1. Introduction
Today, many people use social media platforms to acquire information or to spread information around the world. From this perspective, social media platforms are popular as hubs for the collection and enjoyment of news. Thus, social media has become a useful tool for newspapers, which use social media platforms to disseminate news and attract users. These users, in turn, are inundated with a vast array of information, often interpreted from different personal and political perspectives.
Newspapers differ from each other in the way they deal with specific topics. It can be difficult for a user to obtain clean and complete information. Different sources could treat the same event in different ways, and some content information could be contradictory. Furthermore, certain newspapers could spread misleading information or fake news [
1]. Thus, each news item can contain, in practice, different details on a specific topic. Users seek to gather as much information as possible on a topic to have the opportunity to form their personal opinions. However, they would like to avoid reading all related news items, which often contain redundant information, choosing instead to only focus on content differences.
Starting from this observation, we propose a system that takes a newspaper article, denoted as the reference article, and retrieves a set of articles, denoted as target articles, on the same topic; the system automatically assesses the contents of these articles in order to pinpoint similarities and differences with respect to the reference article by means of sentence-level similarity. The identified differences can be interpreted as novel and possibly interesting content. Our end goal is to provide the users with an abstractive summarization of such content, thus reducing their reading time and effort.
The system is based on a methodology that leverages the similarity between sentences to find groups of them with varying degrees of similarity. In order to define and exploit a metric for determining sentence similarity, we turn to the literature on natural language processing (NLP), particularly distributional semantics. Most modern approaches in this area are based on neural language models and, more recently, Transformer architectures. At their core, such models define a data-driven probability distribution over sequences of tokens. A token is typically an approximation of the concept of a word and a discrete entity in texts. This distribution is used to learn a fixed-length representation of textual units in a latent space. Distances between such representations in the space can be used to approximate semantic similarity by exploiting the so-called distributional hypothesis [
2], which states that similarities in distribution tend to have similar meanings. Thus, similar representations reflect similar word meanings. In recent years, Transformer architectures such as BERT [
3] have established themselves as the de facto standard, obtaining state-of-the-art results in many NLP-related tasks, including token-level contextualized representations. In the context of sentence-level comparisons, we can identify two major shortcomings in employing a standard classification approach. First, as the authors of BERT pointed out, sequence-level representations are not to be considered as semantically relevant for determining similarity between sentences [
3]. Indeed, token-level representations extracted with BERT-like models tend to obtain results that are generally on par with—if not better than—more traditional approaches, such as word2vec [
4] for token-level semantic similarity. Nevertheless, sequence-level representations are typically learned as feature vectors for subsequent classification tasks, thus BERT-like models are not very reliable for determining similarity between sentences. Second, employing a classification model for such a problem may prove to be a rather costly approach. Transformer-based neural language models typically require GPU acceleration during the training phase.
As for the quality of sentence-level representations, we considered Sentence-BERT [
5]. It is a method used for further fine-tuning a Transformer model that leverages Siamese and triplet network structures, semantic textual similarity, and natural language inferencing training tasks in order to improve the sequence-level representations provided by a Transformer model. Sentence-BERT is specifically designed to derive semantically meaningful sentence embeddings that can be compared using cosine as a similarity metric [
5]. This latter aspect is helpful when designing approaches aimed at reducing the computational cost of solving the problem. We can argue that the computational cost of Transformer-based models is a slightly less prominent issue if we consider them only from a feature extraction perspective. Thus, we propose leveraging Sentence-BERT to obtain sentence-level similarity ratings for newspaper articles.
We exploit these similarities for the sentence classification task described in
Section 3. Specifically, we leverage the cosine similarity between sentences as a proxy of their similarity to classify sentences of the target articles with one of three classes, namely
similar (SS),
different (DS), and
very different (VDS), representing the difference level with sentences in the reference article, based on their cosine similarity. Although our aim is to discriminate between similar and different sentences, we realized that some sentences are neither too similar nor too different. Thus, we introduce an intermediate class that represents sentences that are different, but not distinct enough to be certain that they contain new information with respect to the reference article. Then, we consider all the target articles and employ a similar approach in order to further refine our sentence selection. Specifically, we aim to discard sentences in the target articles that are similar to the sentences in other target articles, in order to reduce the number of overall sentences considered and avoid duplicated information. We describe this process in
Section 3.3. Clearly, semantic differences lie on a spectrum and are challenging to reduce to distinct classes. However, we believe that choosing a three-class distinction allows us to avoid performing a too-simplistic distinction between similar and non-similar sentences while giving us enough descriptive power to perform a reliable early analysis of the results. Finally, we employ a Transformer-based abstractive summarization model in order to generate easy-to-read summaries of novel information based on the survived sentences. We describe this process in
Section 3.4.
We performed a set of experiments aimed at evaluating both the performances of the sentence classification and the quality of the summarization model for our goal. More specifically, we measured the effectiveness of the sentence classification in identifying novel content in target articles, with respect to the reference article by comparison with human judgments. Such judgments were obtained by means of crowdsourcing. This also enabled us to release a dataset of sentences labeled for similarity, which is likely to be very helpful in several tasks. In addition to this, we compared the performance of our system against a BERT-based classifier that was fine-tuned for the same task, and we employed the same BERT model as a frozen model, applying the prompt tuning technique to utilize it to solve the task. We show that our system is able to achieve comparable performance at a fraction of the computational cost. In fact, while the standard classification pipeline is based on (i) fine-tuning the model, or learning soft prompts to condition the frozen model to the classification task, and (ii) producing the results at inference time by feeding all the test data to the trained classifier, our pipeline allows us, on the one hand, to leverage a pre-trained model without additional tuning on the data itself and, on the other hand, to provide the final results by simply considering the similarity matrix between sentences. This is much more efficient to compute, thus making our system more efficient. Concerning the generated summaries, we again performed a crowdsourcing experiment aimed at evaluating how the summary is perceived by human readers in comparison with the reference article and with the sentences used to generate it. In particular, we aimed to assess, for each summary, the novelty with respect to the reference article, and the completeness and factual correctness of information with respect to the sentences that generated it.
The paper is organized as follows. In
Section 2, we present an overview of the state of the art in the field of semantic textual similarity and some related studies that concern textual differences.
Section 3 provides an overview of the system and describes in detail the single modules.
Section 4 shows some experiments performed to validate the sentence classification process. Finally, in
Section 5, we draw some conclusions and highlight possible future directions.
2. Related Works
Semantic textual similarity is a challenging task in NLP and text mining and is closely related to the field of distributional semantics. From the linguistic perspective, distributional semantics is based on a simple assumption called
distributional hypothesis. For the distributional hypothesis, the more two words are semantically similar to each other, the more they tend to appear in the same, or similar, linguistic context due to the fact that “difference of meaning correlates with difference of distribution” [
6]. From a computational perspective, we can suppose that words are represented as vectors encoding the properties of their contexts in a vector space. Their (semantic) similarity is given by the distance between their vector representations. We usually refer to vector representations of words as word embeddings [
2].
The NLP field has made large use of the distributional hypothesis and the distributional properties of words to encode their meaning. While the earliest attempts exploited co-occurrence matrices to represent words based on their contexts, more modern approaches leverage machine learning and deep learning in the form of neural language models. Among such models, the earliest ones typically employed unsupervised learning to obtain fixed-length representations of words [
4] and sentences [
7].
In recent years, Transformer-based neural language models have established themselves as the de facto standard for many NLP tasks. BERT is an architecture based on the self-attention mechanism to deal with complex tasks involving human language [
3]. A very attractive aspect of the BERT-like architectures is that their internal representations of words and sequences are context-aware. The attention mechanism in Transformers facilitates the consideration of relationships between words within a sentence or across more significant portions of a text, establishing deep connections. Furthermore, researchers have proposed other architectures with attention-based mechanisms, such as AlBERT [
8] and DistilBERT [
9], which have gained significant attention and continue to be exploited by the NLP community. Nevertheless, it is fair to admit that BERT and similar models face some limitations, especially when applied to tasks related to semantic textual similarity, particularly at the level of sentence-level embeddings.
One of the limitations of BERT and BERT-like models is evident in tasks regarding semantic textual similarity, particularly when coping with sequence-level embeddings [
5]. It is well known that BERT’s sequence-level embeddings are not directly trained to encode the semantics of the sequences and, thus, are not suited to compare them with standard metrics such as cosine similarity [
3]. To overcome these limitations, Sentence-BERT [
5] was proposed. Sentence-BERT is a modification of the pre-trained BERT network with Siamese and triplet network structures. It can produce sentence embeddings that are semantically meaningful and compared using a similarity measure (for example, cosine similarity or Manhattan/Euclidean distance). The process of finding the most similar pair is reduced from 65 h with BERT/RoBERTa to about 5 s with Sentence-BERT while maintaining the accuracy achieved by BERT [
5]. Research has been conducted to design and evaluate various approaches for employing Siamese networks, similarity concepts, one-shot learning, and context/memory awareness in textual data [
10]. Furthermore, recent efforts have focused on developing an unsupervised contrastive learning method that transforms pre-trained language models into universal text encoders, as seen with Mirror-BERT [
11] and subsequent models [
12].
In recent years, we have also seen the rise of large language models, with a considerable number of parameters reaching the tens or even hundreds of billions. These models differ from their predecessors in terms of scale and, in some instances, they incorporate reinforcement learning techniques during training. Prominent examples of large language models include OpenAI’s GPT [
13], Google’s LLaMA [
14], and Hugging Face’s BLOOM [
15]. These models typically outperform smaller counterparts and are recognized by their zero-shot learning capabilities and emergent new abilities [
16]. However, they are affected by two significant limitations. First, most of these models are controlled by private companies and are only accessible via APIs. Second, the computational costs of such models often pose challenges for running them on standard commercial hardware without resorting to parameter selection and/or distillation techniques.
The problem of semantic textual similarity between pairs of sentences has been discussed in several papers and some studies have faced the issue of extracting semantic differences from texts. In particular, research has been carried out on the ideological discourses in newspaper texts. For instance, some authors proposed a statistical model for ideological discourse based on the assumption that we can detect ideological perspectives through lexical variants [
17]. Following this idea, others investigated the utility of applying text-mining techniques to support the discourse analysis of news reports. They found contrast patterns to highlight ideological differences between local and international press coverage [
18]. In recent years, critical discourse analysis has been applied to investigate ideological differences in reporting the same news across various topics, such as the COVID-19 in Iranian and American newspapers [
19], and the representation of Syrian refugees in Turkey, considering three Turkish newspapers [
20].
Recent research in the realm of newspaper text analysis has explored a variety of topics. Sentiment analysis, for instance, has been a key area of focus, as seen in reference [
21,
22,
23], and more recently in [
24]. Some approaches, such as reference [
25], and resources, such as the SentiCoref 1.0 dataset [
26], have also been made available in recent years. Another related topic is the application of opinion mining techniques on noisy data, such as blogs. A semi-automated approach (in which these texts are first cleaned using domain knowledge and then subjected to mining) was proposed in [
27]. Moreover, studies have been conducted on the narrative and factual evolution of news articles. A novel dataset on news revision histories, named NewsEdits, and three novel tasks aimed at predicting actions performed during article version updates have been made available in [
28]. Here, the authors show that, to date, these tasks are possible for expert humans but are challenging for large NLP models. Furthermore, the application of statistical learning algorithms to pattern analysis not only in the newspaper domain but also in different media has been studied in [
29]. Several studies have been conducted in completely different domains, such as scholarly documents. A hybrid model, which considers both section headers and body text to recognize automatically generic sections in scholarly documents, was proposed in [
30]. There also exist studies in the corpus linguistics domain that provide quantitative evidence by examining collocations [
31]. These studies typically use frequency, keywords, or concordance-based pattern analysis techniques.
