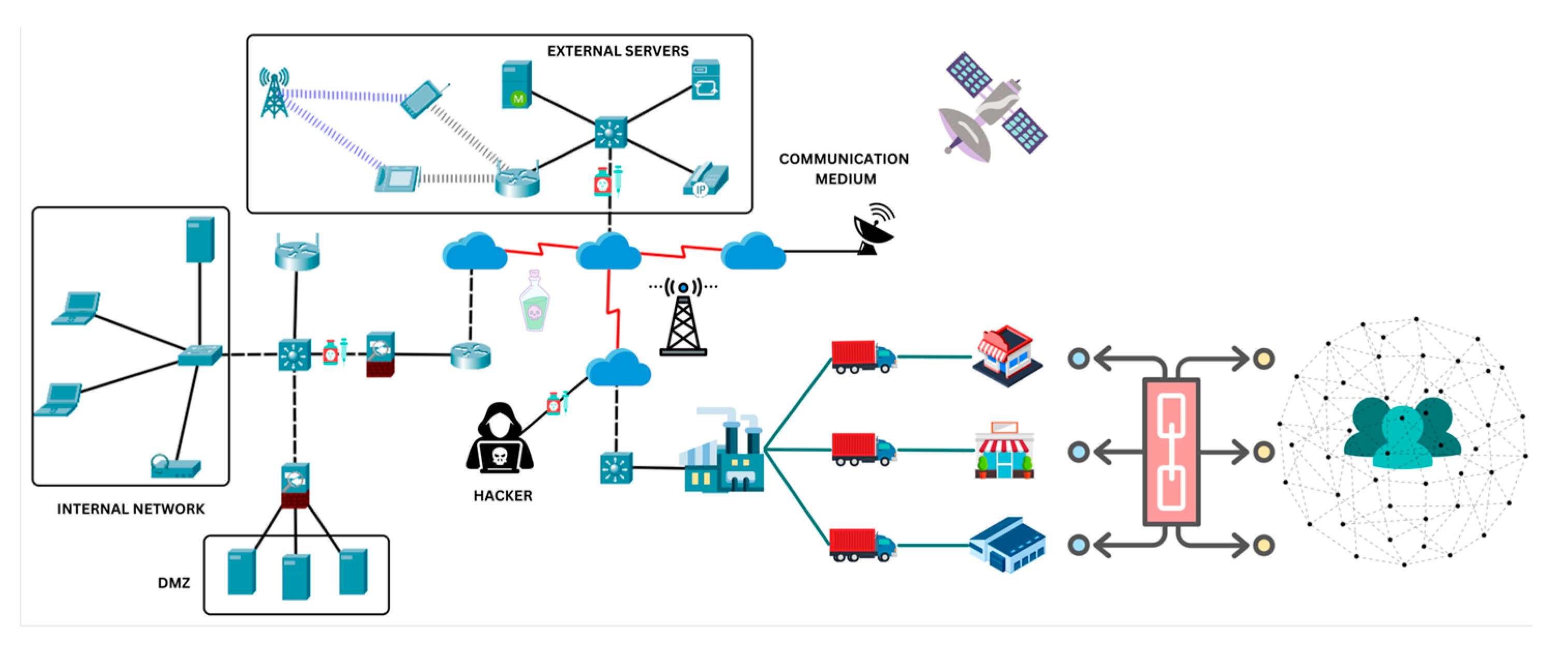
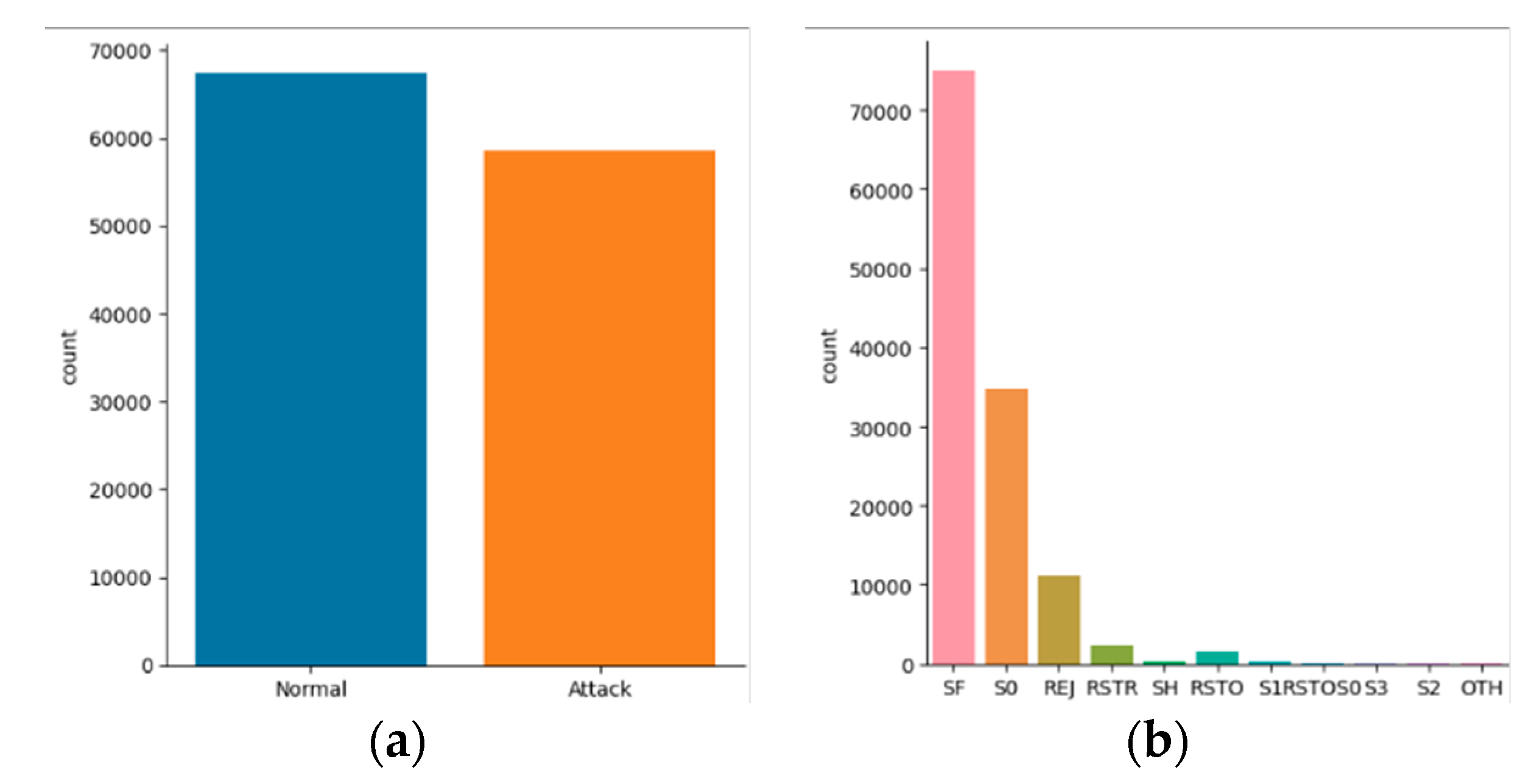
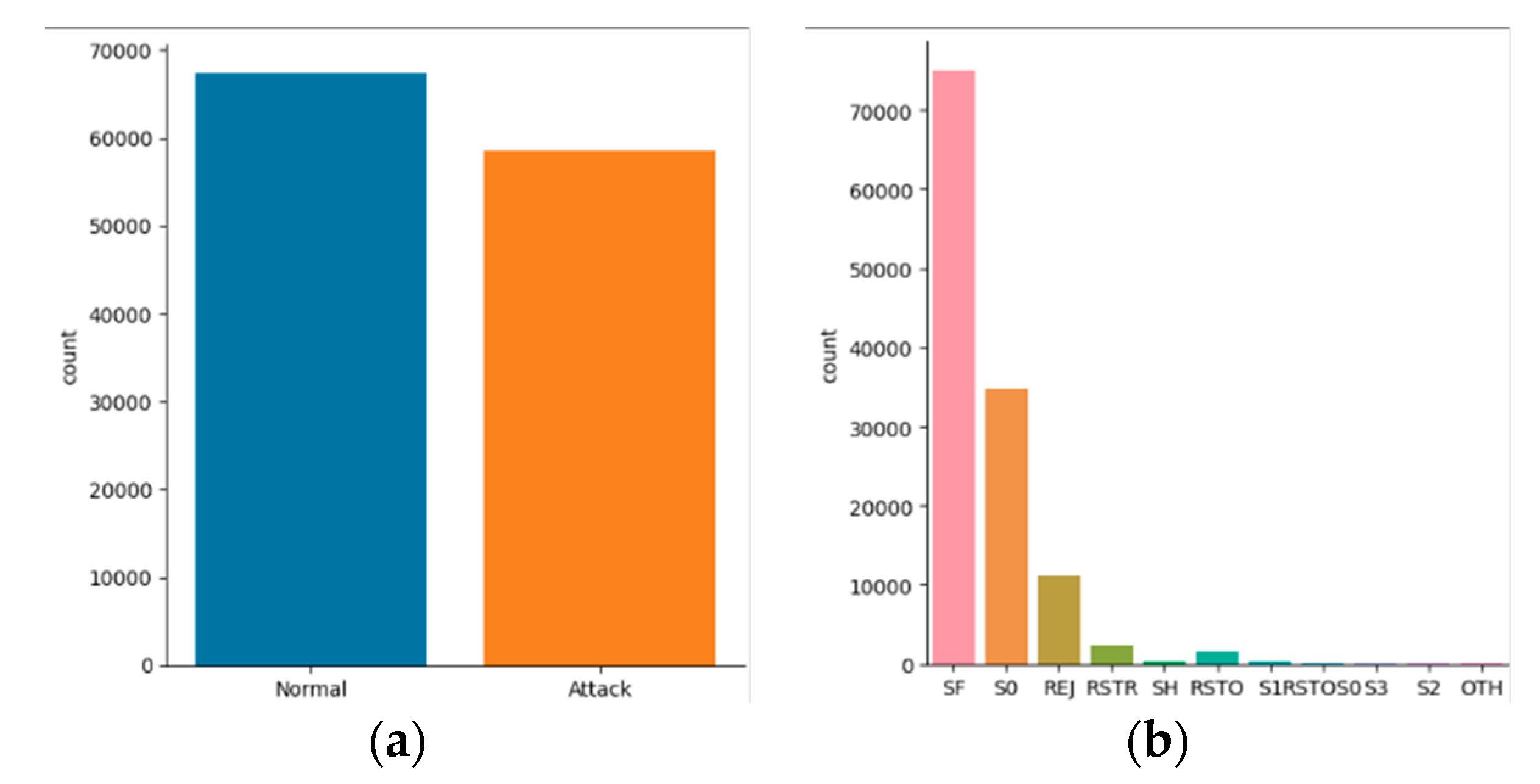
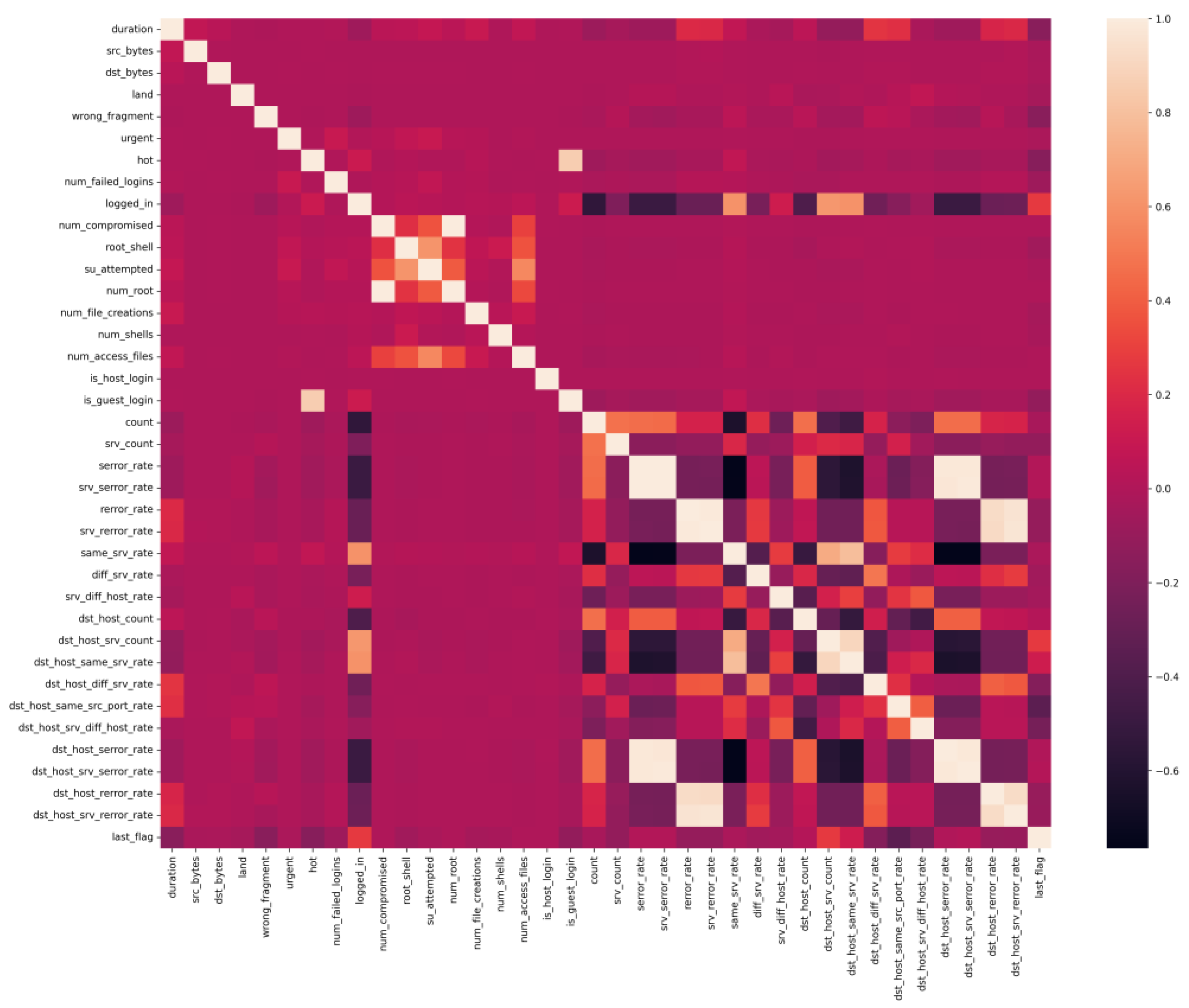
3. Dataset
- It has 41 features, such as duration, protocol type, service, source bytes, destination bytes, etc., that describe each connection.
