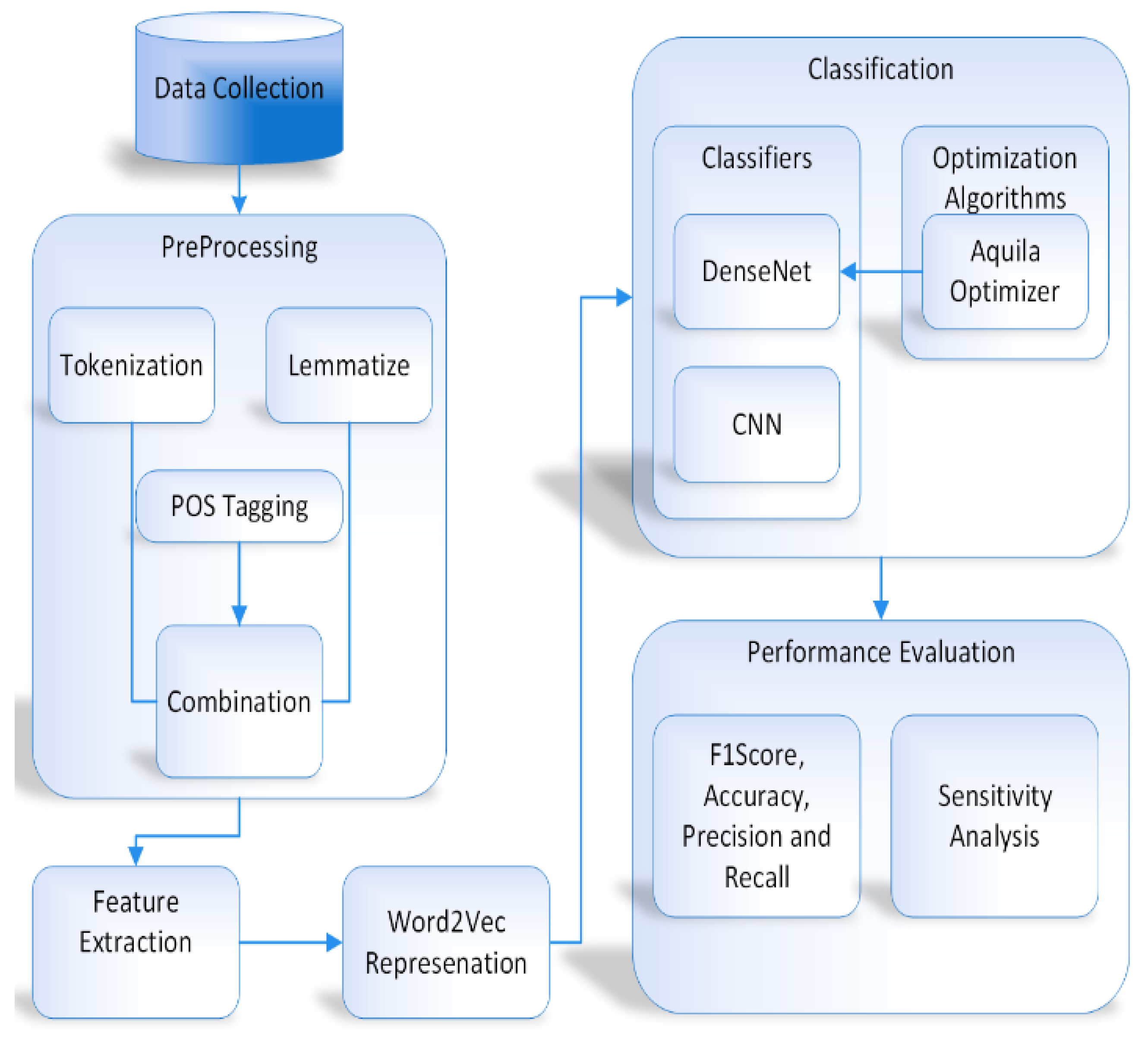
This section provides an extensive description of the experimental results along with an in-depth analysis of the outcomes. A system with specification a ninth-generation Core i7 processor with 2.4 quad-cores was used for the research. The main programming language used for this study is Python, and the programming environment used was the Spyder IDE.
4.2. Metrics for Performance Evaluation
This section will apply five essential multi-label metrics, as previously introduced and discussed in our work. These metrics have gained significant attention in the current literature, making them fundamental for our analysis. To illustrate, consider the scenario within our multi-label datasets, which consist of multiple instances represented as (ci, pi), where “ci” represents a specific label and “pi” is the associated input. We will use the notation h(pi) for the predictive label collection. Additionally, we will introduce ci, f to denote the individual MLL h function and ci, f for the separate MLL h function, each corresponding to a specific (ci, pi) pair. Regarding the variable “ci”. This variable reflects how the learner rates input “pi” at label “ci”, ensuring that "ci” accurately corresponds to the label assigned to input “pi”. This alignment holds significant importance in our analysis.
4.2.1. Accuracy
The ratio of accurately anticipated observations to all observed data points (or observations plus predictions) is the most easily understood performance metric (or observations). High-precision models are the most accurate because they are the most precise (high accuracy). Precision is essential, but only an asymmetric dataset will have nearly equal-sized negative and false positive results.
4.2.2. Precision
It establishes the percentage of cases correctly diagnosed out of all those that received favorable labels under specific conditions. The ratio of all correctly predicted positive observations to the amount of all foreseen positive sightings plus the number of significant positive observations is known as precision. A low rate of false positives in medical diagnosis is associated with good diagnostic accuracy.
4.2.3. Recall
Recall, also known as the true positive rate or sensitivity, is a crucial metric in multi-labeling. It measures the proportion of correctly predicted positive observations within the context of our multi-label dataset. It is calculated by dividing the total number of observations by the correctly predicted positive observations. This metric is significant, alongside accuracy and other key metrics, for assessing the performance of multi-label classification models.
4.2.4. F-Measure
The F-measure combines precision and recall, providing a balanced evaluation of multi-label classification performance. This metric, also known as the balanced F-score, represents the harmonic mean of precision and recall. The formula for computing it involves the square of the scaling factor divided by the weighted sum. It is essential to note that precision and recall are equally weighted in this metric, commonly referred to as the F1-measure.
4.3. Compared Models
The suggested EDAO was put through its paces in a full comparison with the most commonly used MLL techniques to demonstrate its efficacy. In the ensemble multi-label learning (EnML) domain, two distinct scenarios, ML-NCL and ML-HISC, stand out. These scenarios optimize a single target to validate the provided objective function. By focusing on individual targets, they serve as valuable testbeds for refining and validating the optimization process within the EnML framework. All of these techniques are summarized in the following sections.
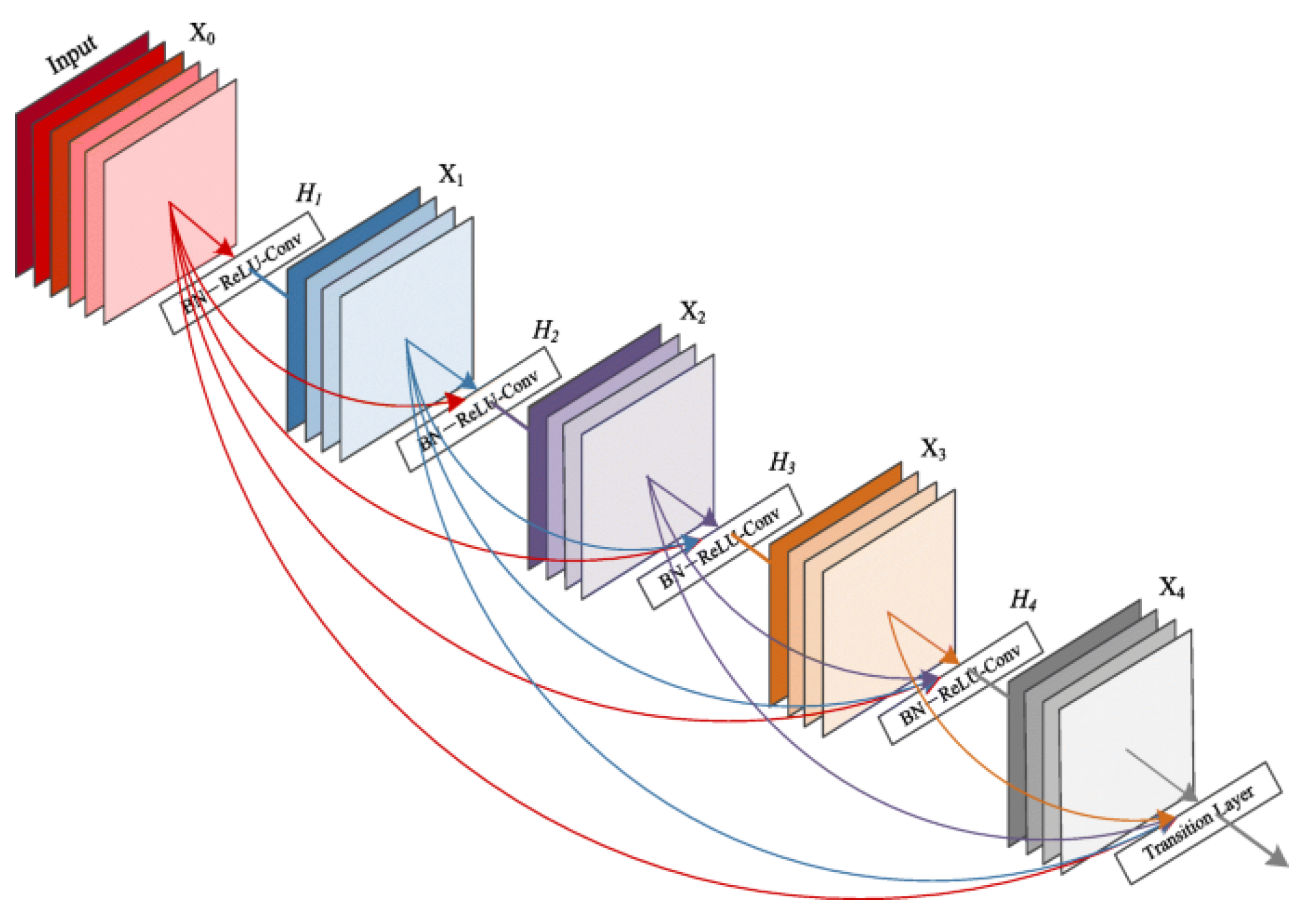
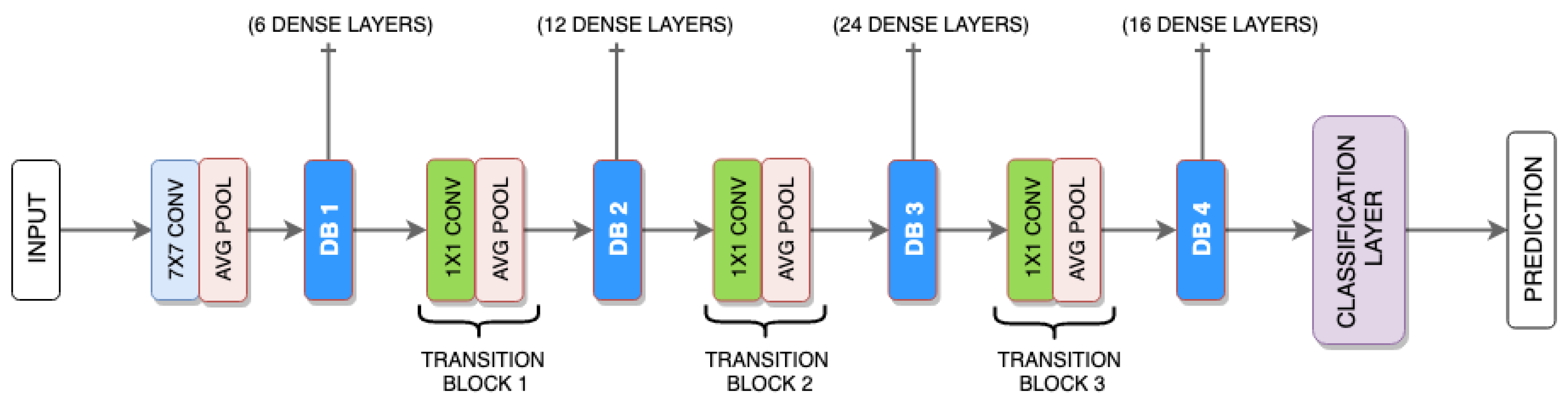
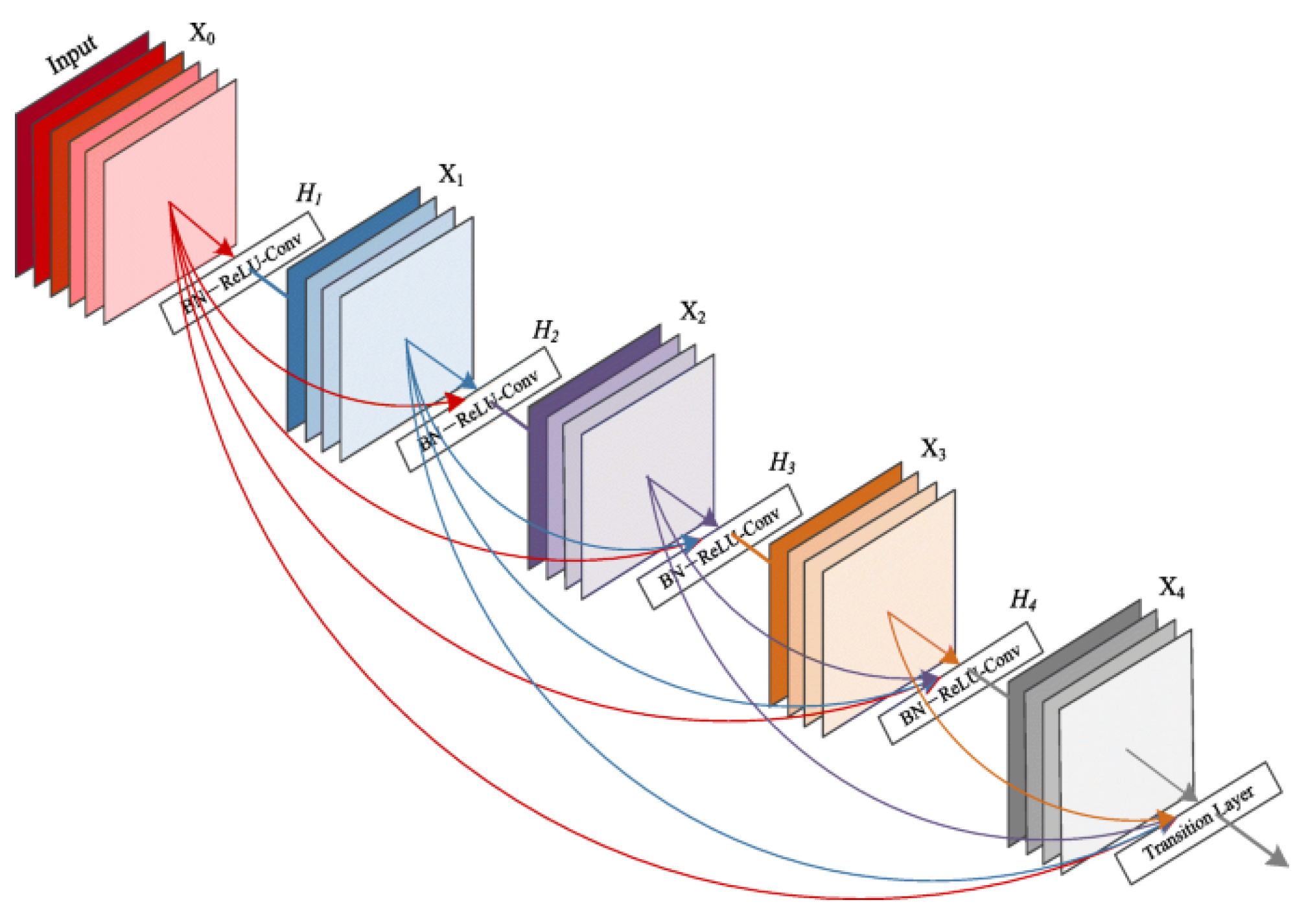
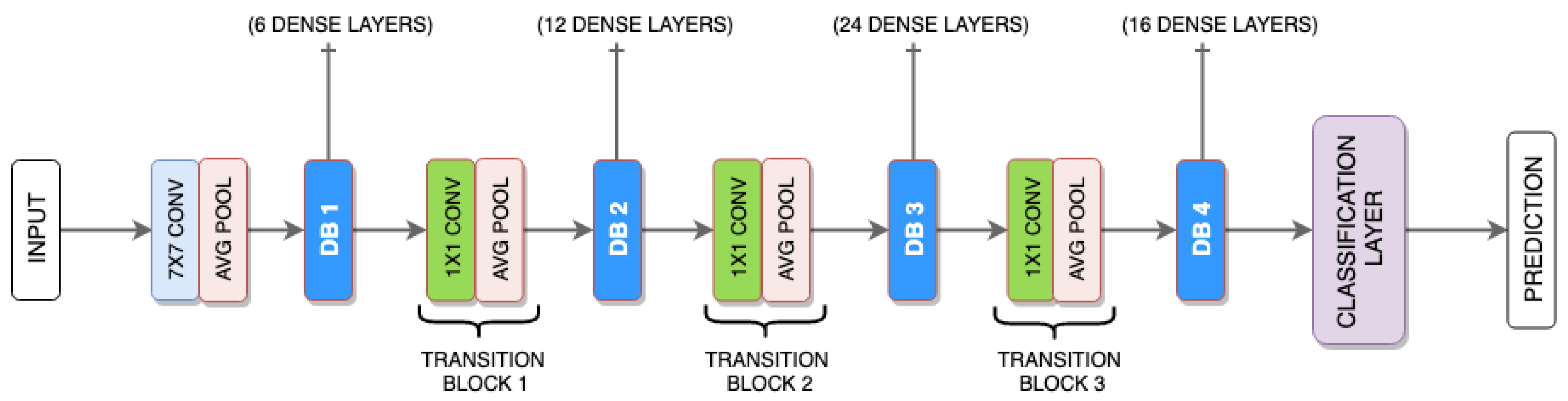
Proposed Ensembler: DenseNet is used as a DNN algorithm ensemble with AO and as an ensembler. The DenseNet makes use of its bunch of layers.