Our system uses an abstractive text summarization model. These kinds of models produce a paraphrasing of the main contents of the given text, using a vocabulary set different from the original document. Several recent models in abstractive text summarization exist. Some of these models are based on classical neural network architectures with attention mechanisms [
32] and conditional RNN [
33]. Other abstractive text summarization models are based on an encoder–decoder architecture with attention [
34]. The CopyNet model incorporates the copying mechanism in the neural encoder–decoder model for sequence learning tasks [
35]. More recent studies applied the Transformer architecture to neural abstractive summarization [
36]. Bidirectional and autoregressive Transformers (BART) [
37] and text-to-text transfer Transformer (T5) [
38] are two widely used sequence-to-sequence pre-trained models. The model we used for our system was PEGASUS (pretraining using extracted gap sentences for abstractive summarization by sequence-to-sequence models) [
39].
It is also important to note systems with approaches or applications similar to ours. For instance, ReviewChomp
https://www.reviewchomp.com/ (accessed on 3 November 2023) is based on multi-document text summarization and provides customer review summaries for various products or services. Users can search for the desired product or service on the website. It is essential to note that while multi-document text summarization and our system share some similarities, they have different objectives. Our system focuses on extracting information differences from several target articles based on a reference article already read by the user. In contrast, multi-document text summarization approaches primarily aim to summarize information extracted from multiple texts. One interesting and recent application is the
lecture summarization service, which is a Python-based RESTful service that utilizes a BERT model for text embedding and K-means clustering to identify the sentences closest to the centroid for summary selection. The primary aim of this service is to equip students with a tool capable of generating summaries of lectures in a specified number of sentences [
40]. A service offering similar summary generation for lengthy lecture videos is detailed in [
41].
3. The Proposed System
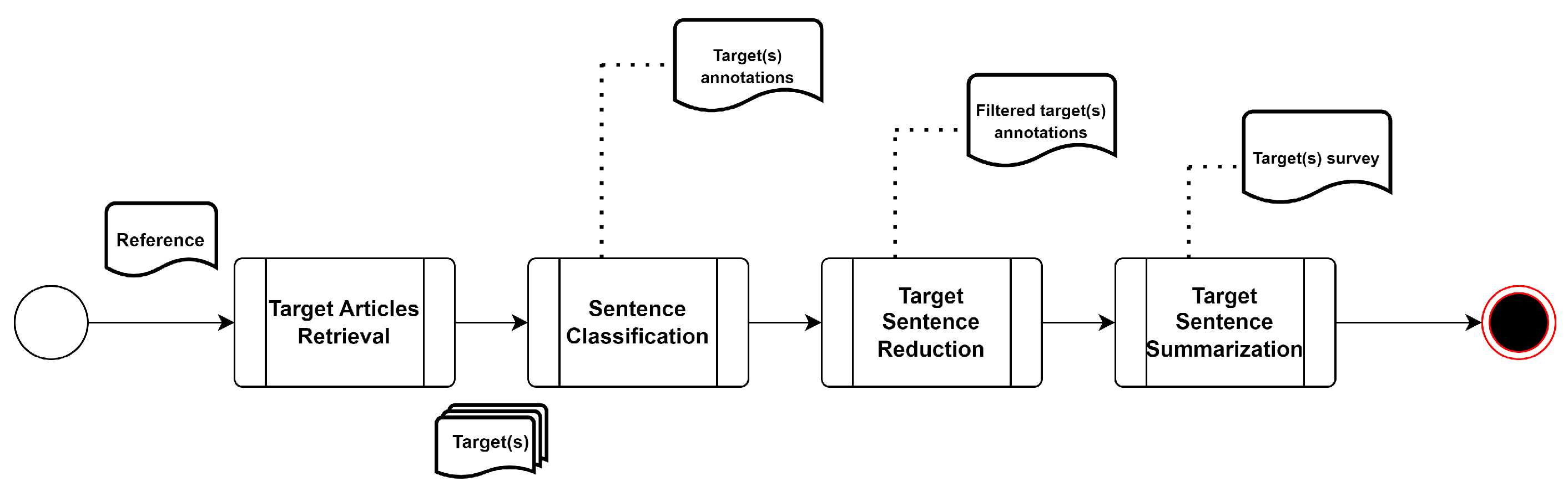
The flowchart of the proposed system is presented in
Figure 1. The system expects a reference article as input. Then, it retrieves a set of target articles that refer to the same topic/event from a set of sources (e.g., newspaper websites) and outputs a summary of the information, which is contained in the target articles and is considered to not be very similar to the one contained in the reference article. We attempt to capture the desires of the typical news readers who read an article from their favorite newspaper websites but also wish to acquire opinions on the same event from other newspapers, possibly of different political connotations. The system consists of four main steps: target article retrieval, sentence classification, target sentence reduction, and target sentence summarization. The core of the system is the algorithm used in the ‘Sentence Classification’ module, which allows labeling the sentences of the target articles into three classes, namely similar sentence (SS), different sentence (DS), and very different sentence (VDS),based on the values of similarity with the reference article computed exploiting sentence embeddings extracted by a Sentence-BERT pre-trained model. We will detail this algorithm in
Section 3.2.
Before performing sentence classification, several pre-processing operations are applied to the articles. In particular, we perform standard text annotation actions, such as sentence splitting and named entity recognition. We also extract keywords using KeyBERT. Then, we use a Sentence-BERT model to obtain the representation for each sentence. Finally, we perform the target sentence classification: each sentence is associated with one of three similarity classes.
Concerning the target sentence reduction, we filter out all the target sentences that contain redundant information with respect to the target articles (i.e., those sentences classified as different from all the reference sentences, but containing information redundant with other target articles). This aspect is described in detail in
Section 3.3.
Finally, for the target sentence summarization, we first choose the sentences to be shown to the user from each target article. Then, we exploit an abstractive text summarization algorithm to generate a summary of the text resulting from the union of these sentences in order to provide an easy-to-read output for the user. We detail the target sentence summarization in
Section 3.4.
3.1. ‘Target Articles Retrieval’
The first module of our pipeline is concerned with retrieving news articles on the same topic or event as the reference article. As previously mentioned, we denote the retrieved articles as target articles. Given a reference article, already read by the user, the module collects articles from a pre-defined set of sources. In the current implementation, sources are widely popular newspaper websites. Each source homepage is scraped in order to retrieve target articles referring to the same topic or event reported in the reference article. In order to assess the degree of similarity of the article acquired by scraping with the reference article, we exploit a simple yet effective and efficient method based on named entity recognition (NER). Specifically, named entities are first extracted from the reference and target articles using the spaCy NLP pipeline
spaCy.io (accessed on 3 November 2023) spaCy is an open-source text processing library in Python. The version utilized is 3.5.0, and the module exploited is the
en_core_web_lg. As for spaCy, we chose it for its widespread use, both in industry and academia, and its ease of implementation in the pipeline. As for the specific
en_core_web_lg model, we used it for two main reasons. First, the model has been trained on web-based data and, thus, is expected to be effective for our task. Second, our goal was to achieve a good balance between the accuracy of the model and its computational cost. Although a more accurate Transformer-based model exists for the English language, it is more expensive to run locally and requires GPU acceleration. The chosen model allows the module to easily run on a CPU-only system while achieving good accuracy.
Articles are considered as target articles if they contain at least a third of the named entities extracted from the reference article. We chose this threshold after an empirical evaluation, guided starting with the following consideration. The use of named entities provides reasonable confidence in retrieving articles whose topics align with that of the reference article, as they refer to the same named entities. Simultaneously, selecting articles that do not share all named entities with the reference article, but only some, ensures that the target articles contain new or different information with respect to the reference article.
This step allows us to efficiently retrieve possible target articles from the web without performing in-depth similarity calculations, which is a more expensive task. Thus, we are able to reduce the number of articles that have to be compared with the reference article, with negligible loss of information. The system will calculate the similarity between the target and reference articles in the subsequent steps, involving more comprehensive analysis and specific techniques.
Note that the set of sources can be redefined provided an appropriate functionality for retrieving information from the new sources. In addition to this, the threshold could be considered as a parameter in future upgraded versions of the application.
3.2. Sentence Classification
The ‘Sentence Classification’ module is based on the algorithm described in the pseudo-code shown in Algorithm 1. Upon receiving a reference article and the previously described set of target articles as input, the ‘Sentence Classification’ module categorizes all sentences within the target articles as SS, DS, or VDS.
First, the reference article is split into sentences by using the spaCy pipeline. Furthermore, keywords from the reference article are extracted by using KeyBERT
https://github.com/MaartenGr/KeyBERT (accessed on 3 November 2023). These keywords are merged with the named entities of the reference article extracted by the ‘Target Articles Retrieval’ module to generate a list of representative words for the reference article. KeyBERT leverages Sentence-BERT to obtain word embeddings. Then, it selects keywords under the assumption that their cosine similarity is the highest with respect to the embedding of the whole document.
Second, with the aim of obtaining reliable representations of semantically relevant news, we exploit a Sentence-BERT pre-trained model to encode the sentences of the reference article. More specifically, we employ the
distiluse-base-multilingual-cased-v2 pre-trained model [
42]. It is a multilingual model, and the training is based on the idea that a translated sentence should be mapped to the same location in the vector space as the original sentence. We employed this model to facilitate the generalization of the proposed methodology with newspaper texts in other languages [
42].
The sequence of elaborations performed on the reference article is applied to each target article. Once the sentences and their distributional representations with Sentence-BERT are obtained for each target article, the sentences are classified with respect to the similarity with sentences in the reference article by calling the TargetSentenceLabeling() function. We formally define our classification problem as follows.
Let
r and
be, respectively, a reference news article and a set of one or more target articles. Both
r and
are represented as sets of sentences,
and
. The goal is to classify each sentence
in each
with one of the three classes (SS, DS, VDS) based on degrees of similarity with all the sentences in
r. In particular, the label is assigned to
by considering the maximum similarity between
and all the sentences in
r. We employ two thresholds, namely high similarity (HS) and low similarity (LS), to discriminate, respectively, between SS and DS, and DS and VDS. The threshold values are considered as parameters. If at least one sentence in
r has a similarity score higher than HS with
, then
is classified into the SS class. If no sentence in
r has a similarity score higher than LS with
, then
is classified into the VDS class. Finally, if none of the two previous conditions are met (i.e., the maximum similarity score between
and a sentence in
r is between LS and HS thresholds),
is classified into the DS class.
| Algorithm 1 The pseudocode of the algorithm used in the ‘Sentence Classification’ module |
- 1:
: the reference article (i.e., the article already read by the user) - 2:
: the list of target articles (i.e., the articles retrieved by the ‘Target Articles Retrieval’ module. They refer to the same topic or event as the reference article) - 3:
: the named entities of the reference article (extracted during the ‘Target Articles Retrieval’ sub-process) - 4:
: the named entities of the target articles (extracted during the ‘Target Articles Retrieval’ sub-process) - 5:
S: the list of target sentences labeled by the algorithm. Each member of the list is a tuple consisting of the target sentence, the label, and the most similar reference sentence to the target sentence. - 6:
function SentenceClassification() - 7:
//(the reference article is split into sentences) - 8:
- 9:
- 10:
//(keywords are extracted from the reference article) - 11:
//(keywords and named entities are merged into a unique list of representative words for the reference article) - 12:
for each in do - 13:
//(the sentences of the reference article are encoded by using Sentence-Bert) - 14:
end for - 15:
for each in do - 16:
//(the target article is split into sentences) - 17:
//(keywords are extracted from the target article) - 18:
//(keywords and named entities are merged into a unique list of representative words for the target article) - 19:
- 20:
for each in do - 21:
//(the sentences of the target article are encoded by using Sentence-Bert) - 22:
end for - 23:
- 24:
- 25:
- 26:
if all the sentences of the target article are labeled as VDS then - 27:
remove all the sentences from S - 28:
end if - 29:
end for - 30:
return S - 31:
end function
|
Once each sentence in the target article has been classified, we tune our labeling by taking the sentence length into account by calling the
LengthBasedRefinement() function. Finally, we further tune the labeling by considering shared keywords between sentences by calling the
KeywordBasedRefinement() function. If all the sentences in the target article are labeled as VDS, the article is removed (all its sentences are removed). This enables us to integrate the check based on the named entities executed in
Section 3.1 with an additional check based on cosine similarity, in order to delete potential articles that do not align with the topic of the reference article.