- It has 4.9 million records, of which 10% are available as a subset for training and testing purposes.
- It has 23 types of attacks, such as denial of service, probing, user to root, remote to local, etc., representing different network intrusions.
- It is based on a simulated military network environment that mimics real-world scenarios.
- It is outdated and does not reflect the current state of network traffic and attacks that are more complex and sophisticated.
- It has some redundant and irrelevant records that may affect the quality and accuracy of the models.
- It has imbalanced classes that may cause some models to be biased or overfitting.
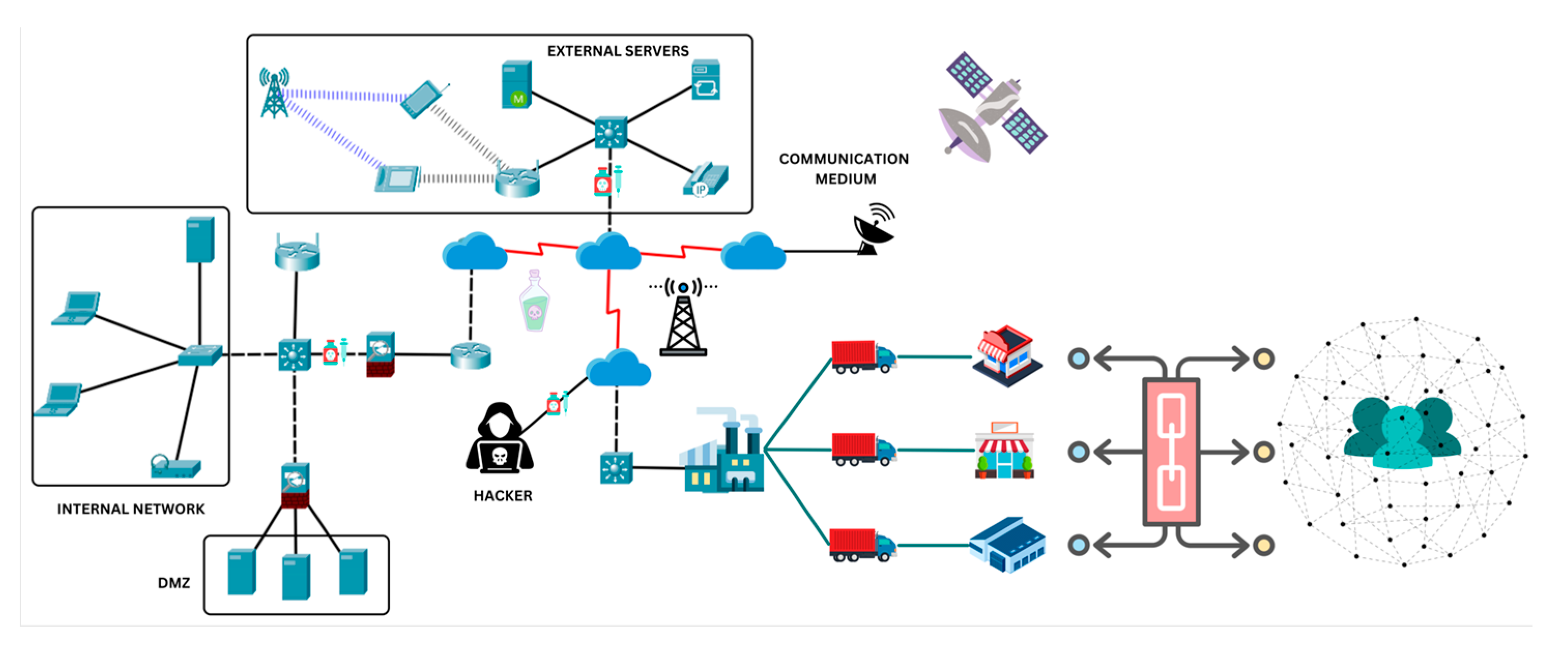
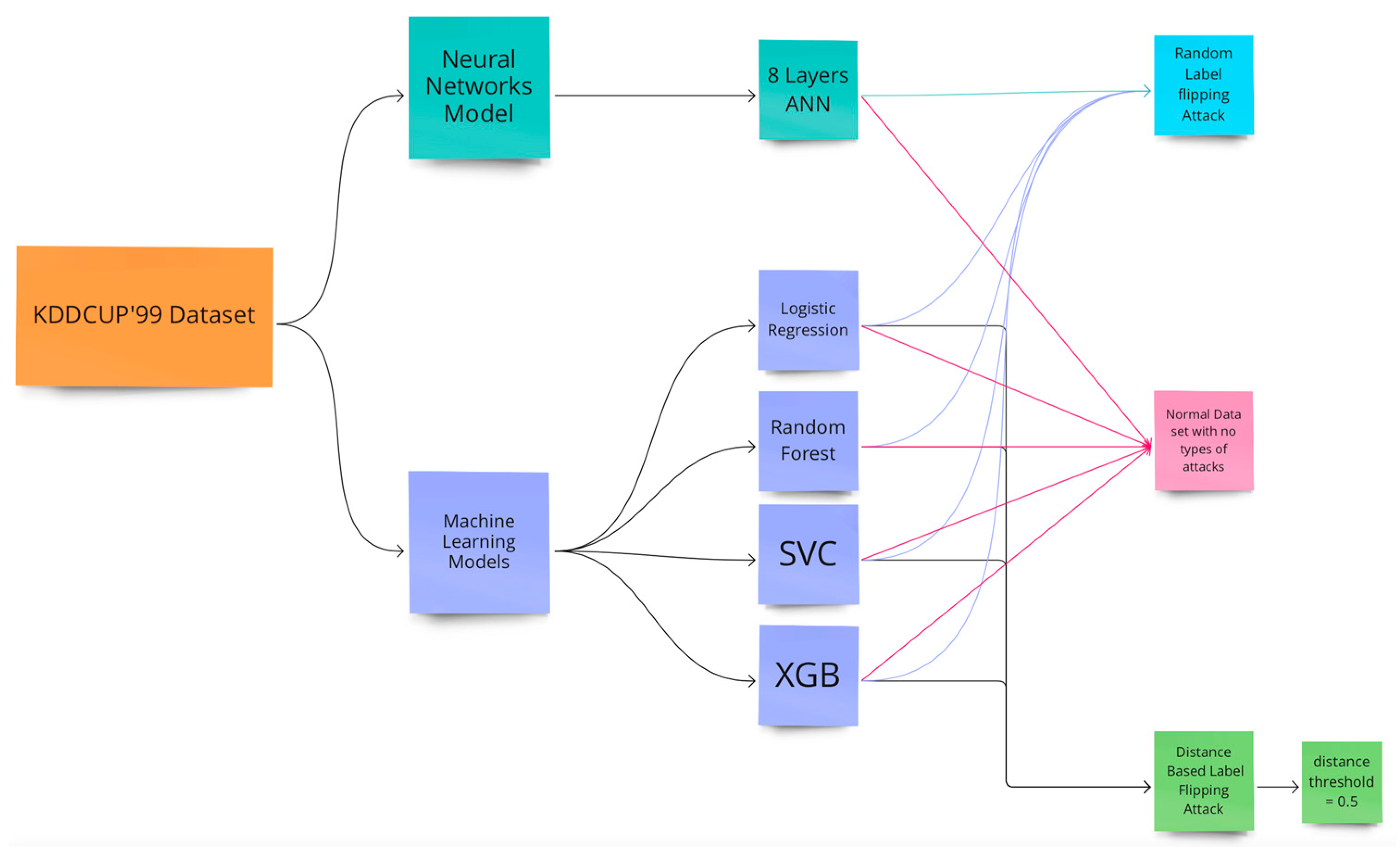