NB: The ML algorithm was utilized in the multi-labeling method.
CNN: The multi-label learning (MLL) algorithm is fundamentally rooted in the domain of NNs.
ML-RBF [
22]: Additionally, the RBF NN algorithm-based MLL algorithm is the primary trainer utilized by the ENL system and is developed based on RBF NN.
RAKEL [
26]: Another approach to multivalued learning. In this approach, a basic learner with a single label makes judgments based on a randomly selected subset of the encountered labels. This limited subset serves as the basis for decision-making, reflecting the nature of most basic learners in this context.
ECC [
24] provides a detailed description of an ensemble approach for MLL based on using classifier chains. To transform EnML into a subproblem, we must first modify the unique goal into the one we used to create EnML.
Enhanced DenseNet with Aquila Optimizer (EDAO) is a revolutionary advancement in sentiment analysis that has unique characteristics that distinguish it from other approaches. The Aquila Optimizer, a customized optimization method created especially for adjusting DenseNet’s parameters, is one of its main contributions. This new optimizer, which prioritizes effectiveness and efficiency, is essential to improving the convergence and general performance of the model. Moreover, EDAO overcomes the drawbacks of other sentiment analysis techniques, excelling especially in multi-label sentiment analysis. Through its optimization process, EDAO combines accuracy and diversity, in contrast to benchmark techniques that could just favor accuracy. This integrated approach is beneficial, allowing EDAO to perform better than approaches with a more limited accuracy-focused scope and to catch sentiment fluctuations with ease.
More specifically, to identify minute emotion differences across various texts, EDAO carefully use DenseNet-AO, a DenseNet variation. By leveraging DenseNet-AO, this approach greatly improves the model’s capacity to traverse the intricacies of multi-label datasets, hence addressing a prevalent sentiment analysis difficulty. DenseNet-AO integration is also essential for increasing generalization efficiency, which enables the model to easily adjust to new or unknown input. A sensitivity analysis is a crucial assessment indicator for the decision-making process in terms of robustness and stability, according to EDAO. This novel approach solves the issues with the robustness of current techniques and offers a thorough evaluation of the model’s dependability in a range of scenarios. Furthermore, EDAO simplifies label space translation, reducing the computational burden involved in this procedure. Using the LP approach for label space translation improves the model’s efficiency and scalability, enabling it to handle large datasets with ease. Essentially, Enhanced DenseNet with Aquila Optimizer is a ground-breaking sentiment analysis system that combines cutting-edge optimization techniques, DenseNet-AO’s strength, and an all-encompassing strategy to overcome the drawbacks of conventional approaches. Together, these unique qualities improve EDAO’s performance, let it capture sentiment nuances more effectively, and present it as a reliable multi-label sentiment analysis solution.
4.4. Performance of Different Methods
For each experimental data collection, tenfold cross-validation is conducted. Using the provided outputs, the selected technique’s standard deviation and average productivity are computed for the entire dataset. The experiments were carried out utilizing a device powered by a robust 2.24 GHz Intel Xeon processor and bolstered by a generous 16 GB of RAM.
Table 6,
Table 7 and
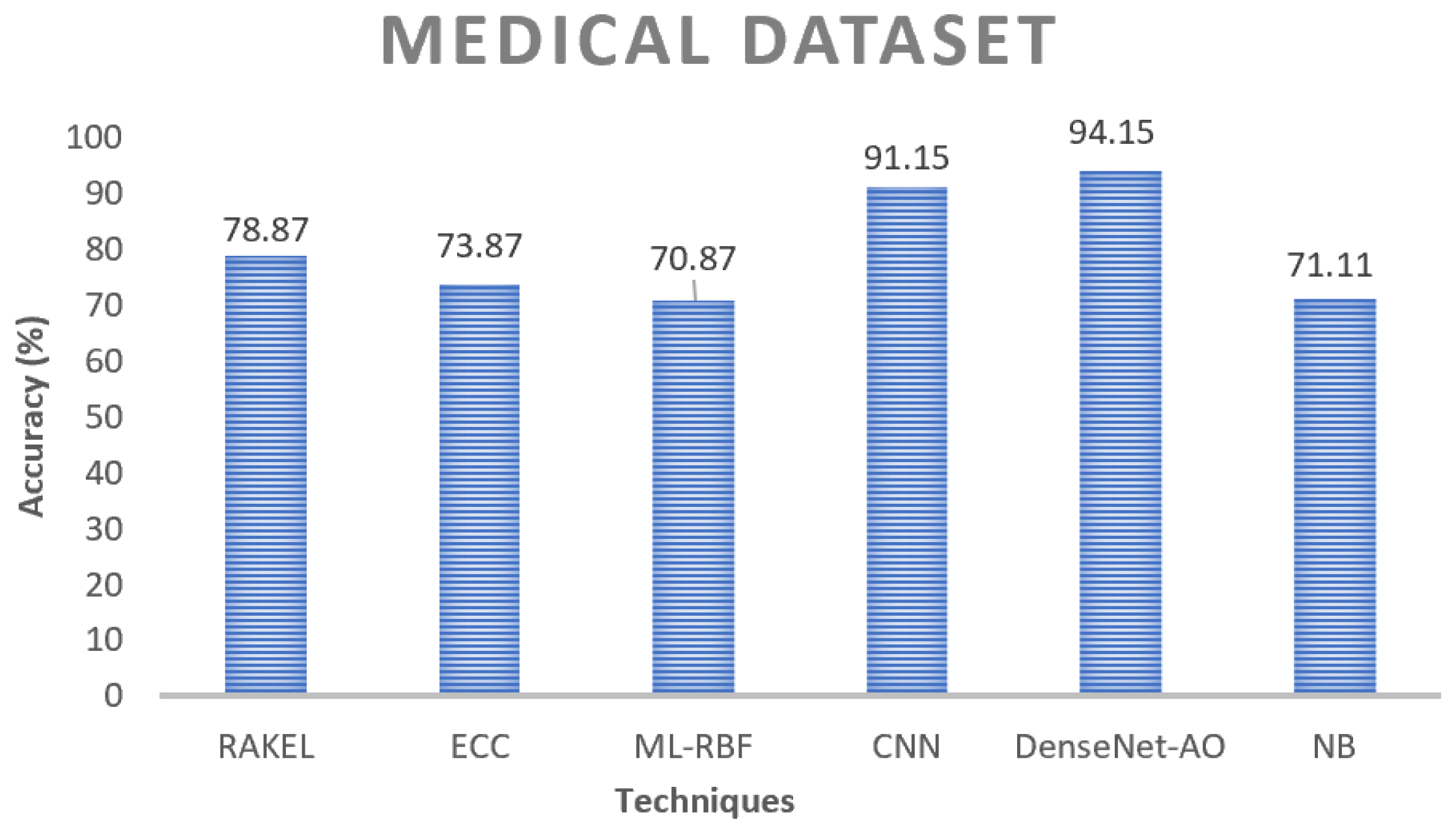
Table 8 show the productivity of six different approaches. Based on all metrics and datasets, the proposed model beats the other methods evaluated, including the ML-RBF process and two combination approaches, RAKEL and ECC. The technique described remains constant across all datasets. It has been demonstrated that, compared to non-ensemble methods, our ensembler EDAO can effectively improve the generalization efficiency of DNN.