Notably, we can highlight some important differences between the proposed system and typical approaches to sentence similarity. These approaches usually compare pairs of sentences to obtain a similarity score, e.g., a value in the [0, 1] range or a similarity label. These sentences are often considered out of their context. Our system takes into account sentence-level similarity in a document-level context: each target sentence (and, thus, each target article) is evaluated based on its similarity with a specific set of reference sentences. The three sentence-level classes provide us with a way to determine document-level similarity as well, answering the question “how many and which parts of the target document are similar/dissimilar to the reference one?”.
In the following, we detail the three functions used in the Sentence Classification module.
3.2.1. Target Sentence Labeling
Function
TargetSentenceLabeling() is described in the pseudo-code shown in Algorithm 2. Once each sentence
in
and each sentence
in
r are represented as embeddings, we compute the similarity between
and
, for each sentence in
and
r, by exploiting the cosine similarity. In
Table 1, we summarize how the sentences
in
are classified based on values of maximum cosine similarity and provide a description for each class.
| Algorithm 2 The pseudocode of the TargetSentenceLabeling() function |
- 1:
function TargetSentenceLabeling() - 2:
for each in do - 3:
if then - 4:
- 5:
else if then - 6:
- 7:
else - 8:
- 9:
end if - 10:
- 11:
- 12:
- 13:
end for - 14:
return S - 15:
end function
|
3.2.2. Length-Based Refinement
The annotation step described in the previous subsection suffers from the following problem: when sentences vary significantly in length, their calculated similarity may be low despite them sharing similar content. Indeed, length is an essential factor for BERT-like models. Although sentence-BERT has proved to provide semantically meaningful representations of sentences in the vector space [
5], the cosine similarity computed between embeddings of sentences with similar content but different lengths is not generally as high as expected for the scope of the presented system.
Table 2 shows an illustrative example. The two sentences express the same information. Nevertheless, since their difference in length is high, the cosine similarity computed between the corresponding embeddings is too small for labeling the target sentence as SS. Thus, the system reiterates all target–reference sentence pairs, specifically focusing on those target sentences not labeled as SS, and that are significantly shorter in terms of tokens compared to the reference sentence (specifically, the reference sentence is at least two times longer in terms of tokens with respect to the target one). The system then determines whether the longer sentence contains additional information by employing the following method, which is based on the function
LengthBasedRefinement() described in the pseudo-code shown in Algorithm 3.
| Algorithm 3 The pseudocode of the LengthBasedRefinement() function |
- 1:
function LengthBasedRefinement() - 2:
for each in S do - 3:
if then - 4:
if then - 5:
- 6:
- 7:
- 8:
end if - 9:
- 10:
for each in do - 11:
- 12:
- 13:
end for - 14:
end if - 15:
if then - 16:
- 17:
end if - 18:
end for - 19:
return S - 20:
end function
|
The system considers the most representative words of the reference sentence shared with the target one. They consist of the keywords extracted using KeyBERT and named entities. Then, the system uses the left and right contexts for each keyword and named entity in the reference sentence to obtain a set of text fragments.
Each text fragment is compared with the target sentence. If the two sentences share some content information, then at least one (target sentence, text fragment) pair will obtain a cosine greater than or equal to HS. If this occurs, the system changes the labeling from VDS or DS to SS for the target sentence; otherwise, no change is made. The iteration continues until there are no more pairs in the VDS or DS groups to compare.
As an example,
Table 3 shows a fragment obtained from the reference sentence of CNN International in
Table 2. This fragment is compared to the target sentence of Fox News, with a cosine score of 0.8.
3.2.3. Keyword-Based Refinement
Another aspect we have to take into account is the fact that the Sentence-BERT representations often position sentences that share numerous significant words (e.g., named entities, keywords) closer together in the latent space, thus hindering the descriptive power of the cosine metric in these cases.
Table 4 provides an example.
Here, sentences share a set of named entities (Mikael Dolsten, Pfizer, third dose), and this yields a high cosine similarity. However, their informative content (and arguably, meaning) is rather different. To deal with this limitation, we further re-examine all the target sentences included in the SS and DS groups. For each of these sentences, the system checks if the information contained in the target sentence is similar to the one included in the reference sentence, excluding all the common keywords and named entities, by adopting the following method, which is based on the function KeywordBasedRefinement() described in the pseudo-code shown in Algorithm 4.
For each pair in and in r, first, the common keywords and named entities are identified. Then the system generates text fragments from the two sentences, excluding those keywords and named entities. Finally, the system compares each text fragment from the reference article with all the text fragments from the target article. If all the combinations of text fragments extracted have a cosine score lower than LS, the class of the target sentence is changed to VDS.
At the end of all these steps, the system outputs a set of classified target articles
, where
is the set of all the sentences of the article
, labeled as SS, DS, and VDS.
| Algorithm 4 The pseudocode of the KeywordBasedRefinement() function |
- 1:
function KeywordBasedRefinement() - 2:
for each in S do - 3:
if then - 4:
- 5:
- 6:
- 7:
- 8:
- 9:
for each in do - 10:
- 11:
- 12:
- 13:
- 14:
end for - 15:
if then - 16:
- 17:
end if - 18:
end if - 19:
end for - 20:
return S - 21:
end function
|
3.3. Target Sentence Reduction
Once the labeled set of sentences included in
is obtained, we further refine the sentence selection process by determining sentences in
that are similar to each other, i.e., redundant. As these sentences generally provide very little further information, we remove them. The target sentence reduction sub-process is based on the function
TargetSentenceReduction() described in the pseudo-code shown in Algorithm 5.
| Algorithm 5 The pseudocode of the TargetSentenceReduction() function |
- 1:
function TargetSentenceReduction(S) - 2:
- 3:
for in S do - 4:
if then - 5:
- 6:
end if - 7:
end for - 8:
//(Each sentence in the target article is ranked based on the similarity value with sentences in the reference article) - 9:
- 10:
for in do - 11:
if then - 12:
- 13:
end if - 14:
end for - 15:
return - 16:
end function
|
First, the system takes the set of labeled target articles as input, and merges the sentences of target articles that are labeled as DS and VDS. SS is disregarded as it can be considered redundant with the reference article. We rank the list of DS plus VDS sentences with respect to their maximum similarity with sentences in r in descending order. Then, starting from the top, for each sentence, we compute its similarity score with all the other sentences on the list. If at least one score is higher than the HS threshold, i.e., there is another sentence similar to the one considered that also has a lower similarity score with the reference article, we consider the sentence redundant and remove it from the list. The final list includes only sentences that are considered non-redundant.
3.4. Target Sentence Summarization
The goal of the system is to supply users with information they may have missed with the article of their choice (i.e., the reference article) in an easy-to-read format. With the aim of making the information promptly available to the user, the system generates a summary of the target sentences and outputs this summary.
According to our definition, all the sentences labeled VDS are selected as they certainly correspond to sentences with information different from the reference article. In addition, all the sentences classified DS with a cosine similarity score lower than LS; all the sentences in VDS are selected as well. All the sentences selected are merged into a unique text.
The system then creates a summary of this text by exploiting a neural text summarization model. In particular, we use Google PEGASUS (Pre-training with Extracted Gap-sentences for Abstractive Summarization) [
39]. It is a pre-trained large Transformer-based encoder–decoder model. PEGASUS uses a gap-sentence generation strategy, in which important sentences are masked by an input document and are then generated together as one output sequence from the remaining sentences.
The final output is a unique and readable text that only reports information included in VDS sentences and some of the DS sentences for each target article. In this way, we can visualize the new content in the target articles with respect to the reference one.
In
Table 5, an example derived from article segments on the Notre Dame fire is presented. The reference article is part of an article published on 16 April 2019 on NBC News, while the two target articles are extracted from the set of articles published on the same date by USA Today and Al Jazeera English. These three example articles are included in a dataset of international newspapers (e.g., CNN, The Guardian, Al Jazeera English) about events that happened occurred 2019 and 2021. The dataset is available on GitHub
https://github.com/pietrodelloglio/dataset-for-system-acquiring-content-differences (accessed on 3 November 2023).
4. Experimental Results
The effectiveness of the proposed approach was evaluated along two dimensions. First, we assessed the performance of the ‘Sentence Classification’ module in determining a class of similarity between sentences. In particular, we compared the output of the module with human judgment collected by crowdsourcing and with two BERT classifiers. Second, we evaluated how much the summary produced by our approach represents a coherent, factually correct, and complete summarization of the target sentences different from the reference article. Again, we used human judgment collected by crowdsourcing.
For the experiments, we first collected and annotated a dataset of online newspaper articles spanning various topics that serve both as ground truth for performance evaluation and as a training dataset for setting the optimal parameters, especially concerning the thresholds. The dataset simulates a scenario with a reference article and at least two other target articles for a given news item. Target sentences are labeled through crowdsourcing with three classes—SS, DS, and VDS—for their similarity with the sentences in the reference article. We detail the creation of the dataset in
Section 4.1. We tuned the model’s parameters (i.e., the similarity thresholds) and applied the sentence classification to target articles. We evaluated the performances of the ‘Sentence Classification’ module in two ways. First, we measured the F1 score with respect to human judgment. Second, we compared the proposed system with two BERT classifiers, applying model tuning and prompt tuning respectively, in order to obtain a reliable comparison with state-of-the-art approaches.
Section 4.2 provides insights into the experiment for parameter tuning and a comparison with the two BERT-based classifiers.
Concerning the evaluation of the summaries, we again performed a crowdsourcing experiment, asking participants to, given a reference article and the target sentences, rate the quality of the summary in terms of completeness, factual correctness, and novelty. We detail this experiment in
Section 4.3.
Finally, in
Section 4.4, we present some examples of how our system works in practice.
4.1. Dataset
We compiled a dataset that includes 43 articles, each relating to one of 8 different news events, with at least 3 articles for each news event. We assume that articles pertaining to the same event and published on the same date (or similar) are comparable. For each news event, we consider one article as the reference article, and the others as target articles.
For each article, we record the news it is sharing, the main topic of that news event (e.g., politics, health, etc.), the newspaper source, the date of publication, and the URL.
To simplify the collection process, we exploited CrowdTangle
https://apps.crowdtangle.com/ (accessed on 3 November 2023). We collected a list of events that occurred between 2020 and 2021 and obtained social media posts from Facebook pages of international newspapers (e.g., CNN, The Guardian, Al Jazeera English) with links to articles about the news. We then collected the news content directly from the newspaper website.
In order to obtain ground-truth labels for sentences in the target articles, we performed a crowdsourcing experiment using Prolific
https://www.prolific.co/ (accessed on 3 November 2023). The annotators were presented with a list of 〈target sentence–reference sentence〉 pairs. Annotators were asked to decide whether the target sentence was similar, different, or very different from the reference sentence. Each pair was labeled by seven different annotators, and the majority vote determined the gold standard label. If the majority vote was uncertain, the pair was discarded.
4.2. Target Sentence Classification Evaluation
First, we aimed to identify the optimal threshold parameters for our proposed system. To achieve this, we conducted a series of experiments involving different values for LS and HS, and compared the automatic classifications generated by our system with human labeling.
We employed a leave-one-out cross-validation approach, where one news article was held out as a test set, while the remaining articles were used to determine the threshold values that best aligned with human labeling. For each fold, we obtained eight different LS and HS pairs that achieved the best performance according to the highest number of news articles. In case of a tie, we randomly selected one pair. We obtained the same LS and HS pairs for all folds. This suggests that the choice of LS and HS thresholds was not particularly sensitive.