4. Experiment
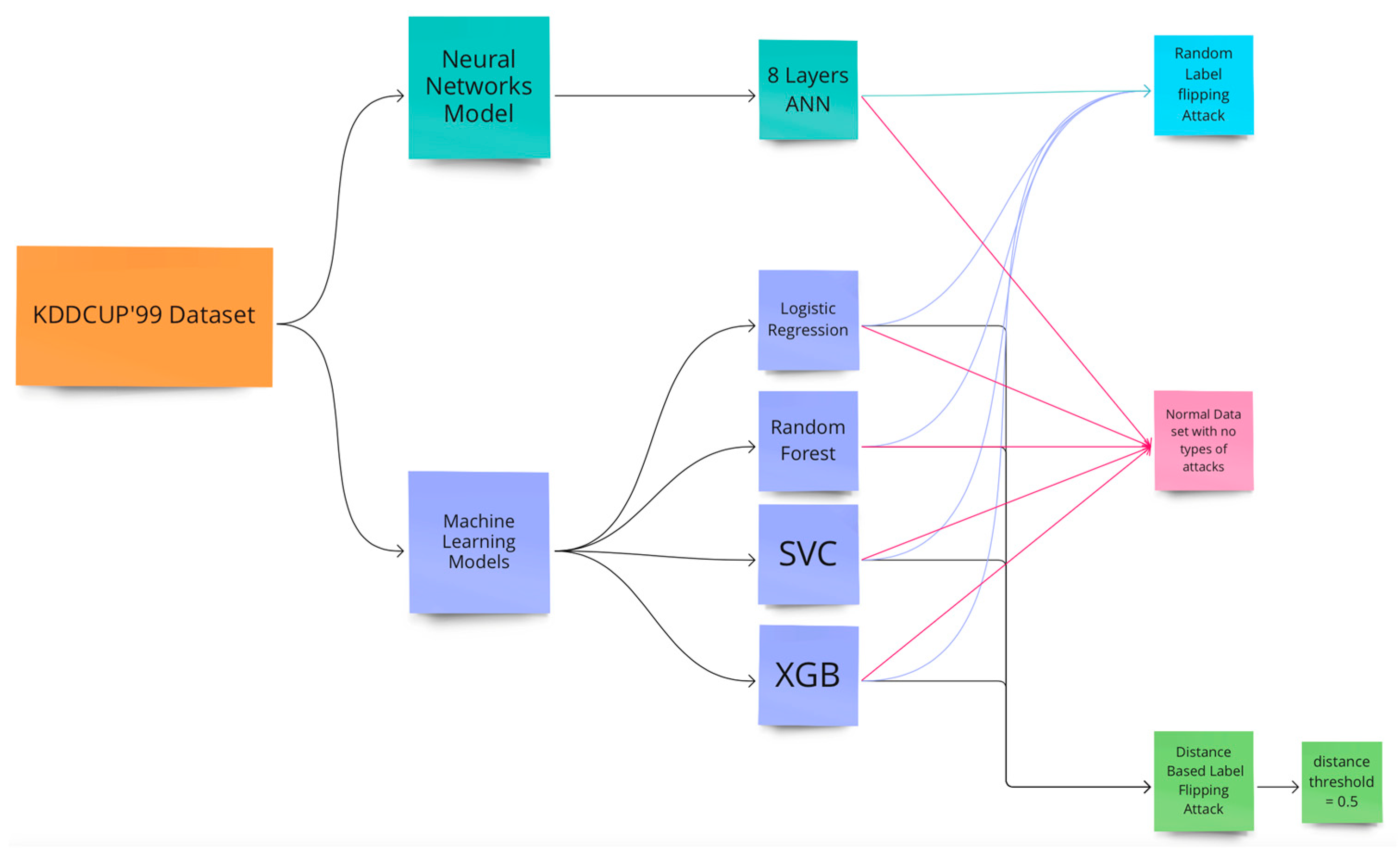
4.1. Experiment Design
4.2. The Experiment’s Models’ Training and Evaluation
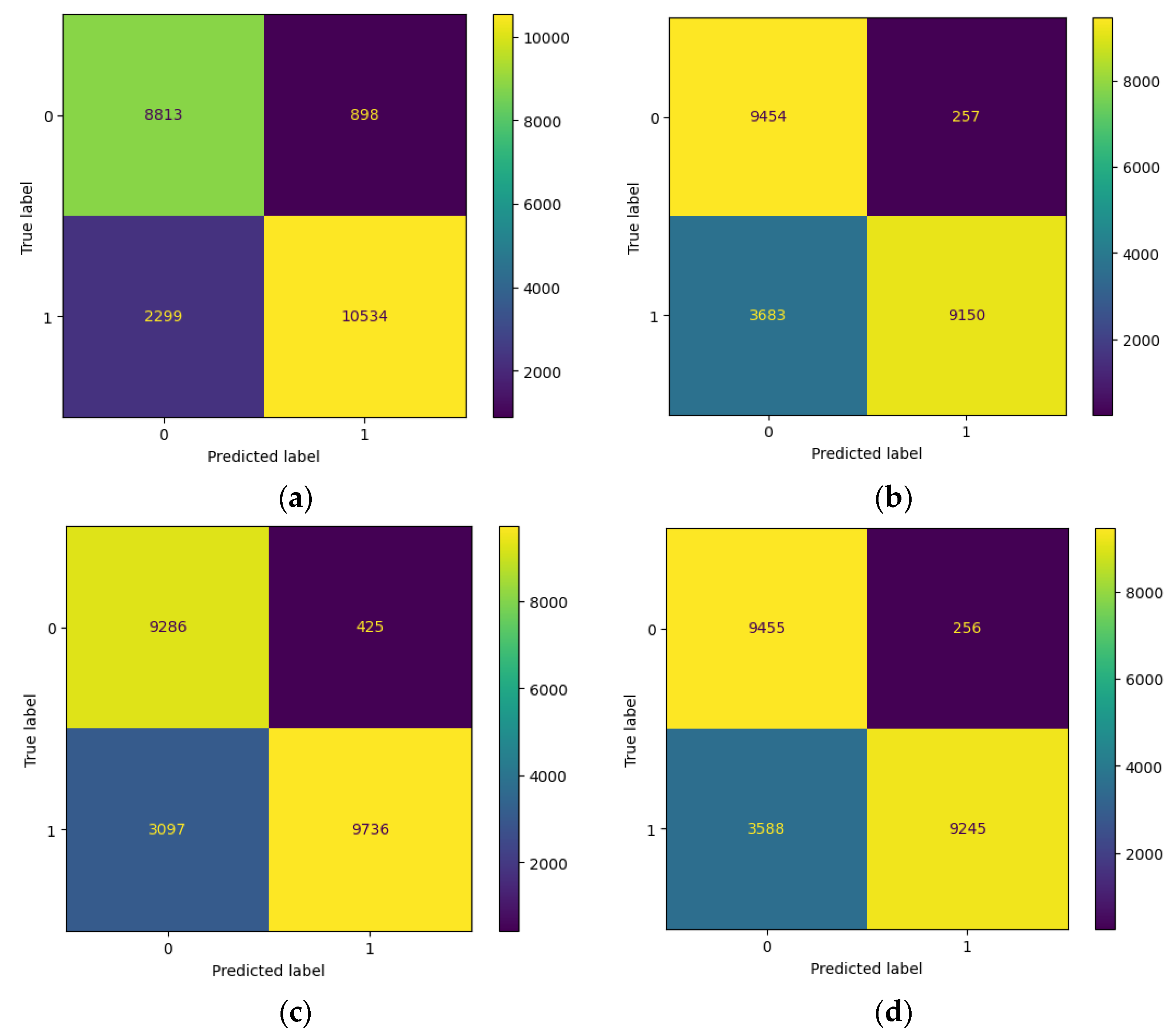
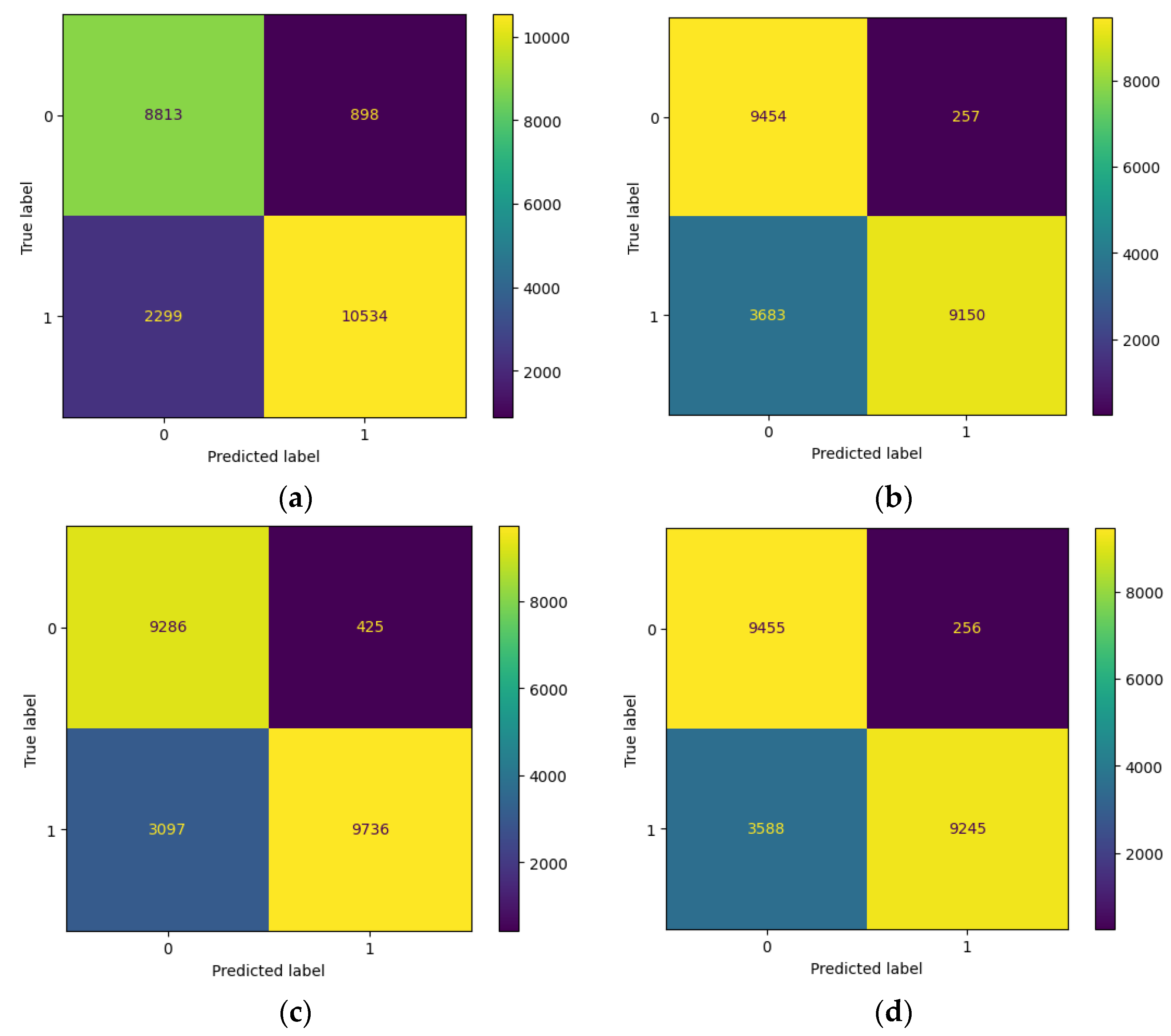
4.2.1. Evaluation of Machine Learning with a Random Label Flipping Attack
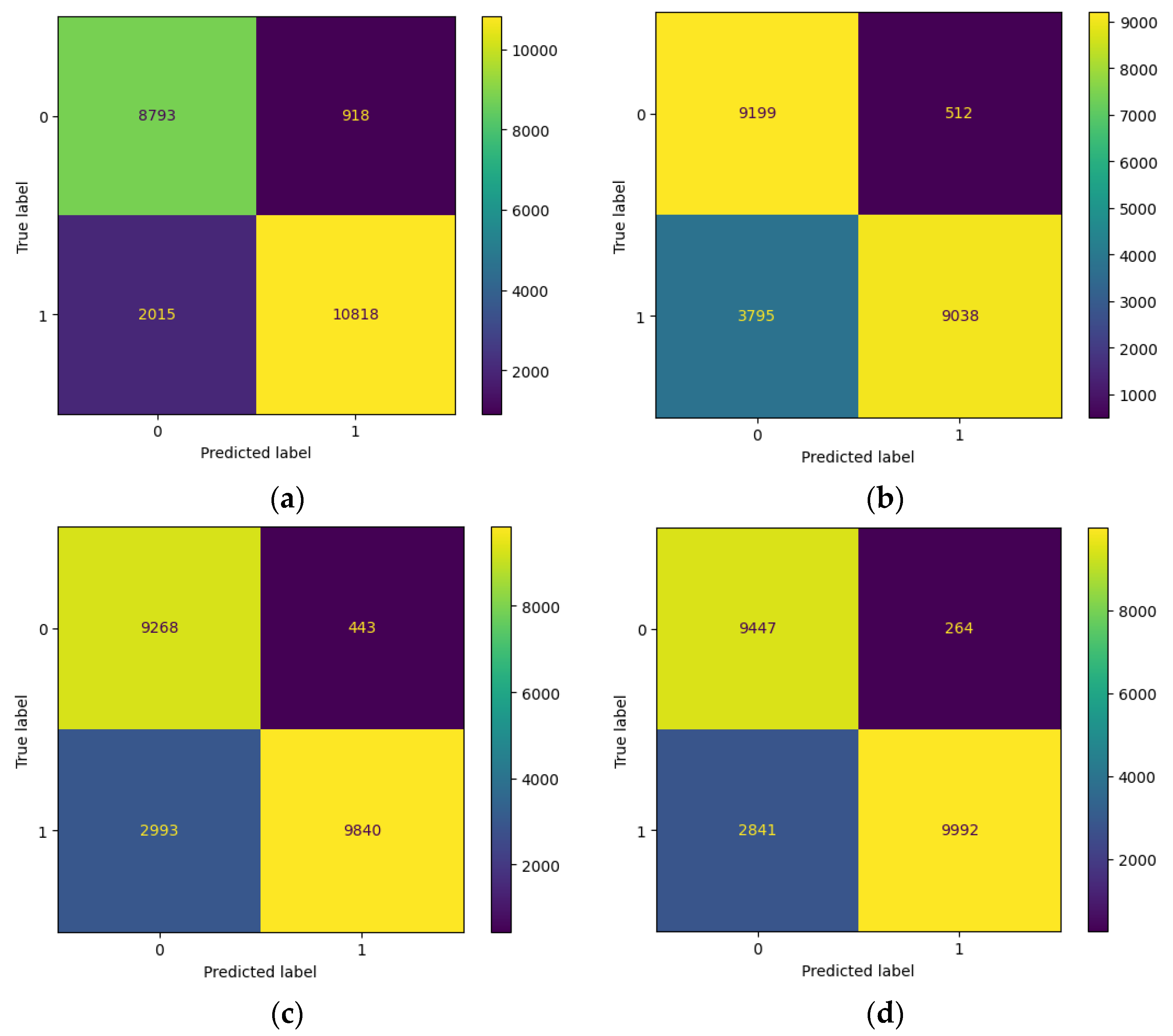
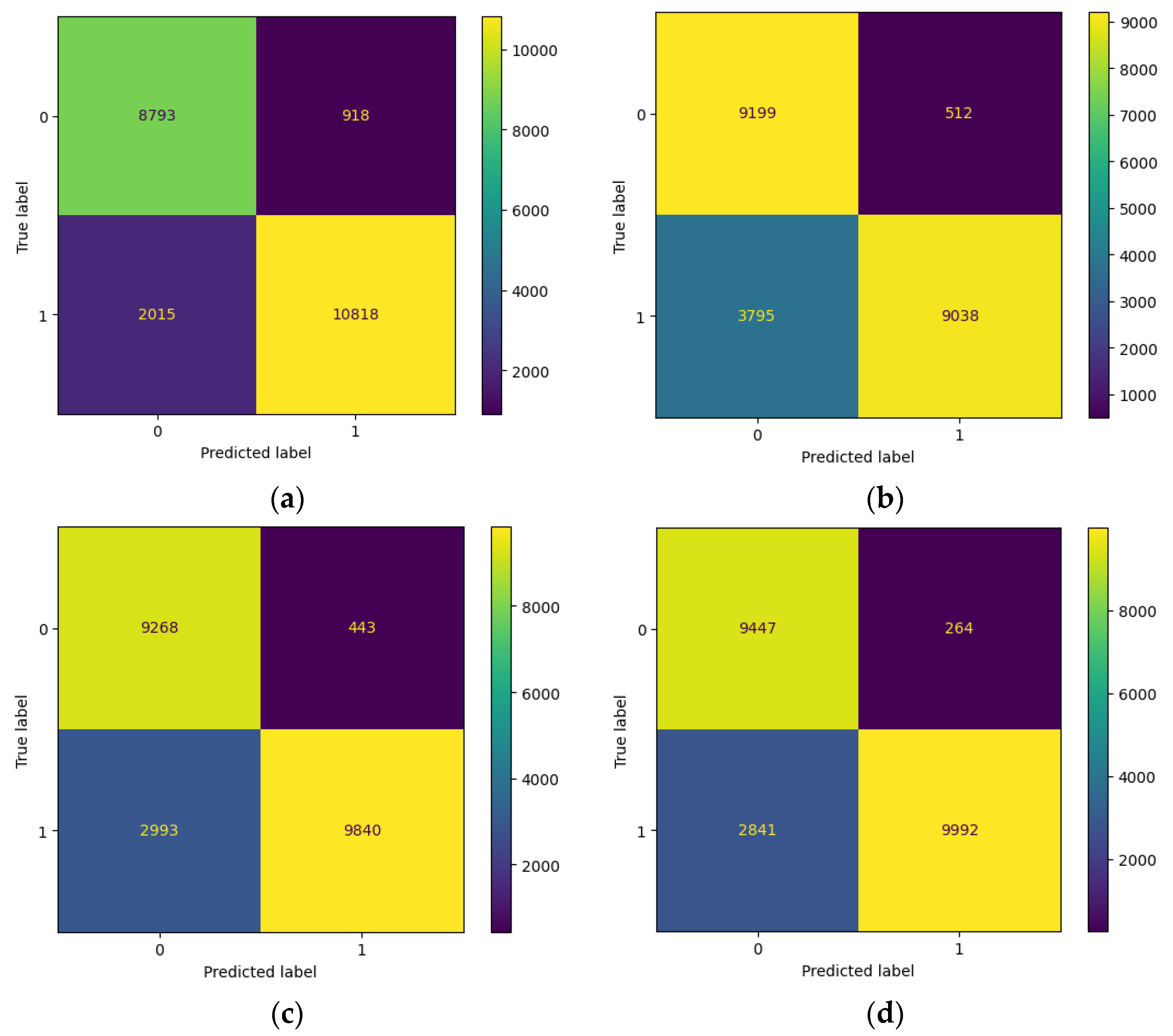
4.2.2. Evaluation of Machine Learning with a Distance-Based Flipping Attack with a Threshold of 0.5
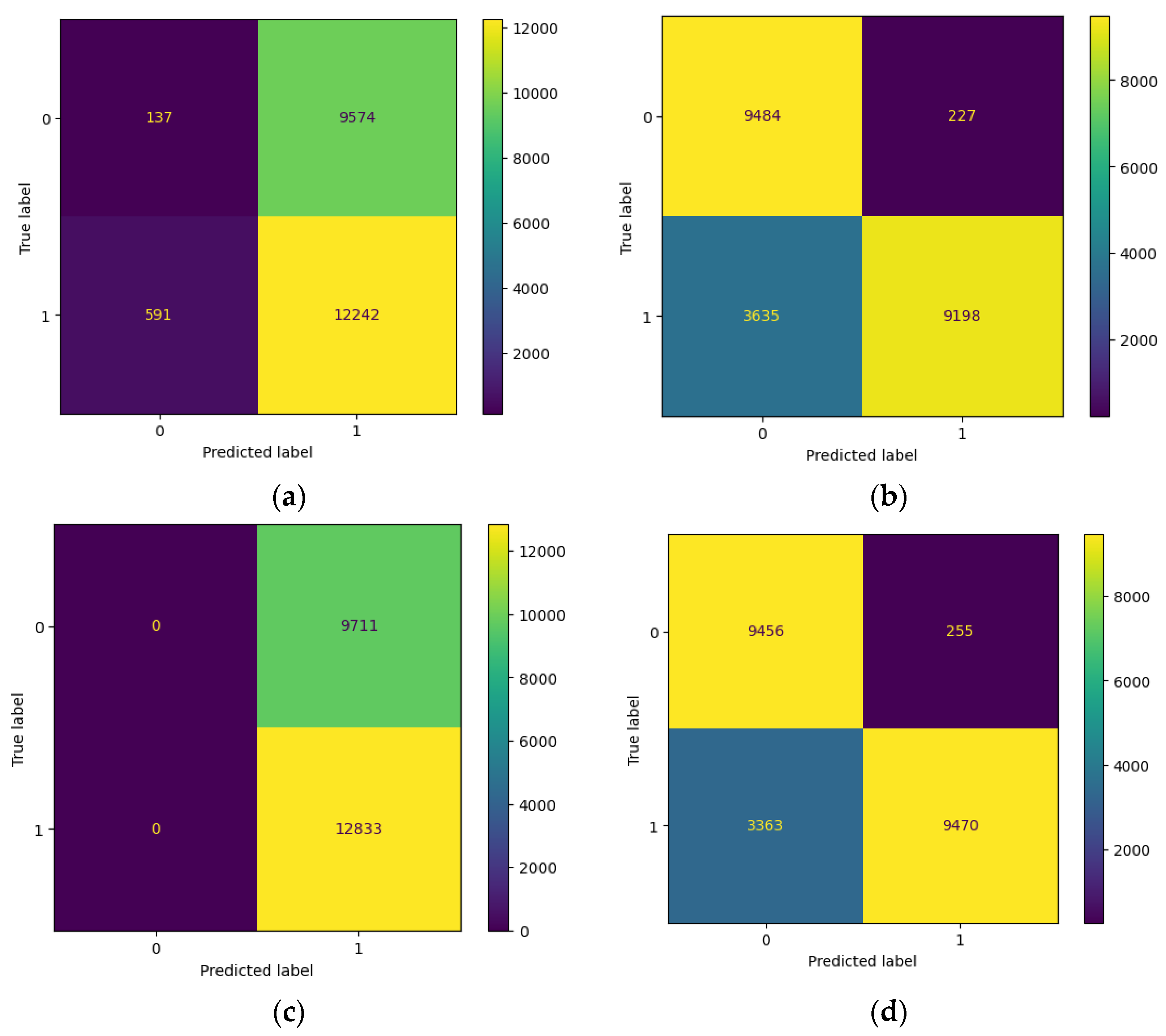
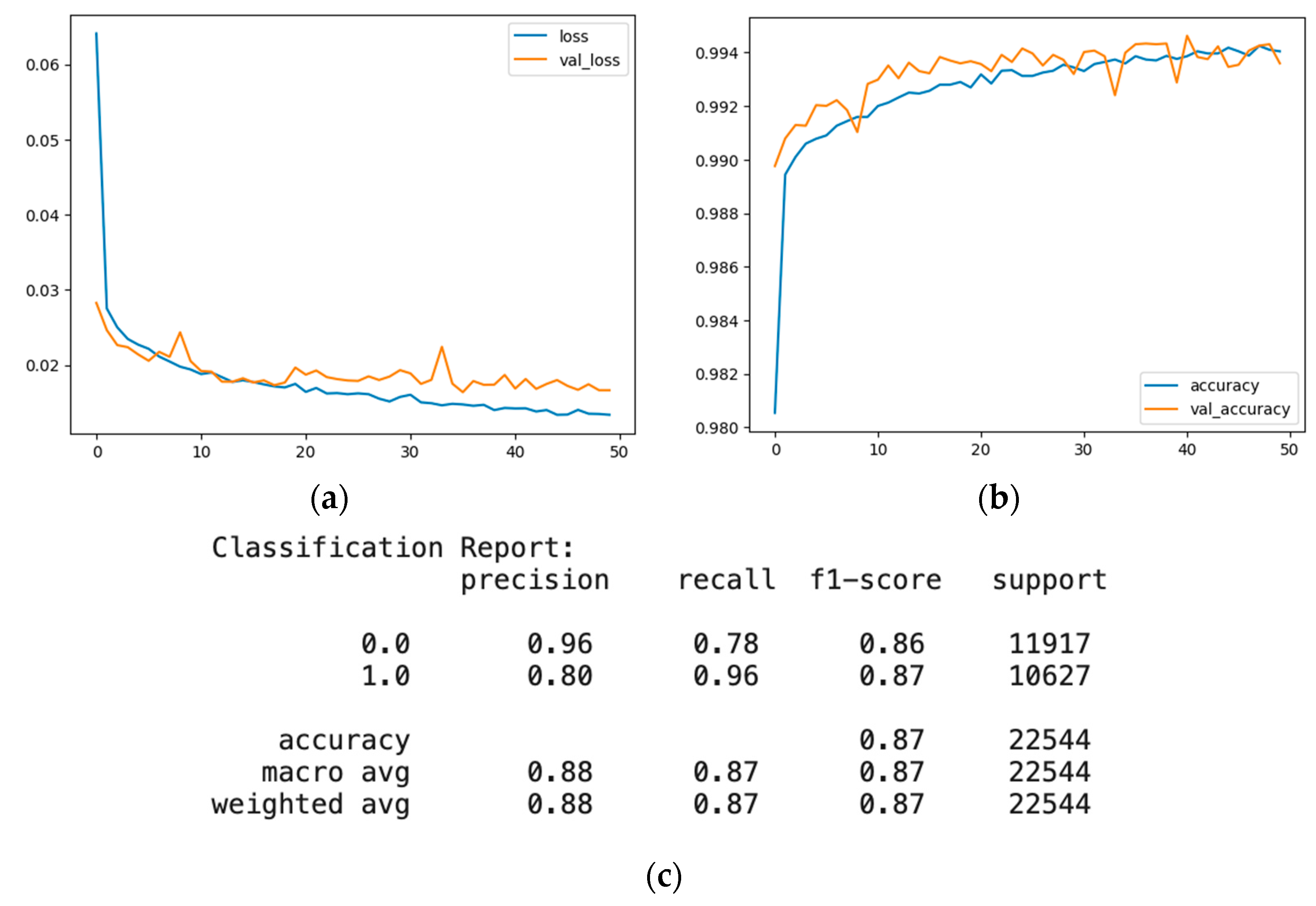
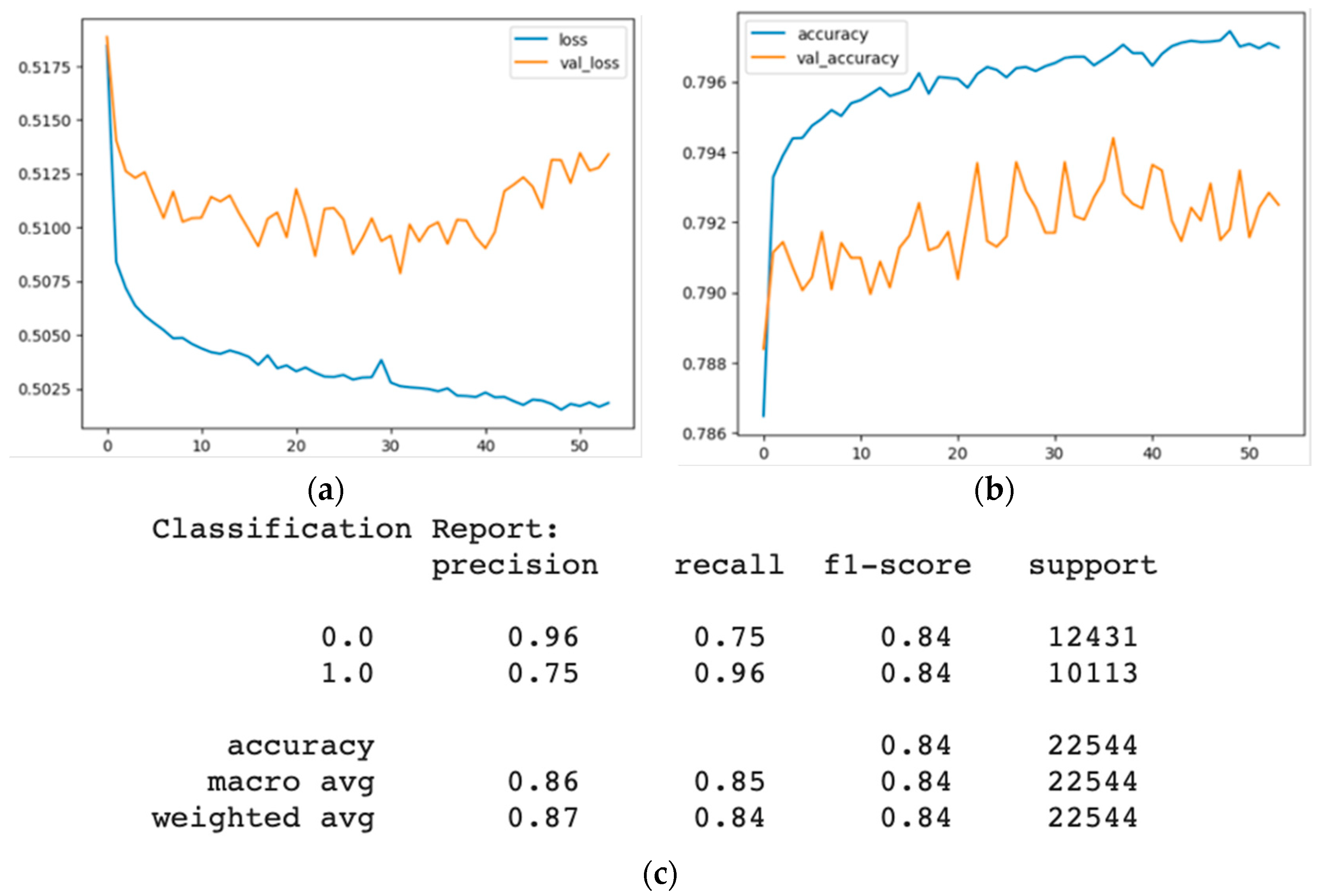
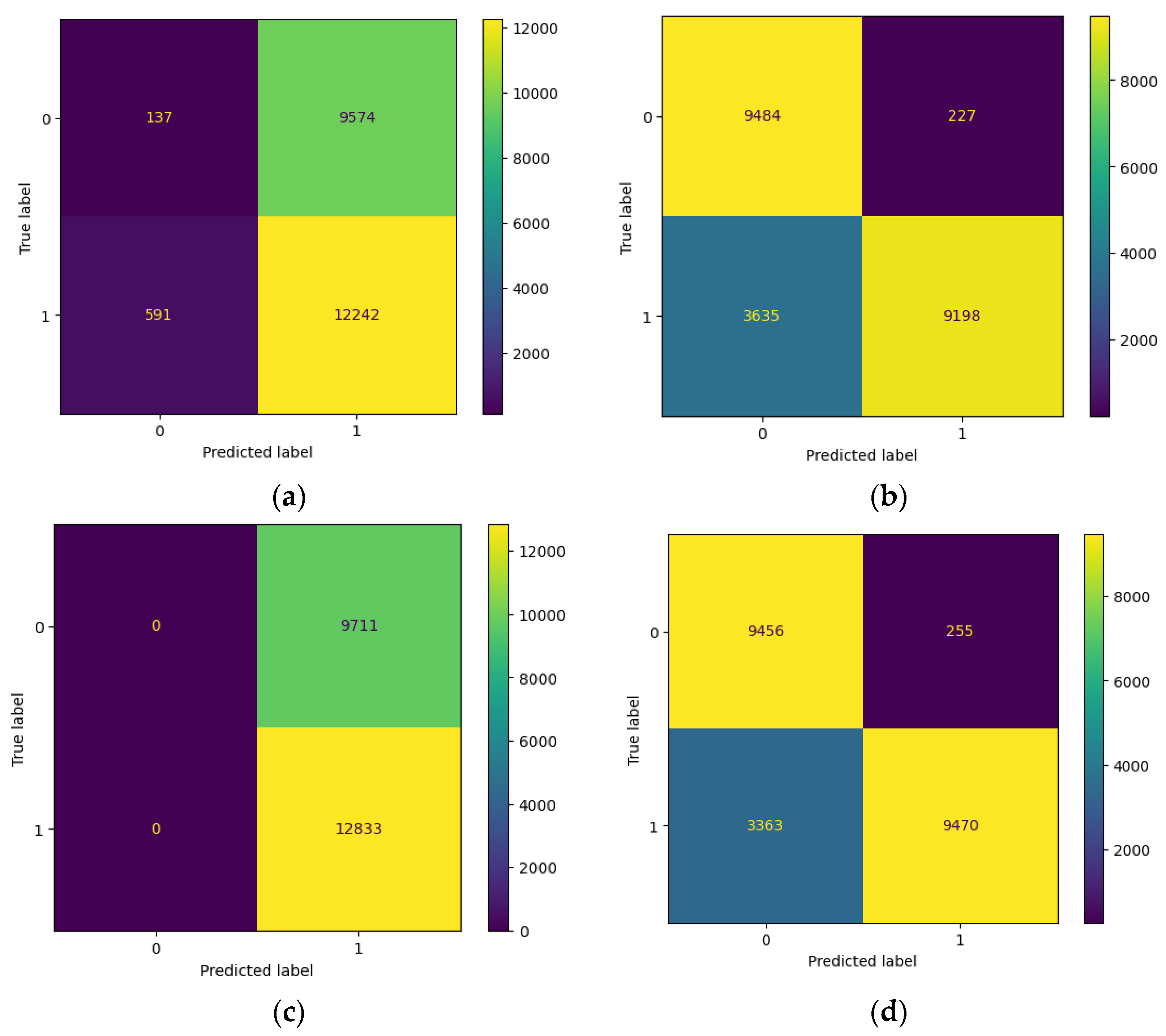
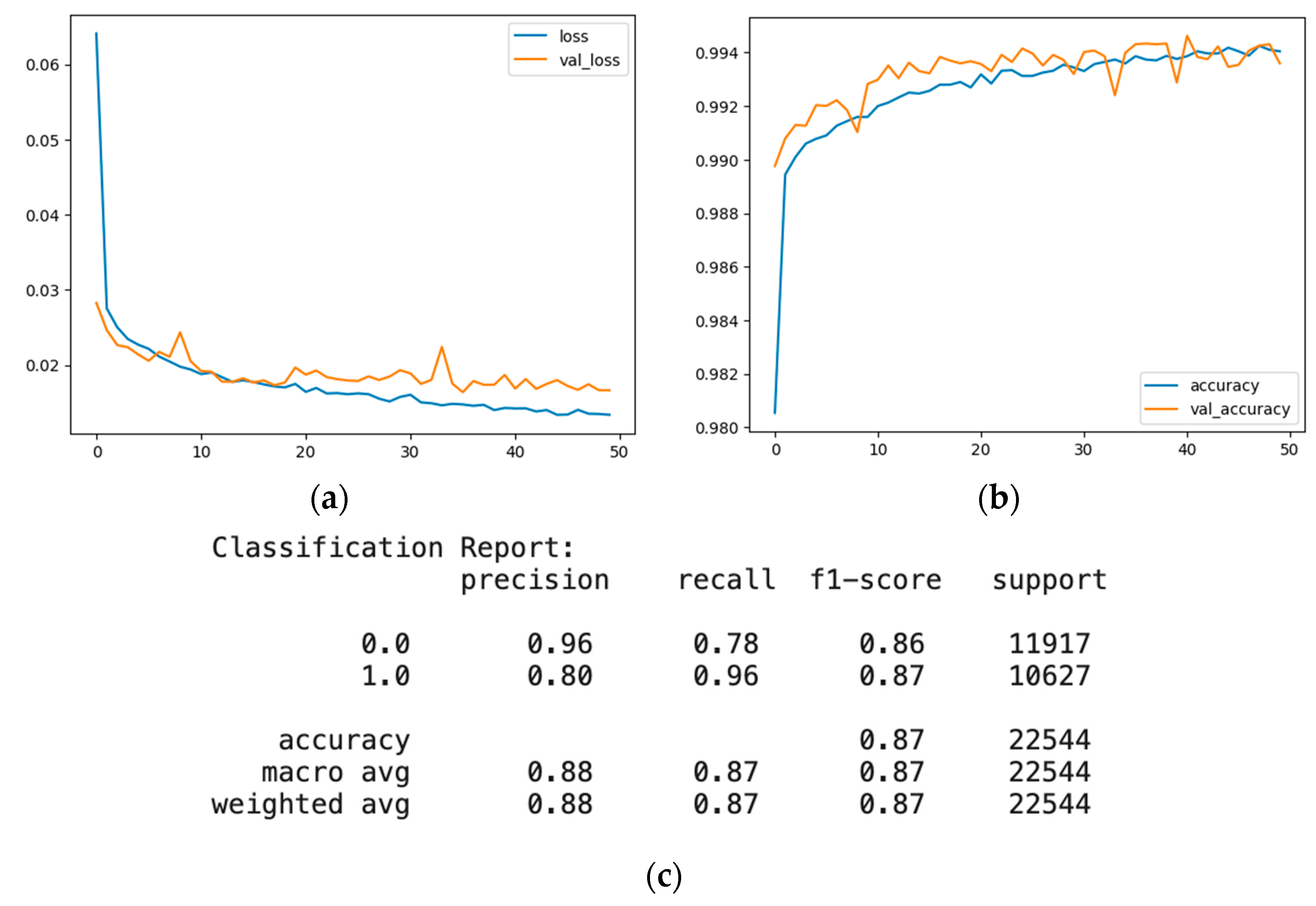
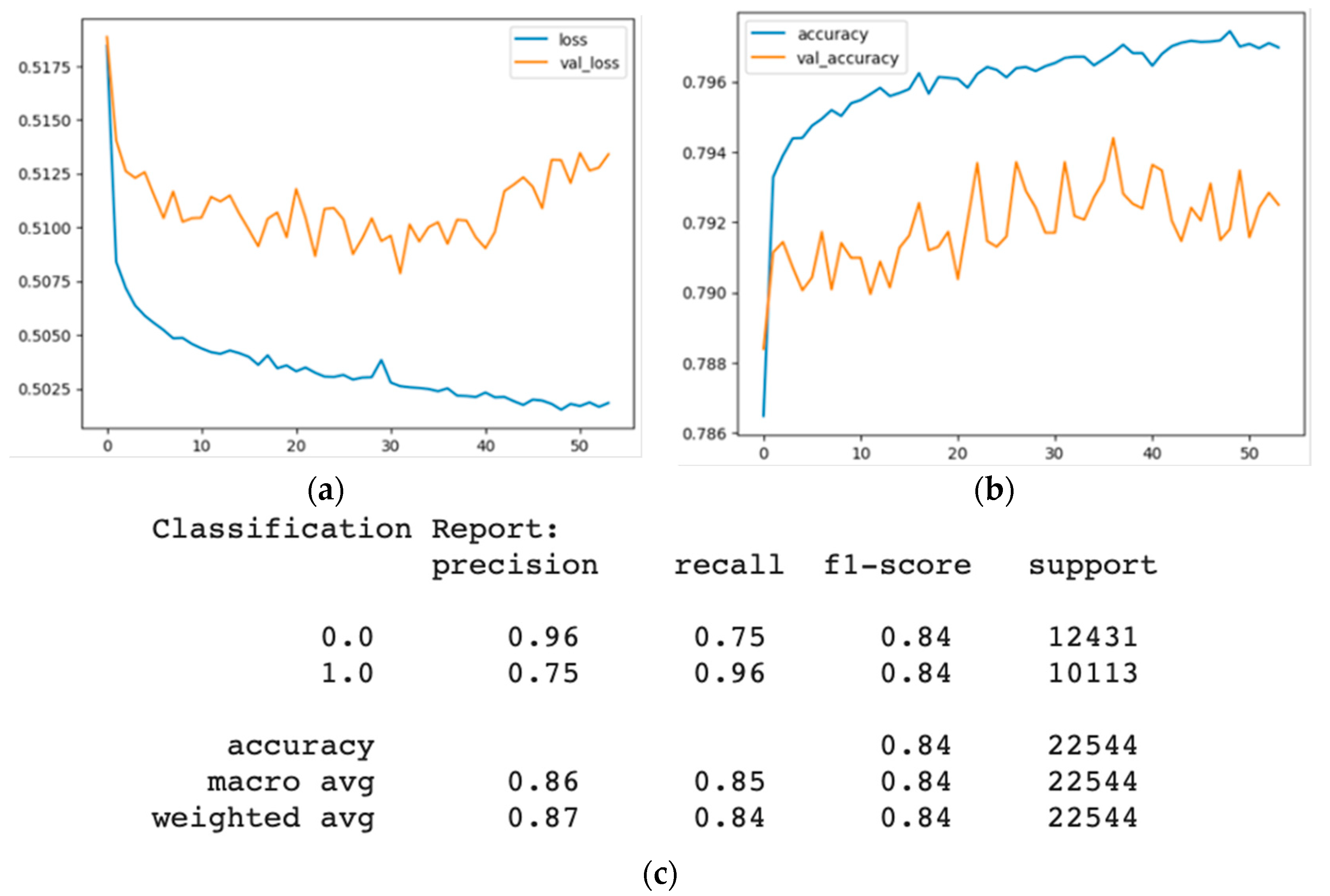
4.3. Artificial Neural Network Data Poisoning Attack