EDAO’s advantages over other multi-component learning techniques, such as ECC and NB, highlight our concept’s effectiveness. By harnessing the potential of integrated learners in conjunction with machine learning, MLL undergoes a significant improvement in generalization. Within this proposed setting, DenseNet excels, driven by its unmatched ability to address diversity-related objectives that have long challenged the field of multi-label research. Through the ingenious use of the AO algorithm, DenseNet transcends conventional boundaries, leading to a movement of diversification across the MLL domain. This distinctive attribute is a fundamental pillar behind DenseNet’s remarkable ascent. In our proposed approach, we examine the impact of objective functions on outcomes by comparing EDAO with CNN and Naive Bayes, representing two types of objective functions. The technique consistently yields the best results across all datasets, as evidenced in
Table 6,
Table 7 and
Table 8. Visualizations of the model loss and suggested model accuracy are presented in
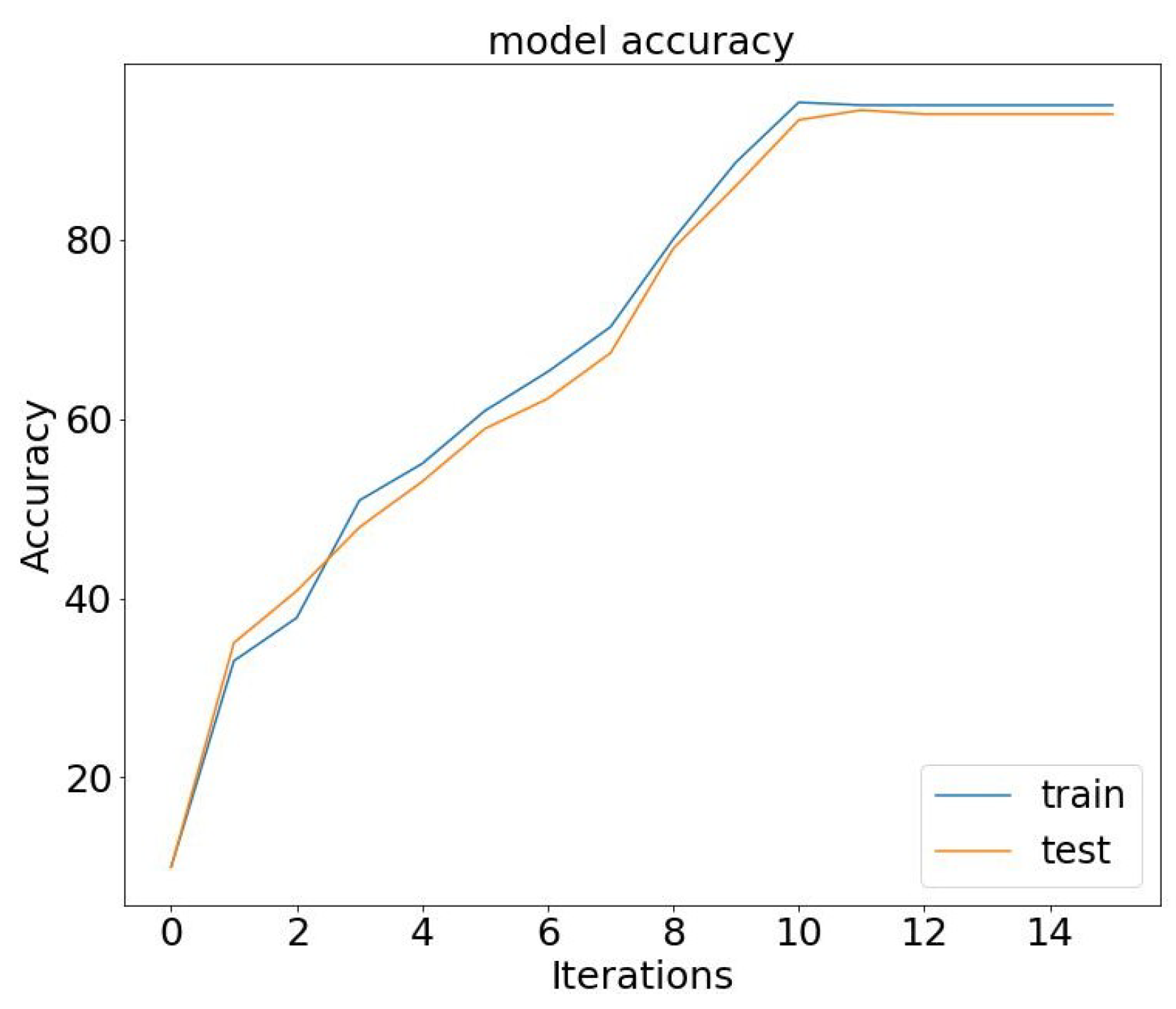
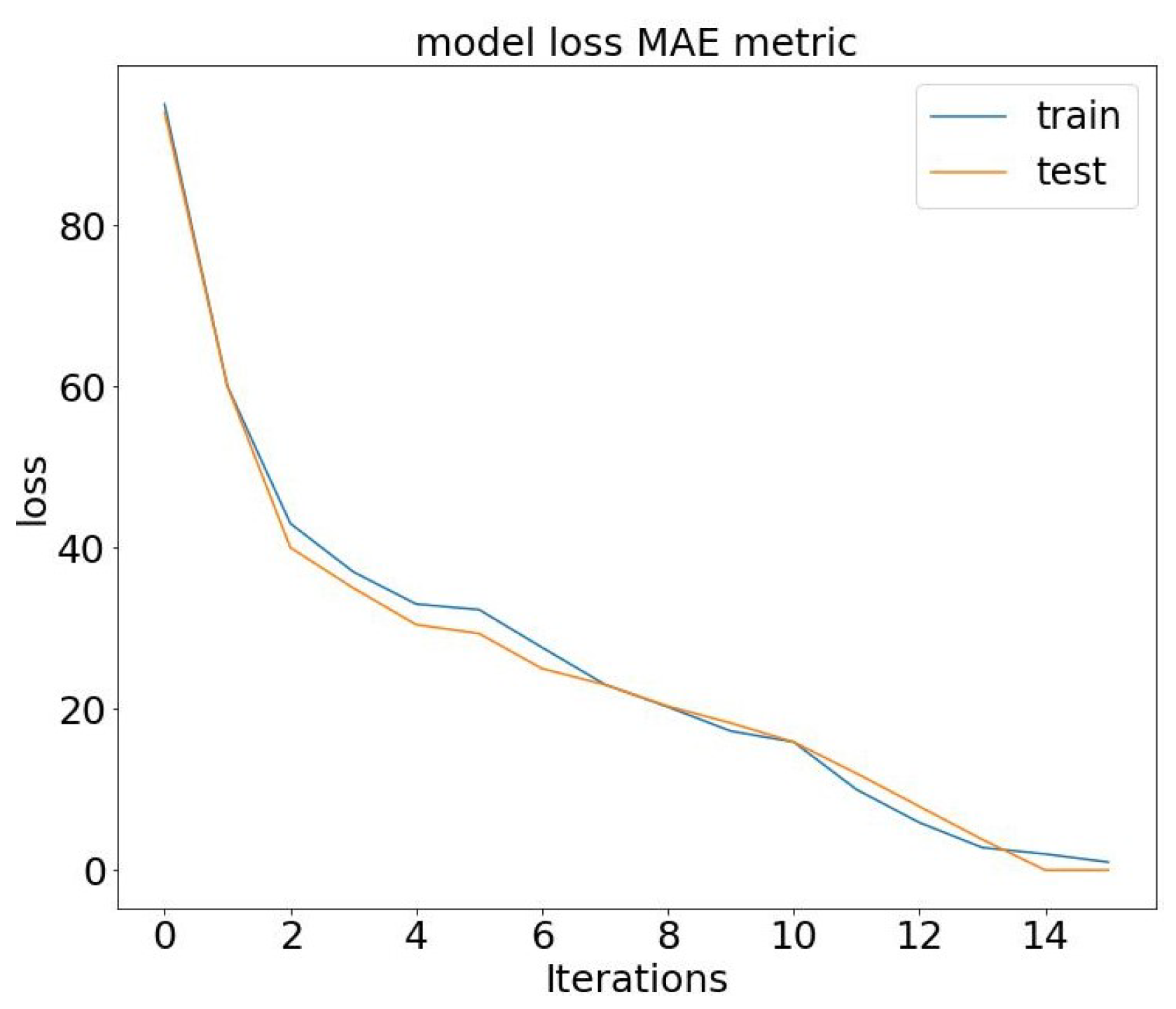
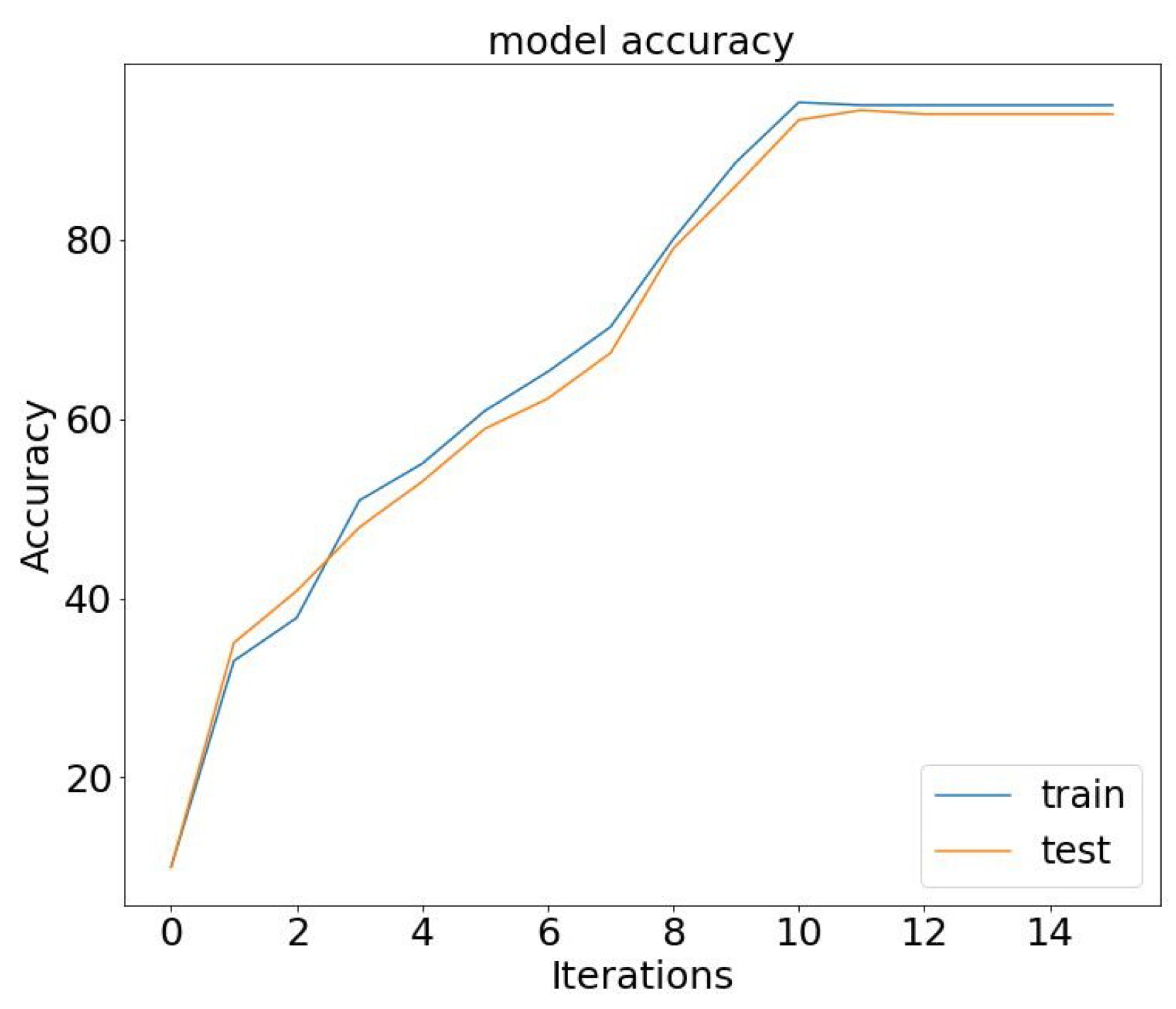
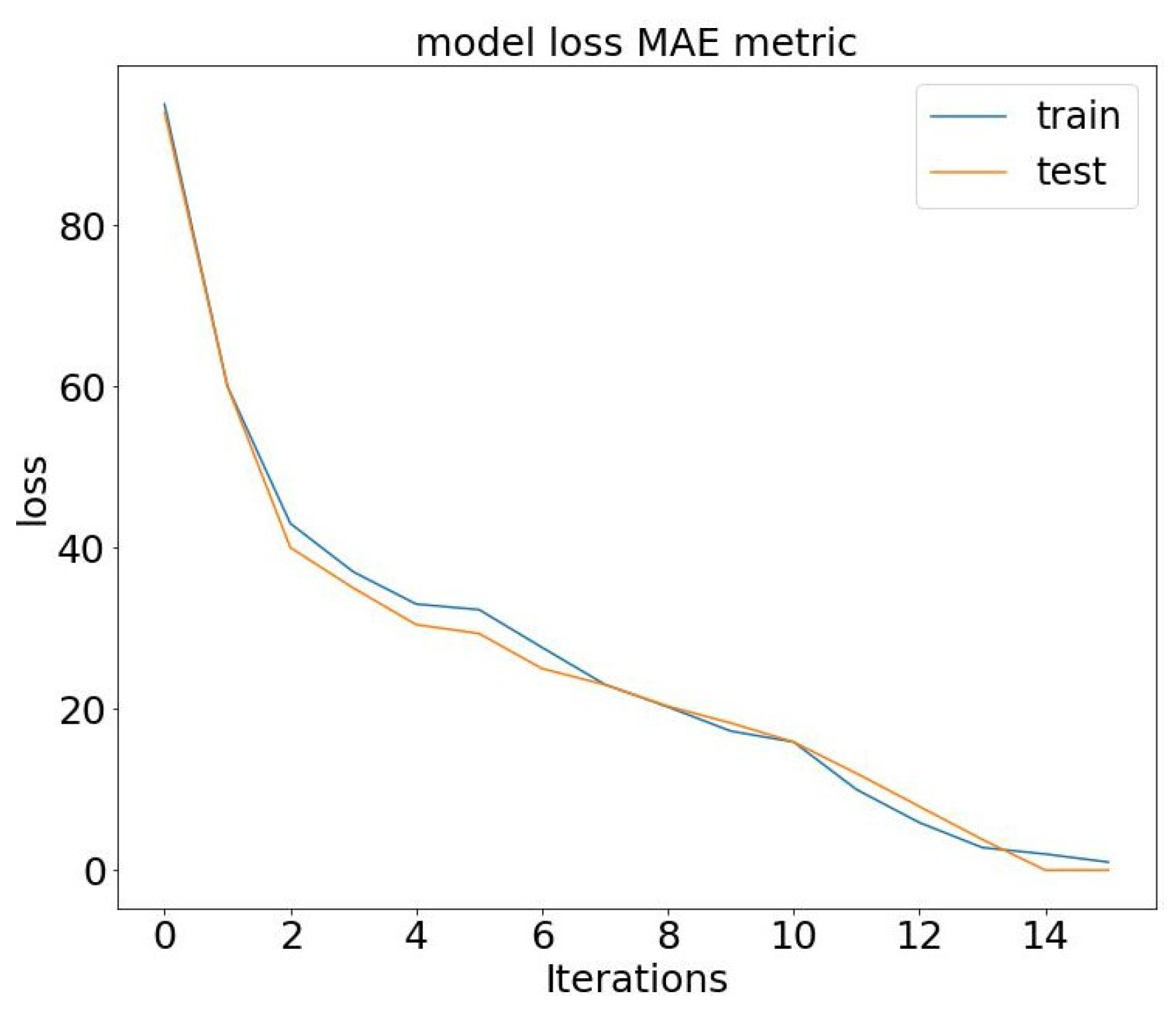
Figure 6 and
Figure 7. In our conceptual model, we observe a compelling trend: As the number of epochs increases, our model’s accuracy demonstrates significant improvement while the loss steadily decreases. This pattern reinforces the effectiveness of our approach, highlighting the positive correlation between training epochs and enhanced model performance.