Table 6 shows an example of F1 scores obtained in an example fold. The table refers to the following events: “Mars Landing” (M.L.), “Italy Lockdown” (I.L.), “Italy Euro 2020” (I.E.), “Global Warming” (G.W.), “George Floyd Death” (G.F.), “Elliot Page coming out” (E.P.), and “China Landed on Mars” (C.L.).
We selected LS = 0.5 and HS = 0.8, as these values are the best parameters in the highest number of news events.
Table 7 displays the F1 score performance of the test news for each fold. On average, our system achieved an F1 score of 0.77, with the lowest value being 0.67 and the highest reaching 0.87.
To compare our system with state-of-the-art classification models, we utilized two BERT classifiers based on the
bert-base-uncased model [
3]. In the first comparison, we fine-tuned the model within the leave-one-out cross-validation setting. The fine-tuning parameters were set as follows: a maximum sequence length of 128, a learning rate of 2 × 10
, and a batch size of 8 (due to computational constraints). The model was trained for 5 epochs in each fold, with the remaining parameters following the standard settings of the Hugging Face implementation
https://huggingface.co/bert-base-uncased (accessed on 3 November 2023).
In the second comparison, we employed prompt tuning with the following parameters: a maximum sequence length of 128, a learning rate of 3 × 10, and a batch size of 8 (again, due to computational limitations). The model was trained for 30 epochs in each fold.
We present the results of the two BERT classifiers and compare them with our system in