4.3.1. Evaluation of the Artificial Neural Network before a Random Label Flipping Attack
4.3.2. Evaluation of the Artificial Neural Network with a Random Label Flipping Attack
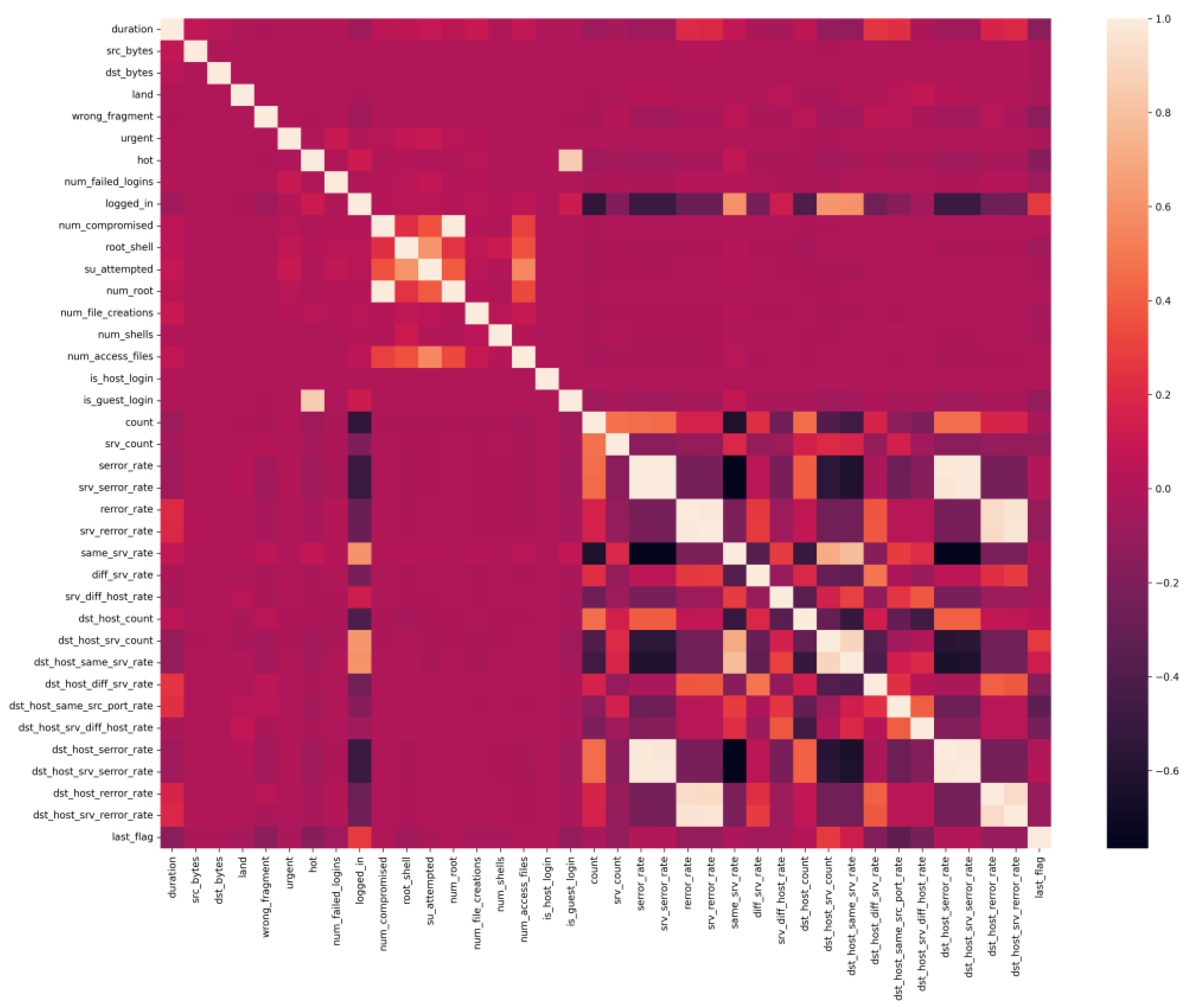
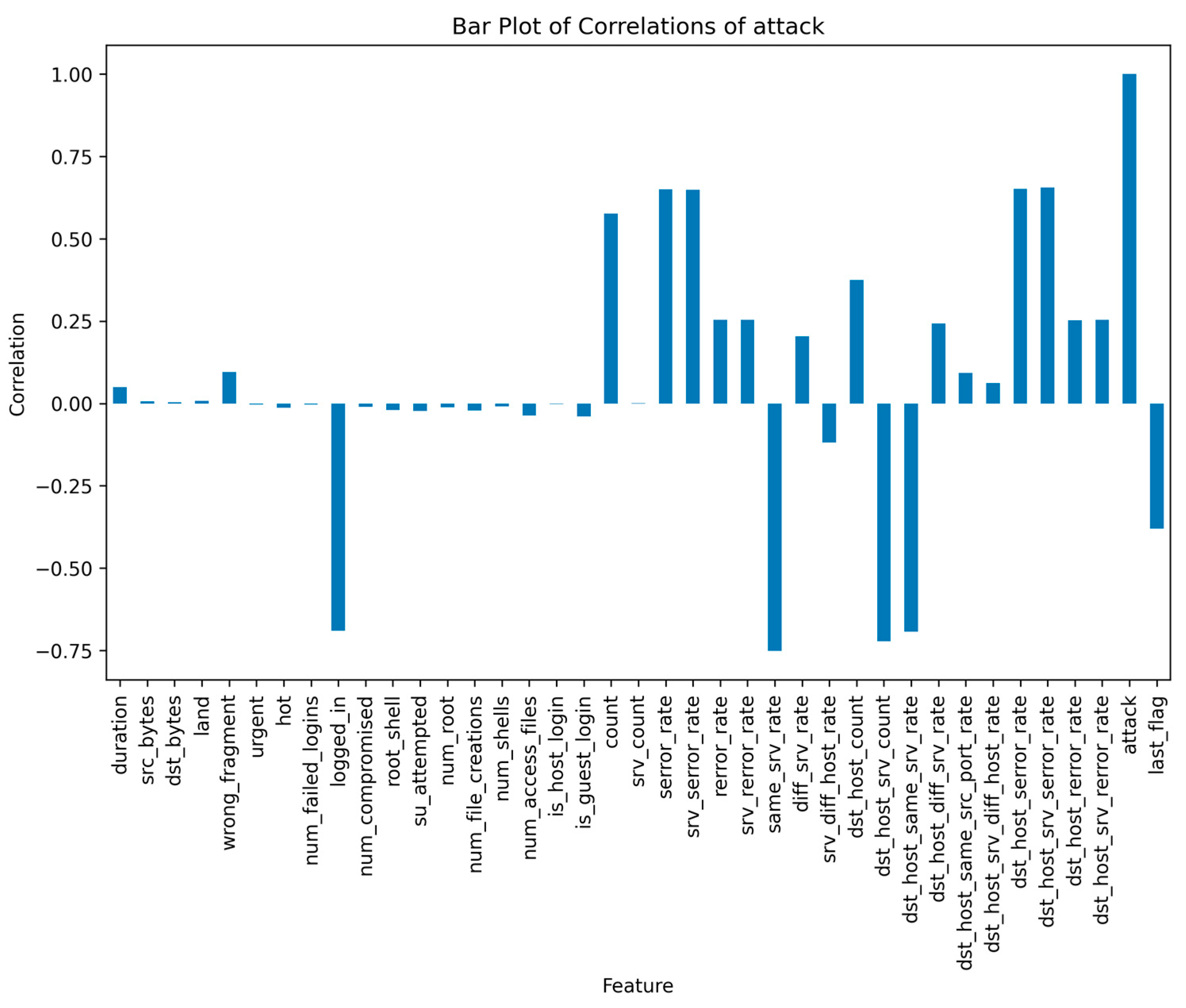
4.4. Experiment Analysis
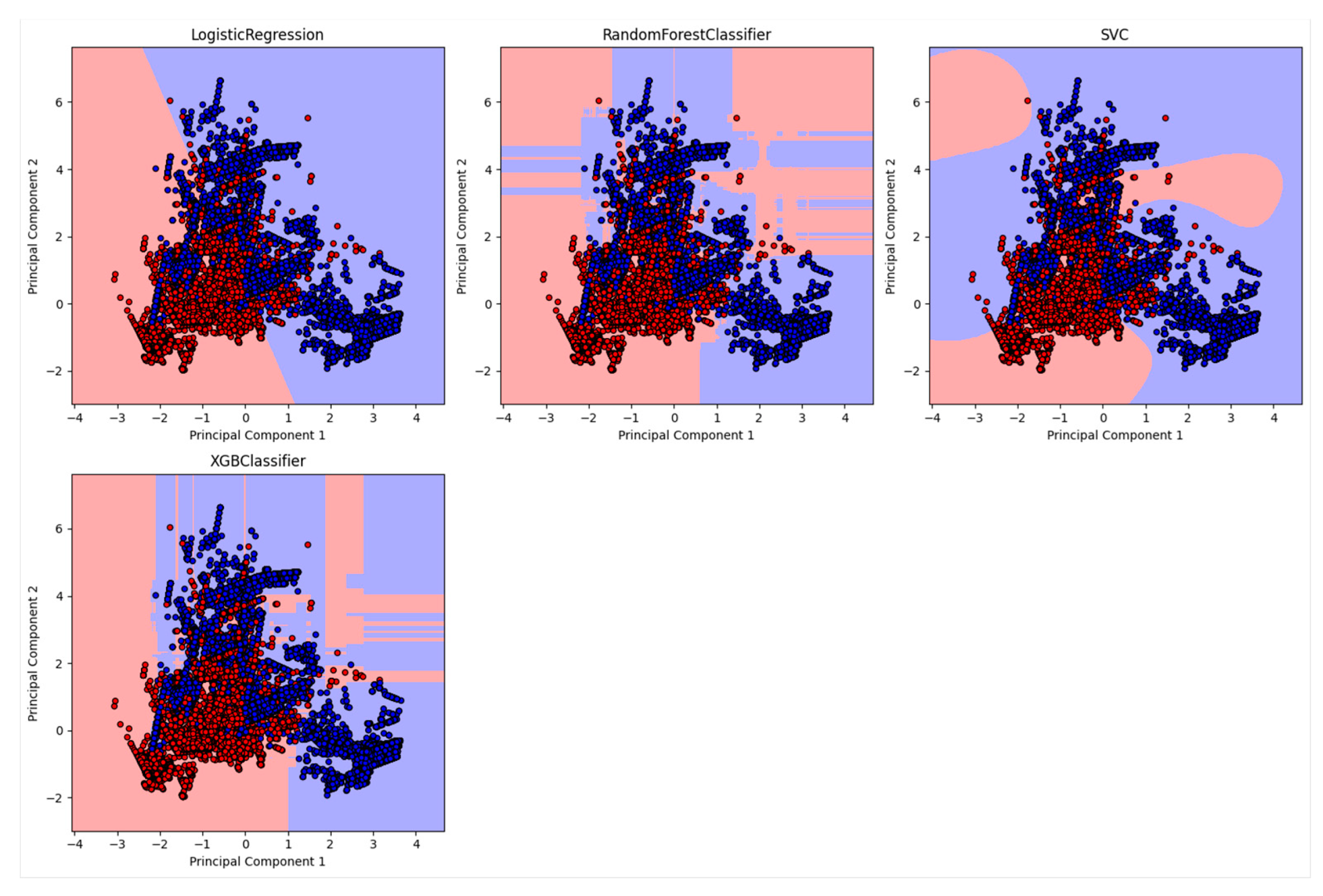
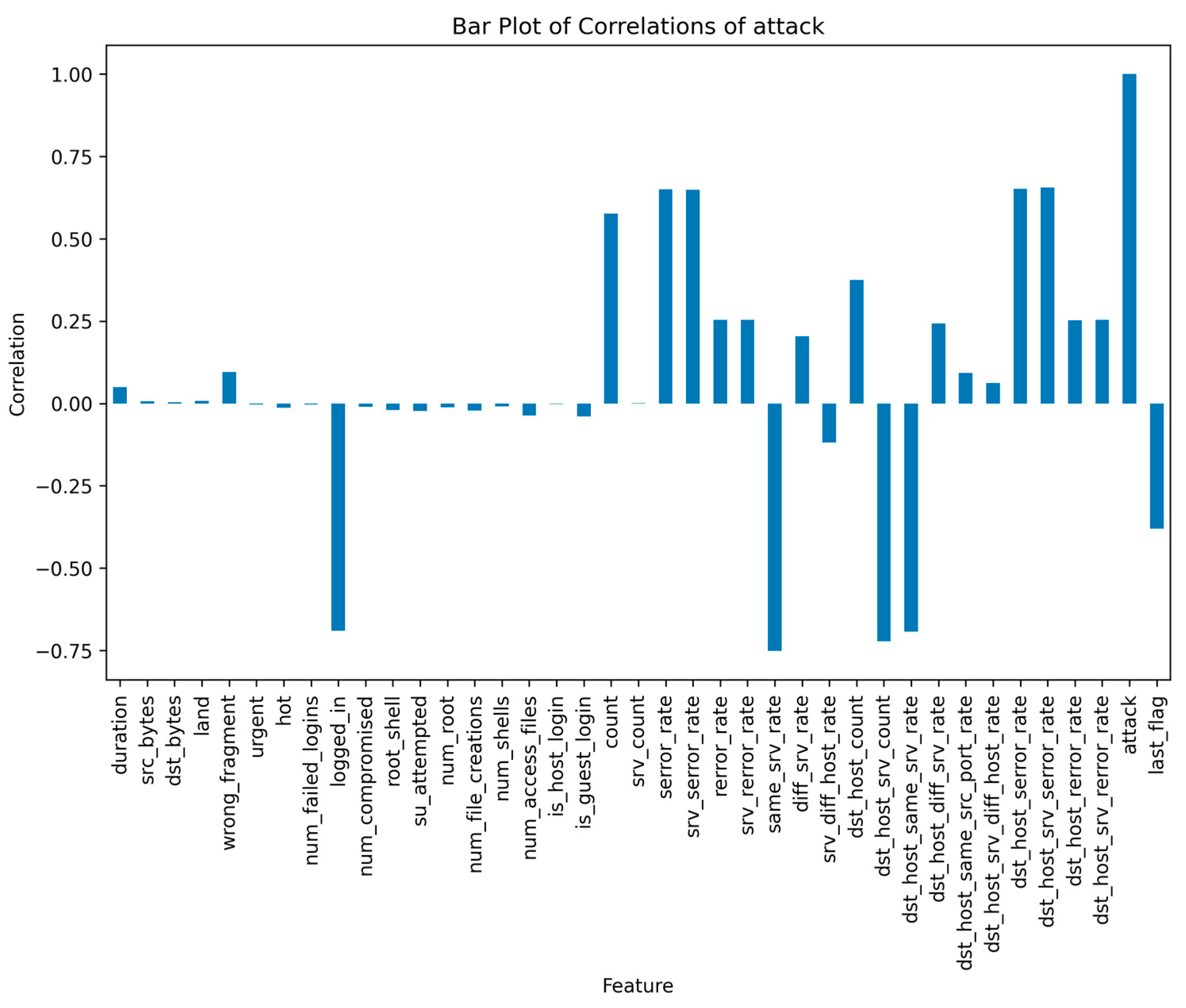
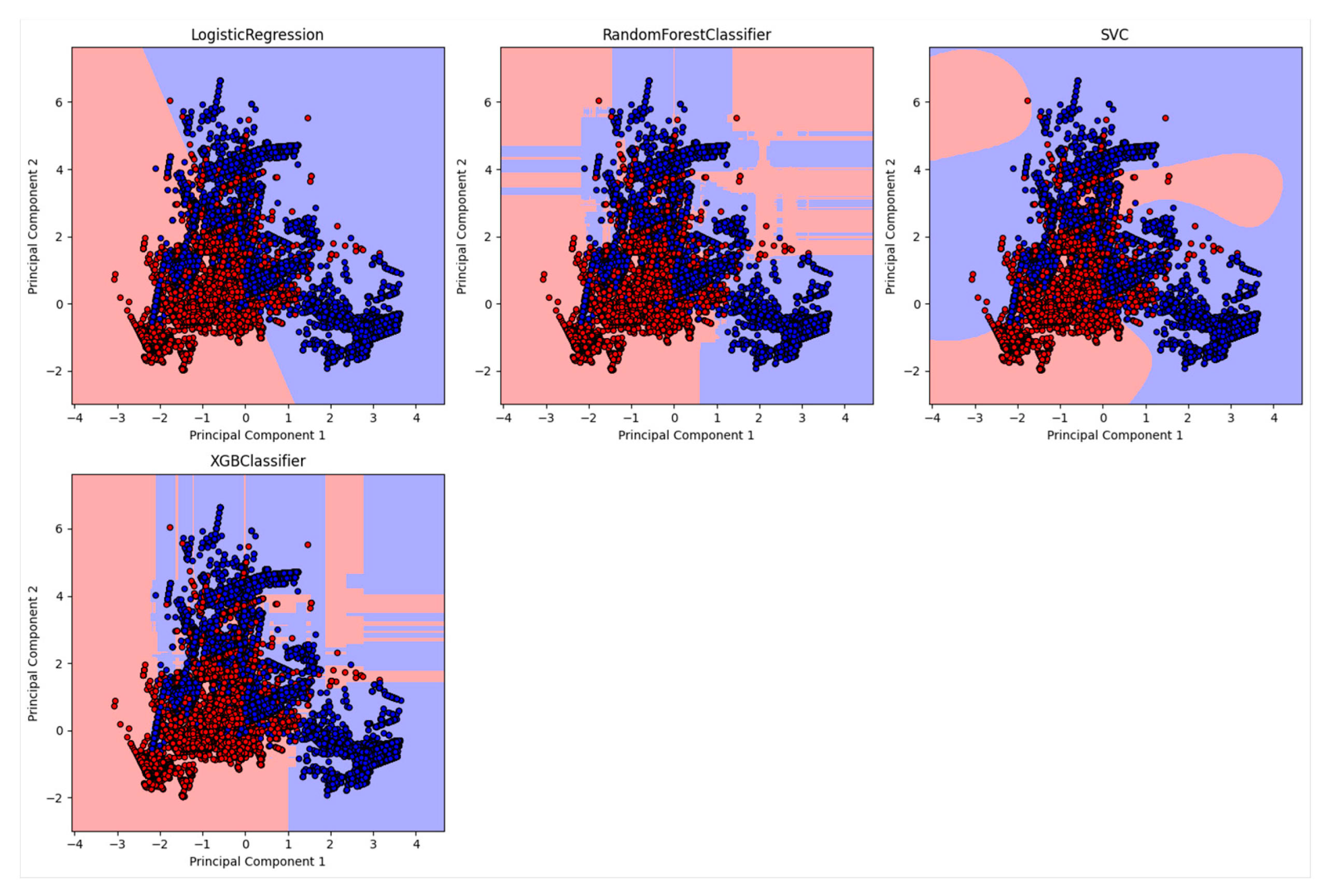
- The logistic regression model is the most resilient to both attacks because it is a linear model with a simple and stable decision boundary less affected by the label changes. The label changes only affect the instances close to the decision boundary, which are fewer in number and have less influence on the