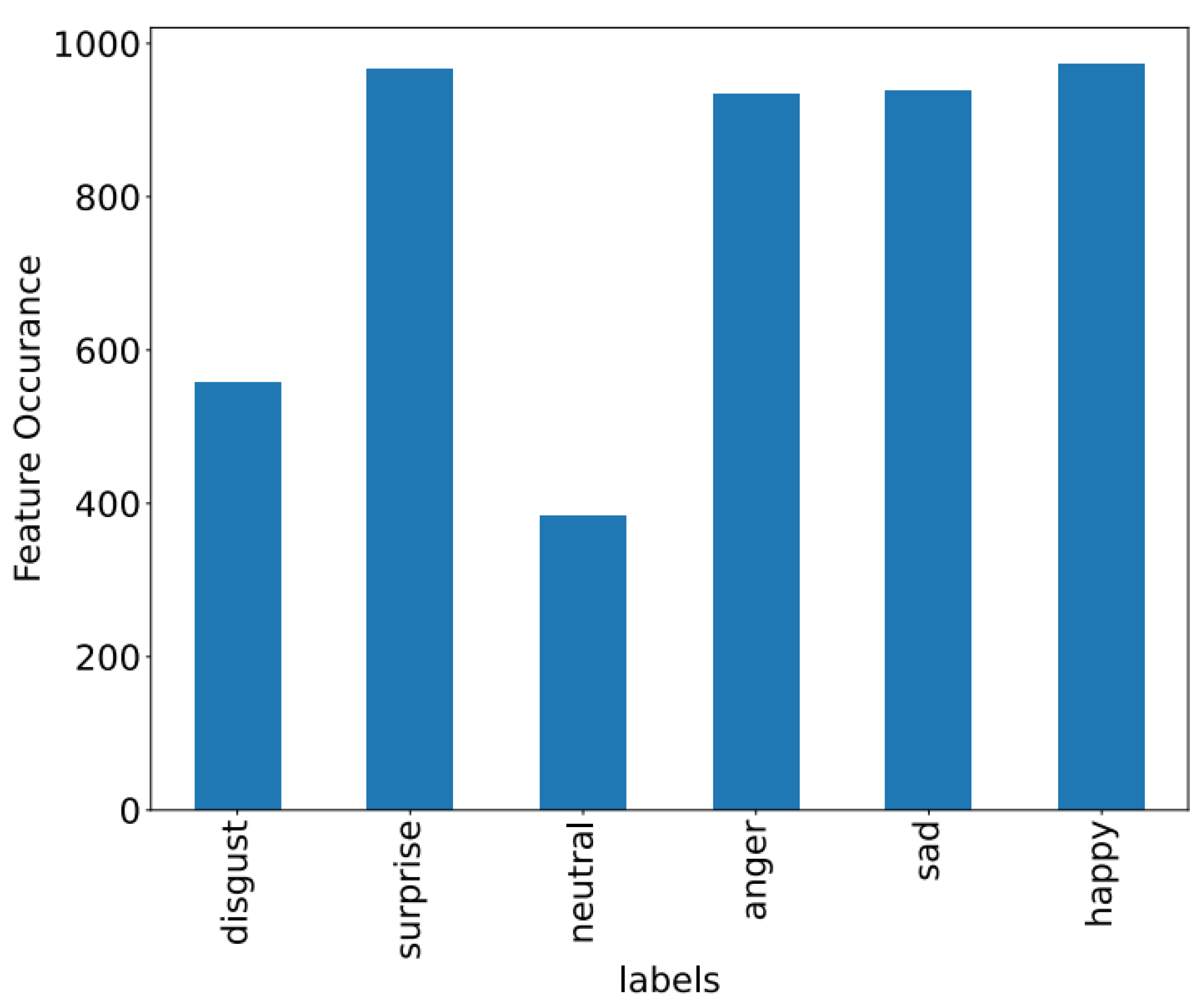
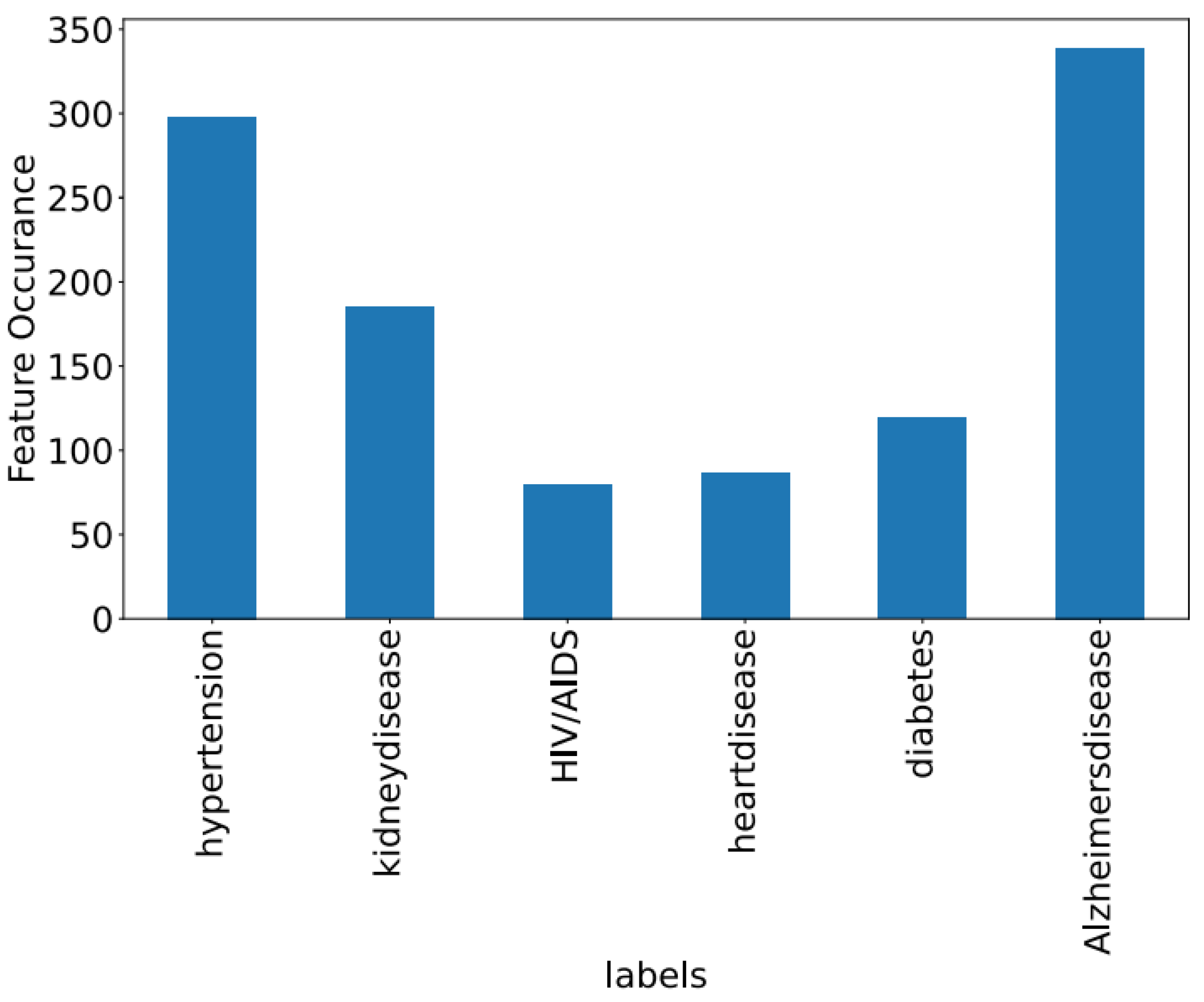
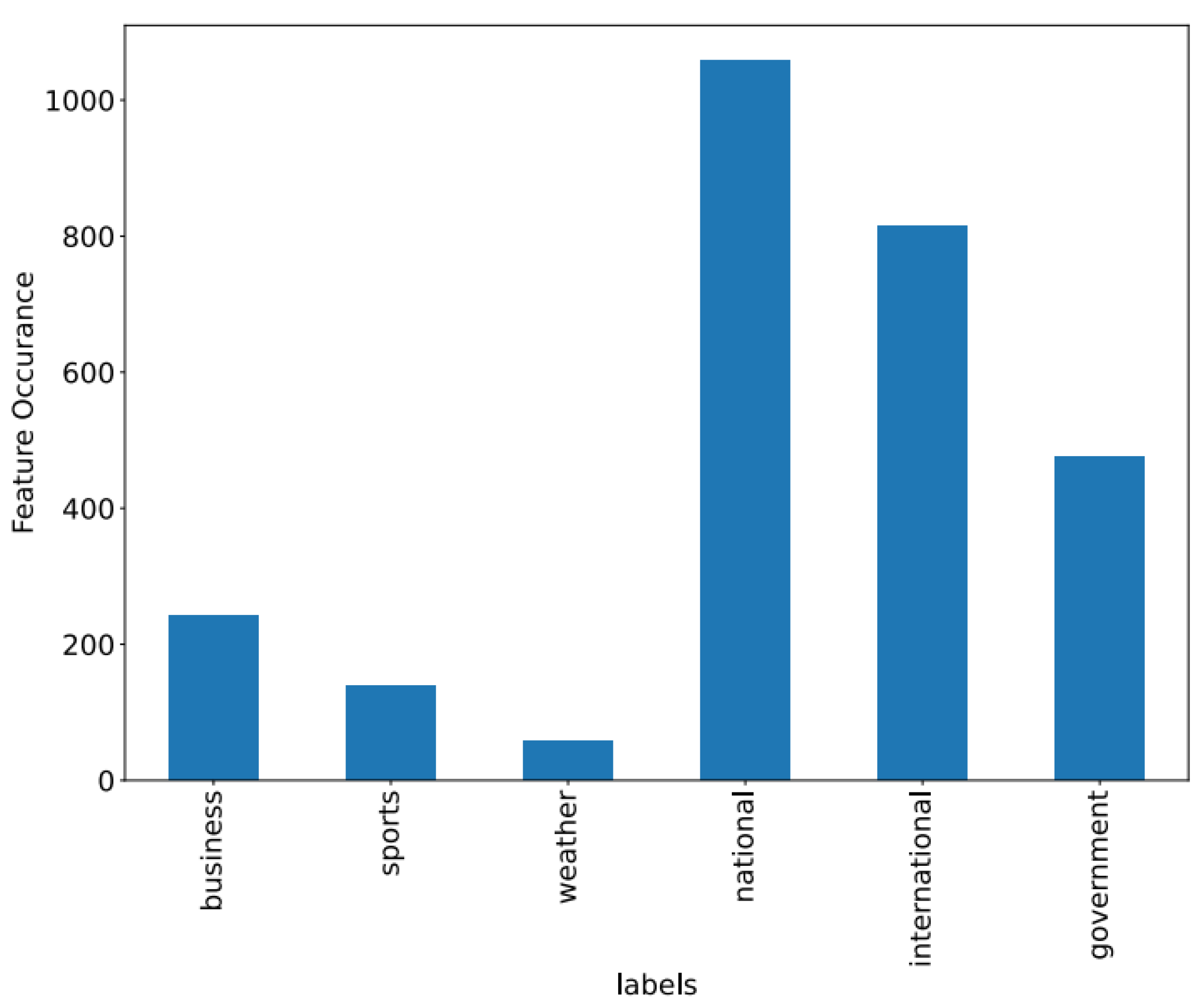
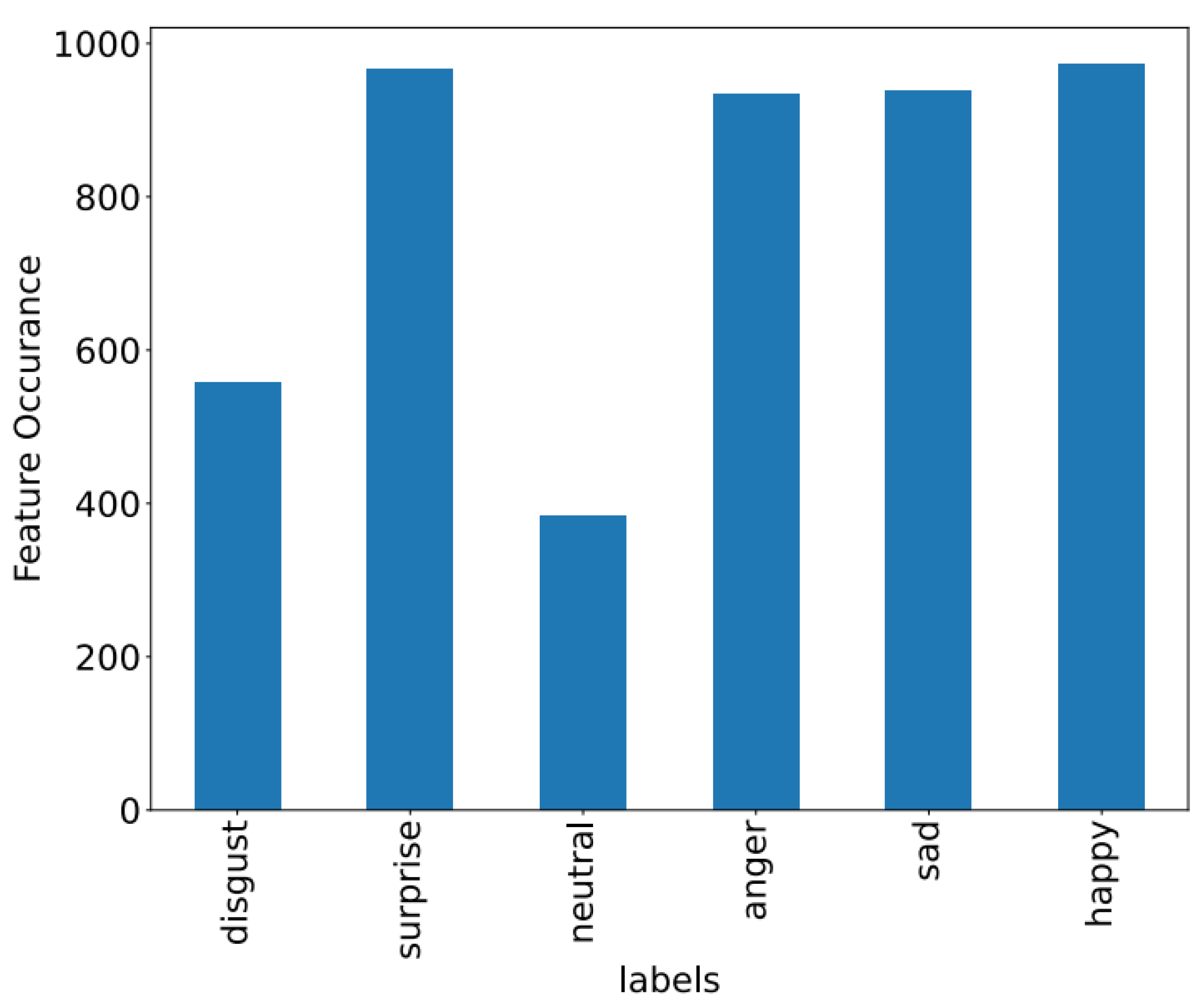
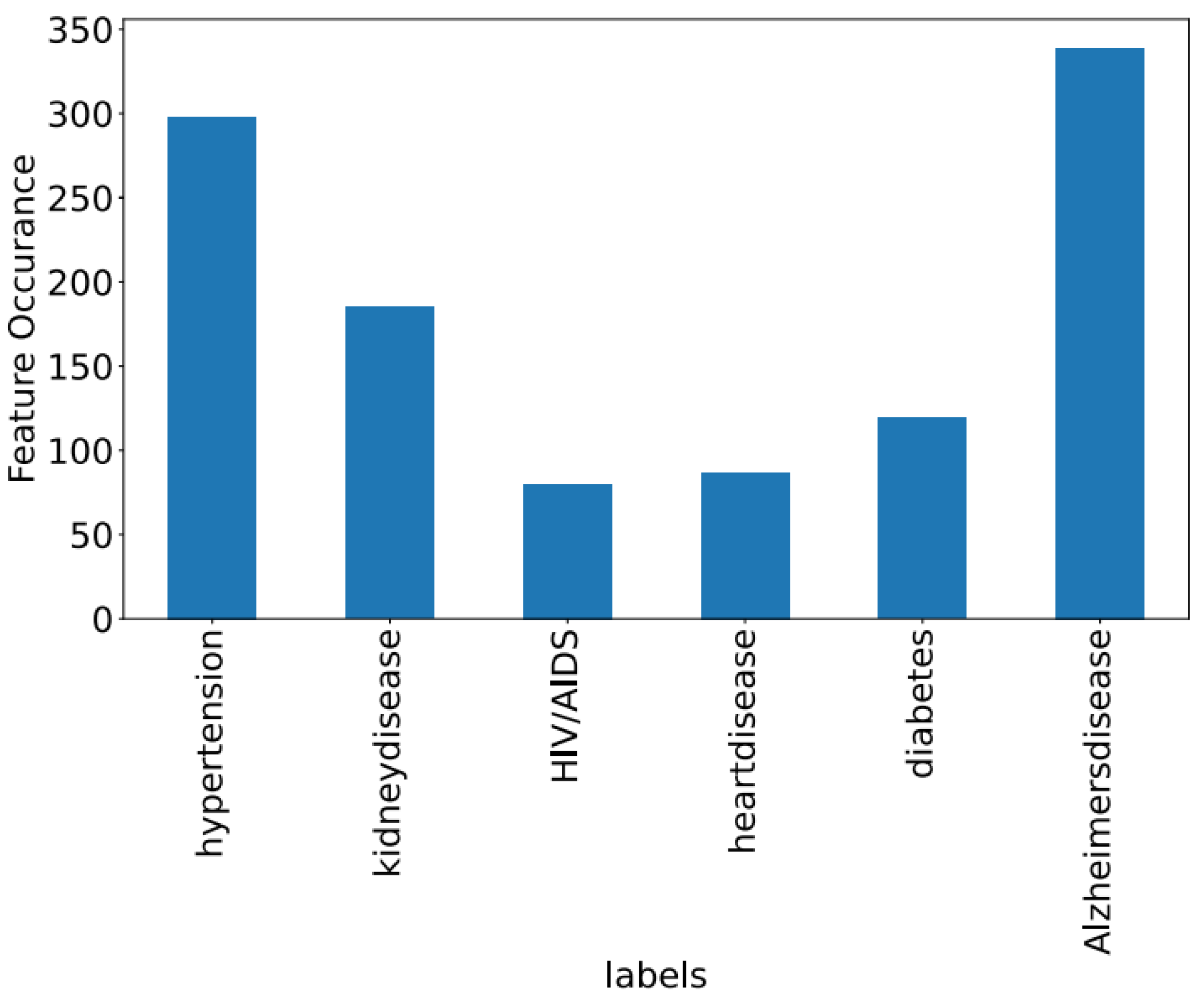
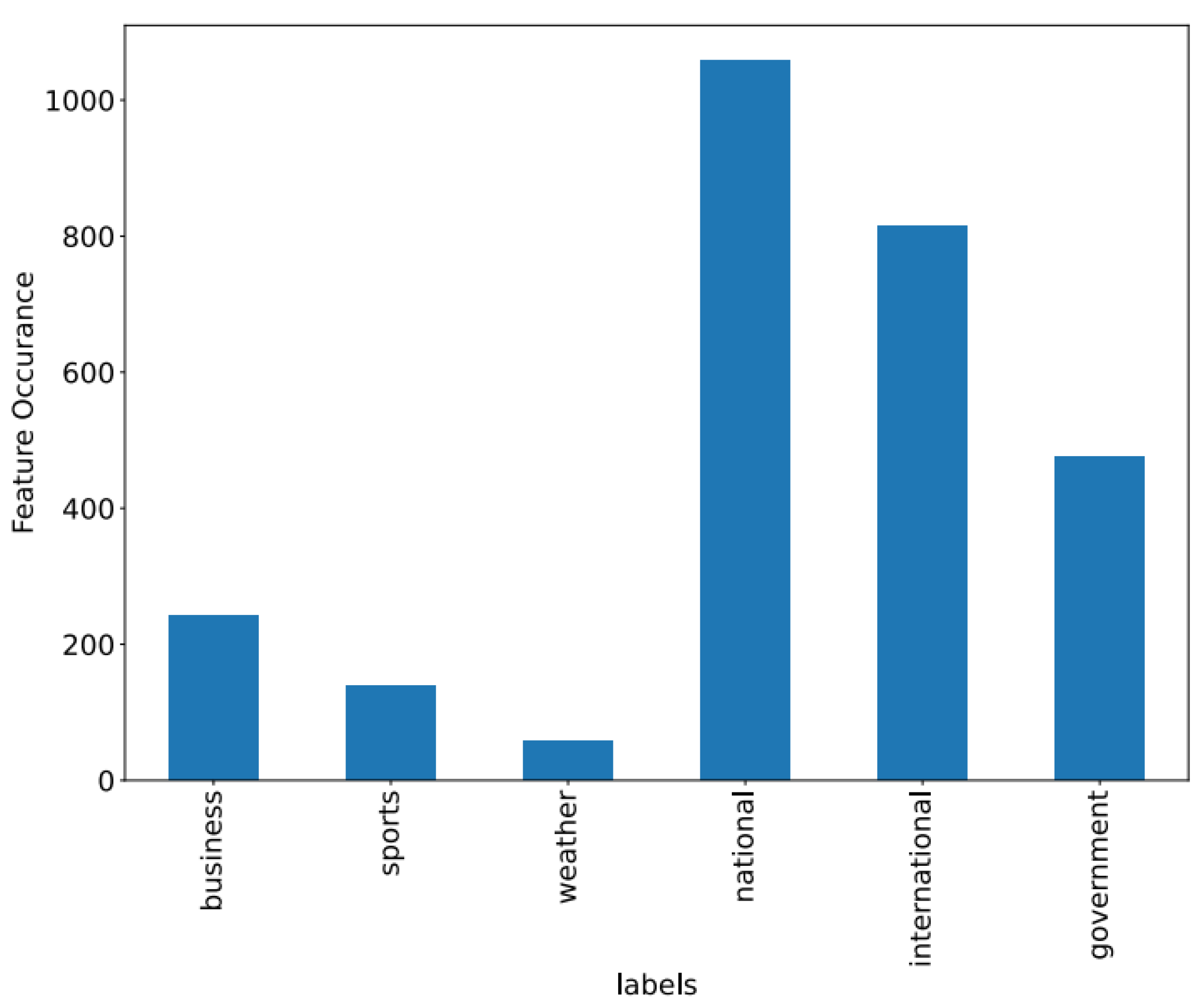
Figure 8,
Figure 9 and
Figure 10 showcase the features of specific datasets. Performance measures such as F1-score, accuracy, precision, and recall are employed to evaluate productivity across diverse datasets.