Table 8. The table demonstrates that, on average, fine-tuned BERT performs slightly better than our system, which, in turn, outperforms the model tuned with prompts. It is worth noting that fine-tuning a classification model based on BERT can be expensive in terms of both time and computational costs. In contrast, our system is significantly more efficient in both the training and classification phases, requiring only the extraction of sentence-level embeddings and the computation of the similarity matrix. Prompt tuning, on the other hand, tends to work better with larger models and demands substantial computational resources.
We computed the Wilcoxon signed-rank test to verify if the differences between the performances of our system and the two BERT classifiers are statistically significant. For the computation of the statistics, we used the SciPy method
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.wilcoxon.html (accessed on 3 November 2023), maintaining the default parameters. In the case of the comparison between our system and the fine-tuned BERT, we obtained
(the minimum of the sum of ranks above and below zero) and
. Thus, we can conclude that there is no statistically significant difference between the two classifiers. In the case of the comparison between our system and the prompt-tuned BERT, we obtained
and
. Thus, we can conclude that there is a statistically significant difference between the two classifiers.
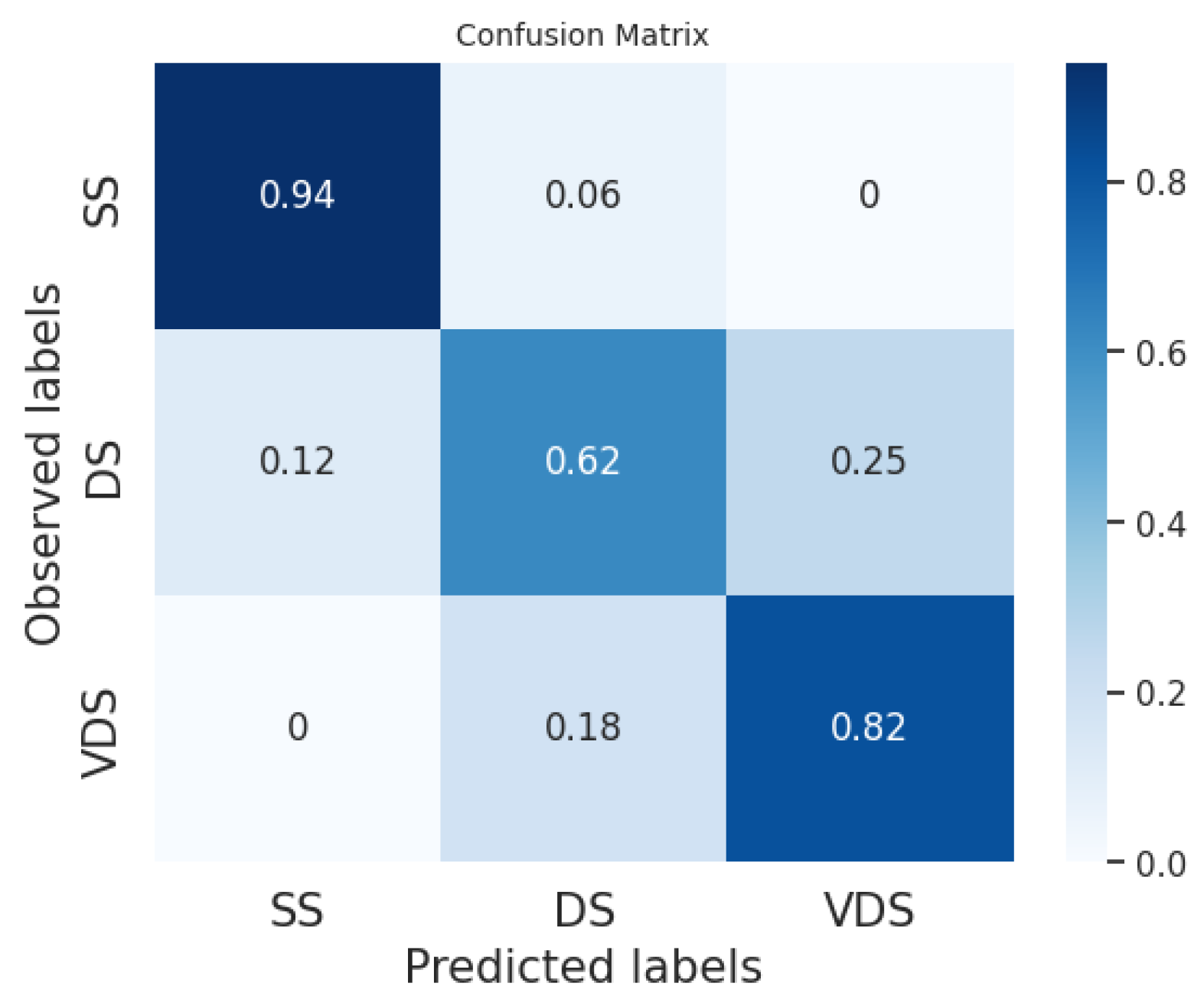
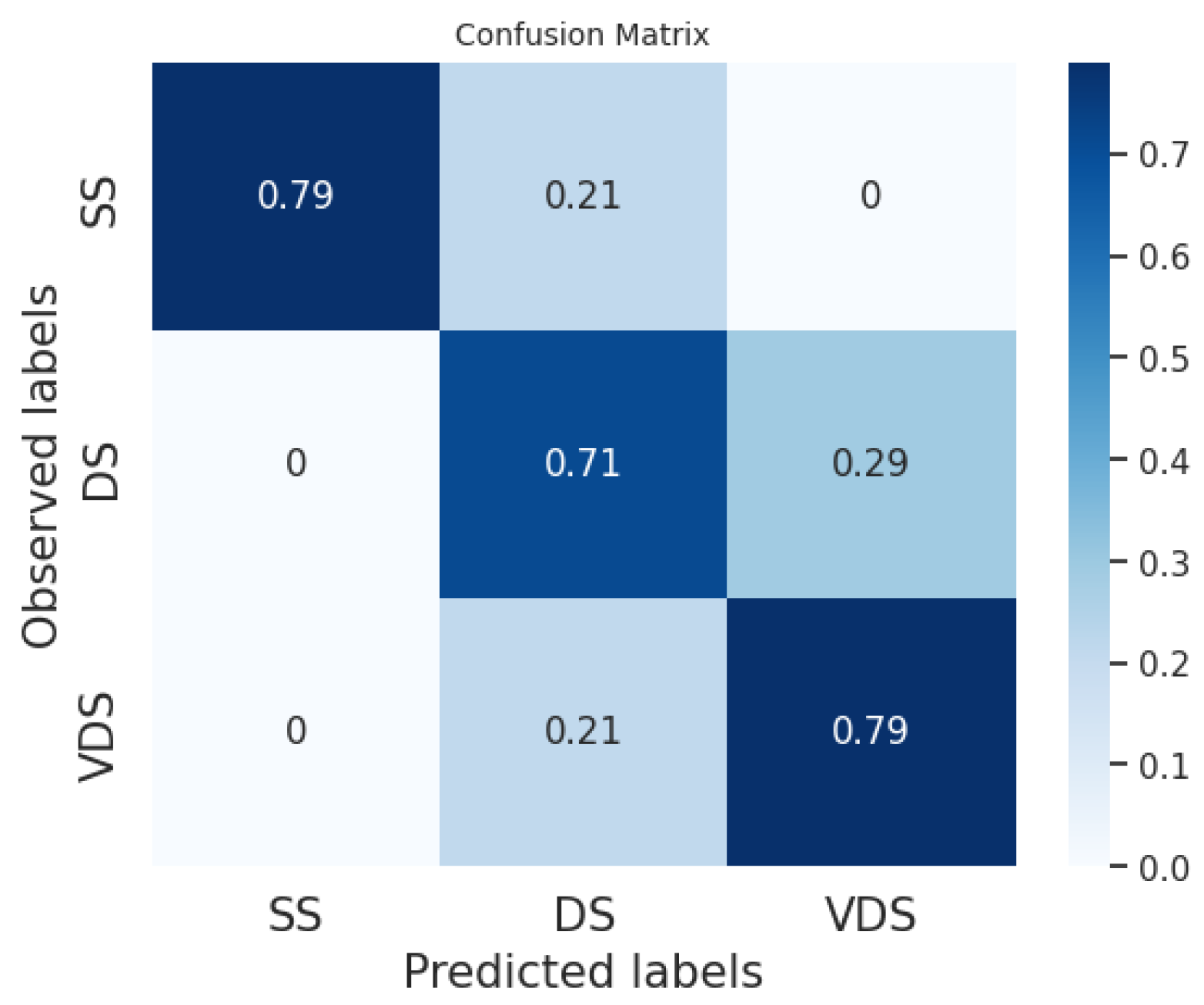
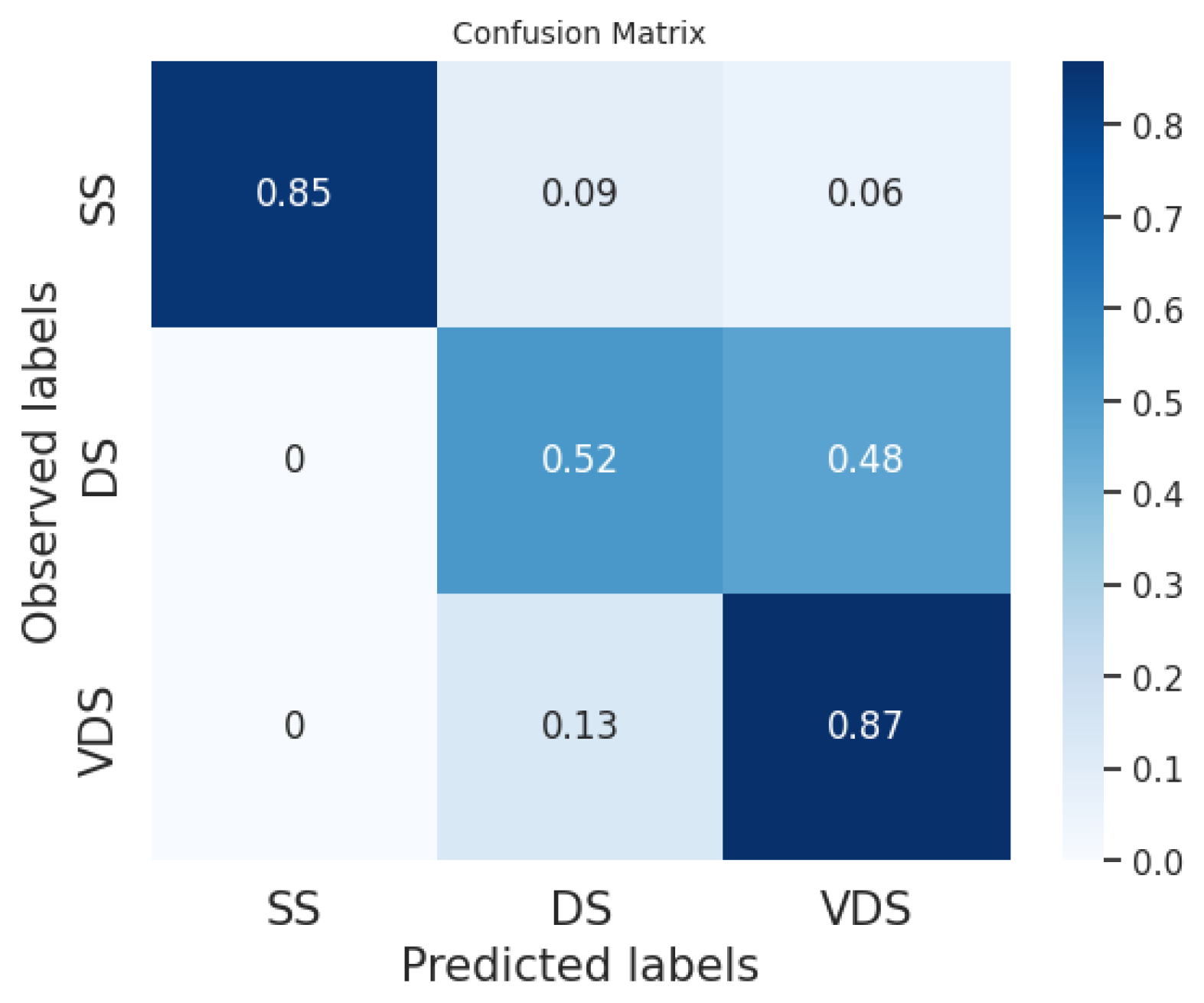
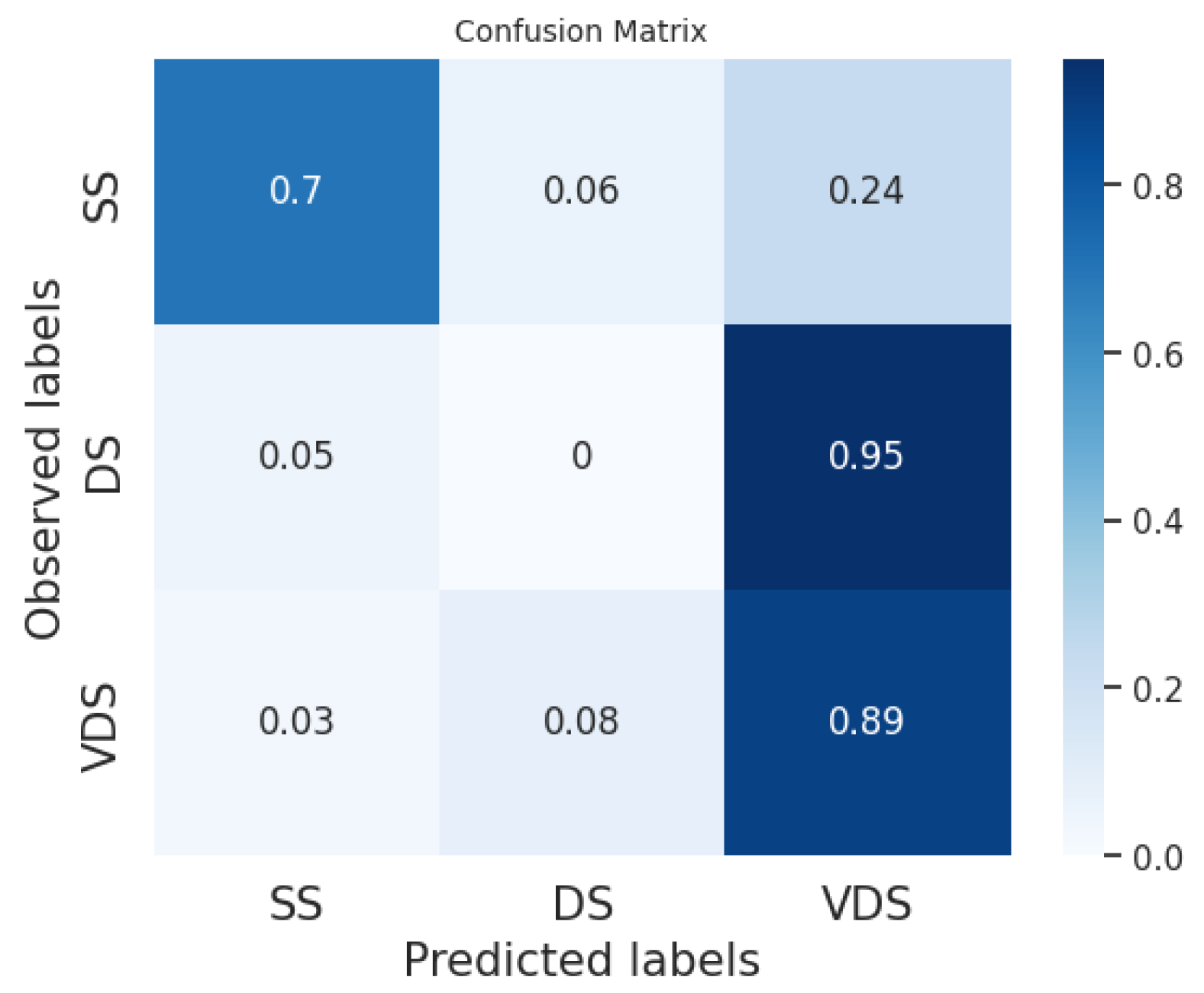
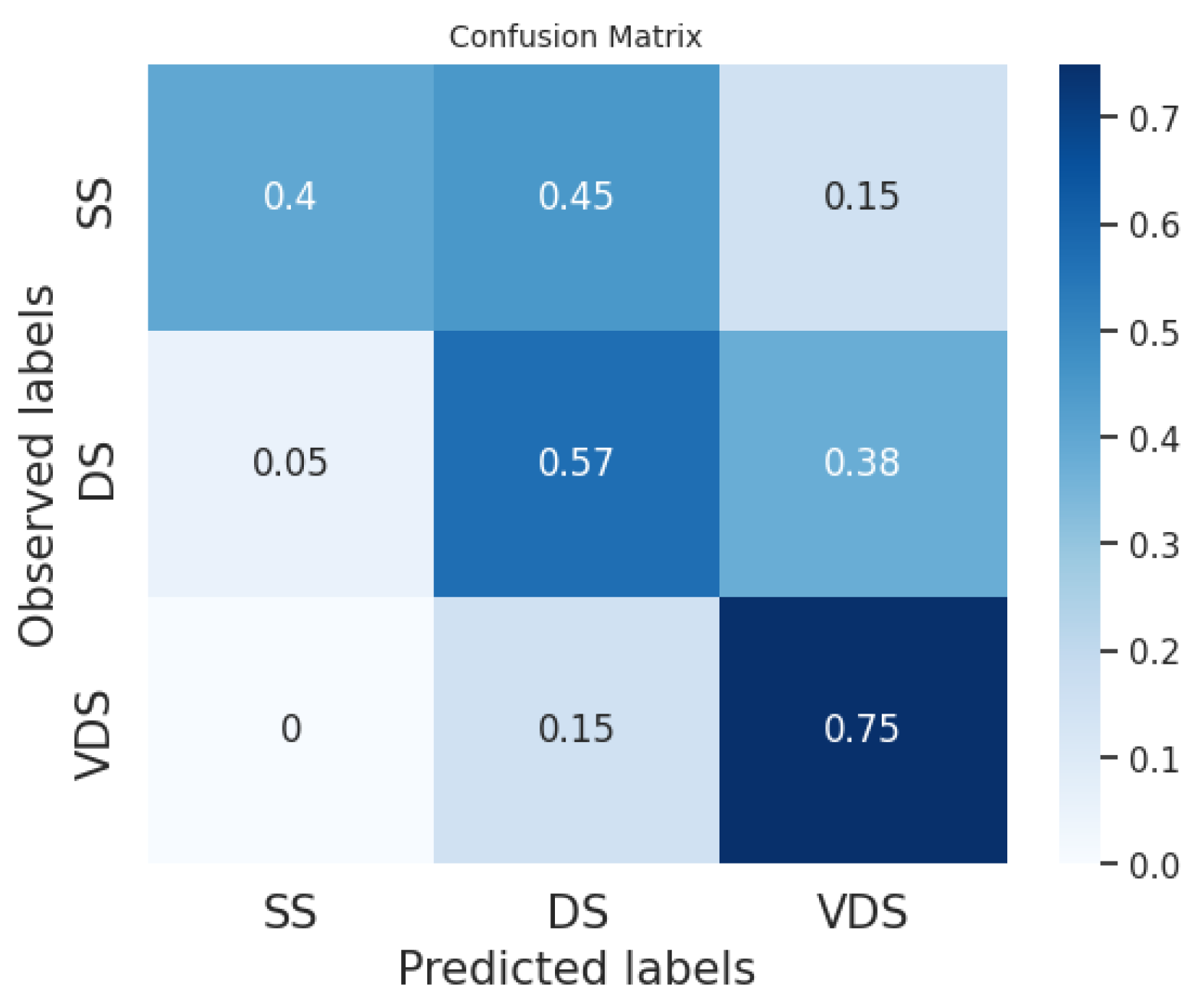
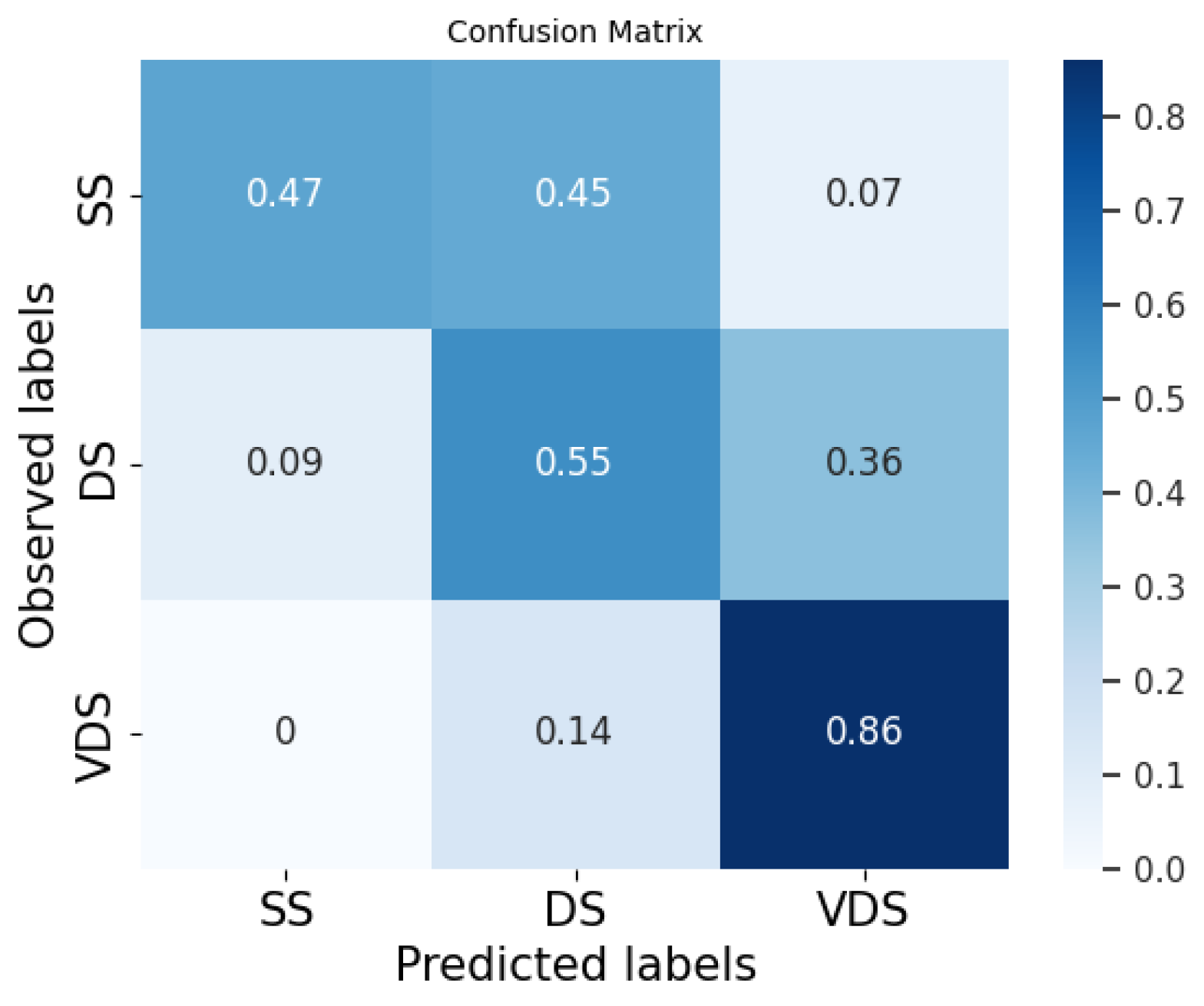
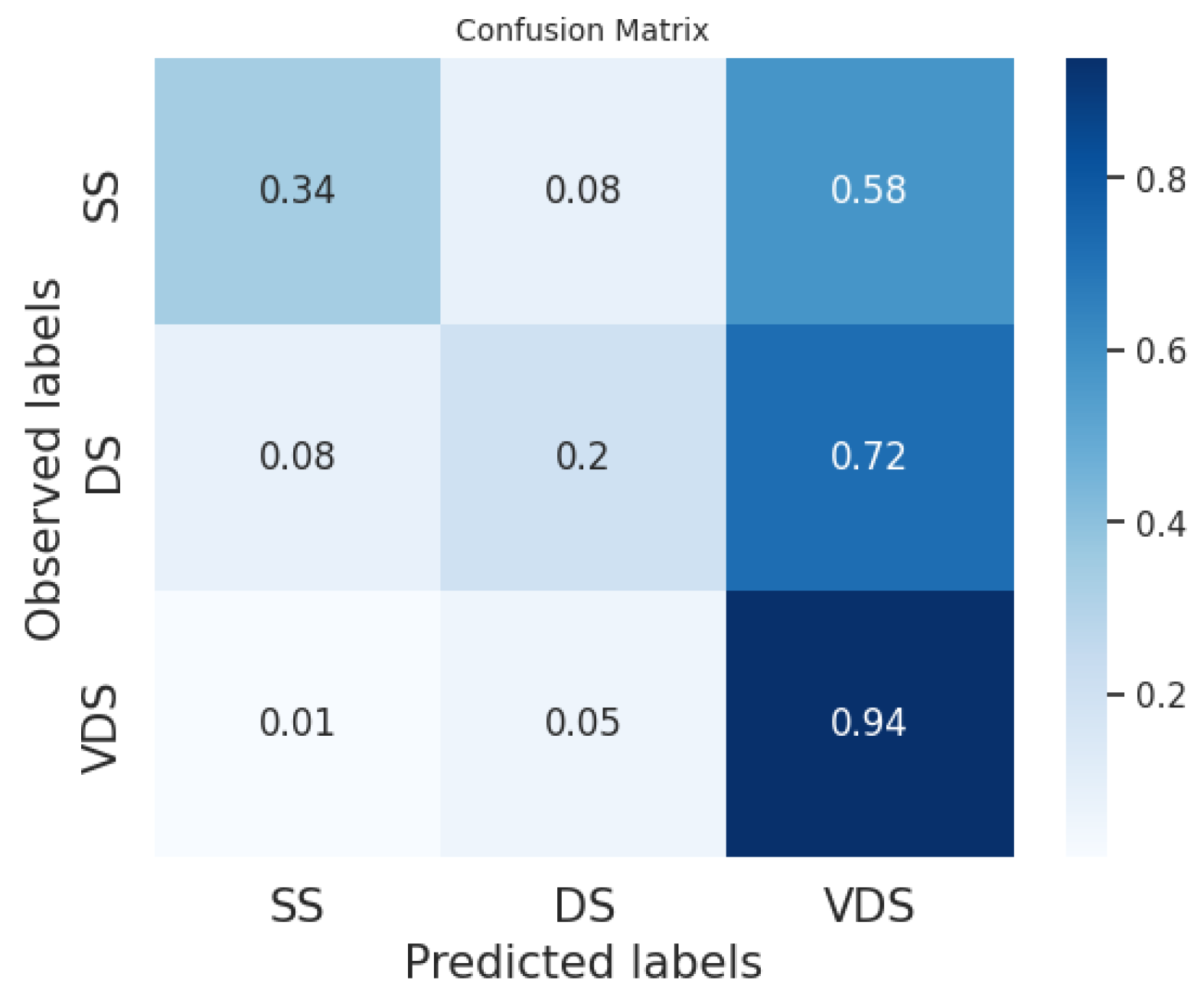
In
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7, we provide examples of confusion matrices for two of the analyzed news articles, respectively, the coming out of Elliot Page and Italy’s victory in the Euro 2020 Championship.