model’s parameters. The logistic regression model also has a regularisation term that prevents overfitting and reduces its sensitivity to noise or outliers.
- The random forest model is the most vulnerable to both types of attacks because it is an ensemble model that combines the outputs of multiple decision trees trained on random data subsets. The label changes affect most instances in each subset, leading to high variance and inconsistency among the decision trees. The random forest model also has high complexity and flexibility which make it prone to overfitting and increase its susceptibility to noise or outliers.
- The support vector machine model is moderately resilient to both attacks because it is a kernel-based model that uses a nonlinear transformation to map the data to a higher dimensional space where it can find a linear decision boundary that separates the classes. The label changes affect the instances close to the decision boundary, which are the support vectors that determine the model’s parameters. The support vector machine model also has a regularisation term that prevents overfitting and reduces its sensitivity to noise or outliers.
- The XGBoost model is moderately vulnerable to both types of attacks because it is a gradient-boosting model that iteratively adds new decision trees trained on the residuals of the previous trees. The label changes affect the model’s residuals and gradients, leading to a high bias and error accumulation among the decision trees. The XGBoost model also has high complexity and flexibility which make it prone to overfitting and increase its susceptibility to noise or outliers.
- The artificial neural network model is highly accurate on both datasets. However, it has lower precision and recall than other models because it is a deep learning model that uses multiple layers of nonlinear transformations to learn complex and abstract features from the data. The label changes affect the model’s features and weights, leading to high confusion and misclassification among the classes. The artificial neural network model also has high complexity and flexibility that make it prone to overfitting and increase its susceptibility to noise or outliers.