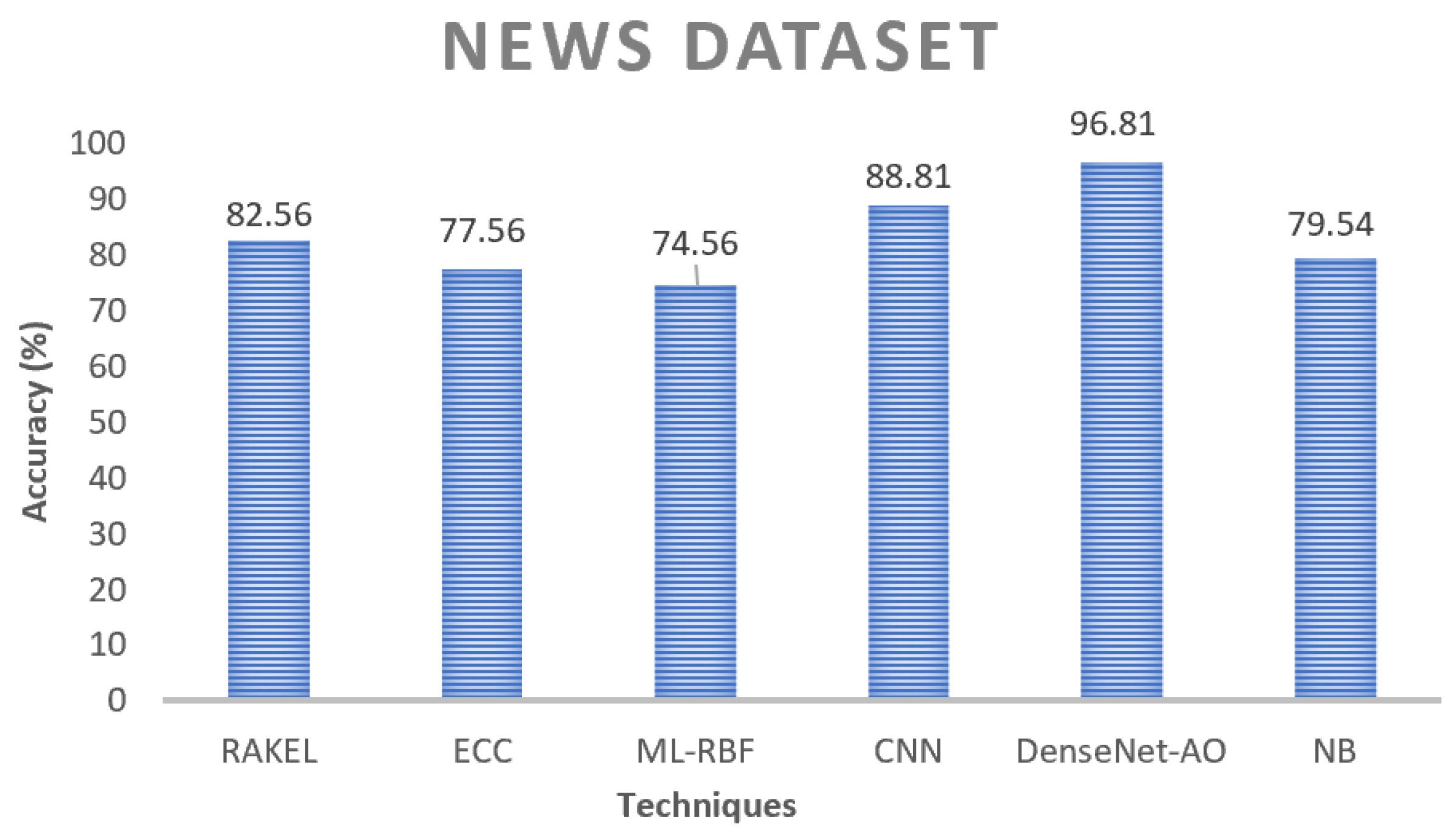
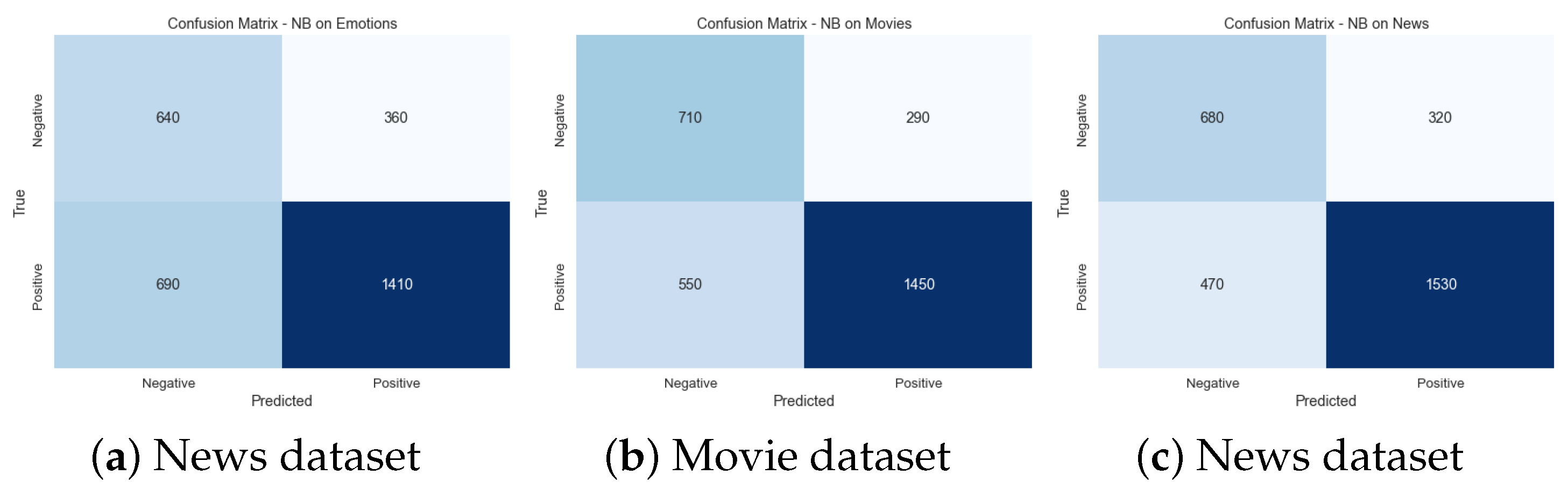
Figure 11 presents an illustrative example of the findings derived from the news dataset. Regarding accuracy, the suggested model EDAO exhibits superior performance compared to other contrasting approaches. Specifically, CNN-CHIO demonstrates higher accuracy on the news dataset than ML-RBF and NB. Notably, NB yields the lowest accuracy ratings among the five models.