The analysis of the figures shows that the results are dependent on the class and the news item. For example, our system and the fine-tuned BERT perform equally on the DS class in the news about Elliot Page coming out, while our system obtains better performances than the fine-tuned BERT on the same class in the case of the news about Italy’s victory, even if the fine-tuned BERT has a higher F1 score in general.
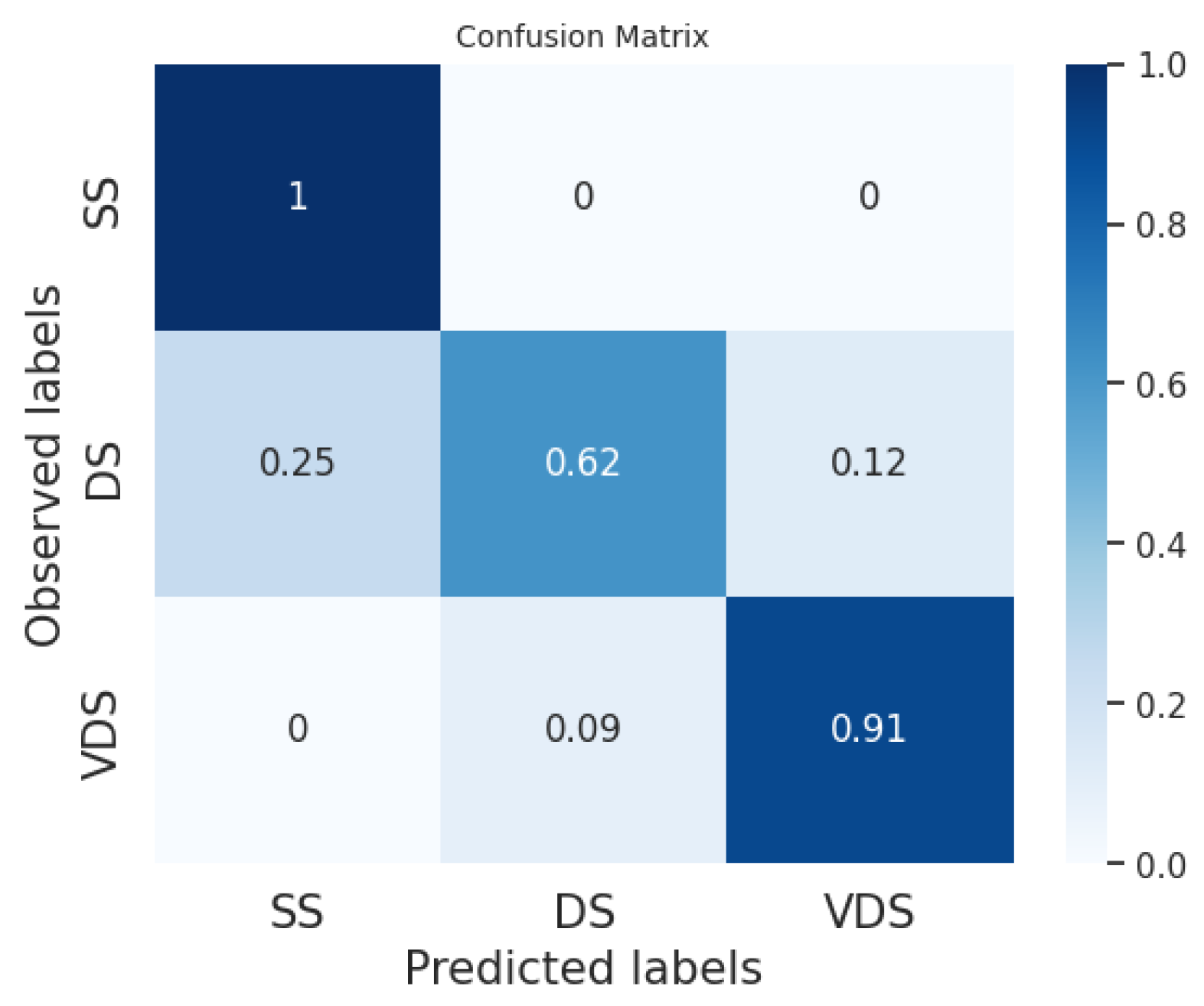
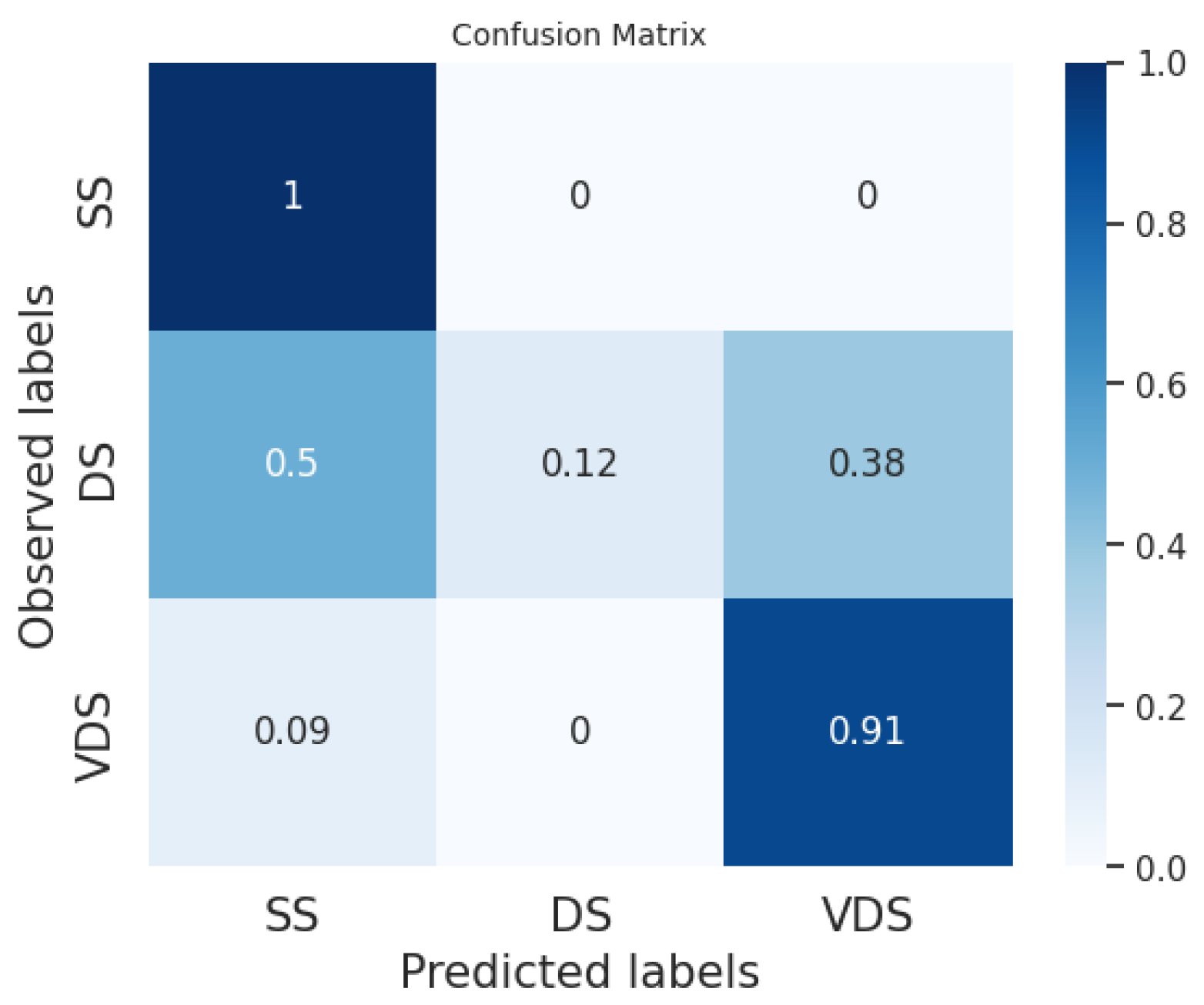
Figure 8,
Figure 9 and
Figure 10 show the average of the confusion matrices on all the tested news. Here, we can observe that the BERT classifiers perform slightly better than our system on the VDS class, while our system performs better on the DS class. Furthermore, the fine-tuned BERT outperforms our system and prompt-tuned BERT on the SS class. In general, the SS and DS classes present the greatest challenges for both BERT classifiers and our system. In the first case, we point out that several events in our datasets are slightly unbalanced with respect to the SS class. This is explained by the fact that two different articles on the same event often have a few similar sentences belonging to the SS class while the majority of the sentences belong to the DS and VDS classes. Conversely, the DS class is certainly the most challenging to predict. This difficulty may arise from the fact that the DS class is the least homogeneous of the three. Typically, it includes sentences with the same informative content as the most similar sentence in the reference article but expressed in a different linguistic style.