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abuali, K.M.; Nissirat, L.; Al-Samawi, A. Advancing Network Security with AI: SVM-Based Deep Learning for Intrusion Detection. Sensors 2023, 23, 8959. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Yan, Q.; Li, M.; Qu, G.; Xiao, Y. A Survey on Data Poisoning Attacks and Defenses. In Proceedings of the 2022 7th IEEE International Conference on Data Science in Cyberspace (DSC), Guilin, China, 11–13 July 2022. [Google Scholar]
- Goldblum, M.; Tsipras, D.; Xie, C.; Chen, X.; Schwarzschild, A.; Song, D.; Mądry, A.; Li, B.; Goldstein, T. Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1563–1580. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Li, Q.; Cui, Z.; Hou, J.; Huang, C. Bandit-based data poisoning attack against federated learning for autonomous driving models. Expert Syst. Appl. 2023, 227, 120295. [Google Scholar] [CrossRef]
- Yerlikaya, F.A.; Bahtiyar, Ş. Data poisoning attacks against machine learning algorithms. Expert Syst. Appl. 2022, 208, 118101. [Google Scholar] [CrossRef]
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Lyu, L.; Liu, J. Data poisoning attacks on federated machine learning. IEEE Internet Things J. 2021, 9, 11365–11375. [Google Scholar] [CrossRef]
- Nisioti, A.; Mylonas, A.; Yoo, P.D.; Katos, V. From intrusion detection to attacker attribution: A comprehensive survey of unsupervised methods. IEEE Commun. Surv. Tutor. 2018, 20, 3369–3388. [Google Scholar] [CrossRef]
- Saxena, N.; Sarkar, B. How does the retailing industry decide the best replenishment strategy by utilizing technological support through blockchain? J. Retail. Consum. Serv. 2023, 71, 103151. [Google Scholar] [CrossRef]
- Cinà, A.E.; Grosse, K.; Demontis, A.; Vascon, S.; Zellinger, W.; Moser, B.A.; Oprea, A.; Biggio, B.; Pelillo, M.; Roli, F. Wild patterns reloaded: A survey of machine learning security against training data poisoning. ACM Comput. Surv. 2023, 55, 1–39. [Google Scholar] [CrossRef]
- Talty, K.; Stockdale, J.; Bastian, N.D. A sensitivity analysis of poisoning and evasion attacks in network intrusion detection system machine learning models. In Proceedings of the MILCOM 2021—2021 IEEE Military Communications Conference (MILCOM), San Diego, CA, USA, 29 November–2 December 2021. [Google Scholar]
- Zhang, Y.; Zhang, Y.; Zhang, Z.; Bai, H.; Zhong, T.; Song, M. Evaluation of data poisoning attacks on federated learning-based network intrusion detection system. In Proceedings of the 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Chengdu, China, 18–21 December 2022. [Google Scholar]
- Zhang, Z.; Zhang, Y.; Guo, D.; Yao, L.; Li, Z. SecFedNIDS: Robust defense for poisoning attack against federated learning-based network intrusion detection system. Futur. Gener. Comput. Syst. 2022, 134, 154–169. [Google Scholar] [CrossRef]
- Lai, Y.-C.; Lin, J.-Y.; Lin, Y.-D.; Hwang, R.-H.; Lin, P.-C.; Wu, H.-K.; Chen, C.-K. Two-phase Defense Against Poisoning Attacks on Federated Learning-based Intrusion Detection. Comput. Secur. 2023, 129, 103205. [Google Scholar] [CrossRef]
- Taheri, R.; Javidan, R.; Shojafar, M.; Pooranian, Z.; Miri, A.; Conti, M. Correction to: On defending against label flipping attacks on malware detection systems. Neural Comput. Appl. 2020, 32, 14781–14800. [Google Scholar] [CrossRef]
- Zarezadeh, M.; Nourani, E.; Bouyer, A. DPNLP: Distance based peripheral nodes label propagation algorithm for commu-nity detection in social networks. World Wide Web 2022, 25, 73–98. [Google Scholar] [CrossRef]
- Gupta, P.; Yadav, K.; Gupta, B.B.; Alazab, M.; Gadekallu, T.R. A Novel Data Poisoning Attack in Federated Learning based on Inverted Loss Function. Comput. Secur. 2023, 130, 103270. [Google Scholar] [CrossRef]
- Deng, X.; Zhu, J.; Pei, X.; Zhang, L.; Ling, Z.; Xue, K. Flow topology-based graph convolutional network for intrusion detec-tion in label-limited iot networks. IEEE Trans. Netw. Serv. Manag. 2022, 20, 684–696. [Google Scholar] [CrossRef]
- Song, J.; Wang, X.; He, M.; Jin, L. CSK-CNN: Network Intrusion Detection Model Based on Two-Layer Convolution Neural Network for Handling Imbalanced Dataset. Information 2023, 14, 130. [Google Scholar] [CrossRef]
- Koh, P.W.; Steinhardt, J.; Liang, P. Stronger data poisoning attacks break data sanitisation defenses. Mach. Learn 2022, 111, 1–47. [Google Scholar] [CrossRef]
- Zhu, Y.; Wen, H.; Zhao, R.; Jiang, Y.; Liu, Q.; Zhang, P. Research on Data Poisoning Attack against Smart Grid Cyber–Physical System Based on Edge Computing. Sensors 2023, 23, 4509. [Google Scholar] [CrossRef]
- Shah, B.; Trivedi, B.H. Reducing features of KDD CUP 1999 dataset for anomaly detection using back propagation neural network. In Proceedings of the 2015 Fifth International Conference on Advanced Computing & Communication Technologies, Haryana, India, 21–22 February 2015. [Google Scholar]
- Divekar, A.; Parekh, M.; Savla, V.; Mishra, R.; Shirole, M. Benchmarking datasets for anomaly-based network intrusion detection: KDD CUP 99 alternatives. In Proceedings of the 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Katmandu, Nepal, 25–27 October 2018. [Google Scholar]
- Zhang, H.; Li, Z.; Shahriar, H.; Tao, L.; Bhattacharya, P.; Qian, Y. Improving prediction accuracy for logistic regression on imbalanced datasets. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019. [Google Scholar]
- Madzarov, G.; Gjorgjevikj, D. Multi-class classification using support vector machines in decision tree architecture. In Proceedings of the IEEE EUROCON 2009, St. Petersburg, Russia, 18–23 May 2009. [Google Scholar]
- Cheng, N.; Zhang, H.; Li, Z. Data sanitisation against label flipping attacks using AdaBoost-based semi-supervised learning technology. Soft Comput. 2021, 25, 14573–14581. [Google Scholar] [CrossRef]
- Li, Q.; Wang, X.; Wang, F.; Wang, C. A Label Flipping Attack on Machine Learning Model and Its Defense Mechanism. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, Copenhagen, Denmark, 10 October 2022. [Google Scholar]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can machine learning be secure? In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21–24 March 2006. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. arXiv 2012, arXiv:1206.6389. [Google Scholar]
- Chen, J.; Gao, Y.; Shan, J.; Peng, K.; Wang, C.; Jiang, H. Manipulating Supply Chain Demand Forecasting with Targeted Poisoning Attacks. IEEE Trans. Ind. Inform. 2022, 19, 1803–1813. [Google Scholar] [CrossRef]
- Lin, J.; Dang, L.; Rahouti, M.; Xiong, K. Ml attack models: Adversarial attacks and data poisoning attacks. arXiv 2021, arXiv:2112.02797. [Google Scholar]
- Qiu, H.; Dong, T.; Zhang, T.; Lu, J.; Memmi, G.; Qiu, M. Adversarial attacks against network intrusion detection in IoT systems. IEEE Internet Things J. 2020, 8, 10327–10335. [Google Scholar] [CrossRef]
- Venkatesan, S.; Sikka, H.; Izmailov, R.; Chadha, R.; Oprea, A.; de Lucia, M.J. Poisoning attacks and data sanitization mitigations for machine learning models in network intrusion detection systems. In Proceedings of the MILCOM 2021—2021 IEEE Military Communications Conference (MILCOM), San Diego, CA, USA, 29 November–2 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 874–879. [Google Scholar]
- Salo, F.; Injadat, M.; Nassif, A.B.; Shami, A.; Essex, A. Data mining techniques in intrusion detection systems: A systematic literature review. IEEE Access 2018, 6, 56046–56058. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Limitations and Research Gaps |
|---|---|---|
| [20] | 2023 | Depending on the loss function (f) the attacker would have to control a larger number of clients with an increasing number of participating devices to uphold the value of f. The research does not directly tackle this aspect, as it does not alter the loss function but rather assesses the impact of data poisoning attacks on existing machine learning models. |
| [17] | 2022 | The research does not include FT-GCN optimisation or the development of an upgraded traffic graph with weighted edges denoting the degree of correlation among traffic flows. Moreover, the research does not explore the multi-classification of harmful internet traffic flows at this point; while the research does not engage with these specific aspects, it concentrates on evaluating the models’ robustness against data poisoning attacks in the existing intrusion detection context. |
| [18] | 2023 | The study focuses on improving the CSK-CNN model’s overall classification performance in the context of intrusion detection datasets. However, it does not detail how well certain anomalous categories like Dos, Web Attack Brute Force, and others, are classified. As such, there may not have been a comprehensive assessment or optimisation of the model’s performance regarding these particular attack categories. Although this research does not offer an optimisation or detailed assessment of the CSK-CNN model’s performance for these specific categories, it focuses on the broader impact of data poisoning attacks on various machine learning models. |
| [9] | 2023 | It does not delve into advanced online models like deep learning and neural networks. As a result, the findings and methods proposed in the study may not be readily applicable to these models. These more complex models might pose distinct challenges and necessitate unique attack and defence strategies. The research in this paper uses several machine learning models such as logistic regression, random forest, support vector classifier, XGBoost, and a deep neural network with eight layers. Also, it focuses on the impact of data poisoning attacks on these models. |
| LR | Random Forest | SVC | XGB | |
|---|---|---|---|---|
| Acc | 0.85,81884315117104 | 0.82,52306600425834 | 0.84,6829607723754 | 0.82,94889992902768 |
| F1 | 0.86,82464454976303 | 0.82,2841726618705 | 0.84,6829607723754 | 0.82,78857347541864 |
| Prec | 0.92,14485654303709 | 0.97,26799192090996 | 0.95,81734081291211 | 0.97,30554678454899 |
| Recall | 0.82,08524896750565 | 0.71,30055326112367 | 0.75,86690563391257 | 0.72,04083222940856 |
| LR | Random Forest | SVC | XGB | |
|---|---|---|---|---|
| Acc | 0.8698988644428672 | 0.8089513839602555 | 0.8475869410929737 | 0.8622693399574166 |
| F1 | 0.8806219219341447 | 0.8075771791091453 | 0.8513583664993943 | 0.8655203776690199 |
| Prec | 0.9217791411042945 | 0.9463874345549739 | 0.9569191870076826 | 0.9742589703588144 |
| Recall | 0.8429829346216785 | 0.7042780331956674 | 0.7667731629392971 | 0.7786176264318554 |
| LR | Random Forest | SVC | XGB | |
|---|---|---|---|---|
| Acc | 0.5491039744499645 | 0.8286905606813343 | 0.5692423704755145 | 0.839513839602555 |
| F1 | 0.7066293399520911 | 0.8264893521430497 | 0.7254996183961331 | 0.839613440907882 |
| Prec | 0.5611477814448111 | 0.9759151193633953 | 0.5692423704755145 | 0.9737789203084833 |
| Recall | 0.9539468557624874 | 0.7167458895036235 | 1 | 0.7379412452271488 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Butt, U.J.; Hussien, O.; Hasanaj, K.; Shaalan, K.; Hassan, B.; al-Khateeb, H. Predicting the Impact of Data Poisoning Attacks in Blockchain-Enabled Supply Chain Networks. Algorithms 2023, 16, 549. https://doi.org/10.3390/a16120549
Butt UJ, Hussien O, Hasanaj K, Shaalan K, Hassan B, al-Khateeb H. Predicting the Impact of Data Poisoning Attacks in Blockchain-Enabled Supply Chain Networks. Algorithms. 2023; 16(12):549. https://doi.org/10.3390/a16120549
Chicago/Turabian StyleButt, Usman Javed, Osama Hussien, Krison Hasanaj, Khaled Shaalan, Bilal Hassan, and Haider al-Khateeb. 2023. "Predicting the Impact of Data Poisoning Attacks in Blockchain-Enabled Supply Chain Networks" Algorithms 16, no. 12: 549. https://doi.org/10.3390/a16120549
APA StyleButt, U. J., Hussien, O., Hasanaj, K., Shaalan, K., Hassan, B., & al-Khateeb, H. (2023). Predicting the Impact of Data Poisoning Attacks in Blockchain-Enabled Supply Chain Networks. Algorithms, 16(12), 549. https://doi.org/10.3390/a16120549