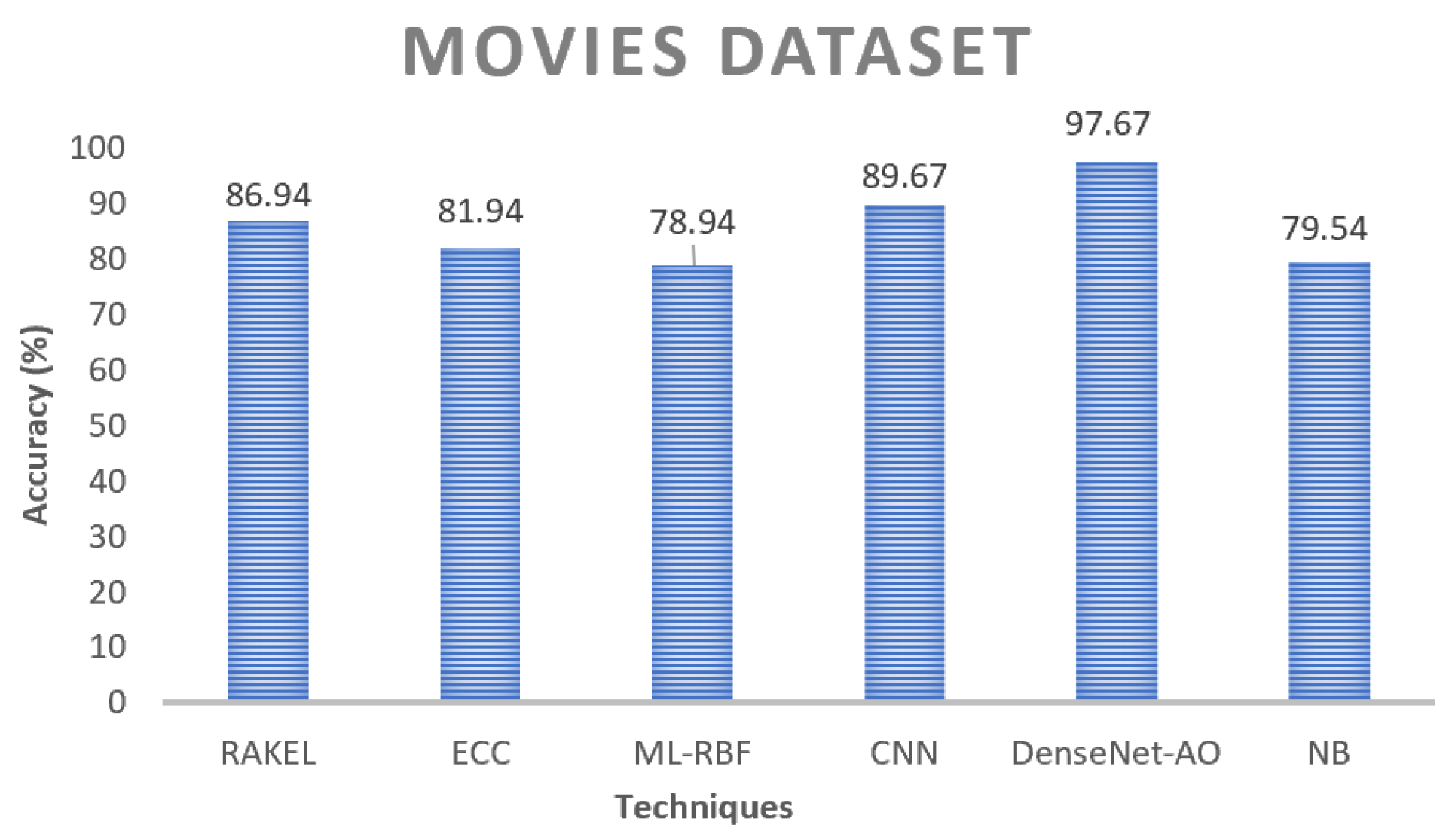
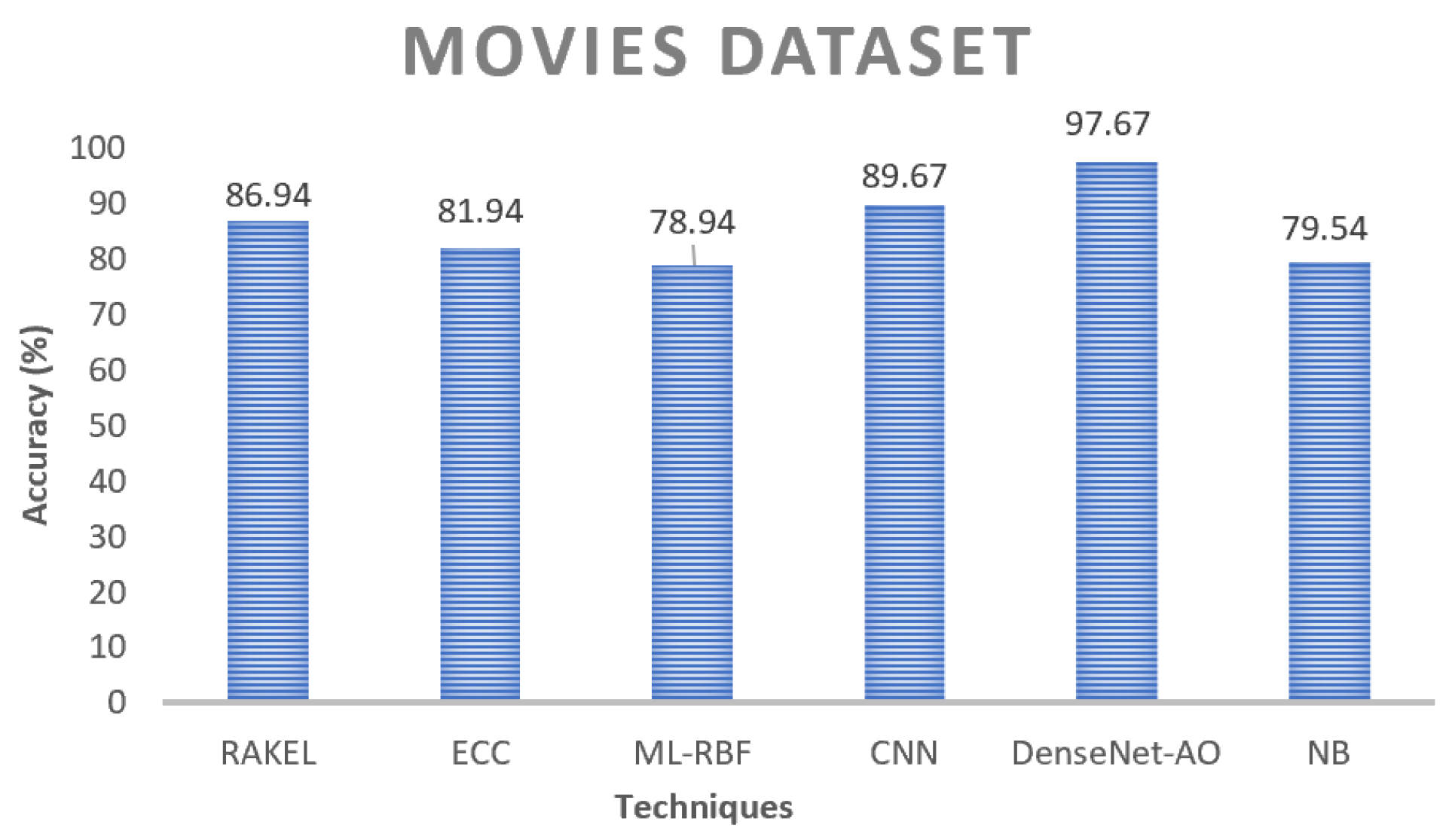
The proposed ensembler achieves a higher overall score on the movie dataset, as seen in
Figure 12. Although it is a multi-labeling dataset, even the most complex method performs well. The proposed ensembler outperforms other techniques in terms of precision, f-measurement, accuracy, and recall, as depicted in
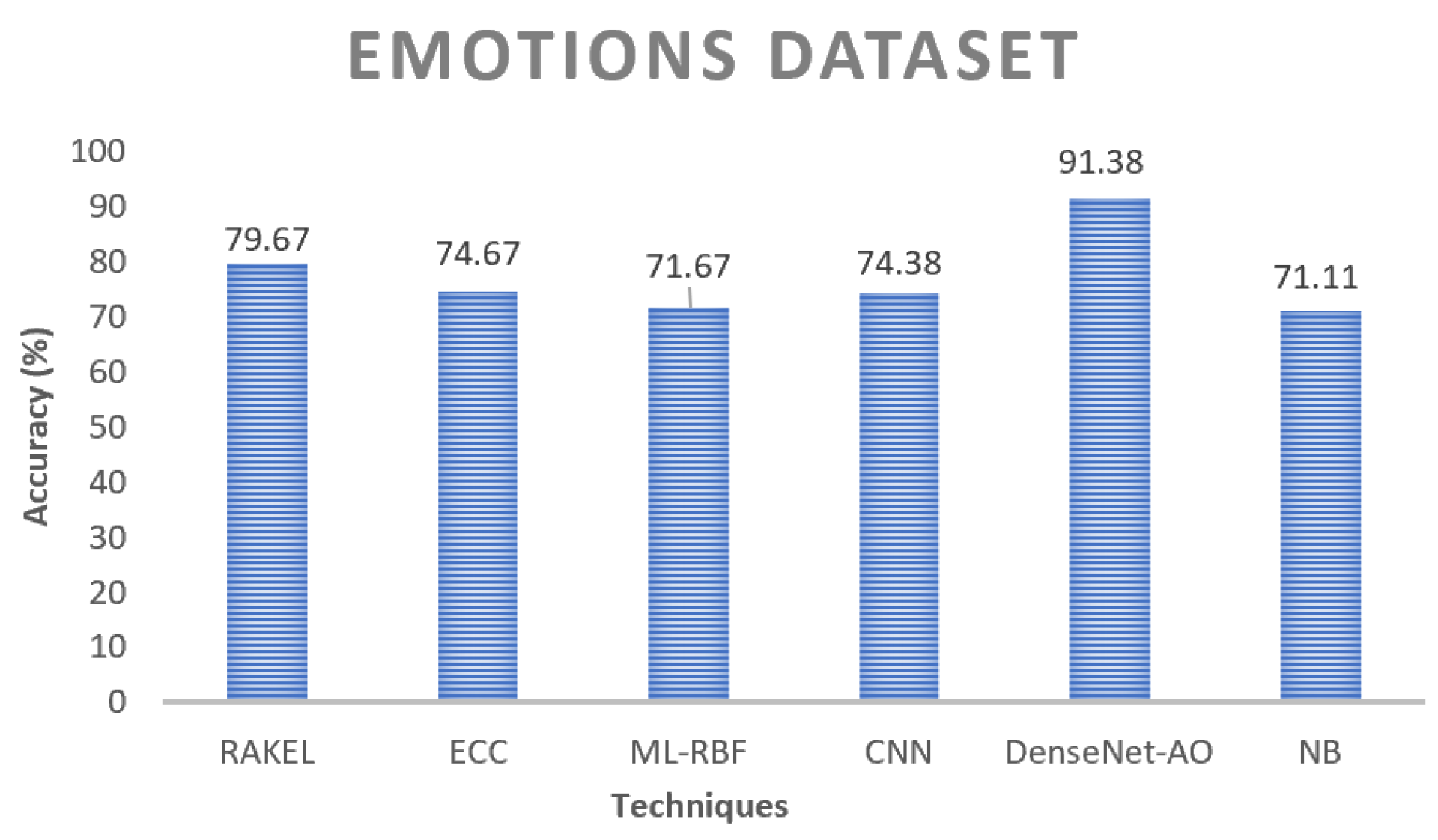
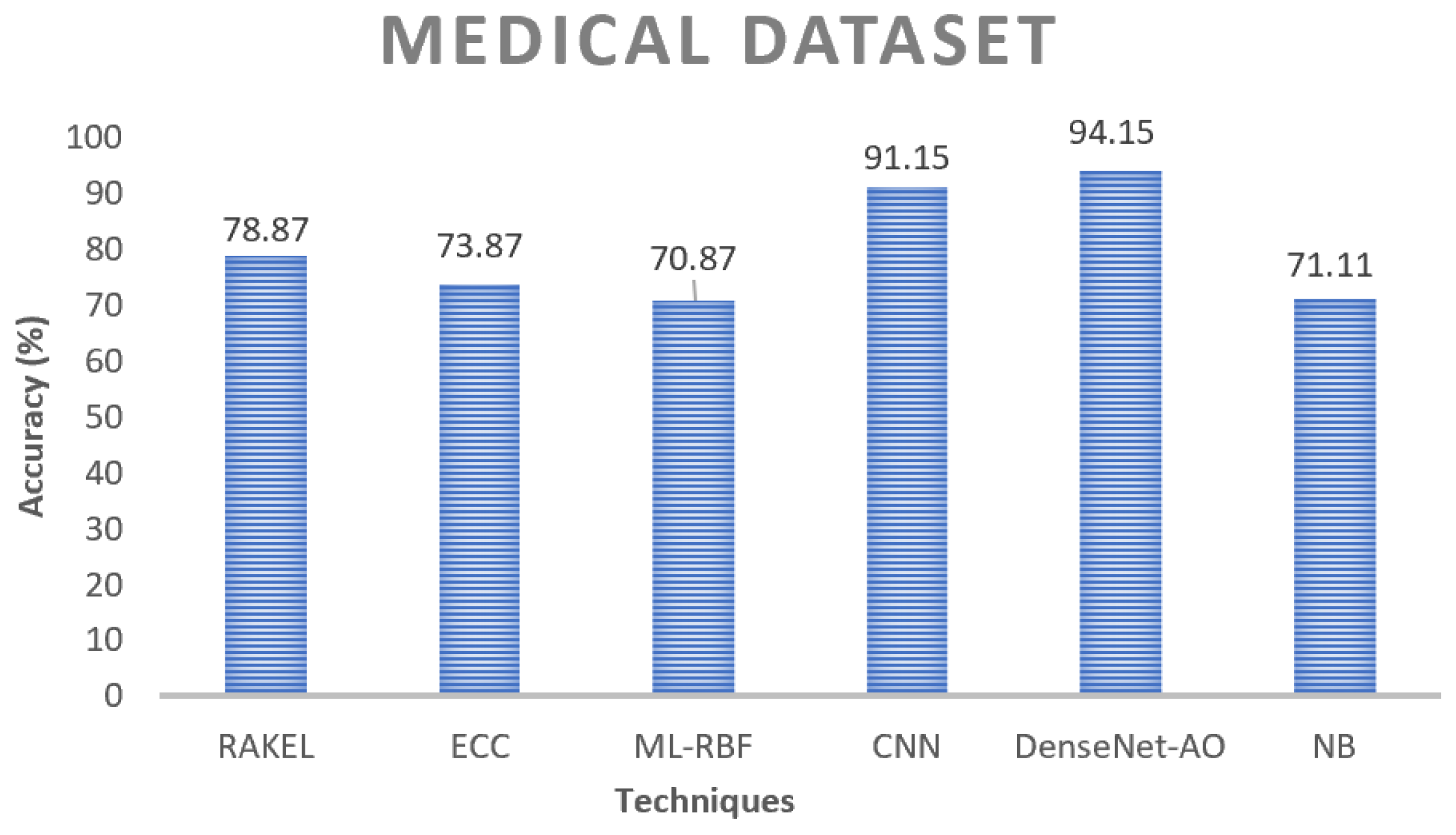
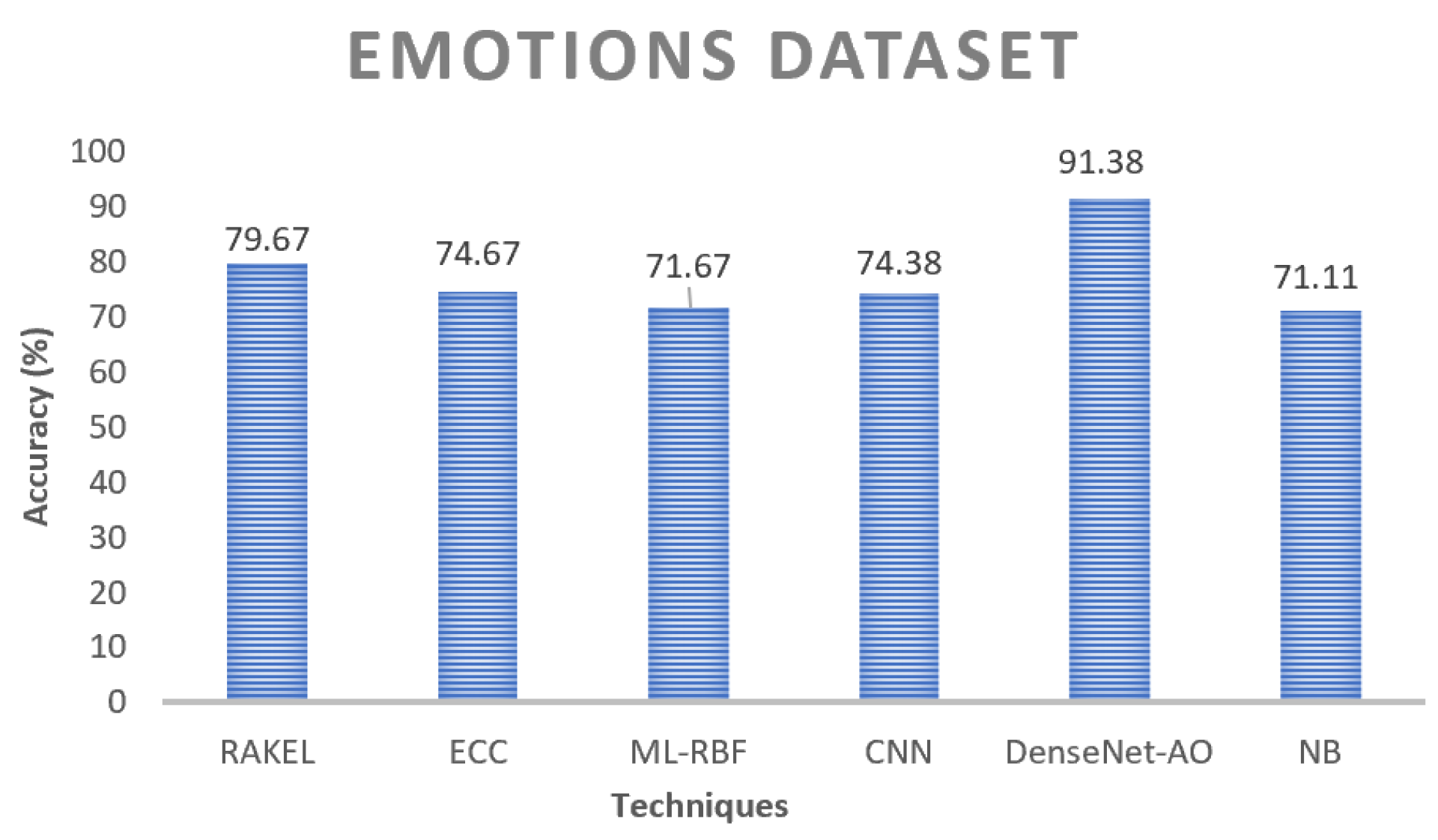
Figure 13 and
Figure 14. The great accuracy implies that the proposed ensembler would produce unexpectedly strong results with multi-labeling data, which is a promising sign. ML-RBF decreases as the running output increases in
Figure 11,
Figure 12,
Figure 13 and
Figure 14. From
Figure 11,
Figure 12,
Figure 13 and
Figure 14, we can conclude that EDAO is improving. The divergent trends of both aims indicate that they are inherently at odds. It should not come as a surprise. Predicted baseline learner labels intersect with the labels correctly due to the ML-RBF optimization. As a result, all of these fundamental learners appear to be the same.