We can conclude that the sentence classification method implemented in our system works quite well compared to the labeling performed by human users and used as ground truth. Furthermore, on average, our classifier achieves slightly lower performance compared to the BERT classifier trained with model tuning. However, it is important to note that BERT always requires fine-tuning with annotated data, whereas our system can be used without any tuning phase. Indeed, we can directly employ default thresholds, as demonstrated in our experiments.
4.3. Text Summarization Evaluation
In order to evaluate the quality of the generated summaries, we resorted again to crowdsourcing. We carried out an experiment to evaluate the quality of the information contained in the summaries generated from the target sentences extracted from our system. Specifically, for each of the news items in the dataset, we presented the raters with (i) the reference article; (ii) the target sentences extracted from the target articles, as described in
Section 3.2 and
Section 3.3; and (iii) the summary generated from such sentences, as described in
Section 3.4. For each summary, raters were asked to provide a rating for (i) the novelty, with respect to the reference article; (ii) factual correctness, with respect to the target sentences; and (iii) information completeness, with respect to the target sentences. Each summary was rated on these 3 characteristics by 7 different people on a Likert-type scale from 1 to 7, with 1 and 7 being the lowest and the highest scores, respectively.
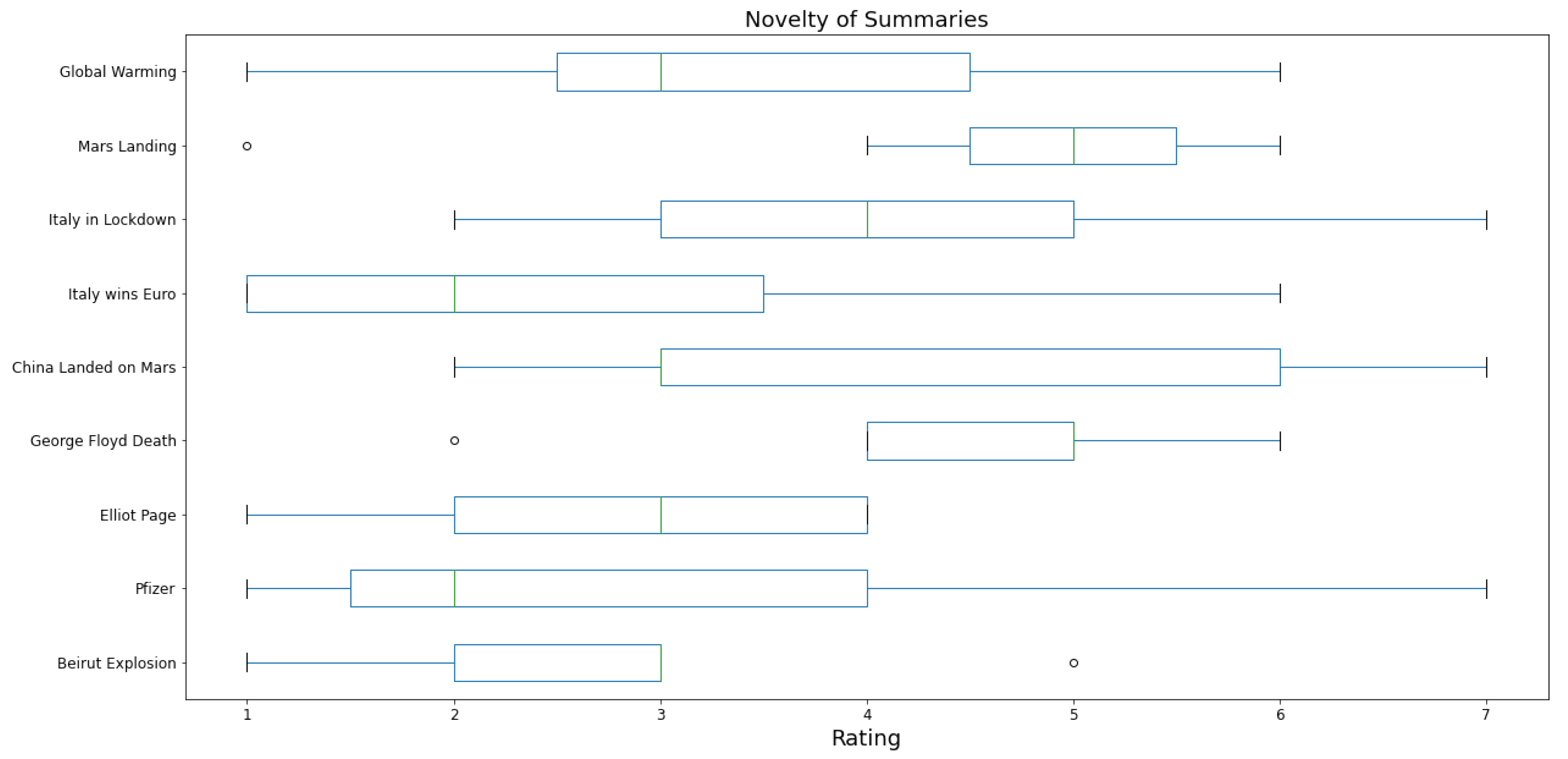
Figure 11 shows the human judgments for each news event regarding the novelty, i.e., the amount of new information contained in the target summary compared to the reference article. On average, the score is
. Some news items have better evaluations than others. In particular, the summaries on Elliot Page coming out, George Floyd’s death, and the Mars landing obtain majority scores between 4 and 6, while the news about Italy winning the Euro championship obtains a low score.
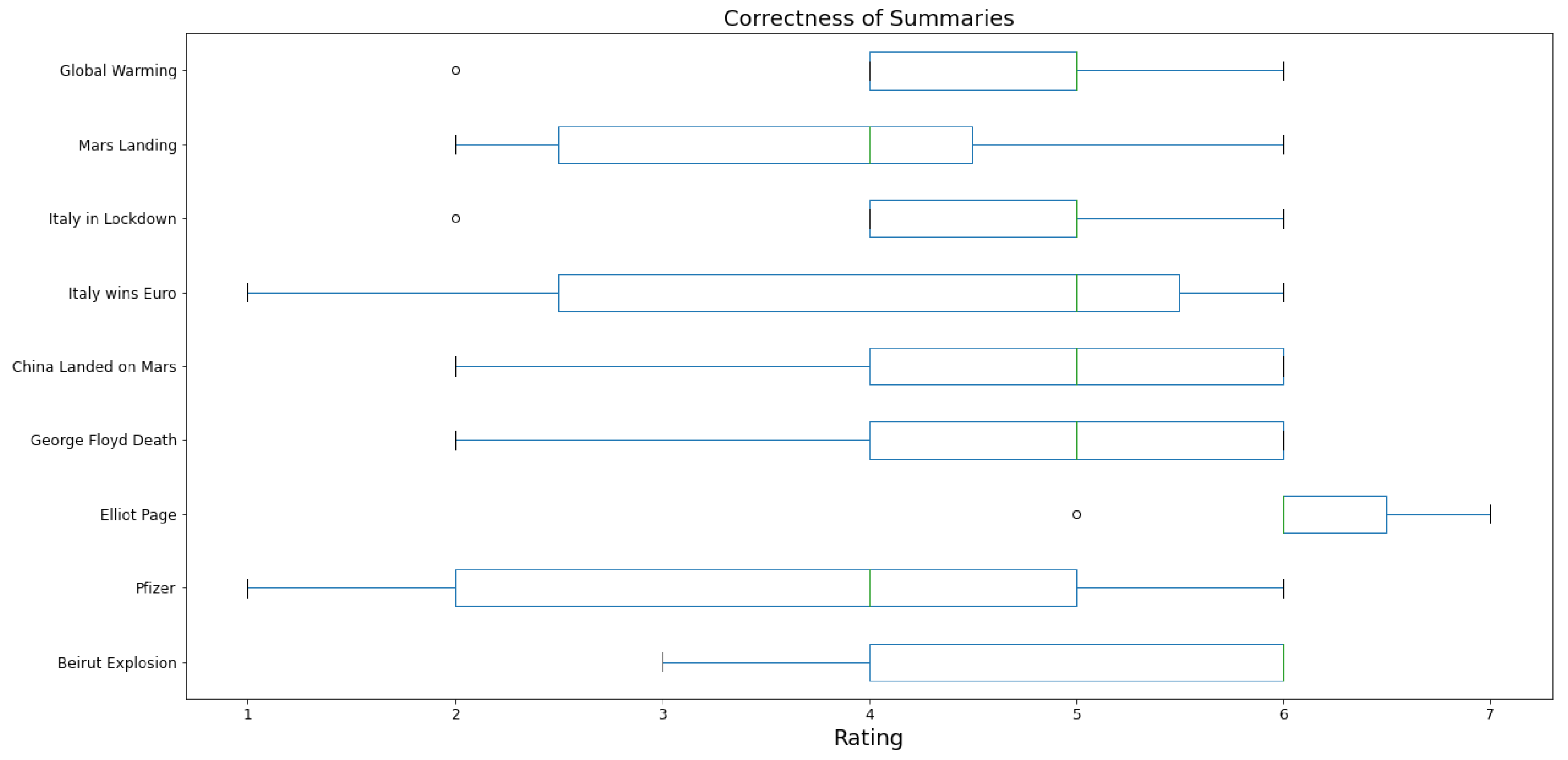
Figure 12 presents a box plot depicting the human judgments for each news event regarding the factual correctness of the target summary in comparison to the reference article. The average score is
, which is quite high, with the majority of scores for nearly all news items ranging between 5 and 6.