In contrast, ECC maximization enables base learners to exhibit maximum flexibility in terms of training error. In most situations, the stated goals are opposed to one another. The conflict allows ML-RBF to use population optimization to balance the two goals. It is crucial to note that in this situation, NB and ECC assess the basic learners’ diversity and correctness, not the ensemble’s overall performance. The decrease in ML-RBF does not suggest that there has been a decline in the ensemble. Despite this, the increase in EDAO implies that base learners are becoming more varied, improving group performance. An optimization technique is used to fine-tune the tuning parameters of the ensembler. The precision of multi-labeling is improved as a result of these discoveries. As a result, EDAO consistently enhances a multi-label ensemble’s ability to generalize, enhancing multi-label categorization competence.
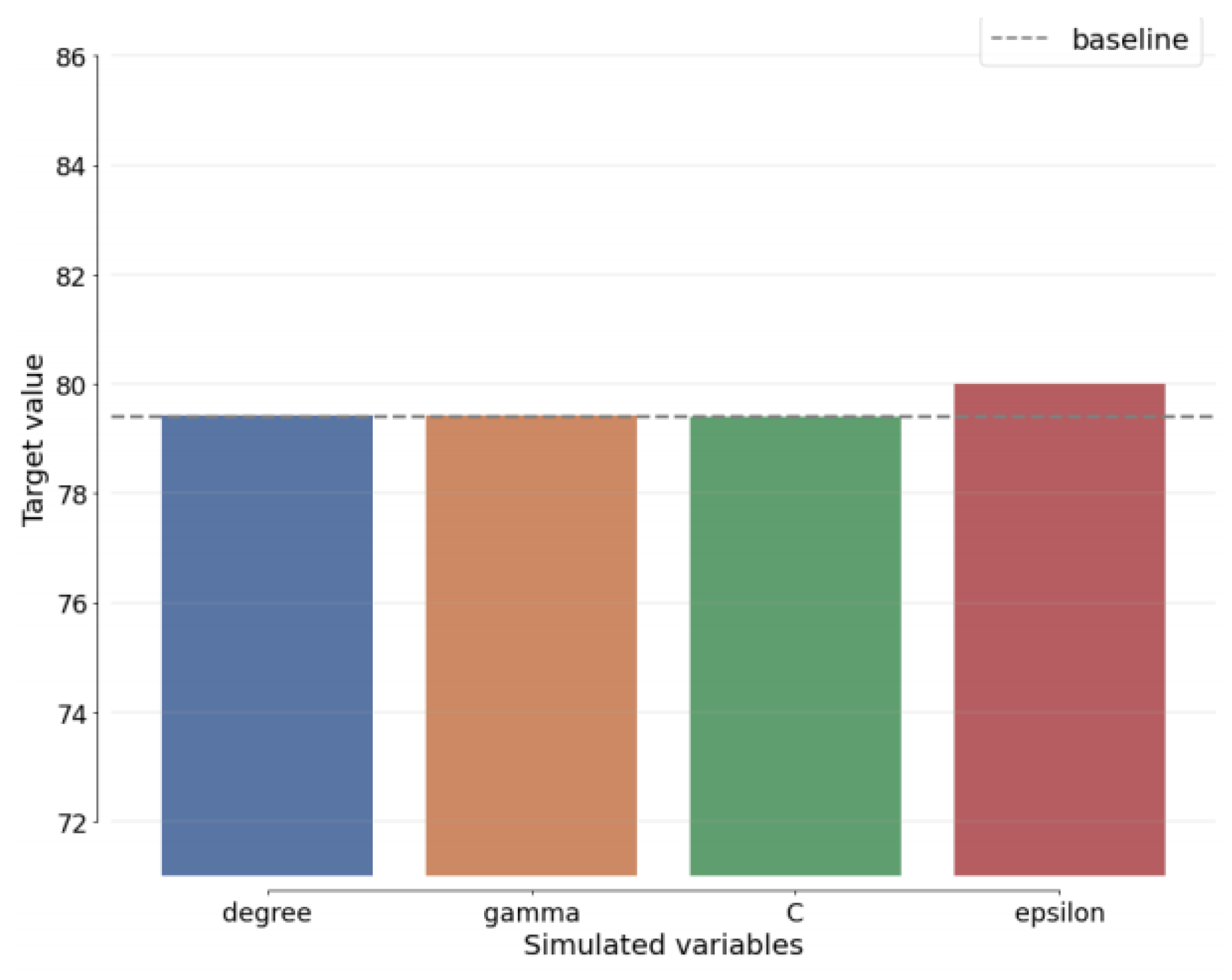
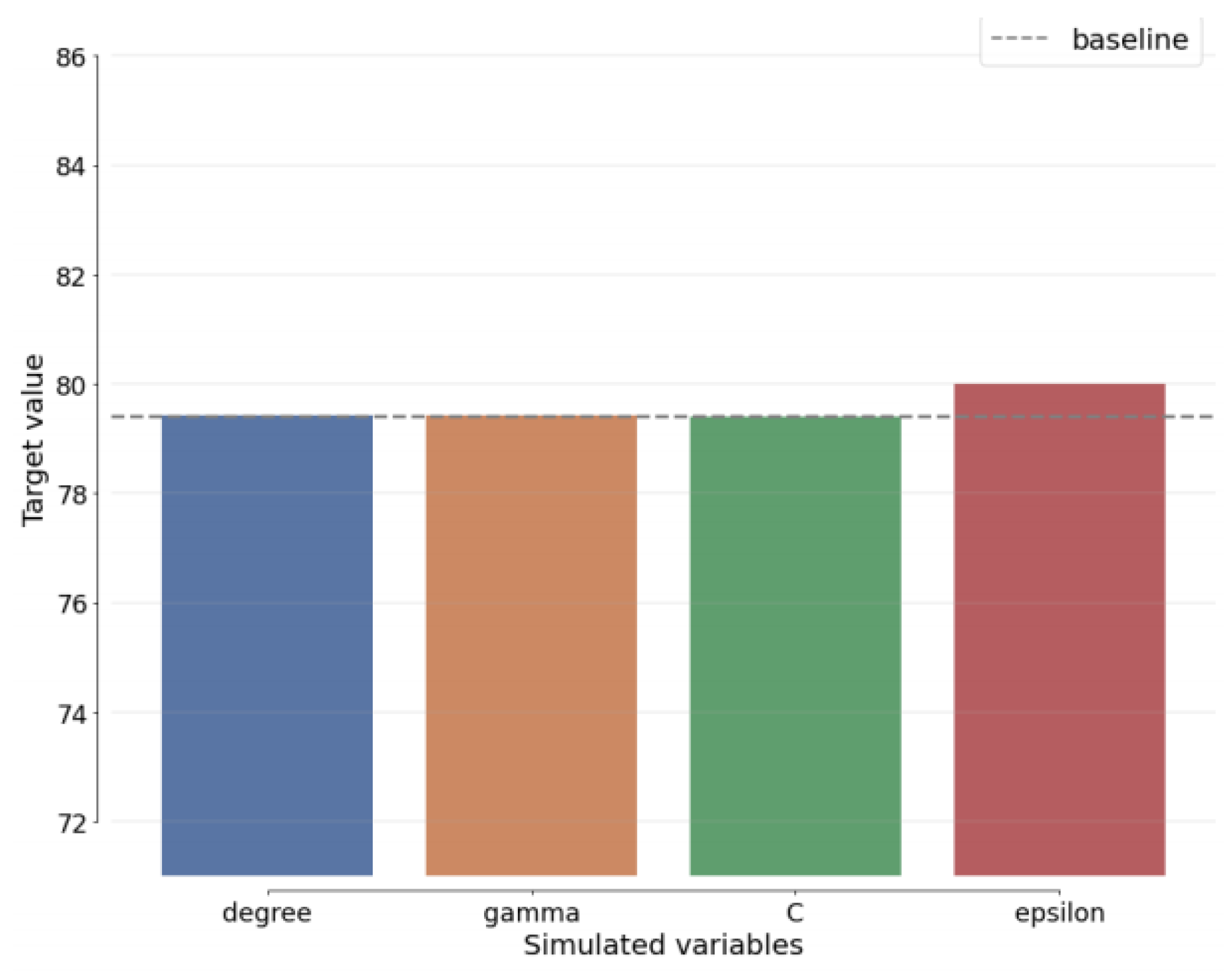
The sensitivity analysis (SA) is a critical aspect of our study as it introduces the element of uncertainty into our evaluation of both benchmark schemes and our proposed algorithm. SA involves calculating the extent of change required for each uncertain element before altering the initial decision. This analysis provides valuable insights into the robustness and stability of our proposed approach.
In
Figure 15, we present the results of the sensitivity analysis specific to our recommended technique, DenseNet-AO. This figure showcases the best estimates for each variable within our approach, highlighting how they deviate from the baseline estimate. By visualizing these variations, we gain a deeper understanding of how our proposed method responds to uncertain component changes, further strengthening our approach’s reliability and effectiveness. The SA in
Figure 15 serves as a vital component of our study, allowing us to assess the impact of uncertainties on our proposed method’s performance and providing valuable insights for optimizing our approach.
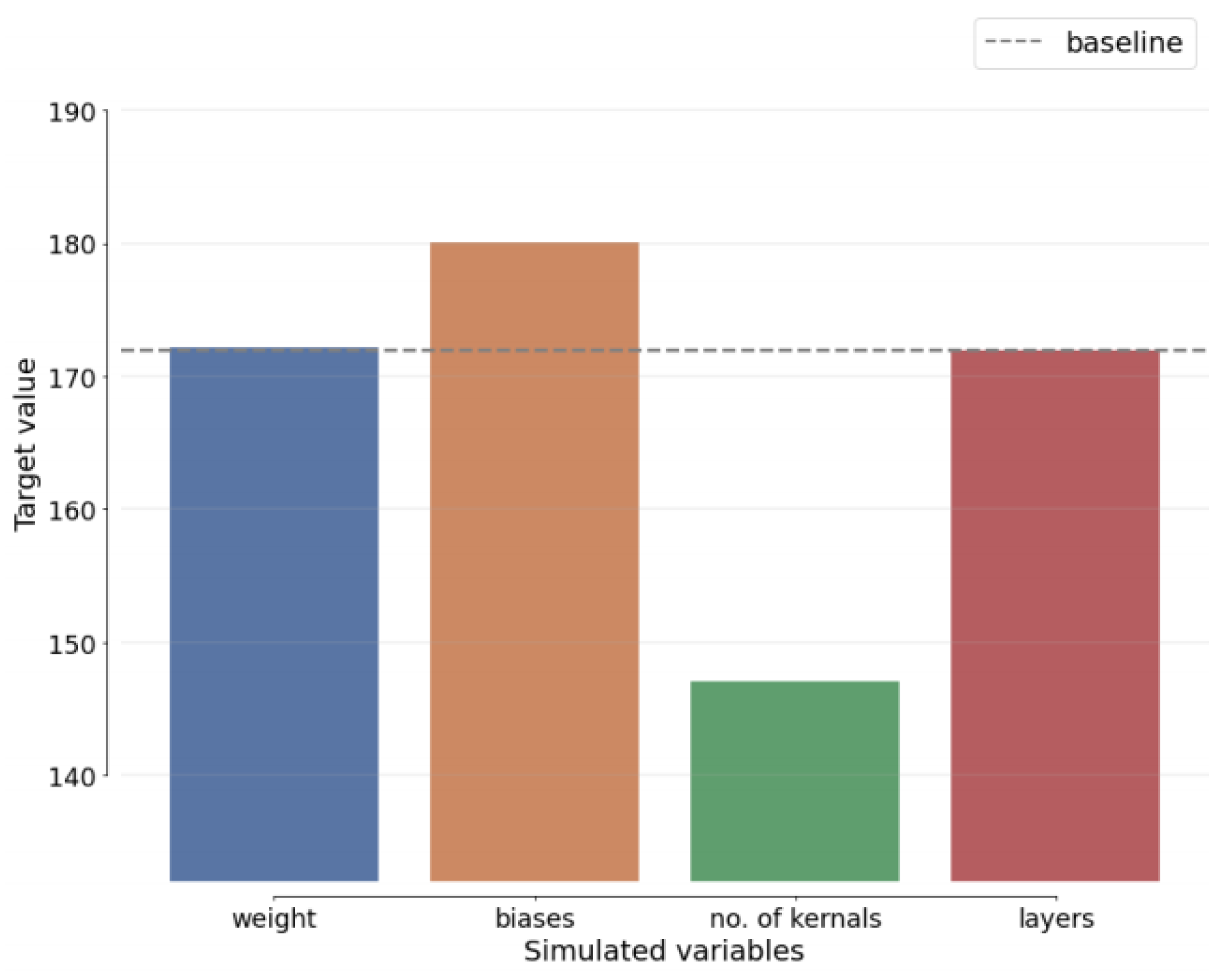
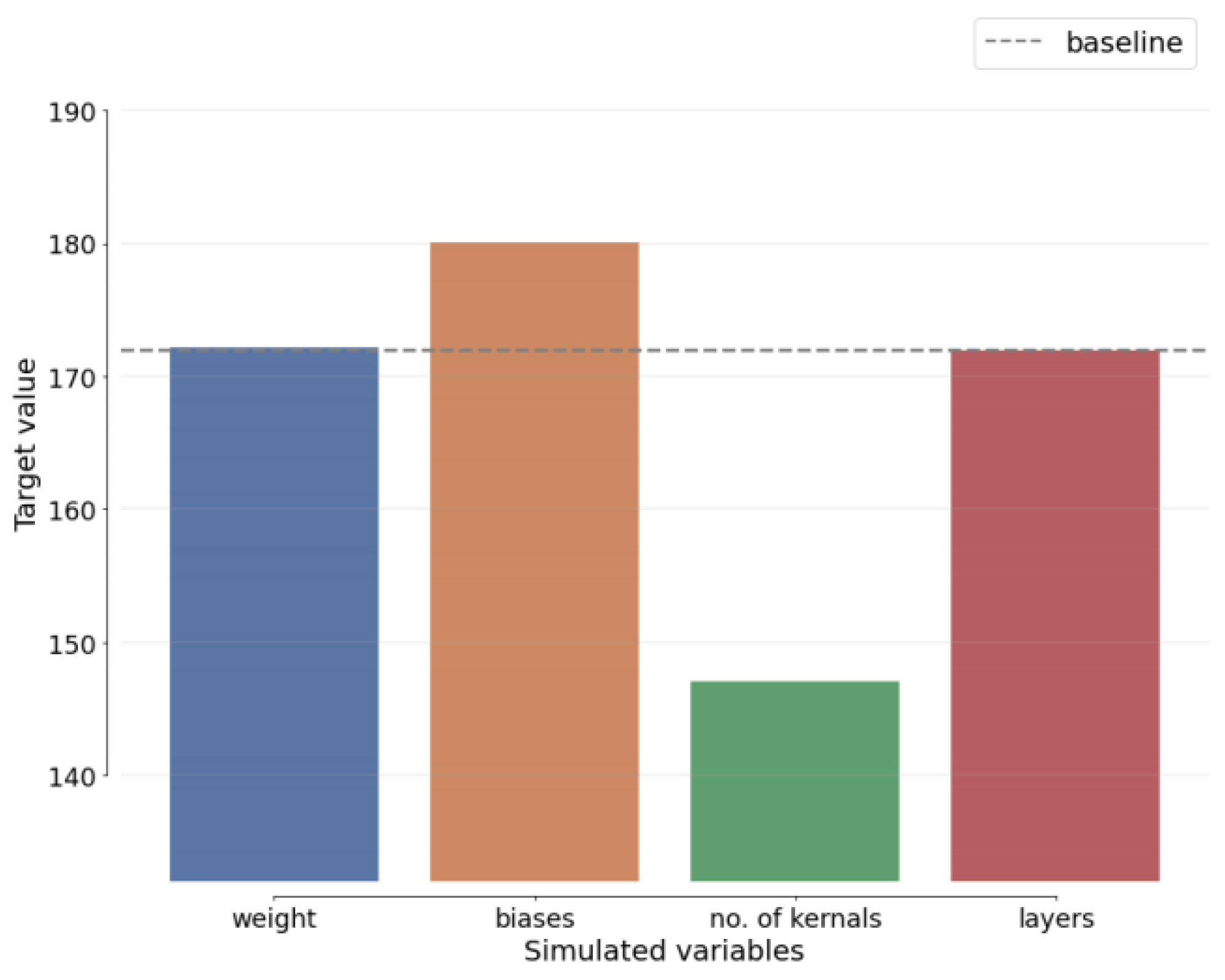
Furthermore,
Figure 16 depicts the SA of the most recent benchmark methods. Through SA comparisons, it is evident that the EDAO variables exhibit the least variation among the baseline-related variables, surpassing benchmark algorithms.
Table 9 determines the limitations the EDAO approach addresses, highlighting its significant advancements in multi-label sentiment analysis. EDAO offers distinct advantages over existing methods through its integration of accuracy and diversity, the utilization of DenseNet-AO, improved generalization efficiency, robust decision-making, and efficient label space transformation. These features contribute to EDAO’s effectiveness in capturing sentiment variations, enhancing performance, and handling complex multi-label datasets.
Table 10 compares execution times in seconds for various techniques used in different domains. These values represent approximate execution times based on real-world scenarios. The DenseNet-AO technique stands out with notably lower execution times across all domains, ranging from 20 to 35. It indicates its efficient computational complexity, making it a promising choice for tasks in the news, emotion, medical, bird, hotel, automobile, movie, and protein domains.
On the other hand, the RAKEL technique demonstrates varying execution times, with some domains taking longer than others. For example, it requires around 120 s for emotions and automobiles. The ECC technique also exhibits variability in execution times, with the medical domain having the longest execution time of 180. The ML-RBF and CNN techniques generally show execution times in the 70 s to 120 s range, while the NB technique requires approximately 180s for the medical domain. BERT, LSTM, Transformer, GAT, ResNet, SVM, Logistic Regression, and random forest techniques also display varying execution times across domains from the 70 s to 200 s range.
Table 11 presents the Pearson correlation coefficients between various techniques and domains. The coefficients serve as gauges that measure the intricate connection between two variables, spanning a scale from −1 to 1. A coefficient that gravitates towards 1 signifies a robust positive correlation, while a coefficient approaching −1 indicates a compelling negative correlation. Delving into the tabulated data, we discover that DenseNet-AO consistently showcases remarkable positive correlations across various domains. Its values gracefully range from 0.86 to 0.92, portraying unwavering strength and cohesion. It indicates a strong linear relationship between DenseNet-AO and the respective domains, implying that DenseNet-AO performs consistently well across different data types.
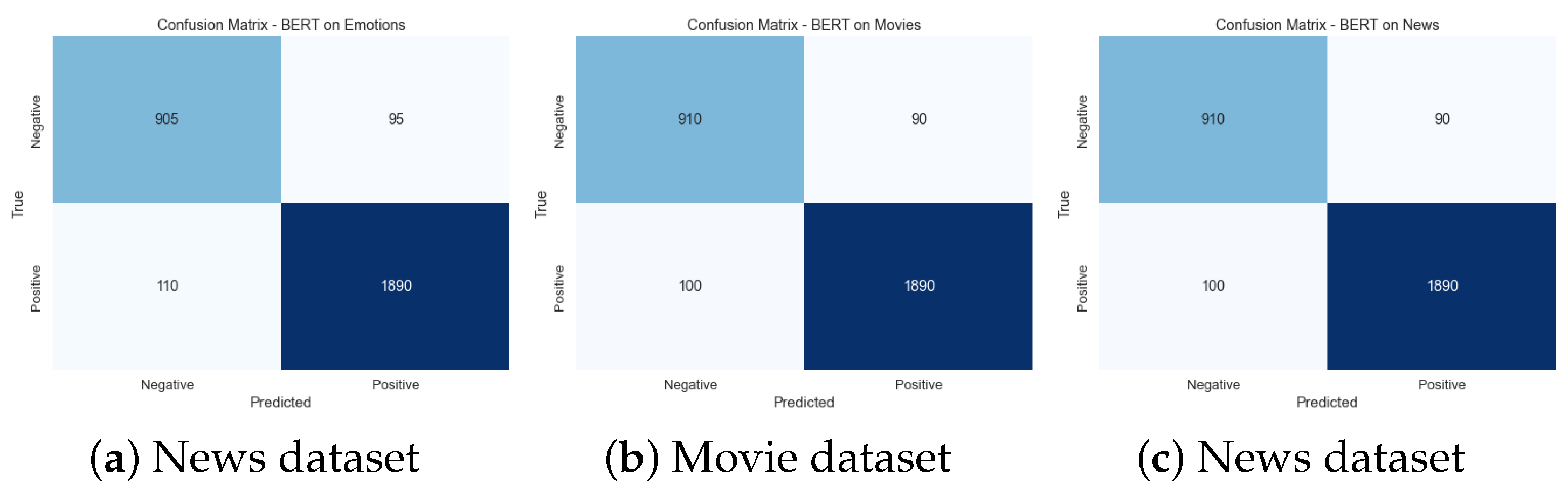
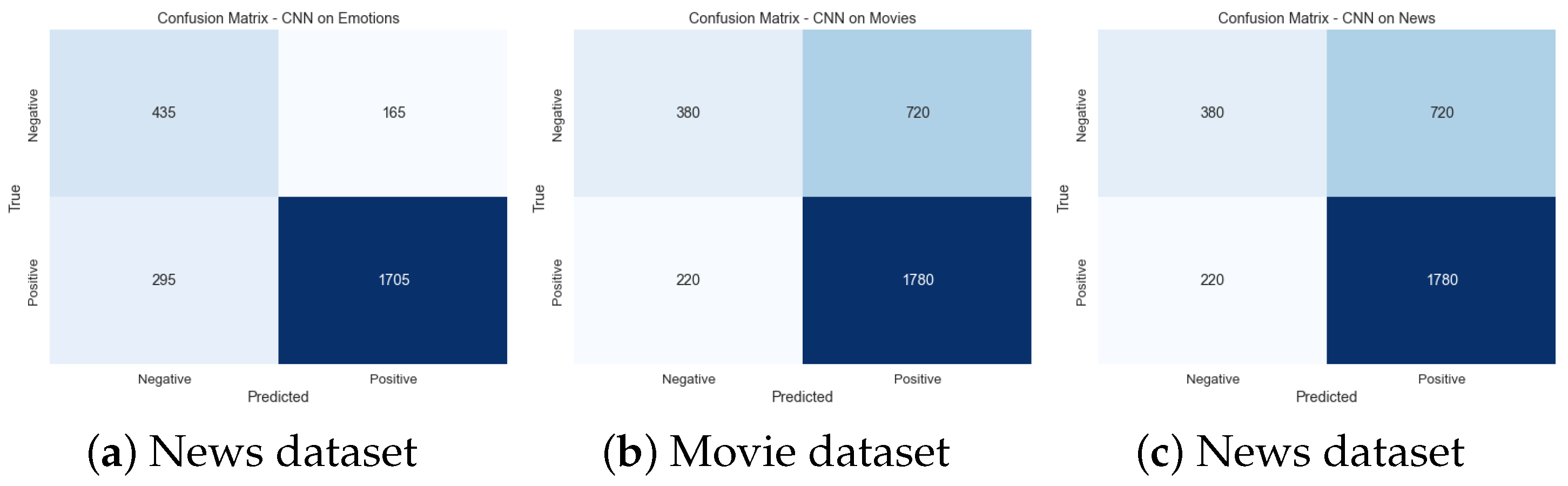
Other techniques such as RAKEL, ECC, ML-RBF, CNN, BERT, LSTM, Transformer, and ResNet also exhibit positive correlations ranging from 0.70 to 0.85, indicating a moderate to strong linear relationship with the domains. These techniques show promising performance in various domains. Conversely, NB reveals negative correlations from −0.32 to −0.35 across most domains. It implies a weak negative linear relationship between NB and the domains, suggesting that NB may not be well-suited for these datasets.
Table 12 presents the results obtained from a comprehensive analysis of variance (ANOVA) conducted on the execution times of various techniques across multiple domains. ANOVA is a robust statistical tool used to determine whether significant differences exist among the means of different groups. Central to this research is the F-value, which indicates the ratio between the observed variability across groups and the variability observed within groups. A higher F-value signifies a more pronounced distinction between the means of these groups. Equally crucial is the
p-value, which plays a pivotal role in assessing the statistical significance of the F-value, offering insights into the probability of obtaining such results purely by chance.
Upon a thorough examination of the table, a notable finding emerges. DenseNet-AO stands out prominently, boasting a substantial F-value of 15.24 and an impressively low p-value of 0.001. It indicates that the execution times of DenseNet-AO exhibit significant variations across the diverse domains considered in our analysis. Similarly, techniques such as CNN, Transformer, and random forest display noteworthy F-values ranging from 5.99 to 7.92, coupled with relatively low p-values ranging from 0.006 to 0.012. It suggests these techniques demonstrate substantial differences in execution times across the analyzed domains. However, it is worth noting that certain techniques, including NB, GAT, SVM, and Logistic Regression, exhibit non-significant F-values and relatively higher p-values. This implies that the execution times of these techniques do not vary significantly across the diverse domains considered in our study.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}