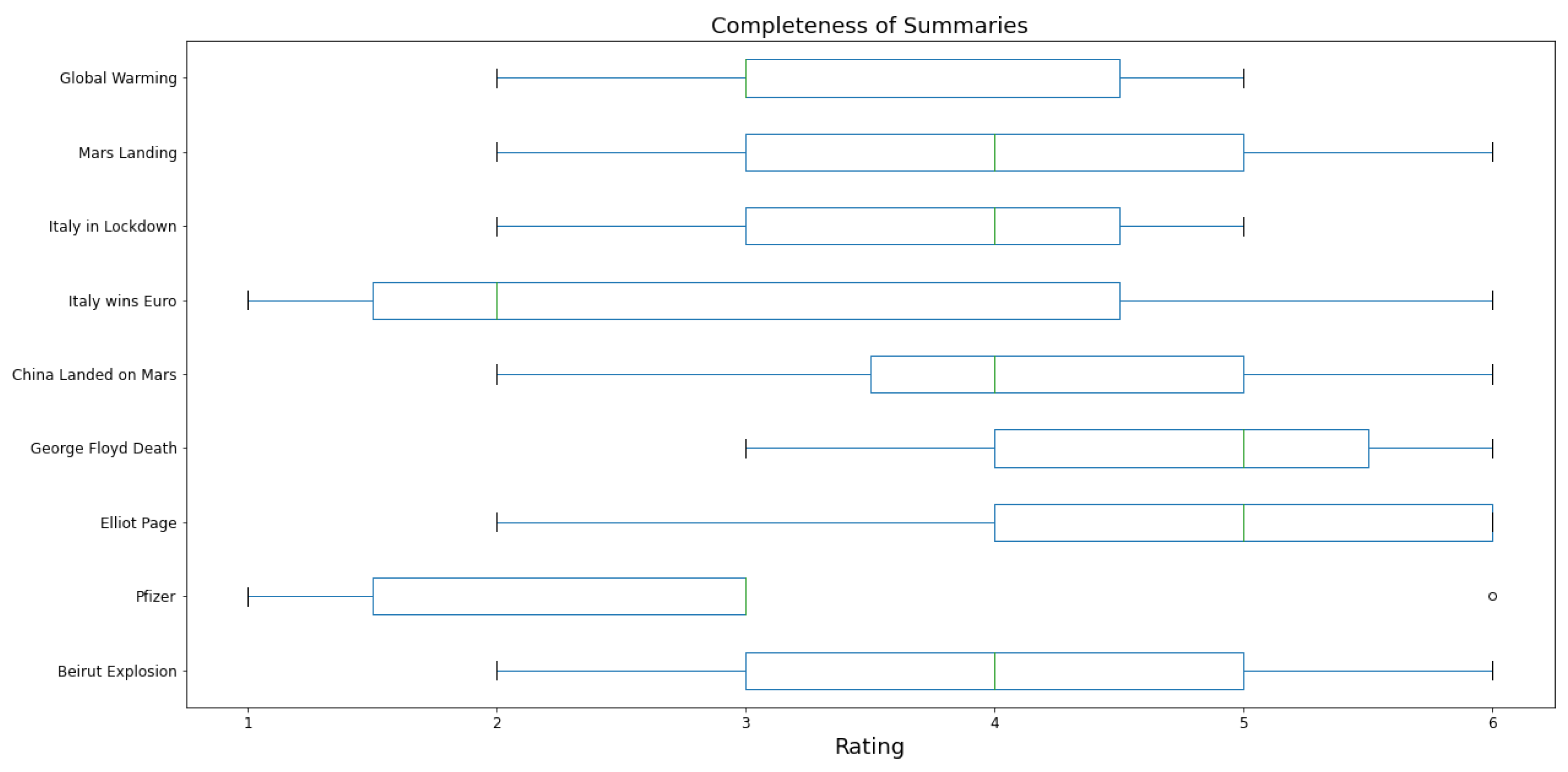
Finally,
Figure 13 presents human judgments on information completeness for each news event, with an average score of
, which is encouraging, as we observe that the majority of scores are high for certain news events, such as Elliot Page coming out and George Floyd’s death, while they are slightly lower for others.
The experiment shows that the automatically generated summaries are able to provide an adequate overview of the target sentences. Specifically, correctness ratings are, on average, rather satisfactory, indicating that the summaries provide factually correct texts with respect to the original news. Completeness ratings are also quite high, even though a significant drop in quality is observed for some of the considered news. Novelty ratings, while generally lower, are still encouraging. Thus, we can conclude that, although some users are less satisfied than others, depending on the specific news, on average, the system is able to output comprehensible and coherent summaries.
4.4. An Example of the Application
In this section, we show an example of how the proposed system can be applied. We choose a reference news article about the war in Ukraine, titled “Second victim of New Year’s Eve strikes on Kyiv dies in hospital”, published on CNN International on 2 January 2023. The system was run on the same date at 10:21 a.m. (CET). The text and the link to the article are included in
Attachment S1 of the supplemental material. The ‘Target Articles Retrieval’ module collected four different articles, all on the same event but focusing on different aspects. The newspaper websites selected for the search were The New York Times, NBC News, Al Jazeera English, USA Today, and BBC News. The system retrieved articles only from NBC News, Al Jazeera English, and USA Today websites. On that particular day, there was no article similar to the reference article in the New York Times and on BBC News websites. The titles of the target articles are listed in
Table 9.
The second module of the system takes the target and reference articles as input. Then, the articles are split into sentences, as explained in
Section 3. First, the system performs an automated classification of all sentences in the target articles (see
Section 3.2).
Table 10 shows a subset of target sentences from the Al Jazeera English article titled “Renewed Russian attacks mark Ukraine’s grim start to 2023”, labeled with this approach.
As for the target sentence reduction (
Section 3.3), for each target article, all the labeled sentences are filtered to obtain only sentences that are not considered redundant. Given the reference article, the system for each target article outputs the list of target sentences that contain new or different information with respect to the reference article. This output is included in
Attachment S2 of the supplemental material. Each row in the CSV file “S2” consists of the target sentence, the labeling, the reference sentence with the highest similarity to the target one, the similarity score, and an integer that represents the index of the target article assigned by the system.
Finally, the output of the target sentence summarization (
Section 3.4) is a text summary that reports only novel or different information with respect to the reference article. The sentences included in
Attachment S2 are used as input for the abstractive text summarization algorithm.
Attachment S3 of the supplemental material includes the results of the target sentence summarization for the example. In particular, we show the summaries of each target article and the summary generated from the sentences of all the target articles. These sentences are those outputted by the target sentence reduction module.
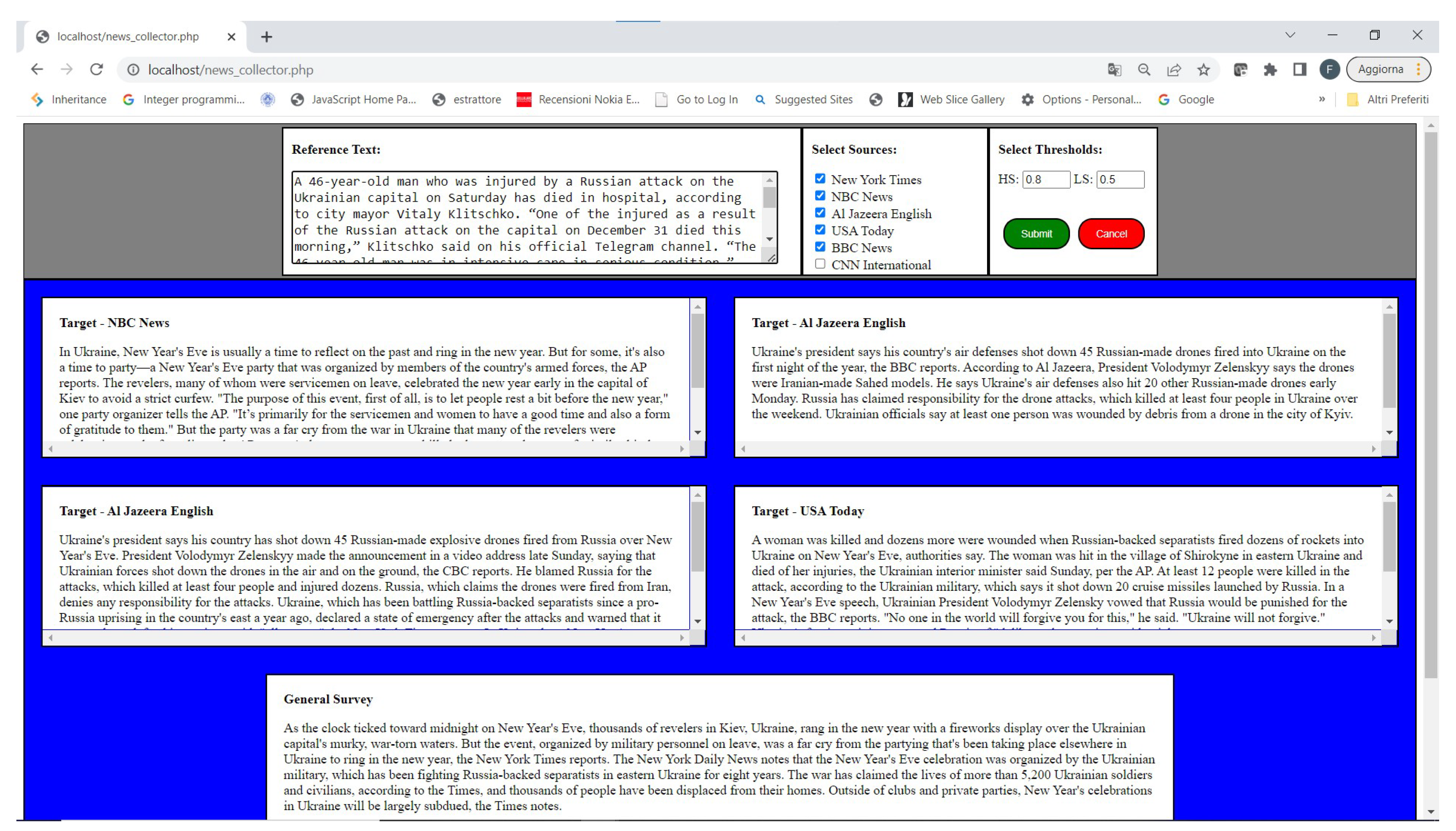
An illustrative simple example is shown in
Table 5. The interface of the application is shown in
Figure 14.
5. Conclusions
In this paper, we proposed a method for (i) identifying novel information from newspaper articles with respect to another article on the same topic, and (ii) making such information available in an easy-to-read format to users. We consider the setting in which there is one reference article (i.e., the article read by a user), and one or more target articles on the same topic. The system employs cosine similarity based on Sentence-BERT embeddings to classify each target sentence as similar, different, or very different, with respect to sentences in the reference article. We implemented a sequence of steps to extract the most relevant sentences (i.e., the different and very different ones) from the target articles. Then, we employed a Transformer-based abstractive summarization model to summarize the sentences in an easy-to-read format.
We conducted experiments using crowdsourced human judgments as the ground truth to assess the classifier’s effectiveness and the summary’s ability to represent information in the target articles that differs from the reference article. We obtained an average F1 score of 0.772 against average F1 scores of 0.797 and 0.676 achieved by, respectively, a fine-tuned BERT classifier and a prompt-tuned BERT classifier. By computing the Wilcoxon signed-rank test, our classifier was statistically equivalent to the first BERT classifier and statistically outperformed the second one. This is a remarkable result considering that our classifier requires less computational effort.
Regarding the summaries—based on the human judgments collected through crowdsourcing, the summaries have been deemed to accurately represent the information contained in the selected sentences of the target articles
We strongly believe that the large availability of data prevents today’s users from finding the information necessary to create their own opinions. The proposed system can be considered a first step toward the end goal of empowering users to discover novel and relevant information, and will be further improved in future work. In particular, we intend to investigate other similarity metrics and classification algorithms to better address the problem of semantic similarity between sentences. Furthermore, we plan to improve the quality of summaries, especially concerning their novelty, by leveraging different methods. Finally, our ultimate goal is to build a platform that allows users to submit a reference article and receive a summary with information different from the reference article.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}